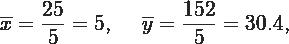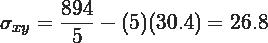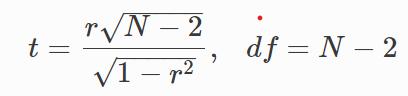
8 minute read
Coeficiente de Correlación de Pearson


Breve repaso introductorio a la correlación lineal y la regresión lineal:
Son métodos que estudian una relación lineal existente entre dos variables, Antes de empezar a profundizar en cada uno de ellos, nos conviene destacar algunas diferencias entre ellas:
Advertisement
La correlación cuantifica como de relacionadas están dos variables, mientras que la regresión consiste en generar una ecuación que, basándose en la relación existente entre ambas variables, permita predecir el valor de una a partir de otra
El cálculo de la correlación entre dos variables es independiente del orden o asignación de cada variable a X e Y, la cual mide únicamente la relación entre ambas sin considerar dependencias. En el caso de la regresión lineal, el modelo varía según qué variable se considere dependiente de la otra (lo cual no implica causa-efecto).
A un nivel experimental, la correlación se suele emplear cuando ninguna de las variables se ha controlado, simplemente se han medido ambas y se desea saber si
están relacionadas. En el caso de estudios de regresión lineal, es más común que una de las variables se controle (tiempo, concentración de reactivo, temperatura…) y se mida la otra
los estudios de correlación lineal preceden a la generación de modelos de regresión lineal. Primero se analiza si ambas variables están correlacionadas y, en caso de estarlo, se procede a generar el modelo de regresión.
Ahora si ya habiendo echo una base sobre la correlación y la regresión pasaremos a definir sus conceptos sus características y un ejercicio de ejemplo:
Que es la correlación lineal: Para poder estudiar la relación lineal existente entre dos variables continuas es necesario disponer de parámetros que permitan cuantificar dicha relación. Uno de estos parámetros es la covarianza, que indica el grado de variación conjunta de dos variables aleatorias.
Covarianza muestral=Cov(X,Y)= ∑∋ ¿ 1 ( xi − x ¯ ¯ ¯ )( yi n−1 − y ¯ ¯ ¯ ) N −1
La covarianza depende de las escalas en que se miden las variables estudiadas, por lo tanto, no es comparable entre distintos pares de variables. Para poder hacer comparaciones se estandariza la covarianza, generando lo que se conoce como coeficientes de correlación. Existen diferentes tipos, de entre los que destacan el coeficiente de Pearson, Rho de Spearman y Tau de Kendall. Todos ellos varían entre +1 y -1. Siendo +1 una correlación positiva perfecta y -1 una correlación negativa perfecta. Se emplean como medida de fuerza de asociación (tamaño del efecto): 0: asociación nula. 0.1: asociación pequeña. 0.3: asociación mediana. 0.5: asociación moderada. 0.7: asociación alta. 0.9: asociación muy alta.
Las principales características entre los tres coeficientes son:
La correlación de Pearson funciona bien con variables cuantitativas que tienen una distribución normal. En el libro Handbook of Biological Statatistics se menciona que sigue siendo bastante robusto a pesar de la falta de normalidad. Es más sensible a los valores extremos que las otras dos alternativas. La correlación de Spearman se emplea cuando los datos son ordinales, de intervalo, o bien cuando no se satisface la condición de normalidad para variables continuas y los datos se pueden transformar a rangos. Es un método no paramétrico. La correlación de Kendall es otra alternativa no paramétrica para el estudio de la correlación que trabaja con rangos. Se emplea cuando se dispone de pocos datos y muchos de ellos ocupan la misma posición en el rango
Además del valor obtenido para el coeficiente de correlación, es necesario calcular su significancia. Solo si el p-value es significativo se puede aceptar que existe correlación, y esta será de la magnitud que indique el coeficiente. Por muy cercano que sea el valor del coeficiente de correlación a +1 o −1, si no es significativo, se ha de interpretar que la correlación de ambas variables es 0, ya que el valor observado puede deberse a simple aleatoriedad.
El test paramétrico de significancia estadística empleado para el coeficiente de correlación es el t-test. Al igual que ocurre siempre que se trabaja con muestras, por un lado, está el parámetro estimado (en este caso el coeficiente de correlación) y por otro su significancia a la hora de considerar la población entera. Si se calcula el coeficiente de correlación entre XX e YY en diferentes muestras de una misma población, el valor va a variar dependiendo de las muestras utilizadas. Por esta razón se tiene que calcular la significancia de la correlación obtenida y su intervalo de confianza.
Para este test de hipótesis, H0 considera que las variables son independientes (coeficiente de correlación poblacional = 0) mientras que, la HaHa, considera que existe relación (coeficiente de correlación poblacional ≠ 0).
La correlación lineal entre dos variables, además del valor del coeficiente de correlación y de sus significancias, también tiene un tamaño de efecto asociado. Se conoce como coeficiente de determinación R2. Se interpreta como la cantidad de varianza de YY explicada por XX. En el caso del coeficiente de Pearson y el de Spearman, R2 se obtiene elevando al cuadrado el coeficiente de correlación. En el caso de Kendall no se puede calcular de este modo. (No he encontrado como se calcula).
Ejercicio 1:
Una compañía desea hacer predicciones del valor anual de sus ventas totales en cierto país a partir de la relación de éstas y la renta nacional. Para investigar la relación cuenta con los siguientes datos:
X representa la renta nacional en millones de euros e Y representa las ventas de la compañía en miles de euros en el periodo que va desde hasta (ambos inclusive). Calcular:
1.La recta de regresión de Y sobre X. 2.El coeficiente de correlación lineal e interpretarlo. 3.Si en la renta nacional del país fue de millones de euros. ¿Cuál será la predicción para las ventas de la compañía en este año?
A continuación, está la solución:
1 La recta de regresión de Y sobre X.


