11 minute read
Evolution of control systems with artificial intelligence


Kence Anderson, Microsoft; Winston Jenks, Wood; Prabu Parthasarathy, PhD, Wood
Advertisement
Can artificial intelligence (AI) prove to be the next evolution of control systems? See three AI controller characteristics and three applications.
Control systems have continuously evolved over decades, and artificial intelligence (AI) technologies are helping advance the next generation of some control systems.
The proportional-integral-derivative (PID) controller can be interpreted as a layering of capabilities: the proportional term points toward the signal, the integral term homes in on the setpoint and the derivative term can minimize overshoot.
Although the controls ecosystem may present a complex web of interrelated technologies, it can also be simplified by viewing it as ever-evolving branches of a family tree. Each control system technology offers its own characteristics not available in prior technologies. For example, feed forward improves PID control by predicting controller output, and then uses the predictions to separate disturbance errors from noise occurrences. Model predictive control (MPC) adds further capabilities to this by layering predictions of future control action results and controlling multiple correlated inputs and outputs. The latest evolution of control strategies is the adoption of AI technologies to develop industrial controls. One of the latest advancements in this area is the application of reinforcement learning-based controls.
Three characteristics of AI-based controllers
AI-based controllers (that is, deep reinforcement learning-based, or DRL-based, controllers) offer unique and appealing characteristics, such as:
1. Learning: DRL-based controllers learn by methodically and continuously practicing – what
we know as machine teaching. Hence, these controllers can discover nuances and exceptions that are not easily captured in expert systems, and may be difficult to control when using fixed-gain controllers. The DRL engine can be exposed to a wide variety of process states by the simulator. Many of these states would never be encountered in the real world, as the AI engine (brain) may try to operate the plant much too close or beyond to the operational limits of a physical facility. In this case, these excursions (which would likely cause a process trip) are experiences for the brain to learn what behaviors to avoid. When this is done often enough, the brain learns what not to do. In addition, the DRL engine can learn from many simulations all at once. Instead of feeding the brain data from one plant, it can learn from hundreds of simulations, each proceeding faster than what is seen in normal real-time to provide the training experience conducive for optimal learning. 2. Delayed gratification: DRL-based controllers can learn to recognize sub-optimal behavior in the short term, which enables the optimization of gains in the long term. According to Sigmund Freud, and even Aristotle back in 300 B.C., humans know this behavior as “delayed gratification.” When AI behaves this way, it can push past tricky local minima to more optimal solutions. 3. Non-traditional input data: DRL-based controllers manage the intake and are able to evaluate sensor information that automated systems cannot. As an example, an AI-based controller can consider visual information about product quality or an equipment’s status. It also takes into consideration
COVER: Applications for the Microsoft Bonsai Brain include dynamic and highly variable systems, competing optimization goals or strategies and unknown starting or system conditions, among others. Images courtesy: Wood
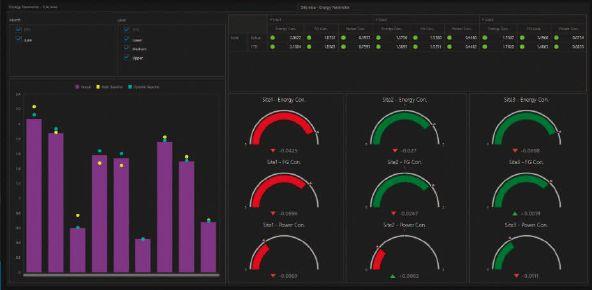
Tracking energy parameters in a dashboard can help visualize optimization goals.
categorical machine alerts and warnings when taking control actions. AI-based controllers can even use sound signals and vibration sensor inputs to determine how to make process decisions, similar to sounds human operators are subject to. The ability to process visual information, such as the size of a flare, differentiates and reveals DRL-based controllers’ capabilities.
Enabling DRL-based control systems
Four steps are involved in delivering a DRL-based controls to a process facility: 1) Preparation of a companion simulation model for the brain 2) Design and training of the brain 3) Assessment of the trained brain; and 4) Deployment.
