
24 minute read
How Search Engines Really Work


By Jeff Ferguson
The Internet and the World Wide Web we know today would be utterly unnavigable without search engines. But how do Google, Bing, and the other search engines really work? The short answer: Search engines work by filling a database, or index, of billions of web pages through crawling. During the crawling process, computer programs called web crawlers, also known as bots or spiders, download the content and the links to other web pages found on these pages. Search engines analyze these web pages using algorithms for factors such a topicality, quality, speed, mobile-friendliness, and more to determine the position, or rank, in the search engine results presented to users. But let’s dive a little deeper. In this study , you will learn: • About Machine Learning • What is a Search Engine? • How Do Search Engines Obtain
Advertisement
Their Results? • How Do Search Engines Understand Your Query? • How Do Search Engines Rank
Web Pages? • Pulling It All Together: How
Google Really Ranks Web Pages • Summary
FIRST LET’S TALK ABOUT MACHINE LEARNING
Before we discuss how search engines work, you should understand a little about Machine Learning. According to Jim Stern, author of Artificial Intelligence for Marketing, “Machine Learning is the automated creation of predictive models based on the structure of the given data.” To say that Machine Learning is a computer teaching itself how to do something is an oversimplification, but it’s an excellent place to start for this discussion. While Machine Learning lives under the Artificial Intelligence (AI) canopy, it should not be confused as being the same thing. Machine Learning is already in use daily in a myriad of computer systems; AI is the name given to a variety of technologies, some of which are still the stuff of science-fiction. Some Machine Learning systems can run on an Unsupervised basis, still requiring data to get started to find patterns in data and reveal correlations. There is also Supervised Machine Learning, whereby we
ensure the algorithms are doing their jobs properly like a teacher grading a student’s homework. Lastly, there is what is known as “Reinforcement Learning,” automated systems that optimize marketing campaigns, such as Google Ads optimizing a handful of variables to get as many conversions as possible at the right price. The big takeaway here is that these systems, while fixed in their purpose, are not fixed in their modeling, and evolve as they consume more data. Know that modern search engines are using Machine Learning systems of all three types in their attempts to organize the world’s knowledge.
WHAT IS A SEARCH ENGINE?
At this point in history, I’m sure just about everyone knows what a search engine is in theory; however, let’s talk a little about what a search engine is from a technical standpoint. The concept of a database, that is, a structured collection of information stored in a computer, has been around since the 1960s. That’s basically what a search engine is, a vast database of web pages combined with a set of algorithms, that is, a collection of computer instructions, that decide which web pages to return and in what order they should appear when someone asks that database a question, or query.
HOW DO SEARCH ENGINES OBTAIN THEIR RESULTS?
That database is filled through the process of crawling, whereby a computer program visits a known web page and downloads the information found on that web page, a process known as parsing, into the database. The data collected during this process is not only the contents of the web page itself but also the links found on that page, which point to other web pages. The links found on that web page get added to a list of web pages for the crawler to visit at another time. Despite the name, crawlers, also known as bots or spiders, do not move from page to page by way of the links found there; instead, it’s more like the parser adds the newly discovered pages to a sort of “to-do list” to visit later. This to-do list is what’s known as a scheduler, and itself is an algorithm that determines how vital those newly discovered web pages are in comparison to all the other web pages on the internet the crawler knows about already. The parser then sends the information it obtained from the web page to what is known as an index (a process known as, well, indexing), which itself is a kind of database. However, an index is more a database of locations (or citations) of information along with brief descriptions of that information (called abstracts). These citations and brief descriptions are basically what search engines provide to you when you query them for information about a given topic.
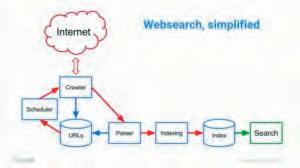
If you would like to learn more about this process, I suggest Andrew Hogue’s excellent tech talk at Google from 2011 called, The Structured Search Engine. Just getting your web page into a search engine’s index is a substantial process, and search engines perform this action thousands and thousands of times a day for new and old web pages alike. Google and the other search engines have made this job of discovery a bit easier for themselves by allowing website owners to provide a list of web pages to them, a file known as a sitemap. Additionally, you can submit new individual pages to both Google and Bing via the Google Search Console and Bing Webmaster Tools websites, respectively. As a website owner, it’s essential to understand this process. When the time comes to determine why your website may or may not receive any attention from the Organic search channel, one of the first questions that you should ask is, “Is our web page even indexed?”, that is, is the web page in question even in the search engine at all. If it’s not, then either the search engine crawlers simply haven’t reached your website yet, or there is something technical in nature keeping your web page from being crawled or indexed. Once included in a search engine’s index, the search engine must then determine when and where that web page will appear to its users when they search for something. That is, the search engine needs to decide which keywords and in what position your web page will appear, or rank, in a search result. This process is where a search engine’s ranking algorithms come into play. Every search engine’s ranking algorithm works a little differently; however, since Google dominates the search engine market in most of the English-speaking world (and beyond), we’ll focus on its ranking process for this discussion.
