
7 minute read
Student Feature: Compressing Neural Networks


by Mayur Dhanaraj and Panos P. Markopoulos
In the modern technological era, artificial intelligence (AI) is ubiquitous. Commonly used devices such as mobile phones, smart TVs, smart watches, and security surveillance cameras, among many others leverage AI in order to offer smart capabilities, revolutionizing everyday life. Some exciting and important applications of AI include self-driven cars, voice recognition, face recognition, disease diagnosis, real-time health monitoring, and enemy aircraft detection in defense, just to name a few. AI is the intersection of compute (including powerful graphical processing units (GPUs) and large storage capabilities), data (availability of large corpus of data to learn from), and algorithms to process this data and derive useful underlying patterns that enable autonomous decision making. These three pillars of AI are shown in Fig. 1.

Fig. 1: The Trinity of Artificial Intelligence.
Thus, the success of AI can be attributed to the availability of large data sets, powerful computational resources, and effective data processing algorithms that enable the system to derive meaningful latent information from data, which in turn is used to make automatic decisions. Just as humans learn their surroundings through many examples and continuous reinforcement, an AI system also learns by looking at many examples of a certain object of interest and updates itself to generalize well on examples that it has not seen before.
An artificial neural network (ANN) is an example of an algorithm that learns an underlying pattern from given data and thus imparts intelligence to the AI system. Traditionally, ANNs were inspired by the neural networks in the human brain. The key idea was to mimic the human brain by recreating artificial neurons on hardware which are inter-connected just as neurons are in a human brain. Similarly, the goal was to strengthen certain connections in an artificial neural network such that it generalizes well on unforeseen data. ANNs employ many layers, each consisting of multiple neurons (nodes). These neurons collect all the connections from a previous layer and aggregate it by means of mathematical operations. This procedure is repeated for all neurons in a layer. It is empirically shown that the layers of artificial neurons are able to learn abstract representation of the data, thereby deriving useful data features, resulting in autonomous decision making. Moreover, if large datasets are available, neural networks with many layers –deep neural networks (DNNs) perform better than shallow ones. A pictorial representation of a deep neural network is presented in the Fig. 2 below.

Fig. 2: Pictorial Representation of a Deep Neural Network.
Typically, these DNNs contain thousands of layers, tens of thousands of neurons, and millions of connections in them. Although deeper neural networks yield better performance, they are bulky and warrant the use of powerful GPUs and large storage capabilities.
For image datasets, a specialized DNN known as the convolutional neural network (CNN) is employed. CNNs leverage the spatial context in images by means of a mathematical operator know as convolution. On a high level, CNNs comprise of a series of convolutional layers, wherein each layer extracts various image features that are later used to make predictions. In general, earlier convolutional layers extract general (low-level) features such as edges, curves in an image and deeper layers extract finer (high-level) features such as shapes and objects. Empirical evidence has proven that CNNs are the backbone of image-based artificially intelligent devices. They attain top performance in computer vision tasks, such as image classification, facial recognition and detection, image segmentation, animation, pose estimation, and object detection, among many others. However, similar to DNNs, state-of-the-art CNNs contain millions of parameters leading to massive model sizes, thereby making them infeasible for use in compact mobile devices.
Need for CNN Compression.
Convolutional neural networks (CNNs) are the backbone of image-based artificially intelligent devices owing to their top performance in computer vision. The superior performance of CNNs can be attributed to their enormous depth and width. State-of-the-art CNNs are thousands of layers deep and consist of tens of millions of parameters, leading to expansive model sizes. Such large models require large storage and computational capabilities. On the other hand, edge devices such as mobile phones and smart watches are resource constrained. The available compute, memory, power, and storage capabilities are limited and therefore, it is infeasible to deploy bulky CNNs on them. In order to leverage the superior generalization capabilities of CNNs, cloud inference is often preferred. In this approach, the large CNN model is hosted on a virtual cloud. When the edge-device collects data samples, it transmits them to the cloud over the internet, wherein the CNN model is used to perform inference on this data. Subsequently, the inference results are transmitted back to the edge-device as depicted in Fig. 3.
Although this is a straight forward workaround to enable edge-devices to access the powerful generalization of CNNs, it is restricted in many Fig. 3: Pictorial Representation of Cloud Inference. ways including, the need for constant, reliable internet connectivity, overhead cloud compute costs, speed of inference being limited by the speed of internet, privacy and security concerns because the data leaves the edge-device and travels through the internet making them susceptible, and more greenhouse emission due to the operation of large deep learning models. One approach to overcome all these issues is to compress the large deep learning models in order to deploy them directly on edge-devices.