Enabling DRL-based controllers requires a simulation or “digital twin” environment to practice and learn how decisions are made. The advantage of this method is the brain can learn both what is considered “good” as well as what is “bad” for the system, to achieve stated goals. Given that the real environment has variabilities – far more than what are usually represented – within a process simulation model and the amount of simulation required to train the brain over the state space of operation, reduced order models that maintain fundamental principles of physics offer the best method of training the brain. These models offer a way to develop complex process simulations and are faster during run-time, both of which allow a more efficient way to develop the brain. Tag-based process simulators are known for a simple design, ease of use and ability to adapt to a wide range of simulation needs, which fit the requirements of a simulation model required to train DRL-based brains.
In this modern age, when panels of lights and switches have been relegated to the back corner of the staging floor, tag-based simulators have become much more significant in making the job of an automation engineer less cumbersome. Using simulation to test a system on a factory acceptance test (FAT) prior to going to the field has been the “bread and butter” of process simulation software for decades – well before the advent of modern lingo, like “digital twin.” The same simulators can be used in training AI engines to effectively control industrial processes. To achieve this, simulators need to be able to run in a distributed fashion across multiple CPUs and potentially in the “cloud.” Multiple instances of the simulations are needed to either exercise, train or assess potential new AI algorithms in parallel execution. Once this is achieved, operator trainer systems that have been developed using tag-based simulators can be used for training DRLbased AI engines.
Design and training of the brain
Designing the brain based on the process targeted to be controlled is crucial in developing a successful DRL-based, optimal control solution. The brain can consist of not only AI concepts, but can also include heuristic, programmed logic, and wellknown rules. When the information from a subject matter expert (SME) is properly gleaned, the ability to implement a brain using that information is key to the success of a project.
Using subject matter expertise to construct insightful training scenarios is crucial to developing a robust AI-based control system. Before a DRL engine can be trained with a model, a human must decide what elements of the model will be exposed as the process state to the brain. The process state is generally a collection of measured values available to the automation system. Levels, temperatures, setpoints, etc., are all typical examples. Exposing too little of the process state will not allow the brain to learn from enough data. With a state that is too large, the number of internal hyperparameters can quickly grow. This prevents the brain from learning as quickly as possible, since a portion of its effort is wasted to figure out what parts of the process state are less important. A similar situation occurs with data that flows from the brain to the process. The human must decide which actions it will allow the brain to manipulate, which determines the effort required to control the most desirable state of the process. Usually, the decision about what to include in the actions available to the brain is easier to determine, as there are only so many control valves or other mechanisms available to control the process.
The decisions about the size of the process state and action space boil down to which simulation tags should be included in each of the state and action structures. In a tag-based simulator, states and actions are defined. Selecting the tags from a list and clicking a button can add them to the state or action structure used by the brain.
Defining state and action spaces
Inkling is a language developed for use in training DRL agents to express the training paradigm in a compact, expressive and easy-to-understand syntax. Tag-based simulators can be programmed to automatically generate the Inkling code defining the state and action structures for the brain.
Once the state and action structures have been defined, the goals of the training need to be defined to the brain. Typical requirements to train the brain are constructs, such as: goal, penalty, the lesson plan, and scenarios. In this example, about 40 lines of code needed to be created by the user to enable an AI brain to be trained using a simulation. The Inkling code generated describes two important things to the nascent AI brain – what to do, and how to do it. Specifically, this code has been generated to control the level in a tank through use of the upstream flow control and the downstream block valves. The “goal” statement describes the desired results of the brain’s actions, and in this case the actual level should be close to the setpoint level.
Choosing the appropriate lessons and scenarios matched to a goal are the results of proper collaboration between the brain designer and the SME without overflowing the tank. The “lesson” and “scenario” statements tell the brain how to learn that goal. In this case, the scenario directs the brain to start each training episode with a random, yet constrained level and setpoint.