HOW DO SEARCH ENGINES UNDERSTAND YOUR QUERY?
Before Google can show you any results for your query, it must first determine what your question is about, that is, not only understanding the words in the query but the intent of those words as well. According to Google, “This involves steps as seemingly simple as interpreting spelling mistakes and extends to trying to understand the type of query you’ve entered by applying some of the latest research on natural language understanding.” This task is more complicated than you may think. The English language is, frankly, a mess, and Google’s ability to decipher that mess has improved steadily over the years. Google continues, “For example, our synonym system helps Search know what you mean by establishing that multiple words mean the same thing. This capability allows Search to match the query ‘How to change a light bulb’ with pages describing how to replace a light bulb.”

During the process, Google attempts to determine if the information you are looking for is broad, or very specific, or if the query is about a local business. Google also tries its best to determine if your question requires more recent, or fresh, information. “If you search for trending keywords, our freshness algorithms will interpret that as a signal that up-to-date information might be more useful than older pages,” Google continues. “This means that when you’re searching for the latest’ premiership scores’, ‘Strictly Come Dancing’ results or ‘BP earnings’, you’ll see the latest information.” And you thought Google just read your question as entered, didn’t you? Now that Google has figured out what you’re asking, it needs to determine which web pages answer that question the best, a process known as ranking. Again, this is no simple matter.
HOW DO SEARCH ENGINES RANK WEB PAGES?
Google reviews hundreds of traits, or signals, of a web page to determine when and where it should appear in its index. Despite what anyone might tell you, no one outside of Google knows all these signals, nor do they know if any signal has a higher priority or importance than another. Although, when Google introduced RankBrain, one of their engineers admitted that it was the third most important ranking signal, but, as you’ll see, that isn’t all that helpful. Google has been kind enough to define some of the groups of signals, which in and of themselves are algorithms dedicated to specific areas of interest by Google. The groups of signals in the above image were shown to me and a small group of SEO professionals by Google spokesperson, Gary Illyes, at the Search Marketing Summit in Sydney, Australia, in early 2019 in what was supposed to be a closed-door session. Gary’s one request was that we didn’t share this information, which is supposedly taught to Google’s engineers “on day one,” on Twitter or any other social media platform. However, this request was honored until just slightly after the session was completed, so I assume it is safe to share it here as well. Not shown in this collection of algorithms is Personalization and Localization, which Google sometimes calls “Context and Settings.” Personalization is the dynamic adjustments to the search engine results page (SERP) based on your Google usage history. Similarly, Localization is the proactive adjustments to the SERP based on, well, your location. These two factors alone are enough to make tracking your web pages’ positions on Google frustrating. Let’s look at the individual algorithms that make up Google’s ranking process.

TOPICALITY Sometimes also referred to as “topical relevance,” this algorithm group’s function is perhaps the most crucial concepts you must understand in Search Engine Optimization. If you, as the creator of a web page, want your content to appear for a given search result, then your web page must be about the topic searched for in the first place. This concept, for some, is Earth-shattering news. Again, Google tells us precisely what they mean here, “The most basic signal that information is relevant is when a webpage contains the same keywords as your search query. If those keywords appear on the page, or if they appear in the headings or body of the text, the information is more likely to be relevant.” However, before you run out and start stuffing your content with the same words repeatedly, which was, honest to goodness, an SEO strategy for years, it’s essential to understand this next sentence. Google’s modern Machine Learning based algorithms use a variety of signals beyond just a word’s appearance in a piece of content to determine if a web page is a relevant answer to a question. Thanks to this collection of signals, the concept of “keyword density” no longer matters, if it ever did at all. Counter to what some SEO bloggers have published, this does not mean that Google looks at engagement metrics such as click-through rate or bounce rate for every page to help determine its rank. Instead, Google’s Machine Learning system has used similar information for thousands of web pages in aggregate over time and then looks for similarities in other content. While this doesn’t mean you shouldn’t concern yourself with metrics such as click-through rate and bounce rate for your content, it does mean that Google isn’t tracking these metrics for every web page in its index to determine that web page’s rank. Instead, focus on these metrics because it is a good indication that the readers of that content find it useful.
