CyrusOne’s CEO
On keeping customers happy amid executive turnover
NorthC’s CEO
On how data centers can be welcomed by locals
Mission Apollo
An exclusive look at Google’s networking revolution
Modernizing VFX

How cloud and Edge compute is changing movie making

The Business of Data Centers

A new training experience created by

6 News
Data4 sold, taking on AI with airstrikes, robot dogs, and long-lived servers
12 Generative AI

The future of data centers, compute & networking, cloud, supercomputers, and more in our largest feature ever


26 CyrusOne’s CEO - Eric Schwartz

Talking data center diplomacy
29 NorthC’s CEO - Alexandra Schless
Conversational data centers
33 The Enterprise Edge supplement
From Mars bars, to ships at sea, to video games, the Edge is finding a home

49 Building APAC’s Digital Edge
A new entrant hopes to build a local player in the competitive APAC region
52 Google’s networking revolution
An exclusive look at Mission Apollo, a major optical circuit switch effort
56 Cloud and Edge come for VFX
How compute advances are changing Hollywood’s biggest projects
59 Everything you need to know about PPAs
How to be green while keeping the lights on
64 A new land for energy & data
Understanding the opportunity at the base of off-shore wind turbines

67 Building smarter supply chains
Google’s head of data center construction on his new venture
70 Get off of the cloud
Repatriation and the end of cloud-only
75 Fiber shortages ease
How telcos adapted to the pandemic fiber crunch
77 Putting Open RAN through its paces
How real is O-RAN?
80 Op-ed: Made by humans
Every word, every thought, every typo in this mag was made by a human. Thank you for supporting our corporeal forms
ISSN 2058-4946 Contents April 2023 Issue 48 • April 2023 | 3 12 64 49 56 75 26

www.amcoenclosures.com/data 847-391-8100 MADE IN THE USA
IS OUR STANDARD. an IMS Engineered Products Brand
OF CONFIGURABLE RACKS AVAILABLE IN TWO WEEKS OR LESS
CUSTOMIZATION
MILLIONS
From the Editor
How will AI reshape our industry?
Revolutions aren't always so revolutionary. Mobile phones and the Internet changed our lives.
Cryptocurrency, and the metaverse, not so much.
Each wave of technology has a wave of hype, followed by hard implementation work - and then actual applications.
AI is different, because all three of these things are happening at once. That's why, in this issue of DCD magazine, our largest ever article investigates the infrastructure behind the latest wave of AI (p12).
Can we afford it?
People developing this wave of AI, and the people working out ways to employ it, seem to care little for the financial, technological and environmental cost.
It all happens in the cloud, and the big players are increasingly secretive about the demands their technology make.
OpenAI essentially stopped talking in 2019, when Microsoft invested $1bn. But before that, it was estimated that the compute demands of the largest AI training runs were doubling every few months. Even if Moore's Law still held, hardware improvements could not deliver those speedups.
Sebastian Moss details that the only way to meet the growing demands of AI is through ever larger amounts of infrastructure. And those demands grow exponentially if applications go mainstream and find millions of users.
The generative AI chat
In the explosion of publicity around ChatGPT, the OpenAI model has been proposed as a replacement for almost every communications task performed by a human - all based on very little evidence of it actually being useful for those jobs.
But progress is fast, and the tool is there for experimenting with (along with othes like Dall-E and Midjourney), so the industry is building out AI hardware at an unbelievable rate, both in the cloud and in national supercomputing centers.
Unbelievably, the entire basis of the data center industry seems to be being redesigned, for an application which is still being written.
300,000
Meet the team
Editor-in-Chief
Sebastian Moss @SebMoss
Executive Editor
Peter Judge @Judgecorp
News Editor
Dan Swinhoe @DanSwinhoe
Telecoms Editor
Paul Lipscombe

Reporter
Georgia Butler
Partner Content Editor
Claire Fletcher
Head of Partner Content
Graeme Burton @graemeburton
Partner Content Editor
Chris Merriman @ChrisTheDJ
Brazil Correspondent
Tatiane Aquim @DCDFocuspt
Designer
Eleni Zevgaridou
Head of Sales
Erica Baeta
Conference Director, Global Rebecca Davison
Channel Management
Team Lead
Alex Dickins
At a time when life on Earth depends on every industry cutting its energy costs, it seems the costs of AI are not even being counted.
Enterprise, Edge and Energy
We also cover our regular beats. Our supplement looks at how enterprises are harnessing Edge technology, while elsewhere we chart the path between cloud and on-premise installations.
We also examine Energy Islands, data driven facilities optimizing windfarms out at sea. And an extended briefing tells you all you need to know about power purchase agreements (PPAs).
All this in an issue which, as Sebastian explains, could only have been created by humans, and not have been made by AI.
Channel Manager
Kisandka Moses
Channel Manager
Emma Brooks
Channel Manager
Gabriella Gillett-Perez
Chief Marketing Officer
Dan Loosemore
Head Office
DatacenterDynamics
22 York Buildings, John Adam Street, London, WC2N 6JU
or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, or be stored in any retrieval system of any nature, without prior written permission of Data Centre Dynamics Limited. Applications for written permission should be directed to the editorial team at editorial@ datacenterdynamics.com. Any views or opinions expressed do not necessarily represent the views or opinions of Data Centre Dynamics Limited or its affiliates.
Disclaimer of liability: Whilst every effort has been made to ensure the quality and accuracy of the information contained in this publication at the time of going to press, Data Centre Dynamics Limited and its affiliates assume no responsibility as to the accuracy or completeness of and, to the extent permitted by law, shall not be liable for any errors or omissions or any loss, damage or expense incurred by reliance on information or any statement contained in this publication. Advertisers are solely responsible for the content of the advertising material which they submit to us and for ensuring that the material complies with applicable laws. Data Centre Dynamics Limited and its affiliates are not responsible for any error, omission or material. Inclusion of any advertisement is not intended to endorse any views expressed, nor products or services offered, nor the organisations sponsoring the advertisement.
The growth in AI compute demands from 2012's eightlayer AlexNet to 2018's AlphaGoZero (OpenAI)
© 2022 Data Centre Dynamics Limited All rights reserved. No part of this publication may be reproduced
Data centers are being redesigned for an application which is still being written
Dive even deeper Follow the story and find out more about DCD products that can further expand your knowledge. Each product is represented with a different icon and color, shown below. Events Intelligence Debates Training Awards CEEDA
Peter Judge Executive Editor
Issue 48 • April 2023 | 5 >>CONTENTS
News
The biggest data center news stories of the last three months
Intel co-founder Gordon Moore dies aged 94
The seminal semiconductor figure passed away in late March.
Moore was one of the traitorous eight who left Shockley Semiconductor to found Fairchild Semiconductor
De Beers to grow artificial diamonds for Amazon’s quantum networks
De Beers subsidiary Element Six will make artificial diamonds to be used by the AWS Center for Quantum Networking for use as quantum repeaters
LiquidStack gets investment from Trane
Brookfield buys Europe’s Data4 from AXA Investment Managers
In the biggest acquisition in the data center space so far this year, AXA IM has sold European data center firm Data4 to another investment company, Brookfield Infrastructure.
Terms of the deal weren’t shared, but earlier reports suggested a deal could value Data4 at around $3.8 billion.
Established in 2006 by Colony Capital (now DigitalBridge), Data4 currently operates around 30 data centers in France, Italy, Spain, Poland, and Luxembourg.
The company was acquired by AXA Investment Managers for an undisclosed amount in 2018, with Danish pension fund PFA acquiring a 20 percent stake in 2020.
The news comes amid a growth period for Data4, with two new projects in the works.
This quarter saw the company announce plans to develop a new data center campus on a former army barracks in Hanau, Germany, that could reach 200,000 square meters (2.1 million sq ft) and 180MW.

The 20-hectare site was bought in February from GIC-backed European logistics real estate firm P3 Logistic Parks, which had previously announced plans for a data center campus of its own there in summer 2022.
At least eight data center modules totaling 180MW were set to be built under P3’s original
plans, but Data4 hasn’t said whether it will change the site layout.
In France, the company is planning a third campus on the outskirts of Paris. In April, Data4 announced it had acquired a 22-hectare site previously used by Nokia as one of its country headquarters.
Data4 aims to develop a total of eight data centers on the new PAR3 site with a total area of 32,000 sqm (344,445 sq ft) and 120 MW of capacity.
The company said it aims to invest €1 billion ($1bn) by 2030 in the project.
Olivier Micheli, president of Data4, said: “This acquisition is part of our ambition to quickly reach a capacity of 1GW and to be the pan-European reference player in the data center sector. We are thus strengthening our roots in the south of Paris.
“After the transformation of the former Alcatel industrial site in Marcoussis into a data center campus, the takeover of the Nokia site in Nozay underlines our territorial commitment as well as our desire to work and make our local ecosystem grow.”
Combined, PAR1 and 2 offer a total potential capacity of 255MW across 24 data centers.At full build-out, the three French campuses will total 375MW.
bit.ly/Brookfield4Data
HVAC company Trane has invested in the immersion cooling company. The Series B funding will be used by LiquidStack to build a new manufacturing facility in the US and further R&D
Stack offers generator power to Switzerland’s electric grid
The infrastructure provider has signed up for the Swiss Winter Reserve Plan. IPI-owned Stack operates four data centers in the country totaling more than 45MW acquired from local provider Safe Host in 2022
China’s Highlander completes first commercial underwater data center
The Chinese company has deployed its first commercial underwater data center facility off Hainan island, and wants to export submerged facilities globally. Microsoft has previously deployed proof of concept underwater data centers.
5.5 million sq ft data center park in propopsed in Virginia’s Stafford County
Peterson Companies, which has previously worked with Stack in Manassas, is filing to rezone more than 500 acres to develop a new data center park outside Fredericksburg.
The project, known as the Stafford Technology Campus, would span more than 25 buildings of varying sizes
Whitespace NEWS IN BRIEF
>>CONTENTS 6 | DCD Magazine • datacenterdynamics.com
Singapore’s NTU proposes cooling servers by spraying chips with fluid
A group at Singapore’s Nanyang Technical University (NTU) has tested a strange, but simple cooling idea: spraying the hot CPUs with dielectric cooling fluid, and allowing it to evaporate.

The team ran 12 servers in a box, and sprayed a dielectric fluid on the CPUs. The university says the systems were kept cool more effectively than by conventional air cooling, according to a paper published in the journal Energy in April.
The team, led by NTU Associate Professor Wong Teck Neng, described the spray system as “a ‘chillerless’ novel spraying architecture which has the capability of performing high heat flux, is highly scalable and easily adaptable by modern data centers.”
The prototype system, built by research fellow Liu Pengfei, sealed a 24U rack, containing 12 servers, in a box. Nozzles sprayed dielectric fluid on each CPU, where it evaporated, cooling the server. The fluid was condensed and collected for reuse in a closed-loop system.
While most data centers are cooled by air conditioning systems, immersing the IT in dielectric fluid, proposed by vendors including Submer, GRC, and Asperitas, removes heat more efficiently and reduces the energy used. Other vendors including LiquidCool and Zutacore, have proposed two-phase cooling, in which the immersion fluid is allowed to boil in order to remove more heat.
The NTU team’s approach eliminates the giant tubs of the immersion vendors, and the piping used by two-phase advocates, as well as heatsinks. However, the existing two-phase solutions currently use PFAS (poly-fluoroalkyl substances) which have been labeled a health risk.
Excerpts seen by DCD do not give details of the fluid used - we have requested a full copy of the NTU group’s paper to find out more.
Data centers use some seven percent of Singapore’s total electricity consumption, and the country has very little renewable electricity supply, so the government has been rationing permissions for new data centers. The Singapore National Research Foundation (NRF) runs a Green Data Centre Research Programme which supported the NTU work.
The group first proposed its idea of spray cooling for tropical data centers in November 2021, based on a more basic prototype, and followed up with an evaluation of performance in January 2022.
Two-phase cooling may face a difficult future. Late last year 3M announced it would phase out Novec, a chemical used in coolants and semiconductor manufacturing, by 2025. Other sources of two-phase coolants will also be under pressure as the US Environmental Protection Agency has classified some PFAS substances as hazardous substances, adding greatly to the difficulties involved in using them.
The ruling should not affect single-phase immersion cooling providers.
bit.ly/SprayMeCool
data center by airstrike” warns AI researcher

Leading artificial intelligence safety researcher Eliezer Yudkowsky has called for a cap on compute power, said GPU sales should be tracked, and believes we should be prepared to blow up rogue data centers.

“If somebody builds a too-powerful AI, under present conditions, I expect that every single member of the human species and all biological life on Earth dies shortly thereafter,” he said in an article for Time. In a podcast, the researcher revealed that he cried all night when OpenAI was founded.
Effectively studying AI safety could take decades, he warned.
He added: “Shut down all the large GPU clusters. Shut down all the large training runs. Put a ceiling on how much computing power anyone is allowed to use in training an AI system, and move it downward over the coming years to compensate for more efficient training algorithms. No exceptions for governments and militaries. Make immediate multinational agreements to prevent the prohibited activities from moving elsewhere.
“Track all GPUs sold. If intelligence says that a country outside the agreement is building a GPU cluster, be less scared of a shooting conflict between nations than of the moratorium being violated; be willing to destroy a rogue data center by airstrike.”
bit.ly/AIAirstrike
“Be willing to destroy a rogue
>>CONTENTS DCD Magazine #48 Issue 48 • April 2023 | 7
Aligned Data Centers acquires Brazil’s Odata for a reported $1.8 billion

US data center firm Aligned is to acquire Latin American operator Odata.
In December Aligned announced the execution of a definitive agreement to acquire Odata from Patria Investments and other selling stakeholders.
Aligned, majority owned by funds managed by Macquarie Asset Management, has also entered into a definitive agreement to receive a structured minority investment in Odata from funds managed by SDC Capital Partners.
The transaction is expected to close in early 2023. Financial terms were not disclosed, but previous reports valued Odata at around R$10 billion (US$1.8bn). The transaction is being funded by Aligned alongside a preferred equity investment from
funds managed by SDC.
“The acquisition combines a significant growth runway for expansion and a proven ability to deliver capacity at maximum speed, with regional expertise and partnerships, enhanced fiscal resources, and a resilient supply chain, to deliver a world-class data center platform that meets the demands of our global hyperscale and enterprise customers,” said Andrew Schaap, CEO of Aligned Data Centers. “We’re excited to welcome Ricardo and the Odata team to the Aligned fold and look forward to fostering our joint commitments to customer centricity and operational excellence as we embark on the next phase of innovation and growth.”
Founded in 2015 by Brazilian private
equity firm Patria Investments and based in Sao Paulo, Brazil, Odata offers colocation services from three data centers in Brazil and one each in Colombia and Mexico. The company has started construction on a facility in Chile, is developing a new building in Rio de Janeiro, and is expanding its campus in Sao Paulo.
At the launch of its first Mexican facility last year, the company said it will begin construction of a second 30MW data center in Querétaro in the future, and is also targeting Peru as its next market, though it didn’t disclose timelines.
“The Odata team and I are very excited to be joining Aligned Data Centers,” added Ricardo Alário, CEO of Odata. “The strategic merger of the Odata and Aligned platforms will provide customers with a broader base of both available and expansion capacity in key locations across the Americas, as well as additional breadth of experience and depth of knowledge across an expanded team of infrastructure experts. We look forward to accelerating the growth of our platform with Aligned and setting a successful cultural course focused on customer and staff centricity, innovation, and operational excellence.”
Odata was majority-owned by Patria via its Fundo Pátria Infraestrutura IV, with CyrusOne owning a stake in the company; it’s unclear whether the sale includes CyrusOne’s stake.
CyrusOne was previously rumored to be the frontrunner to acquire the company, with DigitalBridge’s Scala also interested. bit.ly/ODataOAligned
Google increases server life to six years, will save billions of dollars
Google plans to increase the useful lives of its servers and some networking equipment to six years.
The company made the announcement in its Q4 2022 earnings release in February, a day after Meta said it was increasing its server lifespan to five years. Google said that it completed a lifecycle assessment in January this year, and realized that it could up the lifespan of its equipment after previously running them for four years.

“We expect [the change] to result in a reduction of depreciation of approximately $3.4 billion for the full fiscal year 2023 for assets in service as of December 31, 2022, recorded primarily in cost of revenues and research and development (R&D) expenses,” Google’s parent Alphabet said in the earnings release.
The same week saw Meta announce that it would extend the expected life of servers and some network equipment to five years. This, it said, would save around $1.5bn. The company previously ran its hardware for around four-anda-half years, a move that was itself an increase from mid-2022. Prior to that, it estimated a four-year useable life.
Microsoft last year confirmed it had increased its server lifespans to six years, while AWS is believed to run its servers for around five to six years.
bit.ly/SaveOurServers
Whitespace
>>CONTENTS 8 | DCD Magazine • datacenterdynamics.com
Digital Realty, Oracle, and Scala test robot dogs in data centers in Switzerland, the US, and Brazil
Colocation firms Digital Realty and Scala, along with cloud provider Oracle, have all been testing robotic dogs in data centers in an attempt to automate routine tasks.
In Switzerland, Digital Realty has partnered with local robotics firm Anybotics to use the firm’s Anymal quadruped machine for routine inspections for more than a year.

In the US, Oracle has been trialing a Boston Dynamics Spot robot in Oracle livery as part of a data center trial at its Chicago, Illinois R&D Industry Lab.
In Brazil, Scala has testing a robot dog for fire safety inspections. While Scala doesn’t name the model or provider, the robot looks likely to be a Go1 from Chinese provider Unitree.
While yet to become industry-standard, robot dogs are becoming increasingly common. Utah-based Novva has deployed Boston Dynamics Spot robots at its flagship campus and said it plans to roll out more in the future. Mexican operator Kio has also previously deployed two Spot machines for data center operations, while GlobalFoundries deployed Spot at a chip fab plant in Vermont for monitoring purposes. bit.ly/WhosAGoodDog
Aisle Containment
The energy efficient addition to your cooling strategy
Incorporating an Aisle Containment solution, whether it be a hot or cold aisle configuration, can substantially reduce your energy costs and lower your data centres’ PUE.
Weatherite’s Airbox® solution dramatically improves the cooling efficiency of your data centre- providing a highly effective way of controlling hot and cold air flow.

Whether you’re designing a new data centre or looking at improvements for an existing facility, we can deliver exactly the right Aisle Containment solution.




For further information
Call: +44 (0) 121 665 2293
Email: sales@weatheriteasl.com or go to our website: www.weatheriteasl.com
Benefits include:-
• Substantial reduction in energy usage.
• Reduced PUE.
• Reduced temperature fluctuation.
• Reduced carbon emissions.
• Improved cooling efficiencies.
• Extended life of cooling equipment.
• More comfortable ‘common area’ for staff.
DCD Magazine #48 Issue 48 • April 2023 | 9
AISLE C ONT AINMENT
Part of the Weatherite Group of Companies
Lonestar Data Holdings raises $5m for data centers on the Moon
Lunar data center company
Lonestar Data Holdings has closed a $5 million seed round.
The startup, which hopes to deploy small data centers on the Moon, raised money from Scout Ventures, Seldor Capital, 2 Future Holding, The Veteran Fund, Irongate Capital, Atypical Ventures, and KittyHawk Ventures. The $5m includes funds that were raised last year as part of the round.
“The $5m is financing our first two missions this year,” CEO Christopher Stott told DCD. “The hardware is complete and awaiting launch.”
The company’s first mission is scheduled in the second quarter of 2023. “We were scheduled for this month, but NASA asked Intuitive Machines, our provider, to move their mission back and to change landing sites,” Stott explained. The landing site was moved last month to the lunar South Pole Region.
The new funding “gets us to revenues from the Moon and well into our third planned mission in 2025,” Stott said, although a Series A is expected in the Fall.
Initial deployments will be a server and storage module the size of a book, powered by solar energy.
bit.ly/LoneStarRanger
Cyxtera fire in Boston was caused by electrical fault which blew the doors off a battery cabinet
A fire at a Cyxtera data center in Boston that took down Oracle NetSuite services across the US was the result of an electrical arc flash that blew the doors off a battery cabinet
On 14 February, the Waltham Fire Department was called to an electrical equipment fire at a data center run by Cyxtera. The building was undamaged, but inside an explosion had destroyed a battery cabinet.


The fire services evacuated the building, shut down power, and ventilated the premises to remove poisonous gases, before checking the damage and eventually allowing operations to resume. One person was taken to hospital with possible smoke inhalation.
The company has declined to comment beyond its initial statement and the Fire
Peter’s fire factoid
Department says the cause of the fire is “undetermined.”
Luckily these workers were on an early lunch break at the time of the explosion, so the only person in the room at the time of the explosion was a 28-year-old security guard on a routine patrol. He remained fully conscious but was taken to hospital to check for possible smoke inhalation.
“There was damage to other cabinets adjacent to the origin cabinet caused by panels blowing off at the time of the explosion,” says the report.
The Fire Department arrived at 11:34am local time, six minutes after the alarm was raised. The incident was cleared up by around 14:30.
Oracle’s NetSuite services were down for several days as a result of the incident.
bit.ly/BostonBatteryParty
OVHcloud has been ordered to pay €250,000 by a French court to two customers who lost data in the 2021 Strasbourg data center fire. The company still hasn’t shared its findings on the fire’s cause.
A data center in Lyon, France, operated by Maxnod has suffered a devastating fire, bringing the French facility offline and severely damaging infrastructure.
Local government Ain said that the fire at the Saint-Trivier-sur-Moignans facility required significant resources, with about 81 firefighters and 49 vehicles mobilized. One firefighter is believed to have been minorly injured.
Freelance network engineer and president of telco association MilkyWan, Hugues Voiturier, was at the data center when it caught fire at around 11 am local time on March 28.

“Well, the Maxnod Datacenter is on fire, fire on the battery room of the photovoltaic panels,” he said on Twitter (translated). “Fire not under control. Good luck to all those affected.”
While some of the racks looked damaged, Voiturier shared pictures of the MilkyWan servers still intact. “Gear a little dirty but it will be fine.” Launched around 2009, the 800 square meter data center is Maxnod’s only facility.
Some outages were reported as a result, including with local FTTH subscribers.
bit.ly/MaxinodUptime
Whitespace
>>CONTENTS 10 | DCD Magazine • datacenterdynamics.com
Maxnod data center in France burns down, battery system likely at fault
QTS and Compass refile updated PW Digital Gateway applications for 20 million sq ft+ data center campuses
Honda deploys hydrogen fuel cell in California for data center backup
Honda has deployed a hydrogen fuel cell system for data center backup at its facility in California.
The automotive company in March announced the operation of a stationary fuel cell power station at its corporate campus in Torrance, California.
US operators QTS and Compass have refiled their respective plans for massive data center campuses in Virginia’s Prince William County.
The companies are looking to develop more than 20 million sq ft of data centers as part of the PW Digital Gateway project near Manassas.
Both Blackstone-owned QTS and Compass originally filed rezoning applications last year but submitted updated applications in February providing more detail.
QTS has filed two applications - Digital Gateway North and South - that seek to rezone 876 acres for data centers, up from the original 771 acres. In total, the company is aiming to develop around 11.3 million gross square feet (1.05 million sqm) of data center space.
Compass has requested to rezone 884 acres, up from 843 acres last year. The company aims to develop up to 11.55 million sq ft (1,07 million sqm) of data center space on the land.
The exact number of data centers the companies are planning at this point isn’t clear, but would be built out over 10-15 years. The buildings will require individual permits. It is unclear how many substations would be built.
DCD understands the updates are mostly related to the requirements put forward in the latest Comprehensive Plan Amendment the county passed in November 2022.
The applications includes a number of proffers the two companies are offering to benefit the area in return for the rezoning authorization.
The gateway land is broken up to 10 land bays, four of which would be open space. Compass and QTS intend to build a trail network through several of the land bays and adjacent stream corridors, as well as a 300ft-wide wildlife corridor.
Most of the buildings will be up to 100ft tall, but after a view-shed analysis conducted from the neighboring Manassas Battlefield Park, certain
buildings will be restricted to heights of 60ft in certain land bays.
Compass proposes to develop data centers and supporting office and conference facilities, but also eating establishments and fast-food restaurants, health clubs and recreational facilities, child care facilities, financial institutions, and other supportive uses and services.
Reports of a PWC Digital Gateway surfaced last year, originally as an 800-acre development later tied to QTS. However, more landowners joined and the proposal expanded to include some 2,133 acres of the county’s “rural crescent” for data centers.
Residents have been strongly opposed. bit.ly/PWGateway
The fuel cell unit has a capacity of approximately 500kW and reuses the fuel cell systems of previously leased Honda Clarity Fuel Cell vehicles, with a design that allows the output to increase every 250kW packaged with four fuel cells. The deployment will act as a proof of concept for future commercialization efforts.
The company said the unit’s layout is adaptable and can accommodate cubic, L-shaped, Z-shaped, and other packaging configurations. While the current unit reuses old cells, Honda said future deployments intended for commercialization will utilize Honda’s ‘nextgeneration’ fuel system set to be deployed from 2024.
bit.ly/Hondrogen
AWS announces modular data center for US DoD customers
Amazon Web Services has announced a modular data center for US Department of Defense customers.

The AWS MDC is available to government customers who are eligible for the Joint Warfighting Cloud Capability (JWCC) contract, the military’s $9 billion cloud deal that was awarded to AWS, Microsoft Azure, Google, and Oracle.
The AWS MDC comes in a ruggedized container designed for disconnected, disrupted, intermittent, or limited (DDIL) environments.
The modular system is self-
contained, with internal networking, cooling, and power distribution equipment. It can be scaled with the deployment of multiple modular data center units.
Once deployed, it needs to be connected to power, and networking if using AWS Outposts.
If networking is unavailable, AWS MDC racked with Snow Family devices allows customers to run workloads using a limited subset of AWS services. JWCC comes after the failure of the long-delayed JEDI contract.
bit.ly/ModuleWars
>>CONTENTS DCD Magazine #48 Issue 48 • April 2023 | 11
Generative AI: Hype, opportunity, and the future of data centers
Sebastian Moss Editor-in-Chief

Generative AI looks set to change how we work, create, and live. Governments, businesses, and individuals are all grappling with what it means for the economy and our species, but struggle as we simply don’t know what AI will be capable of, or the costs and benefits of applying it.
Behind this transformation lies a deeper story, of vast changes in compute architectures, networking topologies, and data center design. Deploying the massive computing resources these systems require could change the cloud industry, and put the traditional supercomputing sector at risk.
To understand what this moment means, and what could be coming next, DCD spent the last four months talking to nearly two dozen AI researchers, semiconductor specialists, networking experts, cloud operators, supercomputing visionaries, and data center leaders.
This story begins with the models, the algorithms that fundamentally determine how an AI system works. We look at how they are made, and how they could grow. In operation, we look at the twin requirements of training and inferencing, and the so-called ‘foundation models’ which can be accessed by enterprises and users. We also ask what the future holds for open source AI development.
From there, we move to the world of supercomputers, understanding their use today and why generative AI could upend the traditional high-performance computing (HPC) sector. Next, we talk to the three hyperscalers that have built gigantic AI supercomputers in the cloud.

DCD Magazine #48
What large language models and the next wave of workloads mean for compute, networking, and data center design
Images made with Midjourney
by Sebastian Moss
>>CONTENTS
Then we turn to chips, where Nvidia has a lead in the GPU processors that power AI machines. We talk to seven companies trying to disrupt Nvidia - and then we then hear from Nvidia's head of data centers and AI to learn why unseating the leader will be so hard.
But the story of compute is meaningless without understanding networking, so we talk to Google about a bold attempt to overhaul how racks are connected.
Finally, we learn about what this all means for the data center. From the CEO of Digital Realty, to the CEO of DE-CIX, we hear from those set to build the infrastructure of tomorrow.
I THE MODELS Making a model
Our journey through this industry starts with the model. In 2017, Google published the 'Attention is All You Need' paper that introduced the transformer model, which allowed for significantly more parallelization and reduced the time to train AIs.
This set off a boom in development, with generative AI models all built from transformers. These systems, like OpenAI’s large language model (LLM) GPT-4, are known as foundation models, where one company develops a pre-trained model, for others to use.
“The model is a combination of lots of data and lots of compute,” Rishi Bommasani, co-founder of Stanford’s Center for Research on Foundation Models, and lead author of a seminal paper defining those models, told DCD
“Once you have a foundation model, you can adapt it for a wide variety of different downstream applications,” he explained.
Every such foundation model is different, and the costs to train them can vary greatly. But two things are clear: The companies building the most advanced models are not transparent about how they train them, and no one knows how big these models will scale.
Scaling laws are an area of ongoing research, which tries to work out the optimal balance between the size of the model, the amount of data, and the computational resources available.
Raising a Chinchilla
"The scaling relations with model size and compute are especially mysterious," a 2020 paper by OpenAI's Jared Kaplan noted, describing the power-law relationship
between model size, dataset size, and the compute power used for training.
As each factor increases, so does the overall performance of the large language model.
This theory led to larger and larger models, with increasing parameter counts (the values that a model can change as it learns) and more tokens (the units of text that the model processes, essentially the data). Optimizing these parameters involves multiplying sets of numbers, or matrices, which takes a lot of computation, and means larger compute clusters.
That paper was superseded in 2022 by a new approach from Google subsidiary DeepMind, known as 'Chinchilla scaling laws,' which again tried to find the optimal parameter and token size for training an LLM under a given compute budget. It found that the models of the day were massively oversized on parameters in relation to tokens.
While the Kaplan paper said that a 5.5× increase in the size of the model should be paired with a 1.8× increase in the number of tokens, Chinchilla found that parameter and token sizes should be scaled in equal proportions.
The Google subsidiary trained the 67 billion-parameter Chinchilla model based on this compute-optimal approach, using the same amount of compute budget as a previous model, the 280bn parameter Gopher, but with four times as much data. Tests found that it was able to outperform Gopher as well as other comparable models, and used four times less compute for finetuning and inference.
Crucially, under the new paradigm, DeepMind found that Gopher, which already had a massive compute budget, would have benefited from more compute used on 17.2× as much data.
An optimal one trillion parameter model, meanwhile, should use some 221.3 times as much compute budget for the larger data, pushing the limits of what's possible today. That is not to say one cannot train a one trillion parameter model (indeed Google itself has), it's just that the same compute could have been used to train a smaller model with better results.
Based on Chinchilla’s findings, semiconductor research firm SemiAnalysis calculated the rough computing costs of training a trillion parameter model on Nvidia A100s would be $308 million over three months, not including preprocessing, failure restoration, and other costs.
Taking things further, Chinchilla found that an optimal 10 trillion parameter model would use some 22,515.9 times as
much data and resulting compute as the optimal Gopher model. Training such a system would cost $28.9bn over two years, SemiAnalysis believes, although the costs will have improved with the release of Nvidia’s more advanced H100 GPUs.
It is understood that OpenAI, Anthropic, and others in this space have changed how they optimize compute since the paper’s publication to be closer to that approach, although Chinchilla is not without its critics.
As these companies look to build the next generation of models, and hope to show drastic improvements in a competitive field, they will be forced to throw increasingly large data center clusters at the challenge. Industry estimates put the training costs of GPT-4 at as much as 100 times that of GPT-3.5.
OpenAI did not respond to requests for comment. Anthropic declined to comment, but suggested that we talk to Epoch AI Research, which studies the advancement of such models, about the future of compute scaling.
“The most expensive model where we can reasonably compute the cost of training is Google’s [540bn parameter] Minerva,” Jaime Sevilla, the director of Epoch, said. “That took about $3 million to train on their internal data centers, we estimate. But you need to train it a number of times to find a promising model, so it’s more like $10m.”
In use, that model may also need to be retrained frequently, to take advantage of the data gathered from that usage, or to maintain an understanding of recent events.
“We can reason about how quickly compute needs have been increasing so far and try to extrapolate this to think about how expensive it will be 10 years from now,” Sevilla said. “And it seems that the rough trend of cost increases goes up by a factor of 10 every two years. For top models, that seems to be slowing down, so it goes up by a factor of 10 every five years.”
Trying to forecast where that will lead is a fraught exercise. “It seems that in 10 years, if this current trend continues - which is a big if - it will cost somewhere between $3 billion or $3 trillion for all the training runs to develop a model,” Sevilla explained.
“It makes a huge difference which, as the former is something that companies like Microsoft could afford to do. And then they won't be able to push it even further, unless they generate the revenue in order to justify larger investments.”
Since we talked to Sevilla, Techcrunch reported that Anthropic now plans to develop a single model at a cost of $1bn.
Issue 48 • April 2023 | 13
Generative AI and our future
>>CONTENTS
What to infer from inference
Those models, large and small, will then have to actually be used. This is the process of inference - which requires significantly fewer compute resources than training on a per-usage basis, but will consume much more overall compute, as multiple instances of one trained AI will be deployed to do the same job in many places.
Microsoft’s Bing AI chatbot (based on GPT-4), only had to be trained a few times (and is retrained at an unknown cadence), but is used by millions on a daily basis.
"Chinchilla and Kaplan, they're really great papers, but are focused on how to optimize training,” Finbarr Timbers, a former DeepMind researcher, explained. “They don't take into account inference costs, but that's going to just totally dwarf the amount of money that they spent training these models.”
Timbers, who joined the generative AI image company Midjourney (which was used to illustrate this piece) after our interview, added: “As an engineer trying to optimize inference costs, making the model bigger is worse in every way except performance. It's this necessary evil that you do.

