
15 minute read
Datenqualitätsassessment vor der Implementierung von Predictive Maintenance

from WINGbusiness Heft 03 2022
by WING

Foto: Pixabay
Kraker Philipp Thomas, Kaiser Florian
Advertisement
Anhand eines Datenqualitätsassessments (DQA) werden verschiedene Use Cases zur Eignung für Predictive Maintenance Strategien überprüft. Über ein Reifegradmodell wird dabei die Datenqualität bewertet im Detail bewertet und durch die Beschreibungen der einzelnen Reifegrade können direkt Verbesserungspotenziale abgelesen werden.
EINLEITUNG
Besonders durch die Digitalisierung wuchsen die Möglichkeiten zur Optimierung von Instandhaltungsorganisationen in den letzten Jahren stark, beispielsweise durch die Entwicklung der Predictive Maintenance (PdM) Strategie. Mit den Potenzialen stiegen jedoch auch die Anforderungen an die benötigten Daten. In diesem Beitrag wird ein Vorgehen zur Bewertung eines ausgewählten Use Cases hinsichtlich der theoretischen Umsetzbarkeit von PdM und zur Aufdeckung von Potenzialen in der Datenqualität in diesem Zusammenhang vorgestellt.
Predictive Maintenance wird als zustandsorientierte Instandhaltung gesehen, die aus Analysen oder bekannten Merkmalen und der Bewertung der wesentlichen Parameter die Degradation des Bauteils ableiten kann und Prognosen erstellen kann. (DIN EN 133606:2018) Mit Hilfe dieser Strategie kann vorhergesagt werden, wann das Bauteil ausfallen wird und wann es ausgetauscht werden soll.(Ran Y. et al., 2019) Eine Studie von Deloitte aus dem Jahr 2017 zeigt, dass mit einer Einführung von prädiktiver Instandhaltung die Betriebszeit von Anlagen, um 10 bis 20 %, erhöht werden kann, die Wartungskosten um 5 bis 10 % reduziert werden können und die Planungszeit um 20 bis 50 % reduziert werden kann.(Deloitte, 2017) Trotz der vielen Vorteile die eine prädiktive Instandhaltung mit sich bringt, treten bei der Einführung auch viele Herausforderungen auf, welche Projekte teilweise scheitern lassen, oder eine große Menge an Ressourcen dafür aufgebracht werden müssen. Diese Herausforderungen sind meist vielfältig und reichen von organisatorischen, kulturbedingten bis hin zu den datengetriebenen, wobei die kritischsten Schwierigkeiten aufgrund der benötigten Daten entstehen.(Tiddens W, 2018)
Anhand verschiedener Studien wurde nachgewiesen, dass viele Unternehmen größtenteils eine reaktive Instandhaltungsstrategie verfolgen und proaktive Strategien wie PdM meiden, obwohl der Nutzen solcher Strategien bereits bekannt ist.(Ylipää T., 2017) Ein Hindernis für die Implementierung tritt bereits in den ersten Schritten auf, Unternehmen folgen bei der Einführung oft keinem strukturierten oder standardisierten Vorgehen, wodurch wichtige Aspekte der Einführung ausgelassen oder vernachlässigt werden.(Veldman J., 2011) Komplexe Strukturen der realen Anlagensysteme stellen eine weitere Herausforderung dar.(Olde Keizer M. et al., 2011) Zu den technischen und datengetriebenen Schwierigkeiten zählen die Bestimmung der richtigen Komponenten, die Auswahl der geeigneten Messmethoden und die Verwendung der passenden Datenanalytikmodelle.(Selcuk S., 2017) Für die Entwicklung der richtigen Algorithmen werden meist Prozessdaten
der Anlagen, sowie Daten während eines Fehlers benötigt, um die Algorithmen für reale Situationen zu trainieren. Gerade die Daten von Fehlern sind oft nicht in ausreichender Qualität oder Quantität vorhanden.(Goyal D., 2015) Allgemein zählt zu den Herausforderungen im Umgang mit den Daten die Erfassung davon, die Analyse für weiterführende Entscheidungen und die notwendige Kompetenz der Mitarbeiter, damit der größtmögliche Nutzen generiert werden kann.(Stecki J. et al., 2013) Aufgrund der vielen Herausforderungen die mit einer Implementierung von PdM einhergehen und den damit verbunden Kosten, schrecken viele Unternehmen vor einer Einführung zurück.
