AdaptiveExperimentsforPolicyChoice:PhoneCallsforHome
Segura,AdamMcCloskey,andKellyW.Zhangwereextremelygenerousinsharingtheirexpertise.WethankKathleenBeegle, DanielBj¨orkegren,EstherGehrke,AndrewFoster,MaximilianKasy,DavidMcKenzie,RobertPless,andseminarparticipants attheWorldBankandRochesterUniversityforhelpfulcommentsandfeedback.Thefindings,interpretations,andconclusions
itsaffiliatedorganizations,orthoseoftheExecutiveDirectorsoftheWorldBankorthegovernmentstheyrepresent.Allerrors areours.
ReadinginKenya BrunoEsposito∗ AnjaSautmann†‡ Latest version here Keywords: adaptiveexperiments;multi-armedbandits;educationtechnology;earlyliteracy;Kenya JELcodes: C11,C93,I25,O15 ∗ DevelopmentEconomicsResearchGroup,WorldBank,email:bespositoacosta@worldbank.org † Correspondingauthor.DevelopmentEconomicsResearchGroup,WorldBank,email:asautmann@worldbank.org. ‡ TheauthorsthankTimSullivanandClotildedeMaricourtatNewGlobeandPeterBergmanforconnectinguswiththem,as wellasGrantBridgman,ChristineVorster,andFaithKibuswaatUliza.IsaiahAndrews,JiafengKevinChen,DanielRodriguez-
expressedinthispaperareentirelythoseoftheauthors.TheydonotnecessarilyrepresenttheviewsoftheWorldBankand
Theuseofexperimentsinresearchoneconomicdevelopmentandpolicyrepresentsoneofthebiggestmethodologicalinnovationsineconomicsinthelastfewdecades.Forresearchthattestspolicyinterventionsand programs,thehopehasbeenthatrigorousexperimentscanleadtobetterpolicydecisions.Inthiscontext, thelearninggoalofapolicymakersuchasagovernmentorNGOmaybecharacterizedasfollows:they wouldliketoimproveacertainoutcome,sayineducationorhealth,andarelookingtoidentifythebest (leastexpensive,mosteffective)policytoaffectthisoutcome.Wecallthisa“policychoiceproblem”for short.
Randomizedcontroltrials(RCT)astheyarefoundineconomicsandrelatedfieldsaretypicallyaimedat identifyingcausaltreatmenteffectsandestimatingtheseeffectsaspreciselyaspossible,anddesignchoices likeequal-sizedtreatmentgroupsandre-randomizationorstratificationsupportthisgoal.Butthisapproach toexperimentaldesignisnotideallysuitedtoinformapolicychoiceproblem.Toseewhy,notethatsample sizesthatdeliverthepowertostatisticallydistinguishtheeffectsizesinmultipletreatmentarmsfromzero (andeachother)quicklygrowlarge.Yetfortheobjectiveofchoosingandimplementingonlyoneofthe testedpolicies,precisetreatmenteffectestimatesforlow-performingoptionsarenotactuallyneeded;expost, someofthesampleassignedtothesearmscouldhavebeenputtobetterusetodistinguishthetreatment effectsinthehighest-performingarms.Thisisparticularlydetrimentalifthesampleissmallorthereare budgetandtimeconstraintsthatpreventprolongedexperimentation.
Whentheexperimentcanbecarriedoutintwoormorewaves,theresearchdesignforpolicychoicecan, inmanycases,beimprovedbyusingadaptivesampling.Theobjectiveinthepolicychoiceproblemis tomaximizetheaverageoutcomeattheendoftheexperiment,orequivalently,minimizeexpectedpolicy regret,thatis,theexpectedlossfromselectingasuboptimalarm.Choosingthearmwiththehighest outcomeafterrepeatedexperimentationisaspecialcaseofthemulti-armedbanditproblemwithapure “exploration”motive,butno“exploitation”motive(Bubecketal.,2009;Audibertetal.,2010).Efficient learningmeansadaptingtheassignmentofexperimentalunitstotreatmentarmsbasedonwhatwaslearned inearlierwaves.1 Thebestadaptivelearningstrategyforpolicychoicetendstoassignalargershareof thesampletohigher-performingarms.Thishelpstodistinguishthesearmsfromeachotherwhilespending lesseffortonlow-performingarms.Inpractice,researchersusesamplingalgorithmsthatapproximatethe optimalstrategytoreducecomputationalburden.
Thispaperputsadaptivesamplingforpolicychoicetothetestbyapplyingittoareal-worldpolicychoice
1Thisistrueformanydifferentlearningobjectives,includingbutnotlimitedtopolicychoice.Itholdsalsoforlearning goalsthatusuallymotivatestandardRCTs,suchasefficienthypothesistesting:itistypicallynotoptimaltorandomlyassign equalsamplesharestoalltreatmentarmsinlaterwaves,seee.g.Tabord-Meehan(2018).
1 Introduction
2
problemineducationtechnology.Thegoalisthreefold:addressingconceptualandpracticalchallengesin implementingadaptiveexperimentsinpolicysettings,studyingperformanceofanadaptiveresearchdesign inashorttimehorizonwhereasymptoticperformanceguaranteesmaynotapply,and,lastbutnotleast, informingtheactualpolicychoiceproblemathand.
Theexampleweuseisanexperimentonusingphonecallswithinteractivevoiceresponse(IVR)technology todeliverregularshortreadingexercisesdirectlytoparentsinKenya.Thecallsareintendedtoencourage parentstoreadwiththeirchildrenathome,apracticeknowntoimprovelanguageacquisitionandfluency (Mayeretal.,2019;Yorketal.,2019;Knaueretal.,2020).TheimplementerwasNewGlobe,anorganization thatbothsupportspublicschoolsandoperatesitsowncommunityschoolsinseveralcountries,includingthe BridgeKenyaprimaryschoolsinoursample.FacedwithmanyoptionsforIVRcallandexercisedesigns, NewGlobewaslookingtodecidewhichcallformat(ifany)theyshouldrollouttoallparents.
WeusetheIVRexperimenttodiscussindetailhowtoapproachdesigningandconductinganadaptive experimentforpolicychoice–fromestimationapproaches,tothealgorithmused,toresearchdesigndecisions, forexampleaboutsamplingandsamplingsize.Inourexample,wetestedsixdifferentIVRcalloptionsduring thethirdtermofthe2020schoolyear.Theexperimentwasdesignedtoidentifythecallformatwiththe highestlevelofengagement,measuredasthenumberofIVRcallsinwhichtherespondentstartedthereading exercises,andtotestwhetherIVRcallscanincreasereadingfluency.Thecallscross-combinetwodelivery formatsfortheexercises–parent-ledvs.IVR-ledreading–withthreedifferentwaysofmatchingexercise contentstothechild’sreadinglevel,motivatedbyevidencethattargetedinstructioncanimproveoutcomes especiallyinthetailsofthedistribution(Banerjeeetal.,2007;Muralidharanetal.,2019;Dossetal.,2019).
Inordertoefficientlyidentifythearmwithhighestcallengagement,theexperimentusesaversionofthe explorationsamplingalgorithmproposedbyKasyandSautmann(2021a)toassignexperimentalunitsto treatmentarms.ExplorationsamplingisaBayesianbanditalgorithmthatwasshowntoperformwellin bothrealandsimulatedexperimentsforpolicychoiceandsharesattractiveasymptoticefficiencyproperties forbest-armidentificationofasetofsimilaralgorithms(Russo,2020;Qinetal.,2017;Shangetal.,2020; KasyandSautmann,2021b).Toourknowledge,therearetodateonlythreepolicychoiceexperimentsthat haveusedit:anapplicationintheoriginalpaper,atestofanSMS-basedinformationcampaigninIndiato reducethespreadofCovid-19(Bahetyetal.,2021),andatrialoncontraceptiveuptakeinCameroonthat isongoingatthetimeofwriting(Atheyetal.,2021).InsteadofaBernoullioutcomewithaBetapriorasin theoriginalpaper(andmanymulti-armedbanditsettings),weuseahierarchicalbinomialmodeltoobtain assignmentsharesandparameterestimates.
TheIVRexperimenthasonlytwoexperimentalwavesandtheoutcomedistributionismorecomplexthan assumedintheoreticaltreatmentsofBayesianbest-armalgorithms.Wearethereforeparticularlyinterested
3
howadaptivesamplinginfluencestreatmentassignment,performance,andestimationresults.Wefindthat afterjustonewave,thereissufficientlearningsothatadaptivesamplingleadstoasubstantialshiftinthe assignmentshares:basedonthedifferentcallsuccessratesineacharmafterwave1,weobtainedsample allocationsharesforwave2thatvariedbetween0%and39%.Afterwave2,weestimatea93%probability thatthebestcalldesignforengagementusesparent-ledreadingexercisesanddeliversthesameintermediatelevelexercisestoallstudents.Inthisarm,parentsengage–meaning,theystartthereadingexercises–with 8.40%probabilitypercall,comparedto3.93%intheleastsuccessfularm.Thearmwithsecondhighest engagement(7.43%)hasonlya5%probabilityofbeingoptimal.Expressingtheexpectedpolicyregretin termsofaverageengagementprobability,theselectedtreatmentarmhasanestimated0.02%expectedloss frompotentiallymakingasuboptimalchoice,comparedto1.27%-4.49%fortheotherarms.
Eventhoughtheexperimenttargetedcallengagement,wealsoestimatethetreatmenteffectsonoral readingfluency(ORF),usingexamscorescollectedbytheimplementer.Althoughthedataisnoisy,wefind thatthearmwiththehighestlevelofengagementleadstoestimatedincreasesinORFof1.68correctwords perminute,equivalentto0.065standarddeviationsofthebaselinedata,withacredibleintervalbetween 0.13and3.21.Theprecisionofthisestimateispartlyduetothelargesampleassignedtothebestarm.
TheresultsoftheIVRexperimentspeaktoanimportantpolicyquestion:whethertherearelow-cost, automatedmethodsofincreasingtheprobabilitythatparentsreadwiththeiryoungchildren,andwhat theirbestdesignmightbe.EspeciallyduringtheCovid-19pandemic,itbecameclearthatthereisan unfilledneedforsustainedlearningathomeandreachingchildreninfamilieswithlimitededucationaland technologicalresources.Personalcallshavebeenshowntobehighlyeffective(Angristetal.,2020b),butmay requiresignificantofresources.Theexperimentshowsthatmass-deployedIVRcallscanincreaseparental involvementinthechild’sschoolingbutthatthecalldesignmatterssignificantlyforuptake.
Beyondthesefindings,themaincontributionsofthispaperareanevaluationofthemeritsofusing adaptivesamplingforpolicychoice,andadetailedguidetoimplementation.2 Inparticular,weusesimulation approachestoexaminetheperformanceoftheexperimentandunderstandtheimpactofdifferentdesign choices.Inafirstexercise,wecompare‘expost’theexplorationsamplingdesignwithanalternativedesign withequal-sized(stratified)treatmentarms,akintoa“standard”RCT,usingsimulatedsamplesdrawnfrom theexperimentalobservations.Thisshowsthatadaptiveassignmentinonlyonewaveachievedmeaningful reductionsinuncertainty–fromonaverage86%probabilitythatthechosenarmisoptimalintheRCTto 93%probabilitywithexplorationsampling–andreducedposteriorexpectedpolicyregretbymorethanhalf from0.05percentto0.02percentengagementprobability.
Thenexttwoexercisescarryout‘exante’simulationsbasedontheoutcomemodelinordertodetermine 2Thiscomplementstheexcellentpractitioner’sguideonadaptiveexperimentsbyHadadetal.(2021).
4
thegainsfrom(a)conductingtwoexperimentalwavesinsteadofone(non-adaptive)wavewiththefull sample,and(b)addingasecondwaveafterhavingobservedtheoutcomesofthefirst.Theseareexamples ofsimulationsaresearchermightconducttodeterminetheresearchdesign,akintopowercalculations.In case(a),thepredictedreductionsinexpectedregretseemplausibleforspecificparametervector,buttheflat priordistributionsofthetreatmenteffectparametersdonotprovideagoodbasisforsimulatingthegains fromadaptivity;researchersmayinsteadchoosetofocusonspecificparametervalues,notleasttoreduce computationalburden(akintopowercalculationswhereaminimumdetectableeffectsizeisimposed).In case(b),wherethewave-1posteriorscanbeusedtosimulateparameterdraws,“agnostic”simulationsdo better,buttheyappeartostillsomewhatunder-predictthegains.
Aswegoalong,wediscussmanydetailsofimplementationandexperimentaldesign,suchasformulating andvalidatingtheBayesianmodelsfortreatmenteffectestimation,calculatingtheexpectedposteriorpolicy regretofeacharm,andwritingapre-analysisplan.Weaddressquestionssuchaswhenanadaptiveexperimentispossibleandwhenitmaybemostvaluable,andapproachestocorrectingestimatedtreatmenteffects andconfidenceintervalsforsamplingbiasandthe“winner’scurse”thataffectsthetreatmenteffectestimate ofthebestarm(e.g.MelfiandPage,2000;Andrewsetal.,2021).Wealsospendsometimediscussingthe trade-offsthatwereinvolvedinchoosingthetargetedoutcome.
Theconstraintsonthisexperimentarerepresentativeofthedecisioncontextsinwhichpolicymakers workday-to-day.InNewGlobe’ssituation,withalimitedbudgetandonlyoneschooltermavailabletotest IVR,manyorganizationsmightdecideagainstanexperimententirely—butourtrialshowsthatadaptive samplingmethodscanenablerigorouslearningevenwhentheparametersofexperimentaldesignareseverely constrained.Thesolutionsweproposecanhelpinformfutureadaptiveexperimentsforpolicychoice,in EdTechaswellasmanyothercontexts.
Thenextsectionintroducestheconceptsbehindadaptivesamplingforpolicychoice,showinghowthe samplingalgorithmusedisdeterminedbytheobjectiveoftheexperiment,describingtheexplorationsamplingalgorithm,anddiscussingtheuseofBayesianestimation.Italsolaysoutsomeconsiderationsfor choosingparametersoftheresearchdesignsuchasthenumberofwaves.Section3discussesthepolicy background,interventions,andexperimentaldesignoftheIVRexperiment,includingthechoiceoftargeted outcome,highlightinglessonsforadaptiveexperimentsingeneral.Section4discussesthedataanddetails themodelsusedforestimation,includinghowtoderivetheprobabilityoptimalandtheexpectedpolicy regret,quantitiesusedintheexplorationsamplingalgorithm.Section5presentstreatmenteffectestimates forparentalengagement,showstheassignmentsharesbasedontheseestimates,anddiscussestheimpact onreadingfluency.Finally,section6picksupthequestionofresearchdesignagain.Intheconcretecontext oftheIVRexperiment,wefirstshowhowtheadaptiveandanon-adaptivedesigncompare‘expost’in
5
simulatedsamplesfromtheexperimentaldata,andthendemonstratehow‘exante’simulationscanbeused todecide,forexample,onthenumberofexperimentalwaves.Section7concludeswithashortdiscussion.
2 UsingAdaptiveSamplinginExperimentsforPolicyChoice
Thissectiongivesanoverviewovertheuseofadaptivesamplingforpolicychoiceandtheexplorationsampling algorithmproposedbyKasyandSautmann(2021a).Westartwiththe“basicingredients”foranadaptive experiment:theobjective,analgorithmthatbuildsonthedatafromeachwavetoadaptivelyallocateunits totreatmentarms,theestimationapproach,andconstraintsthatdeterminewhetheranadaptiveexperiment isfeasible.ThecorrespondingfeaturesoftheIVRexperimentaredescribedindetailinsections3and4.
Thissectionalsodiscussesthegainsfromadaptivevs.non-adaptivesamplingoraddingadaptivewaves, andhowthesegainscanbecalculatedinsimulationstochoosethenumberofexperimentalwaves.Wereturn tothisinsection6,buildingonthedatacollectedinKenyaandtheestimationresultsinsection5.Tobegin with,however,weassumethatthereare t =1,...,T exogenouslygivenconsecutivesampledraws(waves)of size Nt availablefortesting.
Objective. Inthecanonicalpolicychoiceproblem,thereare K> 2policyoptions–ortreatmentarms–labeled k =1, 2,...,K.Eacharmhasunobserved(stationary)averageoutcome θk,andthepolicymaker wantstoimplementthearmwiththehighestaverageoutcome.Formally,let k(1) =argmaxk θk bethetrue bestarm,and k∗ thearmthatischosen.Wecalltheloss(perunit)fromimplementingasuboptimalarm k thepolicyregret,∆k = θk(1) θk.Expost,thepolicymakerwillselectthearm k∗ thathasthehighest averageoutcome,orlowestpolicyregret,basedontheobserveddata.
Itisassumedthattheoutcomesoftheexperimentalunitsareobservedattheendofeachperiod t.This meanswecanlearnfromwave t andadjusttheallocationofunitstotreatmentarmsinwave t +1,i.e. useadaptivesampling.Inthepolicychoiceproblem,thepolicymaker’swantstoimplementanadaptive samplingstrategythatmaximizeswelfare,thatis,minimizestheexpectedpolicyregretfromthefinalchoice giventhetrue(unobserved)vectorofaverageoutcomes: E[∆k∗ |θ].Adaptivityincreasestheefficiencyof learningforagivenobjectivebyover-samplingsomearmsbasedonwhatwaslearned,attheexpenseof otherarms(andotherobjectives).
Remark:OtherObjectives. Largeliteraturesconsidersamplingforspecificlearninggoals.
Theclassicalmulti-armbanditproblem(MAB)considerstheobjectivetomaximizeaverageoutcomes duringtheongoingexperiment,orequivalentlytominimizein-sampleregret,whichintroducesthewellknownexploration-exploitationtrade-off(e.gLaiandRobbins,1985;BubeckandCesa-Bianchi,2012).The policychoiceproblemofchoosingthearmwiththehighestaverageoutcomecanbeseenasaspecialcase
6
oftheMABproblem,wheretheexperimenterhasno“exploitation”motive(Bubecketal.,2009;Audibert etal.,2010).Closelyrelatedtothe“pureexploration”problemofpolicychoiceistheproblemof“bestarm identification”(BAI),tothepointthattheyareoftentreatedasinterchangeable.Here,theexperimental designaimstoeitherminimizetheprobabilityofchoosingasub-optimalarmafteragivennumberofwaves (the“fixedbudget”setting),orminimizetheexpectednumberofwavestoachieveagivenlevelofcertainty aboutwhicharmisoptimal(the“fixedconfidence”setting(GarivierandKaufmann,2016);seee.g.Lattimore andSzepesv´ari(2020)foranexcellentandin-depthoverview).
Eveninnon-adaptiveexperiments,commonsamplingtechniquessuchasstratificationandre-randomization aimtomaximizepowertodetectadifferencebetweentreatmentandcontrolgroup(AtheyandImbens, 2017).3 Adaptivestrategiescanfurtherincreasepowerforparticulartests(Robbins,1952).Forexample, Tabord-Meehan(2018)proposesanadaptivestratificationprocedureforatwo-stageexperimentwiththe objectiveofminimizingthevarianceoftheestimatorfortheaveragetreatmenteffect.
ABayesianBanditAlgorithmforPolicyChoice. Althoughtheallocationofexperimentalunitsto armsforagivenexperimentoflength T isafinitedecisionproblem,determiningtheoptimalallocation exactlyiscomputationallyprohibitivelycostly.4 IntheIVRexperimentthisisthecaseevenwithjustone adaptivewave(seealsosimulationsinsection6).Thishasledtothedevelopmentofvariousheuristicsfor treatmentassignment.
TheexplorationsamplingalgorithmusedhereisaBayesianbanditalgorithm:itstartsfromaprior overthemodelparameters–withidenticalpriorsforthe k treatmenteffects–andupdatestheparameter distributionsastheoutcomesofeachwave t areobserved.Theposteriordistributionforthearm-specific θk isusedtocalculatetheposteriorprobabilitythat k isthebestarm, pk t =Prt(k = k(1))andthe(posterior)
expectedpolicyregret Et(∆k).In t +1,thealgorithmassignsexperimentalunitstoarm k withsampling shares
ExplorationsamplingisamodificationofThompsonsampling,whichdirectlyusestheprobabilities pk
minimaxdecisioncriterion.However,Banerjeeetal.(2020)arguethat(some)randomizationimprovestheabilitytoconvince diverseandpotentiallyadversarialaudienceswitharangeofpriors.Theargumentisrelevantforadaptivedesignsaswell: reducingthesamplesizeofsomearmsinfavorofotherarmsislikelytobethewrongdecisionunderatleastsomepriorsabout thetrue
,andthereforeanadaptiveexperimentislessconvincingtoanadversarialaudiencethananon-adaptiveexperiment.
q k t = pk t (1 pk t ) K k=1 pk t (1 pk t ) (1)
t as theassignmentsharesinthenextwave.ThompsonsamplingisaMABheuristicforminimizingin-sample 3Thespecificobjectivealsomattersforstratification.Kasy(2016)considersstratificationwithcontinuouscovariatesand showsinastatisticaldecisiontheoryframeworkthatadeterministicdesigndeliversmaximalpowerforagivenpriorora
θ
4ThesupplementtoKasyandSautmann(2021a)showssomesimpleexamplesoftheoptimaltreatmentassignment. 7
regret(Thompson,1933).ComparedwithThompsonsamplingandotheralgorithmsthattargetin-sample regret,explorationsamplingshiftsmeasurementeffortawayfromthebestarm,increasingexplorationand decreasingexploitation.Thisisbecauseweneedtolearnnotonlyaboutthebestarmbutalsoitsclose competitorsforefficientpolicychoice.Atthesametime,itshiftsmeasurementefforttowardsthehigherperformingarmscomparedtoanexperimentwithuniformassignment(i.e.,equalsamplingshares1/K), becauseinformationaboutthelow-performingarmsisunlikelytoberelevant.