“If you look at the GPT-4 paper, you can make the model deeper to make it better. But the thing is, it makes it a lot slower, it takes a lot more memory, and it just makes it more painful to deal with in every way. But that's the only thing that you can do to improve the model.”
It will be hard to track how inference scales, because the sector is becoming less transparent, as the leading players are subsumed into the tech giants. OpenAI began as a not-for-profit company and is now a for-profit business tied to Microsoft, who invested $1 billion in the company Another leading player, DeepMind, was acquired by Google in 2014.
Publicly, there are no Chinchilla-esque scaling laws for inference that show optimal model designs or predict how it will develop.
Inference was not a priority of prior approaches, as the models were mostly developed as prototype tools for in-house research. Now, they are beginning to be used by millions, and it is becoming a paramount concern.
“As we factor in inference costs, you'll come up with new scaling laws which will tell you that you should allocate much less to model size because it blows up your inference costs,” Bommasani believes. “The hard part is you don't control inference fully, because you don't know how much demand you will get.”
Not all scaling will happen uniformly, either.
AI and its models - important terms
AI - Artificial Intelligence, computer systems applied to tasks such as speech recognition, image creation, and conversation, which have been considered the province of human intelligence.
Generative AI - an AI that produces new output based on inputs and training data. ChatGPT is a very well-known example, along with DALL-E, Stable Diffusion, and many others.
Model - the AI algorithms which underly the way an AI operates. Important models include the “transformer” models, in which feedback or “self-attention” adjusts the
values of parameters. Transformer models are used in ChatGPT and other generative AIs.
Large language models - These transformer models are trained on text and used to generate language and source code.
Parameters and tokens - Parameters are internal values within the AI model, which determine the linkage between “tokens” or data.
In simplistic terms, the number of parameters measures the size of the model, while the number of tokens
Large language models are, as their name suggests, rather large. “In text, we have models that are 500bn parameters or more,” Bommasani said. That doesn’t need to be the case for all types of generative AI, he explained.
“In vision, we just got a recent paper from Google with models with 20bn parameters. Things like Stable Diffusion are in the billion parameter range so it’s almost 100× smaller than LLMs. I'm sure we'll continue scaling things, but it's more a question of where will we scale, and how we will do it.”
This could lead to a diversification in how models are made. “At the moment, there’s a lot of homogeneity because it's early,” he said, with most companies and researchers simply following and copying the leader, but he’s hopeful that as we reach compute limits new approaches and tricks will be found.
“Right now, the strategies are fairly brutish, in the sense that it's just ‘use more compute’ and there's nothing deeply intellectually complicated about that,” he said. “You have a recipe that works, and more or less, you just run the same recipe with more compute, and then it does better in a fairly predictable way.”
As the economy catches up with the models, they may end up changing to focus on the needs of their use cases. Search engines are intended for heavy, frequent use, so inference costs will dominate, and become the primary factor for how a model is developed.
Keeping this sparse
As part of the effort to reduce inference costs, it’s also important to note sparsitythe effort of removing as many unneeded parameters as possible from a model without impacting its accuracy. Outside of
determines the size of the dataset on which it is trained.
Training and inference - AI systems are “trained” with a large amount of data, from which they extract underlying trends, and set parameters.
The pre-trained AI can then be applied to specific tasks, which it performs using “inference.”
Foundation models - pre-trained AIs which are available for multiple applications. ChatGPT is an example, which has been tested in many applications.
14 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
LLMs, researchers have been able to remove as many as 95 percent of the weights in a neural network without significantly impacting accuracy.
However, sparsity research is again in its early days, and what works on one model doesn't always work on another. Equally important is pruning, where the memory footprint of a model can be reduced dramatically, again with a marginal impact on accuracy.
Then there's mixture of experts (MoE), where the model does not reuse the same parameters for all inputs as is typical in deep learning. Instead, MoE models select different parameters for each incoming example, picking the best parameters for the task at a constant computational cost by embedding small expert networks within the wider network.
"However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs, and training instability," Google researchers noted in a 2022 paper where they outlined a new approach that solved some of those issues. But the company has yet to deploy it within its main models, and the optimal size and number of experts to put within a model is still being studied.
Rumors swirl that GPT-4 uses MoEs, but nobody outside of the company really knows for sure. Some of the technically largest models of out China take advantage of them, but are not very performative.
SemiAnalysis' chief analyst Dylan Patel believes that 2023 "will be the year of the MoE," as current approaches strain the ability of today's compute infrastructure. However, it will have its own impact, he told DCD: "MoEs actually lead to more memory growth versus compute growth," as parameter counts have to increase for the additional experts.
But, he said, no matter which approach these companies take to improving the efficiency of training and inference, “they’d be a fool to say ‘hey, with all these efficiencies, we're done scaling.’”
Instead, “the big companies are going to continue to scale, scale, and scale. If you get a 10× improvement in efficiency, given the value of this, why not 20× your compute?”
Where does it end?
As scale begets more scale, it is hard to see a limit to the size of LLMs and multimodal models, which can handle multiple forms of data, like text, sound, and images.
At some point, we will run out of fresh data to give them, which may lead to us
feeding them with their own output. We may also run out of compute. Or, we could hit fundamental walls in scaling laws that we have not yet conceived of.

For humanity, the question of where scaling ends could be critical to the future of our species.
"If the scaling laws scale indefinitely, there will be some point where these models become more capable than humans at basically every cognitive task,” Shivanshu Purohit, head of engineering at EleutherAI and research engineer at Stability AI, said.
“Then you have an entity that can think a trillion times faster than you, and it's smarter than you. If it can out plan you and if it doesn't have the same goals as you…”
That’s far from guaranteed. “People's expectations have inflated so much so fast that there could be a point where these models can't deliver on those expectations,” Purohit said.
Purohit is an “alignment” researcher, studying how to steer AI systems towards their designers' intended goals and interests, so he says a limit to scaling “would actually be a good outcome for me. But the cynic in me says that maybe they can keep on delivering, which is bad news.”
EleutherAI colleague Quentin Anthony
is less immediately concerned. He says that growth generally has limits, making an analogy with human development: “If my toddler continues to grow at this rate, they're gonna be in the NBA in five years!”
He said: “We're definitely in that toddler stage with these models. I don't think we should start planning for the NBA. Sure we should think ‘it might happen at some point,’ but we'll see when it stops growing.”
Purohit disagrees. “I guess I am on the opposite end of that. There's this saying that the guy who sleeps with a machete is wrong every night but one.”
II THE PLAYERS Foundation and empire
It is impossible to say how fast the compute demands of training these models will grow, but it is nearly universally accepted that the cost of training cutting-edge models will continue to increase rapidly for the foreseeable future.
Already, the complexity and financial hurdles of making a foundation model have put it beyond the reach of all but a small number of tech giants and well-funded AI startups. Of the startups able to build their
Issue 48 • April 2023 | 15
Generative AI and our future >>CONTENTS
own models, it is not a coincidence that most were able to do it with funding and cloud credits from the hyperscalers.
That bars most enterprises from competing in a space that could be wildly disruptive, cementing control in the hands of a few companies already dominating the existing Internet infrastructure market. Rather than representing a changing of the guard in the tech world, it risks becoming simply a new front for the old soldiers of the cloud war.
"There's a number of issues with centralization," Dr. Alex Hanna, director of research at the Distributed AI Research Institute (DAIR), said. "It means certain people control the number of resources that are going to certain things.
“You're basically constrained to being at the whims of Amazon, Microsoft, and Google.”
Those three companies, along with the data centers of Meta, are where the majority of foundation models are trained. The money that the startups are raising is mostly being funneled back into those cloud companies.
“If you take OpenAI, they're building the foundation models and lots of different companies would not be incentivized to build them at the moment and would rather just defer to using those models,” Stanford’s Bommasani said.
“I think that business model will continue. However, if you need to really specialize things in your particular use cases, you're limited to the extent that OpenAI lets you specialize.”
That said, Bommasani doesn’t believe that “we're ever going to really see one model dominate,” with new players like Amazon starting to move into that space. “Already, we have a collection of 10 to 15 foundation model developers, and I don't expect it to collapse any smaller than five to 10.”
Even though the field is relatively nascent, we’re already seeing different business models emerge. “DeepMind and Google give almost no access to any of their best models,” he said. “OpenAI provides a commercial API, and then Meta and Hugging Face usually give full access.”
Such positions may change over time (indeed, after our interview Google announced an API for its PaLM model), but represent a plethora of approaches to sharing access to models.
The big players (and their supporters) argue that it doesn’t matter too much if they are the only ones with the resources to build foundation models. After all, they make
pre-trained models available more broadly, with the heavy lifting already done, so that others can tune specific AIs on top of them.
Forward the foundation
Among those offering access to foundation models is Nvidia, a hardware maker at heart whose GPUs (graphics processing units) have turned out to be key to the supercomputers running AI.
In March 2023, the company launched the Nvidia AI Foundations platform, which allows enterprises to build proprietary, domain-specific, generative AI applications based on models Nvidia trained on its own supercomputers.
"Obviously, the advantage for enterprises is that they don't have to go through that whole process. Not just the expense, but you have to do a bunch of engineering work to continuously test the checkpoints, test the models. So that's pre-done for them," Nvidia's VP of enterprise computing, Manuvir Das, explained.
Based on what they need, and how much in-house experience they have, enterprises can tune the models to their own needs. "There is compute [needed] for tuning, but it's not as intensive as full-on training from the ground up," Das said. "Instead of many months and millions of dollars, we're typically talking a day's worth of computebut per customer."
He also expects companies to use a mixture of models at different sizes - with the larger ones being more advanced and more accurate, but having a longer latency and a higher cost to train, tune, and use.
While the large models that have captured headlines are primarily built on public data, well-funded enterprises will likely develop their own variants with their own proprietary data.
This could involve feeding data into models like the GPT family. But who then owns the resulting model? That is a difficult question to answer - and could mean that a company has just handed over its most valuable information to OpenAI.
"Now your data is encapsulated in a model in perpetuity, and owned by somebody else," Rodrigo Liang, the CEO of AI-hardware-as-a-service company SambaNova, said. "Instead, we give you a computing platform that trains on your data, produces a model that you can own, and then gives you the highest level of accuracy."
Of course, OpenAI is also changing as a company and is starting to build relationships with enterprises which gives customers more control over their data.
Earlier this year it was revealed that the company charges $156,000 per month to run its models in dedicated instances.
The open approach
While enterprises are concerned about their proprietary knowledge, there are others worried about how closed the industry is becoming.
The lack of transparency in the latest models makes understanding the power and importance of these models difficult.
“Transparency is important for science, in terms of things like replicability, and identifying biases in datasets, identifying weights, and trying to trace down why a certain model is giving X results,” DAIR’s Dr. Hanna said.
“It's also important in terms of governance and understanding where there may be an ability for public intervention,” she explained. “We can learn where there might be a mechanism through which a regulator may step in, or there may be legislation passed to expose it to open evaluation centers and audits.”
The core technological advances that made generative AI possible came out of the open source community, but have now been pushed further by private corporations that combined that tech with a moat of expensive compute.
EleutherAI is one of those trying to keep open source advances competitive with corporate research labs, forming out of a Discord group in 2020 and formally incorporating as a non-profit research institute this January.
To build its vision and large language models, it has been forced to rely on a patchwork of available compute. It first used Google's TPUs via the cloud company's research program, but then moved to niche cloud companies CoreWeave and SpellML when funding dried up.
For-profit generative AI company Stability AI has also donated a portion of compute from its AWS cluster for EleutherAI’s ongoing LLM research.
“We're like a tiny little minnow in the pool, just kind of trying to grab whatever compute we can,” EleutherAI’s Anthony said. “We can then give it to everybody, so that hobbyists can do something with it, as they’re being completely left behind.
“I think it’s a good thing that something exists that is not just what a couple of corporations want it to be.”
Open source players like EleutherAI may regard the resources they have as scraps and leftovers, but they are using systems
16 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
that were at the leading edge of computing performance when they were built.
III THE SUPERCOMPUTERS
The role of state supercomputers
Most AI training activity is now focused around the huge resources available to the tech giants, who build virtual supercomputers in their clouds. But in earlier days, research was largely carried out on supercomputers in government research labs.
During the 2010s, the world’s advanced nations raced to build facilities with enough power to perform AI research, along with other tasks like molecular modeling and weather forecasting. Now those machines have been left behind, but their resources are being used by smaller players in the AI field.
When the US government launched Summit in 2018, at the Oak Ridge National Laboratory, the 13-megawatt machine was the world's most powerful supercomputer. Now, by traditional Linpack benchmarks (FP64), it is the fifth fastest supercomputer in the world at 200 petaflops, using older models of Nvidia’s GPUs.
For the frontiers of AI, it is too old and too slow, but the open source EleutherAI group is happy to pick up the scraps. "We get pretty much all of Summit," said EleutherAI’s Anthony.
"A lot of what you're bottlenecked by is that those old [Tesla] GPUs just don't have the memory to fit the model. So then the model is split across a ton of GPUs, and you're just killed by communication costs," he said.
"If you don't have the best and latest hardware you just can't competeeven if you're given the entire Summit supercomputer."
A similar story is found in Japan, where Fugaku was the world’s fastest machine when it launched 2020.
“We have a team trying to do GPT-like training on Fugaku, we’re trying to come up with the frameworks to build foundation models on it and scale to a fairly large number of nodes,” said Professor Satoshi Matsuoka, director of Japan’s RIKEN Center for Computational Science.
“By global standards for systems, Fugaku is still a very fast AI machine,” he said. “But when you compare it to what OpenAI has put together, it's less performant. It's much faster in HPC terms, but with AI codes it's not as fast as 25,000 A100s [Nvidia GPUs].”
Morgan Stanley estimates that OpenAI’s
next GPT system is being trained on 25,000 Nvidia GPUs, worth around $225m.
Fugaku was built with 158,976 Fujitsu A64FX Arm processors, designed for massively parallel computing, but does not have any GPUs.
“Of course, Fugaku Next, our nextgeneration supercomputer, will have heavy optimization towards running these foundation models,” Matsuoka said.
The current supercomputer, and the research team using it, have helped push the Arm ecosystem forward, and helped solve issues of operating massively parallel architectures at scale.
“It's our role as a national lab to pursue the latest and greatest advanced computing, including AI, but also other aspects of HPC well beyond the normal trajectory that the vendors can think of,” Matsuoka said.

“We need to go beyond the vendor roadmap, or to encourage the vendors to accelerate the roadmap with some of our ideas and findings - that's our role. We're doing that with chip vendors for our next-generation machine. We're doing that with system vendors and with the cloud providers. We collectively advance computing for the greater good.”
Morality and massive machines
Just as open source developers are offering much-needed transparency and insight into the development of this next stage of artificial intelligence, state supercomputers provide a way for the rest of the world to keep up with the corporate giants.
"The dangers of these models should not be inflated, we should be very, very candid and very objective about what is possible,” Matsuoka said. “But, nonetheless, it poses similar dangers if it falls into the wrong hands as something like atomic energy or nuclear technologies.”
State supercomputers have for a long time controlled who accesses them. “We vet the users, we monitor what goes on,” he said. “We've made sure that people don't do Bitcoin mining on these machines, for example.”
Proposals for compute use are submitted, and the results are checked by experts. “A lot of these results are made public, or if a company uses it, the results are supposed to be for the public good,” he continued.
Nuclear power stations and weapons are highly controlled and protected by layers of security. “We will learn the risks and dangers of AI,” he said. “The use of these technologies could revolutionize society,
Issue 48 • April 2023 | 17
Generative AI and our future >>CONTENTS
but foundation models that may have illicit intent must be prevented. Otherwise, it could fall into the wrong hands, it could wreak havoc on society. While it may or may not wipe out the human race, it could still cause a lot of damage.”
That requires state-backed supercomputers, he argued. “These public resources allow for some control, to the extent that with transparency and openness, we can have some trustworthy guarantees. It's a much safer way than just leaving it to some private cloud.”
Building the world’s largest supercomputers
"We are now at a realm where if we are to get very effective foundation models, we need to start training at basically multi-exascale level performance in low precision," Matsuoka explained.
While traditional machine learning and simulation models use 32-bit “singleprecision” floating point numbers (and sometimes 64-bit “double-precision” floating point numbers), generative AI can use lower precision.
Shifting to the half-precision floatingpoint format FP16, and potentially even FP8, means that you can fit more numbers in memory and in the cache, as well as transmit more numbers per second. This move massively improved the computing performance of these models, and has changed the design of the systems used to train them.
Fugaku is capable of 442 petaflops on the FP64-based Linpack benchmark, and achieved two exaflops (that is 1018) using the mixed FP16/FP64 precision HPL-AI benchmark.
OpenAI is secretive about its training resources, but Matsuoka believes that "GPT-4 was trained on a resource that's equivalent to one of the top supercomputers that the state may be putting up," estimating that it could be a 10 exaflops (FP16) machine "with AI optimizations."
“Can we build a 100 exaflops machine to support generative AI?” Matsuoka asked. “Of course we can. Can we build a zettascale machine on FP8 or FP16? Not now, but sometime in the near future. Can we scale the training to that level? Actually, that’s very likely.”
This will mean facing new challenges of scale. “Propping up a 20,000 or a 100,000 node machine is much more difficult,” he said. Going from a 1,000node machine to 10,000 does not simply require scaling by a factor of 10. “It's really hard to operate these machines,” he said,
“it’s anything but a piece of cake.”
It again comes down to the question of when and where models will start to plateau. “Can we go five orders of magnitude better? Maybe. Can we go two orders of magnitude? Probably. We still don't know how far we can go. And that's something that we'll be working on.”
Some people even warn that HPC will be left behind by cloud investments, because what the governments can invest is outclassed by what hyperscalers can spend on their research budgets.
Weak scaling and the future of HPC
To understand what the future might hold for HPC, we must first understand how the large parallel computing systems of today came to be.
extent that we now have machines with this immense power and can utilize this massive scaling,” Matsuoka said. “But we are still making progress with this weak scale, even things like GPUs, it's a weak scaling machine."
That is “the current status quo right now,” he said.
This could change as we near the end of Moore’s Law, the observation that the power of a CPU (based on the number of transistors that can be put into it) will double every two years. Moore’s Law has operated to deliver a continuously increasing number of processor cores per dollar spent on a supercomputer, but as semiconductor fabrication approaches fundamental physical limits, that will no longer be the case
“We will no longer be able to achieve the desired speed up just with weak scaling, so it may start diverging,” Matsuoka warned.
Already we’re beginning to see signs of different approaches. With deep learning models like generative AI able to rely on lower precision like FP16 and FP8, chip designers have added matrix multiply units to their latest hardware to make them significantly better at such lower orders of precision.

Computing tasks including AI can be made to run faster by breaking them up and running parts of them in parallel on different machines, or different parts of the same machine.
In 1967, computer scientist and mainframe pioneer Gene Amdahl noted that parallelization had limits: no matter how many cores you run it on, a program can only run as fast as the portions which cannot be broken down and parallelized.
But in 1988, Sandia Labs' John Gustafson essentially flipped the issue on its head and changed the focus from the speed to the size of the problem.
"So the runtime will not decrease as you add more parallel cores, but the problem size increases," Matsuoka said. "So you're solving a more complicated problem."
That's known as weak scaling, and it's been used by the HPC community for research workloads ever since.
"Technologies advanced, algorithms advanced, hardware advanced, to the
“It’s still weak scaling, but most HPC apps can't make use of them, because the precision is too low,” Matsuoka said. “So machine designers are coming up with all these ideas to keep the performance scaling, but in some cases, there are divergences happening which may not lead to a uniform design where most of the resources can be leveraged by all camps. This would lead to an immense diversity of compute types.”
This could change the supercomputer landscape. “Some people claim it's going to be very diverse, which is a bad thing, because then we have to build these specific machines for a specific purpose,” he said. “We believe that there should be more uniformity, and it’s something that we are actively working on.”
The cloudification of HPC
Riken, Matsuoka’s research institute, is looking at how to keep up with the cadence of hyperscalers, which are spending billions of dollars every quarter on the latest technologies.
“It's not easy for the cloud guys eitheronce you start these scaling wars, you have to buy into this game,” Matsuoka said.
State-backed HPC programs take around 5-10 years between each major system, working from the ground up on a step-
18 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
change machine. During this time cloudbased systems can cycle through multiple generations of hardware.
“The only way we foresee to solve this problem is to be agile ourselves by combining multiple strategies,” said Matsuoka. He wants to keep releasing huge systems, based on fundamental R&D, once or twice a decade - but to augment them with more regular updates of commercial systems.
He hopes that a parallel program could deliver new machines faster, but at a lower cost. “It will not be a billion dollars [like Fugaku], but it could be a few $100 million. These foundation models and their implications are hitting us at a very rapid pace, and we have to act in a very reactive way.”
Riken is also experimenting with the 'Fugaku Cloud Platform,' to make its supercomputer available more widely in partnership with Fujitsu.
IV THE CLOUD
As Riken and others in the supercomputing field look to the cloud for ideas, the hyperscalers have equally turned to the HPC field to understand how to deploy massively interconnected systems.
But, as we have seen, the giants have found that their financial resources have enabled them to outflank the traditional supercomputers.
Sudden changes are always possible but, for now, this leaves hyperscalers like Microsoft and Google in the lead - and developing new architectures for their cloud in the process.
Microsoft: Hyperscale to superscale
"My team is responsible for building the infrastructure that made ChatGPT possible," Nidhi Chappell, Microsoft GM for Azure AI, said. "So we work very closely with OpenAI, but we also work on all of our overall AI infrastructure."
Chappell’s division has been responsible for deploying some of the largest compute clusters in the world. “It's a mindset of combining hyperscale and supercomputing together into the superscale generation,” she said.

This has been a multi-year transition at the company, as it brings the two worlds together. Part of that has involved a number of high-profile hires from the traditional HPC sector, including NERSC's Glenn Lockwood, Cray's CTO Steve Scott, and
the head of Cray's exascale efforts, Dr. Dan Ernst.
“All of these people that you're talking about are a part of my team,” Chappell said. “When you go to a much higher scale, you're dealing with challenges that are at a completely different scale altogether. Supercomputing is the next wave of hyperscale, in some regard, and you have to completely rethink your processes, whether it's how you procure capacity, how you are going to validate it, how you scale it, and how you are going to repair it.”
Microsoft does not share exactly what that scale is. For its standard public instances, they run up to 6,000 GPUs in a single cluster, but “some customers do go past the public offerings,” Chappell said.
OpenAI is one of those customers, working with Microsoft on specialized deployments that are much larger, since the $1bn deal between the companies. “But it is the same fundamental blocks that are available for any customer,” she said.
Size is not the only challenge her team faces. As we saw earlier, researchers are working with ever-larger models, but are also running them for much longer.
“When you're running one single job nonstop for six months, reliability becomes front and center,” she said. “You really have to rethink design completely.”
At the scale of thousands of GPUs, some will break. Traditionally, “hyperscalers will have a lot of independent jobs and so you can take some fleet out and be okay with it,” she said. “For AI training, we had to go back and rethink and redesign how we do reliability, because if you're taking some percentage of your fleet out to maintain it, that percentage is literally not available.
“We had to think how we could bring capacity back quickly. That turnaround time had to be reduced to make sure that all the fleet is available, healthy, and reliable all the time. That's almost fighting
physics at some point.”
That scale will only grow as models expand in scope and time required. But just as OpenAI is benefitting from the flywheel of usage data to improve its next generation of models, Microsoft is also learning an important lesson from running ChatGPT’s infrastructure: how to build the next generation of data centers.
“You don't build ChatGPT's infrastructure from scratch,” she said. “We have a history of building supercomputers that allowed us to build the next generation. And there were so many learnings on the infrastructure that we used for ChatGPT, on how you go from a hyperscaler to a supercomputing hyperscaler.”
As the models get bigger and require more time, that “is going to require us to continue on the pace of bigger, more powerful infrastructure,” she said. “So I do think the pivotal moment [of the launch of ChatGPT] is actually the beginning of a journey.”
Google: From search to AI
Google also sees this as the start of something new. “Once you actually have these things in people's hands, you can start to specialize and optimize,” said the head of the search giant’s global systems and services infrastructure team, Amin Vahdat.
“I think that you're gonna see just a ton of refinement on the software, compiler, and the hardware side,” he added. Vahdat compared the moment to the early days of web search, when it would have been unimaginable for anyone to be able to index the contents of the Internet at the scale that we do today. But as soon as search engines grew in popularity, the industry rose to the challenge.
“Over the next few years, you're going to see dramatic improvements, some of it from hardware and a lot of it from software and optimizations. I think that hardware specialization can and will continue, depending on what we learned about the algorithms. But certainly, we're not going to see 10× a year for many more years, there's some fundamental things that will quickly break.”
That growth in cloud compute has come as the industry has learned and borrowed from the traditional supercomputing sector, allowing for a rapid increase in how much the hyperscalers can offer as single clusters.
But now that they have caught up, fielding systems that would be among the top 10 of the Top500 list of fastest supercomputers, they are having to pave their own path.
Issue 48 • April 2023 | 19
Generative AI and our future >>CONTENTS
“The two sectors are converging, but what we and others are doing is fairly different from [traditional] supercomputing, in that it really brings together the end-toend data sources in a much more dramatic way,” Vahdat said.
“And then I would also say that the amount of specialization we're bringing to the problem is unprecedented,” he added, echoing Professor Matsuoka’s concerns about diverging HPC types.
“In other words, a lot of what these models are doing is they're essentially preprocessing just enormous amounts of data. It’s not the totality of human knowledge, but it’s a lot, and it’s becoming increasingly multimodal”. Just preparing the input properly requires data processing pipelines that are “unprecedented.”
Equally, while HPC has coupled generalpurpose processors with super low latency networking, this workload allows for slightly higher latency envelopes, tied to an accelerated specialized compute setup.
“You don't need that ultra-tight, almost nanosecond latency with tremendous bandwidth at the full scale,” Vahdat said.
“You still need it, but at medium to large scale not at the extra large scale. I do see the parallels with supercomputing, but the second and third-order differences are substantial. We are already into uncharted territory.”
The company differentiates itself from traditional HPC by calling it “purpose-built supercomputing for machine learning,” he said.
At Google, that can mean large clusters of its in-house TPU chip family (it also uses GPUs). For this type of supercomputing, it can couple 4,096 TPUv4s. “It's determined by your topology. We happen to have a 3D Torus, and the radix of your chip,” Vahdat said, essentially meaning that it is a question of how many links come out of every chip and how much bandwidth is allocated along every dimension of the topology.
“So 4,096 is really a technology question and chip real estate question, how much did we allocate to SerDes and bandwidth off the chip? And then given that number and the amount of bandwidth that we need between chips, how do we connect the things together?”
Vahdat noted that the company “could have gone to, let's say double the number of chips, but then we would have been restricting the bandwidth. So now you can have more scale, but half the bisection bandwidth, which was a different balance point.”
The sector could go even more specialized and build clusters that aren’t just better at machine learning, but are specifically better at LLMs - but for now, the sector is moving too fast to do that.
However, it is driving Google to look beyond what a cluster even means, and stitch them together as a single larger system. That could mean combining several clusters within a data center.
But, as these models get larger, it could even mean multiple data centers working in tandem. “The latency requirements are smaller than we might think,” he said. “So I don't think that it's out of the question to be able to couple multiple data centers.”
All of this change means that traditional lines of what constitutes a data center or a supercomputer are beginning to blur. “We are at a super exciting time,” he said. “The way that we do compute is changing, the definition of a supercomputer is changing, the definition of computing is changing.
“We have done a lot in the space over the past couple of decades, such as with TPUv4. We're going to be announcing the next steps in our journey, in the coming months. So the rate of hardware and software innovation is not going to be slowing down in the next couple of years.”
V THE CHIPS
But even with the huge investments made in building out supercomputers in the cloud or in the lab, problems can arise.
“Recently, we saw that due to some issue with the GPUs on our cluster, we actually had to underclock them, because they would just blow past 500 watts a GPU at full throttle, and that would basically burn the GPU and your run would die,” EleutherAI’s Purohit said.
“Even the cloud provider didn't consider it because they thought it shouldn't happen, because it doesn't usually happen. But then it did.”
Similarly, high energy particles “can break through all the redundancies and corrupt your GPU,” he said.
“There might be new problems as we scale beyond where we are right now, there's a limit to how many GPUs you can store in a single data center. Currently, the limit is around 32,000, both due to power and challenges on how to actually design the data center.”
Perhaps the answer is not to build ever larger data centers, but instead move away from GPUs.
Computing’s new wave
Over the past half-decade, as Moore’s Law has slowed and other AI applications have proliferated, AI chip companies have sprouted like mushrooms in the rain.
Many have failed, or been acquired and asset-stripped, as a promised AI revolution has been slow to occur. Now, as a new wave of compute again seems poised to flood data centers, they are hopeful that their time has come.

