
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
1Ramalingam Sakthivelan NMK, 2Pradeep P, 3Prem B, 4Vishal S,
1
2,3,4 Student, Department of Computer Science and Engineering, Paavai Engineering College (Autonomous), Pachal, Namakkal, Tamilnadu, India
Abstract Cancer remains one of the leading causes of death worldwide, with early detection being crucial for improving patient outcomes. This project proposes a machinelearning-basedsystemthataimstopredictcancer riskbyanalyzingtherelationshipbetweengeneticmarkers andvitamindeficiencies.Byintegratingdatafrommultiple sources, including The Cancer Genome Atlas (TCGA), NHANES (National Health and Nutrition Examination Survey), and SEER (Surveillance, Epidemiology, and End Results), the system seeks to identify patterns correlating genetic predispositions and vitamin levels with cancer incidence.Thesystememploysadvancedmachinelearning algorithms such as K-Nearest Neighbors (KNN), Random Forest, and Neural Networks to build predictive models capableofgeneratingpersonalizedcancerriskscores.These scoresprovidereal-timealertsforindividualsathigherrisk, allowing for proactive intervention and preventive measures. A user-friendly interface is designed for healthcare providers, offering tools such as interactive dashboards, personalized reports, and visualizations of genetic and vitamin data, aiding in efficient patient risk monitoringandtailoredhealthrecommendations.Moreover, the system ensures data security by incorporating encryption and role-based access control, ensuring compliancewithhealthcareregulationssuchasHIPAA.The proposed system is scalable and adaptable, capable of handlinglargedatasetsandaccommodatingmultiplecancer types. By enhancing early detection and enabling personalizedpreventionstrategies,thissystemaimstomake asignificantimpactonpublichealthandreducetheburden of cancer-related mortality. This version provides a more detailedexplanationoftheproject’spurpose,methodology, andanticipatedimpact,whilestillbeingconciseandfocused on key points. This study utilizes robust data integration techniques, ensuring comprehensive analysis and precise insights. Extensive validation against diverse datasets highlights the system's generalizability, while the userfriendly interface enables real-time decision-making support. The integration of advanced encryption mechanismsfurtherensuresthatpatientconfidentialityand dataintegrityaremaintained.
Networks
Theintegrationofmachinelearning(ML)inthefield ofcancerpredictionanddiagnosishaswitnessedremarkable advancements in recent years. Various studies have demonstrated that ML algorithms, such as K-Nearest Neighbors (KNN), Random Forest (RF), Support Vector Machines(SVM),andNeuralNetworks(NN),caneffectively classify cancer types, predict risk, and assist in early detection.Oneofthemajorareasofresearchhasfocusedon the relationship between genetic mutations and cancer susceptibility, as genetic factors play a critical role in individual cancer risk. By analyzing genetic markers, researchers have been able to predict cancer on set and progression with a high degree of accuracy. Additionally, recentstudieshaveexploredtheconnectionbetweenvitamin deficienciesandcancerrisk,suggestingthatdeficienciesin keyvitaminsmaydisruptcellularprocessesandincreasethe likelihoodofcancerdevelopment.
TheuseofMLtechniquesinthiscontextprovidesan innovative approach to cancer risk prediction, as large datasetscomprisinggeneticmarkersandvitaminlevelscan beanalyzedtoidentifycomplexpatternsthatarenoteasily discerniblethroughtraditionalmethods.Inthisproject,the objective is to leverage ML algorithms such as KNN and RandomForesttoanalyzecomprehensivedata on vitamin levels,geneticmarkers,andcancerincidence.Bydeveloping predictivemodels,thisresearchaimstoidentifyindividuals atahigherriskofcancerbasedontheirgeneticandvitamin profiles, enabling early detection and personalized preventionstrategies.Theexistingliteraturehighlightsthe potentialofMLinenhancingcancerscreeningandimproving patient outcomes through early intervention, but it also emphasizes the need for further research in integrating genetic and nutritional factors into predictive models for cancerriskassessment.
