11 minute read
Computer Science


Isaac Winston
Abstract: In this project, I trained a computer to play rock-paper-scissors through gesture recognition from a webcam feed. I did this by segmenting skin from the video, and then feeding the result through a classifier that decides whether the current image is rock, paper or scissors. The computer randomly chooses a gesture itself and decides the winner. Provisional results show that the images are classified with an accuracy of ~91%. In the future, I want to add a tactics engine to infer what the user is likely to pick next based on past actions. Adding a robotic arm to show the computer’s choice would make the game more interactive.
Advertisement
Introduction Rock-paper-scissors Rock-paper-scissors (RPS) is a two-player game, where players secretly choose rock, paper or scissors before revealing their choice using a hand gesture. Each of the items (rock, paper or scissors) beats one other specific item, loses to one other specific item, or draws if the opponent picks the same item. In this project, I aim to use computer vision to recognise the RPS hand gestures so that a computer can act as the second player. Computer vision/AI Computer vision is a subset of Artificial Intelligence (AI) techniques. It aims to let computers process (“look at”) images/videos and interpret them for further processing such as decisionmaking. Here, I aim to train a computer to look at a video feed and decide if a person is playing rock, paper, or scissors. If I imagine my brain playing RPS, I first look at an opponent, then separate the hand from the rest of the image, work out what gesture the hand is showing, and finally work out who won. On a computer, we will use a similar set of processes. Neural Networks Neural networks are a type of Machine Learning, which is a type of AI technique as illustrated in Figure 1.
Artificial Intelligence
Machine Learning
Neural Networks
Figure 2: Terminology in the hierarchy of AI techniques16
16 Image idea source: Neural Networks from Scratch (nnfs.io), by Harrison Kinsley and Daniel Kukiela P. 11, Published 2020
Figure 3: The inner workings of an individual neuron in a neural network
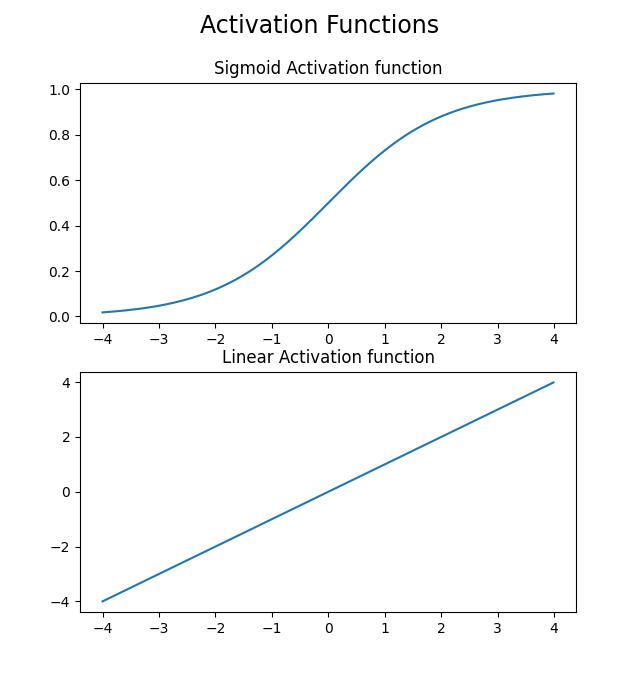
They provide a way of using computers to solve problems that are hard to solve by writing rules out manually. They work by having lots of “neurons” (so-called because neural networks resemble aspects of the way the brain is structured) that are connected. Each neuron holds a value, which is calculated as the sum of all of its inputs multiplied by their associated weight. A bias is added to the value to give the neuron’s output (Figure 2). On top of these weights and biases, each neuron’s output gets transformed through an “activation function”. There are many types of activation function, for example Figure 3 shows sigmoid and linear activation functions.
Figure 4: Sigmoid and Linear activation functions
Figure 4 shows my code (implemented in Python) for a forward pass of one “layer” of neurons (one vertical column in Figure 5). This code calculates the neurons’ output by multiplying the inputs by the weights and adding the biases.
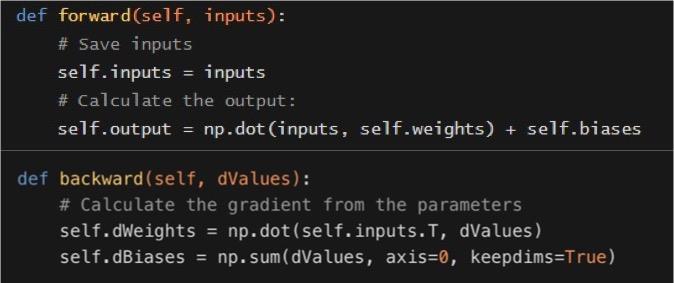
Figure 5: The code (implemented in python) for the forward and backward pass of a neural network layer
The neurons are connected together in layers to form a neural network. Three main types of layers form a neural network: input layers, output layers and hidden layers. Typically, there is only one input and one output layer. Hidden layers are in the middle of the network and if there are more than two hidden layers, the neural network is considered ‘deep’. Figure 4 shows a simple neural network with one input layer, a single hidden layer and an output layer.
