
1 minute read
PREDICTING FLOOD INUNDATION IN CALGARY USING LOGISTIC REGRESSION


Flooding is a common type of natural disaster which could cause huge economic and social damages. In this project, we built a model using logistic regression to predict the flooding inundation of Calgary.
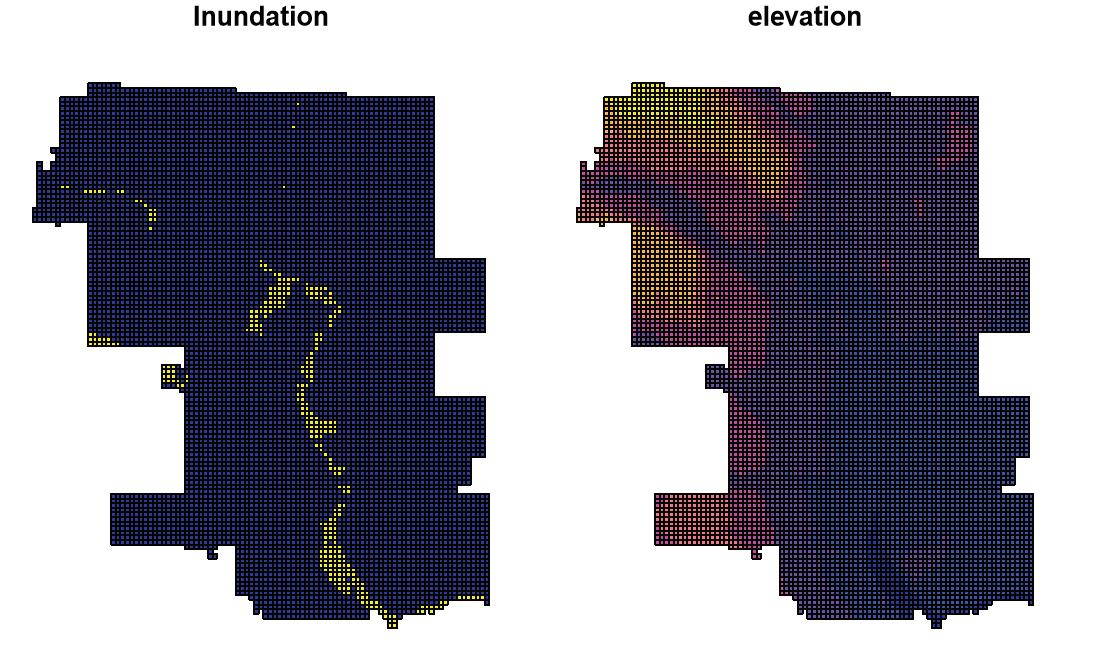
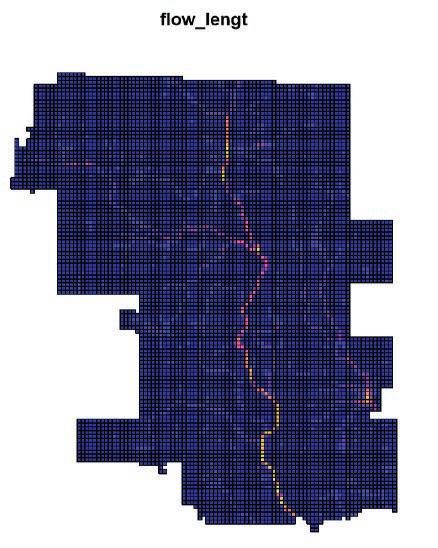
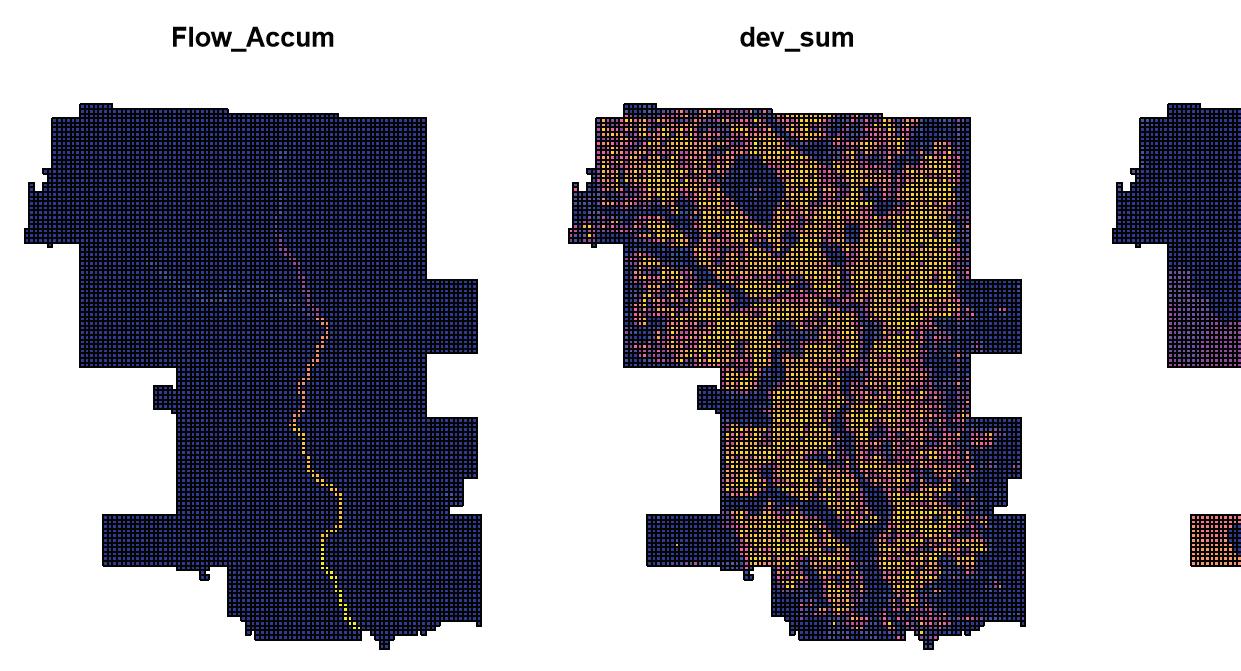
In the feature engineering phase, we took three different categories of variables, including Geographical and census data, spatial, and hydrological data as predictive variables to capture the characters of flooding locations. For instance, we included Flow Accumulation,, Flow Length, Basins, and Distance to water bodies to represent the hydrological condition of Calgary. These variables then, have been put on fishnet to determine their association with flood in 2013.
Advertisement
March. 2020 Group Work with Haitian Wang