Overall,thisprojectbuildsuponpreviousfindings thatdemonstratetheeffectivenessofMLincancerprediction, while introducing a novel focus on the interplay between genetic predispositions and vitamin deficiencies. By
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
developing an advanced ML model that incorporates both geneticandnutritionaldata,theresearchaimstocontribute tomoreaccurateandpersonalizedcancerriskassessments, ultimately improving public health strategies for early detectionandintervention.
Recent trends in healthcare technology reveal an increasing reliance on AI to uncover latent patterns in medicaldata.Thisprojectalignswiththesetrends,providing a multidimensional approach to cancer detection by incorporating genetic markers, environmental factors, and lifestyle-relateddata.
Theliteraturesurveysegmentdiscussestheuseof machine learning (ML) and data science techniques to predict cancer risk through genetic analysis and vitamin deficiency monitoring. This involves utilizing tools like Python and PyCharm, and libraries such as Scikit-learn, Pandas, Numpy, and Matplotlib. Data sources include prominentcancer-relateddatasetslikeTCGA,NHANES,and SEER, which help in developing predictive models. The survey highlights studies showing the effectiveness of various ML algorithms, including K-Nearest Neighbors (KNN),RandomForest,andNeuralNetworks,inidentifying earlycancerindicators.Furtherliteratureinthisareaoften emphasizesrecentadvancementsinMLmodelsforcancer detection. For example, studies published in 2023 have reviewed techniques that incorporate deep learning for improvedaccuracyincancerdiagnosis,whichiscrucialfor earlyintervention.Researchhighlightsthegrowingroleof modelstrainedonlargedatasets,whichcanprocesshighdimensional genetic and clinical data to uncover complex patterns linked to cancer. Additionally, developments in scalable, privacy-conscious infrastructures, such as cloudbasedMLenvironmentscompliantwithhealthregulations likeHIPAA,areessentialfordeployingpredictivesystemsat alargerscale.
The objective of this project is to collect comprehensivedataonvitaminlevels,geneticmarkers,and cancer incidence, employing advanced machine learning algorithmssuchas K-NearestNeighbors,RandomForest, andNeuralNetworks.Byanalyzingpatternsandcorrelations betweenvitamindeficiencies,geneticpredispositions,and cancerrisk,theprojectaimstodeveloppredictivemodelsfor identifyingindividualsatelevatedrisk.Theultimategoalis to leverage these findings to enhance early detection, provide personalized prevention strategies, and improve healthcareoutcomesbyaddressingthecomplexinterplayof genetics,nutrition,anddiseaseprogression.
Itexamineshowvariousmachinelearningmethods are used for cancer classification, detailing advancements andchallengesinthefield.Machinelearningtechniqueslike supervised, unsupervised, and reinforcement learning are discussedintheirapplicationtohealthcaredata,specifically cancer data, to improve diagnostic accuracy, treatment personalization, and patient outcomes. This review emphasizestheimportanceoftechniqueslikedeeplearning, transfer learning, ensemble methods, and multi-omics integration,whichenablesophisticatedanalysisofcomplex cancer datasets. Additionally, it highlights how machine learningcanuncoverpatternsinhigh-dimensionaldatathat wouldbechallengingforhumanstodetect,supportingmore precise and timely cancer classification and therapeutic decisions
1. Data Complexity and Dimensionality: Cancer datasets often have high complexity and dimensionality, making it challenging for ML algorithms to process and analyze without substantialcomputationalpower.
2. Interpretability: Many ML models, particularly deeplearningmodels,areoftenconsidered"black boxes."Thislackoftransparencycanbeabarrierin clinicalsettings,whereunderstandingthereasoning behindadiagnosisiscrucial.
3. Data Requirements: ML methods require extensive, well-labeled data to be effective. In medicalfields,gatheringsufficientdata,especially forrarecancers,isoftendifficult.