ForthecaseofBernoullidistributedbinaryoutcomeswithaBetaprior,KasyandSautmann(2021a,b) showthatexplorationsamplingbalancesthesamplingallocationinthelimitat T →∞ betweenthesuboptimalarms,yieldingconstrainedoptimalposteriorconvergence(subjecttothesamplingshareofthebest armconvergingtoapre-selectedproportion).IntheBernoullicase,posteriorexpectedregretconvergesat thesameratebecauseregretisboundedby1.SeveralBayesianbest-armalgorithms–appliedtospecific outcomedistributions–havebeenshowntohavethisproperty(Qinetal.,2017;Russo,2020;Shangetal., 2020).5 Eachheuristichasitsownmerits,butexplorationsamplingisappealingforitssimpleformthat doesnotrequireatuningparameter,itsconvenienceforbatchsettings(waveslargerthan1unit),andits motivationbasedonsamplingthebestarmfromtheposteriorfor θ withtherestrictionofneverassigning thesamearmtwiceforincreasedexploration.6 Theexistingtheoreticalperformanceguaranteesapplyonly asymptoticallyandforspecificoutcomedistributions.However,KasyandSautmann(2021a)demonstrate thegoodperformanceofexplorationsamplingforexpectedpolicyregretintheBeta-Bernoullicaseinsimulationsbasedonpre-existingdataandforposteriorconvergenceinanexperimenttestingdifferentenrollment methodsforanagriculturalextensionservice.Wealsousesimulationsinsection6toassessthegainsfrom explorationsamplingoveruniformassignment.
IntheIVRexperiment,theprimaryobjectivewastoidentifythebestarmmeasuredbytheparents’ engagementwiththeIVRcalls.Wethereforeusedexplorationsamplingon6/7thofthesample.Asecondary goalwastounderstandwhethertheIVRcallshaveaneffectonreadingability.Thedesignthereforeincluded a(fixed)controlgroupof1/7thofthesampleforidentifyingthetimetrendinreadingfluencyandestimating treatmenteffects(seesections3and4).Designsthatcombineadaptivetreatmentarmswithacontrolgroup
5Allare“top-two”algorithmsbasedonexpendinggreatermeasurementeffortonthecurrentbesttwoarms,withatuning parameter β determiningtheallocationbetweenthemaswellasthelimitsampleshareofthebestarm.Russofirstproposed threealgorithmsandestablishconstrainedoptimalposteriorconvergenceforafamilyofoutcomedistributions:Top-TwoProbabilitySampling(TTPS),Top-TwoValueSampling(TTVS),andTop-TwoThompsonSampling(TTTS).Top-TwoExpected Improvement(TTEI)byQinetal.(2017)modifiestheexpectedimprovementalgorithmforGaussianoutcomes.Theauthors alsoshowthatthealgorithmisasymptoticallyoptimalinthefixed-confidencesetting,whichrequiresthatthelimitallocation isattainedinfinitetime.Shangetal.(2020)proposeaversioncalledTop-TwoTransportationCost(T3C)thatislesscomputationallydemandingthanTTTSandappliestoalargersetofoutcomedistributionsthanTTEI,andproveoptimalityof bothTTTSandTTEIinthefixedconfidencesettingforGaussianoutcomes.Finally,theyestablishposteriorconvergencefor TTTSforNormalandBernoullidistributedoutcomes.
6Thompsonsamplingisequivalenttotakingsimpledrawsfromtheposteriorwithoutprohibitingrepeatassignments.TTPS andTTVSdeterminetwo“top”candidatearmsineachwaveandrandomlyselectthefirstwithprobability β andthesecond otherwise,makingthempoorlysuitedforbatchallocation.TTEIisspecifictonormallydistributedoutcomes.Exploration samplingisclosesttoTTTSandT3Candwith β =0.5allthreeconvergetothesamelimitallocation.
8
arealsousedbyBahetyetal.(2021)andAtheyetal.(2021).
Estimation. IntheIVRapplication,wefocusonBayesianestimationtoobtainfinalparameterestimates. InKasyandSautmann(2021a),theoutcomeofeacharm k isBernoullidistributedwithaBetaprior,sothat theposteriorsafter t haveclosedforms.IntheIVRexperiment,wegeneralizetheapproachandestimate Bayesianhierarchicalmodelswithschool-specificeffectsandaBinomialoutcomedistribution(Normalfor readingfluency),describedindetailinsection4.TheBayesianapproachwithupdatingbetweenwavesis internallyconsistent7 andnaturallyproduces pk t thatweneedforexplorationsampling.Bayesianinference isvalidwithadaptivelycollecteddata.
However,usersmaybeinterestedinfrequentistinferenceabouttheparameterestimates.Frequentist estimatesthatdonotaccountforthedatabeinggeneratedbyanexperimentforpolicychoicearesubject topotentialbiases(MelfiandPage,2000;Xuetal.,2013).First,observationsfromanadaptiveexperiment ceasetobeiiddraws–intuitively,adaptivityintroducessamplingbiasbecauserandomfluctuationsinearly observationsinagiventreatmentarm k affecttheweightoftheseobservationsintheoverallsampleassigned to k (bychangingtheassignmentsharesofthisarminfuturewaves).Second,inferenceonthebestarmout ofaset,wheretherankingisbasedonthetreatmenteffectestimates,createsanupwardbiasandinvalidates standardconfidenceintervalsevenwithnon-adaptivesampling(Andrewsetal.,2021).
Inferencefromadaptivelysampleddataisanactivefieldofresearch,withparticularfocusonalgorithms targetingin-sampleregret,whichexacerbateselectionbiasbyquicklyfocusingonhigh-performingarms. Adaptivelyweightedestimatorscancorrectsamplingbiasandproduceasymptoticallynormalestimators (Hadadetal.,2021;Zhangetal.,2021).Andrewsetal.(2021)proposecorrectionsforthe“winner’scurse” whenestimatingtheaverageoutcomeofthehighest-performingarmthatapplytoasymptoticallynormal estimators.Toourknowledge,therearetodatenoapproachesthatcanprovideconfidenceintervalswith correctcoveragefortheoptimalarminanadaptiveexperimentinamodelwithrandomeffectsasweused intheIVRexperiment.However,insection5weestimateafrequentistBinomialmodelforengagementand illustratehowtheestimatesareaffectedwhen(a)applyingtheweightsproposedinZhangetal.(2021)to restoreasymptoticnormalityandthenapplyingthewinner’scursecorrectionbyAndrewsetal.(2021).
Remark:HybridAlgorithms. Giventheproblemswithinferenceinadaptiveprocedureswherelow-performing armsareunder-sampled,recentapplicationshaveusedmodifiedalgorithmsforahybridgoalof(frequentist) estimationaswellasregretminimization.Forexample,the“temperedThompson”algorithminCaria etal.(2020)usesaconvexcombinationofThompsonsharesand1/k equal-sizedshares.Anothercommon
7Inprinciple,updatingtheposteriorfromanyearlierwavewiththedatacollectedafterwardsshouldleadtothesame posterioroutcomedistributionat t,includingre-estimatingthemodelwithallthedatacollectedandtheinitialprior,whichis inpracticethemethodweuse.
9
modificationistoimposealowerboundonthesamplingshareineacharm(“clipping”,appliede.g.inAthey etal.(2021)withexplorationsampling).Suchmodificationscanbecombinedwithsettingasideasample shareforoneexperimentalarmandinparticularacontrolgroup,seeforexamplethe“control-augmented” ThompsonsamplingalgorithminOffer-Westortetal.(2021).
Animportantdecisionforresearchdesignsinpracticeisthesizeoftheexperimentalsample N .The MABliteratureoftenassumesthatexperimentalunitsarrivethroughanexogenousprocessandcanbeused costlesslyforexperimentation,oftenindefinitely.Inpractice,researchersusingadaptiveexperimentsneed todecidehowtosplitthesampleintowaves,orhowmanywavesoffixedsizetoconduct.Weapproach thesequestionsintwosteps,byfirstdiscussingconstraintsthatdelineatethespaceofpossibleexperimental designs,andthenoutlininghowtoassessalternativeswithintheseconstraints.
ConstraintsonAdaptiveExperimentalDesigns. Theuseofmultiplewavesimposessomeconstraints onthesetofpossibleadaptiveexperimentaldesigns.Weoutlinetheseherebriefly,partlytoillustratewhen adaptivedesignareinpracticefeasible.
Totaltime Dmax available. Duetoexternalconstraints,suchasfundingtimelinesordeadlinesforoperational deliverables,themaximaldurationofanexperimentistypicallylimited.8 Comparablewaves. Mostbanditalgorithmsassumesomeformofstationarity,e.g.thattheobservationsin allwavesrepresentiiddrawsofthepotentialoutcomesinthepopulation.Forefficientlearningacrosswaves, thetreatmenteffectsmustbestationaryandanytimetrendsmustbecommontoallarms.Annualcohorts ofstudentsorbatchesofsurveyparticipantsrecruitedatrandommayfulfilltheseconditions,bute.g.job seekersinaseasonalindustryatdifferenttimesoftheyearlikelydonot.
Lengthofawave d Tocompleteawave,theinterventionmustbeadministeredinfull,outcomechangesin responsetothetreatmentsmusthavemanifested,andpost-interventionoutcomemeasuresmustbecollected beforethestartofthenextwave.Thisdetermineswaveduration d
Together,theseconstraintstypicallyimposealimitonthenumberofwaves T max.Ifthepolicyenvironmentchangesrapidly,dataiscollectedinatime-consumingsurvey,ortheavailabletimedoesnotinclude twocomparableperiods,onlyone“wave”maybepossible, T max =1.Ontheotherhand,ifawavetakes onlyhoursordaysanddataareautomaticallyrecorded,manywavesmaybepossible,e.g. T =10inBahety etal.(2021)or T =17inKasyandSautmann(2021a). Otherconstraintsmaylimite.g.themaximumsamplesizeperwaveorthetotalsample N max.IntheIVR experiment,duetotimeandcomparabilityconstraints,thechoicewaseffectivelyonlybetweenconducting 8Suchalimitisareasontousepolicychoicealgorithmsthatminimizeexpectedregretaftertheexperiment,ratherthanan algorithmthatsimplycontinuesindefinitelyandtargetsin-sampleregret.
10
oneortwoexperimentalwaves.TheavailablesamplewasthefullpopulationoffirstgradersintheBridge Kenyaschoolsinterm3of2020,seesection3.
ChoosingtheResearchDesign. Evenifconstraintsnarrowdownthedesignspace,theexperimenter maystillneedtodecidewhethertouseadaptivesamplingandchoosesamplesize,wavesize,andnumber ofwavestorun.Anaddedconsiderationisthatevenforagivensamplesize N ,therearesomecoststo conductingtestinginwaves.
Per-waveImplementationCosts. Maintainingtheinfrastructurefordatacollectionandinterventionsforall treatmentarms,includingthehumancapitalcostsofmanagingtheexperiment,addsfixedcosts ct perwave, ontopofanyper-unitcosts ck i (whichmayvarybytreatmentarm). CostofDelay. Eachnewwaveaddsdelayuntilthegainsfromtheexperiment–theaverageestimated treatmenteffectofthebestarm–arerealizedforallpotentialbeneficiaries.
Balancingthesecostsaretheefficiencygainsfromadaptivity.Itiscomputationallyinvolvedtoestimate thesegains,andsotheresearchercantypicallyonlyconsiderasmallnumberofdesigns.Here,webriefly discusstwosituationsthatwillfrequentlyariseinpractice.First,experimentersoftenhaveafixed N availableandhavetodecidewhetherandhowtodividethesampleintowaves.Second,theexperimenter mayneedtodecideattime t whethertorunanadditionalwavein t +1.
Thiscouldbesetupasasimpleoptimizationproblem.Forexample,considerchoosingthenumberof waves T ∈{1,...,T max} forgivensamplesize N ,sothatthewavesizeis Nt = N/T (assumingequalsizedwavesforsimplicity).Wewouldexpectmoreefficientlearningwithmorewavesandmorechancesto adapt,andindeedthesimulationsinKasyandSautmann(2021a)withdatafromthreeexistingexperiments showhowsplittingthesampleinto2,4,and10wavesmonotonicallyshrinkstheexpectedpolicyregret. Inpractice,however,themarginalgainsarelikelydecreasingin T 9 Moreover,thegainsmustbeweighed againstthecost.Theexperimentermightsolve
Thesecondtermpenalizesthecostofincreasing
ofthenumberofbeneficiaries
totheimplementationdelay.
,discountedby
growsandthewavesizeshrinks,itbecomeshardertoimplementthe adaptivealgorithmfaithfully,andtheactualassignmentsharesmaydiffersubstantiallyfromtheexplorationsamplingshares
9Thisisatleastinpartduetoindivisibilityissues.As
t ,especiallyifthesampleisalsostratified(seealsosection5).Withmanytreatmentarms,insmallwavessomearmsmay notbeassignedatall,updatingaboutthesearmswillproceedslowlyintermsof t,andtheassignmentsharesmayremainfar fromoptimalforalongperiodoftime.
t N
max T ∈{1,...,T max} δT +1E(Mθk∗ |T ), T t=1 ct
T .Thefirsttermisthetermofinterest:theexpectation
M timestheper-personoutcomeinthechosenarm θk∗
δT due
T
qk
k
11
Inthesecondsituationwedefined,waveshavefixedsize Nt andtheexperimenterneedstodecidewhen toendtheexperiment.Inadditiontotheper-waveanddelaycostsgivenby ct and δT +1,increasing T incurs qk t Nt timestheperunitcost ck i foreachexperimentalarm.10 Inexchange,theexperimenterobserves additional Nt unitsineachwave t
Ineachcaseabove,theresearcherneedstoestimate E(θk∗ )asafunctionoftheresearchdesign.Since closedformsarenottypicallyavailable,theseprojectedgainsfromadaptivityhavetobeobtainedfrom simulations.Thisrequiressimulatingnotonlyexperimentaloutcomesunderdifferentrandomsampledraws, butalsothedifferentsamplingpathsthatarisefromadaptivity.Theexperimenteristypicallyrestrictedto comparingonlyafewhypothetical θ andasmallnumberofpossibleresearchdesigns.Weillustratesuch simulationsinthecontextoftheIVRexperimentinsection6.
3 IVRCallsforReadinginKenya:BackgroundandExperimentalDesign Choices
3.1 BackgroundandSetting
OurapplicationforadaptivesamplingforpolicychoiceisanEdTechinterventionthatusesinteractive voicecallingaimedatencouragingparentstoreadwiththeirchildren.Theimplementingorganization (“theimplementer”)isNewGlobe,theparentofBridgeInternationalAcademies.Atthetimeofthestudy, NewGlobeoperated112privateprimaryschoolsalloverKenya.11 TheKenyanschoolyearusuallyhasthree termsthatstartjustafterNewYear’sandendlateOctober.DuetoCovid-19,the2020terms2and3 tookplace1/3-3/19and5/10-7/16of2021(withthe2021termscompressedinto7/26/21-4/2/22).All Kenyanschoolsattheimplementingorganizationhadintroducedoralreadingfluency(ORF)assessments forthefirsttimeinthemidtermandendtermexamsofterm2of2020.
Theimplementerwantedtomakeadecisionaboutwhetherandhowtouseinteractivevoiceresponsecalls (IVR)toencourageparentstodoreadingexerciseswiththeirchildren.Readingwithachildathomehas benefitsforlanguageacquisitionandfluency,evenincontextswhereparentsthemselvesmayhavelimited readingskills(Mayeretal.,2019;Yorketal.,2019;Knaueretal.,2020).Kenyanschoolswereclosedforpartof 2020duetoCOVID-19,highlightingthebenefitsofdevelopingeffectivehomeinterventionstargetingreading andnumeracy.12 Morebroadly,parentalengagementisanimportantdeterminantofchildren’slong-term successinschool.Recentresearchhasshownthatrelativelylight-touchinterventionssuchaspersonalized
10Itmayalsoreducethenumberofbeneficiariesbytheadditionalexperimentalsubjects.
11TheschoolsfollowBridge’sspecificteachingmodelandchargefees;thesefeesarelowerthantypicalprivateschoolfeesand similartotheadministrativecostsofpublicschools.
12Priorresearchhasshownthatparentalengagementinterventionscancounteractthedetrimentaleffectofextendedperiods outofschool(e.g.KraftandMonti-Nussbaum(2017)).Acombinedtextmessageandphonecallinterventionwasabletoreduce learninglossduringCOVID-19-relatedschoolclosuresinBotswana(Angristetal.,2020a).
12
textmessagesincreaseparentalengagement,whichinturnimprovesearlyliteracyoutcomes(Yorketal., 2019;Dossetal.,2019).Forolderchildren,parentalengagementalsoincreasesparents’informationabout attendanceandperformanceatschoolandimprovesoutcomesthroughthischannel(Berlinskietal.,2021; BergmanandChan,2021;Bergman,2021;Bettingeretal.,2021).
Whilemanyparentcommunicationinterventionsrelyontextmessages,parentalliteracybarriersand lengthrestrictionslimittextmessagingasatooltodeliverreadingexercises(ICTworks,2016).Theimplementeralreadyroutinelyusestextmessagingtocontactparentswithinformationabouttheirkid’sschooling, andcollectsphonenumbersandconsentforthispurpose.However,towhatdegreethesemessagesarereceivedandreadbyparents,andwhethertheyleadtobehaviorchange,isonlyincompletelyknown.Inan earliertrialwiththesameimplementerinNigeria,whichusedtextmessagestoencourageparentstousea WhatsApp-basedquizplatform,almostnoneofthemessagerecipientsengagedwiththequizzes(Sautmann, 2021b).
Phonecallsprovideanalternativethatmaysustainhigherratesofengagementandallowslongerinteractionsandbetterinstructionsforhomeexercises.Personalcallshavebeenshowntobeeffectiveforincreasing parentalengagement(KraftandMonti-Nussbaum,2017),butarecostlyandtimeconsumingforteachers. IVRcallsarepre-recordedandautomated,designedbyrecordingasetofmodulartextsnippetsandjingles thataresequencedinresponsetolistenerinputthroughthekeyboardorthroughspokenword.Thereisto datelimitedevidenceontheeffectivenessofIVRforimprovingearlyliteracy.Asmallpilotwith38familiesinruralCˆoted’IvoirereportsencouragingqualitativeresultsontheuseofIVRtofosterphonological awarenessinlow-literacyenvironments(Madaioetal.,2019).
3.2 IVRInterventionDesign
Duringpilotinganddiscussionspriortotheexperiment,itwasdecidedtotestsixIVRcallvariants.All treatmentarmsconsistoftwiceweeklycallstotheparents’phone.TheIVRdeliversasequenceofreading exercises,eitherbasedonlettercombinationsorwordsthattheparentnotesdownduringthecall,orbased onpassagesfromthechildren’sterm3homeworkbook.Anexperimentalwavecontains9setsofcalls(see below),andeachcallcontains4differentexercises.Theexerciseschangefromcalltocall.Beforeeach wave,weconductedaphonebasedopt-outprocedurethatexplainedthecallsandalsoallowedparentsto changetheenrollednumber.Thefullinterventiondesign,calllogictrees,andsamplerecordingsoftwoof theinteractivecallscanbefoundinanonlinesupplement(Sautmann,2021a).
AllIVRrecordingswerecreatedbyafemaleKenyanvoiceartistandeditedbythevoicecallprovider, Uliza.TheIVRsystemmakesmultiplecallattemptsandalsoallowstheparentto“flash”Uliza’snumber, meaningthattheycancallthenumberataconvenienttime,andthesystemhangsupandimmediatelycalls
13
Figure1:Term2midtermandendtermoralreadingfluencyscores,inunitsofcorrectwordsperminute, asusedforexerciselevelassignment.Theleftpanelshowsthatindividualstudentscoresareonlynoisily correlated.Therightpanelshowsthatthereissomemovementfromhigherlevelingcategoriestolowerones, aswellassmallbutsignificantnumbersofstudents“skipping”frombasictoadvancedlevel.For22.5% studentsinoursample,scoreinformationwasmissing.
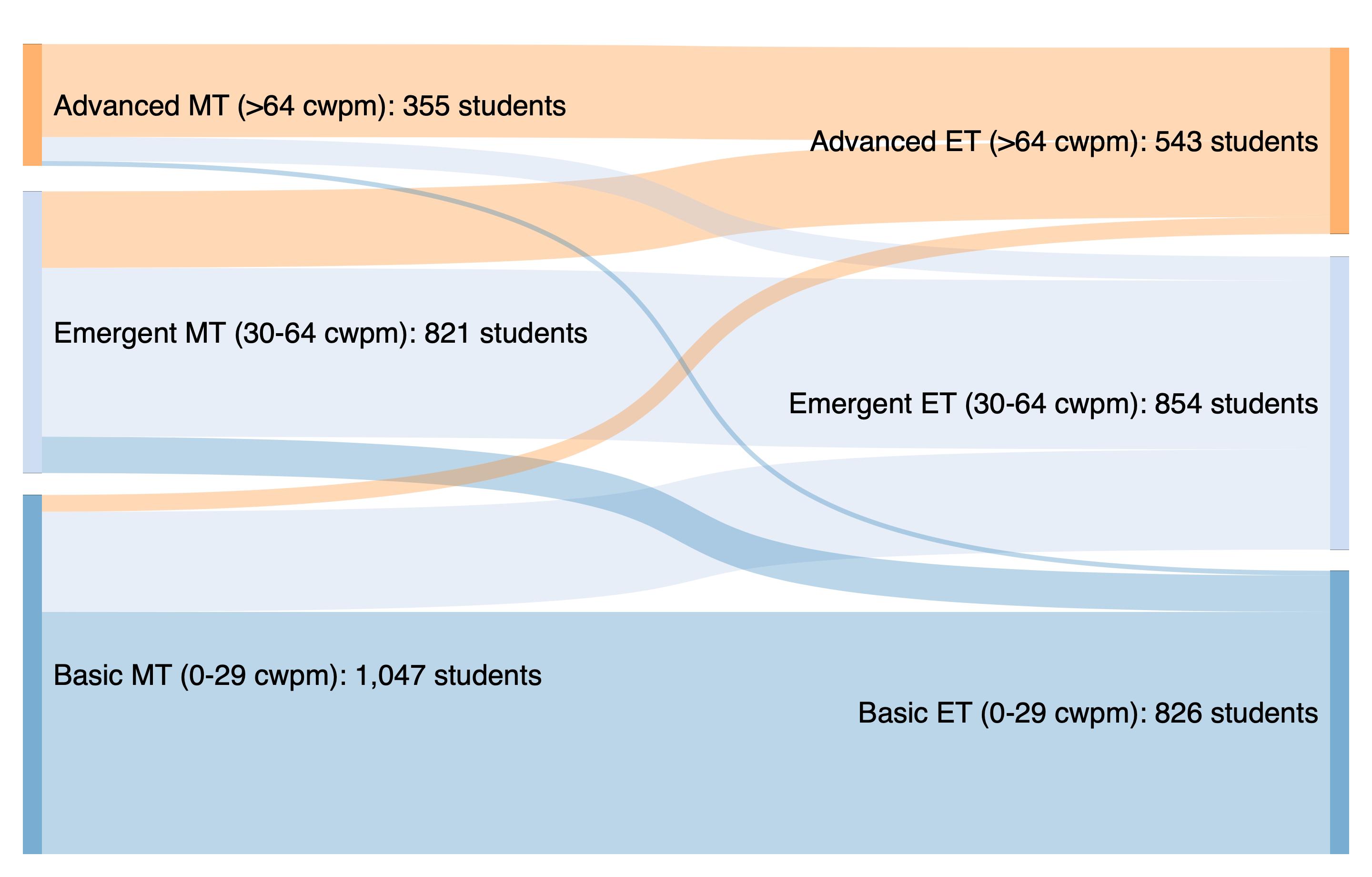
back.ThisisacommonmethodinKenyathatavoidscallingchargestotheparents.
