11 minute read
Model behaviour


Model behaviour
WE HAVE DECIDED to extend this short run of features, taken as an edited version from Byron Rogers’s blog (www.performancegenetics.com) to three parts instead of the anticipated two, in order to give the detailed explanations that are required.
In this Part II, Rogers explains in detail about how he has used video and image recognition to create his predictive models.
Part I can be accessed online (www.internationalthoroughbred.co.uk) and in that article Rogers explains how he has brought together a data set in order for the computer to categorise the elite and non-elite racehorse.
MODEL STACKING is a machine-learning technique that combines the predictions of multiple models to make a better forecast.
Imagine you have a group of bloodstock agents who are all trying to predict if a yearling is potentially an elite racehorse.
Each agent will have their own unique perspective and will take their own view (let’s say a score from 1 to 100).
If you took the average of the independent predictions of all the experts, you will get a better prediction than any individual expert could make.
Model stacking works in a similar way. We train multiple models – some that are based on video recognition and some on image recognition – on the same dataset.
Each model will learn different patterns in the data and will make its own prediction.
Some models will be very precise (they have a high-strike rate for the ones they like, but miss a lot of good horses), while others will have higher recall (they like more of the good horses, but like a lot more in general), but having variation and ensuring that their predictions are different enough, but useful overall, is what builds a strong model stack.
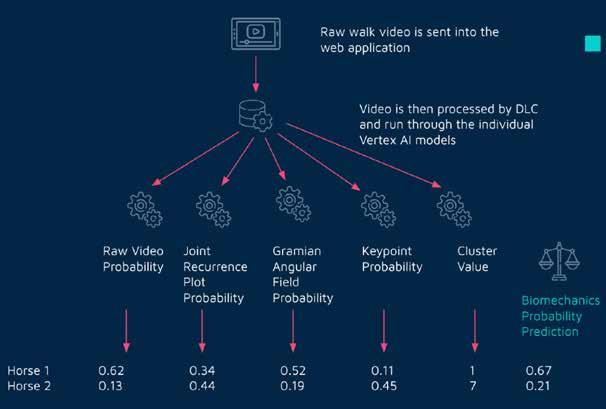
So, for instance, the diagram opposite shows the five models that we have as the base models for our tabular Biomechanics model.
Each base model is trained on the same dataset and then we score all the records in the database and create a second dataset, which is just the probabilities from each of the base models.
The second dataset then produces the overall prediction.
But let’s rewind a little in order to explain the elements of the base models and how they are used.
The Biomechanics Model
The tabular Biomechanics model is our most predictive model, mainly because it is trained on the largest dataset and it uses five different base models to generate the data to make a prediction. Let’s walk (no pun intended) through the process.
We start by clipping a 10-second raw video of the horse walking left to right. It is important to get a good representation of the horse so we want to see it walk as best we can.
Once we have the video, the first process that is undertaken when it is loaded into the application is what is known as “Embedding Clustering”.
In machine learning, embeddings are a type of feature representation that can be used to represent data as vectors.
To explain, let’s say we have a dataset of images of different flowers. We can use a deep-learning model to learn the embeddings for these images.
Once we have the embeddings, we can then use a process called “k-means clustering” to group the images together so that all the roses are in the one cluster, while all the pansies are in another.
It’s not saying one flower is better than another, rather it is just getting them into the same group.
We use Embedding Clustering of the walk videos we input as the first process in order to deal with two things:
1. Variation of distance of the horse from the camera
2. Variation in light/contrast in the video.
So the clustering algorithm puts each of the videos into a cluster, depending on its similarity to other videos.
If they pass the clustering process they are then sorted into one of 10 different clusters.
Each cluster then has its own video and image models trained.
What this means is that within each cluster we are training models that have “like” videos together, but are looking at fine-grained differences between them.
It is significantly more accurate to train the base models on a per-cluster basis than it is to have one general base model.
The Custom Raw Image model: A custom video model is a machine-learning model that is trained on your own data to perform a specific task, such as classifying videos or detecting objects in videos.
For our purposes we are looking at using the custom models for a variety of tasks, but specifically its ability to separate out elite and non-elite horses from walk video.
Effectively we are trying to train a model to judge a “way of going” at a yearling sale and see if it is predictive of its performance later.
It’s no different to what anyone does at a yearling sale, watching a horse walk from left to right, but the model has the benefit of knowing what turned out to be bad as well as good.
The first probability that is scored with any new video is from the raw video model.
As I said each cluster has its own model, so their predictive power is slightly different depending on the cluster. That said, the raw video models for all clusters are invariably the ones with the highest predictive power.
This is the first probability that we get out when a new video is put into the application.
The Keypoint Probability model: DeepLabCut is an open source toolbox that uses deep neural networks to track the posture of animals in different settings. DeepLabCut was primarily built for neuro science studies to understand how the brain
controls movement or how animals interact socially but, for our purpose, we wanted to quantify the variation in bone lengths and angles on a horse at the walk as accurately as possible.
The basics of Deeplabcut is that it is a “markerless biomechanics programme” that allows you to train a neural network to place landmarks on a horse.