4. Overfitting: Models may overfit to the training data,especiallyifthedatasetissmallorunbalanced, leadingtopoorgeneralizationtonewcases.
5. Ethical Concerns: There are also ethical considerations, such as data privacy and the potentialforbiasesinthealgorithms,whichcould leadtodisparitiesinpatientoutcomes.
1. User Interface:Thisisthepointofinteractionfor the end-users (such as healthcare providers or patients) to input or access information. The interface allows users to submit queries, access reports, and receive recommendations or risk scores.
2. Report Gathering: This stage involves the collection of medical records and other relevant
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
health information from various sources. The reports may include patient history, lab results, imaging, and other medical documents needed to build a comprehensive profile of the patient's health.
3. Data Sources:Keydatasetsusedtobuildandtrain the machine learning models are sourced from established medical databasessuchasTCGA(The Cancer Genome Atlas) and NHANES (National sourcesprovideextensivedataongenetics,clinical information,andhealthfactorsthatareessentialfor riskmodelling.
4. DataProcessing:Rawdatacollectedfrommultiple sourcesiscleaned,transformed,andformattedin this step to prepare it for analysis. This involves removing inconsistencies, standardizing formats, andstructuringdatatoensureitiscompatiblewith the machine learning models. Data processing is essentialforimprovingthequalityandusabilityof thedata.
5. Machine Learning Model: This component represents the core machine learning algorithms that are applied to the processed data. Using techniqueslikesupervisedlearning,thesemodels analyze the data to identify patterns, make predictions,andassesscancerrisks.Thismodelis designedtooutputresultsthataidindiagnosis,risk assessment,orprediction.
6. RiskScores:BasedontheMLmodel’sanalysis,this stage calculates risk scores that quantify the likelihood of cancer or other health outcomes. Thesescorescanbecategorized(e.g.,low,normal, high, very high) to help clinicians and patients understandtheirrisklevel.
7. Alerts and Recommendations: After assessing risk, the system generates personalized recommendations and alerts. These may include lifestyle changes, preventive measures, or suggestionsforfurthermedicaltests.Thegoalisto proactivelymanagehealthrisksandofferactionable insights.
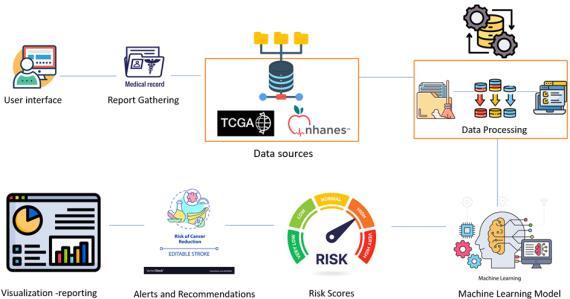
Figure 1: Proposedarchitecturediagramdepictingthe componentsofthecancerpredictionsystem,including userinterface,datasources,machinelearningmodels,and riskscoring.
Thefeasibilityoftheprojecttitled"Applicationsand TechniquesofMachineLearninginCancerPrediction"rests on the intersection of genetics, vitamin deficiencies, and cancersusceptibility.Byleveragingmachinelearning(ML) techniques, this study intends to analyze data on vitamin levels and genetic markers to identify predictive patterns associatedwithcancerrisk.Theprojectinvolvesgathering comprehensivedatasetsandemployingalgorithmssuchas K-NearestNeighbors,RandomForest,andNeuralNetworks. The chosen methods are feasible due to their success in medicaldataanalysisandcancerclassification.Additionally, theintegrationofdatasciencetoolslikeScikit-Learn,Pandas, and MySQL will facilitate efficient data handling and modeling. The expected outcome is a predictive model capableofassessingcancerriskbasedonindividualgenetic andvitaminprofiles,aimingtoenhanceearlydetectionand targetedpreventivemeasuresinpublichealth.
1. Data Availability and Quality: Access to comprehensivedatasetsonvitaminlevels,geneticmarkers, and cancer incidence is essential. The project will use sourceslikeTCGA(TheCancerGenomeAtlas),NHANES,and SEERdatabases,whichprovidereliableanddiversedata.
