Classical Chess Die Out? by Anirudh Shidlagatta (Fifth Year, HELP Level 3)
To what extent is a badger cull necessary in controlling Bovine Tuberculosis in England?
Tom Cahill (Upper Sixth, HELP Level 4)
What am I, who knows? by Alexander Lidblom (Fifth Year, HELP Level 3)
Disapproval Voting – What Electoral Reform Could Look Like by Edmund Ng (Upper Sixth, HELP Level 4)
To what extent does the application of joint criminal enterprise liability differ between domestic and international criminal cases? by Ben Bates (Fifth Year, HELP Level 3)
Clive Wearing: Living in the Eternal Present by Louis Spight (Upper Sixth, HELP Level 4)
Would the universe exist if there was nothing around to observe it? by Arie Biju (Fifth Year, HELP Level 3)
Using Natural Language Processing and Machine Learning Techniques for Data Extraction and Reading Comprehension by Patrick Moroney (Fifth Year, HELP Level 3)
Sustainable Development in Nigeria: Assessing Present Challenges and Future Potential by Adam Gaunt (Upper Sixth HELP Level 4)
FOREWORD
The Hampton Extended Learning Programme (or HELP for short) is a programme of extended learning open to pupils in the Second Year and above.
HELP provides an opportunity for Hamptonians to extend their learning in an academic area of their choice.
There are four levels of HELP:
• Level 1 – Second Year
• Level 2 – Third Year
• Level 3 – Fourth/Fifth Year
• Level 4 – Sixth Form
A pupil completing a HELP project pairs with a teacher supervisor who guides them through the process, providing useful mentoring throughout the research and projectwriting phases. This gives Hamptonians an invaluable opportunity to develop research, communication, and organisational skills, working one-to-one with their teacher. The only pre-requisite for completing a HELP project is that the topic must be genuinely outside the curriculum.
The prize-winning projects from 2024-25 in this collection represent just a small fraction of those submitted by pupils. I hope you will agree that Hamptonians’ intellectual curiosity and enthusiasm for their interests shine through in these pieces of work.
I thank Mark Cobb for designing this e-publication, as well as the many teachers who have given generously of their time in supervising their HELP mentees. I also thank the scores of pupils who have completed a HELP project this year – it has been a pleasure reading each and every one.
Dr J Flanagan Assistant Head and HELP Coordinator
WILL CLASSICAL CHESS DIE OUT?
BY ANIRUDH SHIDLAGATTA
(Fifth Year – HELP Level 3 – Supervisor: Mr J Barnes)
Will Classical Chess Die Out?
“Without error can be no brilliancy”
Emanuel Lasker
Introduction
In this article, there will be a few games that will be featured to illustrate key ideas. For those who are unfamiliar with the chess notation, please refer to page 20 Whilst there will be chess positions presented every now and then, it is important to understand how chess notation works to understand some of the diagrams better
Chess, the “King of games”, has grown in popularity recently Many different events have contributed to this growth such as lockdown, the release of the Queens Gambit series on Netflix and chess controversies Throughout history, it has been played to symbolise intellect, political tension and art. Out of all the different formats, classical chess has demonstrated these attributes the best from flamboyant attacks to cunning manoeuvring, but in recent years, there is already a lot of evidence that its significance is already starting to fade.
There are many different formats to play chess depending on the total time each player begins with to play the game In classical chess, the players each have a minimum of 1h + 30s increment and sometimes have bonus time at move 40 of the game Although some online platforms do have a “standard” or “classical” time control, this is often much shorter than OTB (Over the Board) classical, hence ill defining it.
Classical chess itself has been around since the mid–19th century but has become increasingly endangered As much as FIDE (the international federation of chess) try to treasure its enriching history, they will have to adapt to the growing community, bringing about one major question: Will classical chess die out?
The History of Chess
Development of the Modern Game
Whilst what we recognise as “chess” has been around in Europe for 500 years, the origins of the game, “Chaturanga”, date back to 6th Century AD in India It was first used to recreate scenes from battles but very soon became a popular boardgame However, this is not the first game to be created that is similar to chess as the Chinese game, Xiangqi, was created between 475221BC. That said, the Xiangqi was entirely different to its modern form which was said to be made in 618-907 AD, and, unlike Xiangqi, Chaturanga has a direct connection to chess.
setup
After the game spread to Persia and soon became known as “chess”, originating from the word “shah” which meant “king”. It was not yet the same chess as we currently have with different pieces but is not too dissimilar either. Up until this point, chess had only been used as a symbol of war, but this changed during the Islamic Golden Age.
Chaturanga
After conquering the Persian empire, chess was introduced to the Islamic world to explore arts and philosophies rather than primarily symbolising warfare Chess spread around the world, and modifications were made depending on the region, thereby creating “chess variants”
At roughly a similar time, Shogi, the Japanese variant of chess, had been created. In this variant, after capturing a piece, a player would be able to deploy it as their own on any empty square of the board within a specified rank (depends on the shogi variant). This meant that as more trades occurred, the game got trickier and more tactical.
Modern chess was developed in Europe. To begin with, as the mighty queen had not become a chess piece yet, a weak advisor piece (known as the “Ferz” in chaturanga) was used from 11th Century until the 15th Century The Queen was a piece which had the combined movement of a Bishop and a Rook. After the 15th Century, classical chess was born. Initially, both players to take as much time as they wanted to in this format, with adjournments (pausing for the day to come back the next day and play)
Chess gained its first boost in popularity in the Romantic period where the game was viewed as an intellectual art form. Many creative attacking games were treasured and are still shown to many players, especially those who are new to the game The first classical chess tournament was a knockout tournament played in London in 1849, with its first international tournament being held in 1851 in Amsterdam. However, as these games never used a chess clock, and due to adjournments, players could spend almost as much time as they wanted on a chess game Towards the end of the 19th Century, the first chess clock was invented by Joseph Henry Blackburne and Thomas Bright Wilson Now, players couldn’t take the entire day or longer to play the game.
After the invention of the chess clock, classical chess was better defined as a time control where both players had 1h or more each for the whole game. The longer time control, correspondence chess, was traditionally played through letters to one–another that gave players a day for each move. However, correspondence chess never held the same prestige as classical chess due to the absence of spectators during games
Classical chess has always had a prestigious aura around it since the 19th Century when chess became more popular. It’s rival time controls today, rapid and blitz, appeared in tournaments quite a bit later. Its rivals aren’t as prestigious because of classical chess’s history of World Champions, and because of how young these time controls are
For rapid (previously known as “Active chess”), its first official World Championship match was hosted in 1987 between the current World Champion at that time, Garry Kasparov, and the British Chess Champion at that time, Nigel Short. Kasparov won the match 4-2.
Shogi – very different pieces to chess
If the red flag falls, the player has only 3 mins left
For blitz (previously known as “Lightning chess”), its first unofficial World Championship match was hosted in 1970 called the “Speed Chess Championship of the World”. Future World Champion, Robert James Fischer, or otherwise known as “Bobby” Fischer won the tournament with 19/22, trailed by the legendary attacking grandmaster and a former world champion, Mikhail Tal, was 2nd with 14½/22.
More rapid and blitz tournaments have been hosted over time, but classical chess continues to remain as the more important time control as this is what FIDE uses to determine which title can obtain.
Chess Titles
In chess, there are 4 different Open titles: Candidate Master, FIDE Master, International Master and Grand Master For the latter 2 titles, 3 norms (a certain performance rating in tournaments with at least 9 rounds) are required along with the rating requirement to get the title. Against a higher rated field of players, fewer points in the tournament are required to achieve the norm It is not possible to obtain any title from only a rapid rating or a blitz rating, but perhaps this will change in time
Classical chess has always been thought as a reliable basis to determine titles because of the superior quality of each game. Fast time controls do not have the same quality as classical does with time trouble happening very regularly and players entering panic mode In classical chess, any mistakes made can be punished easily rather than getting missed, revealing the player who would be truly stronger.
But as the quality of chess improves, it becomes much harder to progress Due to this, classical chess is becoming less relevant over time, a tragedy for a time control with such a rich history
Evolution of Classical Chess
Being the oldest time control, classical chess has seen the development of the game from one of the greats to another. When players begin learning chess, they will almost always be shown instructive classical games that the masters, who too were figuring out the game, had conducted. To get rid of a time control that has produced countless of such games is not something that most players, especially chess federations will want to do, but might be necessary.
During the mid-19th century, when chess enjoyed a rise in popularity, masterclass attacking games were frequent The best demonstrated a series of brilliant tactical sacrifices, tearing their way towards the enemy king to finally deliver checkmate. Games from this era have been studied and shown to countless others, but amidst all the excitement of an attack, some players developed a strategic side
“A win by an unsound combination, however showy, fills me withartistic horror” Wilhelm Steinitz [12]
The first World Chess Champion, Wilhelm Steinitz, is considered the “Father of Positional chess”. In the 1870s, he tried sharing his new style, but this was looked down upon as a timid playing style. However, overtime it was gradually accepted, and top players started experimenting with this unique style. However, none could play it better than the Champion himself.
Steinitz accumulated a small advantage out of the opening before searching for tactical strikes. He played many games with ingenious positional ideas, even the very tricky positional exchange sacrifice such as the one in the diagram.
After studying positional chess, players first began to discover that the bishop was more useful than the knight in many different situations The ability to attack from far away and at 2 different sides of the board proved it to be more potent than the knight, despite its inability to attack opposite coloured squares.
“When you see a good move, lookfor a better one” Emanuel Lasker [13]
Emanuel Lasker, the 2nd World Champion, was the inventor of positional squeezes and was an endgame aficionado. Instead of producing raging attacks, Lasker outplayed his opponents as the game drew closer to the endgame
In the diagram, Lasker used a very modern technique of provoking weaknesses through threats as well as to tie down enemy pieces, accumulating a greater advantage each time. He also very patiently poked at black’s position rather than simplifying everything into what might be a winning position.
Despite material equality, Lasker won this endgame by using minute imbalances to push for the win
“I only lookone move ahead but it is always the right one” Jose Raul Capablanca [14]
After the 1st World War, positional chess was further developed by José Raul Capablanca, the 3rd World Champion, experimented with different pawn structures. Despite Lasker’s best attempts, the Cuban prodigy would outplay Lasker, primarily using his intuition.
During this time, positional chess reigned supreme, disallowing players to attack with its solidity. But as positional chess grew, others took a unique interpretation to positional chess.
Here, Steinitz played 26. Rb6!! against Chigorin, due to the lack of open files for the rook
Hypermodern chess
Aside from further developments into how middlegames and endgames were to be played, new sets of theory (memorised moves in the opening stage) were being created. Instead of the traditional method of controlling the centre with pawns to launch an attack later (or positionally bind and constrict your opponent until they collapsed at the top level), revolutionary players would let their opponent take the full centre so that they could use it as a target!
This new style was called “Hyper-modernism”, a style led by Aaron Nimzowitsch, Richard Réti, Ernst Grünfeld, Efim Bogoljubov and Gyula Breyer. This innovative style relied upon using pieces to control the centre rather than pawns.
A very common idea also emerged with this playing style from the Italian word “fianchetto” which means “little flank” Bishops that had been fianchettoed were able to attack the centre directly from afar, utilising the longest diagonal. A kingside fianchetto also allowed for safer kings whilst the bishop was still present if the player were to castle kingside as there would be an extra piece to help with defending.
However, there were still flaws with this hypermodern idea: if the centre ever became totally locked, the fianchettoed bishop would render almost useless; if the bishop ever got traded off, the squares the bishop originally attacked would become incredibly weak as all the pawns surrounding the bishop would be attacking oppositely coloured squares; if there are no targets on the long diagonal, the bishop loses its purpose.
Unfortunately, the hypermodern school of chess never truly dominated chess like Lasker and Capablanca’s solid positional playing style did. Whilst it too took a positional approach to chess, the style was very difficult to carry out as attacks could appear very easily if the player wasn’t careful
Universal Playing Styles
“A lifetime is not enoughto learn everything about chess ” Alexander Alekhine [16]
Although the hypermodern school never dethroned Capablanca, Alexander Alekhine successfully dethroned the Champion with a playing style that was both aggressive and positional, a universal playing style. Universal players are very rare in chess and often remain dominant for a long time due to their flexibility to
A double “fianchetto”
Capablanca blundered, playing 34…Qc7?? and Alekhine found 35. Nc5!, winning the rook after a long sequence
switch gears based on the position’s demand. Robert James Fischer, another universal player once managed to win 20 games in a row, and secured a peak rating of 2785, still within the top 20 highest ratings peak ratings and was 125 rating points ahead of the second highest of his time.
Alekhine had 2 different reigns as world chess champion: one from 1927 – 1935 which began after beating Capablanca but ended after his loss to Max Euwe, and another from 1937 – 1946 Unfortunately, his reign was ended by his death after choking on his food, leaving the title up for grab, which allowed the Soviets domination in the chess world
The Soviet Empire
“Chess is the art whichexpresses the science oflogic ” Mikhail Botvinnik [18]
Up until this point, there had never truly been a totally dominant country when it came to chess. After Mikhail Botvinnik won the World Chess Championships in 1948, Botvinnik grew a Soviet empire through educating others and writing chess books Botvinnik was a very solid positional player who gave strong emphasis in studying chess in order to improve.
Through teaching other Soviet chess players, the USSR dominated chess for half a century Whilst the two legendary players, Mikhail Tal and Bobby Fischer, did win the World Champion titles respectively, both of their reigns were too short lived to break the empire With the rise of the Soviets, chess became a possible profession rather than a hobby supported through another job, and the game found countless Russian prodigies following after it.
Some of the most famous prodigies involved Kasparov, considered the Greatest of All Time by many, and Anatoly Karpov, easily one of the best positional players ever known.
Although Anatoly Karpov was looked down upon by Mikhail Botvinnik (who said that “there’s no future at all for him in this profession”), he took the throne after Fischer from 1975 –1985, suffocating his victims with his positional squeezes. His reign was a very political one as he fought with two anti-Soviet, elite Russian chess players: Viktor Korchnoi in 1978 and Garry Kasparov in 1984–1985 (after which Kasparov became the World Champion). Unfortunately for Karpov, there was quite a lot of drama involved in his reign as World Chess Champion as the USSR began to fall apart.
Kasparov was yet again another dominant chess player who had a peak elo of 2851, the 2nd highest peak rating of all time. But as the competition was becoming tougher for the top level, a new entity would appear soon, skyrocketing past humanity’s limitations
Garry Kasparov (left) and Anatoly Karpov (right) about to play each other in the World Chess Championships
The Rise of the Engines
“Someday computers willmake us allobsolete ” Robert James Fischer [21]
Chess engines had never truly shocked the audience before the famous match between Garry Kasparov and Deep Blue. Up until this point, humans had clearly shown to be stronger with a much clearer positional understanding. There were still major flaws that had been unveiled even after Garry Kasparov played Deep Blue, but it would only be a matter of time until all chess engines would be practically unbeatable.
The true first chess machine was built in the early 20th Century, called “El Ajedrecista”. Although the Mechanical Turk built in the 18th Century was thought to be an autonomous chess machine at the time, it was discovered to be a hoax where a player would play inside it.
The Ajedrecista used arms to pick up pieces and knew if an illegal move was made. The machine could checkmate in only a handful of endgames with a few mistakes, but this was an incredible milestone, being the first machine to play chess competently
After the 1950s, many chess engines were being developed, calculating deeper and improving their evaluation. However, there were still two significant problems that were difficult to fix: material-greed and the lack of long-term understanding
The initial drive in the mid-20th century to make strong engines came through incentives, such as IM David Levy’s bet in 1968 of $3000 to any chess engine that could beat him in 10 years. Unfortunately for Levy, the chess engine Kaissa managed to beat him in every single game in 1977, and Levy had lost his bet, just a year short.
$10,000 was offered for the first engine to beat a GM, and $100,000 was offered for beating the world champion
Deep Thought was the first engine to ever defeat a grandmaster. In 1988, GM Bent Larsen was beaten by the machine in an OTB tournament, just a year after the engine was created. The engine was beaten by Garry Kasparov but won the World Computer Chess Championship with a perfect score.
The team behind Deep Thought developed a significantly stronger engine, called Deep Blue, which made history by defeating Kasparov in 1997, taking the throne as the new World Champion, and beginning a new era where machines would overpower humans
The quick success of chess engines has been strongly correlated with the advancements in computer science. Improvements in software produced more efficient algorithms for finding the correct moves, and improvements in hardware (following Moore’s Law) provided more
El Ajedrecista
Garry Kasparov playing against the computer, Deep Blue
memory storage for the machines. However, engines were still heavily reliant on human programming to improve during the 20th century.
In 2017 however, things changed yet again for chess engines as Google’s Deepmind team developed a unique engine that was able to improve by itself. The engine, known as Alpha Zero, had a Neural Network system which could be developed for each game it played. The engine was very unusual to prior engines with a very different approach to chess, having a very similar playing style to romantic era chess players.
Just like other engines, AlphaZero was built around brute force calculation, and positional evaluation. As for calculation, it would use a DFS (depth first search) to calculate all legal moves in one branch up until it had reached its depth limit before calculating a new branch AlphaZero used a MCTS (Monte Carlo Tree Search) which falls within the DFS category
However, where it really started to deviate from other engines was on how its evaluation of final positions were built
At the end of each line, all engines must give a value for the final position after a DFS based on certain factors:
• Material – counting the total value of the pieces for each side
• Piece placement
o Piece-Square Tables - giving pieces a value based on what square they are on. This updates during the game
• Mobility – Number of legal moves for each side
• King safety – (one of the most complex things to implement) …and more factors.
Up until AlphaZero was made, engines were programmed by humans to prioritise certain factors more than others, but the DeepMind team took an entirely different approach AlphaZero made its own priorities without any human intervention by playing itself repeatedly, playing a total of 44 million games against itself This way, the machine would make its own judgements on what factors had to be prioritised over others.
In the first 2 hours, it was better than every human in the world, and within 4 hours was better than every chess engine. AlphaZero played 100 games with stockfish 8 in December 2017, winning the match by a landslide: 28 wins, 72 draws and 0 losses In 2018, the two engines had a 1000 game rematch, only with AlphaZero to win with an even greater victory with a result of 155 wins, 839 draws and 6 losses.
From this moment onwards, engines began to switch towards neural network development To ensure an even easier time evaluating positions, table bases (a list of positions that have been completely solved through brute force) are inputted to improve their evaluation in endgames. So far, chess has been
AlphaZero’s King walked to e3 but Stockfish couldn’t do anything about it!
solved with 7 pieces in the board, with 8-piece table bases currently being solved. Human intervention by giving slightly more priority to some factors than others (such as activity) is also applied but can vary based on the engine’s preference.
Engines have significantly improved the quality of chess, revealing strange yet powerful concepts that could be used in games. Thanks to engines, it has become much easier to analyse games as they can pick up where mistakes had been made and suggest what they believe to be the best move in those positions. However, with the rise of engines came threats to the chess world that could make it obsolete.
Online Chess
Over the last 2-3 decades, online chess has made a strong appearance in the chess world. In fact, many argue that the online chess platforms (such as Chess.com and Lichess.org) have a bigger impact on chess than FIDE does!
On July 20th 2024 marking international chess day, a Guiness World Record had been broken with 7.2 million chess games globally played in under 24 hours. 109 chess federations participated in attempting to break the record together, hosting numerous tournaments. However, in total, only over 1% of the 7.2 million games played came from tournaments hosted by these federations, leaving 99% that came from the 5 online platforms: Chess.com (and ChessKid), Lichess.org, FIDE online Arena, SimpleChess, The Chess Alliance and Zhisai. Chess.com on its own contributed to over 6 million games, making up over 83% of the record. On top of this, on December 16, 2022, Chess.com had recorded 100 million users on its site.
Some of the major reasons for so many more online games than OTB games are the difficulties with playing in tournaments. With OTB tournaments, only the top 2-3 players tend to win prize money, typically with the 2nd place prize not being too much higher than the entry fee in smaller tournaments. There can also be a lot of difficulties with finding tournaments as many tend to be very far away, or often it can be the case that the players do not even know how to find tournaments
Unlike OTB tournaments, it is much easier to play an online game, sometimes without even needing an account. Many tools can be accessed for free such as the analysis board, playing variants, playing chess engines (which the site provides). Lichess.org itself provides everything for free as it is a non-profit organization that thrives on donations made, even providing studies where you can store a list of games with your own analysis (or even purely the engine’s analysis). Because of how easy it is to use online websites, online chess has thrived, hosting their own tournaments such as Titled Tuesday and the Pro Chess League, and has been used to livestream professional games such as the Candidates. But with the rise of online chess, major issues that threaten the game have become increasingly relevant.
Threats to Classical Chess
Cheating
In online chess, cheating involves sandbagging (deliberately losing rating, giving a false impression of strength) or having any assistance during the game whatsoever. According to chess.com, in 2020, over half a million accounts had been banned for cheating with an average of 800 closures per day. It’s important to note that there can be false bans when chess.com closes accounts, which is why the anti-cheating team must carefully review most accounts that have been deemed suspicious by their automated system. However, it is still very easy for chess.com to catch most untitled cheaters as a lot of them have very suspicious things about their games:
• Play highly accurately for most of the game
• Have weird time usage (very consistent from 4 seconds to 10 seconds)
o To hide this, they may deliberately spend a lot of time on moves that really do not require a large time consumption (but do not actually know that it’s an easy move)
• New account (accounts under a year old)
• Get a worse position from the opening and then start playing super accurately
o Sometimes, they may go as far to stop using an engine when they have an almost crushing position, only to fail to win it
• Win streak (and very few losses to break it)
• Sandbagging (deliberately losing games)
o Often, they will not intentionally lose them, but will lose them as they are not using an engine (these losses tend to be in under 15 moves)
Chess.com’s monthly closures of untitled accounts from January 2021 to September 2022
When it comes to titled players, cheaters become much harder to catch. Unlike most untitled players, a titled player only needs a few hints to win against some of the best players rather than for the entire game This means that for most of the game, they will be playing normally as they won’t be using an engine, so banning them (without banning authentic players) becomes a tough challenge The main cheating accusations arise from when Underdog Titled
players beat very strong Titled Players, but according to Chess.com’s stats report, there is too little evidence that a lot of Underdogs cheat against stronger players. Nevertheless, they do continue to ban a few titled players every Titled Tuesday.
In OTB tournaments, currently it is extremely difficult to cheat in them. Unlike online tournaments where there wouldn’t be anyone monitoring people at their homes, in OTB tournaments the arbiters and other players will all be able to see what you are doing. Along with this, all devices must be turned off and placed on your desk or in your bag according to FIDE rules, and if these devices ever turn on or make a sound, then the player who this device belongs to automatically loses the game. In tournaments with a bigger prize pool, arbiters will scan players with a metal detector before and after a game, where if a device is detected, then the player automatically loses the game they are about to play or have just finished (depending on if it’s before or after the game).
With all of that said, it is not impossible to cheat in OTB tournaments. Without going too many times to avoid suspicion, you could go to a cubicle in the toilets to cheat as here, nobody will be watching, and it would be fairly easy to get a device in the cubicle before a round begins making sure that neither the scans before or after the game will catch you, but it is imperative that the device doesn’t get removed In big tournaments (invitational tournaments, national tournaments) DGT smartboards can keep track of every move played during the game, making it even easier to cheat as the player would not have to remember the position exactly before going to the cubicle with the current position already being accessible online
As for other methods of cheating in OTB tournaments, no other methods of cheating using engine assistance have been uncovered Although there are some violations of basic rules in youth tournaments (such as the touch–piece rule where the player must move the first piece touched unless indicated that they were adjusting it), there aren’t too many major ways to cheat at chess.
In the 2 most recent cheating scandals in OTB chess, both defendants had received very serious sanctions:
The Carlsen – Niemann scandal began with the former World Champion Magnus Carlsen getting outplayed by Hans Niemann in an endgame during the Sinquefield Cup After the victory, Niemann briefly stated that the “Chess speaks for itself” after getting asked about his thoughts on the game. Very soon, Carlsen withdrew from the tournament, posting an implication on twitter that Niemann had been cheating. After a year’s worth of the long-drawn controversy, Niemann was finally declared innocent with Carlsen paying a $10,000 fine as compensation, but the damage had already been dealt as Hans suffered from a lack of invitations from the St Louis Chess club and other invitational tournaments which are crucial for gaining rating at the top level.
Carlsen (left) playing Niemann (right)
In the most recent scandal, a toilet cheating scandal, there is currently a lot of evidence for the defendant, Romanian GM Kirill Shevchenko ranked 69th globally, cheating during the games. During the Spanish Team Championships, Shevchenko’s opponents had noticed that he had been very frequently going to the toilets without an arbiter to follow them (which is mandatory if a player does go too frequently), and Shevchenko would play a series of moves very quickly after coming back from the toilet. Along with this, Kirill only went during the games, neither before nor after, and would only go to one specific cubicle which had a phone in it with a note saying “¡No toques! ¡El teléfono se dejó para que el huésped contestara por la noche!" ("Don't touch! This telephone has been left so the owner can answer it at night!"). The phone was later confiscated and Shevchenko was disqualified from the tournament with further investigations to proceed. Forensics revealed that the handwriting of the note was very similar to Shevchenko’s writing, the ink was the same as the pen that Shevchenko was using, and the time zone of the phone was also an hour ahead of Spain, indicating that it was in Romanian time. Prior to the tournament, Shevchenko had won Titled Tuesday with 10/11, which had already drawn suspicion. If Shevchenko would be found guilty of cheating, he would be the highest rated player in an OTB tournament to ever get banned for cheating and could potentially be stripped of his GM title
Cheating is easily the biggest threat to chess as engines are many more times stronger than some of the best minds Whilst currently there is not a lot of OTB cheating, it could be very dangerous for its integrity if more cheating does occur here as authentic players may struggle more to make money from chess. In classical chess, the whole system of titles could be undermined if cheating reaches a new level in this format as it is only here that people earn titles.
With many accusations being thrown about, especially by former World Champion Vladimir Kramnik, it’s hard to get a good understanding of how well cheating has been handled. Soon after Shevchenko was disqualified from the Spanish Team Championships, Kramnik posted how it was expected and that more were to come on social media.
Kramnik had also been accusing many young players and rising stars during 2024, posting his statistics that he thought were “interesting” (i.e. that he believed that they were cheating) on chess.com, especially when it came to Jose Martinez. Jose Martinez, or “Jospem” as his username is on chess.com, has had a very positive score against Kramnik online, with only 1 or 2 losses previously. Jospem was also 3100+ in blitz on chess.com, yet had a FIDE elo of 2600+ For Kramnik, this itself seemed very suspicious as he couldn’t understand how there could be such a large rating gap between OTB chess and online chess, which is also why so many youngsters have been accused by Kramnik. In reality, this gap is actually perfectly normal because many of these people will be much better at playing online chess than OTB chess, but
Shevchenko at the Spanish Team Championships
for someone who never grew up during the online era, this can be very hard to grasp as Nakamura pointed out.
To prove his innocence, Jose Martinez agreed to play with Kramnik in the “Clash of Claims” where out of 36 games played, half would be OTB blitz, and the other half were online blitz However, as Kramnik started complaining about issues with his screen early on, Martinez agreed to play fewer online games, a big disadvantage for him who was much better online. Despite all the commotion, Jose Martinez managed to win the match with a 2-game lead, proving his innocence Perhaps if they had played more online games, Martinez would have secured an even bigger lead
Whilst there are still a lot of cheaters, Chess.com do believe that it is certainly not as much as many believe it to be but do still ban a lot of accounts. However, according to GM Hikaru Nakamura, whilst he does believe that accusations and scepticism from players like Kramnik is highly overestimated, he believes that the numbers of cheaters that exist lies in the middle between Chess.com’s estimation and Kramnik’s estimation. Unfortunately for chess, alongside cheating, there lies yet another problem derived from engines, but this time revolves around a completely different issue.
The Draw–with–Black Strategy
In the rich history of chess, for the most part both sides were able to fight for a win from the very start if they chose to. Because of this, many brilliant games from both colours could be played, and countless different openings were playable. If one side were to try and play for a win, they could very easily push for one out of the opening as very few openings had become unplayable due to an easy way to counter it.
But after the engine revolution, many openings died out as engines can very easily exploit the smallest weaknesses in a position. Engines also made it very easy to prepare against certain openings as they can analyse entire lines within seconds. In order to get out of the opponent’s preparation and avoid what all the engine unveiled, players have been forced to play sidelines; these sidelines would often be quite risky compared to the mainline, and over time would also be uncovered. As a result, top players have adopted a new strategy in classical chess: rather than playing for a win with both colours, most players would try to draw with black and only press for a win with white rather ever than going all in.
In the match between Fabiano Caruana and sitting World Champion Magnus Carlsen in 2018, all the 12 classical games ended in a draw. Although one player was slightly better in each of the games, neither player could obtain a win as many games simplified down to a worse but easily drawable endgame. However, after they reached the rapid tiebreakers, Carlsen managed to win 3 games and win the match with a score of 9-6. At the time, Caruana was in his peak form in classical chess with a rating of 2844 but was still unable to change better positions into a victory.
Despite such a dominant position, Carlsen (black) held against Caruana, drawing the game
With the help of engines, players have learnt to draw many worse but not losing positions In 2017 and 2018, for players rated above 2750, 70% of their games ended in a draw, leaving only 30% of games as victories or losses Whilst this has improved the level chess is played at, this has also made it less enjoyable to watch classical chess. In many single-player sports (e.g Tennis), the concept of a draw is either very rare or not possible due to the circumstances, so as both players become more skilled the sport also continues to become more exciting. As for chess, if the opponent plays a near perfect game, then the other player has no better option than to play into a draw or to accept defeat With the same starting position each time, it’s very easy to replicate such perfection at the highest level and avoid all the risks
Although this is not a problem for the integrity of the game itself, it is still a big problem for making money from competitive chess.
For all sports, competitive players are only able to make the enormous sum of money that they do through sponsorships, who only would make these deals if the sport is easy to engage in and watch. As for classical chess, there is already a flaw in that few people would be able to watch a game that could last the whole day To watch chess, people must themselves be able to vaguely understand what is happening, eliminating a lot of possible audience when watching the elite players
Thankfully, engines do help the audience out a lot here through the evaluation bar and can show possible lines that could occur but still do allow the players themselves to draw easily due to opening preparation with the engine, making it much less watchable with fewer dangerous moments. This is not to say that all games would end in a draw, but if more games end in a draw each tournament, then chess may earn fewer sponsorships, and less people would be willing to make a career through chess with more financial risks.
It is unlikely that chess would receive fewer sponsorships in the near future as it continues to grow rapidly, but if fewer sponsorships occur then classical chess is in deep trouble Luckily, there have already been efforts made trying to find an alternative to classical chess to save long format games.
Alternatives to Classical Chess
It’s needless to say that as players’ opening theory continues to cover more sidelines that eventually classical chess may become so easy to draw that it becomes practically unplayable for top level chess. This could also take a toll on rapid and blitz format but is unlikely to have as much of an effect on these time controls. Luckily, players and chess federations are already beginning to experiment with new formats that still share the same time control.
Chess 960
The popular online chess variant chess960 was first introduced on June 19, 1996, by former World Champion Bobby Fischer with the variant initially being known as Fischer Random. In Fischer Random, the starting position is set up randomly on the 1st rank with some criteria:
1. White and Black must have identical setups
2. The bishops must be on opposite colours
3. The king must be in between the 2 rooks
There are a total of 960 starting positions with the 3 criteria met (which is why the variant is called chess960), but the standard rules of chess will always apply with the only exception being castling. To castle in chess960, there must not be any pieces in between the king and the square it would traditionally move to, nor between the rook and where it would move to. Other rules around castling still apply.
Fischer invented the variant as he wanted to eliminate memorisation and opening preparation, leaving the players with only their raw positional understanding and skills to help them. In theory, this would be the perfect solution to long time–control games as it enables both players to play for a win from the very start due to the absence of opening theory, and the game may become more enjoyable to watch as the audience as both players try to figure out the crazy positions that appear on the board with fewer draws. Thanks to engines, the audience also do not have to work out each position themselves because of the eval bar and lines provided (along with the commentators’ analysis).
However, there is still one major problem with chess960 replacing classical chess. In many top level chess960 tournaments, mistakes have even happened as early as the 1st move of the game and happen very frequently, despite sometimes an analysis of the position (without an engine but with other players) beforehand If other players, especially those new to chess, were to transition from regular classical chess to classical chess960, they will not only struggle in the positions much more than the top players but will also struggle to improve with a constantly changing starting position as building proper foundations becomes harder If rapid and blitz do remain as normal chess alongside this change, then it may not necessarily be as much as a struggle to improve but will still be a slower process than before.
That said, classical chess960 has proven to be a very possible alternative for classical chess, shown in the recent Freestyle Chess GOAT Challenge at the Weissenhaus Luxury Resort. The organisers, Magnus Carslen and the resort’s owner, Entrepreneur Jan Henric Buettner, collaborated to create their own company which earned a $12 million sponsorship from VC Left Lane Capital making Freestyle Chess.
During its first tournament on February 9th 2024, many features had been put in place to achieve Carlsen’s goal of making chess more enjoyable for the spectators such as heartrate
Not so drawish anymore between Carlsen and Caruana with 5 of Carlsen’s pawns on the 4th rank!
monitors and confessional booths, and many different platforms streamed the event which featured 8 of the top players including Carlsen
The company hopes to host many more tournaments in future, with 6–8 Freestyle Chess Grand Slam tournaments each year, and soon we may find many more OTB chess960 tournaments.
Casablanca Chess
Casablanca Chess was a tournament that happened on May 18th 2024 in Morocco’s biggest city – Casablanca. Here, a new variant was featured where players must start from a position chosen for them that has already been played with a few criteria to be met:
1. The position is roughly equal (either 0.0 or around +0.3)
2. The position is from moves 6–15 of the game
Unlike chess960, the starting position is more familiar as the pieces haven’t been shuffled, so spectators may have a slightly better understanding of the position with the engine than with chess960. Casablanca Chess also holds the benefits of more players being able to adapt to it as the only difference from the original game is that the opening has already been played out. This stops players from playing out deep lines of opening theory to force a draw or reach a very dry position, but also comes with its own problems itself
Whilst very few people can recall a few of their own games exactly just through memory, most if not all the top players can recall hundreds if not a few thousands of games, both games they’ve played and iconic games that have been played by others. As Hikaru Nakamura pointed out in one of his recaps on the tournament, players such as Carlsen who know where the game is from very quickly just by looking at the position will be able to remember all the analysis that they did on the position, and because of this will have a huge advantage in every game. This way, theory is not fully eliminated from the game, and the variant is effectively a memory game where those who recall the most games have the best chances of winning.
However, one thing that the tournament does very well is encouraging different openings for all the spectators rather than the standard Ruy Lopez, Sicilian Defence or Queens Gambit
Declined. As more light is given to other openings, more unique positions will appear giving not only a new flavour for the spectators to try themselves, but also a different style in each game that has been adapted around the opening.
With solutions to save classical chess in the long–run being developed, it’s safe to say that if Classical Chess does become obsolete then there will always be a replacement to save longtime controlled games. But will Classical Chess truly get to this stage?
Conclusion
Classical Chess has had a very long history, but it is only recently in the era of engines that we have started to see potential problems in the future. In terms of spectators, thanks to online chess and many events and drama in succession, there have been more spectators than ever watching the game. During the World Chess Championship match of 2023 between Ding Liren and Ian Nepomniatchi, a peak at 572 000 viewers were recorded watching it from different platforms, only beaten by the 2021 match between Carlsen and Nepomniatchi consisting of peak at 613 000 viewers Perhaps if the 2023 match had involved Carlsen, there may have been even more viewers, but nevertheless stands as the 2nd most watched worldwide chess event
However, Magnus’s reasoning for not playing in the match does bring about quite a few concerns for Classical Chess, even if the figures for the event paint it in a bright light. During the Candidates, for the match, Magnus declared that he would only play the winner if it was the young prodigy Alireza Firouzja, stating “I would say the main reason is that I don’t enjoy it. It’s as simple as that.”. In an interview during the Chess World Cup, Magnus described Classical Chess as “stressful and boring” for him, and that losing a game would be a humiliation in the World Cup. For someone who is idolised by almost all chess players and seen as a genius even by those who don’t play chess but have heard of him, this itself is very concerning for the future of classical chess
For someone who has won plenty of World Chess Championships in the format, finding that they don’t enjoy classical chess really begs the question of whether it will die out within the next century or earlier However, many other top players still do enjoy classical chess more than rapid and blitz, such as 18–year–old Dommaraju Gukesh, the challenger of the upcoming World Chess Championship match, and the popular streamer Hikaru Nakamura, both of which have many supporters and are more famous than many of their colleagues. Through these personalities, more players are exposed to classical chess through news coverage of different events, leading to more players at tournaments and hence also at classical tournaments. That said, Magnus arguably has a much bigger impact with his views on the chess world than his competition, so more people may get swayed away from the time control than those getting into it.
Although online chess has really benefited chess as a whole, it doesn’t at all help the situation for classical chess with so few classical chess games on different sites.
Online, “classical” chess is defined as at least 15 + 10 on lichess, the same time control as many rapid OTB tournaments, with many other sites not even having “classical” or “standard” as a defined time control One reason for this is cheating: as time controls get longer, cheaters can use an engine on more moves of the game without losing on time and get more flexibility with their time usage which can make it harder to catch them. Another big reason is that many players on these sites don’t have as much free time to play chess online, let alone travel to tournaments on weekends, so longer time controls would be very unpopular. For most players, they will have only gotten into chess through online chess, perhaps to uncover their childhood nostalgia of the game, or to find a new hobby to pursue, so for them there is no point in playing classical chess as their aims wouldn’t be to become a professional and would be more focused on online goals instead
As for the financial side to chess, the game is not very rewarding compared to other sports, with only the top 100 players able to play chess professionally whilst earning enough money to support themselves. Due to this, parents have begun getting their children into chess at increasingly younger ages, with the youngest to ever obtain a FIDE rating being 3 years, 8 months and 19 days old. For many children, they must get sponsored to play in big tournaments due to their financial background as the game does not pay enough. With increasing competition among younger players, more money must flow into the chess economy soon to support a growing population, which means FIDE must start to make chess more watchable if they are to obtain enough sponsors. That said, today the game has become much more financially successful than ever before
Previously even some of the World Champions had jobs other than chess, such as Mikhail Botvinnik, a computer scientist and electrical engineer in the 1950s; and Dr Emanuel Lasker, a writer, mathematician and philosopher in the early 1900s, whereas now at least the top 10 can make a good sum of money from chess alone, with the top 100 not requiring a side job.
With all of this said, chess itself is very much alive in this era with the innumerable rising stars and growing attention to it, but classical chess is still endangered. Overall, there are just too many problems from top players beginning to dislike the format, to the lack of possible sponsorships in this format purely and by the way it is played with 70% of the elite games ending in a draw. If chess is going to keep growing rapidly, classical chess is just not going to keep up with the pace and may die out. Using alternatives, long format will not die out as new solutions develop to make the game more interesting, but it is certainly a bleak future that lies ahead for classical chess. FIDE may change their system to make rapid and blitz viable to earn titles and norms, but must leave some incentive in long formats to keep it alive It’s sad to see a format with such a rich history, only to now show signs of a struggle, but in the end FIDE must begin to shape towards what the public wants and finds more entertaining if they are to grow the game, and hence classical chess will die out as a result.
“Without the element of enjoyment, it’s not worth trying to excelat anything. ” Magnus Carlsen
Chess Notation
The notation system in this article is called “Algebraic” notation, the simplest and most popular notation. Some older chess books may contain “Descriptive” notation, but there are so few of them using this system, so it is best to focus on Algebraic notation.
Each piece is represented with a letter: K = King, Q = Queen, R = Rook, B = Bishop, N = Knight Pawns are not represented with letters being the weakest pieces in chess.
The chess board is like a map: to locate each piece, you need to find the name of the file it is on (the “xcoordinate”) and find its rank number (the “ycoordinate”).
The notation of moving the f-knight to d7 on move 4 is 4…Nfd7 instead of just 4…Nd7 as 2 knights can go here, hence the specification
King is on the e-file and the 4th rank, so
To move a piece, you need to state the name of the piece (and also the file or rank if at least two of the same piece type can move to the given square), indicate if it’s a capture (x), locate the square the piece will move to, and indicate if it is a check (+) or a checkmate (#).
The move number will also be indicated in front of the first move of the diagram with “…” if it is black’s move For each diagram, the position before the first move has been played will be shown
The
it is on “e4”
Sources and References
Websites and Videos
[1] “A Brief History of Chess” – Ted Ed (Alex Glender): https://www.youtube.com/watch?v=YeB-1F-UKO0
[9] “The Evolution of Chess” – Gothamchess (Levy Rozman): https://www.youtube.com/watch?v=vxJDty0vBJk
[10] “From Steinitz to Carlsen & Ding Liren: Tracing the History of the World Chess Championship” –chessify: https://chessify.me/blog/world-chess-champions
[11] “10 things to learn from William Steinitz” – thechessworld.com (IM Zaur Tekeyev): https://thechessworld.com/articles/general-information/10-things-to-learn-from-william-steinitz/
[17] “Magnus Carlsen has the record rating but is not as dominant as Bobby Fischer” – theguardian.com: https://www.theguardian.com/sport/2015/feb/20/magnus-carlsen-rating-bobby-fischer
[26] “Deep Blue versus Garry Kasparov” – wikipedia.org: https://en.wikipedia.org/wiki/Deep_Blue_versus_Garry_Kasparov
[27] “AlphaZero Chess: How It Works, What Sets It Apart, and What Can It Tell Us” –towardsdatascience.com (Maxim Khovanskiy): https://towardsdatascience.com/alphazero-chess-how-it-works-what-sets-it-apart-and-what-it-can-tell-us4ab3d2d08867
[32] “Fair Play On Chess.com” – chess.com: https://www.chess.com/fair-play
[33] “Chess.com Fair Play Report: Are There Too Many Upsets in Titled Tuesday?” – chess.com: https://www.chess.com/blog/FairPlay/chess-com-fair-play-report-are-there-too-many-upsets-in-titled-tuesday
[34] “Carlsen and Niemann settle dispute over cheating claims that rocked chess” – theguardian.com: https://www.theguardian.com/sport/2023/aug/28/magnus-carlsen-hans-niemann-chess-cheating-allegationssettlement
[35] “Shevchenko Expelled From Spanish Team Championship After Phone Found In Toilet” – chess.com (“Collin_McGourty”):
Shevchenko Expelled From Spanish Team Championship After Phone Found In Toilet - Chess.com
[39] “What is chess960 or Fischer Random Chess?” – digitalgametechnology.com: https://digitalgametechnology.com/what-is-chess960-or-fischer-random-chess
[42] “Magnus Carlsen Raises $12 Million For Freestyle Chess Grand Slam. New Series With Prize Money Of $1 Million Per Tournament” – freestyle-chess.com: https://www.freestyle-chess.com/news/magnus-carlsen-raises-12-million-for-freestyle-chess-grand-slam-newseries-with-prize-money-of-1-million-per-tournament/
[43] “Back to the Future with Casablanca Chess” – fide.com: https://www.fide.com/news/3024
[44] “Magnus Carlsen triumphs in first Casablanca Chess Variant Tournament” – fide.com (Anna Burtasova): https://fide.com/news/3031
[45] “FIDE World Championship 2023 becomes the second most watched chess tournament in the history of live streaming services” – chesswatch.com: https://chesswatch.com/news/fide -world-championship-2023-viewership-stats
[46] “Carlsen still has no equal — FIDE World Chess Championship 2021 Recap and Viewership Records” –chesswatch.com: https://chesswatch.com/news/fide -world-chess-championship-2021-recap
[56] “The Chess Computer from 1912” – hackaday.com: https://hackaday.com/2023/07/03/the-chess-computer-from-1912/
[57] “How IBM’s Deep Blue Beat World Champion Chess Player Garry Kasparov” – spectrum.ieee.org: https://spectrum.ieee.org/how-ibms-deep-blue-beat-world-champion-chess-player-garry-kasparov
[58] “The Chess.com Logo Story” – chess.com: https://www.chess.com/blog/erik/the-chess-com-logo-story
NECESSARY IN CONTROLLING BOVINE TUBERCULOSIS IN ENGLAND?
BY TOM CAHILL
(Upper Sixth – HELP Level 4 – Supervisor: Mr P Langton)
To what extent is a badger cull necessary in controlling Bovine
Tuberculosis in
England ?
By Tom Cahill
1 Introduction
Since the early 20th century, Bovine Tuberculosis (bTB) has posed a major threat to the UK’s cattle and farming industry. In the 1930s, 40% of all UK cattle were infected with Bovine Tuberculosis, and the UK government sought to eliminate this rapidly spreading disease as quickly as possible. Voluntary testing was introduced in 1935, which was then made compulsory by 1950. Any cattle that reacted positively to this test were immediately slaughtered, with compensation provided to the affected farmers. This ‘test and slaughter’ approach was extremely successful, a nd by the 1970s, Bovine Tuberculosis was almost fully eradicated, with the bTB herd incidence reaching a historic low.
However, there was an anomaly. In certain areas of Southwest England, the bTB herd incidence remained notably higher than the rest of the country. In 1973, The Ministry of Agriculture attributed this to the European Badger ( Meles meles) acting as a reservoir of infection in these areas. In an attempt to eradicate the disease, the government undertook a policy of culling badgers which has continued in various forms up to the present day. For a number of reasons, these culls have become a deeply contentious and polarising issue, and have embroiled farmers, scientists, conservationists and vets for the past 50 years.
My HELP project aims to look at why this is, and to answer the question as to whether or not a badger cull is necessary to control bTB. The answer is not as clear -cut as its supporters and opposers make it seem, and I have tried look at evidence and arguments from both sides to come to my own conclusion. I have seen first-hand the devastating effect a bTB outbreak can have on farmers by wiping out whole herds of cattle whilst on work experience, and it was clear to me that something has to be done to control this disease. However, whether a badger cull is the answer or not is up to debate, which I hope this project will clarify
2 Bovine Tuberculosis
2.1 What is bTB and what does it do ?
Bovine Tuberculosis is a chronic respiratory disease caused by the bacterium Mycobacterium Bovis. It primarily affects cattle but is also found in many other species such as badgers and deer, and can even spread to humans. It was because of this danger to humans that in the early 20th century, bTB was treated primarily as a public health issue. The risk of catching bTB from the milk of infected animals was incredibly high, and it was not until the widespread adaptation of milk pasteurisation in the 1960s that the disease levels in humans fell and bTB began to be treated as solely an issue regarding animal health. Nonetheless, the impact bTB has on cattle and the wider farming industry remains , and it continues to be a major problem that must be resolved.
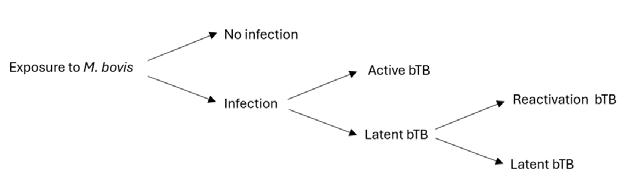
An animal can become infected with bTB, upon exposure to M. bovis bacteria. Whilst on some occasions the bacteria will be successfully engulfed and destroyed by macrophages, often the bacteria survive and are able to reprogram the macrophages, allowing them to then multiply, albeit slowly. In these instances, their host’s immune system will trigger the formation of granulomas - clusters of immune cells that surround the bacteria. The aim of this
is to isolate the M. bovis so that it cannot continue to multiply. If this fails to contain the bacteria, it will continue spread to other organs, and the host will be said to have active bTB. In other cases, the bacteria will be contained, and the centre of the granuloma is left to calcify, forming cottage-cheese like legions called tubercules. Normally, the bacteria in these granulomas would usually die due to the lack of oxygen. However, M. bovis is adapted to survive through this, and instead use s the granulomas as shelters, entering a dormant state called quiescence in which it can remain alive for many months or years, only reactivating once its host’s immune system weakens. This weakened immune sy stem could be due to anything – usually it is because of the host being infected with another disease. The newly reactivated M.Bovis can then multiply and escape, spreading to the rest of the body, causing further infection, and leading to eventual death. These routes of becoming infected with either latent or active bTB are summarised below in Figure 1.
Figure 1
The symptoms of bTB include a persistent cough, weight loss and fatigue, however, due to the slow progressive nature of the disease, these often only manifest in the final stages of infection. Treating any cattle with these symptoms is too slow and costly, and cattle can become infectious before any obvious signs appear. For these two reasons, tests are necessary to detect and remove infected animals before they are able to spread the disease to other cows.
2.2 How do we test for bTB?
To test for bTB, cows are subjected to regular tuberculin skin tests (SICCTs), ranging from tests every 6 months in high -risk areas, to tests every 4 years in low -risk areas. These tests involve injecting a cow ’s neck with both bovine tuberculin and avian tuberculin - mixtures of dead Mycobacteria proteins, coming from either M. bovis or M. avium If a cow has previously been exposed to or infected with Mycobacteria, the injections will trigger an immune response, seen through lumps/swellings appearing at the injection sites. These responses to the two injections are then measured and compared.
A cow is classed as positive when the lump in response to bovine tuberculin is larger than the lump in response to avian tuberculin. This shows that the cow is actually infected with M. bovis, rather than having just been exposed to other environmental Mycobacteria that do not cause bTB. Following this, positive cattle will be sent to slaughter, and compensation for them will be paid to farmers by the government. Farms will be put on lockdown , meaning no cattle are allowed to enter or leave the herd , and restrictions are only lifted following 2 consecutive tests where all cows are deemed bTB -free.
SICCTs are the internationally accepted standard for bTB testing throughout the world, however, they are not perfect. The biggest advantage of these tests is their very high specificity, which is the probability that the test will correctly identify a cow that is free fr om infection as negative. At 99.98%1 , this means only 1 in 5000 uninfected cattle will be false positives. In simpler terms, it is highly likely that any cow that is free from bTB will not mistakenly be classed as positive. From an economic standpoint, thi s is very beneficial. Less healthy cattle will be slaughtered, and the government will spend less money on compensation for these animals. The biggest disadvantage of these tests, however, is their very low sensitivity, which is the probability that the te st will correctly identify an infected cow as positive. Lying between 50% and 80%2 , 3 , this means that a minimum of 1 in 5 infected cattle are false negatives. In simpler terms, a fairly high number of cows infected with bTB will mistakenly be classed as ne gative, meaning they will remain in the herd and can continue to spread bTB to other cattle.
As a result, interferon gamma (IFN -γ) blood tests are occasionally used alongside SICCTs in certain circumstances. These tests have a much higher sensitivity of around 90%, with an albeit lower specificity of 96.5%. 4 ,5 The test works is in similar way to the SICCT, in which bovine and avian tuberculin is added to a blood sample and the immune response to this is compared by measuring interferon gamma levels. Interferon gamma is a type of immunological protein called a cytokine, and higher levels of this in response to bovine tuberculin indicate an animal has been infected with bTB.
Due to its higher sensitivity, far fewer infected animals will be missed, which from and epidemiological standpoint, makes this the superior test. However, its specificity prevents it from becoming the principal bTB test used. The test results of roughly 1 in 30 uninfected cattle would be false positives, as opposed to 1 in 5000 with the SICCT, and the cost of this, alongside the additional emotional toil laid onto farmers, is not considered to be justifiable.
A number of other non-validated tests exist or are in development. The most promising of these is the Actiphage® test. Developed by the University of Nottingham, this rapid test uses bacteriophages and PCR testing to test for the presence of M. bovis in blood samples. Bacteriophages are viruses that infect and replicate inside bacteria, resulting in the bacteria rupturing and their interior DNA being released. Actiphage ® uses a virus specific to mycobacteria. When the bacteria ruptures, the DNA released is recovered and analysed by a PCR test, which can show whether or not M. bovis was present.
Currently, there are no definitive values for the test’s sensitivity or specificity. However, a study carried out by the test’s manufacturers found that in a herd of 41 M. bovis infected cattle, the test’s sensitivity was 95%, and its specificity was 100%. 6 Whilst this is obviously a small study and further research will have to be carried o ut to confirm these values, it is nonetheless really exciting. Furthermore, in 2021 the test was granted £2.3 million in funding to take it through to validation by the World Organisation for Animal Health. 7 If Actiphage® is successfully validated, and proves to be effective as it seems, it could soon play a major role in England’s future bTB control strategy.
2.3 What is the i mpact of bTB?
Despite these promising advancements, bTB continues to have a disastrous effect Each year 20,000 cows test positive for the disease 8 , and the impact of this on farmers is devastating. As
already mentioned, every cow that tests positive for bTB is sent to slaughter. Although compensation for these animals is provided by the government, any additional costs incurred have to be borne by farmers. Whilst these vary, a DEFRA report estimated the median cost for a herd breakdown to be £6600, increasing to £18,600 for farms with over 300 cows.9 Primarily, these costs were down to being unable to replace animals, lower milk yields, the labour involved in preparing for testing , and decreased productivity in general. It is also important not to forget the considerable emotional costs involved Losing livestock can be heartbreaking for farmers, and coupled with its financial implications, a bTB diagnosis can push farmers to breaking point.
However, bTB does not impact just farmers. The disease costs UK taxpayers £100 million a year.10 This money is spent on compensation, testing and a range of other measures employed to combat the disease, one of which is the badger cull. Before I look at these measures in greater detail however, it is first important to look at how bTB actually spreads.
2.4 How does bTB spread?
Primarily, bTB is transmitted between infected and uninfected cattle. The majority of this occurs via the inhalation of infected droplets expelled from the lungs of animals with active bTB However, bTB can also be spread indirectly, through the consumption of food, water or pasture contaminated with M. bovis The saliva, faeces and urine of infected cattle can all contain high levels of the bacteria, which when deposited, can remain alive in the environment for long periods of time. This is due to the bacteria again being able to enter a quiescent state, which allows it to endure tough environmental conditions that other bacteria would not be able to. In winter, cattle are often housed together, meaning they regularly come into contact with each other ’s excretions. If these are accidently deposited on food or in water tanks, cattle can unknowingly consume this and b ecome infected. The same can be said for saliva. In summer, cattle are left out on fields to graze, and as they are more spread out, this should be less of an issue. However, in order to grow the pasture required for these outdoor periods, farmers commonly spread slurry (a mixture of cow faeces and water), as a natural fertiliser. Slurry is readily available – just one cow produces roughly 23 tonnes a slurry a year,11 and saves thousands that would otherwise have to be spent on fertilisers. Unfortunately, this spreading of slurry may also be contributing to the spread of bT B. M. bovis has been found to survive in stored slurry for up to 6 months,12 and whilst it is uncertain whether or not the levels of M. bovis in the slurry would be high enough to cause bTB, sending cattle out to pasture less than 2 months after spreading has been linked to an increased risk of disease. 13 Farmers also commonly share excess slurry with neighbouring farms, meaning that M. bovis may be being introduced to previously uninfected herds, spreading the disease even further. Finally, the milk of infected cattle also contains M. bovis, meaning suckling calves can become infected with the disease from their mothers, who can then further spread the disease throughout the herd.
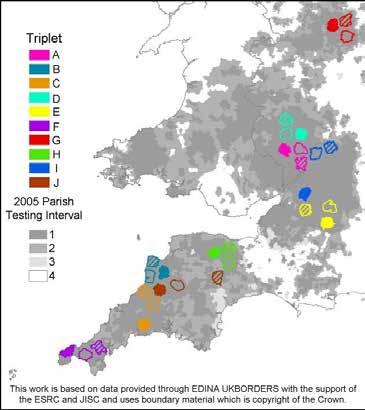
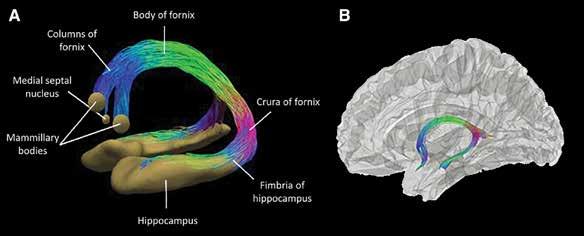
However, cattle are not the only animals that carry and spread bTB. Wildlife can act as maintenance hosts for the disease, with badgers in particular frequently spreading bTB to cattle. In 1982, a laboratory study proved that the transmission of M. bovis from badgers to cattle was possible,14 and whilst the routes of this transmission are not fully known, they are thought to be similar to that of cattle to cattle transmission. Studies have shown that badgers will enter farms and their surrounding buildings, primarily on the hunt for food , and whilst
doing this may engage in ‘nose-to-nose’ contact with cattle and excrete on and around cattle feed, spreading and depositing M. bovis 1 5 The saliva of infected badgers can also contain the bacteria, and as badgers have been proven to drink from cattle water troughs1 6 (see Figure 2), cattle can become infected with bTB from drinking this water. In addition, badgers frequently traverse cattle pasture, and GPS tracking has shown that badgers favour it to other habitats, such as woodland or arable farmland.17 As badgers mark areas with urine as they walk, M. bovis will be deposited by infected badgers, further spreading bTB to cattle if the y consume this contaminated pasture
Figure 2 18
It is currently not known whether or not bTB is self-sustaining in badger populations, i.e., without cattle also transmitting the disease back to badgers bTB in badgers would die out. Whilst cattle to badger transmission does occur, thought to be due to badgers coming into contact with infected cattle and contaminated pasture, the evidence surrounding the size of its impact is mixed. Because of this lack of concrete evidence, if we want to fully eradicate the disease, we must assume that bTB is self-sustaining in badgers. Therefore, the control measures that we employ must aim to prevent the spread of bTB from both cattle and badgers. This is what the UK government is currently trying to do.
2.5 How do we control bTB?
Alongside the regular testing measures already mentioned , a number of other procedures are in place that aim to control the disease. The first of these are pre-movement and postmovement tests for cattle that are sold and transported to new herd s. Pre-movements tests are mandatory for any cattle moved that are older than 42 days in herds testing at least annually, and they can be carried out up to 60 days before movement. P ost-movement tests on the other hand, are only required for cattle moving from higher to lower risk areas, and must be carried out between 60 and 120 days after a cows arrival. The aim of these tests is to prevent infected animals entering and spreading bTB to new herds. However, currently the SICCT is the only test allowed to be used for these. Given these cattle will only be tested once before they enter a herd, and there is between a 1 in 2 and 1 in 5 chance infected animals will test negative, the movement of these animals could be a significant factor in the spread of bTB.