Weusedthreedifferentwaysofchoosingadifficultylevelfortheexercises,andtwodifferentdelivery formats,describedindetailbelow.Wecross-combinedthe3x2interventionstocreatethe6treatment arms.Inselectingthetestedinterventions,theaimwastocreatetreatmentvariationsthatweregenuine “contenders”forhavingthegreatestimpactonhowoftenparentsreadwiththeirchildrenathome.
Varyingexerciseleveling. Baselineinformationonoralreadingfluency(ORF)fromterm2showed highvariationinreadingscores,inlinewithothercomparabledataindeveloping-countrycontexts(for instance,seeMuralidharanetal.,2019).Inthepresenceofsuchvariation,priorevidencehassuggested thattherecanbebenefitstolevelingremedialprograms(see,e.g.,Banerjee,Cole,Duflo,andLinden, 2007;Banerjee,Banerji,Berry,Duflo,Kannan,Mukerji,Shotland,andWalton,2017),andthatcustomized EdTechinterventionscouldbenefitthelowestachievingstudentsthemost(deBarrosandGanimian,2021; Dossetal.,2019).
However,ouranalysisofORFscoresshowedthattheavailabletestdataareverynoisy(asseeninfigure1) and22.5%percentofthesampleweremissingatthestartofwave1.Thereisreasontobelievethatthereis selectionbiasinnon-missingscores(seealsobelow).Thiscouldmakelevelingbasedonobservedorimputed pastscoresineffectiveorevencounterproductive.Analternativeistoleverageparents’knowledgeoftheir child’sreadingskillsandletthemchoosethedifficultylevelduringthecall.Butparentsmaybeunableto accuratelyassesstheirchildormaychooseapoorlysuitedexercise,perhapsbecausetheythemselvesare notsecurereadersorbecausetheirviewoftheirchildistoooptimistic.Acallthatallowschoicealsotakes
14
longer,andparentsmaystopusingthesystemiftheyfinditfatiguingorchallenging.
Basedontheseconsiderations,threeinterventionvariantswerechosen,(A)levelingonactualorimputed baselinescores,(B)providingthesamesequenceofintermediate-levelexercisestoallkids,and(C)giving parentsachoiceofexercisesfromamenu.ArmAusesobservedfluencyscoresfromtheendofterm2and assignsstudentswithfluencyscoresof0-29intothe“basic”group,30-64intothe“intermediate”group,and 65+intothe“advanced”group.Thesecutoffswereusedpreviouslyinasimilarcontext(seePiperetal., 2018).Studentswithmissingscoresareassignedtheirclassmedian.Wholeclasseswithmissingscoresare assignedtotheintermediategroup(whichalsohappenstobethefullsamplemedian).Theexactexercise sequencesinthebasic,intermediate,andadvancedgroupsaredescribedindetailinAppendixA.ArmB assignsallstudentstotheintermediategroup,whileArmCallowsparentstopickoneexercisetype(from basicletters,tolettercombinations,toadvancedtextpassages)outofasetofthree.
Varyingdeliveryformat. WealsotesttwoformatsthatusetheIVRfunctionalityindifferentways.In thefirst,thevoicecallexplainstotheparenthowtodothereadingexercisesandasksthemtocarrythem outwiththeirchildafterthecall(T1).Inthesecond,theIVRasksparentstoputthecallonspeakerphone, andthengoesthroughtheexerciseswiththeparentandchildonthecall(T2).
Apriori,eitherapproachmightworkbetterfordifferentreasons.Inbothcalltypes,theparentisasked totakenotesontheexercisesduringthecall.Theparentisinstructedtopointtothewrittenlettersor wordswhiletheIVR(ortheparent)reads,andthenagainwhilethechildreads.However,inT1,theparent maynotpronouncelettercombinationscorrectlyfrommemory.Shemayalsolistentotheexercisesduring thecallbutthennotcarrythemoutwiththechildlater.Ontheotherhand,T2maycausedifficultyifthe phone’sspeakerispoorortheIVRmovestoofastforthechildorisnotresponsiveenough.Allpartiesmay bemoremotivatedwhenthechildandparentpracticetogether,ratherthanfollowinginstructionsfroman unknownanddisembodiedvoice.
3.3 TheResearchDesign
A“standard”RCTofIVRforhomereadingwouldlikelyconsistofextensivepiloting,carryingoutpower calculationstodeterminesamplesizeandnumberoftestedinterventionarms,randomizingatthecluster (school)level,andthenadministeringanIVRprogramforatleastafullschoolyear,possiblyaccompanied byahomesurveyandindependenttestsofreadingfluency.Basedonthebudgetfordeliveringanddeploying messages,thesizeofthesample,andtheavailablestafftime,suchacomprehensivestudywasnotfeasible forNewGlobe.Atthesametime,attheoutset,itwasnotevenknownwhetherparentswouldlistentothe messagesatall,andthereistoourknowledgenoexistingguidanceonhowbesttodesignsuchcalls.In
15
suchasituation,NGOsandpolicymakersmightresorttosimplynotusingexperimentalmethods.They mightconductaninformalpilot,implementtheprogramatscale,andthen“tinker”withitafterroll-out, orconversely,simplyabandontheidea.Adaptivesamplingcouldofferasolutionthatenablesarigorous experimentandmakesthemostofthelimitedsampleandtimeavailable.Theimplementersawasan attractivefeaturefromanethicalperspectivethatevenduringtheexperiment,alargershareofparticipants benefitfromthehigher-performingtreatmentarms.
Objective. Inconversationsabouttheexperiment,ontheonehand,theimplementerwantedtoidentify the“best”IVRcallvariant,andontheother,theywantedtoverifythatIVRcallswithreadingexercises actuallyhavepositiveeffectsonreadingfluency.Thishybridgoalwasareasontokeepacontrolgroupthat receivednointervention.Atthesametime,itsuggestedtouseadaptivesamplingtochoosebetweenthe sixcallformats.Wediscusshowthenotionofthe“best”IVRcalltranslatedintothechoiceoftargeted outcomebelow.
Constraintsontheexperimentaldesign. Theimplementerwasabletosetasideonlyonefirstgrade cohortandonetermoftheschoolyearfortestingtheIVRcalls,bothduetootherongoingstudiesanddue totheimplementer’sinternalcost-benefitassessment.
TheKenyanschooltermis10weekslong,splitequallyinto5weeksfromstarttomidtermexamsandfrom midtermtoendtermexams.Readingtestsareconductedaspartoftheseexams,providinganadministrative sourceofdata.Moreover,therhythmoftheschooltermfromstarttomidtermandfrommidtermtoendterm issimilar.Forexample,parents’attentiontotheirchild’sschoolworkmayincreaseclosertotheexams.
Relativetothecostpercall,thecost(intermsofbothmoneyandtime)ofdevelopingsequencesofreading exercisesandrecordingthemishigh.13 Therewasalsoconcernthattoomanycontactattemptsfromthe schoolcreatefatigueinparents,especiallywithpilotprogramsthatmaynotyetbeoptimallydesigned.For bothreasons,anexercisesequencecoveringonehalfofthetermwaspreferredtorunningtheinterventions forafullterm.
Jointly,theseconstraintsreducedthespaceofpossibleresearchdesignstoconductingoneortwoexperimentalwavesinthefirstandsecondhalfoftheterm,withthetotaloffirstgradersenrolledthatyearacross allschoolsastheavailablesample.
Outcomemeasurement. Theavailableoutcomevariablesweretake-upoftheIVRcalls,orcallengagementforshort,andoralreadingfluency(ORF)scorescollectedbytheschool.Measuresforbothoutcomes
13Theexercisesweredevelopedbytheimplementertogetherwiththeresearchteam.Dozensofsoundsnippetswererecorded byavoiceartisthiredbyUliza.Afirstsetofexerciseswaspilotedwithasmallsampleofparentsinanolderagegroupbefore completingalltheexercisesandrecordings.
16
wereprovidedbytheimplementer,withrandomIDnumbersreplacingparents’phonenumbersandthe child’snameandschool.
WeuseIVRproviderrecordstomeasureengagementwiththecalls,thatis,whetherthecallrecipient actuallystartstheexercises.Uliza’srecordsshoweverycontactwiththeparent’sregisteredphonenumber, alongwiththelengthofeachcallinseconds.Wedefineacallassuccessfuliftheparentstartedthefirst exercise,whichrequirestappingaphonekeytoconfirm.Wedefineaparentashavingengagedinoneofthe twiceweeklyexercisesetsiftheIVRmadeatleastonesuccessfulcallinthatset.Sincethereare9exercise setsperwave,engagementcantakevaluesbetween0and9.Callrecordsareavailableimmediately,and theyarecompleteandaccurate.
Theimplementermeasureschildren’sORFscoresduringthemidtermandendtermexaminationperiods. In2-3hourperiodssetasideforthefluencytest,ateacherexamineseachchildbycountingthenumberof wordsonalistthatachildcanreadcorrectlyinoneminuteoftime(seeRodriguez-Seguraetal.(2021)for theuseofthismeasuretoassessreadingandliteracy).Theteacherthensubmitsthescorestotheschool’s graderecordsystem.ORFscoresrangebetween0and85correctwordsperminute(cwpm)basedonthe lengthoftheprovidedwordlist.14
ThereareanumberofissueswithORFmeasurement,whichwerepartlyrevealedonlyafterwave1of theexperimenthadalreadystarted.Figure1showsthehighvariationinORFscoresbetweenmidtermand endterm.Amongthenon-missingscores,anunusuallyhighproportionaremultiplesoffive,andinsome classrooms,thereareimplausiblymanyveryhighscores.Inaddition,ahighpercentageofscoresaremissing orsubmittedlatetotherecordingsystem:ORFscoreswereavailableforonly73.5%-88.9%ofchildren dependingontheexam.15 Teacherreportsonwhyagivenscoreismissingareoftenambiguous.Overall, thedataqualityforORFscoresisfairlylow.
TargetedOutcome. Inordertouseadaptivesampling,itisnecessarytodefineanoutcomemeasure thatdecideswhichisthe“best”arm,whichinturndetermineswhichtreatmentarmswillbesampled more.Inmanysettings,thisisnotstraightforward,giventhatmultipleindicatorsrelatedtothedesired outcome(s)aretypicallyavailable.Here,theimplementerwantstoincreaseparents’engagementintheir children’seducationingeneral,becauseparentalengagementisknowntohavepositiveeffectsonchildren’s performanceinschool;atthesametime,thecallsexplicitlyencourageasetofreadingexerciseswiththeaim
14Theimplementerchoosesastandardized,grade-appropriatewordlist,trainsteachersandprovidesequipment.Themeasure caninprinciplerangefromzerotoover200,butforfirstgradersitistypicallynotabove120.
15Thetotalshareofscoresthataremultiplesof5is36%,andtheobservedscoredistributionsshowunusualheapingeven whenaccountingforcensoringat0and85.Teacherssometimesdelaysubmissionorentirelyfailtosubmitexamscoresfortheir class.WedescribethepatternsofmissingnessandsuspectedroundinginmoredetailinAppendixBinTablesA.1andA.2. Partofthereasonthattheproblemsofmissingandroundedscorespersististhatatelementaryschoollevel,thesescoresdo notaffectthestudent’sprogressionintothenextgrade,nordotheyaffecttheteacher’sevaluation.
17
toimprovereading.Callengagementmeasureswhetherparentslistentothereadingexercises,butwedo notobservetheinteractionstheyhavewiththeirchildren.Asdiscussedabove,ORFscoresareanimperfect measureofthechild’sreadingability.
Inprinciple,bothcallengagementandORFscorescouldbeusedtocreateacombinedoutcomemeasure. Moreover,ifthereisa(known)relationshipbetweenthetwomeasures,e.g.highercallengagementimplies greaterreadingimprovementsandthereverse,thenanadaptiveexperimentcouldequivalentlytargeteither outcome.16 Apriori,weconjecturedthatcallengagementispositivelycorrelatedwithreadinggains.First, someoneactuallylisteningtotheexercisesisanecessaryconditionforthechild’sexposuretotheseexercises. Beyondthefirstcoupleofcalls,asimplemodelofmarginalreturnsalsosuggeststhatparentsaremorelikely toengagewiththecallsiftheyfeelthatthechildlearnssomethingandtheyplanonactuallydoingthe exercises.However,therecouldbereasonsthatcallengagementandORFarenotaligned:anyincreasein readingabilityisacombinationof(i)thechild’s exposure totheexercises,and(ii)conditionalonexposure, howeffectivelythedeliveryandcontentoftheexercisesinthisarmimprovereading(efficacy ofthearm forshort).Treatmentvariants(T1)and(T2)couldpotentiallyhavedifferentexposure,conditionalon observedcallengagement,andthetreatmentarmdesignchoicesregardingleveling(A,B,andC)may exhibitdifferencesinefficacy.
Withoutanyconstraints,theimplementermighthavechosenthebestarmbasedonaweightedaverage ofORFandengagement.However,wewereunabletodetermineassignmentsharesinwave2basedon themidtermORFscores.17 Thegradingdaywasmovedduringwave1andtookplaceafterthestartof thesecondhalfoftheterm.Duetothesubmissiondelaysdescribedabove,ORFscores“tricklein”for severalweeks,andevenaftertheendoftheterm,morethanaquarterofthemidtermdatawasmissing(see TableA.1).Thechoiceinpracticewasthereforetoeitherexclusivelytargetcallengagementinanadaptive experiment,startthesecondwavelateandwithincompletedataforsomeformofadaptiveassignmentbased onORFscores,orconductanexperimentwithuniformassignment(orabandonthetest).
Inthisdecision,itplayedarolethateveninthebestcaseoftimelyandaccurateORFmeasurements, anyeffectsofIVRcallsonreadingabilitywerelikelytobeonlyincompletelyrealizedbytheendofthetrial intervention.Comparableearly-readinginterventionsmeasureeffectsafteraninterventionperiodofseveral monthsorawholeschoolyear(Dossetal.,2019;Yorketal.,2019).Moreover,cumulativeeffects–e.g. duetohabitformation–arelikelytoaccrueforasignificantperiodoftimeafterinterventionend,soitis
16Thisrelationshipwouldneedtobeestablished,e.g.frompilotdata.Cariaetal.(2020)makereferencetotheliteratureon statisticalsurrogates–measurableorshorttermoutcomesthatcan“standin”forhardertomeasureorlonger-termoutcomes–toarguethatadaptiveexperimentscouldtargetshort-termoutcomestoachievehigherwelfareinthelongterm;seealsoAthey etal.(2019)foraproposaltocreate“surrogateindices”frommultiplevariables.
17Initially,weplannedtouseadaptivesamplingtotargetORFscores.Thechangeisdocumentedinthepre-analysisplan, see(Sautmann,2022).
18
unlikelythattheimpactsofthetreatmentwerealreadyfullyrealizedbytheendoftheterm.
Basedontheseconsiderations,itwasdecidedtoexclusivelytargetcallengagement.Ultimately,the implementervaluedparentalengagementsufficientlytofocusonmaximizingcallresponserates,ratherthan attemptingtochooseatreatmentarmbasedonverynoisyeffectestimatesoffluencygainsandrisking inconclusiveresults.Anotherwaytoviewthisdecisionistomaximizelearningaboutwhicharmhasthe highestcallengagementrates,attheexpenseoflearningmorepreciselywhicharmhasthegreatestORF gains.Whilethissolutionmaynotbeoptimal,itreflectsanotherrealityofpolicychoice,thatpolicymakers sometimeshavetomakedowithimperfectdata.
SampleandRandomization.
Wedeterminedthesampleusingthephonenumberonrecordforthe parent.18 Wedropped2schoolsthathadfewerthan5students,and2schoolswithveryinflatedORF scores,leavinguswith108schoolswith3,163uniquestudent-phonenumbercombinations.
Wefirstrandomlyassignedhalfofthesampletowave1and2(1,581and1,582phonenumbers,respectively).Wedidnotformallyassessthebestsamplesplitbetweenfirstandsecondwave,butsmall-sample simulationssupportequal-sizedwaves(seesupplementofKasyandSautmann(2021a)).Beforethestart ofeachwave,parentsreceivedanintroductorycall,followedbyatextmessageconfirmingenrollmentand explainingproceduresforoptoutandforswitchingphonenumber.Someparentsoptedoutexplicitlyand somephonenumberswereinvalid,leavingasampleof1,494inwave1and1,384inwave2.
Therandomizationwasstratifiedattheschoollevel.19 Inwave1,theassignmentsharesforthe6treatment armswereequally1/7;inwave2,weusedtheassignmentsharesgivenbyexplorationsampling,keeping1/7 ofthesampleasacontrolgroupineachwave.Duetoindivisibilities,thetotalsharesareclosebutnotequal tothetargetedshares,asshowninTable2insection5.
EstimatingORFeffects. Inmanyapplications,outcomesotherthanthetargetedoutcomeareofinterest totheexperimenter.Here,weestimatetheeffectsofthetreatmentsonORFwithreadingfluencyexam scoresobtainedaftertheexperimentwascompletedtolearnwhetherthetreatmentarmwiththehighest engagementseesincreasesinchildren’sreadingperformance.Wealsobrieflydiscussthepossibilitythat therearedifferencesinhowengagementwiththecallstranslatesintoreadinggains,whichmightimplythat thecallformatwiththehighestcallengagementmaynotbetheformatwiththehighestreadinggains.
18Theimplementerhasparentalconsenttousethisphonenumberforschoolrelatedcommunications.Basedonenrollment datafromthestartofterm3,werandomlyselectedonestudentIDformeasurementinthefewcaseswhereseveralstudent IDswereassociatedwiththesameparentalphonenumber(likelysiblings).Phonenumbersandschoolsarede-identifiedbythe implementerbeforesharingwiththeresearchers.
19Wealsostratifiedassignmentonwhethertheopt-incallorconfirmationtextmessagewereanswered.Forexample,inwave 1,alargeproportionofthesample(796studentIDs)neitheroptedinnorexplicitlyoptedout.However,theextensive-margin results(AppendixC.4)showedthatmostnumbersansweredthephoneatleastonceduringtheexperiment,andsoweignore thisintheestimation.
19
Figure2:Timelineforthestudy.
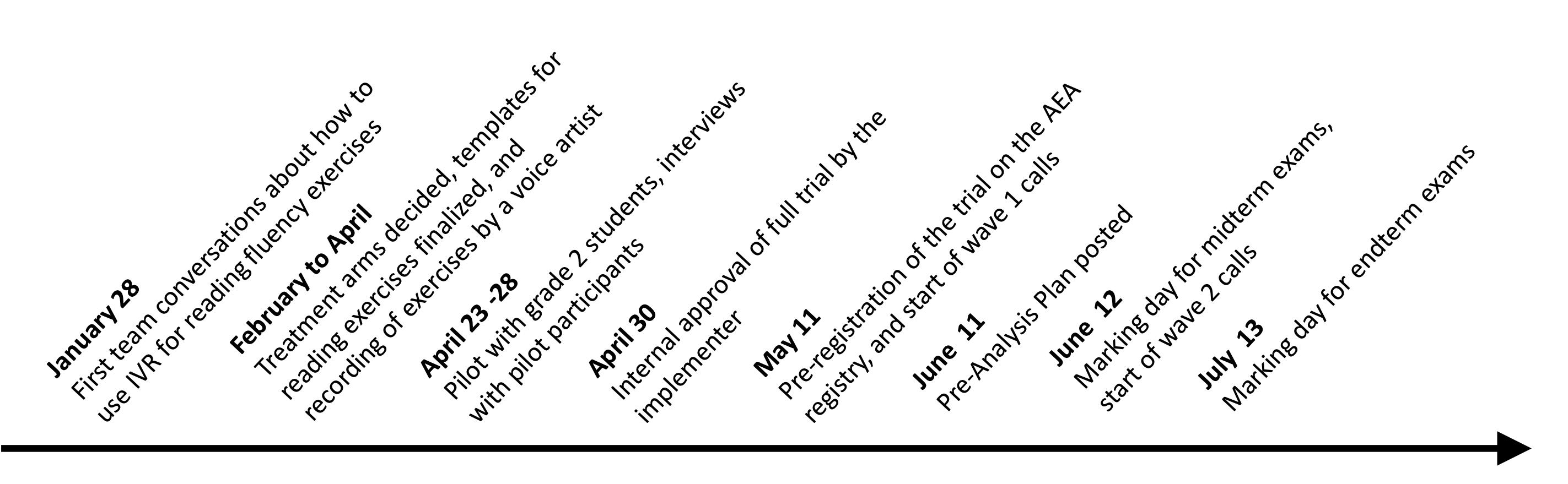
ImplementationandPre-Specification. Figure2showsthattheIVRexperimentwascarriedouton averyshorttimeline.Developmentandimplementation,includingdesigningthereadingexercisesand recordingandprogrammingthecallsforalltreatmentarms,werecompletedinthreemonthsuptoApril30. Theresearchteamdevelopedthestatisticalmodelforparentalengagementandcarriedoutthetreatment assignmentduringwave1(termstartMay11tomidtermexamonJune12),andthemodelforestimating readingfluencyduringwave2(midtermtoendtermexamJuly13)andafter.Thishasdownsides;for example,notenoughpilotdatawasavailabletoimproveourpriorse.g.aboutschoolrandomeffects,and whilethefirstwaveoftheexperimentwasongoing,newinformationwasstilllearned,suchasthedelay toobtainingORFscores.Thetimelinealsoshowsthattheexperimentwaspre-registeredpriortothefirst wave,butbythetimethepre-analysisplanwasfiledonJune11(beforestartofwave2),theplansforthe experimenthadchangedsignificantly.Ingeneral,shorttimewindowsandincompleteinformationinthe experimentaldesignphasemaymakeadaptivesamplingmoreattractive,butwillalsomakepre-specification morechallenging.
