The Future of Information Access in the Era of Large Language Models

Jimmy Lin
Northeastern University
Distinguished Lecturer Seminar
Wednesday, April 26, 2023
What’s the problem we’re trying to solve?

How to connect users with relevant information
search (information retrieval)…
… but also question answering, summarization, etc.
“information access”
… on text, images, videos, etc.
… for “everyday” searchers, domain experts, etc.


Source: Wikipedia


tl;dr –


None of this is fundamentally new! We now have more powerful tools! It’s an exciting time for research!
What’s the problem we’re trying to solve?
How to connect users with relevant information
Where are we now and how did we get here?
Source: https://www.engadget.com/microsofts-next-gen-bing-more-powerful-language-model-than-chatgpt-182647588.html

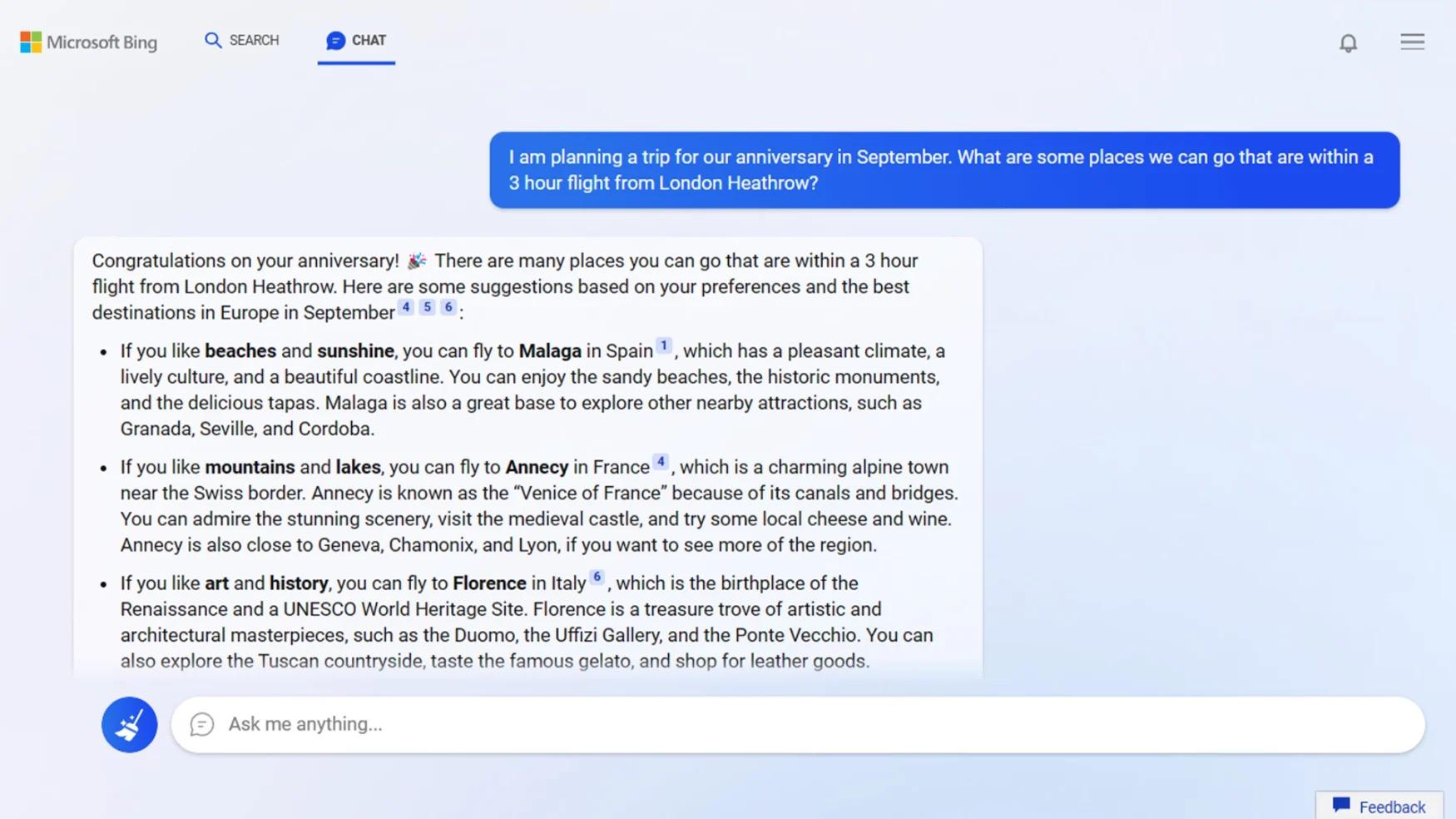

Source: https://www.businessinsider.com/heres-what-google-looked-like-the-first-day-it-launched-in-1998-2013-9
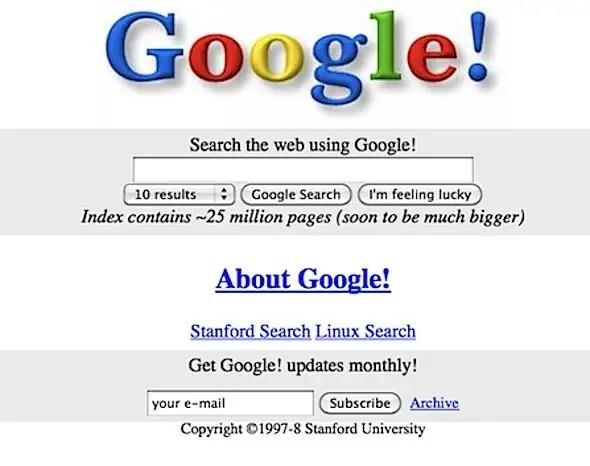
Source: https://www.businessinsider.com/heres-what-google-looked-like-the-first-day-it-launched-in-1998-2013-9




