

acceso a datos en aplicaciones web del entorno servidor


UF1845
José Ramón Santos Dios es diplomado en Ciencias Empresariales por la Universidad de Vigo, graduado superior en TIC por la Universidad de Santiago de Compostela y máster en Software Libre por la UOC.
Desde el año 2003 se ha dedicado a la docencia, impartiendo acciones formativas relacionadas con las Tecnologías de la Información y las Comunicaciones en las principales empresas de formación de la comunidad autónoma de Galicia y como Agente TIC para la red CEMIT de la Xunta de Galicia.
En la actualidad, combina su profesión de docente con la elaboración de contenidos didácticos adaptados a diferentes niveles formativos y la elaboración de manuales relacionados con certificados de profesionalidad, también el desarrollo del diseño y programación web ocupan parte de su actividad profesional.
Para ver su currículum profesional completo puede acceder a el enlace de la red Linkedin:
https://www.linkedin.com/in/santosdios/
Datos Del autor
Ficha
Acceso a datos en aplicaciones web del entorno servidor. Informática y comunicaciones.
1ª Edición
Certia Editorial, Pontevedra, 2022
Autor: Jose Ramón Santos Dios
Formato: 170 x 240 mm • 190 páginas.
Acceso A dAtos en AplicAciones web del entorno servidor. informáticA y comunicAciones
n o está permitida la reproducción total o parcial de este libro, ni su tratamiento informático, ni la transmisión de ninguna forma o por cualquier medio, ya sea electrónico, mecánico, por fotocopia, por registro u otros métodos, sin el permiso previo y por escrito de los titulares del Copyright.
Derechos reservados 2022, respecto a la primera edición en español, por Certia Editorial.
ISBN: 978-84-17328-82-5
Editor: Cenepo Consult, SLU
Depósito legal: PO 221-2022
Impreso en España - Printed in Spain
Certia Editorial ha incorporado en la elaboración de este material didáctico citas y referencias de obras divulgadas y ha cumplido todos los requisitos establecidos por la Ley de Propiedad Intelectual. Por los posibles errores y omisiones, se excusa previamente y está dispuesta a introducir las correcciones pertinentes en próximas ediciones y reimpresiones.
Fuente fotografia portada: Pixabay, autoriza a copiar, distribuir, comunicar publicamente la obra y adaptar el trabajo.
CON TECNOLOGÍAS WEB (RD 1531/2011, de 31 de octubre modificado por el RD 628/2013, de 2 de agosto)
Correspondencia con el Catálogo Modular de Formación Profesional Horas Unidades formativas H.CP Módulos certificado H. Q 60 UF1841: Elaboración de documentos web mediante lenguajes de marca 180
Programación
el entorno cliente 180 90 UF1842:
componentes software
mediante lenguajes de guión 30 UF1843: Aplicaciones técnicas
entorno cliente 90 UF1844: Desarrollo
aplicaciones
entorno servidor. 240
entorno servidor 240 90 UF1845:
aplicaciones
entorno servidor. 60 UF1846: Desarrollo de aplicaciones web distribuidas. 90 90 MF0493_3: Implantación de aplicaciones web en entorno internet, intranet y extranet 90 80 MP0391: Módulo de prácticas profesionales no laborales 510 Duración horas módulos formativos 590 Duración horas totales certificado de profesionalidad 510 Familia profesional: INFORMÁTICA
COMUNICACIONES Área profesional: Desarrollo
MF0491_3:
web en
Desarrollo y reutilización de
y multimedia
de usabilidad y accesibilidad en el
de
web en el
MF0492_3: Programación web en el
Acceso a datos en
web del
Y
FICHA DE CERTIFICADO DE PROFESIONALIDAD (IFCD0210) DESARROLLO DE APLICACIONES
9 INTRODUCCIÓN................................................................................. 15 Unidad didáctica 1 1. Modelos de datos ................................................................................ 17 1.1. Concepto de dato. Ciclo de vida de los datos ..........................................21 1.2. Tipos de datos ..............................................................................................22 1.2.1. Básicos .............................................................................................22 1.2.2. Registros 23 1.2.3. Dinámicos .......................................................................................24 1.3. Definición de un modelo conceptual........................................................24 1.4. Patrones .........................................................................................................25 1.5. Modelos genéricos 25 1.6. El modelo relacional ....................................................................................28 1.6.1. Descripción .....................................................................................28 1.6.2. Entidades y tipos de entidades .....................................................29 1.6.3. Elementos de datos. Atributos 30 1.6.4. Relaciones. Tipos, subtipos. Cardinalidad ..................................31 ÍnDice
10 1.7. Claves. Tipos de claves ................................................................................33 1.8. Normalización. Formas normales 34 1.9. Construcción del modelo lógico de datos ................................................38 1.10. Especificación de tablas .............................................................................39 1.11. Definición de columnas .............................................................................39 1.12. Especificación de claves 40 1.13. Conversión a formas normales. Dependencias ......................................41 1.14. El modelo físico de datos. Ficheros de datos .........................................41 1.15. Descripción de los ficheros de datos .......................................................42 1.15.1. Tipos de ficheros 43 1.15.2. Modos de acceso ............................................................................44 1.15.3. Organización de ficheros. .............................................................44 1.16. Transformación de un modelo lógico en un modelo físico de datos .47 1.17. Herramientas para la realización de modelos de datos 48 Unidad didáctica 2 2. Sistemas de gestión de bases de datos (SGBd) ................................. 51 2.1. Definición de SGBD ...................................................................................53 2.2. Componentes de un SGDB. Estructura ...................................................53 2.3. Gestión de almacenamiento .......................................................................55
11 2.4. Gestión de consultas....................................................................................56 2.5. Motor de reglas 57 2.6. Terminología de SGDB ..............................................................................57 2.7. Administración de un SGDB .....................................................................59 2.8. El papel del DBA .........................................................................................59 2.9. Gestión de índices 60 2.10. Seguridad ......................................................................................................61
Respaldos y replicación de bases de datos ..............................................62 2.12. Gestión de transacciones en un SGBD ...................................................63 2.12.1. Definición de transacción 64 2.12.2. Componentes de un sistema de transacciones ..........................65 2.12.3. Tipos de protocolos de control de la concurrencia ..................66
Recuperación de transacciones ....................................................67
Soluciones de SGBD 67
Distribuidas .....................................................................................67
Orientadas a objetos ......................................................................69 2.13.3. Orientadas a datos estructurados (XML) ...................................71
Almacenes de datos (data warehouses) 72
Criterios para la selección de SGBD comerciales ..................................74
2.11.