The government also provides biosecurity advice to farmers to try and limit the spread of bTB . Biosecurity refers to measures that can be taken to prevent the introduction of M. bovis onto farms, from both cattle and wildlife. The majority of the government’s advice to farmers focuses on preventing badgers from entering farms and preventing them from being able to deposit M .bovis if they do. Possible measures taken include creating electric fences around fields, raising feed and water troughs so they are out of reach of badgers, ensuring gaps between the bottom of gates and the floor are small enough for badger to be unable to pass through (<7cm), and keeping cattle feed in locked bins or silos. Some advice is also given to try and prevent the spread of bTB from either cattle to cattle or from cattle to badgers . Slurry is advised to be stored for more than 6 months before spreading, and cows are advised to be kept off this slurry until at least 60 days after it has been spread. More general advice includes recommending farm equipment to be cleaned and disinfected regularly, in particular feed and water troughs If all of these measures were to be implemented, it should have a significant impact on reducing the spread of bTB . However, the government only advises these changes to be made, and they are not mandatory. Unlike in Wales, where the devolved government only provides compensation for bTB positive cattle if biosecurity rules are followed, in England, there are no consequences for failing to comply. This may be having a seriously detrimental effect on the spread of bTB. The lack of changes made by some farmers is quite shocking, shown in a 2019 DEFRA survey into bTB biosecurity measures . The survey found that only 17% of farms ‘badger-proof’ their buildings, only 15% fence off badger setts and only 33% of farms that store slurry wait 6 months before spreading it. 1 9 This is only a handful of the concerning statistics found, and it paints the picture that the government’s advice is not being listened to.
The final, and most well-known measure brought in to control the spread of bTB is the badger cull. As the next chapter of my project will look at in detail, a cull of badgers has been going on in England in some form for the past 50 years, but whether it is needed or not is up to debate. It is clear the measures mentioned above have some serious faults , which are likely to limit their effectiveness in controlling the disease . Is it the same for the badger cull? By looking at its effectiveness, the law around it, and any possible alternatives, I will aim to answer this question.
3 The Badger Cull
3.1 History of the cull
Following the success of the post-1950 ‘test and slaughter’ approach towards combatting bTB, by the 1970s, bTB levels were nearing all-time lows. Yet, in certain areas of Southwest England, a number of herd breakdowns persisted. There was no apparent reason for this. These occurred in ‘closed herds’, sparking speculation that something other than cows could be spreading the disease.
The first sign that badgers may have been involved came in 1971, where on a farm in Gloucestershire, a dead badger infected with M. bovis was discovered. The farm had recently experienced a bTB outbreak, highlighting a possible link between badgers and cattle. This was the first time a badger had been proven to be infected with M. bovis and was a key
turning point in the government’s bTB strategy. A further study conducted in Gloucestershire between 1971 and 1973 revealed that 36 (22%) of 165 badger carcasses autopsied in the county contained tuberculosis legions and 12 (11%) of 112 faeces samples take n were infected with M. bovis. Of the 23 different locations these carcasses and faeces samples were taken from, 17 were areas with persistent bTB herd breakdowns. 20 Struggling to fully eradicate bTB, the government saw this information as the final piece of the puzzle. This seemed to suggest that not only were badgers carriers of bTB, but they were also the vector spreading it to farms. If the badgers were removed from the equation, the final bTB hotspots should disappear, and the country would be back on track to eradic ating the disease.
This led to the first culls being introduced in 1973, where farmers were permitted to kill any badgers found on their farms by shooting . These were quickly met with backlash on animal welfare grounds and badger control soon was taken over by the government. This began with the gassing of badger setts in 1975. If a bTB outbreak on a farm was attributed to badgers, surrounding setts were gassed with hydrogen cyanide. This had initial success, with the bTB incidence rate in the south -west dropping to 0.5% by 1979. However, from 1980 onwards, the herd incidence rate began to rise gradually. Gassing was replaced with cage trapping and shooting as part of a ‘clean ring’ strategy in 1982, on the basis that badgers being gassed were often exposed to non-lethal quantities of hydrogen cyanide causing them unnecessary suffering. This ‘clean ring’ strategy involved the of culling successive social groups of infected badgers, until a clean ring of uninfected social groups remained. This was also unsuccessful, with herd incidence continuing to rise in the Southwest. By 1986, it was replaced with what was called the ‘interim’ strategy, where badgers were only culled on individual infected farms, again through cage trapping and shooting. However, this still failed to stop the increase in incidence rates in the Southwest, and a similar trend was now being seen across the rest of the UK 2 1 (see Figure 3). Something had to be done, and so 1996, the government set up an independent review into badger culling and bTB, chaired by Professor John Krebs.
Figure 3
A graph showing the proportion of total herds with reactors from 1962 -1996.2 1
Upon publication in 1997, the Krebs report concluded that whilst correlational evidence pointed in the direction that badgers were a significant source of infection in cattle, it was ‘not possible to state quantitatively what contribution badgers make to cattle infection, because the relevant data have not been collected and analysed. ’ Because of this, Krebs recommended to set up large-scale, randomized trial that would provide ‘unambiguous evidence on the role of the badger in cattle TB’. The trial, called the Randomized Badger Culling Trial (RBCT), was overseen by an Independent Scientific Group (ISG ) and led by Professor John Bourne. The trial was completed in 2005, and Bourne concluded in his final report to government that, 'while badgers are clearly a source of cattle TB …badger culling can make no meaningful contribution to cattle TB control in Britain .’2 2
However, the Government’s Chief Scientific Advisor, Sir David King, did not accept these conclusions. In a report responding to the ISG, he insisted that badger culling could be effective, and that the removal of badgers ‘should take place alongside the continued application of controls on cattle’.2 3 The ISG maintained their previous position, stating that King’s report was flawed. King did not take into account the economic and practical issues surrounding badger culling, both of which were key in determining whether the cull would be successful in reducing bTB in cattle or not. Alongside this, King’s report misinterpreted the ISG’s data on a number of occasions, further reduc ing its credibility.2 4 After further back and forth, in 2008, the government eventually agreed with the ISG, deciding not to issue any culling licenses to farmers, and instead to prio ritise investing into vaccines for both badgers and cattle 2 5 It seemed this would be the end of badger culling for the foreseeable future.
However, a change in government in 2010 brought a change in policy. A ll but one of the previous government’s planned badger vaccine trials were scrapped , and within a year, badger culls were planned to be reintroduced 2 6 ,2 7 These culls materialised in 2013, in the form of a small-scale pilot cull in 2 areas of Gloucestershire and Somerset, where badgers were killed by free shooting. The culls were extended in 2014, and in 2015 a new culling area in Dorset was added. Ever since the culls have continued to expand, and as of 2023 there were 58 active cull areas in 21 different counties. 2 8 As shown in Figure 4, the total number of badgers culled each year has rapidly increased , resulting in over 230,000 badgers being killed by 2023. Figure 4 2 8
Whether these culls have worked or not is a hotly debated topic . Whilst the Conservative government would have continued the culls if they had remained in power , Labour branded them as “ineffective” in the run up to the election.2 9 Now in power, Labour seem to have altered their stance. The Secretary of State for Environment, Food and Rural Affairs , Steve Reed, recently committed to continu ing any pre-existing cull licences, meaning badger culling will now continue until at least 2026. The future of the badger cull remains uncertain, with its effectiveness still in question
3.2 Is a cull effective?
This section of my project aims to take a deeper look at the scientific evidence behind the cull. Firstly, I will look at how big a role badgers play in spreading bTB. Then, I will look at to what extent reducing the number of badgers reduces the spread of the disease in cattle. Together, these should paint a much clearer picture of whether culling badgers can be an effective method to controlling bTB
3.2.1 What role do badgers play in spreading bTB to cattle?
In order to justify culling badgers, we must first prove that they play a significant role in spreading bTB to cattle. The best information we have available to answer this question comes from a study conducted by Donnelly and Nouvellet in 2013 30 What is interesting is that this study is often referred to by both pro -cull and anti-cull campaigners, either as a justification that badgers are a significant part of the problem, or rather, that they play a very minor role. This is due to the study producing 2 separate conclusions. Using a mathematical model on data from the aforementioned RBCT, it concluded that:
1) 6% of bTB transmission is from badgers to cattle herds. 2) 52% of all bTB herd breakdowns are due to badgers.
From an outsider’s perspective, this may look like two vastly different results for the same thing. However, looking closer there is a key difference – cattle to cattle transmission is only taken into account in the second figure. This means that whilst only 6% of cattle herds are directly infected by badgers, these herds could go onto spread bTB to other herds . This could happen if an undetected cow carrying bTB w as sold to another farm, for example. Badgers would still be to blame for this. If that cow had never been infected by a badger in the first place, it would never have transmitted bTB the other herd. Therefore, when this is factored in, badgers seem to play a much larger role , contributing to 52% of overall bTB herd breakdowns.
It is important to note that this study has a number of limitations. The biggest of these are the large degrees of uncertainty around the 2 estimates produced. The first figure has a confidence interval of 1% to 25%, whilst the second has one of 9% to 100%. This means that both figures needed to be treated with caution, in particular the second, due to just how large the uncertainty is.
Nonetheless, the study’s findings do show that badgers play at least some role in bTB transmission. Because of this, we would think that reducing the number of badgers, i.e. badger culling, would have some effect in reducing bTB , and this is what I will be moving on to look at next.
3.2.2 Does culling badgers reduce the spread of bTB in cattle?
The Randomised Badger Culling Trial
I will begin by looking at the Randomised Badger Culling Trial. Earlier, I stated that the ISG, the group that oversaw the trial, concluded that badger culling could make “no meaningful contribution to cattle TB control in Britain .” This appears to be a very clear answer to the question of whether culling works or not However, the ISG’s conclusion took into account a number of factors, including financial and practical issues. If we look at the RBCT from a purely scientific perspective, we get a slightly different answer.
The trial consisted of 30 randomly selected 100-kilometre areas split into 10 groups of 3 (see Figure 5). In every triplet, each of the 3 areas were assigned a different ‘treatment’, which consisted of either:
• Proactive badger culling - badgers culled across the whole area, regardless of a farms bTB status (approximately annually)
• Reactive badger culling - badgers culled only around farms experiencing bTB breakdowns
• Survey only – no badger culling
Alongside each of these, regular cattle testing and the slaughtering of infected animals continued as usual. The cattle TB incidence in each of these areas could then be surveyed post-‘treatment’, clearly showing whether culling badgers did or did not reduce bTB in cattle. Alongside this, it would also show which method of culling (if any) was the most effective.
Figure 5
Locations of RBCT trial areas, denoting areas allocated to proactive culling (solid), reactive culling (hatched), and survey -only (clear).3 1
The first set of results of the RBCT came from an interim analysis carried out in 2003, which showed that reactive culling caused bTB herd incidence to increase by 27%, compared to areas with no culling. 3 2 This was ascribed to a phenomenon called the ‘perturbation effect’, defined as the increased migration of badgers into culled areas due to the disruption of territoriality, increased ranging and mixing between social groups . This is because of badgers living in social groups of 4-7 animals, who stick to territorial boundaries. When a number of badgers in these groups are culled, their social structure is disrupted. This causes the remaining badgers to travel further than they normally would, interacting with other animals, whether that be badgers or cows, and possibly spreading bTB to them. This discovery led to the reactive culling treatments being discontinued by the government, on the grounds that it could not be an effective method of controlling bTB. The trial continued, but now only with the proactive culling and survey only treatments.
Upon its completion in 2005, multiple different analyses of its results took place . Proactive culling was shown to have been effective in reducing badger populations, seen through a 73% reduction in the density of badger latrines, a 69% reduction in the density of active burrows and a 73% reduction in the density of road -killed badgers.3 3 This reduction in badger numbers resulted in an average 23.2% reduction in cattle TB incidence inside the proactive culling areas, proving that badger culling does reduce bTB in cattle in some capacity. However, it had also resulted in an average 24.5% increase in cattle TB incidence in areas up to 2km from the proactive culling boundary. 3 1 This was again ascribed to the ‘perturbation effect’ When the ISG made their final report to government in 2007, a cost benefit analysis using this data showed that the benefits gained from reducing bTB inside the proactive culling areas was majorly outweighed by the costs of culling and increased bTB in surrounding areas. This was what led them to conclude that culling badgers could make “no meaningful contribution to cattle TB control.”
A follow up report in 2010 looked at bTB incidence in and around RBCT areas up to 5 years proactive culling had ended. They found that in areas where proactive culling had occurred, the positive effects initially increased throughout and just after the trial, before declining gradually to a 28.3% overall reduction by the end of the fifth year. In surrounding areas up to 2km from the culling boundary, the increased bTB herd incidence thought to be caused by the ‘perturbation effect’ appeared to diminish on successive annual culls and was comparable to areas that had experienced no culling 5 years after the trial. 3 4
The report was carried out by 3 scientists, 2 of whom were members of the ISG. Again, on the basis of cost-effectiveness, they concluded that “badger culling is unlikely to contribute to the control of cattle TB in Britain .” However, they also recognised that “ widespread badger culling can achieve overall reductions in the incidence of cattle TB .” As this section of my project only questions whether or not culling reduces bTB levels in cattle, and not whether it is a cost-effective method of doing so, any economic caveats to the benefits of culling can be forgotten about for the time being . Therefore, there are a number of conclusions of our own we can make from the RBCT:
Firstly, we can conclude that the proactive culling of badgers does have an effect on reducing bTB in cattle More specifically, the culling of a large number of badgers, around 70%, should reduce the bTB herd incidence in these culling areas by 20 -50%. However, we can
also conclude that the culling of badgers results in a ‘perturbation effect’ in areas up to 2km from culling boundaries, leading to a temporary increase in bTB herd incidence in these areas. Despite this, it seems that the culling of badgers does have an overall net positive effect on reducing bTB in cattle, even if it may not be cost-effective.
The Birch Review
Whether or not these effects are seen outside the context of a study is a different matter As a badger control policy (BCP) has been ongoing in England for the past 14 years, there is now a wealth of evidence into its impact. The most recent study that looks into this data is the Birch Report, published in 2024.
The specific data the review looked into was the bTB incidence rate from the first 52 areas that were licenced for badger culling between 2013-2020 A difference in differences analysis was used. This involves comparing the bTB incidence rate within and between the 52 different areas, before and after the start of BCP interventions. The approach estimates the average effect of the BCP across all of the areas.
The review found that the bTB incidence rate declined significantly over time, with an average reduction of 56% four years after the start of BCP interventions Beyond 4 years of BCP interventions, the size of the effect did not increase any further.3 5 This seems to show that by culling badgers for 4+ years, the bTB herd incidence can be more than halved , even exceeding the effects of culling forecasted by the RBCT.
However, one of the biggest limitations of this study is that it does not single out the effects of badger culling alone. The BCP involves a combination of badger culling, increased interferon-gamma testing and the increased provision of biosecurity advice. To say that the 56% reduction in bTB incidence was solely down to badger culling, as many of those in favour of the cull have done, would be simply untrue. The Birch Review itself acknowledged this, stating, “this data analysis cannot explicitly distinguish the effects of the BCP’s component measures.” It is much more likely that badger culling has resulted in a reduction more similar to that seen in the RBCT, although exactly how big of a reduction this cannot be quantified.
Nonetheless, the evidence available does seem to show that reducing the number of badgers reduces the spread of bTB in cattle , demonstrating that badger culling can be an effective measure of controlling bTB. The government appear to be willing to accept the financial costs a badger cull incurs, so long as it reduces the spread of bTB. A key question that remains unanswered is whether or not badgers themselves have any value, and if this should be taken into account when considering a cull? This is what the next section of my project will look at.
3.3 Do badgers have a ny value?
Since 1992, badgers have been a protected species in the UK , however this was to prevent the cruel practice of badger baiting, rather than because they were at risk of extinction . Because of this, many of those in favour of a cull see no issue with a reduction in their population numbers. There are a number of problems with this.
Firstly, large-scale badger culling has been proven to have knock-on effects on the wider ecosystem. For example, research carried out during the RBCT found that the number of hedgehogs doubled in some habitats following badger culling,3 6 and culled areas also experienced an increase in roughly 2 foxes per km2 compared to areas without culling. 3 7 It is vital that the possible impacts of this are taken into account when considering implementing a wildlife cull.
Furthermore, the British badger has a high value in international conservation of the species, due to 25% of the European population being found in the UK. It is our responsibility to conserve this population, meaning culling should only occur if truly necessary. This is recognised in the Berne Convention on the Conservation of European Wildlife and Natural Habitats, which the UK signed on the 19 September 1979. Under this agreement , the culling of badgers is only permitted as part of a bTB reduction strategy if no satisfactory alternative exists.3 8 This is key in determining if a badger cull is necessary. Whilst it may be somewhat effective in reducing bTB levels in cattle, it should only be made a part of the UK’s bTB strategy if there are no other feasible alternatives. Whether or not any of these alternatives exist is what the next section of my project will look at.
3.4 Are there any alternatives to a badger cull ?
Badger Vaccination
A large-scale badger vaccination programme could be one alternative to a badger cull. The idea of vaccinating badgers for bTB has been around since the late 1990s, and in recent years a number of small-scale trials into its impacts have been carried out. Badgers are currently vaccinated using B acillus Calmette-Guérin (BCG), the same vaccine given to humans, but in a much higher dose. In order to be vaccinated, badgers are usually cage trapped and then injected.
One of the biggest limitations of badger vaccination is that it cannot cure already infected badgers of bTB. As there is no test for bTB that produces immediate results, there is always the chance that a number of the badgers that are trapped and vaccinate d already carry bTB and will go on to spread the disease following their release. Many argue that it is simply safer to just kill these badgers, eliminating the possibility that they could ever go on to spread the disease. However, not having an effect on infected badgers does not mean that vaccination cannot reduce TB in badger populations. Badgers have a lifespan of roughly 4 years. If we were to vaccinate badgers annually over a 4 -year period, the number of infected badgers would die off, whilst vaccination would prevent healthy badgers from contracting the disease. Over time, this should lead to a significant decrease in the number of badgers infected with bTB. Evidence from a recent study supports this hypothesis:
Over a 4-year period, 265 badgers were vaccinated an 11km2 area in Cornwall By the final year of the study, researchers found that the percentage of badgers testing positive for bTB had reduced from 16% to 0%.
Not only did this study prove that vaccination was effective at reducing the number of badgers carrying bTB, but it also proved it could be cost-effective and dispelled claims that vaccination would be more difficult to carry out that culling The number of badgers vaccinated per square kilometre in the study was greater than those culled on nearby land,
despite vaccination being carried out for only two nights per location whilst culling operations took place for a minimum of 6 weeks.
Overall, this totalled to an estimated 74% of the local badger population being vaccinated. 3 9 It’s important to note that we would not need to vaccinate all badgers to eradicate bTB within the species. Herd immunity is achieved when enough of a population is vaccinated that the disease runs out of unvaccinated hosts to spread to and dies out. In the case of badgers and bTB, the study’s results show that vaccinating 74% percent of the population seems to be sufficient to achieve this.
The study did not show whether or not this reduction in badger bTB levels translated to the local bTB herd incidence. However, given the trends seen from culling badgers, we would assume that vaccination would have a similar or superior effect Logically, reducing the number of infected badgers should reduce the number of infections in cattle. Whilst the epidemiological landscape of the UK is obviously unique, that of the Republic of Ireland is likely to be similar, and a large-scale badger vaccination programme has occurred there for a number of years. A study carried out from 2011-2017 found that bTB incidence rates in cattle were similar in areas that had either vaccinated or culled badgers , 40 implying that vaccination is no inferior to culling as a method to control the spread of bTB and would indeed be a suitable alternative.
Cattle Vaccination
Another possible alternative to badger culling is cattle vaccination , however as of yet, this is not fully feasible. Whilst the same BCG vaccine used in badgers and humans has been proven effective at reducing bTB in cattle – a recent study showed it reduces B TB transmission in cattle by almost 90% 4 1 – it would also sensitise cattle to the current skin tests used. With current tests, approximately 80% of vaccinated cattle would test positive for bTB As no vaccines are 100% effective, a small number of vaccinated animals could still catch the disease, meaning a new test for bTB that can distinguish infected and vaccinated animals would be required.
Luckily, the APHA has recently developed such a test The test is referred to as a DIVA (Detect Infected among Vaccinated Animals) format of the current SICCT skin test and is based on the immune response of 3 antigens found in bTB infected animals but not in BCG vaccinates. Whilst the test is estimated to have a similar sensitivity to the current skin test, it is also estimated to have a similar specificity, which is not ideal. N onetheless when combined with the use of the BCG vaccine, the implementation of this test would have a major impact on reducing bTB in cattle, much larger than any of the other measures mentioned in this project.
Trials for both the test and vaccine are currently underway. These aim to further test the safety of these two measures and to confirm the specificity of the DIVA test to a precise value, hopefully providing enough evidence for it to be authorised for use by the VMD (Veterinary Medicines Directorate). The third stage of trials, which will involve testing these measures on a large number of herds, is soon to commence, and is estimated to be completed by 2026. Following this, subject to receiving the right authorisation, vaccination and DIVA testing of cattle can be rolled out across the whole of the country. Obviously, all of this is still a number of years away, and obstacles could still appear delaying its implementation even
further. This means that cattle vaccination, at least for the time being, is not a feasible alternative to culling.
3.5 What is the f uture of the cull?
As of 2024, the future of the cull seems uncertain. Before the new government took power, they stated that they would aim to tackle bTB with measures that did “not include culling,” and instead would prioritise the implementation of “vaccines and biosecurity measures.” 4 2 They also branded the cull as “ineffective” , which although to me seems more like political point-scoring, rather than an evidence-based opinion, does imply that they would stop the badger cull once they took office. Now in power, this has not been the case. Steve Reed, the Secretary of State for Environment, Food and Rural Affairs, recently confirmed that the government will keep pre-existing cull licences in place , 2 9 meaning that the culling of badgers will continue until at least 2026. What happens after this point is yet to be seen. By that time, cattle vaccination and DIVA testing may be authorised for use , but it seems unlikely. The government has indicated that following the current badger culling licences expiring, w e will see a pivot from badger culling to badger vaccination , alongside stricter laws regarding biosecurity. To me, this is a step in the right direction . However, given this is almost identical to what was said before they took power, and culling is still going on, time will tell whether any of these changes materialise or not.
4 Conclusion
Throughout this project, I have tried to provide a balanced view of all the evidence there is surrounding badger culling. I also hope I have been able to show just how devastating a disease bTB can be, and why, as a country, we must do everything we can to eradicate it. We know that badgers play some role in the spread of bTB, and if the disease is to be controlled, this reservoir needs to be addressed. The evidence used in the project has shown that in some capacity, badger culling can be effective. If done on a large enough scale, where a large enough number of badgers are culled, the level of bTB will reduce in cattle, probably by around 20% For some, this is enough evidence to prove that badger culling is necessary, and should continue. However, I still believe this is not the answer. As stated in the Berne Convention, badger culling should only occur, “provided that there is no other satisfactory solution.” This project has clearly shown that badger vaccination is an option , and that it is no inferior to badger culling It has also shown that it is also no more difficult to implement, and that it is cost-effective To me, this makes the answer clear - the government’s widespread badger culling policy should end, and the phasing in of widespread badger vaccination should begin.
However, if we really want to control bTB we need to do a lot more than just eliminating the disease in badgers. Whilst it is true badgers that play a role in introducing bTB to cattle, the size of their impact is amplified by the subsequent spread of disease between herds C attle vaccines and DIVA tests would be ideal to prevent this, however these cannot be used yet, and the same can be said for novel tests like Actiphage ® Finding solutions is therefore difficult. Use of interferon gamma testing as a part of pre- and post-movement testing could reduce the spread of bTB , but the increase in false positives would have large financial implications. This also applies for its increased use in routine testing. Therefore, we have to
look at what changes could be feasibly made. The best example I can see is following Wales, and only providing full compensation for bTB positive cattle if advised biosecurity measures are undertaken. Proper, robust biosecurity could stop badgers entering farms, and stop them depositing M. bovis, reducing the spread of bTB to cattle. If slurry were always to be kept for 6+ months, until any M. bovis had died, the risk of further cattle (or badgers) contracting the disease via this route could be eliminated. Implementing these measures would obviously cost farmers money, and some changes are more difficult to make than others However, if bTB is to be successfully controlled, something has to be done
This is only a recommendation, and it is down to the new government to make the changes the English farming industry desperately needs. Exactly what all of these changes are is not black and white, however, I strongly believe that badger culling is not necessary, and a switch to badger vaccination should be one of them.
5 Afterword
A few days after finishing my project, the government launched a new bTB eradication strategy.4 3 This provides clarity to a number of the uncertainties mentioned in my project, and paints a much more hopeful picture for both the disease and for badgers. The headline is that badger culling will end by the end of this parliament. Whilst this means culling could continue up until 2029, it seems likely that it will end much sooner, with DEFRA sources stating that it is unlikely any new culling licences will be granted following the expiration of current ones in 2026.4 4 In order to achieve this goal, the strategy introduces a number of measures similar to the recommendations laid out in my project. Without going into too much detail, the most imminent of these is the creation of a ‘Badger Vaccinator Field Force,’ that will rapidly increase the number of badgers vaccinated across the country. Work on getting a cattle vaccine ready for deployment in the next few years is also being accelerated, wh ilst a number of other measures aimed at improving testing and reducing the spread of bTB through cattle movements are being considered.
It is reassuring to see that the conclusions I drew from my research are being backed up by this new government strategy. As long as these changes come to fruition, the future for badgers looks brighter and we will hopefully be one step closer to finally eradicating this devastating disease.
6 Reference List
1 - Goodchild, A. V. et al. (2015). Specificity of the comparative skin test for bovine tuberculosis in Great Britain. The Veterinary record , 177 (10), 258.
2 - Karolemeas, K. et al. (2012). Estimation of the relative sensitivity of the comparative tuberculin skin test in tuberculous cattle herds subjected to depopulation. PLOS ONE.
3 - Nuñez -Garcia, J. et al. (2018). Meta -analyses of the sensitivity and specificity of ante -mortem and post-mortem diagnostic tests for bovine tuberculosis in the UK and Ireland. Preventive veterinary medicine , 153 , 94 – 107.
4 - de la Rua -Domenech, R. et al. (2006). Ante mortem diagnosis of tuberculosis in cattle: a review of the tuberculin tests, gamma-interferon assay and other ancillary diagnostic techniques. Research in veterinary science , 81 (2), 190 – 210.
5 - Schiller, I. et al. (2009). Optimization of a whole -blood gamma interferon assay for detection of Mycobacterium bovis -infected cattle. Clinical and Vaccine Immunology , 16 (8), 1196 -1202.7
6 - Swift, B. M. C. et al. (2020). The development and use of Actiphage ® to detect viable mycobacteria from bovine tuberculosis and Johne's disease -infected animals. Microbial biotechnology , 13 (3), 738 – 746.
7 - Game changing Actiphage TB test gains funding for full validation . (2021 ) University of Nottingham.
8 - Quarterly TB in cattle in Great Britain statistics notice: June 2024 . (2024 ). GOV.UK.
9 - Barnes, A. P. et al. (2023). The consequential costs of bovine tuberculosis (bTB) breakdowns in England and Wales. Preventive Veterinary Medicine , 211 , 105808.
10 - Bovine TB: Consultation on proposals to evolve badger control policy and introduce additional cattle measures . (2024) GOV.UK
11 – Green, D. (2021) Fertiliser for 2022. Douglas Green Consulting Ltd.
12 - Scanlon MP, Quinn PJ. The survival of Mycobacterium bovis in sterilized cattle slurry and its relevance to the persistence of this pathogen in the environment. Irish Veterinary Journal. 2000;53(8):412 -5.
13 - Griffin, J. M. et al. (1993). The association of cattle husbandry practices, environmental factors and farmer characteristics with the occurrence of chronic bovine tuberculosis in dairy herds in the Republic of Ireland. Preventive Veterinary Medicine , 17 (3 -4), 145 -160.
14 - Little, T. W. et al. (1982). Laboratory study of Mycobacterium bovis infection in badgers and calves. The Veterinary record , 111 (24), 550 – 557.
15 - Tolhurst, B.A. (2008). Behaviour of badgers ( Meles meles) in farm buildings: Opportunities for the transmission of Mycobacterium bovis to cattle? Applied Animal Behaviour Science 117 (1), 103113.
16 - O'Mahony D. T. (2014). Use of water troughs by badgers and cattle. Veterinary journal (London, England : 1997) , 202 (3), 628 – 629.
17 - Woodroffe, R. et al. (2016). Badgers prefer cattle pasture but avoid cattle: implications for bovine tuberculosis control. Ecology letters , 19 (10), 1201 – 1208.
18 – Protect your herd from TB. (2020) tbhub .co.uk
1 9 - An Official Statistics publication: Defra official statistics are produced to the high professional standards set out in the Code of Practice for Official Statistics. Grazing and cattle housing (Section 1). (2019). GOV.UK.
20 - Muirhead, R. H., Gallagher, J., & Burn, K. J. (1974). Tuberculosis in wild badgers in Gloucestershire: epidemiology. CABI Digital Library.
2 1 - Krebs, J et al. (1997). Bovine Tuberculosis in Cattle and Badgers. MAFF.
2 2 - Bourne J. et al. (2007). Bovine TB: the scientific evidence. The National Archives.
2 3 - King, D. (2007). Tuberculosis in cattle and badgers: a report by the Chief Scientific Adviser. The National Archives.
2 4 - Bourne, J. et al (2007). Response to ''Tuberculosis in cattle and badgers: a report by the Chief Scientific Adviser''. The National Archives.
2 5 - House of Commons Statement by Hilary Benn (2008). Bovine TB. UK Parliament.
2 9 - Badger Trust. (2024). Confusion and disappointment as Labour now say they will not end the badger cull immediately. Badger Trust.
30 - Donnelly CA, Nouvellet P. (2013). The Contribution of Badgers to Confirmed Tuberculosis in Cattle in High -Incidence Areas in England. PLOS Currents Outbreaks. Edition 1.
31 - Donnelly, C.A. et al. (2007). Impacts of widespread badger culling on cattle tuberculosis: concluding analyses from a large -scale field trial. International Journal of Infectious Diseases 11 , 300 -308.
3 2 - Donnelly, C.A. et al. (2003). Impact of localized badger culling on TB incidence in British cattle. Nature 426 (1), 834 - 837.
3 3 - Woodroffe, R. et al. (2008). Effects of culling on badger abundance: implications for tuberculosis control. Journal of Zoology 274, 28 -37.
3 4 - Jenkins, H.E. et al. (2010). The duration of the effects of repeated widespread badger culling on cattle tuberculosis following the cessation of culling. PLO S ONE 5 (2), e9090.
3 5 - Birch, C.P.D. et al. (2 024) Difference in differences analysis evaluates the effects of the badger control policy on bovine tuberculosis in England. Sci Rep 14 , 4849 .
3 6 - Trewby, I.D. et al. (2014). Impacts of removing badgers on localised counts of hedgehogs. PLOS ONE, 9 (4), e95477.
3 7 - Trewby, I.D. et al. (2008). Experimental evidence of competitive release in sympatric carnivores. Biology letters , 4 (2), 170 -172.
3 8 - Convention on the Conservation of European Wildlife and Natural Habitats (ETS No. 104) (1979) Conventions.coe.int.
3 9 - Woodroffe, R. et al. (2024). Farmer‐led badger vaccination in Cornwall: Epidemiological patterns and social perspectives. People and Nature .
40 - Martin, S. W. et al. (2020). Is moving from targeted culling to BCG -vaccination of badgers (Meles meles) associated with an unacceptable increased incidence of cattle herd tuberculosis in the Republic of Ireland? A practical non-inferiority wildlife intervention study in the Republic of Ireland (2011 -2017). Preventive veterinary medicine , 179 , 105004.
4 1 - Fromsa, A et al. (2024). BCG vaccination reduces bovine tuberculosis transmission, improving prospects for elimination. Science , 383 (6690), eadl3962.
4 2 - Horton, H . (2023). Labour promises to end badger cull in England. The Guardian .
4 3 - Government to end badger cull with new TB eradication strategy. (2024). GOV.UK
4 4 - Horton, H. (2024). Badger culling to end in England by 2029, government says. The Guardian.
WHAT AM I, WHO KNOWS?
BY ALEXANDER LIDBLOM
(Fifth Year – HELP Level 3 – Supervisor: Mr B Clark)
HELP Project
What am I, who knows?
It will be argued that there is no self and thus no personal identity over time, diachronic identity.
In so arguing , I will be discussing various theories namely Locke’s Memory Theory, Descartes’ dualism, Parfit’s no -self theory, Hume’s bundle theory and Buddhist beliefs , regarding the notion of personal identity, or what it is that constitutes the I, an d whether it persists through time
These q uestions bear a lot of significance in relation to other philosophical areas such as ethic s and legal studies: for example, when considering the judicial system, if someone no longer is the same person who committed the crime, who is to be punished? And is it fair to punish a survivor, ie. someone who doesn’t have the identity but is still a survivor of the old self? The problem of personal identity also has numerous implications for the actio ns of individuals, as if there is no persisting self, what makes an action of self-interest any less altruistic than an action intended to benefit someone else?
Firstly, in order to understand the problem of identity, it should be considered in relation to something less complex than that of a person. For there to be the identity of an object, there must be a direct history linking the object at point A in time to point B in time , i.e. that the atom present a second ago is the same as the one now, because it has persisted through that second, without changing , otherwise there cannot be certainty that it is the very same atom. A common thought experiment regarding the problem of identity of objects, is that of the Ship of Theseus, or Theseus’ paradox. Imagine a ship, which has all of its parts gradually replaced , until no pa rts of the original ship remain , is it still the same ship? Leibniz presents the logical rule of the Identity of Indiscernibles , which is that if X is identical to y, then x and y must share all properties. Similarly, if x is not identical to y, then there must be a property, which x holds and y does not, or y has and x does not. Therefore, the new ship cannot be the same ship, since the old ship has properties (the old parts), which the new ship does not have. This is important in relation to the problem of personal identity over time as it establishes that the self in one point in time, must share all properties with the self at another point in time. If we were to ap ply Leibniz’s Identity of Indiscernible to the notion of personal identity, bodily identity does not hold. This is because your body changes and grows, your cells die and are replaced, so it cannot be said that all the properties of your body yesterday, are shared by your body today.
The idea of bodily identity has clear flaws, thus philosophers sought to find more reasonable alternatives. Locke was one of the first to consider this problem, and he sought to find what about us persists over time.
Memory Theory
Instead of bodily identity, with its array of flaws, Locke proposed that it is in fact memory which can constitute identity with who we were before. Locke argues that since we can remember doing our past experiences and actions, we can be sure that we are still that person, since the memory persists. Initially, there are some flaws with Locke’s theory, as our memories can be erroneous Firstly, as expressed by Reid, Locke has confounded the evidence for identity with the person itself. According to Reid, Locke claims that our identity lies within memory, whereas to Reid, memory is no more than evidence for identity. Our memory allows us to know our past, and that it is our past, but it doesn’t inherently constitute identity.
Also, consider the situation where a person fa lsely remembers an action that they didn’t do : are they the n iden tical with a person that doesn’t exist? Perhaps they forget an action that they did : are they no longer that person anymore? One significant example of this is birth, since no one can remember their
own birth . According to Locke , they cannot be the same person as the one born, which could be problematic , since we tend to identify with the person we were when we were born. Similarly, take someone who has dementia : do they become a different person ; as they lose memory of their old actions, do they also lose identity with that earlier person ?
Furthermore, personal identity should be a transitive relationship, as it would make sense that if person X is identical with person Y and person Y is identical with person Z, then person X should be identical with person Z. However, with this definition of personal identity, identity would not be transitiv e. A demonstration of this issue, presented by Reid, is found when considering the example of a lieutenant who recalls his actions as a child. However, when he becomes a general, he no longer recalls the actions of the child, but does remember the actions of the lieutenant. Hence, X (general) remembers doing the actions of Y(lieutenant) and , Y remembers the actions of Z ( the child), but X does not remember Y. Therefore, X is identical with Y, Y is identical with Z, but X is not identical with Z, thus what Locke describes as memory connectedness is an intransitive relationship. In order to solve this, Locke introduces the ancestral relation:
Just as how the definition of your ancestor is someone who is:
a) your parent or
b) the ancestor of your parent
Although it is seemingly circular, it functions to iterate the definition, and can be similarly replicated for the issue of transitivity, regarding memory continuity :
X is memory -continuous with Y if:
a) X is memory -c onnected with Y i.e.. X r emembers Y’s action or
b) X can remember someone who is memory -continuous with Y (X remembers someone remembering Y)
This ancestral relation allows for the continuity to come in steps, e.g. you don’t need to remember all your actions several years ago , only the you an instant ago, who remembers you an instant before that, which iterates. However, a further flaw, is that slee p or coma would seem to break the continuity of consciousness , as although you could still have identity with a person before sleep, you when waking up wouldn’t be identical with you whilst you were sleeping. Suppose the person in a coma has no brain a ctivity, breaking the continuity of consciousness. In this situation, identity of the physical brain or body would be more desirable, as t o us it seems that it is the same person, since it’s the same body before, during and after the coma.
However, there are other issues with Locke’s theory for personal identity , concerning the circularity of his argument In regards to the issue of q uasi m emory, which Derek Parfit (whose account of identity will be discussed below ) defines as a belief about an experience, which is dependent upon that experience in the same way in which a memory would be. Say you wake up with someone else’s memory, you would then say that is not a genuine (your own) memory, and hence it does not “count” when constituting identity. Therefore, you would only count the memory as genuine if there is personal identity (with the person whose memory it is ), but since memory constitutes personal identity, you cannot distinguish or discriminate memories. Therefore, all memory must count, which does present the issue that if you falsely remember the actions of someone else, you must be , according to Locke, identical to that person !
Ultimately, Locke’s account of personal identity has too many u navoidable issues. The circular reasoning of quasi memory demonstrates that memory is not suffici ent for identity, and it is also not
necessary. As argued by Reid, memory is evidently not a condition of identity, rather a n indicator ie. A person who has identity with someone often remembers experiencing the experiences of that person, but that is not what makes them the same person .
Descartes presents a different criterion for personal identity, also rejecting bodily identity, and not accepting the flawed Memory Theory. He argues for identity of “thinking matter ”, that it is our mind which persists through time rather than the need for memory linking us to our past selves.
Descartes
Descartes’ idea of identity of thinking matter is demonstrated through a thought experiment : imagine removing various parts of your body, your arm or your leg, what remains is still you. However, if you remove your ability to think, or your mind, the same seems to no longer be true, therefore, the mind is a necessary condition of identity, but it is still not necessarily sufficient. Descartes argument therefore for the existence of dualism is that we cannot seem to remove or divide our mind into constituent parts, in the same way we can for our body , and thus, applying Leibniz principle, since there is a property that the bodily matter holds and the mind (thinking matter) doesn’t , this being spatial indivisibility, they cannot be identical, thus resulting in the existence of 2 separate substances.
In regards to the notion of diachronic identity, according to Descartes the only certainty is our thought, as by doubting this, you know you are thinking as evidenced by the fuller form of his famous quote : “dubito, ergo cogito, ergo sum” (I doubt, therefore I think, therefore I am). Therefore, the only constant in our existence can be the faculties of the mind facilitating such thought: the thinking matter, hence if your thinking matter persists, then so must you. There are some immediate concerns with Descartes account of identity, one lying within his theory of mind -body dualism. Descartes describes how people are a union between the thinking matter and our bodily matter, where Descartes describes our bodily matter as an extended substance (extended in space), whereas the thinking matter is non -extended (immaterial). This leads to the “interactionist’s problem” , first put forward by Princess Elisabeth of Bohemia, as how can there be a union or interactions between physical and nonphysical matter, since they share no common ground. How can our thinking matter receive inputs from our body, and then control it?
There are different ways to try and solve this glaring omission . Some argue that it cannot be certain that there is a causal relationship between our thoughts and actions, maybe there is only a correlation Malebranche argued that in order to have the seemingly impossible interactions between a nonextended and an extended substance, it must be facilitated by an omnipotent being , as he believed that there cannot be any causal relationship or interactions , as God is the only being with sufficient ability to facilitate such or ultimately any casual relations. Leibniz presents a different argument, with a different form of divine intervention. Leibniz argues that once again there is no causal relation, and instead , the current state of the min d - would be dependent not on the state of the body, but a prior state of the mind. Consider the example of a stimulus (the bodily state) and this supposedly causes pain (the mental state) , Leibniz would argue that there was a prior mental state which was the causal factor for the state of pain. Leibniz, therefore , argues whilst the se states seem to have a causal relationship they are instead coordinated. However, he does argue that there is a way in which mental states have an influence over body events, for if you will the movement of a body part, the will is the cause of said movement, but it is because “one expresses distinctly what the other expresses more confusedly” 1 . What Leibniz means by this is that what we observe as causation is that perceptions of, for example, the mental state (which would be seemingly causally active) become more distinct,
Kulstad, Mark, and Laurence Carlin. “Leibniz’s Philosophy of Mind.” Stanford Encyclopedia of Philosophy , Stanford University, 29 June 2020, plato.stanford.edu/entries/leibniz -mind/.
whereas the perceptions of the bodily state (causally passive) become more con fuse d. Therefore, there is no causation, rather our understanding of the relationship becomes impaired. This is the cas e because according to Leibniz , substances are programmed at creation to act causally active or passive at relevant moments. However, again, this theory is inherently dependent upon the existence of an omnipotent being, either within the causal process itself, or at creation .
An issue with this theory is that we don’t have any indication of any confusion of our perceptions, although this itself could be a weak criticism as our perceptions are innately flawed, and we aren’t omniscient, so we are unable to criticise the supposed manner in which God creates this preprogrammed co -ordination .
Th e solutions to the interactionist’s problem are unconvincing and this therefore poses to o large a threat to Descartes’s theory of identity to be ignored and thus leading to the search of alternative solutions
Ultimately, the previous accounts of personal identity have irresolvable criticisms. Parfit instead proposed a different perspective on identity, arguing that identity itself is not significant, presenting instead the concept of psychological continuity as a superior measure.
Parfit
Parfit raises further issues with these theories:
Fission (Wiggin’s division operation) :
Take the example of a brain transplant where your brain is transplanted into a new body, and the same memories and personality persist. Locke’s view of memory theory would still hold here , and it seems necessary th at there would be personal identity. If you were to take another example where half your body and brain become damaged, but the functioning half of your brain is transplanted into a new body, and again the same memories and personality persist, therefore according to Memory Theory, there is still a personal identity relation.
However, imagine the scenario where half of your brain is transplanted into another body, resulting in two people with the same memories and character. According to Lockean Memory Theory, since both people have memory, they would be the same person . However, if this situation were to be extended any longer in time, the personal identity relation to each other, and the person before, would no longer hold as they develop new memories with each action and experience, and hence you are not identical with either of the remaining people . Puc cetti presents a different idea, that within each body there are 2 brains : “2 modes of thinking” and thus Puccetti argues that there are 2 separate people. Thus, in the event of a brain division, the result is 2 separate people, but that is not problematic , since there are already 2 separate people within 1 body However, this infers identity of the physical mind, or half of it, subjecting it to the issues of bodily identity: cells in the brain also die and are replaced. If instead one interprets this to infer identity of non -physical spheres of consciousness, then the interactionist’s problem would dismiss this claim once aga in.
So, if we consider not surviving as both people , disregarding Memory Theory and Puccetti’s notion of 2 people , it raises the question of whether we survive as one of the two people or not at all. Since there is no reason for one person to have any stronger claim to personal identity, we are left with the
idea that there is no survival at all. However, since there is survival in both the examples mentioned above and the only difference between this instance of fission and our second example, is the increase in how much of “you” exists, so how can more of “you” lead to no survival , in the same way that a drug to double your lifespan doesn’t result in death, only in this instance the two lifespans run concurrently; or as Parfit writes “ how can a double success be a failure” 2 . Perhaps that is not actually the result, and instead it should be considered as one person with two bodies, if it is believed that there should be personal identity in this instance. One issue that arises because of this is that personal identity is generally regarded as a 1 to 1 relation, and hence a n identity relation cannot exist between the two currently existing people, or the one that existed before, as it would be in obvious breach of transitivity. However, this is if survival is taken to infer personal identity, but Parfit does not take it this way (precisely due to the issues of the theories of personal identity) , so it leads him to believe that a 1 to 1 relation, although essential for personal identity, is not what matters for survival. Instead Parfit argues that there is a different criterion for survival, whilst disregarding the importance of personal identity. He considers that “psychological continuity” is what bears the most significance in relation to survival. Psychological continuity consists of continuity of psychological information such as memory, beliefs, personality, emotions and so on . Parfit argues that personal identity should be defined as ‘non branching psychological continuity’, exclusively a 1 to 1 relation. However, he argues that psychological continuity is more important, rather than identity which must be transitive and hence non-branching Parfit says, "X and Y are the same person if they are psychologically continuous and there is no person who is contemporary with either and psychologically continuous with the other”.3
Generally, Parfit’s idea of psychological continuity is advantageous over Locke’s Memory Theory in regards to issues such as quasi-memory, as identity or survival, is not only constituted by memory Considering another case of fission where a brain split into several different bodies , the result would be several Parfitian survivors, as the products of this division have psychological continuity with the initial person. This notion of several different aspects of someone’s psychology existing at the same time, is strikingly similar to the Buddhist idea of skandhas
Fusion :
Consider the example of two people, whilst unconscious, having their bodies grow into one. Quasi memories are maintained, but some are naturally lost since conflicting desires and beliefs can’t both persist. Therefore, according to Parfit, fusion is more likely to be considered as death since not all parts of your psychology remain, yet enough of it can exist, depending on how much is lost due to conflict with the other party involved in fusion. This does, however, raise a concern with Parfit’s reasoning, how can we decide what amount of remaining psychology is enough to constitute survival, without it being inevitably arbitrary, and can survival be in degrees or only a binary concept?
Ancestral Relation
Just as how Locke’s idea of memory continuity was the ancestral of memory connectedness, Parfit’s idea of psychological continuity is the ancestral of psychological connectedness . Although continuity is transitive, and connectedness is intransitive, Parfit views psychological connectedness as more
significant in relation to survival. However, both psychological continuity and connectedness , come in quantities of degrees so survival must as well.
However, degrees of survival or psychological continuity are ultimately arbitrary thus quantifying the degree of survival would be essentially impossible, leading to a significant problem when considering any ethical or legal significance
Hume:
Hume takes a completely different approach to the problem of personal identity as not only does he consider the problem of diachronic identity, but also whether a self exists at any point in time.
Once again considering Leibniz’s identity of Indiscernibles, Hume argues that there can be no diachronic identity, since we are all constantly changing, considering both material and immaterial substance. Hume goes on to also reject the idea of the self completely, a notion many others who considered this problem did not consider, as he argues that there is no identity at any given point in time Instead, Hume presents the bundle theory, which is that an object is nothing more than its properties . Therefore, what we think of as the self is nothing more than a collection of impressions (perceptions experienced by the mind). Some argue that we are continuously aware of the self, Hume argues that introspection does not yield such a result. Instead, we experience a constantly changing perceptions such as heat or cold; love or hated; pain or pleasure ; yet Hume argues that there is nothing more to the mind but these perceptions. For example, we can feel hunger, but introspection never reveals any indication of the ‘I’ experiencing hunger. Hume argues that if we had an impression of a persisting self, then that impression should be constant throughout our life, just as the self would be constant. However, introspection doesn’t yield that result, and there is no impression of the experiencer, only their impressions. If there is no impression of this self, there can be no idea of it, since an idea according to Hume is a faint image of an impression. Therefore, there is no idea of a persisting self, or of diachronic identity, so there is no reason for us to believe that that should be the case.
Hume goes on to discuss the difference between identity and diversity. Identity is one object persisting through time, diversity is the “idea of several different objects existing in succession and connected together by a close relation ” 4 Hume believes that despite the clear distinction between these two concepts, they are often confused in what he describes as the “common way of thinking ”. By this he means that people often claim that an object at one time has persisted and is identical with an object at another time, but according to Hume, it is a succession of different objects, impressions, with a close relation. This claim is justified by the concept of a self, based upon the false pretence of our continued senses, or the supposed existence of some object which binds all our perceptions together through time. After Hume’s dismissal of the notion of personal identity, he further goes on to inquire what causes us to mistake diversity for identity. Hume describes that when we perceive an object that undergoes a change, we often fail to recognise this change and in stead assume that the object itself has persisted, especially so when the change experienced is gradual or minimal.
Similarly to Parfit, Hume believes that most of the “nice and subtile” questions about identity are nothing more than issues of grammar, as they are more so based on minor technicalities regarding the usage of personal identity language, rather than philosophical queries. 5
Criticisms:
4, Giles, James. “The No -Self Theory: Hume, Buddhism, and Personal Identity.” Philosophy East and West , vol. 43, no. 2, 1993, pp. 175 – 200. JSTOR, https://doi.org/10.2307/1399612
There are however some criticisms of Hume raised by Penelhum Penelhum argues that Hume fails to consider that an object can have several parts.
However, these criticisms are quite easily dismissed as Hume makes it clear in A Treatise on H uman Nature that objects can have parts: “suppose any mass of matter, of which the parts are contiguous and connected…we must attribute a perfect identity to this mass, provided all the parts continue uninterruptedly” . Hume’s argument is instead that these parts rarely continue interruptedly and certainly don’t when considering the self and impressions.
Penelhum also claims that Hume does not make a clear distinction between numerical and specific identity. The specific sense of identity is for an object to remain the same through time, whereas the numerical sense is that for the object to change, it must be one and the same object undergoing the changing. Penelhum says that an object can only lose its identity by changing if it is by definition an unchanging object. To take this in reference to the famous “Ship of Theseus” dilemma, imagine again a new ship constructed from all the parts of the old ship. T h e new ship that exists now might resemble perfectly the old ship before any repairs, thus these 2 ships have a specific identity, as they exactly resemble each other. They do not, though , have numerical identity, since it is clearly not one and the same ship . Penelhum argues that there would in fact be numerical identity since the only thing which would prevent it, would be if a ship were defined to be unchanging. However this leads to the fact that there is no means of distinguishing between a ship which has persisted without any changes, and a ship which has replaced every part, as Penelhum would ascribe specific identity to both, as Penelhum would argue there is no distinction. However it does seem necessary for a distinction to be made, as it is clearly not the same ship, which is only possible according to Hume’s account.
Penelhum raises further criticisms of Hume as he claims that any extensions of Hume’s account of identity would lead to rather extreme ramifications. Penelhum argues that if we were to accept Hume’s theory of personal identity, we would be forced to refer to someone or even ourselves with a different name at each moment something changed. This leads Penelhum to conclude that Hume’s account of identity would require a “complete overhaul of the concepts and syntax of our language”.
However, this is not necessar ily the case as Hume, in A Treatise of Human Nature says that it is possible to refer to two objects by the same name without error. He describes the scenario where a church that has fallen to ruins, and then was rebuilt, and claims that “without breach of the propriety of language” one can refer to these two churches by the same name. Similarly, despite there being no numerical or specific identity, between you now and in any other in stan t, since ultimately there is no t one object changing but multiple , it is still possible to be denominated the same. Hume goes on to argue that further disputes about the identity of successive objects is not a philosophical one but “merely verbal”, as it concerns our linguistic conventions rather than our views on identity. This once again references a belief shared by Parfit and Hume about the relative insignificance of personal identity, since they both claim that several questions that arise from it are grammatical in nature, not philosophical, and often rather arbitrary.
Buddhism
Buddhism presents an account of identity which is strikingly similar to Hume’s bundle theory. The notion of “anatta” (no self) is fundamental within the Buddhist belief system and reaffirms Hume’s presentation of the lack of a persisting self. Buddhism instead argues for the existence of skandhas , a Sanskrit word translating to heaps ; o nce again the similarity to Hume’s bundle theory is cle ar, but with a difference being that the Buddhist doctrine seemingly refers to multiple bundles , whereas Hume’s singular bundle theory seems to refer to one bundle containing the perception, sensation and consciousness skandhas. However, this difference is insignificant, as Buddhism mer ely creates one
more subdivision and Hume’s idea of impressions is compatible when considering inside the skandhas themselves .
There are said to be 5 skand has: Rupa (form), Vijnana(consciousness), Samskara (mental formations), Samina (perception) and Vedana (sensation). In the Pali Canon, this idea of the skandhas is introduced through the story of King Milinda’s Questions, where a person is likened to a chariot, but Nagasena explains that there is nothing “outside them [the constituent parts] t hat is the chariot”. 6 This is then likened to a person, as there is nothing to a person but their constituent parts. However, I would argue that the skandhas are not really constituent parts of a person, in the same way that, according to Hume, impressions do not constitute a person, but are rather ‘factors of the human experience ’ as they are described to be ‘arising’ and changing . 7 Furthermore, there is really no self for them to constitute, as these skandhas and Hume’s impressions refer more to experiences, but there is ultimately no experiencer, only a collection of changing experiences. This is also relevant to the Buddhist belief of Anicca ‘impermanence ’ and the Mahayana belief of Sunyata ‘emptiness’ , as the skandhas themselves do not possess any intrinsic property and are themselves constantly changin g . This is demonstrated by considering any of one of the skandhas, take the form Skandha , our body is constantly changing and replacing itself, thus there is no permanence of this body. If you consider the sensation or perception skandhas there is no experiencer (a persisting self) of these, nor any constant sensation or perception (or as Hume would say impres sion), just like Hume concluded from his introspection.
Buddhism, whilst adopting a clear doctrine of no-self, makes the same point as Hume, we still refer to a n object of changing constituent parts as one thing, even if the thing itself is just the parts, such as the chariot, or even if they aren’t constituent parts and are constantly changing, such as the skandhas, as evidenced by this section of the Varijisutta: “Why do you believe there’s such a thing as a ‘sentient being’? Māra, is this your theory? This is just a pile of conditions, you won’t find a sentie nt being here. When the parts are assembled we use the word ‘chariot’. So too, when the aggregates are present ‘sentient being’ is the convention we use” 8 It is important to note that here too the distinction acknowledged between the chariot and a person a s the aggregates are describes as “present” , like experiences are, rather than “assembled”, as constituent parts of a chariot are.
Overall Conclusion
To conclude, Buddhism presents an account of personal identity that can be combined with Hume’s similar bundle theory, and Parfit’s psychological continuity. The most convincing argument I believe, is for the notion of no -self, as through introspection we cannot observe a persisting self. Instead, we are aware of different impressions, constantly replacing each other, of different skandhas, each of which are also constantly changing , but there is no perceivable or rationally derivable sense of a persisting self. Both Locke and Descartes’ arguments for personal identity come with irresolvable flaws such as the issues of quasi memory and the interactionists problem that ultimately render these
“ Simile of the Chariot.” Encyclopedia of Buddhism, Encyclopedia of Buddhism, 9 Apr. 2024, encyclopediaofbuddhism.org/wiki/Simile_of_the_chariot.
7 Wynne, Alexander. “Early Evidence for the ‘no Self’ Doctrine? A Note on the Second ...” Oxford Centre for Buddhist Studies , ocbs.org/wp -content/uploads/2015/09/awynne2009atijbs.pdf
8 “Vajirāsutta.” Encyclopedia of Buddhism, Encyclopedia of Buddhism, 1 Sept. 2024, encyclopediaofbuddhism.org/wiki/Vajir%C4%81sutta.
propositions unconvincing. All these arguments omit the possibility of no self at all, no self to have memories , whereas Hume and Buddhism aptly consider and conclude with this notion .
Other Implications
Hume , Buddhism and Parfit agree that personal identity itself is not of significanc e, as it is instead relegated to a question of language, rather than one of philosophy. Yet the notion of no -self must have impacts to ethical fields and law. Regarding the notion of acting in self -interest (actions intended to benefit our future selves), if what is defined as our future selves is essentially arbitrary, which would be the result of accepting the concept of Parfitian survivors and psychological continuity, then it becomes increasingly difficult to motivate the principle that this particular future self is any more important to us than any other person. Another important application of the problem of personal identity, is that of the fear of death. If again, what co nstitutes our future self is arbitrary, worrying about death, aging or any problems concerning ‘our’ future, is more of a matter of how we use language regarding personal identity, rather than any philosophical question. Therefore, Parfit’s conclusion on personal identity is that if you can remove personal identity from the questions and problems where it seems necessary, these queries are reduced to issues of convention and formality, not philosophy
Further ethical conclusions could follow from the notion of no-self, such as the following of Buddhist ethics, which has a priority of “altruism”, or rather acting to benefit consciousness skandhas on their path to Parinirvana , due to the Buddhist metaphysical belief of interconnectedness : “ paticcasamuppada” Utilitarianism is another possible ethical conclusion, this time consequentialist as opposed to the deontological focus of Buddhist ethics , for if there is no reason to prioritise anyone over anyone else; should it then be moral to act for the good of as many as possible?
Another significant implication from the acceptance of no personal identity is the problem of legal and ethical responsibility : Should someone be punished for the actions of someone they no longer have identity with ? Parfit argues that the degree of our responsibility would be proportional to the degree of psychological continuity. However, the degree of psychological continuity would be impossible to effectively quantify From a Buddhist perspective, ka rma associates a qualitative description of morality to the mental formations and consciousness skandhas and thus it becomes ‘self’-sabotaging as unskilful karma generated by these skandhas, will prohibit them from attaining Parinirvana . Thus, the existence has its own method of punishment, karma, and this does not need to be imposed by humans. The laws of karma in Buddhism are also described to be unintelligible to anyone who is not yet enlightened. Therefore, although we cannot understand or formulate a system of punishment due to the lack of a persisting self, according to the Buddhist doctrine, the governing of the universe already accomplishes this.
APPENDIX A
Identity of the Christian God
Many of the aforementioned philosophers share the Christian faith and have considered the problem of personal identity, however questions of the identity of God are some that have not received as much discussion. It could be said that the problem of personal identity could also have significant effects in a theological context. For example, how do we know that the Christian Creator God has persisted until today? And if not do we still have any reason to worship him?
Diachronic identity is the identity persisting over time and it would be imperative for a God to have this, since it would make no sense, as a follower of this religion, to worship a God that is not the same one as the God that created humanity or saved us from our sins.
According to the previously mentioned Identity of Indiscernibles, for two things to be identical, they must share all the same properties. So, this leads to the question, does God now share all the same properties as the God described by the Bible?
Perhaps not, as in the Old Testament, God himself caused the flood to wipe out humanity, an action that doesn’t demonstrate omnibenevolence, and one never since repeated. This suggests that God has in some way changed, as the God who did this was seemingly not omnibenevolent, whereas the current God supposedly is , hence there is no identity as not all the properties are shared.
However, there are other issues with the identity of God, besides in the diachronic sense, but instead regarding the hypostases. Transitivity is assumed in the problem of personal identity; hence it is not an unreasonable assumption that the same should be true in regards to God.
However, the hypostatic union is in obvious breach of this, as Jesus is God, the Father is God, and the Holy Spirit is God, but Jesus is neither the Father nor the Spirit, nor is the Spirit the Father. So, it seems that A = X, B = X, C=X, but A ≠B, A ≠C, a nd B≠C.