What’s the problem we’re trying to solve?
How to connect users with relevant information
Where are we now and how did we get here? I’ve been working on this for a while…
1997: My journey begins

 Source: Philip Greenspun, Wikipedia
Source: Philip Greenspun, Wikipedia
1993: The START System
First QA system on the web!
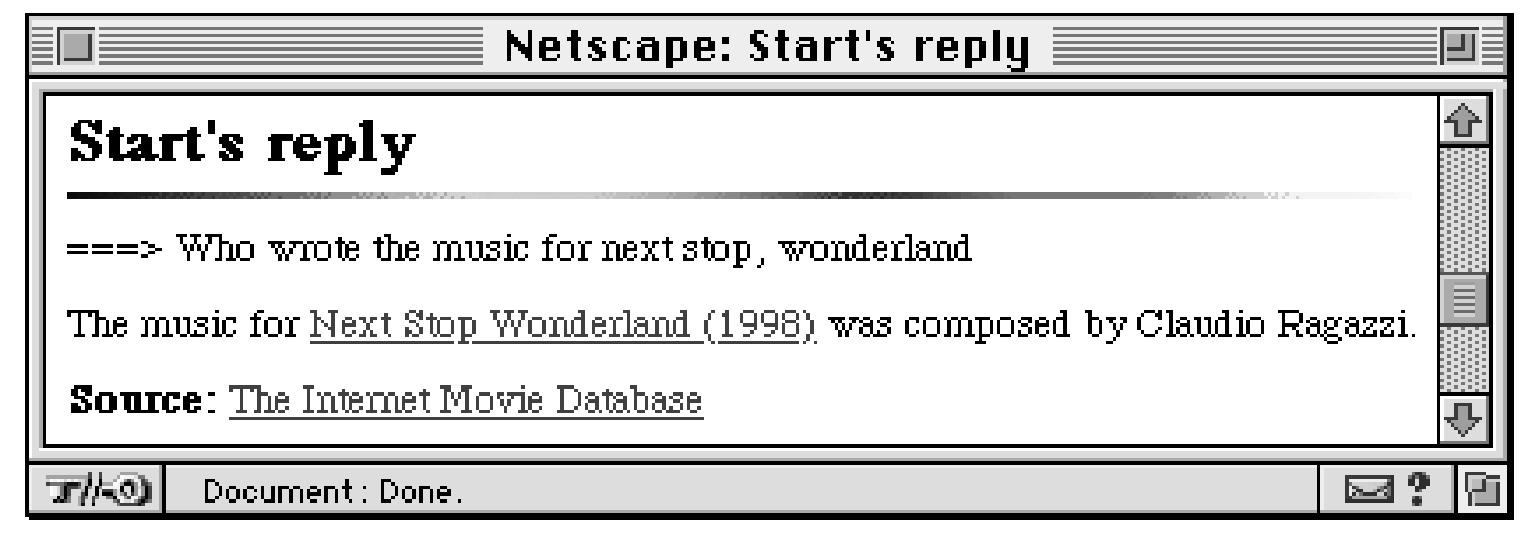
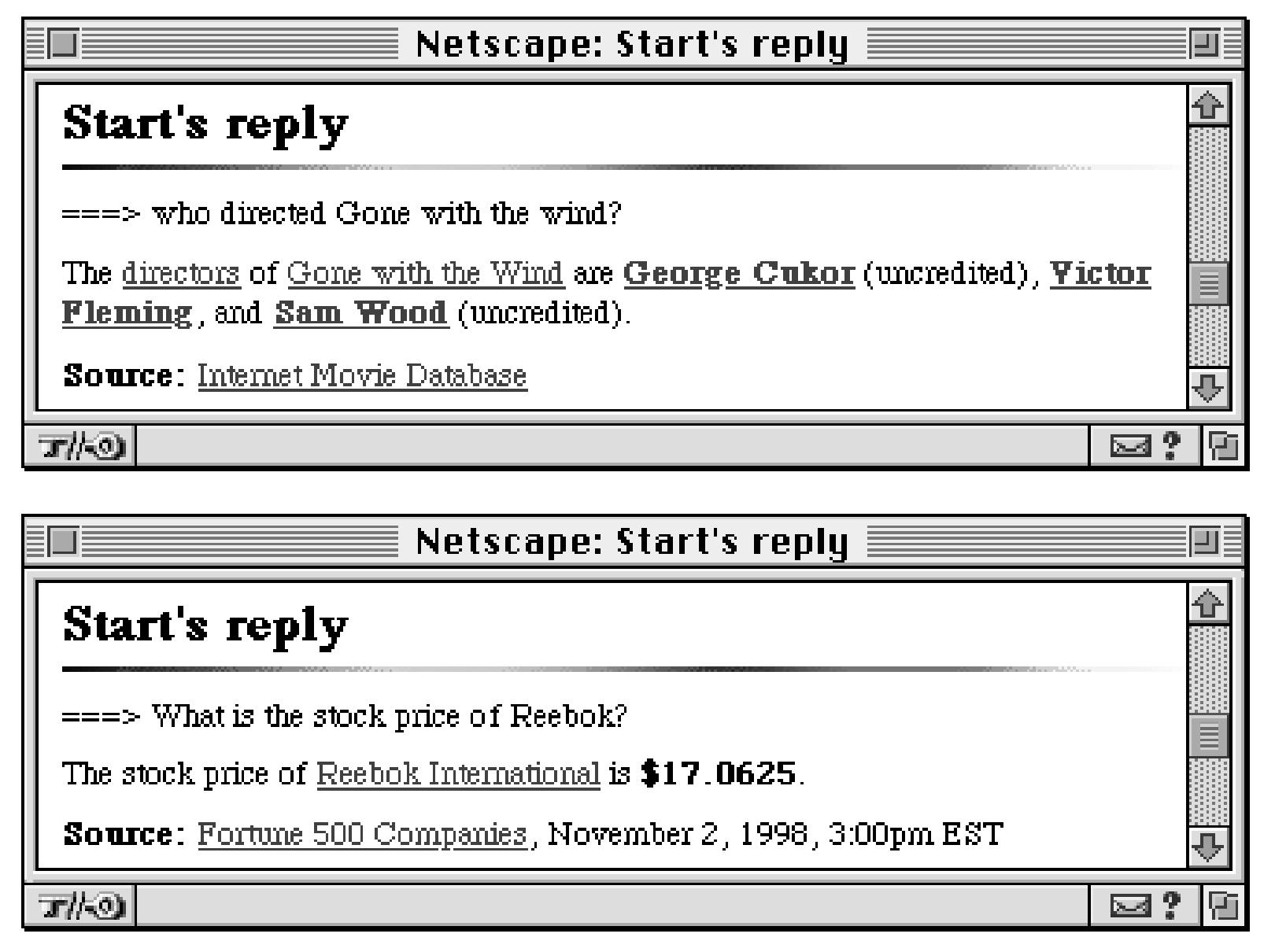