2.12.4.
2.13.
2.13.1.
2.13.2.
2.14.
2.15.
12 Unidad didáctica 3 3. Lenguajes de gestión de bases de datos. El estándar SQL .............. 75 3.1. Descripción del estándar SQL ................................................................ 79 3.2. Creación de bases de datos ...................................................................... 80 3.3. Creación de tablas. Tipos de datos ......................................................... 80 3.4. Definición y creación de índices. Claves primarias y externas 86 3.5. Enlaces entre bases de datos ................................................................... 87 3.6. Gestión de registros en tablas ................................................................. 89 3.6.1. Inserción ....................................................................................... 89 3.6.2. Modificación ................................................................................ 90 3.6.3. Borrado ......................................................................................... 91 3.7. Consultas .................................................................................................... 91 3.7.1. Estructura general de una consulta .......................................... 92 3.7.2. Selección de columnas. Obtención de valores únicos ........... 93 3.7.3. Selección de tablas. Enlaces entre tablas ................................. 94 3.7.4. Condiciones. Funciones útiles en la definición de condiciones .................................................................................. 95 3.7.5. Significado y uso del valor null ................................................. 97 3.7.6. Ordenación del resultado de una consulta .............................. 97 3.7.7. Conversión, generación y manipulación de datos .................. 98 3.7.8. Funciones para la manipulación de cadenas de caracteres ... 99
13 3.7.9. Funciones para la manipulación de números ......................... 102 3.7.10. Funciones de fecha y hora ......................................................... 103 3.7.11. Funciones de conversión de datos ........................................... 105 3.7.12. Consultas múltiples. Uniones (joins) ......................................... 106 3.8. Definición de producto cartesiano aplicado a tablas ........................... 107 3.9. Uniones de tablas (joins). Tipos: inner, outer, self, equi, etc. ............. 108 3.9.1. Subconsultas ................................................................................ 111 3.9.2. Agrupaciones ............................................................................... 112 3.9.3. Conceptos de agrupación de datos 112 3.9.4. Funciones de agrupación ........................................................... 112 3.9.5. Agrupación multicolumna ......................................................... 114 3.9.6. Agrupación vía expresiones ...................................................... 115 3.9.7. Condiciones de filtrado de grupos ........................................... 115 3.10. Vistas 116 3.10.1. Concepto de vista (view) ............................................................. 116 3.10.2. Criterios para el uso de vistas .................................................... 117 3.10.3. Creación, modificación y borrado de vistas ............................ 118 3.10.4. Vistas actualizables ...................................................................... 119 3.11. Funciones avanzadas 120 3.12. Restricciones. Integridad de bases de datos ......................................... 122 3.13. Disparadores ............................................................................................. 123 3.14. Gestión de permisos en tablas ............................................................... 126
14 3.15. Optimización de consultas ..................................................................... 127 Unidad didáctica 4 4. Lenguajes de marcas de uso común en el lado servidor .................. 131 4.1. Origen e historia de los lenguajes de marcas ........................................ 133 4.1.1. El estándar XML ......................................................................... 136 4.1.2. Características de XML .............................................................. 136 4.2. Partes de un documento XML: marcas, elementos, atributos, etc. 137 4.3. Sintaxis y semántica de documentos XML: documentos válidos y bien formados 137 4.4. Estructura de XML ................................................................................... 138 4.5. Esquemas XML: DTD y XML Schema ................................................ 139 4.6. Hojas de estilo XML: el estándar XSLT y XSL .................................... 143 4.7. Enlaces: XLL ............................................................................................. 145 4.8. Agentes de usuario: XUA ........................................................................ 146 4.9. Estándares basados en XML ................................................................... 146 4.10. Presentación de página: XHMTL .......................................................... 147 4.11. Selección de elementos XML: Xpath y XQuery ................................. 148 4.12. Firma electrónica: XML-Signature y Xades ......................................... 149 4.13. Cifrado: XML-Encryption ...................................................................... 150 4.14. Otros estándares de uso común ............................................................ 150
15 4.15. Análisis XML ............................................................................................ 151 4.15.1. Herramientas y utilidades de análisis ....................................... 152 4.15.2. Programación de análisis XML mediante lenguajes en servidor ......................................................................................... 153 4.16. Uso de XML en el intercambio de información ................................. 158 4.17. Codificación de parámetros .................................................................... 158 4.18. Ficheros de configuración basados en XML ....................................... 159 rESUMEn finaL .............................................................................. 161 actividadES .................................................................................... 163 aUtoEvaLUaciÓn finaL ............................................................. 177 SoLUcionES ..................................................................................... 183 BiBLioGrafÍa ................................................................................. 185
El manual «UF1845. Acceso a datos en aplicaciones web del entorno servidor» forma parte del módulo formativo «MF0492_3: Programación web en el entorno servidor», del Catálogo Nacional de Cualificaciones Profesionales, y pertenece al certificado de profesionalidad «IFCD0210: Desarrollo de aplicaciones con tecnologías web».
El manual tiene por objetivo aprender uno de los aspectos más importantes en el desarrollo de aplicaciones web como es el acceso y tratamiento de los datos persistentes en la aplicación. Para ello, revisaremos todos los aspectos relacionados con los gestores de bases de datos más utilizados en la web, concretamente la base de datos MySQL. A lo largo de los capítulos del presente manual trataremos además los diferentes aspectos de los lenguajes de servidor como PHP para acceder a estas bases de datos, procesar su información y mostrarla correctamente en la página web de la interfaz.