Each company we spoke to believes that its unique approach will be able to solve the challenge posed by ever-growing AI models.
Tenstorrent
“We believe our tech is uniquely good at where we think models are going to go,” said Matt Mattina, head of AI at chip startup Tenstorrent.
“If you buy into this idea that you can't just natively get to 10 trillion parameters, or however many trillions you want, our architecture has scaling built in.
“So generative AI is fundamentally matrix multiplies [a binary operation that produces a matrix from two matrices], and it’s big models,” he continued. “For that, you need a machine that can do matrix multiply at high throughput and low power, and it needs to be able to scale. You need to be able to connect many, many chips together.
“You need a fundamental building block that's efficient in terms of tops (Tera Operations Per Second) per watt, and can
20 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
scale in an efficient way, which means that you don't need a rack of switches when you add another node of these things.”
The company’s chips each have integrated Ethernet, “so the way you scale is you just connect the chips together over standard Ethernet, there's not a labyrinth of switching and stuff as you go to bigger sizes,” and the company claims its software makes scaling easy.
“It is a very promising architecture,” SemiAnalysis’ Dylan Patel said. “It's very interesting from a scaling and memory standpoint and a software programmability standpoint. But none of that is there yet.
The hardware exists in some capacity and the software is still being worked on. It's a tough problem for them to crack and be usable, and there's a whole lot that still needs to be done.”
Cerebras
Rival Cerebras has a different approach to scaling: Simply make the chip larger.
The Wafer Scale Engine 2 (WSE-2) chip has 2.6 trillion transistors, 850,000 'AI optimized' cores, 40GB of on-chip SRAM memory, 20 petabytes of memory bandwidth, and 220 petabits of aggregate fabric bandwidth. It is packaged in the Cerebras CS-2, a 15U box that also includes an HPE SuperDome Flex server.
“When these big companies are thinking about training generative AI, they're often thinking of gigaflops of compute,” Cerebras CEO and co-founder, Andrew Feldman, said. “We're more efficient [than the current
GPU approach], for sure, but you're still going to use an absurd amount of compute, because we're training in a sort of brute force manner.”
Feldman again believes that there will be a limit to the current approach of giant models, “because we can't go bigger and bigger forever, there's some upper bound.” He thinks sparsity approaches will help bring model sizes down.
Still, he agrees that whatever the models, they will require huge compute clusters. “Big clusters of GPUs are incredibly difficult to use,” he said. “Distributed compute is very painful, and distributing AI work - where you have to go tensor model parallel, and then you have to go pipeline model parallel, and so on - is an unbelievably complicated process.”
The company hopes to solve some of that challenge by moving what would be handled by hundreds of GPUs onto one multi-million dollar mega-chip.
“There are two reasons you break up work,” he said. “One is you can't store all the parameters in memory, second reason is that you can't do a calculation that is needed, and that's usually a big matrix multiply in a big layer.”
In the 175bn parameter GPT-3, the largest matrix multiply is about 12,000 by 12,000. “We can support hundreds of times larger, and because we store our parameters off-chip in our MemoryX technology, we have an arbitrarily large parameter store100-200 trillion is no problem,” he claimed. “And so we have the ability to store vast numbers of parameters, and we have the ability to do the largest multiplication step.”
The single huge chip is not big enough for what the biggest models require, however. “And so we built Andromeda, which is 13.5 million cores. It's one and a half times larger than [Oak Ridge’s exascale system] Frontier in core count, and we were able to stand it up in three days. The first customer put on it was Argonne [another US national computing laboratory], and they were doing things they couldn't do on a 2,000 GPU cluster.”
The Andromeda supercomputer, available over the cloud, combines 16 of Cerebras’ CS-2 systems, but Cerebras has the potential ability to scale to 192 such systems as one cluster. “The scaling limitation is about 160 million cores,” said Feldman.

Cerebras is not the only company to offer its specialized hardware as a cloud product.
Graphcore
“We have decided to change our business
model from selling hardware to operating an AI cloud,” Simon Knowles, the CTO of British AI chip startup Graphcore, said.
“Is it realistic to set up and operate an AI cloud? Clearly, it's sensible because of the enormous margins that Nvidia is able to harvest. The real question is, is there a market for a specialized AI cloud that a generic cloud like AWS doesn't offer? We believe, yes, there is, and that is with IPUs.”
The company’s IPU (Intelligence Processing Unit) is another parallel processor designed from the ground up for AI workloads.
“IPUs have been designed from day one with a mandate not to look like GPUs,” Knowles said. “I'm amazed how many of the startups have tried to basically be an alternative GPU. The world doesn't need another Nvidia; Nvidia are quite good.”
He believes that “what the world needs is machines of different shapes, which will perform well on things where Nvidia can clearly be beaten.” That’s part of the reason why GraphCore is building its own cloud. While it will still sell some hardware, it found that customers won’t commit to buying hardware, because they want it to be as good as or better than Nvidia GPUs on all workloads.
“They wanted insurance that it would satisfy all their future needs that they didn't know about,” he said. “Whereas, as a cloud service, it's like ‘for this set of functions, we can do it at half the price of them.’”
Equally, he does not want to compete with AWS on every metric. “You'd have to be quite bold to believe that one cloud based on one technology could do everything well,” he said.
SambaNova
Another startup offering specialized hardware on the cloud, on-prem, or as a service, is SambaNova. “As the models grow, we just believe that [SambaNova’s architecture] Dataflow is what you're going to need,” CEO Rodrigo Liang said. “We just believe that over time, as these models grow and expand, that the power required, the amount of cost, all those things will just be prohibitive on these legacy architectures.
“So we fundamentally believe that new architecture will allow us to grow with the size of the models in a much more effective and much more efficient way, than the legacy ways of doing it.”
But the incumbent legacy chip designers have also fielded hardware aimed at serving the training and inference needs of the latest AI models.
Issue 48 • April 2023 | 21
Generative AI and our future >>CONTENTS
Intel
“Habana Gaudi has already been proven to be like 2× the performance of the A100 GPU on the MLPerf benchmark,” Dr. Walter Riviera, Intel’s AI technical lead EMEA, claimed of the company’s deep learning training processor.

“When it comes to the GPU, we have the Flex series. And, again, depending on the workload, it is competitive. My advice for any customers out there is test and evaluate what's going to be best for them.”
AMD
AMD has in recent years clawed CPU market share from Intel. But in the world of GPUs it has the second-best product on the market, SemiAnalysis’ Patel believes, and has yet to win a significant share.
“If anyone is going to be able to compete, it's the MI300 GPU,” he said. “But it's missing some things too, it's not there in the software, and there are some aspects of the hardware that are going to be more costly. It's not a home run.”
AMD's data center and accelerated processing CVP Brad McCredie pointed to the company’s leadership in HPC as a key advantage. “We’re in the largest supercomputer on three continents,” he said. “Such a big piece of this exploding AI mushroom is scale, and we've demonstrated our scale capability.
McCredie also believes that AMD’s successes with packing a lot of memory bandwidth onto its chips will prove particularly compelling for generative AI. “When you go into the inferencing of these LLMs, memory capacity and bandwidth comes to the fore. We have eight stacks of high-bandwidth memory on our MI250, which is a leadership position.”
Another key area he highlighted is power efficiency. “When you start getting to this scale, power efficiency is just so important,” he said. “And it's going to keep growing.”
Google’s TPU
Then there’s the tensor processing unit (TPU), a custom AI chip family developed by Google - the same company that came up with the transformer model that forms the basis of current generative AI approaches.
“I think one of the main advantages of TPUs is the interconnect,” researcher Timbers said.
“They have really high networking between chips, and that's incredibly useful for machine learning. For transformers generally, memory bandwidth is the
bottleneck. It's all about moving the data from the RAM on the machine onto the onchip memory, that's the huge bottleneck. TPUs are the best way to do this in the industry, because they have all of this dedicated infrastructure for it.”
The other advantage of the chip is that it’s used by Google to make its largest models, so the development of the hardware and models can be done in tandem.
“It really comes down to co-design,” Google’s Vahdat said. “Understanding what the model needs from a computational perspective, figuring out how to best specify the model from a language perspective, figuring out how to write the compiler, and then map it to the hardware.”
The company also touts the TPU’s energy efficiency as a major advantage as these models grow. In a research paper, the company said that its TPUv4s used DSAs ~2-6× less energy and produced ~20× less CO2e than contemporary chip rivals (not including H100) - but the major caveat is that it was comparing its hyperscale data center to an on-premise facility.
Amazon Trainium
Amazon also has its own Trainium chip family. It has yet to make as much of a splash, although Stability AI recently announced that it would look at training some of its models on the hardware (likely as part of its cloud deal with AWS).
"One capability that I would like to highlight is hardware-accelerated stochastic rounding," said AWS’ director of EC2, Chetan Kapoor.
“So stochastic rounding is a capability that we've built in the chip that intelligently says, okay, am I going to round a number down or up?,” he said, with systems normally just rounding down. “It basically means that with stochastic rounding you can actually get the throughput of FP16 datatype and the accuracy of FP32.”
Nvidia:
The king of generative AI
Nvidia has not been napping - and chip rivals that hope to disrupt its fat margins will find the task daunting, like Microsoft's Bing nibbling away at Google's image of search superiority.
Rather than seeing this as an end to its dominance and a 'code red' moment akin to what's happening at Google, Nvidia says this is the culmination of decades of preparation for this very moment.
“They've been talking about this for
years,” SemiAnalysis’ Patel said. “Sure they were caught off guard with how quickly it took off in the last few months, but they were always targeting this. I think they're very well positioned.”
Outside of Google’s use of TPUs, virtually all the major generative AI models available today were developed on Nvidia’s A100 GPUs. The models of tomorrow will primarily be built with its newly-lanched H100s.
Decades of leading the AI space has meant that an entire sector has been built around its products. “Even as an academic user, if I were to be given infinite compute on those other systems, I would have to do a year of software engineering work before I can even make them useful because the entire deep learning stack is on Nvidia and Nvidia Mellanox [the company’s networking platform],” EleutherAI’s Anthony said. “It's all really a unified system.”
Colleague Purohit added: “It’s the whole ecosystem, not just Mellanox. They optimize it end-to-end so they have the greatest hardware. The generational gap between an A100 and H100 from the preliminary tests that we have done is enough that Nvidia will be the compute king for the foreseeable future.”
In his view, Nvidia has perfected the hardware-improves-software-improveshardware loop, “and the only one that competes is basically Google. Someone could build a better chip, but the software is optimized for Nvidia.”
A key example of Nvidia’s efforts to stay ahead was its launch of the tensor core in late 2017, designed for superior deep learning performance over regular cores based on Nvidia’s CUDA (Compute Unified Device Architecture) parallel platform.
“It changed the game,” Anthony said. “A regular user can just change their code
22 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
to use mixed precision tensor cores for compute and double their performance.”
Now, Nvidia hopes to push things further with a transformer engine in the H100, for FP8. “It’s a hardware-software combination, actually,” Nvidia’s head of data centers and AI, Ian Buck, said. “We basically added eight-bit floating point capability to our GPU, and did that intelligently while maintaining accuracy.”
A software engine essentially monitors the accuracy of the training and inference job along the way, and dynamically lowers things to FP8.
“Tensor cores killed FP32 training entirely. Before that everything was on FP32,” Anthony said. “I don't know if the move to FP8 will be the same, maybe it is not enough precision. We’re yet to see if deep learning people can still converge their models on that hardware.”
But just as the Tesla GPUs in Summit are too old for today’s challenges, H100s won’t be up for the models of the future.
“They're evolving together,” Buck said, pointing out that Nvidia’s GTX 580 cards were used to build AlexNet, one of the most influential convolutional neural networks ever made, way back in 2012.
“Those GPUs are completely impractical today, a data center could not even be built to make them scale for the models of today, it would just fall over,” Buck said.
“So are current GPUs going to get us to 150 trillion parameters? No. But the evolution of our GPUs, the evolution of what goes into the chips, the architecture itself, the memory interconnect, NVLink, and data center designs, will. And then all the software optimizations that are happening on top is how we beat Moore's Law.”
For now, this market remains Nvidia’s to lose. “As everyone's trying to race ahead in
building these models they're going to use [Nvidia’s] GPUs,” Patel said. “They're better and easier to use. Generally, actually, they're cheaper too when you don't have to spend as much time and money on optimizing them.”
This may change as models mature. Currently, in a cut-throat space where performance and speed of deployment are at a premium, Nvidia represents the safe and highly capable bet.
As time goes on and that pressure eases, companies may look to alternative architectures and optimize deployments on cheaper gear.
VI THE NETWORK
Just as silicon is being pushed to its very limits to handle huge AI models, networking and the architecture of data centers are facing challenges.

“With these large systems, no matter what, you can't fit it on a single chip, even if you're Cerebras,” SemiAnalysis’ Patel said. “Well, how do I connect all these split-up chips together? If it's 100 that’s manageable, but if it's thousands or tens of thousands, then you're starting to have real difficulties, and Nvidia is deploying just that. Arguably it's either them or Broadcom that have the best networking in the world.”
But the cloud companies are also becoming more involved. They have the resources to build their own networking gear and topologies to support growing compute clusters.
Amazon
Amazon Web Services has deployed clusters of up to 20,000 GPUs, with AWS’ own purpose-built Nitro networking cards. “And we will deploy multiple clusters,” the company’s Kapoor said. “That is one of the things that I believe differentiates AWS in this particular space. We leverage our Nitro technology to have our own network adapters, which we call Elastic Fabric Adapters.”
The company is in the process of rolling out its second generation of EFA. “And we're also in the process of increasing the bandwidth on a per node basis, around 8× between A100s and H100s,” he said. “We're gonna go up to 3,200Gbps, on a per node basis.”
Google
At Google, an ambitious multi-year effort to
overhaul the networks of its massive data center fleet is beginning to pay off.
The company has begun to deploy Mission Apollo custom optical switching technology (for more, go to page 52) at a scale never seen before in a data center.
Traditional data center networks use a spine and leaf configuration, where computers are connected to top-of-rack switches (leaves), that are then connected to the spine, which consists of electronic packet switches. Project Apollo replaces the spine with entirely optical interconnects that redirect beams of light with mirrors.
"The bandwidth needs of training, and at some scale inference, is just enormous,” said Google’s Vahdat.
Apollo has allowed the company to build networking “topologies that are more closely matched to the communication patterns of these training algorithms,” he said. “We have set up specialized, dedicated networks to distribute parameters among the chips, where enormous amounts of bandwidth are happening synchronously and in real-time.”
This has multiple benefits, he said. At this scale, single chips or racks fail regularly, and “an optical circuit switch is pretty convenient at reconfiguring in response, because now my communication patterns are matching the logical topology of my mesh,” he said.
“I can tell my optical circuit switch, ‘go take some other chips from somewhere else, reconfigure the optical circuit switch to plug those chips into the missing hole, and then keep going.’ There's no need to restart the whole computation or - worst case - start from scratch.”
Apollo also helps deploy capacity flexibly. The company’s TPUv4 scales up to blocks of 4,096 chips. “If I schedule 256 here, 64 there, 128 here, another 512 there, all of a sudden, I'm going to create some holes, where I have a bunch of 64 blocks of chips available.”
In a traditional network architecture, if a customer wanted 512 of those chips they’d be unable to use them. “If I didn't have an optical circuit switch, I'd be sunk, I'd have to wait for some jobs to finish,” Vahdat said. “They're already taking up portions of my mesh, and I don't have a contiguous 512 even though I might have 1,024 chips available.”
But with the optical circuit switch, the company can “connect the right pieces together to create a beautiful 512-node mesh that's logically contiguous. So separating logical from physical topology is super powerful."
Issue 48 • April 2023 | 23
Generative AI and our future >>CONTENTS
Colos and wholesalers
If generative AI becomes a major workload, then every data center in the world could find that it has to rebuild its network, said Ivo Ivanov, CEO of Internet exchange DECIX. “There are three critical sets of services we see: 1) Cloud exchange, so direct connectivity to single clouds, 2) Direct interconnection between different clouds used by the enterprise, and 3) Peering for direct interconnect to other networks of end users and customers.”
He argued: “If these services are fundamental for creating the environment that generative AI needs in terms of infrastructure, then every single data center operator today needs to have a solution for an interconnection platform.”
That future-proof network service has to be seamless, he said: “If data center operators do not offer this to their customers today, and in the future, they will just reduce themselves to operators of closets for servers.”
VII THE DATA CENTERS
A potential shift in the nature of workloads will filter down to the wider data center industry, impacting how they are built and where they are located.
Bigger data centers, hotter racks
Digital Realty’s CEO Andy Power believes that generative AI will lead to “a monumental wave of demand.
“It's still new as to how it plays out in the data center industry, but it's definitely going to be large-scale demand. Just do the math on these quotes of spend and A100 chips and think about the gigawatts of power required for them.”
When he joined the business nearly eight years ago “we were moving from one to three megawatt IT suites, and we quickly went to six to eight, then tens,” he recalled. “I think the biggest building we built was 100MW over several years. And the biggest deals we'd sign were 50MW-type things. Now you're hearing some more deals in
the hundreds of megawatts, and I've had preliminary conversations in the last handful of months where customers are saying ‘talk to me about a gigawatt.’”
For training AI models, Power believes that we’ll see a change from the traditional cloud approach which focuses on splitting up workloads across multiple regions while keeping it close to the end user.
“Given the intensity of compute, you can’t just break these up and patchwork them across many geographies or cities,” he said. At the same time, “you're not going to put this out in the middle of nowhere, because of the infrastructure and the data exchange.”
These facilities will still need close proximity to other data centers with more traditional data and workloads, but “the proximity and how close that AI workload needs to sit relative to cloud and data is still an unknown.”
He believes that it “will still be very major metro focused,” which will prove a challenge because “you’re going to need large swaths of contiguous land and power, but it’s harder and harder to find a contiguous gigawatt of power,” he said, pointing to transmission challenges in Virginia and elsewhere.
As for the data centers themselves, “plain and simple, it's gonna be a hotter environment, you're just going to put a lot more power-dense servers in and you're gonna need to innovate your existing footprints, and your design for new footprints,” he said.
“We've been innovating for our enterprise customers in terms of looking at liquid cooling. It's been quite niche and trial, to be honest with you,” he said. “We've also been doing co-design with our hyperscale customers, but those have been exceptions, not the norms. I think you're gonna see a preponderance of more norms.”
Specialized buildings
Moving forward, he believes that ”you'll have two buildings that will be right next to each other and one will be supporting hybrid cloud. And then you have another one next to it that is double or triple the
size, with a different design, and a different cooling infrastructure, and a different power density.”
Amazon agrees that large AI models will need specialized facilities. “Training needs to be clustered, and you need to have really, really large and deep pools of a particular capacity,” AWS’ Kapoor said.
“The strategy that we have been executing over the last few years, and we're going to double down on, is that we're going to pick a few data centers that are tied to our main regions, like Northern Virginia (US-East-1) or Oregon (US-West-2) as an example, and build really large clusters with dedicated data centers. Not just with the raw compute, but also couple it with storage racks to actually support high-speed file systems.”
On the training side, the company will have specialized cluster deployments. “And you can imagine that we're going to rinse and repeat across GPUs and Trainium,” Kapoor said. “So there'll be dedicated data centers for H100 GPUs. And there'll be dedicated data centers for Trainium.”
Things will be different on the inference side, where it will be closer to the traditional cloud model. “The requests that we're seeing is that customers need multiple availability zones, they need support in multiple regions. That's where some of our core capability around scale and infrastructure for AWS really shines. A lot of these applications tend to be real-time in nature, so having the compute as close as possible to the user becomes super, super important.”
However, the company does not plan to follow the same dense server rack approach of its cloud competitors.

“Instead of packing in a lot of compute into a single rack, what we're trying to do is to build infrastructure that is scalable and deployable across multiple regions, and is as power-efficient as possible,” Kapoor said. “If you're trying to densely pack a lot of these servers, the cost is going to go up, because you'll have to come up with really expensive solutions to actually cool it.”
Google’s Vahdat agreed that we will see specific clusters for large-scale training, but noted that over the longer term it may not be as segmented. “The interesting question here is, what happens in a world where you're going to want to incrementally refine your models? I think that the line between training and serving will become somewhat more blurred than the way we do things right now.”
Comparing it to the early days of the Internet, where search indexing was handled by a few high-compute centers but
24 | DCD Magazine • datacenterdynamics.com
DCD Magazine #48 >>CONTENTS
is now spread across the world, he noted: “We blurred the line between training and serving. You're gonna see some of that moving forward with this.”
Where and how to build
While this new wave of workload risks leaving some businesses in its wake, Digital Realty’s CEO sees this moment as a “rising tide to raise all ships, coming as a third wave when the second and first still haven't really reached the shore.”
The first two waves were customers moving from on-prem to colocation, and then to cloud services delivered from hyperscale wholesale deployments.
That’s great news for the industry, but one that comes after years of the sector struggling to keep up. “Demand keeps outrunning supply, [the industry] is bending over coughing at its knees because it's out of gas,” Power said. “The third wave of demand is not coming at a time that
Could it all just be hype?
As we plan for the future, and try to extrapolate what AI means for the data center industry and humanity more broadly, it is important to take a step back from the breathless coverage that potentially transformational technologies can engender.
After the silicon boom, the birth of the Internet, the smartphone and app revolution, and cloud proliferation, innovation has plateaued. Silicon has gotten more powerful, but at slower and slower rates. Internet businesses have matured, and solidified around a few giant corporations. Apps have winnowed to a few major destinations, rarely displaced by newcomers. Each new smartphone generation is barely distinguishable from the last.
But those who have benefitted from the previous booms remain paranoid about what could come next and displace them. Those who missed out are equally seeking the next opportunity. Both look to the past and the wealth generated by inflection points as proof that the next wave will follow the same path. This has led to a culture of multiple false starts and overpromises.
The metaverse was meant to be the next wave of the Internet. Instead, it just tanked Meta's share price. Cryptocurrency was meant to overhaul financial systems. Instead, it burned the planet, and solidified wealth in the hands of a few. NFTs were set to revolutionize art, but rapidly became a joke. After years of promotion, commercial
is fortuitous for it to be easy streets for growth.”
For all its hopes of solving or transcending the challenges of today, the growth of generative AI will be held back by the wider difficulties that have plagued the data center market - the problems of scale.
How can data center operators rapidly build out capacity at a faster and larger scale, consuming more power, land, and potentially water - ideally all while using renewable resources and not causing emissions to balloon?
“Power constraints in Northern Virginia, environmental concerns, moratoriums, nimbyism, supply chain problems, worker talent shortages, and so on,” Power listed the external problems.
“And that ignores the stuff that goes into the data centers that the customer owns and operates. A lot of these things are long lead times,” with GPUs currently hard
for even hyperscalers to acquire, causing rationing.
“The economy has been running hot for many years now,” Power said, “And it's gonna take a while to replenish a lot of this infrastructure, bringing transmission lines into different areas. And it is a massive interwoven, governmental, local community effort.”
While AI researchers and chip designers face the scale challenges of parameter counts and memory allocation, data center builders and operators will have to overcome their own scaling bottlenecks to meet the demands of generative AI.
“We'll continue to see bigger milestones that will require us to have compute not become the deterrent for AI progress and more of an accelerant for it,” Microsoft’s Chappell said. “Even just looking at the roadmap that I am working on right now, it's amazing, the scale is unprecedented. And it's completely required.”
quantum computers remain as intangible as Schrodinger’s cat.
Generative AI appears to be different. The pace of advancement and the end results are clearly evidence that there are more tangible use cases. But it is notable that crypto enthusiasts have rebranded as AI proponents, and metaverse businesses have pivoted to generative ones. Many of the people promoting the next big thing could be pushing the next big fad.
The speed at which a technology advances is a combination of four factors: The intellectual power we bring to bear, the tools we can use, luck, and the willingness to fund and support it.
We have spoken to some of the minds exploring and expanding this space, and discussed some of the technologies that will power what comes next - from chipscale up to data centers and the cloud.
But we have not touched on the other two variables.
Luck, by its nature, cannot be captured until it has passed. Business models, on the other hand, are usually among the easier subjects to interrogate. Not so in this case, as the technology and hype outpace attempts to build sustainable businesses.
Again, we have seen this before with the dotcom bubble and every other tech boom. Much of it is baked into the Silicon Valley mindset, betting huge sums on each new tech without a clear monetization strategy, hoping that the scale of transformation will eventually lead
to unfathomable wealth.
Higher interest rates, a number of highprofile failures, and the collapse of Silicon Valley Bank has put such a mentality under strain.
At the moment, generative AI companies are raising huge sums on the back of wild promises of future wealth. The pace of evolution will depend on how many can escape the gravity well of scaling and operational costs, to build realistic and sustainable businesses before the purse strings inevitably tighten.
And those eventual winners will be the ones to define the eventual shape of AI.
We do not yet know how expensive it will be to train larger models, nor if we have enough data to support them. We do not know how much they will cost to run, and how many business models will be able to bring in enough revenue to cover that cost.
We do not know whether large language model hallucinations can be eliminated, or whether the uncanny valley of knowledge, where AIs produce convincing versions of realities that do not exist, will remain a limiting factor.
We do not know in what direction the models will grow. All we know is that the process of growth and exploration will be nourished by ever more data and more compute.
And that will require a new wave of data centers, ready to meet the challenge.
Issue 48 • April 2023 | 25
AI
future
Generative
and our
>>CONTENTS
Talking data center diplomacy with CyrusOne’s CEO





 Peter Judge Executive Editor
Peter Judge Executive Editor
The focus of the data center sector has shifted towards large-scale projects, where very demanding customers want very standardized products, delivered very quickly to their precise needs and budgets.



This requires large investments. Data center builders typically have large backers, who want to own a piece of an organization that is both expanding and profitable.
The CEOs who run these outfits have to juggle those two demands, along with the conflicting difficulties of supply chains, power supplies and local legislation. Their

>>CONTENTS
Data center builders have to keep both customers and investors happy. That means being circumspect, Eric Schwartz tells us
role is increasingly a diplomatic one, saying the things which will please all their stakeholders.
Eric Schwartz is the latest executive to drop into one of these roles at a big data center builder. Three months into his tenure as CEO at CyrusOne, he spoke to us about what data center building entails - and he spoke somewhat guardedly.

He is perhaps the most diplomatic CEO we’ve spoken to. He is the fifth CEO at CyrusOne in the last three years, a period which began in February 2020, when nineyear CEO Gary Wojtaszek stepped down. The next incumbent, Tesh Durvasula lasted only four months, before CyrusOne appointed Bruce Duncan, a realtor with no data center
experience in July 2020. Duncan lasted a whole year, before the company brought back its co-founder and former CEO David Ferdman. After another year Schwartz arrived.
What was all that about? Schwartz declines to comment on CyrusOne’s revolving door of leadership: “That was clearly before my time, and I didn't really have visibility into that,” he says.
Constant change
While it played musical CEOs, CyrusOne was also looking for backers. It was up for sale. Eventually, it was bought by investors Kohlberg Kravis Roberts (KKR) and Global Infrastructure Partners (GIP), and taken private. At $15 billion, this was the largest data center M&A ever, agreed in November 2021 and finalized in March 2022.
The day we speak to him, the industry certainly feels volatile. News has just broken that industry long-timer Bill Stein has abruptly stepped down as CEO at one of the industry’s giants, Digital Realty.
Schwartz’s guard is still up: “I read the press like everybody else. I don't have any particular insight into what happened. Bill was in that role for well over 10 years, and built a body of work that was formidable.”
He doesn’t think CEOs are changing more frequently: “I haven't observed things to be demonstrably different. There's certainly more data center companies that we all track, and that just means there are more CEOs to keep track of. As it gets bigger, there's just a larger universe to observe these transitions. Maybe that's overly simplistic on my part, but I think there's always going to be a certain level of turnover.”
Whatever the reality across the industry, it’s obvious that Schwartz wants to offer stability. He says that’s what he brings from a steady 16-year stint at industry colossus Equinix.
“That was certainly the pitch I made, convincing them to bring me on here,” he laughs. “I'm aiming to be both permanent and a source of stability and leadership for the company. Whatever the circumstances were for my predecessors, my track record of having been at my previous job for 16 years, has sent a clear signal.”
Strategy and expansion
There’s more to it than that, of course. Schwartz left Equinix as chief strategy officer, with experience in steering a large company around big opportunities and risks. But before that, he spent some ten years running Equinix’s European operations.
That’s an interesting background, because
CyrusOne began as a US colocation provider with roots as far back as the year 2000. It expanded through acquisition and building organically for a decade, then went public with an IPO in 2013.

In 2017 made the big step of expanding into Europe with the acquisition of Zenium.
“For CyrusOne, more than half of our business is in the US, but it is growing at a faster rate in Europe - just off of a smaller base,” he says. “So my experience having been in Europe, and a leader in that business, makes for the right profile for what CyrusOne is doing right now.”
He’s clearly pleased at the prospect: “The opportunities we're seeing just make me very enthusiastic about the growth potential [in Europe].”
And he’s ready to address the fragmented nature of the European market: “It's not Europe, it's ultimately Germany, the UK, France, the Netherlands, Ireland, and Spain, which are all European countries, but different markets unto themselves.”
Success here will demand that CyrusOne knows how to address those differences, he says, “rather than try and mold it to fit the model that we have for our American business. Trading in Europe requires understanding the European markets and working to those requirements.”
Understanding the different regulations, and levels of availability of land and power in different European countries, is “right up my alley,” he says, following his stint at Equinix. “To me, this is very familiar ground, and we have a very good team based out of London.”
Serving big customers - and big backers
Of course, CyrusOne is addressing different users than Equinix. Instead of serving a lot of enterprise customers and others with a business model that involves connectivity, CyrusOne is creating large amounts of space for a small set of hyperscale customers and large enterprises.
“Our focus is on being a data center developer,” he says. “Finding land, getting the power to the site, constructing a reliable design and then operating it to the specifications of very demanding customers who usually have large deployments with us.
“In my three months here, I've been very impressed with how the company has been built to execute and deliver to that specific set of market requirements,” he says.
To be honest, the requirements he mentions don’t sound that special. Everyone deals with efficiency, sustainability, and supply chain disruption.
Issue 48 • April 2023 | 27 CyrusOne's CEO
>>CONTENTS
And his answers sound like common sense: standardization and good relationships
“At any given moment we've got at least five different developments underway. We manage the supply chain with vendors and components across that entire portfolio in a common way. So we are operating one supply chain that is supplying five projects.
“It's an absolute necessity, because if they were five independent projects operating on their own, we would be no different than a data center company in any of those locations working in isolation.”
Companies buying big data centers wholesale are now a distinct and demanding bunch, he says: “Years ago, we just talked about data centers, and that was the industry. Now there are definitely segments.”



