IAES International Journal of Artificial Intelligence (IJ-AI)
Vol. 5, No. 1, March 2016, pp. 1~12
ISSN: 2252-8938

IAES International Journal of Artificial Intelligence (IJ-AI)
Vol. 5, No. 1, March 2016, pp. 1~12
ISSN: 2252-8938
Pampa Sinha* , Sudipta Debath** , Swapan Kumar Goswami**
* Electrical Engineering Department, Netaji Subhash Engineering College, Technocity, Garia ** Electrical Engineering Department, Jadavpur Univrsity
Article Info
Article history:
Received Dec 4, 2015
Revised Feb 7, 2016
Accepted Feb 25, 2016
Keyword:
Detail Reactive Powers, Power System, Probabilistic Neural Network.
Switching-Transients, Wavelet Decomposition
Corresponding Author:
ABSTRACT
Power quality studies have become an important issue due to widespread use of sensitive electronic equipment in power system. The sources of power quality degradation must be investigated in order to improve the power quality. Switching transients in power systems is a concern in studies of equipment insulation coordination. In this paper a wavelet based neural network has been implemented to classify the transients due to capacitor switching, motor switching, faults, converter and transformer switching. The detail reactive powers for these five transients are determined and a model which uses the detail reactive power as the input to the Probabilistic neural network (PNN) is set up to classify the above mentioned transients. The simulation has been executed for an 11kv distribution system. With the help of neural network classifier, the transient signals are effectively classified.
Copyright © 2016 Institute of Advanced Engineering and Science All rights reserved
Pampa Sinha, Electrical Engineering Department, Netaji Subhash Engineering College, Technocity, Garia. Kolkata-700152, Email: pampa.sinha.ee@gmail.com
Detection and classification of transient signals have recently become an active research topic in the area of power quality analysis [1-5]. In [6-7] the authors have proposed a method to classify the power system transients based on dual tree complex wavelet transform (DTCWT). But in this method computational complexity is very high. Power transients occur from variety of disturbances on the power system like, capacitor bank switching, different types of faults, converters and different apparatus switching. In order to improve the power quality, the location of such disturbances must be identified. Techniques like wavelet transforms, mathematical morphology etc have been used to identify them [5-7]. Wavelet analysis, can extract the essential features of transient signal effectively for its classification. With these features as inputs to the neural network, classification of the switching transients, short circuit fault, primary arc, lightning disturbance and lightning strike fault is possible [8]. Authors of paper [9] have proposed a discrete wavelet transform (DWT) based on multiresolution analysis technique and parseval’s theorem which is employed to extract the energy distribution features of transient signal at different resolution levels. Probabilistic neural network (PNN) classifies the extracted features to identify the disturbance type. In paper [10] a discrete wavelet transform and multi fractal analysis based on a variance dimension trajectory technique have been used as tools to analyze the transients for feature extraction. A probabilistic neural network is used as a classifier for classification of transients associated with power system faults and switching. The authors of paper [11] presented DWT-FFT based integrated approach for detection and classification of various PQ disturbances with and without noisy environment. Ibrahim and Morcos [12] have given a survey of artificial intelligence technique for power quality, which includes fuzzy logic, artificial neural network (ANN) and genetic algorithm. Wavelet based on line disturbance detection for power quality applications have been discussed in [13]. Perunicic et al. [14] used wavelet coefficients of discrete wavelet transform (DWT) as
Journal homepage: http://iaesjournal.com/online/index.php/IJAI
inputs of a self organizing mapping neural network to identify DC bias, harmonics, voltage sags and other transient disturbances. Elmitwally et al. [15] have proposed a method in which wavelet coefficients are used as inputs to the neuro- fuzzy systems for classifying voltage sag, swell, interruption, impulse, voltage flicker, harmonic and flat-topped waves. Chang and Wenquang [16] analyzed the effect of transients arising due to utility capacitor switching on mass rapid transient. Liu et al .[17] extracted features from the DWT coefficients of some typical power transients using scalogram. In [18] the authors have proposed a novel method for identifying, characterizing and tracking grounded capacitor banks connected to a power distribution line in a cost effective manner. Beg et al .[19] proposed a simple method based on DWT and a multi- layer feed forward artificial neural network for classification of capacitor, load switching and line to ground fault. In this method success rate is 97.47%.
To identify the type of transient the first step is to extract the feature of the transient signal. These features are used as input to a classifier for classification. The Probabilistic neural network (PNN) is used as a classifier in [20-29]. Probabilistic neural network combines some of the best attributes of statistical pattern recognition and feed-forward neural networks. Therefore, the PNN is chosen as a proper classifier of transients signals. In [30] have shown wavelet based reactive power computation resulting from 90° phase shift networks which gives the reactive power is shown. Wavelet transform has been used to reformulate the newly defined power components [31]. Wavelet analysis is able to extract the features of data, breakdown points and discontinuities very effectively.
The present paper attempts to classify the different types of transients such as capacitor switching, motor switching, different fault induced transients, converter and transformer inrush using a simple PNN based technique. To extract unique feature of each transients first discrete wavelet transform (DWT) has been performed to calculate the detail reactive power at level 1 and 3. As artificial neural network has the capability to simulate the learning process and work as a classifier, probabilistic neural network has been used to classify the mentioned transient disturbances and it has been shown that this single point strategy is very effective in classifying the different transient signals.
This section redefines power components definitions contained in IEEE Standard 1459-2000 [31] for single phase system under nonsinusoidal situations. Consider the following sinusoidal and nonsinusoidal voltage and current waveforms:Tables and Figures are presented center, as shown below and cited in the manuscript. v
(1)
Where, v1, i1 represent power system frequency components (ω=2πf=100π rad/sec) while vH, iH represent the total harmonic voltage and current components, α1 and β1 represent the fundamental voltage and current phase angle, respectively, while and represent individual harmonic voltage and current phase angle respectively.
The RMS values of voltage and current are
Where T is the time period. The reactive power as proposed in [30] is measured where vt-90° and it are the voltage and current signals. vt-90° is obtained by introducing a 90° phase lag at each frequency over its range. If vt-90° and it are periodic signals with time period T, then reactive power Q is given as
(6)
In wavelet domain the total reactive power (Q) is defined as
Q=Qapp+Qdet [24] (7)
Where Qapp is the approximation reactive power and Qdet is the details reactive power. Qdet is defined as
Qdet=∑ ∑ [23] (8)
Where, j0 is scaling level, the voltage and current signals are digitized with n=0, 1, 2P-1, dj,k is wavelet coefficient of current and d"j,k is the coefficient of voltage with 90° phase shift at wavelet level j and time k.
A radial distribution network is shown in Fig. 1.The fundamental frequency internal impedance of the voltage source ZS is considered to be (0.5+j0.5) Ω and the line impedance is (1+j1) Ω for each section. The fundamental frequency impedance of each load viz. Z1, Z2, Z3, Z4 and Z5 is (300+j300) Ω when all the loads are linear. Transformer, capacitor, motor and converter have been connected with time controlled switch to each bus to get detail reactive power under different transient conditions. EMTP simulation package has been used to capture instantaneous voltage and current signals. The voltage and current signal have been processed and analyzed using discrete wavelet transform (DWT) in MATLAB.
An 11 kv distribution system is studied in this paper and its EMTP model is set up as shown in Fig.1. All the input signals are generated with 128 samples per cycle. Its recording time is 0.1 second and hence sampling frequency of the signal is 6.4 kHz. Reference frequency is 50 Hz. There are various types of mother wavelets for signal processing but one of the most popular mother wavelet is Daubechies [36] which has been used to detect and characterize power transients. So the authors have used daubechies wavelet with four filter coefficients (db4) for transient analysis. Simulation of five types of transients is carried out in this network. They are capacitor switching, converter switching, motor switching, fault and transformer switching. The switching transients are classified by probabilistic neural network (PNN). The original signal is decomposed up to level 5 using DWT and after considering all the parameter the authors of this paper have chosen the detail reactive power at level 1 and level 3 i.e. Qdet1 and Qdet3 as inputs to the classifier. The proposed method is a single point strategy because in this method all the voltage and current signals are captured from the sending end side only.
a. Capacitor switching
Figure. 2.1 and Figure. 2 show the capacitor switching transients in the above mentioned radial network. In this paper the authors have used capacitors of different ratings (50µF to 550µF) and they varied the switching time to capture the detail reactive power to distinguish the capacitor switching transients from other transients. Table 1 shows the values of Qdet from level 1 to level 5 at different buses when 150µF capacitor is switched on.
b. Motor switching
Figure. 3 shows the motor switching transients of the above mentioned radial network. To perform the simulation, induction motor with different rating (5 KW to 10 KW) has been considered and their switching time is also varied to collect sufficient number of data.
Table 2 shows different values of Qdet from level 1 to level 5 at different buses when a 9KW induction motor is switched on when voltage was at its peak value.
c. Fault induced events
In Figure. 4 the faults induced transients are shown and Table 3 shows different values of Qdet from level 1 to level 5 when unsymmetrical fault occurs at different buses.
d. Converter
Figure. 5 shows the transients which are generated by the converters. In this paper the authors have used both 6 pulse and 12 pulse converters with varying firing angles. Table 4 shows the different values of Qdet from level 1 to level 5 at different buses.
e. Transformer switching
Figure. 6 shows transformer generated transient. Transformers with different KVA ratings have been chosen to distinguish the transformer inrush with the other transients. Table 5 shows the different values of Qdet from level 1 to level 5 when a 100 KVA transformer is switched on.
After calculating the DWT based detail reactive power at level 1 and 3, the authors have classified the different transient signals in the network. The problem of multi-class classification has been considered in this paper. A set of data points are given from each class and objective is to classify any new data sample into one of the classes. Hence the authors used the probabilistic Neural Network (PNN) as a classifier because it can learn the complex nonlinear mapping from the input space to output space.) The base of PNN is the Bayes classification rule and Parzen’s method of probability density function (PDF) estimation [10].
An unknown sample X=(x1,….xp). is classified into class k if
uk lk fk(X)>uf lf fj(X) for all classes j not equal to k.
Bayes classification rule improves the classification rate by minimizing the expected cost of misclassification. In this rule first PDF has to be estimated based on a training set. A method of determining a univariate PDF from random samples has been presented by Prazen [10]. With the increase of number of samples the univariate PDF converges asymptotically to the true PDF. Assuming there are nk number of training cases for a given class k and the estimated univariate PDF for that class, vk(x), is
Where W(x) is a weight function (kernel) and the σ is scaling parameter which defines the width of the kernel. W(x) is the Gaussian Function. Since the PNN processes p inputs variables, the PDF estimator must consider multivariate inputs [10]. Fig. 7 shows the PNN architecture which consists the four layer organization.
The input neurons distribute input variables in the input layer to the next layer. One neuron consists with one training case and it computes distance between the unknown input x and training case represented by that neuron. An activation function, known as the Parzen estimator, is applied to the distance measured. In the summation layer, the neurons sum the values of the neurons corresponding to the class who’s estimated PDF has to be determined in the pattern layer by the Bayes discriminate criterion. In the output layer, which is simple threshold discriminator a single neuron has been activated to represent a projected class of the unknown sample.
To check the validity of the proposed method simulation work has been conducted to classify the different transients in power system. Each type of transient is treated as an individual class and assigned the classification number from 1 to 5. MATLAB code is used to calculate the DWT based detail reactive power i.e. Qdet1 and Qdet3. These detail reactive powers are used as input to the ANN model. For each transient 75 sets of features are extracted, in which 25 sets are used as training purpose i.e. 125 features are taken as training samples and another 50 sets i.e. 250 features are used for testing purpose. To obtain the training and testing data for ANN model for each transient, the authors have varied value of the capacitance of the capacitor, KW rating of the induction motor, converter firing angle, KVA rating of transformer, fault resistance and time of occurrence of fault.
The simulations produced 375 sets of detail reactive power (Qdet) up to level 5 individually for the above mentioned five transients. Table 6 shows the assigned classes of transient samples.
Applying this method it is noticed that success rate for identifying the different classes of transients depends on the decomposition level also. Table 7 shows the variation of success rate by varying decomposition level. From this table it is observed that if the original signal is decomposed up to level 5 instead of level 3, the success rate remains same. It is also observed that the success rate at 1st, 3rd and 6th row is same. But in remaining rows the success rate is quite low. So considering all the results the authors have chosen only level 1 and 3 i.e. row 6th to reduce the computational burden.
The classification results can be described in terms of confusion matrix which is a standard tool for testing classifier. From Table 8 one can see that a confusion matrix has one row and one column for each class. The row represents the original class and the column represents the predicted class by the PNN classification. The number in the matrix shows the various pattern of misclassification that is obtained from the testing set. For instance, in Table 8, we can observe that out of 50 cases of motor switching only one has been misclassified as fault. In this table network classification error rate for each type of transients are mentioned. From the above result it can be concluded that using this method the network classifies correctly 249 data out of 250. That means the correct classification rate is 99.6%. In Table 3 it can be seen that most of the classification error occurs in between class 2 and 3, because characteristic harmonics of these two switching are nearly similar.
In Table 9 a comparative study with the other existing method is presented. These methods are somewhat similar with the methodology proposed in this paper i.e. they extracted the features of distorted signal using wavelet transform and then classified those signal by using artificial intelligence technique. The results presented in Table 9 have shown that the proposed method gives better performance compared to the existing methods because in this method success rate is 99.6% and computational complexity is lower than the method proposed in [6].
In a monitoring system the indicators that contain the unique features of power systems are acquired for distinguishing disturbances. But for effective classification of the disturbances, storage of a large number of data should be avoided.
In this paper a novel and simple method has been proposed based on DWT and PNN for classification of capacitor switching, converter switching, motor switching, transformer switching and fault induced events. An accurate and reliable power transient classifier has been developed to distinguish these transient signals. DWT has been used to calculate the detail reactive power at level 1(Qdet1) and 3 (Qdet3) which are used as the input to the ANN model. Here Probabilistic Neural network has been used as a classifier. To check its validity and reliability different case studies are considered which show that this technique is well suited for classification of transients in power system network.
Table 1. Capacitor Switching Data At Different Bus