Nachfolgend wird das angewandte Modell sowie die methodische Vorgehensweise näher beschrieben, bevor auf die Ergebnisse des untersuchten Use Cases eingegangen wird.
DQA – MODELL & METHODISCHE VORGEHENSWEISE
Angelehnt ist das folgend vorgestellte Assessment an das Reifegradmodell von Bernerstätter, welches die Wichtigkeit der Inputfaktoren für datenanalytische Anwendungen behandelt (Bernerstätter, 2019). Das Reifegradmodell, auf welchem das DQA basiert, besteht aus sechs Kategorien (Datenerfassung, -bereitstellung, -formate, -darstellung und -codierung, -umfang, -konsistenz) und vier Reifegraden (deskriptiv, diagnostisch, prognostisch, präskriptiv), welche nachfolgend beschrieben werden.
Die Reifegradkategorien:
Die Datenerfassung ist entscheidend für die Evaluation und die Planung des Einsatzes des erstellten Modells. Anhand dieser Kategorie wird bestimmt, ob eine spätere Implementierung des Modells möglich ist. Es wird bewertet, wie der Zustand eines Objektes, Prozesses oder der Umwelt in Form von Daten abstrahiert wird. Die Erfassung kann manuell oder automatisch, digital oder analog, sowie regelmäßig oder unregelmäßig erfolgen.
Die Datenbereitstellung ist wichtig für die Operationalisierungsphase des CRISP-DM. Die Art der Datenarchitektur und –modellierung spielt hier eine Rolle. Die Bereitstellung von Daten ist wesentlich für eine reibungslose Integration des Modells in den laufenden Geschäftsbetrieb. Schnittstellen und Medienbrüche führen bei der Datenübertragung zu Problemen und Leistungsverlusten. Ein spezielles Problem bilden proprietäre Schnittstellen, welche für Dritte nicht offen zugänglich sind. Echtzeitdatenübertragung vermeidet das Fehlen von Daten in bestimmten Momenten bzw. falscher Übertragung in das System durch nachträgliche Eingabe. In dieser Kategorie wird untersucht, wie aufgezeichnete Daten für die Weiterverarbeitung bereitgestellt werden.
In der Kategorie der Datenformate wird festgehalten, wie die Daten semantisch und syntaktisch abgebildet werden. Eine Kombination mehrerer Datenformate ist im Echtzeitbetrieb aufwendig aufzubereiten und daher für den Einsatz bei zeitkritischen Aufgabenstellungen unmöglich. Die Formalisierung und Standardisierung zwischen den Daten ist ein Grundstein für die maschinengestützte Auswertung der Daten.
Die Datencodierung behandelt das Skalenformat, in welchem Daten abgebildet sind bzw. ob sie strukturiert oder unstrukturiert vorliegen, geht also über die Betrachtung der Datenformate hinaus. Die gesamte Durchführungsphase wird durch diese Kategorie beeinflusst. Sind die Daten unstrukturiert (z.B. Texte in natürlicher Sprache), müssen Informationen aufwendig extrahiert werden, um sie für die spätere Modellierungsphase zugänglich zu machen. Für die Modellierung ist diese Kategorie wichtig, da unterschiedliche Skalenformate unterschiedliche Analysealgorithmen erlauben.
Der Datenumfang bzw. dessen Bestimmung ist besonders relevant für die Modellierung. Die Datenmenge erlaubt es maschinellen Lernalgorithmen allgemein gültige Muster zu erkennen. Ein geringer Datenumfang kann die Datenaufbereitung vor die Herausforderung stellen Daten oder Merkmale zusätzlich zu erzeugen. Für einfache Visualisierungen und manuell durchgeführte Analysen sind große Datenmengen weder nötig noch zielführend.