Pleasing the investors
He has to keep the investors happy. Big data center builders like CyrusOne, DigitalBridge and Goldman Sachs’ GCI, have big backers. While there’s a data center boom, their job is easy: building big barns and shoveling cash back to the backers.
But right now, with some suggesting the pace of data center building may slacken off, those investors are starting to ask questionsconsider Legion’s ultimatum to Marc Ganzi at DigitalBridge.
So Schwartz spends some time with us praising his investors (and making sure we mention both of them): “They're both very, very impressive firms. And as you can tell, they're both my boss.”
KKR and GIP have expertise, he says: “Not so much about data centers, because they're counting on us to help. But about the capital markets, about the energy markets, about investment in all sorts of adjacent areas. The opportunity to have them closely involved in the business just gives us a little bit more market intelligence than we would otherwise have.”
He doesn’t expect to see them consolidating CyrusOne with any of their other holdings, as it has its own unique value: “We're going to continue to operate CyrusOne as a standalone company.




Taking a company private is often seen as a liberation from quarterly reporting and public disclosures, but Schwartz isn’t so blasé: “Ultimately, it's trading one set of stakeholders, a set of public shareholders,
for a different set of stakeholders, which are private investors.”
Perhaps not as pointedly as Ganzi at DigitalBridge, Schwartz is under pressure.

“KKR and GIP have deep resources when it comes to raising capital and accessing the capital markets,” he says, but the onus is on CyrusOne to bring a return on that investment: “This is a capital-intensive industry. We've got to access that capital to continue to fuel our growth.
“I'm very confident that we can access the capital we need for investments in projects that are feasible. I'm equally confident that they’ll be equally direct with us about projects that aren't.”
Dealing with regulators
Speaking of projects, CyrusOne is building in several markets in Europe, including London and Frankfurt, and a number of others in the US, he says.
Today there is something of a backlash against data centers, with energy supplies in crisis and new regulations. Are things tougher now, we ask?
“It's very different than it was a number of years ago, where data centers weren't really on the agenda of governance,” he says. “They all recognize the importance and the relevance of data centers, and they've got to balance that against other policy concerns.”
That’s “part of the world that we're living in,” he says.
“I think the industry as a whole is doing a better job of engaging with policymakers and regulators to explain not only what we're doing and the value that it has to the broader economy - and to align the development programs that we're executing with what regulators and governments are looking to accomplish.”
In response to concerns about energy in Europe, he says “we're steadily improving efficiency, and we're getting better and better at cooperating with the energy regulators as to the demands that we place on the grid and related infrastructure.”
He also calls out concerns about privacy and land use.
“Whether the scope of regulation expands or not, will depend on where the government
sees the need to be involved ve they let the market dictate.”
rusOne has accelerated its ommitment to be net-zero by 2030, an s also been active in material and water efficiency, “because we operate in several locations that are quite constrained on water.”
The company has done an analysis of the trade-off between water and energy use, concluding that in some instances water savings beat energy savings.
As a generalization, he thinks the US may be leading on water use, which produces ideas that can be applied in Europe, while Europe’s current energy crisis may produce lessons that can be applied in the US
“We're applying the learnings on water from the US to Europe, and we're applying learnings on energy efficiency and power efficiency in Europe back to the US,” he says. “But the energy market in the US is quite different than Europe today - and the energy market in the UK is different from the energy market in Germany and Spain.”
Projects underway
Like any giant data center builder, CyrusOne is looking to expand into other territories, but Schwartz won’t say what they are: “We've got several different options that we're considering, but I can't narrow it down until I've got something tangible to share with you.”
Outside London, CyrusOne has announced a plan for a 90MW data center in Iver, which he is proud of: “We really took into account the topology of the site, to come up with a distinctive design, with a green roof. It's very well integrated into the surrounding area, and there was a lot of engagement with the local planning authorities and other constituencies, so the design only going to be effective for the customers, but also for the broader community.”
Schwartz is hoping for recognition from this project, perhaps because CyrusOne is still less well-known than its rivals.
The company is not widely perceived as a large player, but he thinks that is changing. “In the broader industry, we're growing in visibility.”

While not as big as Equinix or Digital Realty, CyrusOne is “larger than people perceive,” says Schwartz.
“And I enjoy being the underdog.”
28 | DCD Magazine • datacenterdynamics.com
>>CONTENTS
Data centers are a conversation
Keep
In the world of data centers, the giant bit-barns run by global hyperscalers get most of the attention, but there’s a world of smaller colocation providers dealing with local needs.
And those smaller players live or die by the quality of their conversations, says Alexandra Schless, CEO of the Netherlands provider NorthC.
Speaking to DCD, she has a clear message. Data centers need a strong local perspective. They need to be part of the community around them. And they can only do that by talking to governments, customers, and other local players
It’s a viewpoint that she thinks she can spread to neighboring countries.
Dutch roots
NorthC began in 2019, when the DWS investment division of Deutsche Bank merged two Dutch providers it owned, NLDC and TDCG. It dubbed the new company NorthC in 2020 and appointed Schless as CEO.
A Dutch data center veteran, Schless spent 16 years at European colocation provider Telecity, running the Netherlands and then Western Europe. In 2016, Telecity was acquired by Equinix, and she stepped up there to become Equinix’s vice president of global accounts & networks for EMEA.
At NorthC, she has narrowed her horizon to become a provider in a single country - albeit as the biggest Dutch provider, with ten data centers to its name.
Or perhaps her arrival was a sign that NorthC intended to expand beyond the borders of the Netherlands.
As she tells DCD, the true story is somewhere between the two. Schless has a vision of how data centers should cater to local markets - and NorthC is starting to expand beyond its Dutch roots.
Birth of the industry
Schless began in the early days of the Internet industry and data centers. The pioneering UK firm Telecity started in 1998 with its first facility in Manchester; two years later Schless opened up the Netherlands for the company.
“I started at TeleCity Group in the Netherlands in 2000, and that was really the early days of the data center industry. At that time, we had a few companies starting off these data centers.”

Telecity grew rapidly, building and acquiring facilities: “We grew the company, over 15 years, to the leading position in Europe. And then when we sold it to Equinix,” she said.
That deal was actually fought over. Telecity was initially sold to its European rival Interxion for $2.2 billion, but then

NorthC's CEO
it local, keep talking, and data centers can be a welcome part of their community, says Alexandra Schless of NorthC
>>CONTENTS
Peter Judge Executive Editor
global player Equinix stepped in, and the price went up to $3.5 billion.
“I stayed at Equinix for three years,” says Schless. Equinix promoted her to a vice president of the whole EMEA region, but her views on the data center sector eventually took her out of the global player, to a more regional one.
“I came in contact with our current shareholders, DWS,” she says, “and they told me about their view on the development of the data center industry.”
Despite - or perhaps because of - her time at Equinix, Schless believes global players can’t do it all: “You will always have the international providers serving an international global market, where customers need global coverage,” she says.
That was the vision behind NorthC - and to be frank, the group needed a vision, to avoid the inevitable process of consolidation and eventual acquisition by a global player like Equinix, or rival Digital Realty.
TDCG was a local group with four facilities, while NLDC was a spin-off from the Dutch telco KPN, a victim of the mismatch between the ambitions of telecoms companies, and their abilities in the data center sector.
Like almost every other telco in the late 2010s, KPN got out of data centers. First it rebranded its six facilities with the bland name NLDC (Netherlands Data Centres), and then sold them to DWS, clearing the way for its own consolidatory $50 million acquisition by US telco GTT.
When DWS merged the two companies, it could have been simply another step in the consolidation of data center providers, but Schless says not: “We started NorthC by buying the data centers of KPN and the TDC group, and formed NorthC based on the vision that organizations value having a data center partner they can phone.”
Customers need local attention because of hybrid IT, she says: “Businesses, public and semi-public organizations do a hybrid solution, using the public cloud or private cloud and still have part of their IT environments on-premises, which may be managed by an IT partner or themselves.”
That makes things more complex: “More and more data is being generated by businesses, and their competitive position is driven by the data. They have the data analysis, and at the same time have to optimize their business processes. Data volumes will increase over time with more data to be analyzed and processed.”
With that complexity, not all customers trust a remote large operator: “We spoke to
existing customers, and also new customers and prospects, and we saw that a lot of these customers really value the fact that their data center partner is in the region where they have their headquarters or their main production sites.”
In her view, data center customers are still hands-on, and they want their partners to be the same.
“They still have their own people coming to the sites, and they use a regional local partner that can also come to the site,” she says. “It was really interesting to see that, apart from having the data close to where it is generated and where it needs to be processed, they also valued the fact that the data center was close to where they're located. And I strongly believe in that.”
Continuity
“If you look at what we, as a data center, provide for our customers, the basic service is power and data halls to put your IT equipment in,” she says.
That need goes back to the early days, when colocation data centers provided a more reliable home for enterprise IT: “In the old days, the customer had their IT environment in their own office or in the basement. And then they thought, I want to have continuity and have it up and running 24/7. So I'll lift and shift the servers and the routers, and put them in a data center, because I don't have a generator in my own basement.”
Continuity is still a major reason to choose a data center, she says: “That is still part of the service, but today, the customers are looking for a data center partner that can be part of the total solution.
“If you look at the hybrid cloud strategy, you need to be able to have data transferred between public cloud, private cloud and maybe keep some of it on-prem,” she says “So, nowadays, the customers are looking for a solution that provides them the possibility to connect to several clouds. They need to have the connectivity to be connected to their own offices.”
That means they need IT partners, “that can help them with creating and maintaining certain business applications.”
Customers looking for a data center partner today, are looking for one which is part of an “ecosystem,” she says, “that can really help you with this digital transformation.”
Keep it local
This places demands on the skills of the data center operators within the company, but it’s also fulfilling for the staff to be in an
environment where their skills are important - and that’s a different picture from a telco, where data centers were an afterthought.
“The companies we bought, the data centers of KPN and the data centers of TCG, had a different positioning,” she explains. “The data centers of KPN were part of a very big telecommunications company, and data center services were just one of the things that they offered to their end customers.
“At NorthC, we have a different focus,” she says. “We are in essence a data center company - and, the conversations we have with our customers are all around the solutions that we can provide from the data center.”
For the staff at TDCG, they can now be “proper data center people,” and this has been a welcome change: “During the integration of the two companies, we really took the people on board, to help them make that change from a big telecommunications company to a focused specialized data center company, where you have different conversations with end customers. And I would say that we have succeeded in that.”
NorthC has kept the experienced staff of its constituent companies, she says: “In an integration period it is normal that some colleagues will leave. But we have that momentum and a lot of colleagues are into the growth. We have a lot of colleagues from the existing organizations, but we also got a lot of new colleagues.”
A regional player - entering Germany
But companies can’t stand still. NorthC is now a major Netherlands provider, but if it is not heading for acquisition, what are its next steps?
“We're really a standalone regional data center player,” she says, with a good proposition for Netherlands-based customers, and plans to expand by replicating the same local services model in neighboring countries.
To avoid confusion, she clarifies. Wholesale colocation giants use the word “regional” to continent-sized areas such as LATAM, APAC, or EMEA. But for Schless, “regional” refers to an area the size of one country, or smaller.
“I think the whole regional play we see in the Netherlands, I'm absolutely convinced that it applies also to other countries in Europe,” she says. So far, that ambition expands to the so-called “DACH” area, consisting of the German-speaking countries of Germany, Austria, and Switzerland.
“And if you look, at Germany, that’s a
30 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
country that is really regionalized,” she says, referring to the German structure of states or “lande,” which often have different laws. “For me, it was quite evident that next to the Netherlands, Germany would be a country and a market where this regional play would be successful.
“In Germany, we bought the data centers of q.beyond, a managed services company,” she says.
Formed as a consultancy, q.beyond bought into the data center sector around 2010, acquiring IP Partner and IP Exchange, a colocation player that had roots back to around the year 2000.
Like NLDC, q.beyond was not exploiting and developing its data center facilities as centers for business, says Schless: “We saw exactly the same thing - the data centers were part of a bigger company that also provided other services.”
As part of NorthC, IP Exchange staff now have a more specific job. “They say - now we can really focus on the data centers, we're going to invest again in data centers, and we're going to really be part of a company that wants to grow in the data center industry.”
To develop NorthC in the Germanic countries, Schless has appointed Frank Zachmann, a 25-year data center veteran, with multiple stints at Equinix, Interxion, and other data center players, as managing director.
NorthC’s press release on Zachman’s appointment hints at wider goals: “In the long term, NorthC wants to continue this growth right across Europe, creating a platform of interconnected regional data centers for regional expertise and locations on a national level.”
“[In Germany] it is even more important to understand properly the regional characteristics and the regional culture, and to have a relationship with a regional IT
partner,” says Schless, emphasizing that IP Exchange is strong in the major cities of the Bavaria (Bayern) region.
“Now we're present in Nuremberg and Munich. And you know, companies in Bayern really like to do business with other companies from that region. We have a lot of customers in Nuremberg and Munich. We also do have customers from other regions, but the majority comes from there.”
Moving into Switzerland
Continuing its DACH expansion, NorthC next bought three data centers belonging to Netrics in Switzerland, where Schless sees a similar micro-state regionalization.
“Switzerland has different cantons, or ‘provinces.’ Although Switzerland is a much smaller country, the different cantons have their own way of interacting and dealing with regional companies.”
Within those cantons, Swiss public and private companies are going through the same digital transformation processes, and adopting hybrid cloud solutions, so Schless believes the country is ripe for the NorthC approach.

Since she mentioned DACH, we ask if the remaining DACH country Austria is the next target. For now, she says, NorthC will be building up in its existing locations.
“We’re quite busy with the first integration phase in Switzerland and Germany,” she says. “We would like to further expand in the countries because ultimately, we want to have a nationwide platform of regional data centers, meaning we're looking at other regions in Germany and Switzerland.”
Beyond that, she says “we don’t have targets, but we look at the countries where we think, is it a logical add-on to our platform of regional data centers? And is it an interesting opportunity?”
NorthC has “the appetite and the ambition,” she says, and “if there are
interesting opportunities for us in Northern Europe, we will seriously look at them.”
The company’s approach of developing local facilities squares well with governments’ desire to establish data centers outside the overcrowded hubs. “In the Netherlands, the national government is looking at different areas where they can where they can establish data center clusters.” NorthC’s facilities in Eindhoven and Groningen meet that demand.
But she’s definite that NorthC has no interest in making big wholesale data centers: “We're, in the enterprise and public sector. Hyperscale is a big market but it already has a number of very good suppliers. And it's a different play. In my opinion, there are already enough suppliers going after the segment.”
“I think what we're good at, and what we really like to do, is that close interaction with different enterprises. The DNA of NorthC is being local, open, flexible, and entrepreneurial. We like creating these regional relationships and ecosystems, That is what our mission is.”
Local governments
Do data centers need more local advocacy in NorthC’s home turf, the Netherlands and Germany? After all, Amsterdam and Frankfurt are two cities where the sector’s demands for land and power have faced strong local criticism, and the authorities have responded with restrictions affecting new facilities.
“In every country, we need to make sure that we build the relationship with the local governmental bodies,” she says. “It’s very important when you can explain to local governments that we need data centers, because of our whole digital economy.”
Local governments can be critical towards data centers, she agrees, but says her approach is to “start the conversation early enough with them, about how we take sustainability on our agenda, and what we
Issue 48 • April 2023 | 31 NorthC's CEO
>>CONTENTS
can do to give something back to the region.”
With that approach, she says, “it has been actually a good cooperation.”
NorthC’s smaller data centers use around four or five MW, and that compares well against the unpopular hyperscale facilities: “Up until now, we tend to get good cooperation with the local governments, but it is up to us to inform them and be open to them as soon as possible.”
Pitched the right way, she says “data centers can actually be part of the energy transition agenda.” She says that colocation data centers can consolidate enterprise IT, eliminating smaller inefficient IT rooms.
She’s ready to offer data center waste heat as an incentive: “Heating up schools, swimming pools, and houses, is a very interesting topic for a local government to further discuss, because that helps them on their sustainable agenda.”
All too often, waste heat reuse falls by the wayside as the data center doesn’t have a heat customer nearby but Schless says, it can be done with enough discussion. “When you have the plans, you have to get into the conversation as early as possible.
“You have to take the government by the hand and say this is possible, we can do this,” she says. “We built a new data center in Rotterdam last year. When we spoke to the local government, we came in contact with another party that wants to maintain and build that whole [heat] infrastructure.
"You need local government, and you need a commercial party who's going to really manage and build the infrastructure.”
The project is running as of early 2023, she says: “We will heat up 11,000 houses in the beginning, and that will grow, the more the data center is filled up. A lot of people talk about this, but you need three parties at the table or even more to get it done.”
Energy prices
Like other providers, NorthC has had to deal with high energy costs during the Ukraine war. “The energy price is something that I have never experienced in my 20 years of data centers,” she says.
“We buy energy on the future market, two, three, or four years ahead, and that has turned out well, for us - although the prices are higher than I'm used to five, six, or seven years ago.”
She also benefits from intelligent customers: “In the data center industry, customers pay for the energy they use. We have a pass-on model of energy. And with what's happened this year, all the customers understand what's happening on the energy market, and understand that energy has become more expensive.”
She’s looking to avoid future trouble, though: “We're thinking about buying energy in a different way. There's the opportunity, as a large user of energy, to buy solar power or wind power directly from a solar park, or wind park, and not get everything from the grid. That is something we're looking into as well, which gives a longer-term, more predictable view of what your power prices would be.
Prices are going up for these power purchase agreements (PPAs), because of heavy buying by the hyperscalers like Google and AWS, but she thinks, there is enough renewable energy to go around.
“There are a lot of initiatives in the Netherlands, as well as in Germany, for smaller solar parks,” she says. “We don't need the size of the parks that the Amazons, Googles, and Microsofts are buying from. We are currently actually already in discussion with different companies that want to build a solar park where we can have dedicated power.
“You will always need some form of energy via the grid, but it's a smaller part of what you're buying, so so you're a little bit less sensitive.”
Eindhoven and hydrogen
NorthC certainly played the sustainability card when it opened a data center in Groningen which has hydrogen as a backup option, and brought out hydrogen once again for another new facility in Eindhoven
But as far as hydrogen is concerned, not all data centers are equal.
“In Groningen, the province is building an infrastructure for hydrogen,” says Schless. so the Groningen facility has hydrogen fuel cells for its backup power. “Ultimately we can connect to this infrastructure directly, and always have the availability of hydrogen for backup.”
In Eindhoven, there is no immediate prospect of a hydrogen infrastructure, but NorthC needed a data center there right away.
"Eindhoven is one of the fastest-growing high-tech regions in the Netherlands," she tells us. "It is well known for its university, but also a lot of startups and technology companies in the area. So for us, it was basically almost a no-brainer that, when our current data center is almost at a maximum capacity, we wanted to build a second data center there.”
With no immediate prospect of hydrogen on tap in Eindhoven, NorthC adopted technology that can work with both natural gas and hydrogen.
“In Eindhoven, we have so-called hybrid generators, that can run both on gas and
hydrogen,” she says. “We are waiting for regions like Eindhoven region to start, and when they're ready, we can use the hydrogen.”
Government arguments
Sometimes, the authorities fall out with data center operators, as happened in Amsterdam’s “sleeping server wars.” The government instructed colocation providers that all idle servers should be put into a lowpower “eco” standby mode. But the colos responded that they could not touch servers belonging to their customers.
“That is now in process. Data centers sending letters and emails to their customers, to ask if they can get [their servers] on eco mode,” she tells us.
“There is probably still a discussion with the local municipality to see where the end responsibility is. But this is an example where as an industry, it's so important to remain in discussion with the local municipality, to come to an agreement, which all parties can agree upon.”
She’s got another discussion to have in Frankfurt, a new Energy Efficiency Act makes strong demands on PUE and heat reuse, and has been described by the local data center group as a “data center prevention act.”
She says the industry is “investing a lot in becoming more sustainable, and I think that sometimes is a little bit off-radar.”
From a pan-European level, the data center sector faces stronger regulations and mandatory reporting of energy use, water use, and more. Schless says: “I think that is something that is is accepted by the industry saying, it's already in place, and it only means that we need to have more people dedicated to making sure that we do the right reporting.”
When European rules come down, they are implemented by local and national governments, and Schless says that’s where the conversations need to happen.
“The real discussion lands with the national government. When the rules are implemented by, national and regional governments, we can say, ‘Yes, we can do that.’ And if not, how can we have good conversations with them to see what's possible?”
Above all, she wants to take a conciliatory approach: “Our industry needs to stay in conversation with local, and national governmental bodies, to educate them, but also to think about solutions together. Because ultimately, I think we all have the same task. We all need to go through this energy transition, rather do it together than against each other.”
32 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
Enterprise Edge Supplement
How Edge adapts to every industry
Shipping to the Edge
> The marine industry finds ways to deliver services over satellite links
Gamers get on the cloud
> Riot Games uses cloud services to get lower latency
Towards dark factories
> Manufacturing pioneered the use of Edge. But can it go all the way?

Sponsored
INSIDE
by

34 | DCD Magazine • datacenterdynamics.com APC Smart-UPS Modular Ultra lets you operate in any edge environment. • Reduces installation cost and saves IT space • 50% smaller, 60% lighter with 2.5x more power. • Simple remote management with EcoStruxure™. • The most sustainable UPS of its kind. when they operate at the edge. IT professionals get more EcoStruxure IT modernized DCIM Smart-UPS™ Modular Ultra apc.com/edge ©2023 Schneider Electric. All Rights Reserved. Schneider Electric | Life Is On and EcoStruxure are trademarks and the property of Schneider Electric SE, its subsidiaries, and affiliated companies. 998-22622616_GMA
The infinite variety of Edge
Edge infrastructure is slowly moving from a buzzword to the norm within many different sectors. With the low latency it provides, companies are finding ways to digitize, automate, and improve their operations by bringing their compute closer to the Edge.
But while progress is being made, the development and utility of the Edge is limited by a variety of factors, including its financial viability and task complexity.
The concept of the ‘Edge’ is also blurred. There is no one-size-fits-all approach, and the version of the Edge for a specific application can look entirely different.
This supplement picks three very different sectors, each in its way a pioneer exploring its own distinct vision of the Edge
The Shipping Edge
It is easy to forget that ships need computational power. But with sustainability regulations and restrictions increasing, ships need more and more sensors to gather information, and they need a way to process this information when connectivity is tenuous at best.

The shipping industry is also looking towards reducing the amount of manpower needed on board, and with this comes an increased reliance on technology to provide key insights into performance and safety for those crew who do remain.
While much of this data is sent to the cloud, there is a need for some data to be processed immediately and, for this, the ships need compute at the Edgeboth on board and on the shore.
So what would this look like for a completely unmanned ship? And could a more-automated vessel backed with on-board Edge resources, have avoided an incident like 2021's Suez blockage (p36)?
Sponsored by
Manufacturing in the dark
The manufacturing industry is, in many ways, pioneering the use of Edge computing and IoT technologies.

The application of this varies, depending on what the company manufactures - from Mars chocolate bars, to electric vehicles. But what doesn’t change is the need for security and low-latency.
As more companies explore the concept of dark factories, and robots take over the roles of people, this is becoming increasingly apparent. But what do the economics of this look like, and is it worth updating equipment to reduce operating costs in terms of the human workforce (p45)?
Online Gaming
The online gaming industry is explosive, and as it gains popularity the expectations for a high-quality experience are only growing.
Riot Games needed to develop its network, as games like League of Legends gained large numbers players, all wanting the kind of low-latency experience that normally takes a business user in the direction of Edge computing. But the vision of Edge adopted by Riot came from the cloud.

Riot adopted AWS Outposts in an attempt to reduce latency for all of its users. We talked with them, and to AWS, about how this works, and how Riot has developed its reach over the years (p42).
This supplement could only cover a tiny sample of the possible sectors where Edge is making a distinctive contribution, and we are bound to be back on this subject regularly.
If you know of exciting Edge case studies, get in touch with us!
36
Contents
42 36. Shipping: At the Edge of the world
digital infrastructure that will be necessary to fully digitize and automate the Maritime Industry 42. In gaming, cloud provides an Edge How Riot Games moved its workloads to AWS, but augments it with the Edge 45. What Edge brings to manufacturing Are dark factories really feasible? 45 Enterprise Edge Enterprise Edge Supplement | 35
The
Shipping: At the Edge of the world
Georgia Butler Reporter

If you wait at the London Gateway port, countless ships will pass you by, behemoths groaning under their weight as they cut through the water.
Once upon a time those ships would have been just an empty husk for transport, reliant on the wind and the people on board to keep the vessel charging forward. But as technology has developed, so has the complexity of the ships. While not yet ‘manless,’ the maritime industry is guided by the data it gathers on board and ashore, and no longer down to human judgment alone.
As we move towards a globally digitized fleet, those ships will need a complex system of digital infrastructure to keep them connected to the shore, to each other, and to process the information on-board

36 DCD Supplement • datacenterdynamics.com
DCD
The digital infrastructure that will be necessary to fully digitize and automate the Maritime Industry
Enterprise Edge Supplement
Digital ships
Ships are now, if not mobile cities, certainly small mobile towns. The 2022 cruise ship, ‘Wonder of the Seas’ can host almost 7,000 people, all of whom expect Internet connectivity throughout. But the number of people demanding connectivity does not even begin to compare with the number of sensors gathering data, and those sensors are demanding to be heard.
Data is constantly being collected on board the ship. Sensors monitor the engine, fuel consumption, ship speed, temperature, and external data like weather patterns and currents.
According to Marine Digital, the modern ship generates over 20 gigabytes of data every day (though this is, of course, wildly variable depending on the size and purpose of the ship). The important takeaway is that this is not a simple undertaking, and there is no one-size-fits-all approach.

For ship management company Thome, there is less IT on-board than on-shore. “We treat all ships as a small office,” said Say Toon Foo, vice president of IT at Thome Group. “On most of our ships, we have at least one server.”
As a management company, Thome doesn’t own the ships it works with Instead of attempting to process the data onboard, Thome processes the majority ashore, communicating with the crews via a very small aperture terminal (VSAT).
VSATs connect the ships by fixing on a geo-stationary satellite and can offer download rates between 256kbps to 90Mbps, and upload rates usually between 100bps to 512kbps. This pales in comparison to 5G’s 20Gbps download and 10Gbps upload, but there are no 5G masts mid-ocean.
“It’s a good speed we have [with the VSAT], but not everything can run from the satellite, so we do need that server. But the VSAT means that if we do have a complication, we can share that with the staff on shore,” explained Toon Foo.

Good is, of course, relative. But, happily for Thome, the shipping management company doesn’t really need to process the data in real time.
Instead, the company relies mostly on daily or hourly data updates transmitted via the not entirely reliable VSAT, which are processed in its on-site server room, or in the majority of cases, sent to the cloud.
As an approach, sending most of the data to the shore to be processed seems to be the norm.
Columbia Shipmanagement uses a unique Performance and Optimization Control Room (POCR and/or performance center) as part of its offering. The POCR enables clients to optimize navigational, operational, and commercial performance by analyzing data both collected on board the ship and ashore.
“The ships are directly in touch with the Performance Center,” said Pankaj Sharma, Columbia Group’s director of digital performance optimization. “We proactively check the routes before

departure, looking for efficiency, safety, and security. Then, as the vessel is moving, the system is monitoring and creates alerts which our team is reacting to 24/7.”
With over 300 ships to manage, much of this is automated into a traffic light system (green means good, and alerts only light up when the color changes).
Some of this is then processed onsite, but the vast majority is clouddriven. “Right now we are on Azure, but we have also used AWS and we have a private instance where we have our own cloud hosting space,” added Sharma.
Edge on board
Having computational power onboard the ship is entirely possible, but it has challenges. There is limited room on a ship, and there are also weight limitations, while IT engineers or specialists are not the norm in the crew.
Edge system vendor Scale Computing designed a server to get around these issues, one that has been used by Northern Marine shipping.
“Looking at Northern Marine, initially they worked with traditional 19-inch rack servers on board the ships - two HPE servers and a separate storage box,” said Johan Pellicaan, VP and managing director at Scale Computing.
“Just over a year ago, they started to use an Intel-based enterprise Edge compute system, the Scale Computing HE150. This is a nano-sized computer [under five square inches).”
The Edge at Sea
Enterprise Edge Supplement | 37
Columbia Ship Management
Scale’s offerings are based around tightly integrated micro-computers. The HE150 and HE151 are based on Intel’s NUC (next unit of computing) barebone systems, running Scale’s HC3 cluster software.
They use significantly less power than a traditional 19-inch server, and take a tiny fraction of the space.
Traditional servers “need about 12 cores and six to nine gigabytes of storage in a three-node cluster as an absolute minimum. In our case, we need a maximum of four gigs per server and less than a core.”
This means that the Scale software has a lower overhead: “In the same size memory, we can run many more virtual machines than others can,” claimed Pellicaan.
Edge is really defined by the kind of work done rather than the location, so it is fair to say The shipping industry is using the Edge - be it on-board, or the Edge on-shore.
Automation - could we have unmanned ships?
In many industries, the next step for digitization is automation. In the maritime sector, this raises the prospect of unmanned ships - but Columbia’s Sharma explained that this would be complex to deliver, given the latency imposed by ship-to-shore communications.
“When we talk about control rooms, which would actively have an intervention on vessel operations, then latency is very important,” he said.