Switching angle 60°)
Table 2. Motor Switching Data

Switching angle 90°)
Table 3. Fault Induced Transient Data At Different Bus

Table 4. Converter Switching Data At Different Bus
Table 5. Transformer Switching Data At Different Bus
Table 6. Classes of transient samples and simulated data set for training and testing of PNN network
Table 7. Decomposition Level And % Of Success Rate
Table 8. Confusion Matrix
Sl. No. Method for identification of Power system transients
1 Wavelet-transform+ANN based classifier[33]
2 Wavelet-transform based classifier [34]
3 S-transform +competitive neural network based classifier [35]
4 DTCWT+ ANN based classifier [6]
5 Proposed method
Computational Complexity high [32]
Computational Complexity less [32]


2.1. (a) simulated current transient during capacitor switching, (b) current signal decomposed at level 1, (c) current signal decomposed at level 3.




Figure 2.2. (a) Voltage profile during Capacitor switching transient, (b) Current profile during Capacitor switching transient (c) detail reactive power profile at level 1, (d) detail reactive power profile at level 3.

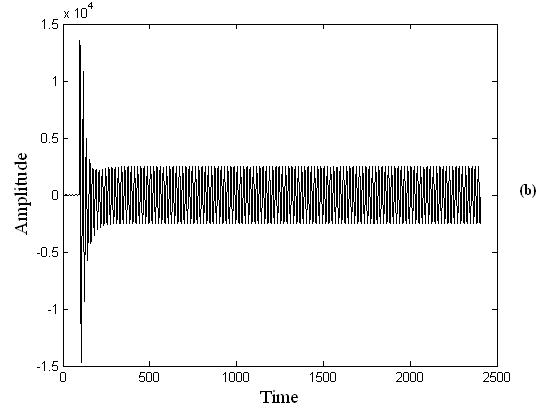


Figure 3. (a) Voltage profile during Motor switching transient, (b) Current profile during Motor switching transient (c) detail reactive power profile at level 1, (d) detail reactive power profile at level 3.




Figure 4. (a) Voltage profile during Fault induced transient, (b) Current profile during Fault induced transient (c) detail reactive power profile at level 1, (d) detail reactive power profile at level 3.




Figure 5. (a) Voltage profile during Converter Switching, (b) Current profile during Converter Switching transiet, (c) detail reactive power profile at level 1, (d) Detail reactive power profile at level 3.
Classification of Power Quality Events Using Wavelet analysis and Probabilistic (Pampa Sinha)




Figure 6. (a) voltage profile during Transformer switching transient, (b) Current profile during Transformer switching transient (c) detail reactive power profile at level 1, (d) detail reactive power profile at level 3.

