
How search at Issuu actually works
At Issuu, search is an integral component of our current website, and it will become increasingly more so as we continuously add new features.
This blog post goes into some detail about the infrastructure supporting and implementation of some of the available search types.
By Martin Koch, Senior Systems Architect

A bit of background So: what can you search for? In order to answer that question, let’s look briefly at what happens when you upload a document to ISSUU.
Documents are uploaded to ISSUU by its users and fed to a conversion pipeline that does all kinds of magic to extract various things from the document such as images in different resolutions of the individual pages, the text on each page, etc. Based on the conversion artifacts, a set of analyses are run such as automatic categorization (is the document a book, a magazine, a newspaper, …?), language detection (is the document in English, Spanish, French, Danish, Japanese, …?), etc.
When a document has made it through the conversion pipeline and becomes available on the site, we collect usage statistics over time. We count how many times a document is displayed (i.e. impressions) and how many times a user spends significant time on it in the ISSUU reader (i.e. reads). These statistics are useful for search because we can use them to rank documents that users like (by being read and displayed frequently) higher than other documents (let’s face it: When anybody can upload content, not all content is of equally high quality). The search engine that we use needs to be able to incorporate dynamic data such as reads and impressions into the ranking. more
We’re growing rapidly at ISSUU, so we’re continuously rethinking our systems, building new ones, and shutting down old ones. For searching, we’re looking for a single platform that is fairly simple to maintain, keep up to date, and scales well. We have used Solr to support searching previously. When deciding on the new search infrastructure we spent some time comparing ElasticSearch and Solr. At the time, ElasticSearch didn’t feel like it was at the level of quality we needed it to be and have used Solr exclusively for the last year or so. We decided to go with Solr-4 as soon as it was out (in the alpha and beta releases) so that search would be based on an Apache-community backed search engine with lots of support from mailing lists, forums, and, if necessary, external consultants with Solr development expertise.
So with that out of the way, the following text will focus on the workings of three different kinds of searches that you can see in action on ISSUU.com right now:
Per document search
Per page search
Searching for recently read documents.
The per-document index ISSUU currently has several million documents available. On average a document has 28 pages and contains around 45KB raw text in addition to the other metadata described above. When building the new Solr-4 infrastructure intended to replace existing infrastructure, we didn’t expect to see substantially many more hits than previously. This means that we expect to see around 200K per-document searches a day. Predicting the index size from the source data is difficult as it depends on stop words, tokenization, stemming algorithms, etc, but we guesstimate at around 45KB/document.
Since we use Amazon infrastructure, this means that the index won’t fit in ram on any of the Amazon instance types, so we jumped at the opportunity when Amazon released their new SSD-based (hi-io) instance types. Disk access speed is important because a query that can’t be fulfilled from the Solr cache will need to hit the disk. If we’re lucky, the relevant page will be in the OS disk cache (and we make sure to leave plenty of memory for that), but many searches will require seeks. Numerous blogposts describe the fickleness of the disk seek speed and throughput that you can get based on the EC2 instance that you happen to get at any time, so access time consistency is also a consideration here.
When we were looking a Solr-4, a number of features – notably SolrCloud – seemed particularly useful to us:
automatic sharding
automatic replication
masterless indexing (any node can index a document; shards are automatically distributed to the relevant host/shard)
a mechanism – the
– exists for holding dynamic values such as reads and impressions that need to be updated regularly in the index
Sharding & ReplicationSharding seems to be a good idea in Solr. The hi-io instance type has 8 hyperthreaded cores for a total of 16 virtual cores, so in the initial deployments we started out with 16 shards. However, experiments showed that the overhead of having 16 shards was too high; performance got quite a lot better using only 8 shards.