…
What’s the problem we’re trying to solve?
How to connect users with relevant information
Where are we now and how did we get here? I’ve been working on this for a while… Technologies change, but the problem hasn’t!
Source: flickr (krzysztofkupren/51216023399)




Results “Documents” Query Content
Acquisition
Salton et al. (1975) A Vector Space Model for Automatic Indexing. Communications of the ACM, 18(11):613-620.

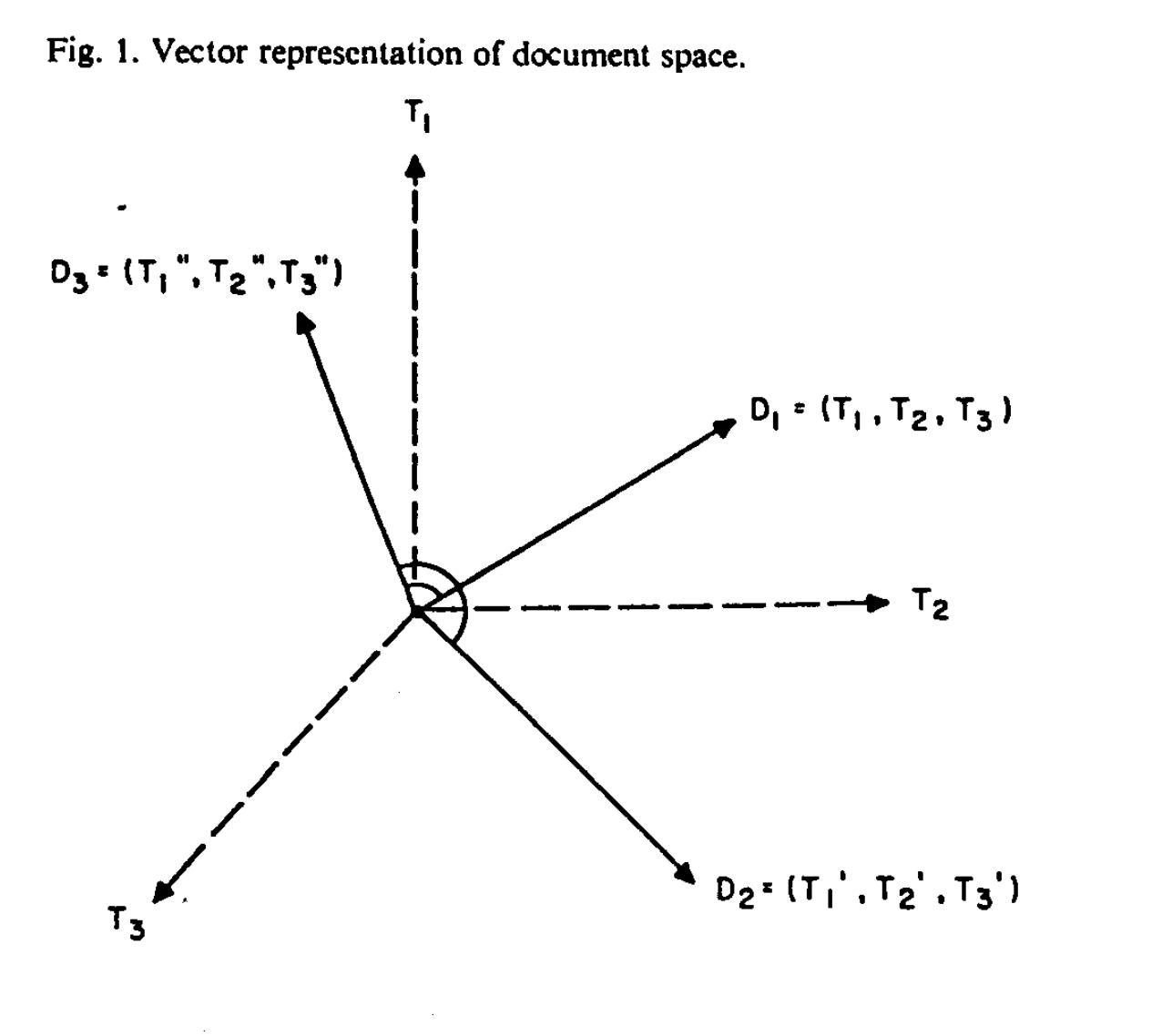

Results “Documents” Query
Term Weighting
The Manhattan Project and its atomic bomb helped bring an end to World War II. Its legacy of peaceful uses of atomic energy continues to have an impact on history and science.
{'atom': 4.0140, 'bomb': 4.0704, 'bring': 2.7239, 'continu':
2.4331, 'end': 2.1559, 'energi': 2.5045, 'have': 1.0742, 'help':