[1] Reddy, M.J.B, and Mohanta ,D.K, Detection, classification and localization of power system impulsive transients using S-transform. In: Environment and Electrical Engineering (EEEIC), 9th International Conference , Prague, Czech Republic May 16-19, 2010.
[2] Styvaktakis, E., Bollen, M.H.J.; Gu, I. Y. H., Classification of power system transients: sychronised switching. Power Engineering Society Winter Meeting, 2000. IEEE. 2681-2686 vol.4.
[3] Gaouda, A. M., Salama, M.M.A.; Sultan, M.R. and Chikhani, A. Y. Power Quality detection and classification using wavelet- multiresolution signal decomposition. IEEE Trans Power Deliv. 2000; 14(4): 1469-1476.
IJ-AI Vol. 5, No. 1, March 2016 : 1 – 12
[4] Angrisani, L.; Daponte, P. and D’Apuzzo, M. Amethod based on wavelet networks for the detection and classification of transients. Instrumentation and Measurement Technology Conference (IMTC/98). Conference proceedings. St. Paul, MN. May 18-21 1998. 903-908 vol.2.
[5] Learned, R. E. Karl, W.C and Willsky, A. S. Wavelet packet based transient signal classification. TimeFrequency and Time-Scale analysis, proceeding of the IEEE- Sp International Symposium. Victoria, BC. Oct.4-6, 1992.
[6] Chakraborty S, Chatterjee A and Goswami S. K.. A sparse representation based approach for recognition of power system transients. Engineering Applications of Artificial Intelligence. 2014;30:137-144.
[7] Chakraborty S, Chatterjee A and Goswami S. K.. A dual tree complex wavelet transform based approach for recognition of power system transients.Expert Syst.,http://dx.doi.org/10.1111/exsy.12066,in press.
[8] Zhengyou H., Shibin G. , Xiaoqin C. , Jun Z. , Zhiqian B. and Qingquan Q. Study of a new method for power system transient classification based on wavelet entropy and neural network. Electr Power Energy Syst.2011; 33: 402-410.
[9] Zwe-Lee Gaing. Wavelet – based neural network for power disturbance recognition and classification. IEEE Trans Power Deliv. 2004; 19(4): 1560-1568.
[10] Chen J, Kinsner W and Huang B. Power System Transient Modelling and Classification. Proceedings of the 2002 IEEE Canadian Conference on Electrical & Computer Engineering.
[11] Deokar S. A, Waghmare L. M. Integrated DWT–FFT approach for detection and classification of power quality disturbances. Electr Power Energy Syst.2014; 61: 594-605.
[12] Ibrahim, W. R. A,. and Morcos, M., Artificial intelligence and advanced mathematical tools for power quality applications: A survey. IEEE Trans. Power Delivery, Vol. 17, pp. 668-673, April 2002.
[13] Mokhtari, H., Karimi- Ghartemani, M,. and Iravani, M. R., Experimental performance evaluation of a wavelet based online voltage detection method for power quality applications. IEEE Trans. Power Delivery, Vol. 17, No. 1, pp. 161-172, January 2002.
[14] Perunicic, B. Mallini, M., Wang, Z., and Liu, Y. Power quality disturbance detection and classification using wavelets and artificial neural networks. Procedings of the 8th International Conference on Harmonics and Quality of Power, pp. 77-82, October 1998.
[15] Elmitwally, A., Farghal, S., kandil, M., Abdelkader, S., and Elkateb, M., Proposed wavelet- neuro-fuzzy combined system for power quality violations detection and diagnosis. Proc. Inst. Elect. Generat. Transm. Generat. Transm. Distribut., Vol. 148, No. 1, pp. 15-20, January 2001.
[16] Chang, C. S., and Wenquang, J., Determination of worst case capacitor switching over voltage of MRT system using genetic algorithm. Elect. Power Compon. Syst., Vol. 27. No. 11, pp. 1161-1170, October 1999.
[17] Liu, J., Pillay, P., and Reibeiro, P., Wavelet analysis of power systems transients using scalograms and multiresolution analysis. Elect. Power Compon. Syst., Vol. 27. No. 12, pp. 1131-1341, November 1999.
[18] Lluna A. P, Manivannan K., Xu P.,Osuna R. G, Benner C. and B. Russell D. Automatic capacitor bank identification in power distribution systems. Electr Power System Research.2014; 111: 96-102.
[19] Beg M. A., Khedkar M. K, Paraskar S. R. and Dhole G. M. Feed-forrward Artificial Neural Network- Discrete Wavelet Transform Approach to Classify Power System Transients. . Elect. Power Compon. Syst., Vol. 41. pp. 586-604, 2013.
[20] Kashyap, K. H. Shenoy, U. J. Classification of power system faults using wavelet transforms and probabilistic neural networks. Circuits and Systems, ISCAS’03. Proceedings of the International symposium on vol: 03. May 25-28, 2003.
[21] Kucuktezan, C. F and Genc, V.M.I. Dynamic security assessment of a power system based on probabilistic Neural Networks. Innovative Smart grid technologies Conference Europe (ISGT Europe) IEEE PES. Gothenburg. Oct. 11-13, 2010.
[22] Mo, F. and Kinsner, W. Probabilistic Neural Networks for power line fault classification. Electrical and Computer Engineering, IEEE Canadian Conference on vol. 2. May 24-28, 1998.
[23] Hu W. B, Li K.C and Zhao D. A novel probabilistic neural network system for power quality classification based on different wavelet transform. Wavelet Analysis and Pattern Recognition. ICWAPR. International Conference on vol.2. Beijing. Nov. 2-4.2007.
[24] Lee, I.W. C and Dash. P.K. S-transform – based intelligent system for classification of power quality disturbance signals. IEEE Transaction Industrial Electronics, 2003; 50 (4): 800-805.
[25] Wahab N. I. A., Mohamed A. and Hussain A. Fast transient stability assessment of large power system using probabilistic neural network with feature reduction technique. Expert systems with Applications, 2011; 38 (9): 11112-11119.
[26] Mohanty S. R, Ray P. K., Kishor N. and Panigrahi B. K. Classification of disturbances in hybrid DG system using modular PNN and SVM. IEEE Transaction Industrial Electronics, 2003; 50 (4): 800-805. Electr Power Energy Syst.2013; 44: 764-777.
[27] Moravej Z, Ashkezari J. D and Pazoki M. An effective combined method for symmetrical faults identification during power swing. Electr Power Energy Syst.2015; 24-34.
[28] Huang N., Xu D., Liu X. and Lin L., Power quality disturbances classification based on S-transform and probabilistic neural network. Neurocomputing. 2012; 98 (3): 12-23.
[29] Biswal B., Dash P.K., Panigrahi B.K. and Reddy J.B.V. Power signal classification dynamic wavelet network. Applied Soft Computing. 2009; 9 (1): 118-125.
[30] Yoon WK, Devaney MJ. Reactive Power Measurement Using the Wavelet Transform. IEEE Trans Instrum Measurement 2000; 49(2):246-52.
Classification of Power Quality Events Using Wavelet analysis and Probabilistic (Pampa Sinha)
[31] Morsi WG , EI- Hawary ME. Reformulating power components definitions contained in the IEEE Standard 14592000 using discrete wavelet transform. IEEE Trans Power Deliv. 2007; 22(3): 1910-16.
[32] Wang Y., He Z., Zi Y., Enhancement of signal denoising and multiple fault signatures detecting in rotating machinery using dual-tree complex wavelet transform. Mechanical Systems and Signal Processing 24 (2010) 119–137.
[33] Mao, P.L.,Agarwal,R.K.,2001.Anovelapproachtotheclassification of the transient phenomena in power transformers using combined wavelet transform and neural network. IEEE Trans Power Deliv 2001. 16: 6654660.
[34] Sedighi, A.R., Haghifam,M.R.,2005.Detection of inrush current in distribution transformer using wavelet transform. Electric. Power Energy Syst.J.27, 361–370.
[35] Mokryani, G., Siano, P., Piccolo, A., 2010. Detection of inrush current using S-transform and competitive neural network. In: Proceedings of the 12th International Conference on Optimization of Electrical and Electronic Equipment.
[36] Morsi WG , EI- Hawary ME. The most suitable mother wavelet for steady state power system distorted waveforms. In: Proc. of IEEE Canadian conf. on Electrical and Computer Engg (CCECE 08), Niagara falls, Ontario Canada, May, 17-22, 2008.
IAES International Journal of Artificial Intelligence (IJ-AI)
Vol. 5, No. 1, March 2016, pp. 13~21
ISSN: 2252-8938
Sachin B Jadhav*, Sanjay B. Patil**
* Bharati Vidyapeeths College of Engineering Kolhapur M.S (India), Ph.D Scholar VTU, Belagaum, K.S, India, ** Principal, MBT Campus, Islampur, M.S. India.
Article Info
Article history:
Received Dec 5, 2015
Revised Feb 8, 2016
Accepted Feb 26, 2016
Keyword: CIE L*a*b
Disease Region Area
Disease Severity
K-Means
Leaf Region Area
ABSTRACT
Traditional method used for disease scoring scale to grade the plant diseases is mainly based on neckaed eye observation by agriculture expert or plant pathlogiest. In this method percentage scale was exclusively used to define different disease severities in an illustrated series of disease assessment keys for field crops.The assessment of plant leaf diseases using this aaproach which may be subjective, time consuming and cost effective.Also aacurate grading of leaf diseases is essential to the determination of pest control measures. In order to improve this process, here we propose a technique for automatically quantifying the damaged leaf area using k means clustering, which uses square Euclidian distances method for partition of leaf image.For grading of soybean leaf disese which appear on leaves based on segmented diseased region are done automatically by estiamting thae ratio of the unit pixel expressed under diseased region area and unit pixel expressed under Leaf region area.For experiment purpose samples of Bacterial Leaf Blight Septoria Brown spot, Bean Pod Mottle Virus infected soybean leaf images were taken for analysis.Finally estiamated diseased severity and its grading is compared with manual scoring based on conventional illustrated key diagram was conducted. Comparative assessment results showed a good agreement between the numbers of percentage scale grading obtained by manual scoring and by image analysis The result shows that the proposed method is precise and reliable than visual evaluation performed by patahlogiest.
Copyright © 2016 Institute of Advanced Engineering and Science. All rights reserved
Corresponding Author:
Sachin Balkrishna Jadhav, Bharati Vidyapeeths College of Engineering,Kolhapur.
Ph.D Scholar VTU, Belagaum, K.S (India), Email: sachinbjadhav84@gmail.com
Soybean Leaf diseases like Bacterial Leaf Blight, Septoria Brown Spot, and Bean Leaf pod Mottlle are cause significant reduction in yield loss and lead to affect quality of soybean Products [1], thus influence economy and farmers life. An effective way to control soybean foliar diseases is by applying fungicides.To test the method for disease assessment, black and white drawings from a manual of disease assessment keys showing foliar diseases with different disease severities [2].Although there is an industrial recognized corresponding standard to grade the leaf spot disease [4-7], the naked eye observation method is mainly adopted in the production practice.Because of the difference of personal knowledge and practical experience; the same samples are classified into different grades by different experts. Therefore, the result is usually subjective and it is impossible to measure the disease extent precisely. Although grid paper method can be used to improve the accuracy, it is seldom used in practice due to cumbersome operation process and timeconsuming. Therefore looking for a fast and accurate method to measure plant disease severity is of great realistic significance. Since the late 1970s, computer image processing technology is applied in the
Journal homepage: http://iaesjournal.com/online/index.php/IJAI
agricultural engineering research, such as agricultural products quality inspection and classification, the crop growth state monitoring, plant disease and insect pest’s identification, and other agricultural robot [8, 9]. With the recent development in the field of image processing and pattern recognition techniques, it is possible to develop an automation system for disease asseesment of plant leaf based on the visual symptoms on leaf image.
The plant disease scoring is important procedure to develop diagnostic plant and investigate resistant varieties to the disease.Conventionally, plant pathologists score the disease level based on their own discretion using illustrated diagram key for particular disease.The various researchers investigated their methods for assessment key of disease severities for different plant diseases which are outlined as follows:
W. CIive James[3] developed method for series of assessment keys for plant diseases in which percentage scale was exclusively used to define different disease severities in an illustrated series of disease assessment keys for cereal,forage, and field crops. The standard area diagrams were accurately prepared with an electronic scanner. Procedures for assessing the different diseases are outlined in order to achieve some degree of standardization in disease assessment methods.Paul Vincelli and Donald E. Hershman [4] developed a diagram key for classifying the severity of soybean leaf disease into 10 levels. In his work he had investigated procedure for rating disease in Corn, Soybean, and Wheat.Shen Weizheng and Wu Yachun [5] developed method for segmentation methods to analyse spot disese of soybean in which thresholding is done by Otsu method and disease spot regions were segmented by using Sobel operator to examine disease spot edges. Finally plant diseases are graded by calculating the quotient of disease spot and leaf areas.
Sanjay patil and Dr.Bodhe [6] developed Histogram based triangular segmentation methods to analysis Brown spot disease on sugarcane plant leaf symptoms was shown on it. Thus Sugarcane Leaf, disease svevrity are assessd by calculating the quotient of lesion area and leaf areas. Evy Kamilah Ratnasari & others [7] developed model for segmentation methods in which thresholding a* component of color independent L*a*b color space to analysis Brown spot disease on sugarcane plant leaf symptoms was shown on it. Kittipong Powbunthorn & others [8] developed segmentation methods for assessment of brown leaf spot Disease in Cassava in which thresholding is done by Otsu method and disease spot regions were segmented by analysis of the histogram based on HSI color space. Thus the plant diseases are assessed by calculating the quotient of disease spot and leaf areas. Jayme Garcia and Arnal Barbedo [9] developed model for segmentation methods in which thresholding based on ROI in CMYK-XYZ color space to analysis whiteflies symptoms disease on soybean leaves was shown on it.The objectives of this work is to develop an image analysis technique for estimating the severity level [11]of soybean disease based on diseased area as well as to compare the results with manual scoring using kentucky [10]diagram key.
The severity extent of the plant leaves diseases is commonly measured by the ratio of disease area and leaf area ratio. Adopting image processing method to measure can be expressed as the following formula. [3]
Ad Disease Region Area; A l Leaf Region Area; P Unit Pixel Expressed Area; R d Disease Region; R l Leaf Region.
Unit pixel in the same digital image represente the same size, so ratio DS can be obtained by segmenting. Diseased region from leaf Region and Calculating pixel number ∑ ( ) of diseased region and ∑ ( ) of leaf region in the clusture image. Then according to disease classification standard consult table the final severity level can be achieved.
Assessing the severity of soybean foliar diseases by using an area diagram key [4] [10] was categorized percentages of inflection of ten levels as show in Figure. 1. Each leaf image samples was visually assessed independently & then with image analysis methods upon to the discretion of the individual raters [11] were taken in to account for method validitation.