CPLN675
Mentor: Ken Steif
Hydrological
Flow Accumulation Flow length Basin Distance to water bodies
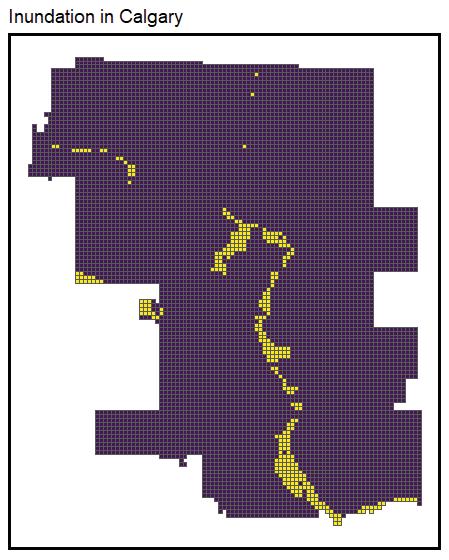
The next step for our model process is split data randomly into 70% training set and 30% test set and then build the model on training set and validate the model on test set. The dependent variable for our regression model is flood inundation ranges from 0 to 1. 0 for non inundation areas and 1 for inundation areas.


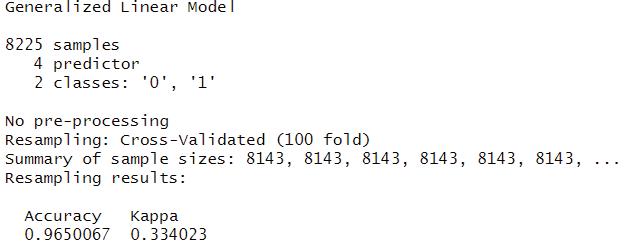
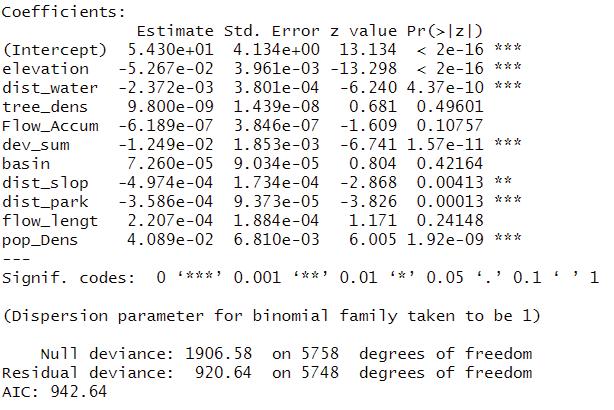
As the result of logistic regression, we can see that “The variables are statistically significant in our model at a 90% confidence interval except for four variables: tree density, flow accumulation,basin, and flow length. After modeling the logistic regression. Our AUC was 0.9617, which indicates that our model is very good at discriminating between flooded and non-flooded.