However, this question might not be relevant to the discussion of identity, since, applying Leibniz’s Identity of Indiscernibles once again, Jesus does not possess the identity relation with God, and neither do the other 2 hypostases. Hence a different rel ation is present altogether, which requires further explanation and a distinctly different discussion.
Bibliography
Perry, John. Personal Identity . University of California Press, 1975.
Olson, Eric T. “Personal Identity.” Stanford Encyclopedia of Philosophy , Stanford University, 30 June 2023, plato.stanford.edu/entries/identity -personal/.
Gordon -Roth, Jessica. “Locke on Personal Identity.” Stanford Encyclopedia of Philosophy , Stanford University, 11 Feb. 2019, plato.stanford.edu/entries/locke -personal-identity/.
Holbrook, Daniel. “Descartes on Persons.” The Personalist Forum , vol. 8, no. 1, 1992, pp. 9 – 14. JSTOR, http://www.jstor.org/stable/20708615
Kulstad, Mark, and Laurence Carlin. “Leibniz’s Philosophy of Mind.” Stanford Encyclopedia of Philosophy , Stanford University, 29 June 2020, plato.stanford.edu/entries/leibniz -mind/.
Giles, James. “The No-Self Theory: Hume, Buddhism, and Personal Identity.” Philosophy East and West, vol. 43, no. 2, 1993, pp. 175 – 200. JSTOR, https://doi.org/10.2307/1399612
Ching, Julia. “Paradigms of the Self in Buddhism and Christianity.” Buddhist-Christian Studies , vol. 4, 1984, pp. 31 – 50. JSTOR, https://doi.org/10.2307/1389935
Wynne, Alexander. “Early Evidence for the ‘no Self’ Doctrine? A Note on the Second ...” Oxford Centre for Buddhist Studies , ocbs.org/wp -content/uploads/2015/09/awynne2009atijbs.pdf
“Simile of the Chariot.” Encyclopedia of Buddhism , Encyclopedia of Buddhism, 9 Apr. 2024, encyclopediaofbuddhism.org/wiki/Simile_of_the_chariot.
“Vajirāsutta.” Encyclopedia of Buddhism , Encyclopedia of Buddhism, 1 Sept. 2024, encyclopediaofbuddhism.org/wiki/Vajir%C4%81sutta.
DISAPPROVAL VOTING –WHAT ELECTORAL REFORM COULD LOOK LIKE
BY EDMUND NG
(Upper Sixth – HELP Level 4 – Supervisor: Mrs S Yoxon)
DISAPPROVAL VOTING
WHAT ELECTORAL REFORM COULD LOOK LIKE
EDMUND NG | MME S. YOXON | HELP LEVEL 4
INFORMATION
Permission is given for this work to be reproduced, distributed, and communicated to the public
Thanks must go to the following people-
Jasper de L and Christopher M, for their input in the design of the ballot paper
Harry N, for helping me with various administrative tasks involving the ballot papers
Mayank K, for helping me conduct surveying
Michael W, Eddie W, and Mrs. A. White, for helping me sort and count ballot papers
Special thanks must go to Mme S Yoxon for supervising this project.
INTRODUCTION
In June 2020, Wendy Chamberlain, the Member of Parliament for North East Fife (UK Parliament, 2024) remarked in a debate that-
Debates on potential electoral reform are a bit like buses: wait a long time for a chance to discuss it, and then, […] two opportunities come along at once. (Hansard, 2020)
A quick search of Hansard, the parliament’s transcript, and official log, shows this to be somewhat the case, with five debates since the 2010 election. One was in 2010, three were in 2016, and one was in 2020.
With a historic election campaign just gone and a new Labour government, the topic has once again been in the media, and save for some fleeting references to Labour’s potential plans to introduce votes to 16-year-olds in their manifesto (Labour Party UK, 2024), it has largely1 come and gone without controversy.
Now, one platform that is no stranger to controversy is X (Wikipedia Editors, 2020) (Fung, 2022) (Press-Reynolds, 2022) (Murphy, 2023), formally known as Twitter2. It was during some mindless scrolling in the run-up to the election that I came across the following tweet3-
Marie Le Conte @youngvulgarian 5:52pm Jul 3 2024 Labour should introduce a new option where you don't vote for anyone but instead get to vote against a candidate if you want to, cancel out one of the votes they got from someone else, like a reverse UNO situation (Conte, 2024)
This caught my eye for several reasons. It was a nice break from the constant memes and jokes surrounding the final few days of campaigning, but more importantly, it seemed like a feasible idea that could reasonably be implemented at an election.
This system that we could potentially call “disapproval voting” appears to solve many problems with the current system, but to understand why, we first need to look at the
1 At the time of writing
2 For the rest of this project, I will refer to the platform as Twitter, partly because this is the more well-known name, but also because the URLs still say Twitter
3 For the rest of this project, I will refer to “posts” as “Tweets,” because of footnote 2
current electoral system for electing Members of Parliament to the House of Commons
We will then conduct some fieldwork to see if using this system could change the outcomes of an election, for better or for worse, and end with my thoughts on the results and the system as a whole.
PART 1 – FIRST PAST THE POST
At present, the UK uses the First Past the Post (FPTP) system to elect Members of Parliament (MPs) to the House of Commons. Voters receive a pre-printed ballot paper with a list of candidates and are asked to put a cross next to only one candidate. The votes are then counted and the candidate with the largest number of votes wins that particular election.
The name First Past the Post was derived from a metaphor for horse racing (Tréguer, 2019), as the end of a race is marked not by a traditional finish line, but by a physical post. Some have argued that this name is a misnomer, as there is no set percentage or threshold to win under this system, but I would argue that the “post” can be set at 50%+1 votes, as any candidate reaching this threshold mathematically cannot be prevented from winning that particular election4.
Regardless of any naming conventions, since George VI gave Royal Assent to the Representation of the People Act 1948 (Cowan, 2019), all parliamentary elections have taken place under the First Past the Post system. The first election under this system, the 1950 General Election, saw Labour’s Clement Attlee take overall control of the House from the Conservative’s Winston Churchill with an overall majority of only five seats (Election Demon, 2012).
Some of the results are reproduced on the next page for the reader’s benefit, as these figures will be referenced in this section-
4 Of course, an election under FPTP can still be won with less than 50% of the vote, but the point still stands
The results of this election highlight some of the most glaring issues with the First Past the Post system.
The first issue with First Past the Post is that it is possible for a majority government to be formed with less than 50% of the popular vote – that is to say, more people did not vote for the party in eventual power than did. In fact, since 1950, no party has ever achieved more than 50% of the popular vote, and yet Tony Blair returned a landslide majority of 179 in the 1997 General Election (Morgan, 2001) It is theoretically possible for a party to form a majority on just over 25% of the popular vote9, as follows-
The government party gets 50%+1 votes in 50%+1 constituencies (326 currently), and 0 votes in all other constituencies
This is, of course, never going to happen, but it proves the point that First Past the Post is flawed in this regard that it allows governments to be formed with a minority of the popular vote.
Some people see this as an advantage of this system, as it returns “strong and stable” majorities much more often than more proportional systems, but to what extent these majorities
5 Of valid votes, not total votes, or turnout
6 Against convention, the Speaker of the House of Commons is included in the seat total. Two seats were uncontested
7 Seat won by an Independent Liberal candidate
8 Individual percentages may not sum to 100.00 due to rounding
9 Assuming that all constituencies have the same number of voters which is the “worst case” scenario. Any smaller constituencies reduce this percentage. Common sense should tell you that all the government party has to do is win 50%+1 seats in the smallest 50%+1 constituencies
are either strong or stable is very much up for debate10. To me, it seems that while it is true that we have workable majorities, we still have a lot of problems passing important legislation. These issues, therefore, have to arise from something other than the electoral system, such as party infighting, or the constant “ping pong” of questions and amendments passed between the Commons and the Lords.
Another problem with First Past the Post that can be drawn from these results, similar to the first, is that the proportion of seats that a party gets is not the same as the proportion of votes that they receive. This can most notably be seen by comparing the results of the Communist and Nationalist parties. The Communist Party may have received nearly 40% more votes than the Nationalist Party, but because the Communist Party ran in only 100 seats (Election Demon, 2012), the overall effect of these votes was heavily diluted compared to the Nationalist Party’s two candidates
A more contemporary example can be found by analysing the results of the Reform Party and the Labour Party at the 2024 election. While the Reform Party got over 40% of the votes that the Labour Party did, they only got 1% of the seats that Labour did. The reason for this is that while Reform has widespread support across the country, the fact that there are so many constituencies makes this support diluted to a level where the party can consistently get third or second, but not enough to win many seats. In fact, Reform came second in ninety-eight seats (Cracknell, Baker, & Pollock, 2024) A full breakdown of the second-place seat totals can be found in Appendix A.
This significant difference between the level of support a party can command and the representation they get in Parliament has led some to call this system “undemocratic,” saying that it undermines the voices of anyone who votes for someone other than the eventual winner.
At a constituency level, it is also generally the case that more people did not vote for a particular candidate than did. In the 2024 General Election, there were only ninety-five11 out of 650 constituencies where the winner had an outright majority of the valid votes cast, and there was no constituency where a candidate had an outright majority of the electorate as a whole. The Labour MP for Westmorland and Lonsdale, Tim Farron, came closest, winning votes from 43.12%
10 Such a discussion is not within the scope of this paper, but if 2021-2023 is anything to go by, then perhaps not very strong or stable
11 Data taken from the same source as that of Appendix A
of the electorate (Cracknell, Baker, & Pollock, 2024). On the other end of this spectrum, Liam Byrne, Labour MP for Birmingham Hodge Hill and Solihull North got votes from only 13.71% of the electorate, the lowest percentage that an MP won a seat with.
More than six out of seven people did not vote for Byrne
The word “democracy” has Greek roots, derived initially from the words demos, meaning “common people”, and kratos, meaning “rule”. So in all, we have “the rule of the common people”, which then, via Ancient Latin and Middle French, became the word we know today in the 1570s (Etymonline, 2021). It would be very difficult to argue that the voice of 1/7 of a population is really “the rule of the common people” when overwhelmingly the “common people” did not vote for the eventual winner. It is without any doubt, in my view, that this presents some tough questions about the legitimacy of the “mandate” that Byrne has to represent his constituency.
Despite all of the democratic issues with the use of the First Past the Post system, it is still used to this day. The public rejected Alternative Vote in the 2011 referendum (McGuinness & Hardacre, 2011) and since then, the issue has largely been swept under the rug. Proponents of First Past the Post say that it is a simple system that everyone can understand, allows for a simple ballot paper, saves time and money by not requiring recounts or a second round, and allows for effective12 local representation, as each MP is elected from a constituency of roughly 75,000 voters on average.
For now, it seems like our current electoral system is here to stay. But should it? If not, why not?
12 The effectiveness of this representation is up for debate, especially if you consider MPs such as Nigel Farage
PART 2 – THE ALTERNATIVES
While the bulk of this paper will be dedicated to what I will be calling “disapproval voting”, I feel that it would provide some important background to the work later in this paper to briefly discuss some of the other voting systems used around the world, and to what extent they solve13 the problems caused by the use of the First Past the Post system.
APPROVAL VOTING
My idea for the name of “disapproval voting”14 came about as a result of the existence of a voting system called Approval Voting. This functions similarly to First Past the Post, but instead of being restricted to a single vote, voters are free to vote for as many or as few candidates as they wish.
This has many of the advantages of First Past the Post (simple ballot paper that is almost identical to FPTP, no second round or recounts required, and allows for local representation) while reducing15 the chance that the winner is elected on less than 50% of the electorate’s support. It also reduces tactical voting, as voters are not punished for voting based on their true beliefs, unlike in First Past the Post where voters may choose to vote for a candidate that is not their favourite to prevent a third candidate from winning. One of the very few disadvantages of switching to this system would be the need for voter education, as most electors will be used to only being able to mark a single candidate.
PROPORTIONAL REPRESENTATION
Proportional Representation aims to go one further by removing the constituency system entirely, in favour of results that match the popular vote as closely as possible. The eventual seat share is simply the popular vote share across the entire country. As a result, there should in theory be no tactical voting as every person’s vote matters.
Often perceived to be one of the fairest electoral systems, this system is used in the Netherlands for governmental elections, among other things.
So that we can see just how good this system actually is, I will reproduce the results of the 2023 snap election (Wikipedia Editors, 2024) on the next page-
13 Or at least attempt to solve
14 It was funnier in my head
15 Although not removing
2023 DUTCH GENERAL ELECTION – ALL 150 SEATS – 76 FOR MAJORITY
Herein lies the first problem with Proportional Representation: it is so unbelievably unlikely for any party to ever win an outright majority. As can be seen from the above results, the resulting parliament structure is incredibly fragmented and this makes it difficult to form a working coalition, let alone pass legislation through the house. In this case, it took 177 days from election day to finalise the coalition agreement (Wikipedia Editors, 2024) (Timeanddate, 2024)
As a consequence of how elections under Proportional Representation are run, there is no longer a local representative for each area. This local representation is seen as an advantage of the Westminster system because MPs are expected to deal with casework from their local community and to represent their views in Parliament.
16 Of valid votes, not total votes, or turnout
17 The only new party to have won any seats
18 Eleven parties returned no seats
19 Individual percentages may not sum to 100.00 due to rounding in multiple places
ADDITIONAL-MEMBER SYSTEM
Scotland has taken the best bits of both systems by combining both First Past the Post and Proportional Representation into their system for electing Members of the Scottish Parliament (MSPs) – the Additional-member system (BBC Bitesize, 2024).
The Scottish Parliament has 129 MSPs. 73 of them are elected from constituencies by First Past the Post, and the other 56 are elected to their region by a modified version of Proportional Representation.
Scotland is divided into eight regions, each with seven regional MSPs. On election day, voters are given two ballot papers with one being for the local MSP and the other for the regional parties. The local results are counted, and the winner is declared under First Past the Post, as would happen in the UK for General Elections. The regional votes are then counted, and the seven MSPs for that region are allocated to each party by Proportional Representation20.
For the sake of demonstration, let us imagine a region with 8 constituencies, so there are 15 MSPs for this region (8 constituency MSPs and 7 regional MSPs).
DEMONSTRATION DATA
Now we use the D’Hondt method to calculate the total seat share for the region-
The method used here is detailed on the Wikipedia page (Wikipedia Editors, 2024). In short, we divide the number of votes each party got by increasing integers and pick the
20 More specifically, by the D’Hondt method
largest 15 to allocate the seats. The numbers with stars next to them represent which seats were won by which party. We can see that the Red party won five, the Yellow party won three, the Green party also won three, and the Blue party won four.
We now calculate the difference between the proportional allocations and the FPTP seats, and we would see that Red is one MSP under, Green is two MSPs under, and Blue is four MSPs under. The parties would then be given this many MSPs from the regional list to make the overall representation fairly proportional21. This process is then repeated for the other regions.
This system is lauded for combining the best bits of multiple voting systems. It keeps the constituency system (and therefore effective local representation) from FPTP, allows for fairly simple ballot papers and voter instructions, makes the result fairer by having a level of proportionality, and allows for more choice as voters can choose a different party for each of their two ballots. One advantage that FPTP does not have is that each voter technically has multiple local MSPs, as they will also have the MSPs allocated to the region by Proportional Representation.
The fact that there are two “types” of MSPs is seen as a disadvantage to some, as it not only complicates the voting system but could also make regional MSPs feel “second tier,” as they did not win their seats directly and also represent a much wider area. It is also confusing for a voter with casework to have up to eight different people to contact.
Coalitions are also much more likely under AMS, and this is mainly due to the element of proportionality in the overall seat share. This proportionality is not perfect, however, with often a few parties having a difference of 3-5% between their vote share and their eventual seat share in Parliament.
These three systems are, of course, just a small fraction of the many voting systems that are available, but these seemed like the best ones to make comparisons between.
21 In the end, Red is overrepresented by 0.25 MSP and Blue is underrepresented by 0.25 MSP, but since you can’t have a quarter of a person (for hopefully obvious reasons), this is the best you can get in this situation. Some contrived examples lead to less proportionate overall seat distributions
PART 3 – DISAPPROVAL VOTING
With the scene set, we are now ready to move on to the main topic of this paper, which is to see what would happen if we implemented Le Conte’s proposal for electoral reform.
The plan is to design a mock ballot paper, and then go outside and conduct fieldwork in various constituencies, with the aim being to see if this system would have altered the result of that constituency’s election After much thought, the following breakdown of the tasks required was devised:
1) Design a mock ballot paper to be printed
2) Find some way of getting it printed
3) Decide where to conduct fieldwork
4) Decide how to choose participants
5) Decide how the data should be analysed
6) Conduct fieldwork
7) Count ballot papers
8) Conduct analysis
DESIGN
Firstly, the question to actually ask had to be settled on.
A number of considerations were made when designing the ballot paper to be used in this research. It should look (vaguely) like an actual ballot paper, require respondents to mark a cross in a box, and be simple to understand. The design found in Appendix B was eventually settled on.
The wording of the instructions has been chosen to be similar to the wording found on actual ballot papers. More specifically, wording from Police and Crime Commissioner ballot papers was amended as required. It was decided that the ballot paper should be as generic as possible, as printing the names of each of the candidates who stood in the July 2024 election would require multiple versions to be printed, at a prohibitively high cost to the project22.
The ballot paper was designed in Microsoft Word, using Courier New font. The font was chosen as it is a fixed-width font, that is to say, every character takes up the same width, and this allowed me to align the boxes more easily. Finally, a
22 One annoying “quirk” of the pricing matrix for the company I ended up using is that printing 500 copies of each of two versions is nearly four times as expensive as printing 1000 copies of only one version
paper size of A5 was chosen as this is similar to23 the size of actual ballot papers.
In the bottom left corner, I placed the numbers 1 through 8. This was so that we could subtly mark different groups or sets of papers, which would prove to be useful later.
The ordering of the parties on the paper was decided by the following method, in line with an Electoral Commission suggestion-
Numbers 1 through 6 were randomly assigned to each party, and then the numbers 1 through 6 were drawn by lots into a random order, denoting which party should appear in which position on the paper
PRINTING
From the start of this project, I had in mind that a couple thousand papers would be required to get statistically reliable results. Unfortunately, 2000 is a large number24, so I found a professional printing company.
For various reasons explained in the footnotes25, all business and research was conducted under the company name.
Eventually, a quantity of 2500 ballot papers was ordered, as this represented the best value for money without ordering tens of thousands of papers.
SAMPLING
To determine how many ballots should be completed for each constituency chosen, you can use a formula that takes into account the confidence interval and margin of error Here is the formula-
23 There is, perhaps surprisingly, no standardised size for ballot papers. This is because different elections and different constituencies have different numbers of candidates, so implementing a standardised size could be wasteful
24 Citation needed
25 It was quickly discovered that the printing companies (and various other institutions) treated you much better if you were a company, instead of an individual, for some reason. It was also much easier, during the fieldwork, to explain what you were doing if you said you were working on behalf of a company. For these reasons, among others, I decided to conduct all my business through my company
Where-
n is the sample size,
Z is the z-score,
p is the estimated proportion of the population, e is the margin of error, N is the total population size
This formula allows us to determine how many samples we need to do in order to get a statistically significant result, and can be applied to any form of sampling, not just ballot papers
The total population size is the size of each constituency, roughly 72,000 people, so for the sake of this calculation, a higher number of 80,000 will be used.
The estimated proportion is how much of that population you expect to have a given trait that you are sampling for, in this case, what party they vote for. The worst-case scenario is that this proportion is exactly 50%, as this leads to the highest possible sample size, so 50% is used here.
95% and 5% were chosen for the confidence interval and margin of error respectively, as these are fairly standard values26. What this means is that when we measure this population and get a result for, say, the number of people who would vote for Labour, we can be 95% sure that our measured value is within 5% of the actual value. The z-score is calculated using the confidence interval. In this particular case, the z-score is 1.96.
We now have all the required information to calculate the sample size that should be used. ���� = 80000 1.962 0.5 (1 0.5) 0.052 (80000 1) + 1.962 0.5 (1 0.5)
We get a result of ���� = 382.32, or, rounding up, ���� = 383. In plain English, in order to get a set of statistically meaningful results, we would have to do at least 383 surveys in each constituency. As a result, a target of 400 ballots was set for each constituency, as this would allow for a small handful of papers to be lost/damaged/otherwise unusable, as well as allow for the fact that there is a non-negligible uncertainty27 associated with counting how many ballot papers to bring to a particular site.
26 According to my father
27 Theoretically 1%
EVENTUAL ANALYSIS
Eventually, we will have data of thousands of ballot papers, from multiple different constituencies. At the constituency level, we will report the results of the fieldwork following the template in Appendix C.
From these results, a number of questions can be answered:
- Does this system result in a different winner to the General Election held under First Past the Post?
- Are there any unintended consequences or unforeseen problems with using disapproval voting?
FIELDWORK
Fieldwork was conducted over many days, starting on Monday 6 August. Including admin time and travel, roughly 48 man-hours were spent on conducting the surveying.
A number of other people were involved in doing this work, so thanks must go to Mayank K for his help in this regard, as well as others who, for various reasons, asked to not be named. In order to attempt to provide a uniform experience for all participants, the “script” found in Appendix D was suggested for use. While some guidance was given to those helping, they were mainly left to themselves in terms of deciding how to speak to people, record results, and so on. It was discovered after a while that it was far easier to have the respondents verbally indicate their choices, rather than pass bits of paper back and forth in the wind. This did make the whole process slightly quicker, while also hopefully reducing potential spoiled ballots.
After much thought, the following constituencies were eventually chosen as the sites for this research-
1- Chelsea and Fulham
2- Barking
3- Orpington
4- Hendon
The reasons for picking these particular sites will be explained in the analysis. Each paper had the site number marked in the bottom corner by having the corresponding number blacked out, to ensure that votes were attributed to the correct constituency.
As will be explained more when all the ballots are counted, there are still some ballot papers where the respondents marked the paper and some where the surveyor failed to mark the paper accurately. In these scenarios (and, to a small
extent, in the counting process as a whole), we will use the Electoral Commission’s guidance on borderline ballots.
400 people were surveyed in each constituency, with the exception of Chelsea and Fulham, where instead there are 600 results due to having more time at that site.
COUNTING
Counting thousands of ballot papers takes a long time28.
I, along with the people who helped me with counting, all very quickly discovered that the job of counting actual ballot papers on a much larger scale on election night was not one to be envied.
It was both difficult and annoying. As one person put it-
“I can count to 100 +/- 2” (White, 2024)
On a more serious note, the ballots were sorted first by constituency. For each constituency, the papers were sorted into piles for the FOR votes, which were then counted in bundles, in line with Electoral Commission advice (The Electoral Commission, 2024), and the result was recorded. These papers were then shuffled and sorted into piles for the AGAINST votes, following the same process.
As stated above, borderline ballots were adjudicated in line with the Electoral Commission guidance.
ANALYSIS
The final question that remains to be answered is does this system make any difference to the election results? If so, for better or for worse?
Of course, “better” and “worse” are highly subjective descriptors, and for the purposes of what is29 an academic project, it would probably be good to come up with some slightly more objective judging criteria.
Firstly, is the result reasonable? That is to say, would I, or the electorate, be able to understand why a particular person has won? The converse of this is that the result should not “come out of nowhere,” that it should be (at least somewhat) predictable, and that it should be reasonable that that result could be reached.
28 Citation needed
29 Supposed to be
Secondly, and slightly linked to the first question, is the result “democratic”? One of the problems with this system that I realised very quickly is that it would theoretically be possible for a party to win with a net vote of something like +3 votes overall by getting a very small number of votes for, and no votes against (because nobody really knows who they are, etc.). Conversely, large parties could lose out by getting a large number of votes for, but a slightly larger number of votes against This is, to put it bluntly, a problem. In more technical terms, the Independence of Irrelevant Alternatives criterion (Wikipedia Editors, 2024) (Wikipedia Editors, 2024) states that-
The election outcome should remain the same even if a candidate who cannot win decides to run
This is a flaw of First Past the Post and is better known in a political context as the Spoiler effect. It goes some way to explaining why the Conservative party did as badly as they did at the election just gone.
In a First Past the Post context, the Spoiler effect occurs when a party’s vote share is split by the existence of a similar party, harming both, and allowing a third party to win, oftentimes with less than 50% of the vote.
Imagine a theoretical constituency with two candidates, the Red Party, and the Blue Party30, and elections run under First Past the Post. In one election, the Blue candidate gets 60% of the vote, and the Red candidate gets 40%. Obviously, the Blue candidate wins the seat.
Now, a few years later, a Navy candidate decides to run in the next election. The Blue vote is split between Blue and Cyan, say 35% and 25% respectively, and the Red candidate now wins with 40% of the vote. This shows a failure of the Irrelevant Alternatives criterion, as Cyan, who mathematically could not win with 25% of the vote, has changed the outcome of the election by causing Blue to lose the seat.
Substitute Labour in place of Red, Conservative for Blue, and Reform for Cyan31 and you can begin to understand part of the reason the Conservative Party performed so badly in the General Election.
30 Any resemblance to any person, living or dead, any group, company or institution, or any event is entirely coincidental
31 Any resemblance to any person, living or dead, any group, company or institution, or any event is entirely uncoincidental
I was worried that a similar effect could also happen using Disapproval Voting, albeit slightly differently from the demonstration above.
For the sake of this demonstration, let us imagine that an election under the Disapproval voting rules was held, with the results as follows-
SOME RANDOM DEMONSTRATION RESULTS
With these results, the Labour Party wins. Now, at the next election, what could theoretically happen if we added a fourth party that almost nobody has heard of or cares about?
SOME MORE RANDOM DEMONSTRATION RESULTS
This 4th party has just stolen votes from the Conservatives and then due to being fairly unheard of, received so few votes AGAINST that they end up winning the election, even though just based on the votes FOR nobody in their right mind would ever think that this result was acceptable.
Of course, it is not as simple as just restating the Independence of Irrelevant Alternatives criterion, as part of the gimmick of this voting system is that it could allow candidates or parties who would not ordinarily win under First Past the Post to have another chance here, so this criterion would not be useful
In the end, I settled on the following philosophy-
The eventual overall winner should hopefully have enough total votes to beat the highest number of votes FOR
The reasoning for this is to make sure that enough people have actually heard of the eventual winner. A vote AGAINST is just as good an indicator32 of how informed the electorate is as a vote FOR. So, for the example above, the 4th party would be removed as the total votes (13) is lower than the highest total of votes FOR (150). It is difficult to determine whether this is a good rule without polling data to base this judgment on. Therefore, if disapproval voting were to be implemented, it is uncertain that this edict would exist.
32 Arguably
PART 4 – RESULTS
After a lot of work, I finally have something to show for it.
The process of counting was carried out as quickly and as accurately as possible. The general outline of the counting process was detailed above in PART 3 DISAPPROVAL VOTING // COUNTING, but it is useful to note here that while we were obviously aiming for 100% accuracy, it was considered to be impractical to recount the ballots again if an error was discovered, due to the time that this would take. For these reasons, I decided that when the votes FOR and AGAINST were reconciled, that a difference of one or two ballot papers could be accepted unless there was a tie. Fortunately, there were no ties, and no recounts were required.
Here are, at long last, the results of the fieldwork.
CHELSEA & FULHAM
Chelsea & Fulham was the first constituency chosen, as it had a very close result in the 2024 General Election. Ben Coleman of the Labour Party gained this seat from the Conservative’s Greg Hands by a little over 100 votes (BBC News, 2024), representing roughly 0.3% of the total votes cast. 2024 DISAPPROVAL FIELDWORK – CHELSEA & FULHAM CONSTITUENCY
LABOUR MARGIN OF 41
The top four parties here finished in the same order as they did at the General Election, both in terms of overall votes and the votes FOR. We could perhaps start to draw the conclusion that the proportions of votes cast FOR each party are fairly similar to the proportion of the vote each party got in July, as people will presumably be thinking in the same way when they choose who to vote for. The slightly larger bias towards Labour could be attributed to their increased presence
in the media after winning the election, perhaps swaying the minds of undecided or borderline voters.
The votes AGAINST show a remarkable bias against the Green Party in this case, for reasons that initially I could not work out. The candidate is uncontroversial, there has not been a complete breakdown of the party33, and aside from some interesting34 views on HS2, it has been a fairly quiet time for the party.
Digging deeper into YouGov polling data, however, we can see that the Green Party was the worst at being in the top half35 of people’s rankings (Difford, 2024). This could show that when people are deciding who to vote AGAINST, they are not necessarily considering a tactical vote (e.g., a tactical vote could be voting FOR Labour and AGAINST Conservative, to give Labour a greater chance of winning) but instead simply their least favourite party. The reason this is not the case for the other constituencies (which you will see) is unknown to me.
BARKING
Barking was chosen not because there was a close race for the winner, but because there was a close race for second place. At the 2024 General Election, the second place and fifth-place candidates were separated only by 4.4% of the vote.
Again, we can hypothesise that the votes FOR each party are roughly similar to the vote share they won in July. To make a
33 As at October 2024
34 Completely out of character for a party called the Greens
35 Calculated by looking at first and second rankings only, because the third-ranking party out of five could be in the bottom “half” of an individual’s rankings
comparison, here are the results of both the General Election and the FOR votes from the fieldwork, both converted into percentages-
These results are fairly consistent, again backing up the idea that under this system, the votes FOR are likely to be similar to the votes gained under First Past the Post. Again, Labour sees a slight increase from the General Election, but this is in part due to the existence of two more candidates (representing 3.3% of the vote share collectively) at that election which were not included on the fieldwork ballot.
It could still be argued that, as above, the recency of a Labour victory increased the proportion of people who would vote Labour.
ORPINGTON
Orpington was selected because many prediction polls got the result of this seat wrong, including the Financial Times “Poll of Polls” (Hawkins, Hollowood, Stabe, & Vincent, 2024), predicting a win for Reform37 at before the election, and the BBC using the Ipsos38 exit poll to predict a win for Labour (BBC iPlayer, 2024)39, despite this being only the 310th closest Conservative seat in 2019. In the end, this seat was held by the Conservatives with a winning margin of over 11%.
36 Individual percentages may not sum to totals due to rounding in multiple places
The results show the Conservatives winning this seat but with a low margin when compared with the first two seats.
It was surprising to me that Reform did not win this seat. Without wishing to make generalisations about the demographic of Reform voters, some of the 2021 census data for Orpington ward may give some clues as to why Reform did quite well here-
76.5% of people living in Orpington are White, and 78.9% of people were born in the UK. The religious makeup of Orpington is 49.2% Christian. 97.1% of respondents identify as Heterosexual, and 99.6% of respondents’ gender identities are the same as the sex assigned at birth. (Office for National Statistics, 2024)
Contrast this with the whole of London-
53.8% (-22.7%) of people living in London are White, and 59.4% (-19.5%) of people were born in the UK. The religious makeup of London is 40.7% (-8.5%) Christian. 95.3% (-1.8%) of respondents identify as Heterosexual, and 99.0% (-0.6%) of respondents’ gender identities are the same as the sex assigned at birth. (Office for National Statistics, 2024)
Some staggering differences, especially looking at the ethnic background of the constituency.
There is no plausible explanation that I could find for why Labour was predicted to win this seat by the BBC except for the exit poll overestimating their vote share.
40 The Workers Party did not run in Orpington, so in the small number of cases where respondents were physically given the ballot to fill in, they were instructed to ignore it and told that any vote attributed to the Workers Party would be voided. There were, thankfully, no votes for the Workers Party
HENDON
Hendon turned red in 2024, with Labour’s David PintoDuschinsky winning the seat by only 15 votes, equivalent to 0.02% of the electorate (BBC News, 2024). This was one of the closest seats in the election.
2024 DISAPPROVAL FIELDWORK – HENDON CONSTITUENCY
CONSERVATIVE MARGIN OF 3
Our data shows the Conservative candidate winning overall but with a lower total of votes FOR than Labour. This is the only constituency surveyed where the overall winner was not also the winner of votes FOR. This was always a possibility and is perhaps the whole point of this system; allowing parties who may not have won under First Past the Post to have a better chance by letting the electorate express their views better.
Of course, this result is exceptionally close, and given the uncertainty levels stated earlier in the paper, it would not be unreasonable if conducting this fieldwork again returned Labour as the winner.
Again, all the parties seem to have a fairly similar41 vote share compared with the July Election, and they finished in a somewhat similar order. We will statistically test the truth of this statement later using a Rank Correlation Coefficient test, as explained in PART 5 FURTHER ANALYSIS
41 In my opinion
PART 5 – FURTHER ANALYSIS
A number of questions raised in earlier parts of the paper can finally be answered.
Firstly, from PART 3 SAMPLING we can find out what the actual error in collating the ballot papers into stacks to be brought to each site was.
Expected value 1800
Actual value 1812 42
Error = 0.67%
This is better than I expected. The method used to separate the boxes of papers into piles of 100 involved weighing stacks on kitchen scales. The theoretical mass of 100 sheets of 80gsm
A5 paper is 250g, but counting one stack of 100 and finding the mass gave me 258g43 on our scales. This was then the benchmark I used for the rest of the measuring.
To measure what I thought was the uncertainty of the scales, I measured 100cm3 of water as accurately as possible and found that this apparently had a mass of 101g. Theoretically, water has a density of 1gcm-3 44 45 (Water Science School, 2018), and so 100cm3 of water should have a mass of 100g. The uncertainty in the scales is therefore calculated to be 1%. 0.67% is obviously less than 1%, so this did not go as badly as I thought it would have.
Secondly, in my comments about the results for both Chelsea & Fulham and Barking constituencies, I mentioned that a slight increase in the votes FOR Labour could be because of the party’s increased media attention since taking office. One way that we could potentially back this up is to look at other polling data, conducted by companies that are far more reputable than Silph Co. Limited YouGov is one of those companies, and they publish voting intention data every week, with sample sizes in the thousands. We can see that the
42 I used the larger number of votes in each constituency, as I felt that double-counting was much less likely than papers sticking to each other during counting and making the result lower than it actually should be
43 While systematic error in the scales cannot be ruled out, it is likely that a few grams of this was as a result of ink on the paper, but I was not able to find any useful resources on the mass of printer ink
44 In other words, 1kg per litre
45 This should really be 0.99802gcm-3 at room temperature (Water Science School, 2018), but this is so close to 1 that a little bit of rounding doesn’t make any difference to the point being made
likelihood of voting Labour in the “next General Election” was at about 4.6 out of 10 before the election, rising to 4.9 just before polling day, and then falling back to 4.1 in the period when our fieldwork was being carried out46 (YouGov, 2024).
It seems that Labour being in power has not had any positive effect on the party’s potential vote share and has actually made things worse if anything. The slight rebound in the proportion of votes FOR Labour in our surveying is probably attributed to something else.
It seems reasonable to suggest that the lack of both independent candidates and parties outside of the main six47 could increase the percentage of votes for Labour, as there are fewer options to choose from. If this was the case, however, why did some parties lose out? Labour in Hendon48 fell by over 1% compared with July 2024, despite the point that I have just made.
The parameters that I selected for sampling were a 95% confidence interval and a 5% margin of error, which means that there is a 5% chance that any given number is out by more than 5%. It is therefore not unreasonable to suggest that any variances in the votes FOR compared with the General Election are just down to chance.
There may also be some slight imperfections in the samples selected. We used opportunity sampling, that is to say, standing out in the street and asking people who walked past us. This is by no means representative of the population of a constituency as a whole at all, since the sorts of people we were surveying we not working or studying at the time, and also people who passed through busy areas such as shopping centres or train stations. It was implausible for us to attempt to make a representative sample, and even more unreasonable to suggest actually carrying it out. To do so would require a lot of knocking on doors to try to find the correct demographics to sample and would have taken far too much time. With more resources49 it could be done, but for a project of this scale, it was completely unreasonable.
46 At the time of writing, this number has slipped even further to 3.75
47 At least, the main six parties in England
48 There are many more examples of parties with a lower share of the votes FOR under our research compared with their vote share in the General Election, but these were this was the first one that I thought of
49 We would need a lot more money and even more time
RANK CORRELATION COEFFICIENT
Third, in my closing remarks about Hendon, I said that the parties “finished in a somewhat similar order.” We can test this statistically by calculating the Spearman Rank Correlation Coefficient.
Put simply, for any bivariate50 set of data, we can calculate a value between -1 and +1 that tells us how well the ranks of those two sets of data correlate. A value of -1 means that when the rank of one variable (the “x” variable), the rank of the other one (the “y” variable) always decreases. Conversely, a value of +1 tells us that when the rank of one variable increases, the rank of the other variable also always increases.
The formula for SRCC is�������� = 1 6 Σ d2 ���� (����2 1)
Where-
rs is the rank correlation coefficient d is the difference in ranks for each data point n is the total number of data points
To make this easier to understand, I will use an example. I will calculate the Spearman Rank Correlation Coefficient of the ranks of results of each candidate in the Hendon constituency, to investigate whether placing higher in the General Election correlates to placing higher overall under this Disapproval Voting fieldwork
As with all statistical investigations, we first need to define our hypotheses. It is almost impossible to prove anything with absolute uncertainty. Instead, in statistics, we instead see what the likelihood of that event happening by chance is, and if it is low enough, conclude that it is unlikely to happen by chance and so something else must be causing it.
Our null hypothesis (denoted by H0) is that the ranks of the parties in July and the ranks in our research have no relationship, are not correlated, and are instead just random. This means that the SRCC would be 0. The alternative hypothesis (denoted by H1) is the one that predicts a relationship between the variables that have been measured. In our case, the alternative hypothesis is that as your rank in the General Election gets better, so too does your rank under
50 Bivariate, as the name suggests, means that each data point has two values, like plotting a point on a graph with two axes
the Disapproval Voting system. This is a positive correlation, and it means that the SRCC would be more than 0. So-
H0: ρ = 0
H1: ρ > 0 where ρ51 52 is the rank correlation coefficient
The significance level of this test is set at 5%. This means that if we reach the conclusion that the two ranks correlate with each other (therefore rejecting the null hypothesis, the one that we take to be true for now), there is a 5% chance that they are actually independent.
It is important to note that this is a “one-tailed” test. This is because we are testing for a relationship in one specific direction, i.e., the positive direction. If we were instead testing only for the existence of any correlation and did not care in which direction this correlation was, it would instead be a “two-tailed” test.
I will do one constituency as a worked example, and then just give the values of the rank correlation coefficients for the other constituencies.
First, we rank the parties in both their results in July and the results in this project.
RANK TABLE FOR HENDON
We now square all the differences and sum them.
32 + 12 + 12 + 22 + 12 + 02 = 16
We plug this value into the formula, using our value of n as six, as there are six different parties.
51 ρ is not the letter p, it is the Greek letter rho 52 Of course I don’t mean ρ to the power of 53, I mean footnote 53, obviously
The 6’s cancel53, and we get-
1 16 35 = 0.5429 (4�������� )
This is the calculated value of rs, the Rank Correlation Coefficient. We now compare this value to the appropriate value, known as the critical value, in the statistical tables. The critical value tells us what our measured value should be for the test to be a success, and to reject the null hypothesis.
For example, if the critical value was 0.6 and we got a result of 0.7, then the test is a success, the null hypothesis is rejected, and there is evidence to suggest the alternative hypothesis is true. On the other hand, if we had instead got a result of 0.5, there would be insufficient evidence to reject the null hypothesis, and the test is considered a failure.
Fortunately, the OCR A Level Formula Book contains the table for the Rank Correlation Coefficient, and for six data points and a 5% significance level, the critical value comes out to 0.8286 (OCR, 2024).
0.5429 < 0.8286
In this case, the test has failed, as our measured value is lower than the critical value, so we do not reject the null hypothesis. In Hendon constituency, there is insufficient evidence to suggest that the ranks of the parties in July and in this research are correlated.
As stated, for the other three constituencies, I will just give the result of the test, and not bother with showing you all of the maths54.
For Chelsea & Fulham-
0.9429 > 0.8286
In this constituency, there is sufficient evidence to suggest that the ranks are correlated, and the null hypothesis should be rejected.
For Barking-
0 4857 < 0 8286
53 Completely by chance
54 This is a Politics project, after all, and I don’t want to turn this section into many pages of Maths
Here, the two ranks seem to be unrelated to each other, as there is insufficient evidence to suggest any correlation between the sets of ranks.
For Orpington-
0 7000 < 0 9000 55
Again, there is insufficient evidence to suggest a correlation between the sets of ranks in this constituency.
So, overall, with only one test suggesting a correlation between the ranks of the parties in July and in this research, maybe this is not the case.
It is not out of the question that people’s voting preferences have changed since the General Election, although it is arguably more likely that the difference in the voting system could have led to these discrepancies.
Consider, for demonstration’s sake, what would happen if we compared the ranks of the parties In July (under First Past the Post), and the theoretical ranks of the parties if that same election were held under Proportional Representation. Obviously, under Proportional Representation, the ranks of the number of seats the parties would have are the same as the ranks of the national vote share.
Again, we define our null and alternative hypotheses-
H0: ρ = 0
H1: ρ > 0 where ρ is the rank correlation coefficient
The test will be conducted at the 5% significance level, as before.
The table of ranks and subsequent calculations are reproduced on the next page-
55 Different critical value (OCR, 2024) as there are fewer data points to rank
RANK TABLE FOR 2024GE
Summing the squared differences, we get-
Plug this value into the formula�������� = 1 6 ∗ 58 14 ∗ (196 1) 1 348 2730 = 0.8725 (4��������)
The critical value for a one-tailed test involving 14 data points at the 5% significance level is 0.4637 (OCR, 2024)
0.8725 > 0.4637
Somehow the null hypothesis is rejected, and this test has found that there is indeed a correlation between the ranks of the parties using two different voting systems.
56 Only parties that returned any seats are included in this table. The Speaker is not included in this table, as by convention, they give up their party affiliation upon being selected as Speaker, and their seat is not contested by the major parties. The ranks for the PR are calculated only from the 14 parties listed here, instead of giving TUV 16th rank, as this would not allow us to use the SRCC calculation
57 All added together
58 Only the Green Party of England and Wales was included because the Scottish Greens are a separate institution
What about if we only took into account the six parties on the ballot paper I used- 59
ABRIDGED RANK TABLE FOR 2024GE
Again, we sum the squared differences12 + 12 = 2
And substitute this value into the formula�������� = 1 6 ∗ 2 6 ∗ (36 1) 1 12 210 = 0.9429 (4��������)
We know the critical value to be 0.8286 from the earlier calculations-
0.9429 > 0.8286
Again, somehow, and unexpectedly to me, we have shown that the ranks of the parties under these two different systems appear to be correlated.
While this is, of course, not conclusive evidence either way, my earlier remark a couple of pages ago about how the changes in ranks could be down to a change in the voting system has less credibility now.
Oh well.
It may be the case that people’s voting preferences have changed substantially since the July election, but it may still be the case that using Disapproval Voting leads to different ranks due to the existence of negative votes. It may be that the ranks under Disapproval Voting better reflect the overall mood of the population, or it may be that people are
59 As before, I will just give the outcome, and not the full calculation
haters and try very hard to prevent a certain party (probably the Conservatives) from winning. Perhaps we will never know.
CHI-SQUARED TEST
Fourthly, in my comments about Chelsea & Fulham, I mentioned that it could be the case that the proportion of votes FOR each candidate is similar to the proportion of the votes that they got in the July General Election. This can also be checked using a statistical test, the Chi60-squared test.
We use this test to see if a set of data fits a model. In this case, the model is to “predict the proportion of the votes FOR by just using the proportion of the vote that the party got in July in that constituency.” We can calculate how well the predicted values fit the observed values.
In crude terms, to carry out this test, we find the sum of the weighted squared differences between the expected and observed values and compare the resulting number to a table of numbers.
This is what the formula is for this test���� 2 = ∑ (���� ���� )2 ����
Where-
X2 is the chi-squared statistic
O is an observed value
E is the associated expected value
The test will once again be conducted at the 5% significance level. It should be noted that this test has 23 degrees of freedom. This is because there are 23 variables (the 23 different combinations of party and constituency, remembering that the Workers Party did not run in Orpington) that could be changed.
Again, we need to define our null and alternative hypotheses-
H0: The observed vote shares FOR each party are consistent with a prediction model that predicts the July 2024 vote shares
H1: The observed vote shares FOR each party are not consistent with a prediction model that predicts the July 2024 vote shares
Let us use the Reform Party in Chelsea & Fulham as an example to demonstrate how this calculation works.
60 Pronounced “kai”
The July 2024 General Election result indicates that we should predict them as having 6.7% of the votes. The observed value was 9.9%, which means that the difference is obviously61 3.2%. We then square this to get 10.24, and then divide by the expected value of 6.7 to get 1.528 (4sf).
This process is then repeated for all 23 combinations of party and constituency. Fortunately, Microsoft Excel exists, which made this whole process somewhat easier, although a lot of manual data entry was still required.
At the end of this rather laborious calculation, we get the following value-
���� 2 = 12.04 (4��������)
Turning again to the trusty OCR Formula Book, we see that the critical value is 13.09 (OCR, 2024)
12.04 < 13.09
We do not reject the null hypothesis, as there is sufficient evidence to suggest that the observed vote shares of the votes FOR are consistent with the prediction model that simply uses the vote shares from the July General Election.
It may be the case that people’s voting intentions have not changed much since July, and it may also be true that there was only a very low level of tactical voting, if indeed there was any at all. What seems the most likely to me is a combination of these two factors.
Whatever the case is, at least there is some evidence to suggest that there has not been a catastrophic shift in people’s voting opinions as a result of using a different system.
61 Well, hopefully obviously
PART 6 –
CONCLUSIONS
Several thousand words later, we have finally reached the end of this paper.
I opened this paper with the subtitle“What Electoral Reform Could Look Like”
To be honest, it was a bit of a lie. There are multiple reasons why any future reform is incredibly unlikely to look like the voting method described in this paper.
For a start, we have the problem of voter education. Trying to tell people how to vote under this system, when many have used First Past the Post for their whole lives is difficult enough for a couple of thousand members of the public, but scale that up to an electorate of over 48 million, and this will cost significant money.
In fact, this was one of the comments made about Alternative Vote in the 2011 referendum. The NOtoAV group had claimed that the cost of voter education could be roughly £39 million62 (Newman, 2011), although the validity of this figure was thrown into doubt by Channel 4 FactCheck.
Secondly, as was previously mentioned in PART 3 DISAPPROVAL VOTING // ANALYSIS, there is the problem of smaller, fairly unheard-of parties being able to “slip in”, and take advantage of the system in order to potentially win the most marginal seats. The problem and potential fix were already described earlier, but it is worth drawing your attention to the Workers Party in Barking constituency. While they did not come first in this seat, they still exhibit a result that is comparable to the problematic situation I described earlier, where an extremist party can get a small number of votes FOR, and an even smaller number of votes AGAINST, giving them a comparatively good net positive score.
While it did not matter so much in this particular seat, in a seat like Hendon perhaps they could have won because of this. Whether or not this is a desirable outcome by the majority is a very easy question to answer-
Of course it is not.
The more subjective question is deciding whether this outcome would be technically fair. I suppose that while it feels a bit
62 This figure is in 2011 prices, and today it would be worth over £56 million (Bank of England, 2024), or roughly £1.16 per elector registered for the 2024 General Election
like cheating or taking advantage of this electoral system, if a party manages to win under this system without breaking any laws or campaign rules, the result should stand, even if it is not the outcome that everyone wants.
Consider the far-right parties winning elections and making gains in France, Austria, and Germany. While most people will inevitably be disappointed to see this happening, it would not be right to seek to reverse these results just because some people do not approve of them.
For people who believe that it is important to prevent extremist parties from getting into power, it should be the case that the focus is on making sure the system does not allow for this to happen in the first place. After all, prevention is better than the cure.
There will inevitably be a number of people who see no problem with the rise of extremist parties’ successes because these gains were obtained legitimately and despite the various voting systems in place. I am not one of these people. I think that one of the best benefits of FPTP is it prevents this from happening fairly effectively. As I mentioned earlier in PART 1 FIRST PAST THE POST, the results of the Reform Party provide evidence of this. Their 14% national vote share was translated into less than 1% of the seats in Parliament.
The question should be asked, do we need electoral reform in the first place?
The Alternative Vote referendum in 2011 had a very decisive result of 32% for AV and 68% for FPTP (BBC News, 2011), unlike the 52%/48% of the Brexit referendum. There is no way to argue that the public could have wanted Alternative Vote to be implemented at that time.
Even nowadays, there is not exactly overwhelming evidence to suggest that there is an appetite for reform. YouGov polling data shows that only a minority of adults would support changing the voting system to Proportional Representation, with 30% undecided (YouGov, 2024).
I think that if a referendum happened tomorrow, there is a decent chance, maybe at least 40%, if not much more, that PR would fail. The undecided voters are likely to be those who do not understand PR enough to make a decision and are likely to choose to stick to the status quo. As many people63 have put it-
63 Citation needed
“I don’t like things I don’t understand”
First Past the Post is likely to stick around for a while. The Labour Party show no signs of being desperate for change, as their landslide can be attributed to the fact that we use First Past the Post. It makes logical sense that of course a party would not want to change the system that got them into power in the first place, so there is no telling when the next referendum on electoral reform may be.
In any case, hopefully, it will not be Disapproval Voting.
REFERENCES
Bank of England. (2024, September 18). Inflation calculator. Retrieved from Bank of England: https://www.bankofengland.co.uk/monetarypolicy/inflation/inflation-calculator
BBC Bitesize. (2024, September 22). Voting systems in Scotland. Retrieved from BBC Bitesize: https://www.bbc.co.uk/bitesize/guides/zt4hv4j/revision/1
BBC iPlayer. (2024, July 4). Election 24 Signed: Part 1.
BBC News. (2011, May 7). Vote 2011: UK rejects alternative vote. Retrieved from BBC News: https://www.bbc.co.uk/news/uk-politics-13297573
BBC News. (2024, September 2). Chelsea and Fulham results. Retrieved from BBC Election 24: https://www.bbc.co.uk/news/election/2024/uk/constituencie s/E14001160
BBC News. (2024, September 29). Hendon results. Retrieved from BBC Election 24: https://www.bbc.co.uk/news/election/2024/uk/constituencie s/E14001279
Conte, M. L. (2024, July 3). Retrieved from Twitter: https://twitter.com/youngvulgarian/status/180854428571476 3897
Cowan, D. (2019, January 11). How long have we used First Past the Post? You might be surprised. Retrieved from Electoral Reform Society: https://www.electoralreform.org.uk/how-long-have-we-used-first-past-the-post/
Cracknell, R., Baker, C., & Pollock, L. (2024, July 23).
General election 2024 results. Retrieved from House of Commons Library: https://commonslibrary.parliament.uk/researchbriefings/cbp-10009/
Difford, D. (2024, July 17). How do Britons rank the main parties? Retrieved from YouGov: https://yougov.co.uk/politics/articles/50091-how-dobritons-rank-the-main-parties
Election Demon. (2012, January 30). General Election Results 1885-1979. Retrieved from The Wayback Machine: https://web.archive.org/web/20120130011015/http://www.ele ction.demon.co.uk/geresults.html
Etymonline. (2021, October 13). Etymology of democracy. Retrieved from Online Etymology Dictionary: https://www.etymonline.com/word/democracy
Fung, B. (2022, December 19). Twitter deletes controversial new policy banning links to other social platforms. Retrieved from CNN Business: https://edition.cnn.com/2022/12/19/tech/twitter-elonmusk-deletes-policy/index.html
Hansard. (2020, June 8). Electoral Reform. Retrieved from Hansard UK Parliament: https://hansard.parliament.uk/Commons/2020-0608/debates/4DC16C52-71ED-4D7D-AD8F89F90B2CD384/ElectoralReform#contribution-8204DFAE-72AF4A86-A822-C9F75BD66DA8
Hawkins, O., Hollowood, E., Stabe, M., & Vincent, J. (2024, July 4). UK general election poll tracker. Retrieved from Financial Times: https://www.ft.com/content/c7b4fa913601-4b82-b766-319af3c261a5
Labour Party UK. (2024, June 13). Change. Retrieved from Labour Party Manifesto 2024: https://labour.org.uk/wpcontent/uploads/2024/06/Labour-Party-manifesto-2024.pdf
McGuinness, F., & Hardacre, J. (2011, May 19). Alternative Vote Referendum 2011. Retrieved from House of Commons Library: https://commonslibrary.parliament.uk/researchbriefings/rp11-44/
Morgan, B. (2001, March 29). General Election results, 1 May 1997. Retrieved from House of Commons Library: https://researchbriefings.files.parliament.uk/documents/R P01-38/RP01-38.pdf
Murphy, H. (2023, December 25). Breaking Twitter Elon Musk’s controversial social media takeover. Retrieved from Financial Times: https://www.ft.com/content/18f2fcd0b1b5-4b00-a7a4-74ce213dfc8d
Newman, C. (2011, April 26). Clegg, Huhne and the £250m question. Who’s right on AV? Retrieved from Channel 4 News: https://www.channel4.com/news/factcheck/factcheckclegg-huhne-and-the-250m-question-whos-right-about-thecost-of-av
OCR. (2024, October 5). A Level Further Mathematics A (H245) Formulae Booklet. Retrieved from OCR: https://www.ocr.org.uk/Images/308765-a-level-furthermathematics-a-formulae-booklet.pdf
Office for National Statistics. (2024, September 29). London Region and England Country. Retrieved from nomis: https://www.nomisweb.co.uk/sources/census_2021/report?com pare=E12000007,E92000001
Office for National Statistics. (2024, September 29).
Orpington Ward (as of 2022), Bromley Local Authority and England Country. Retrieved from nomis: https://www.nomisweb.co.uk/sources/census_2021/report?com pare=E09000006,E92000001#section_7
Press-Reynolds, K. (2022, October 31). A Pelosi conspiracy theory and $20 blue checkmarks: Here's everything that's happened in the chaotic few days since Elon Musk took over Twitter. Retrieved from Business Insider: https://www.businessinsider.com/elon-musk-takeovertwitter-controversies-antisemitism-blue-checkmarksconspiracy-theories-2022-10
Qpzm. (2024, September 29). Orpington Demographics (Bromley, England). Retrieved from Qpzm LocalStats UK: http://www.orpington.localstats.co.uk/censusdemographics/england/london/bromley/orpington
The Electoral Commission. (2023, March 7). Doubtful ballot papers. Retrieved from Guidance for Returning Officers administering Local Government Elections in England: https://www.electoralcommission.org.uk/guidancereturning-officers-administering-local-governmentelections-england/verification-and-count/count/doubtfulballot-papers
The Electoral Commission. (2024, February 29). Ballot paper design. Retrieved from Guidance for Returning Officers administering Local Government Elections in England: https://www.electoralcommission.org.uk/guidancereturning-officers-administering-local-governmentelections-england/voter-materials/production-ballotpapers/ballot-paper-design
The Electoral Commission. (2024, March 14). Counting the votes. Retrieved from Guidance for Returning Officers administering Local Government Elections in England: https://www.electoralcommission.org.uk/guidancereturning-officers-administering-local-governmentelections-england/verification-and-count/count/countingvotes
Timeanddate. (2024, August 21). Days Calculator: Days Between Two Dates. Retrieved from Calculate Duration Between Two Dates:
Tréguer, P. (2019, May 11). Origin of "First Past the Post" (as applied to a voting system). Retrieved from Word Histories: https://wordhistories.net/2019/05/11/firstpast-post/
UK Parliament. (2024, July 5). Wendy Chamberlain. Retrieved from MPs and Lords: https://members.parliament.uk/member/4765/career
Water Science School. (2018, June 5). Water Density. Retrieved from United States Geological Survey: https://www.usgs.gov/special-topics/water-scienceschool/science/water-density
White, M. D. (2024, October 6). London.
Wikipedia Editors. (2020, May 17). Category: Twitter controversies. Retrieved from Wikipedia: https://w.wiki/AjbL
Wikipedia Editors. (2024, July 25). 2023 Dutch general election. Retrieved from Wikipedia: https://w.wiki/Atwh
Wikipedia Editors. (2024, September 21). D'Hondt method. Retrieved from Wikipedia: https://w.wiki/BGvB
Wikipedia Editors. (2024, August 30). Independence of irrelevant alternatives. Retrieved from Wikipedia: https://w.wiki/B55p
Wikipedia Editors. (2024, August 31). Spoiler effect. Retrieved from Wikipedia: https://w.wiki/B55r
YouGov. (2024, September 22). Likelihood to vote Labour in the next general election. Retrieved from YouGov UK: https://yougov.co.uk/topics/politics/trackers/likelihoodto-vote-labour-in-the-next-general-election?period=6m
YouGov. (2024, January 29). Should we change our current British voting system? Retrieved from YouGov UK: https://yougov.co.uk/topics/politics/trackers/should-wechange-our-current-british-voting-system
APPENDIX A – SECOND-PLACE RESULTS
The following table shows what the results of the 2024 General Election would be if the candidate with the second-highest number of votes won each constituency2024 2ND PLACE RESULTS – ALL 650 SEATS – 326 FOR MAJORITY
This data was compiled from the House of Commons Library’s “Detailed results by constituency” (Cracknell, Baker, & Pollock, 2024), which was then manipulated in Microsoft Excel.
The accuracy of the underlying figures has not been verified.
64 An unintended consequence of deriving these results is that the Speaker’s seat is given to the Green Party, and so there would be no Speaker
65 Calculated as 650 minus the total number of seats won by the above parties and therefore includes independent candidates
APPENDIX B – MOCK BALLOT PAPER
This is a screenshot of the actual ballot paper, which was sent off to the printing company, and eventually used in fieldwork. 2500 copies were printed in A5 size, so this image is not necessarily a true reflection of the actual size.
2024 DISAPPROVAL FIELDWORK – [XXX] CONSTITUENCY
[XXX] MARGIN OF [XXX]
The order of the parties here matches the order in which they were printed on the ballot papers (see APPENDIX B MOCK BALLOT PAPER)
APPENDIX D – FIELDWORK SCRIPT
This page was given to everyone who helped with fieldwork, as a suggestion of the wording that could be used when talking to participants. It was later scrapped as the method of surveying was changed from asking respondents to physically fill in the paper to asking only for a verbal response in most cases.
Hi Sir/Madam, do you have a second?
Do you live around here? [Reject if NO]
We’re doing some surveying on voting systems, so we’d appreciate you filling in this ballot paper.
You get one vote for and one vote against.
[After being handed back the paper] Thank you for your time.
If in trouble with TfL staff, BTP, Met Police, etc, read/show this-
I AM CONDUCTING POLITICAL FIELDWORK ON BEHALF OF SILPH CO. LIMITED, A PRIVATE COMPANY LIMITED BY SHARES IN ENGLAND AND WALES NUMBER 15529467. MY PRIMARY CONTACT IS EDMUND NG, COMPANY DIRECTOR, WHO CAN BE CONTACTED ON 07368156370.