Por último, describiremos la sintaxis y los elementos básicos de los lenguajes de marcas en el lado del servidor destinados a la representación y almacenamiento de datos persistentes, así como sus diferentes aplicaciones.
Finalmente, encontraremos diferentes actividades y pruebas de evaluación para poner en práctica los contenidos aprendidos.
Este manual te permitirá adquirir las siguientes capacidades y criterios de evaluación:
• C1: Desarrollar componentes que permitan el acceso y la manipulación de las informaciones soportadas en bases de datos y otras estructuras.
o CE1.1 Crear componentes software utilizando objetos o componentes de conectividad específicos para acceder a informaciones almacenadas en bases de datos y otras estructuras.
o CE1.2 Integrar sentencias SQL en los componentes software para acceder y manipular la información ubicada en bases de datos.
UF1845. Acceso a datos en aplicaciones web del entorno servidor 17
introDucción
o CE1.3 En un supuesto práctico en el que se pide construir componentes de software que accedan a datos soportados en bases de datos u otras estructuras de almacenamiento, se pide:
Identificar los elementos y estructuras contenidas en una base de datos.
– Utilizar los objetos, conectores y middleware necesarios en la construcción del componente para realizar los accesos a los datos soportados en la base de datos u otras estructuras según especificaciones dadas.
– Realizar operaciones de definición y manipulación de informaciones soportadas en bases de datos mediante el lenguaje SQL.
o CE1.4 Determinar las características principales de un lenguaje estándar de marcas extendido para compartir información entre componentes software y bases de datos u otras estructuras.
o CE1.5 Integrar características de un lenguaje estándar de marcas extendido en el desarrollo de componentes software para compartir la información soportada en bases de datos u otras estructuras.
UF1845. Acceso a datos en aplicaciones web del entorno servidor
18
–
Modelos de datos
Contenido
1.1. Concepto de dato. Ciclo de vida de los datos
1.2. Tipos de datos
1.3. Definición de un modelo conceptual
1.4. Patrones
1.5. Modelos genéricos
1.6. El modelo relacional
1.7. Claves. Tipos de claves
1.8. Normalización. Formas normales
1.9. Construcción del modelo lógico de datos
1.10. Especificación de tablas
1.11. Definición de columnas
1.12. Especificación de claves
1.13. Conversión a formas normales. Dependencias
1.14. El modelo físico de datos. Ficheros de datos
1.15. Descripción de los ficheros de datos
1.16. Transformación de un modelo lógico en un modelo físico de datos
1.17. Herramientas para la realización de modelos de datos
19
UF1845. Acceso a datos en aplicaciones web del entorno servidor
U nidad
1
En este tema estudiaremos los conceptos más básicos relacionados con las bases de datos. En primer lugar, definiremos qué es una base de datos, cuáles son los elementos que la componen y la utilidad de estos elementos.
concepto:
Podemos definir una base de datos como una colección de datos persistentes, relacionados y estructurados a través de un elemento fundamental que son las tablas de datos.
Estas tres características de las bases de datos se concretan en:
• Persistentes: se almacenan en archivos y estos en equipos informáticos.
• relacionados: cooperan en la descripción de informaciones.
• Estructurados : se mantienen en estructuras de datos organizados (registros, tablas).
Pero, a partir de aquí, cuando nos refiramos a una base de datos estaremos haciendo referencia implícitamente a una base de datos digital, que debe estar gestionada por algún programa o grupo de programas, que denominaremos gestor de base de datos.
concepto:
Al conjunto de ambos conceptos se le denomina Sistema de Gestión de Bases de datos (SGBd): es un conjunto de datos relacionados entre ellos y un grupo de programas para tener acceso a esos datos, el principal objetivo es poder manejar gran cantidad de información de forma conveniente y eficiente.
Un SGBD es una aplicación que permite trabajar con una base de datos:
• Definir la información.
• Insertar la información.
• Eliminar la información. UF1845. Acceso a datos en aplicaciones web del entorno servidor 21
• Consulta la información.
• Ordenar la información.
• Filtrar la información.
ventajas de un SGBD:
• control centralizado. Un único SGBD, bajo el control de una persona o grupo, puede asegurar unos estándares de calidad de datos, aplicar ciertas restricciones de seguridad, solucionar las peticiones conflictivas entre varios usuarios y mantener así la integridad de los datos.Los datos pueden ser manejados de forma eficiente, controlada y a la vez flexible.
• a cceso directo a usuarios no cualificados . Casi todos los SGBD actuales presentan una interface de usuario a través de la cual usuarios no programadores pueden realizar sofisticados análisis, encargándose siempre el sistema de control inherente al SGBD de mantener la integridad y coherencia de los datos.
• Posibilidad de controlar la redundancia de datos. En los sistemas que acceden directamente a los ficheros de la base de datos es fácil que existan ficheros con datos duplicados. Un SGBD puede ser usado para monitorizar y reducir el nivel de redundancia.
• i nformes . Un SGBD suele proporcionar una interface de usuario a través de la cual podemos solicitar distintos tipos de informes para los datos almacenados.
desventajas de un SGBD:
• coste. El software y cualquier hardware asociado a un sistema de base de datos puede resultar extremadamente caro. En cualquiera caso siempre implica un coste adicional en el diseño del sistema.
• c omplejidad añadida . Un SGBD es siempre más complejo que un sistema de procesado de ficheros. Además, en teoría, cuanto más complejo es, más susceptible es de tener errores. en la práctica, existen sistemas comerciales libres de errores.
• riesgo centralizado. Al estar centralizados todos los datos y reducir
UF1845. Acceso a datos en aplicaciones web del entorno servidor
22
al mínimo su redundancia, el riesgo a tener un error en el sistema que deje corruptos los datos es mayor mientras está corriendo el sistema. Sin embargo, los backup’s y los procedimientos de recuperación de datos que facilitan los sistemas comerciales minimizan este tipo de riesgos.
