
11 minute read
Biz of Digital


Biz of Digital — Coordinating Coordinates: Adding Plat Books and Plat Maps to Our Digital Repository
By Nicole Smeltekop (Special Materials Catalog Librarian, Michigan State University Libraries, 366 W. Circle Drive, Room W108C, East Lansing, MI 48824; Phone: 517-884-0818) <nicole@msu.edu>
Column Editor: Michelle Flinchbaugh (Acquisitions and Digital Scholarship Services Librarian, Albin O. Kuhn Library & Gallery, University of Maryland Baltimore County, 1000 Hilltop Circle, Baltimore, MD 21250; Phone: 410-455-6754; Fax: 410-455-1598) <flinchba@umbc.edu>
Abstract
In 2019, the Michigan State University Libraries Map Library identified a collection of plat books published by W. W. Hixson as a good candidate for our digital repository. Published in the 1920s-1930s, the MSU Libraries collection of these plat books covers nearly every county in Michigan. In addition to adding the books to the digital repository, the Maps Librarian was very interested in adding the page-level township map metadata into the Big 10 Academic Alliance Geoportal. This presented the digital repository team with various challenges; mainly, how to parse book-level MARC metadata for the book as well as page-level metadata in spreadsheets into functional MODS and Dublin Core (DC) records. This paper details our decision process and workflows for handling the complexity of page- and book-level metadata in preparing the plat books not only for our local digital repository, but also for the consortial geoportal. The XSL stylesheets described in this paper are available here: https://github.com/MSU-Libraries/PlatMapMetadata
Overview
The MSU Libraries Digital Repository provides access to born-digital and digitized library material, including newspapers, books, journals, images, and maps. The repository is a local instance of Islandora 7, an open-source digital repository software that combines Drupal, Fedora 3, and Solr.1 In 2018,the digital repository team (RepoTeam) began adding digitized sheet maps to the repository. The following year, the Map Librarian selected a set of plat books published by W. W. Hixson for the digital repository. The Hixson plat book collection spanned most Michigan counties and included townships (or portions of townships) on each page. Rather than only including book-level metadata, the Map Librarian also wanted to include page-level metadata, so that each township was described as well as the overarching county. This would allow each township map to be findable in the Big 10 Academic Alliance Geoportal, a collaborative geoportal that utilizes coordinates in the metadata for finding resources from across the thirteen Big 10 universities.2 The digital repository utilizes both Metadata Object Descriptive Schema (MODS) and Dublin Core (DC) records to populate item pages and provide data for searching. We also use both metadata standards because the Michigan DPLA hub requires MODS records, while our library discovery layer requires Dublin Core. To create both metadata types, team members write Extensible Stylesheet Language (XSL) stylesheets that convert various source metadata into MODS. Then, a standard XSL stylesheet, used for all the repository collections, converts the MODS to DC. Typically source metadata begins as MARC records or Excel spreadsheets that the team converts to XML. The XSL to create page-level MODS records needed to pull information from both the book-level MARC record and the page-level metadata spreadsheet to make page-level metadata. RepoTeam made decisions for how to best provide access, considering the plat books needed to be described as both books and individual pages. Because the covers did not contain information beyond the title of the book, the team decided to not create metadata and not display the covers of the books as individual items; instead, the covers were included in a downloadable PDF of the entire book (excluding blank pages). The link to the full downloadable PDF was available on each township page description.
Workflow
RepoTeam requires stakeholders to coordinate and complete the creation of digital images and metadata prior to taking a project. For the Hixson plat books, the pre-work was divided between the Map Library staff and the cataloging team. Map Library student employees scanned the book pages and added page-level metadata to a shared Google spreadsheet. The students added the following information: • County covered by the book • OCLC number • Call number • Page title • Township • Range • Bounding coordinates of township map (acquired systematically using a tool in ArcGIS called “Add Geometry Attributes” that quickly calculates the min/max X and Y data for a polygon) • Map library filename • Barcode • Item record number (from the catalog) • Scanner initials The Map Librarian and I devised instructions for various irregularities, such as if a page did not include a title or if the page contained advertisements rather than a map. While the Map Library employees completed the page-level metadata and scanning, the cataloging team undertook cataloging the plat books. There are many Hixson plat book catalog records in OCLC, but the records lack many details to correctly identify the edition (such as descriptions or date ranges). This is largely because the Hixson books themselves lack differentiating details between various editions — most importantly the date of publication. The catalogers estimated the date of publication by researching the history of roads depicted in the maps . With no way to verify
whether the OCLC records described the same edition as the piece held by MSU, catalogers opted to create new records in OCLC. These new records were described using RDA and catalogers added notes detailing how they arrived at the date estimation listed in the catalog record. This also ensured that the dates listed in the repository would be more granular and the metadata more robust to better aid in faceted searching. See Figure 1. Although each plat book depicted a different area, the catalog records included very similar data, such as publisher location, publisher, subject headings, genre headings and creator names. Because of this, cataloging was handled by deriving records from OCLC one after another. As mentioned above, notes were added to detail date estimations. Additionally, subject headings and genre form terms were added to reflect if the book contained advertisements. Because the work was quite repetitive, once complete, the workflow incorporated generating a file of records to review in MarcEdit to catch any inconsistencies in data that should have been the same.