Remark:Pre-AnalysisPlansandTrialRegistration. Aquestionfortheresearchcommunitywillbewhether adaptivepolicychoiceexperimentsshouldbesubjecttothesamenormsofregistrationandpre-specification as“standard”experimentsforcausaleffectestimation.20 Afullanalysisoftheincentivesatplayrequires alargerbodyofevidenceonthemethod,butapriori,theneedfor pre-specification seemslesspressing: dependingoncontextthereisoftennospecificincentivetodemonstratetheeffectivenessofonetreatment armoveranother;themetricofexpectedpolicyregrethasnoestablishedcut-offsakintop-valuesfor conventionalsignificancelevels;and,mostimportantly,afterthefirstadaptivewaveitisnotpossibleto changethetargetedoutcomeortheestimationapproach,creatingcommitmentbeforethedataisfully 20Resultsshowingsignificanteffectsoftenhavehighervaluetobothresearchersandpolicyorganizations,whichcontributes toissuessuchasdatamining,thefiledrawerproblem,publicationbias(e.g.,AndrewsandKasy,2019)andsoon,familiarfrom theliteratureonresearchtransparency(ChristensenandMiguel,2018).
20
known.Theoppositeistruefortrial registration:policychoiceexperimentsarelikelytobeusedtolearn abouttheeffectivenessofmanydifferentpolicyoptionsforthesameoutcome.Adaptivetrialsmayinform preliminaryworkwherelesssuccessfulinterventionsareneverimplementedortestedatscale.Thefiledrawer problemseemsparticularlysalientinthecontext.Infact,anaturalextensionofadaptivesamplingacross wavesistoincorporateexistingevidenceintothepriorsthatinformtheresearchdesignofnewexperiments (seee.g.PouzoandFinan,2022).Thisformofiterativelearningrequiresacompleterecordofallprior evidencegatheredonthetreatmentsunderconsideration.
4 ModelsandEstimation
ThissectiondescribeshowweestimatetreatmenteffectsonparentalengagementandORFmeasures,and howtheengagementestimatesareusedforadaptivetreatmentassignmentandfinalarmchoice.Wealso commentonthemodelingchoicesandimplicationsforpolicychoiceexperimentsmoregenerally.
4.1 TheModelsforCallEngagementandOralReadingFluency
CallEngagement. Let Z sk i bethenumberofsuccessfulcallstoaparentofchild i inschool s allocated totreatmentarm k ∈{1,..., 6}.Weassumethatpotentialengagementisstationaryacrossthetwoterms andforsimplicitysuppresstheindexforwave t.Nocallsweremadetothecontrolgroup,sowerestrictthe sampletoenrolledphonenumbersinthe6treatmentarms.Weassumethat Z sk i isadrawfromaBinomial distributionwithatmost9successesandaverageprobabilityofengagement θsk ∈ [0, 1].Thisismotivated bythedistributionoftheobservednumbersofsuccessfulengagementsineachtreatmentarm,shownin AppendixC.1.Wemodeltheaverageengagementprobabilitywithahierarchicallogisticregressionmodel withschoolrandomeffects.Thus,wehave
informationinthismodel–theonlyindividual-levelinformationwehave–becauseoftheproblemswith missingandnoisydataoutlinedearlier.
Wedonothavemuchpriorinformationonexpectedengagement,soweuseanon-informativeimproper prioron
Z sk i | θsk ∼ Binomial(9,θsk) , θsk =logit 1(βE x k + κ E η E s ) (2) Thevector xk isaunitvectorindicatingthetreatmentarm k, βE isa1 × 6vectorofaveragetreatment effects,and κE ηE s istheschool-levelrealizationoftherandomeffect.WedonotincludebaselineORF
{βE k }6 k=1 andaHalf-Normalpriordistributionfor κE (thestandardNormalon[0, +∞)),andassume 21
Thehyperparameters
describetheaverageengagementprobabilityineachtreatmentarm andthearm-independentvarianceoftheengagementprobabilityacrossschools.Each
isarealizationof theaveragesuccessprobabilityspecifictotheschoolandtreatmentarm.
Whileourmainestimatesfocusontheaveragenumberofcallsperphonenumber,inappendixC.4wealso reportestimatesoftheextensivemarginoftake-up.Theseusebinarylogitmodels,withtheonlychangeto themodelabovethattheoutcomehasaBernoullidistributionwithprobabilityofsuccess
Remark:ModellingTreatmentEffects. Themodelisagnosticaboutpotentialinteractioneffectsanduses dummiesforalltreatmentarms.Acommonapproachtoestimatingtheeffectsofcross-randomizedinterventionsistoimposeadditionalstructure,e.g.byassumingadditiveeffectsoftheinterventionvariantsT1/T2 andA/B/C.However,notethatthisimposesconstraintsacrosstreatmentarmsthatmayinterferewith efficientlearningiftheunderlyingassumptionsareincorrect.Conversely,ifitisknownthatthetreatment effectshaveaspecificstructure,theoptimalassignmentshareschange,asobservationsfromonetreatment armprovideinformationaboutotherarms,andtheefficiencypropertiesofalgorithmssuchasexploration samplingarenotknowninthissetting.
OralReadingFluency. OurestimationoforalreadingfluencyusesORFscoresfromthreeperiods:the endtermexamofterm2(E2),andthemidtermandendtermexamsofterm3(M3,E3).Thismeanswe captureallstudentspre-treatment,wave-1studentsintwoperiodsposttreatment,andwave-2students inoneperiodposttreatment(providedtheirORFscoreisnotmissing).WeuseaBayesianapproachfor consistencyandbecauseBayesianinferenceisvalidevenwithadaptivesampling.
aStandardNormaldistributionfortheschoolrandomeffects.21 p(βE k ) ∝ 1 ∀k =1,..., 6 , κ E ∼ Half-Normal(0, 1) , η E s ∼ N (0, 1)
{βE k }6 k=1 and κE
θsk
θsk
Let Y sk it denotetheORFscoreofastudent i attime t inschool s,assignedtotreatmentarm k.Define γsk it astheaverageORFscoreofstudent i inschool s forperiod t ∈{E2,M 3,E3} andarm k ∈{0,..., 6}, where k =0nowincludesthecontrolgroup.Weassumethat Y sk it hasanormaldistribution,andmodelthe 21Weusethisrandomeffectsparameterizationtoavoidwhatisknownas“Neal’sfunnel”whensamplingfromthejoint distributionofthetreatmenteffectsandrandomeffectvariance(Neal,2003). 22
Remark: Notethat,unlikeforcallengagement,weexpectthatORFscoresincreaseovertimeindependently oftheintervention,asstudents’readingabilityimprovesoverthecourseoftheschoolterm.Thecontrol grouphelpsdistinguishthepuretimetrend,capturedby
,fromanycommoneffectsoftheIVRcalls onORF.Inpurepolicychoiceexperimentswithstationaryoutcomes,acontrolgroupisnotneeded.But samplingacontrolgroupandincludingaperiodrandomeffectinthemodelcanbeusefuliftheoutcome targetedforadaptivesamplingisexpectedtovaryovertime,evenifthetreatmenteffectshavethesame distributionacrosswaves.
ModelFitness. Weconductstandardchecksonthedistributionofpredictedoutcomesforthecallengagementandtheoralreadingfluencymodeltovalidatewhetherourmodelsarecorrectlyreplicatingthe characteristicsoftheobservedoutcomevariable.Wealsocheckthesensitivityofourresultstodifferentprior distributionspecifications.Forthecallengagementmodel,weselectfourdifferentpriordistributionsfor βE k (βF k forORF):(i)anormaldistributioncenteredon0andvarianceequalto100,(ii)aT-Studentdistribution with1degreeoffreedom,mean0andvarianceequalto100,(iii)anormaldistributioncenteredon0and
averageORFscorewithahierarchicallinearregression: Y sk it | γ sk it ∼ N (γ sk it ,σ 2) , γ sk it = β0 + βF x k t + κ F η F s + φαi + ριt (3) Asbefore, βF isa1 × 6vectorofaveragetreatmenteffects.Thevector xk t , k ∈{1,..., 6} isaunit vectorthatindicateswhetherthestudentexperiencedtreatment k inperiod t orearlier,asinasimple difference-in-differencespecificationwittime-invarianttreatmenteffects. Theproduct κF ηF s istherealizationofaschool-levelrandomeffect, φαi istherealizationofastudent-level randomeffectand ριt istherealizationofaperiod-levelrandomeffect.Weuseanon-informativeimproper prioron {βF k }6 k=0 andaHalf-Normalpriordistributionforeachoneoftherandomeffectvarianceterms {σ,κF ,φ,ρ},andassumeaStandardNormaldistributionforeachoftherandomeffects {ηF s ,αi,ιt}.We have: p(β0) ∝ 1 , p(βF k ) ∝ 1 ∀k =1,..., 6 , {σ,κ F ,φ,ρ}∼ Half-Normal(0, 1) , {η F s ,αi,ιt}∼ N (0, 1)
ριt
23
varianceequalto1,and(iv)aT-Studentdistributionwith1degreeoffreedom,mean0andvarianceequal to1.Next,wefollowthesameapproachwith κE (κF forORF)andtestthefollowingpriordistributions: (i)ahalfnormaldistributionwithmean0andvarianceequalto100,(ii)aninverse χ2 distributionwith 1degreeoffreedom,and(iii)ahalfT-Studentdistributionwith1degreeoffreedom,mean0andvariance equalto1.Inallthesecases,theresultsarenotaffectedbytheselectionofthepriordistribution.Given thelargesamplesize,thelikelihoodisdominatingtheprior.
4.2 TreatmentAssignmentandExplorationSampling
Inwave2,wewanttousetheExplorationSamplingalgorithmproposedinKasyandSautmann(2021a)to assignexperimentalunitstotreatmentarms.Doingsorequirescalculatingtheprobabilityoptimal pk t after eachwave.InthepolicychoicemodelinKasyandSautmann,theoutcomeisbinary,therearenocovariates, andtheparameterofinterestissimplythearmmean θk withaBetaprior.Theposteriorsusedtoderive pk t thereforehaveaclosedform.Here,weestimateageneralizedlinearmodelthatallowsforaschool-specific averagecallsuccessrate;appropriateifweexpectoutcomestovarysignificantlybetweenclusters(suchas schools).However,thisimpliesthattheexpectedoutcomeinarm k, θk = ET [θsk|k],dependsontherandom effects(notethat θsk isthere-scaledexpectationofcallengagement Z sk i ).Moreover,wesampletheposterior distributionofallparametersusingMCMCwhichrequiresmanynumericaldraws.
Inordertosimplifythecalculationof
,weusethat
ifandonlyif
>β
.Inourmodel,this isthecasesince
isstrictlyincreasingin
E .Thisimpliesthat
foranyrealizationoftheschooleffect
orthedispersion parameter
Pr
andthereforewecansimulatetheprobabilitythatarm
(4)
Attheendof
pk t
θk t > θk t
βk
k
θsk
βE
ηE s
κ
t(k =argmax k θk t )=Prt(k =argmax k βk ),
k isoptimalusingjusttheposterioroftheparameters {βE k }6 k=1,ratherthanthe(joint)distributionofalltheparametersentering θk i 22 Thisshortcutcansimplify derivingtheexplorationsamplingassignmentsharesformanymodelswithcovariatesorrandomeffects. PosteriorProbabilityofSuccessfulEngagementandPosteriorExpectedRegret.
theexperiment,wewanttoimplementthearmwiththehighestaverageoutcome,orequivalently,lowest policyregret.Here,wetranslatethistochoosingthetreatmentarmwithlowestposteriorestimatedregret intermsoftheengagementprobability, ET [∆k]= ET [θs(1) θsk|k](wheretheexpectationsareformed overtheposteriorsfor β and κ andthenormallydistributedschoolrandomeffects,and θs(1) denotesthe 22NotethatthesameapproachwouldalsobevalidifwehadtargetedORFandweretosimulateprobabilityoptimalbase onthe {βF k }6 k=1 24
school-specificsuccessprobabilityundertheoptimaltreatmentarm).
Theexpectedprobabilityofasuccessfulengagement θk = ET [θsk|k]andtheexpectedregret ET [∆k]cannot bederivedfromthedistributionofthe {βE k } alonebecauseofthenon-linearinverselogittransformation logit 1(x)= e x 1+ex 23 Wethereforedrawfromtheposteriordistributionsof κE and βE andthestandard normaldistributionof ηE s tocalculatethesuccessprobabilityineacharmandschool.Thenweaverageover these θsk drawstoobtain θk aswellas ET [∆k].
Remark:Predictingprobabilityofsuccessandpolicyregretwithschool-leveleffects. Bydrawingtheschool randomeffectsfromthenormaldistribution,weimplicitlytakean“out-of-sample”approachthatignores thedistributionofrealizedrandomeffectsinthestudentsample.Thisisinformedbythefactthatwedid notfindimportantdifferencesbyschoolsize,suchasacorrelationbetweenaverageORFscoresandsize.We thereforetreatnewgenerationsofstudentsasrandomdrawsfromthedistributionofschoolrandomeffects. Analternativewouldbetotreattheschoolrandomeffectsaspersistentandcombinetheposteriorsofthe schoolrandomeffectswithassumptionsabout(future)classsizestoobtaintheexpected(future)engagement probabilityandregret.Theuseofexpectedregretbasedonpredictedtreatmentoutcomesasthedecision criterionrequiresmakingexplicitwhatassumptionsareusedtomakepredictions.
Remark:Heterogeneity. Relatedly,ourapproachtocalculating pk t restsonthemonotonicityofthe θsk in βk Theapproachdoesnotapplywhen“preferencereversals”occur.Asasimpleexample,supposearm k hasa strongeffectinsomeschoolsandnoneinothers,whereas k hasamoderateeffectinallschools.Inthiscase, itdependsonthetreatmenteffectdistributionwhicharmhasthehighestaveragetreatmenteffect;here,for example,thesizeofthedifferentschools.Ifsuchheterogeneityisexpected,theresearcherneedstoestimate thedistributionof θk i moreflexibly,forinstancebyallowinginteractionsbetweencovariatesandtreatment, inwhichcasederivingboththeprobabilityoptimal pk t andexpectedregret ET [∆k∗ ]requiresassumptions aboutthecovariatedistributioninthepopulation.Notealsothatpreferencereversalsimplythattreatment k isoptimalforsomeschools,whereasforothersitis k ,inotherwords,theunconstrainedoptimalpolicyis specifictoeachschool.TargetedpolicychoiceisdiscussedbrieflyinKasyandSautmann(2021a),andCaria etal.(2020)describeatargetedadaptiveexperimentusingtheirproposedtemperedThompsonalgorithm. Targetinghastheadvantagethatwedonotneedto“trade-off”strataforwhichdifferentpoliciesareoptimal, butitisnotalwayseasytoimplementinreal-worldcontexts.
23Noteforexamplethattheestimateoftheaveragesuccessprobability, θk = ET [logit 1(βE xk + κE ηE s )|βE k ]isdifferent frombothlogit 1(βE k ),theinverselogitofthepointestimateofthetreatmenteffect,andfrom ET [logit 1(βE k )],theexpected successrateatthemedianschoolwith ηE s =0. 25
FrequentistInference
Asdiscussed,treatmenteffectestimatesfromadaptivelycollecteddataaresubjecttosamplingbias,and focusingontheeffectinthebestarmleadsto“winner’scurse”.Correctionsforthesesourcesofbiasare rapidlyevolvingfieldsofresearch.
Toourknowledge,thereisnomethodyetavailabletocorrectforadaptivesamplingbiasinmodels withrandomeffects,butthereexistweightingapproachesforarangeofsettingsthatmakeestimators asymptoticallynormal(Hadadetal.,2021;Zhangetal.,2021,2020).Inparticular,thesquarerootinverse propensityweightingproposedbyZhangetal.(2021)–whichinoursettingcorrespondstoweights 1 qk t forobservationsinarm k —appliestom-estimatorsincludingBinomialGLM.Usingtheseadaptiveweights resultsinanestimatorthatisasymptoticallynormal.Insection5.3,weexaminehowtheseweightsaffects pointestimatesandconfidenceintervalscomparedtoanunweightedBinomialGLMestimate.
Inaddition,Andrewsetal.(2021)havedevelopedcorrectionsforthe“winner’scurse”thatarisewhen estimatingthetreatmenteffectinthebestarm.Weconstructconfidenceintervalswith“unconditional coverage,”whichallowvalidinferenceontheeffectofIVRcallsonengagementwhenthebestcallformat isimplemented(butregardlesswhichofthesixformatsthatis).24 Thesecorrectionsrequirenormally distributedestimates.FollowingasuggestionbyHadadetal.(2021),weusetheadaptivelyweightedBinomial GLMestimatesasinputsintothesecorrectionsandshowhowthischangesthepointestimatesandconfidence intervals(section5.3).TheseapproachesarenotdirectlycomparabletotheBayesianestimateswithrandom effects,buttheyallowustogainsomeintuitionabouthowthetreatmenteffectestimateschange.Tworecent softwarepackagesmakeiteasytoapplythe“winner’scurse”corrections(Shreekumar,2020;Bowen,2022).
5 ResultsoftheIVRExperiment
5.1 CallEngagement
Table1presentsestimatesofthetreatmenteffectsfromBayesianBinomialGLMmodelsasspecifiedin Equation(2).Weshowboththeestimatewithonlywave-1dataandwithdatafrombothwaves.The tablereportsthemeansand,inbrackets,the95%highest-probabilitydensity(HPD)intervalsoftheposteriordistributions.25 Ahighercoefficientisassociatedwithagreateraverageprobabilityofsuccessful engagement.26
Onemaydebatewhetherconditionalorunconditionalcoverageisappropriate.Inanexperimentthatcomparesdifferent
4.3
24
typesofinterventions–say,conditionalcashtransfersandIVRcalls–wemaybeinterestedintheeffectofIVRcallsonlyif theyyieldbetteroutcomesthanthecashtransfer.Weseethisasacaseofconditionalinference,becausetheidentityofthe bestarmmatters. 25The95%-HPDregion H isdefinedbythehighest k suchthat u l f (θ)dθ =95%and f (θ) ≥ k forall θ ∈ H,where f denotes theposteriorpdfof θ.Forunimodaldistributions, H isaninterval. 26Recallthat,forapointestimateforthetreatmenteffect βE k andthemedianschoolwithrandomeffect0,wewouldhave thattheprobabilityofsuccessinarm k equals θk = exp(βE k ) 1+exp(βE k ) 26
Notes:
Valueofzeroliesoutsideofthe95%credibleinterval.Wesimulate4independentMarkovchainsof4,000 posteriordrawseachanddiscardthefirst2,000aswarmup. Theremaining8,000drawsareusedtogeneratetheposterior distributionsofthecoefficients.TheSplit-R ofeveryposteriordistributionisbelow1.01andtherearenodivergent transitions.
Table1:Callengagementestimatesafterwave1and2. BayesianBinomialGLM Wave1Fullsample (1)(2) T1A 2 84∗ 2 63∗ [ 3 09; 2 60][ 2 81; 2 46] T1B 2 64∗ 2 49∗ [ 2 87; 2 42][ 2 63; 2 36] T1C 2 75∗ 2 78∗ [ 3.00; 2.52][ 2.93; 2.63] T2A 2.94∗ 2.89∗ [ 3.19; 2.70][ 3.11; 2.68] T2B 2 83∗ 2 67∗ [ 3 08; 2 60][ 2 85; 2 50] T2C 3 46∗ 3 32∗ [ 3 74; 3 20][ 3 57; 3 07] Num.students12832462 Period11and2
∗
27
Table2:Treatmentallocationinwaves1and2.
Wave1Wave2
TreatmentTarget%Actual%Num.Target%Actual%Num. studentsstudents
T1A14.28%14.12%2117.44%8.45%117
T1B14.28%14.73%22039.26%40.46%560
T1C14.28%13.86%20728.45%26.81%371
T2A14.28%14.32%2140.89%1.01%14
T2B14.28%13.72%2059.68%8.53%118
T2C14.28%15.13%2260.00%0.00%0
Control14.28%14.12%21114.29%14.74%204
Notes:treatmentarmsampleallocationonwaves1and2.Target%showsthetargettheoreticalshares ofeachtreatmentarm.Observed%showstheactualtreatmentallocationafterrandomizationwith stratification.Num.studentsisthenumberofstudentsineachtreatmentarm.
Theestimatesfromwave1inTable1wereusedtodeterminetheexplorationsamplingsharesforwave2. Table2showsthetheoreticalsamplesharesineachtreatmentgroup,aswellastheassignedsampleshares afterstratifyingbyschool,bothforwave1andwave2.Explorationsamplingreducedthesamplingshare assignedtotreatmentsT2AandT2Ctozerooralmostzero.Moreover,T1AandT2Breceivedonlyslightly over8%ofthesample.ThebulkoftheallocationwenttoT1BandT1C(asidefromthecontrol).These arebothcallswheretheIVRinstructstheparenttoleadreadingexercises,butinBthesameintermediate exercisesequencingisusedforall,whereasinCtheparentcanchoosetheexercises.