1.1. concepto de dato. ciclo de vida de los datos
Como mínimo la base de datos tendrá que contener obligatoriamente una tabla de datos. Las tablas son los principales e imprescindibles objetos de las bases de datos, ya que estas contienen los conjuntos de datos con los que realizamos las operaciones a través del resto de los objetos de la base. Estos datos estarán estructurados en columnas verticales. Aquí definiremos los campos y sus características.
Estas tablas pueden estar relacionadas entre sí; es decir, los datos que las contienen pueden estar vinculados con los datos de otra tabla, por medio de su clave principal, existen varios tipos de relaciones posibles.
UF1845. Acceso a datos en aplicaciones web del entorno servidor 23


Desde el punto de vista de su vida útil, podemos encontrarnos con diferentes tipos de datos, desde datos constantes a lo largo de toda la vida del sistema de bases de datos, como por ejemplo el DNI de un usuario, hasta datos cambiantes a lo largo de determinados períodos, como sería el precio de un producto, hasta datos cambiantes con una gran frecuencia como la cantidad de pedidos de una tienda.
1.2. tipos de datos
Los tipos de datos definen la naturaleza de la información que contiene la base de datos, cada columna o campo de una tabla de nuestra base de datos puede ser de un tipo dependiendo de las características de la información que pretendemos almacenar en dicho campo.
Podemos clasificar las bases de diferentes maneras según como estén organizados estos tipos de datos, la más común es según su variabilidad, atendiendo a los procesos de recuperación y preservación de los datos, podemos hablar de tipos de datos estáticos y dinámicos
1.2.1. Básicos
Los datos básicos o estáticos, como su nombre indica, son de solo lectura. Es decir, de ellos se puede extraer información, pero no modificar la ya existente. Solamente en casos excepcionales se modificará la información de este tipo de datos.
Los tipos de datos básicos que nos podemos encontrar en una base de datos son:
• texto: para introducir texto o combinaciones de texto y números, así como números que no requieran cálculos, como los números de teléfono, hasta un máximo de 255.
• Memo: para introducir un texto extenso. Hasta 65.535 caracteres.
UF1845. Acceso a datos en aplicaciones web del entorno servidor
24
• numérico: datos numéricos utilizados en cálculos matemáticos.
• fecha/Hora: para introducir datos en formato fecha u hora.
• Moneda: para introducir valores de moneda y datos numéricos utilizados en cálculos matemáticos en los que están implicados datos que contengan entre uno y cuatro decimales.
• autonumérico: número secuencial (incrementado de uno a uno) único, o número aleatorio que Microsoft Access asigna cada vez que se agrega un nuevo registro a una tabla. Los campos autonuméricos no se pueden modificar una vez se han introducido en la tabla de datos.
• Sí/no: campo lógico. Este tipo de campo lo utilizamos solamente si queremos un contenido del tipo Sí/No, Verdadero/Falso, etc.
• Hipervínculo : texto o combinación de texto y números almacenada como texto y utilizada como dirección de hipervínculo.
1.2.2. registros
Las tablas son objetos fundamentales de una base de datos porque en ellas es donde se conserva toda la información o los datos.
concepto:
Una tabla consiste en una colección ordenada de datos organizados en «Campos» (columnas). Cada campo es un tipo de datos de naturaleza distinta y puede tener varios «Registros» (filas). En los registros se almacena información ycada registro está formado por uno o varios campos.
Los campos equivalen a las columnas de la tabla:
UF1845. Acceso a datos en aplicaciones web del entorno servidor 25
Un registro contiene datos específicos, como información acerca de un determinado empleado o un producto.
Un campo contiene datos sobre un aspecto del asunto de la tabla, como el nombre o la dirección de correo electrónico. Cada registro tiene un valor de campo.
1.2.3. dinámicos
Los datos de tipo dinámico manejan procesos de actualización, reorganización, añadidura y borrado de información. Este tipo de datos son generados por algún tipo de operación sobre el registro de los datos. Por ejemplo, podríamos tener una función fecha actual que registrara cada día la fecha actual del sistema para realizar cálculos como la edad del usuario en base a su fecha de nacimiento. Otra manera de generar datos dinámicos es por medio de lenguajes de programación del servidor como PHP que posteriormente volcaría los resultados al lenguaje SQL para finalmente almacenar el dato en el SGBD.
1.3. definición de un modelo conceptual
Un modelo de datos consiste en un conjunto de herramientas conceptuales destinadas a la descripción de los datos y las relaciones entre los mismos dentro
UF1845. Acceso a datos en aplicaciones web del entorno servidor

26
de un sistema de gestión de base de datos. Esta descripción de los datos incluye la semántica, restricciones, relaciones entre estos, etc.
1.4. Patrones
Los patrones de bases de datos permiten realizar sistemas de almacenamiento con mayor fortaleza, asegurando un resultado correcto a partir de modelos genéricos preestablecidos. Suelen incluir una serie de procedimientos con soluciones reutilizables para diferentes casos con condiciones similares dentro de un contexto dado. Estos patrones de diseño pueden estar orientados para diferentes aspectos, procedimientos o tipos de sistemas de bases de datos, los más comunes son los patrones de bases de datos orientadas a objetos, también podemos encontrar patrones para la creación de tablas, relaciones, almacenamiento jerárquico de datos, etc.
1.5. Modelos genéricos
Existen diferentes tipos de bases de datos cada una con su propio modelo, que define la manera en la que los datos están estructurados, los modelos más habituales que podemos encontrarnos son el modelo plano, modelo jerárquico, modelo relacional y modelo de red.
Los modelos de base de datos planos solamente disponen de dos dimensiones de datos, esta estructura plana se compone de una sola columna de información de un tipo.
Por ejemplo podemos disponer de un modelo plano de DNI de usuarios, con una fila por cada DNI de usuario, de la siguiente manera:
UF1845. Acceso a datos en aplicaciones web del entorno servidor 27
DNI
52459051Y
76516914P
52454597S
76965529P
52933743W
Las ventajas de utilizar un modelo plano es que los datos se almacenan en un solo lugar mediante una estructura simple, por lo que es la fórmula más adecuada para las bases de datos que tienen pocos requisitos de almacenamiento. Las desventaja es obvia ya que no permiten el almacenamiento de estructuras de datos complejas.
