Backend de una aplición con: Node Js & Express Js

 Robinson Rincon Bernal
Robinson Rincon Bernal

Robinson Rincon Bernal
El Backend, también conocido como CMS o Backoffice, es la parte de la app que el usuario final no puede ver. Su función es acceder a la información que se solicita, a través de la app, para luego combinarla y devolverla al usuario final, las funciones son:
● Acceder a la información que se pide, a través de la app: cuando usamos una aplicación móvil pedimos información de manera continua, no importa si la app es de búsqueda de información, un juego o una red social. Esto implica que una parte de la app (el Backend), tiene que ser capaz de encontrar y acceder a la información que solicitemos.Right-click and choose “Copy”.
● Combinar la información encontrada y transformarla: Una vez encontrada, el Backend combina la información para que resulte útil al usuario. Pongamos, como ejemplo, una aplicación de transporte y una orden de búsqueda: “cómo llegar del trabajo a casa”.
En este caso, nuestra aplicación necesitará acceder a las bases de datos no sólo de todas las compañías de autobuses de la ciudad, sino también las de las empresas de taxis, metro y, por supuesto, Google Maps. La ingente cantidad de información con la que el Backend trabaja, hace que su diseño deba ser sumamente preciso, ya que debe ser capaz de encontrar y filtrar lo que es relevante de lo que no, para luego combinarlo de manera útil.
● Devolver la información al usuario: Finalmente, el Backend envía la información relevada de vuelta al usuario. Pero, ¿cuántos usuarios son capaces de leer datos escritos en código puro? Pocos. Es por ello que el Backend necesita de traductores capaces de convertir los datos escritos en código a lenguaje humano. Es aquí donde intervienen las famosas APIs, trabajando en conjunto con el Frontend. En pocas palabras, las APIs son las herramientas encargadas de transportar la información desde el Backend hasta el Frontend, que es donde el proceso final de traducción toma forma, y donde la información escrita en código se convierte en los diseños, las imágenes, las letras y los botones que el usuario final entiende y con los que puede interactuar. Este proceso es hecho por en Frontend en dos fases, que tienen lugar en dos subcapas que conforman su estructura:

es un modelo de aplicación distribuida en el que las tareas se reparten entre los proveedores de recursos o servicios, llamados servidores, y los demandantes, llamados clientes. Un cliente realiza peticiones a otro programa, el servidor, quien le da respuesta. Esta idea también se puede aplicar a programas que se ejecutan sobre una sola computadora, aunque es más ventajosa en un sistema operativo multiusuario distribuido a través de una red de computadoras. La red cliente-servidor es una red de comunicaciones en la cual los clientes están conectados a un servidor, en el que se centralizan los diversos recursos y aplicaciones con que se cuenta; y que los pone a disposición de los clientes cada vez que estos son solicitados. Esto significa que todas las gestiones que se realizan se concentran en el servidor, de manera que en él se disponen los requerimientos provenientes de los clientes que tienen prioridad, los archivos que son de uso público y los que son de uso restringido, los archivos que son de sólo lectura y los que, por el contrario, pueden ser modificados, etc. Este tipo de red puede utilizarse conjuntamente en caso de que se este utilizando en una red mixta.
Internet
Cliente
Petición http Solicitud http
Respuesta http (html, pdf, gif…)
Respuesta http (html, pdf, gif…)

Servidor


Node.js, es un entorno en tiempo de ejecución multiplataforma para la capa del servidor (en el lado del servidor) basado en JavaScript. Node.js es un entorno controlado por eventos diseñado para crear aplicaciones escalables, permitiéndote establecer y gestionar múltiples conexiones al mismo tiempo. Gracias a esta característica, no tienes que preocuparte con el bloqueo de procesos, pues no hay bloqueos, se caracteriza por:
● Velocidad. Node.js está construido sobre el motor de JavaScript V8 de Google Chrome, por eso su biblioteca es muy rápida en la ejecución de código.
● Sin búfer. Las aplicaciones de Node.js generan los datos en trozos (chunks), nunca los almacenan en búfer.