Column(1)inTable1showsthatsomedifferencesintreatmenteffectsalreadyemergedinwave1,which ledtothedifferencesintreatmentassignmentinwave2.Thefullsampleestimateincolumn(2)bothshows slightlydifferentpointestimatesandsignificantlytighterHPDintervals,especiallyforthehigher-performing treatments.Figure3displaysthetreatmenteffectposteriordistributionsafterwave2,correspondingtothe estimateincolumn(2)ofTable1.Theshapeofthedistributionsshowsthatthehighertreatmenteffects areestimatedwithsignificantlygreaterprecision.ThisallowsafinerdistinctionbetweenT1A,T1B,and T2B.Afterwave2,T1Bisthetreatmentarmwiththehighestlevelofengagement,withapointestimate of
Table3providesadditionalinformation.Columns(1)and(2)showtherawnumbersofattemptedengagementsandshareofsuccessfulengagements(dividingthenumberofsuccessfulcallsbythenumberofcall attempts).Columns(3)to(5)arebasedontheposteriorofthetreatmenteffectvector βE .Themeanand standarddeviationineacharmreplicatetheestimationresultsincolumn(2)ofTable1andshowoncemore thathighermeansareassociatedwithlowerdispersionoftheestimate.Column(5)showstheprobability optimal
2 foreacharm k.TheposteriorprobabilitythatT1Bistheoptimalchoiceisover93%;three
ˆ βE T 1B = 2 49,whereasT2Chasthelowestengagementwith ˆ βE T 2C = 3 32.
pk
28
Notes:thefigureshowstheposteriordistributionofparentengagementcoefficientsafterwave2.Greatervalues areassociatedwithahigherprobabilityofasuccessfulengagement.Theverticalbarmarksthemedianofeach posteriordistribution.Theshadedareasindicatethe95%credibleintervals.Atotalof8,000posteriordraws sampledfrom4independentMarkovchainswereused.
Figure3:Posteriordistributionsofparentengagementcoefficients.
arms(T1C,T2A,andT2C)haveessentiallyzeroposteriorprobabilitythattheydeliverthehighestlevelof engagement.ArmT1A,parent-ledreadingwithleveledexercises,hasthesecondhighestengagementrate of7.43%,buthasonlya5.24%probabilityoptimal.
Thelasttwocolumnstransformtheposteriorestimatesintoanaverageprobabilityofsuccessfulengagementforeacharm, θk,andreporttheexpectedpolicyregretbasedontheprobabilityofengagement,the objectiveofinterest(seesection4).ThisstatisticshowsthatimplementingT1Bwouldleadtoanexpected lossintermsoftheprobabilityofasuccessfulcallofonly0.02percentagepoints.Fortheothertreatment arms,thelossrangesbetween0.99ppand4.49pp.Theseexpectedlossesareequivalenttolessthan1%,12%, and53%ofthehighestestimatedsuccessprobabilityinarmT1B(of8.40%).
Inordertolookmoreintoparents’decisiontoanswerthebiweeklyIVRcalls,wealsoanalyzetheextensive marginofengagement.AppendixC.4showsestimatesfortheprobabilityofanysuccessfulengagement (i.e.,whethertherecipientstartedthereadingexercisesinanyofthecallsreceived)andtheprobabilityof answeringthephoneatleastonce.TablesA.6andA.7reportthecoefficientestimatesandthecorresponding treatmentarmaverages.Thearmshadnearlyidenticalinitialresponserates:infivearmsatleastonecall wasansweredwith84.1%-86.6%probability,andtheresponseratewasonlyslightlylowerinT2A(81.7%). Theshareofphonenumberswithatleastonesuccessfulengagementvariessomewhatmoreacrossarms, andisparticularlylowinT2C,wheretherateisonlyabouthalfofwhatitisinotherarms.However, T1A,T1BandT2Bhavenearlyidenticalengagementprobabilities.Itisinstructivetoalsocomparethe
T2C T2B T2A T1C T1B T1A −3.5 −3.0 −2.5
29
Table3:Callengagement:treatmenteffectestimatesafterwave2. RawnumbersPosteriorsof
E Average engagement
k
ArmCallShareMeanSDProb.SuccessPost.exp.policy attemptssuccessfuloptimal pk t prob. θk regret ET (∆k) (1)(2)(3)(4)(5)(6)(7)
T1A2, 9527.28%-2.630.095.24%7.43%0.99%
T1B7, 0208.40%-2.490.0793.19%8.40%0.02%
T1C5, 1936.47%-2.780.080.00%6.49%1.93%
T2A2, 0525.95%-2.890.110.00%5.86%2.56%
T2B2, 9077.05%-2.670.091.57%7.15%1.27%
T2C2, 0343.98%-3.320.130.00%3.93%4.49%
Notes:(1)Acallattemptisascheduledcalltoaparent,9perwave(notcountingrepeatedattemptsandcall backs).(2)Thesharesuccessfulisthepercentageofcallattemptsinwhichtheexerciseswerestarted.(3-4)The posteriormeanandstandarddeviationof βE werecalculatedfromatotalof8,000posteriordrawssampledfrom4 independentMarkovchains.(5)TheprobabilityoptimaliscalculatedasinEq.4.(6)Theaverageprobabilityof successiscalculatedasinEq. ??.(7)Theposteriorexpectedpolicyregretistheexpectedlossfromchoosingthis arm,expressedintermsoftheprobabilityofasuccessfulcall,afterobservingbothwavesoftheexperiment.
“probabilityhighest”foreacharmbasedontheextensivemarginestimates,reportedincolumn(2)ofTable A.7.Theseprobabilitiesaretheanalogoftheprobabilityoptimalincolumn(5)ofTable3(asthesecan becalculatedforanyoutcomeinanyexperiment,regardlesswhetheradaptivesamplingwasused).These probabilitiesneverexceed35.3%.Thepointestimatesandprobabilityhighestindicatethatthesixcall formatsaremuchlessclearlydifferentiatedbasedontheprobabilityof“anyengagement”thanbasedonthe overallcallengagementrate.Thissuggeststhattheintensivemarginmatters,anddifferencesinresponse ratesemergemoreclearlyasparentslearnaboutthecallsanddecideaboutcontinuedengagement. Oneinterpretationoftheresults,comparingAandBarms,isthatlevelingexercisecontentinthissetting isnotvaluable–perhapsbecauseofthenoisyandoftenmissingORFscoresusedforleveling–oratleastnot valuedbyparents,whomayperceivetheexercisesastooeasyortoodifficult.BothCarmshaverelatively lowcallengagementrates.Itisworthnotingthattheoptiontochoosebetweenexercisesincreasesthe lengthofthecall,whichmaydiscouragethelistener.ThecallsuccessrateinT2Cisparticularlylow,and weconjecturethatthisisbecausethelistenerisnotonlyaskedtochoosewhichexercisestoplay,butthe IVRherealsoaddressesthechilddirectly.This“gamification”aspectmayleadtheparenttoworryabout overlylongcallsinwhichthechildskipsaroundbetweenexercises.BetweenT1andT2,theposteriormeans suggestthatT1armshaveslightlyhigherengagementrates,perhapsbecausethe“listennow,practicelater” formatallowstheparentmoreflexibility.
ThesamplingsharesinTable2andthenumbersofattemptedandsuccessfulengagementsinTable3 alsodemonstrateapropertyofadaptivesamplingthatisattractiveinthecontextofpolicychoice:the
β
θ
30
reassignmentoftreatmentarmsharesinlaterwavesmeansthatalargerpercentageofparticipantsbenefit fromthetreatmentarmswithbetteroutcomes.Here,thismeansmorestudentsgetIVRcallswithhigh engagementlevels.Attheendofthisexperiment,27.10%percentofstudentsparticipatedinT1Bcompared toonly7.85%inarmT2C.
5.2 OralReadingFluency
Eventhoughtheadaptivesamplingalgorithmwasgearedtowardslearningaboutcallengagement,wewould alsoliketoestimatetreatmenteffectsonreadingfluency.ORFmayincreasedirectlyifparentsregularly carryouttheactualexercisesdeliveredwiththeirchildren,improvingtheirreading.Thecallsmayalso increaseparents’awarenessoftheirchild’sreadingabilitymoregenerally,leadingthemtoexpressinterest andencouragereadingpracticeinday-to-dayinteractions.
Table4presentsestimatesfromtwodifferentsamples.Column(1)inbothpanelsshowstheestimated treatmenteffectsonORFscoresusingonlythesampleofstudentswithcompletescoreinformationinall threeexams,whereascolumn(2)usesallstudentsforwhomwehaveatleastonetreatedandoneuntreated examscore.Figure4showstheposteriordistributionsoftheORFcoefficientscorrespondingtoPanelAof Table4,panel(a)forthebalancedpaneldataandpanel(b)fortheunbalancedpaneldata.
Inbothsamples,theORFtreatmenteffectsshowninPanelAaresmallandestimatednoisily,ranging from0.90to1.90correctwordsperminute.Bycomparison,inthecontrolgroup,ORFincreasedonaverage by1.62cwpmand2.92cwpminthefirstandsecondhalfoftheterm,respectively.Overall,goingfrom column(1)tocolumn(2),thetreatmenteffectstendtobeestimatedlarger,althoughwithsimilarcredible intervals;despitethemuchlargersampleintheunbalancedpanel,theprecisionoftheestimatesdoesnot increasemuch,perhapsduetothestudent-levelrandomeffects.Inthebalancedpanel,thecredibleinterval forallsixcoefficientsincludes0.However,theunbalancedpanelestimateforthearmwiththehighestcall engagement,T1B,indicatesanincreaseinfluencyby1.68cwpm,andthecredibleintervaldoesnotinclude zero.NotethatT1Bhasarelativelylargeshareofthesamplebecauseoftheuseofadaptivesampling,and thereforetheeffectonfluencyismorepreciselyestimatedinthisarmthaninothers,eventhoughthemean estimatedORFeffectsareslightlylargerinsomeotherarms.Thelargersamplesizeinthetreatmentarms chosenforimplementationisanadvantageofadaptivesamplingfortheestimationofnon-targetedoutcomes.
Inordertotestwhethersimplyreceivinganycallshasaneffectonfluency,wepoolthesixtreatment groupsinPanelB.Inbothsamples,theHPDintervalsdonotinclude0,andtheeffectis1.31cwpminthe balancedpaneland1.53cwpmintheunbalancedpanel.
Itisworthemphasizingoncemorethatthefluencyestimatesareonlyindicative,becauseofthelow dataqualityandbecausetheeffectsofanytreatmentwouldhavelikelybeenincompletelycaptureddue
31
(a)Balancedpanel
(b)Unbalancedpanel
Notes:thefigurespresenttheposteriordistributionoftreatmenteffectsafterwave2.Theverticalbarmarksthemedianofeach posteriordistribution.Theshadedareasindicatethe95%credibleintervals.Atotalof8,000posteriordrawssampledfrom4 independentMarkovchainswereused.
Figure4:PosteriordistributionsoftreatmenteffectsforORFscores. totheshortexposureandtheone-offmeasurementofORFimmediatelyaftertreatment.Thatsaid,the estimatessuggestthatanIVRinterventionforparentalengagementintheirchildren’sreadingwillhavea positiveimpactonchildren’sreadingskills.Thisisanencouragingfindinggiventherelatively“lighttouch” ofthisintervention.Basedontheestimatesfromtheunbalancedpanel,itismorethan95%likelythat implementingthearmwiththehighestengagement,T1B,whichasksparentstocarryoutafewsimple readingexercisessequencedthesameforallchildren,willleadtopositivereadingfluencygains.Whilethe effectsofthe4.5-weekinterventiontestedhereweremoderate,itstandstoreasonthatexposureforthefull termoreventhefullschoolyearwillgeneratelargereffects.Theprogrammayalsoleadtocontinuedjoint readingbetweenparentsandchildrenafterthecallsend.
Aremainingquestionishowthetreatmenteffectsonfluencycomparebetweenthedifferentarmsand whethercallexposureandefficacyvarysignificantlystronglysothatoneofthearmswithlowercallengagementcouldbemoreeffectiveforreadingoutcomes.Unfortunately,theanswerishamperedbythequality ofthedataandtherelativelysmalleffectsizes.FromFigure4,thereissignificantoverlapinthecredible intervalsofallarms,evenforthetreatmentarmswithalargeshareofobservations.Togetasenseof theuncertainty,TableA.4inAppendixCshowsthe“probabilityhighest”andtheexpectedregretforeach armbasedontheposteriordistributions oftheORFmodel.TheprobabilitythatT1Bleadstothehighest possiblereadinggainsamongthesixarmsliesbetween12%and20%accordingtotheseestimates.T1B generatesaposteriorregretof0.94cwpminthebalancedpaneland1.14inintheunbalancedpanel.Inthe balancedpanel,T1Bisthearmwiththelowestposteriorregret.Intheunbalancedpanel,armT2Bhas thelowestposteriorregret,with0.92cwpm.WhiletheprobabilityoptimalishigherthanforT1Bforthree arms(T2A,T2B,andT2C),itisbelow26.3%forallofthem,andthedifferenceinexpectedregretisless than0.24cwpm.
Thelowprobabilityoptimalforthearmswithlowestregretreflectsthenoiseintheseestimates.Notealso
T2C T2B T2A T1C T1B T1A −2.5 0.0 2.5 5.0 7.5
T2C T2B T2A T1C T1B T1A −2.5 0.0 2.5 5.0 7.5
32
Table4:ORFscoresestimates.
PanelA:Treatmenteffects
BalancedPanelUnbalancedPanel (1)(2)
(Constant)46.90∗ 46.54∗ [43 98;49 92][43 76;49 31]
T1A0 901 29 [ 1 26;3 09][ 0 70;3 30]
T1B1 601 68∗ [ 0 04;3 26][0 13;3 21] T1C1 080 91 [ 0.72;2.92][ 0.79;2.59]
T2A1.401.85 [ 1.01;3.81][ 0.42;4.04]
T2B1 411 90 [ 0 75;3 55][ 0 12;3 92]
T2C1 321 79 [ 1 06;3 71][ 0 49;4 05]
PanelB:Pooledtreatmenteffects
BalancedPanelUnbalancedPanel (1)(2)
(Constant)46 91∗ 46 63∗ [43 87;50 02][43 77;49 49]
Pooledtreatment1.31∗ 1.53∗ [0.08;2.52][0.34;2.69]
Num.obs.54696701 Num.students18232439
Notes:Reportingmeansand95%HPDintervals(insquarebrackets)of theposteriordistributionsoftreatmenteffects. ∗ :zerooutside95%credibleinterval.Wesimulate4independentMarkovchainsof4,000posterior drawseachanddiscardthefirst2,000aswarmup.Theremaining8,000 drawsareusedtogeneratetheposteriordistributionsofthecoefficients. TheSplit-R ofeverycoefficientisbelow1.01andtherearenodivergent transitions.
33
thatT2AhasahigherprobabilityoptimalthanT2Binboththebalancedandunbalancedpanel,highlighting thatthearmwiththehighestprobabilityoptimalmaynotalwayshavethelowestpolicyregret.Thiscan occurifsome“unlikely”statesoftheworldhaveveryhighregretrealizationsandoccursmoreoftenwhen thebestarmisfairlyuncertain.
Overall,basedontheseresultsthereissignificantuncertaintyaboutwhicharmhasthehighestORFgains. Thereisnostrongevidencethatchoosingapolicybasedonmaximalcallengagementissystematicallyat atensionwithalsoincreasingoralreadingfluency,butwecanalsonotconcludethatthetwooutcomesare definitelyaligned.Iftheimplementerwouldliketorevisethedecisiontotargetengagementonlyandlearn whichcallformatmaximizesORFgains,additionaltestingwouldlikelybeneeded.
5.3 CorrectingforSamplingBiasandWinner’sCurse
WhilemostofouranalysisisBayesian,researchersmayalsobeinterestedinconductingfrequentistinference withthedataobtainedfromapolicychoiceexperimenttodrawbroaderconclusionsabouttheinterventions tested,andthisrequirescorrectingsamplingandwinner’scursebiases.
34
Table5:Callengagementestimatesapplyingtheadaptivelyweightedm-estimatorbyZhangetal.(2021) andthe“winner’scurse”correctionbyAndrewsetal.(2021).
PanelA:Binomialmodelestimates,unweightedandwithadaptiveweighting. UnweightedUnweightedAdaptivelyweighted WithschoolREWithoutschoolREWithoutschoolRE (1)(2)(3)
T1A 2.63
2.80; 2
T1B 2 49
2.54
45][ 2.79; 2
2 39
2.52
3][ 2.78; 2.27]
2 39
2 62; 2 36][ 2 54; 2 24][ 2 55; 2 24]
T1C 2 77
2 67
2 66
2 92; 2 62][ 2 86; 2 49][ 2 85; 2 46]
T2A 2 88
2 76
2 79
3 09; 2 67][ 3 09; 2 43][ 3 20; 2 39]
T2B 2.67
2.58
2.57
2.84; 2.49][ 2.82; 2.34][ 2.81; 2.33]
T2C 3 31
3 18
3 18
[ 3 55; 3 06][ 3 59; 2 77][ 3 59; 2 77]
∗
∗
∗ [
.
.
∗
∗
∗ [
∗
∗
∗ [
∗
∗
∗ [
∗
∗
∗ [
∗
∗
∗
Num.students246224622462 SchoolREYesNoNo PanelB:“Inferenceonwinners”correctiononT1B. WithschoolREWithoutschoolRERe-weighted (1)(2)(3) T1B 2 49∗ 2 39∗ 2 39∗ [ 2 66; 2 32][ 2 59; 2 19][ 2 60; 2 18] Notes: ∗Valueofzeroliesoutsideofthe95%confidenceinterval.(1)Frequentistestimate, unweightedandwithschoolrandomeffectsasintheoriginalmodelspecification(Table1,Column 2).(2)Frequentistestimatewithoutschoolrandomeffects.(3)Frequentistestimatewithout randomeffects,applyingadaptiveweightsasinZhangetal.(2021).PanelA:fullestimatesforall treatmentgroups.PanelB:MedianestimateandadjustedconfidenceintervalsforT1B,applying correctionsforinferenceonthebestarmasinAndrewsetal.(2021).Notethatthiscorrectionis onlytheoreticallyvalidincolumn(3)wheretheunderlyingestimatorisasymptoticallynormal. 35
Asdiscussedinsection4.3,amethodtocorrectforthebiasesthatarisefromadaptivesamplingwhen therearerandomeffectsdoestoourknowledgenotyetexist.Wethereforepresentresultswithoutrandom effectsforillustrativepurposes.InTable5,weshowasetoffrequentistestimatesthatiterativelyapply adaptiveweightingandthewinner’scursecorrection.Incolumn(1),weshowunweightedestimatesfrom aBinomialmodelwithrandomeffects.ThesearethefrequentistequivalenttotheBayesianestimatesin column(2)ofTable1(andtheyareverysimilar).
Column(2)showsunweightedestimatesagain,butthistimewithoutrandomeffects.Asiscommon, thisshiftstheestimatedcoefficientssomewhattowards0.InColumn(3),weapplytheadaptiveweights proposedbyZhangetal.(2021)toobtainasymptoticallynormalestimates.Itisinstructivetocompare columns(2)and(3)inPanelA:forthebestarm,theestimatesarealmostidentical,whereasforexample forT2Athepointestimateisshiftedandtheconfidenceintervalsignificantlywider.Thisreflectsthatarms whoinitiallyperformpoorlyreceiveonlyasmallshareofthesample,andtheweightedestimatortherefore givesthosefewobservationssignificantlygreaterweights,withthepotentialtochangetheoveralltreatment effectestimate.AsHadadetal.(2021)observe,thisisanindirectconsequenceofthefactthatsampling biasprimarilyaffectsthesub-optimalarms(whichare“dropped”fromthesample)ratherthantheoptimal arm,whereinitialbiaseshaveachancetoself-correct.
InPanelB,weapplythewinner’scursecorrectionbyAndrewsetal.(2021)tothetreatmenteffect estimatefortheempiricallybestarm,T1B.Notethatthemethodrequiresnormallydistributedestimators, soitisstrictlyspeakingonlyapplicablewiththeweightedestimatesincolumn(3).However,forillustration purposeswecarryoutthesamecorrectioninallcolumns.Thecorrectedconfidenceintervalsweobtain aresomewhatwiderthanthe“na¨ıve”estimatesinPanelA.However,thepointestimatesforthetreatment effectsremainvirtuallythesame.ThisreflectsthatatleastintheIVRexperimentthebestarmisfairly unambiguouslyidentified,andthedistributionoftheestimatoristhereforenotsignificantlytruncated.This meansalsothatawinner’scurseislesslikely.AsAndrewsetal.(2021)alsopointout,uncorrectedfrequentist estimatesareasymptoticallyvalid.
WemaydeducethatweneednotbetooworriedabouttakingtheBayesiantreatmenteffectestimatesfor theIVRexperimentatfacevalue.However,inexperimentswithsmallersamples,bothsamplingbiasesand thewinner’scurseproblemmaybemorepronounced.
6 AlternativeResearchDesigns
Inthissection,weturnbacktothequestionofhowtochoosetheresearchdesign.Potentialusersof explorationsamplingandadaptiveexperimentsmoregenerallywillbeinterestedinthelearninggainsfrom adaptivity,aswellasthebestdesignfortheiradaptiveexperiment.
36
AfirstquestioniswhetheradaptivesamplingimprovedlearningintheIVRexperiment.Themotivation touseadaptivemethodsistoincreaseefficiencyandmakethemostofalimitedsampleandtime.However, asymptoticconvergenceresultsforexplorationsamplingandotherbest-armalgorithms(KasyandSautmann, 2021a;Russo,2020;Qinetal.,2017)onlyapplytospecificoutcomedistributionsandwhenthenumberof wavesgrowslarge.Inthisexperiment,welearnonlyfromonepriorwaveandadapttheassignmentshares forhalfofthesampleinasecondwave.Possiblelearninggainsfromadaptivityarefurtherlimitedby thefactthattheexplorationsamplingalgorithmcanonlyapproximatetheoptimalassignment.Inafirst exercisebelowwethereforeusesimulationstoevaluatethegainsfromadaptivesamplinginwave2,relative tonon-adaptivesamplingwhereanequalshareofthesampleisallocatedtoeachtreatmentarm(a“standard RCT”).Weusethedataactuallygatheredinthisexperiment.Thegoalistoquantifytheperformanceof explorationsamplingexpostandforthespecificcontextoftheIVRexperiment.Thiscontributestoan evidencebaseaboutthegainsfromadaptivesamplinginpolicychoice.