El modelo jerárquico organiza los datos mediante una estructura de árbol, separando dichos datos en entidades que se relacionan entre ellas. Cada entidad contiene un grupo de datos agrupados.

El modelo jerárquico permite una relación individual entre cada una de las entidades, es decir la relación de uno a uno del modelo E-R, en el que las entidades dependientes no son más que una concreción de las entidades de las que dependen. Por el contrario, no permite el resto de las relaciones así que no nos permite establecer el modelo E-R completo.
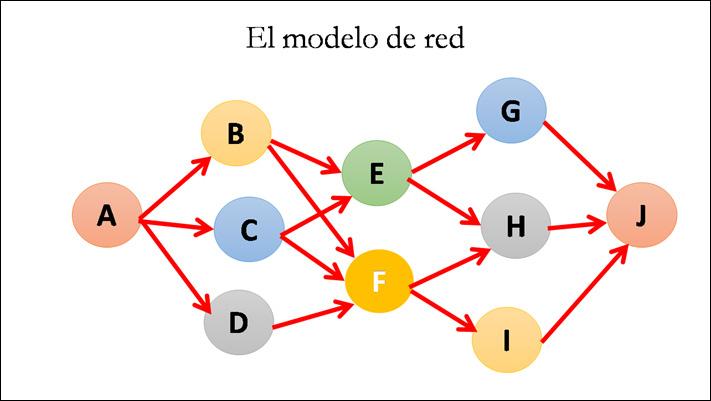
En el modelo de red, las entidades están comunicadas entre si mediante enlaces de un registro a otros, de manera que se van vinculando los datos en forma de red. Normalmente este tipo de redes suele utilizarse para un conjunto de información relacionada de diferente naturaleza.
UF1845. Acceso a datos en aplicaciones web del entorno servidor
28
La manera de relacionar datos del modelo en red es más desarrollada que la del modelo jerárquico ya que nos permite establecer varias relaciones padrehijo manteniendo la integridad de los datos. De esta forma, se eliminan tablas redundantes, lo que mejora la eficiencia y rendimiento general del sistema.
El modelo relacional es el modelo más comúnmente aceptado hoy en día para almacenar y gestionar información en bases de datos. Al igual que los anteriores modelos, la información es almacenada en tablas o entidades que a su vez pueden contener registros con diferentes campos. Las entidades pueden estar relacionadas entre ellas, esta relación se establece por alguno de los campos de la entidad.
Cada entidad lleva un tipo especial de campo llamado clave principal que identifica de manera única el conjunto de registros de la entidad.
El modelo relacional es un estándar ampliamente utilizado en la actualidad, a diferencia del modelo jerárquico no es necesario acceder desde la raíz hacia abajo por lo que permite más flexibilidad. El modelo requiere de menor uso de memoria y recursos al no existir la duplicidad de datos.
El concepto del modelo orientado a objetos es similar a la programación orientada a objetos, de hecho se suele utilizar con este tipo de lenguajes de programación.
Los objetos consisten en entidades independientes categorizadas bajo una clase que define el tipo de datos que utilizará y sus métodos de procesamiento. Estas clases intercambian los datos entre sí mediante los métodos predefinidos.
UF1845. Acceso a datos en aplicaciones web del entorno servidor 29
Las clases permiten implementar rápidamente sus propiedades mediante la herencia que transmite las propiedades de una clase a otra, de esta manera se pueden agrupar clases con características similares. Esto reduce la redundancia de datos y código y permite un mantenimiento más simplificado de la estructura de datos.
Los modelos multidimensionales de las bases de datos representan cubos de datos que representan diferentes dimensiones de los datos, combinando las características de las beses de datos jerárquicas y las relacionales.
El tipo de modelo optimizado suele responder de manera más rápida a las consultas debido a su indexación multidimensional que permite un procesamiento de datos más eficaz.
El modelo objeto-relacional consiste en una base de datos relacional combinada con conceptos orientados a objetos como las clases, herencia y polimorfismo, y trabaja de manera similar a las bases de datos relacionales.
El modelo abarca lo mejor de los anteriores modelos, el relacional y orientado a objetos.
1.6. El modelo relacional
El modelo relacional fue ideado por IBM para obtener grupos de datos de un conjunto más grande, utilizando un proceso llamado normalización en el que se depuraban los datos duplicados. En los siguientes años se empezó a utilizar el modelo cada vez más por parte de otros desarrolladores hasta hacerse tan popular que la mayoría de las bases de datos de hoy en día siguen ese modelo.
1.6.1. descripción
El modelo Entidad-Relación consiste en un método de diseño para implementación de bases de datos.
La implementación del modelo relacional persigue una serie de objetivos:
UF1845. Acceso a datos en aplicaciones web del entorno servidor
30
• Uniformidad: la estructura lógica siempre debe producir los mismos resultados en la implementación de la base de datos, generando las mismas tablas sea cual sea el gestor que estemos utilizando.
• independencia física: separando la manera de almacenar los datos en el hardware del modelo conceptual del sistema, de esta manera podemos modificar el modelo conceptual independientemente del hardware que estemos utilizando.
• independencia lógica: la base de datos debe ser independiente de su marea de acceder a ella por medio de aplicaciones externas, por lo que no debemos modificar el sistema de bases de datos dependiendo de su acceso a ella.
La representación del modelo relacional se realiza a través de diagramas por medio del modelo Entidad-Relación, y comprende los siguientes elementos:
1.6.2. Entidades y tipos de entidades
concepto:

La entidad es un elemento que representa objetos reales o abstractos con una serie de características que los diferencian de otras entidades.
En el diagrama E-R la entidad se representa mediante un rectángulo con su nombre, cuando se implementa en una base de datos la entidad se convierte en una tabla.
Las entidades deben tener una serie de características formales asociadas:
• Cada entidad debe tener un nombre diferente.