XSL
The RepoTeam had previously created a MARC to MODS XSL to handle standard sheet map metadata creation. Creating the MODS metadata for the book could utilize the same XSL and required minimal editing. However, the page-level metadata required data from both the shared spreadsheet and the MARC record for the book. It also needed to accommodate whether a page displayed a map or advertisements, and various irregularities, such as if the title field was blank, or if the page included township and range information. Because no MODS needed to be created for the cover pages, I first ran a simple XSL and removed the cover metadata from the source XML. To create the source XML from the shared Google Spreadsheet, I used FreeFormatter.com’s CSV to XML converter.3 See Figure 2. For the page-level XSL, I queried the book-level MARC record by creating a variable for the MARC record. The filenames for the MARC records were the corresponding OCLC number for the book-level catalog record. The variable in the XSL matched the filename against the OCLC number listed in the spreadsheet metadata to pair the two together. I ran the XSL stylesheet over the page-level XML document and pointed to the directory of MARC records for the variable. Data pulled from the MARC record included information that applied to all the pages within the book, such as: • Publisher (264 field, subfield a) • Edition statement (field 250) • Date issued (pulled from the 008 field) • Scale and projection information (255 field)
Figure 1: Note on publication date estimation from the catalog record. Figure 2: xsl variable that matched the filename against the OCLC number.
• Subjects (650, 655 fields) • Original description standard used (leader field) • Institution that created the original MARC record (040 field) • Record creation date (005 field) • Language of cataloging (040 field) We also decided to include a note in the MODS record that stated the larger book that included the page described. This note pulled the title of the book from the 245 field. We also included a related item link to the book-level catalog record for the print book in our local catalog. See Figure 3. Adding subjects from the book level meant that the subjects describe the county rather than the individual townships shown in the township map. This is not a perfect solution, but we agreed that since it is clear the page is from the larger book and the township is included in the larger county, it was an acceptable generalization. The data pulled from the page-level spreadsheet were unique to each page-level MODS record. This included the title, township, range, and coordinates. Although the subjects were not granular enough to provide access to the individual township, the township names were accessible using a keyword search of the repository. Additionally, the Map Librarian agreed that if a researcher was searching for a particular township, it is a logical step to search for the county, since maps of counties inevitably show townships included in the larger jurisdiction.
Figure 3: Code to add “Page from” note in the MODS record.
The XSL also checked whether the page depicted advertisements instead of maps based on the title field labeled “Advertisements” in the page-level XML file. For those pages, the MODS records included subjects for small businesses in the county instead of the map specific information of scale and coordinates. Since running the XSLs required setting up a directory of MARC records in the directory of the page-level XML file, I created a README outlining the workflow to create the MODS records for the book-level and page-level metadata. This was very helpful for other colleagues when they needed to update the metadata to a newer version of MODS. We also anticipate that more plat books and atlases will be added to the digital repository in years to come and writing down the established workflow will save us time and energy when we inevitably forget some of the details in the process.
Geoportal
Typically, the BTAA Geoportal team crosswalks various metadata schemas from partner institutions to the Geoblacklight schema. The Geoblacklight schema mainly uses elements from Dublin Core, but also includes some unique cartographic elements not typically included in standard Dublin Core. Although our digital repository includes Dublin Core records, the coordinates are stored in the MODS records. Additionally, the persistent URLs are added to the MODs records after the local records have been uploaded to Fedora and only stored in Fedora. Thus, we needed to export the MODS records from Fedora for the Geoportal team to crosswalk to their Geoblacklight schema. To retrieve the MODS records as a batch, a team member queried Fedora using Solr to pull the modified MODS records and then ran a simple XSL to exclude any advertisement pages. Because the geoportal includes records for both the plat books and individual maps within the books, both page and book-level metadata were sent.
