
18 minute read
It’s Easy to Scale Out a MongoDB Deployment


MongoDB is a unique NoSQL open source database, which is scalable and adaptable. It is an application of choice for many Fortune 500 companies and start-ups alike. In this, our second article in the series on MongoDB, discover how to scale out a MongoDB deployment.
MongoDB is a big name among NoSQL databases. One of its most significant features is that you can scale out your deployments quite easily, i.e., additional nodes can easily be added to the deployment to distribute data between them so that all data needn’t be stored in one node. This concept is known as sharding, which when combined with replication, offers great protection against failover. So let’s take a closer look at sharding and how it can be implemented.
Advertisement
I assume that you have MongoDB installed on your system. Well, just in case I am wrong, you can get it from http://www.mongodb.org/downloads. Download the zip file as per your operating system and extract the files once the download is completed. For this article, I am using MongoDB on a 32-bit Windows 7 system. Under the extracted directory, you will see a number of binary files. Among them, mongod is the server daemon and mongo is the client process.
Let’s start the process by creating a lot of data directories that will be used to store data files. Now switch to the MongoDB directory that you extracted earlier. I have put that directory on my desktop (Desktop\mongodb-win32-i386-2.6.0\ bin). So I’ll open a command prompt and type:
cd Desktop\mongodb-win32-i386-2.6.0\bin.
Let’s create the required directories, as follows:
mkdir .\data\shard_1 .\data\shard_2 mkdir .\data\shard_1\rs0 .\data\shard_1\rs1 .\data\shard_1\rs2 mkdir .\data\shard_2\rs0 .\data\shard_2\rs1 .\data\shard_2\rs2
Here we’ve created directories for two shards, with each having a replica set consisting of three nodes. Let’s move on to creating the replica sets. Open another command prompt and type the following code:
mongod --port 38020 --dbpath .\data\shard_1\rs0 --replSet rs_1 --shardsvr
This creates the first node of the first replica set rs_1, which will be using port 38020 and .\data\shard_1\rs0 as data directory. The --shardsvr option indicates that sharding will be implemented for this node. Since we’ll be deploying all the nodes in a single system, let’s just change the port number for additional nodes. Our first node is now ready and it’s time to
Figure1: Replica set configuration
create the two others.
Open two more command prompts, switch to the MongoDB root directory and type the following commands in each, respectively:
mongod --port 38021 --dbpath .\data\shard_1\rs1 --replSet rs_1 --shardsvr
mongod --port 38022 --dbpath .\data\shard_1\rs2 --replSet rs_1 --shardsvr
Three nodes for the first replica set are ready, but right now they are acting as standalone nodes. We have to configure them to behave as replica sets. Nodes in a replica set maintain the same data and are used for data redundancy. If a node goes down, the deployment will still perform normally. Open a command and switch to the MongoDB root directory, and type:
mongo --port 38020.
This will start the client process and connect to the server daemon running on Port 38020 that we started earlier. Here, set the configuration as shown below:
config = { _id: “rs_1”, members:[ { _id : 0, host : “localhost:38020”}, { _id : 1, host : “localhost:38021”}, { _id : 2, host : “localhost:38022”} ] }
Initiate the configuration with the rs.initiate (config) command. You can verify the status of the replica set with the rs.status() command.
Repeat the same process to create another replica set with the following server information:
mongod --port 48020 --dbpath .\data\shard_2\rs0 --replSet rs_2 --shardsvr mongod --port 48021 --dbpath .\data\shard_2\rs1 --replSet rs_2 --shardsvr mongod --port 48022 --dbpath .\data\shard_2\rs2 --replSet rs_2 --shardsvr
The configuration information is as follows:
config = { _id: “rs_2”, members:[ { _id : 0, host : “localhost:48020”}, { _id : 1, host : “localhost:48021”}, { _id : 2, host : “localhost:48022”} ] }
Initiate the configuration by using the same rs.initiate (config) command. We now have two replica sets, rs_1 and rs_2, up and running; so, the first phase is complete.
Let’s now configure our config servers, which are mongod instances used to store the metadata related to the sharded cluster we are going to configure. Config servers need to be available for a functional sharded cluster. In our production systems, we use three config servers, but for development and testing purposes, usually one does the job. Here, we’ll configure three config servers as per the standard practice. So, first, let’s create directories for our three config servers:
mkdir .\data\config_1 mkdir .\data\config_1\1 .\data\config_1\2 .\data\config_1\3 Next open 3 more command prompts and type mongod --port 59020 --dbpath .\data\config_1\1 --configsvr mongod --port 59021 --dbpath .\data\config_1\2 --configsvr mongod --port 59022 --dbpath .\data\config_1\3 --configsvr
This will start the three config servers we’ll be using for this deployment. The final phase involves configuring the Mongo router or mongos, which is responsible for query processing as well as data access in a sharded environment, and is another binary in the Mongo root directory. Open a command prompt and switch to the MongoDB root directory. Type the following command:
mongos --configdb localhost:59020,localhost:59021,localho st:59022
This starts the mongos router on the default Port 27017 and informs it about the config servers. Then it’s time to add shards and complete the final few steps before our sharding environment is up and running. Open another command prompt and again switch to the MongoDB root directory.