1.8157, 'histori': 2.4213, 'ii': 3.0998, 'impact': 3.0304, 'it':
2.0473, 'legaci': 4.1335, 'manhattan': 4.1345, 'peac': 3.5205, 'project': 2.6442, 'scienc': 2.8700, 'us': 0.9967, 'war':
2.6454, 'world': 1.9974}
Results
“Documents” Query





Results Term Weighting Multi-hot Top-k Retrieval “Documents” Query
Index
Inverted
Multi-hot
Inverted Index

Results
Top-k Retrieval “Documents” Query
tl;dr – research during the 70s~90s were mostly about how to assign term weights

Results BM25 Multi-hot Top-k Retrieval “Documents” Query
Skipping ahead a few years…

Source: Wikipedia
Source: https://www.engadget.com/microsofts-next-gen-bing-more-powerful-language-model-than-chatgpt-182647588.html

BERT! E[CLS] T[CLS] [CLS] E1 U1 A1 En Un An E[SEP1] T[SEP1] [SEP] F1 V1 B1 Fm Vm Bm E[SEP2] T[SEP2] [SEP] Class Label … … … … … … … … … … … … … Sentence 1 Sentence 2 … … Google’s magic pretrained transformer language model! Does classification! Does regression! NER! QA! Does your homework! Walks the dog!

BERT! https://blog.google/products/search/search-language-understanding-bert/
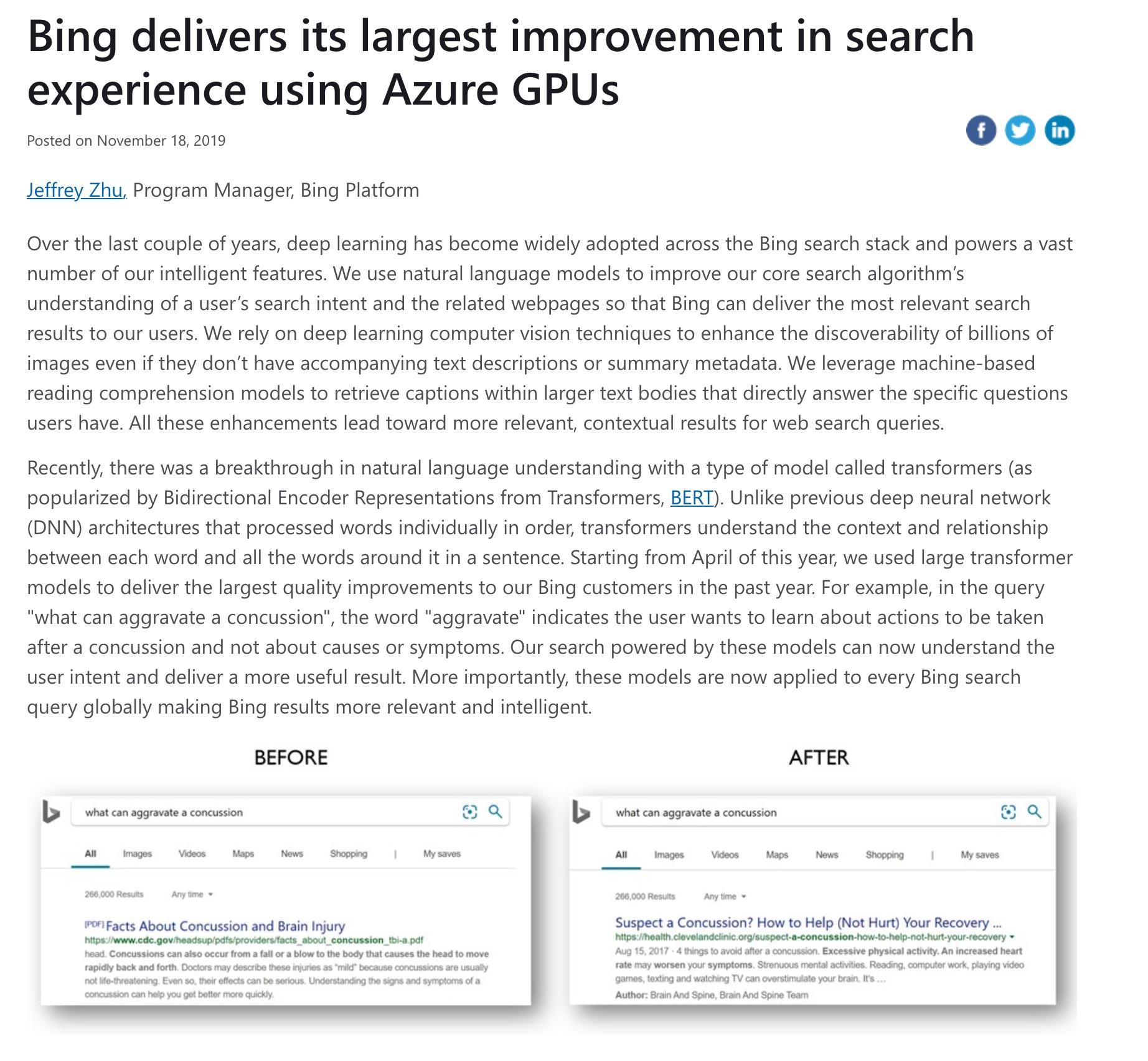
BERT! https://azure.microsoft.com/en-us/blog/bing-delivers-its-largest-improvement-in-search-experience-using-azure-gpus/
Results “Documents” Query
Select candidate texts