● Asíncrono y controlado por eventos. Como hemos dicho anteriormente, las APIs de la biblioteca de Node.js son asíncronas, sin bloqueo. Un servidor basado en Node.js no espera que una API devuelva datos. El servidor pasa a la siguiente API después de llamarla, y un mecanismo de notificación de eventos ayuda al servidor a obtener una respuesta de la llamada a la API anterior.
● Un subproceso escalable. Node.js utiliza un modelo de un solo subproceso con bucle de eventos. Gracias al mecanismo de eventos, el servidor responde sin bloqueos, como hemos dicho. Esto hace que el servidor sea altamente escalable comparando con los servidores tradicionales como el Servidor HTTP de Apache.

“Un framework es un conjunto de estándares que te brinda funcionalidades para un proyecto de principio a fin, diferencia de las librerías que te ayudan con un inconveniente en especifico ejm (librería para hacer animaciones, Liberia para validar formularios, etc…), es un aspecto mas global que otra cosa al poder acceder a funcionalidades ya especificas que facilitan el trabajo modular, brindándote todo el marco de trabajo, asegurándote la compatibilidad entre todos los componentes, te brinda un esqueleto y los mismo comandos, donde y como ejecutar comandos.
En conclusión es un entorno de trabajo que te brinda las herramientas directamente sin necesidad de accediendo a liberias externas, por una parte te limita un poco, pero por otra te brinda estabilidad en tus proyectos”
Algunos ejemplos de frameworks que encontré son:


EsunodelosframeworsbackendmáspopularparaNode.js,yesunaparteextensadelecosistema JavaScript. Estádiseñadoparaconstruiraplicacioneswebdeunasolapágina,multipáginaehíbridas,tambiénse haconvertidoenelestándarparadesarrollaraplicacionesbackendconNode.js,yeslapartebackend dealgoconocidocomolapilaMEVN.
¿Para Qué se Utiliza Express.js?: AplicacionesdeunaSolaPágina: Las aplicaciones de una sola página (SPAs) son el enfoque moderno de desarrollo de aplicaciones en el que toda la aplicación se enruta en una sola página de índice.
Herramientas de Colaboración en Tiempo Real: se utiliza para desarrollar aplicaciones en tiempo real, como aplicaciones de chat y de escritorios, donde resulta sencillo integrar WebSocket en el framework.
Aplicaciones de Streaming: Las aplicaciones de streaming en tiempo real como Netflix son complejas y tienen muchas capas de flujos de datos. Para desarrollar una aplicación de este tipo, necesitas un framework sólido que maneje eficazmente los flujos de datos asíncronos.
Aplicaciones Fintech: Fintech es un programa informático y otras tecnologías utilizadas para soportar o permitir los servicios bancarios y financieros. La construcción de una aplicación fintech es la tendencia actual del sector, y Express.js es el framework elegido para construir aplicaciones fintech altamente escalables.




Una de las principales funciones de las API es poder facilitarle el trabajo a los desarrolladores y ahorrarles tiempo y dinero. Por ejemplo, si estás creando una aplicación que es una tienda online, no necesitarás crear desde cero un sistema de pagos u otro para verificar si hay stock disponible de un producto. Podrás utilizar la API de un servicio de pago ya existente, por ejemplo PayPal, y pedirle a tu distribuidor una API que te permita saber el stock que ellos tienen. Con ello, no será necesario tener que reinventar la rueda con cada servicio que se crea, ya que podrás utilizar piezas o funciones que otros ya han creado. Imagínate que cada tienda online tuviera que tener su propio sistema de pago, para los usuarios normales es mucho más cómodo poder hacerlo con los principales servicios que casi todos utilizan.



Un ORMes un modelo de programación que permite mapear las estructuras de una base de datos relacional (SQL Server , Oracle , MySQL, etc.), en adelante RDBMS(RelationalDatabaseManagementSystem), sobre una estructura lógica de entidades con el objeto de simplificar y acelerar el desarrollo de nuestras aplicaciones. Las estructuras de la base de datos relacional quedan vinculadas con las entidades lógicas o basededatos virtualdefinida en el ORM , de tal modo que las acciones CRUD(Create , Read , Update , Delete) a ejecutar sobre la base de datos física se realizan de forma indirecta por medio del ORM .