QUALITY When I took some of my first computer science classes in high school, one of my teachers attempted to demonstrate the complexities of a computer program by having her students tell her, acting as a computer, how to make a peanut butter and jelly sandwich. The teacher would sit at the front of the class with jars of peanut butter and jelly, a knife, and a bag of sandwich bread, and say, “Where do I start? Tell me, the computer, what to do.” The first student to take on this challenge would usually say something like, “Ok, first put the peanut butter on the bread,” only to have the teacher grab the entire jar of peanut butter and place it on the bag of bread. After a few giggles, the students would understand that they first needed to tell the computer to open the bag of bread, take a slice of bread from the bag, open the jar of peanut butter, use the knife to obtain some peanut butter, and so on. Even now, I’m

simplifying these instructions, as she would sometimes get hung up on using the twist tie on the bread bag. My point here is that getting a computer program to replicate human activity is incredibly complex. So, you can imagine how difficult it is to try and teach an algorithm the definition of something so multifaceted as quality. Google’s Machine Learning systems are once again used to bridge the gap between our human opinions on the subject of quality and a machine’s interpretation of that opinion. After it was leaked onto the web in late 2015, Google released its Search Quality Evaluator Guidelines to the public in its entirety. Leaks of this document had occurred a few times since 2008. In 2013, Google even released an abridged version in response to the continued leaks; however, this was the first time that Google responded by publishing the entire 160-page guide to the public. When the Guidelines were released, some SEO professionals treated them like the Dead Sea Scrolls. To calm the SEO community down a bit, Google’s Ben Gomes stated in a 2018 interview with CNBC, “You can view the rater guidelines as where we want the search algorithm to go. They don’t tell you how the algorithm is ranking results, but they fundamentally show what the algorithm should do.” It is incredibly important here to point out that the Search Quality Evaluator Guidelines are not ranking signals. Instead, these guidelines are used by actual humans to check the accuracy of Google’s algorithms so that the Machine Learning systems used to assess the complicated concept of quality can continue to learn and improve their results. Once again, does this mean you shouldn’t concern yourself with the matters we’re about to discuss? Of course not. As you will see, what Google is looking for here is solid advice for anyone trying to create quality content. You, as a web page creator, may try your best to follow all the guidance provided in those quality guidelines, like you were checking items on a to-do list, and still not end up on the first page of results. Google’s Machine Learning algorithm doesn’t have a specific way to track all these elements; however, it can find similarities in other measurable areas and rank that content accordingly. Let’s discuss what those elements are in more detail. Beneficial Purpose – Although not added to the guidelines until 2018, this aspect has become the top priority in the process of determining quality content at Google. It specifically states that “websites and pages should be created to help users.” If your page is trying to harm or deceive Google’s users or to make money with no effort to help users, then Google’s quality raters are not going to rate your content well. Chances are Google’s algorithms wouldn’t like it much either. Google is not against your website selling products or services; it’s just that you need to be helpful in the process. As Google’s John Mueller stated in a 2011 Webmaster Central blog post, content creators should focus on providing “the best possible user experience” rather than treating the various aspects of Google’s algorithms as a checklist. Your Money or Your Life (YMYL) – Google has stated in its guidelines that the accuracy of some content must be judged more critically than other content. This type of material, which they refer to as “Your Money or Your Life” pages, can “impact a person’s future happiness, health, financial stability, or safety.” Quoting directly from Google’s guidelines, this content takes the form of the following: • News and current events: news about important topics such as international events, business, politics, science, technology, etc. Keep in mind that not all news articles are necessarily considered YMYL (e.g., sports, entertainment, and everyday lifestyle topics are generally not YMYL). Please use your judgment and knowledge of your locale. • Civics, government, and law: information important to maintaining an informed citizenry, such as information about voting, government agencies, public institutions, social services, and legal issues (e.g., divorce, child custody, adoption, creating a will, etc.). • Finance: financial advice or information regarding investments,
taxes, retirement planning, loans, banking, or insurance, particularly webpages that allow people to make purchases or transfer money online. • Shopping: information about or services related to research or purchase of goods/services, particularly webpages that allow people to make purchases online. • Health and safety: advice or information about medical issues, drugs, hospitals, emergency preparedness, how dangerous an activity is, etc. • Groups of people: information about or claims related to groups of people, including but not limited to those grouped on the basis of race or ethnic origin, religion, disability, age, nationality, veteran status, sexual orientation, gender or gender identity. • Other: there are many other topics related to big decisions or important aspects of people’s lives which thus may be considered YMYL, such as fitness and nutrition, housing information, choosing a college, finding a job, etc. Please use your judgment. To sum this up, if you’re trying to share facts, not opinions, about a topic, Google is going to take the evaluation of this content seriously, and so should you.