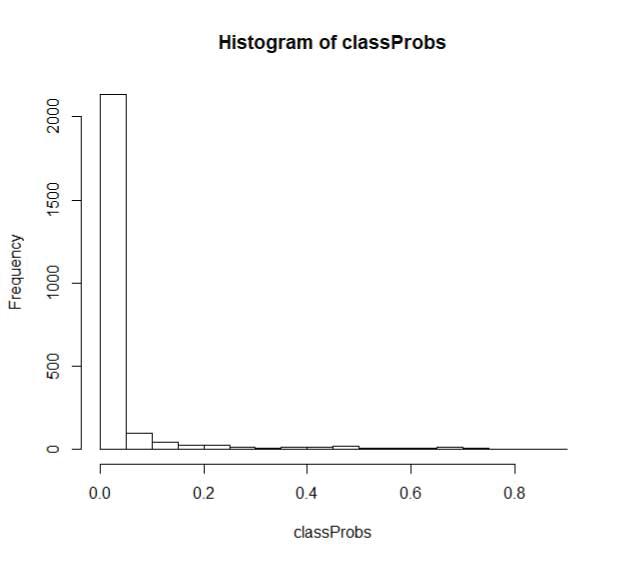
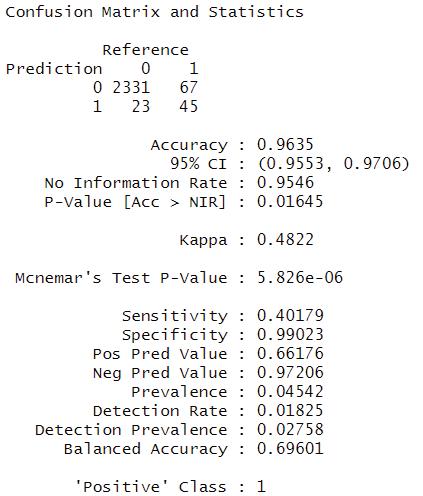
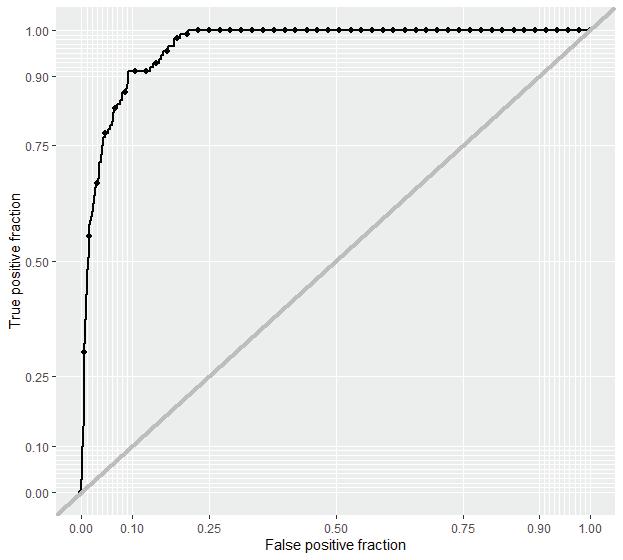
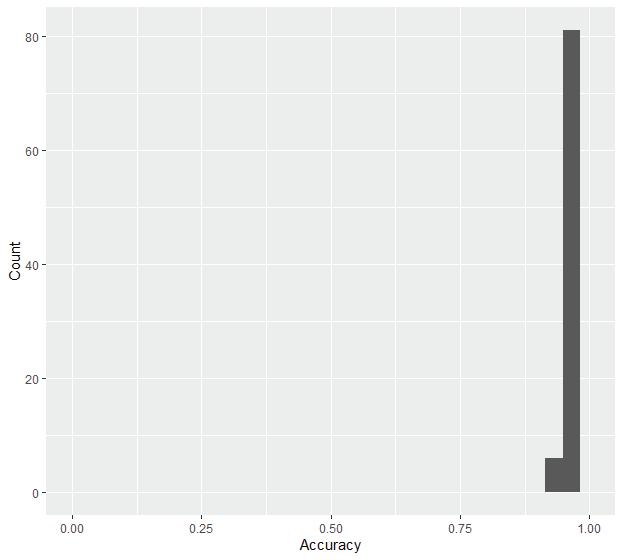
We also performed a Cross validation presenting a 0.9650 accuracy, which means our model is quite solid in prediction. As observed, the predicted flooding area fits in the trend of actual flooding area while presenting a larger coverage with both severely and mildly affected areas. This is because our model is based on many hydrological variables .
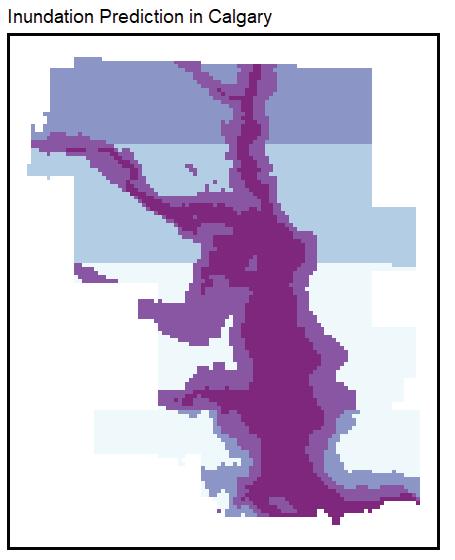
Data Visualization
Arc