“Understand” selections
Results “Documents” Query
Select candidate texts

Reranking

Results “Documents” Query
E[CLS] T[CLS] [CLS] E1 U1 A1 En Un An E[SEP1] T[SEP1] [SEP] F1 V1 B1 Fm Vm Bm E[SEP2] T[SEP2] [SEP] Class Label … … … … … … … … … … … … … Sentence 1 Sentence 2 … … query f([A1 … An], [B1 … Bm]) ➝ y candidate text prob. relevance
Cross-Encoder (relevance classification)
BERT
Select candidate texts
How relevant is candidate 1?
How relevant is candidate 2?
How relevant is candidate 3?
How relevant is candidate 4? …
“Documents” Query
rerank
Optimum Polynomial Retrieval Functions Based on the Probability Ranking Principle
NORBERT FUHR
Technische Hochschule Darmstadt, Darmstadt, West Germany
We show that any approach to developing optimum retrieval functions is based on two kinds of assumptions: first, a certain form of representation for documents and requests, and second, additional simplifying assumptions that predefine the type of the retrieval function. Then we describe an approach for the development of optimum polynomial retrieval functions: request-document pairs (fi, d,) are mapped onto description vectors Z(fr, d,), and a polynomial function e(i) is developed such that it yields estimates of the probability of relevance P(R 1i(fi, d,)) with minimum square errors. We give experimental results for the application of this approach to documents with weighted indexing as well as to documents with complex representations. In contrast to other probabilistic models, our approach yields estimates of the actual probabilities, it can handle very complex representations of documents and requests, and it can be easily applied to multivalued relevance scales. On the other hand, this approach is not suited to log-linear probabilistic models and it needs large samples of relevance feedback data for its application.
Categories and Subject Descriptors: G.1.2 [Numerical Analysis]: Approximation-Least squares approximation; H.3.1 [Information Storage and Retrieval]: Content Analysis and Indexingindexing methods; H.3.3 [Information Storage and Retrieval]: Information Search and Retrieval-retrieoal models
General Terms: Experimentation, Theory
Additional Keywords and Phrases: Complex document representation, linear retrieval functions, multivalued relevance scales, probabilistic indexing, probabilistic retrieval, probability ranking principle
1. INTRODUCTION A major goal of IR research is the development of effective retrieval methods. TOIS 1989! We
would call this pointwise learning to rank today!
Computation of Term Associations by a Neural Network
S.K.M. Wong and Y.J. Cai
Department of Computer Science, University of Regina
Regina, Saskatchewan, Canada S4S 0A2
Y.Y. Yao
Department of Mathematical
Abstract
Thunder Bay, Ontario,
This paper suggests a method for computing term associations based on an adaptive bilinear retrieval model. Such a model can be implemented by using a three-layer feedforward neural network. Term associations are modeled by weighted links connecting different neurons, and are derived by the perception learning algorithm without the need for introducing any ad hoc parameters. The preliminary results indicate the usefulness of neural networks in the design of adaptive information retrieval systems.
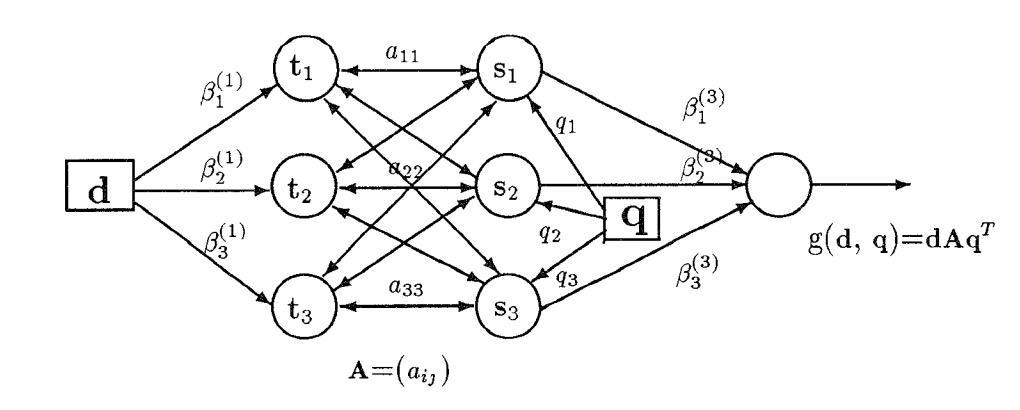

1 Introduction
In information retrieval, many methods have been proposed to enhance the performance of a retrieval system. In particular, the use of semantic relationships (term as-
tion in a document collection (Spark Jones, 1971; van Rijsbergen, 1979; Salton, 1989). These methods are based on the hypothesis that term co-occurrence statistics provide useful information about the relationships between terms. That is, if two or more terms co-occur in many documents, these terms would be more likely semantically related. For example, in the linear associative retrieval model (Giuliano & Jones, 1963), the term co-occurrence information is used to construct a termassociation matrix to be incorporated into a bilinear retrieval function (Schable, 1989). However, Raghavan and Wong (1986) pointed out that these methods may lead to inconsistent usage of the vector space model, al-
sociations) between index terms has led to considerable
SIGIR 1993!
BERT!
Source: https://www.engadget.com/microsofts-next-gen-bing-more-powerful-language-model-than-chatgpt-182647588.html
Connection?
Transformers!