Type mongo, which will connect to the mongos router on the default Port 27017, and type the following commands:

Figure 2: Sharding configuration

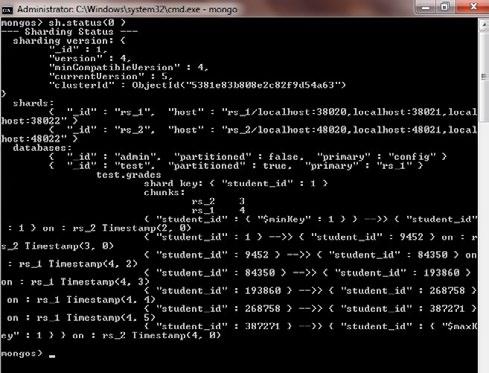
Figure 3: Sharding status
sh.addShard(“rs_1/localhost:38020,localhost:38021,localho st:38022”) sh.addShard(“rs_2/localhost:48020,localhost:48021,localho st:48022”)
These two commands will add the two shards that were configured earlier. Enable sharding for the test database using the following command:
db.adminCommand({enableSharding:“test”})
Finally, enable sharding on the grades collection under the test database by using the code shown below:
db.adminCommand({shardCollection:“test.grades”,key:{student_ id:1}}) Figure 4: Data distribution between shards
In this instance, student_id is our shard key, which is used to distribute data among shards. Do note that this collection does not exist right now. To use sharding, we need an index on the shard key. Here, the collection does not exist and the index will be created automatically. But if you have data in your collection, then you’ll have to create an index on your shard key. You can verify your sharding status by using the sh.status() command.
We now have our sharded environment up and running, and it’s time to see how it works by inserting data in the grades collection. So type the following simple javascript code snippet to insert data:
for (var I = 1; I <= 500000; i++) db.grades.insert( { student_id : I,Name:”Student”+I } )
Now if you type db.grades.stats(), you’ll find that some of these records are stored in the rs_1 shard and others are stored in the rs_2 shard.
You can see that out of 500,000 records inserted, 377,819 are stored in shard rs_1 while the remaining 122181 go to shard rs_2. If you fire the sh.status() command, you can figure out how data is distributed between these two shards.
In Figure 4, you can see that student IDs ranging from 1 - 9452 and 387,271 - 500,000 (represented by $maxKey) are stored on rs_2 while the remaining data is on rs_1.This data distribution is transparent to the end user; data storage and retrieval is handled by the mongos router.
Try to configure and explore the overall process a few more times so that you can feel more confident in implementing sharding in MongoDB.
By: Vinayak Pandey
The author is an experienced database developer, with exposure to various database and data warehousing tools and techniques, including Oracle, Teradata, Informatica PowerCenter and MongoDB.
Sandya Mannarswamy
CODE SPORT
In this month’s column, we feature a set of interview questions based on algorithms and data structures.
For the past few months, we have been discussing information retrieval and natural language processing, along with the algorithms associated with them. Some of our readers had written in requesting if we could discuss a ‘practice set’ of questions in algorithms and data structures as it would help in preparing for campus interviews. Hence, in this month’s column, let’s take a break from natural language processing and, instead, explore potential interview questions on algorithms and data structures. 1. You are given a circular list of ‘n’ numbers that are strictly increasing. Since it is a circular list, the end of the list wraps over to the beginning of the list. You are given an arbitrary pointer to an element in the list. You need to find the minimum element in the list. To simplify things, you can assume that all the elements are distinct. 2. You are given an array of N integers. There are no duplicates in the array. Consider the subsets of this set, the cardinality of which is (N-1). There are (N-1) subsets of cardinality (N-1). For each such set, your program should output the product of the elements present in it. For instance, if you are given the array containing 10, 20, 30, 40, we have the three subsets: {10, 20, 30}, {20, 30, 40}, and {30, 40, 10}. The algorithm should output the three values 6000, 24000 and 12000. Can you come up with an O(N) algorithm for computing all the (N-1) products? 3. Given an NXN matrix of integers, where each row and each column is sorted independently, design an algorithm to search for an integer
‘k’. How many comparisons does your algorithm make before it can either find the integer or determine that the integer does not exist in the matrix? 4. You are given two strings: ‘s’ and ‘t’. You need to determine whether ‘t’ is a cyclic rotation of string ‘s’. For instance, string ‘t’ is obtained
by rotating each character of string ‘s’ by ‘k’ positions. For example, the string ‘kite’ is a cyclic rotation of string ‘teki’. You are told that N is the maximum size of the string. Can you write code to determine this in O(N) time with constant additional storage? 5. Let A be a sorted array of integers. You are given an integer K. Write a program to determine whether there are two indices ‘i' and ‘j’ such that
A[i] + A[j] = K. Note that ‘i' and ‘j’ need not be distinct. Can you do this in O(N) time? 6. Different sorting algorithms exhibit efficiency depending on the type of input data. 'As an example, some algorithms behave well if the input data is almost sorted. As an example, consider insertion sort. When the data is mostly sorted, how many comparisons do you need to make for sorting it using insertion sort? Let us consider the situation in which we need to process a stream of integers. Each integer is at most 100 positions away from its correct sorted position. Can you design an algorithm to sort the integers that use only a constant amount of storage, independent of the number of integers processed? 7. You are given a sequence of ‘n’ numbers whose values vary between 1 to n-2, with two of the numbers repeating twice. For instance, instead of having <5,2, 3, 4, 1>, you are given <2,1,3,2,1>.