● El ORMnos permitirá acelerar el desarrollo de la aplicación evitando la escritura repetitiva de código para ejecutar operaciones CRUD . Además, ya que el rendimiento de las consultas no es crítico, podremos confiar en el ORMpara interactuar con el RDBMSsin dedicar mucho tiempo a supervisar las acciones ejecutadas. desarrollador
CRUD o solicitud de consulta
Respuesta del servidor consulta
Servidor
El MVC o Modelo-Vista-Controlador es un patrón de arquitectura de software que, utilizando 3 componentes (Vistas, Models y Controladores) separa la lógica de la aplicación de la lógica de la vista en una aplicación. Es una arquitectura importante puesto que se utiliza tanto en componentes gráficos básicos hasta sistemas empresariales; la mayoría de los frameworks modernos utilizan MVC (o alguna adaptación del MVC) para la arquitectura, entre ellos podemos mencionar a Ruby on Rails, Django, AngularJS y muchos otros más. En este pequeño artículo intentamos introducirte a los conceptos del MVC.”
“

Las siglas HTTP, acrónimo de Hypertext Transfer Protocol, es un protocolo de transferencia de hipertexto. En otras palabras, HTTP es un protocolo de comunicación que permite la transferencia de información en Internet.
La principal diferencia entre HTTP y HTTPS es la seguridad. El protocolo HTTPS impide que otros usuarios puedan interceptar la información confidencial que se transfiere entre el cliente y el servidor web a través de Internet.

Por decirlo de una manera muy sencilla, el protocolo HTTPS es la versión segura del HTTP. Su diferencia radica en el nivel de seguridad a la hora de operar con datos de los usuarios. Además de mostrarse HTTPS en la barra de direcciones al inicio de la URL de la página, también hay un elemento que diferencia claramente una web segura y otra que no lo es: un candado verde.
● Las páginas web, blogs o tiendas online que todavía funcionan con HTTP y no tienen instalado un certificado SSL no son seguras. Además, Google se encargará de que los usuarios lo sepan indicando en la barra de navegación que tu sitio no es seguro.


Una API, o interfazdeprogramacióndeaplicaciones , es un conjunto de reglas que determinan cómo las aplicaciones o los dispositivos pueden conectarse y comunicarse entre sí. Una API REST es una API que se ajusta a los principios de diseño de REST, un estilo de arquitectura también denominado transferenciadeestadorepresentacional . Por este motivo, las API REST son a veces denominadas API RESTful.
Interfaz uniforme: Todas las solicitudes de API para el mismo recurso deben ser iguales, independientemente de la procedencia de la solicitud. Separación entre cliente y servidor: En el diseño de API REST, las aplicaciones de cliente y de servidor deben ser completamente independientes entre sí. La única información que la aplicación de cliente debe conocer es el URI del recurso solicitado. Sin estado. Las API REST son sin estado, lo que significa que cada solicitud debe incluir toda la información necesaria para procesarla. En otras palabras, las API REST no requieren ninguna sesión en el lado del servidor.
Capacidad de almacenamiento en memoria caché. Siempre que sea posible, los recursos deben poder almacenarse en la memoria caché en el lado del cliente o el servidor. Arquitectura de sistema de capas. En las API REST, las llamadas y respuestas pasan por diferentes capas. Como regla general, no debe suponer que las aplicaciones de cliente y de servidor se conectan directamente entre sí. Código bajo demanda (opcional). Generalmente, las API REST envían recursos estáticos, pero en algunos casos, las respuestas también pueden contener un código ejecutable.
JSON (JavaScript Object Notation) y XML (Extensible Markup Language) son formatos populares para el intercambio de datos. Sin embargo, aunque tienen muchas similitudes, no son lo mismo.
¿Qué es JSON?