TO WHAT EXTENT DOES THE
APPLICATION OF JOINT CRIMINAL ENTERPRISE LIABILITY DIFFER BETWEEN DOMESTIC AND INTERNATIONAL CRIMINAL CASES?
BY
BEN BATES
(Fifth Year – HELP Level 3 - Supervisor: Mr T Townshend)
To what extent does the application of joint criminal enterprise liability differ between domestic and international criminal cases?
a HELP project by Ben Bates
Foreword
Criminal law has long been a particular interest of mine, given its intricate technicalities and wide range of incorporated concepts. However, it provides a unique challenge when selecting a narrow and targeted point of enquiry and investigation . Such a broad topic causes challenges to stay on topic, and not to be lost in the endless swathes of potential areas of discussion . After what must have ultimately been hours of research merely to find a more specific topic to make my focal point, let alone a question to act as the epicentre to my project, I happened to almost trip over, so to speak, the concept which I have finally chosen to inspect in greater depth – that of Joint Criminal Enterprise. Before I begin, I would give a preliminary thanks to my ever-gracious supervisor, Mr Townshend, for agreeing to work with me on this project (despite its distance from his area of geographical expertise)
Key concepts within criminal law
There are three broad categories of crime within the legal system : those of conduct crimes ; result crimes; and circumstance crimes. Conduct crimes are crimes in which the criminal act itself is the crime, such as assault or arson. Result crimes are similar but require a particular outcome or consequence following the defendant’s action, such as the causation of death. Examples of result crimes would naturally include murder and manslaughter, as well as grievous bodily harm and robbery. The third and final variety, circumstance crimes, revolve around the situation and context in which the defendant finds themself, and includes crimes such as the possession of stolen goods or illegal firearms. Furthermore, for a defendant to be prosecuted, there are four ‘elements’ of which at least two must have taken instance for the prosecution to be passed. T hese elements are the actus reus, the mens rea, causation, and concurrence The actus reus, Latin for ‘guilty act,’ denotes the physical action or conduct whi ch makes up the tangible aspect of the crime. For example, an actus reus may be breaking into private property or stabbing someone –any physical action that may be charged and prosecuted , as long as an intention to commit the crime is logically proven, and the physical action itself Is proven to have caused the ultimate result afflicting the victim, whether said victim is an individual, group, corporation, or property.
An actus reus is typically a physical action, but to be proven within a prosecution, it must have been proven to be a voluntary act committed by the defendant . If the action taken by the defendant cannot be proven voluntary or is conversely proven to be involuntary, the actus reus is typically insufficient to secure a conviction, except in circumstances such as strict liability offences or other circumstance crimes. However, an omission can also be proven to constitute actus reus, so long as a set of certain criteria is met. An omission is the failure to complete an action when it is legally required that said action is completed , resulting in potential criminal liability. Omissions are typically more difficult to prove to be actus reus, as the circumstance of both the crime and defendant come into play. For an omission to be proven as actus reus, the defendant must be proven to have a legal duty to complete the omitted action, knowledge of this legal duty, and the capability to fulfil this legal duty. There is a third and final instance in which actus reus may be proven, alongside those of voluntary act and omission, and that is crimes referred to as ‘State of Affairs’ crimes. These are also known as strict liability offences and denote cases in which the defendant can be proven to have actus reus, even if no physical action was taken or omitted. In these instances, the defendant’s presence or status, known as their state of affairs, is sufficient to establish an actus reus, provided that the defendant’s state of affairs is criminalised by the law. Examples may include, but are not limited to, the illegal possession of drugs, firearms, or explosives, or the operation of a business without official licensing.
It is important to note, however, that the actus reus alone does not constitute a crime – whilst the actus reus is typically the focal point of the crime, in instances such as robbery, there are many cases in which the actus reus does not directly align with the crime. Driving into a person, causing their death, is not necessarily murder, and setting a building on fire is not necessarily arson, among other instances. Whether or not an act is criminal is usually determined by the mens rea, literally Latin for ‘guilty mind,’ but used to refer to the intention of the defendant within the crime. A crime’s successful prosecution is often heavily determined by whether the mens rea can be proven, as it is this element which often determines the very crime itself.
Take murder as an example. A murder requires an actus reus and a mens rea to be charged, and if either of these two elements cannot be proven then the charge against the defendant is altered or dropped If solely the actus reus is proven, and the mens rea cannot be, the defendant may be charged for manslaughter, which is the crime of ending another person’s life without the specific intention to do so, or in which the defendant cannot be responsible for their actions Conversely, if only the mens rea can be proven, then the defendant may be charged for attempted murder. However, if the actus reus has been proven, i.e., the defendant inflicted the damage on the victim, and the mens rea has been proven, i.e., the defendant intended to kill or seriously harm the victim, then the defendant can be charged with murder.
However, a prosecution would also require the other two elements to be fulfilled, those of causation and of concurrence. The causation element of a prosecution refers to the required presence of a consequential relationship between defendant’s action, and the ultimate state of the victim. This means that a crime can only be prosecuted if there is a link between the action taken by the defendant and the outcome afflicting the victim. Building upon the earlier murder example, the murder could be charged if th e defendant put a knife through the victim’s heart and ended their life there and then. However, if th e victim is not immediately killed by the damage inflicted upon them by the defendant – regardless of whether this harm would ultimately be lethal – and then dies of an unrelated cause, such as an infection, the defendant could not be charged for murder. This is because the cause of death is not directly linked to the actus reus of the defendant. In this instance, it is likely that a charge of serious or grievous bodily harm would be prosecuted
The final element of a prosecution is concurrence, referring to the simultaneous and cohesive existence of both an actus reus proven to have caused the crime and a mens rea. In theory, if the actus reus and mens rea do not hold concurrence with one another within the same point in space or time, then no crime was committed. This applies in all instances except those of strict liability, or in cases in which either the actus reus or mens rea are not required for the prosecution of a crime, albeit this often leads to the prosecution of a different but related crime, such as attempted murder or manslaughter instead of murder The other instance in which concurrence may not entirely apply, and instead only applies by proxy, involves cases in which members of a group may be charged for crimes committed indirectly or by other members of the group, under the legislation of Joint C riminal Enterprise.
Element of prosecution
Actus reus (plural acti rei)
Mens rea
Causation
Concurrence
Definition
Latin for “guilty act” – the physical aspect of the committed crime.
Latin for “guilty mind” – the intention to commit the crime.
The linkage between the defendant’s action and the final state of affairs.
The simultaneous coexistence of an actus reus and mens rea
The concept of Joint Criminal Enterprise
Joint Criminal Enterprise (JCE) is an internationally applicable legal doctrine which controls the prosecution of multiple offenders involved in the same crime. It is used to determine the prosecution of members of a group, by way of considering every member of said group individually responsible for the criminal activity of the group – in a sense, each member of a group is charged for a crime, even though in fact the crime may well have only been physically committed by one of them The doctrine may also be used to convict a single member of a group on behalf of the entire group’s actions, even if that member was not the one who themselves committed the crime. JCE is therefore a frequently used doctrine within cases involving war crimes or acts against humanity in which parties larger than one are convictable. A good example of this would be the charges that were brought against members of the Nazi party following the Holocaust and other war crimes committed under Hitler’s rule.
However, it is equally important to note that the JCE doctrine is not solely applicable to international criminal tribunes. Cases which exist on a domestic level, such as murder, robbery, or fraud, can also employ Joint Criminal Enterprise doctrine in order to charge members of the offending party, if such a party was engaged in the crime.
Criminal conspiracy is another legal doctrine related to the involvement of numerous parties within the completion of a crime, but one which is marginally different from JCE, and therefore routinely confused by many. Conspiracy is the agreement between multiple parties to commit a crime at some given point in the future. Typically, the agreement and plotting are enough to constitute a crime under criminal conspiracy, as the actus reus is determined to be the plot and is therefore a continuous one which further parties may join at a later stage and still incur liability together with other conspirators. There is no need for conspirators to even take action to complete the crime, but if attempts are made then the sentence will increase to a varying degre e The key distinction between JCE and conspiracy is that JCE requires an action to have been taken – if no physical action is taken, the charge will likely be one of conspiracy, wherein members of the offending group are considered separate conspirators. In addition, conspiracy requires no physical complicity, as no physical crime need be committed . JCE requires complicity by some manner in order to associate members of a group with the crime, but said complicity may come in the form of accessory (someone who assists with, but never physically participates in, a crime, often via aiding and abetting ), accomplice (someone who physically aids with the committing of crime, as opposed to merely aiding or abetting), or vicarious liability (legal doctrine which determines the extent to which corporations can be held liable for the criminal actions of their employees or clients and business partners).
The question, however, is to what extent does the application of Joint Criminal Enterprise differ between these international and domestic ca ses? Does the discrepancy in scale lead to a discrepancy in the doctrine’s usage? To answer this question, one might observe examples, case studies if you will, of either variety of instance, and compare the application of Joint Criminal Enterprise liability in each, in order to truly discover how distinct from one another they are.
International instance: the International Criminal Tribunal for the Former Yugoslavia
The International Criminal Tribunal for the Former Yugoslavia (ICTY) was a court of law hosted by the United Nations which handled war crimes committed in the Balkans in the 1990s. The Tribunal existed by mandate from 1993-2007, and it altered the state of humanitarian law across the globe. The Tribunal also laid down much of the foundation for the application of joint criminal enterprise on an international scale and did so by identifying and defining three categories of the form of liability. The first is that of “basic” joint enterprise, in which all co -perpetrators of a crime possess the same mens rea, and act as a group pursuant of the same goal. This is true even for instances in which perpetrators have distinct roles within the scheme of the crime, but all possess the same intention for the ultimate result of the crime. For example, in a planned assassination, even if multiple perpetrators each have varying roles within the killing, they are all equally complicit in the crime as they all intended for the victim’s death to occur. This is also the form of joint enterprise typically associated with crimes that were handled by the ICTY.
The second category is that of “systemic” joint enterprise, a variant of the “basic” form, but which includes a specific and organised system by which mistreatment or harm can be exacted. A good example would be that of a concentration camp, in which inmates are abused, harmed, starved, forced into labour, or killed, in acts contributing towards the joint enterprise of the party using the camp.
The final category is “extended” joint enterprise, which concerns cases with a common purpose to commit a crime. In these instances, a perpetrator commits a criminal act which is not strictly within the limits of the common purpose but is instead a foreseeable and logical consequence of executing the overall purpose. Take, for example, two people, A and B, go to rob a bank . A never enters the bank, instead only waiting outside as a getaway driver. B enters the bank with a firearm. A knows about the firearm, and that B intends to use it to intimidate and threaten those who are in the bank. It is therefore a foreseeable consequence of this course of action that someone in the bank may be shot and killed. Before this happens, both A and B can be convicted of armed robbery under the basic form of joint criminal enterprise liability. After the shooting, however, both parties can be convicted of murder as well (depending on B’s mens rea, of course), despite the fact that A never even enters the bank. This is because the death was a foreseeable consequence of the use of a firearm as a threat, so A is liable for the crime even though he never intended to commit it, since he foresaw its commission and continued in the venture regardless. These three varieties of JCE liability have been employed countless times throughout international criminal cases which may call upon the doctrine as a whole and demonstrate the significance of the ICTY on a legal level and on a global scale, even outside of the prosecutions themselves.
The ICTY was responsible for bringing to justice the perpetrators of one of the greatest joint criminal enterprises in history, the Srebrenica massacre, also known as the Srebrenica genocide Srebrenica is a quaint town in eastern Bosnia and Herzegovina, close to the Serbian border. In 1995, a large contingent of Bosnian Serb forces took control of the town, methodically eradicating over 7,000 Bosnian Muslim men and boys. Across the many courts held by the ICTY regarding the events in Srebrenica, over 1,000 testimonies were brought before the tribunal, the majority of these from survivors of the conflict. The ICTY’s convictions for genocide were the first to be
entered by an international criminal tribunal in Europe. The Tribunal indicted twenty individuals for their crimes in Srebrenica. Eighteen of these resulted in convictions for genocide and other crimes, a single terminated case due to the death of the defendant prior to his trial , and one acquittal.
Following the crimes committed in Srebrenica and a host of cover-up operations enacted by the offending Serb forces, such as a re -burial of the deceased victims in a mass grave, the Tribunal found that the executions en masse of Bosnian Muslims constitu ted the grave crime of genocide – a term coined by Raphael Lemkin in 1944 to refer to the deliberate mass killing of a large number (of people) from a specific population with the aim of destroying said population . It is important to note that all of these convictions fall under the domain of joint enterprises, as technically only a single umbrella crime was committed by a particular group of people, and therefore the convictions could be applied to all guilty defendants by way of joint criminal enterprise doctrine.
Radovan Karadžić
Among the prosecutions was the trial of Radovan Karadžić, a founding member of the Serb Democratic Party of Bosnia and Herzegovina and served as its President for six years. He also served as the National Security Council’s President . After December 1992, he became the sole president of Republika Srpska, the northernmost of the two entities making up Bosnia and Herzegovina. This position also gave Karadžić supreme command of the armed forces of the Republika Srpska. Karadžić stood trial on eleven criminal counts: two counts of genocide, four counts of violations of customs of war (specifically murder, terrorism, taking of hostages, and harm of civilians), and five counts of crimes against humanity (specifically persecution , murder, deportation, forcible transfer, and extermination). Within the indictment, the prosecution alleged that the Accused (Karadžić) had participated in four joint criminal enterprises. The allegations stood as follows:
1. The Accused participated in a JCE, from October 1991 to 30 th November 1995, whose objective was to permanently remove Bosnian Muslims and Croats from Serb - claimed territory in Bosnia and Herzegovina. This was known as the “Overarching JCE .”
2. The Accused participated in a JCE, from April 1992 to November 1995, whose objective was to establish and conduct a campaign of sniping and shelling against the civilian population of Sarajevo, and whose primary purpose was to instil terror within the civilian population of Sarajevo. This was known as the “Sarajevo JCE .”
3. The Accused participated in a JCE, from 26 th May to 19th June 1995, whose objective was to take over two hundred United Nations peacekeepers and observers hostage, so to force NATO into abstaining from th e conduct of air strikes against Bosnian Serb targets. This was known as the “Hostages JCE .”
4. The Accused participated in a JCE, from July 1995 to November 1995, whose objective was to eliminate the Bosnian Muslim population in Srebrenica by the killing of all men and boys of Srebrenica, and forcibly removing the women, children, and elderly. This was known as the “Srebrenica JCE.”
On top of these allegations, the prosecution charged Karadžić for having planned, instigated, and aided and abetted the crimes in the indictment. The prosecution made its opening statement on the 27th October and 2nd November 2009, the first witness was heard on 13 th April 2010. Closing
arguments ended on 7 th October 2014 In total, 11,469 exhibits were used by the Tribunal as evidence, and a total of over 330,000 pages of trial record were compiled for Karadžić’s trial alone. Karadžić was found guilty of ten of the eleven counts with which he was charged, only being found not guilty for count one of genocide. Karadžić’s sentence was established to be a forty-year stint in prison, an interesting decision since murder, only one of the ten counts Karadžić was found guilty of, typically holds a life sentence for the offender.
The most prominent and most broad of the Joint Criminal Enterprises for which Karadžić stood trial for, the Overarching JCE, was established by the Trial chamber to be the Joint Criminal Enterprise encompassing the happenings of Srebrenica and those in Sarajevo, which aimed to permanently remove Bosnian Muslims and Croats from the areas. The JCE was orchestrated and supported by a number of persons, including Karadžić, in order to achieve an ethnically homogenous Bosnian Serb state. Karadžić and other Bosnian Serb leaders sought to accomplish their goal via methodical crimes such as forcible displacement and targeted persecution, as well as structured discriminatory systems in place across multiple Bosnian Serb municipalities. Karadžić was found by the Trial Chamber of the ICTY to have actively promoted the JCE, as well as personally directing and contributing to it to a significant degree. His political influence was found to have been used to create parallel Bosnian Serb governmental and military structures, instrumental in the implementation of the JCE’s objectives. The Trial Chamber also noted that Karadžić was critical to the planning, coordination, and facilitation of this system of authority. It was then concluded that Bosnian Serb forces, including military troops, police, and paramilitary, directed by Bosnian Serb authority such as Karadžić, were methodically used to commit the crimes essential to the JCE’s success, including violent takeover and unlawful detention. Karadžić was found to be aware of the potential for violent crimes yet continued with the planned action. Karadžić’s indifference to these foreseeable crimes implied his tacit endorsement of the criminal activity, further entrenching his responsibility within the JCE. This endorsement was further proven by Karadžić ‘s failure to prevent the crimes he foresaw or punish them as an authoritative figure following their commission. By way of the Joint Criminal Enterprise Liability doctrine, the Trial Chamber held Radovan Karadžić individually responsible for the crimes committed for the pursual of the goal of the Overarching JCE . However, despite the severity of the crimes committed as part of this JCE, the Chamber could not find conclusive evidence of genuine genocidal intent on Karadžić’s behalf, and therefore he was not found guilty of genocide by JCE liability under Count 1 of the trial. Karadžić was, however, found guilty under the Overarching JCE of persecution, murder, extermination, deportation, and forcible transfer as crimes against humanity, and murder also as a war crime.
The other significant JCE in this instance for which Karadžić stood trial was aptly named the Srebrenica JCE and was established by the Trial Chamber to be the evolution of the Bosnian Serb plan to permanently remove Bosnian Muslims and Croats from Serb - claimed territories into a series of systematic mass killings, culminating as the infamous Srebrenica massacre. Karadžić first aided and abetted this goal by his issuing of “Directive 7”, the aim of which was to make living unbearable for the Bosnian Muslims and Croats in order to force them out. Karadžić, four months later, then actively approved a violent military takeover of Srebrenica . The Trial Chamber concluded that the apparent “choice” to leave Srebrenica given to Bosnian Muslims and Croats was but a façade, and that the proven coercion and forced removal of the population revealed
genocidal intent. Karadžić’s involvement was irrefutably proven once it had been proven that communication between him and other parties within the JCE occurred in a specifically developed code, confirming Karadžić’s active and voluntary cooperation within the JCE. The Chamber concluded that Karadžić’s actions demonstrated a specific genocidal intent to destroy the Bosnian Muslim and Croat community of Srebrenica . Among Karadžić’s acti rei lay actus reus by omission, as Karadžić was proven to have failed to act preventatively or punitively on his knowledge of the crimes committed by his forces, despite his unique power and position to do so. This exacerbated his culpability and proved his guilt beyond doubt, and the Trial Chamber therefore found that Karadžić had genuine intent to destroy as a part of the Srebrenica JCE , and intent which extended beyond the desire to forcibly remove the Bosnian Muslim and Croat populations from Srebrenica, but to entirely eradicate them – an intent equitable with genocide. These findings by the Chamber substantiated Karadžić’s role in the Srebrenica JCE, and he was individually charged as such under JCE liability doctrine with genocide, extermination, and other crimes against humanity.
It is vital to note that Karadžić was not held solely responsible for the happenings of Srebrenica under JCE liability – the Trial Chamber acknowledged his active participation within a JCE and prosecuted him accordingly. The majority of his culpability stemmed from the combination of his position of power and authority, his irrefutable for esight of the crimes committed by his troops and his failure to use this power preventatively or punitively, rather in alignment with the aims of the JCE.
Popović et al
Popović et al, the ICTY’s largest case, by way of number of accused, was that of seven formerly high-ranking Bosnian and Serb officers, all of whom were convicted for war crimes by joint enterprise doctrine following the takeover of Srebrenica by Bosnian Serb forces. The case involved the following accused:
• Vujadin Popović;
• Ljubiša Beara;
• Drago Nikolić;
• Ljubomir Borovčanin
• Radivoje Miletić
• Milan Gvero; and
• Vinko Pandurević.
The ICTY found that two JCEs had been committed in Srebrenica in July 1995 – the JCE to murder able-bodied Bosnian Muslim men from Srebrenica, and a second JCE to forcibly remove the Bosnian Muslim population from Srebrenica. The Trial Chamber found Popović to have known the intent to commit genocide against the Bosnian Muslim population of Srebrenica, and to have shared this intent personally, and this finding was confirmed by the Appeal Chamber. Popović and Beara were both sentenced to lifelong incarceration for genocide, conspiracy to commit genocide, violation of the customs of war, and crimes against humanity. The remaining five accused were sentenced to imprisonment on a timescale ranging from five to thirty -five years. The counts were named as follows:
1. Genocide;
2. Conspiracy to commit genocide;
3. Extermination;
4. Murder (crimes against humanity);
5. Murder (violation of war customs) ;
6. Persecution;
7. Inhumane acts and forcible transfer ; and
8. Deportation.
The indictment against each Accused stood as follows:
During their trial, the Trial Chamber of the ICTY established the existence of two Joint Criminal Enterprises, the first of which to murder able -bodied Bosnian Muslim men from Srebrenica, and the second to forcibly remove the remainder of the Bosnian Muslim population from these enclaves. The JCEs were initiated simultaneously in March 1995, as Radovan Karadžić issued the aforementioned Directive 7. All seven individuals were charged for involvement within one or both JCE in some manner, expressing the vital importance the doctrine developed by the ICTY was following Srebrenica and in instances of international war crimes as a whole.
Popović and Beara were both found directly responsible for genocide and murder under JCE liability. Nikolić was found guilty of aiding and abetting said genocide, with evidence to prove his role in the first murderous JCE. As a result, Popović and Beara, on the basis of individual criminal responsibility within a Joint Criminal Enterprise, were both charged with genocide, conspiracy to commit genocide, extermination, persecution, and murder as a war crime, meaning the only crimes that they were indicted for and subsequently found not guilty of were murder as a crime against humanity, inhumane acts, and deportation. Nikolić, on the basis of individual criminal responsibility within a Joint Criminal Enterprise, was charged with aiding and abetting genocide, extermination, persecution, and murder as a war crime. However, while Popović and Beara were sentenced to life imprisonment, whereas Nikoli ć only received a 35-year sentence. This is down to the differing extents of liability held by the Accused within the JCE. Whilst Popović and Beara were both found guilty of the commission of genocide and prior conspiracy to commit genocide, Nikolić was only convicted for aiding and abetting genocide, meaning he held a lesser responsibility regarding the pursuit of the goal of the JCE , since aiding genocide does not further the aim to commit genocide to the same extent as the genuine commission of genocide, and therefore was sentenced accordingly.
Miletić and Gvero were both found to have contributed to the second JCE by contributing to operations to forcibly displace Bosnian Muslim civilians, thus directly participating in the JCE . Pandurević was found guilty of aiding and abetting the forcible transfer and deportation of Bosnian Muslim civilians, upholding the JCE’s objective to remove the Bosnian Muslim population from Srebrenica. On the basis of individual criminal responsibility within a JCE, Miletić was sentenced to 19 years’ imprisonment, and Gvero to 5 years’ imprisonment. It is not clear and has not been released by the Trial Chamber as to the reason for the discrepancy in the sentences of Miletić and Gvero, but it most likely comes down again to extent of responsibility differing between primary parties to a single JCE, in this case Mileti ć and Gvero.
Superior criminal responsibility is a more nuanced variety of JCE liability which differs from the typical individual criminal responsibility regularly employed by the ICTY. It indicts parties with commanding authority over other parties for the crimes com mitted by their subordinates, essentially extending the liability of the subordinate parties to their commanding figures, their “superiors” – hence, superior responsibility. Both varieties (superior and individual) may be classed as basic JCE or as extended JCE, depending on circumstance.
Pandurević and Borovčanin, both high-ranking officials within the Bosnian Serb military, were found liable under superior responsibility for failing to prevent criminal activity conducted by their subordinates or punish subordinates involved in either established JCE in this instance. Both men were responsible for the actions of their own forces, actions which advanced the objectives of both JCEs primarily via large-scale killings or displacements. Both men were therefore indicted under both JCEs, leading to their prosecutions on the basis of superior criminal responsibility for the crimes against humanity and war crimes committed by their subordinates. Pandurević was sentenced to just 13 years’ imprisonment, and Borovčanin to 17 years’. Interestingly, Borovčanin’s sentence stood at four years longer than Pandurević’s, despite Pandurević’s liability within the second JCE as well as under superior responsibility. In an analogous way to Miletić and Gvero, this is probably down to the extent of Borov čanin’s authority being greater than Pandurevi ć’s, meaning he is liable for a greater extent of criminal activity under superior responsibility.
The Chamber concluded that all seven Accused shared a common criminal purpose under the two JCEs, and this alignment of intent evidenced their full commitment to the genocidal intent shared by both JCEs. To summarise, then, the ICTY applied JCE liability, both as individual criminal responsibility and superior criminal responsibility, by linking the acti rei, both action and omission, of each Accused directly to the collective purpose shared by those involved in the JCE, leading to seven convictions and the completion of the ICTY’s largest case in the aftermath of Srebrenica.
Momčilo Perišić’s acquittal
Momčilo Perišić was the Chief of the General Staff of the Yugoslav Army from Serbia-Montenegro. He was indicted for crimes committed in Srebrenica, as well as in Sarajevo and Zagreb, the capital cities of Bosnia and Herzegovina and Croatia, respectively. The Tribunal found Perišić guilty for the vast majority of the alleged crimes within his indictment and sentenced him to 27 years of incarceration. However, the Appeals Chamber of the Tribunal later found that the presented evidence in Perišić’s trial could not prove beyond reasonable doubt (the standard proof required for a conviction) that Perišić specifically assisted the crimes committed by the Bosnian Serb army
in Srebrenica, leading to his acquittal, the only one of the ICTY’s convictions following the Srebrenica massacre. The ICTY Appeal Chamber was unable to prove Perišić’s involvement within any JCE incorporated in the Srebrenica massacre, so his conviction was overturned. This acquittal also addressed a previously major criticism of the ICTY’s prosecution system: anti-Serb bias. There had been controversy prior to Perišić’s acquittal as to the political motivation of the ICTY – Croatian and Kosovan officials had been acquitted without any Serbians experiencing the same fate, leading to Serbian officials arguing that the ICTY was politically biased against them, and that the denial of acquittal for Serbian officials should negate the accusations against the Serbs. Of course, this is a complete twisting of legal doctrine and was not accepted, but the questions as to the ICTY’s political allegiance remained. However, the acquittal of Perišić proved that the ICTY was in fact politically neutral, and shifted the sentiment held by Serbian officials, thereby resolving the controversy which came hand -in-hand with this Serbian perception. This was a key point for the ICTY’s future, as critics believe that the doubt or denial of the ICTY’s legitimacy and political integrity would embolden criminals and extremists to deny accountability in the face of a dubious organisati on, undermining the ability of the body to serve justice for the victims of the war crimes being prosecuted.
The ICTY was also questioned in its judicial capability in that its Trial and Appeal Chambers contradicted one another, with the former deeming Perišić sufficiently culpable for a conviction and the latter overturning that verdict However, the grounds of this distinction between the respective chambers’ findings lay within the interpretation of Perišić’s intent, a naturally subjective matter which can easily be mistaken. The Appeal Chamber concluded that his aid to the JCE in which he seemed to be involved lacked criminal intent, therefore negating his culpability, and causing his acquittal. This overturning of the Trial Chamber’s judgement by the Appeal Chamber in fact represents a major positive within the ICTY’s judicial system – the ability to make certain, clear, and accurate judgements via the involvement of two separate judicial chambers. In fact, this internal judicial pluralism – the coexistence of multiple judicial entities within a singular jurisdiction, in this case the ICTY – and the division in judgement between entities within this pluralism reflects a true attempt at total impartiality on the ICTY’s part, thus challenging conspiracies and doubts as to the ICTY’s political motive.
However, Perišić’s acquittal also brought to light flaws within the ICTY, particularly in the context of the Srebrenica JCE. It has been argued frequently that the ICTY was unable to truly comprehend the dynamics of the war efforts enacted by the Yugoslav and Bosnian Serb armies, leading to arguable prosecutorial errors such as the pursuit of Perišić’s prosecution rather than other highranking officials with genuine commanding authority within the army, and with clear evidence against them. Perišić’s acquittal underscores not only the political neutrality of the ICTY, but also the challenges in prosecuting higher-ranking figures without solid evidence of intent or responsibility, and the imperfect manner in which the ICTY handled these challenges.
To conclude upon the international instance
The ICTY was vital in the bringing to justice of some of the criminals involved in the tragedies of Srebrenica and the surrounding areas, as well as those involved in other international criminal events such as the crimes against humanity committed on a similar basis to Srebrenica in Sarajevo, the capital of Bosnia and Herzegovina. Whilst their integrity and political motivation has
been questioned time and again, particularly by the Serbians who felt they had been wrongly treated, the acquittal of Momčilo Perišić and discrepancies in judgement shown by the Trial and Appeal Chambers prove beyond doubt the Tribunal’s total political neutrality, and therefore prove beyond doubt that their judgements are sound, logical, and above all just, both in punishing the offenders in Srebrenica and beyond, and in providing comfort and closure for those affected by the horrors which occurred in Bosnia and Herzegovina.
JCE liability is a key doctrine within international law, particularly with regards to macro -scale criminals events, such as war crimes or crimes against humanity. Having been developed in detail by the ICTY, it has been used repeatedly for the prosecution of international criminals, such as in the Special Court for Sierra Leone, the Italian Supreme Court’s trial against fascists, and the trials against Nazis involved in the Holocaust. The vast majority of international cases of JCE revolve around systemic JCE or around extended JCE, both as individual criminal responsibility and superior criminal responsibility. Prosecutions tend to occur over an extended period of time, often taking decades for trials to even be held, let alone closed. The trials themselves also occur on a macro scale, and multiple thousands of testimonies and even more evidence and statements are presented to the judicial authority. The cases of Karadžić, Popović, and Perišić prove that tribunals such as the ICTY are vital for the maintenance of justice and order in the world, and that their pioneering development of JCE doctrine has led to some of the most horrific human beings to ever scar the face of the Earth facing righteous justice.
Domestic instances
Joint Criminal Enterprise liability is not solely applied in instances of international tribunals following war crimes en masse. It can also be applied on an albeit smaller scale in domestic cases, in this case in the United Kingdom, for crimes such as murder or armed robbery. Its application in these instances is distinguishable from its application on a macro scale, but also holds some crucial similarity.
R. v Powell & Daniels
Among the most famous of domestic joint enterprise cases in the UK is that of R. v Powell & Daniels in the late 1990s. The case dealt with the murder of a known drug dealer, murdered by gunfire at his own residence when Powell, Daniels, and a third unknown man arrived to purchase drugs. At the following trial, Powell provided evidence that his sole intention and motive for travelling to the abode of the dealer was to purchase cannabis. Daniels was unable to present any tangible evidence but argued that Powell was responsible for the shooting , and that he himself had no knowledge of the presence of a firearm until it was physically fired. The Crown was unable to determine which of the three men fired the weapon and killed the drug dealer However, it was alleged that if it was the third man who physically committed the murder, the two defendants were also guilty of the murder due to the knowledge they held that the third party was armed and that he might intend to use it to end the life of the drug dealer, or at least seriously injure them. Similarly, if it was one of the two defendants who had killed the dealer (albeit it could only have been Daniels due to Powell’s evidence), then the other must equally be guilty of the murder on the same basis. Ultimately, both Powell & Daniels were convicted of murder by joint enterprise. Both defendants appealed, but both were rejected by Her Majesty’s Court of Appeal .
Within the UK legal system, a judgement can be appealed to the Court of Appeals after it has been officially made. The appeal can subsequently be raised further to the House of Lords, now known as the Supreme Court. The decision of the Supreme Court is ultimate and closing – the appeal cannot be continued further once its hearing is terminated by the Supreme Court.
The appeals of Powell & Daniels were heard by the House of Lords, who posed the following question:
“Is it sufficient to found a conviction for murder for a secondary party to a killing to have realised that the principal party might kill with intent to do so, or must the secondary party have held such intention himself?”
In other words, it was debated as to what level of mens rea is necessary in order to convict a secondary party of murder by joint enterprise. The judicial conclusion was that it is adequate to prove that a secondary party considered the notion or was aware of the fact that the principal party may kill or cause severe harm with mens rea, in order to found a conviction of murder for the secondary party on the basis of joint enterprise. The jury reasoned that if the secondary party did not foresee the actions taken by the principal party, the secondary party cannot be liable for said actions, as their participation within a joint enterprise would be impossible. However, there is a legal principle encompassed by the doctrine of JCE which states that a secondary party may be criminally liable for a greater offence committed by a principal party which the secondary party foresaw or knew about but may not have intended. In other words, if the secondary party had contemplated that the principal party may commit a crime, and then a crime (of the ilk as predicted by the secondary party) is committed by the principal party, the secondary party is convictable of that crime, regardless of whether the secondary party had any modicum of mens rea for the crime. Therefore, in instances where the issue regards whether an action taken falls into the scope of a joint enterprise, due to the established presenc e of a secondary party, is it faster and far more pragmatic for a jury to determine whether foresight was held by the secondary party, especially more so than the other obvious test, which would be to determine whether the extent of the crime goes beyond what was implicitly agreed by the primary and secondary parties within the joint enterprise. Overall, therefore, the jury’s decision was a sound one and the Court of Appeal’s dismissal of both Powell’s and Daniels’ appeals was equally accurate. To conclude, the Joint Enterprise Case is an apt demonstration of how joint enterprise can be applied within instances involving a primary and secondary party to a major criminal offence at a domestic level , especially regarding the level of mens rea required by the secondary party to be convicted by joint enterprise.
The House of Lords for this trial was ruled by Lord Hutton, who concluded upon the appeal with the following statement:
“My lords, I recognise that as a matter of logic there is force in the argument advanced on behalf of [Powell & Daniels], and that on one view it is anomalous that if foreseeability of death or really serious harm is not sufficient to constitute mens rea for murder in the party who actually carries out the killing, it is sufficient to constitute mens rea in a secondary party. But the rules of common law are not based solely on logic but relate to practical concerns and, in relation to crimes committed in the course of joint enterprises, to the need to give effective protection to the public against criminals operating in gangs.”
Therefore, the appeals of both Powell & Daniels were dismissed, and both were thereby convicted of murder. This ruling became known as “parasitic accessory liability”.
R. v English
However, there have been similar instances in which the defendant has been acquitted following their appeal to court, such as that of R. v English. The case had equitable context to that of R. v Powell & Daniels – the appellant, English, and another man attacked a police officer with wooden posts. During the attack, the other person stabbed the police officer with a knife, causing his premature death. Both English and the other were convicted of the murder of the police officer on the basis of Joint Criminal Enterprise. English then appealed his conviction to the House of Lords.
The House of Lords heard the appeals of Powell & Daniels and English at the same time. Lord Hutton ruled on both appeals, and in both cases the other Lords agreed with him. Both Powell & Daniels and English posed the aforementioned question, but English also posed a second question:
“Is it sufficient for murder that the secondary party intends or foresees that the principal party would or may act with intent to cause grievous bodily harm , if the lethal act carried out by the principal party is fundamentally different from the acts foreseen or intended by the secondary party?”
This case once again ultimately comes down to the issue surrounding the extent of mens rea required to convict a secondary party on the basis of Joint Criminal Enterprise. However, the ruling used by the House of Lords demonstrates a fundamental difference between the cases of Powell (and Daniels) and English . In Powell & Daniels’ instance, the appeal to the House of Lords was dismissed on the basis that, under domestic legal doctrine surrounding joint enterprise liability, it is sufficient to found a convi ction for murder for a secondary party if the secondary party is proven to have foreseen that the principal party may kill with intent or cause serious injury. Since the third man in their case was using a firearm as a threat, it was beyond doubt that Powell & Daniels’ contemplated this outcome. Therefore, their conviction on the basis of Joint Criminal Enterprise as a secondary party stood. However, if the secondary party did not foresee that the principal party may commit an act fundamentally different to the one jointly contemplated , the secondary party cannot be convicted of the murder, unless the weapon involved in the jointly contemplated act is as dangerous (or more so) than the weapon used to c ause death. Therefore, English’s conviction was dismissed, and he was acquitted following a successful appeal. The discrepancy in the prosecutions of English and Powell & Daniels was based upon a previous authority – Chan Wing-Siu v The Queen, a case from 1985.
The extent of mens rea necessary to prosecute a third party for a crime as severe as murder requires extensive deliberation from the jury, since questions of pre- contemplation and even personal intention come into play and are typically difficult to prove one way or another. Of course, the logical conclusion would be that if two parties threaten a nother, one with a firearm, the second party would surely consider the notion of the threatened being shot. However, this proof must be based on word and logic alone, meaning prosecutions could easily be mistaken. That said, established legal doctrine surrounding liability and complicity as a second party hints
towards the two courts being adjourned following two correct judgements (those of Powell & Daniels and English’s appeal) , since ignorance is rarely considered an alibi in cases of bodily harm or murder, even with a second party. The only instances in which negligence or ignorance can be applicable is to distinguish between murder and manslaughter when ignorance stands in place of a mens rea Powell & Daniels were well aware of the firearm used, and saw it being used as a threat before it was used to cause d eath, and therefore the logical conclusion is that they considered the possibility of the victim being shot. Conversely, English was unaware of his coperpetrator’s knife’s presence when attacking the officer, mea ning that it is impossible for English to have foreseen a stabbing resulting in death. Evidence presented by the defendant in the appeal was able to prove his lack of knowledge regarding the knife possessed by the other, and therefore his appeal was allowed and his conviction for murder acquitted.
Hutton’s final ruling stood as follows:
“Where the principal party kills with a deadly weapon, which the secondary party did not know that he had and therefore did not foresee the use of it, the secondary party should not be guilty of murder.”
English’s conviction for murder was overturned, as it was deemed that English was unaware of the lethal weapon wielded by the principal party and that said weapon lay beyond the realm of lethality incorporated within the JCE.
R. v Jogee and Ruddock v the Queen
This was a joint appeal heard by the Supreme Court (the House of Lords, following its renaming) in 2016. The judgements were delivered by the ruling Lord Hughes and was agreed upon by the other present Lords.
R. v Jogee
The case of R. v Jogee revolved around a conviction for murder which went against Jogee. In the crime, Jogee and another man, Hirsi, spent an evening drinking alcohol and taking d rugs, to a sufficient extent that they became deeply intoxicated and aggressive. Both men went to the house of Jogee’s ex-girlfriend and threatened violence against her current boyfriend, the ultimate victim. They left, but later returned when the victim came home. Hirsi grabbed a knife from the kitchen while Jogee was outside, hit ting the victim’s car with a bottle and encouraging Hirsi to “do something” to the victim. Hirsi then stabbed and killed the victim with the knife.
The Judge directed the jury that Jogee would be guilty of murder if he participated in the attack and realised that Hirsi might utilise the knife with the intent to commit at least serious bodily harm – in other words, the Judge directed the jury towards a basic application of parasitic accessory liability, the principle founded during Powell & Daniels and English. Jogee was thereby convicted of murder, but the conviction was appealed up to the Supreme Court, which was invited to deliberate as to whether th e principle of parasitic accessory liability should be reviewed.
Ruddock v the Queen
The second case within the joint appeal was that of a man called Ruddock’s conviction for murder. The facts were established as follows: Ruddock and another man, Hudson, both of whom
lived in Jamaica, robbed a taxi. Within the course of the robbery, Hudson slit the driver’s throat with a knife. Ruddock confessed to the investigating police that he had tied the victim’s hands and feet before Hudson murdered him, and that together they dumped the body in Montego Bay, a body of water off the north -west coast of Jamaica.
The Judge in this instance directed the jury that if the prosecution could prove that the two men had a common interest to commit the theft, and Ruddock knew of the possibility that Hudson would commit murder with a knife but continued regardless with the venture, that he would be guilty of murder – another basic application of parasitic accessory liability. Ruddock was convicted for murder, but his conviction too was appealed up to the Supreme Court for a joint hearing with Jogee, to consider whether paras itic accessory liability was in fact sound under English law.
The judgement of the Supreme Court
The Supreme Court were required to consider the principles of Joint Criminal Enterprise liability under English law, reverting all the way back to the Accessories and Abettors Act of 1861. The Supreme Court stated:
“It Is generally accepted that the modes of involvement [of accessories in a joint criminal venture] cover two types of conduct, namely the provision of assistance or encouragement.”
They went on to state that historic case law suggested that :
“If a crime committed by person A requires a particular intent, person B must encourage or assist person A to act with such intent.”
The Supreme Court then went on to consider an extensive stream of case law on joint enterprise liability, and concluded that the court in Chan Wing-Siu (the case which was followed in Powell & Daniels and English) laid down a departure from established principles of English law – those founded by the Accessories and Abettors Act – when they said that the requisite mens rea to find a secondary party liable for a principal party ’s actus reus was solely to have foreseen said actus reus as a possibility, regard less of whether the secondary party had intended it.
They said that this principle was incorrect under English law – that the established principle from before Chan Wing-Siu, going back as far as the Accessories and Abettors Act , was that the secondary party must authorise, not simply foresee as a possibility, the departure from the originally intended criminal venture. Further, they held that authorisation cannot automatically be inferred from continued participation in crime X, simply because crime Y has been foreseen and subsequently occurs.
In the context of murder, the Supreme Court cited a case which pre -dated Powell & Daniels and English, which stated:
“Only he who intended that unlawful and grievous bodily harm should be done is guilty of murder. He who intended only that the victim should be unlawfully hit and hurt will be guilty of manslaughter if death results.”
The court noted that it was within the Supreme Court’s power in Powell & Daniels and in English to change the way that joint enterprise principles should apply if they considered it appropriate
for reasons of public policy to do so. However, based on their thorough review of the case law which came before these cases and before Chan Wing -Siu, they decided that the principle of parasitic accessory liability that had been developed in those cases was wrong law and should no longer be followed. The court issue a clear statement of how liability by way of joint enterprise should be assessed going forward, as follows:
In cases of secondary participation, there are likely to be two issues:
1. Did the defendant participate in the crime? (recognising that participation can take different forms)
2. Did the defendant intend to encourage or assist the principal to commit the crime in question, acting with the same mens rea the offence requires from the principal party? In other words, if the crime requires a particular mens rea, the accessory must intend to assist the principal to act with such mens rea.
In cases of secondary liability arising from a prior joint criminal venture, the intention to assist, and indeed the intention that the crime should be committed, may be conditional . To return to a previous analogy, if bank robbers attack a bank whilst at least one of them is armed, it is undoubtedly the criminals’ hope that violence will not be needed. However, it may be entirely correct to infer that all were intending to resort to the use of violence (with intent to commit grievous bodily harm) if they were to be met with resistance. This is a matter of fact and evidence which may be proven at trial. That said, it is no longer sufficient to simply operate on the basis that an accessory is guilty if they foresaw the escalation of violence as being possible.
Finally, if a person is party to a violent attack on a victim but without an intent to cause death or really serious bodily harm, but violence escalates and results in death , the accessory will be guilty of manslaughter, not of murder. Applying the new principles to the cases, Jogee’s sentence was reduced from murder to manslaughter, while Ruddock’s appeal was passed (although this successful appeal was reliant on a plethora of other problems also present in the trial, which are not relevant to the principl es of Joint Criminal Enterprise liability ).
These principles are now the standard authority that is followed in English law for cases of joint enterprise.
Within the English legal system, there exists a concept known as the doctrine of binding precedent. This doctrine states that courts of the English legal system are bound to follow the decisions of any court of equal or superior standing. There therefore a lso exists a hierarchy of legal courts in England, in which the Magistrates’ Court is of the least significance, followed by the Crown Court and the Court of Appeal, and finally the Supreme Court. Solely the Supreme Court has the authority to decide to not follow its own previous decisions, but this is a power rarely invoked and not exercised lightly, as it often signifies a fundamental change in the legal system. The doctrine of binding precedent revolves around the idea that justice requires law to be applied consistently from case to case, so substantial changes in approach by the Supreme Court, particularly those which are a notable departure from previously imposed legislation, are particularly notable cases. This is why what happened in Jogee and Ruddo ck was relatively rare –these substantial changes in approach are typically imposed by Parliament through legislation , not through the Supreme Court itself switching its approach.
To conclude upon the domestic instances
The realm of joint enterprise liability has been a fluid one in the context of English law, since the Accessories and Abettors Act of 1861 and through various critical cases in the development of the doctrine. The cases of Chan Wing-Siu, and subsequently Powell & Daniels and English, were vital in the establishment of the principle of parasitic accessory liability, which was equally vitally reviewed and repealed in favour of new law. This new law was founded directly by the Supreme Court and therefore employed by all courts in the English legal system by way of binding precedent. This new law, the new authority for JCE cases in the UK, is an evolution of the Accessories and Abettors Act, and necessitates the secondary party to actively share the mens rea held by the principal party to a crime in order to be fully convicted for it. The appeals of Jogee and Ruddock were critical in the development of this law and annulling of the previous parasitic accessory liability which stood as the primary doctrine for JCE cases in the UK .
The Supreme Court’s decision in Jogee and Ruddock has been labelled by some as among the most important historical decisions with English criminal law. Parasitic accessory liability was problematic for a number of reasons, most notably due to the number of appeals to which it gave rise and due to the controversy which it caused.
For a principal party to be convicted of murder, it must be shown that there was specific mens rea to cause at the very least grievous bodily harm. However, under parasitic accessory liability, the same did not apply to the secondary party, the party who did not even commit the actus reus Prior to the Supreme Court’s judgement in February 2016, a secondary party could be held liable for a murder committed by the principal party for merely foreseeing it as a possibility. This meant that a lower threshold of mens rea was required to convict a secondary party for a principal party’s murder than that required to actually convict the principal party. This resulted in significant blurring of lines between the concepts of foresight and intent, even when foresight might be better viewed as evidence rather than mens rea. The principle of parasitic accessory liability was justified on the basis of public policy, in spite of appreciation that it was not genuinely logically sound. Lord Steyn, the ruling Lord during the hearing for the appeals of Powell & Daniels and English, said in his judgement:
“The criminal justice system exists to control crime. A prime function of that system must be to deal justly but effectively with those who join with others in criminal enterprises. Experience has shown that joint criminal enterprises only too readily esca late into the commission of greater offences. In order to deal with this important social problem the accessory principle is needed and cannot be abolished or relaxed.”
This legislation brought with it criticism amongst the legal communities both in the UK and in other Commonwealth countries. In Clayton v The Queen (2006), Kirby J said in his dissenting judgement in the High Court of Australia:
“To hold an accused liable for murder merely on the foresight of a possibility is fundamentally unjust. It may not be truly a fictitious or “constructive liability”. But it countenances what is
“undoubtedly a lesser form of mens rea”. It is a form that is an exception to the normal requirements of criminal liability. And it introduces a serious disharmony in the law, particularly as that law affects the liability of secondary offenders to convict ion for murder upon this basis.”
The appeals of Jogee and Ruddock caused the Supreme Court to consider whether foresight of murder is sufficient mens rea to convict a secondary party for it. The 18th February 2016 marked the date of the Supreme Court’s unanimous decision to overturn the principle of Chan Wing-Siu, returning the requisite mens rea for a secondary party to its position before 1985. It was stated in the appeals of Jogee and Ruddock:
“The error was to equate foresight with intent to assist, as a matter of law; the correct approach is to treat it as evidence of intent. The long -standing pre-Chan Wing-Siu practice of inferring intent to assist from a common criminal purpose which includes the further crime, if the occasion for it were to arise, was always a legitimate one; what was illegitimate was to treat foresight as an inevitable yardstick of common purpose.”
It was clarified that the Privy Council in Chan Wing -Siu erroneously elevated a rule of evidence into a rule of law. By overturning the principle, the following was strongly underlined:
1. The Supreme Court benefitted from a much fuller analysis of the law than was previously utilised by other courts. The judgement in itself provides a thorough analysis of previous case law;
2. There have been a large number of appeals, and it therefore cannot be justly said that the law has been previously operating well;
3. Accessory liability is an important part of the common law and, where an error –particularly one of widening of the law – has been made, the law should be corrected ;
4. It was noted that the Chan Wing -Siu principle allowed a secondary party to be more easily convicted than the principal party to a crime.
The Supreme Court concluded that, when approaching cases involving accessory liability, foresight can now act as evidence of mens rea but cannot entirely constitute it nor be conclusive of it.
Consider the following example. A group of people attack a victim and one among them delivers a fatal blow, ending the victim’s life, and each denies their culpability in the murder. It would previously have been acceptable to have stated as matter of fact that all of the members of the group had foresight of the murder as a possible outcome, meaning that all members of the group could be convicted for the murder. As the law now stands, however, the prosecution may still adduce evidence that the group may have had foresight of resulting excessive harm . But, the prosecution must prove, so that the jury are sure, that all members of the group actively aided or abetted another member to cause serious injury or death. A person who intentionally encourage s or assists the commission of a crime will still be as guilty of said crime as the principal party who physically committed it, under simple Joint Criminal Enterprise liability. A jury may also be entitled to infer intentional encouragement or assistance from a person’s behaviour and their state of affairs, such as possession of a weapon. If a person participates in a crime in circumstances which logically a person would realise involves a risk of serious harm and death results, that person would be liable for manslaughter.
Following this reversal of approach by the Supreme Court, there has been extensive speculation as to whether those convicted under the old law of parasitic accessory liability, such as Powell and Daniels, may be granted right of appeal, for their conviction to be reduced from murder to manslaughter. The situation regarding past convictions was addressed by the Supreme Court in its judgement following Jogee and Ruddock:
“The effect of putting the law right is not to render invalid all convictions which were arrived at over many years by faithfully applying the law as laid down in Chan Wing -Siu and in Powell and English.”
It does not logically follow that simply because legislation has been altered, a person convicted under previous legislation is rendered no longer guilty of the offence. If this were to come to pass, even greater questions against the integrity of English law would be asked than those asked following the passing of parasitic accessory liability. This dissolution of gu ilty judgement cannot occur due to logical inconsistency and due to public policy. At the time, the convictions were correct and faithful applications of the law which was current at the time.
Overall then, JCE liability has been questioned and scrutinised in English law, but the appeals of Jogee and Ruddock have resolved the known logical flaws within the legal system effectively and justly. Whilst the correction of the illogical principle had been overdue for over thirty years, it is a vital change in the maintenance of the integrity and ability to administer justice of the English legal system.
The extent to which the application of JCE differs
To conclude then, it is clear to see that there is notable discrepancy the application of Joint Criminal Enterprise liability between international and domestic instances. In fact, there is actual distinction between the doctrine itself on international and domestic scales. By examining examples of both domestic and international cases, one can come to grips with the magnitude and extent of the discrepancies between the application of JCE between them.
Among the key differences is the difference in liability which applies on the international scale but not on the domestic. Popović, Beara, and Nikolić were all charged with the same crimes However, Nikolić received a lesser sentence compared to Popović and Beara, given he was only found guilty of aiding and abetting genocide, rather than the full crime of genocide. This starkly contrasts English law following the repealing of parasitic accessory liability, which states that secondary parties found to have aided or abetted a crime are equally as culpable for it as the principal party. If English law was followed, Nikolić would have received the same sentence as Popović and Beara, regardless of the difference in their involvements in the genocide. This is likely born of the fact that there are generally multiple crimes within an indictment for culprit of an international JCE, whereas there is only a single crime in a joint venture on a domestic scale. This means that those involved in the overall JCE are charged with crimes for which they participated in, on the basis of individual criminal responsibility, not for the sum of the crimes of the entire JCE. This is a good example of a large-scale basic joint enterprise, as all of the co -perpetrators act pursuant of a single goal but play varying roles within said pursuit. This is not a concept which even exists in English law, since in that instance all co -perpetrators are equally and entirely liable
for the committed crime as long as they were involved in some way – those ways being as the principal party or as an aider or an abettor (a secondary party).
This leads onto a second key difference between international and domestic JCE liability: the literal differences between the doctrines. As pioneered by the Nuremburg trials and subsequently developed and refined by the ICTY, international JCEs exist in one of three categories ; those of basic, systemic, and extended joint enterprise. However, these are concepts which simply do not exist in English law, where there is merely single category of joint criminal venture. This means that the potential prosecution may differ on an international basis for the same crime depending on, for example, whether it involved an organised system designed to inflict harm. The same cannot be said for English law; circumstances of the crime such as these are entirely irrelevant when it comes to trials and convictions, aside of course for actually establishing the nature of the crime. Rather, it would not particularly matter if a group set up a n organised system to commit serial homicide against a collection of say, ten people, or if members of the group simply murdered those ten people. Assuming all members of the group were culpable in some way, whether that be as the principal or a secondary party, the sentence would be universal for all of them and the same in both instances. Every member of the offending group would be charged and convicted for murder under Joint Criminal Enterprise liability.
Conversely, on an international basis, the presence of this organised, harmful system would make a difference and could lead to a varied prosecution. Of course, each member of the offending group would still be charged with the same sentence, assuming the system consisted of a single (and possibly repeated) crime, in this instance that of murder. If the system not only enabled murder but also separate counts of, say, genocide and persecution, then the convictions for each member of the offending group may vary – assuming, that is, that members of the group had roles of varying significance in the commission of the crime. Each member of the group would then be individually and entirely responsible for the crimes they were deemed complicit in, on the basis of individual criminal responsibility, another concept which does not exist in domestic JCE cases, along with superior criminal enterprise.
The legislation to this most similar in English law would be the principle founded following Jogee and Ruddock’s appeal. This idea states that, should a secondary party be complicit in a JCE which escalates to cause death, but lacked the mens rea to cause death or grievous bodily harm, that party would be guilty of manslaughter, not murder. This is similar, but not identical by any means, to the idea in international JCE cases that different co -perpetrators of a JCE can be liable for its crimes to different extent. There are two key differences between the two, however :
1. The international law exists on the basis of multiple crimes being committed beneath an umbrella JCE, whereas in English law the joint venture is a single crime which escalates from one crime to another. This does not count as a further crime being committ ed, rather an extension of the original crime.
2. The international law on varying degrees of liability revolves primarily around the coperpetrators’ acti rei in each crime of the joint enterprise, in order to establish their liability for said crime and whether or not the y will be charged for it on the basis of individual criminal responsibility. The English law, however, is based upon the difference in the mens rea held by the principal party compared to a secondary party. If a secondary party
does not have the requisite mens rea for the criminal actus reus committed by the principal party, they must naturally not be as liable for the crime. This logic is also the reason why the principle of parasitic a ccessory liability from Chan Wing-Siu and later Powell & Daniels and English was dispensed with. It is not just or right for the secondary party to a murder to be more easily convictable than the principal party, following the principal party’s successful conviction.
All of this is not, however, to say that the doctrine is entirely different between international and domestic bases, or to criticise the clear discrepancies. These distinctions are crucial for the achievement of justice in the two naturally distinct instances. It would not be just to convict a war criminal for crimes against humanity he had no part in or knowledge of simply because they were committed by other members of the joint venture in which they participated in. Similarly, it would not be just for an aider or abettor of a murder to not be convicted of it on the basis of varying degrees of liability. However, it is entirely just for secondary parties to be completely culpable for the crime they aided or abetted, in the same way it is entirely just for a war criminal to be entirely liable for any crime in which they played a part in pursuit of its goal or the goal of the overall JCE. In this instance, and in many others, the domestic and international doctrines are extremely similar.
Another key instance in which this is true is the striking similarity between superior criminal responsibility and vicarious liability. The former, of course, is the culpability of a figure of authority in the crimes committed by their subordinates on an international basis. A good example would be Borovčanin in the Popović et al case of the ICTY.
Vicarious liability (occasionally known as imputed liability) , on the other hand, is a principle in English law which imposes liabilit y on people for the criminal wrongdoings of another It usually applies to those in control of or partnership with someone who causes some variety of harm to a victim. For example, a corporation (the principal) is in control of all of its employees. If an employee (the agent) causes harm to someone in the course of their employment, the principal could be held vicariously liable for it.
Vicarious liability comes into play when one party is liable for the negligence of another, meaning those sued by way of vicarious liability can be held accountable for losses even without personal negligence. For example, imagine someone is involved in a car crash caused by a delivery truck, driven by an employee of the company owning the truck during their shift, running a red light . The company for whom the driver works for would be vicariously liable as the principal for the actions of the driver, despi te the management of the company’s lack of direct involvement and lack of any negligent action. This is different from strict liability, in which instance negligence does not need to be proven. Rather, it requires that defendants be held accountable for damages regardless of whether said actions were negligent or intentional. A good example of a strict liability case would be speeding. A driver is responsible for driving over the speed limit, regardless of whether they intended to speed or not.
Vicarious liability can generally be imposed in a number of circumstances, most commonly:
1. Employer to employee: an employer can be held vicariously liable for the criminal actions of an employee if the employee was actively working for their employer at the
time and the employee’s actus reus falls within the scope of their employment. For example, if a doctor administers incorrect medicine to a patient and causes harm, the practice would be vicariously liable for the doctor’s actions
2. Partner to partner : when a partnership is formed between people, each person acts on behalf of that partnership. If one commits a criminal act and harms a third party, the partnership as a whole may be held liable under vicarious liability. Consider the following example. Persons X, Y, and Z start up a law firm, XYZ Solicitors. Person Y gives incorrect legal advice to a client, causing the client to suffer from financial losses. The partnership, and therefore by extension persons X and Z, can be held vicariously liable for the financial damages caused by person Y’s negligence, even though they were not personally involved in the act.
3. Parent to child: in the UK, parents are criminally responsible for the actions of their child until it reaches ten years of age, the legal age of criminal responsibility in the UK. For example, if a seven -year- old child vandalises their school, the parents would be responsible for the damages.
It is clear to see, then, that vicarious liability and superior criminal enterprise hold striking resemblance to one another. Of course, they are distinct in many ways: for example, vicarious liability relies on negligence as the mens rea of the criminal action, or else it may escalate to strict liability. However, the mens rea behind a subordinate’s action for a figure of authority to be convicted by way of superior criminal responsibility is largely irrelevant; as long as the subordinate was acting in pursuit of the goal of the JCE, the superior may be held liable for their actions. The negligence involved in this instance is in fact on the superior’s behalf, as their lack of usage of authority to implement preventative or punitive measures lead to the subordinate’s capability to act criminally. Overall, however, they are more alike concepts than they are different. Whilst the same cannot be said for the international and domestic versions of Joint Criminal Enterprise liability as a whole, it can equally no t be said that the two are wholly distinct beyond merely their name.
To conclude, the application of Joint Criminal Enterprise liability differs to a fairly major extent between international and domestic cases, due to the literal discrepancies in the doctrine and highly probable discrepancies in circumstance. The magnitude of the cases in which JCE liability is employed internationally is vast, compared to the comparatively insignificant trials or lawsuits which may occur in the UK. Fundamentally, however, the two doctrines are the same – both exist to exact justice unto members of a group engaging in criminal activity to the fullest extent, and both are vital in the dissuasion of future joint ventures, regardless of their scale.