Expertise, Authoritativeness, Trust-
worthiness (E-A-T) – A close, yet less uptight cousin to the YMYL content mentioned above, the concept of E-A-T has become a source of considerable discussion in the SEO community since its release. Research on the matter will reveal numerous explanations of the idea along with a few well-meaning articles on “How to Write E-A-T Content for Google” and the like. If you don’t understand the words “expertise,” “authoritativeness,” and “trustworthiness,” feel free to seek these blog posts out as defining (and redefining) the words themselves seem to be their favorite pastimes. That said, the lesson you should learn from Google’s inclusion of these terms in their Guidelines is that Google is looking at more than your ability to construct a proper sentence when it comes to the concept of quality. Therefore, your content must then prove that you have a respectable level of understanding of a given topic (Expertise), that others in your industry or community agree with your understanding by citing you as an expert (Authoritativeness), and that few disagree with that authority (Trustworthiness). E-A-T is a dynamic concept. Someone writing a guide on foods you can grill during BBQ season doesn’t need to meet the same content standards as someone writing about cancer research. As Google states in their Guidelines, “Keep in mind that there are high E-A-T pages and websites of all types, even gossip websites, fashion websites, humor websites, forum and Q&A pages, etc.” As I stated earlier, there are numerous blogs and slide presentations that try and turn E-A-T into a checklist of tactics (SEO professionals love a good list); however, the best way to learn about this concept is through example. Luckily, you can read the same standards that Google provides to its quality raters in the Guidelines itself (specifically, section 4.6, “Examples of High Quality Pages” in the 2019 edition of Search Quality Evaluator Guidelines). Just remember that these examples were written by humans, for humans, who are attempting to teach a computer to do their job. Avoid getting overly fixated on certain details or try to attach a specific quantity to the quality rates actions. For example, when some SEOs read the section header, “A Satisfying Amount of High-Quality Main Content” from these Guidelines, they try to assign


a specific number of words that need to be written or prove that “longer is better,” but that is simply not the case. As Google’s John Mueller and a bevy of other Google employees will tell you, “Write for the readers, not us.”
PAGERANK One of Google’s oldest algorithms, PageRank, is charged with evaluating the quality of inbound links to a website. Google’s long-held idea that “if other prominent websites link to the [web] page, that has proven to be a good sign that the information is well trusted,” is one of the things that has set the search engine apart from its competitors. While many SEO tools and bloggers love to question the importance of links in Google’s algorithms, according to Google, it is still very much a part of the equation. Occasionally, in blog posts on the matter, an SEO will state that links have a “high correlation” to ranking, which is kind of a silly statement when Google has already indicated that they use inbound links in their algorithm since 1998. Claiming you confirmed this is like saying you figured out a Manhattan cocktail uses bourbon when there are recipes readily available.
RANKBRAIN Introduced in 2015, RankBrain is, well, complicated. According to Danny Sullivan, when he still worked for Search Engine Land (he works for Google now), RankBrain is “mainly used as a way to interpret the searches that people submit to find pages that might not have the exact words that were searched for.” Every day, Google processes something like three billion searches. Of those searches, anywhere from fifteen to twenty-five percent have never been done before. Let that sink in a little. That means that every day, there are 450 million to 750 million searches done every day that Google sees for the first time. While that may seem daunting, many of those previously unknown searches are close to inquiries made before. That’s where RankBrain gets involved. Google had systems in place before to help with this sort of thing. Early in its history, it was able to start understanding the similarities between words like “bird” and “birds” through a process called stemming, that is, reducing a word down to their word stem, or root form. Additionally, in 2012 Google introduced the Knowledge Graph, which is a database of known facts like, “Who was the third President of the United States?” (Thomas Jefferson) that it could quickly answer without having to refer you to a website. The Knowledge Graph also allowed Google to understand the connections to other facts. For instance, as Sullivan illustrated, “you can do a search like ‘when was the wife of Obama born’ and get an answer about Michelle Obama… without ever using her name.” RankBrain was designed to take these concepts even further by looking for similarities between new and old searches, or, as Greg Corrado, a senior search scientist at Google, put it, “That phrase seems like something I’ve seen in the past, so I’m going to assume that you meant this.” Some SEO bloggers claim that the introduction of RankBrain to the algorithm set was the point when Google first started understanding what SEO professionals call “search intent,” that is, Google’s alignment of search results with users’ purpose for searching. However, nothing that was ever officially reported by Google upon the release of RankBrain confirms this theory. There is also a lot of conjecture in the SEO community if you could really “optimize” for this algorithm or not. Additionally, many SEO professionals focused on this algorithm’s importance in the overall collection of algorithms. A quoted Google representative said it was the third most
important after “links” and “words,” as Sullivan put it, which we can safely assume to be PageRank and Topicality, accordingly. I wouldn’t concern yourself as much with these theories, and instead, just be thankful that you don’t need to write content with every possible variation of a word to appear for relevant searches.