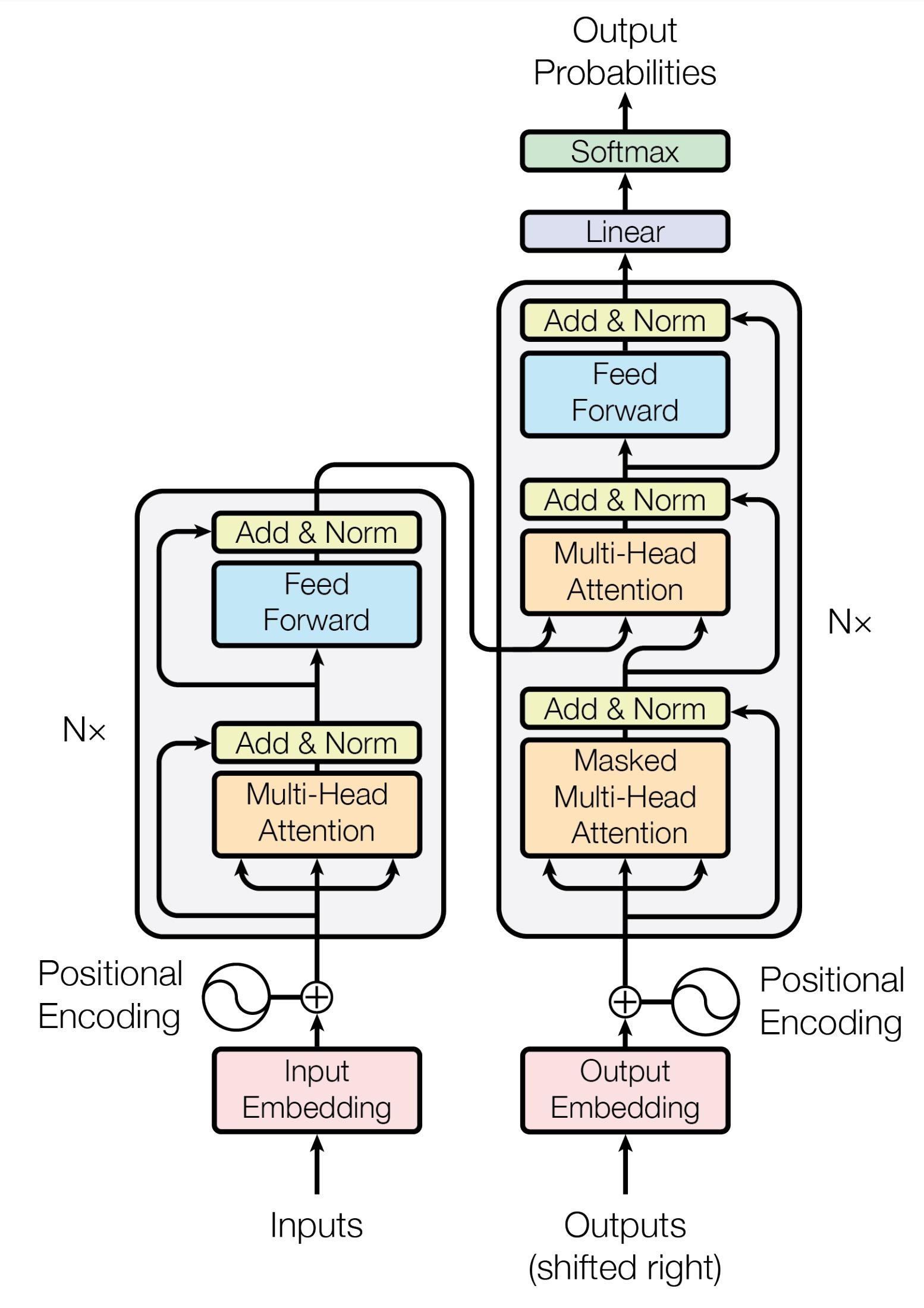

GPT (2018)
Generative Pretrained Transformer
BERT (2018)
Bidirectional Encoder Representations from Transformers
T5 (2019)
Text-To-Text Transfer Transformer
Transformer (2017)
Select candidate texts
“Understand” selections
Results “Documents” Query


Results BM25 Multi-hot Top-k Retrieval “Documents” Query Reranking Transformer-based reranking
The Manhattan Project and its atomic bomb helped bring an end to World War II. Its legacy of peaceful uses of atomic energy continues to have an impact on history and science.
{'atom': 4.0140, 'bomb': 4.0704, 'bring': 2.7239, 'continu':
2.4331, 'end': 2.1559, 'energi': 2.5045, 'have': 1.0742, 'help':
1.8157, 'histori': 2.4213, 'ii': 3.0998, 'impact': 3.0304, 'it':
Reranking Transformer-based reranking
2.0473, 'legaci': 4.1335, 'manhattan': 4.1345, 'peac': 3.5205, 'project': 2.6442, 'scienc': 2.8700, 'us': 0.9967, 'war':
2.6454, 'world': 1.9974}
Results BM25 Multi-hot
“Documents” Query
Top-k Retrieval
Transformer-generated representations learned from query-document pairs


The Manhattan Project and its atomic bomb helped bring an end to World War II. Its legacy of peaceful uses of atomic energy continues to have an impact on history and science.
Reranking Results “Documents” Query
k Retrieval
Query Encoder
Transformer-based reranking
[0.099843978881836, 0.8700575828552246, 0.520509719848633, 0.030491352081299, 0.7239298820495605, 0.134523391723633, 0.4331274032592773, 0.644286632537842, 0.645430564880371, 0.0473427772521973, 0.070496082305908, 0.504533529281616, 0.8157329559326172, 0.133575916290283, 0.9974448680877686, 0.0742542743682861, 0.1559412479400635, 0.421395778656006, 0.014032363891602, 0.996794581413269...]
Query Encoder
Transformer-generated representations learned from query-document pairs
k Retrieval
“Vector Search”
= kNN search over document vectors using a query vector
Reranking
Transformer-based reranking
Results “Documents”
Query
Source: https://www.engadget.com/microsofts-next-gen-bing-more-powerful-language-model-than-chatgpt-182647588.html
What’s the big advance?
Source: https://www.businessinsider.com/heres-what-google-looked-like-the-first-day-it-launched-in-1998-2013-9
Source: flickr (krzysztofkupren/51216023399)
Pretraining Corpus + Instructions
Prompt
Large Language Model



“Documents” What’s going on here? Pretraining Corpus + Instructions
Reranking Results “Documents” Query Doc Encoder Query Encoder
k Retrieval
have been used in search since
Top-
Transformers
2019!