Glossary
Abet: to encourage another to commit a crime.
Accessories and Abettors Act: a mainly repealed Act of the Parliament of the United Kingdom of Great Britain and Northern Ireland which consolidated statutory English criminal law related to accomplices, including many classes of inciters.
Accessory: alternatively secondary party, someone who is involved in a joint criminal venture but does not personally commit the actus reus, in English law.
Actus reus (plural acti rei): Latin for “guilty act,” it is the physical criminal act(s) which occurred
One of the four elements of a prosecution.
Aid: to assist another in their commission of a crime.
Attempted murder: a crime in which someone tries to kill another human being with intent to do so but fails or aborts their action partway.
Basic Joint Criminal Enterprise: a joint criminal enterprise in which all perpetrators are of similar mens rea in alignment with the goal of the joint enterprise, and in which the perpetrators are all in some manner responsible for some part of the crime. Founded by the ICTY.
Binding precedent: a doctrine which applies to courts of the English legal system , which states that courts are bound to follow the decisions of any court of equal or superior standing.
Causation: the direct consequential relationship between the actus reus and the ultimate state of the crime One of the four elements of a prosecution.
Concurrence: the simultaneous existence spatially and temporally of an actus reus and a mens rea necessary to prove a crime, excluding instances of strict liability. One of the four elements of a prosecution.
Conspiracy: the agreement between multiple parties to commit some variety of crime at some point in the future, and the subsequent plotting of said crime.
Crime against humanity: a deliberate act which causes human suffering or death, typically as part of a systematic campaign.
Extended Joint Criminal Enterprise: a joint enterprise in which the primary perpetrator commits a crime outside of the joint enterprise’s specific intention, but one which roughly aligns with said intention or is a logical and foreseeable consequence of the original intention being carried o ut. Founded by the ICTY.
Genocide: the mass deliberate killings of a large number of a specific population, with the aim of eradicating said population from the area, a term coined by Raphael Lemkin in 1944.
Grievous bodily harm: The intentional or reckless infliction of serious bodily harm on another person, to a more severe degree than actual bodily harm. Injuries incorporated in GBH include broken bones, deep lacerations, or serious concussions.
ICTY: the International Criminal Tribunal for the Former Yugoslavia, a tribunal responsible for the prosecution of crimes committed in Former Yugoslavia and the Balkans, such as those in Srebrenica and Sarajevo.
Individual criminal responsibility: The form of Joint Criminal Enterprise liability used to convict multiple offending parties within a single crime, by charging each one as individually responsible for the crime’s commission, despite their involvement within a group.
Joint criminal enterprise: multiple parties acting in a criminal manner, either via a single crime or a collection of crimes, in order to achieve a mutually agreed criminal aim.
Joint Criminal Enterprise liability: a legal doctrine proposed by the ICTY, which in summary states that all members of a joint enterprise are individually culpable and can be charged with the full sentence, regardless of the fact that multiple parties committed the crime. In essence, each party can be convicted of committing the crime, even though the crime was only committed once in time and by the entire group.
Manslaughter: the crime of killing another human being without malicious mens rea, or in circumstances not fully amounting to murder.
Mens rea: Latin for “guilty mind ,” it is the intention and motive underscoring the commission of a crime. One of the four elements of a prosecution.
Murder: the unlawful and premeditated killing of a human being by another.
Omission: a form of actus reus involving the failure to complete a legally required action.
Parasitic accessory liability: an outdated doctrine in English law which stated that a secondary party could be held responsible for a crime committed by a principal party if the secondary party foresaw the possibility of the primary party committing the crime.
Principal party: the person in a joint criminal venture who physically committed the actus reus
Republika Srpska: one of the two governing entities of Bosnia and Herzegovina, the other being the Federation of Bosnia and Herzegovina. It is located in the northern and eastern areas of the country.
Robbery: the action of taking property unlawfully from a person or place, by threat or by force.
Srebrenica: a small mountain town and municipality in Republika Srpska, Bosnia and Herzegovina.
State of Affairs: a form of actus reus involving the current status of a person, such as possession of an illicit firearm or Class A drugs like heroin or cocaine.
Strict liability: a standard of liability under which a person or party is legally responsible for the consequences flowing from a criminal activity.
Superior criminal responsibility: the form of Joint Criminal Enterprise liability often used to convict figures of authority by charging them for the actions committed by their subordinates, given that said subordinates answer to them – an extension of the subordinate’s liability to their superiors.
Supreme Court, the: the highest court in the English legal system, which holds binding precedent over all others and alone has the power not to follow its previous decisions.
Systemic Joint Criminal Enterprise: a joint criminal enterprise similar to basic joint criminal enterprise, but in which the perpetrators arrange an organised system for the mistreatment or infliction of harm on the intended victim of the joint venture. Founded by the ICTY.
Vicarious liability: a principle in English law which imposes liability on people for the criminal wrongdoings of another.
War crime: a violation of the international laws and customs of war.
This project has been a true test of my somewhat procrastinatory habits, given the volume I needed to research, write up, and fine-tune all within a realistically quite brief period of time. Ultimately, however, I’ve found true delight in the intricacies and controversies intertwined with the fascinating legal doctrine I stumbled upon right at the beginning of this project. The law will forever be interesting, particularly when it regards such novel and exciting concepts such as JCE liability. The unique challenge I spoke of to begin with in remaining focused in such a wide field was just that – a challenged I have seldom handled before. That said, I strongly believe that this project has been a genuine pleasure, if sometimes a burden, to undertake. In that regard, I would once again like to say a closing thanks to my supervisor, Mr Townshend, a reliable source of guidance for the development of project, despite its existence somewhere outside of his extensive geographical expertise. In addition, a word of final thanks to both of my parents, a true inspiration and aid in this project for me – I honestly believe that I wouldn’t have even considered undergoing a project of this topic’s ilk without them, let alone enjoy it to the extent that I have.
Finally, a word of thanks to you. The reader. I hope that this journey through the realm of criminal law and deep dive into JCE has left you with something to think abou t, something new that you have learnt. I shall leave you with this : in a world where complex criminal networks are increasingly sophisticated, joint criminal enterprise liability exists as a crucial mechanism in the attainment of order and justice, ensuring that those who collaborate in criminal activity collectively bear individual responsibility for their actions. However, this doctrine also presents the challenge of carefully balancing collective accountability with individual rights. As the scope of JCE liability is continuously refined , the task remains to ensure that the law not only deters and punishes, but also preserves the integrity of individual justice within the collective liability, and the integrity of the legal system as a whole.
CLIVE WEARING: LIVING IN
THE ETERNAL PRESENT
BY LOUIS SPIGHT
(Upper Sixth – HELP Level 4 – Supervisor: Miss H Peck)
HELP Project
Clive Wearing
Introduction
Overview of the different topics
The purpose of this article is to explore one of the most unique and fascinating psychological and neurological cases in recorded history. This article will include a broad range of topics related to Clive, using credible sources to provide the reader with a breadth of knowledge that should clear up any uncertainties and misinformation spread on this extraordinary individual.
To ensure this article is clear, concise and comprehensive for the reader, the separate distinctive sections will be outlined as follows:
Section 1 will provide the reader with a brief understanding of Clive Wearing’s life before his illness. It is imperative that Clive is remembered as more than just a ’Case study’ studied by scholars but also as a human with a life and family
Section 2 will focus on the biological aspects of the virus that affected Clive and caused his illness. This section explores the structure of the virus, the symptoms and progression of the illness, available treatments at the time of his illness and the wider variety of treatments offered today.
Section 3 investigates the neurological impacts of the virus. With the visual aid of images from brain scans, I will detail the affected areas of Clive’s brain and explain the significance of these brain regions and how they contribute to memory and cognition. Lastly, this section explores Clive’s unaffected areas of the brain.
Section 4 focusses on the unique impacts of the virus on Clive’s memory including multiple of the tests they carried out on him. Did he retain his musical ability? I will also explore the mystery that is consciousness and discover whether Clive was having a delusion.
Section 5 will feature some of the responses from Deborah Wearing when I conducted an interview with her. Lastly, I will compare Clive’s condition to other similar famous psychological case studies to establish any similarities and differences between their conditions.
Section 6 ties the article together and describes the implications of Clive’s condition for psychology and neuroscience.
Lastly all sources used will be appropriately referenced at the bottom of this article.
Louis Spight
Section
Background information
Clive Wearing was born in Cheshire, England on the 11thMay in 1938 From a young age he demonstrated high levels of intelligence and found a passion for music during his childhood. Clive’s passion for music led him to study at Cambridge University where he later received a Bachelor of Arts in Music.
After graduating from Cambridge, Clive pursued a very successful career in the music industry through a combination of his unwavering dedication and talent. Before his illness he was a musicologist, conductor, tenor and pianist. Eager to showcase his talent to a wider audience, Clive set up the ‘Europa Singers of London’ in 1968. This choir performed a breadth of music from the 17th, 18th and 20th centuries and most notably received praise for a performance of the ‘Vespro della Beata Vergine’. Later in 1982, Clive was tasked with organising the ‘London Lassus Ensemble’ to commemorate the composers 450th anniversary. Perhaps the highlight of Clive’s music career was when he was responsible for the musical content on BBC radio 3 at Prince Charles and Diana Spencer’s wedding. To commemorate such a momentous event Clive decided to recreate the scores used at the Bavarian royal wedding 1568. This required countless hours of meticulously researching the scores and then reproducing the music using authentic instruments.
Clive married Deborah a year prior to his illness which was in March of 1985 after meeting six years earlier at a choir that Clive conducted At the time of his illness Clive was in his mid-forties. The onset of the illness was fast as Clive experienced severe headaches on the Sunday morning followed by confusion on Wednesday. Clive regularly saw two doctors during this week however they were unable to correctly diagnose Clive’s condition. By Friday Clive reached his worse state and collapsed abruptly He was immediately rushed to St Mary’s Hospital, Paddington where a specialist doctor recognised Clive’s illness and diagnosed it as the herpes simplex 1 virus that had somehow entered his brain and caused encephalitis. At the time of Clive’s illness this was incredibly rare as only 1 in a million people living in the UK would experience this condition Miraculously Clive survived after being given a 20% chance of survival from the doctors. Clive was administered an anti-viral drug during the first week which helped him to improve physically despite the irreversible damage already caused to his brain. Deborah Wearing later became an expert in understanding Clive’s condition, assisting world-leading expert psychologist Barbara Wilson in writing ‘Prisoner of Consciousness: A state of just awakening following herpes simplex encephalitis’. Deborah Wearing also published her moving book ‘Forever today’ whilst raising awareness and campaigning for people with brain injuries to get the care they deserve.
Photograph taken in 1961 after ClivegraduatedfromCambridge.
There are two types of the herpes simplex virus: HSV-1 and HSV-2 which differ mainly through their respective methods of transmission. This virus is commonly known as the ‘cold sore virus’ and as of the 5th of April 2023 according to the World Health Organisation 3.7 billion individuals (67% of global population) aged under 50 have HSV-1. Whilst this may seem quite an alarming figure, most people with the virus are asymptomatic (the virus essentially lies dormant in most of the population) meaning they do not experience any of the usual symptoms such as blisters/ulcers around the mouth, itchiness or a fever
Individuals suffering from HSV-2 are approximately 300% more likely to contract HIV (Human Immunodeficiency virus) a retrovirus that causes AIDS Immunosuppressed individuals have weakened immune systems resulting in a lesser ability to fight infection and severe illness. Immunosuppression can be caused by AIDS, chemotherapy, certain cancers, genetic conditions and old age. Immunocompromised individuals that acquire HSV are at risk of experiencing complications with much greater severity
On rare occasions HSV-1 and HSV-2 can be life threatening and cause encephalitis or meningoencephalitis which is a condition where the individual suffers from both meningitis and encephalitis at the same time. Meninges are comprised of
three membrane layers (dura mater, arachnoid mater and pia mater) and are found on the outside of the brain and spinal cord. The meninges play an important role in protecting the brain and spinal cord from damage. Meningitis is a condition that results in the inflammation of the meninges Consequently, the cranial nerves (vital for head and neck control) may suffer abnormalities Encephalitis is a condition that causes inflammation of the brain. The swelling caused by encephalitis can be fatal if left untreated, although deaths from encephalitis are less common than they were several decades ago. Encephalitis also can cause memory loss (amnesia), personality changes, speech issues, language issues and balance issues.
Methods of diagnosing encephalitis or meningoencephalitis has improved over the years as our medical and technological understanding has advanced. Clive Wearing was diagnosed after having a lumbar puncture. This procedure involves removing some cerebrospinal fluid (clear fluid found that surrounds the brain and spinal cord) from your lower back using a needle. Today MRI scans are a preferred method as they are non-invasive and do not use radiation meaning they are also safe and can produce detailed images of the brain or meninges.
Individuals with the Herpes Simplex Virus are commonly treated with antiviral
ImageshowingthestructureoftheHerpesSimplex1Virus
Structure of the HSV
Both HSV-1 and HSV-2 are incredibly small and spherical with a size ranging between 150 and 200nm (for comparison an ant is around 5 million nanometres!). Inside the virus is an icosahedral protein capsid which is a 20-sided shape consisting of triangular faces. In the HSV the icosahedral shape comprised of 162 hollow hexagonal and pentagonal capsomeres (small subunits that make up the capsid). In the centre is an electron-dense core which is where the double stranded DNA genome resides inside of the nucleocapsid. Surrounding the nucleocapsid is a thin lipid layer that provides some protection to the genetic material held within from external environmental factors in the virus. The tegument sits in between the nucleocapsid and lipid envelope. Within the tegument is a cluster of different proteins that aid in viral DNA replication and evasion of the host’s immune response vital for its survival. Examples of proteins in the tegument include the enzyme VP16 involved in viral nucleic acid replication and the VHS protein that switches off the host cell’s protein synthesis process in the cytoplasm On the outside of the virus is the trilaminar lipid host-derived envelope. This structure is a lipid bilayer incorporating proteins and lipids from the host cell’s membrane. Projecting outwards from the lipid envelope are spikes of viral glycoproteins 8nm in length allowing the virus to infect host cells by binding to specific host receptors.
medication Acyclovir was the drug eventually administered to Clive that saved his life Acyclovir acts as an inhibitor to the HSV DNA polymerase enzyme which is an essential enzyme in the synthesis of viral DNA. As a result, the virus is unable to replicate which means it cannot grow or spread any further. Acyclovir is effective in around 95% of cases after being administered regularly However, acyclovir and any other medical treatments are unable to completely eradicate the HSV from your body as there is no cure.
Viral protein ICP47
Infected cell protein 47 (ICP47) is encoded by the HSV. ICP47 is essential to the virus’s survival as it helps to evade the host’s immune response. The MHC class 1 molecules play a role in triggering the host cells immune response. When a cytotoxic T cell encounters a cell displaying a foreign peptide on its MHC, the cytotoxic T cell activates and kills the infected cell, stopping the spread of the virus. However, ICP47 inhibits the transport of viral peptides to MHC class-1 molecules, preventing recognition from the cytotoxic T cells and evading detection from the hosts immune
Progression of the illness
After becoming infected by HSV symptoms may show up within a couple days. The virus is fast spreading although it very rarely causes encephalitis. The big question ‘how does the HSV travel into the brain?’ remains unanswered There are several hypothesis’s that suggest the virus gains access via the bloodstream or through the nerves although all these theories lack conclusive evidence
The first hypothesis suggests that the virus travels from the initial site of infection to the brain via either the trigeminal or olfactory nerves. The trigeminal nerves (cranial nerve 5) are part of the 12 cranial nerves inside your brain and consist of three branches (ophthalmic, maxillary and mandibular nerves) These nerves are responsible for transmitting motor and sensory information between the skin on the face and brain The olfactory nerve (cranial nerve 1) is the shortest sensory nerve in your entire body and is responsible for smelling. It is believed that HSV-1 infects the olfactory epithelium in the nasal cavity and then travels along the nerve connected to the brain.
The second possible explanation is that the virus reactivates after the latent stage. This process can be split into 4 main stages Firstly, the initial infection from HSV-1 which gains entry often through the mouth and then spreads to sensory neurons. Next is the latency stage, this occurs when the virus is found within nerve cells whilst remaining dormant thereby not causing any symptoms to the host. During this stage the HSV-1 remains undetected from the immune system
The third stage takes place when the virus is reactivated and begins replicating rapidly. The reactivation of HSV-1 is more commonly triggered by illness, immunosuppression or hormonal changes. Finally, upon reactivation the HSV-1 will work its way along sensory nerves typically on the skin causing cold sores (hence the cold sore virus name). However, in an infinitesimal number of cases it will travel up the central nervous system (CNS) an into the brain where it will cause inflammation (encephalitis).
The third possible explanation differs from the other theories previously described as it involves movement through the bloodstream and across the bloodbrain barrier Perhaps the most common way HSV-1 enters the bloodstream is through cell damage caused by inflammation. During replication of the virus, infected cells may become damaged causing a breakdown of tissue barriers therefore establishing a pathway for HSV1 to enter the bloodstream In order for HSV-1 to infect the brain it must cross the robust blood-brain barrier (BBB). The BBB is selectively permeable which acts as a highly controlled filter allowing a select number of essential things to pass through into the brain. However, it is thought that the inflammatory response causes an increase in BBB permeability Consequently, viruses will be more capable of crossing over into the brain.
The uncertainty about how HSV-1 travels to the brain stems from a multitude of factors. Firstly, as there are several pathways that HSV-1 has of travelling into the brain it is challenging to establish a single method of entry. Secondly HSV-1 affects every individual differently due to variances predominantly in health, age and immune responses which significantly influences viral entry. Thirdly as HSV-1 often remains dormant for long periods of time during the latency stage, studying its behaviour can be difficult. Lastly, studying animals has many ethical issues and using humans can pose practical challenges - not to mention the rarity of the virus means finding a volunteer would be highly unlikely.
The blood-brain barrier
The blood-brain barrier (BBB) is crucial for protecting the brain against harmful substances in the blood. It consists of endothelial cells from the capillary wall, astrocytes and pericytes together making the BBB selectively permeable Astrocytes are star-shaped glial cells, and they have biomechanical control over the endothelial cells in the BBB. Pericytes are multi-functional mural cells that wrap around the endothelial cells. At the bloodbrain barrier passive diffusion, facilitated diffusion and active transport all carry small molecules and ions across the barrier. In most cases the BBB prevents the passage of pathogens and large or hydrophilic molecules into the brain. On the other hand, it allows hydrophobic and small non-polar molecules to pass through – examples include both O2 and CO2 as well as some hormones. As antibodies are too large, they are also unable to pass Whilst infections are very rare, if they do occur it can be difficult to treat as a select few antibiotics can pass. Usually, treatments would instead be administered into the cerebrospinal fluid, entering the brain by crossing the blood-cerebrospinal fluid barrier. Acyclovir does cross the blood-brain barrier making it a desirable treatment for HSV encephalitis.
The neurological impacts of the virus on Clive’s brain
Shortly after Clive woke from his coma lasting 16 days, he had a CT scan that indicated areas of low density, in particular both the interior and posterior frontal lobe as well as the right medial temporal lobe. Later in 1991 Clive had an MRI scan which was analysed and detailed by three independent raters. The MRI scan revealed the true extent of the damage caused by the virus. In the observers report both hippocampal formations were damaged – specifically the entire left hippocampus was destroyed, whilst he had a small piece of his right hippocampus remaining. Both left and right amygdala, both mammillary bodies, both temporal lobes and the substantia innominate on both sides all showed significant signs of abnormality. Additional damage highlighted by the MRI included the left fornix, the left inferior temporal gyrus, the anterior portion of the left middle temporal gyrus, the anterior portion of the left superior temporal gyrus and the left insula. Lastly, there was reported mild abnormality in the posterior portion of the left middle temporal gyrus, the left medial frontal cortex, the left striatum, the right insula, the right fornix and the anterior portion of the right inferior temporal gyrus The third ventricle and both lateral ventricles were substantially dilated. As this long list has evidenced, Clive’s brain injuries were severe and after later reading about the importance of these damaged areas, it is nothing short of a miracle that he has survived whilst retaining some of the most important human qualities.
How did the virus cause Clive’s neurological damage?
As previously stated, Clive suffered from encephalitis which is the inflammation and swelling of the brain. The brain can become inflamed during infection because the virus triggers an immune response. The inflammation results in an accumulation of immune cells and fluid in the regions impacted by the virus. This build-up in fluid causes swelling known as a brain edema The surrounding skull is rigid and non-compressible as it is made up of several bones, this means that swelling within the cranial cavity (space inside the skull where the brain resides) increases intracranial pressure, thereby exerting a large force on the brain tissue causing irreversible damage
As the brain tissue is pressed against the skull, compression may lead to reduced blood flow to various parts of the brain also known as cerebral ischemia. As a consequence of the reduced blood flow, there will not be sufficient oxygen delivered to the brain regions resulting in necrosis (irreversible tissue death).
Which parts of Clive’s brain remained largely intact?
Upon examination of Clive’s MRI scan it was discovered that both his left and right thalamus were unaffected by the virus. This was perhaps not surprising as the thalamus is located in the centre of the brain reducing the chance it could compress against the skull when inflamed. The thalamus is responsible for relaying sensory and motor signals to the cerebral cortex (located on top of the cerebrum). In addition, it controls sleep, consciousness and alertness. Clive’s cerebellum which regulates movement and balance and is located at the back of the brain remained mostly intact. Clive’s brainstem - vital for carrying out processes to keep you alive such as breathing, and heart rate also remained undamaged.
The left MRI scan is of Clive Wearing’s brain from 1991, and the right MRI scan is a comparison of a healthy non-brain damaged and age-controlled individual
Clive’s brain
The important function of each impaired region
The brain is often cited as the most intricate structure in the entire universe – and for good reason. It is challenging to even comprehend all the processes that occur inside all our brains. For a comparison, Christof Koch Ph.D. who is Chief Scientist and President of the Allen institute for brain science stated, ‘we don’t even fully understand the brain of a worm’. Typical worms have 302 neurones in total, we have between 80 and 100 billion neurones with over 300 trillion connections… As a result of this complexity, it may seem unsurprising that a great deal is still unknown and will remain unknown for years to come despite continuous breakthroughs with the aid of emerging technology.
Firstly, we will look at the hippocampus highlighted in orange above. The hippocampus is located deep within the brain in a region called the medial temporal lobe and it sits posterior (meaning behind) to the amygdala. One of the biggest misconceptions with the hippocampus is that it is a singular structure. As seen in image 1, there are two hippocampi (one on each hemisphere) making it a paired structure. The two hippocampi are connected by a structure called the fornix (further information below). The hippocampus is essential for learning and memory formation. Whilst overseeing the transfer of short-term memories into longterm memories and assisting the retrieval of these memories at a later date, the hippocampus also helps with our spatial navigation – essential to our survival.
The hippocampus is part of the limbic system and forms part of a larger structure called the hippocampal formation. The hippocampal formation consists of three other structures called the dentate gyrus, subiculum and entorhinal cortex. Each structure has an integral role in memory. Firstly, the dentate gyrus is responsible for episodic memory – memory of personal events that occur in everyday life. Damage to the dentate gyrus explains why Clive has episodic memory deficits. The subiculum is implicated in spatial memory tasks and is also believed to be the cause of some cases of human epilepsy and drug addiction although there is not as much research on this component. Lastly the entorhinal cortex is involved with spatial navigation, to help individuals move through an environment without difficulty. It also aids with temporal memory (remembering when specific events occur).
The next structure damaged in Clive’s brain was the amygdala. Similar to the hippocampus, the amygdala is also a paired structure as there is an amygdala in each hemisphere. As evidenced by the image above they are small almond shaped structures (the word amygdala is Greek for almond). To find your amygdala, point both your fingertips on your temple (aligned with your eyes) facing inwards. The amygdala also forms part of the limbic system. Despite its small size, the amygdala has a variety of functions that are essential to our survival, experience of emotions and memory formation.
Firstly, the amygdala is largely responsible for learning fear associations. As such classical conditioning (a process involving associating a neutral stimulus with a conditioned response) can cause fear conditioning to occur. A real-world example of this is the famous case study ‘Little Albert’. This boy was 9 months old and was exposed to a series of stimuli. Firstly, he was exposed to a white rat, the neutral stimulus as Albert had no reaction. He was then exposed to a loud banging noise, the unconditioned stimulus as it triggered his unconditioned response of fear. The white rat and loud banging stimuli were then shown to Albert at the same time (conditioned stimulus), triggering his fear response once more. Later when Albert was shown solely the white rat his conditioned response was fear. This demonstrates how the fear emotion can be conditioned into an individual. However new research contradicts our previous understanding of the amygdala as it has not been shown to have an essential role in the experience of fear.
The second role of the amygdala is in memory formation, specifically emotional memories. As such, highly emotional events are likely to be remembered for many years whilst memories of little significance and emotion will be forgotten much sooner. The downside of this process is that traumatic events that caused strong negative emotions will be retained for a long time, making it challenging to overcome. Lastly the amygdala influences aggression. Whilst not exclusively determining aggressive behaviours, the stimulation of the amygdala produced aggression from animals whilst the removal of the amygdala from both animals and humans resulted in less aggression.
The third structure that Clive suffered damage to were both his mammillary bodies. As shown by the image (top right) this structure is very small and rounded. Once again it is a paired structure, and the mammillary bodies form part of a larger structure called the diencephalon (part of
the limbic system). The main function of the mammillary body is recollective memory. Damage to this structure may lead to retrograde amnesia. This form of amnesia is an inability to remember information acquired at a previous date. The severity varies as some people cannot remember an event from years ago whilst more serious cases involve people that cannot remember what happened the day before.
This large structure highlighted above in orange is the temporal lobe. Clive also suffered heavy damage to this region. Unlike all the other structures looked at so far, the temporal lobes are much larger – in fact the temporal lobe is one of four major lobes that makes up the cerebral cortex. The other lobes are the frontal lobe, parietal lobe and occipital lobe Each of the lobes have a left and right side making them paired structures Both the hippocampus and amygdala are found within the temporal lobe. The temporal lobe contains structures that are vital for explicit (conscious) longterm memory formation. Explicit memories are divided into two categories: episodic and semantic Episodic memories are of personal events whilst semantic memories are factual/knowledge-based memories Alongside aiding with memory formation, the temporal lobe is also responsible for processing sensory stimuli.
Firstly, within the temporal lobe is the primary e complex that receives sensory information from the ears and processes it into speech or words that we can understand.
Secondly, areas such as the fusiform gyrus and parahippocampal gyrus are responsible for visual processing of complex stimuli. The fusiform gyrus bridges the gap between the temporal and occipital lobes. It rapidly analyses things we see and compares them to stored memories, if they match or are close to matching the memory is linked to what you can see so that you recognise it. This incredible feature is what enables us to recognise familiar faces accurately. Also within the temporal lobe is the Wernicke’s area which is one of two areas in the cerebral cortex responsible for speech (the other is the Broca’s area). The Wernicke’s area is accountable for the comprehension of written and spoken language.
Also in the region of the hippocampus is the fornix. This is another paired structure as the fornix connects the hippocampus to the mamillary bodies, illustrated by the large image at the top of the page. Mirroring his hippocampal damage, Clive suffered greater damage to his left fornix than his right fornix despite suffering from abnormalities in both.
The fornix also connects the mammillary bodies to the anterior nuclei of the thalamus and connects the hippocampus to the septal nuclei and nucleus accumbens. This structure is made of white matter, specifically a bundle of nerve fibres. Similar to the other structures in this region, the fornix is believed to play a role in some aspects of memory. In particular the regulation of episodic memories.
The inferior temporal gyrus is concerned with many cognitive processes such as visual perception and integrating information from different senses. In addition, this structure forms a part of the ventral stream which is responsible for both object and visual recognition and leads to the temporal lobe. Damage to the inferior temporal gyrus region could lead to aphasia which is the inability to comprehend language or agnosia which is the inability to recognise specific object categories.
areas specialise in processing combinations of frequencies whilst other areas process changes in amplitude or frequency. Another critical region is the Wernicke’s area –briefly mentioned in the temporal lobe section on the page above. The Wernicke’s area is typically found in the left superior temporal gyrus and is heavily involved with processing speech so that it can be understood as language.
Up next is the inferior temporal gyrus illustrated in orange above. Once again this is a paired structure as there is one on each hemisphere. Clive suffered damage to both the left and right inferior temporal gyrus although the most abnormality was on his left with some mild abnormality on the right. The inferior temporal gyrus is one of three gyri found within the temporal lobe. The other two are the middle and superior temporal gyri. As a clarification for some of the terms that will be used to describe the position of brain structures in relation to each other, anterior refers to the front of the brain whilst posterior refers to the back of the brain. Inferior means below and superior means above. As such, the inferior temporal gyrus is found below the middle temporal gyrus. Furthermore, it is located in the anterior region of the temporal lobe
The middle temporal gyrus sits in between the inferior and superior temporal gyri Clive suffered damage to both the anterior and posterior portion of the left middle temporal gyrus This structure is divided into four subregions each with a distinct role. Firstly, the anterior middle temporal gyrus recognises sound and oversees semantic retrieval. The middle middle temporal gyrus (mMTG) solely deals with semantic memory. The posterior middle temporal gyrus is involved in language processing. The sulcus middle temporal gyrus decodes intelligible speech and processes verbal mental arithmetic.
The superior temporal gyrus is shown in the image above and as illustrated by its elevated height it sits above the other temporal gyri. Clive suffered damage to the anterior portion of the left superior temporal gyrus. This region contains several key structures that manage speech and sound. One of these regions is the primary auditory cortex which receives, analyses and categorises different sound frequencies. Within this structure some
Moving onto the insula also referred to as the insular cortex. This is a paired structure with one on each hemisphere. Following on from the pattern of damage that Clive sustained, his left insular cortex suffered more damage than his right. As indicated by the image the insular cortex is embedded deep within the brain instead on the outer surface. The precise structure it is located within is called the lateral sulcus, separating the temporal lobe from the frontal and parietal lobes. The insular cortex is a fascinating structure that is linked to so many different functions Of particular interest is its believed role in consciousness – a topic that will be discussed later in relation to Clive. In addition to consciousness, the insular cortex plays a role in homeostasis (the regulation of the body’s internal conditions) and self-awareness. Recent neuroimaging studies have linked the insular cortex to many psychiatric disorders, therefore establishing its importance in psychopathology. The disorders the insular cortex is believed to impact include schizophrenia, OCD, PTSD, and anxiety disorders.
Another current topic of scientific study and debate is the insular cortex’s influence on addiction. Recent reliable brain imaging studies have shown that the insular cortex activates when a drug user is exposed to a variety of drugs. Research has indicated cocaine, alcohol, nicotine and opiates all activate the insular cortex. Despite this evidence, most of the scientific literature fail to mention the insular cortex as it does not target the dopamine system – pivotal to the dopamine reward system theories of addiction. Additional supporting research
from 2007 also indicates the role of the insular cortex in addiction with cigarette smokers. Cigarettes contain nicotine which is highly addictive. In the study smokers that had a damaged insular cortex from external circumstances such as a stroke were up to 136 times more likely to undergo disruption to their smoking habits than smokers without this damaged region. This meant the smokers addiction to cigarettes were essentially eliminated.
Shown above in orange, the medial prefrontal cortex was the next structure that Clive suffered damage to As the name suggests it is found within the frontal lobe – relatively close to your eyes. The prefrontal cortex is split into three regions: lateral, medial and orbitofrontal The latest research indicates that the medial prefrontal cortex is responsible for regulating many cognitive functions. Specifically habit formation, attention and long-term memory. Furthermore, the medial
prefrontal cortex is well integrated with other brain regions such as the hippocampus, thalamus and amygdala. On going research has evidence to suggest that medial prefrontal cortex abnormality (shown using MRI scans) is consistently found in patients with neurocognitive disorders such as Parkinson’s and Alzheimer’s suggesting the importance of an intact medial prefrontal cortex.
The last structure Clive suffered damage to is known as the striatum (sometimes called the corpus striatum). The image above shows the striatum in orange –although it may show some resemblance to the fornix and hippocampus shown on the previous page these structures are entirely separate. The striatum is the largest component of the basal ganglia In particular, Clive suffered damage to his
left striatum. This structure is split into the ventral striatum and dorsal striatum. Examining the ventral striatum further, it contains the nucleus accumbens and olfactory tubercule. The nucleus accumbens is an essential component of the reward system as it processes the rewarding stimuli. The olfactory tubercule plays a role in attentional behaviours and locomotion. Moving onto the dorsal striatum it contains the putamen and caudate nucleus. The putamen influences many motor behaviours such as motor planning. The caudate nucleus is one of the components involved in the ‘worry circuit’ typical in individuals suffering from OCD. In neurotypical individuals only major worries would pass through caudate nucleus whilst the insignificant worries would be supressed. However, individuals with OCD have a dysfunctional caudate nucleus which fails to supress the insignificant worry signals sent from the orbitofrontal cortex. Consequently, these signals reach the thalamus and are directed around the body leading to some of the repetitive behaviour’s characteristic of individuals with OCD
The unique case of Clive Wearing
In 1995 Alan D. Baddeley, Babara Wilson and Narinder Kapur published a journal of clinical and experimental neuropsychology on Clive Wearing stating they ‘had never encountered someone so densely amnesic as Clive’. This was a bold statement considering there were some other famous amnesic cases reported in the world, notably patient H.M (Henry Molaison). Clive had severe semantic and episodic deficits for both visual and verbal information. In their report the amnesic syndrome is described as being ‘characterised by (a) severe difficulty in learning and remembering new information of nearly all kinds, (b) normal short term memory (STM) as measured by digit ears Clive took part in a number of neuropsychological assessments which will be detailed below, although due to the severity of his condition many tests, he was involved in were abandoned. Clive suffered from extensive retrograde amnesia as he can hardly recall anything prior to his illness except who he was, where he went to school, where he studied music and that he married Deborah. Clive also has very severe anterograde amnesia as he is unable to form new memories since his illness.
General intellectual functioning
For context, prior to Clive’s illness he was estimated to be in the superior or highly superior range of ability based on his scores on the National Adult Reading Test placing a world leading musician and scholar from Cambridge. Clive’s intelligence was assessed in 1985 using the Wechsler Adult Intelligence Scale (WAIS) and again in 1992 using the Revised R estimates both verbal and 8 lower than the scores obtained on the WAIS. In 1985 Clive’s verbal and performance IQ was rated at 105 and 106 placing him in the average range. This indicates that his illness has led to some intellectual decline. When assessed again in 1992 his verbal IQ had declined to 92, even when factoring in the 7-8 difference. Upon closer examination, there appears to be a deterioration in the quality of Clive’s responses as he forgets knowledge about the world. Two examples of this include when Clive was asked in 1985 to describe “In what are North and West alike?” he replied, “part of the compass” whereas in 1992 he replied, “at right angles to each other”. The other example is when he was asked “In what ways are air and water alike?” Clive initially responded, “Both have oxygen” whereas in 1992 he replied with “naturally part of the climate”. Contrast to his verbal IQ, his performance IQ potentially increased when accounting for the different test methods. The digit span test is part of the verbal subtests and aims to measure the short-term memory and working memory. In the forward digit span test Clive was asked to listen to a series of digits in order and then repeat them, he scored 6 in 1985 and 1992. In the backward digit span test Clive was instructed to repeat the digits in reverse order (more challenging), he scored 4 in 1985 and 1992. These scores place Clive in the average range despite his impairment.
Semantic battery test
In 1992 Clive was given a total of 120 questions split into two categories: Living and nonliving. These questions were testing his ability to name pictures, descriptions and recognize pictures. Based on the results his performance is generally lower than would be expected – especially as he is only able to name 2/4 of the musical instruments described considering he was an expert musician.
Similarly in a second test when Clive was asked to recall as many of each category within 1 minute, he was only able to correctly provide a total of 18 living and 40 non-living which is considerably lower than he would have scored prior to his illness.
Performance on the autobiographical interview
In 1985 and 1992 Clive was interviewed by Baddeley, Kopelman and Wilson. Unlike standard interviews where individuals are typically asked a wide range of questions about various topics, the autobiographical interview involved asking Clive questions specifically about his childhood, early adult life and more recent memories (within the last year). Furthermore, to ensure the interview was comprehensive, Clive was asked a mixture of personal semantic (factual) questions and questions about autobiographical incidents. The table above shows his results from both tests in 1985 and 1992 and Clive scores in the impaired range consistently Whilst his memory is notably impaired, there is some evident improvement in his personal semantic memory between 1985 and 1992 as his total score increased by 7.5. Of particular note is his childhood memories which increased from 6 to 11. In contrast his autobiographical incident memory saw little change. The conclusions drawn from this interview were that he shows severe retrograde amnesia for virtually his whole adult life and for much of his childhood. However, his immediate memory span is normal, and he shows implicit learning (learning information unintentionally).
Retrograde amnesia test
In 1985 Clive was asked to estimate the price of 12 everyday items that should be simple task for most, items included a pint of milk and a first-class stamp. The mean error score for the control group participating in this test was 0, Clive’s error score was 18 highlighting his memory is years out of date.
In 1989 he took part in a modified version of Narinder Kapur’s retrograde amnesia test where he was asked to specify whether world famous icons were alive or dead These individuals were so well-known at the time it would have been hard for non-amnesic individuals to answer a question incorrect. Out of a total of 20 questions he only correctly answered 1 which was Elvis Presley. For context Clive claimed that he had never heard of John Lennon, John F. Kennedy, Margaret Thatcher or Mohammed Ali.
Semantic processing test
Once again in 1985 and 1992 Clive took part in another test titled the Speed and Capacity of Language Processing (SCOLP) developed by Baddeley, Emslie and Nimmo-smith. In this test Clive had 2 minutes to read as many simple sentences as possible and verify whether each one is true or false. The sentences were designed to be obviously true or false so that there was no ambiguity. An example of a true statement was ‘Rats have teeth’ and an example of a false statement was ‘Nuns are made in factories’ In 1985 Clive’s performance placed him in the impaired range as scored a total of 6 errors and took an average of 4.8 seconds to verify the statement. Two of Clive’s incorrect judgements were ‘dragonflies have wings (false)’ and ‘forks have a lot of industry (true)’. As a comparison the control group rarely made more than 1 error and took an average of 2 seconds to verify each statement. Remarkably his score on his next attempt in 1992 looked very different to his first attempt. Whereas in 1985 when Clive only managed to verify 25 statements, in 1992 Clive managed to verify 45 statements in 2 minutes. Clive’s mean response time dropped to 2.44 seconds which is almost a 100% improvement, and he only made one error.
Reaction time test
In order to determine Clive’s speed of motor response to a cognitively undemanding task he participated in the simple reaction time test. In this test participants are asked to push a button the moment they see the red light in front of them flash. In order to gauge an average reaction time, the red light will randomly flash over a 5-minute duration. Clive’s mean reaction time was clocked at 0.24 seconds, faster than the control group that scored an average of 0.30 suggesting that his reaction time is unimpaired.
Graded naming test
In the graded naming test, Clive was given 30 different photographs and asked to identify the object shown. Once again these were objects that were all familiar to him prior to his illness so there should not have been any ambiguity. Nevertheless, Clive only managed to score 2/30 correctly. There were several reasons for this score, firstly Clive struggled to find the appropriate word to say even if he knew it inside. For example, he said ‘a swimming tortoise’ instead of ‘turtle. The second reason is that he simply did not recognise the object which led him to guess at what it might be or do. Clive did not recognise a photograph of a scarecrow as he replied ‘a worshipping point for certain cultures’. At a later date, Clive’s response to the spoken name of the initial objects were observed to draw comparisons. The table on the left showcases 10 of his responses to pictures and then the responses to spoken names.
This is a photograph taken from one of Clive’s diaries featuring his handwriting. On the left you can see the exact time he wrote a message. You might notice that he repeatedly claims to become conscious or awake for the first time and occasionally crosses out preceding statements as he has no recollection of any previous writing, despite recognising his own handwriting.
Clive’s musical abilities after illness
The severity of Clive’s anterograde amnesia
Clive Wearing has quite possibly the most severe case of anterograde amnesia in recorded history. Anterograde amnesia in the most serious of cases means you cannot learn or retain any new information. Consequently, every conversation, interaction, sensation will be permanently forgotten within seconds. It is puzzling to even grasp what this must feel like, constantly having your memory wiped and reset systematically. The severity of Clive’s anterograde amnesia coined the ITV’s documentary title ‘The man with a seven second memory’. As the title depicts, Clive typically could remember anything for 7-30 seconds before having his memory reset and claiming he just woke up from a coma. To assess the true severity of Clive’s anterograde amnesia, the Wechsler Memory Scale was revised and made available for Clive in 1989. He was scored in different categories including general memory, verbal memory, visual memory and delayed memory. Clive achieved the lowest possible score index in all those categories – lower than any other impaired individual. Furthermore, on the visual reproduction subtest, he scored 0 on delayed recall. When later compared to a group of 10 other individuals all with various forms of memory impairment as a direct consequence of Herpes Simplex Virus Encephalitis, it was revealed that Clive suffered from the most severe anterograde amnesia.
When listed with all the different neurological structures that Clive suffered damage to, it would seem inconceivable to imagine Clive maintaining his musical ability. With large areas of his brain missing how could he maintain the high levels of co-ordination, rhythm and accuracy required to play complex pieces of music?
Although Clive’s episodic and semantic memories are severely impaired, his procedural memory has remained intact. Procedural memory is a type of implicit memory where you can perform a previously learned skill without conscious awareness of prior experiences. Clive had spent the best part of his life perfecting his musical ability including sight reading all pieces of music he performed. This has meant that he is still able to play the piano even after his illness. One of the reasons that this is possible is because Clive sight reads when playing the piano which means he does not have to memorise the notes of pieces to play In this regard Clive is fortunate because as a result of his severe amnesia he is not able to remember any musical pieces or even their composers. To most listeners with a musical ear, his piano playing might seem as skilled as ever, however that is not entirely the case. Clive is still able to obey repeat marks, play from a figured bass, transpose, extemporise and he can also ornament. Whilst it is true that his ability to sight read is unaffected by his condition, Clive’s pianistic skills have deteriorated from his previous world class standard Leading up to Clive’s illness he was admired for his ability to perform the most complicated modern scores with great accuracy and speed whereas he now lacks confidence in his ability to play and restricts himself to play simpler pieces from the sixteenth to twentieth centuries. Furthermore, Clive occasionally will play pieces at speeds no longer within his skill which has put him off attempting anything noticeably challenging.
In 1990 Clive also started to suffer from musical delusions in which he claimed to hear his own music playing. This may have been the case because Clive would occasionally hum the song mid-phrase instead of from starting at the beginning which would likely occur if he was pretending to hear music playing. Furthermore, when considering the areas of his brain that suffered damage, it is very possible the musical hallucinations arose from extensive left temporal lobe damage Additional supporting evidence from Lishman in 1998 states that musical hallucinations often are found in conjunction with temporal lobe epilepsy and Clive was prescribed anti-convulsant medication to stop his complex partial seizures.
For a short period of time, Clive was also observed playing the piano in times of immense agitation or frustration which led him to hit the piano keys with a great deal of force and little accuracy. Clive’s frustration peaked when he was momentarily taken of tranquilisers when he was in the process of being transferred to a new special home.
Consciousness
Consciousness has been a topic of discussion and debate for centuries and is still When the first paper and articles were published about Clive’s condition, there was limited available scientific documents about consciousness which made it challenging to comment in depth about gave a argued that there are three types of consciousness which have been referenced in Barabara Wilsons’ 2008 paper on Clive Wearing. The first type of consciousness is the ‘proto self’. The proto self is a “collection of neural patterns which map, moment by moment, the state of the physical structure of the organism in its many dimensions”. The proto self is an unconscious process that is essentially a template from which the core and autobiographical self can build upon. The second type of consciousness is the core self which occurs when an individual can recognise its thoughts as its own and is also aware of changing feelings. Damasio states that the core self only requires a brief short-term memory (which Clive had). The third type of consciousness is the autobiographical self develops over time and ‘draws on memories of past experiences’. Whilst Clive had some autobiographical memory as he could remember some childhood facts, he is unable to lay down hardly any new autobiographical facts. Consequently, according to Damasio’s theory of consciousness Clive has core consciousness but lacks autobiographical consciousness which accounts for why he is not whole.
Often Clive’s first remark after his memory refreshes is “I have just become conscious for the first time, this is the first sight I’ve had, the first taste I’ve had, it’s like being dead. Does anyone know what it’s like being dead? No” From Clive’s perspective he is correct because when in a coma you remain unconscious Those often around him have reported that he often will speak as if he is in fact dead. When confronted and being told that he has a memory disorder he would categorically deny it and become increasingly frustrated if told otherwise. Moreover, when Clive was shown videotapes of himself, he claimed “I wasn’t conscious then”. The statement “I have just become conscious for the first time” has fascinated professionals studying him who have tried to question him what he meant by this. Unfortunately, this is impossible for him to answer because his memory impairment has inhibited him from having in-depth conversations.
Is Clive suffering from a delusion?
Similar to consciousness, defining precisely what a delusion is can be very difficult. As such there have been a number of definitions provided over the years which have different criteria to qualify as ‘delusional’. In 2003 Hahn defined a delusion as ‘a belief that is clearly false and indicates an abnormality in the affected person’s content of thought’. Clare and Mullen defined delusions as ‘false beliefs that are held as absolute convictions, not amenable to argument, not culturally explicable, and that they are often bizarre and usually preoccupying’. Regardless of which definition is used to define a delusion they can all be critiqued and may not be applicable to all scenarios. A common misconception with delusions is that they are only found in people with psychiatric disorders such as schizophrenia, and whilst some psychiatric patients do experience delusions of all sorts, individuals with neurological conditions like Clive can also suffer from delusions. With this said, delusions are not commonly found in people with neurological conditions however current neuropsychological literature has highlighted four of the more common delusions found in these patients. Firstly, the Capgras syndrome causes individuals to believe their loved ones have been replaced by an identical imposter. This ‘imposter’ will look and behave very similarly to the person they are ‘replacing’ however there will some small giveaway signs to the individual which reinforces their belief to the point where it is near impossible to correct it. The second delusion is the Fregoli delusion that triggers a belief that multiple different unfamiliar people are in fact a singular familiar person that is able to change their appearance Next is reduplicative paramnesia which occurs when an individual believes an entire location has been cloned so that it exists in multiple different places at the same time. Lastly Cotard’s syndrome is a belief that you are dead and do not exist (sometimes you also believe that you have lost internal organs).
In 1995 when Wilson, Baddeley and Kapur wrote their previous paper on Clive they suggested that Clive was suffering from a delusion which explained his consistent lack of awareness for the past. Applying the definitions of a delusion to Clive circumstances would likely classify him as delusional as he does have a false belief that is held as an absolute conviction. As written in the 1995 paper Clive’s ‘delusion can be interpreted as an attempt to provide a rational and acceptable solution to strange and dramatic experiences’. The issue labelling Clive as delusional is that it is entirely plausible for him to believe he has just awoken from a coma considering the magnitude of neurological damage he suffered from. It has been reported how unique Clive’s condition is and that he is the most densely amnesic patient recorded, so perhaps to him it truly isn’t a false believe which would explain why he becomes frustrated when doubted over his claims. In Barbara Wilson’s 2008 report the standpoint on whether Clive was delusional had changed. Whilst it would be difficult to claim that Clive’s belief is not consistent with the definition for a delusion, he does not have any other psychiatric features typical of patients suffering from delusions. As such, the overall verdict is that ‘organic psychosis (mental illness that has occurred from medical illness causing abnormal brain function) is the explanation for his belief of ‘just awakening’ therefore Clive does not suffer from a delusion.
Interview with Deborah Wearing
Prior to the start of writing this article, I had the opportunity to speak with Deborah and ask lots of questions to find out about Clive from the person who knows him best. Deborah’s responses to some of the questions alongside sharing some of the published literature on Clive has been instrumental in the creation of this project. Deborah is a distant relative which meant setting up a suitable time to conduct the interview was straightforward. The format of the discussion differed slightly from many conventional interviews which I found beneficial as it allowed for me to learn as much as possible ahead of writing the project. In the weeks leading up to the interview I began brainstorming initial questions I could ask Deborah and with the assistance of my project supervisor I had a variety of questions that would cover a range of topics relevant to this article. As part of the A-level psychology syllabus we explore some interview structures which I aimed to utilise in the interview. I deemed the semi-structured interview to be the most suitable as it meant that I could use the pre-planned questions but then also ask any follow up questions whenever necessary. On the day of the interview, we began by discussing what the A-level psychology syllabus teaches us about Clive. Over the years, there had been lots of misinformation spread about Clive’s condition particularly due to its complexity and how unique he was. I showed Deborah the section about Clive in our online textbook and on the whole, it was accurate (despite simplifying his condition), but it surprised me how some of the information in the textbook was inaccurate. The biggest mistake Deborah highlighted was that Clive’s ‘semantic memories were relatively unaffected’. As explained in the previous pages, further illustrated by the semantic battery test, Clive has severe semantic memory deficits. Deborah then shared three documents with me which we looked through and discussed. The first was the 1995 journal of clinical and experimental neuropsychology titled ‘Dense Amnesia in a Professional Musician Following Herpes Simplex Virus Encephalitis’ by Barabara Wilson, Alan D. Baddeley and Narinder Kapur. The second was published in 1995 and was written by Barabara Wilson and Deborah Wearing titled ‘Prisoner of Consciousness: A State of Just Awakening Following Herpes Simplex Encephalitis’. The third was published in 2008 and was written by Barbara Wilson, Michael Kopelman and Narinder Kapur titled ‘Prominent and persistent loss of past awareness in amnesia: Delusion, impaired consciousness or coping strategy?’. What stood out to me the most was Deborah’s disagreement with Clive being labelled as delusional in the earlier papers.
After this discussion we commenced with the interview questions which were arranged into three categories. Below features the questions I asked and Deborah’s responses. When conducting the interview, I typed down the Deborah’s responses however some of the responses featured below are paraphrased although carry the same message
Background information on HSV-1
After Clive contracted the virus how fast did it spread and cause noticeable changes such as the onset of amnesia?
Clive experienced severe headaches on Sunday morning on the 24th of March 1985 and that kept him awake all day night on Monday and Tuesday. On Wednesday he started becoming confused and a doctor arrived and gave him sleeping pills. Clive’s condition dramatically worsened, and he was rushed into hospital on Friday. On Sunday he had a terrible seizure and received the lifesaving drug treatment although the virus had already dealt its damage to Clive’s brain.
Is there an understanding of how the Herpes Simplex Virus was able to cross through the blood-brain barrier in Clive but not in other individuals with the virus?
At the moment it remains unclear how HSV-1 was able to cross the blood-brain barrier. Current research has led to the development of some hypothesis’s but there is no definitive evidence.
Was there any medication or treatment available at the time that could have slowed or prevented the effects of the virus?
Yes, Acyclovir was a relatively new drug at the time of Clive’s infection, and this was the drug that was administered to him in hospital that likely saved his life. Unfortunately, by the time doctors correctly identified his condition much of the damage was done to his brain, perhaps if he received acyclovir earlier, he would have made a full recovery.
The effects of the virus on Clive’s memory
What were the effects of the virus on Clive’s hippocampus, and how did this affect his memory formation and recall?
The whole of Clive’s left hippocampus was destroyed but he still has a tiny portion of his right hippocampus
Does Clive’s memory loss extend to both recent events and events that have occurred prior the viral infection?
Clive has virtually no recollection of any events in his past apart from a couple of childhood memories. Since his illness he also doesn’t have any memory of recent events
How has Clive’s memory impairment affected his ability to learn and retain new information?
Clive has implicit memory and shows implicit learning, but he does not really have any explicit memory.
Is Clive able to recall any personal memories or events from his past?
Clive still knows who I am but he doesn’t really have any personal memories.
Are there any strategies or techniques that Clive has used to help aid his memory recall such as specific cues?
Clive hasn’t got any specific methods of helping his memory but in some ways his memory recall has improved marginally. (e.g. personal semantic memory)
Has Clive been able to learn anything new since the amnesia set in? memories/skills
Clive has shown some evidence of semantic learning such as the name and use of a mobile phone since his illness, he can also navigate some parts of his home
Has Clive had any brain scans and if so, what did they reveal?
Clive has had both CT and MRI scans over the years since his illness. The MRI scans have revealed lots about all the structures which have been damaged particularly the hippocampus.
How has Clive’s amnesia changed over time?
The amnesia itself has not changed much, but Clive has become more withdrawn from the world.
The impact of the virus on Clive’s daily life
How has Clive’s amnesia affected his personality or emotional state in any way?
It hasn’t really, he is still very funny and himself and is also very kind.
Has Clive experienced any changes in his sleep patterns or sleep quality due to the virus?
If he has been well looked after he has better quality sleep, but he sometimes has disrupted sleep. For many years he was administered anti-psychotic drugs but is now sleeping much better.
Has Clive shown any signs of improvement or recovery over time or has his condition remained relatively stable?
Yes, none of the doctors can account for it, when he moved into a new care facility that was a specialised neurobehavioral unit there was some improvement because his environment was less hideous than the previous psychiatric hospital. This led to some behavioural improvements but no memory improvements. In the second half of 1999, despite no changes to his drugs or environment he started to improve and when Barbara Wilson next met him, she couldn’t believe how different he was because she used to find it difficult to do tests on him.
What message would you give to people about Clive’s story?
Clive is evidence that no matter the extent of your brain injury, you are still whoever you are Regardless of much of Clive’s brain is impaired, he still knows who he is and still retains his sense of humour. It teaches us that the spirit of Clive is undimmed.
How does Clive’s condition compare to other similar psychological cases?
Alongside Clive, patient H.M (Henry Molaison) was the most famous amnesic subject. Both individuals suffered from retrograde and anterograde amnesia. However, Clive had a longer retrograde amnesia than H.M who was able to remember past experiences up to 2 years before his operation. Furthermore, H.M does not have semantic memory impairments, whereas Clive does. Patient H.M is aware of there being other days as he describes his situation as ‘every day is alone in itself, whatever joy I’ve had and whatever sorrow I’ve had’. Clive believes he has just woken up and is not aware that there have been other days. S e c t i
The implications of Clive’s condition for psychology and neuroscience
Clive Wearing’s unique case has transformed our understanding of memory and consciousness. The extensive array of studies that have been conducted on him have redefined the distinction between the different types of memory and the regions that are responsible for episodic, semantic and procedural memory. Moreover, Clive’s condition has reinforced the importance of the hippocampus in memory formation and subsequently supports similar case studies which are often criticised for being unreliable. Clive’s unique experience has also raised questions about our understanding of consciousness and perhaps will influence future adaptions definitions regarding the term ‘delusion’. Lastly Clive is testament to the remarkable resilience of our brain to overcome challenges whilst maintaining your personal identity.
Bibliography:
1. Wearing, D. (2005) Forever today: A True Story of Lost Memory and Never-Ending Love. Corgi.
2. Wilson, Barbara A., Kopelman, Michael and Kapur, Narinder (2008) 'Prominent and persistent loss of past awareness in amnesia: Delusion, impaired consciousness or coping strategy?', Neuropsychological Rehabilitation,18:5,527 540 Available at URL: http://dx.doi.org/10.1080/09602010802141889
3. Wilson, B. A., & Wearing, D. (1995). ‘Prisoner of consciousness: A state of just awakening following herpes simplex encephalitis’. In R. Campbell & M. A. Conway (Eds.), Broken memories: Case studies in memory impairment (pp. 14–30). Blackwell Publishing.
4. Wilson, B.A., Baddeley, A.D., Kapur, N. (1995). ‘Dense Amnesia in a Professional Musician Following Herpes Simplex Virus Encephalitis’. Journal of Clinical and Experimental Neuropsychology, Vol.17, pp.668-681.
5. ‘Clive Wearing’ (19 July 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Clive_Wearing
6. World Health Organisation. (5 April 2023). ‘Herpes Simplex Virus’. Available at URL: https://www.who.int/news-room/factsheets/detail/herpes-simplex-virus
7. Hazell, T., Vincent, P. (25 October 2023). ‘Immunosuppression’. Available at URL: https://patient.info/allergies-bloodimmune/immune-system-diseases/immune-suppression
8. ‘Meningoencephalitis’ (25 July 2023) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/diseases/25157meningoencephalitis
9. ‘Meninges’ (11 January 2022) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/articles/22266-meninges
10. ‘Meningitis’ (4 August 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Meningitis
11. ‘Encephalitis’ (30 July 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Encephalitis
12. ‘Encephalitis’ (15 May 2023) NHS. Available at URL: https://www.nhs.uk/conditions/encephalitis/
13. ‘Encephalitis’ (18 December 2023) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/diseases/6058encephalitis
14. ‘Lumbar puncture’ (26 January 2024) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/diagnostics/12544lumbar-puncture-spinal-tap
15. ‘Acyclovir’ (1 July 2022) NHS. Available at URL: https://www.nhs.uk/medicines/aciclovir/about-aciclovir/
16. ‘Acyclovir: 7 things you should know’ (26 July 2023). Available at URL: https://www.drugs.com/tips/acyclovir-patient-tips
17. Whitley RJ. Herpesviruses. In: Baron S, editor. Medical Microbiology. 4th edition. Galveston (TX): University of Texas Medical Branch at Galveston; 1996. Chapter 68. Available at URL: https://www.ncbi.nlm.nih.gov/books/NBK8157/
18. ‘Infected cell protein 47’ (26 December 2020). Available at URL: https://en.wikipedia.org/wiki/Infected_cell_protein_47
19. ‘Herpes Simplex Virus’ (2 August 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Herpes_simplex_virus
20. Aryal, S. (2022). ‘Herpes Simplex Virus 1 (HSV-1) – an overview’. Available at URL: https://microbenotes.com/herpes-simplexvirus-1-hsv-1/
21. AK AK, Bhutta BS, Mendez MD. Herpes Simplex Encephalitis. [Updated 2024 Jan 19]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan- Available at URL: https://www.ncbi.nlm.nih.gov/books/NBK557643/
22. ‘Herpes Simplex Encephalitis’ (26 October 2023). Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Herpes_simplex_encephalitis#:~:text=The%20virus%20lies%20dormant%20in,has%20been%20fou nd%20in%20humans.