Figure 1. Diagram key for assessment of Foliear diseases of Soybean (Based on A figure in KENTUCKY Integrated Crop Manual for Soybeans IMP-3.2009.PG.3)
4.1. IMAGE SEGMENTATION
Segmentation is the classifications of an image into meaningful data for easy analysis of the image. The existing methods for segmentation are thresholding, region growing and clustering. Thresholding is the simplest method of image processing. From an RGB image converted to the corresponding gray level intensity image [17], image can be partitioned by binary values, 1 and 0. The region above the threshold may be assigned 1 and that of below the threshold may be assigned zero. This histogram approach cannot be relayed upon for effective classification of the image information as the binary approach of classification limits the representation of image segments and further reduces proper detection[14][16][18] of the required area. Considering this limaitation k-means clustering method for leaf image segmentation is used in this paper.
4.2 PROPOSED CLUSTURING
Segmentation approaches based on clustering has many advantages over other approaches as it provides an efficient classification of image information and can be implemented in many fields of humaninterest such as aviation, military and medical fields.The implementation of segmentation on agriculture has aroused the interest of many scholars for it paves an easy to implement and effective method for detecting various pathogens and it is harmless due to low consumption of artificial pesticides and herbicides
K-means clustering is used to partition the leaf image into four clusters in which one or more clusters contain the disease in case when the leaf is infected by more than one disease. K means clustering algorithm was developed by J.MacQueen (1967) and then by J. A. Hartigan and M. A. Wong [14]. The kmeans clustering algorithms tries to classify objects (pixels in our case) based on a set of features into K number of classes. The classification is done by minimizing the sum of squares of distances between the objects and the corresponding cluster or class centroid In our experiments, the K-means clustering is set to use squared Euclidean distances.
4.2.1. Description of Algorithm
The algorithm is very similar to Forgy’s algorithm [19]. Besides the data, input to the algorithm consists of k, the number of clusters to be developed. Forgy’s algorithm is iterative, but k-means algorithm makes only two passes through the data set.
1. Begin with k cluster centres, each consisting of one of the first k samples. For each of the remaining n-k samples, find the centroid nearest it. Put the sample in the cluster identified with this nearest centroid. After each sample is assigned, recompute the centroid of the altered cluster.
2. Go through the data a second time. For each sample, find the centroid nearest it. Put the sample in the cluster identified with this nearest centroid. (During this step, do not recompute any centroid) Addition of certain features in the existing k means algorithm improves the detection of the interested region effectively with minimum chance of faulty clustering. The first step in k-means clustering is the initialisation of cluster centres. Common methods for initialisation include randomly chosen starts or using hierarchical clustering to obtain k initial centres [19]-[20].
The initialisation steps can be explained as follows.
1. Convert n×p image matrix X to n× (p -1) matrix Z, where each row Zi of Z is the polar representation of the corresponding row (X i S p) of X.
2. For each column Z, find the pair of neighbouring points with the largest angular distance between them and rotate Z such that these neighbours have the largest linear distance between them.
3. One dimensional matrix for k-means is initialized with greatest value integer obtained from (K (p -2)1/ ( p -2) equi-spaced quantities.
4.2.1. Applying masking to K-means algorithm. For a given k and initial cluster centres { k; k=1…k}, the general strategy is to position the datasets into k clusters, then to iterate the cluster mean directions until convergence [20]. The exact algorithm can be explainedas follows.
1. Given ―k‖ initialising cluster mean directions 1, 2, … k, find the two closest mean directions for every Observation Xi; i= 1, 2…n.
2. Classify the groups by C1i and C2i respectively. Assign the update equation
V k- = (nk- 1)2 – nk2 ||Xk ||2-1 and (1)
V k+ = (nk+ 1)2 – nk2 ||Xk ||2-1 (2) (2)
All clusters are in the live image set at this stage.
3. The live set is updated to find optimum convergence
4. Optimum transfer stage: For each Xi, i= 1,2…n, we calculate the maximum reduction in the objective function. By replacing the live function !i with another class, maximum reduction can be obtained as

If Wi > 0, then the only quantity to be updated is C2i = Ki .
5. Quick transfer stage includes swapping and the objective function and the change in the objective function can be calculated as
It is providing a quick way of obtaining final value.
The exact extraction of the lession areas of the soybean leaf can be detected by masking the clustered sample containing the plant region and then subtracting it from the acquired image. The modified algorithm developed using k-means clustering can be discussed with the experimental results obtained from a, Bacterial Blight, Septoria Brown Spot, and Bean pod Mottle infected diseased leaf resepectively.
5.1. Image Acquisition
This study takes Bacterial Leaf Blight, Septoria Brown spot, Bean Pod Mottle Virus infected soybean leaf images of soybean as example for illustrating the plant disease extentgrading method [14]. Infected leaves are placed flat on a white background. The optical axis of digital camera is perpendicular to the leaf plane to shoot images, which are deposited in the computer for future use. Figure 2(a-c) shows acquired image of soybean leaf diseses.



©
Figure 2. Acquired Image of soybean (a) Bacterial Leaf Blight. (b) Septoria Brown spot. (c) Bean pod mottle.
5.2. Segmentation To Extract Diseased Objects In The Cluster
After acquiring the image, clustering is done to separate the background and the foreground image.This is done by updating the live set with cluster groups of lower intensities as a group. In this step it is checked whether the Cni group satisfies Wi > n. The foreground image is thus mapped with a zero level intensity to perform further logical operations on the cluster group. Figure 3(d-f) shows Segmentation to extract the region of interest (ROI).



Figure 3. Segmentation to extract the region of interest (ROI) for Bacterial Leaf Blight (d), Septoria Brown spot (e), and Bean leaf pod mottle (f).
5.3. Clustering Based On Intensity Mapping
The acquired image is then separated to cluster groups based on k-means clustering. Then gray level mapping is performed to separate the image to intensity fields which helps in separation of the leaf image from the obtained image. The leaf image area to be highlighted is labelled in with the cluster index as shown in figure 4(g-i) for Bacterial Leaf Blight. (g) Septoria Brown spot. (h) and Bean pod mottle (i).
Grading of Soybean Leaf Disease Based on Segmented Image Using K-means (Sachin Balkrishna J )



5.4. Highlighting The Leaf Area
The pixel groups belonging to the intensity marked area alone are extracted and is shown in the image below to obtain the highlighted leaf area alone from the acquired image. The extracted leaf image is further corrected by masking with an image matrix of similar intensity pixels. It provides a better clarity for the obtained image and aids the separation of image using distinguishable features of the leaf image. An example of the output of K Means clustering for a leaf infected with Bacterial Leaf Blight (k), Septoria Brown spot (l), and Bean leaf pod mottle(m) disease is shown in figure 5(k-m).






The final clustering is done by subtracting the reference image from the base image formed from convoluting the cluster obtained from fig 4 with the acquired image. The advantage of this algorithm is that it gives high precision with low operating time. The final clustered image showing the Bacterial Leaf Blight (n), Septoria Brown spot (o), and Bean leaf pod mottle (p) in figure 6(n-p).
The overall flow of the program can be summarized with the following steps.
Step1: Acquiring the image.
Step2: Storing the ROI as the base image to be clustered for further operations.
Step3: Cluster to extract useful leaf area from the ROI
Step 4: Storing the leaf image obtained after applying the cluster field and using it as reference image.
Step 5: Subtracting the reference image from the base image.
A suitable gray level clusters used to obtain useful leaf area. From the figure it can be seen that the leaf region can be well detected and after subtracting the clustered leaf image from the base image disease region can be well detected. It can be seen from the figure that although some veins can be detected, they can be dealt as noise since they are scattered and their unit area is small compared to the lesion case. To select the appropriate circular structure elements to unseal to obtain the final clustered area containing the infected area image of lesion. After final clusturing the number of pixels ∑ ( ) in the desease region is 33430 and the number of pixels ∑ ( ) in the leaf region is 144704 for (Bacterial Leaf Blight). Thus it can be calculated that the ratio DS of the diseased and leaf area is 0.231 and its severity is 23.10%. and disease scale rating is 5 According to the grade table, as the following table 1, of the soybean leaf disease provided by the literature [4][5][6], the disesed severity is lies between 10.1 – 25% and hence disease scale rating (Grade) is 5 after programming to check up the table.
Subsequently, ten images–of area diagram key for assessment of bacterial leaf blight, Septoria brown leaf spot and Baean lef pod mottle mosaic virus were tested and calculated DS value by image analysis. Analysis of the area diagram key was analyzed by images processing number of pixel lies in disesed area and leaf region area but percentage of infect considerably approxiamte especially levels of 1–7 (Table 1). The image analyses were used further classification of the severity levels.
Table 1. Soybean Leaf Disease Severity Scale Rating [4] Disease Scale Rating Disease Severity Description
0 No lesions/spots
1 1% leaf area covered with lesions/spots
3 1.1 - 10% leaf area covered with lesions/spots, no spots on stem
5 10.1 – 25% leaf area covered with lesions/spots, no defoliation; little damage
7 25.1 – 50% leaf area covered with lesions/spots; some leaves drop; death of few plants; damage conspicuous
9 50% of Above More than 50% area covered, lesions/spots very common on all parts, defoliation common; death of plants common; damage more than 50%.
Disease severity is the lesion area of the leaves showing symptoms of spot disease and it is most often expressed as a percentage [6]. The disease severity of the soybean leaves is measured by comparing the number of infected pixel lesion area with the total pixels of leaf area from the segmented image [7][12][13]. The lesion percentage of leaf is computed using equation (5).
Where, DS is lesion of disease severity is total pixel in diseased area of segmented lesion, and is total pixel of leaf area. Figure 7 (q-s) shows estimated soyben disease severities with its scale rating for Bacterial Leaf Blight (DS=23.10% & Grade= 5). (g) Septoria Brown spot (DS=26.20% & Grade= 7) (h) and Bean leaf pod mottle (DS=44.16% & Grade= 7) (i).



