
9 minute read
Data Management


ARCH9090 2h
DATA DATA MANAGEMENT MANAGEMENT
Advertisement
Reply to ARCH9090...
DATA MANAGEMENT
Public involvement in this study was conducted by consulting the public through three methods – Searching internet databases (Twitter), Online Questionnaire and Online In-depth Interviews. All the process has been carried out collaboratively by four researchers (authors of this report), who are based in Sydney during the Intensive December 2021 session of the University of Sydney.
INTERNET DATABASE (TWITTER)
Data from secondary data sources like internet databases (Twitter) has been used to understand the opinion of various stakeholders like public, personalities, government, social media platforms, third party organisations on social media censorship across the world.
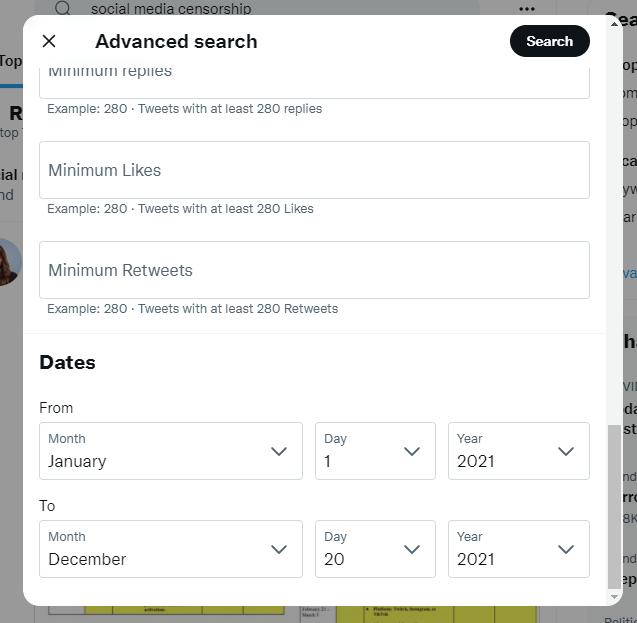
Although various methods and software are available to scrape twitter data, considering the time and cost constraints for this report, the twitter data has been collected using the in-built ‘advanced search’ filter in twitter (as shown in Fig. 7). Key words, hashtags, languages, and dates have been used to filter out relevant information (as shown in Fig. 8). Although twitter data is available in many languages, it is to be noted that the report captures opinions and information that are posted in English only (as shown in Fig. 9). To maintain the relevancy of the data, the search was limited to post from 1st January 2020 onwards (as shown in Fig.10). This process of scraping twitter data was conducted over the intensive December session of the University of Sydney from 29th of November to 22nd of December 2021.
This non-linear research path explored the opinions and information on social media censorship from various mainstream and minority organisations including Chron, The Hill Corporation, Talk Radio, 7 Amleh based out from different parts of the world. The posts were explored and illustrated in the findings section of this report to understand various topics like the type of content that are censored and the social media governance structure across the world. The findings sections also explore the freedom of speech in social media platforms by following minority organisations as well. The number of tweets and followers of an organisation were taken as a data point to measure the popularity and the credibility of the organisation followed.
Figure 7: Shows the filter option with respect to location and social networks in twitter (Twitter, 2006) Figure 8: Shows ‘advanced filter’ through hashtags and keywords in Twitter (Twitter, 2006)


Figure 9: Shows ‘advanced filter’ through language in Twitter (Twitter, 2006) Figure 10: Shows ‘advanced filter’ through date range in Twitter (Twitter, 2006)
ONLINE QUESTIONNAIRE
Online survey has been used as one the consultation strategy to gauge a broad understanding of the public on the issue of social media censorship. The method was used as a primary strategy to study the characteristics, behaviour, and expectations on social media censorship across different backgrounds and age groups.
DESIGN OF QUESTIONNAIRE
The questionnaire design is a critical component to give effect to this consultation strategy. The length of the questionnaire was decided based upon a reasonable time of five minutes to complete the entire survey by the respondents. The questions were initially drafted through collaborative effort of all the researchers on a Google word document, which after final draft was entered on the Qualtrics platform. The total of nine questions were subdivided into 4 sections, while the first two sections recorded the characteristics of the respondents, the last two sections recorded the experience & opinion regarding content and governance structure for the censorship respectively. It is to be noted that although the first two sections record the characteristics of the respondents, the first section is also used to filter out the participants who do not use social media. This is done by terminating the survey for those respondents who chose the exclusive option of “I do not use social media” in question one (Refer Appendix).