SITE SPEED/CORE WEB VITALS In 2010, Google first started using how quickly a web page loads on a desktop computer as a ranking signal. Why? Because slow loading web pages are bad for business for both Google and the web page owners. In 2018, Google expanded this focus on site speed to include mobile web pages as well, further proving that they are not messing around in this area. In early 2020, Google introduced a new set of tools to its Google Search Console, called the Core Web Vitals, and stated explicitly that the metrics found there would become ranking signals starting in 2021. Core Web Vitals absorbed the site speed metrics looked at previously and expanded into new areas that thankfully needed to be addressed (such as the sloppy way some web pages load advertisements and other images).
MOBILE Depending on which study you read, anywhere from 60%-70% of all searches start on a mobile device. Google has been pushing mobile-friendliness as a ranking signal since at least 2015; however, in 2018, they made it official by focusing on what they call the “Mobile-First Index” process. “Mobile-First” does not mean “mobile-only,” but instead that Google now looks at the mobile version of your website first during the process of evaluating your website. After the introduction of this algorithm, the days of website owners not concerning themselves with mobile-friendliness were officially over. While the “Mobilegeddon” update wasn’t the bloodbath that the SEO press made it out to be, the importance of mobile cannot be undersold here. There have been numerous articles written on the subject on mobile optimization, most of them by the legendary Cindy Krum, who literally wrote the book on the subject, so I won’t spend any time on what to do here. Just know that it needs to be done. Google’s focus on Site Speed and Mobile are great examples of the search engine forcing website owners to do what they should have been doing for years, making their websites easier to use. This requirement is kind of like the government telling you to wear a seat belt when riding in an automobile – you should do it because it keeps you safe and is a smart thing to do, but sometimes, people just want their “freedom” (to be ejected through the windshield of their car). As a website owner, you should want to make your website fast loading and functional on mobile devices because your customers want that, but that wasn’t happening as much as it should. So, Google said, “if you want to show up in organic search results, you should do these things,” so now more website owners concern themselves with these matters.
PULLING IT ALL TOGETHER: HOW GOOGLE REALLY RANKS WEB PAGES
Now that you know all the various aspects of Google’s ranking system, here’s the most important lesson: How Google combines these multiple algorithms to determine the rank of a given web page. While most would assume that Google assigns a score for each of these areas then simply adds them up for a total score that equates to rank for a given query, they would be using the incorrect arithmetic operator. In fact, according to Gary Illyes, on that beautiful day in Sydney, Google assigns a score for each of these areas then multiplies those scores for a total score that determines the rank for a web page in the results for a given query. To see why this is important, one has only to remember the difference in outcomes for 1 plus 0.1 versus 1 multiplied by 0.1, which is 1.1 and 0.1, respectively. This mind-blowing news means that there is no specific priority for these various algorithms in the grand scheme of things. One could spend all their time making sure that their website was the fastest amongst their competitors but get dragged down by low-quality content. You could spend all your marketing budget on the best writers for your content only to be ranked lower because your website wasn’t optimized for mobile devices. There is no silver bullet when it comes to Search Engine Optimization. In summary , If you learn anything from this discussion of how search engines work, remember this: Search Engine Optimization is about doing all the marketing, website design, and public relations tactics that roll up to form SEO. These tactics aren’t about writing a specific number of words in an article or attempting to trick Google by abusing canonical tags, but about creating excellent content for your target audience on a properly built website. Search Engines are incredibly complex systems, but they are systems designed to bring out our best efforts. SEO is work and lots of it.