Creating code to create an AI brain
Effective training of the brain requires a very large state-space of operation to be explored. Cloud technologies allow for simulators to be containerized and run in a massively parallel environment. However, when desiring successful results, testing ideas to train the brain need to be run through the simulator locally first to “iron out” the bugs. Once the user is satisfied, the simulator can be containerized and run in the cloud. Typical brain training sessions can be anywhere between 300,000 and 1,000,000 training iterations. Training progress of a brain can be shown easily on screen, such as with a simple tank demo. Cloud resources can manage to train a simulator requiring half of a million iterations in less than one hour.
A graph can demonstrate progress of brain training as a function of the number of iterations. The “Goal Satisfaction” parameter is a moving average of training episodes, resulting in the total number of goals being met. Typically, one requires a goal satisfaction value that reaches 100% to achieve effective control from the brain for all scenarios it has practiced on.
Assessment of trained brain
After a brain is trained, it needs to be tested to assess its viability. During this phase, the brain is run against the model to judge its behavior. However, this time the scenarios should be varied in the simulation – performing tests on the brain with situations it may not have encountered during the original rounds of testing.
For instance, if a value is controlled by a combination of three valves, what happens if one valve is now unavailable? Can the brain do something reasonable if one of the valves is stuck, or out for maintenance? This is where simulator models developed for operator trainer systems or control system testing can be adapted. As one would do with control system testing, the AI controller needs to be put through a rigorous formal testing procedure. A simulator with an automated test plan can significantly reduce the effort required to assess the “trained” brain.
Deployment of the brain
Once the brain has passed the assessment test, it can be deployed. While there are many modes of deployment, the unique advantage of using tag-based simulators used for testing control systems is they can be used as the middleware to integrate the brain with the control system. With a large assortment of
available drivers for various control sys- Mtems, integration into a customer-specific site is much easier than using a custom solution. Additionally, from a software maintenance perspective, minimizing the number of custom deployments is always appreciated.
Artificial intelligence use cases
DRL-based brains have been designed for over 100 use cases and have been deployed spanning a wide variety of industries and vertical markets. Read examples with this article online. ce
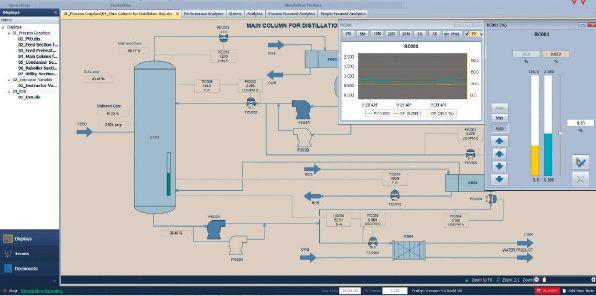
Artificial intelligence technology can extend to any complex problem that can be modeled using simulations, such as controlling intermittent production upsets in topsides equipment in upstream oil and gas sector and refinery/chemical plant performance optimization and control.
More
ANSWERS KEYWORDS: Artificial intelligence,
control systems, VP Link, Bonsai, simulation, reinforcement learning
Characteristics of AI-based controllers include learning, delayed gratification and non-traditional input data. The AI controller needs its brain trained. AI controller use cases include energy optimization, quality control and chemical processing.
Kence Anderson is the principal program manager, Autonomous Systems, with Microsoft. Winston Jenks is a technical director for Applied Intelligence with Wood, and Prabu Parthasarathy, PhD is the vice president of Applied Intelligence with Wood, a system integrator and CFE Media and Technology content partner. Edited by Mark T. Hoske, content manager, Control Engineering, CFE Media and Technology, mhoske@cfemedia.com.
CONSIDER THIS
Will you be giving your next control system the tools it needs to learn how to serve its applications better? ONLINE
If reading from the digital edition, click on the headline for use cases, details, figures, and images. www.controleng.com/magazine See related New Products for Engineers at www.controleng.com/NPE