Die zeitliche Konsistenz schränkt den Einsatz von Methoden zur Darstellung von Sequenzen und Abläufen ein. Eine schlechte Konsistenz der Daten, speziell auf zeitlicher Ebene, erfordert unter Umständen aufwendige Aufbereitungsschritte, um die Konsistenz der Daten herzustellen. Grundvoraussetzung für die Abbildung der Realität ist das Vorhandensein eines Zeitstempels bzw. eine ausreichende Granularität, welche abhängig vom datenanalytischen Ziel definiert werden muss.
Die Reifegradstufen:
Die Reifegrade ergeben sich aus der Fähigkeit, datenanalytische Fragestellungen beantworten zu können. Sie spiegeln die Bandbreite des Datenmanagements und der Datenstruktur von der rudimentären oder nicht vorhandenen Digitalisierung bis hin zur vollständigen horizontalen und vertikalen Integration wider.
Reifegradstufe 1 (Deskriptive Reife) erfüllt nur die Voraussetzungen für deskriptive Analysen wie jene der deskriptiven Statistik, mit welcher die Frage „Was ist geschehen?“ beantwortet werden kann. Der Aufwand dieser Analysen (einfach numerisch oder visuell) ist gering, da keine großen Datenmengen vorliegen und diese manuell aufbereitet und ausgewertet werden können. Die Analysen in diesem Reifegrad dienen vorrangig der Berichterstellung.
Die Reifegradstufe 2 (Diagnostische Reife) ermöglicht das Finden von Gründen für bestimmte Ereignisse, da Muster und Zusammenhänge (Korrelationen und Kausalitäten) aufgezeigt werden können. In diesem Reifegrad kommen explorative Analysen der Statistik, die datengesteuert nach Mustern suchen, zum Einsatz. Strukturprüfende Verfahren wie jene des unüberwachten Lernens sind diesen zugeordnet und beantworten die Frage „Warum ist etwas geschehen?“.
Reifegrad 3 (Prognostische Reife) beschreibt den Übergang zur vollständigen horizontalen und verti-
Abbildung 1: Methodisches Vorgehen Datenqualitätsassessment
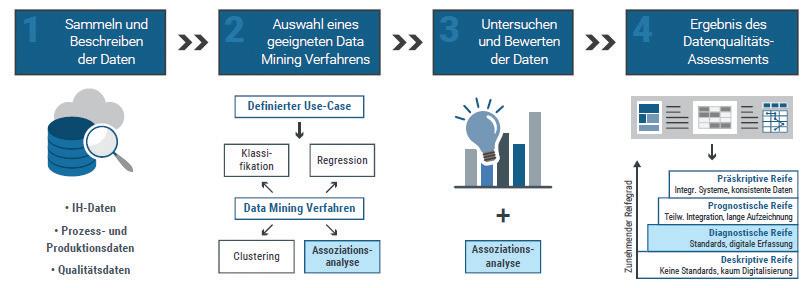
kalen Integration der IT-Systeme. Daten werden teilweise automatisch aufgezeichnet und Standards bei den Formaten und der Darstellung umgesetzt. Eine Analyse und die Erstellung von Prognosemodellen mit hoher Güte ist möglich, wenn auch die Zusammenführung von Daten aus unterschiedlichen Quellen mit erheblichem Aufbereitungsaufwand verbunden sein kann. Die Fragestellung „Was wird geschehen?“ kann in diesem Reifegrad beantwortet werden.