“When you think of autonomous vehicles, the latency with 5G is good enough to do that. But with ships, the 38
latency is much worse. We’re talking about satellite communication. We’re talking about a very slow Internet with lost connection and blind spots.”
The fact is that satellite connectivity is simply not fast enough to allow ships to take the step towards autonomous working and full automation.
“There is sufficient bandwidth for having data exchanged from sensors and from machinery, and eventually being sent to shore. But latency is a big issue and it’s a barrier to moving into autonomous or semi-autonomous shipping.”
Much of this makes it seem like ships are at the end of the world, rather than at the Edge. But ships do not travel at dramatically fast speeds like other vehicles, so latency can be less of a problem than one might expect.
A relatively fast container ship might reach 20 knots (37km per hour), compared to an airplane which could reach 575 mph (925kmph), meaning
that most of the time, hourly updates would be sufficient - but not always, there are plenty of incidents where fast responses are essential, and even then things can still go wrong.
For instance, in a highly reported incident in 2021, a container ship blocked the Suez Canal for six days. It’s worth exploring the incident to ask whether having more compute on board (even if it is only one server) might have helped avoid the problem.
Could on-board IT have helped prevent the Suez Canal blockage?
In March 2021, the ‘Ever Given,’ a ship owned by Shoei Kiden Kaisha, leased to Evergreen Marine and managed by Bernhard Schulte Shipmanagement ran aground at the Suez Canal in Egypt, with its bow and stern wedged in opposite banks of the 200m wide canal.
Blocking the major trade route prevented 369 ships passing, representing $9.6 billion in trade. The

DCD Supplement • datacenterdynamics.com
Enterprise Edge Supplement
Ever Given IMO 9811000 C Hamburg 06-02-2023
crash was put down to strong winds (around 74km per hour) pushing the 400 meter (1,300ft) ship off course, and speculation was made by the Egyptian authorities that technical or human errors may have played a role, although this was denied by the companies involved.
The weather is something that is not taken for granted in the Maritime industry. “Weather based-data was the first machine learning project we did in the POCR,” said Sharma. While this research was not focused on an incident like the Suez Canal blockage, Columbia did explore the impact of wind on efficiency.
“Weather is a really important factor,” explained Sharma. “A badly planned weather voyage can increase the fuel consumption by 10 to 15 percent, while a well-planned voyage might save five percent.
The company “did a project where we got high-frequency data from the vessel AIS position, and every 15 minutes we layered that with speed data, consumption data, and weather data. We then put this into a machine learning algorithm, and we got some exceptional results,” he said.
Instead of being able to work on a 20 or 30 degrees basis, the company was able to operate at 5 degrees. “It became a heat map rather than a generic formula and we could then predict the speed loss very effectively,” he said.
Simulating ships
Evert Lataire, head of the Maritime Technology University at Ghent University in Belgium, conducted data analysis using ship tracking websites to find what happened in the Suez Canal incident, putting much of this down to the ‘Bank Effect,’ an effect of hydrodynamics in shallow waters.

DCD reached out to Lataire to find out whether he thinks that having more compute on-board, could potentially prevent disasters like the Suez Canal blockage.
Lataire’s research doesn’t require intensive compute power, real time data analysis can have a big impact on control. When a ship is out at sea, the data can be gathered around its position, but not the impact of forces on the ship.
“The surrounding water has an enormous impact on the ship and how it behaves. A ship sailing in shallow water will have a totally different turning circle compared to deep water, to a magnitude of five.
“So the diameter you need to make a
circle with your ship will be five times bigger in shallow water compared to deep water.”
This is where the bank hypothesis came into account for the Suez Canal disaster. According to Lataire, the crew manning the ship will have been aware something was going wrong, but by then it would have been too late.
“Once you are there, it’s lost. You have to not get into that situation in the first place,” said Lataire.
On-board Edge computing could be enough to alert the crew, and the ship management company, that an issue was going to arise, but it is not yet able to predict, nor prevent, the outcome.


Lataire’s research generates calculations that can then be used to create simulations - but this isn’t currently possible in real-time on the ship. Lataire believes that autonomous ships will come to fruition, but will be limited to small city boats, or to simple journeys like those taken by ferries, in the near future. In the distant future, this could expand further.
The ‘manless’ ship is still a work in progress, but the digitized and ‘smart’ ship is widely in practice. By using a combination of on-board Edge computing, on-shore and on-premise computing, the cloud, along with VSAT for connectivity and geostationary satellites, the ships themselves and those controlling them can make datadriven decisions.
Until we can find a solution to the latency-problem for ships, automation will remain a pipedream, and sailors will keep their jobs. But with technological advances, it is only a matter of time.
The Edge at Sea Enterprise Edge Supplement | 39
The Ever Given blocking the Suez Canal -Wikimedia
Modern DCIM’s Role in Helping to Ensure CIO Success

It is widely reported [1] ,[2] that the role of a Chief Information Officer (CIO) is experiencing a sea change. IT is now at the center of business strategy as digital technologies power and sustain the global economy. The criticality of IT in every aspect of business has driven CIOs from only filling the tactical role of deploying, operating, and maintaining IT to also focusing on business strategy. CIOs increasingly have a leading role in driving business innovation, aligning IT projects with business goals, digitalizing business operations, and leading corporate organization change programs, for example. This role expansion has made their job more critical and complex.
What has not been as widely reported, however, is that the traditional CIO role of IT service delivery has become more critical and complex as well. After all, a CIO’s impact on business strategy and execution depends on continuous IT service delivery. As shown in the figure below, the success of a CIO is ultimately
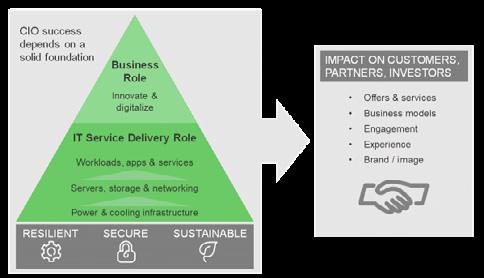
rooted in a solid foundation of maintaining resilient, secure, and sustainable IT operations. But, in an environment of highly distributed hybrid IT, this becomes harder to do.

Modern data center infrastructure management (DCIM) software, optimized for distributed environments, plays an important role in maintaining this foundation for hybrid data center environments with distributed IT infrastructure. Schneider Electric White Paper 281, “How Modern DCIM Addresses CIO Management Challenges within Distributed, Hybrid IT Environments” explains in some detail, using real world examples, how DCIM can make the electrical
and mechanical infrastructure systems powering and cooling your distributed and edge IT installations more resilient, physically and cyber secure, as well as more sustainable.
Traditional DCIM was fundamentally designed and used for device monitoring and IT space resource planning for larger, single data centers. But the days of managing a single enterprise data center are over. Business requirements are forcing CIOs to hybridize their data center and IT portfolio architecture by placing IT capacity in colocation facilities and building out capacity at the local edge – sometimes in a big way. In addition to managing and maintaining resilient and
Patrick Donovan Schneider Electric
secure operations at all these sites, CIOs are now being asked to report on the sustainability of their IT operations. DCIM software tools are evolving so CIOs and their IT operations teams can do their jobs more effectively.
Modern DCIM offers have simplified procurement and deployment, making it easier to get started and use the tool across your distributed IT portfolio. A single log-in will provide a view of all your sites and assets in aggregate or individually from any location. Software and device firmware maintenance can be automated and done from afar. These newer offers not only make it easier to have remote visibility to power and cooling infrastructure to maintain availability, but they also address security and sustainability challenges.
How DCIM improves security
Data center environmental monitoring appliances can be used to not just detect and track temperature, humidity, fluid leaks, smoke, and vibration, but they also typically integrate with security cameras, door sensors, and access cards to provide physical security for remote IT installations. Monitored and controlled through DCIM software, these appliances help remote operations teams monitor and track human activity around critical IT as well as environmental conditions that could also threaten the resiliency of business operations. In the case of cyber security, modern DCIM solutions provide tools to help ensure network-connected power and cooling infrastructure devices do not become a successful target for a cyberattack.
All these devices, as well as the DCIM server and gateway, must always be kept up to date with the latest firmware or software patches. Cyber criminals are constantly working to find vulnerabilities in existing code to hijack devices to steal data, control devices, cause outages, etc. New firmware and software patches not only fix bugs and provide additional performance enhancements, but they often address known security vulnerabilities. These code updates should be installed or applied as soon as they become available from the vendor. Without an effective DCIM solution, this process requires on-going discipline and action from the operations team.
Also, the security features and settings that were enabled and configured during
the initial setup and installation also need to be maintained throughout the life of the infrastructure device, network appliance, or management server/gateway. By minimizing the number of users with the ability to change these settings, you reduce the chances of unintended or non-permitted changes being made. Beyond that, these settings must be checked regularly to ensure they remain set properly over time. This requires additional, on-going discipline and regular action by the ops team.
However, DCIM tools with a security assessment feature can simplify all this work described above significantly, at least, for power and cooling infrastructure devices. These assessments will scan all connected devices across the entire IT portfolio to provide a report highlighting out-of-date firmware and compromised security settings. Some DCIM tools will also automate the updating of firmware and provide a means to perform mass configurations of security settings across multiple devices at once to greatly simplify the process.
How DCIM helps achieve sustainability goals
DCIM can be used to reduce your IT operation’s energy use and greenhouse gas (GHG) emissions, as well as give you basic information to start tracking and reporting sustainability metrics. Energy reductions can be accomplished using DCIM planning & modeling functions. These tools work to better match power consumption to the IT load by turning down or turning off idle infrastructure resources. Or the software can make you aware of where to consolidate the IT load to reduce both IT energy consumption as well as the power losses from the supporting infrastructure. The new white paper describes several specific use cases of how DCIM planning & modeling tools can help reduce energy consumption.
Modern DCIM can also help CIOs and their teams to begin tracking and reporting basic sustainability metrics for their portfolios of on premise data centers, edge computing sites, and colocation assets. Some DCIM (“out of the box”) offers will collect data and report for individual sites and in aggregate:
PUE: current and historical
Energy consumption: usage at sub-system level to show in both real-time and
historical trends of total consumption, IT consumption, and power losses
Carbon footprint (Scope 2 emissions) based on local carbon emissions factors in total and by subsystem including IT, power, and cooling.
For these metrics to be meaningful, of course, it is important for the DCIM software to be able to communicate with and normalize data from all power and cooling infrastructure devices, regardless of make or model. This ensures a complete picture of environmental impact. So DCIM tools and infrastructure devices that embrace common, open protocols (e.g., SNMPv3) and accommodate the use of APIs/web services should be used.
Note, DCIM is in the early phase of its evolution towards becoming an environmental sustainability reporting management tool for data center white space and edge computing installations, in addition to being a tool for improving resiliency and security. The white paper explores a bit how DCIM will likely evolve in this direction in the near term. But, again, for most enterprise businesses that are just getting started with sustainability, modern DCIM tools can be used today to track and report the basics.
In summary
As the role of enterprise CIOs expands to driving business strategy, digitalization, and innovation, their traditional role of IT service delivery remains critical. However, this role has become much more challenging as IT portfolios have become more distributed geographically and spread among cloud, colocation, and the edge. IT resiliency and security must be constantly monitored and maintained across an entire portfolio of IT assets. At the same time, urgency and pressure are growing to track, report on, and improve environmental sustainability. Our new white paper describes in detail how DCIM monitoring & alarming as well as planning & modeling functions address these challenges and serve to make distributed, hybrid IT more resilient, secure, and sustainable
Schneider Electric | Advertorial
Enterprise Edge Supplement | 41
Riot Games’ ‘valorant’ use of Edge computing
How Riot Games moved its workloads to the cloud and the Edge
When you enter into a game's universe, you are temporarily transported out of your current reality.
The gaming industry has successfully commercialized escapism and with the advent of cloud and Edge computing, players can escape into the same world no matter their actual location.
It is no surprise then that, according to Statista, the video gaming industry
is expected to reach a revenue of $372 billion in 2023 - around $30 billion more than projected for the data center industry.
But the two sectors are interlinked, with the former heavily reliant on the latter.
Hitting the network
Initially, gaming developments needed only the user's computer or device to be powerful enough to run the current
state of the art. In 1989, the 8-bit Game Boy could support a simple game like Tetris; but a more recent arrival, the more complicated Sims 4 (launched in 2014) needed a 64-bit operating system, and a 4-core AMD Ryzen 3 1200 3.1 GHz processor as a bare minimum.
But alongside their increasing local demands, games have gone online, enabling players in different locations to compete or collaborate with one another, in increasingly complex games. This means gaming now has increasing

42 DCD Supplement • datacenterdynamics.com Enterprise Edge Supplement
Georgia Butler Reporter
Courtesy of Riot Games
networking, bandwidth, and digital infrastructure requirements, the nuances of which vary on a case-by-case basis.
Riot Games is one of the major game developers in the field. The company is particularly well known for its 2009 multiplayer online battle game League of Legends (LoL), and the 2020 first-person shooter, Valorant

The company also runs almost entirely on Amazon Web Services (AWS).
“Games are composed of a few different workloads, and the compute infrastructure for those tends to meet different requirements as well,” David Press, senior principal engineer at Riot Games, told DCD
Online games are many-layered. From the website where the game can be downloaded or where players can access additional information, to the platform where Riot collects data about the players and uses that to make data-informed decisions, to the platform service which supports all the around-the-game features.
All of these, for the most part, do not require any different infrastructure than a digitized company in a different sector. The workloads may be different, but as Press explained, they aren’t ‘special.’
Where video games cross over into the unique, is in the game servers themselves which host the simulation.
“If it's a first-person shooter game like
Valorant, where you're in a map running around and using your weapons to try to defeat the other team, it’s a very highfrequency simulation,” explained Press.
Speedy protocol
That high frequency presents a different type of workload. The simulation tends to be very CPU-heavy, and Riot is running thousands or tens of thousands of these matches, all at once and across the globe.
“It's generally a very large homogenous fleet of compute,” Press said. “Then, from a network perspective, it's also a bit different. These machines are sending a lot of very small User Datagram Protocol (UDP) packets.”
The simulation is creating a 3D world for the game player. The server has to generate, in real time, things like the character’s movements and the different plays - in League of Legends, this could be casting a spell that moves through space and hits another player.
That simulation has to run incredibly fast.
“We're running the simulation very quickly, and we need to be able to distinguish between a spell or bullet hitting another player, or missing them, and then we need to broadcast all those changes to all the players that are in that world,” Press said.
“All these little UDP packets carry the
information that this person moved here or this person cast this spell, and that is happening maybe 30 times a second or 120 times a second depending on the game.”
UDP packets work in gaming because they run on top of the Internet Protocol to transmit datagrams over the network. Unlike the TCP protocol used in other applications, UDP packets are small and can avoid the overhead of connections, error checks, and retransmission of missing data, meaning that they can move very quickly.
But the speed at which this can transfer - the latency - is also dependent on the digital infrastructure available, and for the cloud to support the gaming industry, it has to come to the Edge.
League of Legends was launched in 2009, and at the time it ran on onpremise infrastructure. But as the number of people playing grew first from the hundreds to the thousands, all the way up to the hundreds of millions, hosting this solely on-premise became impossible.
Not only did the sheer quantity of game players create issues, but the global spread of the game also introduced new challenges.
Latency is directly proportional to the distance between the player and the game server, so distributed IT became a requirement to enable a reasonable quality of gameplay.
LoL Enterprise Edge Supplement | 43
Courtesy of Riot Games
Moving to the cloud
Riot Games began moving its workloads onto AWS in a slow process - and one that is still ongoing.
“We started that migration workload by workload,” said Press.“Websites were probably the first thing we moved to AWS and then following that, our data workloads moved to AWS pretty early on. And that is being followed by the game platform and the game server. We're still in the process of migrating those.”
The company did this by building an abstraction layer which is, internally, called R-Cluster.
“[R-Cluster] abstracts computeincluding networking, load balancers, databases, all the things that game platform game servers need. That abstraction can run on both AWS and our on-prem infrastructure, so our strategy was to first create that layer and migrate League onto that abstraction.
"It was still mostly running on-prem initially. But then once most of League was migrated to that abstraction, then we could more easily start moving the workloads to AWS and nothing had to change with LoL itself once it was targeting that abstraction.”
That process is being done region by region, and instead of Riot relying on having enterprise data centers in every region, the gameplay is instead on AWS - be it an AWS region, Local Zone, or Outposts which are deployed in Riot’s onpremise data centers.
The decision of which AWS service to
use depends on the accessibility in the region, and which service brings reduces latency for the customer. According to Press, Riot aims for latency under 80 milliseconds for League of Legends, and under 35 milliseconds for Valorant
But according to Press, there is a balance to be found in this. If you were to put a game server in every city, the service risks becoming too segmented.
“If we put a game server location in every big city in the United States, that would actually be too much because it would carve up the player base and you'd have far fewer people to match up against,” said Press. “It’s a balance between better latency, and making the match-making time too long, or matching players with those at different skill levels.”
Dan Carpenter, director of the North American games segment at AWS, agreed: “You want the server itself to be close to all the players but also to work in a network capacity, so people from all over the world, whether it's someone in Korea playing against someone in Dallas, can still have a similar experience within the game itself.
“That's represented from a hardware perspective, where of course you have the game server that is both presented to the end user but also needs to scale very quickly in the back end, especially for big events that occur in games.”
Massive tournaments
For games like LoL, which fall under ‘esports,’ players can take part in massive multiplayer tournaments, and those games are occurring simultaneously, and

the infrastructure needs to be close to every end user.
“You need that hardware close to the end user, but also with high-performance networking, storage, and a variety of other facets within the infrastructure ecosystem that are required to attach to that.”
AWS currently offers 31 cloud regions globally, and 32 Local Zones (smaller cloud regions). When neither of these options provides low enough latency, Riot can then turn to AWS Outposts.
“In certain cases, an Outpost, which is a piece of AWS hardware that we would install in a physical data center, could be used to become closer to customers and enable more computing opportunities at the Edge.”
Outposts put Edge computing, game servers, and storage closer to the customer, which then backhauls to AWS’ global backbone via the big fiber that connects the regions.
It’s not perfect
There will, of course, always be some locations where one simply can’t get quite as low latency. As an example, David Press offered Hawaii. But for the most part, with Edge computing working alongside the cloud, the infrastructure needed for online games like those offered by Riot is solid enough to provide a strong gaming experience.
This of course changes as we explore next-generation gaming technologies, like those using virtual reality, and those entirely streamed via the cloud. But that is for another article.
44 DCD Supplement • datacenterdynamics.com
Enterprise Edge Supplement
What Edge computing brings to the manufacturing sector
Are dark factories really feasible?
The world of manufacturing is extremely competitive, with massive conglomerates all vying for that competitive edge, while smaller outfits look to survive long enough to become a conglomerate.
Increasingly, as we move to a more digitized version of factories, it has become apparent that what can give the manufacturing industry that competitive edge is, well, the Edge.
The digital revolution brings with it the essential need for digital infrastructure, and as we progress towards smart and even dark factories, that infrastructure will need to change its form.
Welcome ‘Industry 4.0’
Georgia Butler Reporter
‘Smart factories’ is something of a buzzphrase, like ‘Edge’ itself. But, despite the danger of overuse devaluing the concept, more and more manufacturers are adopting some principles into their facilities that deserve the description.

The smart factory curates data via sensors on the machines and around the factory floor, analyzes the data, and learns from experience. In order to do this effectively, that processing has to happen where the action is.
“There will potentially be thousands of sensors, and they’re all collecting data, which then needs to be analyzed,” explains
The Edge of Production
Enterprise Edge Supplement | 45
Matt Bamforth, senior consultant at STL Partners.
“This is a huge amount of data, and it would be extremely expensive to send all of this back to a central server in the cloud. So in analyzing and storing this data at the Edge, you can reduce the backhaul.”
According to Bamforth, Edge computing will leverage four key use cases in the world of manufacturing: advanced predictive maintenance, precision monitoring and control, automated guided vehicles or AGVs, and real-time asset tracking and inventory management. Another key purpose of Edge computing can be found in digital twins.

A good example of how this is implemented can be seen in the factories of confectionery company Mars. While Mars prefers ‘factory of the future’ as opposed to ‘smart factories,’ the premise remains the same.
Scott Gregg, global digital plants director for Mars, said in a podcast that prior to using this kind of technology, “the plant floor was a bit of a black box. Data really wasn't readily available, plant and business networks were not necessarily connected, and engineering was at the forefront to solve some of those traditional challenges.”
Mars, along with the introduction of sensors on the factory lines, has also implemented digital twin technology.
Digital twins
“The twin allows us to use and see data in real-time to help us reduce nonquality costs and increase capacity. As for innovation, it's now pushed our plant floor associates to look at solving problems in a very different way, providing them with a toolset that they've never had before and with a different way of thinking,” added Gregg.
Digital Twins work by simulating the real equipment and technology, and can be used to test operational experiments without having to run equipment and risk wasting or damaging it. As can be imagined, however, this technology needs to be leveraged by a complex IT setup.
“With the introduction of the twin, we've had to go across engineering, traditional IT functions, networks, servers,
and cloud hosting. So all these different groups are now coming together to solve problems on the plant floor, which we've never done before,” explained Gregg.
The task of actually digitizing the Mars factory was taken on by Accenture, and uses the Microsoft Azure platform along with Accenture Edge accelerators.
Starting in 2020, Accenture introduced on-site Edge processing as well as implementing sensors directly onto the factory lines.
“The sensor literally screws into the line itself and uses the data from the machine to understand what's happening,” Simon Osborne, Accenture’s technology lead on the Mars Project told DCD
One example of this is on the Skittles factory line. According to Osbourne, the sensor would be doing things like counting the number of Skittle candies going into each bag, and using that data to measure performance.
“The twin would be, firstly, just monitoring. But then over time, predicting and making the machine more accurate. They're trying to reduce waste, reduce energy, to help the sustainabiltity agenda, and save money,” Osborne explained.
Osborne went on to admit, however,
that he couldn’t confirm if the sustainability benefits of the system outweighed the energy used to run the digital twin system and supporting IT, as Accenture didn’t have access to that information.
While some of the data will be collected and processed at the Edge, it is mostly sent to the cloud for processing.
“They have a lot of servers on each site, but most of the heavy processing would be on the cloud,” said Osborne.
“But where you have, for example, a camera, there would be Edge probes sitting right near it because they need to make the decision in real-time. From a latency perspective, they want the decision-making done immediately, they don't want to send it off and wait.
“So we use Edge as often as we can to get the processing as near to the production line as possible.”
Richard Weng, managing director at Accenture, also pointed out that it isn’t just about latency, but the complexity and quantity of the data that needs to be processed.
“Some of the simple use cases may use around 2,000 data points per minute. But some of the more sophisticated ones,
Enterprise Edge Supplement
46 DCD Supplement • datacenterdynamics.com
"We are slowly seeing fewer and fewer people in the factories. Will they ever be completely lights out? I think it depends on the product, but I think that we are still quite a way off"
especially when you're talking about videos and things like that, is enough to crash the system, which is why we do that processing and run the camera as close to the Edge as possible.”
In factories, there is also a security concern. In the case of Mars, they don’t want their patented recipes to be public knowledge - after all the Mars Bar is a sacred treat.
Keeping data close to your chest
Mars worked around this by having ‘two sides’ to its Edge server set up. One side communicates with the operations technology, which then passes that information through to the IT side via a demilitarized zone.
Weng explained that the IT side communicates with the outside world, while the internal one is “basically responsible for aggregating, computing, and providing that one single proxy or one single thread from the factory to the outside.”
While Mars is running what it calls a ‘factory of the future,’ it is still a long shot away from a dark factory or a lights-out factory.
The dark factory is so automated, that it renders human input redundant - at least in theory. In reality, most dark factories will need some human workers monitoring the equipment or carrying out repairs and maintenance.
But what is undisputed is the need for additional intelligence in the technology to bring about the benefits available from
this hands-off approach to manufacturing.
‘Industry 5.0’ and lights out factories
For now, the sheer quantity of data points that would need to be analyzed, along with the energy needed to power such an exploit, and the Capex and the Opex costs, leaves the manufacturing industry unable to make the dark factory a widespread phenomenon.
Those who are actively pursuing a reduced human workforce, are thus exploring futuristic technologies, like the Boston Dynamics Spot dogs.
The Spot, while dancing uncomfortably close to the uncanny valley, is able to patrol the factory and monitor the goingson through its series of sensors. The technology has been utilized in factories and facilities.
One user is GlobalFoundries, a semiconductor manufacturer, which gathers data on the thermal condition and analog gauge readings of pumps, motors, and compressed gas systems.
While Spot dogs are a useful technology, they have not yet rendered human interaction unnecessary.
Some manufacturers have successfully implemented the dark factory but it is by no means the norm and is limited by a variety of factors.
Mark Howell, technical specialist and manager of IT facilities at Ford, told DCD that, despite increased automation, we are still a while away from the lights-out manufacturing of vehicles.
“Manufacturers work on a ‘just in
time’ basis,” he said. “The amount of parts on the production line is only going to get you through the next few minutes, possibly half an hour. But things are constantly coming to the workstations on the line, regardless of whether that's people standing there putting those things together or it's robots that are assembling components on those production lines.
“Using information technology to communicate, we are slowly seeing fewer and fewer people in the factories. Will they ever be completely lights out? I think it depends on the product that you're manufacturing, but I think that we are still quite a way off from assembling a vehicle that way.”
It isn’t only down to the complexity of the product, though this is a significant consideration. The technology is for many products readily available, the hesitation comes from economics, politics, and local regulations.
“If you're going to build a lights-out factory, you pretty much build it in a country like the UK,” explained Howell.
Manufacturers need to balance the cost of labor, with the cost of machinery. In the UK, you have a high cost of labor and the machine is manufactured in similar places. Once you manufacture that machinery, you can begin to see a return on investment.
But in those countries where there are limited wage regulations or even no minimum wage at all, it no longer makes sense. As with anything, it is a cost-benefit analysis, and lights-out factories need to make sense to the businesses before they will invest the upfront money on the equipment needed.

For the time being, dark factories are more a demonstration of what technology can do, rather than a practical global solution. The futuristic robots we see monitoring a factory floor in publicity stunts, while very exciting, would need to be a cheaper solution than just hiring someone to do the job themselves.
In many sectors and areas of the world, that cost-benefit analysis is not yet producing a close call. But when it does, the dark factories of the future will be heavily dependent on Edge computing, and the low-latency 5G networks needed to support this, even more so than the smart-factories of today
Enterprise Edge Supplement | 47 The Edge of Production
62% of IT outages can be attributed to IT infrastructure failure1. Our Data Center Infrastructure Management (DCIM) 3.0 offer provides device monitoring, health assessments, and more so you can:

• Run simulated impacts to expose vulnerabilities in IT infrastructure and address them immediately
• Reduce physical threats by monitoring IT environmental conditions

• Improve sustainability efforts by tracking PUE, energy, and carbon emissions
Software to
monitor, and
Realize your company’s IT potential EcoStruxure™ IT modernized DCIM APC Smart-UPS™ Modular Ultra apc.com/edge #CertaintyInAConnectedWorld ©2023 Schneider Electric. All Rights Reserved. Schneider Electric | Life Is On and EcoStruxure are trademarks and the property of Schneider Electric SE, its subsidiaries, and affiliated companies. 998-22622616_GMA 1Uptime Institute Global Data Center Survey, 2018
design,
manage your IT space
Building APAC’s Digital Edge
DCD talks to Samuel Lee about the importance of being a local player
While demand in traditional data center hotspots remains as high as ever, many developers are looking for opportunities on new fertile ground. Some are turning to Latin America, others Africa, while some are eyeing Europe’s secondary markets.
But many are targeting Asia, with a focus on India and Southeast Asia, lured by the massive population, growing demand for data centers from both local and international cloud & Internet companies, and relative lack of competition.
US companies such as Stack and Vantage have made moves to expand into APAC, while the likes of Digital Realty, Equinix, NTT, and STT GDC have all begun to expand existing footprints in the region.

But there’s also a new breed of local companies looking to develop region-wide footprints. The likes of Princeton Digital Group, BDx, and AirTrunk are offering APAC-based platforms spanning multiple countries in the region.
Among them is Digital Edge, a Stonepeak-backed company with operations across the region already and plans to expand rapidly over the next few years.
A new Asian Tiger?
New York-based private equity firm Stonepeak Infrastructure Partners formed Digital Edge in August
Dan Swinhoe News Editor

APAC's Digital Edge
>>CONTENTS
2020. Digital Edge began by taking a stake in ITOCHU Techno-Solutions Corporation’s Mejirozaka data center in Tokyo and announcing plans for a 12MW facility in central Osaka.

Since then, the company has rapidly expanded through a combination of building and buying across APAC.
In Japan, the company acquired two data centers in Nihonbashi and Shinjuku

known as ComSpace I and ComSpace II from Japanese telco Arteria Networks Corporation, and then acquired five more data centers from ICT Services company Itochu TechnoSolutions (CTC).
The new facility in Osaka has launched this year and the company recently announced plans for another new-build in Tokyo in partnership with local real estate developer Hulic.
In South Korea, the company acquired Sejong Telecom’s data center assets in Seoul and Busa, and is also planning a new 120MW campus in Incheon in partnership with SK ecoplant.
In Indonesia, the company acquired a majority stake in Indonet for $165 million. Indonet’s Edge DC then launched a 6MW data center in Jakarta and Digital Edge has plans for a 23MW facility in the city.
In the Philippines, the company launched a joint venture with local real estate firm Threadborne Group to build a 10MW data center in Manila. That has since been announced as ready for service with a second facility in the works.
The firm is led by Samuel Lee, who previously served as president of Equinix’s Asia Pacific business.