The questionnaire was designed with single choice or multiple-choice answers to enable precise measurement between all respondents. It is to be noted that most of the single/multiple choice questions had an option of ‘other’ with space for data entry to record the answers not listed in the options. This feature allowed a flexibility in closed questions to discover answers not previously hypothesised by the researcher. The different types of scales used in the questionnaire were the discrete scale and the Likert scale. For instance, in question no. 2, the ages were grouped into discrete scales depending upon the characterises of the social media usage. While in question no. 3, the data of average time spent on social media from the fact sheet were used to formulate its discrete scale. On the other hand, question number 6, shows the application of the Likert scale in the questionnaire (Refer Appendix).
RELIABILITY
The overall quality of the questionnaire was controlled through various settings. An introduction section with an outline of survey and participation consent has been introduced in the beginning of the survey (as shown in Fig. 11). Additionally, human captcha verification has been introduced to eliminate bots participating in the survey (as shown in Fig. 12). To improve the response quality, all the questions in the questionnaire were made compulsory, by choosing the ‘Force response’ option in the Qualtrics. The user interface of the survey was enhanced through improving the graphics by introducing thematic background image, completing bar and transition effect.
After the completion of the questionnaire, the survey was published for beta testing through Qualtrics, and the ‘anonymous link’ was generated. The link was circulated among the researchers, supervisor, and few close friends to understand the quality of the questionnaire. The questionnaire was subsequently improved with the feedback received for the final rollout.
DATA COLLECTION
The sampling for the data collection has been carried out through a non-probabilistic convenience sampling method. Each of the four researchers listed down 25 close friends and families to whom the generated anonymous link was circulated. Although it was ensured to circulate the link among people of varying age groups, it is to be noted that the age and social network of the researchers play a dominant role in the sampling of the participants. The survey was collected from the public on 13th and 14th of December 2021. The quality of the responses was maintained by deleting the incomplete entries. A total of 100 fully completed survey were collected.
DATA ANALYSIS
The data collected was analysed using the inbuilt ‘data and analysis’ feature of the Qualtrics. Each of the responses was tabulated into bar graphs, and pie charts to analyse the responses. It is to be noted that the outlier information has also been captured during the analysis. The analysis of the data provided insights on the experiences, opinion, and expectation of the wider public on the future of social media censorship.
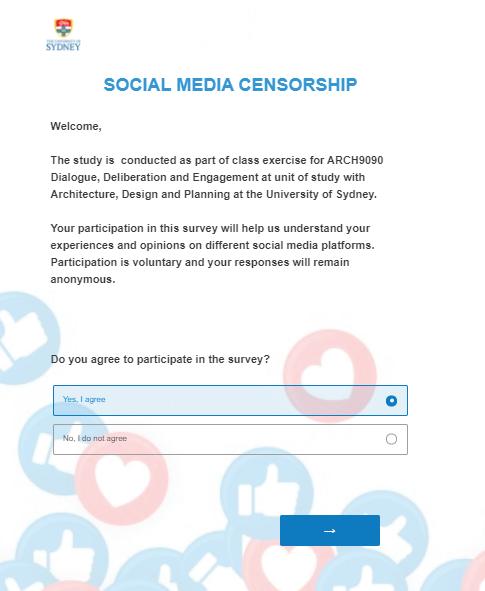
Figure 11: Introduction section of online survey showing the outline of the survey and consent to proceed (Begum et al., 2021).
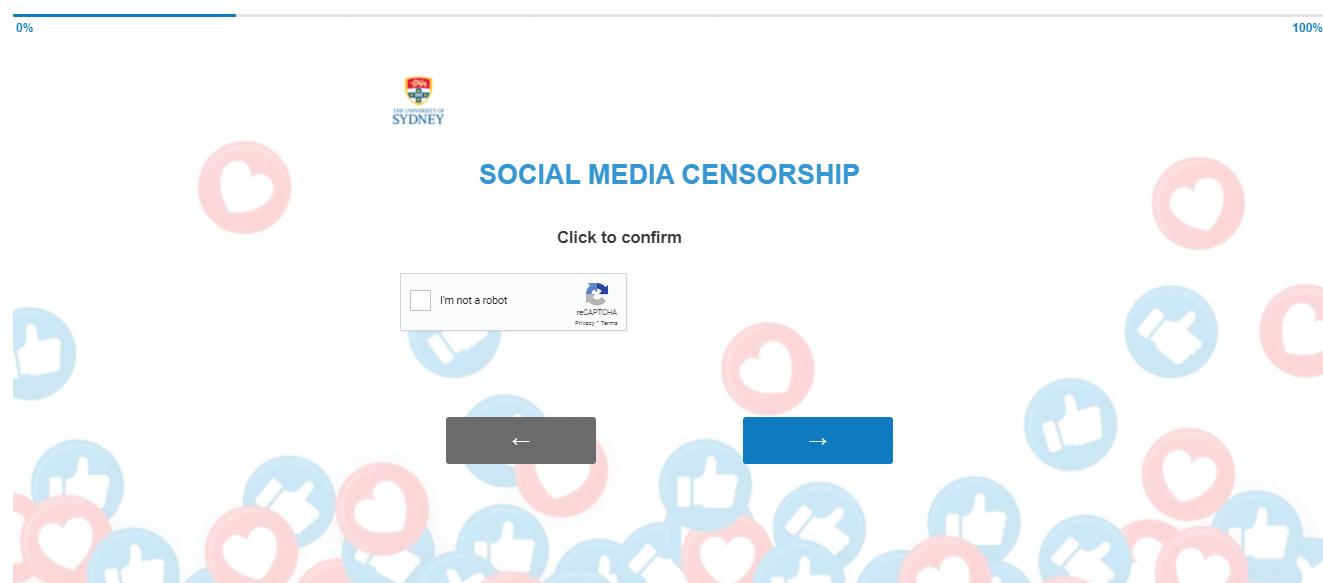
Figure 12: Introduction of human captcha verification in the online questionnaire has been introduced to eliminate bots participating in the survey (Begum et al., 2021).