23. Davies, N. (2022). ‘Herpes Simplex Virus Encephalitis’. Available at URL: https://www.encephalitis.info/types-ofencephalitis/infectious-encephalitis/herpes-simplex-virus-encephalitis/
24. ‘Trigeminal nerve’ (22 July 2024) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/body/21581-trigeminalnerve
25. ‘Olfactory nerve’ (21 May 2022) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/body/23081-olfactorynerve
26. ‘Cranial nerves’ (27 October 2021) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/body/21998-cranialnerves
27. ‘Pericyte’ (19 July 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Pericyte
28. ‘Fornix (neuroanatomy)’ (15 January 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Fornix_(neuroanatomy)
29. ‘Mammillary body’ (8 July 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Mammillary_body
30. Hernández, A. (2022). ‘Hippocampus’. Available at URL: https://www.osmosis.org/answers/hippocampus
31. ‘Hippocampal formation’ (23 February 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Hippocampal_formation
32. Shahid, S. (2023). ‘Dentate gyrus’. Available at URL: https://www.kenhub.com/en/library/anatomy/dentate-gyrus
33. ‘Subiculum’ (8 May 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Subiculum
34. ‘Amygdala’ (11 April 2023) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/body/24894-amygdala
35. Guy-Evans, O. (2023). ‘Amygdala: What it is and its functions’. Available at URL: https://www.simplypsychology.org/amygdala.html
36. Hamann, S. (2010). ‘Affective Neuroscience: Amygdala’s Role in Experiencing Fear’. Available at URL: https://www.cell.com/current-biology/pdf/S0960-9822(10)01593-9.pdf
37. ‘Temporal lobe’ (8 January 2023) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/body/16799-temporallobe
38. Sendić, G. (2023). ‘Fornix of the brain’. Available at URL: https://www.kenhub.com/en/library/anatomy/fornix-of-the-brain
39. ‘Inferior temporal gyrus’ (13 June 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Inferior_temporal_gyrus
40. ‘Middle temporal gyrus’ (8 July 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Middle_temporal_gyrus
41. ‘Insular cortex’ (25 July 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Insular_cortex
42. Vasković, J. (2023). ‘Insula’. Available at URL: https://www.kenhub.com/en/library/anatomy/insula-en
43. Dan D Jobson, Yoshiki Hase, Andrew N Clarkson, Rajesh N Kalaria. (2021). ‘The role of the medial prefrontal cortex in cognition, ageing and dementia’, Brain Communications, Volume 3, Issue 3. Available at URL: https://doi.org/10.1093/braincomms/fcab125
44. ‘Striatum’ (1 August 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Striatum
45. ‘Anterograde Amnesia’ (5 June 2022) Cleveland Clinic. Available at URL: https://my.clevelandclinic.org/health/diseases/23221anterograde-amnesia
46. ‘Consciousness’ (12 August 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Consciousness
47. ‘Damasio’s theory of consciousness’ (11 January 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Damasio%27s_theory_of_consciousness
48. Shah KP, Jain SB, Wadhwa R. Capgras Syndrome. [Updated 2023 May 29]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan- Available at URL: https://www.ncbi.nlm.nih.gov/books/NBK570557/
49. ‘Fregoli delusion’ (28 June 2024) Wikipedia. Available at URL: https://en.wikipedia.org/wiki/Fregoli_delusion
50. Ruminjo A, Mekinulov B. (2008). ‘A Case Report of Cotard's Syndrome’. Psychiatry (Edgmont). Available at URL: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2695744
51. Wills, C. (2023). ‘Studies of brain damaged patients’. Available at URL: https://www.studocu.com/en-gb/document/university-ofcambridge/psychology/case-studies-hm-and-clive-wearing/51670605
53. France, L. (2005). ‘The Death of Yesterday’. Available at URL: https://www.theguardian.com/books/2005/
WOULD THE UNIVERSE EXIST IF THERE WAS
NOTHING AROUND TO OBSERVE IT?
BY ARIE BIJU
(Fifth Year – HELP Level 3 – Supervisor: Mr D Schofield)
1. Introduction
1.1. Setting out the question
1.2. Defining key terms
2. Arguments for the Universe’s existence
2.1. The Universe preceding consciousness
2.1.1. The Big Bang Theory
2.1.2. The timeline of the evolution of life
2.2. Indirect Realism
2.3. Quantum Decoherence
3. Arguments against the Universe’s existence
3.1. Interpretations of Quantum Mechanics
3.1.1. The Double-Slit Experiment
3.1.2. The Copenhagen Interpretation
3.1.3. Schrödinger’s cat
3.1.4. Eugene Wigner
3.1.5. The Many Worlds Interpretation
3.1.6. John Wheeler
3.1.6.1. Delayed choice experiment
3.1.6.2. Participatory Universe Theory
3.1.7. Evaluations
3.2. Idealism, Dreams and the First Person Perspective
4. Conclusion
4.1. Summary and evaluation
4.2. Bibliography
1. Introduction
1.1. Setting out the question
At first glance, this question seems rather straightforward. As Albert Einstein jested to Niels Bohr, ‘is the moon there when nobody looks at it?’, it is often immediately assumed that our observations don’t make much of an actual impact on the universe itself. Even if we turned away from the moon, it would still continue to exert its gravitational force on the earth, causing waves among other phenomena , so how could it not exist? However, there are arguments against even the simple assumption I just used as an example. Quantum mechanics has evidence for the different types of observations that we choose leading to significant effects on particles, and idealism and similar arguments back up the belief that all of reality may be dependent on the mind. There are many arguments like these that have been crafted by both philosophers and scientists over the past few centuries, and so this question is very difficult to navigate. In addition to this, there really is no definitive answer to this question. Therefore, my aim is to provide an overview and evaluation of some of the strongest arguments for both sides, while simplifying them so that they are clear and understandable. As Joseph Joubert said, “It is better to debate a question without settling it than to settle a question without debating it.” (Hasan, 2023) In order to get started with the arguments, the key definitions that shall be used throughout this book must be first laid out and clearly explained.
1.2. Defining key terminology
To fully understand the arguments used for this essay, it is important to come to agreed definitions of different key words. Firstly, the Universe can be described in different ways by different sources, but for this essay we shall define it as ‘the totality of all the things that exist’ (Harper Collins Publishers, 2010), or basically everything that has existed, is existing and will exist. In this definition, the term existence has come into play too. This shall be defined as the manner in having being or reality rather than having nonexistence or nonbeing. Another key definition is that of sense-data, which has been described by Bertrand Russell as ‘the things immediately known in sensation’ (Russell, 2015), and he gives examples, such as colours, sounds and smells. This is meant to be caused by a mind-independent external world, and is private to yourself, only existing in the mind. He also defines the term ‘sensation’ as the ‘experience of being immediately aware of these things’ (Russell, 2015). The most important definition for this essay however must be that of observation. This is the ‘act of noticing or perceiving and acquiring information from a primary source’ (Metaphysics Research Lab, 2017). In addition to this, there are two types of observation: conscious, which employs the senses, as well as non-living, which refers to the perception and recording of data without the use of senses. As Werner Heisenberg stated, ‘it does not matter whether the observer is an apparatus or a human being’ (Heisenberg, 2007), it does not matter in which manner observation occurs for the observer effect, which we will discuss in Section B of this essay, to take place.
SECTION A:
2.
Arguments for the Universe’s existence
2.1. The Universe preceding consciousness
The argument using the claim of the universe preceding consciousness is particularly fascinating as it can make other arguments seem ridiculous and paradoxical – how were conscious beings, and thus observers, even formed if this argument meant that the universe could not exist before they came into being? This claim follows on the idea of the universe existing long before the start of conscious life as we know it, which has been upheld by evidence from the Big Bang theory, with the big three being the expansion of the universe, cosmic microwave background radiation, and wrinkles in said radiation, along with the timeline of evolution of life.
Before the big bang theory became accepted, many philosophers were not happy with the idea that the universe had a beginning. A reason for this was to avoid divine intervention to start the universe. An example is the famed Greek philosopher Aristotle, who believed that something eternal was more perfect than something created. He suggested that the progress we saw as humans were actually the results of setbacks from floods or natural disasters. There were also many different arguments to the belief that the universe had a beginning, such as the question
of what came before the beginning, and why the Universe waited an infinite time before it began. Immanuel Kant called the latter problem the thesis – but this mainly relied on his assumption that time was absolute.
In 1915 Einstein introduced his ground-breaking theory of relativity, which unified time and space. This stated that space and time were dynamical quantities which were determined by the matter and energy in the universe, and so time was a property that was only defined within the universe, and thus there was no time before the universe began. However, this theory told us little regarding space itself.
In the 1920s, Edwin Hubble, using the hundred-inch telescope on Mount Wilson in the 1920s, discovered that the universe was expanding. He did this by analysing the light from other galaxies and found that nearly all other galaxies were moving away from us, and that the further that they were, the faster they were moving away. This meant that if the galaxies must have been closer together in the past. Using the present rate of expansion, it looked like everything in the universe may have been in the same point in space about 10-15 billion years ago. This provided strong evidence to the rough theory of a Belgian priest named Georges Lemaitre (Staff, 2024) in the 1920s, called the Big Bang Theory, in which he stated that the universe began from a single, primeval atom.
Stephen Hawking and Roger Penrose also managed to prove geometrical theorems to demonstrate that the universe must have had a beginning, provided that Einstein’s general theory of relativity was correct and some reasonable conditions were
satisfied. This mathematical proof could not be easily rebutted, and therefore it became accepted that the universe must have had a beginning.
However, the theory of relativity was not without downside. The Big Bang Theory means that there was originally a very compact point of infinite density as the universe, which breaks down Einstein’s theory, and therefore we cannot use it to predict the universe’s beginning. In order to truly completely understand the origin of the universe we must incorporate the Uncertainty Principle, which says that we cannot know the values of some pairs of quantities simultaneously, into Einstein’s general theory of relativity. This is because the universe is, unlike Einstein famously fiercely believed, governed by probability. We can relate this to rolls of dice, just as Einstein said ‘God does not play dice’. I think that I will answer as Bohr did. Einstein, stop telling God what to do. (The Center of History of Physics, 1996) When rolling dice, over large numbers of rolls, the result averages out to something one can predict, as would therefore be in a large universe. However, when the universe is little, there are few dice rolls, and thus the uncertainty principle becomes very significant. This means that in order to know the manner of the start of the universe we must merge the two theories, and so this is a significant challenge is the modern physics world.
In October of 1965, Arno Penzia and Robert Wilson (The European Space Agency, N/A) stumbled on a scientific gemstone by chance. The two radio astronomers came across the phenomenon known as cosmic microwave background radiation. The only reasonable interpretation of the radiation led
it to be defined as the “cooled remnant of the first light that could travel freely throughout the universe”, being released “soon after the Big Bang” (The European Space Agency, N/A) . This backed up the Big Bang theory, as it was the only model that could convincingly explain the existence of the cosmic microwave background radiation.
An extraordinary aspect of our universe relates to the cosmic microwave background radiation, which acts like a ‘fossil’ record of the previous universe. When changing the direction of observation, there are minor discrepancies in the radiation by a difference of 0.00001%, or one part in 100,000 (Hawking, 2018). These differences need an explanation, and so Stephen Hawking wrote a paper that stated that these discrepancies arose from quantum fluctuations – a by-product of the Uncertainty Principle. This had happened during the rapid period of inflation in the early stages of the universe. This theory was illustrated by the WMAP satellite in 2003, which captured a map of the temperature of the microwave radiation sky when the universe was just 400,000 years old (Hawking, 2018). This, again, does support the Big Bang Theory. So, God really does play dice, Einstein.
In addition to the Big Bang Theory, we must also show that life could not have existed before the universe formed. To do this, we must have an idea of when life began existing. The exact time and method in which life came into being is still very uncertain, but the beginning of evidence for life’s existence dates back 4.1 billion years. Mark Harrison made the discovery of a shard of rock containing two microscopic flecks of graphite, and these ‘flecks were found in a zircon crystal that had lain…
for 4.1 billion years’ (Stuart, 2016). While this seems very underwhelming at first, this small evidence could be enough to prove that life existed even before when anyone had ever believed it originated. However, with the Big Bang Theory informing us that the universe had come into existence around 10-15 billion years ago, it is almost certain that life did not exist before the universe began. This means that when regarding this question, as observation could not have occurred before life began, the first signs of life was around 6-11 billion years after the creation of the universe. This leads us to the question of how we got to this point in time if the universe could not exist without observation, as when life did not exist, observation could not have been occurring. Therefore, the universe would not have existed and so could not be existing right now. Therefore, this argument concludes, that observation should not be needed for the existence of the universe.
This is a very strong argument, and when we get to the theory of decoherence, that fits very well with this too. However, there are different rebuttals to this argument, such as panpsychism. This is the view that consciousness is fundamentally a part of everything, in contrast to it being a derivative result obtained by the universe’s evolution. This would mean that despite ‘life’ forming only around 4.1 billion years ago, consciousness itself would be embedded in the universe and everything in it and so observation could be perpetually occurring. It has had many famous advocates, such as Max Planck, who himself said “I regard consciousness as fundamental. I regard matter as derivative from consciousness. We cannot get behind consciousness. Everything that we talk about, everything that we regard as existing, postulates consciousness.” (Planck, 1931).
However, the main chink in panpsychism’s armour lies in the lack of testable hypotheses it leads to. This makes it an easy target for criticism as we may never be able to conclusively tell if it is true or not.
Another argument I want to very briefly mention here is one regarding to God’s existence. It is possible that God existed and caused the Big Bang to create the universe, thus observing the universe since and before its start. While this argument has immense potential, there is not only no scientific evidence and no proper testing possible for this argument, but the question of God’s existence is an entirely separate debate in itself and complicates matters significantly. With this in mind, I think it is better to steer away from this chain of thought while just making mentioning the possibility. Finally, other arguments against this include some interpretations of Quantum Mechanics, as well as arguments against the existence of an external reality, which we will discuss in Section B.
Overall, I think that we can definitely see that this argument is very strong, and while panpsychism offers a perfect explanation and argument against this, it really does not have any evidence to its side to tilt the favour in its side. Furthermore, Quantum Decoherence also goes quite well with this argument, and we will talk about this pretty soon. I will finish the evaluation for this section in the conclusion, as it must combat the arguments in section B: it is a very strong argument, and so will decide which side I will end up arguing for.
2.2. Indirect Realism
Indirect realism is the view that there is a reality that exists independently of our minds. In this view, we perceive this external reality indirectly, through sense-data, and so it is all about sense-data not being the only thing that exists. The view thus argues in the favour of an existence irrespective of whether anything existed to observe it or not.
Bertrand Russell describes some arguments supporting this in his famous book, The Problems of Philosophy. One example involves using a cloth to completely cover a table. If the table was only sense-data, then the action of covering it would mean that it would have stopped existing, as it loses all of its sensedata, leaving the cloth suspended in empty air. This in itself is an “absurd” (Russell, 2015) statement, but we cannot simply conclude an argument at one such case.
Another argument that Russell utilises involves a cat and our senses. Let us see the cat at one moment in a part of a room, and then stop watching it and move to another room, where we then see it enter after us. It seems natural to assume that the cat had passed “over a series of intermediate positions” (Russell, 2015), in order to move from the first room to the next. However, if the cat was only a set of sense-data, then it cannot have existed where we did not see it, so it must have suddenly popped into existence. This makes changes in the attributes of the cat, such as its hunger or tiredness, near inexplainable when considering it to be merely a construction of sense-data, thus leading Russell to argue that the cat passing over a series of places is the best
hypothesis possible. This means that there should be an external reality behind this sense-data, as it cannot exist by itself.
However, one may argue that this result is due to the cat being a living being, saying that this is not a valid argument of indirect realism, as it does not mean that there is a complete external world. In response to this, I thought up the idea of substituting a block of copper into the place of the cat in this argument. This material, while not being a living organism, oxidises and changes colour from a pink -brown to a green colour. Therefore, if you left an unoxidized block of copper in a room and left the room for some time, before returning to find it changed in colour, it really seems impossible that the copper block is merely a set of sense-data, as it changed from pink-brown to a green colour independently of our minds. As the copper block is non-living, this argument does back up the existence of an external world, thus supporting the view of indirect realism.
These arguments provide a relatively strong argument that sense-data is merely what we perceive, and resembles the external, consciousness-independent external world. However, this case can be argued against very strongly. Some of these arguments include idealism, dreams and the first person perspective, which are a topic together in the second section of this essay, as well two more which we will talk about now.
Firstly, George Berkeley argued that the differences between sense-data and consciousness-independent objects undermine indirect realism. This argument is based on the views that sensedata’s properties are not constant, as well as entirely different to the properties of the mind-independent objects. For example,
moving around an object can lead it to appear differently. A circular table can appear to look like an oval from one angle and like a circle from another, while the actual constant object of the table does not change in its data. How can this changing data translate to a constant object? Furthermore, how can the sensedata of objects be like the properties of mind-independent objects? For example, would a circular table have circular sensedata? They are really fundamentally different things! Therefore, we can see that Berkeley’s rebuttal is very powerful.
The final argument (in this section) against indirect realism regards the inability of humans to actually access the external reality that this refers to. As we can really only access sensedata, not the actual object in question, we really have no idea if sense-data actually represents the external world, and therefore no idea if the external world actually exists at all! Bertrand Russell replied to this argument, and said that we indeed cannot be ‘perfectly certain that an external world exists’ (Princeton University, N/A), and that we have to treat the existence of an external world as a hypothesis. He then says that as it makes sense and is the most logical option, an external world is the only reasonable hypothesis. This highlights the significance of this rebuttal, as there is no way to prove indirect realism completely.
In conclusion, we can see that the strength of the argument itself unravels with these two rebuttals. It is reduced to the most reasonable hypothesis, which holds little overall value. We still have to talk about idealism, dreams and the first person perspective, and so we will have to complete the evaluation for this section on that part.
2.3. Quantum decoherence
Decoherence is a theory ‘based on the idea that the environment destroys quantum coherence’ (Yam, June 1997), leading to ‘environment-induced superselection’ . (Zurek, Decoherence and the Transition from Quantum to Classical Revisited, 2002). This is a massive amount of complex information, so I’ll break this statement up into more reasonable chunks to swallow. Quantum coherence is essentially the ability of a quantum system to be able to maintain a stable superposition of quantum states, allowing it to be able to be described by a wave function.
Diagram 1: Wave function collapse: inspired in part by (DK, 2021) , drawn by me.
Zurek, a famous backer of the theory of decoherence, described the theory by saying that the coherence “leaks out” (Zurek, Environment-Induced Superselection Rules., 1982) from the system, losing quantum information by doing so. This happens
due to the system interacting with the wave functions of its environment, as the superposition of quantum states undergoes a collapse, leading to it not being in superposition any longer, and causing outcomes to be determined. This can be taken to explain that consciousness is not needed to collapse the wave function. It also explains that large systems would not enter a superposition, as all of the wavefunctions would interact with each other to make coherence impossible.
This allows it to fit almost seamlessly with the argument for the universe preceding consciousness, as it provides an explanation for how the universe could have existed without consciousness for the 6-11 billion years it is believed it did so for. However, I realised that decoherence has less of an effect on smaller systems. This leaves us with no explanation for when the universe itself was comprised only of small systems and so it would remain in a superposition between states , and so the argument using decoherence here can still be seen to be flawed as it is still incomplete.
It is also criticised heavily for not actually explaining how particular outcomes are achieved. ‘Quantum superpositions must somehow yield outcomes that conform to our everyday sense of reality’ (Yam, June 1997), but as decoherence only ‘reduces the… (superposition) to a probabilistic choice between outcomes’ (Tony Hey, 2003), it does not say anything about how they are chosen. As such, it actually provides little explanation. Bell said that unless we know “exactly when and how it (wave function reduction) takes over… we do not have an exact and unambiguous formulation of our most fundamental physical theory” (Tony Hey, 2003). Therefore, it is said that the
Many Worlds Interpretation, which we will discuss in section B, is better as it provides an explanation for the collapse and how we get specific macroscopic results.
While the theory of decoherence would assure Einstein that the moon would exist whether or not anyone was looking at it , we can see that it is a very open argument for and against it. On one hand, it does well with the motion of the universe preceding consciousness, but it still lacks a complete explanation even after being paired with it. It is also flawed as it really does not explain how a single, specific outcome is chosen, and therefore the Many Worlds Theory, which we will discuss, has been treated by some scientists as a superior theory. I would conclude that it makes the argument for the universe preceding consciousness stronger, but still is quite flawed in itself.
Section B:
3. Arguments against the Universe’s Existence
3.1. Interpretations of Quantum Mechanics
3.1.1. The Double-Slit Experiment
The renowned double-slit experiment is not only a way to demonstrate the wave and particle-like properties of ‘particles’ such as electrons and photons, but also the remarkable effects of measurement. To go through this, who better than to follow in the footsteps of than the legendary Richard Feynman.
In his third volume of lectures, which is specifically on quantum mechanics, he begins to describe the two slit experiment by first describing an experiment that displays the “familiar behaviour of particles like bullets” (Richard Feynman, 2012). He does this by describing a setup of a gun that fires bullets randomly over a large area in front of it, and so randomises where the bullet shall go. There is a wall with two slits in front of it, where the bullets can go through, and a backstop behind it that where the bullets can sink into. The bullets travelling through the two slits can either go directly through without hitting the wall, or hit the wall
and deflect, changing course in varying ways, therefore randomising some results even further but with a lower probability. I have given my best effort at drawing this out for reference below. A little note I would like to add is that P1
Diagram 2: A bullet interference experiment, inspired by (Richard Feynman, 2012), drawn by me represents the results obtained by the hole 1. The main message from this is that when we are dealing with particle-like substances, there is no interference observed.
Therefore, if we were to perform this experiment with electrons, we would expect no interference too, right? This view was mirrored by many other physicists around the 19th century before the experiment was actually performed, as electrons had shown to exhibit particle-like behaviour before. However, when putting this into practise, we are stunned to find that this is wrong.
In fact, electrons produce an interference pattern, as they behave like waves during this experiment. This is caused by the electrons approaching the two slits like waves, but getting refracted once they reach it. From there, the resultant waves
interfere with each other, to cancel out and amplify at certain points, causing the famous interference pattern.
Diagram 3: The double-slit experiment, made by me It can’t get any weirder right? Surely not? Well, look what scientists found next. If we wanted to measure which slit the electron went through when it did so, we can place a particle detector close to each slit. From there, we can repeat the experiment. When we do so, we find that our interference pattern has disappeared!
Diagram 4: The measured double -slit experiment, made by me
When we take the measurement of which slit the electron goes through, we find that each electron only goes through one slit ! We can deduce from this that the act of measuring the electron, or observing it, causes it to exhibit particle-like features. This
means that there are no waves to interfere with each other, and so we get a result of no interference. Therefore, we can see that just by observing the system, we have changed the observed reality. This phenomenon became known as the Observer Effect. This has therefore provided a very strong foundation for theories to be built on observation creating a, or the, reality.
3.1.2. The Copenhagen Interpretation
Now that we have accepted that just by observing something, we can change it, we can move on to one of the most popular interpretations of quantum mechanics: the Copenhagen Interpretation. In the late 1920s, physicist Niels Bohr proposed the Copenhagen interpretation for the first time in a lecture in Como, Italy (Gribbins, 1984). It states that before measurement, events follow quantum rules, and systems can be described by wave functions and exist in all the possible states simultaneously rather than in just one. Then, when an observer measures the state of a quantum system, the wave function of the system collapses into a single value, which is what we see when it is measured. For example, measuring which slit an electron goes through in the double-slit experiment. This explains the erratic behaviour of a quantum particle, and maybe could soothe the stressed Schrödinger over his “damned quantum jumping” (Heisenburg, 1971), since it explains how particles can easily be put into a different observable state.
It also introduces the “pragmatic” (Zohar, 1997) approach taken by many physicists and chemists. Bohr said to not worry about the hows and whys of measurement, and to just accept that it
causes the collapse of the wave function. How very kind of you Bohr, to worry about us getting stressed. He also gives us another mystery that he says we shouldn’t worry about, his Complementarity view, in which he says that all of the seemingly contradictory parts of quantum reality complement each other, such as light sometimes behaving like a wave and sometimes like a particle.
As such, the Copenhagen Interpretation can be seen to be flawed. It is too vague, not defining what a measurement is, and it also says that an object does not have a definite value preceding measurement. This latter criticism really did not sit well with Schrödinger, and he ended up creating what is now the face of quantum physics to try and prove this theory wrong – the Schrödinger’s cat paradox.
3.1.3. Schrödinger’s cat
Schrödinger decided that the Copenhagen Interpretation was just absurd. To try and prove his point, he introduced the thought experiment (so don’t worry, no cats were harmed in the making) that is now widely known as ‘Schrödinger’s cat’. This involves a cat in a chamber, with an incredibly small amount of radioactive substance that has a 50-50 chance of decaying in an hour. If this occurs, a relay mechanism is activated, causing a hammer to be released which then shatters a flask of hydrocyanic acid which would kill the cat. In the case of the radioactive substance decaying, the cat must have been killed by the poison, and if the radioactive substance has not decayed, then the cat lives. Therefore, according to the Copenhagen Interpretation, the wave
function of the system will have equal amounts of alive and dead cat, as the cat is told to be in a superposition between dead and alive. This paradox does therefore highlight the problems with the Copenhagen Interpretation, as this seems ridiculous. Surely the cat can only be either dead and alive at one time ? What would the cat even feel if it were in a superposition between dead and alive? We can also consider if the cat c ould cause its own collapse of its superposition between states as it is conscious – but then at which point do living beings stop possessing consciousness? Does it need to have a PhD in quantum mechanics or is it fine if it’s only a computer that measures the result to collapse the superposition between states?
However, common sense really doesn’t prove much of an obstacle to quantum mechanics. We have seen the double slit experiment, regarding electrons, which proved that electrons were not particles but sometimes behaved like particles and sometimes behaved like waves. So, we must continue to be critical of such assumptions and look for real evidence. The fact is, we don’t actually know what happens until we look inside the box. Due to these lines of reasoning, this paradox has had continual debating by many other philosophers and physicists. One such extension to this paradox was made by Eugene Wigner.
3.1.4. Eugene Wigner
Eugene Wigner, holding the then popular belief that consciousness was the reason for the collapse of superpositions between states, was deeply interested in the paradox of
Schrödinger’s cat. After much thought and consideration, he created his own unique addition to the popular problem – a thought experiment by the name of ‘Wigner’s friend’. It goes, if we have a human friend of Wigner watching over the cat, then we could ask them if the decay had already occurred or if the superposition only collapsed when we opened the box to check if the cat was dead or not. And this means that by the Copenhagen Interpretation, Wigner’s friend also exists in a superposition between having seen the death of the cat and not, until we observe the entire system as a whole and determine the reality. Wigner rejected this belief, as he thought that conscious observers could not be in superposition between states.
This can continue in a chain of infinite regression. We can imagine this: if people are in a room with a box with Wigner’s Friend and Schrödinger’s cat in it, and then check on Wigner’s friend by opening the box, then we (outside the room) still don’t know what has happened, and so the people in the room inside are also in a superposition between states.
This chain of regression can keep on continuing, and drove Wigner and von Neumann to their own (well, we’ll see to what extent that is though) interpretation. This is because they argued that this result of a chain of regression implies that the consciousness of the observer does indeed lead to the collapse of the superposition between states. The von Neumann–Wigner Interpretation, as it is called, states that a conscious observer causes the collapse of that superposition. This is almost exactly the Copenhagen Interpretation, but it is a much more “specific variation” (Kendall, 2019). This crucial element removes key flaws from the interpretation, keeping this a strong argument.
The main argument against this is the question of which point a living ‘observer’ does not have sufficient consciousness to collapse the superposition. We have already mentioned it in the section on Schrödinger’s cat, but I would say that it is not such a significant flaw, more similar to a yet unsolved issue with it, as to disregard it being a strong argument.
3.1.5. The Many Worlds Interpretation
This argument is simple and astonishingly appealing. Hugh Everett, a student of John Wheeler (the creator of the next argument we will look at) at Princeton University, proposed the first draft of this argument as his 1957 Ph.D. thesis (Tony Hey, 2003). It gained little traction for the first 10 years, until Bryce DeWitt wrote an article on this proposal, calling it the ‘Many Worlds Interpretation’. This stated that all possibilities of measurements or observations were all real, and as each was made, an alternative copy of the universe is made as the universe multiplies itself.
Despite what would be a very satisfying explanation to the entire question, this has one critical flaw. It’s the reason that there is so little to say about it: it has no method of obtaining evidence for it. Each of these separate universes cannot interact with each other, and so it cannot be tested and backed up with scientific results. Even though it is so, it still has much support from scientists, such as Stephen Hawking, and Sean Carroll, who said that the theory is “not science fiction. This is what many of us including myself think is likely true; a correct description of
nature.” (Carroll, 2020) I think that overall, this is a very strong argument, despite the lack of evidence for it.
3.1.6. John Wheeler 3.1.6.1. Delayed Choice Experiment
John Wheeler, the man who created the name for “black holes”, also invented a thought experiment in which our decision determines the actions of a photon in the past. This became known as the delayed choice experiment, and there are many different versions of it. For the purposes of this essay, we will utilise the cosmic scale version, as it is simpler and easier to understand. I have illustrated this below, to make it easier to visualise.
Diagram 5: Delayed Choice experiment, drawn by me, inspired by (Horgan, 1992)
In this thought experiment, we have a quasar that emitted a photon some million years ago. It travelled as a wave, and went
around a black hole, as gravitational lensing caused it to be able to travel in two different (relevant) paths, in which it can travel down both or just one, similar to in the double-slit experiment. Gravitational lensing occurs when a large body of matter “causes a sufficient curvature of spacetime for the path of light around it to be visibly bent, as if by a lens” (NASA/ESA Hubble, N/A), and is caused by the large gravitational forces of attraction. This also causes the photon to be able to split down two paths. Let us say these paths then come close to converging on the Earth in a science facility, where we want to study th e photon.
We then can choose from two sets of apparatus: two detectors or an optical screen to view the photon. If we choose the optical screen, we then find that an interference pattern has been generated, as the photon has gone both ways around the galaxy and then interfered with itself, and therefore created an interference pattern. However, if we choose the two detectors, we are directly observing and measuring the photon, and so the photon has only travelled one way or the other around the galaxy. This means that only one of the detectors will receive a photon. Again, this is just like the double slit experiment!
But wait. This means that the choice of an action that we made now decided whether the photon went down both paths or one path… a few million years ago? Surely this is just a thought experiment though, and it has no evidence, right? But in fact, in 1984, physicists in the University of Maryland and in the University of Munich (Horgan, 1992) set it up independently, successfully, and proved that the paths photons took were not fixed until the measurements were made!
3.1.6.2. Participatory Universe
The delayed choice experiment’s results led Wheeler into his theory of a Participatory Universe. In this theory, the observer plays a role in actively “bringing about the very reality they then look at.” (Zohar, 1997) I like the idea of comparing this theory to an unfinished story, where the author writes not only the end but also the beginning based on the events unfolding in the middle of the book. This suggests that by observing things like “the photons of cosmic background radiation” (Gribbins, 1984), we may be creating the Big Bang in the past. Like the Many Worlds interpretation, this approach is very bold and daring, and also appealing as it does have solid evidence behind it.
The only main argument with this theory is the question of how would we have got here at all if we are shaping history? This poses a slight issue, but it is really a problem that must come with this type of argument. Therefore, Wheeler’s theory of a Participatory Universe remains a strong, valid argument.
3.1.7. Conclusions
Overall, in this section, we can see that while the popular Copenhagen Interpretation holds many flaws and so is not a very good argument to use in this argument, the von NeumannWigner interpretation, the Many Worlds Interpretation and the theory of a Participatory Universe are all very strong arguments for the universe’s existence relying on observation.
3.2. Idealism, Dreams and the First Person Perspective
Idealism is the view that there is no external reality independent of the consciousness. It claims that “all that exists are ideas”, and “unless something is being perceived, it doesn’t exist . ” (Philosophy A-Level, N/A). However, this case is very complex, having many arguments for it and so I aim to cover the best, most understandable ones. Furthermore, some famous arguments in favour of Idealism include the assumption of the presence of a God, which as I talked about earlier in this essay, is an entirely different debate within itself. This would make this essay even more complex and so I will leave it out. We also have to define some key words here, such as the distinction between primary and secondary qualities. Primary qualities are those that are “inherent in the objects” while secondary qualities “depend on a person’s subjective sensory experience” (Bodleian Libraries - Oxford University, N/A). Another important term is perception, which is very similar to observation, and is just about using the senses to extract information.
Bishop Berkeley, whose motto was “esse est percipi” – “to be is to be perceived”, was the first philosopher to try and establish idealism in a serious attempt. He was famous for his idealist and empiricist arguments. In one of his most famous books, Three Dialogues between Hylas and Philonous (Berkeley, 1713), he first addressed that sense-data must be part of the mind, as it would not exist if we did not have any senses. He said that it was all that we perceived and therefore all that we can truly
know by our senses. Then, he goes on to state that secondary qualities, like heat, must be mind-dependent, as they can be experienced together with the mind-dependent pain as one sensation. He further argues that primary qualities, such as size, shape and motion, change in different points of view (for example differently for a human compared to a fly), and so are also mind-dependent. As all we perceive is either a primary or secondary quality, which are mind-dependent, all sense-data is mind dependent and so all we truly know is mind-dependent. This suggests that there is no external reality that is mindindependent, and so if there was nothing to observe this minddependent universe, it would not exist.
Furthermore, Bertrand Russell mentions the argument of dreams suggesting that there is no external world. In dreams, we are usually convinced by everything happening around us, as all of our senses provide sense-data that misleads us into believing that the dream is real. We can feel fear, joy or even pain. However, when we wake, we realise that it was actually all just a dream. As all we know of the external reality is the sense -data that we perceive, and we can doubt the sense -data which misleads us in dreams, how do we know if there really is an external mind-independent reality? How do we know if this so called reality is a dream or not, while our so called dreams are the true reality? We could be in a simulation or hallucination for all we know. As there is no proven scientific theory for why this happens yet, this implies that may be no mind-independent reality, and therefore backs up the claim that observers are needed for the existence of the universe.
Finally, the presence of a first-person perspective in life seems to indicate that there is a direct correlation between consciousness and reality. As we can only interact with reality through this first-person perspective, which depends on our mind, there is no reason to assume that there is an external reality to our mind. Whether that may regard the existence of other people or other objects, we can therefore only be certain of our consciousness, if we use this critical thinking.
There are also arguments against the belief that there is no external world. For example, Bertrand Russell counters these arguments using the existence of instinctive beliefs. He says that as they tend to “simplify and systematize our account of our experiences, there seems to be no good reason for rejecting it” (Russell, 2015) and then believing that there is no external reality. Therefore, he concludes that “the external world does really exist” (Russell, 2015). However, I would disagree with this. We instinctively believe many things, which can easily be proven wrong, like assuming that electrons are particles. Furthermore, I decided that most instincts exist to try and protect us. What if the instinct to try and not question the existence of an external world is to protect us from giving up and so harming our own lives, as we decide that nothing matters if we only exist?
To conclude this section, we must weigh it up as a whole and compare it to indirect realism. I think that from what we have covered, the arguments for there being no mind-independent world are actually quite strong, holding up against scrutiny , unlike what Bertrand Russell concluded. In comparison to the conclusion for indirect realism, which highlighted the weakness
of the argument after the criticisms, I think that the argument s of idealism, dreams and the first-person perspective are much stronger, despite the arguments against it.
4.1. Conclusion
In conclusion, after deciding that idealism, dreams and the firstperson perspective were stronger arguments than that of indirect realism, we must finally decide which of the universe preceding consciousness together with decoherence or the interpretations of quantum mechanics that we have discussed are better arguments. For the former argument, we find that it is very strong, but lacks in the sense of being incomplete as an entire argument, while the latter has three very strong arguments that are only argued against due to inherent problems in the arguments themselves, such as not being able to be tested. I would argue that even though it’s pretty hard to say which one is conclusively stronger, the interpretations of quantum mechanics are stronger and so I am on the side of the universe not existing without anything to observe it. This is in part due to the strength of the arguments for there being no external mindindependent reality outweighing those against this claim, but mainly because of the strength of the different interpretations of quantum mechanics.
4.2. Bibliography
Carroll, S. (2020, June 24). Sean Carroll: The many worlds of quantum mechanics, 1:57 - 2:06. https://www.youtube.com/watch?v=p7XIdFbCQyY . New Scientist.
DK. (2021). Simply Quantum Physics. London: Dorling Kindersley Limited. Gribbins, J. (1984). In search of Schrödinger's cat. Great Britain: WIldwood House.
Harper Collins Publishers. (2010). Webster’s New World College Dictionary, 4th Edition. U.S.: Houghton Mifflin Harcourt Publishing Company. Retrieved from Collins Dictionary website: https://www.collinsdictionary.com/dictionary/english/universe
Hasan, M. (2023). Win Every Argument: The Art of Debating, Persuading, and Public Speaking. Henry Holt and Company . Hawking, S. (2018). Brief Answers to the Big Questions. Great Britain: John Murray.
Heisenberg, W. (2007). Physics and Philsophy: The Revolution in Modern Science. United Kingdom: HarperCollins.
Heisenburg, W. (1971). Physics and beyond: encounters and conversations. London: G. Allen & Unwin.
Horgan, J. (1992, July). Quantum Philosophy. Scientific American, pp. 94-97. Kendall, A. (2019). Quantum Mechanics & Its Broader Implications: The von Neumann– Wigner Interpretation . Mechanicsburg: Messiah University. Metaphysics Research Lab. (2017). Philosophy of Cosmology - The Stanford Encyclopedia of Philosophy. Stanford: Stanford Universiy. Mulder, D. H. (N/A). Objectivity. Retrieved from Internet Encyclopedia of Philosophy: https://iep.utm.edu/objectiv/ NASA/ESA Hubble. (N/A). Gravitational Lensing . Retrieved from esahubble.org: https://esahubble.org/wordbank/gravitationallensing/#:~:text=Gravitational%20lensing%20occurs%20when%20a,accordi ngly%20called%20a%20gravitational%20lens.
Planck, M. (1931, January 25). Interviews with Great Scientists - VL-Max PlanckThe Observer. (J. W. Sullivan, Interviewer) Retrieved from https://www.informationphilosopher.com/solutions/scientists/planck/ Princeton University. (N/A). Responses to Cartesian Skepticism / Untitled Document. Retrieved from Princeton University: https://www.princeton.edu/~grosen/pucourse/phi203/responses.html
Richard Feynman, R. L. (2012). The Feynman Lectures on Physics, Vol. 3. New York: Basic Books.
Russell, B. (2015). The Problems of Philosophy. New Jersey: J.P.Piper Books. Staff, M. G. (2024, August 16). How did the universe begin and what were its early days like? Retrieved from Natural Geographic: https://www.nationalgeographic.com/science/article/origins -of-the-universe Stuart, C. (2016, April 20). How two tiny dots defy the history of life and the solar system. Retrieved from New Scientist: https://www.newscientist.com/article/mg23030700 -400-how-did -we -gethere-a-lot-earlier-than-we-thought-it-turns-out/ The Center of History of Physics. (1996, November n/a). Einstein and Bohr. Retrieved from AIP center for history of physics: https://history.aip.org/exhibits/einstein/ae63.htm#:~:text=Einstein%20and% 20Bohr,Photograph%20by%20Paul%20Ehrenfest.
The European Space Agency. (N/A). Cosmic Microwave Background (CMB) radiation. Retrieved from The European Space Agency: https://www.esa.int/Science_Exploration/Space_Science/Cosmic_Microwav e_Background_CMB_radiation
Tony Hey, P. W. (2003). The New Quantum Universe. Cambridge: Cambridge University Press. Yam, P. (June 1997). Bringing Schrödinger’s Cat to Life . Scientific American, Vol. 276, No. 6, 124-129.
Zohar, I. M. (1997). Who's afraid of Schrödinger's cat? New York: William Morrow.
Zurek, W. H. (1982). Environment -Induced Superselection Rules. Phys. Rev. D, 26.
Zurek, W. H. (2002). Decoherence and the Transition from Quantum to Classical Revisited. Los Alamos Science , 5-6. Retrieved from arXiv: https://arxiv.org/pdf/quant -ph/0306072
USING NATURAL LANGUAGE PROCESSING AND MACHINE LEARNING TECHNIQUES FOR DATA EXTRACTION
AND READING COMPREHENSION
BY PATRICK MORONEY
(Fifth Year – HELP Level 3 – Mr V Ting)
Contents:
Introduction
Language used
Example flow through
Flowchart
Theoretical example
Tokenisation
Purpose
Coded implementation
Stemming
Purpose
Coded implementation
Term frequency – Inverse document frequency (TF-IDF) and its use to create vectors
Purpose
Maths behind it
Coded implementation
K nearest neighbours (KNN) to identify and remove
Stopwords:
Purpose
Maths behind it
Selecting ����
Visualising the data
Areas of further research
Coded implementation
Cosine similarity
Purpose
Maths behind it
Coded implementation
HTML reader
Purpose
Coded implementation
Extracting example questions data from Google Natural
Questions
Purpose
Coded implementation
Project, using functions for a complete run through
Purpose
Coded implementation
Main loop and test vs user input
Purpose
Coded implementation
Results and accuracy for Articles, Paragraphs and Sentences
Notation guide
Glossary
Introduction:
The aim of this project is to create a program that will be able to accurately extract relevant information from a text to answer questions using natural language processing (NLP) and machine learning (ML) techniques. In this written aspect of the project I will explain the purpose, what is it, maths, and coded implementation of each element of the project.
The user will either input a question or select a pre-prepared question. This will then be tokenised. Split into a list of words. Every word will then be stemmed or reduced to its root word. Words are then numericized using term frequency – inverse document frequency (TF-IDF). Aiding removal of stopwords (words that don’t add significant meaning) in the ���� nearest neighbours algorithm (KNN). Word vectors are then compared using cosine similarity. The most similar text span is then outputted as an answer.
To provide suitable questions and target answers for testing , the Natural questions dataset from Google AI1 published in 2019 was used. The dataset includes many questions of varying difficulties and corresponding paragraph size long answers and sentence length short answers . The expected upper bound for a human answering the data set is 87% for long answers and 76% for short answers.2
For the code of the project the use of libraries was avoided wherever possible so as to focus on the inner workings of each element of the project. Where they are used in the project their reason for use will be explained.
The project uses fundamental NLP and ML techniques in its approach unlike more modern successful techniques such as dee p learning neural networks and transformers (as in the transformer ChatGPT). The project is built on the basis that the answer will be similar in meaning to the question. So the techniques and method outlined below is a computationally in-expensive approach which pre-processes and numericizes text as described above to see varying sections similarity to the question. This though is a naïve approach at its core as it assumes the perfect answer would be the question asked .
The entirety of this project will be written in the python programming language. To understand some of the equivalents given knowledge of other programming languages the first section of https://cs231n.github.io/pythonnumpy-tutorial/#python may be useful and includes links to the python documentation for further information . For any further information on how to use in built python functions the documentation (https://docs.python.org/3/library/functions.html#built-in-functions ) gives simple but accurate explanations.
Example flow through:
Flowchart:
Theoretical example:
The above is the flowchart that represents how the program works. I am now going to explain a theoretical implementation of the program when it has access to the Wikipedia article on Lasagna and the input question: “What country did Lasagna originate in?”
Firstly, the program will tokenise the words into a list like below removing punctuation and cases : [“what”, “country”, “did”, “lasagna”, “originate”, “in”]
All words are stemmed to leave us with ['what','countri', 'did', 'lasagna', 'origin', 'in']
The program removes unnecessary words that add little meaning and could make the question appear more relevant to sentences including these words which are not the correct answers. As well as stem the words. This would leave us with for instance [“countri”, “did”, “lasagna”, “origin”]. Note the output of the KN N is dependant on what words it was trained with so this is only an intended example.
In this instance the word “what ” has not been added to the list of stopwords to remove as it has not been encountered in the set of words in the article about Lasagna. So using the KNN it will compare the calculated TF-IDF vectors of “what” with other already categorised words. If it is similar to the stopwords it will be added. Added words will then be removed from the question leaving [“country”, “did”, “lasagna”, “origin”]
The program then calculates the term-frequency inverse document frequency (TF-IDF) for each word. Creating a vector for the question representing the questions meaning. There would also be dimensions for words not in the question but in the article so they are the same size and can be compared later.
For example we might get the vector: [0.095 0 0.060 ⋮ ]
The program will then compute the cosine similarity with the vector for th e question and the article to find how similar they are in meaning compared to other articles. The article for Lasagna should be the most similar. The vector is then compared for paragraph and sentence. This should leave us with the sentence “Lasagna originated in Italy during the Middle Ages”. This will then be outputted back to the user.
Tokenisation:
Purpose:
Tokenisation is essential for any part of text processing. Token’s in NLP is a piece of text, in this project they are all words except for two tokens explained in the following code which act as placeholders to help with processes later on in the program. In short a token in this project is almost always a word which has had some degree of NLP performed on it 3 . All words have individual meaning so if we want to attempt to analyse the meaning of a text we need to split it up into tokens (words) and remove punctuation (otherwise the strings "Hello" and "Hello!" will be treated differently by the program) . This allows us to look at them individually. It also helps later as TF-IDF vectors are calculated for individual words. The main aim of this process is to facilitate for more efficient processing later.
Coded implementation:
Above is the coded implementation for tokenisation, it takes up to three inputs but if remove_token is not specified it defaults to the string "qwerty". The token "qwerty" was chosen as it is not a word that does not occur in any text in the project and could therefore be accidently removed.
3 In more advanced versions of tokenisation tokens can include punctuation, suffixes, prefixes and other subsections of words. But I have decided not to go to that degree of complexity as the added nuance gained from this is not worth the added difficulty in this scenario .
After checking that the two special tokens (the remove token and the paragraph_separator_token which indicates the beginning of a new paragraph) are different the inputted text string is then split into a list based off whitespace characters. So, the string "please tokenise this string." will be replaced with the list of strings ["please", "tokenise", "this", "string."] , where each element is a word. From there the program iterates through every word in the resulting text list, the enumerate command done in this iteration also means that i will store the index of the word. If the word is the paragraph_separator_token then the corresponding index ( i) of text will be replaced with the word. This command is superfluous but prevents the else loop from executing.
If the word is not an instance of the paragraph separator token then code within a nested loop that iterates through punctuation is executed. For every item of punctuation (stored in the variable punct) in the pre-defined list of punctuation if that item is in the word then all instances of that element of the punctuation list will be replaced with an empty string. e.g. deleted in such a way that the text either side is joined together. So that "e-mail" becomes "email" and "opt-in" becomes "optin".
The decision to keep characters separated by punctuation as one token and not split them into two smaller tokens is significant. As shown in the above examples this approach can have disadvantages. For the word e-mail it makes most sense to keep as the recognisable token “email” but for opt-in which is short for opted in, it makes most sense to split. There is no logical pattern to suggest that either course is more obvious for a word other than hard coding certain examples to lead to a pre-defined token. Therefore I have decided to make the program create longer tokens as they are usually un-problematic in later steps such as the stemmer (the one word token of “s” in the stemmer produces an empty string , as a result and the information is lost) .
After punctuation is removed the variable word is then set to a version of itself where any trailing white space characters are removed by .strip() so that "word" and "word " will be viewed as the same and the word is turned to lower case using .lower() so that ”word” and “Word” are equated.
We now initiate an instance of the porter_stemmer, an object whose functionality will be explained in more detail later. The code will then attempt to stem the word, if it is unable to stem the word an error will be raised and the token will be replaced with the special remove token. This step removes
the numerous variations of whitespace characters4, empty strings and any problematic lone "s" characters.
Finally at the end of the processing the corresponding index of the original word in text is replaced with the new processed token. After the loop iterating through text finishes and all words have been processed into tokens , the program will, count how many instances of the remove token there are and will for that number of times .pop() the index of the remove token. Where .pop() will remove a specified index passed to it. This occurs in a loop as index will only return one value at a time, the index with a value closest to zero.
After this last step of processing the function returns a list of tokens with no punctuation. Crucially though numbers will remain unaltered as they could be key in differentiating information from the question .
4 For example '\xa0'or chr(160) is a whitespace character and would be removed in this step
Stemming:
Purpose:
The method used in this project to compare words sees each word as unique even if they may have similar meanings. For example talk and talked would be viewed as different words despite having very similar meanings, they are simply different conjugations of the same word . The differing tenses is likely to make little difference in how relevant the information is so they can be viewed as the same. This means it is easier to spot more similarities , increasing the programs likelihood of identifying the correct answer. This is done through stemming so that all words are converted to a root word so different conjugations of the word have the same route and therefore are viewed by the program as having the same effect on meaning. The root word does not have to make sense as a proper English word for example email, emailing, emailed etc. all stem to "emai".
The Porter stemmer a rule based system devised by Martin Porter in 1980 was used to achieve this. Because of computer limitations at the time ( a cutting edge hard disk drive could hold 5 megabytes 5 , current school laptops can hold up to 118GB or 23,600 times more data) huge vocabularies could therefore not be stored. Therefore words were stemmed to reduce the amount of storage needed and the vocabulary size to ease the stress on smaller processors. The processor mentioned in the original paper6 a $200,000 IBM 370/165 at the University of Cambridge had a maximum of 3Mb of storage capacity (about one photo nowadays) I have therefore chosen to implement this stemmer for three reasons as i) it is still widely used to this day7, ii) The limited memory capacity it was designed with mean I will not face problems running it on a laptop and iii) the paper includes clear instructions on the steps the algorithm undergoes so it can easily be coded. It also includes for each step a input and desired output so each step can be tested so it can be shown to be working as intended.
The algorithm works by checking if a suffix is in a word and if so it will either remove or replace it with a shorter suffix. To make sure the word does not get
5 https://www.computerhistory.org/timeline/memory-storage/ source of memory capabilities 1980
6 Porter stemmer paper https://tartarus.org/martin/PorterStemmer/def.txt
7 https://www.nltk.org/howto/stem.html natural language toolkit is a widely used nlp library and includes a implementation of the porter stemmer
completely destroyed there are also checks on the number of repeating sequences of vowel constants or the measure of the word. There are also other conditions such as ending in a certain letter, if the stem contains a vowel, ends with a double constant, ends in a constant vowel constant sequence or alternatively for some steps no condition is used.
From this if suffix X is present in the word and a Boolean and or expression made of the above conditions is true then suffix X in the word is replaced with Y. In short:
if condition and (X == word[-len(X):]):
word = word[:-len(X)]
word += Y
Coded implementation:
The porter stemmer was implemented as a class object due to its size (253 lines)8. The class is assigned to a variable when created, in this project almost always stemmer. It can then have attached to the object multiple functions or methods and variables for example .run() and the variable .word. Each method though in the porter stemmer class will be described individually. Also a note on Boolean operations, they are short circuit operators9, this means for and statements if the first element is False the second is not calculated as the only possible output is False. Therefore if an ending must be matched the program will complete that first to avoid calculating the measure of words were more than their length would have been removed.
Thie __init__ method is run every time a new instance of the porter_stemmer() class is created. It takes one argument10 tokens which
8 For more information on the syntax of classes here is the documentation https://docs.python.org/3/tutorial/classes.html
9 https://docs.python.org/3/library/stdtypes.html under Boolean operations for more on short circuit operators
10 I am not counting self as an argument as all methods in a class take self as an argument
then becomes an object of the class as well as initialising the dictionary self.stem token map.
This is the main method of the porter stemmer class. After an empty list stems is created the program will iterate through each word assigning it to the classes self.word variable. It will then execute the methods for all the steps described in Martin Porters paper before the classes self.word variable is appended to the list of stems. The stem token map dictionary has a new element added where self.word maps to the original word. At the end, the method returns the list of stems
As was mentioned in the purpose of the stemming this is the stem function. It will remove the length of argument X from self.word and adds string Y to the result. Argument Y defaults to "" or an empty string so if no argument is specified the length of X will simply be removed. Importantly though X does not have to be the ending it will just remove a string of equivalent length , though in the program X is specified as the ending to be removed for readability and to make sure the correct length is being removed .
This is a method which is designed for multiple purposes being called within three methods (checking for a vowel, checking for a consonant-vowelconsonant and in calculating measure). First we define a string of vowels and consonants. We also have the character "y" assigned to the variable dependant case as the algorithm will sometimes treat it as a vowel when preceded by a consonant.
Following this the word currently being processed is iterated through letter by letter and added to the list letters. Then for each letter and its index in letters it is determined whether it is a vowel or a consonant. If it is the dependant case and the letter before it in letters is a consonant it is a vowel otherwise a consonant. If it’s in the string consonants it’s a consonant and vice versa for vowels. After all these conditions the index of the letter in letters is either replaces with "V" or "C" for vowel and consonant, respectively.
If an index is not the default assignment of None e.g. it has been given a value. Then letters will be shortened to include only letters up to the index. Then letters is assigned to the class variable self.letters (this is then called in the consonant-vowel-consonant check).
Finally, letters are grouped, grouped letters is created by iterating through each letter in letters if the letter is new and does not equal the previous letter it is added to grouped letters . The resulting list of grouped letters is assigned to self.grouped letters. The aim of this is to turn a sequence of vowels and consonants into the number of vowel consonant sequences. For example, the string "CCVVCC" to the grouped "CVC" for use in calculating the measure of a word.
It takes a singular argument of a stem and runs the above described method but with an index of -len(stem) this means that self.evaluate type and group will be given a negative index to cut off from. So if the stem was of length three then the index would be -3 or the index third from the end. So the last three letters would be cut off. If "V" is in the resulting self.grouped_letters then it means the new stem would contain a vowel so True otherwise False is returned
This function is designed to check the word to see if it ends with a double consonant of the same letter, for example -tt, -ss or -ll. The function works by defining a list of consonants. Then if the final and penultimate letters are equal and the final letter is in consonants a list is returned containing True and the final letter if not [False, penultimate letter]. The reason why a list is returned and not just a Boolean is because in its use the double letter sequence can either not be certain letters or must be a certain letter.
First the type and group of self.word is evaluated before we check if the word’s ungrouped letters end in "CVC". An extra check was added here to make sure letters is long enough to check to avoid index errors. Finally if the
final letter of the word is not a w, x or y True is returned any other case returns False.
The method of calculating the measure of a word takes one argument: stem. This is so that the measure can be calculated for the stem of self.word without the ending. This argument if given will be passed to evaluate type and group as an index. If it is none no index will be given. If the length of the grouped letters is less than two it is guaranteed to be zero so that is returned. Then as the measure is the number of sequences of vowel -consonant groups if a consonant is at the start it is removed and likewise for if a vowel is at the end.
Now self.grouped_letters is a sequence of vowel-consonant groupings. This means we can simply divide by two to find the number of pairs, the measure, which the method returns.
The remaining methods in the porter stemmer class are all coded versions based on the corresponding step in Martin Porter ’s paper. For this I will not explain every line as many share similarities. For example all lines here stem if an ending is matched. The only significant difference is for the ending "SS"
where there is no stemming as it is there only to make sure in case there is a double ‘s’ that the step to stem a single ‘s’ is not triggered.
Step 1b is one of the most complicated steps with the possibility of words being stemmed twice. If the word is stemmed in one of the conditions involving a vowel check then rule 2 or 3 is set to True causing another if condition to be triggered. This includes three stems which lengthen the word so it can be stemmed later. Then the fourth of these additional rules uses the double consonant check where if it is true and it is not a double L,s or z the final letter is stemmed. This is one of the cases where X for self.stem is not the actual letter being removed. Finally we have a rule where self.stem is not used at all, if the measure of a word is 1 and it ends with a consonantvowel-consonant an "e" is added to the word.
If the possible new stem contains a vowel and ends in a y, the y is replaced with an I.
This step removes many large endings for shorter alternatives given that the measure of any possible new stem is greater than zero.
This step is much like step 2 removing any medium sized stems left over from that step and ones that were larger, all given that the stems measure is greater than zero.
This is where the final suffixes are removed with all instances of self.stem having no Y. they all have the sole condition that measure is greater than 1 apart from for the suffix "ion" which requires that the new stem ends in s or t.
This step is designed to help tidy up the stems with e’s removed f rom stems with a measure greater than one. For words of measure one ending in e, the e is removed if the word do es not end in a consonant-vowel-consonant.
If the measure is greater than one and the word ends in a double L that is stemmed.
Term Frequency – Inverse Document Frequency
(TF-IDF) and its use to create vectors:
Purpose:
TF-IDF was first written about by University of Cambridge Professor SpärckJones in the 1972 paper A statistical interpretation of term specificity and its application in retrieval. 11 Where she suggested “to correlate a terms matching frequency with its collection frequency”. With the help of Professor Stephen Robertson this weighting of term frequency finished as IDF. 12 In the end TF-IDF was created where “matches on less frequent, more specific terms are of greater value than matches on frequent terms.”
TF-IDF can be used to either calculate document or word vectors. For example, a word vector in a set of ���� documents and a question would be a ���� + 1 dimensional vector ���� ⃗ , where each dimension of the vector represents the TFIDF of the word in a given document. Vectors for documents are constructed were they have a vocabulary of size ���� leading to a ���� dimensional vector. Each dimension in this case represents the TF -IDF of a word.
The purpose of TF-IDF in this project is to create mathematical representations of i) words or ii) a series of words so that the distances between them can be computed in a KNN for the former and for measuring similarities using cosine similarity for the latter.
Maths behind it:
Above is the equation for TF -IDF. There are two aspects the term frequency which is the proportion of words in the document that are ���� , and this is then weighted by the logarithm of the inverse document frequency or (the
11 https://www.staff.city.ac.uk/~sbrp622/idfpapers/ksj_orig.pdf link to paper
12 https://www.staff.city.ac.uk/~sbrp622/idf.html link to various papers and letters explaining the development of IDF, on the UL website where Robertson studied after Cambridge.
proportion of articles containing ���� ) 1 . The result of this is the term frequency of a word weighted by its specificity as described by Professor Spärck-Jones in her paper.
Coded implementation:
The TF_IDF function takes three arguments: i) a word, ii) document index which is the index of the relevant document from the iii) stemmed_tokens_list which is a 2D list where each element is a list of stemmed tokens. First of all, document is set to the document index of stemmed_tokens_list. The number of_appearances of word X is set to the count of word in the document and the number of words in document to its length. The number of articles word x appears in is initialised to zero before iterating through each article in the stemmed_tokens_list and increasing the count by one if word is in the article
Finally, a new TFIDF variable (without an underscore) is set to the computation of the TF-IDF. This is one of the instances where an external library was needed for the .log10() function which calculates the log base 10 of its input13.
This calculation is in a Try: except: condition, this means if the error after except occurs in this case a ZeroDivisionError. TFIDF will be set to -1. -1 is an impossible output of the TF-IDF equation so therefore it is clear it is an error, this result would only ever be produced if there are no words in the document or the word appears in no articles. During iteration when a vector is being created one of these two scenarios can occur, almost always the latter, so to make sure the code continues to run this is in place.
13 https://docs.python.org/3/library/math.html documentation for math library including the .log10() function
After TFIDF has been calculated the value is then returned.