“APAC’s digital infrastructure development in the last 20 years has been driven by global companies getting into Asia,” he says. “Now there are lots of Asia Pacific-based digital infrastructure companies, cloud companies, Internet companies, emerging from China, from Japan, from Korea.
“When I look at the next ten years I have no doubt that the next wave of growth in Asia is going to be driven by those Asia-based companies. And most of the growth will be within the region and in the local countries.”
“Part of our business model is to bridge the digital divide in Asia,” he adds. “We
are not only just trying to build digital infrastructure in tier-one markets such as Japan and Korea. But we are also looking at bringing the state-of-the-art technology and getting into some young and highgrowth markets such as the Philippines and Indonesia.”
Lee founded Telekom Consulting Limited in the 1990s before serving as managing director of Pacific Gateway Exchange and then joining Equinix in 2000.
“Leaving a company where I spent almost 20 years wasn’t an easy decision,” he says. “But Asia Pacific is a growth engine of the world, and we have our own company that can better take this opportunity and help Asia-based companies, instead of working for a global company where Asia is only 20 percent of the business.
“Not a lot of people have this opportunity in their career. We are seeing tremendous growth and lots of opportunities happening on daily basis. So it's been a very exciting three years and we are very excited looking to the next few years.”
Going region-wide by thinking local
Stonepeak also owns US operator Cologix and is a significant investor in CoreSite When asked why the company bothered to launch a new company rather than simply expand one of its existing US companies, Lee says that localization is a key part of the strategy.
“We talk about globalization, but the US has a different culture, different regulation, different rules in doing business to Europe and Asia Pacific as well.”
He adds that while we talk about Asia Pacific as a region, he says it is really only a “convenient word” to encompass a varied and complicated landscape.
“There's nothing really to tie all those countries together. There's different currencies, different languages, different business practices, different laws, and sometimes those countries are actually competitive with each other,” he says.
To deal with such a vast market, Digital Edge’s strategy has generally been to acquire a local partner and facilities – such as Indonet or select assets from Sejong Telecom or Arteria Networks – and use that as a base from which to build with a view to developing larger facilities in future.
“A data center is a whole ecosystem; with a brand new empty new data center, its not easy to attract customers,” says Lee.
“You need something to start with to solve the chicken and egg problem. And for us, there's nothing more important than getting a level of density and cloud on-ramp density. The likes of Seijon and ComSpace I & II
50 | DCD Magazine • datacenterdynamics.com
DCD Magazine #48
>>CONTENTS
become a solid foundation when we enter a new market.”
“That's how you show the customer that your brand new shiny new data center is not an island, they actually get connectivity options. And once you get the network density, then you can think big and pick your targets.”
The goal, he says, is to offer a consistent platform across different markets in the region: “When we look through from the customers' eyes, they just want to have a reliable partner that has a data center infrastructure across Asia so that they can deploy in the market they want to deploy and have peace of mind.”
“The local teams have the best knowledge and relationships in market, and that's how we develop, through local expertise. Without the local team there and without the knowledge, it is hard to execute. But as a platform as a company, we are going to make consistency in our product and strategy, so to make it consistent in the customer’s eyes.”
The company is largely deploying a modular design that offers standardization across all the company's new facilities, albeit with some localization where required. That helps the company offer a consistent PUE figure across its facilities – a water-cooled design with an annualized target of 1.2 and a WUE of 1.4.
Targeting cloud players and network density
The company aims to lure international companies looking to operate locally, but also help local companies that might be customers, including ISPs, software, and cloud companies.
Lee says Japan is the company’s most stable and mature market. And while there may be more risk in nascent markets, with it comes greater opportunity. There may be less chance to acquire local partners in some markets, though,
“Our focus is to try to do M&A for assets with connectivity and cloud density,” he explains. “A lot of assets in young markets are in the hands of the old telcos, and we need to make sure whether those assets are attractive enough; do they have enough network density and will it be a magnet for more customers?
“If it's just an old data center with some enterprise customers, that may not be ideal in our strategy so we may just partner with someone and build a new one.”
The company has followed this approach of eschewing acquiring a local partner and instead going straight in with a new build in tandem with a developer in markets such as the Philippines and India.
“We didn't go out and buy anything in the Philippines because we believe the market is on the edge to take over. We believe the new subsea cables will attract the cloud guys and digital infrastructure guys and we don't want to miss the window.
"We’ve found a very good local partner who knows how to develop, and we feel comfortable that like we can bring the customers to us.”
That lure of cloud companies is important.
“Before we can effectively go to the enterprise market, we need to have the cloud guys there. We need to have the system integrator there. We need to have the connectivity option there.
“The digital infrastructure companies want to push their deployments to the local countries and as close to the customer as possible. That is basically our core target market for the next couple of years, because they will enable the latter part of our strategy to attract enterprise customers.”
The company hasn’t shared its current occupancy levels or pre-lease rates of its new facilities, but Lee says the company is “excited and optimistic” about take-up on its new builds.
Further expansion and entry into India
In late 2022, Lee said Digital Edge aims to more than double its data center capacity over the next five years to more than 500MW, with plans to enter India, Vietnam, and Thailand.
“Today we have 15 data centers in five markets and roughly 120MW in our portfolio,” says Lee. “But we are definitely not going to stop there; we continue to expand into new markets building new sites.”
Bangkok is cited as a potential target –Thailand is another market branded “very exciting” by Lee – while you “cannot ignore” India. Vietnam he describes as “interesting” and one the company is keeping a close eye on.
“Bangkok and Vietnam, we really need to spend more time to learn the local markets and find the right partners.”
Since DCD originally spoke to Lee, Digital Edge announced its expansion into India with a 300MW data center campus in Navi Mumbai with the Indian sovereign wealth fund National Investment and Infrastructure Fund (NIIF) and real estate investment firm AGP.
We followed up to ask why the company jumped straight into India without first buying a local partner as it had done in many other markets, with Lee saying there were “fewer viable options” in India’s nascent data center market.
“Given the strength and local knowledge of our partners NIIF and AGP, we are confident that pursuing a greenfield development is the best way for us to enter this fast-growing market,” he says.
Lee says the partnership offer NIIF’s local and operational expertise along with AGP’s on-the-ground real estate development and construction experience will help Digital Edge increase its speed to market in India’s growing and increasingly competitive market.
Mumbai was picked given its status as one of the country’s major data center hubs and its availability of power and fiber, but the aim is to create a ‘pan-India portfolio’ of facilities.
Lee notes there are other local markets –New Delhi, Chennai, and Hyderabad – and will listen to customers to “ensure we are in the metros where they need us to be.”
International expansion from China a key to fuel growth
In China, Digital Edge has entered into a partnership with local operator Chuanjun Information Technology (Shanghai) Co., Ltd, and established PEK1 in Beijing.
Operated by Chuanjun with support from Digital Edge, PEK1 one offers 8,360 sqm (90,000 sq ft) and 7.8MW of capacity, with space for 1,800 racks.
Like Digital Edge, Lee says Chuanjun intends to launch data center operations and services in major metros throughout China via M&A and new build activity.
“We have a comprehensive sales and marketing partnership to promote and support Chinese customers to expand their digital presence overseas,” he says.
Lee described the Chinese partnership as a “critical” part of the company’s platform not only because of the local demand in China but also because it means the company is able to keep Chinese customers on the platform outside China.
“Lots of those big Chinese Internet companies are expanding everywhere. Our sales team in China generate a lot of opportunity in the sales pipeline for Indonesia, for Japan, for Korea, as well.”
When asked about expansion into regions further west, Lee suggests the plan to remain focused on Asia but utilize the benefits of Stonepeak’s network.
“We see a lot of our customers based in Asia Pacific have a big appetite to go and establish their presence in North America, and that will be an opportunity for us, not only to take care of their needs in Asia,” he says.
“That’s why we picked Stonepeak as a partner, because they have a platform outside Asia and we can work with their portfolio companies in other parts of the world.”
Issue 48 • April 2023 | 51
APAC's Digital Edge >>CONTENTS
Mission Apollo: Behind Google's optical circuit switching revolution
Sebastian Moss Editor-in-Chief
Over the past few years, Google has been quietly overhauling its data centers, replacing its networking infrastructure with a radical in-house approach that has long been the dream of those in the networking community.
It’s called Mission Apollo, and it’s all about using light instead of electrons, and replacing traditional network switches with optical circuit switches (OCS). Amin Vahdat, Google’s systems and services infrastructure team lead, told us why that is such a big deal.

DCD
Magazine #48
How Google saw the light, and overhauled its data centers
>>CONTENTS
Keeping things light
There’s a fundamental challenge with data center communication, an inefficiency baked into the fact that it straddles two worlds. Processing is done on electronics, so information at the server level is kept in the electrical domain. But moving information around is faster and easier in the world of light, with optics.
In traditional network topologies, signals jump back and forth between electrical and optical. “It's all been hop by hop, you convert back to electronics, you push it back out to optics, and so on, leaving most of the work in the electronic domain,” Vahdat said. “This is expensive, both in terms of cost and energy.”
With OCS, the company “leaves data in the optical domain as long as possible,” using tiny mirrors to redirect beams of light from a source point and send them directly to the destination port as an optical cross-connect.
Ripping out the spine
“Making this work reduces the latency of the communication, because you now don't have to bounce around the data center nearly as much,” Vahdat said. “It eliminates stages of electrical switching - this would be the spine of most people's data centers, including ours previously.”
The traditional 'Clos' architecture found in other data centers relies on a spine made with electronic packet switches (EPS), built around silicon from companies like Broadcom and Marvell, that is connected to 'leaves,' or topof-rack switches.
EPS systems are expensive and consume a fair bit of power, and require latency-heavy per-packet processing when the signals are in electronic form, before converting them back to light form for onward transmission.
OCS needs less power, says Vahdal: “With these systems, essentially the only power consumed by these devices is the power required to hold the mirrors in place. Which is a tiny amount, as these are tiny mirrors.”
Light enters the Project Apollo switch through a bundle of fibers, and is reflected by multiple silicon wafers, each of which contains a tiny array of mirrors. These mirrors are 3D Micro-Electro-Mechanical Systems (MEMS) which can be individually re-aligned quickly so that each light signal can be immediately redirected to a different fiber in the output bundle.

Each array contains 176 minuscule mirrors, although only 136 are used for yield reasons. “These mirrors, they're all custom, they're all a little bit different. And so what this means is across all possible in-outs, the
combination is 136 squared,” he said.
That means 18,496 possible combinations between two mirror packages.
The maximum power consumption of the entire system is 108W (and usually it uses a lot less), which is well below what a similar EPS can achieve, at around 3,000 watts.
Over the past few years, Google has deployed thousands of these OCS systems. The current generation, Palomar, ”is widely deployed across all of our infrastructures,” Vahdat said.
Google believes this is the largest use of OCS in the world, by a comfortable margin. “We've been at this for a while,” says Vahdat.
Build it yourself
Developing the overall system required a number of custom components, as well as custom manufacturing equipment.
Producing the Palomar OCS meant developing custom testers, alignment, and assembly stations for the MEMS mirrors, fiber collimators, optical core and its constituent components, and the full OCS product. A custom, automated alignment tool was developed to place each 2D lens array down with sub-micron accuracy.
“We also built the transceivers and the circulators,” Vahdat said, the latter of which helps light travel in one direction through different ports. “Did we invent circulators? No, but is it a custom component that we designed and built, and deployed at scale? Yes.”
He added: “There's some really cool technology around these optical circulators that allows us to cut our fiber count by a factor of two relative to any previous techniques.”
As for the transceivers, used for transmitting and receiving the optical signals in the data center, Google co-designed
low-cost wavelength-division multiplexing transceivers over four generations of optical interconnect speeds (40, 100, 200, 400GbE) with a combination of high-speed optics, electronics, and signal processing technology development.
“We invented the transceivers with the right power and loss characteristics, because one of the challenges with this technology is that we now introduce insertion loss on the path between two electrical switches.”
Instead of a fiber pathway, there are now optical circuit switches that cause the light to lose some of its intensity as it bounces through the facility. "We had to design transceivers that could balance the costs, the power, and the format requirements to make sure that they could handle modest insertion loss," Vahdat said.
"We believe that we have some of the most power-efficient transceivers out there. And it really pushed us to make sure that we could engineer things end-to-end to take advantage of this technology."
Part of that cohesive vision is a softwaredefined networking (SDN) layer, called Orion. It predates Mission Apollo, "so we had already moved into a logically centralized control plane," Vahdat said.
"The delta going from logically centralized routing on a spine-based topology to one that manages this direct connect topology with some amount of traffic engineering - I'm not saying it was easy, it took a long time and a lot of engineers, but it wasn't as giant a leap, as it would have been if we didn't have the SDN traffic engineering before."
The company "essentially extended Orion and its routing control plane to manage these direct connect topologies and perform traffic engineering and reconfiguration of the mirrors in the end, but logical topology in real time based on traffic signals.
"And so this was a substantial undertaking, but it was an imaginable one,
Issue 48 • April 2023 | 53 Google networking
>>CONTENTS
Google
rather than an unimaginable one."
Spotting patterns
One of the challenges of Apollo is reconfiguration time. While Clos networks use EPS to connect all ports to each other through EPS systems, OCS is not as flexible. If you want to change your direct connect architecture to connect two different points, the mirrors take a few seconds to reconfigure, which is significantly slower than if you had stayed with EPS.
The trick to overcoming this, Google believes, is to reconfigure less often. The company deployed its data center infrastructure along with the OCS, building it with the system in mind.
"If you aggregate around enough data, you can leverage long-lived communication patterns," Vahdat said. "I'll use the Google terminology 'Superblock', which is an aggregation of 1-2000 servers. There is a stable amount of data that goes to another Superblock.
"If I have 20, 30, 40 superblocks, in a data center - it could be more - the amount of data that goes from Superblock X to Superblock Y relative to the others is not perfectly fixed, but there is some stability there.
"And so we can leave things in the optical domain, and switch that data to the destination Superblock, leaving it all optical. If there are shifts in the communication patterns, certainly radical ones, we can then reconfigure the topology."
That also creates opportunities for reconfiguring networks within a data center. “If we need more electrical packet switches, we can essentially dynamically recruit a Superblock to act as a spine,” Vahdat said.
“Imagine that we have a Superblock with no servers attached, you can now recruit that Superblock to essentially act as a dedicated spine,” he said, with the system taking over a block that either doesn’t have servers yet, or isn’t in use.
“It doesn't need to sync any data, it can transit data onward. A Superblock that's not a source of traffic can essentially become a mini-spine. If you love graph theory, and you love routing, it's just a really cool result. And I happen to love graph theory.”
Always online
Another thing that Vahdat, and Google as a whole, loves is what that means for operation time.
“Optical circuit switches now can become part of the building infrastructure," he said. "Photons don't care about how the data is encoded, so they can move from 10 gigabits per second to 40, to 200, to 400 to 800 and beyond, without necessarily needing to be upgraded."

Different generations of transceiver can operate in the same network, while Google upgrades at its own pace, “rather than the external state of the art, which basically said that once you move from one generation of speeds to another, you have to take down your whole data center and start over,” Vahdat said.
“The most painful part from our customers' perspective is you're out for six months, and they have to migrate their service out for an extended period of time,” he said.
“Given at our scale, this would mean that we were pushing people in and out always, because we're having to upgrade something
somewhere at all times, and our services are deployed across the planet, with multiple instances, that means that again, our services would be subject to these moves all the time.”
Equally, it has reduced capex costs as the same OCS can be used across each generation, whereas EPS systems have to be replaced along with transceivers. The company believes that costs have dropped by as much as 70 percent. “The power savings were also substantial,” Vahdat said.
Keeping that communication in light form is set to save Google billions, reduce its power use, and reduce latency.
What’s next
“We're doing it at the Superblock level,” Vahdat said. “Can we figure out how we will do more frequent optical reconfiguration so that we could push it down even further to the top-of-rack level, because that would also have some substantial benefits? That's a hard problem that we haven't fully cracked.”
The company is now looking to develop OCS systems with higher port counts, lower insertion loss, and faster reconfiguration times. "I think the opportunities for efficiency and reliability go up from there," Vahdat said.
The impact can be vast, he noted. “The bisection bandwidth of modern data centers today is comparable to the Internet as a whole,” he said.
“So in other words, if you take a data center - I'm not just talking about ours, this would be the same at your favorite [hyperscale] data center - and you cut it in half and measure the amount of bandwidth going across the two halves, it’s as much bandwidth as you would see if you cut the Internet in half. So it’s just a tremendous amount of communication.”
54 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
Google
>>CONTENTS
“Making this work reduces the latency of the communication, because you now don't have to bounce around the data center nearly as much. It eliminates stages of electrical switching - this would be the spine of most people's data centers"
DCD>Academy & iMasons partner on college student scholarship program in the US
iMasons Capstone Project prepares graduates for careers in data center design engineering

DCD>Academy, DCD's data center training, learning, and development unit, has partnered with data center community group Infrastructure Masons for a new scholarship program for college students in the US.
Announced at this year's DCD>Connect event in New York in March, the partnership will see DCD>Academy’s full training portfolio be made available, free-of-charge, to all students taking part in the project.

The iMasons Capstone initiative acts as a year-long mentorship program that
culminates in a final data center design project for STEM students in their final year of college. The program was piloted at Hampton University, a Historically Black College or University (HBCU) in South Virginia during the 2020/21 academic year.
The Capstone Project is currently made up of 20 students, with DCD>Academy pledging over $250,000 of free training. However, DCD>Academy's managing director, Darren Mcgrath, said that “the sky's the ceiling” in terms of how much could be committed moving forward, saying that the DCD>Academy funding will grow in tandem
with the size of iMasons’ project.
“Thanks to the generous support of DCD>Academy, these students will be able to enter the workforce with industry-recognized credentials,” said Courtney Popp, EDU Program Manager at iMasons.
Last year’s Uptime Institute report stated that the headcount for extra staffing requirements will reach 300,000 by 2025. With a rapidly aging workforce and talent poaching rife, there are legitimate concerns that the industry is sleepwalking into an early grave.
While the data center labor shortage is both widely acknowledged and talked about at industry events at great length, a lack of practical action threatens to continue to exacerbate the issue.
“As an industry, it’s vital we come together around education,” said George Rockett, founder & CEO of DCD>Academy. “If staffing needs are going to be met, we need to look outward. Getting data center-focused curriculums in front of those in higher education is crucial if we are to create a talent pipeline that the industry so desperately needs.”
The initiative follows others, like the UKbased UTC Heathrow program, in helping students increase their career opportunities while also looking to create long-term benefits for the data center industry through educating the next generation of engineers.
Issue 48 • April 2023 | 55 DCD>Academy | Advertorial >>CONTENTS
Tom Liddy
Computing the universe of visual effects
How the VFX industry is evolving with new technologies

Movies use visual effects (VFX) to enhance and visualize the impossible, and create scenes that could not be captured with live-action filming on its own.
VFX are rendered digitally, and the workloads have been traditionally run on-premises. Groups of creatives would sit editing frame-by-frame while the hum of servers would be heard from the next room.
But as visual effects grow increasingly detailed and computationally demanding, housing an on-prem data center for every project no longer makes sense for the sector.
Whether it is a particularly complex project that needs dramatically more computational power than the on-prem facility can provide, or it is new technology that needs the compute to be on the film set itself, the VFX IT footprint is diversifying from the cloud to the Edge.
 Georgia Butler Reporter
Georgia Butler Reporter
>>CONTENTS
A practical set piece from The Mandalorian in the StageCraft volume. Image courtesy of Industrial Light & Magic.
The continued role of on-premise computing
“On every film production, there will be lots of people working and they always need access to a central pool of storage to pull media from so the work stays synchronized, and this is how it's been since people figured out how to use network storage for video editing,” explained Arvydas Gazarian, solutions architect at Evolutions TV, a London Sohobased post-production house.
For this reason, a big part of Evolutions’ IT remains on-prem to ensure that all editors can access the correct version of the footage.
“We have nine petabytes of media across four of our locations. There is at least one petabyte in each location, with an average distribution of 200TB per project."” added Gazarian.
But beyond that, Evolutions will turn to a cloud-type service, called European Raid Arrays (ERA). ERA offers a cloud-based workstation and storage system specifically designed for media, broadcast, and postproduction workloads. Here, Evolutions has around about four petabytes of storage and close to 130 workstations in a data center, which the on-prem locations are linked to via a 40-gigabit line.
The role of the cloud
The VFX industry is naturally ‘spikey,’ with sudden and dramatic increases in demand, explained Gazarian. A new project will be commissioned, and the compute needed will suddenly multiply, and this will sometimes bring the requirements outside of what can physically be housed on-prem.
Turning to a cloud-type service for VFX is becoming increasingly common, and was particularly publicized when Weta FX announced that Avatar: The Way of Water was rendered entirely on the Amazon Web Services (AWS) cloud.
Weta FX averaged around 500 iterations per shot, each of which contains thousands of frames. Rendering each frame took 8,000 thread hours or the combined power of 3,000 virtual CPUs in the cloud for an hour. In total, the team ran 3.3 billion thread hours over 14 months on AWS.
According to the company, achieving this on-premise would require the company to gain planning permission from the local council to physically expand its data center. Producer Jon Landau said: “The difference when we went to the cloud was truly palpable. We would not have finished but for the support we got from AWS.”
It is not unusual now for post-production houses to take this route and spin up temporary clusters in the cloud to help manage workloads. But these workloads are continuing to grow more challenging for post-production houses to handle.

Introducing in-camera visual effects
When it comes to post-production and VFX, increased GPU power and better resolution simply result in more believable simulations, and with options like moving the workload to the cloud available, it is simply a matter of being willing to throw money at the problem.
In the meantime, most VFX houses will find that a hybrid-IT solution of on-prem and cloud computing will do the trick for a traditional post-production timeline. But the sector is moving away from ‘traditional.’ No longer are all VFX done in post-production
The rise of in-camera visual effects is seeing more processing needed in real time,
or even before actual filming begins.
John Rowe, head of VFX at Boomsatsuma, a university dedicated to all things postproduction, explained the relatively new concept of in-camera visual effects (ICVFX) to DCD
This approach to VFX fundamentally changes the pipeline. No longer is the simulation done in post, it is done before filming even begins, and uses the same type of servers we see in video games that enable real-time rendering. In the majority of cases, this involves using Epic Games’ Unreal Engine.
Rowe had been working with students that day, creating a shoot where the simulated backdrop of a dinosaur attack played out behind the actors in real-time.
“You take your environment to a studio and you play it on a screen and then you put your actors in front of it and film them,” explained Rowe.
“The camera has to be synced to the game engine and it uses a video processor to do that. There are lots of computers and several other people involved with that technique and it all has to lock together.
“The screen plays back your environment through a game engine so that you can look around the environment and display it on the screen, which you then sync together using another part of the same game engine to link to the camera in the computer. So when you actually move the camera, the one in the simulation moves at the same time, using a tracking system and sensors that are spread out around the studio.”
One of the companies that pioneered the
Issue 48 • April 2023 | 57 VFX in the cloud
>>CONTENTS
“In a traditional VFX pipeline, you can use 16K textures. But if you tried to run that through an Unreal Engine, or any GPU-based renderer, it’s going to crash"
use of ICVFX is Lux Machina. It is behind the well-known graphics of films like The Irishman, and the television series The Mandalorian, among others.
The world’s a stage
The company's Prysm Stages are basically entirely new worlds, David Gray, managing director of Lux Machina Consulting, told DCD
“The London stage is 74 meters of screen around, which is 26,000 pixels wide by 2,800 pixels high. The wall alone is nine times the resolution of 4K, and that doesn’t include the ceiling.”
Not only is this an incomprehensible amount of processing, it must also be rendered in real-time, meaning that it has to occur on-site at the Edge of production.
“Because of the resolutions and data we're dealing with at the moment. It's just not feasible [to run on the cloud] with that size of LED volume. So we're generally running a 100 gig backbone with a 25 gig machine to be able to pull the data between them,” explained Gray.
But while it is real-time generation, it isn’t real-time content creation. There are still plenty of hours that are dedicated to the production of graphics beforehand. The lighting, generation of the assets, and their textures, are all done pre-emptively. According to Gray, this is in many ways more taxing than a traditional pipeline, as everything needs to be optimized. So why do it?
Real-time is the perfect time
The reason is that the Prysm Stages are entirely controllable environments. The images can be optimized and perfected, and lighting replicated perfectly in a second. Film directors will obsess over the concept of the
‘golden hour,’ that brief period of time each day when natural light is so beautiful it is almost ethereal. But with a Prysm Stage, the ‘golden hour’ can become a golden day, even a golden week.
ICVFX changes the scheduling for the production team significantly. For example, in typical production environments, the lighting team won’t show up until final filming is ready to commence. With ICVFX, lighting can be available from the very first test shots, at little additional cost.
“With ICVFX, if there’s a lack of ‘human’ talent, we can use Unreal Engine and produce cinematic lighting with it,” said Junaid Baig, vice president of Rendering and Research & Development at Lux Machina.
This front-ended VFX approach is new to the industry and takes a while for those working in it to get their heads around. Normally, you would look at a shot and then decide what lighting is needed, but ICVFX needs you to decide the lighting before you even see the actors in the room. To get around this, meaningful conversations are had before filming begins to really understand the director's vision.
There are some things that ICVFX can’t achieve. For example, a convincing explosion or blast would be difficult.
“The Unreal Engine can’t really do that in a way that would look convincingly good,” said Baig, “So you would shoot everything else with ICVFX, then add the explosion later as a traditional form of VFX. That way, you would only need two teams - the ICVFX team and the post. You wouldn’t need the lighting or the building team to make that happen physically.”
To achieve ICVFX, Lux Machina uses, on average, 24 rendering machines with two GPUs each - in this case, Nvidia RTX 6000salong with various high bandwidth cables. In order for this to happen in real-time, and then

be seen reflected on the LED stages, the closer to the Edge, the better.
“VFX artists don’t really think about speed, they think about quality,” said Baig. “It has to be done in at least 24 frames per second. In a traditional VFX pipeline, you can use even 16K textures. But if you tried to run that through an Unreal Engine, or any GPU-based renderer, it’s going to crash. So with ICVFX, you are constantly balancing quality, versus quality of the Edge compute.”
The power required for this is significant but is only amplified by the sheer requirements of the stage itself. According to the Prysm Stages website, the stage production space spans 7,700 sqft, all of which is covered by LED tiles used to produce images with a resolution as big as 22,176 × 3,168 pixels on the main back wall.
“It uses a lot of power, and the building needs to be prepared to host this huge structure. Heat is a big issue, and you need to find ways to distribute the heat, and the server room itself generates a lot of noise.”
Because of this, Lux Machina stores its servers in an outside insulated room with lots of cooling equipment. For shoots that aren’t hosted at Lux’s own stages, this server room will have to be created at the new set.
Whether VFX companies are using an on-prem data center, spinning up workloads in the cloud, or creating a data center at the Edge of the film set, what is consistent across the sector is that the computational power needed to accomplish desired effects is increasing, and it is not doing so gradually.
Resolutions are increasing at exponential rates. Simulations are longer “good enough to tell the story?’ but a close-to-perfect simulation of real life, generated from lessthan-perfect current technology.
Whether this is done in post or preproduction, visualizing the impossible has become increasingly virtual.
58 | DCD Magazine • datacenterdynamics.com
>>CONTENTS
Everything data center operators need to know about Power Purchase Agreements (PPAs)
A PPA primer for data center companies
There are few buildings more energy intensive than data centers. As densities increase, single facilities can now eat up more energy than whole towns.
To offset this and ensure their green credentials, many companies are signing power purchase agreements (PPAs), which help bring new renewable energy projects online and help organizations claim their operations are sustainable.

Data center hyperscalers such as Meta, Amazon, Microsoft, and Google are some of the largest corporate buyers of renewable energy in the world, each having procured multiple gigawatts of renewable energy and investing in hundreds of renewable energy
Dan Swinhoe News Editor
PPAs explained
>>CONTENTS
projects globally.
But what are PPAs, and what do data center operators need to know about them?
What is a Power Purchase Agreement (PPA)?
Power purchase agreements (PPAs) are a way for companies, including data center operators, to ensure the energy demands of their operations are covered by an equivalent amount of renewable-generated energy being generated.
“In its simplest form, a power purchase agreement is a way for large energy consumers to meet their sustainability goals by receiving energy attribute certificates from renewable energy projects, and do it at scale,” explains Joey Lange, managing director of the renewables team at energy consultancy firm Edison Energy.
The specifics will vary depending on the project, location, and the regulations of the local energy market, but at its simplest, a company will form an agreement with an energy provider to invest in a renewable energy project such as a wind or solar farm and then procure the output of that facility to cover some or all of the energy requirement of one or more data centers, once the project is live.
There are multiple types of PPA. Onsite PPAs will install renewable energy infrastructure at a company’s location where it can feed power directly. These are less common and usually smaller scale than offsite PPAs, in which companies procure the energy from large renewable plants at other locations.
Off-site PPAs can be broken down into physical PPAs and Virtual PPAs (VPPAs,
aka financial PPAs). Physical PPAs will see companies agree to off-take the output of specific projects i.e. a particular wind farm, while VPPAs will see companies buy renewable energy from an energy provider’s portfolio but not attributed directly to specific projects. If investing in a particular project, companies can procure the entirety of that site’s output or a portion of it.
PPAs are usually for wind or solar projects, but hydroelectric, biogas, geothermal, and even nuclear power can be covered under PPAs.

It’s worth noting that any offsite PPAs, even if they are attributed to particular renewable projects, do not directly power data centers. The project’s output is pumped into the grid and mixed with all other energy plants, dirty and clean; PPAs merely ensure an equivalent amount of a customer’s agreed energy demand is being generated by renewable sources.
In many instances, companies still have to procure energy through their utility provider alongside a PPA. However, in ‘sleeved’ PPAs, the utility provider will handle the PPA energy and supply additional power as required. The specifics of an agreement will vary depending on the market you are aiming to operate in.
Pricing dynamics of a PPA also vary. Deals can be price-fixed for the duration of the contract, fixed with set or variable escalations, fixed but include settlements between different parties depending on wholesale price, indexed to energy markets with various discounts, and floors & ceilings, or a combination of each. The structure of the deal will depend on the amount of risk each party is willing to take on and the nuances and regulations of the local market.
Fixing prices provides long-term cost visibility but may end up more expensive in
the long term compared to market prices, while variable ‘floating’ PPAs tied to market energy prices and/or hedging are more unpredictable but offer a greater chance for lower prices if the dynamics are favorable. The World Business Council for Sustainable Development has published an in-depth guide to the various pricing structures of PPAs that is worth a read.
Why do companies need PPAs?
Customers want to decarbonize their supply chains (including their data center provision), and operators are setting themselves sustainability targets or meeting targets imposed on them.
Given these drivers, digital infrastructure has become the largest global customer for PPAs.
Hyperscalers procure gigawatts worth of renewable energy. Likewise, telcos are major purchasers of PPAs as they look to offset both their data center footprint and their mobile network operations. Even enterprises such as State Farm and eBay have signed PPAs to cover their operations, of which on-premise data centers can be a large – if not the largest – proportion.
“The large tech players are certainly still driving a lot of the renewable purchases and taking a lot of the supply in the market at the moment,” says Edison’s Lange. “We have seen a number of enterprise clients using PPAs to cover that data center load because it's such a large part of their overall load.”
Colo firms including Equinix and Digital Realty are large buyers of PPAs, as are the likes of QTS, Scala, STT GDC, Supernap Thailand, Sify, Element Critical, and OVH. But Lange says colos procure PPAs less often than hyperscale or enterprise operators.
“Equinix is dedicated to sustainability and reducing its carbon footprint, with PPAs being a key part of its approach," says Bruce Fransden, director, project and program management at Equinix.
Our customers want their infrastructure to be powered by renewable energy, and this trend has driven some of Equinix's decisionmaking around renewable energy and influenced its approach to PPAs."
"We started down this journey and started looking at pathways to renewables in earnest as far back as 2015," adds Arron Binkley, VP of sustainability at Digital Realty. "Electricity is the largest contributor to Scope 2 carbon emissions for data centers, so anything we can do to decarbonize that is going to be the most impactful."
"Our customers are very much in favor of telling their customers that they are being hosted in data centers that are working on PPAs and offsetting their usage by
60 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
certificates," adds
Vinh Thong ‘VT’ Le Nhut, operations director at Digital Realty.
PPAs for colocation vs cloud and enterprise
Colo firms are buying energy on behalf of multiple customers, not all of which will have particular requirements or interest in procuring renewable energy – or the desire to deal with any added costs or accompanying carbon accounting requirements.
“In the case of colos, the load that you're trying to cover with the renewable energy purchase is typically on behalf of their customers,” says Edison’s Lange. “Do the terms of their agreements with those tenants align with the term of a 15-year PPA? That’s a big question we often address upfront with our data center clients; just how confident are you in your load projections and when do you actually need this project to start generating?
“Another is what is your relationship with your tenants,” he says. “How are the cost and benefits of a PPA passed on, and are they willing to take that cost? We hear from data center companies that their tenants want renewable energy and they want it at a better or comparable prices to brown power; right now in this market, that's really not possible.”
Larger colocation companies – especially ones with hyperscale or long-term enterprise customers – can probably be confident in their load projects. With smaller retail colo customers and providers, the picture can be more difficult.
“For colocation providers like Equinix, renewable energy PPAs can be more complicated compared to enterprises and hyperscalers that are the end-users of that energy,” says Equinix’s Fransden. “Colocation providers must balance several competing priorities, including their own sustainability goals vs those of their customers and both parties' desire to keep energy costs low.
“As part of the economic analysis, Equinix must decide whether to pass on the additional cost to its customers in the form of higher prices, or to absorb the cost and maintain competitive pricing. To balance these competing priorities, Equinix works closely with its customers to understand their energy needs and to find solutions that meet both parties' needs.”
What to look for in a PPA project
Data center operators with multiple facilities in multiple markets will likely need to deal with a number of PPA providers in order to achieve their sustainability targets on energy use. But it isn’t uncommon to see operators partner with the same renewable project developers for multiple PPAs.
“Large buyers will have four to six different developers that they work with on a routine basis,” says Edison’s Lange. “We want to build a relationship where we can see their pipeline early and have negotiations. Then you can build that trust with them and have an openbook relationship around costs which is really critical to these long-term large renewable goals versus just a one-time contract.”
Fransden says Equinix has taken a “flexible” approach to PPAs and doesn’t have a specific preference for either small-scale or large-scale projects.
“We evaluate each PPA opportunity based on its individual merits, including factors such as developer reputation; cost; risk factors; impact on the local community and environment; and overall alignment with Equinix's sustainability goals,” he explains.
Digital Realty's Binkley tells DCD the company is generally looking for projects that are in the same grid region where its facilities operate, as it allows the production of energy to be tied with the consumption of energy in the same grid.
"All things equal, we would prefer to transact in dirtier grid regions rather than low carbon grid regions," he says. "We want to not only add renewables but add them where it has the biggest impact in terms of displacing dirty power from fossil fuels. But there can be trade-offs with economic competitiveness and availability of projects."
"We don’t have any preferred partners per se, however, we do tend to gravitate towards partners that have proven track records of constructing and bringing projects online consistently, as well as those that offer long-term support throughout the life of the contract," Binkley adds.
“We've transacted in multiple jurisdictions, multiple countries with multiple types of projects over a number of years, so we feel good that we can come to a developer and say, we get deals done, and we're not a onetime buyer in many cases.”
While many data center operators will be looking to procure energy for existing facilities, companies should also be considering renewable energy in tandem with new developments.