ONLINE IN-DEPTH INTERVIEW
An online in-depth interview was conducted to comprehend the context and gain a deeper understanding on the issue of social media censorship. This resource intensive task involved interview structure formation, organising interview logistics, conducting interviews, and analysing its data.
INTERVIEW STRUCTURE FORMATION
The interview structure was formulated as a collaborative effort of all the researchers. An exhaustive list of possible questions was tabulated in a google word document, considering topics like interviewee’s characteristics, experience, opinions, knowledge, and expectations. Although the list has been exhaustive, it included the important questions (demarcated in red) and the probe questions (as shown in the Appendix). The integrity of the answers was maintained by keeping the questions open ended and unbiased. For instance: An open question like “Have you ever been reported or have you ever reported any content on social media?”, is followed up with probe questions like “Would you like to elaborate more on the incident?” (For those who have answered YES) or “What type of content do you usually post or see on social media?” (For those who have answered NO). This process not only keeps the question open ended, but probes to extract more detailed information.
In addition to formulation of questions, a ‘participation information statement’ and ‘participant consent form’ were drafted for the interview (as shown in Appendix). These forms provided information on the interview topic, stakeholders, process and requested consent for recording, quoting, identifying the participant, respectively.
An interview schedule for the 30 minutes interview was drafted with questions on Introduction, Characteristics, Behaviour, Opinion, Knowledge, and Expectations sections being allocated one, three, six, six, five, and seven minutes respectively.
ORGANISING INTERVIEW LOGISTICS
The logistics for the online interview were organised by each of the four researchers by scheduling a personal interview room on Zoom application. It is to be noted that settings for the meeting were set to ‘Automatically record the meeting’ ‘In Cloud’ (as shown in Figure 13). This process would enable the automatic transcription of the meeting after the end of the meeting. A setting to enable zoom waiting room was enabled to prevent zoom bombing or entry of other participants during the interview process. After the beta testing of the scheduled interview zoom room to prevent any technical glitches, the zoom meeting link was shared on the padlet on ARCH 9090 in the canvas for the interviewees to enter the room during their time slot.
ORGANISING INTERVIEW LOGISTICS
A total of 12 interviews were conducted with each of the researchers individually conducting three interviews in their respective zoom room. The interviews were conducted on 14th December 2021 from 13:10 hours to 14:40 hours AEST with each of the interviews lasting for upto 30 minutes approximately.
As soon as the zoom meeting was started by the interviewer, the recording was stopped. When the first participant entered the zoom room the interview process began. The process began with introducing the interviewer, explaining the interview topic & process followed by requesting the consent for recording, identifying, and quoting the participants. When the participants granted their consent the recording ‘in cloud’ option was selected by the interviewer. The interview was guided by the researcher in accordance with the above discussed interview schedule and all the meetings were completed ahead of the scheduled time. After the first participant exited the zoom meeting, the recording was stopped and the next participant in the waiting room was allowed to enter. This process was repeated for all the participants. It is to be noted that the participants were pre-determined by the ARCH9090 unit coordinator and were well informed about the topic through the Fact Sheet shared before the interview process.
DATA ANALYSIS
After the completion of the meeting, the recorded interview was automatically transcripted in English by the zoom application. The recordings and the transcription that were available on the cloud (accessible through university mail id) were individually reviewed by the researchers and synthesised into the answers for each of the questions as outlined in the question formulation section. The main answers revolved around the characteristics (age, location, work), behaviour (social media usage pattern & purpose), experience (reporting or have been reported), knowledge (awareness on existing terms and conditions), and expectation (future of social media censorship in terms of content and governance structure).

Figure 13: Advanced setting for scheduling meetings on Zoom Application (Yuan, 2021).