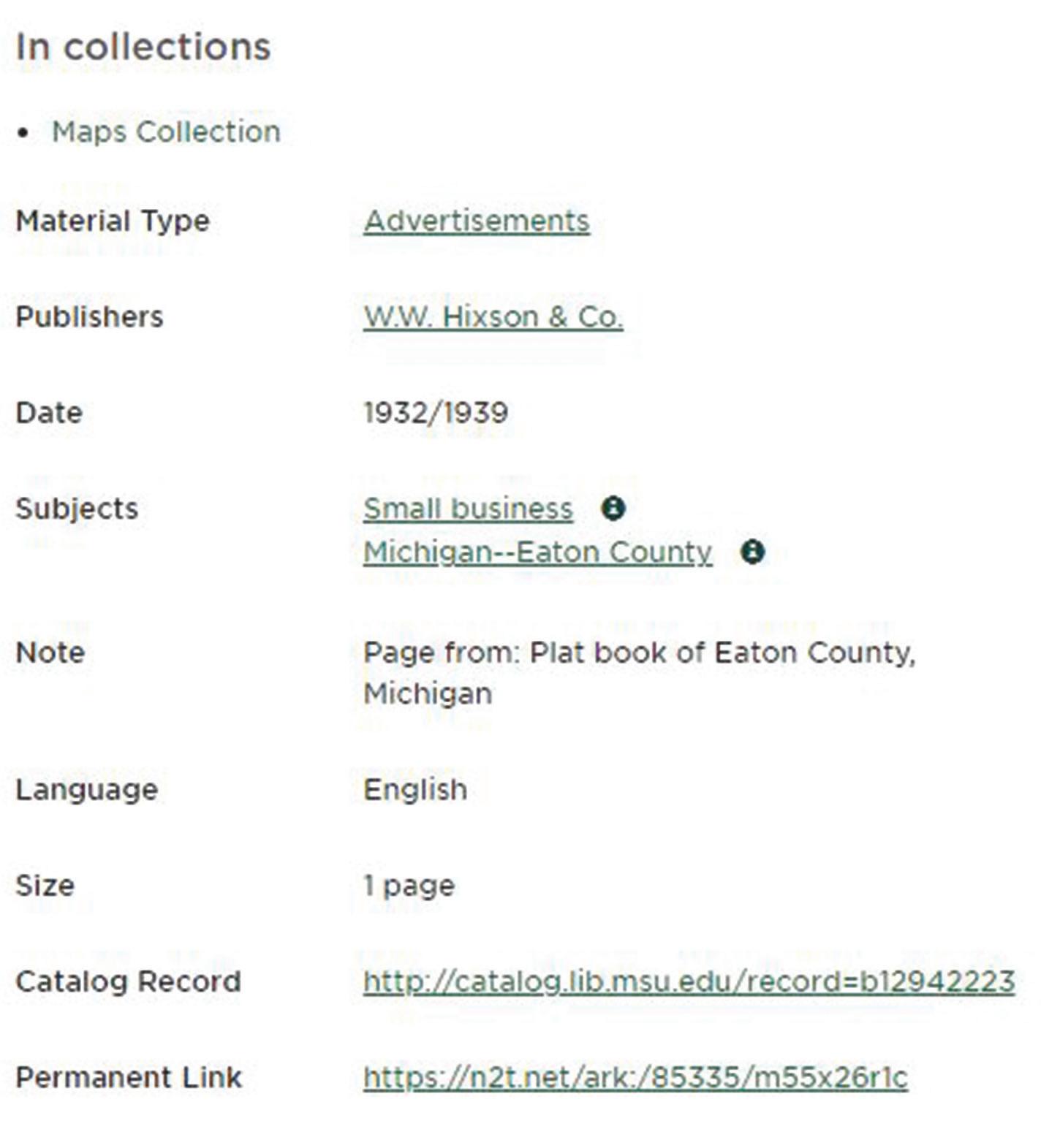
Figure 4: Item page for an advertisement page:
https://n2t.net/ark:/85335/m55x26r1c
Figure 5: Item page for a map:
https://n2t.net/ark:/85335/m5h990r4w

Conclusion
As a result of this work, 40 plat books containing over 600 maps were added to our digital repository and the BTAA Geoportal. Additionally, this workflow has given the digital repository team a path forward for handling books where page level information is also important for discoverability and access. We look forward to utilizing this workflow in the future for more unique and interesting atlas collections held in the MSU Map Library. See Figures 4 and 5 on this page, and Figure 6 on the next page.