In Reifegrad 4 (Präskriptive Reife) ist die vollständige horizontale und vertikale Integration vollzogen. Ein durchgängiges Daten- und Informationsmanagement sichert Standards in der Datenaufzeichnung, den Formaten, der Darstellung sowie der Speicherung und Weitergabe. Die Analyse setzt eine Kombination komplexer Algorithmen ein, um die Frage zu beantworten „Was soll geschehen?“. Wie bei der prädiktiven Analyse werden Vorhersagen auf der Grundlage aktueller Parameter und verfügbarer historischer Daten durchgeführt. Im Gegensatz dazu berücksichtigt die prädiktive Analyse jedoch Beziehungen, für die es keine historischen Daten gibt, die aber eine definierte Wahrscheinlichkeit haben, dass sie auftreten werden. Die präskriptive Analyse verhilft einem System dazu, autonom Entscheidungen zu treffen.
Das methodische Vorgehen (Abbildung 1):
In einem ersten Schritt ist das Ziel hinter dem Data-Mining Vorhaben zu definieren. Es gilt einen businessrelevanten Use-Case inklusive der dafür notwendigen Daten zu schaffen, welche anschließend gesammelt und beschrieben werden müssen. Dabei ist sowohl das erforderliche Datenvolumen, die Datenformate, verfügbare Skalenniveaus, etc. zu achten. Diese Daten sind nach Überprüfen ihrer Quellen auf Konsistenz in eine Datenbank zu integrieren. In diesem Schritt kann es notwendig sein, Daten aus unterschiedlichen Quellen zu verknüpfen und Use-Case spezifische Datentabellen zusammenzustellen.
Nachfolgend ist der definierte UseCase detailliert aufzubereiten. So gilt es, im multidisziplinären Team Störungsmerkmale und -ursachen zu definieren und festzulegen, welche vorhandenen Daten diese bereits abbilden bzw. welche noch fehlen. Auf Basis des definierten Use-Cases wird eine passende Data Mining Methode gewählt. Die Wahl des Data Mining Verfahrens ist notwendig, weil diese die Anforderungen an die Datenreife erheblich beeinflussen kann.
Im nachfolgenden Schritt erfolgt die eigentliche Bewertung der Datenlage in Bezug zum definierten UseCase. Die vorhandenen Daten sowie die dahinterliegende Infrastruktur (z.B. Schnittstellen) werden mithilfe statistischer Methoden, bestimmter Visualisierungen und anderen Instrumenten der explorativen Datenanalyse untersucht und mittels des Datenreifegradmodells evaluiert. Innerhalb der sechs Reifegradkategorien werden sowohl qualitative Kriterien als auch quantitative Qualitätsmetriken, unter Berücksichtigung von Domänenwissen der Prozessexperten, zur Beurteilung eingesetzt.
Abschließend wird die Bewertung sowohl des Gesamtdatenbestandes als auch der einzelnen wesentlichen Datenquellen (Instandhaltungsdaten, Prozessdaten…) in das Reifegradmodell überführt und das Ergebnis hinsichtlich der Umsetzbarkeit des UseCases beschrieben. Dies bildet die Basis für weitere Entscheidungen, sei es eine Umsetzung des Projektes oder das Setzen von Maßnahmen zur Datenqualitätssteigerung oder gar eine Neuorientierung auf Grund einer für eine Umsetzung nicht ausreichenden Datenqualität.