K
nearest
neighbours (KNN) to identify and remove stopwords:
Purpose:
The purpose of the KNN algorithm is to identify and remove stopwords based on their TF-IDF vector co-ordinates. The KNN’s aim is to learn to identify new points based off the points neighbours , “think of coloured dots in space, the dimension being the number of features and the colour being the categories. We want to classify a new dot, i.e. figure out its colour given where it is in space”14.
The program identifies the classification of a new point by measuring the Euclidian (straight line) distance between all other points and the point it wants to classify. It then looks at the ���� closest points to the new one it wants to classify. Then it is a simple vote based off classification, of the ���� nearest neighbours (hence the name) whichever class is the most populous , or has the most “votes,” the new point is assigned to. Overtime as more points are added and classified the program should improve as with more data the furthest point away in the ���� closest will have a smaller Euclidian distance to the new point , allowing it to learn.
Critically though this is a “lazy” supervised ML algorithm. “Lazy” means that when training it simply takes the labels its given to expand its abilities, it does not attempt to predict based off new data then adapt unlike “eager” algorithms. It is also supervised “the goal of supervised learning is to learn a function that maps from the values of the attributes describing an instance to the value of another attribute, known as the target attribute of that instance.”15 In this case the target attribute is whether the word is a stopword or informative.
14 Machine Learning: an applied mathematics introduction by Dr Paul Willmott
15 Data Science by Professor John D. Kelleher and Brendan Tierney
Maths behind it:
The distance metric used in this project is the Euclidian or “straight line” distance between two vectors. The equation is below.
For every element in the ���� dimensional vectors ���� ⃗ and ���� ⃗ the squared difference is calculated. Squaring is important as both positive and negative values will give the same results. Once the squared differences have been added up the square root of that is then taken to give the resulting straight-line distance.
But why does this give the straightline distance? It is simply an extension of two dimensions to a higher dimension. Take the below image of the right-angled triangle with point A and point B.16 Since it is a right-angled triangle then Pythagoras theorem ( ���� 2 + ���� 2 ≡ ���� 2 ) can be used to find the straight line distance between point A and point B which is side C. so the straight line distance ���� = √���� 2 + ���� 2 . Now if we were to rewrite this calculation using coordinates A and B (essentially small vectors) then we get ����
. We can then rewrite this using a summation to get the bellow equation which is the above Euclidian distance formula with a dimension of two. In short it gives the straight-line distance because it is an expansion of Pythagoras theorem.
16 https://www.desmos.com/calculator/f5pobx11hu
Selecting ���� :
One of the most crucial elements of the KNN algorithm is what value of ���� is chosen, as different values will produce different results. “If it is small then you get low bias but high variance. A large ���� gives the opposite, high bias but low variance … in the extreme case in which we use the same number of neighbours as data points then every prediction would be the same . ”17 Therefore a test method has been added to the KNN class implementation in python so to experiment with different values of ���� and see how this effects accuracy.
Firstly, word vectors where every item is zero will be set to being a stopword. This is because one of two scenarios. Either the word does not appear in a document, so the term frequency is zero or it appears in every document (fraction is ���� ���� or 1 and log 1 = 0). In both cases it demonstrates that the word has no use in distinguishing between documents and is therefore a stopword.
The training data for the KNN will be the first article (about email marketing) in the complete natural questions data. It will be a dictionary format with word keys assigned Boolean values of True for stopword and False for useful. This will be saved as a first_article_seed. The final decision for a word’s classification is subjective and purely on my opinion18
The below code was used in the shell to prepare the seed file :
>>> for token in data: file.write(token + ":" + str(False) +","+"\n")
17 Machine Learning: an applied mathematics introduction by Dr Paul Willmott
18 https://gist.github.com/sebleier/554280 some initial guidance
Curly brackets were manually added at either end and changed to True any word deemed to be a stopword to set up the training data. This was repeated to create a test data set In following file: second_article_test_data.
A variety of metrics have been used to evaluate KNN accuracy as shown in the above code. These metrics are: accuracy, precision, recall, ����1 and an average of these metrics. The NQ data processor element of the project contains more detailed explanations, but a brief overview will be given now. Accuracy is defined as the proportion of classifications which were correct, precision is the proportion of stopwords it identified which were correct, recall is the proportion of stopwords it identified out of true stopwords and ����1 is the harmonic mean of recall and accuracy. Multiple metrics were chosen because if the KNN were simply to evaluate all words as useful we would receive a deceptively high accuracy score due to the class imbalance of useful words and stopwords. This is because about 90% of words in the test set are useful and only 10% are stopwords. So other metrics which avoid the persuasion of this class imbalance are utilised as well.
The results are as follows19:
As you can see all metrics bar recall follow a similar pattern. A reasonable result for k = 1 is followed by a drop for k = 3 before slightly recovering at k = 5. We then see the highest scores so far (and identical ones) at k = 7 and k = 9. We then rise further for k = 11 reach a peak 0.1% – 0.7% higher at k = 13 before all further values of k tested produce identical results to k = 11. Therefore, from these metrics we see a convincing case for k = 13. An accuracy and precision of 96.1% and 94.0% respectively and an ����1 score just short of eighty at 79.3%.
No better value of k was found as all further tested values produced identical results including with the extreme case of k = 101. Suggesting that the density of classifications for different words is largely similar as you look outwards from new points.
The recall score is the joint third highest at k = 13 so i have no worry about choosing it but it is interesting that the only higher scores were what other metrics suggested were worse. Despite increases in the accuracy the accuracy within Stopwords identified had fallen 2.1% though this amounts only to a 2word difference and is an acceptable loss given success in other areas which would be neglected.
Visualising the data:
The following is an attempt to visualise the distribution of the vectors of words by taking a 2-dimensional slice and plotting them. This should give a general idea of the structure of the data. There are other ways to project highdimensional data to 2 or 3 dimensions including principal components analysis; self organizing maps and t-distributed stochastic neighbour embedding. But those algorithms are all unsupervised ML techniques and therefore require time to train and run. This more crude method has th erefore been chosen so as not to detract from other areas of the project .
Above is the scatter plot for both the first and second article data. Since the scale is logarithmic zero values have been set to 1 × 10 5 . As you can see from the cluster of words which appear in both, stopwords have similar TF-IDF scores in both documents as seen by them having a line of best fit with a gradient close to one. We can also see that there is no clear dividing line between the two classifications suggesting that small values of ���� might be best at identifying whether a word is in a pocket.
As we can see above this is inaccurate compared to the value of ���� that works most effectively. This could be due to the logarithmic scale skewing the true distances or the fact that this cruder slicing method can not give us a full picture of what the data actually looks like.
Areas of further research:
The KNN implementation used is a brute force method with computational complexity O(�������� + ��������). With ���� the number of data points; ���� the dimension of the data points and k being the number of nearest.20 This is based off the need to do calculations with every dimension ���� in a vector for the ���� data points its compared to. Then after each distance calculation (which happens ���� times) it is
20 https://stats.stackexchange.com/questions/219655/k-nn-computational-complexity from https://towardsdatascience.com/k-nearest-neighbors-computational-complexity-502d2c440d5
appended to a dictionary of classifications and distances of length ���� + 1, sorted and then truncated to length ���� . Given that ���� items are already sorted we will go for a sorting O(���� log ���� ) . This in turn gives us our final complexity of O(�������� + �������� log ���� ). Which for the large values of ���� used in this program is slow (the value of ���� can rise by 768 to 7314 per article classified in testing to reach 31918).
There is a way to speed this process up though using K-D and Ball trees. K-D trees create a binary search tree of points based on which side of cuts in K dimensional space the points are on. The depth of the tree and parameters used to construct it are additional parameters which must be modified. But after traversing to the “leaves” of the trees you then have a smaller number of points to search for the ���� closest in, ball trees are the same principle but instead of cuts it uses spheres of points.22
Both have an average training complexity of O(�������� log ����) – the time created to create the tree. And prediction complexity of O (���� log ����). The complete process has a complexity on average of O(�������� log ���� + ���� log ����) . The worst case complexity if a unbalanced tree is created as the median is not found is O(����2 ���� + ��������), worse than the brute force method. Overall, both the average and worst case are slower. But if you were to construct a tree for every time there is a new data point for both the average and worst case scenario the KNN is slower.
A solution to this is to only update the tree after every ���� instances are processed. For ���� instances the currently implemented method would have a complexity given below.
21 This is the worst case scenario listed here https://en.wikipedia.org/wiki/Timsort from https://stackoverflow.com/questions/14434490/what-is-the-complexity-of-the-sorted -function 22 https://medium.com/@narasimharaodevisetti14/kd -tree-and-ball-tree-in-knn-algorithm -09a86d1bc6e6
Which is the complexity rearranged to consider the growth of ���� as more examples are added. Whereas for the tree the complexity is kd or ball tree = O
+ ����)���� log(���� + ����)
=0
���� log(���� + ���� )
The above equations are both quite large and they do not share many similarities to factor out. Therefore different values of ���� and ���� were inputted to see how they compared. The result is interactive, and used to see how for large and small ���� ’s and ���� ’s the complexity changes.23
Overall for even a modest ���� of 50, for a small value of ���� such as 500, the algorithm is 41x more computationally efficient than the brute force method. For a large ���� such as 40,000 the KD and ball trees are still the most efficient. The mathematics for the growth of ���� is correct as with an ���� of zero both equations give the same output.
These further potential optimizations have not been implemented in the program but have been included in a demonstration method in the stopword_KNN from the machine learning library sckicit-learn. The optimizations were not implemented to avoid putting to much focus on this part of the project. Additionally the needed experimentation to find the most accurate parameters could limit the accuracy of the final model which is more critical than time constraints. This is because the project ’s aim is to demonstrate that even on a laptop with hardware constraints top class results can still be achieved using simple techniques.
Coded implementation:
This part of the project was implemented as a class object (despite being a more manageable 140 lines) so variables can be shared across the class object. The code is as follows
23 https://www.desmos.com/calculator/bpif0cbnlj
When the class is initialised it must receive a value of k, a vocab to use and a stemmed tokens list. The K is used as the number of nearest neighbours to look at and is then attached to the class object. Shortly afterwards the program will “assert” whether the value of K given divided by two does not equal the floor division of K by two (where the result at the end is rounded down). This is used to make sure is odd and that there will be no ties in votes. The vocab which is a list of all tokens already classified. The paragraph_separator_token is then assigned to the argument of the same name. If unspecified it defaults to the string "xtx". Finally the stemmed_tokens_list is added to the class’s variable of self.articles so it can calculate word vectors later.
Then the .all_points() method of the class is called , this effectively pre calculates the vectors of each word in the vocab to try and remove redundant computations and will be explained in more detail later.
After this the object will then try and reset self.stopwords if it has a length less than one, which means it is empty. If there is an attribute error though the program will reset self.stopwords anyway. An attribute error in this scenario can only occur if self.stopwords does not exist.
If a parameter of stopwords in the vocab is given then the program will loop through the list given and every element in the list not already in the list self.stopwords will be added.
Finally a dictionary of .word_classifications is created. For every item in the vocab if it is in a optionally given list of unclassified_words then the dictionary with the key of that word will be assigned a value of None. If it can be evaluated then it will be assigned a value of either True or False depending on whether it is in the list of stopwords .
The .all points method is used to reduce the need to calculate coordinates, instead of calculating the coordinates of a word it indexes the .word_to_cordinate_map which will return the relevant vector. This method creates the dictionary, it does this by merging the current .word_to_cordinate_map with a dictionary which is every word and the NumPy array24 of the .calculate_cordinates of the word if the word is not already a key in the dictionary. This is the first instance of NumPy in the program so I will use this opportunity to explain its use in the program. NumPy is a library designed to compute mathematical operations faster. It does this by limiting some extra functionality of lists for example adaptable sizes and multiple data types so that operations can be executed using compiled c -code which is much faster than python. NumPy array ’s can be indexed in the same way as python lists.25
The . reset_stopwords method starts by overwriting the list of stopwords attached to the class object to every word in the vocab if the vector of the word retrieved from the .word_to_cordinate_map dictionary is equal to a np.zeros 26 27 list of dimension, the length of the retrieved vector 28 . But when
24 https://numpy.org/doc/stable/reference/generated/numpy.array.html# documentation for np.array()
25 They also include additional functionality (https://numpy.org/doc/stable/user/basics.indexing.html ) but this is not used in the project
26 https://numpy.org/doc/stable/reference/generated/numpy.zeros.html for np.zeros()
27 This could have been instead of np.zeros() [0 for i in range(len(self.word_to_cordinate_map[word]))]
28 Interestingly there is also np.zeros_like() which will create an array of the same dimension as whatever is passed to it but this is slower than np.zeros() as demonstrated here https://stackoverflow.com/questions/27464039/why-the-performance-difference-between-numpy-zeros-andnumpy-zeros-like so i have opted not to use it
comparing NumPy areas a Boolean is not given for if the whole list matches but an array of Boolean’s based on if that element matches. Therefore .all() 29 is used. If all elements are True then that is returned otherwise False. If True and all elements are zero then the word is added to the list of stopwords. This method creates a vector of a word based off its TF-IDF scores in the articles specified when the class was initialised. word vector is set to a list of the TF_IDF of the word a incrementing index i and the .articles for the index i in the range up to the length of the .articles
The aim of this method is to calculate the Euclidian distances between a batch of vectors stored in Matrix and a vector vector. First the program asserts that each vector has equivalent dimension. This is done by asserting that the length of the Matrix’s first element and the vector are equivalent. Any element in the Matrix can be chosen as 2D structures in NumPy can not be ragged, e.g. they must be m x n so any row can be picked to find the value of n . Then Matrix and vector are assigned to be np.array versions of themselves. Then the Euclidian distance is calculated using np.linalg.norm30 which returns a list of the Euclidian distances for each row and the vector. The norm function in the linear algebra section of NumPy can calculate many different types of norms for both matrices and vectors. The type of which can be decided with using the ord parameter. For an ord of 2 the documentation31 describes how the calculation will be the sum(abs(x)**ord)**(1/ord). for two this can be written as
29 https://docs.python.org/3/library/functions.html#all could of created a function to do it myself but this is neater
30 Alternatively the commented out code below could be used but it is much slower. This is proven by running this file linalg proof.py
As any number to the power of a half is the same as its square root and both negative and positive numbers give the same square root so the absolute value of ���� is irrelevant and is likely there for computational efficiency. Finally because the input of ���� into the equation is two vectors lets say ���� ⃗ and ���� ⃗ . We get the following equation:
Which is Euclidian distance! The result of this operation is then cast as a float (instead of a NumPy object32) and returned.
Compromising of nearly 50 lines this method contributes to the bulk of the class. It takes a single argument word which is a string. Initially the program
32 Python float is compatible with the NumPy double: https://numpy.org/doc/stable/reference/arrays.scalars.html#numpy.double among other various float types https://numpy.org/doc/stable/reference/arrays.scalars.html#floating -point-types
checks if the word is in the vocab if not the word is added to the vocab and a new key is assigned in the .word_classifications dictionary to None (as the word is unclassified). Then two more dictionaries top_matches and results are initialised as well as the variable word_to_add which is initialised as an empty string.
The word_classifications dictionary is indexed using word and if it has already been classified by checking the value in the word_classifications dictionary for the key is not None. If so the dictionary results will have a new entry added for the word with the result being the words classification in the word_classifications dictionary. If that classification is True then a variable word_to_add is set to the word. If the word is not already classified then word_vector will be assigned the pre-calculated coordinates from the .word_to_cordinate_map dictionary. If there is a KeyError (e.g. it has not been calculated) then self.all_points() is called to update the dictionary. The assignment for word_vector is then reattempted
We now enter the section of code where the bulk of the calculations are done, for every word in the vocab - as long as the piece of vocab is not the word being classified and the classification of the word is not None – the word is added to a list of vocab_to_calculate and its corresponding vector added to to_calculate. Distances is then set to the .euclidian_distance_batch of the list of lists or Matrix which is to_calculate and the word_vector. top_matches is then set to a dictionary mapping every distance to its corresponding item of vocab for every distance and piece of vocab in the zip() of distances and vocab_to_calculate. The zip() 33 function allows us to iterate through items in multiple lists concurrently without having to use their indices. The .items() of the dictionary are then called to turn it into a list before this is sorted and truncated to include just the first .K items. It is then cast back to a dictionary
After that section, a new list is created k_nearest_classifications which is the word classification for each word in a list of the values of the top_matches dictionary. If the count of True in this list is greater than False than the results dictionary has a new index added with key word which maps to the value True. The same process happens with the
word_classifications dictionary and word_to_add is assigned a value of word. The opposite happens for if there is a greater count of False.
If there is a word_to_add and that is not in the list of self.stopwords the word_to_add is added to the list of self.stopwords
This is the method for training the KNN, since it is a “lazy ” model though its mainly updating variables. First the .reset stopwords() method is called. The file containing the training data is then opened and read. The text is then split into a list off newline characters "\n" before all these items are joined together with an empty string. This one line string stored in first_article is then executed using the eval() command34. The file is then closed . The executed file now stored in first_article is a dictionary object in {word : classification} format. A list of words is then assigned to the variable words created from first_article’s keys.
An instance of the porter_stemmer is created and named stemmer. It is then run to produce a list of stemmed_words. For every word in this list if it’s not a key in the first_article dictionary then a key of that word will map to the original unstemmed words value (having gone back using the .stem_token_map).
34 eval() executes any code objects with a string so if x = eval("2+2") than x would equal the integer 4
Finally for every word in the list of stemmed words if the value from the dictionary of the word is True and the word is not in the list of self.stopwords then it is added to self.stopwords. the stemmed_words are then returned.
Like the load seed code above the second_article goes under the same preprocessing from file to dictionary, with a list of inputs created and stemmed if the stemmed item is not in the second_article dictionary then it is added and assigned its unstemmed value. After this results is assigned the returns from the .classify_words method (not .classify_word).
The remaining code is to evaluate and output the accuracy given these results. First total_words_processed is assigned the length of the inputs and a counter, correct, is assigned zero. Then for every word in inputs if the assigned value for the word is equivalent to the actual value the correct variable is incremented by one.
Then the count of classifications per category begins percent_classified_stopwords and perecent_classified_useful are both initialised at zero. Then for every word inputted to be classified if in results its True percent_classified_stopwords is incremented by one
and the opposite for percent_classified useful. The percentages from these are then stored as a string overriding the original counts. The same process is done using the second_article and similarly named correct_classified_stopwords and correct_classified_useful where the same process is undergone. The accuracy scores are then printed and the proportion vs intended proportion for both stopwords and useful words.
We then calculate the ����1 , precision and recall scores as additional metrics. How these are calculated will be elaborated on later in the project. Firstly we initialise three variables true_positives, false_positives and false_negatives as zero. Then for every word in the inputs we increment these counters should the case be made. True in both for true_positives
Predicted True when False for false_positives and predicted False when true for false_negatives. We then calculate precision as true_positives divided by the sum of true_positives and false_negatives and recall as the same proportion but with false_negatives instead of false_positives. ����1 score is then set to 2 by precision by recall divided by precison plus recall. These are all then outputted to the user.
Given a list of tokens for every token in tokens if the token is in self.stopwords list and not the paragraph separator token then while the token is in the list of tokens the index of the token is removed. Once the removal is complete the processed list of tokens is returned.
First of all results is initialised as an empty dictionary. Then for every word in inputs the word is classified using .classify_word() and the result stored in the variable result The results list is then overwritten to be itself merged with result35 Then we iterate to update .word_classifications to make sure there is
35 Originally went for results[list(result.keys())[0]] = list(result.values())[0] but wondered if there was another way which I found here https://stackoverflow.com/questions/38987/how-do-i-
a key for every word in the vocab. When iterating through inputs it is cast as a tqdm generator this with the parameters "words classified" and leave of False will generate a progress bar for the iteration including the predicted end time and the words classified per second. It is not needed for functionality and could be removed but is more user friendly.36
This method is never executed in the program and is largely copied from the library sckicit-learn’s37 first example and is purely demonstrational . First of all the BallTree class is imported from the afore mentioned library. Results is set to an empty dictionary. For every word and its index ( i) in words if the division if the division of m is equal to the floor division of m (e.g. it is a multiple of 50) than a tree an instance of the BallTree class is created using a coordinate_matrix. The matrix is a 2D list with each row being a words coordinate.
Following this .all_points() is called and the word_classifications dictionary updated . The tree is queried to produce the k closest distances and indices (for the matrix). A list of classifications is then created by using the index of the list of keys in the .word_cordinate_map the resulting word is then used as they key for .word_classifications to find its value. This is done for every index in indices. If the count of True is greater than False
merge-two -dictionaries-in -a-single-expression-in-python since its so compact and unlike anything in python I had ever seen before I decided to include it
36 https://tqdm.github.io/docs/tqdm/ documentation can be found here
the entry in the results dictionary is True for that word and vice versa. At the end of the loop the results are returned
The final method in the KNN class is the method used to create a crude visualisation (above). First .all_points() is called before vector_classification is initialised as an empty list. Then for every word in .vocab the first item in the words corresponding coordinate list is set to x the second y and the rest unpacked into the list which is not used further. A list containing the float casting of x and y and the .word_classifications of the word is then added to vector_classification. Once the vector_classification list is complete a file is opened with a name of the argument filename in .csv format. Then headings are written before every row in vector_classification in string format. At the end, the file is closed.
Cosine Similarity:
Purpose:
At a high level, the project is simply looking at which document/paragraph/sentence is most similar to the question asked. I have already gone through the methods to remove noise and increase chances of similarity through stemming and stopword removal. There is also a method to convert words into mathematical vectors, points in space. This means we can now use an equation to decide how similar these points in space are to each other and therefore the words they represent.
The reason cosine similarity was chosen to measure similarity and not Euclidian distance like used in the KNN is that magnitude does not make a difference. For example, two dimensional vectors [22] and [11] would be treated as identical. It is the direction of the point from the origin. This means the focus is placed on the fact the documents words are about the same topic rather than the documents words having similar frequencies of the same words.
Also Euclidian distance can show documents as dissimilar if one document is much longer than another. The paragraph closest in length to the question is unlikely to be a convincing measure for whether its correct.
Maths behind it:
Like Euclidean distance though this is another equation derived from Pythagoras. For any 2 dimensional triangle it is true that ���� 2 = ���� 2 + ���� 2 2�������� cos ���� 38 (this is the law of cosines)39
If we substitute into this equation given
(Note a side length in the triangle is the magnitude of the vector). Given this we get
38 Source of image and proof: https://towardsdatascience.com/cosine-similarity-how-does -it-measure-thesimilarity-maths-behind-and-usage-in-python-50ad30aad7db
39 A proof for this can be found here: Patrick @ Hampton School under cosine rule or alternatively there is another proof on the same page the image was from https://towardsdatascience.com/cosine-similarity-howdoes-it-measure-the-similarity-maths-behind-and-usage-in-python-50ad30aad7db
If we add 2 ||����⃗||
⃗ || cos ���� and minus ||���� ⃗ ����⃗||2 from the equation we get:
Then if we can expand any lengths on the right hand side:
Now removing squares of square roots (as they are the inverse of each other)
And now lets assume vectors ���� ⃗ and ���� ⃗ are 2 dimensional (any dimension works but this is the most compact). So given ���� = 2
Then if we multiply out the bracket on the right hand side
Then if we collect terms (which in turn subtract away the squares)
And divide both sides by 2
Following this we can rewrite the right hand side with a summation:
Then if we divide by
we get
Also the above summation is simply the product of 2D vectors ���� ⃗ and ���� ⃗ so
Or the cosine of the angle between two vectors is the dot product of the vectors divided by the product of their magnitudes. The equation for cosine similarity written out in full with summations is below:
Coded implementation:
As well as showing the coded implementation for cosine similarity I will also explain the coded implementation for the find_highest_similarity() and the identify_tokens_from_stems() functions. They return an index of most similar words given a list of words and calculate what most likely was the unprocessed version of a text respectively.
At the start the program validates that the two inputted vectors vectorA and vectorB are the same length. If not an assertion error is raised with the message "vectors must be the same dimension". Next n is set to the length of vectorA (it could be either as they are the same length). The dot product of the vectors is calculated by multiplying the ith elements of vectorA and vectorB for values of i up to n. The results are summed together and stored in the variable dot_product. Following this magnitudes are calculated for vectorA and vectorB and stored in magnitudeA and magnitudeB respectively. This is done by summing the squ ares of the ith element of each list up to n that square rooting the resulting value. These two values are multiplied together and stored as the product_of_magnitudes. Finally, the similarity is calculated by dividing the dot_product by the product_of_magnitudes. This value is now returned.
Given a 2D token_list of either documents, paragraphs or sentences and a question this function will return the most similar document, paragraph, or sentence to the question. First, the dictionary index_similarity_map is initialised as empty. For every set of tokens and its index in token_list every token in tokens and the question is added to the list mini_vocab. mini_vocab is cast as a set() of itself (an unchangeable list with only unique entries) before being cast back to a list using list()
A question_vector of dimension the length of the mini_vocab is calculated by measuring the TF-IDF scores for each word in the vocab in the question.40 The same is done for the index currently being used and assigned to section_vector
The similarity between these two vectors is computed with the current index in index_similarity_map mapping to the similarity value calculated. After each section has been iterated through the best index and similarity are identified. This is achieved by casting the dictionaries items as a list to create a list of (index, similarity) tuples. This is then sorted based off the key which is the sort_item() function (below)
This means that when python tries to sort element x it will base this calculation off the second element in x - preventing the list from being sorted on the indexes but the similarities instead. 41 From this sorted list of tuples, the final tuple in the list is selected (as it has the highest similarity score) and stored in the variable best_tuple. The most_similar_section_index is set to the first element from this tuple. The “confidence score ” is printed which
40 Note instead of creating a new variable to store token_list + [question] it is done automatically due to how python stores data which meant that whatever parameter that was passed as token_list would be edited as well. https://medium.com/@alexroz/5-python-features-to-make-your-code-more-advanced533f1153c688 explained in more detail of number 3 in the link
41 sorted() function documentation: https://docs.python.org/3/library/functions.html#sorted
is the cosine similarity as a percentage (as all values range from -1 to 1 as the cosine function is bounded). The element from tokens_list which is most similar is indexed and returned.
Given the arguments of a 2D token_list and a 1D list of stems this function will aim to see which element of token_list is likely to be the unprocessed version of the list of stems First a flattened_token_list is created by going through each set of tokens in the token_list and every token in tokens which is appended to flattened_token_list. A stemmer instance is created based off the tokenisation of this list joined together to form a large string. The stemmer is .run() but the results are not stored.
For every stem in the list of stems they are converted from stem form to token using the stemmer .stem_token_map and added to the list unstemmed. This method is not perfect as the whole point of the process is to map many inputs to a smaller number of outputs and stemming is a lossy process so we can never perfectly convert it back to the original form. So all stems will result in the same unstemmed output. This therefore may make this step seem unnecessary but there are no stemmed words in the unprocessed list whereas there is guaranteed to be at least one instance of the unstemmed version. Therefore increasing the chances of a useful match.
unprocessed_tokens is then set to the highest similarity between this unstemmed list and the inputted tokens_list and returned.
HTML reader
Purpose:
All versions of Wikipedia pages, long answers and short answers in the natural questions database are stored as HTML (hyper text markup language) code42. This is not explicitly a program but just a way of describing the layout of web pages (in fact all web pages at heart are written and organised in HTML43). They can therefore not be “run” they are just a way of representing a file. Running HTML code through the project will require extra methods to handle and ignore “tags” which describe the type of data enclosed within them and how it should be represented , therefore text will be extracted from the file, specifically all paragraphs, to avoid this. This class therefore does this process with the aid of the beautiful soup library.44
Coded implementation:
When the class is initialised it takes 1 argument a paragraph_separator_token which is then attached to the class.
Given a html document ( html_doc) this method will extract all paragraphs and tables from the document and convert it into plain text 45 (or if short answer is set to False just the text irrespective of tag type). First a beautiful soup soup is
42 You can see any websites HTML code by typing view-source: before https://. If you then hit enter it will show the websites HTML code.
43 In Natural Questions: a Benchmark for Question Answering Research (Kwiatkowski et al), which I will explain in more detail at a later stage. The source of the questions is described as being “ real anonymized aggregated queries issued to the google search engine” and the most relevant Wikipedia article from this search. Therefore the articles are most likely selected via a program given these queries and google results and therefore handles the HTML versions of web pages rather than the displayed versions .
45 As described in the NQ paper or long answers are paragraphs or questions
created using the html_doc and a html.parser 46 and the result is assigned to a second soup soup2 after it is .prettify(). If it is not a short answer html_paragraphs is set to all text found enclosed in <p> or <table> tags (which represent paragraphs and tables respectively). 47 For every paragraph in the html_paragraphs the text from the .get_text() function is stored in a list of paragraphs. These are then joined with the self.paragraph_separator_token in between. If short_answer is True the text is retrieved immediately from the neatened HTML. The resulting text is then returned.
This makes the text returned by the above function easier to understand. The text is split (thereby eliminating whitespace characters and empty strings) before being joined together with just a space between words.
Given the name of a Wikipedia page stored in the "corpus" folder this function will return the text of this file when stored in .html format. First the file (always stored within the corpus folder as name_wiki_page.txt) is opened. If the file is not found the string "not found" is returned. The html is read from the file before being closed. The raw and neat text is extracted and returned.
46 https://www.crummy.com/software/BeautifulSoup/bs4/doc/#quick-start as demonstrated in this section of the library’s documentation (second example) . All functions are from this section unless specified otherwise
47 https://www.w3schools.com/tags/ref_byfunc.asp contains the meanings of many common html tags (unfortunately I could not find an official documentation)
Extracting example questions data from Google
Natural Questions:
Purpose:
The Natural Questions (NQ) data set was developed by a team from Google AI in 2018. The purpose of this as described in Natural Questions: a Benchmark for Question Answering Research (Kwiatkowski et al)48 is “1) To provide largescale end-to-end training data for the QA problem. 2) To provide a dataset that drives research in natural language understanding. 3) To study human performance in providing QA annotations for naturally occurring questions.” The paper also includes a set of contemporary Baseline performances including human accuracy and a human upper bound.
The format of the dataset is as follows. The publicly available dataset contains 307,373 examples of question, Wikipedia page, long answer, and short answer sets. These have been created using real queries issued to google if there was a Wikipedia article in the top five search results. To select the long answer the first paragraph or table which completely answers the question is selected if one is not found then the answer is set to null. If a long answer is identified annotators will select the section within the long answer which answers the question. If there is no shorter span which answers the question then the short answer is null.
Some differences exist in how this dataset was designed to be used and how it will be used in the project. Firstly, instead of selecting a word span for the short answer a sentence will be chosen. Secondly, I am reducing the size of the data set to only include non null answers as the program will always output an answer. So testing it on a output where we know it should not output anything is redundant as it is guaranteed to get it wrong. This though will not interfere with the baseline results given as varying accuracy metrics are given which can still be used.49
49 https://aclanthology.org/M92-1002.pdf first introduction of F measure based on the definitions of precision and recall on page 7 and on the prior work of professor C.J. Van Rijsbergen
The main accuracy metric given is ����1 score or the harmonic mean of precision and recall. Given:
And:
So put simply, precision is the proportion of instances where an answer given was correct and recall is the proportion of correct answers identified.
�������� is defined as:
So ∴ ����1 is:
So since precision and accuracy have been used to calculate ����1 they are given in the paper. Since we have no ��������������������
classification , as the program will always output an answer and will never decide the information is irrelevant we will use the precision scores for the baseline
Coded implementation:
The purpose of the below code is solely to extract the relevant sections of the data set50. This is done by traversing the single JSON object made of dictionaries, lists and strings in each line to condense it to a single list of dictionaries containing the relevant information from the data set for the program.
The nq_data_processor class is initialised with two parameters. A filepath for the file which contains the nq data and a paragraph_separator_token. These are both attached to the class object and self.data, self.notices, self.invalid questions, self.valid questions and self.complete data are all initialised as empty lists.
This method aims to extract n number of lines from the file containing the NQ data. First of all, a max_number is defined as 307,37351. If max_number is greater than the given n then it is unchanged otherwise n is assigned the value of max_number. A count is initialised at 0 and all_lines is set to an empty list.
The data is read line by line from the self.filepath adapted from the code here52. This is done because the data set is very large. So if we simply did .readlines() the computer would not be able to handle it so line by line processing is required. Attempts to extract the whole data set resulted a MemoryError 53 . First the text "open" is printed then for every line in the file using this different reading technique the count is incremented by one. Then JSON_line is set to the .rstrip() version of the line54. This JSON_line is
51https://medium.com/data-bistrot/python-tips-and-tricks-for-efficient-coding -81b3c0195410 (number2.4). For long numbers a underscore can be used as a comma to improve readability.
54 Removes trailing whitespace to the right https://docs.python.org/3/library/stdtypes.html#str.rstrip
then added to the all_lines list. This repeats till the count is equal to the value of n in that case the file is closed and we break out of the loop.
After "retrieved" is printed for every line and its index i in all_lines the variable question is set to the result of .extract_info() on the current line. From here is / self.info is equal to an empty dictionary, a notice is appended to the list of notices saying it is invalid and the question is added to the objects list of .invalid_questions. If it is not empty self.info is added to self.data and the question added to self.valid_questions.
Following this the notices, the number and list of valid and invalid questions and the percentage of lines successfully extracted (e.g. not fully null answers) are printed. For every info dictionary in self.data if it has a "short_answer" and "long_answer" key the info is added to self.complete_data. The percentage of complete examples given n lines and the number of complete examples is printed.
Note as described by Kwiatkowski et al 49% of examples have a long answer and 35% have both short and long answers. So we should expect to see similar proportions to this. Given an n of thirty-two we get the values of 46% and 34% which would suggest that the function is getting a similar proportion to what is expected.
Given a JSON line the above function will return a dict ionary info containing a question, simple tokens, a long answer, and a short answer. First of all trailing whitespaces are removed from the line using .strip(). The .loads() method of pythons built in json library is called and the results assigned to the class objects .row variable.55 Most of the structure is python objects such as lists dictionaries etc so the eval() function could have been used. The reason
why eval() (which executes the contents of a string passed to it) is not used , is because it contains JSON true, false and null as opposed to the python True, False and None. Therefore json.loads() is needed for this mapping.
Following this the .info dictionary is initialised. Following this the classes .basic_tokens() method is called. From here the key in .info for "question" is set to the "question_text" of .row. invalid question is set to the result of the class’s .long_answer method on the split "document_text" of .row. the same input is passed to the .short_answer() method with the result being stored as notice.
The variable url is set to the "document_url" from the row. The key in .info is set to this result. If the invalid_question variable returned from .long_answer is True a variable question is set to the value in info of the key of the same name. The dictionary is cleared56 (removing all items from the dictionary) before the question is returned. If notice which .short_answer() returned is not empty or False a string is appended to the list of .notices including the content of the notice and the offending question. Finally at the end the question in the info dictionary is returned.
Given a list of article tokens, this function will extract the relevant span which has been identified as a long answer. long_answer is set to be the indices of the given article_tokens list joined together by spaces. Importantly, the article_tokens are not actual tokens but rather the string split based off of whitespace characters. The long answer in the NQ data is stored as a text span so to find the long answer we slice the relevant tokens from the article_tokens list and rejoin them with whitespace characters (what they were split by). In the .row of JSON data this is stored in a dictionary which can be accessed by using the first element of the "annotations" key list and the "long_answer" key on that dictionary. From this we can access the "start_token" and "end_token" to slice the list off
If the long answer is an empty string we check if the start and end tokens both equal -1. If this is the case True is returned. This indicates that there is no long answer. If the string is empty and there is a valid token span then a syntax error is raised57 with the message "bad data format long answer not in extractable format", as it is attempting to slice non -existent indices meaning there is an error in the data file. If the long_answer is not empty then the .info dictionary will have a "long_answer" assigned as the result of the long_answer after a .html_clean(). In this case False is returned to show a valid question has been given.
A similar process is repeated with the short answer being extracted using the relevant token slices given in .row of JSON data. If this is successful .info will have its "short_answer" equal to the .html_clean() of the short_answer when the short_answer parameter is also True. Finally, None is returned (as the result is appended to notices in other methods of the class).
If an index error occurs which will happen when trying to access the first element of the list returned by "short_answer" as if there is no short answer this list is empty thereby prompting an index error. If this happens the "short answer" in .info is set to None and a string notice is returned saying there is no short answer for the question and the question itself.
This method will create a list of crude tokens cleaned of HTML. First of all, an instance of the HTML _ reader is created with the self.paragraph_separator_token. The html_doc is then set to the "document_text" from the JSON data. We use the text_converter class to return raw_text given this html_doc. The text is set to the result of the
57 https://docs.python.org/3/tutorial/errors.html#raising -exceptions how to raise exceptions manually
.return_neat_text() given raw_text. The simple tokens are created by .split() based off whitespace. Proper tokenisation is not undergone as we want punctuation and other elements removed in tokenisation in the output and as this is what is compared against only whitespace is removed as that is easily reversible. The tokens are set to the "article_tokens" entry in the .info dictionary.
Firstly this method initialises a HTML_reader instance with the .paragraph_separator_token as text_converter. Raw text is created from this html_doc using the .return_raw_text method and short_answer being a default of False unless specified. Text is created using the .return_neat_text() method and returned.
Project, using functions for a complete run
through:
Purpose:
This is the full project were all functions previously defined and explained are put together to go from document and question input to results including testing methods.
Coded implementation:
Note due to the size of this function a screenshot is unfeasible (as it is 186 lines and spans five pages) so colour formatting has been forgone in exchange for readability. The main project is as follows:
question (string): a question you want answered based off articles articles (1d list of strings): contains a string version of each article (no html otherwise it wont work)
test (Boolean) = False: if you want it to run off googles natural question data which has a corresponding question, article and correct long and short answer each
PARAGRAPH_SEPARATOR_TOKEN (string) = "xtx": must be ascii letters just a placeholder and can not appear in any word or it will be lost
nq_testing_data_filepath (string) = "corpus/nq -data-from-google.jsonl": link to extract test data from filepath to the nq data in jsonl format
n (int) = 32: number of lines to extract from nq data not every line is a complete example, max 307,373 (upon attempting this with my computer I received a memory error and task manager crashed)
K (int) = 13: number of nearest neighbours for stopword classification, must be odd
returns:
predicted_info (dictionary) : results will be printed anyway but for further use
if you want to test it both question and articles can be none and it will extract test data from filepath to the nq data in jsonl format
"""
if test:
question_index = int(input("question index: "))#used for retrieving answers
nq = nq_data_processor(nq_testing_data_filepath,PARAGRAPH_SEPARATOR_TOKEN) nq.extract_n_questions(n)#5 = 3 complete examples (ce), 31 = 10ce, 32 = 12ce #1 = 1ce #v.slow to open the large file
long_answers = [tokenisation(info["long_answer"],PARAGRAPH_SEPARATOR_TOKEN) for info in nq.complete_data]
short_answers = [tokenisation(info["short_answer"],PARAGRAPH_SEPARATOR_TOKEN) for info in nq.complete_data]
document_list = [" ".join(info["article_tokens"]) for info in nq.complete_data] #so it works in find similarity #unprocessed version tokens_list = [tokenisation(" ".join(info["article_tokens"]),PARAGRAPH_SEPARATOR_TOKEN) for info in nq.complete_data]
print("premade question found now answering question")
else:
document_list = [article for article in articles] #so it works in find similarity #unprocessed version, and removes need for if test tokens_list = [tokenisation(article,PARAGRAPH_SEPARATOR_TOKEN) for article in articles]
if test: question = tokenisation(nq.complete_data[question_index]["question"],PARAGRAPH_SEPARATOR_TOKE N)
stemmed_tokens_list = [] for tokens in tokens_list: stemmed_tokens = [] stemmer = porter_stemmer(tokens) stemmed_tokens = stemmer.run() stemmed_tokens_list.append(stemmed_tokens)
stemmed_vocab = [token for tokens in stemmed_tokens_list+stemmed_question for token in tokens] stemmed_vocab = list(set(stemmed_vocab))
#stopword removal load_KNN = stopwords_KNN(K,stemmed_vocab,stemmed_tokens_list,unevaluated_words=stemmed_vocab) #none of the vocab is evaluated seed_vocab = load_KNN.load_seed()
KNN = stopwords_KNN(K,seed_vocab,stemmed_tokens_list,stopwords_from_vocab=load_KNN.stopw ords)#give full list of tokens to test at max dimensions KNN.evaluate_accuracy_on_second_article()
if input("write a slice of the vectors the KNN processed to a file for viewing? (any key for yes then enter, enter key only for no): "): KNN.return_visulisation_data(input("please choose a filename for saving: "))
print("classifying articles: this is the longest stage please be patient...") for i,tokens in enumerate(stemmed_tokens_list): print(f"{i}/{len(stemmed_tokens_list)}") #therfore added a countdown KNN.classify_words(tokens) #most computationally intensive e.g this section takes the longest print(f"{len(stemmed_tokens_list)}/{len(stemmed_tokens_list)}")
unprocessed_paragraphs = " ".join(identify_tokens_from_stems([document.split() for document in document_list],predicted_info["stemmed_document_tokens"])).split(PARAGRAPH_SEPARAT OR_TOKEN)#maybe change this
stemmed_selected_text = " ".join(predicted_info["stemmed_document_tokens"]) stemmed_selected_paragraphs = stemmed_selected_text.split(PARAGRAPH_SEPARATOR_TOKEN) stemmed_selected_paragraphs = [tokenisation(paragraph.strip(),PARAGRAPH_SEPARATOR_TOKEN) for paragraph in stemmed_selected_paragraphs]
print("results paragraph/long answer") selected_long_answer = find_highest_similarity(stemmed_selected_paragraphs,stemmed_question) #must give tokens
unprocessed_paragraphs = [paragraph.strip() for paragraph in unprocessed_paragraphs]
print("selecting unprocessed answer") #since the answer must follow these rules so should the unprocessed one as it would only be even longer unprocessed_selected_long_answer = " ".join(identify_tokens_from_stems([paragraph.split() for paragraph in unprocessed_paragraphs],selected_long_answer))#here
print(f'question: {" ".join(question)}')#as question is tokens print("")
unprocessed_selected_short_answer = " ".join(identify_tokens_from_stems([sentence.split() for sentence in unprocessed_sentences],selected_short_answer))
For this function, unlike the others, a doc string was added58. As you will have seen the parameters that must be given are a question (string or None) and articles which is a list of strings or None. Importantly if the subsequent test (Boolean) parameter is not its default True then it can be None as the parameters will be overwritten anyway otherwise it must be the first type given. The other parameters with default assignments include the paragraph_separator_token which defaults to the string "xtx", the nq_testing_data_filepath which defaults to the string "corpus/nqdata-from-google.jsonl" as that is the name assigned to it in this project and it is within the corpus folder. We also have n the number of lines to extract which is 32 as that gives 11 complete examples and K = 13, this was evaluated as the most efficient value earlier. The function will then return a dictionary with string keys which map to either string values or lists of strings.
This is followed by a docstring describing the varying arguments it takes and what it returns.
Firstly, if the test argument is True the user is prompted to enter a question_index which is cast as an integer. Secondly, using the nq_testing_data_filepath and the paragraph_separator_token an instance if the nq_data_processor is created and called nq. This will extract n questions.
A list of long answers are created by iterating through each info dictionary in the nq.complete_data and appending the tokenisation of the "long_answer" value in the dictionary given the "paragraph_separator_token". Likewise is done for short_answers. document_list is created using the "article tokens" key joined together and tokens_list using the tokenised equivalent for each element in document_list.
If test is False document_list is assigned every article in the articles argument and tokens_list again the tokenised equivalent.
58 This has not been done for other functions as the code is unlikely to be updated frequently or used by many other people other than myself. It has been added purely so the help(project) (pun intended) command can be run to produce some information about the project.
If test is True the question is set to question_indexth extracted dictionaries tokenised question otherwise it is simply the tokenised question given.
The question is used to initialise a porter_stemmer called stemmer which is .run() to produce a stemmed_question. A stemmed tokens_list is created by iterating through tokens_list and creating a list of stemmed_tokens with the porter_stemmer before adding this to the stemmed_tokens_list to create the 2D stemmed_tokens_list. Given these lists we create a stemmed_vocab list containing every token in stemmed_tokens_list and the question. This stemmed_vocab is cast as a set() which is like a list but un-editable and can only take unique values. So when we cast it back to a list using list() we get a list of all unique tokens. This will be useful for our next stage: stopword removal.
First, a stopwords_KNN object is named load_KNN with the arguments of K, the newly created stemmed_vocab, the stemmed_tokens_list, and an unevaluated_words equivalent to the stemmed_vocab. This load_KNN object is used to create a seed_vocab using the .load_seed() method. We then create another stopwords_KNN object called KNN which is initialised slightly differently from the first as its vocab is now equal to the seed_vocab with there being no unevaluated_words given and stopwords_from_vocab being the .stopwords of the load_KNN object.
The KNN’s accuracy is evaluated on the second article. The user is prompted to see if they want to write a slice of the vectors to a .csv file for viewing later any key or combination of keys can be entered if they do not want to the enter key should be pressed. If a response was given the .return_visulisation_data() method of the KNN is called with a filename of a separate user input.
The user is prompted to be patient for the computationally intense classification stage. For every list of tokens and its index i in the stemmed_tokens_list a counter is printed to display the index /the length of the stemmed_tokens_list. The KNN then .classify_words the given tokens. At the end of this operation the length of the stemmed_tokens_list / its length is displayed to show the process is complete.
We then output we are moving on to removing stopwords f rom every list of tokens and its index in stemmed_tokens_list the corresponding index of stemmed_tokens_list is set to the results of the .remove_stopwords_from_tokens() method of the KNN given the tokens. And likewise for the stemmed_question.
The user is prompted that the results for the document is coming. A dictionary called predicted_info is set up with the key "question" mapping to the stemmed_question. The labelled stemmed_question is printed. A new entry is created labelled "stemmed_document_tokens" which is set to the find_highest_similarity() of the stemmed_tokens_list and stemmed_question. The resulting most similar article is outputted with the label "processed document tokens: "
We then identify the unprocessed version of this article by identify_tokens_from_stems() the unprocessed document_list and the predicted_info["stemmed_document_tokens"] we just found. And .split() it based off the paragraph_separator_token to create a list of strings. The stemmed_selected_text is set to the selected document tokens joined together by whitespace. Essentially it becomes a string version of stemmed_selected_text. We use this to create a list of strings based off paragraph_separator_token’s in the string. This list is cleaned with every paragraph in it having its index replaced by the tokenisation of the paragraph with trailing whitespace removed. This process in short reshapes the article from a list of tokens to a 2D list of paragraph tokens.
The selected_long_answer is now set to the find_highest_similarity() between the stemmed_selected_paragarphs and the stemmed_question. For every paragraph in our unprocessed paragraphs we strip trailing whitespaces and overwrite itself with this updated version. We print the selected_long_answer with the label "processed answer" (processed answers are outputted to test that the right unprocessed version is selected and to see how the text has changed out of curiosity). Before outputting we are now selecting the unprocessed version. This is simply set to the results of identify_tokens_from_stems() of the unprocessed_paragraph and the long answer. Further output to the user is given , including the unprocessed question tokens joined by whitespace labelled question and the unprocessed_long_answer labelled complete selected. If test was True
the "long_answer" in the question_indexth dictionary of the .complete_data is outputted with the label actual. This is the desired answer from the NQ database. The predicted_info dictionary is updated to include the unprocessed selected long answer.
Utilising this unprocessed_selected_long answer is separated off full stops to create a list of strings labelled stemmed_selected_sentences. For every sentence and its index it is tokenised, stemmed and has its stopwords removed. It is joined with whitespaces and overrides its old index to maintain being a list of strings. The user is prompted that there is a result for a sentence or short answer coming. The selected short answer is set to the tokenisation of the highest similarity between stemmed_selected_sentences and the stemmed_question Unprocessed sentences are created by splitting the unprocessed_long_answer into sentences and stripping trailing whitespace characters. The selected_short_answer is outputted with the label processed answer. The unprocessed_selected_short_answer is identified from stems before the question, the unprocessed section and if applicable the actual answer are outputted. The unprocessed selected long answer is added to the dictionary and the predicted_info is returned.
Main loop and test vs user input:
Purpose:
This section describes the user interface and how we transition user input to arguments applicable for the project function which can then be run.
Coded implementation:
This code simply imports relevant used libraries into the program for use
When the program is run the user is notified with the text "program has begun" and fifty equal signs either side for aesthetic purposes. The paragraph_separator_token is set to "xtx" and used to initialise a HTML_reader called html_processor. We run help(project) to output the doc string and inputs of the code to create a neatly formatted information
page. The user is prompted if they want a premade input or free question. If they type in any key but enter the project function is called with all parameters being None but test being True. At the end results are printed. Otherwise articles is set to an empty list and the invalid_user_flag to True. While this flag value is True the user is prompted for an article name. This is turned to lower case, trailing whitespace removed , and any spaces are replaced with underscores The article is set to the extracted text from the html file name the user specified. This article is then added to the list of articles. If the string "not found" which signifies that there was no article of that name is in articles it is removed and the user is notified their article does not exist. If the length of the articles list is less than 2 the flag is set to True to prevent the loop ending prematurely. If the flag or the user input is "stop" the flag is set to False. If no conditions are met it is set to True.
Results is then set to the return value of project() with an inputted question and the articles. The results are then printed.
Results and accuracy for Articles, Paragraphs and Sentences:
From the 11 questions available through testing at n = 32 we get the following precision scores:59
At a first glance it appears that given the other models for comparison the project performed quite poorly. But if you take a closer look this is a David vs Goliath competition. DocumentQA was created by two researchers at the Allen institute for artificial intelligence in 201861 which is a partner with the University of Washington and was founded by Microsoft Co-founder Paul Allen62. DecAtt + DocReader was a model implemented by Kwiatkowski et al
59 final%20results%20for%20all%20paramaters%20(actual) (version 1).xlsb.xlsx full spreadsheet of results
60 Note this is an underestimate and CoPilot is generative and not capped by 2018 knowledge or a select corpus to choose from. So the task is likely to be harder for it as it was not designed for that purpose
61 https://aclanthology.org/P18 -1078.pdf Clark et Gardner, 2018
62 https://allenai.org/ and https://allenai.org/about
team based off research done at Stanford University63, New York University64, Google65 and Facebook AI66 from 2015-18. So to consider that despite far fewer resources than these organisations have we are even close to these modelsincluded as baselines by Kwiatkowski et al because they were state of the art at the time (2018) - is quite an achievement. With the current method of extracting short answers from long answers working better than the DocReader developed by Facebook AI and Stanford. For further context I have added a “simple” help project baseline with the same data. This uses some of the functions given in the project but with no pre-processing or tokenisation , splitting off whitespace the codei was then executed in the shell. The long answer score received from just directly comparing the similarities using HELP baseline is in fact 5% better than the given lower bound just selecting the first paragraph from each article Beyond the many preprocessing steps, the answer given it is built upon the assumption that the function to describe the answer of a text ���� (���� ) where ���� is the question vector is ���� (���� ) = ���� . Or that the perfect answer is the question. The afore mentioned contemporary models are all deep learning neural networks. Or they start with ���� (���� ) is equivalent to a composite function of matrix multiplication and activation functions and adjust the parameters in such a way to minimise loss or inaccuracy to effectively create a complex function to map input to output. So compared to these computationally intense and sophisticated deep learning techniques the program looks relatively naïve.
So with this, to be closer to neural models (13.74% and 9. 78%) than Microsoft CoPilot - which passed the Turing test - is to the lower of the two human baseline (16.76% and 8.85%) is a great achievement. The program gets more wrong than right but when it gets one stage (the long answer) right it is likely to get the next (short answer) as well as most of the other models in the results table.
63 https://aclanthology.org/D15 -1.pdf page 632-642 Bowman et al, 2015
64 https://aclanthology.org/N18 -1101.pdf Williams et al, 2018
65 https://aclanthology.org/D16 -1244.pdf Parikh et al, 2016
66 https://aclanthology.org/P17 -1171.pdf Chen et al, 2017
Notation guide:
the notation used in th e project is explained below:
this means vector A this is a list of numbers representing x-dimensional coordinates. E.g. in two dimensions a point would be a vector like this [��������] and for three dimensions [���� ���� ���� ] etc.
This means you add up the ���� th dimension of vector A up to dimension n from in this case one. Importantly though indexes will start at 1 and go to ���� (in this project ���� is always unless specified otherwise the dimension of the vector) this differs from indexing arrays or list in code where the first index is zero. log ����
This is used to scale a value, with default base ten. Where log 10���� = ���� O(����)
The operational complexity of an algorithm given ���� inputs. This project I mainly deals with: linear ���� , logarithmic log(����) and quadratic ����2 . 67
67 First devised by German mathematician Paul Bachmann (link to work: https://gallica.bnf.fr/ark:/12148/bpt6k994750 ) unfortunately I have not read it as the only copy I could find was in German
The size or magnitude of vector ���� ⃗ and is equivalent to the below equation68 . It is also a vector ’s Euclidian distance from the origin. A link to the earlier proof of Euclidian distance.
HTML: Hyper text markup language. How web pages are stored in the internet. Not technically a Language but a way of representing how information should be displayed
JSON: Java script object notation. Way of storing data using key value pairs and arrays
KNN: K nearest neighbours algorithm. Machine learning technique to identify the classification of a point based off its position compared to other classified points
library: "Repository of software for the Python programming language." -PyPI (python package index). pre-made functions though not necessarily written in the python programming language. Usually open source
ML: Machine learning, algorithms or programs that can “learn” patterns from data
NLP: Natural language Processing, a branch of computer science focused on processing words object: A entity which can either be built in ( e.g. lists) or user defined through classes. Can have attributes (data types) and methods (functions).
python: High level programming language
QA: Question answering. A problem in how to program computers to produce coherent output reading comprehension: Being able to read a text and find a relevant answer
stem: A base conjugation of a word
stemming: The process of converting a word to its stem . A lossy process that conflates words by removing endings
stopword: A word used in speech for clarity of communication but has little true meaning: a, the, and…
TF-IDF: Term frequency - inverse document frequency, a way to numericise words based off their distribution in a text
tokenisation: Splitting text into processed words or "tokens"
type hints:
whitespace:
In function definitions to show the data type of inputs. Not enforced or required by python
Control characters in text and spaces between text. Different sizes and styles including (https://unicode-explorer.com/articles/space-characters)
Boolean: Datatype, either True or False.
i HELP baseline implementation: >>> raw_document_tokens = [nq.complete_data[i]["article_tokens"] for i in range(len(nq.complete_data))]
question = "when do the eclipse supposed to take place".split() document = find_highest_similarity(raw_document_tokens,question) print(" ".join(document))
reshaped_document = [para.split() for para in (" ".join(document)).split("xtx")]
SUSTAINABLE DEVELOPMENT IN NIGERIA: ASSESSING PRESENT CHALLENGES AND FUTURE POTENTIAL
BY ADAM GAUNT
(Upper Sixth, HELP Level 4, Supervisor: Miss C Brown)
Sustainable Development in Nigeria: Assessing Present Challenges and Future Potential
Introduction
It is generally agreed upon by geographers that Africa will be the home of the global growth in the next century, both in terms of economic development and population increase. The abundance of raw materials, rapid development in many countries and cultural expectations about having large families mean the continent is expected to drive global change in the coming decades. Nigeria epitomises this. Although estimations vary, the World Bank (2023a) places Nigeria as the second largest economy in Africa, with a GDP of $362.81 billion. In 1960, this value was just $4.2 billion (World Bank, 2023b). This rapid economic growth has been primarily down to the exploitation of the country’s raw materials, most notably its huge quantities of oil. Trans-National Companies (TNCs) such as Shell have thus played a significant role in Nigeria’s development in the last century, as it is these conglomerates that invest in the country in order to find, and extract, oil to export and sell.
Nigeria also has an extremely large population of over 223 million people (Worldometer, 2024a). Moreover, its growth rate of 2.41% ( Worldometer, 2024a) means that the population will continue to expand until birth rates fall. The country also has a strong, rich tribal history and culture, with around 371 unique tribes. Whilst this creates an incredibly important and unique dynamic, it can also lead to internal civil conflict and disputes, as people tend to view their tribal identity as more important than their national one. This is undoubtedly a product of the Berlin Conference of 1884, when African borders were created without consideration of the people and tribes grouped within them In the modern day, the conflicts created by these historical factors has profound political implications and impacts, as different tribes have differing opinions of how the country should be run, as demonstrated in the most recent Nigerian election. In addition, Nigeria has a major issue of corruption within government, being ranked 145 out of 180 countries in the Corruption Perceptions Index (Transparency International, 2023)
The many changes that have been seen in Nigeria in the last century have generally been beneficial for the country and those living in it. However, the speed of its development gives rise to an interesting question - is Nigeria’s development sustainable? Sustainability is famously defined as “meeting the needs of the present without compromising the ability of future generations to meet their own needs” (Brundtland Commission, United Nations, 1987). With this in mind, the evidence comprehensively underlines that Nigeria is not currently sustainable – it is heavily dependent on oil for its economic output, suffers from severe corruption, has over 150 million in poverty, and suffers from numerous other issues. Therefore, it is essential that not only Nigeria’s current sustainability is considered, but also its capacity to become sustainable in the future. This is a very important topic to discuss, as in a country with such a large population, experiencing such rapid changes, inaction or poor decisions could be catastrophic for the future of the people living in Nigeria. Yet on the other hand, if managed correctly, Nigeria has the existing conditions to become a far more developed and sustainable country. In this essay, discussions about Nigeria’s sustainability will be broken into four key aspects:
1. Economic development
2. Political stability, tribalism, and corruption
3. Social development and inequality
4. Environmental sustainability
1. Economic development
Background
Nigeria’s economic development has a long, complex, and difficult past, and yet a single commodity has ultimately become synonymous with the country’s economy itself in recent decades: oil. To truly understand how oil has taken a such a grip on the country, it is important to look back to the period of time before its first oil boom, when under British rule as a colony. For better or worse, the economic development of Nigeria was initially triggered by the arrival of colonists from Britain, who viewed Nigeria as a strong economic asset with a readily available supply of cheap raw materials. (Adeyeri and Adejuwon, 2012) As such, they created infrastructure and systems designed to exploit these raw materials, with the intention of exporting these back to the UK. However, as they were only interested in exports, and not the development of Nigeria as a whole, economic activity was made to be almost entirely orientated around the exports of primary goods, in particular palm oil (Adeyeri and Adejuwon, 2012). This made Nigeria completely dependent on imports from other countries to acquire many basic goods, as locals were encouraged to grow ‘cash crops’ instead of carrying out their own agriculture. Consequently, Nigeria became commodity dependent, as their only real source of income and foreign currency, which was needed to import basic goods they did not produce themselves, was the exportation of unprocessed goods to wealthier, more economically developed countries. (Adeyeri and Adejuwon, 2012). This legacy of heavy exporting primary goods created the perfect environment for the development of its current dominant commodity, as in the early 20th century the British started to search for oil fields in the country. In 1937 Shell D’arcy (now Shell) was allowed full access to the Niger Delta for oil exploration, (Nairametrics, 2013) leading to significant progress in the development of its early oil industry and causing increased foreign interest in the region. Yet it was not until 1961 that Nigeria saw its first oil boom, as a result of newfound independence and the introduction of many new Transnational Corporations (such as Texaco). Oil production skyrocketed from 5100 bpd in 1958 to 2.4 million in 1979 (Nairametrics, 2013). From the 1970s onwards, Nigeria became one of the top 10 largest oil exporters on the planet (Nairametrics, 2013).