“Documents” Query Pretraining Corpus
Instructions Doc Encoder Query Encoder Topk Retrieval Reranking
Large Language Model
+
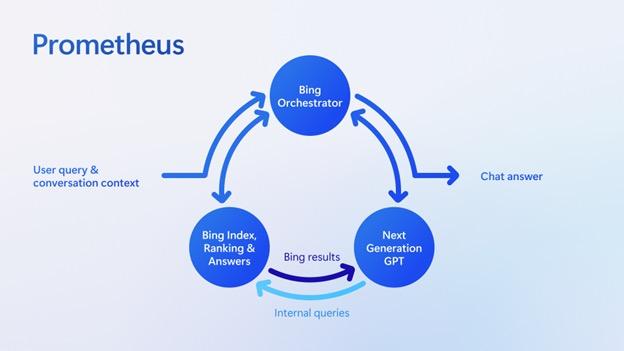
Large Language Model Retrieval Model “Documents” Query “Retrieval Augmentation” Retrieval forms the foundation of information access with LLMs! Pretraining Corpus + Instructions Source: https://blogs.bing.com/search-quality-insights/february-2023/Building-the-New-Bing
Tell me how hydrogen vs. helium are different.
Given the following facts, tell me how hydrogen and helium are different.
-
-
-
-
Hydrogen is the first element in the periodic table.
Hydrogen is colorless and odorless.
75% of all mass and 90% of all atoms in the universe is hydrogen.
Hydrogen makes up around 10% of the human body by mass.
- Helium makes up about 24% of the mass of the universe.
-
Helium is the second most abundant element.
- The word helium comes from the Greek helios, which means sun!
-
Helium atoms are so light that they are able to escape Earth's gravity!
Large Language Model Retrieval Model
“Retrieval Augmentation” Pretraining Corpus
Instructions Source:
“Documents” Query
+
https://blogs.bing.com/search-quality-insights/february-2023/Building-the-New-Bing
What are the roles of LLMs and Retrieval?
Large Language Model
Model
Query Pretraining Corpus + Instructions
Retrieval
“Documents”
What’s the problem we’re trying to solve?
How to connect users with relevant information Omission!
Why?
“the support of people in achievement of the goal or task which led them to engage in information seeking.”*
* From Belkin (2015)… and dating back much further
What’s the problem we’re trying to solve?
How to connect users with relevant information to address an information need
What’s the problem we’re trying to solve?
How to connect users with relevant information to support the completion of a task
What’s the problem we’re trying to solve?
How to connect users with relevant information to aid in cognition*
cog · ni · tion
noun. the mental action or process of acquiring knowledge and understanding through thought, experience, and the senses.
* Thanks to Justin Zobel!
Results “Documents” Query
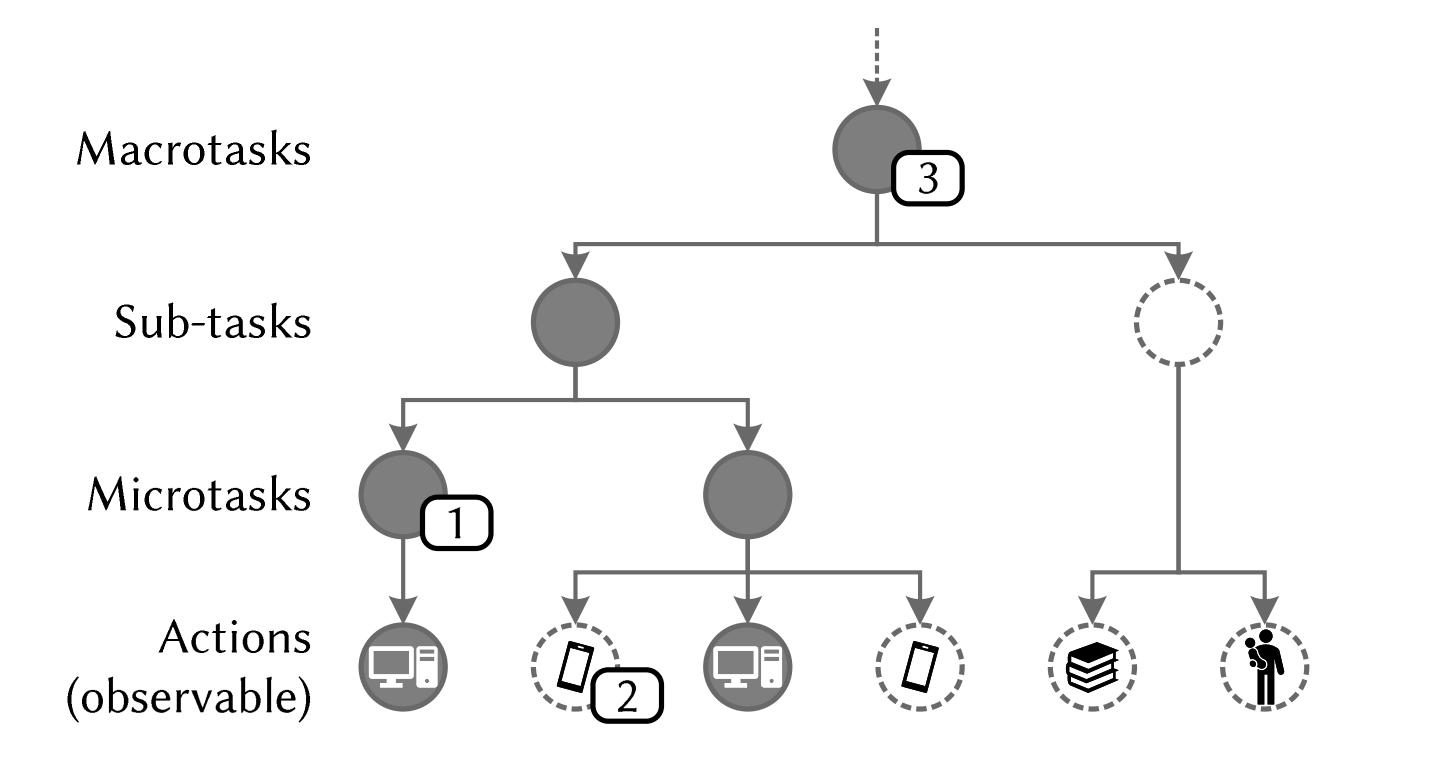