Asecondquestionishowresearchersshouldexantecompareandmakedecisionsaboutresearchdesigns basedonpriorinformation,andwhethersuchcomparisonsarereliable.Asdiscussedabove,operational andlogisticalconstraintsintheIVRrestrictedthespaceofpossibleresearchdesignsessentiallytoeither conductingoneexperimentalwave(possiblyinonlyonehalfoftheterm)ortwowaves.Withreferenceto thetwoscenarioslaidoutin2,exante,wemighthaveaskedwhetherweshouldsimplyconductaone-wave, non-adaptiveRCTwiththefullsample,oriftherearesignificantgainsfromholdingbackhalfofthesample andadjustingthetreatmentassignmentusingexplorationsamplinginwave2.Alternatively,aftercarrying outwave1andobservingtheresults,wemighthaveaskedwhetherthelearninggainsfromthesecondwave maketheeffortworthwhile.Inthesecondandthirdexercisebelow,wethereforecarryoutsimulationsthat answerthesequestions,inthesamewayanexperimentermighthavedonetomakedecisionsabouttheIVR experiment.Thesesimulationsarebynecessitynotbasedontheactualdatacollected,butontheBayesian modelandparameterdistributionswespecified.Thepurposeisbothtocomparethepredictedgainsfrom adaptivesamplingobtainedexantefromthemodelwiththoseobtainedexpostfromthedata,andto illustratehowonemightgoaboutconductingsuchsimulations.
6.1 ExPostCounterfactual:Non-AdaptiveExperiment
Inafirstexercise,weaskwhatexpectedregretandprobabilityoptimalintheexperimentmighthavebeen ifwehadcarriedouta“standardRCT”,thatis,anexperimentwithuniformassignmentshares.Sincethe assignmentsharesinwave1wereequal,wesimulatelearningoutcomesfromalargenumberofbootstrapped samplesforwave2,drawnfromrealexperimentalobservationsinwave1and2.
Allourbootstrapsamplesforwave2have N =1384observations,thedrawsarestratifiedbyschool,
37
Table6:Expostcounterfactual:performanceofexplorationsamplingandstandardRCT
ExplorationSamplingStandardRCT
Treat-SuccessSuccessProb.PosteriorSuccessSuccessProb.Posterior mentprob.prob.SDtreatexp.policyprob.prob.SDtreatexp.policy meanoptimalregretmeanoptimalregret (1)(2)(3)(4)(5)(6)(7)(8)
T1A6.96%4.45%4.33%1.56%7.28%5.29%6.14%1.38%
T1B8.50%5.24%91.93%0.03%8.59%6.06%85.13%0.06%
T1C6.89%4.39%1.59%1.64%7.27%5.28%6.40%1.39%
T2A6.12%3.99%0.11%2.41%5.92%4.44%0.05%2.74%
T2B6.77%4.34%2.03%1.76%6.92%5.07%2.28%1.73%
T2C3.89%2.67%0.00%4.64%4.03%3.17%0.00%4.63%
Selected8.50%5.25%92.58%0.02%8.60%6.07%86.39%0.05%
Notes:Thetableshowsaveragesofestimatesforeachtreatmentarmobtainedfrom1,000simulatedsamplesdrawnfromthe observedexperimentaldata.Columns(1)and(5):meanposteriorprobabilityofasuccessfulcall.Columns(2)and(6):standard deviationoftheposteriorsuccessprobability.Columns(3)and(7):probabilitythatthetreatmentarmisoptimal.Columns(4) and(8):posteriorpolicyregretintermsofengagementsuccessprobability.
andweappendthebootstrappedsampletotheobservedwave1datatoestimateahierarchicalBayesian BinomialGLMasdescribedinEq.2.Wecarryout1,000drawsthatsimulateanRCTand1,000drawsthat simulateanexplorationsamplingexperiment.ForthesimulatedRCTs,webootstrapawave2ofequal-sized treatmentarms.Forthesimulatedexplorationsamplingexperiments,weusethetreatmentassignment sharesderivedfromtheoriginalwave1posteriordistributions.27 Foreachsampledraw,wecalculatethe posteriormeanandstandarddeviationof θk,theprobabilityoptimal,andtheposteriorexpectedpolicy regretforeacharm.TheaveragesforeacharmacrossdrawsareshownininTable6.Inaddition,weshow theaverageoftheposteriorregretandprobabilityoptimaloftheselected(lowest-regret)arm k∗ ineach simulatedexperiment.
Theaverageposteriormeanoftheprobabilityofasuccessfulcallissimilarbetweenexplorationsampling andstandardRCT,asseenincolumns(1)and(5).Asexpected,thestandarddeviationoftheposterior distributionofthemeansuccessprobability θk islowerunderexplorationsamplingforthehigh-performing treatments,buthigherforthelow-performingarms.Inbothresearchdesigns,thetreatmentarmthatismost oftenassociatedwiththehighestprobabilityofengagementisT1B.However,intheexplorationsampling experiment,T1Bischosen97.4%ofthetime,whereasthisisthecase94.9%ofthetimeinthesimulated RCTs.Thisreflectsthegreateruncertaintyandconsequentlyhighervarianceinthefinaldecisionthatresults
27Thisexerciseisnotperfect,becausewere-samplefromthesixarmsatdifferentproportionsforthetwodesigns.Sincewe usedatafrombothwaves,thebootstrappedwave-2sampleisalwayssmallerthantheoriginalsamplewedrawfrom.However, theprobabilityofrepeatdrawsisaffectedbyboththesizeoftheoriginalarmandthetargetsize,andthisratiovariesacross thetwodesigns.Analternativeapproachistousearandomlydrawnsub-sampleoftheoriginaldatathatisproportionalto thetargetedwavesize.Thisequalizesthechanceofrepeatsamplingacrossarms,butitimpliesthatthetwobootstrapsdraw fromdifferentunderlyingpopulations.Ultimatelythisseconddrawbackseemedmoreproblematicthanthefirst.
38
fromanon-adaptiveexperiment.
Explorationsamplingincreasestheprobabilityoptimalofthebestarmonaveragefrom86.39%to92.58% andreducestheaverageposteriorregretfrom0.05%to0.02%.Thereductionissmallinabsoluteterms fortworeasons;first,thestudentsampleislargeenoughsothatevenanRCTwouldleadtheresearcher torelativelyfirmconclusionshere,andsecond,inthisparticularprobleminstanceitturnsoutthatthe armaveragesareclusteredcloselytogether,meaningthatevenasuboptimalchoiceislikelytobebenign. However,inrelativetermstheimprovementislarge,andinapolicychoiceproblemwherethebestarmis actuallyimplemented,evensmallper-unitgainsinpayoffsmayaccumulateintolargewelfaredifferences. Overall,theex-postsimulationssuggestthatwecanachieveameaningfuldecreaseinuncertaintyand improveddecisionsfromjustonewavewithadaptivesamplinginvolvinghalfoftheexperimentalsample. Remark:DecisionMetrics. ThesesimulationshighlightanadvantageoftheproposedBayesianapproach:the metricsofexpectedpolicyregretandprobabilityoptimalprovidethedecisionmakerwitheasytounderstand, intuitivemeasuresoftheuncertaintyattachedtothepolicychoicestheyaremaking.Thisfacilitatesthe comparisonoftreatmentarmsaswellasexperimentalresearchdesigns.
6.2 ExAnteComparison:Model-BasedSimulationofExplorationSamplingvs.RCT
Inthesecondexercise,weimaginetheexperimenteraskingbeforetheIVRexperiment,“shouldIcarry outone(non-adaptive)wavewiththewholesample,ortwo(adaptive)waveswithhalfthesampleeach?” Forthesesimulations,takeagivenparametervector(βE ,κE ).BasedonthisvectorandEq.(2),wecan simulateoutcomes Z sk i forthestudentsineachwave(drawingtheschooleffects ηE s fromtheStandardNormal distribution).Thefirstsimulatedsampleusesequalassignmentshares,thesecondisgeneratedunderan adaptivedesign,wheretheassignmentsharesforwave2areobtainedfromestimatingourmodelabovefrom thesimulatedwave1data.Wecanthencomparetheestimationresultsunderthesetwosamplingstrategies tocalculatethepredictedgainsfromtheadaptivevs.thenon-adaptivedesignforthegivenparametervector. Thisisreminiscentofconductingpowercalculationsforanassumedeffectsize.
PanelAofTable7showstheresultofsuchanexercise,usingastheparametervectorthemeanofthe posteriordistributionsof βE and κE afterwave2,asreportedinTable3.Usingthewave-2estimatesfrom theexperimentservestoshowhowwelltheexantesimulationdoesinpredictingtheseestimates,andhowex antesimulationresultscomparewiththeexpostsimulationabove.Thepredictedgainsfromusingadaptive samplingintermsofposteriorregretareverysimilartoourpreviousexercisebasedontheactualIVRdata. TheaverageposteriorexpectedregretfromarmT1Bis0.02%withadaptivesamplingbut0.08%withthe “standardRCT”onaverage.Theaverageposteriorprobabilityoptimalforbothsamplingstrategiesisalso similartowhatweobtainedinTable6.
39
Table7:Exantecomparison:performanceofexplorationsamplingandstandardRCTinsimulatedsamples basedonparametervector(
PanelA:AveragesofPosteriorEstimates.
ExplorationSamplingStandardRCT
Avg.posteriorAvg.posteriorAvg.posteriorAvg.posterior Treatmentexpectedpolicyprobabilityexpectedpolicyprobability regretoptimalregretoptimal
T1A1.18%4.39%1.08%12.61%
T1B0.02%92.2%0.08%81.29%
T1C2.10%0.45%2.01%0.48%
T2A2.67%0.07%2.66%0.03%
T2B1.52%2.89%1.38%5.60%
T2C4.51%0.00%4.61%0.00%
PanelB:AverageRealizedValues.
ExplorationSamplingStandardRCT AveragePercentageAveragePercentage policybestarmpolicybestarm regretidentifiedregretidentified 0.01%99.00%0.07%93.00%
Notes:Thetableshowsaveragesfrom100simulatedsamplesdrawnusingtheparametervectorgivenbythemeansoftheestimatedposteriorsfromwave2oftheIVRexperiment, ˆ βE = ( 2 63, 2 49, 2 78, 2 89, 2 67, 3 32)andˆ κE =0 5.Foreachsampledraw,thesamefirstwavewas used,thesecondwavewasdrawneitherusingtheexplorationsamplingsharesbasedontheestimates fromthefirstwave,orusingequalassignmentshares.
PanelBofTable7usesthefactthatweknowtheparametervectorthatgeneratedthesimulatedsamples, andthereforeknowthepolicyregretfromchoosingadifferentarmfromT1B.Thismeanswecancalculate theaveragepolicyregretandshareofoptimaldecisionsfrommakingthefinalchoiceaftereachsimulated experiment(whichisbasedonposteriorpolicyregret).AccordingtopanelB,in99%ofthetime(93%inthe RCT)theexperimentercorrectlychoosesT1Bbasedonthisdecisionmetric.Theaverageposteriorregret fromT1Bisonlyslightlyhigherthantherealizedaveragepolicyregret;28 bothshowan0.06%reductionin regretfromadaptiveovernon-adaptivesampling.PanelBshowsthedecisionmetricthatshouldbeusedto choosebetweentheadaptiveandthenon-adaptivedesign(PanelAshowstheexpectedvalueoftheposterior estimatesaftertheexperiment).Theposteriorestimatesshowsomeremaininguncertainty.Thisispartly duetotheschoolrandomeffects:someofthemeasurementeffortisspentonestimatingtheschoolaverages, whichaddsuncertaintytothefinalestimates.
Priortoanexperiment,theresearcherofcoursedoesnotknowwhatthetrueparametersare,andthey 28NotethatregretinPanelBonlyoccurswhentheexperimenterdoes not chooseT1B.
ˆ βE , ˆ κE ).
40
maywanttocarryoutthecalculationinPanelBofTable7formultipleparametervectorsinordertoget asenseofthedistributionofgainsfromadaptivity.Themostconsistentapproachwouldbetodrawmany valuesfromthepriordistributionofthemodelparameters,butthiscangiveamisleadingpictureofthe gainsfromadaptivitywhenuninformativepriorsareused(nottomentionthatthecomputationalcostis high).Asanexample,intheIVRexperiment,theflatpriorscombinedwiththelogittransformationin themodelmeanthattreatmentarmaveragesbasedonrandomdrawsfromthedistributionsofthe βE are almostalwayscloseto0or1.InAppendixC.3,wethereforeshowresultsfromamodifiedexerciseinwhich weindependentlyandrandomlydrawthe θk fromtheuniformdistributionon[0, 1].Asitturnsout,this exerciseisnotmeaningfuleither:inmanycases,thedrawnparametersaresofarapartthat,givenourlarge sampleofstudents,evenequalassignmentsharesleadtoaveryhighprobabilityofpickingthecorrectarm. Amoremeaningfulapproachmightbetoassumecorrelatedpriordistributionsforthe βE k ,orusetheprior samedistributionforeach θk butwithameanobtainedfrompilotdata.Analternativetodrawingfroma priordistributionistoexaminelearninggainsforafewwell-chosenparametervectors.Again,thisissimilar totheapproachtakenintypicalpowercalculationsforexperiments,see(e.g.Dufloetal.,2007).
Remark:WhenisAdaptiveSamplingMostValuable? Asthesimulationsshow,theefficiencygainsfrom adaptivesamplingvarysignificantlyacrossdifferentprobleminstances.Forbest-armidentification,closely clusteredtreatmenteffectaveragesmaketheproblem“hard,”asitisdifficulttodistinguishthesearms. Fromawelfare-maximization(regretminimization)perspective,however,twoormoretreatmentarmswith verysimilarsuccessratesmayoftenleadtoasub-optimalchoice,butthelossfromthatchoicewillbe small.Intuitionsuggeststhatadaptivesamplingisparticularlyvaluablewhentherearetwoormore“nearoptimal”armsbutalsoseveral“farfromoptimal”armsthatcanbequicklyruledout.Anexamplecould beanexperimentthatcomparestwoormoredifferenttypesofinterventionsbutalsotestsseveralvariants withineachtype.Itwillbefruitfultoexplorethesequestionsinmoredetail.
6.3 ComparisonafterWave1:Model-BasedSimulationofaSecondAdaptiveWave
Inourlastexercise,weimaginetheexperimenter,afterhavingcarriedoutwave1,asking,“shouldIconduct asecondadaptivewave?”Thisissomewhatlesscomputationallycostlythantheaboveexercisebecauseafter wave1,theexplorationsamplingsharesforwave2areknown.Asbefore,foragivenparametervector βE and
E ,wesimulateasecondwaveoftheexperimentbygeneratingarandomsampleofsize N =1384following themodelinEq.(2)andusingtheassignmentsharesinTable2.Wedraw200parametervectorsfromthe wave-1posteriorsandcalculateaveragepolicyregretandpercentageoftimesthebestarmisidentifiedfor each.
PanelAofTable8showstheposteriorexpectedregretandprobabilityoptimalforarmT1Bafterwave
κ
41
Figure5:Distributionoftheposteriorexpectedregretfromwave1dataand200simulatedsamplesforwave 2,basedon
1.Theposteriorexpectedregretat t =1wouldbethebasisfordecisionmakingifnootherwavewas conducted,andT1Bwasthearmwiththelowestexpectedregretatthatpoint.PanelsBandCshowthe resultsofthesimulationsofwave2.PanelBshowstheaverageandmedianposteriorpolicyregretand probabilityoptimalofthechosenarm.Onaverage,thesimulationpredictsanimprovementinexpected regretfromcontinuedexperimentationof0.04%,andanincreaseintheprobabilityoptimalforthechosen armfrom74.14%to77.86%.Usingthemedianofthedistribution,theimprovementwouldbe0.07%and toaprobabilityoptimalof83.01%.Notethattheaverageposteriorexpectedregrethasaheavilyskewed distribution.Theactualvalueof0.02%observedafterthesecondwaveintheIVRexperimentisatthe38th percentileofthatdistribution,asseeninFigure5.
PanelCshowstheaveragerealizedpolicyregretandthepercentageoftimesthebestarmisidentified, bothafterwave1(wheretheexperimenterwouldhavechosenarmT1B)andafterwave2.Comparing thenumbersforwave1withPanelAshowsthatthedistributionofthesimulateddrawsreplicatesthe theoreticalposteriors,asexpected.Thenumbersforwave2showrealizedgainsthatmorethanhalvethe predictedpolicyregretofwave1andincreasetheshareofoptimaldecisionsby10%.IntheactualIVR experiment,hadweconductedthesecalculationsbetweenwaves,wewouldhavelikelyconcludedthatthe lowmonetarycostofsendingtheIVRcallstothesecondhalfofthesamplewouldhavemorethanjustified thegainsincertaintyabouttheoptimalchoice.TheactualIVRexperimentperformedevenbetterthan thesesimulationspredict.Abetterpriorforourparameters,forexamplebasedonpilotdata,islikelyto generatemorereliableanswerstoresearchdesignquestions.
Wave 2 posterior regret in IVR experiment 0.0 12.5 25.0 37.5 50.0 0.000 0.001 0.002 0.003 Posterior regret associated with the treatment arm selected Count
βE , κE and ηE drawnfromtheirposteriordistributionsafterwave1.
42
Table8:Comparisonafterwave1:endingtheexperimentvs.conductingasecondwave.
PanelA:PosteriorEstimatesafterWave1.
ExplorationSampling
PosteriorPosterior
Treatmentexpectedpolicyprobability regretoptimal
T1B0.12%74.14%
PanelB:PosteriorEstimatesafterWave2.
ExplorationSampling
Avg.posteriorAvg.posterior Waveexpectedpolicyprobability regret[median]optimal[median]
1and20.08%[0.05%]77.86%[83.01%]
PanelC:AverageRealizedValues.
ExplorationSampling
AveragePercentage Wavepolicybestarm regretidentified 10.13%71.00% 1and20.06%81.00%
Notes:Thetablesummarizestheresultsof200simulated samplesbasedon βE , κE and ηE drawnfromtheirposterior distributionafterwave1.
7 Conclusion
Thispapershowsaconcreteapplicationoftheexplorationsamplingalgorithmtodemonstratethesuccessful useofadaptivesamplinginreal-worldpolicychoiceproblems.Theexperimentweconductedprovidesan opportunitytoanswermanyimplementationquestionssurroundingthisnewmethod.Forinstance,aspart oftheIVRexperiment,wegivetwoexamplesofBayesianmodelingfortheoutcomesofinterest–herecall engagementandoralreadingfluency–andshowhowtousesuchmodelstocomputetheassignmentshares ineachwaveandtheposteriorexpectedregretthatisusedtochooseonearmforimplementation.We discusssomeoftheconstraintsontheresearchdesignthatareuniquetoadaptiveexperimentsaswellasthe approachestochoosingbetweenalternativedesignsbasedonsimulations.
Oursampleapplicationtestssixdifferentdesignsforanewparentoutreachmethod,interactivevoice responsecalls,toencouragehomereadingwithchildreninKenya,whichisknowntoimproveearlyliteracy. Eventhoughthetimeandbudgetfortheexperimentwerelimited,theadaptivedesignisabletoidentify
43
thecallformatwiththehighestlevelofengagementwith93%probability,leadingtominimalexpected lossesfrommistakenlyselectingthewrongcallformat.Despitetheshortexposureperiodofjust5weeks (9callsintotal)anddespitethemoderateuptake,thecallformatwiththehighestengagementlevel,which asksparentstocarryoutexercisesafterthecallwiththechildandusesthesame“intermediate”exercise sequenceforallchildren,leadstoamoderatebutdetectableimprovementinORFtestscoresof1.68correct wordsperminute([0.13-3.21],or0.065standarddeviationsofthebaselinereadingfluencylevel).These findingsmakeIVRcallsapromisingmethodofeducationaloutreach.Identifyingsuchmethodshasbecome anurgentpolicypriority,giventhedelaystoschoolingexperiencedbymillionsofchildreninthewakeofthe Covid-19pandemic.
ThisEdTechapplicationprovidesacompellingexampleforusingadaptivesamplinginpolicychoice experiments,showingthatthereareexpectedgainsinthetargetedoutcomewithevenmoderateadaptivity andarelativelylargesample.Wewouldexpectevenlargergainswhenmorewavesarepossible,andin probleminstanceswhere(forexample)afewinferiorarmscanberuledoutquickly,focusingsamplingeffort onasmallersubsetofpromisingcandidates.
Aslongastheadded(perwave)costislow,adaptivesamplinghasthepotentialtoimprovelearningin manyareasofpolicy,inparticularwhenoutcomedataisregularlyreceivedaspartofongoingadministrative datacollection.Therangeofcontextsinwhichthisisthecasecontinuestoexpandaspublicadministrations shifttowardsdigitalrecordkeepingandonlineinteractionswithbeneficiariesandcitizens.Inothersituations, thecostofadaptivitymaybehigh,forexampleduetotheaddeddatacollectioneffort,butthegainsfrom increasedefficiencyarepotentiallyalsohigh;forexamplewhentheavailablesampleissmallorthewelfare gainsfromimplementinganeffectivepolicyfasterarepotentiallylarge.Fromanethicsperspective,adaptive methodsforpolicychoicecanreducetheburdenofexperimentationwithhumansubjectstwofold;first, becausetheshareofexperimentalsubjectswhoreceivethehighest-performingpoliciesincreasesaslearning progresses,andsecond,becausethesamesamplesizegeneratesgreaterlearninggainswithanadaptiveover anon-adaptivedesign,increasingthepotentialforbetterpolicyoutcomesafterwards.
Aspartofdescribingthedesignofthisexperiment,thepapertacklesmanyimplementationquestionsthat weanticipateotherswillencounteraswell.Asmoreeconomistsandpolicymakersbegintouseadaptive methods,wehopetheybenefitfromthisexampleandthesolutionswepropose.Thepaperalsorevealssome potentialchallengesandhighlightsthatanimportant–andinpracticeoftendifficult–stepintheresearch designischoosingtherightoutcomemeasure.Thismayinfutureapplicationsinvolvemoreformalmethods ofelicitingpreferencesfromthepolicymakerinordertobeabletocorrectlyconstructtheposterioroutcome distributionsandselecttheoptimalarm.Manyoftheissuesraisedpointtofruitfulareasforfutureresearch andwillhopefullyspurongoinginnovationtoimprovethemethodfurther.