Input layer Hidden layer Output layer
Figure 6: A diagram of a simple, 3-layer neural network
The weights and biases are tuned in a process called optimisation. In optimisation, input data for which the true result is known is used (“training data”), e.g. we show it a picture of “rock” and see if the network thought it was a “rock”, “paper” or “scissors”. We then measure the “loss” of the neural network, which is a metric of how close we are to the desired output. In the optimisation process, we aim to minimise loss, meaning the meaning the network is generating accurate predictions, and this is done by changing the weights and biases to move the performance of the neural network closer to the correct answer. Derivatives are used to see what a small change in the weights does to the output, and then we calculate the gradient over those small points. A piece of code (“the optimiser”) looks to see if the changes make the neural network behave more or less optimally, by comparing the target outputs to the current outputs that the neural network offers. The weights and biases are then changed accordingly. This process is repeated lots of times until the network behaves in a way that is optimised. If the optimisation process results in more accurate expected outcomes, then the neural network has trained successfully. The backward pass code (Figure 3) is similar to the forward pass, but here we change the weights, so we can calculate the gradient.
One of the other common problems in machine learning is ‘over-fitting’. This is where the neural network memorises the training data, so it thinks it is doing well, but in reality it is not –when it is tested on new data that it has not seen previously, it fails. The way I mitigate this problem is with batching (dividing up the data and running lots of versions of the neural network at once), and with dropout. Dropout randomly resets weights and biases, and according to this paper17, it works! Methods: Overview In this project, when I was planning the overall workflow, I divided it into sub-problems: Camera reader → Skin segmentation → Classifier to classify masks → Game engine → Interface
The first step is to obtain the data from the computer camera. I next thought it would be important to restrict the image to only the parts which are skin as this will remove any background that could otherwise distract or confuse the classification of the hand as showing “rock,” “paper” or “scissors.” Segmenting the image into skin and non-skin will give a “binary mask” (a special type of image where ones are skin and zeros are everything else) and this will be classified as “rock,” “paper” or “scissors.” This decision will be fed to a game engine which chooses what the computer plays (before seeing the camera result) and works out who won.
The camera reader (step 1 above) is relatively simple, as the Python plugin ‘opencv’ has a VideoCapture18 function that lets the computer access a webcam feed. The other problems have their own dedicated sections below.
Skin Segmentation
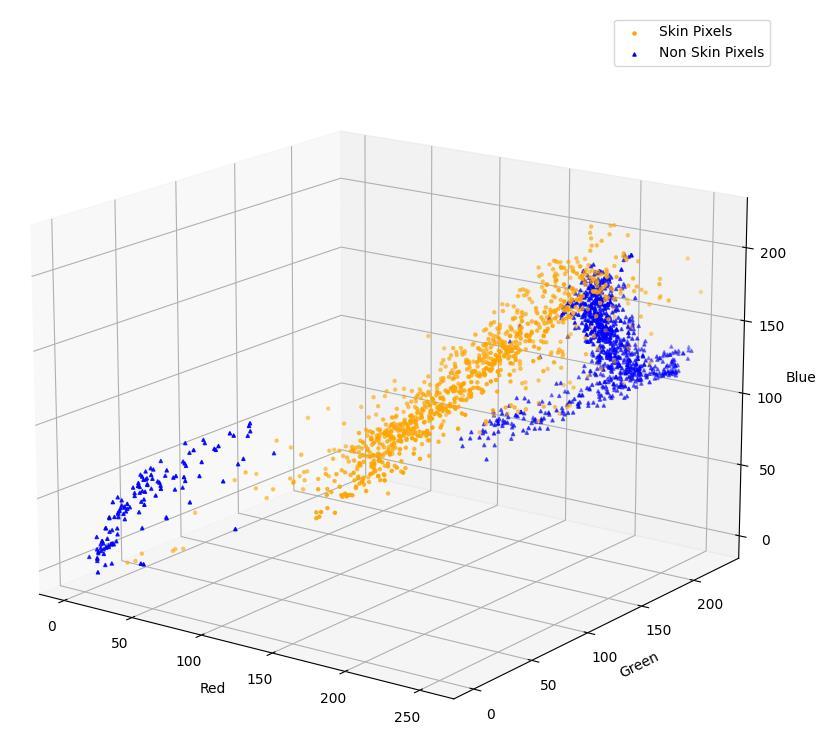