ERGEBNIS
Bei der folgenden Ergebnisdarstellung wird ein Use Case gezeigt, der in Kooperation mit Pro2Future und der voestalpine Stahl GmbH durchgeführt wurde. Am Standort der voestalpine befindet sich eine Vielzahl an Kränen, die regelmäßig inspiziert werden müssen, ob sich an den Drahtseilen bereits Drahtbrüche gebildet haben, welche zu einer Ablegereife des Drahtseils führen. Um diese regelmäßigen Inspektionen zu verringern, sowie die Lebensdauer des Seils bestmöglich auszunutzen, wird das Ziel verfolgt, die Seilablegereife mit Hilfe von Predictive Maintenance vorherzusagen. Dadurch kann die Inspektionszeit der Mitarbeiter reduziert werden, sowie durch die längere, bzw. optimierte Nutzungszeit der einzelnen Seile, Kosten gespart werden. Ob dieser Use Case mit den gegebenen Bedingungen und Daten für den Einsatz von Pre-

Abbildung 2: Ergebnis Reifegradmodell
dictive Maintenance geeignet ist, wird mit Hilfe des Datenqualitätsassessments bewertet. Wie im vorherigen Kapitel beschrieben, muss mindestens ein Reifegrad der Stufe drei in allen Kategorien erreicht werden, um prognostische Methoden anwenden zu können, die für PdM eine Voraussetzung sind. Ein weiterer Vorteil des Datenqualitätsassessments ist der reduzierte Aufwand für die Ersteinschätzung des Use Casees, da nur wenig Ressourcen dafür in Anspruch genommen werden. Folgend werden die Ergebnisse des DQA für einen automatisch betriebenen Kran dargestellt.
Anhand der Bewertung mit dem Reifegradmodell und dem strukturierten Vorgehen konnten für die einzelnen Systeme, die für die Datenerfassung verwendet werden, die Reifegrade festgestellt werden. In Abbildung 2 stehen die unterschiedlichen Farben für die verschiedenen Systeme, die für den Use Case ausgewählt wurden und für die Bewertung herangezogen werden. Dabei sind die aufgezeichneten Messdaten, die direkt von der Sensorik des Krans aufgezeichnet werden, in blau eingezeichnet. Die Auftragsdaten, die für die Steuerung dienen und somit die gesamten Aufträge und Kranfahrten abbilden in violett. Als letztes werden die Daten der Instandhaltungstätigkeiten, wie Inspektionen, Reparaturen und Wartungen für den Use Case erfasst, diese Informationen sind in der Abbildung in gelb dargestellt.
Die erfassten Messdaten werden in einem hohen Level automatisch erfasst und befinden sich bei der Bewertung auf Reifegrad 4. Mit Reifegrad 3 wird die Bereitstellung bewertet, wodurch die erhaltenen Informationen für prognostische Modelle geeignet sind. Die Formate, sowie Codierung der Informationen aus diesem System sind in sehr guter Qualität vorhanden und dadurch auf Reifegrad 4, ebenso die Datenkonsistenz ist in diesem System auf diesem Level. Lediglich der Datenumfang wurde mit Reifegrad 1 bewertet, was auf die Speicherung der historischen Werte zurückzuführen ist. Ein sehr ähnliches Bild zeigen die Auftragsdaten der Steuerung, hier sind lediglich die Erfassung und die Konsistenz auf Reifegrad 3, was besagt, dass die Daten für prognostische Modelle geeignet sind.
Wie bei den Messdaten ist der Datenumfang mit dem Reifegrad 1 bewertet, allerdings nicht aufgrund der Datenhistorie, sondern der geringen Anzahl an unterschiedlichen Parametern. Bei den Instandhaltungsdaten befindet sich die Einstufung zwischen Reifegrad eins und zwei. Dies liegt hauptsächlich an der aktuell noch unzureichenden Erfassung der Tätigkeiten im Informationssystem. Des Weiteren ist eine Verknüpfung zu den anderen Systemen schwer, da die Aufzeichnungen der Tätigkeiten nachgelagert zur Durchführung geschehen und dadurch die zeitliche Zuweisung nur unter sehr hohem manuellem Aufwand gelingt. Die Informationen im Freitext der Instandhaltungsmeldungen, in welchem Details zur Durchführung hinterlegt werden, sind nur mit größerem Aufwand verarbeitbar.
Für eine erfolgreiche Einführung ist es notwendig, den Umfang der Daten in allen Systemen zu erhöhen, sodass die historischen Daten für ein Prognosemodell verwendet werden können. Die Instandhaltungsdaten müssen in allen Kategorien auf Reifegrad drei gebracht werden, um die Datenqualität für prognostische Modelle sicherstellen zu können. Dadurch soll eine Verbindung zwischen den Instandhaltungstätigkeiten und den Messdaten geschaffen werden. Anhand der strukturierten Bewertung im Reifegradmodell konnte festgestellt werden, was an den einzelnen Systemen noch verbessert werden muss, um ein Projekt zur Einführung einer Predictive Maintenance Strategie erfolgreich umsetzen zu können.