“Documents” Task Completion Synthesis from Shah et al., 2023
Results

Results “Documents” Query Interactive Retrieval Query Reformulation Task Completion Synthesis LLMs are helping more and more! from Shah et al., 2023
Source: https://www.engadget.com/microsofts-next-gen-bing-more-powerful-language-model-than-chatgpt-182647588.html
Before: come up with query terms, add/remove terms
With LLMs: natural language interactions
Before: multiple queries, multiple results, manual synthesis
With LLMs: (semi-)automated synthesis
from Shah et al., 2023
Results
Before: manually keep track of subtasks
With LLMs: helpful subtask tracking
Query Interactive Retrieval Query Reformulation Task Completion Synthesis
“Documents”
Source: https://www.engadget.com/microsofts-next-gen-bing-more-powerful-language-model-than-chatgpt-182647588.html
But none of this is fundamentally new!

CL 1998!



 Source: University of North Colorado
Source: University of North Colorado
None of this is fundamentally new! LLMs just allow us to do it better!
For example?

CL 1998!
Results “Documents” Query Interactive Retrieval Query Reformulation Task Completion Synthesis
from Shah et al., 2023
We can now tackle the entire problem!

Source: Gael Breton, from Twitter
Large Language Model Retrieval Model
Query Pretraining Corpus + Instructions
“Documents”
Retrieval Augmentation is a promising solution!
Pretraining
Tell me how hydrogen vs. helium are different.
Corpus
+ Instructions
Given the following facts, tell me how hydrogen and helium are different.
-
-
-
-
Hydrogen is the first element in the periodic table.
Hydrogen is colorless and odorless.
75% of all mass and 90% of all atoms in the universe is hydrogen.
Hydrogen makes up around 10% of the human body by mass.
Query
-
-
-
-
Helium makes up about 24% of the mass of the universe.
Helium is the second most abundant element.
Large Language Model
The word helium comes from the Greek helios, which means sun!
Helium atoms are so light that they are able to escape Earth's gravity!
“Documents”
Retrieval Model
Tell me how hydrogen vs. helium are different.
Given the following facts, tell me how hydrogen and helium are different.
- Hydrogen is the first element in the periodic table.
- Hydrogen is colorless and odorless.
- 75% of all mass and 90% of all atoms in the universe is hydrogen.
-
-
-
Hydrogen makes up around 10% of the human body by mass.
Helium makes up about 24% of the mass of the universe.
Helium is the second most abundant element.
- The word helium comes from the Greek helios, which means sun!
- Helium atoms are so light that they are able to escape Earth's gravity!
Large Language Model “Documents”

Query Pretraining Corpus + Instructions Doc Encoder Query Encoder Topk Retrieval Reranking
GI/GO
Large Language Model “Documents” Query Pretraining Corpus + Instructions Doc Encoder Query Encoder Topk Retrieval Reranking GI/GO Don’t screw it up here!
None of
this is fundamentally new! LLMs just allow us to do it better! There’s plenty left to do!
What’s the problem we’re trying to solve?
How to connect users with relevant information to aid in cognition*
cog · ni · tion
noun. the mental action or process of acquiring knowledge and understanding through thought, experience, and the senses.
* Thanks to Justin Zobel!
Manual Effort
Artifacts
Cognition
Artifacts
System Assistance
Manual Effort
Cognition
Artifacts
System Assistance
Manual Effort
Cognition
Artifacts
System Assistance
Manual Effort
Cognition
Source: WALL-E
Artifacts
Manual Effort System Assistance
Cognition
Greater efficiency!
Manual Effort System Assistance
Artifacts
Cognition
Greater complexity!
IA
not AI assisting and augmenting, not replacing
None of this is fundamentally new!
People have needed access to stored information for millennia
Transformers have been applied in search since 2019.
Multi-document summarization is 20+ years old.
Technology has augmented human cognition for centuries.
We now have more powerful tools!
Will make us more productive + expand our capabilities. There’s plenty left to work on!
tl;dr –
None of this is fundamentally new!
People have needed access to stored information for millennia
Transformers have been applied in search since 2019. Multi document summarization is 20+ years old.
Technology has augmented human cognition for centuries.
We now have more powerful tools!
Will make us more productive + expand our capabilities.
tl;dr
–
It’s an exciting time to do research!

Questions?