• Cada entidad debe tener una serie de datos agrupados bajo el mismo
UF1845. Acceso a datos en aplicaciones web del entorno servidor
31
concepto que los relaciona.
Los tipos de entidades o tablas que podemos encontrarnos son los siguientes
• Persistentes : consisten en entidades permanentes que definen la estructura del modelo relacional y por lo tanto de la base de datos.
• temporales: son entidades creadas temporalmente tanto por el sistema o por el usuario para registrar datos de tipo temporal, o copias de respaldo.
1.6.3. Elementos de datos. atributos

Los atributos son los elementos que definen las características o propiedades de las entidades, cada entidad tendrá entonces sus propios atributos. Estos pueden ser de diferentes tipos (numéricos, texto, fecha, etc.).
Cuando se implementa el modelo en la bases de datos, los atributos se corresponden con las columnas de la tabla. En el modelo E-R los atributos se representan con círculos que están conectados a su entidad.
El conjunto de elementos representados por los diferentes atributos y que constituyen una fila de la tabla de datos se denomina tupla. Cada tupla se debe corresponder con un elemento real.
Los atributos de las entidades a su vez deben tener una serie de características:
• El orden de los atributos no importa.
• Cada atributo tiene un nombre distinto en cada tabla, aunque puede
UF1845. Acceso a datos en aplicaciones web del entorno servidor
32
coincidir en tablas distintas.
• Cada tupla es única (no hay tuplas duplicadas).
• Cada atributo de la tabla solo puede tener un valor en cada tupla.
El dominio está formado por un conjunto de valores del mismo tipo que hace referencia a todos los posibles valores que puede tener un determinado atributo. La diferencia entre los conceptos de tipo de dato y dominio es que el segundo además de expresar el tipo de datos que puede contener el atributo define los valores válidos para ese dominio.
Por ejemplo, en el caso de el atributo fecha de nacimiento, el tipo de dato sería fecha, mientras que el dominio sería una fecha válida y lógica, no tendría sentido por ejemplo utilizar una fecha del pasado para usuarios registrados en la actualidad.
Dos atributos diferentes podrían tener el mismo dominio.
1.6.4. relaciones. tipos, subtipos. cardinalidad concepto:

La relación es el elemento que permite definir el tipo de dependencia que se da entre los datos de las entidades, compartiendo ciertos atributos entre ellos.
Por lo tanto, la relación representará una interdependencia entre los datos que se da en el mundo real y se representa mediante un rombo en el diagrama
33
UF1845. Acceso a datos en aplicaciones web del entorno servidor
E-R. Existen tres tipos de relaciones, cada una se implementará en la base de datos de diferente manera como veremos más adelante.

Para explicarlo de una manera más práctica vamos a ver un pequeño ejemplo de una organización que debe gestionar un conjunto de coches y a sus propietarios. En nuestro ejemplo, por lo tanto, tendremos dos entidades, la entidad coche y la entidad propietario. Las entidades se relacionan mediante una acción definida en la relación, es decir, «un propietario posee un coche».
En la estructura de cualquier base de datos encontramos principalmente tres tipos de relaciones que se describen del siguiente modo:
• relación Uno a Uno: no es un tipo de relación muy habitual en las bases de datos. A efectos prácticos quiere decir que un registro amplía su información en otra tabla. En realidad, podríamos ampliar estos campos en una sola tabla pero este tipo de relación nos permite ampliar los campos de cada uno de los registros en otras tablas. Para establecer esta relación debe haber una clave principal idéntica en cada una de las dos tablas.
Ejemplo: Tenemos en una tabla los datos personales de personas (alumnos), y en otra tabla datos más concretos sobre estos alumnos, como datos de encuestas personales sobre gustos, aficiones, etc.
• relación Uno a varios: establece que un registro de una de las tablas está relacionado con varios registros de la otra tabla. Para establecer esta relación debemos duplicar la clave principal de la entidad «uno» en la entidad «varios», como un campo normal, pero del mismo tipo.
Ejemplo: Disponemos de una tabla con una lista de profesores y otra tabla con los departamentos, cada profesor puede pertenecer a un solo
UF1845. Acceso a datos en aplicaciones web del entorno servidor
34
departamento, un departamento puede tener varios profesores.
• relación varios a varios: establece que varios registros de una tabla están relacionados con varios registros de la otra. Para establecer esta relación debemos duplicar las claves principales de las entidades «varios» en una nueva entidad (tabla), además de su propia clave principal.
Ejemplo: Tenemos una tabla de alumnos y otra tabla de cursos, cada alumno puede estar matriculado en varios cursos, un curso puede tener varios alumnos.
La cardinalidad hace referencia al número de tuplas de una relación, o número de filas de la tabla que la define. Hay tablas que pueden tener una enorme cardinalidad: cientos, miles e incluso millones de filas.
1.7. claves. tipos de claves
concepto:
Una clave consiste en uno o varios atributos que identifican inequívocamente cada tupla de una entidad o relación. Es decir columnas cuyos valores no se repiten en ninguna otra fila de esa tabla.
Podemos encontrarnos varios tipos de claves:
• clave candidata: cualquier atributo o conjunto de atributos que cumplan la definición de clave, es decir que puedan identificar de manera única los registros de una tabla de datos, por lo que nos sirve de identificador de registros de forma que con esta clave podamos saber sin ningún tipo de error el registro al cual identifica, la clave principal debe cumplir dos condiciones:
o El campo clave principal siempre deberá contener un valor obligatoriamente.
o Todos los registros del campo clave principal deben ser únicos, no
UF1845. Acceso a datos en aplicaciones web del entorno servidor 35
se puede repetir el mismo valor en dos registros distintos.
Toda tabla, en el modelo relacional, debe tener al menos una clave candidata, pero puede haber muchas más.
• clave principal o primaria: es la clave candidata que se escoge como identificador de la tabla, en determinadas ocasiones podemos crear un nuevo atributo para utilizarlo como clave primaria. El tipo de dato autonumérico cumple estos dos requisitos, un campo que se irá incrementando en valores numéricos enteros.