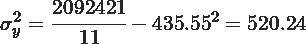
2 El Coeficiente de correlación lineal e interpretarlo.

Es un coeficiente de correlación positivo y cercano a uno, por lo que la correlación es directa y fuerte.
Si en la renta nacional del país fue de millones de euros. ¿Cuál será la predicción para las ventas de la compañía en este año?
RELACION LINEAL EN EL AREA DE PROBABILIDAD Y ESTADISTICA
En estadística, el análisis de la regresión es un proceso estadístico para estimar las relaciones entre variables. Incluye muchas técnicas para el modelado y análisis de diversas variables, cuando la atención se centra en la relación entre una variable dependiente y una o más variables independientes (o predictoras). Más específicamente, el análisis de regresión ayuda a entender cómo el valor de la variable dependiente varía al cambiar el valor de una de las variables independientes, manteniendo el valor de las otras variables independientes fijas.
Más comúnmente, el análisis de regresión estima la esperanza condicional de la variable dependiente dadas las variables independientes - es decir, el valor promedio de la variable dependiente cuando se fijan las variables independientes.
Con menor frecuencia, la atención se centra en un cuantil, u otro parámetro de localización de la distribución condicional de la variable dependiente dadas las variables independientes. En todos los casos, el objetivo de la estimación es una función de las variables independientes llamada la función de regresión. En el análisis de regresión, también es de interés caracterizar la variación de la variable dependiente en torno a la función de regresión, la cual puede ser descrita por una distribución de probabilidad.
El análisis de regresión es ampliamente utilizado para la predicción y previsión, donde su uso tiene superposición sustancial en el campo de aprendizaje automático. El análisis de regresión se utiliza también para comprender cuales de las variables independientes están relacionadas con la variable dependiente, y explorar las formas de estas relaciones.
En circunstancias limitadas, el análisis de regresión puede utilizarse para inferir relaciones causales entre las variables independientes y dependientes. Sin embargo, esto puede llevar a ilusiones o relaciones falsas, por lo que se recomienda precaución, por ejemplo, la correlación no implica causalidad.
Muchas técnicas han sido desarrolladas para llevar a cabo el análisis de regresión. Métodos familiares tales como la regresión lineal y la regresión por cuadrados mínimos ordinarios son paramétricos, en que la función de regresión se define en términos de un número finito de parámetros desconocidos que se estiman a partir de los datos.
La regresión no paramétrica se refiere a las técnicas que permiten que la función de regresión consista en un conjunto específico de funciones, que puede ser de dimensión infinita.
El desempeño de los métodos de análisis de regresión en la práctica depende de la forma del proceso de generación de datos, y cómo se relaciona con el método de regresión que se utiliza. Dado que la forma verdadera del proceso de generación de datos generalmente no se conoce, el análisis de regresión depende a menudo hasta cierto punto de hacer suposiciones acerca de este proceso. Estos supuestos son a veces comprobables si una cantidad suficiente de datos está disponible. Los modelos de regresión para la predicción son frecuentemente útiles, aunque los supuestos sean violados moderadamente, aunque no pueden funcionar de manera óptima. Sin embargo, en muchas aplicaciones, sobre todo con pequeños efectos o las cuestiones de causalidad sobre la base de datos observacionales, los métodos de regresión pueden dar resultados engañosos.
EJEMPLO RELACIONADO A LA INGENIERIA DE SISTEMA
Cinco niños de 2, 3, 5, 7 y 8 años de edad pesan, respectivamente, 14, 20, 32, 42 y 44 kilos.
1- Hallar la ecuación de la recta de regresión de la edad sobre el peso.
2- ¿Cuál sería el peso aproximado de un niño de seis años?
Respuesta:
Hacemos la siguiente tabla

Calculamos los promedios
Calculamos la covarianza y la varianza de
La recta de regresión de la edad sobre el peso es aquella que pasa por el punto y
tiene pendiente