XML
¿Qué es XML?
XML es un estándar abierto de almacenamiento e intercambio de datos. Es un lenguaje de marcado para describir la estructura y el contenido de cualquier archivo de XML, como documentos, páginas web o bases de datos. Se puede pensar en XML como en HTML, pero mejor: permite adjuntar información adicional a los nodos del documento sin cambiar el formato subyacente.

XML Se ha hecho muy popular con el tiempo, pero algunos sectores siguen utilizando SGML en lugar de XML porque les resulta más fácil trabajar con sus estándares de codificación existentes, especialmente si utilizan plantillas de estilo Microsoft Word en lugar de HTML5.
JSON es un formato de intercambio de datos. Es independiente del lenguaje, lo que significa que puede utilizarse con cualquier lenguaje de programación, y la estructura de datos subyacente es independiente de la plataforma. La naturaleza independiente del lenguaje de JSON hace que sea ideal para su uso en el desarrollo web, donde se puede necesitar el intercambio de datos con otros lenguajes de programación como Ruby o JavaScript.
JSON utiliza etiquetas para marcar los datos: "{"key": value," "otherKey": anotherValue}." Las claves y los valores deben ir siempre rodeados de llaves ({) y corchetes ([]), respectivamente. Además, cada par clave-valor debe estar rodeado por el mismo número de comillas - por ejemplo: {"name": "John"} no sería válido porque hay muy pocas comillas después de la etiqueta nombre.
.
Accept
La proporciona el solicitante y se utiliza en la negociación de contenido para determinar el formato de la respuesta.
Proporciona los datos en el idioma solicitado..
Accept-Language
-El parámetro de consulta _lang puede proporcionar el código de idioma y la misma prestación que la propiedad de cabecera Accept-Language.
-El parámetro de consulta _locale habilita que los números y las fechas se devuelvan en el entorno local del solicitante.
Cache-Control
Content-Length
la propiedad Cache-Control tiene el valor private para asegurar que sólo el usuario actual puede reutilizar el contenido en la memoria caché.
Contiene la longitud de la respuesta.
Content-Type
Notifica al solicitante del formato de la representación que se envía. Por ejemplo, puede especificarse el valor application/xml (para formato de respuesta XML) o application/json (para formato de respuesta JSON).
Si el almacenamiento en memoria caché está habilitado, contiene el valor Etag para el recurso que se solicita. La memoria caché del navegador del solicitante conserva el valor para futuras solicitudes para el mismo recurso.
If-None-Match
Si el almacenamiento en memoria caché está habilitado, contiene el valor Etag para el recurso que se ha solicitado anteriormente, de forma que la API pueda determinar si el contenido de la memoria caché puede volver a utilizarse.
Last-Modified Notifica al solicitante la fecha y hora en las que el recurso se ha modificado por última vez.
Location
Contiene el enlace a un recurso (código HTTP 201) creado por un HTTP POST.
_ rlid
Contiene el ID de la colección de recursos y se utiliza para desplazamiento dentro de la sesión.
Los códigos de estado de HTTP se entregan a tu navegador en el encabezado de HTTP. Aunque los códigos de estado se devuelven cada vez que el navegador solicita una página web o un recurso, la mayoría de las veces no los ves. Los códigos de estado HTTP se dividen en 5 «tipos». Se trata de agrupaciones de respuestas que tienen significados similares o relacionados.
Códigos de estado 100 Un código de estado de nivel 100 te dice que la solicitud que has hecho al servidor sigue en curso por alguna razón. Esto no es necesariamente un problema, es sólo información extra para que sepas lo que está pasando.
Esto significa que el servidor en cuestión ha recibido las cabeceras de solicitud de tu navegador, y ahora está listo para que el cuerpo de la solicitud sea enviado también. 100