ZUSAMMENFASSUNG
Für eine erfolgreiche Einführung von Predictive Maintenance ist die Wahl des richtigen Pilotprojekts entscheidend. Mit der strukturierten Vorgehensweise des CRISP-DM und dem Datenqualitäts-Assessment für die Bestimmung der geforderten Datenqualität können die passenden Use Cases ausgewählt werden. Durch die Vorstudie können höhere Kosten für
Versuche vermieden werden und dank der danach besseren Umsetzbarkeit von Predictive Maintenance steigt die Akzeptanz und Motivation zur Durchführung weiterer Schritte in Richtung Industrie 4.0.
ACKNOWLEDGEMENT
Diese Forschungsarbeit wird in Zusammenarbeit mit Pro2Future und voestalpine Stahl GmbH durchgeführt. Diese Arbeit wurde von der FFG unterstützt, Vertrag Nr. 881844: "Pro²Future".
REFERENCES
Bernerstätter, R. (2019), Reifegradmodell zur Bewertung der Inputfaktoren für datenanalytische Anwendungen – Konzeptionierung am Beispiel der Schwachstellenanalyse. Dissertation. Montanuniversität Leoben. Deloitte (2017), Predictive Maintenance Taking pro-active measures based on advanced data analytics to predict and avoid machine failure DIN EN 13306:2018-02, Instandhaltung_- Begriffe der Instandhaltung; Dreisprachige Fassung EN_13306:2017. Goyal, D.; Pabla, B. S. (2015): Condition based maintenance of machine tools—A review. In: CIRP Journal of Manufacturing Science and Technology, Jg. 10 Nr., S. 24–35. Olde Keizer, M. C.A., Flapper, S. D. P.; Teunter, R. H. (2017): Condition-based maintenance policies for systems with multiple dependent components: A review. In: European Journal of Operational Research, Jg. 261 Nr. 2, S. 405–420. Ran, Y., Zhou, X., Lin, P., Wen, Y.; Deng, R. (2019): A Survey of Predictive Maintenance: Systems, Purposes and Approaches. Selcuk, S. (2017): Predictive maintenance, its implementation and latest trends. In: Proceedings of the Institution of Mechanical Engineers, Part B: Journal of Engineering Manufacture, Jg. 231 Nr. 9, S. 1670–1679. Stecki, J. S., Rudov-Clark, S.; Stecki, C. (2013): The Rise and Fall of CBM (Condition Based Maintenance). In: Key Engineering Materials, Jg. 588 Nr. , S. 290–301. Tiddens, W. (2018): Setting sail towards predictive maintenance: developing tools to conquer difficulties in the implementation of maintenance analytics. ISBN 9789036546034. Veldman, J., Klingenberg, W.; Wortmann, H. (2011): Managing condition-based maintenance technology. In: Journal of Quality in Maintenance Engineering, Jg. 17 Nr. 1, S. 40–62. Ylipää, T., Skoogh, A., Bokrantz, J.; Gopalakrishnan, M. (2017): Identification of maintenance improvement potential using OEE assessment. In: International Journal of Productivity and Performance Management, Jg. 66 Nr. 1, S. 126–143.
Autoren:
Dipl.-Ing. Philipp T. Kraker ist seit 2020 am Lehrstuhl für Wirtschafts- und Betriebswissenschaften der Montanuniversität Leoben als wissenschaftlicher Projektmitarbeiter im Bereich Anlagenwirtschaft und Qualitätsmanagement tätig. Davor studierte er Werkstoffwissenschaften an der Montanuniversität Leoben.