44
Andrews,I.andM.Kasy(2019).Identificationofandcorrectionforpublicationbias. AmericanEconomic Review109 (8),2766–94.
Andrews,I.,T.Kitagawa,andA.McCloskey(2021).Inferenceonwinners. Workingpaper
Angrist,N.,P.Bergman,andM.Matsheng(2020a).School’sout:Experimentalevidenceonlimitinglearning lossusing“lowtech”inapandemic. NBERWorkingPaper28205
Angrist,N.,P.Bergman,andM.Matsheng(2020b).School’sout:Experimentalevidenceonlimitinglearning lossusing“low-tech”inapandemic.Technicalreport,NationalBureauofEconomicResearch.
Athey,S.,S.Baird,J.Jamison,C.McIntosh,andB. Ozler(2021).Asequentialandadaptiveexperiment toincreasetheuptakeoflong-actingreversiblecontraceptivesinCameroon. AEARCTRegistryMay14 https://doi.org/10.1257/rct.3514.
Athey,S.,R.Chetty,G.W.Imbens,andH.Kang(2019).Thesurrogateindex:Combiningshort-termproxies toestimatelong-termtreatmenteffectsmorerapidlyandprecisely.Technicalreport,NationalBureauof EconomicResearch.
Athey,S.andG.W.Imbens(2017).Theeconometricsofrandomizedexperiments.In HandbookofEconomic FieldExperiments,Volume1,pp.73–140.Elsevier.
Audibert,J.-Y.,S.Bubeck,andR.Munos(2010).Bestarmidentificationinmulti-armedbandits.In COLT, pp.41–53.Citeseer.
Bahety,G.,S.Bauhoff,D.Patel,andJ.Potter(2021).Textsdon’tnudge:Anadaptivetrialtopreventthe spreadofCOVID-19inIndia. JournalofDevelopmentEconomics153,102747.
Banerjee,A.,R.Banerji,J.Berry,E.Duflo,H.Kannan,S.Mukerji,M.Shotland,andM.Walton(2017, November).Fromproofofconcepttoscalablepolicies:Challengesandsolutions,withanapplication.
JournalofEconomicPerspectives31 (4),73–102.
Banerjee,A.V.,S.Chassang,S.Montero,andE.Snowberg(2020).Atheoryofexperimenters:Robustness, randomization,andbalance. AmericanEconomicReview110 (4),1206–30.
Banerjee,A.V.,S.Cole,E.Duflo,andL.Linden(2007).Remedyingeducation:EvidencefromtworandomizedexperimentsinIndia. TheQuarterlyJournalofEconomics122 (3),1235–1264.
Bergman,P.(2021).Parent-ChildInformationFrictionsandHumanCapitalInvestment:Evidencefroma FieldExperiment. JournalofPoliticalEconomy129 (1),286–322.
Bergman,P.andE.W.Chan(2021).Leveragingparentsthroughlow-costtechnology:Theimpactof high-frequencyinformationonstudentachievement. JournalofHumanResources56 (1),125–158.
Berlinski,S.,M.Busso,T.Dinkelman,andC.Mart´ınez(2021).Reducingparent-schoolinformationgapsand
References
45
improvingeducationoutcomes:Evidencefromhigh-frequencytextmessages.Technicalreport,National BureauofEconomicResearch.
Bettinger,E.,N.Cunha,G.Lichand,andR.Madeira(2021,May).AretheEffectsofInformationalInterventionsDrivenbySalience? WorkingPaper
Bowen,D.(2022).Multipleinference.https://dsbowen-conditional-inference.readthedocs.io/en/latest/ ?badge=latest.
Bubeck,S.andN.Cesa-Bianchi(2012).RegretAnalysisofStochasticandNonstochasticMulti-armedBandit Problems. FoundationsandTrends® inMachineLearning5 (1),1–122.
Bubeck,S.,R.Munos,andG.Stoltz(2009).Pureexplorationinmulti-armedbanditsproblems.In InternationalconferenceonAlgorithmiclearningtheory,pp.23–37.Springer.
Caria,S.,M.Kasy,S.Quinn,S.Shami,andA.Teytelboym(2020).Anadaptivetargetedfieldexperiment: Jobsearchassistanceforrefugeesinjordan.
Christensen,G.andE.Miguel(2018).Transparency,reproducibility,andthecredibilityofeconomicsresearch. JournalofEconomicLiterature56 (3),920–80.
deBarros,A.andA.J.Ganimian(2021).WhichStudentsBenefitfromPersonalizedLearning?Experimental EvidencefromaMathSoftwareinPublicSchoolsinIndia. WorkingPaper
Doss,C.,E.M.Fahle,S.Loeb,andB.N.York(2019).Morethanjustanudge:supportingkindergarten parentswithdifferentiatedandpersonalizedtextmessages. JournalofHumanResources54 (3),567–603.
Duflo,E.,R.Glennerster,andM.Kremer(2007).Usingrandomizationindevelopmenteconomicsresearch: Atoolkit. Handbookofdevelopmenteconomics4,3895–3962.
Garivier,A.andE.Kaufmann(2016).Optimalbestarmidentificationwithfixedconfidence.In Conference onLearningTheory,pp.998–1027.PMLR.
Hadad,V.,D.A.Hirshberg,R.Zhan,S.Wager,andS.Athey(2021).Confidenceintervalsforpolicy evaluationinadaptiveexperiments.
Hadad,V.,L.R.Rosenzweig,S.Athey,andD.Karlan(2021).Practitioner’sguide:Designingadaptive experiments.
ICTworks(2016,August).Theblindspotofsmsprojects:Constituentilliteracy.
Kasy,M.(2016).Whyexperimentersmightnotalwayswanttorandomize,andwhattheycoulddoinstead.
PoliticalAnalysis24 (3),324–338.
Kasy,M.andA.Sautmann(2021a).Adaptivetreatmentassignmentinexperimentsforpolicychoice. Econometrica89 (1),113–132.
Kasy,M.andA.Sautmann(2021b).Correctionregarding“adaptivetreatmentassignmentinexperiments forpolicychoice”. Workingpaper
46
Knauer,H.A.,P.Jakiela,O.Ozier,F.Aboud,andL.C.Fernald(2020).Enhancingyoungchildren’slanguage acquisitionthroughparent–childbook-sharing:ArandomizedtrialinruralKenya. EarlyChildhoodResearch Quarterly50,179–190.
Kraft,M.A.andM.Monti-Nussbaum(2017,November).CanSchoolsEnableParentstoPreventSummer LearningLoss?AText-MessagingFieldExperimenttoPromoteLiteracySkills. TheANNALSofthe AmericanAcademyofPoliticalandSocialScience674 (1),85–112.
Lai,T.L.andH.Robbins(1985).Asymptoticallyefficientadaptiveallocationrules. AdvancesinApplied Mathematics6 (1),4–22.
Lattimore,T.andC.Szepesv´ari(2020). Banditalgorithms.CambridgeUniversityPress. Madaio,M.A.,V.Kamath,E.Yarzebinski,S.Zasacky,F.Tanoh,J.Hannon-Cropp,J.Cassell,K.Jasinska, andA.Ogan(2019).”yougivealittleofyourself”:Familysupportforchildren’suseofanivrliteracy system.In Proceedingsofthe2ndACMSIGCASConferenceonComputingandSustainableSocieties, COMPASS’19,NewYork,NY,USA,pp.86–98.AssociationforComputingMachinery.
Mayer,S.E.,A.Kalil,P.Oreopoulos,andS.Gallegos(2019,October).UsingBehavioralInsightstoIncrease ParentalEngagement:TheParentsandChildrenTogetherIntervention. JournalofHumanResources54 (4), 900–925.
Melfi,V.F.andC.Page(2000).Estimationafteradaptiveallocation. JournalofStatisticalPlanningand Inference87 (2),353–363.
Muralidharan,K.,A.Singh,andA.J.Ganimian(2019,April).DisruptingEducation?Experimental EvidenceonTechnology-AidedInstructioninIndia. AmericanEconomicReview109 (4),1426–1460.
Neal,R.M.(2003).Slicesampling. AnnalsofStatistics,705–741.
Offer-Westort,M.,A.Coppock,andD.P.Green(2021).Adaptiveexperimentaldesign:Prospectsand applicationsinpoliticalscience. AmericanJournalofPoliticalScience65 (4),826–844.
Piper,B.,J.Destefano,E.M.Kinyanjui,andS.Ong’ele(2018).Scalingupsuccessfully:Lessonsfrom Kenya’sTUSOMEnationalliteracyprogram. JournalofEducationalChange19 (3),293–321.
Pouzo,D.andF.Finan(2022).ReinforcingRCTswithmultiplepriorswhilelearningaboutexternalvalidity. NBERWorkingPaper29756
Qin,C.,D.Klabjan,andD.Russo(2017).Improvingtheexpectedimprovementalgorithm.In Proceedings ofthe31stInternationalConferenceonNeuralInformationProcessingSystems,pp.5387–5397.
Robbins,H.(1952).Someaspectsofthesequentialdesignofexperiments. BulletinoftheAmericanMathematicalSociety58 (5),527–535.
Rodriguez-Segura,D.,C.Campton,L.Crouch,andT.S.Slade(2021).Lookingbeyondchangesinaveragesinevaluatingfoundationallearning:Someinequalitymeasures. InternationalJournalofEducational
47
Development84,102411.
Russo,D.(2020).SimpleBayesianalgorithmsforbest-armidentification. OperationsResearch (6),1625–1647.
Sautmann,A.(2021a).Onlinesupplement:BridgeKenyaIVRliteracyinterventionmaterials.https://bit. ly/3LosOgM.
Sautmann,A.(2021b).Textmessagingforparentalengagementinstudentlearning. AEARCTRegistryMay 6.https://doi.org/10.1257/rct.6701.
Sautmann,A.(2022).Interactivephonecallstoimprovereadingfluency. AEARCTRegistryApril9 https://doi.org/10.1257/rct.7663.
Shang,X.,R.Heide,P.Menard,E.Kaufmann,andM.Valko(2020).Fixed-confidenceguaranteesfor Bayesianbest-armidentification.In InternationalConferenceonArtificialIntelligenceandStatistics,pp. 1823–1832.PMLR.
Shreekumar,A.(2020).winference.https://github.com/adviksh/winference.
Tabord-Meehan,M.(2018).Stratificationtreesforadaptiverandomizationinrandomizedcontrolledtrials. arXivpreprintarXiv:1806.05127
Thompson,W.R.(1933).Onthelikelihoodthatoneunknownprobabilityexceedsanotherinviewofthe evidenceoftwosamples. Biometrika25 (3/4),285–294.
Xu,M.,T.Qin,andT.-Y.Liu(2013).Estimationbiasinmulti-armedbanditalgorithmsforsearchadvertising.InC.Burges,L.Bottou,M.Welling,Z.Ghahramani,andK.Weinberger(Eds.), AdvancesinNeural InformationProcessingSystems,Volume26.CurranAssociates,Inc.
York,B.N.,S.Loeb,andC.Doss(2019,July).Onestepatatime:Theeffectsofanearlyliteracy text-messagingprogramforparentsofpreschoolers. JournalofHumanResources54 (3),537–566. Zhang,K.,L.Janson,andS.Murphy(2020).Inferenceforbatchedbandits. AdvancesinNeuralInformation ProcessingSystems33,9818–9829.
Zhang,K.,L.Janson,andS.Murphy(2021).Statisticalinferencewithm-estimatorsonadaptivelycollected data. AdvancesinNeuralInformationProcessingSystems34
48
A InterventionDesign
ThethreecontentinterventionvariantsA,B,andCareasshowninfigureA.1:
A. Levelingbybaseline:assignstudentstoa“basic”,“intermediate”,or“advanced”arm;
B. Preset:assignallstudentstoan“intermediate”exercisesequence;
C. Options:allowparentstoselecttheexercisefromamenu.
Thelevelingbybaselineusesobservedfluencyscoresfromtheendofterm2andassignsstudentswith fluencyscoresof0-29intothe“basic”arm,30-64intothe“intermediate”arm,and65+intothe“advanced” arm.Thesecutoffswereusedpreviouslyinasimilarcontext(theexternalTUSOMEevaluationinKenya, seePiperetal.(2018)).Forstudentswithmissingbaselinescores,weassignthemtheirclassmedian.For classeswithmissingscores,weassigntheintermediatelevel(whichinthissamplealsohappenstobethe samplemedian).
FigureA.1:Exerciselevelingvariations.
A.1
InthissectionweprovidemoredetailsonthedataqualityissueswithORFscores.
TableA.1:Non-missingORFscoresineachexam,bytreatmentarm,andbywave. Wave1and2Wave1Wave2
PeriodCT1AT1BT1CT2AT2BT2CTotalTotalTotal
T2ET89.6%88.2%88.2%87.8%91.8%90.0%88.9%88.9%88.9%88.8%
T3MT74.0%74.8%73.8%71.4%74.0%73.3%74.8%73.5%74.3%72.6%
T3ET79.3%81.5%81.9%78.0%83.5%79.9%77.4%80.3%80.5%80.1%
Total81.0%81.5%81.3%79.1%83.1%81.1%80.4%80.9%81.2%80.5%
N.students415330781581231329226289315091384
Notes:thetablepresentsthepercentageofvalidORFmeasurementsforstudentsallocatedtoeachtreatmentarminWave1and2.
TableA.1displaysthepercentageofnon-missingORFmeasuresacrosstreatmentarmsandperiods.There isnoevidenceofasystematicrelationshipbetweenORFattritionandthetreatmentsarms.However,after thelastdatadeliveryreceivedbytheresearchersinfall2021,theendtermexamofterm2hasthehighest averagepercentageofORFmeasures(88.9%)comparedtothemidtermofterm3(73.5%)andtheendterm ofterm3(80.3%).
Therearemanypossiblereasonsforthesepatterns.Onereasonfortheendtermdifferencecouldbethat teachersevenatthelastdatadeliveryhadnotsubmittedalltheirscoresforterm3.Thenumberofscores collectedinthemidtermmaybelowerbecausetheexaminationperiodforORFwasshorter(2hours)than intheendterms(3hours).Childrenmayalsobemorelikelytomissthemidtermthantheendterm.
TableA.2:AverageORFscoresfromseparatedatadeliveriesforendtermsofterm2andterm3.
TreatmentarmNumberof
CT1 AT1 BT1 CT2 AT2 BT2 Cstudents
E239.738.841.740.139.741.242.12285
E2updated62.35360.658.653.655.658.2286
E348.749.95249.151.851.250.21897
E3updated42.246.147.344.635.943.848.4425
Notes:firstsetofscoresobtainedforeachendtemexamshortlyaftergradingday.OriginalE2scoreswereused forlevelingforterm3.TheupdatedscoresareORFscoresforchildrenwhosegradeswereuploadedtothesystem laterandobtainedinaseconddatadeliveryforallexamsweeksafterinterventionend.Midtermofterm3not shownbecausetherewerelessthan20studentswithanupdatedscoreintheseconddatadelivery.
TableA.2showsaveragescoresfromseparatedatadeliverieswereceivedfortheendtermexamsofterm2 andterm3.Eachdatadeliveryincludedallscoresthatweresubmitteduptothatpoint.Thefirstdelivery wasreceivedshortlyaftereachexamtookplace.Crucially,forterm2,thiswasalsothetimewhenexercise
B OralReadingFluencyDataQuality
A.2
levelingbasedonreadingabilityforthenexttermwasdetermined,inordertostartIVRcallsintimefor thenextterm.Theseconddatadelivery(forallexams)wasreceivedinFall2021.
Thedatashowlargedifferencesbetweenthescoressubmittedsoonaftertheexamvs.later(duringthe nextterm).Thisisespeciallytrueforthedatafromterm2.Thisgapinscorescouldbeanexplanation forwhylevelingreadingexercisesisnotassuccessful:childrenwithmissingscorestendedtohavebetter readingskills,andtheymighthavereceivedtooeasyexercisesonaverage.Interestingly,whiletheaverage intheseconddatadeliveryishigherforendterm2,forendterm3itislower.Thesedifferencescouldbe duetosystematicpatternsinthetimeofscoresubmission,suchasremotelocationshavingpoorerinternet connectivityandalsolowerreadinglevels:notethattheseconddeliveryforterm2wasmuchsmallerthan forterm3.Butthedifferencecouldalsostemsimplyfromvariationthatarisesbecausescoresforawhole schoolorclassroomaresentatonceandthereisalotofinter-schoolvariance.
Inanycase,thetwotablesshowthatevenaftermanyweeks,asubstantialshareofORFscoresforeach examwasstillmissing.Whenexaminingscores,weadditionallyfoundanunusuallylargepercentageof scoresthataremultiplesof5(“rounded”scores).Onereasonforthiscouldbemeasurementerror,stemming forexamplefromtheteacherhavingonlyimprecisemeanstomeasuretime.
C AdditionalResults
C.1 Observedcallengagement
TableA.3showstheaveragenumberofcalls(outofninecalls)withsuccessfulengagement,bytreatment armandwave,andFigureA.2showsthehistogramofobservedcallengagement.Thefirstbarshowsthe numberofphonenumberswithzeroengagement.Thisshareisnearlythesameineverycallformatexceptin treatmentarmT2C,suggestingthatthesameshareofparentslistentotheexercisesatleastonce.Differences insustainedengagementarisefromthesecondcallonward.
TableA.3:Meannumberofsuccessfulengagementsbytreatmentarmandwave.