«Cambiando protocolos». Tu navegador ha pedido al servidor que cambie los protocolos, y el servidor ha cumplido. 101
«Primeros avisos». Esto devuelve algunos encabezados de respuesta antes de que el resto de la respuesta del servidor esté lista. 103
Este es el mejor tipo de código de estado HTTP que se puede recibir. Una respuesta de nivel 200 significa que todo funciona exactamente como debería. «Todo está bien». Este es el código que se entrega cuando una página web o recurso actúa exactamente como se espera. 200
203
«Información no autorizada». Este código de estado puede aparecer cuando se utiliza un apoderado. Significa que el servidor proxy recibió un código de estado de 200 «Todo está bien» del servidor de origen, pero ha modificado la respuesta antes de pasarla a su navegador.
«Sin contenido». Este código significa que el servidor ha procesado con éxito la solicitud, pero no va a devolver ningún contenido. 204
202
«Creado». El servidor ha cumplido con la petición del navegador y, como resultado, ha creado un nuevo recurso 201 «Aceptado». El servidor ha aceptado la solicitud de tu navegador pero aún la está procesando. La solicitud puede, en última instancia, dar lugar o no a una respuesta completa.
«Restablecer el contenido». Como un código 204, esto significa que el servidor ha procesado la solicitud pero no va a devolver ningún contenido 205
«Contenido parcial». Puedes ver este código de estado si tu cliente HTTP (también conocido como tu navegador) usa «cabeceras de rango». Esto permite a tu navegador reanudar las descargas en pausa- 206
La redirección es el proceso utilizado para comunicar que un recurso ha sido trasladado a una nueva ubicación. Hay varios códigos de estado HTTP que acompañan a las redirecciones, con el fin de proporcionar a los visitantes información sobre dónde encontrar el contenido que están buscando.
300
«Opciones Múltiples». A veces, puede haber múltiples recursos posibles con los que el servidor puede responder para cumplir con la solicitud de su navegador. Un código de estado 300 significa que tu navegador ahora tiene que elegir entre ellos.
301
«El recurso solicitado ha sido trasladado permanentemente». Este código se entrega cuando una página web o un recurso ha sido reemplazado permanentemente por un recurso diferente. Se utiliza para la redirección permanente del URL.
307
304
«El recurso solicitado no ha sido modificado desde la última vez que accedió a él«. Este código le dice al navegador que los recursos almacenados en la caché del navegador no han cambiado. Se usa para acelerar la entrega de páginas web reutilizando los recursos descargados previamente.
«Redireccionamiento temporal«. Este código de estado ha reemplazado a 302 «Encontrado» como la acción apropiada cuando un recurso ha sido movido temporalmente a una URL diferente. A diferencia del código de estado 302, no permite que el método HTTP cambie.
302
«El recurso solicitado se ha movido, pero fue encontrado«. Este código se utiliza para indicar que el recurso solicitado se encontró, pero no en el lugar donde se esperaba. Se utiliza para la redirección temporal de la URL
303
308
«Ver otros». Para entender un código de estado 303 es necesario conocer la diferencia entre los cuatro métodos de solicitud HTTP principales.
«Re direccionamiento permanente». El código de estado 308 es el sucesor del código 301 «Movido permanentemente». No permite que el método HTTP cambie e indica que el recurso solicitado está ahora localizado permanentemente en una nueva URL.
400
400
En el nivel 400, los códigos de estado HTTP comienzan a ser problemáticos. Estos son códigos de error que especifican que hay un fallo en su navegador y/o en la solicitud.
«Mala petición». El servidor no puede devolver una respuesta debido a un error del cliente. Vea nuestra guía para resolver este error.
401