Endnotes
1. Islandora. 2021. “Islandora: Open source digital asset management.” Accessed May 26. https://islandora.ca/ 2. Big 10 Academic Alliance Geoportal. 2021a. “About the BTAA Geoportal.” Accessed May 26. https://geo.btaa.org/ 3. FreeFormater. 2021b. “CSV to XML Converter.” Accessed May 26. https://www.freeformatter.com/csv-to-xmlconverter.html
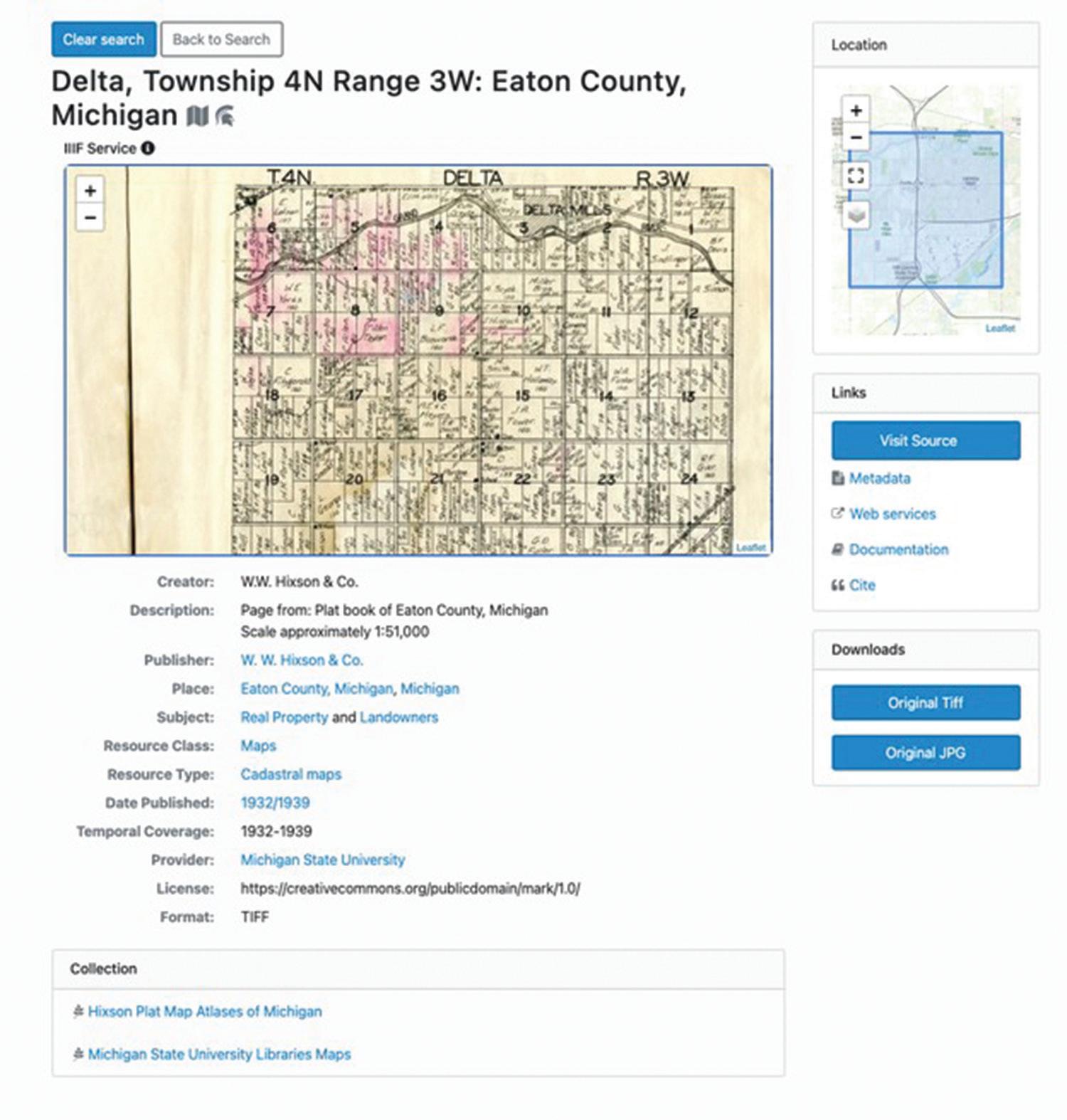
Figure 6: Item in BTAA Geoportal: https://geo.btaa.org/catalog/ark-85335-m5h990r4w