Dipl.-Ing. Florian Kaiser ist seit 2018 am Lehrstuhl für Wirtschafts- und Betriebswissenschaften der Montanuniversität Leoben als wissenschaftlicher Projektmitarbeiter im Bereich Anlagenwirtschaft und Datenanalytik tätig. Davor studierte er Petroleum Engineering an der Montanuniversität Leoben.

Dipl.-Ing. Philipp T. Kraker
wissenschaftlicher Projektmitarbeiter für Anlagenwirtschaft und Qualitätsmanagement am Lehrstuhl für Wirtschafts- und Betriebswissenschaften der Montanuniversität Leoben Dipl.-Ing. Florian Kaiser

wissenschaftlicher Projektmitarbeiter für Anlagenwirtschaft und Datenanalytik am Lehrstuhl für Wirtschafts- und Betriebswissenschaften der Montanuniversität Leoben
WING to your success
…wir sind für Sie garantiert von Nutzen … Gerade in Zeiten wie diesen stellen ein reizvoller Workshop, das Verteilen von lukrativen Flyern oder eine interessante Firmenpräsentation effiziente und kostengünstige Möglichkeiten zur Werbung für Unternehmen in Fachkreisen dar. Hervorzuheben ist der Zugang zur Technischen Universität als Innovations- und Forschungsstandort der besonderen Art, denn im Zuge von Bachelor- und/oder Masterarbeiten können Sie Studenten in Ideen für Ihre Firma miteinbeziehen und mit ihnen innovative Lösungen ausarbeiten. Nicht zuletzt wird auf diesem Weg auch für die Zukunft vorgesorgt. Denn schließlich sind es die heutigen Studenten der Technischen Universität, die morgen als Ihre Kunden, Händler oder Lieferanten fungieren. Mit WINGnet-Werbemöglichkeiten kann man diese nun schon vor dem Eintritt in das Berufsleben von sich und seiner Firma überzeugen und somit eine gute Basis für eine langfristige und erfolgreiche Zusammenarbeit schaffen. WINGnet Wien veranstaltet mit Ihrer Unterstützung Firmenpräsentationen, Workshops, Exkursionen sowie individuelle Events passend zu Ihrem Unternehmen. WINGnet Wien bieten den Studierenden die Möglichkeit- zur Orientierung, zum Kennenlernen interessanter Unternehmen und Arbeitsplätze sowie zur Verbesserung und Erweiterungdes universitären Ausbildungsweges. Organisiert für Studenten von Studenten.Darüber hinaus bietet WINGnet Wien als aktives Mitglied von ESTIEM (European Students of Industrial Engineering and Ma-
nagement) internationale Veranstaltungen und Netzwerke. In 24 verschiedenen Ländern arbeiten 66 Hochschulgruppen bei verschiedenen Aktivitäten zusammen und treten so sowohl untereinander als auch zu Unternehmen in intensiven Kontakt. Um unser Ziel - die Förderung von Studenten - zu erreichen, benötigen wir Semester für Semester engagierte Unternehmen, die uns auf verschiedene Arten unterstützen und denen wir im Gegenzug eine Möglichkeit der Firmenpräsenz bieten. Die Events können sowohl in den Räumlichkeiten der TU Wien als auch an dem von Ihnen gewünschten Veranstaltungsort stattfinden. Weiters können Sie die Zielgruppe individuell bestimmen. Sowohl alle Studienrichtungen als auch z.B. eine Festlegung auf Wirtschaftswissenschaftlichen Studiengängen ist möglich. Außerdem besteht die Möglichkeit eine Vorauswahl der Teilnehmer, mittels Ihnen vorab zugesandten Lebensläufen, zu treffen. Auf unserer Webseite http://www.wing-online.at/de/ wingnet-wien/ finden Sie eine Auswahl an vorangegangenen Events sowie detaillierte Informationen zu unserem Leistungsumfang WINGnet Wien: Theresianumgasse 27, 1040 Wien, wien@wingnet.at ZVR: 564193810
WINGbusiness Impressum