«No autorizado» o «Se requiere autorización». Esto es devuelto por el servidor cuando el recurso de destino carece de credenciales de autenticación válidas.
406
«Respuesta no aceptable«. El recurso solicitado es capaz de generar sólo contenido que no es aceptable según los encabezamientos de aceptación enviados en la solicitud.
407
«Pago requerido». Originalmente, este código fue creado para ser usado como parte de un sistema de dinero digital. 402 «El acceso a ese recurso está prohibido». Este código se devuelve cuando un usuario intenta acceder a algo a que no tiene permiso para ver. 403 «No se encontró el recurso solicitado». Este es el mensaje de error más común de todos ellos. 404
405
«Método no permitido«. Esto se genera cuando el servidor de alojamiento (servidor de origen) soporta el método recibido, pero el recurso de destino no lo hace.
408
«Se requiere autenticación de proxy». Se está utilizando un servidor proxy que requiere que el navegador se autentifique antes de continuar.
412
La condición previa falló». Tu navegador incluyó ciertas condiciones en sus encabezados de solicitud, y el servidor no cumplió con esas especificaciones.
413
«El servidor se agotó esperando el resto de la petición del navegador». Este código se genera cuando un servidor se apaga mientras espera la solicitud completa del navegador.
409
«Conflicto». Un código de estado 409 significa que el servidor no pudo procesar la solicitud de su navegador porque hay un conflicto con el recurso correspondiente.
410
«El recurso solicitado se ha ido y no volverá». Esto es similar a un código 404 «No encontrado», excepto que un 410 indica que la condición es esperada y permanente.
411
«Longitud requerida». Esto significa que el recurso solicitado requiere que el cliente especifique una cierta longitud y que no lo hizo.
414
«Carga útil demasiado grande» o «Entidad solicitante demasiado grande». Su solicitud es más grande de lo que el servidor está dispuesto o es capaz de procesar.
«URI demasiado largo«. Esto suele ser el resultado de una solicitud GET que ha sido codificada como una cadena de consulta demasiado grande para que el servidor la procese.
«Tipo de medios de comunicación sin apoyo«. La solicitud incluye un tipo de medio que el servidor o recurso no soporta. 415 «Rango no satisfactorio». Su solicitud fue por una porción de un recurso que el servidor no puede devolver. 416
417
«La expectativa fracasó». El servidor no puede cumplir los requisitos especificados en el campo de cabecera de la solicitud.
418
«Soy una tetera». Este código es devuelto por las teteras que reciben solicitudes para preparar café. También es un chiste del «día de las bromas de abril» de 1998.
«No autorizado» o «Se requiere autorización». Esto es devuelto por el servidor cuando el recurso de destino carece de credenciales de autenticación válidas. 422
«Pago requerido». Originalmente, este código fue creado para ser usado como parte de un sistema de dinero digital. 425
«No se encontró el recurso solicitado». Este es el mensaje de error más común de todos ellos. 428
«Método no permitido«. Esto se genera cuando el servidor de alojamiento (servidor de origen) soporta el método recibido, pero el recurso de destino no lo hace. 429
431
«El acceso a ese recurso está prohibido». Este código se devuelve cuando un usuario intenta acceder a algo a que no tiene permiso para ver. 426
«Respuesta no aceptable«. El recurso solicitado es capaz de generar sólo contenido que no es aceptable según los encabezamientos de aceptación enviados en la solicitud.
«Se requiere autenticación de proxy». Se está utilizando un servidor proxy que requiere que el navegador se autentifique antes de continuar. 451
499
«El servidor se agotó esperando el resto de la petición del navegador». Este código se genera cuando un servidor se apaga mientras espera la solicitud completa del navegador.
500