Franek Sodzawiczny, founder and CEO of KKR-backed Global Technical Realty (as well as both Zenium and Sentrum), is currently developing data centers in the UK and Israel with his new firm. The company broke ground on the first of three 13.5MW, 5,400 sqm (58,000 sq ft) buildings at its Slough campus in January 2022, and the company is eyeing potential PPA partners with an eye for the future.
"For a new data center facility, even if they’re up and running in six months, will need a stable and predictable load before they can get a PPA in place," he says.
"Essentially you are agreeing to purchase a pre-agreed amount of power, and during at least the first six months of a data center coming online, the usage is usually sporadic, ramping up for a while as the halls come online.
"We are already investigating some renewable assets, due to go live Q4 2023, and looking to procure. Typically, you are looking at a lead time of a nine months minimum from the start of inquiry to a PPA going live," he adds. "The most sensible approach is to arrange a ‘standard’ contract until the load is stable and then look to procure PPA from there, rather than run the risk of paying for power you don’t utilize."
Issue 48 • April 2023 | 61
PPAs explained >>CONTENTS
PPAs more common in US & Europe
Climate and regulations play a big part in the PPA sector, and markets differ depending on where you aim to locate a project.
PPA markets in Europe and the US are well-established but the regulatory environment can vary between different markets. In the US regulations can vary stateto-state and also depend on the transmission system where you aim to place a renewable project. This means that even a project in one state can be in two markets, if it covers two interconnections.
In Europe, the costs are likely higher, but grids will cover the whole country, meaning it can be easier to take a wider approach. There is, however still variation between each market, even within the EU.
“We have big operations in countries like France and Germany,” says Digital Realty’s VT, “and we know that it is very difficult to find PPAs in these markets, as opposed to the Nordics or Spain for instance. The market in Europe has become mature in the last three to five years, but it is not as mature as in North America.
“In the Asia-Pacific region, the PPA market is still in its early stages, and the regulatory environment for PPAs can be more challenging compared to the US and Europe,” says Equinix’s Fransden.
“However, the cost of renewable energy in that region has been decreasing, making it more accessible. We are also working with a group of companies in Australia evaluating projects for an aggregated PPA in that market.”
PPA trends – Seller’s market for the foreseeable
PPA costs have been increasing rapidly in recent years, with 2022 seeing a significant spike in prices – up to 50 percent in some European markets
This has partly been driven by high demand for new projects pushing up against supply chain constraints across materials, labor, and transportation, regulations slowing down new project authorizations and interconnection permits, along with the war in Ukraine.
“2020 was probably the best year from a buyer's perspective to be in the market; PPA prices were low and demand wasn't exceeding the supply,” notes Lange. “The pendulum has definitely since swung towards the supply side.”
Equinix’s Fransden tells DCD: “Increased demand has led to a seller's market, where developers and owners of renewable energy projects have more bargaining power and can command higher prices. While this trend has been particularly pronounced in markets
such as the US, it is becoming prevalent in all markets where PPAs are an option.”
Edison’s Lange notes that more developers are entering the space while the existing players are ramping up their portfolios ‘fairly drastically’ in part due to the Inflation Reduction Act helping the economics of certain projects.
Prices largely leveled off by the end of 2022 as some of these issues eased, but are yet to drop noticeably. This is partly due to a large supply and demand imbalance for solar
“The vast majority of our clients still have a requirement for new-build renewable energy – sometimes termed 'additionality' – because companies want to be able to make the claim that they're adding additional renewable energy to the grid,” says Edison’s Lange.
“With the current market, we have started to see that change a bit. Some companies with near-term goals of needing renewable power by 2025 that are falling behind, may say the overall goal is additional projects, but are comfortable signing a short-term PPA on an existing asset to bridge the gap. This

panels. However, as more panels begin to be manufactured locally – Microsoft is backing one effort to build solar panels in the state of Georgia – costs may come down.
During 2022 when energy prices reached record highs, the price of PPAs may have been more bearable, but as the wider market calms down, companies may begin to balk at paying high PPA prices.
“I think something has to give at some point,” says Lange. "There's going to be a point where corporates just stop saying ‘we can bear that cost'.”
Market dynamics mean ‘net new’ desires limited
Almost all PPAs are for ‘net new’ projects i.e. investing in projects that are not yet complete, as opposed to off-taking energy from already-operational projects.
However, looming target deadlines and capacity crunches mean new projects aren’t always viable, especially in the current market.
wasn’t common several years ago, but is now part of companies’ strategies.”
Equinix’s Fransden says his company’s focus on new projects “provides a high impact and helps increase the reliability of the local grid.
“While our current renewable energy PPA portfolio consists of only new build projects, we will consider existing renewable energy projects as opportunities present themselves,” he adds.
Digital Realty is also focused on net new projects: “We want to have that additionality impact of bringing new renewables onto the grid,” says Binkley.
“We've been able to find deals, for the most part, where we want them. Where we've had issues have been typically where the deals are there, but the price point is just not attractive, or in emerging markets where there isn't a mature renewable market.”
24/7 matching in PPAs
By its nature, renewable energy can be fickle.
62 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
"We hear from data center companies that their tenants want renewable energy and they want it at a better or comparable prices to brown..."
>>CONTENTS
The sun doesn’t always shine and the wind doesn’t always blow, but the constant energy demand of data centers means that even companies with PPAs will inevitably see the grids powering data centers relying more heavily on fossil or non-renewable fuels during these lulls.
To counter this, some companies have begun to explore the use of 24/7 (or hourly) matching PPAs, which look to ensure that operations are covered by renewable energy on a constant basis, even when particular renewable projects might be
operating at a lower efficiency.
These may include over-provisioning on more projects, investing in different energy types, utilizing energy storage systems, or buying renewable energy from the wider market.
Microsoft and Google have previously made efforts to ensure at least some of their facilities have around-the-clock 100 percent carbon-free matching. Colocation firm Bulk has also signed a matching PPA, as has Iron Mountain.
What do data center operators need to know about PPAs?
• Understand your climate goals; Sustainability targets are many and varied. Understanding what they mean and how you aim to achieve those is an important first step.
• Identify what you want; Understand your current and future capacity loads and where they are located. This will help you figure out what kind of projects are right to invest in.
• Understand the costs; investing in PPAs can be pricey, and the economics of procuring energy through these agreements is different from your traditional energy purchase. The better you understand the costs, the better you can identify the risks.
• Get buy-in; Ensuring leadership is on board is key to getting sign-off on any PPA. Having a clear picture of how PPAs help sustainability goals, showing the costs and potential risks ahead of time will help create the best story to get buy-in from leadership.
Other factors
Our experts add the following thoughts:
“Data center operators evaluating PPAs for their renewable energy needs should consider the following key factors: energy price volatility, penetration of existing and proposed renewable energy generation, contract structure, grid interconnection/ congestion, and contract length. Impact on the local community and the environment are also important ‘beyond the megawatt’ considerations related to reputational risk,” says Equinix’s Bruce Fransden.
“Consideration should be given to how the length of the contract fits with energy and sustainability goals. It is important to understand grid connection and
transmission infrastructure constraints for the renewable energy project being considered, as this can impact the cost and reliability of the energy generated.
Digital Realty's Arron Binkley says it is important to understand the financial implications: "It's helpful to go into these transactions understanding what role they play in your energy and renewable stack: are you using them as a hedge? Are you using them purely for low-cost renewable credits? Are you comfortable with the financial risk, both on the upside and on the downside? Being aware of the range of those settlement swings is important. And being comfortable with those is certainly critically important.”
"These deals are not the same as physical power transactions. If you're in a deregulated power market where you're used to buying energy and buying hedges, these are not the same transactions; the contracts are different, the terminology can be different, and the ongoing performance of them can be very different as well.
Edison Energy's Joey Lange notes it's important to ensure the length of the PPA aligns with your load projections and your relationships with your tenants and understand who is going to bear that cost or benefit and how that is pass through. Credit also needs consideration.
"You need to be creditworthy in this environment really to be an off-taker for these projects. We work with treasury and finance teams looking at options for how you can post credit for the contract, and what that cost of debt looks like. Is there a parent or a sister company that can back this contract on your behalf, how do they need to be involved in the contract, and what are the risks?"
Google has been very open about the energy mix of its facilities, allowing customers to make decisions about where to host workloads to ensure they are as green as possible, and has been working on migrating certain parts of its own workloads between different facilities to try and achieve the greenest operations. Microsoft also publishes the energy mix data of its Azure cloud regions.
Iron Mountain is also using carbon tracking for greater visibility in the energy mix of its facilities with ClearTrace; Aligned Ascend, T5, and Corscale are doing something similar with nZero (formerly Ledger8760).
However, 24/7 hourly matching can be difficult, and Edison’s Lange says investing in an entirely new project in a dirtier grid can have a larger overall impact compared to a 24/7 PPA in a grid that is largely already renewable.
“We've had a lot of discussions around that. Does it matter if you have every hour of the day covered with renewables, or does it matter that you're buying renewables from a dirtier grid and making the biggest carbon impact possible?”
“There's no right or wrong; both are good That idea of emissionality – making the largest climate impact – is certainly a lot easier to do than 24/7,” he adds
Lange notes that battery storage is becoming increasingly common in certain markets, such as Texas’ ERCOT grid, and can be key for 24/7 matching.
“In every instance, we have a discussion with the client and the developer around whether it makes sense for the client to be part of a battery storage contract as well.
"There's certainly carbon benefits to batteries from a time shift perspective and when that energy gets generated and put onto the grid at more carbon-intensive times. But it comes at a steep cost.”
Equinix tells DCD it is ‘not currently pursuing’ a 24/7 strategy, but notes the growing interest in the area.
Hourly matched renewable energy PPAs present the challenge of a much more complex procurement process, higher administrative burdens, and sophisticated reporting scheme,” says Fransden
Likewise, Digital Realty tells us 24/7 matching is something the company is ‘closely investigating and tracking’ and is part of industry groups working to improve hourly emissions data tracking.
“Currently, however, there are limitations in many markets in terms of getting visibility into hourly emissions, which is a vital part in making 24/7 energy matching work,” Binkley says.
Issue 48 • April 2023 | 63
PPAs explained
>>CONTENTS
A new land for energy and data
Emma Woollacott Contributor

It's now near-universally accepted that the world needs to move swiftly to renewable energy - indeed, according to the UN, global emissions need to be reduced by almost half by 2030 and reach net-zero by 2050 if we're to avoid the worst impacts of climate change.
However, there's rather less agreement on how this is to be achieved. While renewable energy sources such as wind, tide, and solar power have in theory almost unlimited potential, appropriate sites aren't always easy to find.
In the case of wind, lack of suitable space and local objections are major limitations when it comes to onshore installations. Meanwhile, at sea, turbines face a trade-off that can limit their viability.
Close to the shore, they face local opposition, and meanwhile generally experience less powerful and more intermittent wind. But siting them further out, where the sea is deeper, presents significant structural problems.

DCD Magazine #48
European countries led by Denmark have plans to connect giant offshore wind farms to new artificial “energy islands” housing hydrogen projects and data centers
>>CONTENTS
"On the island, a data center can directly access renewable energy on a large scale from the connected windfarms and to the fiber grid"
A new land
One potential solution that's now receiving serious attention is to create 'energy islands'artificial islands sited well offshore that would house large numbers of wind turbines.
The energy produced could be stored in batteries or transmitted to shore via hybrid interconnectors to multiple landing points. These allow the creation of an interconnected offshore wind grid, making electricity from the wind farm available wherever it's needed. When electricity isn't being produced through lack of wind, the same interconnectors will allow countries to trade electricity.
The wind energy could also be converted to hydrogen via electrolyzers; these could either be sited on the island itself, with the hydrogen piped back to shore, or on the mainland, where the excess heat from the process could be fed into district heating networks to heat homes.
The biggest cheerleader for energy islands is the Danish Energy Agency (ENS), which is leading a project to build two islands, one in the North Sea and one in the Baltic Sea. The successful bidders will be announced next year (2024).
"Denmark has a lot of coastline, and the North Sea particularly is a fantastic area for offshore wind projects - very windy and with relatively shallow waters," says a spokesperson.

The North Sea and the Baltic
The North Sea installation will be built on an artificial island around 80km off the coast of Thorsminde, a town in Jutland, and will serve as a hub for a number of offshore wind farms. It will house facilities for routing electricity from the wind turbines into the electricity grid and, potentially, a harbor with service facilities for the first 3-4GW of electricity generation.
This 3GW capacity represents twice as much energy as the total offshore capacity of wind turbines in Denmark today, and around half of the country's total electricity consumption. Later, says the ENS, there are plans to expand capacity to up to 10GW.
The project involves two major firsts - turbines that are larger than existing installations, and sited further from the coast than has been attempted before.
Meanwhile, the Baltic Sea island is less extreme. It will be built on an existing natural island, Bornholm, around 15km off the coast, where electricity from offshore wind farms will be routed to electricity grids in Denmark and neighboring countries. The turbines will have a capacity of 3GW.
In the case of both islands, the aim is to convert electricity from the offshore wind farms into other forms of energy, known as Power-to-X, as well as to house equipment that can store surplus electricity when the supply of electricity exceeds demand.
The projects are currently up for tender, with two consortia openly bidding.
Modular island building
One consists of Danish multinational power company Ørsted, along with Denmark's largest institutional investor ATP and digital infrastructure and connectivity company GlobalConnect.
Jesper Kühn Olesen, project director for Ørsted’s North Sea Energy Island proposal, envisages a 'future proof' construction, based on a modular approach.
"It consists of a small artificial island, which can be expanded with flexible modules that can be added and replaced as required," he says.
"The modules are built onshore and connected to the North Sea Energy Island, meaning that the island can easily be upgraded to accommodate more than the 10GW of offshore wind power that is Denmark’s current ambition. It can also be adapted to accommodate the rapid developments in Power-to-X and other technologies in both 2030, 2050, and after."


Meanwhile, one other bidder for the project has publicly entered the fray: the VindØ consortium consists of two of Denmark’s largest pension funds, PensionDanmark and PFA, along with its largest utility company, Andel, and infrastructure investment firm Copenhagen Infrastructure Partners (CIP).
This group foresees carrying out electrolysis on the island itself, claiming that it's cheaper to lay a hydrogen pipeline to the mainland than a power cable, and is also considering the production of ammonia to be used in shipping and industry.
It's not clear whether any other bidders have expressed an interest: "Both consortia have been very explicit about their interest in the North Sea Energy Island in particular. But we are still preparing the tender documents and can’t say more about potential bidders at this stage," says the ENS spokesperson.
Issue 48 • April 2023 | 65 Island living
>>CONTENTS
Data center proposals
While data centers aren’t a major part of official plans, both consortia have expressed interest in housing them on the energy islands, with the Ørsted group envisioning their proposals acting as digital hubs as well as energy hubs.
"On the island, a data center can directly access renewable energy on a large scale from the connected windfarms and at the same time be placed on an intersection for the fiber grid that sends data through the North Sea region," says a GlobalConnect spokesperson.

"Being placed in the middle of an ocean will also provide a generally cooler area, which will lessen the data center’s need for cooling, while the ocean offers submerged cooling possibilities."
Denmark is open about its ambitions to take a lead in the creation of energy islands, in much the same way as it has pumped resources into wind power in the past.
Beyond the two current projects, it is leading in a more distant project, BrintØ or 'Hydrogen Island' planned for the shallow waters of Dogger Bank on the Danish side of the North Sea, connected to 10GW of offshore wind power and with a green hydrogen production capacity of around one million tons.

The hydrogen will be sent to neighboring
nations such as Germany, the Netherlands, and Belgium.
Enter Belgium
While its plans are the most extensive, Denmark is not the only country to be looking into the possibilities of energy islands.
A Belgian consortium, TM Edison, has won the tender from electricity transmission system operator Elia for the construction of an artificial energy island, again in the North Sea, but this time off the coast of Belgium.
Princess Elisabeth Island will be located 45km from the coast within the Princess Elisabeth wind zone. The idea is to connect a 3.5GW wind zone with the UK and Denmark through the Nautilus and TritonLink interconnector projects, as well as Belgium itself.
The plan is to link all wind farms in the zone to the mainland by 2030, and ultimately to generate 300GW of offshore electricity by 2050.
Construction of the foundations is set to start next year and is expected to take two and a half years, with the high-voltage infrastructure installed after that. It will, says the team, be the world’s first artificial energy island to combine both direct current (HVDC) and alternating current (HVAC) facilities.
"This project is a pioneering one for several reasons. It is the most cost-effective and reliable way to bring offshore wind to shore. It will be an island that provides options for the future," says Chris Peeters, CEO at Elia Group.
"When we connect it to other countries, the Princess Elisabeth Island will become the first offshore energy hub. After our construction of the first hybrid interconnector in the Baltic Sea, the island is another world first."
Pushing the technology
Energy islands will require a number of advanced and little-tested technologies - the construction of the islands themselves, the building of larger-than-usual turbines, and the positioning of large-scale hydrogen electrolyzers far out at sea.
However, with the total potential of the North Sea alone in terms of offshore wind generation estimated at 180GW - around a third of the total wind power that the EU is aiming to achieve by 2030 - the prize is a big one.
"The energy islands will be a huge step in the transition towards more green, renewable energy and secure energy supply – not only in Denmark but in Northern Europe," says the ENS spokesperson.
66 | DCD Magazine • datacenterdynamics.com >>CONTENTS
Sebastian Moss Editor-in-Chief

Building smarter supply chains for data centers


Moving to a decentralized and standardized supply chain
As the world recovers from a series of shocks to global supply chains, the data center industry is not unique in wanting to build redundancy into its logistics network while still supporting rapid growth and razor-thin margins.



But the sector, which straddles the worlds of traditional construction and cutting-edge technology, faces a set of distinctive challenges. Now, as things normalize, there is an opportunity to address those challenges and build the supply chains of tomorrow.
"I do think, in many ways, the data center industry is much slower to change than other industries, which is quite interesting," Brett Rogers, CEO and founder of supply chain software company KatalystDI, said.


Rogers would know: He spent nearly 11 years as a data center contractor for AOL, General Dynamics, and other Fortune 500 companies, and nearly five years as a VP of critical facilities for Mark G. Anderson, where he was responsible for facility development of almost $1 billion of critical infrastructure.

Issue 48 • April 2023 | 67
Simplifying supply chains >>CONTENTS
After a year-long stint building out Tesla's Gigafactories, Rogers returned to the data center industry for a nearly six-year spell at Google, where he eventually ran the company's US data center buildout.
It was there that he began to see that the industry, for all its apparent love of data, was failing to make use of information to improve its supply chain.
Every building is different
"If you think about each data center construction project, it has its own unique supply chain - everything's individualized and bespoke,” he recalled. “In fact, this was the genesis for the company - back in September 2018, when I was at Google, we had released something like 600-800 megawatts of orders into the marketplace. And right away we started learning about these delays in a very specific part of our delivery plan, it was something as simple as busway.”

Those delays compounded “because of the way that construction works, where coordination and detailing are done at the job site,” he said. “We have never stopped to standardize, so every project did things a little bit differently. Every order was custom.”
We have the tools and data to move from traditional construction to a more industrialized construction vision “where supply chains become repeatable, more productized,” and construction is akin to following Lego instructions. “If you just dumped 7,000 Lego pieces on the floor, and handed somebody an exploded diagram showing how they went together, that would be a nearly impossible task,” he said.
“What Lego does is they package them into these little packages with maybe 20 pieces and a set of instructions for them. You put these all together, and then those little
sub-components go together. That's really what I think construction becomes."


The hope is to move from bespoke projects to a decentralized standardized supply chain. "And so that's the problem that we're working on within our software,” he said. In essence, the company provides a web platform where customers input their data center design, and layer in suppliers and commodities in a hierarchical structure where you can zoom in and out of each product’s supply chain. This, in theory, allows companies to spot an overreliance on vendors, surface supply issues, or see alternative options.
While the vision predated Covid, back in those pandemic-free days “nobody really even talked about the concept of the supply chain,” Rogers claimed. “And then Covid hit, and everybody wanted to talk about the supply chain.”
This allowed his company to start conversations, but the virus still impacted how businesses approached change: “It's hard to plan for the long term when you're trying to put out these giant fires within your program, so that was the downside.”
Supply chains have steadied out a bit
now, but there are still enough issues to keep people focused, “it's become sort of a more mature discussion of ‘we're moving through the storm, how do we make sure we're better positioned for the future?’"
The supply chain industry has no shortage of companies offering to use big data and a splash of AI to solve challenges, even though software in itself could not have avoided the chaos of Covid or black swan events like a boat being stuck in the Suez Canal.
"It's by no means perfect,” Rogers admitted. “This is a huge journey that's going to take a lot of time to get to, but it's also by no means smoke and mirrors. The software's real.”
Basic and obvious?
In fact, parts of the software seem simple, he countered. “I'm an industrial engineer, by education. If I were to show this to people I went to college with 30 years ago, they would laugh and be like, ‘Oh, this is so basic and obvious,’ and they would be right from a manufacturing perspective.”
When he was working at Tesla, he saw
68 | DCD Magazine • datacenterdynamics.com
DCD Magazine #48
>>CONTENTS
a similar project management ethos for products. “But construction’s different, it’s not like working at Tesla where you do a little experiment and record some outputs for 24 hours and see what happens and then you can make a call,” he said.

“Instead, it’s big cycle times and very, very low throughput. So we're trying to find the middle ground: What's the information that's needed, and how does the supply chain organize for each of these components?”
We’re only at the beginning of our journey to understand our supply chains, Rogers noted, but that journey should be done bi-directionally with suppliers. That means that “if I'm putting an order into the network, how do I make sure that that second or third-tier supplier has access to the right information? Just as importantly, how do I make sure that I understand their lead times, their inventories, and how it's going to impact my projects and planning decisions?”
Data sharing required
Of course that requires companies to put potentially confidential information into the system, and then convince their suppliers to do the same.
When asked whether some suppliers would fail to provide information, Rogers countered that “if we talk to potential customers that have that concern, we generally know those are not great customers for us, because what we're working towards is an aligned philosophy of what the future looks like.”
In his view, companies need that data anyway, even without his platform. “It needs to exist somewhere. If you're building a project, without that data, you're building it with one arm tied behind your back.”
The platform is also not necessarily zero-sum - while the more data it is fed the better, it can operate with less-than-perfect information. Customers have different comfort levels, and have differing levels of granular insight into their supply chains.
“We look at this more as a journey than somebody thinking that they’re just going to sign up and it’ll work perfectly. I will never make that customer happy.”
Over a longer time period, building a repository of data center firms’ supply chains could provide a lot of insight - especially given everyone uses a very similar supply chain. In future, Rogers envisions offering trends or reporting on sectors, but first, the company has to figure out customers’ comfort level with data sharing.
Another challenge is that vendors don’t give the same information to everyone. “What's interesting, is that if you're a Google and Microsoft-type company, and somebody else is a Vantage-like business, and we call the same vendor and ask for lead times on the same piece of equipment, we might get three different answers.”
Data centers may not be so special Rogers was coy on sharing specific customers, but claimed that “we work with a couple of the hyperscalers, three or four
of the colo or wholesale type developers, a couple of general contractors and integrators that build in the data center space, and a couple of the big semiconductor programs outside of the data center space.”
He also wouldn’t confirm how many were using the product across their businesses, and how many were simply trialing it, but said that it was a mixture.
Already he claims the software has proved cost-effective. “I'm talking around 20-30 percent savings on electrical modules and integrated mechanical equipment, just by understanding how you're planning and purchasing certain elements,” he said.
That’s thanks to the years of supply chain management neglect he believes there has been in the industry. “It's a pretty immature space, which means that there's a lot of upside potential," he said.
Now, he argued, it is time for a shake-up. “Data centers for whatever reason have been very insular, and view themselves as special. And the truth is, what is a data center? It's a hardened warehouse,” he said.
“It has a somewhat complicated electrical system to make sure that the electrons keep flowing and it has a heat rejection system to remove heat from the servers. And obviously, there are controls and monitoring layers, etc. But I don't think data centers are nearly as technically complex as they appear to the outside, particularly when you compare them to battery or semiconductor factories.
"This is about understanding them as products to make better supply and demand decisions, inventory matching decisions, and inventory management strategies."
Issue 48 • April 2023 | 69
Simplifying supply chains >>CONTENTS
Cloud repatriation and the death of cloud-only
Dan Swinhoe News Editor
Once it began gaining traction, the cloud was billed as a panacea for companies looking to reduce their IT costs. For many, going all-in on the cloud meant the capex costs of data centers could be done away with and expensive legacy infrastructure closed and sold off.

Browse the pages of DCD and most of our enterprise stories are companies migrating en masse to public cloud as part of a ‘cloud-first/ cloud-native/cloud-only’ strategy.



But recent headlines are suggesting that companies may be retreating back from the cloud and ‘repatriating’ data, workloads, and applications back to on-premise or colocation facilities. Are companies really growing cold on the cloud, or is this hype from hardware vendors and service providers looking to cash in?
Cloud repatriation: is it real?
Does the promise of cloud still ring true? By and large, yes. Companies of all shapes and sizes rely on public cloud infrastructure for a variety of mission-critical workloads.
However, the idea of going all-in on ‘cloudonly’ and abandoning on-premise and/or colocation facilities is fading away in lieu of a more hybrid ‘cloud-and’ approach.
70 | DCD Magazine • datacenterdynamics.com DCD Magazine
#48
Companies are realizing a hybrid mix of cloud and on-prem could be a better strategy than a binary approach
“We're seeing that the application would have actually done better in a private environment from a cost and latency standpoint”
>>CONTENTS
Most of the service and colocation providers DCD spoke to for this piece said repatriation was happening, though to varying degrees. IT analyst firm IDC told us that its surveys show repatriation as a steady trend ‘essentially as soon as the public cloud became mainstream,’ with around 70 to 80 percent of companies repatriating at least some data back from public cloud each year.
“The cloud-first, cloud-only approach is still a thing, but I think it's becoming a less prevalent approach,” says Natalya Yezhkova, research vice president within IDC's Enterprise Infrastructure Practice. “Some organizations have this cloud-only approach, which is okay if you're a small company. If you're a startup and you don't have any IT professionals on your team it can be a great solution.”
While it may be common to move some workloads back, it’s important to note a wholesale withdrawal from the cloud is incredibly rare.
“What we see now is a greater number of companies who are thinking more about a cloud-also approach,” adds Yezhkova. “They think about public cloud as an essential element of the IT strategy, but they don’t need to put all the eggs into one basket and then suffer when something happens. Instead, they have a more balanced approach; see the pros and cons of having workloads in the public cloud vs having workloads running in dedicated environments.”
“We are seeing it, it is real. But we're really seeing a future that's hybrid,” says DataBank CTO Vlad Friedman. “What we're really seeing is people are more intelligently thinking about placing their workloads.”
Who is repatriating data?
While any company could reclaim data back from the cloud, most of the companies DCD spoke to said enterprises that made wholesale migrations to the cloud without enough preparation and cloudnative startups that had reached a certain scale were the most likely candidates for repatriation.



Dropbox notably pulled significant amounts of data back from Amazon Web Services (AWS) between 2013 and 2016 According to a 2021 interview with DCD, the decision to remain on-prem – known as ‘Magic Pocket’ – worked out significantly cheaper and gave Dropbox more control over the data the company hosted. The company still also uses AWS where required, however.
More recently, web company 37signals – which runs project management platform Basecamp and subscription-based email
Coming back from the cloud
service Hey – announced the two services were migrating off of AWS and Google Cloud.
"We've seen all the cloud has to offer, and tried most of it," CTO and co-founder David Heinemeier Hansson said in a blog post. “It's finally time to conclude: Renting computers is (mostly) a bad deal for medium-sized companies like ours with stable growth. The savings promised in reduced complexity never materialized. So we're making our plans to leave."
37 Signals didn’t reply to DCD’s request for an interview, but in subsequent posts the company said it was spent more than $3 million on the cloud in 2022 and would be saving some $7 million over five years by switching to Dell hardware – some $600,000 worth – located in two colocation facilities in partnership with Deft who will manage the installation.
"Any mid-sized SaaS business and above with stable workloads that does not benchmark their rental bill for servers in the cloud against buying their own boxes is committing financial malpractice at this point,” Hansson said. The migration is underway and expected to be completed this year.