You need to find out the two numbers that each get repeated. Can you find the two numbers if you are told that you can only use extra storage of a constant size? 8. Assume that you are given a singly-linked list that does not contain a loop, and the last node of which has its next field set to NULL. How will you find the node that is Kth nodes away from the last node on the list? 9. Given that you are asked to design a dictionary data structure for integer data elements, which


is expected to support, insert, delete and find operations, please compare the following data structures as potential candidates in terms of time complexity: • Unsorted array • Sorted array • Unsorted singly linked list • Sorted singly linked list • Unsorted doubly linked list • Sorted doubly linked list • Binary search tree • Hash table • Binary heap 10. We are all familiar with merge-sort. Given an array of N integer elements, let’s break up the array into two halves, sort each half separately and then merge the two sorted halves. This is a classic example of the ‘divide and conquer’ approach, by which the problem is broken down into several sub-problems. Each is solved recursively, and then you combine the solutions for the sub-problems to solve the original problem. Is it always possible to design a‘divide and conquer’ algorithm to all problems? If not, what characteristics should a problem exhibit to be amenable to this approach? Can you give an example of a problem which is not amenable to the ‘divide and conquer’ approach and explain why it is not suitable? 11. You are given a set ‘A’ containing N integer elements and asked to solve the problem of finding the minimum in a given range of A. For instance, if A is {8, 2, 9, 5,1,4, 11, 3, 14}, the range minimum for A[1…5] is given by the element
A[5], since A[5] is 1 and that is the minimum element in the range A[1..5]. Can you come up with an O(N) algorithm for solving the range minimum query if you are allowed to preprocess the set A? 12. Let A be a multi-set of integers consisting of N numbers.
You are allowed to pick up two integers at a time. If both are even or both are odd, you discard both and insert an even integer. If not, you discard the even integer. Given that there are an even number of odd integers initially in A, can you tell whether the last integer will be even or odd? What is the reasoning behind your answer? 13. You have 100 doors in a row, all of which are initially closed. You make 100 passes over these doors starting with the first door. The first time when you make the pass, you visit every door and toggle the door (i.e., if the door is open, you close it. And if it is closed, you open it). During the second pass, you visit every second door (doors numbered 2, 4, 6,8…). During the third pass, you visit only every third door (doors marked 3, 6, 9, 12…). You repeat these passes until you finish all the 100 passes. Now can you determine what state each door is in, after the 100th pass? Which doors are open and which are closed? 14. The lowest common ancestor (LCA) of two nodes ‘u’ and ‘v’ in a binary search tree is defined as node A, which has both
‘u’ and ‘v’ as its descendants (note that a node can be its own descendant). Write an algorithm to find the lowest common ancestor of a binary search tree. Instead of writing a new algorithm for finding the LCA, if you are given the in-order traversal of the binary search tree along with the nodes ‘u’ and ‘v’ for which the LCA needs to be found, can you use the in-order traversal information to determine the
LCA? Does this work in all cases? If so, explain why. If not, give a counter-example. 15. You are given an undirected graph G (V, E) where V represents the set of vertices and E represents the set of edges, and a weight function c(u,v), which associates a non-negative weight with the edges of the graph. A minimum weighted cycle in the graph is defined as the cycle, whose sum of edge weights is the minimum over all cycles in the graph. A maximum weighted cycle is one whose sum of edge weights is the maximum over all the cycles in the graph. (i) Can you come up with an algorithm for finding the minimum weighted cycle? What is the complexity of your algorithm? (ii) Can you come up with an algorithm for finding the maximum weighted cycle? What is the complexity of your algorithm? Can you come up with a polynomial time algorithm for this problem? If not, why not?