Automatic replication seems like a good idea too: In Solr-4, once you have decided on the number of shards that you want, adding extra servers should just result in replicas of the shards being made on the spare capacity. In that sense, scalability and redundancy comes ‘for free’. Our requirements are that search should always be available, but not necessarily indexing; we can live with new documents not appearing right away in a few exceptional cases. To support this, we deployed four machines in two clusters in two availability (physically separate) zones on Amazon. (See below for a discussion of how failover is handled). Once we had built our first complete index – a process which caused a number of headaches but succeeded in the end – one of the first experiments we did was to try to kill a node in the cluster. We expected that when we brought it back up, it should just sync up and resume. Unfortunately, this process failed almost every time we tried it; it certainly didn’t give us the warm, fuzzy feeling that we require for something that would be stable enough for a highly-available production environment. Since we needed separate setups in two availability zones anyway, we ended up concluding that Zookeeper would give us mostly administrative overhead and no real value.
In the end, we observed that one high-io instance in each availability zone can handle the search load; we set up a HAProxy in front of each instance. This proxy routes queries to the instance in the local zone if it is up; if not, it will route requests to the other zone. Thus, if Solr is down, HAProxy will route to the other zone. If the entire zone is down, we rely on Amazon ELB to route traffic to the alternative zone. We’re not using any of the built-in failover mechanisms in Solr at all, and we’re not really using Zookeeper for anything either. The Solr instances are completely separate and unaware of the others. The only small downside to this is that each index also needs separate indexing, so that we have to retrieve some of the data several times from the source: once for each index.
We currently see around 200K documents searches per day (average 2.3 requests/second; peak at 14 requests/second); the response times with this setup are shown in this graph. The graph shows the results of both per-page and per-document searches. We see that 80% of requests are served in less than 500ms, and 90% of requests are served in less than 1 second; just a few requests take longer than 1 second. The dips around 6AM on each date are an artifact of log file rollover.

Graph of per-page and per-document response times in one of the availability zones. The units on the x-axis are dates. The colored bands correspond to the % of requests that complete in less than some fixed time as specified by the color.
External file fieldsFor document searching we’d like to rank results not only by textual relevance on the search terms, but also on various dynamic popularity measures such as reads. Further, we’d like to include the popularity measure in the result that is returned to the user. In order to update a single field in a document, Solr requires that the entire document is reindexed, which is a fairly expensive operation.
As a workaround for this, Solr supports ExternalFileFields (EFFs).
The EFF is simply a list of IDs and values, e.g:
121100121234-62bfe32580c34aa4bb896dedf54aa7b1=123456.0 110911014321-fc482c8694554c998e040836a61bd2a4=654321.0
The EFF is placed in the parent of the index directory in each core; each core reads the entire EFF and picks out only the IDs that it is responsible for.
In the current 4.0.0 release of Solr, Solr blocks completely (doesn’t answer queries) while re-reading the EFF. Even worse, it seems that the time to re-read the EFF is multiplied by the number of cores in use (i.e. the EFF is re-read by each core sequentially). The contents of the EFF become active after the first external commit (commitWithin does NOT work here) after the file has been updated.
In our case, the EFF was quite large – around 450MB – and since we use 16 shards, the whole system would block for several (10-15) minutes when we issued an external commit. This is not acceptable in a production environment.
We got some help to try to fix the problem so that the re-read of the EFF proceeds in the background (see here for a fix on the 4.1 branch) in the same way that documents can be indexed in the background without blocking searches. However, even though the re-read proceeds in the background, the time required to launch Solr now takes at least as long as re-reading the EFFs. Again, this is not good enough for our needs.
The next issue that we discovered was that Solr 4.0 is not able to sort on EFF fields (though you can return them as values using &fl=field(my_eff_field)). This is also fixed in the 4.1 branch.
Even after these fixes EFF performance is not that great, and we decided to do without. Our solution has two components:
The actual value of the popularity measure (say, reads) that we want to report to the end-user is inserted into the Solr search response by our query front-end. This has the benefit that the value will be the authoritative value at the time of the query rather than the necessarily slightly out-of-date value that would otherwise reside in Solr.