• clave alternativa: se denomina a cualquier clave candidata que no se ha elegido como primaria.
• clave externa o secundaria: en una relación, es la clave con la que se relaciona una tabla con otra.
1.8. normalización. formas normales
concepto:
La normalización consiste en un proceso que se realiza en las bases de datos para aplicar una serie de reglas a las relaciones y restricciones de las entidades.
La normalización implica las siguientes ventajas en una base de datos.
• Proteger la integridad de los datos.
• Evitar que haya redundancia de datos.
• Disminuir la probabilidad de que se den problemas de actualización de datos.
Alguna de las formas normales hace referencia al concepto de dependencia funcional, que se trata de una conexión entre uno o más atributos por la que los valores de uno dependen de otro, por ejemplo como es el caso de los atributos
UF1845. Acceso a datos en aplicaciones web del entorno servidor
36
EDAD y FECHA DE NACIMIENTO.
Este tipo de dependencia puede ser de diferentes tipos:
• dependencia total: cuando un atributo depende totalmente de otro y de ninguno mas.
• dependencia Parcial: cuando un atributo depende de varios atributos.
• dependencia transitiva: cuando un atributo depende de otro del que depende a su vez un tercero.
Las formas normales especifican una serie de características para que una tabla esté normalizada. Para ello, tienen estar aplicadas al menos las tres primeras formas normales. De esta manera, una base de datos estará normalizada si todas sus tablas están en forma normal.
Primera forma normal (1fn): la tabla no debe tener grupos repetitivos.
En el siguiente ejemplo, tenemos una tabla de estudiantes se presenta un grupo repetido
cod_estudiante nombre apellido1 apellido2 estudios
1 Ramón Marcos Serra Comercio
2 Adela Santos Castro Matemáticas Lengua
Como podemos observar en la fila de la alumna Adela tenemos un valor repetido para el campo estudios lo cual incumple la Primera Forma Normal.
La manera correcta de construir esta tabla es la siguiente:
cod_estudiante nombre apellido1 apellido2 estudios
1 Ramón Marcos Serra Comercio
2 Adela Santos Castro Matemáticas
3 Adela Santos Castro Lengua
De este modo los estudios están separados en 2 tuplas, lo que hace cumplir con la 1FN.
37
UF1845. Acceso a datos en aplicaciones web del entorno servidor
Segunda forma normal (2fn): se cumple cuando la tabla está en 1FN y además cada atributo que no sea clave depende funcionalmente respecto de cualquiera de las claves.
Toda la llave primaria debe hacer dependiente al resto de atributos, si hay atributos que dependen solo de parte de la llave primaria, entonces esa parte de la llave y esos atributos formarán otra tabla.
En el siguiente ejemplo disponemos de los datos de una serie de alumnos en la tabla Titulación:
ID código curso nombre apellido1 apellido2 nota
142343 36
223423 38
324232 21
453453 11
566544 24
655444 26
Ramón Marcos Serra 5
Adela Santos Castro 7
Carlos Martínez Juárez 4
Sandra Vázquez Pereira 8
Izan Mancho Pérez 9
Petra Pacheco Castelo 9
Suponiendo que el conjunto de ID y Código de Curso formen una clave primaria para esta tabla, solo la nota tiene dependencia funcional completa de estos datos, mientras que el nombre y el apellido dependen únicamente del ID, no de toda la clave primaria.
Para pasar este caso a la 2 FN debemos desglosar los datos en dos tablas diferenciadas:
Tabla Alumnos:
ID nombre apellido1 apellido2
142343 Ramón Marcos Serra
223423 Adela Santos Castro
324232 Carlos Martínez Juárez
453453 Sandra Vázquez Pereira
UF1845. Acceso a datos en aplicaciones web del entorno servidor
38
566544 Izan Mancho Pérez
655444 Petra Pacheco Castelo
Tabla Notas:
Ahora solo la nota depende totalmente de la clave primaria en la tabla Notas, la tabla Alumnos tiene el Nombre y Apellido, que existe una dependencia completa sobre el ID de alumno.
tercera forma normal (3fn): se cumple cuando una tabla está en 2FN y además ningún atributo que no sea clave depende funcionalmente de atributos que no son clave. No debe haber dependencias entre los mismos atributos.
Como ejemplo disponemos de los siguientes datos de usuarios:
ID nombre apellido1 apellido2 cod Postal Provincia
142343 Ramón Marcos Serra 15960 Ribeira
223423 Adela Santos Castro 15438 Castellón
324232 Carlos Martínez Juárez 14521 Valencia
453453 Sandra Vázquez Pereira 15811 Palencia
566544 Izan Mancho Pérez 14524 Oencia
En esta tabla la provincia depende funcionalmente del código postal, lo que hace que no esté en 3FN. Para solucionarlo:
Tabla Usuarios:
UF1845. Acceso a datos en aplicaciones web del entorno servidor 39
ID código curso nota 142343 36 5 223423 38 7 324232 21 4 453453 11 8 566544 24 9 655444 26 9
142343 Ramón Marcos Serra 15960
223423 Adela Santos Castro 15438
324232 Carlos Martínez Juárez 14521
453453 Sandra Vázquez Pereira 15811
566544 Izan Mancho Pérez 14524 Tabla
Ahora la provincia no está en la tabla de usuario y está en la tabla provincia, donde hay una depende completa con el Cód. Postal de la tabla.
1.9. construcción del modelo lógico de datos
El modelo lógico de datos contiene una serie de conceptos que nos permiten realizar la abstracción del sistema de datos por parte de la organización y sus necesidades para recopilar y manejar estos datos. Por lo tanto, se trata de un diseño conceptual para representar la manera de utilizar de la forma más eficiente los datos de la organización, definiendo como se conectan entre sí, cómo se procesan y se almacenan dentro del sistema y dando como resultado un esquema lógico de la gestión de los datos.
Este esquema lógico describirá detalladamente los datos independientemente de cómo se implementarán físicamente en la base de datos.