Los códigos de estado de nivel 500 también se consideran errores. Sin embargo, denotan que el problema está en el extremo del servidor.
Esto puede hacer que sean más difíciles de resolver.
«Hubo un error en el servidor y la solicitud no pudo ser completada». Este es un código genérico que simplemente significa «error interno del servidor». Algo salió mal en el servidor y el recurso solicitado no fue entregado. Este código es típicamente generado por plugins de terceros, PHP defectuoso, o incluso la ruptura de la conexión a la base de datos.
500 «No implementado». Este error indica que el servidor no es compatible con la funcionalidad necesaria para cumplir con la solicitud. Esto es casi siempre un problema en el propio servidor web, y por lo general debe ser resuelto por el host.
«El servidor, actuando como una puerta de enlace, se ha agotado esperando a que otro servidor responda». 504
501
«Versión HTTP no soportada». El servidor no soporta la versión HTTP que el cliente usó para hacer la solicitud. 505
502
«Mala entrada». Este código de error significa típicamente que un servidor ha recibido una respuesta inválida de otro, como cuando se utiliza un servidor proxy.
«El servidor no está disponible para manejar esta solicitud en este momento.» La solicitud no puede ser completada en este momento. 503
«Se ha alcanzado el límite de recursos» Se han alcanzado los límites de recursos establecidos por tu alojamiento web.. 508
511
«Se requiere autenticación de la red». Este código de estado se envía cuando la red que está tratando de usar requiere alguna forma de autenticación antes de enviar su solicitud al servidor.
521
«El servidor web está caído». El error 521 es un mensaje de error específico de Cloudflare. Significa que su navegador web fue capaz de conectarse con éxito a Cloudflare, pero Cloudflare no fue capaz de conectarse al servidor web de origen.
«Límite de Ancho de Banda Excedido» significa que tu sitio web está utilizando más ancho de banda del que permite tu proveedor de hosting. 509
525
«SSL Handshake Failed«. El error 525 significa que el Protocolo de enlace SSL entre un dominio que usa Cloudflare y el servidor web de origen falló.
La same-origin policy (SOP o política de seguridad del mismo origen) prohíbe que se carguen datos de servidores ajenos al acceder a una página web. Todos los datos deben provenir de la misma fuente, es decir, corresponder al mismo servidor. Se trata de una medida de seguridad, ya que JavaScript y CSS podrían cargar, sin que el usuario lo supiese, contenido de otros servidores (y, con este, también contenido malicioso). Tales intentos son denominados “cross-origin requests”. Si, por el contrario, ambos administradores web saben del intercambio de contenido y lo aprueban, no tiene sentido impedir este proceso. El servidor solicitado (es decir, aquel del que se quiere cargar contenido) puede permitir entonces el acceso mediante cross-origin resource sharing, en castellano, intercambio de recursos de origen cruzado.
El propósito del CORS es eludir la medida de seguridad establecida como configuración predeterminada (la política de seguridad del mismo origen). Dicha política es, de hecho, un medio muy eficaz para bloquear conexiones potencialmente peligrosas. Internet, sin embargo, se basa a menudo precisamente en este tipo de cross-origin requests, ya que muchas de las conexiones entre hostssí son deseadas.
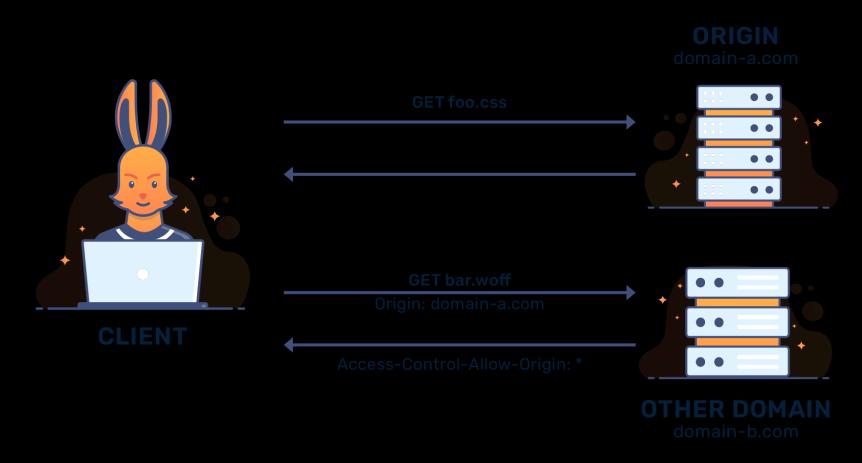
Por eso, el CORS ofrece una solución intermedia, permitiendo hacer excepciones a la prohibición en aquellas situaciones en que las solicitudes de origen cruzado son expresamente requeridas. No obstante, se corre el riesgo de que los administradores web se aprovechen de las wildcards por comodidad, haciendo que la protección de la SOP sea en vano. Por eso, es importante utilizar el CORS solo en casos especiales y configurarlo de la manera más restrictiva posible.