Impacts of Oil Production
This undoubtedly had a huge economic impact on Nigeria, which was in many ways a profoundly positive one. Clearly, Nigeria’s oil production has driven huge amounts of economic growth in the country. Its GDP has increased many times over, and the country has consistently seen periods of over 5% annual growth during boom periods (World Bank, 2023). This growth has led to a greatly increased amount of wealth in Nigeria, which has allowed other sectors and industries to grow, and had an incredibly positive economic effect. On top of this, TNCs and oil conglomerates themselves can have, in some respects, a positive effect on the country. In 2021, Shell alone provided 2,500 jobs to Nigerians directly, and far more through the indirect creation of economic activity. (Shell, 2021). Moreover, they paid nearly 1bn to the government in taxes (Shell, 2021), which is incredibly important in a country struggling greatly with a weak government. This money is essential in providing public services, infrastructure development and combatting increased poverty in the face of huge population growth. As a whole, it is clear
that for the people of Nigeria as a whole, the economic development caused by the oil industry has improved their standard of living greatly, as healthcare services, access to contraception and clean water, amounts of disposable income and job availability have all been increased. Whilst it is debatable as to whether the quality of life in the country has risen, it is important to note that even from the early 2000s to today, Nigeria’s HDI has risen from 0.449 to 0.548. (UN Human Development Report, 2024).
Despite this, the oil industry has also created many extremely prevalent and pressing issues in Nigeria. Whilst some factors come to mind immediately (poor working conditions and extreme environmental damage, for example), there are also numerous economic problems that have arisen as a result of the country’s current economic makeup. Nigeria’s oil may be a blessing in some respects, but it is also seen by many as a ‘resource curse’. Its abundancy of oil has led to its exports being incredibly successful, which has led to it experiencing ‘Dutch Disease’. This is the process by which the mass exporting of a single successful commodity (in this case oil) causes the strengthening of domestic currency, resulting in other exports becoming less competitive in the global market. This has resulted in Nigeria experiencing overdependency on its single main commodity. Whilst there are limited exports of some cash crops like seed oils and nuts, oil contributes to over 90% of its exports (TradeImeX, 2023). Consequently, Nigeria has extreme economic vulnerability, as its lack of diversification leads to a cycle of ‘boom’ and ‘bust’ periods as global oil prices fluctuate. This gave Nigeria its huge periods of economic growth in the 1970s and 2000s but can also lead to devastating crashes and recessions. For example, in the 1980s, global oil prices plummeted, resulting in huge economic damage that greatly reduced the standard of living in the country, and forced huge amounts of borrowing from the IMF, raising debt levels drastically. Even after multiple attempts at economic reform and diversification, it is still incredibly reliant on oil and gas exports. Nigeria also struggles as a result of not only oil dependency, but its entire economic structure put in place during its time under colonial rule. Decades later, Nigeria is still dependant on the imports of many goods, both high value and basic, such as a need for over $10bn worth of food imports per year (US International Trade Administration, 2021). Inevitably, this leads to food insecurity and a dependency on foreign nations to be consistent and reliable in their supply of imports, leaving Nigeria very vulnerable to global shocks and events. However, this situation is made far worse by its own economic fragility, as an oil crash could prevent it from having to financial capacity to buy these exports altogether. Hence, oil dependency makes it likely that Nigeria will periodically see periods of catastrophic economic hardship, that will have a huge impact on many millions, who will no longer be able to afford even the most basic of goods.
Oil production has also greatly exaggerated existing inequalities in wealth distribution within Nigeria. There has always been an ethnic divide between the mostly Muslim north and predominantly Christan south of Nigeria, as well as an economic disparity as a result of differing levels of colonial investment (Mancini, 2009). Britain was focused on exports and economic value, so primarily invested in the coastal, southern regions of the Niger Delta, instead of the rural, dry north. (Mancini, 2009). This has meant ever since the creation of the British Nigeria Protectorate the north has always been less economically developed. However, as the majority of exploited oil fields are in the Niger Delta, this economic inequality has been massively increased, as TNC and governmental investment has been in the south, in cities such as Lagos and the Niger Delta region as a whole. As a result, the north of Nigeria has experienced an extreme cycle of deprivation in numerous aspects. There is a far lower education rate and less access to university (Dapel, 2018), poorer healthcare provision, and an overall lower quality of life that has allowed political instability and extremism to thrive in the region (Nwankpa, 2021). If
Nigeria is going to improve its level of economic development and sustainability as a whole, encouraging the growth of industry and economic activity in the north is essential, to reduce north-south economic inequalities.
Solutions
Although Nigeria’s oil production still dominates its economy, the size of the industry is starting to decline. In 2013, Nigeria slumped to just the 14th largest oil producer globally and produced 1 million less barrels per year than in the 1970s (Nairametrics, 2013). More recently, Shell and numerous other oil conglomerates and TNCs have pulled out of the Niger Delta or reduced activities, primarily due to concerns about widespread oil insecurity and theft (Iyatse, 2024), as well as desire to shift to renewables and offshore drilling. This could pose a huge threat to Nigeria’s economy – its primary source of exports and income looks set to shrink, which could leave a huge hole in Nigeria’s economy that has no single clear successor. However, this could also provide Nigeria with a huge opportunity to diversify its economy, as the government will no longer be allowed to enjoy the boom-recession process created by oil exports. Hopefully, this will force officials to enact reform that will hopefully better the nation as a whole. In particular, it is imperative Nigeria sees a drastic sectoral shift away from primary and secondary industries towards high skilled, tertiary labour. This will have numerous long-term positives for the country, such as increasing its capacity for future economic development, as Nigeria would no longer be reliant on exports with prices determined by external organisations, allowing for far more consistent and sustained growth. For the population itself, high wages would be available with greatly improved working conditions, and labour would be far more accessible for women (EFinA, 2022).
The tertiary sector is already showing extreme promise in Nigeria, as in 2023 it grew roughly 18.4%, whilst primary and secondary industries saw very limited growth. (Ekeruche et al., 2023). Change is already occurring, but it must be committed to wholeheartedly if Nigeria truly wants to see long term economic development. Much of this responsibility will lie with the government: it must incentivise both the population and businesses to support and commit to sectoral shift through the use of taxes, subsides and policy. In this respect, the government must be credited to some extent. In 2023, President Tinubu commenced his bold economic reform with the intention of diversifying and stabilising the economy, that included over $2.25bn (Laker, 2024) worth of spending on both small- and large-scale businesses. He also controversially removed the heavy fuel subsidy in place for oil and gas, which made Nigerian fuel prices far less competitive globally. (Laker, 2024). As a result, he gave an overwhelming impression that he is committed to moving Nigeria’s economy away from commodity dependency and towards the tertiary sector. Yet these policies have had many negative impacts as well. Reducing government support of oil and gas will force companies to diversify, but by doing so in such an abrupt manner, Tinubu caused transport and production costs for companies to rise drastically. Inevitably, this cost was passed on to the consumer, meaning it has been very costly to the Nigerian public. His policies have also caused the Naira to devalue and inflation to rise to over 20% (Laker, 2024). Even so, these reforms should be seen as a sign to be cautiously optimistic about Nigeria’s future. It is true the policies could have been far better implemented to reduce their impact on the poorest, but removing such a vital element of the economy will inevitably cause some short-term problems. It has been made clear that there is a commitment from the current government to act, and if it utilises the money freed up by the removal of the subsidy to attempt to alleviate the economic pressures placed on those hit hardest, it can be seen as a significant step towards economic sustainability.
However, to achieve economic sustainability in the future, the Nigeria must also look at tackling the ever-growing north-south divide in the country. It is essential that the north sees increased investment as a means of creating economic activity and growth. To some extent, foreign investment may be important. For example, in 2019 the UK FCDO created the Nigerian Links programme, with the intention of creating a new, diversified economy in areas of northern Nigeria that could create up to 100,000 full time, taxable jobs (LINKS, 2023). However, budget cuts meant the scheme closed early, and whilst it had made some steps to attract business and investments to its focus areas, it ultimately spent less than one quarter of the money it initially committed. What this means is that if Nigeria wants to improve the economic development of the north, it cannot rely on aid alone. Foreign government assistance can be beneficial, but if sustained, significant change is going to occur it ultimately must come from within. Hence, the government must themselves invest in the region if they want economic improvements. One solution is the creation of jobs and economic activity through the implementation of infrastructure projects in the region. For example, the government claims that 52% of all new road projects being created by the new administration are in the north (Addeh, 2024). It is also pivotal that improvements in secondary school and university enrolment take place, as the education level of the north must be brought up to allow for the growth of a more skilled labour force, who can access higher wages and spend in local economies. Currently, over 70% of farms in Nigeria are subsistence, the majority of which are located in the north (Suleiman, 2023). Improving education levels in the north will also aid in the shift to the tertiary sector, as these people can now move into high quality finance and business service jobs, instead of subsistence farming where they have a very low standard of living and earn little to no wages.
Nigeria’s economic development is currently not sustainable, but a sectoral shift away from oil production could allow it to become so, through the diversification of its economy and the creation of high skilled, tertiary sector jobs. The Nigerian government will hold lots of responsibility in improving the economic situation in Nigeria, as it is their spending and policy decisions that will ultimately dictate whether Nigeria can detach itself from an industry it has been almost wholly dependent on for multiple decades. Though they have shown examples of a desire to shift away from oil, most notably President Tinubu’s bold economic reforms of 2023, it is essential a wiser, more considered approach is taken when employing policy to reduce shortterm economic impacts. The government must also ensure northern Nigeria sees substantial economic development through the creation of infrastructure projects, education provision and foreign assistance, as subsistence farming and low-paid agriculture mean this region is not currently economically sustainable. If it can achieve this, Nigeria could achieve almost complete economic sustainability in the next few decades.
2. Political stability, tribalism, and corruption
Tribalism
Nigeria is home to over 250 different ethnic groups, the largest being the Hausa-Fulani, Yoruba, and Igbo tribes. Each group has its own culture, identity and dialect which create an intensely rich and unique demographic within the nation. It is essential that the benefits of tribalism are not forgotten when considering the future of Nigeria. It shapes art and music, is essential for community and unity within local areas, and most importantly allows people to feel a sense of connection to their ancestry and heritage. In spite of the damage carried out by colonial powers and the artificial borders they created, the Nigerian population’s strong connection to its tribal
history has endured and flourished, and its importance cannot be understated. Thus, to ensure cultural and political sustainability, tribal influences must remain as the country tries to develop elsewhere.
However, the strength of tribalism and its impact on Nigerian politics and distribution of power also leads to significant problems. One such issue is that Nigerians tend to identify with their tribe first and nation second. This is unsurprising and understandable – many Nigerians, especially in rural areas, will have grown up in closely knit tribes with historical leaders and chiefs. Even if this isn’t the case, senior household figures often instil tribal values into children and young people as means of connecting with their ancestry. By comparison, the Nigerian nation was created by merging two British ‘Protectorates’ barely a century ago (COICO, 1960). Thus, the Nigerian state as a concept is fundamentally a Western one that was created without the interests of the population in mind and may seem foreign and unacceptable to many in Nigeria. The result of this is that every day decisions are heavily influenced by an individual’s tribal background and ancient tribal conflicts of the Niger Delta. People are frequently selected for promotions and employment based on their tribe instead of merit (Ebegbuna, 2019), which reduces productivity, and on a large scale may hinder economic growth as a whole in the longterm, as skilled, qualitative labour is not prioritised. On a more personal, social level, people may be prevented from marriage or business with those of another tribe as a result of tribal expectations, structures, and hierarchies (Ebegbuna, 2019). But arguably most importantly, in a political context, Nigerian people generally vote in support of their tribe instead of policies they agree with. This can be seen in the most recent elections, which took place in 2023. Bola Tinubu was elected with just 36% of the vote, with opposition members Atika Abubakar and Peter Obi gaining over 25% of the vote each (Orjinmo, 2023). Each of these candidates were from major tribes, and the vast majority of their respective voter bases were their own ethnic groups.
This is problematic for a number of reasons. Firstly, an underlying suspicion of politicians of other ethnicities, and the incentive for officials to electioneer in favour of their own tribes means political progress occurs much slower, as politicians prioritise their ethnic group over the success of the entire nation. Furthermore, such a split parliament clearly indicates huge divisions and a lack of unity within the country. This has facilitated increasingly polarised and divisive politics in Nigeria, which is making the political situation in Nigeria extremely fragile and volatile. As a consequence, tribal conflicts in a political context are becoming increasingly aggressive, sometimes to the stage of violence, hindering people’s capacity to vote altogether. In Lagos, there were reports of Igbo people being beaten and chased away from polling booths by armed men (Adeyemi, 2023). This prevented people from voting, and utterly undermined any sense of fair democratic voting in Nigeria. Shockingly, this event was not isolated, and such instances were common during the election. It is clear that voter intimidation, violence and vote rigging were commonplace on all sides of the political spectrum (Adeyemi, 2023). In fact, the issue was so deep -rooted and systematic that Abubakar and Obi both called for the election result to be completely overturned. (Adeyemi, 2023). Fundamentally, the population’s desire to vote for politicians of their own tribes means that inevitably officials will heavily favour their own ethnic groups, both in campaigning and policy making. Policies are also often designed to benefit wealthy tribal donors (Lloyd, 2019) who fund campaigns as means of gaining soft power. Therefore, a positive feedback loop is created, as increased tribalist voting ensures policies become more ethnicity-focused, resulting in even stronger tribal voting. Consequently, political development is vastly reduced, which results in reduced economic growth, social development, and overall unsustainability in Nigeria.
Corruption
However, Nigeria’s political issues extend beyond tribalism into an arguably even more difficult issue to combat - corruption. How Nigeria created an environment where corruption is able to thrive in such high levels of government is a complex question. Inevitably, historical colonial influences are a major factor. Political systems that were put in place by British officials were intended to facilitate foreign control and the exploitation of Nigeria’s environment and population. As a result, the structures left behind as colonialism ended were not in any way equipped or designed for independence and actual control. On the other hand, tribalism also has a heavy impact, as ethnicity-based voting has created a culture where corrupt officials can thrive. Provided they favour their own ethnic group, politicians will usually keep receiving votes, even if they are exploiting the rest of the country from within government. It can also be argued that various military coups and violence in recent decades have created a legacy and culture of dishonesty, greed and power-grabbing within government that is extremely difficult to break away from. However, this instability is likely a product of the other two previous factors, as a stable, honest democracy is far more difficult to seize power in than a corrupt, fragile one.
The scale of corruption in Nigeria cannot be understated, and it is important to understand that unlike other issues the country faces, it is not a problem it seems equipped to resolve, nor has it taken many significant and meaningful steps in doing so. As recently as January of this year, Nigeria’s poverty minister was suspended for diverting over £500,000 worth of naira to a personal bank account (Abubakar and Chibelushi, 2024). Their position in government seems cruelly ironic, but also underlines the extent and severity of Nigeria’s corruption, as the money he stole would have likely otherwise gone to the most deprived members of the population. Immorality and corruption are so widespread that it is estimated that 44% of all Nigerian public officials have taken a bribe in the last 12 months (Transparency International, 2023), and the recently elected President himself has been accused of corruption in the past. Perhaps most shockingly, Oxfam estimates that public office holders had stolen $20 trillion from the treasury between 1960 and 2005 (Oxfam, 2024). In 2005, Nigeria’s entire GDP was roughly 113 times less than this number. This is arguably the underlying issue for most of Nigeria’s sustainability issues as a whole. Economic and social development is incredibly difficult if those in power are not only not facilitating development, but also actively preventing it to such a great extent. It is also clear Nigeria is making minimal progress in tackling this corruption, as 43% of its population believed its corruption had increased from the start to end of 2023 (Transparency International, 2023). In the same year, the Corruption Perceptions Index gave Nigeria a score of just 25/100, ranking it 145/180 countries recorded. Despite multiple governments taking power, including Mohammadu Buhari’s parliament which specifically promised to stamp out corruption (Premium Times Nigeria, 2015), Nigeria’s CPI value is identical to its score a decade prior. Therefore, it can be argued that it has made no progress on a nationwide scale in tackling corruption in recent years.
It is clear that corruption has plagued Nigeria for much of its history, and hugely hindered its development in the past. However, the sustainability of its development in the future may also be greatly affected if it does not find ways to reduce governmental corruption. Long term corruption has created a deep lack of trust in institutions such as the electoral system, government, and public services, which makes it difficult for progress towards a true democracy to be achieved. Corruption also results in instability and difficulties in predicting economic growth, which will likely reduce FDI. By 2030, current corruption levels could reduce Nigeria’s GDP by up to 37%. That is nearly $2000 per person. (PWC, 2024). The removal of money from
government finances would also reduce the tax base to just 8% of GDP (PWC, 2024). This would have a huge social impact on Nigeria, as public service provision would be heavily limited, and thus people would be forced to rely even more on TNCs to provide healthcare and services. As established previously, there is a clear sign of reduced TNC activity in Nigeria that will only increase in future years, meaning a service catastrophe could be seen in the near future. Worsening services will also reduce human capital, evidenced by the 2020 World Bank statistic that a child born in that year would be just 36% as productive as if they had had access to a full education and health (World Bank, 2020). Therefore, political instability, exploitation, and poor governance as a result of corruption have had an extremely adverse impact on governmental policy, integrity, and sustainability. This has resulted in hugely negative socioeconomic impacts, as the quality of life of the Nigerian population has been heavily impacted by embezzlement and poor government choices. Without immediate and drastic reductions in corruption levels, the future of Nigeria looks extremely fragile and challenging, as the economic and social difficulties caused will only worsen as it tries to develop.
Solutions
To attempt to achieve political sustainability in Nigeria will be a long and complex task, as the root of the issue is within government itself. To combat corruption Nigeria will have to apply multiple approaches and methods with the aid of both internal and foreign parties and stakeholders. Combatting tribalism will be equally important. To create a true sense of unity and collective identity, Nigerians must start identifying with their nation first, and tribe second. Tribal tensions, suspicions and distrust is allowing corruption to thrive and grow and preventing it will be a countrywide task which all must be committed to. One potential solution to reduce tribal tensions is integrated education in schools. Currently, many go into education solely with those of their own tribe or ethnic groups. By placing children in an environment containing those of other backgrounds from a young age, younger generations should develop an increased sense of tolerance and shared national identity. This has led to the government setting up 105 ‘Unity Schools’, which are designed to create institutions with increased ethnic diversity and improved understanding of different cultures. The National Youth Service Corps has also been created, which is a military skills training course that must be taken by all Nigerian University and Polytechnic graduates. Placing young adults in a physically demanding scenario will help strengthen social bonds and trust between those of different cultures, which should also encourage unity and a shared national identity to develop. This scheme is especially important as it is those in higher education who take part in it. As a result, there is a focus on those who will likely end up in government or positions of power and influence, and thus will have the greatest impact on the future of Nigeria. Hence, whilst small, this is undoubtedly a positive step towards sustainability.
However, tackling corruption within government will be a far more difficult issue, as a careful balance must be struck between maintaining open, democratic values and effectively removing deep -rooted corruption at all levels of government. As a result, a unified effort between public, government and foreign parties is absolutely imperative. For example, the ACORN project created by the UK government (Lawal, 2021) attempted to improve collaboration between state and non-state parties to improve the efficiency of anti- corruption responses. It also carried out some education efforts in teaching general education about corruption and used social media to create awareness and debates about corruption (Lawal, 2021). Whilst social media could have been an effective tool in an increasingly interconnected and technologically developed Nigeria, it ultimately misses out on the poorest and most deprived. Hence, though it creates
very public criticisms of the government, they cannot be seen by the millions living in slums and rural areas that do not have internet access. Furthermore, in 2020, a lack of foreign office funding meant ACORN was shut down before it could truly enact the extent of change it was intended to. This underlines how although foreign influences can have some limited and useful impacts, to truly combat political unsustainability in Nigeria action must be made internally, within the country and government. Civil Society Organisations must have the ability to regulate and call out governmental corruption, and stricter regulations must be put in place to make embezzlement more difficult for government officials to carry out.
To achieve political sustainability in Nigeria, it must first combat the extreme corruption it suffers. For this to happen, the population must first become far more unified and trusting of each other, by overcoming historical tribal conflicts and creating an increased sense of shared identity and connection. Only then can the government truly be held to account for its actions and policies, and corruption truly be combatted. This will be extremely difficult and will rely on both the will of the population and those in power having integrity and facilitating political progress today, through educational schemes and the creation of genuinely independent regulators. As evidenced by a lack of progress in recent years, limited government policies alone will not have any meaningful impact due to the extent of the corruption Nigeria faces. Therefore, Nigeria is not currently politically sustainable, and it will be an incredibly long and difficult task to try and eradicate its corruption and civil tensions.
3. Social development and inequality
Background
Nigeria is posed with a difficult path to social sustainability, that primarily stems from its huge population. As of 2023, the nation had a population of 223.8 million, by far the greatest in Africa (Worldometer, 2024). Not only is its population extremely large, but it is set to grow dramatically in the next few decades, as a result of its 2.41% growth rate (Worldometer, 2024). Due to this natural growth, as well as rural-urban migration, Nigeria will see the development of multiple megacities (huge urban areas with over 10 million people living within them). Most importantly, Lagos is set to become the largest city on the planet by 2100 (Ontario Tech University, 2024). This extremely large population will pose two key social challenges, which are already extremely prevalent today in Nigeria – huge levels of socioeconomic inequality (in particular extremely high poverty levels), and the need for provisions of services to hundreds of millions of Nigerians. Currently, Nigeria’s 5 richest men have a combined wealth of almost $30 bn, and yet over 112 million are under the poverty line (Oxfam, 2024). This is a clear sign of severe economic disparity; the country is home to multiple billionaires, and yet nearly half of the entire population of Nigeria is in poverty. Moreover, the wealth of the richest highlights that Nigeria is in many ways economically prosperous- its oil and gas productions have boomed, and it has evergrowing numbers of people in skilled, well-paid labour. However, poor management of resources, corruption, or even a fundamental lack of caring for the least wealthy by government has created an unequal nation with an overall poor quality of life. These governmental issues are also a major cause of poor provision of services. Less than 10% of the national budget is spent on education, health, and sanitation (Oxfam, 2024), which has resulted in over 57 million being left without safe water, and over half the entire population of Nigeria does not have access to adequate sanitation (Oxfam, 2024). Furthermore, over 10 million Nigerian children are not in school. (Oxfam, 2024).
Current policy and issues
It is clear the government is not doing nearly enough to tackle social issues in Nigeria. However, it has been able to neglect this responsibility to some extent in recent years due to the presence of Transnational Corporations (TNCs) and Non- Governmental Organisations (NGOs). Whilst NGOs offer large amounts of free healthcare and education throughout Africa, heavy social responsibility had also been placed on many TNCs, such as Shell, to support local communities as a sort of offset for any environmental damage caused by oil and gas production in Nigeria. The Shell Petroleum Development Corporation (SPDC) has provided large amounts of services and infrastructure in the Niger Delta, where their operations formerly took place. For example, the Community Health Insurance Scheme provided affordable healthcare to over 100000 people (Shell, 2022a), as Shell both provided and subsidised medical support for locals. Shell also provided over 2600 full secondary school scholarships per year as part of their Nigeria Secondary School Scholarship Scheme (Shell, 2022b). This investment in the local communities was especially important as Nigeria only provides free compulsory education for primary students, so many in poverty drop out of the school system at 12. Therefore, Shell enabled those from deprived backgrounds to receive a full education, setting them up for skilled jobs in the future. However, due to the diminishing oil industry and other factors, multiple TNCs including Shell have withdrawn operations from Nigeria. As a result, there is no longer an incentive for aid and investment systems such as the SPDC to be in place, essentially meaning TNC service provision will be greatly reduced in the future.
Clearly, Nigeria is reaching a crisis point. TNC service provision is diminishing, yet population growth means the demand for social services will only increase in the future. The government is going to have to take on a greatly increased burden in terms of providing amenities and services, particularly for those in deprived communities, a responsibility it is not currently prepared to deal with. Fortunately, the two key issues of inequality and services it must deal with are heavily linked. If more in poverty are given access to healthcare, clean water and education, their quality of life will greatly improve, thus reducing inequality. By providing more public services, the whole country benefits. There is also a clear answer to where the focus of government investment and spending must be to improve the lives of many Nigerians: the slums. 49% of Nigerians live in slum settlements (World Bank, 2020), meaning over 100 million Nigerians are subjected to high density, informal living spaces without access to even the most basic amenities and services. High child mortality rates, disease, poverty, and low standards of living all contribute to an incredibly low quality of life. For example, Makoko, Lagos is believed to be the world’s largest floating slum, and one of the biggest slums in Africa. It contains over 250,000 people, a third of whom live in buildings built on stilts over a lagoon (Ottaviani, 2020). Although there are no exact numbers due to the nature of the settlement, it is clear there is very little service provision in Makoko. There is no formal transport, so the only means of travel is by canoe through the heavily polluted lagoon. Access to clean water or healthcare is very limited and costly, and any education provided is run by local volunteers and charities. The quality of life is clearly unacceptably poor for a Middle-Income Country, and yet Makoko is one of 157 slum communities in Lagos alone (Ileyemi, 2023), meaning high levels of deprivation are common all across the city and entire nation. The provision of even basic services to these slums could improve the living conditions of tens of millions of Nigerians. For example, over a million people die from unclean drinking water each year globally (Ritchie, Spooner and Roser, 2019). By providing just this one basic service could save tens of thousands of lives in Nigeria. Moreover, by improving the health and education of people in slums can allow them to work
better jobs or achieve higher levels of education, potentially helping to eradicate the cycle of deprivation that is evident throughout the deprived areas of urban settlements in Nigeria.
However, recently, the government has generally approached the issue of slum settlements in the completely wrong way. In 2012, the Nigerian government attempted to forcibly evict the residents of Makoko, with the intention of destroying the slum to replace it with formal developments. Whilst there was a clear economic reasoning behind this decision, it is also likely the government simply wanted to remove the slum as it perceived it as an embarrassment. Makoko is located within the inner city of Lagos, in close proximity to the Third Mainland Bridge, an impressive architectural feat that is the second longest bridge in Africa (over 7 miles long). Hence, the slum served as a stark reminder to the wealthy that inequality and economic disparity is still extremely rife in Nigeria. The Nigerian government managed to evict over 30,000 people through extreme violence and the support of armed police. Moreover, there were even reports police set fire to areas of the slum to force people to leave the area (Morka, 2012) Unsurprisingly, there was huge outrage and pushback from the people of Nigeria, leading to the halting of demolition and the slum ultimately surviving. This event gives a clear representation of the issues Nigeria currently faces- the government understands the slums are a major issue but had fundamentally oversimplified the problem. Instead of focusing on improving the lives of people in the slum, they instead tried to remove it completely to eradicate the problem. Clearly, the issue is far more complex. People rarely have informal settlements as their first choice of living space. Many of the people of Makoko are from Benin, who migrated looking for work and an improved quality of life. They only chose to live in Makoko because there was no formal housing available to them. The events of 2012 are also important as they highlight that it is essentially impossible to remove existing slum settlements, as they are simply too large, and embedded with their own identities and cultures. Therefore, to improve the situations in slums the government has two solutions: urban planning to prevent the growth of new slums; and improve service provision in existing slums to raise the quality of life of the people already living within them.
Solutions
Urban land planning and the provision of affordable housing is an important solution in preventing the development of new slums in Lagos. As of 2023, Nigeria has a 28 million housing deficit (Uduu, 2023), with over 3 million of that number being located in Lagos alone. Government-backed affordable housing projects are needed to reduce the demand for slum housing and reduce the pressure on existing formal settlements. Whilst investing in and subsidising these houses will be costly, it is undoubtedly a good decision for the government to make, as it benefits both those in poverty and the government itself. For those under the poverty line, affordable housing gives access to waste disposal, clean water, and other amenities, leading to a safer, cleaner, and vastly improved quality of life. For the government, the amount of people looking for informal housing will be reduced, which should both decrease the rate of growth of existing slums, and also prevent new slums from forming. However, it is equally important the government improves the lives of those already living in slums to improve social sustainability. One key aspect that needs to be improved is the access to electricity in the slums of Nigeria. Electrification is an extremely important and urgent improvement that is needed to greatly improve the standard of living in Nigeria and reduce social inequality. This is a challenging task though, as the informal infrastructure of slum settlements is not connected to the national grid. Hence, the government must find off-grid solutions to the electricity problem. One potential solution is the instillation of solar panels in slums, utilising the warm climate of
Nigeria. The Nigerian government has actually made some progress in this regard- the Rural Electrification Agency has installed numerous solar panels, including 1572 Solar Home Systems in Makoko (REA, 2024). The electricity generated is used to power Makoko’s education and local healthcare facilities, making it vital in improving the lives of the poorest and lifting them out of poverty.
Nigeria also needs to improve access to clean, potable water for washing, cooking, and drinking in Makoko and other slums. Despite being located on a lagoon, the high levels of numerous harmful substances, such as E-Coli, ammonia and nitrates (Code for Africa, 2020) in the water mean access to clean water is extremely limited. The only access to cleaner (though still not always clean) water is through groundwater extracted from boreholes. However, all of these boreholes are privately owned, resulting in water being sold at an extremely high premium. For some families, potable water can cost over $1 a day, rendering it unaffordable for many. Therefore, it is crucial government- owned subsidised boreholes are created to provide clean water to those in Makoko and other slums. Access to clean drinking water is a basic need that will drastically reduce mortality rates, so should be a top priority for the government when taking action.
More generally, the government simply needs to invest more into education, healthcare, and other services. Improvements will not occur without government intervention, and so an acceptance of increased spending is required. For example, less than 3% of the Nigerian population have medical insurance, meaning even if there is healthcare close to those in poverty, they likely will not be able to afford it Finally, though not a sustainable solution longterm, if Nigeria wants to develop socially it needs to continue to rely on aid to some extent. Crucially, those in poverty today in Nigeria should look to NGOs such as Médecins Sans Frontières (Médecins Sans Frontières, 2010) for safe, free healthcare and social support. Nigeria is a country constantly growing in population, and with dwindling social support from TNCs. As a result, it will undoubtedly struggle to become socially sustainable in the future. With over 100 million Nigerians below the poverty line and living conditions within Nigerian slums being extremely limited and poor quality, the government will already struggle to combat the poor provisions of services and high inequality in the country today. Yet for social sustainability to be achieved, it must bring its population of today and the future (which will be far larger) out of poverty. This will require bold, progressive, and forward-thinking policies that far exceed their current limited successes (such as the instillation of solar panels in Makoko). This is possible, but the government must be willing to spend heavily, and work in unison with the general population to target the areas where poverty is most prevalent and social services are most desperately needed. Unfortunately, in the current political landscape within Nigeria, the government is fundamentally too corrupt, unstable, and weak to be able to carry out such a large and difficult task. Consequently, Nigeria could well be on the verge of a social crisis, unless a stable, integral, and secure government that is willing to take far more action than is currently being carried out is put into place with urgency. Hence, for Nigeria to take any meaningful steps towards social sustainability as it continues to grow and develop, political reform and sustainability must first be achieved.
4, Environmental sustainability
Background
Environmentally, Nigeria is not currently sustainable. This is unsurprising, as it has followed the same development pathway that almost all other middle-income countries have: it’s economic development has caused an extreme rise in energy consumption as people demand a better quality of life. More and more people want access to electricity, heating and private transport. Whilst this is undoubtedly beneficial for the country as a whole, it does lead to a negative environment impact. This is because countries have to use the cheapest, most accessible energy sources to try and meet this demand. That energy source is almost always fossil fuels. Nigeria is no exception. For example, in 2023, 32.3 tWh of a total 40.65 tWh of electricity produced was from natural gas (Ritchie, Roser and Rosado, 2020), and oil is the dominant source of energy and fuel. Hence, a major environmental issue in Nigeria stems from its demand for fossil fuels, which contribute greatly to its total greenhouse emissions.
Issues
However, Nigeria’s environmental issues are worsened dramatically by its own economic activities. Namely, its oil and gas production, which have had catastrophic environmental implications for the Niger Delta and beyond in the last century. One example of this is the emissions created by flaring of natural gas. Flaring is the burning of crude oils, in this instance gas, which releases harmful gases directly into the atmosphere. (carbon dioxide is the most abundant, but also extremely dangerous and potent greenhouse gases such as sulphur dioxide and oxides of nitrogen). This can be for safety reasons but is usually as a result of inefficient extraction and management, so excess fuel that cannot be processed is simply burnt. This completely usable fuel is burnt simply due to poor management in staggering amounts. It is estimated that in 2005 over 2.5 billion cubic feet of natural gas was flared in the delta every single day (Osuoka and Roderick, 2005). Not only does this produce huge quantities of greenhouse gases, but also leads to respiratory diseases due to carbon particulates, carbon monoxide and other gases being released. Around 4.2% of all mortality in the Niger Delta is due to respiratory diseases, which are caused by high levels of pollutants heavily contributed to by flaring practices (Johnbull, Emmanuella and Peter, 2023)
Nigeria’s environment has also been heavily impacted by oil spills, caused by either the illegal theft of oil or improper maintenance of pipelines leading to spills. Between 2009 and 2018, $46bn worth of crude oil was stolen from Nigerian oil companies and the government. (Edeh, 2019). Economically, this has reduced the profitability of oil extraction in Nigeria, which could explain Shell and other TNC’s exits from the delta. However, environmentally, this theft greatly increases the frequency of oil spills. This is because theft is done with no regulations, safety protocols or regard for the environment, and usually occurs very quickly and hastily. Thus, leaks, spills and explosions are common. Poor maintenance of pipelines can be equally detrimental to the environment as theft, and this is arguably more preventable, as companies can be held accountable far easier than individual thieves. The Bodo pipeline explosion of 2011 caused the spill of 600,000 barrels worth of crude oil and was attributed to poor maintenance of a 55-yearold Shell pipeline. To the local environment, this event was catastrophic – oil entered water sources, decimating fish populations (which also destroyed the livelihoods of the local fishermen) and decreasing biodiversity. On land, oil spills suffocated the wildlife and nature, destroying many thousands of acres of important mangrove forests. Therefore, whilst oil spills
do not emit greenhouse gases, they still very much contribute to environmental unsustainability in Nigeria as a result of their destruction of habitats and wildlife.
Solutions
Nigeria government has created multiple policies to try and reduce its environmental impact and improve sustainability. In an attempt to combat both pollution and future issues in energy supply, Nigeria has started to turn away from oil and look towards renewables to supplement its energy mix. Whilst many different renewable energy types, such as wind and solar, have been carried out to limited success, hydroelectric power generation is real extreme promise for Nigeria. As of 2023, over 20% of Nigeria’s electricity production came from hydro (Statista, 2023), meaning it provides electricity for around 50 million Nigerians. This is a huge step forward and is symbolic of Nigeria’s willingness and desire to shift to renewables, which will have clear benefits both economically and environmentally in the coming decades. It is estimated that as much as 60% of Nigeria’s energy demand could be supplied by renewable, sustainable sources by 2050 (IRENA, 2023). Ultimately, Nigeria’s path to environmental sustainability should be a simple one – shift from fossil fuels to clean renewables as means of generating energy
Nigeria can also reduce its more immediate environmental impact in a number of ways. A key factor is the prevention of needless flaring. In 2021, the Nigerian government pledged to end the flaring of gas in oil production completely by 2030, having already reduced it by 70% between 2000 and 2020 (Lo, 2021). Progress has therefore already been made, but this would be another huge step forward. Eradicating flaring would remove one of the biggest contributors to fossil fuel emissions in the country, and also prevent a practice that is inherently wasteful and inefficient. Unfortunately, the policy seems to have very little actual substance behind it. There are numerous loopholes in the law that enable companies to continue flaring, and whilst the fines proposed would be costly to oil producers, they are rarely enforced. Ultimately, the policy has been ineffective, as $960 million worth of natural gas was flared in Nigeria in 2023 (NOSDRA, 2023). It is clear the government must take more responsibility. If flaring fines were collected, it is estimated $551 million would have been generated in 2023 (NOSDRA, 2023). This money could be used to increase government spending on services such as healthcare and education, or even used to invest into renewables. Not only this, but companies would actually be deterred from flaring, as there would be actual financial implications for doing so. Whilst this would be the ideal solution, the government in Nigeria is weak, and corruption is deep rooted. Hence, launching such an offensive on oil conglomerates is very unlikely. Instead, the natural gas that would be otherwise be flared and wasted should be utilised as fuel source Whilst still a fossil fuel, natural gas is far cleaner than oil, gas, and most biofuels, so could provide a feasible shortterm alternative to oil use for fuel. Equally, the gas could be used to for electricity. Whilst the majority of electricity produced is already done through gas exploitation, it is inconsistent, and blackouts are common. Hence, the excess gas would increase energy security and reduce shortages, having a positive social impact.
Alternatively, the natural gas could be used as a source of cooking fuel. Currently, over 175 million Nigerians use traditional biofuels, such as wood, for cooking (Roche et al., 2024) These fuels can be extremely bad for the environment, as large amounts of carbon dioxide are stored within these fuel sources. On top of this, burning wood emits huge amounts of pollutants such as carbon monoxide and sulphur dioxide, which are extremely dangerous to humans. It is estimated that in 2019 over 128,000 Nigerians died from household air pollution related diseases ((Roche et al., 2024). Therefore, a shift from wood to natural gas would hugely decrease household pollution. Whilst greenhouse gas emissions may not be greatly reduced,
air quality would massively improve, as the burning of gas does not emit carbon particulates, carbon monoxide and other harmful gases. Hence, this could be an extremely beneficial use for the currently flared natural gas, that would actually improve the environmental sustainability of Nigeria. In the longer term, the installation of electric stoves linked to the National Grid could provide a sustainable way for Nigerians to cook their food. However, with 4 blackouts occurring from January to July 2024 alone (Addeh, 2024), the Grid would need to be greatly improved for this to be feasible. Equally, other new fuel sources and technologies are being developed around the world, which may become a viable option for Nigerians in decades to come. For example, hydrogen gas fuelled hobs are being developed, trialled, and researched (Collins, 2024) as countries around the world look for newer, cheaper, cleaner ways of living. Nigeria is also looking towards newer, cleaner biomass alternatives (NREEEP, 2015) such as biodiesel. If employed properly, these could provide a renewable, carbon neutral energy source with far fewer environmental impacts than current biofuels.
Finally, to increase their environmental sustainability Nigeria must look to prevent oil spillages. The most effective way to do this is to reduce oil production in the Niger Delta. This should start to happen in the coming decades as Nigeria shifts away from oil, meaning oil spills will hopefully become a thing of the past in a few decades time. However, in the short term, the government and companies must bear responsibility and take action to prevent spillages occurring. This means increasing security on pipelines to prevent oil thefts and enforcing tougher penalties on companies who do not take the necessary and proper measures to upkeep their pipelines. Moreover, if a spill does occur, action must be taken to minimise its environmental impact. The Bodo oil spill has still not been cleared up over 15 years after the spillage (Leigh Day, 2023), meaning mangroves, fish and other biodiversity will have long since suffocated under the oil. If Shell had taken responsibility for the cleanup at the time it occurred, the devastating impact on the environment could have been vastly reduced.
Currently, Nigeria is clearly not environmentally sustainable. It has extremely high greenhouse emissions that have been created by a reliance on fossil fuels and biofuels for fuel, energy, and electricity production. In addition, harmful oil and gas production practices have reduced air quality, and destroyed huge amounts of biodiversity and wildlife, especially in the Niger Delta. This pollution is impacting not only nature, but Nigerians as well, as people have seen livelihoods destroyed, illnesses or even death as a result of this unsustainability. However, there has been improvement in Nigeria’s environmental sustainability over the last few decades, and it is evident there is a willingness from individuals and some members of government and companies to enact change. The country’s energy mix is gradually moving towards cleaner, renewable fuels, and flaring has been greatly reduced. Whilst the use of biofuels for cooking is still a prevalent issue that must be addressed, Nigeria must be commended to some extent for the environmental progress they have made thus far. Whilst there is an extremely long road ahead to reach environmental sustainability, it should be approached with a sense of cautious optimism that a clear, achievable pathway to sustainability is starting to take shape. Whilst it is not currently environmentally sustainable, Nigeria has the capacity to greatly reduce its environmental impact in the next few decades.
Conclusions
It is almost undisputable that Nigeria’s development is currently unsustainable, as all four aspects covered in this paper have been shown to be individually unsustainable to varying degrees
Economically and environmentally, there are causes for optimism. Nigeria is one of the strongest economies in Africa, having fared far better than other former colonies in the region. Equally, though Nigeria is an incredibly heavy polluter, but its emissions should start to decline as a result of external factors, namely the phasing out of the oil and gas industries, which will force energy companies to use alternative, more sustainable sources.
However, in terms of the political and social aspects of development, Nigeria is currently wholly unsustainable. The country suffers from severe inequality and poverty on an incredibly large scale, and a lack of government action in resolving poor provision of services and civil tensions indicate that the problem is only going to increase in size. Moreover, the rapidly increasing population, as well as the exit of many TNCs, means the government is faced with an evergrowing number of people it must provide services for, and its high levels of corruption mean it is utterly unequipped to manage these issues. If nothing changes, Nigeria is headed towards a social and political catastrophe.
To truly achieve sustainability in its development, Nigeria must tackle its underlining political issues. Drastic change is needed in multiple areas if the country wants to improve and progress, and good governance will be essential in enabling this. A corrupt and inactive government will not be able to carry out and manage the huge economic sector shift, changes in energy mix, increased provision of housing and public services, and effective resolution of civil tensions that are urgently needed. Currently, the government has demonstrated a fundamental misunderstanding of what is needed in the country: Tinubu’s reforms had economic positives but an incredibly detrimental impact on the impoverished, and the attempted destruction of Makoko in 2012 underlined a fundamental lack of understanding of the complex and difficult issues that must be addressed to truly prevent the development of slum settlements. Therefore, it is essential that an integral, benevolent, and truly democratic government is put in place in Nigeria before any other meaningful steps towards sustainability can be taken. This means the creation of a shared national identity (to prevent tribe-based voting) is critical, highlighting the importance of educational schemes such as the ‘Unity Schools’ project and Youth Service Corps. It is also essential that responsibility is taken within Nigeria – the failure of both the ACORN and LINKS Nigeria schemes highlight how foreign intervention can only go so far – the establishment of Civil Society Organisations with real power within Nigeria, and a willingness from those currently in power to assist in both reducing current corruption and preventing it taking hold in the future is absolutely necessary.
Fundamentally, achieving sustainability in Nigeria is possible, but will be an incredibly difficult and challenging task. The cooperation of both the public and the government to create a state with a far higher level of political development is essential, as only then can policies be put in place that will allow for steps to be taken towards achieving sustainability of development as a whole.
Bibliography
Introduction
Brundtland Commission, United Nations (1987) Sustainability. Available at: https://un.org/en/academic-impact/sustainability (Accessed: July 14, 2024)
Transparency International (2023) Corruption Perceptions Index. Available at: https://www.transparency.org/en/cpi/2023?gad_source=1&gclid=CjwKCAjw1920BhA3EiwAJT3l SZjG_cDZVOi7JJSrzbqOMhf_QZwLrv9qJe_21oniF5sJv6GkFm7NRRoCewoQAvD_BwE (Accessed: July 16, 2024)
World Bank (2023a) GDP (current US$). Available at: https://data.worldbank.org/indicator/NY.GDP.MKTP.CD?most_recent_value_desc=true (Accessed: July 13, 2024)
World Bank (2023b) GDP (current US$) – Nigeria. Available at: https://data.worldbank.org/indicator/NY.GDP.MKTP.CD?locations=NG (Accessed: July 13, 2024)
Worldometer (2024a) African Countries by Population (2024). Available at: https://www.worldometers.info/population/countries-in-africa-by-population/ (Accessed: July 14, 2024)
Economic development
Addeh, E. (2024) Nigerian Government Debunks Allegations of Southern Bias in Road Projects, Cites 52% Of Projects in Northern Nigeria. Available at: https://www.arise.tv/nigeriangovernment- debunks-allegations-of-southern-bias-in-road-projects- cites-52- of-projects-innorthern-nigeria/ (Accessed: October 5, 2024)
Adeyeri, O., Adejuwon, K.D. (2012) The Implications of British Colonial Economic Policies on Nigeria’s Development. Available at: https://garph.co.uk/IJARMSS/Aug2012/1.pdf (Accessed: October 6, 2024)
Dapel, Z. (2018) Poverty in Nigeria: Understanding and Bridging the Divide between North and South. Available at: https://www.cgdev.org/blog/poverty-nigeria-understanding-and-bridgingdivide-between-north-and-south (Accessed: October 6, 2024)
EFinA (2022) Women’s Economic Empowerment in Nigeria: A critical look at Access to Financial Services. Available at: https://efina.org.ng/wp - content/uploads/2022/07/Womens-EconomicEmpowerment-in-Nigeria-A- critical-look-at-Access.pdf (Accessed: October 5, 2024)
Ekeruche, M.A, Okon, A., Folarin, A., Ihezie, E., Heitzig, C. and Ordu, A.U. (2023) Nigeria’s industries without smokestacks are delivering better economic opportunities than traditional
sectors. Available at: https://www.brookings.edu/articles/nigerias-industries-withoutsmokestacks-are- delivering-better- economic- opportunities-than-traditional-sectors/ (Accessed: October 6, 2024)
Iyatse, G. (2024) Oil corporations exit Nigeria, leaving a trail of environmental destruction behind. Available at: https://panafricanreview.com/oil- corporations-exit-nigeria-leaving-a-trailof- environmental-destruction-behind/ (Accessed: October 5, 2024)
Laker, B. (2024) Nigeria’s Economic Recovery Under President Tinubu’s Leadership. Available at: https://www.forbes.com/sites/benjaminlaker/2024/07/29/nigerias- economic-recovery-underpresident-tinubus-leadership/ (Accessed: October 5, 2024)
LINKS (2023) About Us. Available at: https://links-nigeria.com/ (Accessed: October 5, 2024)
Mancini, L. (2009) Comparative Trends in Ethno -Regional Inequalities in Ghana and Nigeria: Evidence from Demographic and Health Surveys. Available at: https://assets.publishing.service.gov.uk/media/57a08b69e5274a31e0000b30/workingpaper72. pdf (Accessed: October 5, 2024)
Nairametrics (2013) Development of Nigeria’s oil industry. Available at: https://nairametrics.com/wp - content/uploads/2013/01/History- of-Oil-and-Gas-in-Nigeria.pdf (Accessed: August 2, 2024)
Nwankpa, M. (2021) The North-South Divide: Nigerian Discourses on Boko Haram, the Fulani, and Islamization. Available at: https://www.hudson.org/national-security- defense/the-northsouth- divide-nigerian-discourses- on-boko -haram-the-fulani-and-islamization (Accessed: October 5, 2024)
Shell (2021) Contributing to Nigeria’s Economy. Available at : https://reports.shell.com/sustainability-report/2021/powering-lives/contributing-tocommunities/contributing-to -nigeria-s- economy.html (Accessed: August 5, 2024)
Suleiman, Q. (2023) Despite funding constraints, Nigerian government established eight new tertiary institutions. Available at: https://www.premiumtimesng.com/news/top -news/635780despite-funding- constraints-nigerian-government-establishes- eight-new-tertiaryinstitutions.html (Accessed: October 5, 2024)
TradeImeX (2023) What are the Top 10 exports of Nigeria in 2023? Available at: https://www.tradeimex.in/blogs/top -10- exports- of-nigeria (Accessed: October 6, 2024)
UN Human Development Report (2024) Nigeria. Available at: https://hdr.undp.org/datacenter/specific- country- data#/countries/NGA (Accessed: August 5, 2024)
US International Trade Administration (2021) Nigeria – country commercial guide. Available at: https://www.trade.gov/country- commercial-guides/nigeria-agriculture-sector (Accessed: October 5, 2024)
World Bank (2023) GDP growth (annual %) – Nigeria. Available at: https://data.worldbank.org/indicator/NY.GDP.MKTP.KD.ZG?locations=NG (Accessed: August 3, 2024)
Political stability, tribalism and corruption
Abubakar, M. and Chibelushi, W. (2024) Betta Edu: Nigerian poverty minister suspended over money in personal bank account. Available at: https://www.bbc.co.uk/news/world-africa67914673 (Accessed: September 21, 2024)
Adeyemi, D. (2023) Nigeria struggles to bridge ethnic divide after the election. Available at: https://www.codastory.com/rewriting-history/nigeria-presidential- election-tribalism/ (Accessed: September 21, 2024)
Central Office for Information for Commonwealth Office (1960) Nigeria – The Making of A Nation. Available at: https://media.nationalarchives.gov.uk/index.php/nigeria-the-making- of-anation2/#:~:text=There%20had%20been%20contact%20with,were%20amalgamated%20into%20one %20Nigeria (Accessed September 21, 2024)
Ebegbuna, D. (2019) The Effect of Tribalism on the Development of Nigeria. Available at: https://medium.com/@debegbuna/the- effect- of-tribalism- on-the-development- of-nigeria285e6d3dfb54 (Accessed: September 21, 2024)
Kenechi, S. (2024) FG to unbundle unity colleges into basic, secondary schools. Available at: https://www.thecable.ng/fg-to -unbundle-unity-colleges-into -basic-secondary-schools/ (Accessed: September 22, 2024)
Lawal, A. (2021) Anti- corruption in Nigeria: Lessons and recommendations for future programming. Available at: https://www.itad.com/article/anti- corruption-in-nigeria-lessonsand-recommendations-for-future-programming/ (Accessed: September 22, 2024)
Lloyd, C. (2019) The Effect of Tribalism on Political Parties. Available at: https://digitalcollections.sit.edu/cgi/viewcontent.cgi?article=4177&context=isp_collection (Accessed: September 22, 2024)
Orjinmo, N. (2023) Bola Tinubu wins Nigeria’s presidential election against Atiku Abubakar and Peter Obi. Available at: https://www.bbc.co.uk/news/world-africa-64760226 (Accessed: September 21, 2024)
Oxfam (2024) Nigeria: extreme inequality in numbers. Available at: https://www.oxfam.org/en/nigeria- extreme-inequality-numbers (Accessed: September 21, 2024)
Premium Times Nigeria (2015) Buhari opens campaign, promises to address corruption, insecurity, economy. Available at: https://www.premiumtimesng.com/news/headlines/174402buhari- opens- campaign-promises-address- corruption-insecurity-economy.html?tztc=1 (Accessed: September 21, 2024)
PWC (2024) Impact of Corruption on Nigeria’s Economy. Available at: https://www.pwc.com/ng/en/press-room/impact- of- corruption- on-nigeria-s-economy.html (Accessed: September 21, 2024)
Transparency International (2023) Our work in Nigeria. Available at: https://www.transparency.org/en/countries/nigeria (Accessed: September 21, 2024)
World Bank (2020) Nigeria Human Capital Index 2020. Available at: https://databankfiles.worldbank.org/public/ddpext_download/hci/HCI_2pager_NGA.pdf (Accessed: September 21, 2024)
Social development and inequality
Code for Africa (2020) Investigating the Access to Quality Water in Makoko. Available at: https://public.flourish.studio/story/798147/(Accessed: September 3, 2024)
Ileyemi, M. (2023) Lagos has over 157 slum communities, must address urbanisation, UNILAG don. Available at: https://www.premiumtimesng.com/news/top -news/606142-lagos-has- over157-slum-communities-must-address-urbanisation-unilag-don.html (Accessed: September 2, 2024)
Médecins Sans Frontières (2010) Nigeria: Providing care in the slums of Lagos. Available at: https://www.doctorswithoutborders.org/latest/nigeria-providing- care-slums-lagos (Accessed: September 5, 2024)
Morka L. (2012) Violence forced 30000 people from homes through evictions. Available at: https://www.landportal.org/news/2013/07/violent-forced- evictions-30000-people-homesnigerias-makoko - community-are-demolished (Accessed: August 7, 2024)
Ontario Tech University (2024) City Population 2100. Available at: https://sites.ontariotechu.ca/sustainabilitytoday/urban-and- energy-systems/Worlds-largestcities/population-projections/city-population-2100.php (Accessed: September 2, 2024)
Ottaviani, J. (2020) Mapping Makoko: A Community Stating its Right to Exist. Available at: https://www.urbanet.info/mapping-makoko -a- community-stating-its-right-toexist/#:~:text=Makoko%2C%20a%20water%2Dfront%20settlement,whom%20live%20in%20dif ficult%20conditions (Accessed: September 3, 2024)
Oxfam (2024) Nigeria, extreme inequality in numbers. Available at: https://www.oxfam.org/en/nigeria- extreme-inequality-numbers (Accessed: September 1, 2024)
REA (2024) A Day in Makoko Community, Lagos Nigeria – Alleviating Energy Poverty for SocioEconomic Growth. Available at: https://rea.gov.ng/day-makoko - community-lagos-nigeriaalleviating- energy-poverty-socio - economic-growth/ (Accessed: September 2, 2024)
Ritchie, H., Spooner, F., and Roser M. (2019) Clean and safe water is essential for good health. How did it change over time? Where do people lack access? Available at: https://ourworldindata.org/clean-water (Accessed: September 3, 2024)
Shell (2022a) Increasing access to affordable quality healthcare. Available at: https://www.shell.com.ng/media/nigeria-reports-and-publications-briefing-notes/increasingaccess-to -affordable-quality-health- care.html (Accessed: September 3, 2024)
Shell (2022b) Shell Nigeria students scholarships schemes. Available at: https://www.shell.com.ng/sustainability/communities/education-programmes/scholarships (Accessed: September 3, 2024)
Uduu, O. (2023) Why Nigeria’s housing deficit quadrupled in three decades. Available at: https://www.dataphyte.com/housing/why-nigerias-housing- deficit- quadrupled-in-3- decades/ (Accessed: September 2, 2024
World Bank (2020) Population living in slums (% of urban population) – Sub -Saharan Africa. Available at: https://data.worldbank.org/indicator/EN.POP.SLUM.UR.ZS?locations=ZG&name_desc=true (Accessed: September 1, 2024)
Worldometer (2024) African Countries by population. Available at: https://www.worldometers.info/population/countries-in-africa-by-population/ (Accessed: September 1, 2024)
Environmental sustainability
Addeh, E. (2024) Nigeria Faces Another Total Blackout as National Grid Collapses Fourth Time in 2024. Available at: https://www.arise.tv/nigeria-faces-another-total-blackout-as-national-gridcollapses-fourth-time-in2024/#:~:text=Nigeria%20Faces%20Another%20Total%20Blackout%20As%20National%20Gri d%20Collapses%20Fourth%20Time%20In%202024,AFRICA&text=Nigeria's%20electricity%20grid%20has%20collapsed,nearly%204%2C000MW% 20to%2057MW (Accessed: August 5, 2024)
Collins, L. (2024) Bosch unveils hydrogen hob with invisible flames that will be installed in 300 homes at H100 Fife Project. Available at: https://www.hydrogeninsight.com/innovation/boschunveils-hydrogen-hob -with-invisible-flames-that-will-be-installed-in-300-homes-at-h100-fifeproject/2-1-1629336 (Accessed: August 5, 2024)
Edeh, H. (2019) NEITI report confirms $42bn lost to crude oil product theft in 10 years. Available at: https://businessday.ng/energy/oilandgas/article/neiti-report-confirms-42bn-lost-to - crudeoil-product-theft-in-10-years/ (Accessed: August 5, 2024)
IRENA (2023) Renewable Energy Roadmap: Nigeria. Available at: https://www.irena.org/Publications/2023/Jan/Renewable-Energy-Roadmap -Nigeria (Accessed: August 5, 2024)
Johnbull, J., Emmanuella A.T. and Peter I.O. (2023) The Contribution of Respiratory Diseases to Mortality in Niger Delta University Teaching Hospital (NDUTH), Bayelsa State Nigeria. Available at:
https://gjournals.org/GJEPH/Publication/2023/1/PDF/041223036%20Johnbull%20et%20al.pdf (Accessed: August 5, 2024)
Leigh Day (2023) Nigeria Bodo community resists attempts by Shell to strike out their claim for oil spill clean-up. Available at: https://www.leighday.co.uk/news/news/2023-news/nigeriabodo - community-resists-attempts-by-shell-to -strike- out-their- claim-for- oil-spill- clean-up/ (Accessed: August 5, 2024)
Lo, J. (2021) Nigeria to end gas flaring by 2030, under national climate plan. Available at: https://www.climatechangenews.com/2021/08/13/nigeria- end-gas-flaring-2030-nationalclimate-
plan/#:~:text=The%20Nigerian%20government%20has%20pledged,huge%20part%20of%20Ni geria's%20emissions (Accessed: August 5, 2024)
NOSDRA (2023) Gas Flare Tracker. Available at: https://nosdra.gasflaretracker.ng/ (Accessed: August 5, 2024)
NREEEP (2015) National Renewable Energy and Energy Efficiency Policy. Available at: https://faolex.fao.org/docs/pdf/nig211220.pdf (Accessed: August 5, 2024)
Osuoka, A. and Roderick, P. (2005) Gas Flaring in Nigeria: A human rights, environmental and economic monstrosity. Available at: https://www.amisdelaterre.org/wpcontent/uploads/2019/10/gas-flaring-nigeria.pdf#page=4 (Accessed: August 5, 2024)
Ritchie, H., Roser, M. and Rosado, P. (2020) CO₂ and Greenhouse Gas Emissions Available at: https://ourworldindata.org/co2-and-greenhouse-gas- emissions (Accessed: August 5, 2024)
Roche, Y.M, Slater, J., Malley, C., Sesan, T., Eleri, E.O. (2024) Towards clean cooking energy for all in Nigeria: Pathways and Impacts. Available at: https://www.sciencedirect.com/science/article/pii/S2211467X24000737#:~:text=Over%20175 %20million%20Nigerians%20rely,pollution%20related%20to%20these%20fuels (Accessed: August 5, 2024)
Statista (2023) Share of electricity generation in Nigeria by 2023, by source. Available at: https://www.statista.com/statistics/1237541/nigeria- distribution- of- electricity-production-bysource/ (Accessed: August 5, 2024)