2 minute read
10. Appendix II: Methodology for multi-class classifier for crack and spall detection


Figure 7. (a) Amplitude for crack image; (b) filtered amplitude for crack image; (c) amplitude for non-crack image; (d) filtered amplitude of non-crack image.
10. Appendix II: Methodology for multi-class classifier for crack and spall detection
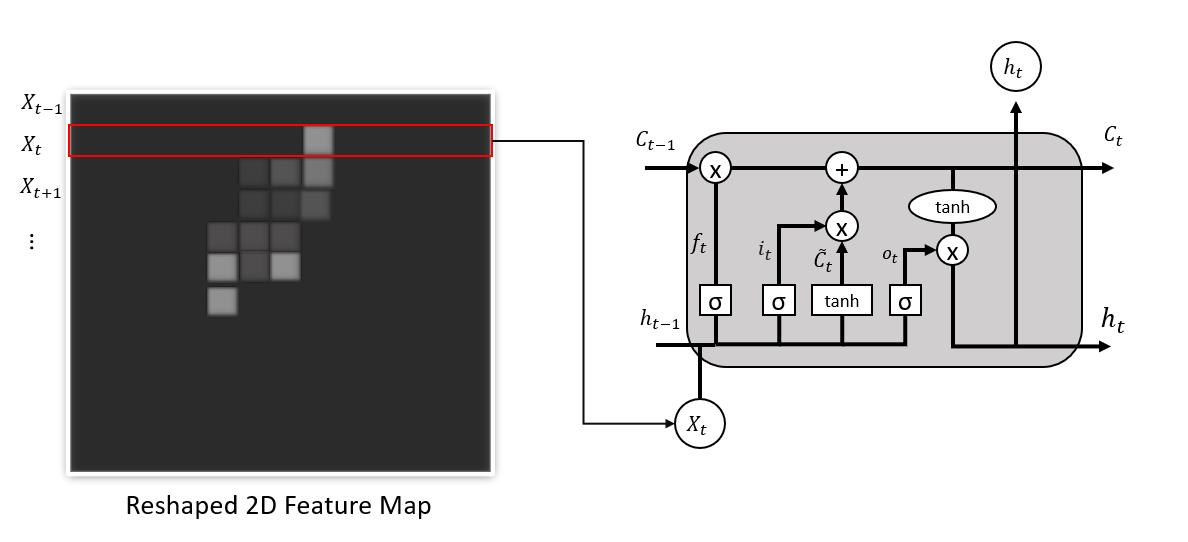
Similar to the methods described in Appendix I, 2D CNN is used here to extract features from images. Then LSTM is applied to feature level for fusion. During the feature extraction stage, the filter window size is always larger than the stride size, and there are overlaps of each step. This makes extracted feature blocks strongly dependent on each other. Extracted feature maps can be reshaped to a 2D map matrix, and each row of the matrix can be regarded as one input. In this sense, all rows of the feature map can be regarded as sequential input data to be passed to LSTM for feature fusion. Figure 8 shows the feature fusion mechanism of LSTM. The optimal CNNLSTM architecture is selected via an extensive trial-and-error approach and developed using TensorFlow modules in python 3.7. The overview of the developed network is shown in Figure 9. As shown in the figure, the feature extraction stage contains two convolutional layers followed by pooling layers. The kernel sizes 6 and 5 with stride size 2 are applied to first and second convolutional layers, respectively. Rectified Linear Unit (ReLU) activation function is applied to each convolutional layer. In the feature fusion stage, extracted features are flattened and simply fused to the desired size with a fully connected layer (FC). Feature vector is reshaped to a 2D feature matrix as sequential inputs for LSTM. Finally, a softmax layer classifies the image into intact, crack, or spall concrete surfaces. For the training process, a stochastic gradient descent (SGD) is chosen as an optimizer with a minibatch size of 32 out of 7200 images. An adaptive
and logarithmically decreasing learning rate is adopted to speed up the convergence. The initial learning rate and weight decay are 0.1 and 0.0001, respectively. A momentum value of 0.9 is applied to avoid overfitting and a dropout ratio equal to 0.5 is applied to the FC and LSTM layers.
Figure 8. Feature fusion mechanism of LSTM
Figure 9. Architecture of 2D CNN-LSTM Network