Figure 7: Colour Distribution of skin and non-skin pixels in RGB. Each pixel in any colour image can be considered as a combination of red (R), green (G) and blue (B) intensities. Here they are plotted according to those three values and divided into skin (yellow) and nonskin (blue)
17 Dropout: A Simple way to prevent Neural Networks from overfitting. [Accessed 17/1/22] (https://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf) 18 Read, Write and Display a video using OpenCV. [Accesed 17/1/22] (https://learnopencv.com/read-write-anddisplay-a-video-using-opencv-cpp-python/)
When looking at this problem, I first took pictures of hands showing the three poses and drew around the outline of the hand/arm to manually define which image pixels showed skin and which were non-skin. I then plotted Figure 6, which shows the colour distribution, in RGB (red-green-blue), of the skin and non-skin pixels. There is clearly some separation, so I trained a neural network using my IAW_AI neural network library, that flexibly implements neural networks in python. Using this, I tried to classify the skin versus non-skin pixels. After looking at the results, I decided to try the colour space LAB (Figure 7), which seems to separate skin from non-skin pixels better, hence I retrained the neural network on pixels that were in LAB colour space and could now get more reliable masks. Masks would sometimes have small holes in them, and small separate parts of the image were incorrectly classified as skin, so I added a post-processing algorithm to take the masks, fill the holes and then take the biggest object to be the hand. This cleaned up the masks considerably. This processing workflow is illustrated in Figure 8.
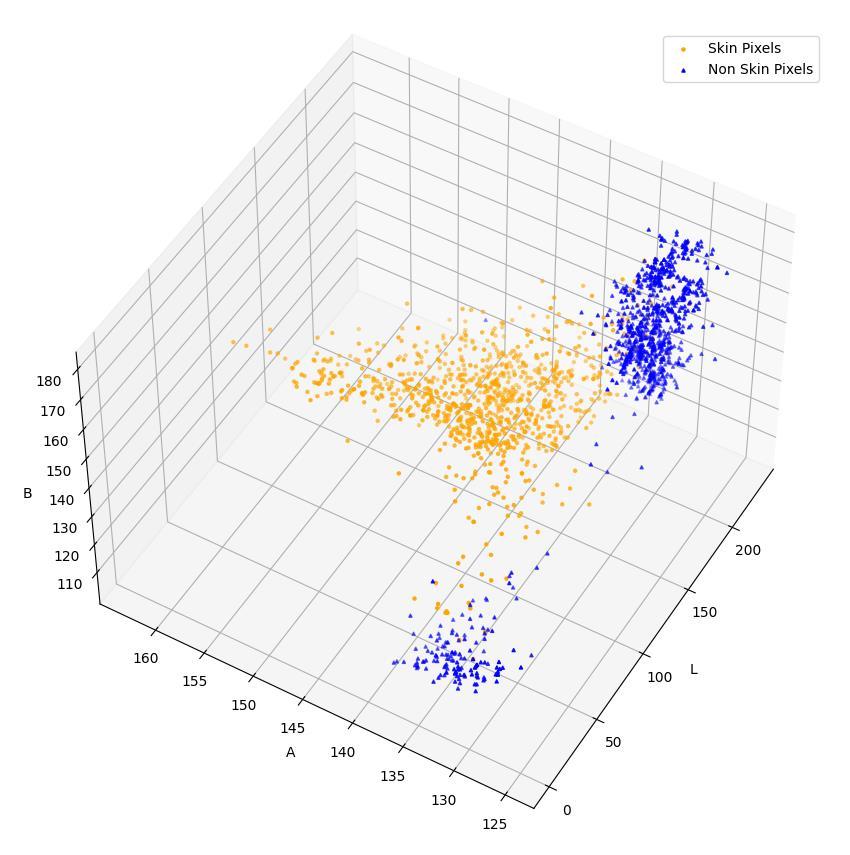
Figure 8: Colour distribution of skin and non-skin pixels in LAB colour space –it is easier to see the separation of skin and non-skin than when the image is represented in RGB
Figure 9: Skin segmentation processing workflow

Another problem that needs to be worked on within skin segmentation is racial discrimination, such that I do not only train data on one skin colour. Avoiding this bias in the neural network would require including hands of a variety of skin colours in training data. This is a really big problem in computer science, particularly in machine learning, as otherwise we
end up with unintentionally “racist” neural networks. LAB colour space may also have some further advantages for skin classification over RGB colour space19 . RPS Classification Once I had masks, I worked on teaching the computer to classify these masks. If the images were 100px by 100px (close to their original resolution), then the neural network would have to have 10,000px inputs. This is impractical as the computer needs to process lots of images in quick succession. Hence, I settled on resizing the images to 20px by 20px and found that I could still easily classify them manually, so I trained the neural network based on these. To account for rotation, I programmed a function to directly find the ‘true centre’ of the image, and then calculate the orientation, so I could rotate an image to be pointing upright in one step (Figure 9).