We observed the value of the popularity measure that we use for boosting in the ranking of the search results needs to change significantly to have a measurable impact on ranking. Therefore we elect to update it only when the value has changed enough so that the impact on the boost will be significant (say, more than 2%). This limits the amount of re-indexing required, so at least we won’t have to re-index a document if it goes from, say, 1000000 to 1000001 reads.
Indexing A Solr index needs to be kept up-to-date with the data it is responsible for indexing. At ISSUU, there are several sources for the data that goes into the index. There is data provided by the users at upload time, artifacts generated by the document conversion processes, and dynamic popularity measures generated by the statistics subsystem.
In the current search architecture, we use a Cassandra store to cache data from these various sources. The process which updates Cassandra has a rule to determine when a document has been changed enough to warrant (re-)indexing (or deletion if that is the case). If this is the case, a message is posted on our message queue (we use the RabbitMQ implementation of AMQP) to a fanout exchange (basically a publish-subscribe exchange). There is a subscriber queue per search host.
On the Solr host we run worker processes that reads update messages from the queue. The workers extract the document details from the message (and, as an implementation detail, may retrieve additional data from S3) and submits documents to Solr for indexing using CommitWithin to control the commit frequency. We’re currently committing every 60 seconds. The worker processes are written in Python. We use pySolr for communicating with Solr. The size of the current document index is 232GB. Re-indexing the per-document index takes around 6 hours using around 32 worker processes.
The Per-Page Index The per-page index holds pretty much the same content as the document index, only indexed by page rather than by document. We only use 8 shards for this index in contrast to the 16 we currently use for document searching; there was no significant change in the transition from 16 shards to 8 here. This means that we have on the order of 200M documents in this index.
We have relatively few per-page queries, so we host this index on the same physical machine as the per-document index (but in a separate servlet container process). If we start seeing substantial load on this system, it will be easy to migrate this index to a new host. The size of the current per-page index is 287GB. Using a few hundred worker processes, the per-page search can be reindexed in 12 hours.
The Popularity Index The popularity index is amongst other things used to search for the most popular documents on ISSUU. The queries that are served by this index do not require the document body text; they only need various metadata and popularity fields. This means that this index is quite small (6GB), so we host it on a server with plenty of memory that will allow the index to fit into memory at once.