My ‘must-read book’ for this month
This month’s book suggestion comes from one of our readers, Shruti, and her recommendation is very appropriate to this month’s column. She recommends an excellent resource for algorithmic problems—the website containing a discussion on algorithms from Jeff Erickson, available at http://www.cs.uiuc. edu/~jeffe/teaching/algorithms/. The link has pointers to lecture notes as well as additional exercises in algorithms and data structures. Thank you, Shruti, for sharing this link.
If you have a favourite programming book/article that you think is a must-read for every programmer, please do send me a note with the book’s name, and a short write-up on why you think it is useful so I can mention it in the column. This would help many readers who want to improve their software skills.
If you have any favourite programming questions/software topics that you would like to discuss on this forum, please send them to me, along with your solutions and feedback, at sandyasm_AT_yahoo_DOT_com. Till we meet again next month, happy programming!
By: Sandya Mannarswamy
The author is an expert in systems software and is currently working with Hewlett Packard India Ltd. Her interests include compilers, multi-core and storage systems. If you are preparing for systems software interviews, you may find it useful to visit Sandya's LinkedIn group ‘Computer Science Interview Training India’ at http://www. linkedin.com/groups?home=HYPERLINK "http://www.linkedin.com/ groups?home=&gid=2339182"&HYPERLINK "http://www.linkedin. com/groups?home=&gid=2339182"gid=2339182
Anil Seth
Exploring Big Data on a Desktop: Where to Start
Big Data is the current buzz word in the world of computing. Typically, for computer enthusiasts with just a single desktop, experimenting with Big Data poses a problem since running a distributed data program requires many computers. But now, Big Data can be run on a single desktop.
Iread about Apache Spark in a news article titled ‘Run programs up to 100x faster than Hadoop MapReduce’, and I wanted to explore it. Spark applications can be written in Python. The trouble was that I hadn’t even got down to trying Hadoop MapReduce, in spite of wanting to do so for years.
If all you have is a desktop, how do you experiment and learn systems that are inherently distributed? You can’t get an insight into them while using a single machine.
Fortunately, even mid-range desktops now come with a quad-core and 8 GB of RAM. So, you can run at least a few virtual machines. Many tools, e.g., VirtualBox, are very good and easy to use. But are they enough?
The scope
Spark is a “…fast and general engine for large-scale data processing” (http://spark.apache.org). It allows you to build parallel applications. It can access the data from various sources, particularly, existing Hadoop data. It can run on the YARN cluster manager of Hadoop 2. So, you may want to understand and set up a Hadoop data source and, possibly, a YARN cluster manager.
You need to set up a cluster of virtual machines on which the master and slave instances of Spark will run. Then set up a HDFS cluster of virtual machines for Hadoop data. There will be a NameNode to manage the file system metadata and DataNodes that will store the actual data.
You may need to play around with the number of virtual machines in order to avoid manually creating each virtual machine that opens a separate window on the desktop display. It’s preferable to manage the machines from a single environment, conveniently.
That brings us to the need to create a local cloud on the desktop. OpenStack is a popular, open source option and Red Hat offers an open source distribution (http://openstack. redhat.com).
The RDO distribution of OpenStack will be included in the repositories of Fedora 21. You can add an additional repository for installing it on Fedora 20.
A bare bones cloud image is available from Fedora’s download site. You can also build your own spin using or expanding the kick-start for a cloud image, fedora-x86_64cloud.ks, a part of the fedora-kickstarts package.
The plan
The process of exploring Big Data on a desktop needs to be broken up into smaller steps, with each step built on top of the previous step. Hopefully, it will run reasonably well on a quad-core desktop with 8 GB RAM to give you an understanding of the additional technology and the programming involved.
The current exploration will be on Fedora because my desktop is Fedora 20. Fedora offers an OpenStack distribution and it will be difficult to experiment on multiple distributions simultaneously.
The first step will be to create a local cloud.
Installing OpenStack
You could use a virtual machine to minimise the risk to your desktop environment. A useful utility is appliancecreator, which is a part of the appliance-tools package. You can use the kick-start file fedora-x86_64-cloud. ks, with a couple of changes in fedora-cloud-base.ks, to allow signing in as the root user. By default, the image requires cloud-init to create an account ‘fedora’ and inject ssh credentials for password-less logging in (see https://www. technovelty.org/linux/running-cloud-images-locally.html as an alternate solution). You need to increase the size of the disk and SELinux should be permissive or disabled.
timezone --utc Asia/Kolkata selinux --disabled #rootpw --lock --iscrypted locked rootpw some-password part / --size 8192 --fstype ext4 #passwd -l root
You will need to make sure that the virtualisation packages are installed (https://fedoraproject.org/wiki/Getting_ started_with_virtualization). Just do the following:
# yum install @virtualization