Figure7. Estiamted diseased severity and its scale rating for: Bacterial Leaf Blight (q), Septoria Brown Spot (r) and Bean leaf pod mottle(s).
A digital image analysis technique proposed in this work is developed to measure percentage of severity for, bacterial leaf blight Septeroial brown leaf spot, and bean leaf pod mottle, soybean diseases resepectively. In the severity estimation, wider lesion results in higher severity estimation. The new technique has resulted high accuracy in identifying soybean leaf disease scoring grade with severity estimations for bacterial leaf blight (DS=23.10% & Grade= 5), Septeroial brown leaf spot (DS=26.20% & Grade= 7) and bean leaf pod mottle (DS=44.16% & Grade= 7) .Manual technique reffered to measure the percentage of disease severity of area diagram key found that values approxiamate corresponds to estimated classified criteria value. Comparative assessment results showed a good agreement between the numbers of percentage scale grading obtained by manual scoring and by image analysis .Compared to thresholding technique clustering k means proves simple and effective in determining the infected area with reduced requirement of manual cluster selection.The usage of proposed image processing technique for plant disease degree grading will help to eliminates the subjectivity of traditional classification methods and humaninduced errors. Hence this approach will be efficient for estimation of disease severity and cause to provide accurate data for disease pesticide control application. An algorithm for updating the clusters through iteration could further improve the obtained results.
ACKNOWLEDGEMENTS
We acknowledge support of this work by Dr. C.T. Kumbhar, Assistant Professor of Plant Pathology, Zonal Agricultural Research Station of, Sub-montane Zone, Kolhapur under Mahatma Phule Krishi Vidyapeeth rahuri, Maharashtra India.
REFERENCES
[1] Dae Gwan Kim, Thomas F. Burks, Jianwei Qin, Duke M. Bulanon, ―Classification of grapefruit peel diseases using color texture feature analysis‖, International Journal on Agriculture and Biological Engineering, Vol:2, No:3,September 2009.
[2] Al-Bashish, D., M. Braik and S. Bani-Ahmad, 2011. ―Detection and classification of leaf diseases using K-meansbased segmentation and neural networks based classification‖. Inform. Technol. J., 10: 267-275. DOI:10.3923/itj.2011.267.275, January, 2011.
[3] W. CIive James, An illustrated series of assessment keys for plant diseases, their preparation and usage' vol. 51, no.2, can. plant dis. surv. june, 7977.pp 39-65.
[4] Paul Vincelli and Donald E. Hershman, ―Assessing Foliar Diseases of Corn, Soybeans, and Wheat‖, Principles and Practices PPFS-MISC-06, 2011.
[5] Shen Weizheng and Wu Yachun, ―Grading Method of Leaf Spot Disease Based on Image Processing,‖ 2008 IEEE International Conference on Computer Science and Software Engineering.pp.491-494.
IJ-AI Vol. 5, No. 1, March 2016 : 13 – 21
2252-8938
[6] Dr.Sanjay B. Patil, Dr. S.K.Bhodhe, ―leaf disease severity Measurement using image Processing.‖ International Journal of Engineering and Technology Vol.3 (5), 2011, pp 297-301.
[7] Evy Kamilah Ratnasari and others, ―sugarcane leaf disease detection and severity estimation based on segmented spot image”. IEEE 2014 International Conference on Information, Communication Technology and System, pp 93-98.
[8] Kittipong Powbunthorn & others, ―Assessment of Brown Leaf Spot Disease in cassava using Image Analysis.‖ The International conference of the Thai Society of Agricultural Engineering 2012, Chiangmai, Thailand.
[9] Jayme Garcia Arnal Barbedo, ―Automatically Measuring Early and Late Leaf Spot Lesions in Peanut Plants Using Digital Image Processing.
[10] Douglas W. Johnson, Lee H. Townsend, ―kentucky integrated crop management manual for field crops soybean‖ IPM-3. 2009.
[11] Srivastava, S. K. and Gupta, G. K. (2010) Proceedings and technical programme 2009-10. Directorate of Soybean Research, Indore. pp 1-79
[12] Tejal Deshpande and K.S.Raghuvanshi, ―Grading & Identification of Disease in Pomegranate Leaf and Fruit,‖ (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 5 (3) , 2014, 4638-4645
[13] Sanjeev S Sannakki, Vijay S Rajpurohit, V B Nargund, et.al(2011), ― Leaf Disease Grading by Machine Vision and Fuzzy Logic‖, Int. J. Comp. Tech. Appl., Vol 2 (5), 1709-1716
[14] Amina Bhaika, ―Estimation of Yellow Rust in Wheat Crop Using K-Means Segmentation,‖ IJSR, VOL.2.Issue12, 2013.
[15] Murali Krishnan & Dr. M.G.Sumitra, ―A Novel algorithm for Detecting Bacterial Leaf Scorch (BLS) of Shade Trees Using Image Processing,‖ 2013 IEEE 11th Malaysia International Conference on Communications pp.474478
[16] G. Anthonys and N. Wickramarachch, ―An Image Recognition System for Crop Disease Identification of Paddy fields in Sri Lanka‖ IEEE Fourth International Conference on Industrial and Information Systems, ICIIS 2009, 28 - 3I December2009, Sri Lanka. PP 403-407.
[17] S. Ananthi and S. Vishnu Varthini, ―Detection and classification of plant leaf diseases‖ IJRES,Vol.2,Issue.2, ISSN: 2249-3905,pp.763-773.
[18] Ajay A. Gurjar and Viraj A. Gulhane ―Disease Detection On Cotton Leaves by Eigen feature Regularization and Extraction Technique‖ International Journal of Electronics, Communication & Soft Computing Science and Engineering (IJECSCSE),Vol .1, Issue.1
[19 ] Pattern Recognition and image analysis., Earl Gose ,Richard Johnsonbaugh, Steve Jost ,Prentice- Hall , India. Pg. 210-219
[20] Constrained K-means Clustering with Background Knowledge Proceedings of the Eighteenth International Conference on Machine Learning, 2001, p. 577-584. Kiri Wagsta, Seth Rogers rogers@rtna.daimlerchrysler.com Stefan Schroed.
BIBLIOGRAPHY OF AUTHORS