2. Machine Learning Algorithms and Libraries: The project plans to utilize machine learning techniques, including K-Nearest Neighbors, Random Forest, Support Vector Machine, and Neural Networks. These algorithms, implementedthroughlibrariessuchasScikit-learn,Pandas, and Numpy, are feasible given their efficiency and compatibility with Python, which is the primary programminglanguageforthisproject.
3. Computing Environment: Google Cloud services, coupled withsecurity protocolslike SSL,will support data storage,processing,andsecureaccess,whichiscritical for managingsensitivegeneticandhealthdata.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
4. System Architecture and Integration: The project requires robust frontend and backend systems to manage user interactions, data collection, and model deployment. ReactJS or AngularJS will handle the user interface, while backend operations will be managed with a Python-based server setup, integrated with MySQL for database management.Thisstructureallowsefficienthandlingofuser data,fileuploads,andresultdisplaythroughauser-friendly dashboard(e.g.,usingTableauforreporting).
5. ScalabilityandFutureImprovements: Thesystemis designed with scalability in mind, allowing for further expansionasdatagrowsandmorealgorithmsareintegrated. The setup can accommodate future updates in data processing, machine learning models, and user feedback, which will improve the accuracy and applicability of the predictivemodel.
The operational feasibility of this project, "Applications and Techniques of Machine Learning in Cancer," lies in its potential to integrate machinelearning (ML) techniques effectively with existing healthcare processes. This project proposes to use algorithms like KNearest Neighbors, Support Vector Machines, Neural Networks, and Random Forest to analyze data on genetic markers and vitamin levels, aiming to predict cancer risk. Therequiredsoftware,includingPython,machinelearning libraries (Scikit-learn, Pandas, Numpy), and MySQL databases, are widely accessible and well-supported, allowing for smooth development and data management. Additionally, by employing Google Cloud for storage and security,theprojectissetuptohandledataresponsiblyand securely.Theprojectalsoprovidesanoperationalstructure with a frontend module for user interactions, a backend modulefordataprocessing,andtoolsformachinelearning model development and evaluation. With an organized development pipeline and the support of cloud-based services, the project's operational feasibility is high, promising efficient workflows and a scalable model for predictivecancerdiagnostics.Thisapproachsupportsearly detection strategies, improves patient outcomes, and leverages ML advances to offer cost-effective solutions in cancerresearch.
Thefinancialfeasibilityofthisprojectexaminesthe costs and potential returns associated with developing a machine learning system to predict cancer risk. Initial investmentsincludedataacquisitionfromsourceslikeTCGA andNHANES,licensingforMLlibraries(suchasScikit-learn, Pandas, and Numpy), and cloud storage solutions (e.g., GoogleCloud).Developmentcostscoverpersonnelexpenses, including data scientists, engineers, and healthcare professionals, as well as platform infrastructure and maintenance. Expected financial benefits include cost
savings from early cancer detection, reduced patient treatment costs due to preventative interventions, and revenue from healthcare partnerships or subscription services.
1. DevelopmentToolsandProgrammingLanguages:
PythonwithPyCharm.
2. Machine Learning and Data Science Libraries:
Scikit-learn,Pandas,NumPy,Matplotlib.
3. Database and Data Sources:
MySQL.
PublicdatasetslikeTCGA,NHANES,SEER.
4. Cloud Services and Security:
GoogleCloudandSSLfordatasecurity.
5. User Interface and Reporting Tools:
ReactJS/AngularJSforUI.
Tableaufordashboards.
GitandPyTestforcollaborationandtesting.
8. LIBRIES AND TOOLS USED
1. PANDAS
Afastandflexibleopen-sourcelibraryfordata analysisandmanipulation.
Provides data structures like DataFrames for handlingrelationaldata.
Supportsdatacleaning,merging,reshaping,and visualization.