Fig. 3: Pictorial Representation of Cloud Inference.
CNN Compression Methods.
Recently, the area of CNN compression has attracted significant research interest, with multiple techniques proposed in the literature to this end. Principal approaches include pruning - wherein some nodes/layers are pruned/removed to reduce the model size, quantization - wherein the parameters are stored in lower precision to achieve space savings, knowledge distillation - wherein a smaller student model is trained to mimic the performance of a larger teacher model, and tensor methods – which involves the use of multilinear algebraic operations to manipulate the parameters in a CNN to achieve compression. Importantly, as the parameters in a CNN assume a natural tensor (multiway array) structure, tensor methods are well-suited to take advantage of this fact to achieve significant model compression. At the MILOS lab, we focus on leveraging tensor methods for CNN compression, wherein we strive to develop lightweight layers to replace parameter-dense convolutional layers, in order to achieve significant reduction in model sizes, while maintaining the original machine learning performance. We present a visual representation of a compressed deep neural network in Fig. 4 consisting of much fewer layers and/or nodes compared to a deep neural network as in Fig. 2.
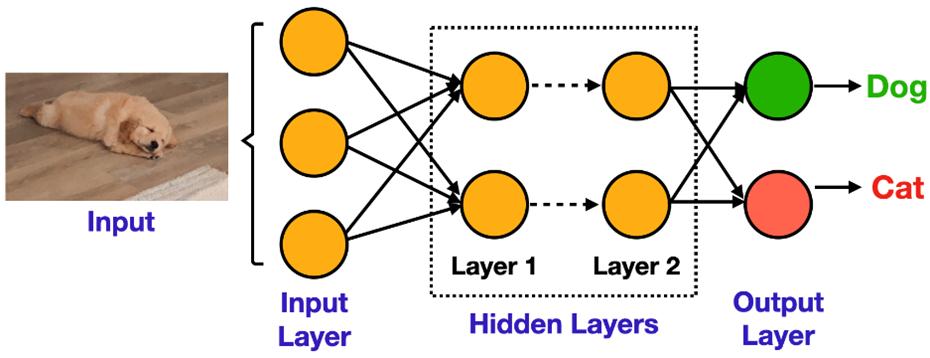
Fig. 4: Pictorial Representation of a Compressed Deep Neural Network.
In summary.
Despite the widespread applicability of AI models, deep learning networks have massive sizes and cannot be deployed on resource-constrained edge devices such as mobile phones and smart watches. Although cloud inference is a straightforward workaround to this issue, it comes with its own problems including the need for constant internet connectivity and privacy and security concerns. Researchers have recently focused on compressing bulky deep learning models in order to deploy them directly onto the edge device. Our research involves the replacement of the bulky CNN layer by a lightweight layer that incorporates multilinear operations, leading to significant parameter savings, and reduction in model size, while preserving the original machine learning capacity. q
Author Bio's:
Mayur Dhanaraj is a PhD candidate and a research assistant at the Machine Learning Optimization and Signal Processing (MILOS) Laboratory, housed in the Department of Electrical and Microelectronic Engineering at the Rochester Institute of Technology. His research interests include machine learning, deep learning, and signal processing, with a focus on the development of theory and algorithms for reliable data analysis, and techniques for deep learning model compression.
Panos P. Markopoulos is an associate professor in the Department of Electrical and Microelectronic Engineering at the Rochester Institute of Technology. He is the director of the Machine Learning Optimization and Signal Processing (MILOS) Laboratory. His research interests include machine learning, data science, and adaptive signal processing, with an aim to advance efficient, explainable, and trustworthy artificial intelligence. His research group has attracted funding on exciting projects from the NSF, NGA, AFOSR, AFRL, NYSTAR/UR CoE in Data Science, L3 Harris, and RIT-KGCOE.