Mr.Sachin. B.Jadhav has pursuing Ph. D from VTU Blgaum and awarded M.E in Electronics and B E in Electronics & Telecommunication from Shivaji university kolhapur. Currently he is working as an Assistant Professor in Department of Electronics & Telecommunication Engineering at Bharati vidyapeeth College of Engineering, Kolhapur. He has keen interest in the field of Image processing
Prof. Dr. Sanjay Bapuso Patil has Awarded Ph.D in subject of Electronics & Telecommunication, Graduation and Post graduation in Electronics Engineering. His field of study is Digital Image Processing. His keen interest in application of image processing for ―Precision Farming‖ He had worked as Professor, Assistant professor and Lecturer under Pune as well as Shivaji Univercity Kolhapur. His total education as well as industrial expeiance is about more than 24 years. Currently working as Principal at MBT Campus, Islampur. He has written several technical papers in reputed international Journal and Conferences. He is life member of ISTE.
Grading of Soybean Leaf Disease Based on Segmented Image Using K-means (Sachin Balkrishna J )
IAES International Journal of Artificial Intelligence (IJ-AI)
Vol. 5, No. 1, March 2016, pp. 22~34
ISSN: 2252-8938
Bouzekri Moustaid, Mohamed Fakir Computer Sciences Department, Sultan Moulay Slimane University
Article Info
Article history:
Received Dec 6, 2015
Revised Feb 9, 2016
Accepted Feb 27, 2016
Keyword:
Business intelligence
Data mining
Data warehouse
Extract Transform
Load
Pentaho Data Integration
Talend Open Studio
Corresponding Author:
Bouzekri Moustaid, Computer Sciences Department, Sultan Moulay Slimane University, Beni-Mellal, BP: 523, Morocco
Today's company operates in a socio-economic environment increasingly demanding. In such a context, it is obliged to adopt a competitive approach by exploiting at best the information that it possesses for developing appropriate action plans and taking effective decisions. The decision support systems provide to the enterprise the tools that help it for decision-making based on techniques and methodologies coming from domain of applied mathematics such as optimization, statistics and theory of the decision. The decision support systems are composed of various components such as data warehouses, ETL tools and reporting and analysis tools.
Copyright © 2016 Institute of Advanced Engineering and Science All rights reserved
Email: fakfad@yahoo.fr, m.fakir@usms.ma
The decision-making systems are based on ETL (Extract-Transform-Load) tools, whose main role is to extract data from one or more source systems (operational databases, files), to clean them, transform and load them into a data warehouse enhancing the coherence and quality of data. Therefore, the ETL system constitutes the interface between the data sources and the data warehouse.
Decision making is the fundamental goal of any organization and any management. One of the main problems is to determine relevant information for decision making It is therefore essential to use Interactive Systems Decision Support, denoted DSS (DSS English: Decision Support Systems), which provide tools for assessing various alternatives and their impacts for optimal decision making
The decision is defined as a choice between several alternative actions at a given moment in time [1]. It is assimilated to an act, action or process of solving problem facing to the individual or organization. In general, we call decision making any mantel process after which everyone, in front of several alternatives, choose one of them.
Decision aiding can be defined as follows: Decision aiding is the activity of the person who, through the use of explicit but not necessarily completely formalized models, helps obtain elements of responses to the questions posed by a stakeholder in a decision process. These elements work towards clarifying the decision and usually towards recommending, or simply favoring, a behavior that will increase the consistency between the evolution of the process and this stakeholder’s objectives and value system [2].
To support this decision support in the most efficient way, the development of computer systems is necessary and inevitable.
Journal homepage: http://iaesjournal.com/online/index.php/IJAI
Keen and Scott-Morton [3] present the Systems Decision Support (DSS) as systems designed to solve decision problems little or poorly structured. The SIAD incorporate the statistics, the operations research, the optimization algorithms and the numerical computations and manage information (databases, file management and information flow within the company).
The decision information system is a set of data organized in specific way, easily accessible and appropriate for the decision making or an intelligent representation of these data through specialized tools [4]. The main interest of a decision support system is to provide the decision maker a transversal vision of the company in all of its dimensions.
Two main functions are designed for decision support tools:
a. Collecting, Storing and Transforming: Extract Transform Load (ETL), Datawarehouse, Datamart, Dataweb
b. Extracting and Presenting: Data mining, On Line Analytical Processing (OLAP).
The different components of a decisional system:
Datawarehouse: is a collection of thematic data, integrated, non-volatile and historiated organized for decision making [5].
Datamart: This is a departmental solution of Datawarehouse supporting a portion of the data and business functions. It is a subset of a Datawarehouse that contains only data of a company's craft.
a. ETL: is an inter-software technology to extract data from multiple sources, transform it and load it in one or more destinations
b. OLAP: Online analytical processing is the technology that can produce descriptive syntheses online (or views) of data contained in Datawarehouses. OLAP is based on a data structure especially adapted to the crossings and extractions: hypercube (or cube).
c. MOLAP: systems whose type is MOLAP constitute an approach which allows representing data of Datawarehouse as a multidimensional array with n dimensions, where each dimension of the array is associated with a dimension of the hyper cube of data.
d. ROLAP: Systems whose type is ROLAP use a relational representation of the data cube. Every fact is a table called fact table and each dimension corresponds to a table called dimension table.
Data mining : Data mining is the set of methods and techniques for exploring and analyzing data sets (which are often large), in an automatic or semi-automatic way, in order to find among these data certain unknown or hidden rules, associations or tendencies; special systems output the essentials of the useful information while reducing the quantity of data [6].
There are two types of Data mining’s techniques:
a. The descriptive (or exploratory) techniques are designed to bring out information that is present but buried in a mass of data (as in the case of automatic clustering of individuals and searches for associations between products or medicines).
b. The predictive (or explanatory) techniques are designed to extrapolate new information based on the present information, this new information being qualitative (in the form of classification or scoring) or quantitative (regression).
BI applications are based on data coming from different data sources, which can be managed by different operating systems. The ELT process provides the fusion of data coming from these heterogeneous platforms and transforms it into a standard format for the target databases in the environment of decision support.
The ETL process is composed of the following:
a. Reformatting: data source coming from different databases and different files must be formatted in a common format.
b. Conciliation: Redundancies cause inconsistencies. They must be found and reconciled during the ETL process.
c. Cleaning: The goal is to clear the erroneous data that were found during the analysis.
Table 1. The ETL process is Composed initial load historical load incremental load
Initialize targets business intelligence databases with current operational data
Initialize targets business intelligence databases with historical data archived
3.2. Design Of The Extraction Programs
Constantly fill targets business intelligence databases with current operational data
The extraction process can be done in two ways: duplicate data sources and give this data to ETL developers in order to exploit them or work directly on the source data by querying the operational system.
The first method has the advantage of avoiding the congestion of the operational system by the massive querying to perform data extraction. However, its disadvantage is the increase and complexity of the task of the team developing the ETL process.
Regarding the second method, it allows the development team of the ETL process to query directly data sources and thus target the subset that they need. However, in some cases, this method can overload the operational system and prevent proper operation.
3.3. Design Of The Transformation Programs
Transformation is the major part of ETL process. During this phase, the main problems of data sources are:
a. Inconsistent primary keys
b. Inconsistent data values
c. Different data formats
d. Inaccurate or missing data values
e. Synonyms and homonyms
f. Embedded process logic
The operations of transformations most encountered are as follows:
a. Part of the data must be renamed according to the standards of naming decision project.
b. Some elements of source data should be merged into a single data element.
c. Translation of certain data elements in mnemonics.
3.4. Design of the load programs
The last step of ETL processes is loading data after the previous two steps in the decision-making target databases, this can be done in two ways: insert new rows in tables or use the load utility DBMS. However, it is necessary to study referential integrity and indexing.
4. OPEN SOURCE ETL: TALEND OPEN STUDIO / PENTAHO DATA INTEGRATION
The field of Business Intelligence saw the appearance of free software covering all areas of decision: reporting, multidimensional analysis, data mining and the ETL.
Talend Open Studio (TOS) and Pentaho Data Integration (PDI) compute effectively the owners ETL, and they have a real alternative. Both tools derive their reputations of their abilities and their performances. Moreover, these two products occupy an important place in the Magic Quadrant of the Gartner Group published in July 2013.
4.1. Presentation of Talend Open Studio
Talend Open Studio is developed by the French company Talend. The first version of "Talend Open Studio" came into being in 2006, and the current version is 5.4. TOS is an ETL whose type is "code generator". It provides a graphical interface, the "Job Designer" (based on Eclipse RCP), which allows the creation of process of data manipulation.
4.1. Characteristics:
a. Compatibility with multiple operating systems
b. Prerequisites: 3GB of memory (4GB recommended), 3GB of disk space for installation and over 3GB for use.
c. Traces and statistics of performance in real time.
d. Enrichment of treatments by adding specific code (in Java or Perl).
e. Integration with large number of DBMS.
4.2. Environment of design under TOS:

Figure 1. Environment of design under TOS
4.3. Modeling space: where developers place and configure the components to build a data integration task. It is the key window of development.
4.4. Component palette: Contains components that can be used in data integration tasks.
4.5. Configuration tabs: shows properties of task or specific components that are selected in the design space.
4.6. Structure: lists the components and allows quick access to standard variables for each component
4.7. Code preview: displays a preview of the code associated with each component.
PDI is an ETL whose type is "transformation engine". PDI originally called kettle, it is acquired by Pentaho Corporation in April 2006. Similarly Matt Casters, the founder of the kettle, also joined the Pentaho team. Pentaho Data Integration has the "Spoon" GUI based on Standard Widget Toolkit (SWT), enabling the creation of two types of treatments: Transformations and Tasks (Jobs).
5.1. Characteristics:
a. Compatibility with multiple operating systems
b. It is easy to install, it comes to decompressing a file containing the tool, available at: http://www.community.pentaho.com/.
c. It allows the preview of the data streams processed
d. It allows the execution of processes on the local machine, a remote server, or set of servers.
e. It fits perfectly with the business intelligence platform Pentaho.
f. Very flexible and easy to customize
5.2. Environment of design under PDI:

Figure 2. Environment of design under PDI
5.3. Navigator: includes objects which are in association with a particular transformation.
5.4. Palette of creation: Contains components that can be used in creating data transformations.
5.5. Design space: where developers place and configure the steps to build a processing or data integration task, it is the key window of development.
5.6. Execution Result: shows the properties of execution results of a transformation or a task.
6. FUNCTIONALITIES COMPARISON
Tabel 2. Access to Relational Databases
Pentaho Data Integration Talend Open Studio
read full table
Yes Yes
read full view Yes Yes calling stored procedures Yes Yes add clause where / order by Yes Yes query execution Yes Yes query design tool No Yes
reading / writing of all the simple types of data Yes Yes
reading / writing of complex data types No cartographic data
Both tools have the ability to access databases implemented within different DBMS.
Tabel 3. Triggering Processes by Message
Pentaho Data Integration
Talend Open Studio
CORBA No Yes
XML RPC No Yes
JMS Yes Yes
MOMS No Yes
TOS stands out regarding the triggering process by message in comparison with PDI. Note that both tools do not support the triggering by the CORBA protocol.
Tabel 4 Transformations And Calculations Default
Pentaho Data Integration Talend Open Studio
Transformation functions of dates and numbers Yes Yes
Statistical functions of quality Yes Yes Allows transcoding with a reference table No No
Heterogeneous joins No No Join modes supported (BD) Yes Only join of Flows
Management of nested queries No No
TOS and PDI provide the basic functions for modeling elementary transformations that is the functions of transformation of dates, strings and numbers.
Tabel 5 Manual Transformations
Pentaho Data Integration Talend Open Studio
possibility of processing by a programming language Yes Yes adding new transformations and business processes Yes Yes
In addition to their transformation functions default TOS and PDI make available to developers the means to add new features to meet their business needs.
Tabel 6. Flat Files
Pentaho
TOS and PDI allow easy access to data in files.
Tabel 7 Triggering by Polling
Pentaho Data Integration
Folder Yes
POP Yes
Socket No
Talend Open Studio
TOS and PDI make available the means to wait for specific events, such as the appearance of a file in a directory, to orchestrate data integration treatments.
8.
Pentaho Data Integration Talend Open Studio
Presence of an API Yes Yes
Integration of external functions Yes Yes Crash recovery mechanism No Entreprise Edition
Parameterization of buffers / indexes / caches Yes Yes
Management team development Yes Yes,but paying
Versioning No Yes
Among the features offered by TOS and PDI, we find API for supporting the development of advanced data integration process. However, these tools do not offer error recovery.
Tabel 9 Processing Data
Pentaho Data Integration Talend Open Studio
Graphical mapping Yes Yes
Drag and Drop Yes Yes
Graphical representation of flows Yes Yes
Data visualization in development Yes Yes
Impact analysis tools Yes Entreprise Edition
Debugging tools Yes Yes
Management of technical documentation No Yes
Management of functional documentation No Yes
Management of documentation through the web Yes Yes
Management of integration errors certain steps Yes
TOS and PDI offer mechanisms graphical Mapping and Drag and Drop which makes them relatively easy to take in hand to develop treatments for data integration.
Tabel 10 Deployment
Pentaho Data Integration Talend Open Studio
Compilation treatments No Yes for JAVA No For PERL Type start of production Command line windows or unix
PDI is 'transformation engine’. Thus each transformation and each task are stored as meta-language and which may be stored either in XML or in a database. Therefore, treatments designed under PDI cannot be compiled. Conversely, TOS is 'code generator’. So it generates a code for each job either in Java or Perl. Therefore, treatments designed under TOS can be compiled for the case of the Java language.
Tabel 11. Connectors
Pentaho Data Integration Talend Open Studio
Connectors OpenERP, SalesForce, SAP (Read) Connectors CRM (SugarCRM, SalesForce, ...) Connectors ERP
Vol. 5, No. 1, March 2016 : 22 – 34
The application connectors allow interoperability between ETL tool and applications. In this context, we note that TOS offers more possibilities than PDI.
Pentaho Data Integration Talend Open Studio
Use of rights of a directory No No
Security type Security DBMS that contains the repository Owner
Security scenario creation Yes Yes
Security update scenario Yes Yes
Security access to metadata Yes Yes
Security on the administration console Yes Yes
Security on the manual launch of tasks Yes No
TOS and PDI are equipped with security mechanisms. The security under PDI is based on the security of DBMS while TOS has its own scenarios.
Pentaho Data Integration Talend Open Studio
Web Services Yes Yes
OLAP Cubes (Mondrian) Yes Yes
Various LDAP, RSS RSS, LDAP, MOM, SCP, XMLRPC
Both TOS tools and PDI support the web service and OLAP.
The comparison of the processing time is made being varied source files and files destinations. So, the following four tests were realized and are graphically presented expressing the processing time according to number of lines treaties
7.1. Test N°1
This test involves extracting data from a CSV file and load them into another CSV file while changing the separator ';' of the source file by ',' in the target file. The source file has a structure that has seven fields: sequence; now; first; second; third; fourth; fifth. Here is an excerpt of this file:
001;2013/09/0510:44:43.014;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 002;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 003;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 004;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 005;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 006;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 007;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 008;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 009;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 010;2013/09/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345
The target file is constructed according to the same structure with the only difference which involves changing the separator.
Based on this test, TOS has taken double more than PDI in terms of the execution time for the extraction of data from a CSV file and loading them into another CSV file.
7.2. Test N°2
The test consists of extracting data from a CSV file and loads it into an XML file. The source file has the same structure as that of the previous test. The target file has a structure that maps each element of the file to a XML tag. Below an illustrative extract from the file structure: <root> <row> <sequence>0000000001</sequence> <maintenant>2013/09/0510:44:43.014</maintenant > <premier>12.345</premier> <second>undeuxtroisquatrecinq</second> <troisieme >0304/12/0500:00:00.000</ troisieme > <quatrieme >Y</ quatrieme > <cinquieme >12345</ cinquieme > </row> <root>
The results of this test are similar for the two tools, they consume almost the same execution time to extract source data from a CSV file and load it into an XML file. Thus, the two tools have the same performances for this test.
7.3. TEST N°3
Here, we perform the extraction and loading of data from a CSV file into a table managed by the MySQL DBMS. The source file has the same structure as in the previous test. Each column of the table is associated with an element of the source file:
FromCSVfile todatabase MySQL
On this test, TOS has much more interesting performance against PDI. TOS is three times faster than PDI to extract source data from CSV files and load them into a table managed by MySQL.
7.4. TEST N°4
This test involves extracting data from a CSV file and loads them into another CSV file. Between the extraction and loading is carried out a transformation of dates. In the case of TOS we use the powerful tMap, while for the case of PDI, we use Rhino.
TOS is twice as fast as PDI to extract source data from CSV files and ensure the transformation and loading in other CSV files.
8. IMPLEMENTATION OF BI SYSTEM
8.1. Data warehouse design
The design of the Datawarehouse schema for commercial management according to the snowflake approach produced a diagram consists of Figure 7:
a. A fact table: FaitFacture.
b. Six dimension Figure: DimProduit, DimClient, DimPays, DimFormeJuridique, DimEffectif and DimTemps.
These Figure and their relationships are shown in the following schema:

Figure 7. These Figure and their relationships are shown in the following schema
9. ETL PROCESS UNDER PDI
The schema below illustrates the ETL design for the fact table FaitFacture:

Figure 8. The Schema Illustrates The ETL Design For The Fact Table Faitfacture
Vol. 5, No. 1, March 2016 : 22 – 34
10.
ETL modeling for the fact table FaitFacture with Talend Open Studio is the following:

Figure 9. ETL modeling for the fact table FaitFacture with Talend Open Studio
In order to proceed to the analysis of data from the data warehouse implemented, we used the Weka software and web interface developed in J2EE.
The results obtained using the Apriori algorithms with Weka are as follows:

Figure 10. The Results Obtained Using The Apriori Algorithms With Weka

Figure 11. The same results are obtained using the Apriori algorithm showed on the web interface developed in J2EE:
The application of Apriori algorithm allows the extraction of knowledge in the form of association rules between products of consequent and the products listed in the antecedent of the rule. For example, consider the association rule:
["JOINT CYLINDRE", "JOINT GROUPE" "JOINT CARTER"]
This rule has a 100% confidence. This result is very important for decision making for procurement. Indeed, it will be more beneficial to order quantities of the product "JOINT CARTER" in proportion to the quantities ordered for products "JOINT CYLINDRE" and "JOINT GROUPE", and to include the product "JOINT CARTER" in any promotional offers including products "JOINT CYLINDRE" and "JOINT GROUPE".
This work consisted in the construction of a decision support system for the management of sales. For that purpose, we presented the notion of the Decision, the notion of Decision-making support and that of the Decision support system as well as their components of extract, transform and load, storage of data, and the presentation tool layer such as querying, analysis (Data Mining) and reporting.
So during this work, we presented both ETL Talend Open Studio and Pentaho Data Integration and then their features were compared between them. Both ETL is of OPEN SOURCE types, are complementary and establish real alternatives to one ETL owners as Informatica Power Center, Oracle Warehouse Builder, Cognos Decision Stream.
At the end of this work, it was preceded to the writing of the query on the data of data warehouse by using the extension of SQL for OLAP (SQL3). So and to extract from the knowledge in the form of rules of associations between products, the algorithm Apriori of data mining was used via the software WEKA. Also, a Web interface was developed in J2EE to facilitate the use of this algorithm.
[1] Schneider, D. K. (1994). Modélisation de la démarche du décideur politique dans la perspective de l'intelligence artificielle. Thèse de l'Université de Genève, Suisse.
[2] ROY B., BOUYSSOU D., 1993. Aide multicritère à la décision: méthodes et cas, Economica, Paris.
[3] Keen, P., & M. Scott-Morton (1978): “Decision Support Systems: an organizational perspective”, AddisonWesley Publishing.
[4] Goglin J.-F. (2001, 1998). La construction du datawarehouse : du datamart au dataweb. Hermes, 2ème édition.
[5] INMON W.H. Building the Data Warehouse. 2nd Ed. New York: Wiley, 1996, 401 p.
[6] Stéphane TUFFERY, 2007. Data mining et statistique décisionnelle: l'intelligence des données.
IJ-AI Vol. 5, No. 1, March 2016 : 22 – 34 34
IAES International Journal of Artificial Intelligence (IJ-AI)
Vol. 5, No. 1, March 2016, pp. 35~40
ISSN: 2252-8938
Alka*, Harjot Kaur*
*Department Computer Science and Engineering, Guru Nanak Dev University Gurdaspur
Article Info
Article history:
Received Dec 4, 2015
Revised Feb 7, 2016
Accepted Feb 25, 2016
Keyword: Collaboration Interact Information Deception
Social media
Corresponding Author:
ABSTRACT
The organization collaboration is very important for the success of the organization. The persons who enter into the organization will interact with the other members of the organization. There exist leaders of the community who will be responsible for the management of the communication among the persons within the organization. Sometimes the information presented by the new person joining the community is not correct. That information will cause the deception over the network. In the purposed paper deception within the social media is going to be analyzed. Deception will cause legion of problems and sometimes death of the person who is deceived. The proposed paper suggests the mechanism for tackling such deceptions.
Alka, Department Computer Science and Engineering, Guru Nanak Dev University Gurdaspur,
Email: alkathaper@ymail.com
1. INTRODUCTION
Copyright © 2016 Institute of Advanced Engineering and Science All rights reserved
The proliferation of web based technologies has been modify the way that the content is generated and exchanged through the internet, leading to proliferation of social media applications and services. Social media like facebook enable creation and exchange of user generated content and design of range of Internet based applications. The services provided by the internet have increased. This not only provides the extra facilities to the users but also has attracted large number of users towards the internet based technologies. As more and more users are intended toward the internet so does the social networking sites. In today’s environment there exists large number of social networking websites. These social networking websites uses large number of interactive mechanisms to impress the users. Each social networking website needs user. So these social networking sites do not use any solid mechanism of authentications. This can cause frauds over the social networking sites.
Previous work on deception found that people in general lie routinely and several efforts have been made to detect and understand the deception. Deception has been used in various contexts throughout human history to enhance attacker’s tactics. Social media provide new environments and technologies for potential deceivers. There are many examples of people being deceived through social media, with some suffering devastating consequences to their personal lives. Deception in the proposed system will be considered the deliberate attempt to mislead others. In the deception the person who is deceived may not be aware of the fact that he/she is becoming deceived. The deception will be more profound in the area where boundary between privacy and deceiving others is not clear. The proposed system will be used in order to introduce the security mechanism known as physical check mechanism to ensure that the account on the social networking websites can only be created if the background check is successfully performed.
Journal homepage: http://iaesjournal.com/online/index.php/IJAI