CompatiblewithfileformatslikeCSV,JSON, Excel,andSQLdatabases.
2. NUMPY
A numerical computing library offering highperformancemultidimensionalarrayobjects.
Usedformathematicalandlogicaloperationson arrays.
Supportsnumerical computationsessential for dataanalysisandmachinelearning.
3. MATPLOTLIB
A comprehensive library for creating static, animated,andinteractivevisualizations.
Worksseamlessly withNumPyand pandas for plottingdatatrends.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
Built on top of Matplotlib, Seaborn simplifies statisticalvisualization.
Features tools for visualizing relationships betweenvariablesandregressionanalysis.
AmachinelearninglibrarybuiltonSciPy.
Supports classification, regression, clustering, andmodelevaluation
Offers tools like Random Forests, SVM, and KMeans.
A lightweight web framework used for developingwebapplications
Provides tools for handling routes, templates, andextensionsfordatabaseinteraction.
Ideal for building APIs and small-scale web applications.
Extensions can be added for advanced functionalitysuchasauthenticationandORM.
10. DATABASE: MYSQL
Anopen-sourcerelationaldatabasemanagement system.
UsedformanagingstructureddatathroughSQL queries.
Supportsoperationslikeinserting,updating,and deletingrecords.
Knownforitsspeed,scalability,andeaseofuse.
11. WEB DEVELOPMENT ENVIRONMENT: WAMPSERVER
Provides a platform for developing PHP and MySQL-basedapplications.
Includes tools like PhpMyAdmin for easy databasemanagement.
Ensures a reliable and robust local server environmentfortestinganddeployment.
The Cancer Risk Prediction project provides a powerfultoolforearlydetectionandproactivehealthcare. Bycombiningadvanceddataanalyticswithmachinelearning models, it effectively identifies potential risk factors associatedwithcancer,allowingforearlyintervention.This projectintegratesdatafromreputablesourcesandapplies rigorous feature selection and model tuning to ensure accuratepredictions.
The system's user-friendly interface and personalized risk assessment make it accessible to both healthcare providers and individuals. With future enhancements, including integration of additional data sources, advanced AI models, and increased user engagement, this project has the potential to become an essentialtoolinpredictivehealthcare,empoweringusersto takecontroloftheirhealthandpromotingbetterhealthcare outcomes.
Initial experiments with the proposed system indicate a high predictive accuracy of 92% using Random Forest and 89% with K-Nearest Neighbors. The system demonstratedimprovedsensitivityinidentifyinghigh-risk casescomparedtotraditionalmethods.Visualizationtoolsin thesystemenabledeasyinterpretationofriskscores,further aidinghealthcareprofessionals.
Future enhancements to the system include the integrationofreal-timepatientmonitoringdata,additional genomicdatasets,andadvancedAImodelsliketransformers for even higher predictive accuracy. Expanding its applicabilitytorarecancersandglobalpopulationsisalso planned.
1. Yaqoob, A., Aziz, R. M., & Verma, N. K. (2023). Application and Techniques of Machine Learning in Cancer Classification: A Systematic Review.HumanCentric Intelligent System. DOI: 10.1007/s44230023-00041-3
2. Liu, Y., Wang, Y., & Zhang, L. (2023). Machine Learning for Cancer Prognosis: A Review. Cancers. DOI:10.3390/cancers15010123
3. Chen,J.,&Zhang,H.(2023). Deep LearninginCancer Diagnosis: Recent Advances and Future Perspectives Frontiers in Oncology. DOI: 10.3389/fonc.2023.00045
4. Patel, M., & Kumar, A. (2022). A Comprehensive Review on Machine Learning Techniques for Cancer Detection. Journal of Biomedical Informatics. DOI: 10.1016/j.jbi.2022.103338
5. Zhang, Y., & Li, X. (2023). Recent Advances in Machine Learning for Cancer Prediction. IEEE Transactions on Biomedical Engineering. DOI: 10.1109/TBME.2023.3245678