Issue 48 • April 2023 | 71
>>CONTENTS
Some repatriation is like 37signals; cloudnative startups that have reached a scale where it can be more economical to switch to on-prem. Another part of the repatriation picture is companies that may have done a full ‘lift and shift’ of their IT estate and later realized not everything may be suited for cloud, especially if it hasn’t been refactored and modernized.
For companies that have a heavy onprem/colo footprint, many new workloads may start in the cloud during development and while they are ramping up to benefit from the speed and flexibility cloud offers. But after a certain level of maturation or compliance threshold – or as soon as IT finds out the workload exists in some cases – applications will then need to be brought home.
DataBank CTO Friedman notes that he has seen a number of service providers repatriate once they reach a certain scale, and are moving back steadystate, computationally- or I/O-intensive applications.
“They're figuring out a hybrid architecture that allows them to achieve savings. But I don't think it's a pure-play move back to colo; it's about moving the right workloads back to colo. Because ‘colo’ or ‘cloud’ is not the desired outcome; it’s efficiency, it’s performance, it’s lower latency.”
Planning is important – companies that just look to do a straight lift and shift to the cloud could see costs increase and performance suffer and lead to regret and repatriation.
“I previously worked with a large system integrator in the Nordic region that had set out to move 80 percent of its workloads into the public cloud. After three years of laborious efforts, they had moved just 10 percent before aborting the project in its entirety and deferring back to on-premise,” says Tom Christensen, global technology advisor and executive analyst at Hitachi Vantara.
Why are companies bringing workloads back?
IDC’s Yezhkova tells DCD that security remains a major driver of repatriation, though this has declined in recent years.
One of the biggest drivers is simply cost – the wrong workloads in the wrong configurations can cost more in the cloud than on-prem.
“Public cloud might be cheaper, but not always,” says Yezhkova. “Ingress-egress fees, the data transfer fees, they add up. And as the workload grows, companies might realize that it’s actually cheaper to run these workloads in on-premises environments.”
A 2021 report from Andreessen Horowitz noted that cloud repatriation could drive a 50 percent reduction in cloud spend, but notes it is a “major decision” to start moving workloads off of the cloud.
“If you’re operating at scale, the cost of cloud can at least double your infrastructure bill,” the report said. “You’re crazy if you don’t start in the cloud; you’re crazy if you stay on it.”
Likewise, cloud costs can be far more unpredictable than on-premise equivalents, especially if configured incorrectly without spending controls in place. For complex deployments, the added cost of a service provider to manage cloud environment can add up too.
Data sovereignty demands can be a driver in some markets. Countries with stricter data residency laws may force enterprises to keep data within their own borders – and in some cases out of the hands of certain companies under the purview of data-hungry governments. Many cloud providers are looking to offer ‘sovereign cloud’ solutions that hand over controls to a trusted domestic partner to overcome some of these issues.
Latency, performance, and management may be a driver – super latency-sensitive applications may not meet performance expectations in public cloud environments to the same degree they might on-premise or in colocation sites.
72 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
“If a new workload can only be run into dedicated environments because of regulatory requirements, what does it mean for other workloads?”
“We're seeing these companies that may have done a lift and shift and thought that this would have been better,” says DataBank’s Friedman, “but the application would have actually done better in that private environment from a cost and latency standpoint.”
Add in the fact that companies inevitably need as many (if not more) people to manage increasingly complex and intertwined environments as they did onpremise, and some companies may prefer to just keep things in-house.
SEO software firm Ahrefs recently posted its own calculations, saying it had saved around $400 million in two years by not having a cloud-only approach.
The company calculated the costs of having its equivalent hardware and workloads entirely within AWS’ Singapore region over the last two years, and estimates the cost would be $440m, versus the $40m it actually paid for 850 on-premise servers during that time.
“Ahrefs wouldn’t be profitable, or even exist, if our products were 100 percent on AWS,” Ahref’s data center operations lead Efim Mirochnik said, although critics have noted that its cloud cost estimates were severely underoptimized and that a more honest evaluation would have shown a smaller gulf in costs.
What workloads should and shouldn’t be in the cloud?
What workloads make the most sense to sit in the cloud versus on-premise will vary depending on a number of factors including the application, its users, geography, and more. The same workload may have different answers at different times.
“A workload is like a living thing and the requirements might change,” says IDC’s Yezhkova, who says that the only definable ‘tipping point’ for when a workload should be repatriated is when performance could be impacted by keeping it untouched.
When it comes to data sovereignty, application interdependency may mean it’s easier to bring all the workloads closer to the most tightly regulated workloads, rather than constantly shifting information between onpremise and the cloud.
“If a new workload can only be run into dedicated environments because of regulatory requirements, what does it mean for other workloads?” says Yezhkova. “It might have this snowball effect on other workloads.”
Workloads that see data moving constantly back and forth in and out of clouds between applications could be candidates for moving as a way to avoid ingress/egress fees; getting data out of the cloud is more expensive than putting it in there.
“Companies need to do cost analyses on a regular basis,” Yezhkova adds. “It shouldn’t be done once and everybody forgets about it, it should be a regular exercise.”
Workloads with high variability are natural bedfellows to sit in the cloud. Backup data that are fairly static in nature could also be good options to keep in the cloud.
Latency-sensitive Edge use cases are another where the public cloud might not make as much sense – Ensono principal consultant Simon Ratcliffe notes manufacturing often needs on-site compute that may not be suitable for cloud – although the introduction of Edge locations such as AWS Local and Wavelength Zones may alleviate issues there.
Hardware performance may also be a driving factor. Jake Madders, director of Hyve Managed Hosting, tells DCD he recently deal with a finance client that needed a particularly high clockspeed that wasn’t available through public cloud instances, and required a customized server distributed to around 20 locations worldwide.
And what about HPC and mainframes? Most of the cloud providers now offer mainframe modernization services aimed to get those workloads off-premise, while many are making major head roads into cloudbased HPC.
Most of those we spoke to for this piece agree mainframes are unlikely to move quickly in the cloud, simply due to their speed, cost, and reliability, coupled with the difficulty of migrating the most legacy of complex workloads.
Ensono’s Ratcliffe even notes that companies with spare capacity on their existing mainframes may well find Linux workloads can be run cheaper and more efficiently on something like an IBM Z-System than a cloud instance.
“One of our biggest customers is Next,” he says. “The whole Next directory is run on a very modern mainframe, they have no intention of changing it.
“However, everything that goes around it that connects it to the user experience, is written in public cloud.”
On HPC, there are arguments for and against on both sides. “We recently built two high-performance computing scenarios for two clients: One each in the data center and the equivalent inside Azure,” says Ratcliffe.
“One decided to keep it on-prem, because of how they collect and feed the data into it. For the other client Azure came out as the right answer for them, again driven about how they collect their data.
“The first organization collects all their data in one place and it's right next to their data center and that works for them. The second company is all over the world and always connecting in through the Internet anyway. The answer is both because they're driven by different use cases, and by different behaviors.”
Hyve’s Madders adds that his company did a similar cost analysis for a BP subsidiary looking at an HPC-type deployment looking at seismic processing data for well-digging.
The companies looked at two options; one was leasing five or so racks within a Hyve environment in an Equinix facility, or in the cloud and running. The system would generally be running one week of intensive processing calculations until the next batch a month or so later.
“We worked it out that with a public cloud environment, the cost of compute required to do one week's calculation cost the same as buying the kit and then reselling it after the month.”
On-premise can offer ‘as-a-Service’ pricing
Colocation seems to be much more of a common destination for reclaimed workloads. Many companies simply won’t be interested in the investment and effort required to stand up a whole new onpremise data center.
But even if companies are looking to colos to save on costs, they should still be cognizant of the investment required in people, hardware, networking, and any other equipment that physical infrastructure will be needed.
Issue 48 • April 2023 | 73 Coming back from the cloud
>>CONTENTS
"It's about moving the right workloads back to colo. Because ‘colo’ or ‘cloud’ is not the desired outcome; it’s efficiency, it’s performance, it’s lower latency"
What companies need to know for a repatriation project
Understand your network, applications, and dependencies: Understand what workloads you have where – including VMs, number of CPUs, and RAM – and how they are interconnected. Figure out where you might be reliant on locked-in cloud services and what the alternatives might be.
Figure out why you’re having issues: If you’re spending more than you thought, or an application isn’t performing as well as it should, understand why. Sometimes it might be easier to update the application and keep it where it is.
Identify the right workloads to bring back: Steady-state, predictable, computationally or I/O-intensive workloads, and those workloads sensitive to latency will be best positioned for repatriation. Understand application dependency and the latency between any workloads affected by a move.
Figure out the costs: Reclaiming data could result in a change between capex and opex and may require a longer view of things. Understand what money you’ll need upfront and how that affects your recurring bills down the line. Bandwidth fees might briefly increase during migration.
Have the right skills: Whether in-house or through a partner, make sure you have the right skills on hand to manage the IT and data center infrastructure.
Test: Test everything works before you begin to exit the cloud in earnest. As downtime window acceptability narrows, the margins for error narrows. Test the latency, test the hardware, run simulation workloads, do failover exercises.
Include room to grow: On-premise workloads, even those in private clouds, don’t have the same near-infinite capacity to scale as public cloud. Be sure you plan ahead and have room to grow without issue.

However, the upfront costs don’t have to be as high as they once were. Many companies are now offering IT hardware in an ‘as-a-Service’ model, reducing capex costs and turning physical IT hardware into an opex cost. Companies include HPE with its Greenlake offering, Dell with Apex, Pure Storage with Evergreen, and NetApp with Keystone.
And for those that demand on-premise enterprise data centers, companies can likewise start to expect similar pricing models. IDC research director Sean Graham recently told us that some vendors are making their data center modules available in an as-a-Service model, essentially making the containers available as a recurring opex cost.
Bringing the cloud on-premise
Many companies are seeking hybrid cloud deployments that combine some on-premise infrastructure with certain workloads in the cloud. Other are pursuing a private cloud approach, which offers some of the benefits of virtualized infrastructure in a singletenant environment, either on-premise or in a colo.
But what about the companies wanting the actual cloud on-premise? While the cloud providers would be loath to admit it, they know they will never have all the world’s workloads sitting in their environments. Proof of this is in their increasing on-premise offerings.
The likes of AWS Outpost, Azure Stack, Google Anthos, and Oracle’s Cloud@ Customer & Dedicated Regions offer on-premise hardware linked to their respective companies’ cloud services and allow environments to be managed through one console. DataBank’s Friedman adds that his company is seeing a number of these ‘on-premise cloud’ redeployments.
“They are for when the customer has bought into the ecosystem and the APIs, and they don't want to change their code, but they want efficiency or to place workloads tangential to their database and AI analytics. It's really a latency elimination play,” he says.
“From the end-user perspective, they're getting the same experience,” adds IDC’s Yezhkova, “but the workloads are running in on-premises environments. Cloud providers realize that it’s inevitable and if they want to be part of this game they need to introduce these types of offerings.
“Previously bringing IT back on premises would be a big deal, it would be
a new capital investment. Now with these types of services and the cloud platforms moving into on-premises, that transition is becoming easier.”
Repatriation is as big of a project as the original migration
Clawing back data from the cloud is no easy or quick fix. Everyone DCD spoke to for this piece acknowledged it should be viewed as a standalone project with the same kind of oversight and gravitas as the migration projects that might have put data and workloads into the cloud in the first place. While the actual data transfer over the wire may only take hours if everything is set up and ready, the buildup to prepare can take months.
Prevention can be better than the cure, and where possible, companies should first look at why an application is having issues and if it can be solved without being moved. Luc van Donkersgoed, lead engineer for Dutch postal service PostNL, recently posted on Twitter how a singleline bug cost the company $2,000 in AWS spending due to the fact it made more API calls than expected.
While some applications may be slightly easier to bring back if they’ve been refactored for cloud and containerized, companies still need to be aware of interdependency with other applications and databases, especially if applications being reclaimed are tied to platformspecific workloads.
A set of isolated virtual machines in a containerized system will be much easier to bring home than a large application tied to several AWS or Azure-only services and connected to latency-sensitive serverless applications, for example.
“If there really is no other alternative [than to repatriate], then look at it as if from a point of view you're planning to start an application from scratch in terms of infrastructure,” says Adrian Moir, senior product management consultant & technology strategist at Quest Software.
“Make sure you have everything in place in terms of compute, storage, networking, data, protection, security, everything ready to go before you move the data set.
“It's almost like starting from scratch, but with a whole bunch of data that you've got straight away to go and deal with. It's going to be an intensive process, and it's not going to happen overnight. It's going to be one of those things that need to be thought through carefully.”
74 | DCD Magazine • datacenterdynamics.com
>>CONTENTS
Keeping fiber shortages in check
Despite reports of fiber shortages last year, the telecoms industry paints a slightly different picture in early 2023
Last summer, reports were suggesting that fiber providers were struggling to get hold of the materials necessary to run their networks.
A report from business intelligence firm Cru Group noted that the global shortage of fiber cables led to delays and price hikes for the sought-after kit.

These shortages led to the cost of fiber optic cables rocketing in price, with Europe, China, and India the worst affected.
At the time, fiber prices grew by up to 70 percent from record lows in March 2021, from $3.70 up to $6.30 per fiber kilometer.
Speaking at the time, Michael Finch, an analyst at Cru, suggested that there may be question marks around targets set for infrastructure deployments.
“Given that the cost of deployment has suddenly doubled, there are now questions around whether countries are going to be able to meet targets set for infrastructure
build, and whether this could have an impact on global connectivity,” he said.
What about now?
But some months on, is this still an issue, and has it impacted fiber broadband providers?
One big player DCD contacted dismissed suggestions that there’s been an issue obtaining fiber cables, with Openreach, a subsidiary of BT noting no such problems.
“We’re broadly insulated from the difficulties in procuring fiber and price rises because of our size and buying power –which means we have long-term buying agreements in place – and our diversified supply chain,” Openreach told us.
The company’s FTTP (Fiber-to-thePremises) footprint currently stands at over eight million homes in the UK. And it wasn’t just Openreach saying they
have been unaffected by these shortages, with CityFibre, another UK fiber provider also reporting no problems.
But just because these companies are dealing with the supposed shortages relatively well, companies are still cautious.
“Around 18 months ago, demand outstripped the supply of fiber across the globe due to multiple countries investing heavily in fiber initiatives, including the USA,” said Matthew Galley, director of strategic partnerships at Jurrasic Fibre, a relative newcomer to the fiber arena.

“Raw materials used in production had also been an issue at this time. Manufacturers have since increased production by investing in extra production lines to meet continuing demand.”
The company said it was aware of shortages from the onset and moved to mitigate this by placing “regular forward orders with delivery and stock updates.”
Issue 48 • April 2023 | 75
Eat your fiber >>CONTENTS
Paul Lipscombe Telco Editor
FTTH Council bullish on growth
“While there is no doubt that the current market situation is tight, we believe that “shortage” is not the appropriate wording,” industry association FTTH Council Europe director general, Vincent Garnier told DCD
“In fact, what we observe at a global level translates into different regional scenarios, depending on how self-sufficient each region of the world is. In particular, our cable manufacturer members report longer lead times on some specific and less demanded products.”
The FTTH Council admits that it’s been a challenging time, noting that the European share in the global production of fiber is currently below 10 percent, while Europe accounts for almost 13 percent of the global fiber demand.
It claims that its FTTH rollout has steadily grown over the years, up from 49.8 percent for FTTH/B coverage in 2019, to 57 percent in 2020 and 2021.
But the association is keen to improve the supply chain around fiber availability, added Garnier.
“The European fiber industry is currently working to improve its supply chain. In particular, the main manufacturers are investing to increase their production and new fiber cable manufacturing units have recently been launched.”
Garnier adds that the association has identified two main factors for consideration when improving Europe’s fiber supply. The first is around “providing faith to local manufacturers that the competition will be fair and sustainable,” while the second is helping companies to cope with high energy costs that have hit Europe.
Suppliers… to meet demand
So how have these businesses dealt with the shortages? According to CityFibre, the company has several suppliers.
CityFibre director of supply chain James Thomas tells DCD that the company identified early on that it would require multiple suppliers to successfully achieve its rollout targets.
“We find ourselves in a position where we’ve got around 10 key material providers on long-term contract commitments with us on our plan to roll out fiber to five million locations.”
Thomas adds that CityFibre works closely with these partners to maintain adequate stock levels, such as fiber cabling.
When asked if the business has been hit by fiber shortages, CityFibre has seen no direct issues from shortages, says Thomas.
“The short answer to that question [regarding shortages] is no, and that is because of the protections we’ve had in place whereby we’ve worked closely with our partners.”
Thomas does, however, acknowledge that there has been a shortage within the industry, noting that the demand for fiber is very high at the moment.
“The global demand for fiber is significant and from a global theme, it’s definitely something we’re vigilant of. But from the perspective of our build-out, we’ve been fortunate to benefit from the relationships we’ve established with our major suppliers, and therefore haven’t been impacted directly.”
The fiber shortages appear to have little impact on the company, with Thomas telling us that CityFibre is on par with its target of reaching an ambitious target of eight million homes with its full fiber service by 2025.
He notes that the figure is 2.5 million for premises passed, with 2.2 million of these ready for service.
Fiber demand has been driven by hyperscalers
It’s also worth looking at what is driving the demand for fiber. Of course, the obvious answer is that broadband providers are looking to roll out faster alternatives, as opposed to the aging copper networks, and while that’s true, it’s not the only factor.
Baron Fung, an industry analyst at Dell’Oro Group, suggests that demand has been driven by some of the big hyperscalers, which have all increased their number of regions in recent years.
He refers to the ‘Big Four’ hyperscalers - Google, Microsoft, Amazon, and Metanoting that these companies have increased their collective number of regions from 110 in 2020 to around 160 in early 2023.
“That's a tremendous increase in the global coverage of these regions, and I would think there's some correlation with the launch of these new regions and the actual demand on optical fibers just to be able to interconnect all these facilities, as all of these facilities are generally connected over longer distances,” said Fung.
“Therefore, cable fiber will be the solution connecting these data centers, as well as the fiber that's needed within the data center to connect all the different networking switches, racks, etc. So I think this could be a market driver behind the strong surge in these cable demands overall.”
He does, however, expect this expansion cycle to wind down in the coming years.
Fung observes that fiber firms operate differently from some other sectors, observing that hoarding of stock is not a practice used by fiber providers, and therefore not a reason to blame for any supply chain disruptions.
“In other product sectors, there's been an inventory buildup right in response to all the supply chain issues with some of the kinds of major vendors like hyperscalers kind of holding a lot of products in anticipation of shortages. After speaking to some of the major fiber optic vendors recently, they don’t believe that there's been such behavior going on.”
Positive signs in the US
In the US it appears that there are positive signs in this sector after American network infrastructure provider CommScope revealed plans to expand its fiber optic cable production
In doing so, the company is aiming to accelerate the rollout of broadband across some of the more underserved areas of the country.
It's part of a $47 million capex investment from the business, which will expand production capacity at its two facilities in North Carolina, one in Catawba and the other in Claremont.
This investment will also create 250 jobs in cable production over the next five years, the company says.
CommScope will push its rollout through its new, rural-optimized HeliARC fiber optic cable product line, which it claims it will be able to support 500,000 homes per year in fiber-to-the-home (FTTH) deployments.
Moving forward cautiously
The need for fiber connectivity is arguably a must in the modern world, and with countries phasing out their legacy copper networks, the demand is likely to only increase.
CityFibre for example says it is FTTP network is being built at a rate of 22,000 premises per week.
You’d imagine that some of the even bigger ISPs are churning out even greater numbers.
From the companies that we did speak to, the shortages have been relatively ineffective on their respective rollouts.
However, all are aware that the supply chain could be hit hard at some point, and are cautious to keep on top of things.
76 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
How real is Open RAN?
Paul Lipscombe Telco Editor
At this year’s Mobile World Congress event in Barcelona it was tough to avoid Open RAN, as several companies announced O-RAN strategies.

And investment is starting to flow. ABI Research estimates that total spending on Open RAN radio units for the public outdoor macrocell network will reach $69.5 billion in 2030.
What is Open RAN?
Open RAN is the latest development of Radio Access Networks (RANs), which connect mobile devices to the core network via base stations.
RANs are important, but have often been
proprietary, so equipment from one vendor will rarely interface with other components from rival vendors.
Open RAN aims to change that by breaking down the RAN into component parts, which communicate through a unified open interface. This will allow a new breed of telecoms kit that allows providers to ‘mix and match’ solutions from multiple vendors, which is impossible under the current network setups.
In theory, this gives mobile operators much more freedom and flexibility to choose vendor partners and frees them from relying on one single vendor.
At the same time, virtualization is providing virtual RAN (vRAN), along with software-defined and cloud architecture,
so telco infrastructure needs less hardware, offering more opportunities for software vendors.

Open RAN is expected to pave the way for breakthroughs in IoT applications, autonomous vehicles, smart homes, buildings, and cities.
Talk turns to action
Plenty of Open RAN proofs of concept and trials have been spoken about in the last few years, but this is now becoming a reality, with many operators deploying Open RAN networks.
Operators are keen to point out new technology, but not everyone is convinced that Open RAN has fully arrived yet
Open your RAN
>>CONTENTS
Speaking in Barcelona, HPE’s head of RAN Geetha Ram told DCD that the MWC buzz is proving doubters wrong.
“When I was last at this event in 2019 there were a lot of people skeptical about Open RAN, almost as if they were dismissive about it.”
Ram praised the range of options within the technology during MWC: "The reason why Open RAN is so important is that the spectrum in 5G is huge. You have the lower end of the spectrum, such as 4G, then the mid-band, plus the millimeter wave, and all of the higher frequencies for IoT applications and so on. The opening up of the RAN space with an open and flexible infrastructure is very, very important in 5G as it can tap into new applications at the Edge and for specific use cases."
She also said deployments are speeding up.
September 2022, towards a target of 20,000 sites by the end of 2025. Like everyone else, the operator echoed promises of flexibility, speed, and efficiency.
European operators pushing for collaboration
In Europe, five major operators have promised to work together. In early 2021, Deutsche Telekom, Orange, Telecom Italia (TIM), Telefónica, and Vodafone committed to working with all industry players to establish Open RAN as the basis for future mobile networks.
The group’s report into the maturity, security, and energy efficiency of the technology found that Open RAN radio units have similar energy efficiency to traditional RAN units, but improve on it with dynamic sleep mode, which works based on actual traffic needs.

As for security, telcos are operating with a ‘zero trust’ approach to every vendor, in an attempt to ensure the established standards and regulations are followed.
On maturity, Open RAN obviously still has to prove itself, with operators expecting full-scale deployments across Europe in 2025.
The five operators are in the O-RAN Alliance, a global body pushing open, virtualized, and fully interoperable networks. The alliance currently has 32 mobile network operators on board, with 323 Open RAN companies in total, according to its website, and was founded in 2018 by AT&T, China Mobile, Deutsche Telekom, NTT Docomo, and Orange.
He is confident that large-scale deployments aren’t too far away, as RAN becomes much more open to vendors and software providers.
“Now it might not be a completely mature technology today as we speak, because the model is so different compared to how the different RANs were built earlier by just one vendor, making them tightly integrated and very much closed,” he told DCD
“But now it's a multi-vendor game, again, like the core network has been for quite a while. Now that new players are coming into the RAN, like Red Hat, for example, it takes some time to get all these mature, which will impact on the performance and price of this technology.”
Governments push Open RAN
Governments around the world have been keen to push Open RAN deployments too, perhaps none more so than the UK.
The UK government has given the four mobile network operators a target: 35 percent of mobile network traffic should pass through Open RAN by the end of the decade.

This was announced in 2021 as part of the UK’s strategy to diversify the 5G supply chain. The ability to choose vendors freely is also designed to enable the UK government to ban Chinese vendor Huawei from its 5G networks back in July 2020.
Other big nations which have banned Huawei, including the US, Canada, and Australia, have endorsed the UK’s Open RAN goals
In the UK, Vodafone announced plans to install the technology on 16 mobile masts in Exmouth and Torquay, before unveiling its prototype Open RAN-compliant 5G network-in-a-box product ahead of MWC.
The operator has also partnered with Orange to build an Open RAN network to spread 4G and 5G coverage in rural parts of Europe, with an initial pilot set for Romania
Dish Wireless recently launched a virtual Open RAN 5G network with South Korean vendor Samsung, to support its plans to provide an open and interoperable cloudnative network to 70 percent of the US population.
Samsung has supplied Dish with 24,000 5G Open-RAN compliant radios and 5G virtualized radio access network (vRAN) software solutions that convert hardwaredriven functions into software-based services.
Verizon has been a big Open RAN supporter, installing 8,000 vRAN sites by
Opening up the game
The whole point of Open RAN is to open up the networks to multiple vendors, operators, and even software companies.
One software company entering the ring is enterprise open source giant Red Hat, a subsidiary of IBM. Red Hat has welcomed Open RAN’s potential to encourage vendor diversity.
“Open RAN provides a space for a software platform company like Red Hat to play in and to host certain workloads,” Timo Jokiaho, chief technologist at Red Hat told us.
Jokiaho agrees Open RAN is the future of mobile networks, but warns that this will take time.
“Open RAN is specifically something for the future. Although it’s something we’re hearing a lot about right now through PoCs (proofs of concept) and trials, these largescale deployments are not going to take place right now.”
"The UK has set out a blueprint for telecoms firms across the world to design more open and secure networks," said Digital Infrastructure Minister Julia Lopez, last December. "With the endorsement of Australia, Canada, and the United States, the industry now has the clarity it needs to deliver a new generation of wireless infrastructure fit for the future."
78 | DCD Magazine • datacenterdynamics.com DCD Magazine #48
>>CONTENTS
The UK has also partnered with Japan to push Open RAN innovation, with these ties further strengthening recently as Japanese operator Rakuten Mobile opened up its Rakuten Open RAN Customer Experience Center in the UK.
This center is the result of a joint commitment by Japan’s Ministry of Internal Affairs and Communications (MIC) and the UK’s Department for Science, Innovation and Technology (DSIT) to increase telecommunications supplier diversity.
Elsewhere, last year the US government pledged $1.5 billion towards helping support rural carriers to replace Huawei equipment and drive Open RAN adoption instead.
Calm down, it’s hype
But not everyone is convinced that Open RAN is at a level where we can get excited about it just yet.
Ookla enterprise principal analyst Sylwia Kechiche thinks that it will take time for Open RAN to arrive, noting that it “requires a mindset shift from operators that are used to ‘seeing’ their network components, as they have to replace them with virtual machines running in the cloud. That takes time,” she said.

“Unsurprisingly, beyond greenfield operators such as Dish and some other PoC and trails, Open RAN deployments have been lackluster. Some governments are strong proponents of Open RAN.”
The cost of Open RAN deployments is something that has generated confusion too, she added.
Kechiche notes that while NEC claims Open RAN can lead to a cost reduction between 23 to 27 percent over ten years, other vendors aren’t so sure.
Huawei has made very little effort to push Open RAN, and appears to be against it, perhaps unsurprisingly given Western governments’ hopes to use Open RAN to ease out the Chinese vendor’s equipment.
Another traditional RAN vendor, Ericsson, unsurprisingly claimed in 2021 that it will be more expensive than traditional RAN for worse performance.
"The reality is that the performance of Open RAN does not compare to integrated RAN," Ericsson told the Federal Communications Commission (FCC). "Even if the cost-saving estimates were true on a per-unit cost basis, the two pieces of equipment are not delivering the same level of performance.
Ericsson's own estimates have indicated that Open RAN is more expensive than integrated RAN given the need for more equipment to accomplish what purposebuilt solutions can deliver and increased
systems integration costs."
Technology Business Research principal analyst Christoper Antlitz says there’s not much more than marketing hype around Open RAN right now.
“Open RAN as a concept makes sense, and ultimately the industry will get there,” he told DCD. “But the timeline for that, where the reality meets the vision, and the theory is the unknown right now. And based on what I've seen, we're still at least a couple of years away from bridging that gap.”
He added: “Open RAN gear has been implemented successfully and is running live traffic in a few commercial networks (mostly in greenfield environments) in various parts of the world, but significant gaps still need to be closed in terms of feature parity, performance parity, and implementation cost parity with traditional RAN, before Open RAN can truly be seen as a replacement, or augmentative, to traditional RAN.”
Tough economic backdrop
The estimated $69.5 billion cost of Open RAN in this decade is a big factor in today’s economic uncertainty. Kechiche thinks operators are currently in a weaker position to invest in a big change.
“Those that have invested in the expansion or rollout of traditional 4G or 5G networks are not going to invest in Open RAN very soon, as they are tied into
contracts with incumbent operators.”
There’s another problem: The open networks which Open RAN promises may be complex to maintain.
“Another challenge is the ownership of the lifecycle management of both software and hardware components, which potentially come from different vendors,” she warns.
It’s a fair point. If there are issues with an open multi-vendor RAN whose job is it to fix them? With closed traditional RAN there’s only one vendor to call.
Time to be realistic
Operators and vendors are excited about new deployments and trials - but in the grand scheme of things, these deployments are minuscule.
Two years ago, DCD noted Open RAN was a few years before its prime, and that appears to be the same now.
The technology still has some way to go before providing a mainstream alternative to traditional RAN.
Antlitz says the timeline for Open RAN is unknown.
He is confident that it will eventually “become the de facto element of the architecture,” but this could take several years.
He believes that vRAN is the first step before Open RAN is fully tapped into, as some of vRAN equipment is Open RAN compliant.
“It’s incremental steps, and on the vRAN side, I think it's easier to make those steps now before you can then introduce the open aspect at some point.
"That is a path that I think can work.”
Perhaps Red Hat’s vice president of global partner ecosystem sales, Honoré LaBourdette, said it best during MWC.
“As all industries continue to navigate 5G transformation, we’ve learned that no single vendor can meet the demand for RAN technologies on their own,” he said.

Issue 48 • April 2023 | 79
Open your RAN >>CONTENTS
Made by humans
Every page in this magazine was written by a human.
That statement is a sign of the pace of change in the past few months. Last year it would have seemed absurdly needless to even suggest it might be otherwise.
Thankfully for the eight journalists that make a living working at DCD, large language models still can't quite do what we do.
They make up quotes, hallucinate alternative facts and, at best, can only regurgitate existing knowledge. Some of these issues will be fixed, potentially frighteningly fast. Others may be beyond the fundamental limits of the current approaches. But is clear that the gap will shrink, and AI will increasingly appear to be able to do what we do.
It is critical that we are not hostages to progress. Yes, to ignore these powerful and transformative tools would be folly - but so would blindly embracing them. We must use them only where they genuinely improve our work and lives, not just where they might make a fast buck, or feel easier.
Yes, they can write faster than us. Yes, they may one day be able to write better and more succinctly than us. But that is meaningless if they only whisper sweet nothings, echoes of reality, factually dubious but seductively convincing.
As we wait to see which jobs will be left standing, and what this means for the concept of truth, I wanted to take this opportunity to thank you for your support of the human-crafted process at DCD now and - hopefully - in the future.
- Sebastian Moss, Editor-in-Chief

88 | DCD Magazine • datacenterdynamics.com DCD Magazine #45
This was typed with fingers >>CONTENTS


Listen to the DCD podcast, new episodes available every two weeks. Hear from Microsoft, Google, Cloudflare, Digital Realty, and more! Brought to you in partnership with Vertiv › Zero Downtime


COMPREHENSIVE ENGINEERING EXCELLENCE www.anordmardix.com