UF1845. Acceso a datos en aplicaciones web del entorno servidor
40 ID nombre apellido1 apellido2 cod Postal
Provincias: cod Postal Provincia 15960 Ribeira 15438 Castellón 14521 Valencia 15811 Palencia 14524 Oencia
Las características de un modelo lógico de datos incluyen:
• Cada una de las entidades con sus atributos.
• Las relaciones entre estas entidades.
• Las claves que relacionan estas entidades, llamadas claves externas.
• La normalización de las entidades y sus relaciones.
El modelo lógico de datos se realiza en los siguientes pasos:
1. Especificación de las claves primarias para todas las entidades.
2. Establecer las relaciones entre las entidades.
3. Establecer todos los atributos para cada una de las entidades.
4. La normalización de todos los elementos del modelo.
1.10. Especificación de tablas
Como hemos visto anteriormente, según el modelo lógico de datos disponemos de una serie de entidades relacionadas entre ellas. Cada entidad dará como resultado una tabla en su implementación del modelo lógico cuando lo convertimos al modelo físico y cada entidad tendrá una serie de atributos que serán implementados en campos o columnas de la tabla. Estos atributos tendrán una serie de restricciones especificadas previamente en el modelo lógico, además deberá tener una clave principal.
1.11. definición de columnas
Las columnas de la tabla de datos se corresponderán con cada uno de
UF1845. Acceso a datos en aplicaciones web del entorno servidor
41
los atributos de las entidades del modelo E-R. Estas columnas deben llevar definidos el tipo de datos que albergarán siendo estos de diferente naturaleza, como los datos de tipo texto, numéricos, fecha/hora, hipervínculos, etc.
1.12. Especificación de claves
Una base de datos debe reflejar la realidad que pretende representar mediante el conjunto de datos que contiene. Esto significa que la extensión de las relaciones, es decir, las tuplas que contienen las relaciones, deben tener valores que reflejen la realidad correctamente, a este concepto se le denomina restricciones de integridad.
Las restricciones de integridad asociadas a las tuplas de una relación establecen que los datos que se ingresen a las tablas en las tuplas deben tener un sentido lógico representativo, algo de acuerdo con la realidad. Por ejemplo, en el caso de registrar la edad, esta debe cumplir unas condiciones, no puede ser menor que cero ni superior a la edad máxima contemplada.
0 ≤ edad ≤ 120.
Algunas restricciones de integridad son específicas para una base de datos concreta y para unos usuarios concretos. Estas se llaman restricciones de integridad de usuario, estas restricciones pueden ser irrelevantes para otras bases de datos.
Por su parte, las reglas de integridad de modelo tratan de condiciones más generales, y se deben cumplir en cualquier base de datos que siga el modelo, por lo que no se deben definir para cada base de datos concreta sino que se consideran preestablecidas para un modelo determinado.
Las reglas de integridad del modelo relacional son las siguientes:
• Unicidad de la clave primaria: Establece que toda clave primaria que se elija para una relación no debe tener valores repetidos.
• integridad de entidad de la clave primaria: Los atributos de la clave
42
UF1845. Acceso a datos en aplicaciones web del entorno servidor
primaria de una relación no pueden tener valores nulos.
• integridad referencial: En el caso de una relación donde tenemos a dos entidades implicadas por sus claves, esta regla determina que todos los valores que toma una clave foránea deben ser valores nulos o valores que existen en la clave primaria que referencia, ya que si el valor de una clave foránea no estuviera presente en la clave primaria correspondiente presentaría una referencia incorrecta.
1.13. conversión a formas normales. dependencias.
Formas normales y dependencias son conceptos ligados, y ambos se han tratado en profundidad en el apartado «1.8. Normalización. Formas normales». Si necesitas repasar estos términos, puedes volver atrás para releer el apartado y los ejemplos que en él se incluyen.
1.14. El modelo físico de datos. ficheros de datos
Dentro de una base de datos podemos diferenciar dos aspectos de su estructura que son la estructura lógica y la física. Como hemos visto, la estructura lógica hace referencia al modelo de abstracción de datos, un modelo conceptual que nos ayuda a planificar y desarrollar posteriormente la base de datos. Por su parte, la estructura física se corresponde con esa implementación por medio de una serie de ficheros del sistema operativo.
El modelo físico está compuesto por una arquitectura que suele tener tres componentes básicos:
• Estructura de memoria : es donde se almacena toda la información
UF1845. Acceso a datos en aplicaciones web del entorno servidor 43
de control que esté utilizando en cada momento el gestor de la bases de datos mediante el uso de instancias que se generan cuando el gestor necesita procesar alguno de los datos del sistema.
• c onjunto de procesos : comprenden todas las rutinas de órdenes o comandos que se ejecutan para permitir el acceso a la gestión de datos. Estos datos se cargarán en memoria y serán enviados finalmente a los usuarios, desde este punto de vista podemos clasificarlos en:
o Procesos de usuarios : se establece cuando el usuario crea una conexión con la base de datos mediante la correspondiente aplicación. Estos procesos no se comunican directamente con la bases de datos y necesitan de los procesos de servidor para ello.
o Procesos de servidor: es el proceso que se encarga de comunicar el proceso de usuario con la instancia de la base de datos, por medio del código SQL.
o Procesos en background o segundo plano: son los procesos del sistema encargados de realizar las funciones necesarias para que el resto de los procesos se lleven a cabo, como la monitorización y control de recuperación de los errores, volcado de datos, etc.
• Sistema de ficheros: los ficheros son los encargados de almacenar la información de la base de datos y todos los procesos que estos llevan asociados para su correcta gestión.
1.15. descripción de los ficheros de datos
La documentación estándar que se utilizará para el modelo de arquitectura física será la siguiente:
• Diagrama de la estructura física de la base de datos donde especifiquemos cada uno de los ficheros físicos junto con el espacio de la memoria con que cuentan cada uno de ellos.
UF1845. Acceso a datos en aplicaciones web del entorno servidor
44