Figure 10: Image mask auto-rotate function
I programmed a function to crop the images to the hand (so scale would not be an issue), and then add blank space to the edges as needed (“pad” them) so that they were all 20px by 20px. To train a neural network, a training dataset is needed. To create this, I first captured video footage of family members and me doing the RPS hand gestures. I then sampled every 20th frame from this footage, and manually marked it as rock, paper, or scissors. This created my training dataset. When training the neural network classifiers, I also flipped all the images in my training data, so that it would accommodate for both left-handed and right-handed input images. RPS Game
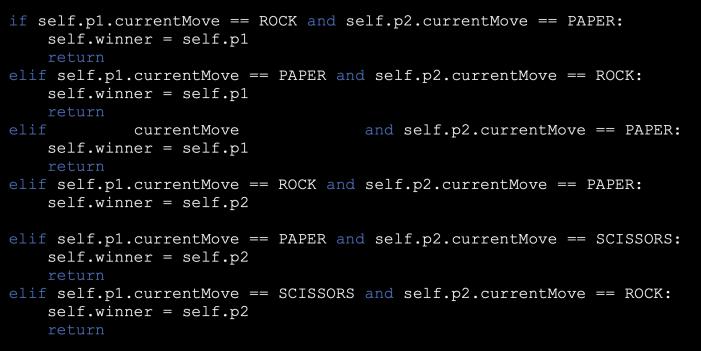
Figure 11: RPS if statements
19 J. Montenegro et al, A comparative study of color spaces in skin-based face segmentation, 2013 10th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), 2013, pp. 313-317
The RPS game is simple. The computer chooses randomly from rock, paper or scissors and follows a group of “if” statements that decides who won (Figure 10). The user interface of the game consists of two interface panels, one that lets the user set left/right-handedness and data-display preferences, and the other panel is the game window. The game window shows a live webcam feed with a box for the user to keep their hand in, and the box colour shows the result (Figure 11).
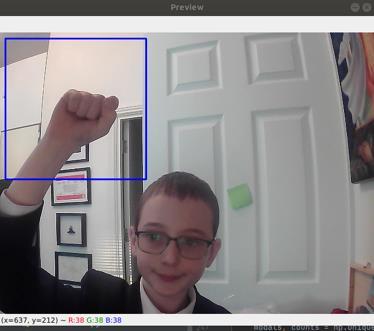
Figure 12: RPS main interface
Conclusion In conclusion, I think that this was a worthwhile project, and highlighted for me some critical issues in AI including human biases in training data. It also taught me a huge amount of array manipulation in python. In the future, I want to improve it in several ways: 1) adding a better interface 2) enhance the classification as it is incorrect around 10% of the time 3) make the classification more robust to challenging environments with imperfect lighting or a noisy background 4) make the computer’s choice non-random, e.g., based upon the players’ historical choices 5) make the game more interactive by having the computer express its choice with a robotic hand
The skin segmentation ended up working really well, and I am very happy with it. In the future, I want to try bypassing this step, and see how well it performs just with one neural network doing all the processing. The RPS neural network could be improved by adding more layers and improving how it loads into RAM (during training I was experiencing memory leaks, so I started to make it more efficient but this could be implemented more professionally).
Bibliography: • Read, Write and Display a video using OpenCV. [Accessed 17/1/22] (https://learnopencv.com/read-write-and-display-a-video-using-opencv-cpp-python/) • Dropout: A Simple Way to Prevent Neural Networks from Overfitting. (2014), (15). Retrieved 17/1/2022, from https://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf. • Harrison Kinsley & Daniel Kukieła Neural Networks from Scratch (NNFS) https://nnfs.io • J. Montenegro et al, A comparative study of color spaces in skin-based face segmentation, 2013 10th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), 2013, pp. 313-317
Further resources used: • Useful introduction to the maths behind neural networks: But what is a neural network? | Chapter 1, Deep learning. (2017). From https://www.youtube.com/watch?v=aircAruvnKk. • Introduction to calculus: The essence of calculus. (2017) https://www.youtube.com/watch?v=WUvTyaaNkzM • This series was very useful to explain computing problems, and it helped me understand lots of critical concepts in how to write fast, efficient code. It was also a great resorse to look information up in: Knuth, D. (1997). The art of computer programming. Addison-Wesley.