Re-indexing the popularity index can be done in less than two hours.
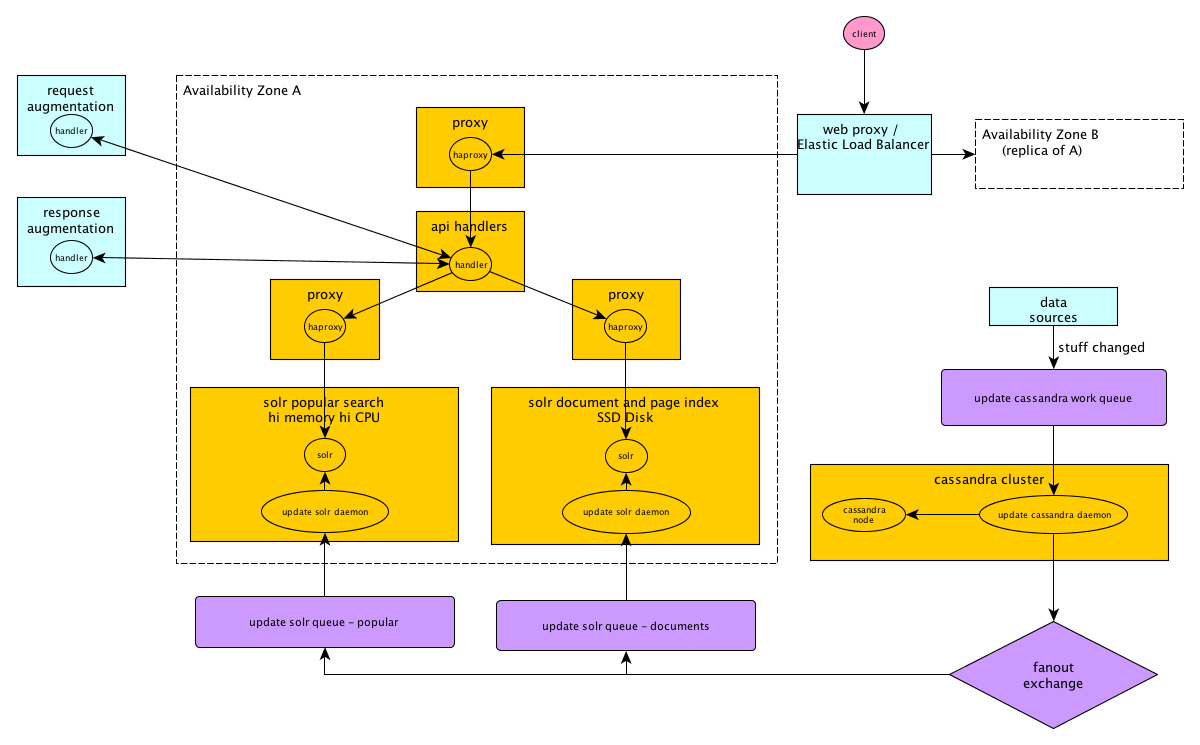
The Architecture Simplified illustration of the architecture supporting the per-document, per-page, and most popular searches at ISSUU. Request augmentation includes e.g. looking up the geo location of the client’s IP to be used as input to Solr for geo boosting. Response augmentation includes inserting the authoritative values of the popularity measures (e.g. reads)

{kind=link}
Some Learnings
In summary, we’d like to share a few learnings. Keep in mind that this applies to our use-cases, so they may not be applicable to you.
Zookeeper is not easy to understand. The documentation is somewhat lacking and the interaction between Solr and Zookeeper is unclear.
Debugging distributed state in the Solr/Zookeeper setup is difficult. The gain from automatic replication is not apparent compared to the simpler manual replication scheme we have employed.
On Amazon, High IO instances need rebooting quite often (we don’t know why – we’re pursuing this issue with Amazon). They become unreachable and have to be remotely rebooted. On the positive side, SSD disks are good for the random-access seek patterns required by Solr.
Using
as the servlet container works just fine for us. Heavy traffic handling and throttling are handled by HAProxy.
We end up re-indexing fairly often. New requirements often come in which might require new fields in the schema. Re-indexing the entire corpus is still quite fast: A few hours for the popularity index, 12 hours for the per-page index. During re-indexing, the speed bottleneck is getting the data from the data store, not the indexing speed (!).
Installation: Initially getting sharding setup correctly was a bit difficult.
Clustering: Failover to shard replicas is not reliable enough for production use.
During load testing, we see Solr crash under heavy load.
We don’t use near realtime (NRT) searching because the transaction log files become very large (and propagation time is good enough without NRT anyway).
The admin interface is very useful (although it would be useful with a sample admin-extras.html file somewhere – where it should go and what can go in it would be good to know. Right now, all we get is an exception in the logs about the file not existing).
We’re going to experiment with updating documents in-place to get rid of our Cassandra store. The idea here is to use Solr itself as the data cache. This requires all fields to be stored, but we think the data volume will still be manageable. See
and
for descriptions of how this is done in Solr 4.
A Solr best practice which we found useful: For ease of maintenance, use suitably named request handlers for each kind of query you’d like an index to serve. This also allows collection of statistics per handler.
Sometimes a shard will fail for no apparent reason even though all cores run in the same servlet container (we haven’t debugged this carefully). Restarting Solr helps.
Setting CommitWithin too high can result in Solr crashing; it seems that too many outstanding commits is a problem.