Wave1Wave2*Wave1and2
T1A0
T2A0
T2C0
6020 7520 655 T1B0 7450 7610 756 T1C0 6330 5540 582
.5420.4290.535 T2B0.5950.7030.635
.358-0.358 Notes:*NoobservationswereallocatedtotreatmentT2C inWave2. A.3
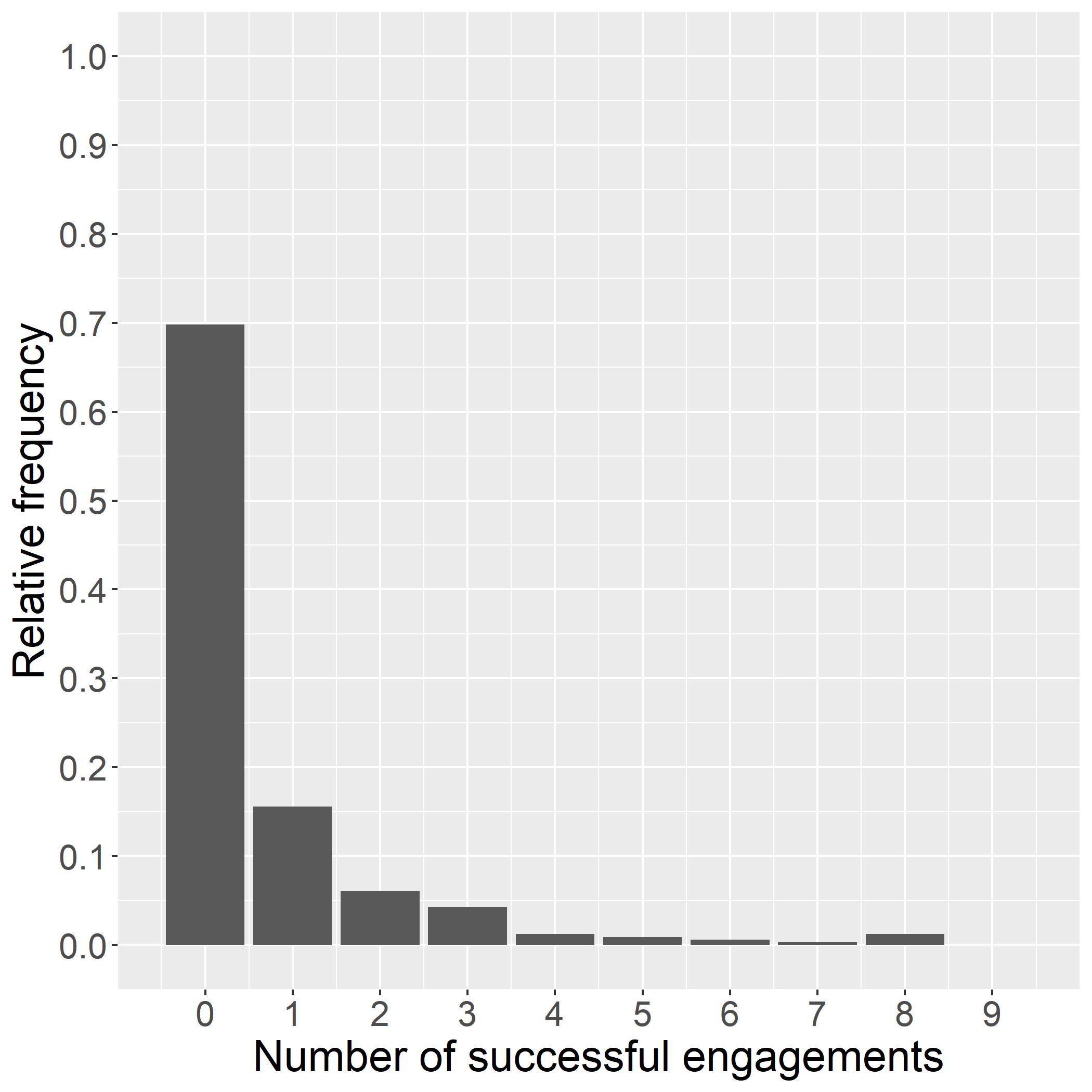
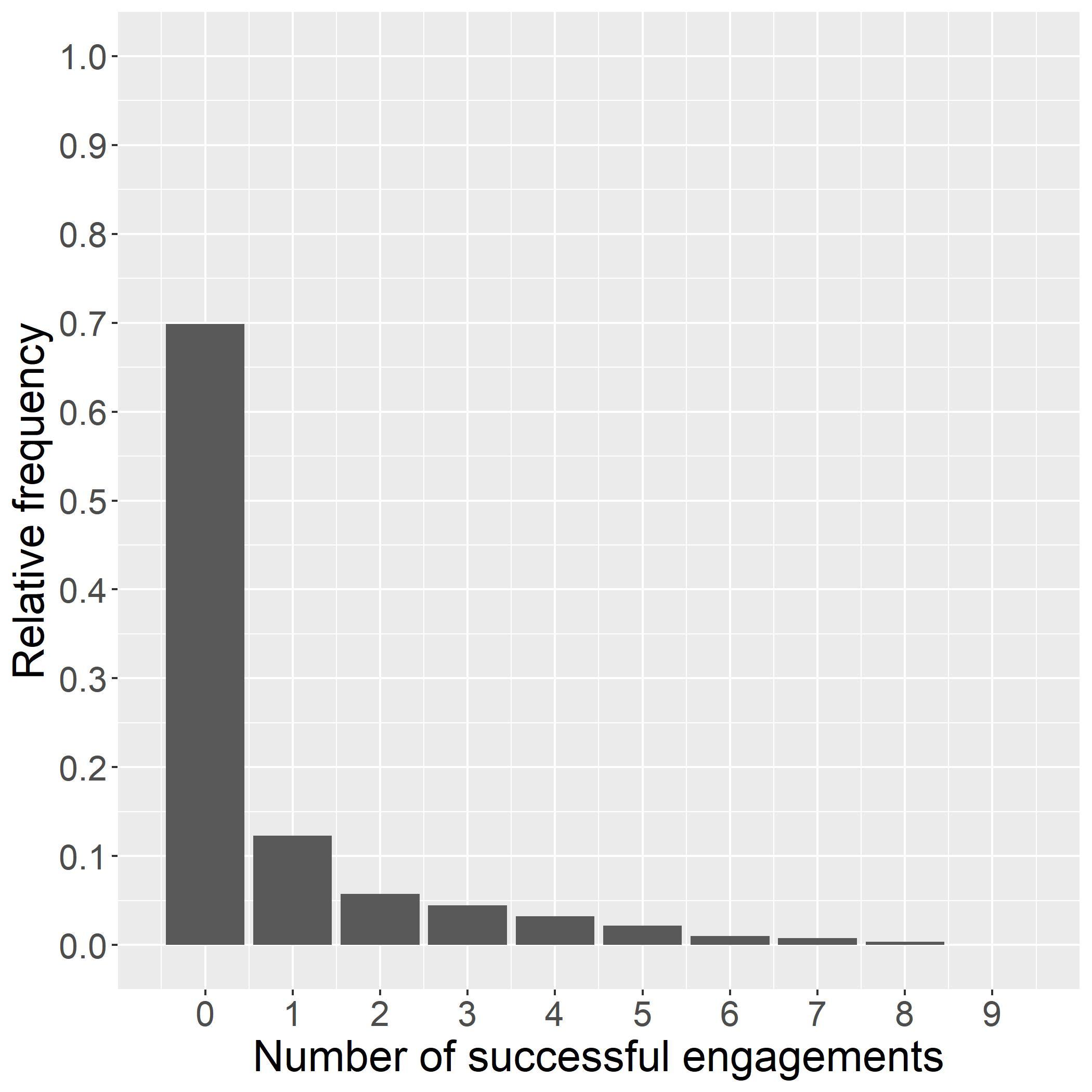
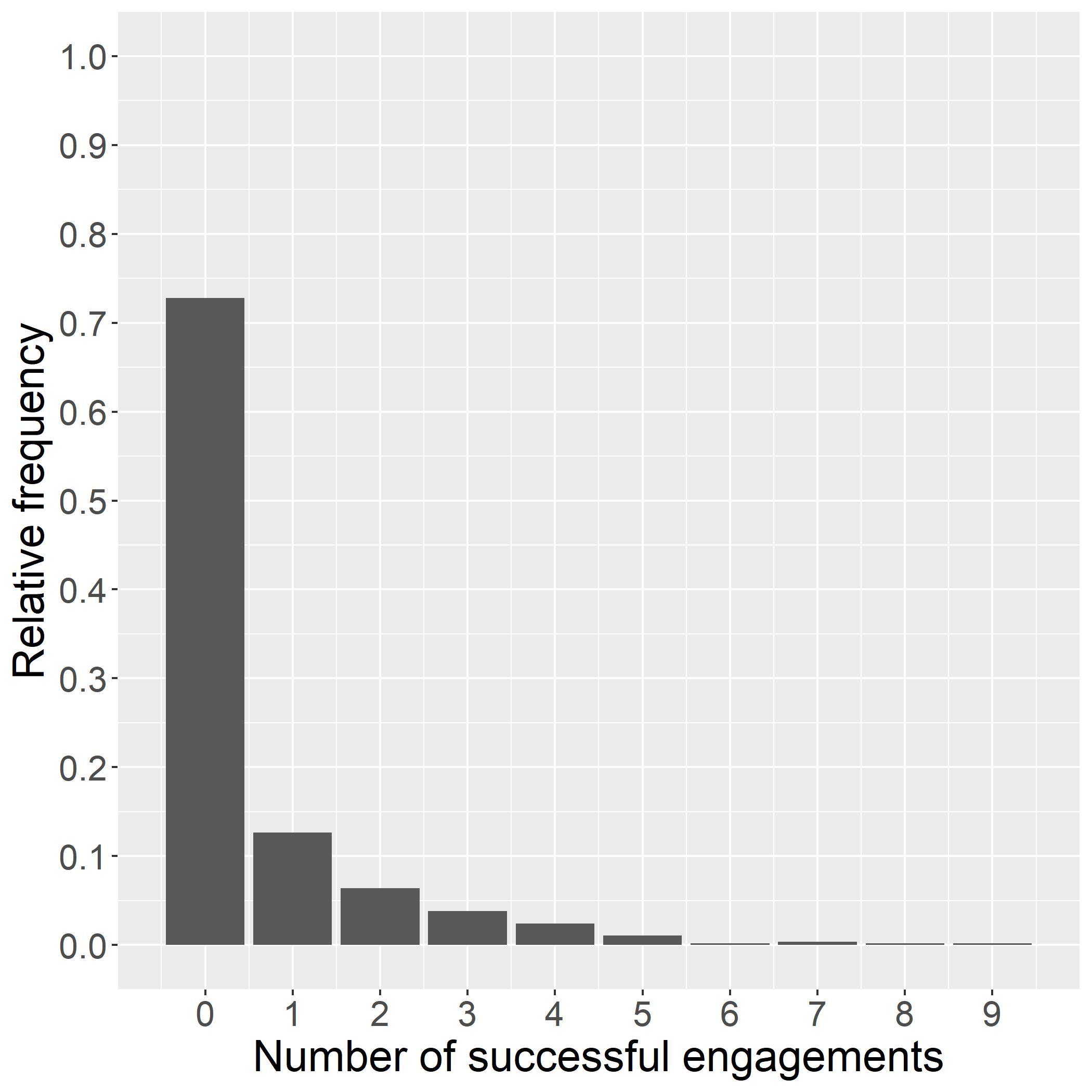
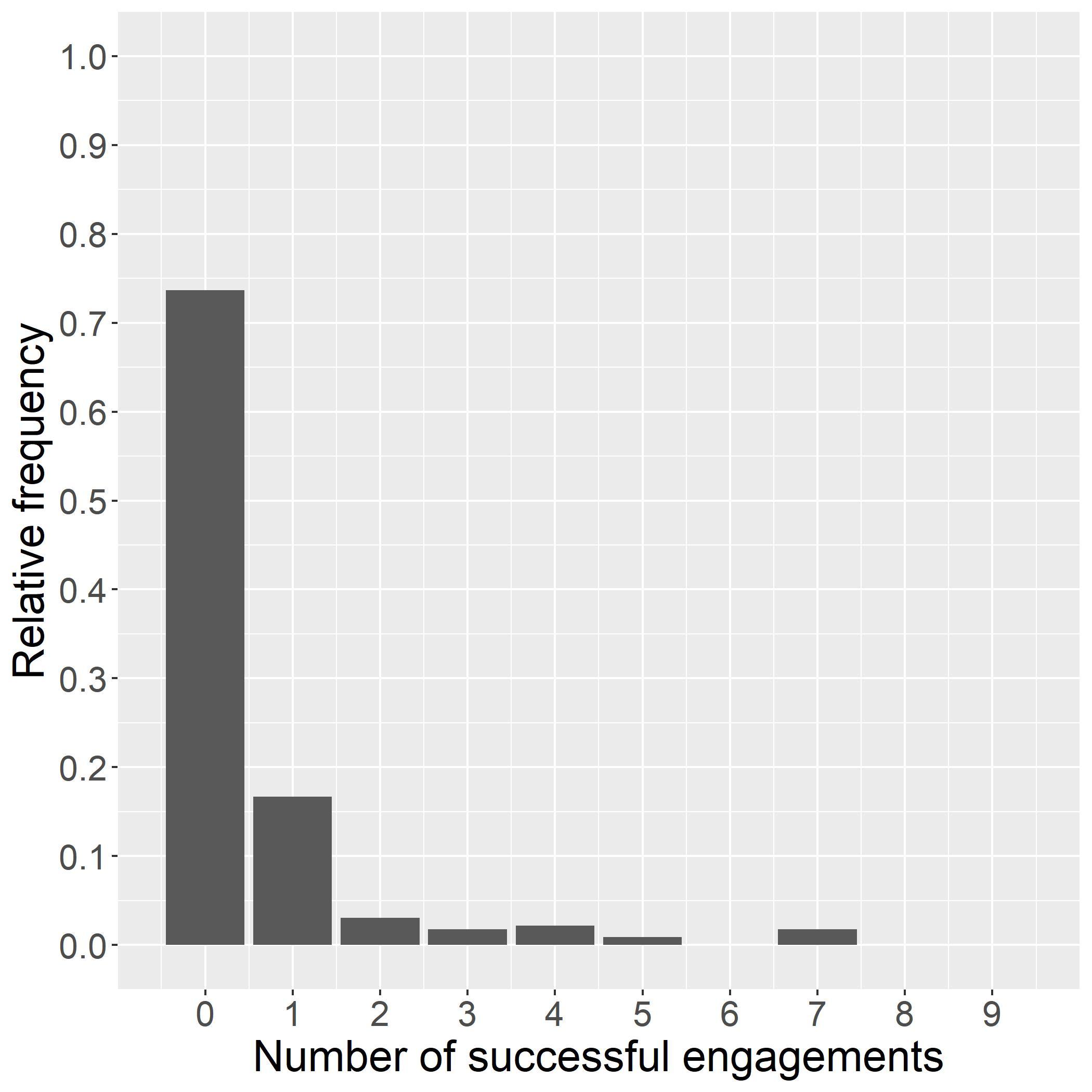
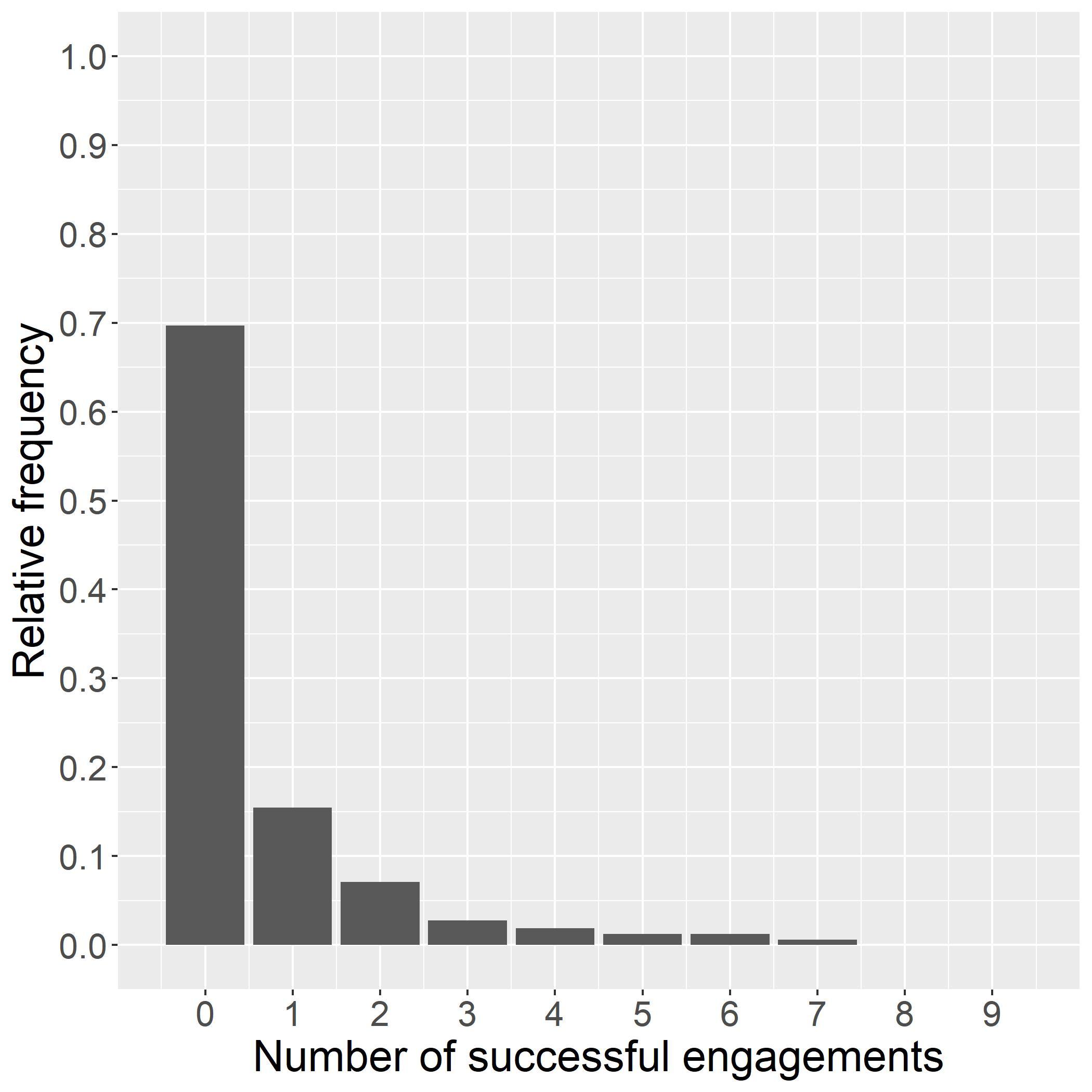
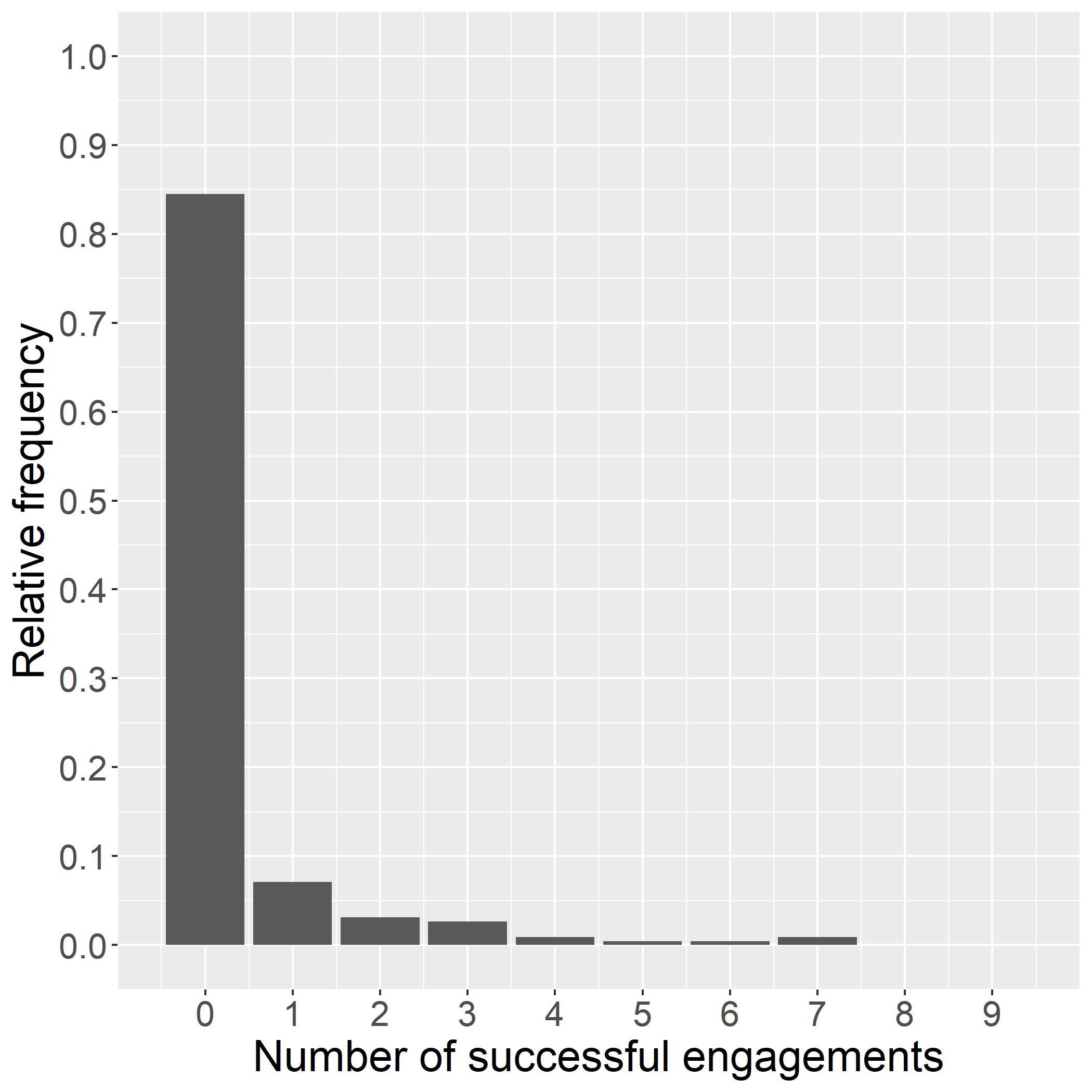
(a)TreatmentarmT1A (b)TreatmentarmT1B (c)TreatmentarmT1C (d)TreatmentarmT2A (e)TreatmentarmT2B (f)TreatmentarmT2C FigureA.2:Observedcallengagement,bytreatmentarm A.4
C.2 ProbabilityoptimalforORF
TableA.4:PosteriorregretandprobabilityofhighestORFscoregains. BalancedUnbalanced
TreatmentPosteriorregretProb.highestPosteriorregretProb.highest
T1A1 6368.55%1 5289.11%
T1B0 93520.30%1 14311.54%
T1C1 4588.33%1 9112.35%
T2A1 13422.23%0 97326.34%
T2B1 12320.60%0 91825.80%
T2C1.21920.00%1.02924.86%
Notes:Posteriorregretexpressedintermsofcorrectwordsperminute.Thetablecontainsinformation from8,000posteriordrawssampledfrom4independentMarkovchains.
C.3 ExAnteComparisonofExplorationSamplingandRCT
TableA.5:Exantecomparison:performanceofexplorationsamplingandstandardRCTinsimulated samplesbasedonmanyparameterdrawsfromtheprior.
PanelA:AveragesofPosteriorEstimates.
ExplorationSamplingStandardRCT
Avg.posteriorAvg.posteriorAvg.posteriorAvg.posterior expectedpolicyprobabilityexpectedpolicyprobability regretoptimalregretoptimal 0%98.97%0.01%98.91%
PanelB:AverageRealizedValues.
ExplorationSamplingStandardRCT
AveragePercentageAveragePercentage policybestarmpolicybestarm regretidentifiedregretidentified 0%98.99%0%98.99%
Notes:Thetableshowsaveragesfrom100simulatedsamplesdrawnusingtheparameter vector
,drawnfromtheirpriordistributions.Foreachsampledraw,thesame firstwavewasused,thesecondwavewasdrawneitherusingtheexplorationsamplingshares basedontheestimatesfromthefirstwave,orusingequalassignmentshares.
TableA.5showssimulationresultswhendrawinghypotheticaltreatmentarmaverages θk fromauniform distribution,simulatingtwoexperimentalsamples(onewithexplorationsampling,onewithnon-adaptive sampling)foreachdraw,andestimatingthemodelparametersfromthesesamples.Notethatbothequal andadaptivesamplingsharesessentiallyleadtozeroregretonaverage.Thisisbecauserandomindependent drawsfortheaveragesuccessrateinthedifferenttreatmentarmsoftenleadtoonearmthatisclearlya
{βE ,κE ,ηE }
A.5
“winner”.Inreality,itislikelythatthesuccessratesinthedifferentarmsarehighlycorrelatedandwillbe clusteredmorecloselythantypicalrandomdrawsfromtheunitinterval.
C.4 Extensivemarginforcallengagement
TableA.6:Extensivemarginforcallengagement:modelcoefficients.
AnysuccessfulAtleastone
Treatmentengagementsecondincall (1)(2)
T1A 0 85
1 71
[ 1 09; 0 61][1 42;2 03]
T1B 0 85
1 84
[ 1 01; 0 70][1 63;2 06]
T1C 1 00
1 91
[ 1 19; 0 81][1 67;2 18]
T2A 1.05
1.54
[ 1.34; 0.76][1.20;1.90]
T2B 0.84
1.86
[ 1 08; 0 60][1 54;2 19]
T2C 1 72
1 82
[ 2 10; 1 37][1 46;2 22]
Num.students24622462
Notes: ∗ Nullhypothesisvalueoutside95%credibleinterval. Wesimulate4independentMarkovchainsof4,000posterior drawseachanddiscardthefirst2,000aswarmup.Theremaining8,000drawsareusedtogeneratetheposteriordistributionsofthecoefficients.TheSplitˆ R ofeverycoefficient isbelow1.01andtherearenodivergenttransitions.
∗
∗
∗
∗
∗
∗
∗
∗
∗
∗
∗
∗
A.6
TableA.7:Extensivemarginforcallengagement:probabilityofengagement. AnysuccessfulengagementAtleastonesecondincall
TreatmentMeanProb.highestMeanProb.highest (1)(2)(3)(4)
T1A30.12%32.15%84.12%5.75%
T1B30.04%26.55%85.70%12.09%
T1C27.15%2.26%86.59%35.15%
T2A26.20%3.78%81.70%0.91% T2B30.28%35.26%85.92%25.11%
T2C15.41%0.00%85.40%20.99%
Notes:(1)and(3):TheaverageprobabilityiscalculatedinanalogwithEq. ??.(2) and(4)TheprobabilityoptimaliscalculatedasinEq.4.
A.7