We did this and trained a model that had a pixel error of about 6 pixels, meaning it was quite accurate at placing the markers.
What the Deeplabcut package also allows you to do is generate a Keypoint video output of the markers as the horse walks (see above).

Those Keypoint videos, which are representations of the markers of joint positions on the horse, can be used to train a second custom video model that produces another probability for the tabular models.
Generally speaking the Keypoint video models aren’t nearly as predictive as the raw video models. That is understandable as we have stripped away a lot of the informative data in each image of the video.
It struggles to find the elite horse, incorrectly predicting 76 per cent of all elite horses as non-elite.
The Keypoint models are what are known as “weak learners” for the tabular models.
It is a little like a bloodstock agent who goes to a sale who doesn’t like many of the horses, misses lots of good ones, but those he does like turn out to be good so he’s somewhat useful.
The Joint Recurrance Plot model: In addition to being able to produce the Keypoint style videos, Deeplabcut also provides output of the time series data for the markers that it places.
If you can imagine that a 10-second video, shot at 30 frame per seconds is 300 images, one after another, the time series provided is the x,y position on the image for that body part, for every frame/image of the video.
You can do a lot with this data but one of the thoughts that I had was to convert this data into an image – at the time I felt that image recognition was a more mature technology than other methods to analyse time series data.
There is a package known as PYTS: a Python package for time series classification. PYTS allows you to take time series data and transform it into an image, one of these being a Joint Recurrence Plot.
A recurrence plot is an image representing the distances between trajectories extracted from the original time series data.
Similar to the Raw Video and also the Keypoint Video model, we train a separate model for each cluster using the Joint Recurrance Plot.
The plot is a single image, so it is quicker to train, but it is not as good a predictive model as the raw video model.
The JRP image model is quite good at predicting an elite horse, getting it right 68 per cent of the time, but when it comes to predicting the non-elite, it is a coin-flip, so not that useful.
Again, similar to the Keypoint videos, it is a “weak learner” that is useful, but not definitive.
The Gramian Angular Field model: The other way of looking at the time series data as an image is to create it as a “Gramian Angular Field”.
Gramian Angular Field (GAF) Imaging turns out one of the most popular time series imaging algorithms.
Similar to the Joint Recurrance Plot, the approach transforms time-series into images and uses a Convoluted Neural Network, or image recognition model, to identify visual patterns for prediction.
What we are trying to do is look at the way a horse moves in a totally different way to just looking at the video. All body parts (nose, eye, withers, etc) are plotted in the time series data over the walk of the horse.
Similar to the Joint Recurrance Plot, we train a separate model for each cluster using the Gramian Angular Field (GAF) Image as the input to train on.
What is interesting here is that the model for the GAF is somewhat the inverse of the JRP image model.
Where the JRP was able to correctly identify the elite horses 68 per cent of the time, the GAF model can only do so 37 per cent of the time.
But where the JRP model could identify the non-elite 50 per cent of the time, the GAF model can do it 61 per cent of the time.
This discordance is actually quite important as it gets back to what we talked about earlier where if you have one agent who predicts a type of horse well, and another agent that predicts another type well, a judgment of their opinions is better than one alone.
So after all this we end up with five variables from the models.
One of the variables is the Cluster value (so it is a number from 1 to 10) while the others are the probabilities (a range from 0 to 1, with 1 being it is sure it is elite) of the four other models detailed above.
It is these five variables that we use as the basis of the tabular models which we will discuss in the next piece.
The Cardio model
THE cardiovascular video model works the same way as the biomechanics model. Once the video is fed into the application, the first thing it does is apply a clustering algorithm to it. This clustering algorithm works the same way as the biomechanics clustering algorithm in that it is able to separate them into distinct groups. Interestingly, when we looked at the race outcomes of the horses in each cluster, it became apparent that it was quite easy to label each of the clusters with a group name (see table below).
The cardio models are good at predicting if a cardio is an elite cardio, getting that right 74 per cent of the time, but it finds it difficult to predict the nonelite, with success at only 39 per cent. This speaks to what is generally true about cardiovascular measurements in racehorses “there are more good hearts in horses than there are good horses”. Cardiovascular scans are only useful under certain circumstances!
The Conformation model
IN ADDITION to the biomechanics model, we have a conformation model that uses a conformation pose of the horse. There is a bit of a process that is undertaken, but one of the variables that the tabular model uses is a prediction from a trained image model.
The single pose photo is cropped and resized in the application to the same size, which means that the computer vision model is seeing data of the same size.
It’s sort of the same idea as we have with putting videos in clusters. From there the image model is asked to try to learn the difference between elite and non-elite horses by just looking at its conformation as it stands in an image.
We used a larger dataset here with 3,000 images, 1,500 who are elite, and 1,500 who are non-elite, but as you can imagine, it is not a straightforward task to predict if a horse is an elite horse just by looking at a photo! That said, just using an image, we have a somewhat useful model.
It can correctly predict the elite horse 60 per cent of the time and correctly predict the non-elite horse 70 per cent of the time. Similar to the biomechanics model, we use the probability from this model in a larger tabular model.