Participants and procedure
A message inviting people to answer a web- based questionnaire was posted in 14 discussion groups. These discussion groups were randomly selected from three different popular Israeli portals. These discussion groups varied in content, and included both groups that discuss a particular sub- ject (e.g., meteorology, internet culture, or new age) and groups that have more general, unspecific top- ics (like a group for 30+, university students, or males).
A total of 257 people returned the questionnaire; 68% reported being female. The reported mean age was 30 (range: 14–70), with the following distribu- tion: 17% under the age of 20, 44% 20–30, 27% 30–40, and the rest over 40. Seventy-nine percent reported having an academic education (students in higher education institutes or postgraduate). On the average, people reported spending 3.5 h per day online (range 0.5–18 h). Average reported on- line competence was 3.2 points (out of 5); 64% reported higher than 3.5 points in this measure.
A two-part “Deception Questionnaire” was con- structed. The first part included the following ques- tions asked on five-point Likert scales (where 1 = not prevalent/never, and 5 = highly prevalental ways: (1) In your opinion, to what extent is online deception (someone who intentionally gives incor- rect details about himself) prevalent? (2) Have you ever deceived online? (3) Have you ever sensed that someone has deceived you online? Those who ad- mitted to having deceived online at least once were asked to mark all issues about which they gave incorrect information when deceiving someone online. The issues were age, sex, residence, marital status, height, weight, sexual preference, health status, occupation, a salient personality trait, or something else (if the last option was marked, respondents were asked to provide details). For each of the issues marked, respondents were asked to mark what motivatedthem most to do so. The options were (a) safety reasons, (b) identity play, (c) changing status, and (d) increased attractiveness. Next, they were asked if they felt that others suspected it was false information. In addition, they were asked to mark the emo- tions that they experienced while deceiving online. Emotions included tension, excitement, enjoyment, stress, oddness, and “another feeling.”
The second part of the questionnaire asked for demographic details (age, gender, hours online, and occupation) and online competence. Online competence was an average score of nine items that the respondents were asked to report their competence with (where “1” means have no competence and “5” means being highly competent). The nine competence items were: searching for information over the Internet, participating in asynchronous discussion groups, participating in Chat rooms, downloading music and movies, using e-mail, using online banking, buying online, participating in online games, and using online dating services. Since this is a first attempt to explore online deception among Israeli users, no external references or criteria were available to test the external valid- ity of the questionnaire. Since participants acted anonymously, reliability (pretest/posttest stability) could not be tested. However, as will be discussed later, the results are similar to those reported for other populations.
Deception will cause legion of problems. Some problems are significant and some are just for matter of laugh. The work has been done toward the deception within the social media. [1] the concept of digital deception is considered in this case. The mechanism of deception is caused because human being nature is to lie. There are efforts which are made in order to detect the deception within the social media. But no solid mechanism is suggested. So analysis of all the techniques which are present will be made in this paper. [2] In the past decade social networking services (SNS) flooded the Web. The nature of such sites makes identity deception easy, offering a quick way to set up and manage identities, and then connect with and deceive
others. Fighting deception requires a coordinated approach by users and developers to ensure detection and prevention. This article identifies the most prevalent approaches in detecting and preventing identity deception (from both a user's and developer's perspective), evaluating their efficiency, and providing recommendations to help eradicate this issue. [3] as internet is becoming more exposed to the users, so does the vulnerabilities. There exists wide verity of users over the internet. The intension of the users will not be certain. So the person with the wrong intension may cause the problem over the online social media. This deception is analyzed within this paper. [4] What makes deceptive attacks on social media particularly virulent is the likelihood of a contagion effect, where a perpetrator takes advantage of the connections among people to deceive them. To examine this, the current study experimentally stimulates a phishing type attack, termed as farcing, on Facebook users. Farcing attacks occur in two stages: a first stage where phishers use a phony profile to friend victims, and a second stage, where phishers solicit personal information directly from victims. In the present study, close to one in five respondents fell victim to the first stage attack and one in ten fell victim to the second stage attack. Individuals fell victim to a level 1 attack because they relied primarily on the number of friends or the picture of the requester as a heuristic cue and made snap judgments. Victims also demonstrated a herd mentality, gravitating to a phisher whose page showed more connections. Such profiles caused an upward information cascade, where each victim attracted many more victims through a social contagion effect. Individuals receiving a level 2 information request on Facebook peripherally focused on the source of the request by using the sender’s picture in the message as a credibility cue. [5] The increased use of emerging digital platforms as new tools in communication has become an integral part of business activities and the social lives of many individuals. Given the Internet’s vulnerable design, however, the rapid growth of online deception poses an extremely serious problem, and there is still little scholarly work on this issue. Using online deception cases from Taiwan, the authors undertook the current study with a twofold objective: (1) to investigate the distribution and patterns of deception tactics, and (2) to test hypotheses about how the identity of a potential victim and the purported identity of the deceiver affect the selection of a specific deception tactic. They found that the selection of deception tactics is significantly influenced by the characteristics of the deceivers and their targets. Implications of their results are also discussed. Keywords: Electronic commerce, online deception, deception tactics, content analysis, logistic regression. [6] The unknown and the invisible exploit the unwary and the uninformed for illicit financial gain and reputation damage.
From the above we have analyzed that the previous work does not concentrate in ensuring a strong background check mechanism in order to ensure that user with mollified intension should not able to create account over the social media. The proposed model will suggest a strong background check mechanism to ensure that the deception over the social media can be reduced
The proposed model will going to create system in which the information presented by the user will be passed through the filter. That filter will verify the information presented by the user. In case the information presented by the user is false then legal action can be taken. The proposed model will ensure that the deception over the network can be reduced. We will introduce the concept of jail. If the person lies then the person account will be sealed. The person will be punished in case of deception. The deception matrix is created in order to verify whether person is deceptive or not. Set of parameters are included within the deceptive matrix. All the parameters if successfully satisfied then the person is not deceptive. The structure of the deception matrix is as follows
1’s in the deception matrix indicates that corresponding condition is satisfied and 0’s in the deception matrix indicates that corresponding condition is not satisfied. The failure of even single parameter will result in the deceptive agent declaration. This matrix will be critical in determination of fair and deceptive agents.
The algorithm for the same will be as follows
Algo Check()
// This algorithm build a network in which information is received from the user(Iu) and then validation mechanism verify the data
1) Record Length of the Record(Rf) in I.
2) Loop until I>0
a) Make user pass through the series of Questions(Q).
b) If InValid(Q) then
B1) Declare user falsifiy(F) and return Else
B2) Goto c End if
c) Perform Background(B) Check
d) If IsValid(B) then
D1) Declare user Valid and goto step e. Else
D2) Declare user invalid. End of if
e) I=I-1
End Loop
3) Stop
The above algorithm suggests that the user has to go through series of steps before user will be able to create account over the network. The questionnaires are also used so that validity of the user can be verified.
The following table shows age wise deception which occurs over the social network like facebook.
AGE AND INTERNET COMPETENCY DIFFERENCES IN DIFFERENT ISSUES OF DECEPTION
Table 2: Showing Deception Age wise Internet competency
Age differences differences Frequency of use
Sex No difference No difference Frequent > Infrequent, y2(1) = 17.69, p < 0.001
Age Younger > Older Competent > Non- Frequent > Infrequent, y2(3) = 9.75, p < 0.05 competent, y2(1) = 7.27, y2(1) = 8.36, p < 0.005 p < 0.01
Residency Younger > Older Competent > Non- Frequent > Infrequent, y2(3) = 10.73, p < 0.05 competent, yc2(1) = 7.27, y2(1) = 4.46, p < 0.05 p < 0.01
Marital status No difference Competent > Non-competent Frequent > Infrequent, competent y2(1) = 8.18, y2(1) = 4.45, p < 0.05 p < 0.005
Occupation No difference No difference Frequent > Infrequent, y2(1) = 6.98, p < 0.01
The deception model we have created is in netlogo. The deception will be handled by the use of leader of the community. The new user will enter into the system and interact with the leader. If leader allow the new agent to enter into the system then credential will be checked. If the credentials are not valid then the new agent entering into the system will be jailed. The concept of jailed will be used to handle the deception present within the online social media. The screen shots of the proposed system will be as follows


Figure 2. showing the deception model through netlogo The agent types will be listed through the graph as follows

3. Showing the agent types
The deception can be the big problem which is present within the social media. Detecting the deception and imposing the fine on them will be the prime objective of this paper. The paper purposes the background check mechanism in order to ensure that the deception never occur in the system. The technique suggested in this paper will efficiently detect and resolve the problems present within the online social media like facebook. The main problem that is present within the proposed technique is that it will be time consuming to perform such a check. So in the future we will try to invent a technique in order to resolve the issue of time consumption.
[1] J. T. Hancock, “Digital Deception: Why, When and How People Lie Online,” Oxford Handb. Internet Psychol., pp. 289–301, 2007.
[2] M. Tsikerdekis and S. Zeadally, “Detecting and Preventing Online Identity Deception in Social Networking Services,” IEEE Internet Comput., vol. 19, no. 3, pp. 41–49, May 2015.
[3] M. Tsikerdekis and S. Zeadally, “Online deception in social media,” Commun. ACM, vol. 57, no. 9, pp. 72–80, Sep. 2014.
[4] A. Vishwanath, “Diffusion of deception in social media: Social contagion effects and its antecedents,” Inf. Syst. Front., vol. 17, no. 6, pp. 1353–1367, Jun. 2014.
[5] C.-D. Chen and L.-T. Huang, “Online Deception Investigation: Content Analysis and Cross-Cultural Comparison,” Int. J. Bus. Inf., vol. 6, no. 1, pp. 91–111, 2011.
[6] M. Tsikerdekis and S. Zeadally, “Online Deception in Social Media,” Commun. ACM, vol. 57, no. 9, pp. 72–80, 2014.
[7] A. Caspi and P. Gorsky, “Online Deception: Prevalence, Motivation, and Emotion,” Cyberpsychology Behav., vol. 9, no. 1, pp. 54–60, 2006.
[8] M. Tsikerdekis and S. Zeadally, “Online deception in social media,” Commun. ACM, vol. 57, no. 9, pp. 72–80, Sep. 2014.
[9] M. Tsikerdekis and S. Zeadally, “Detecting and Preventing Online Identity Deception in Social Networking Services,” IEEE Internet Comput., vol. 19, no. 3, pp. 41–49, May 2015.
[10] M. Tsikerdekis and S. Zeadally, “Multiple Account Identity Deception Detection in Social Media Using Nonverbal Behavior,” IEEE Trans. Inf. Forensics Secur., vol. 9, no. 8, pp. 1311–1321, Aug. 2014.
[11] “Online Deception in Social Media.” [Online]. Available: http://cacm.acm.org/magazines/2014/9/177936-onlinedeception-in-social-media/abstract. [Accessed: 25-Feb-2016].
[12] “The Stranger Among Us: Identity Deception in Online Communities of Choice | Patricia J MooreAcademia.edu.” [Online]. Available: http://www.academia.edu/1629343/The_Stranger_Among_Us_Identity_Deception_in_Online_Communities_of_C hoice. [Accessed: 25-Feb-2016].
IAES International Journal of Artificial Intelligence (IJ-AI)
Vol. 5, No. 1, March 2016, pp. 41~44
ISSN: 2252-8938
Ashwin V Departement of Information Technology, SRM University
Article Info
Article history:
Received Dec 4, 2015
Revised Feb 7, 2016
Accepted Feb 25, 2016
Keyword:
Microblogging Tweets Stemming Machine learning algorithm
ABSTRACT
This paper addresses the task of building a classifier that would categorise tweets in Twitter. Microblogging nowadays has become a tool of communication for Internet users. They share opinion on different aspects of life. As the popularity of the microblogging sites increases the closer we get to the era of Information Explosion.Twitter is the second most used microblogging site which handles more than 500 million tweets tweeted everyday which translates to mind boggling 5,700 tweets per second. Despite the humongous usage of twitter there isn’t any specific classifier for these tweets that are tweeted on this site. This research attempts to segregate tweets and classify them to categories like Sports, News, Entertainment, Technology, Music, TV, Meme, etc. Naïve Bayes, a machine learning algorithm is used for building a classifier which classifies the tweets when trained with the twitter corpus. With this kind of classifier the user may simply skim the tweets without going through the tedious work of skimming the newsfeed.
Copyright © 2016 Institute of Advanced Engineering and Science All rights reserved
Corresponding Author:
Ashwin V, Dept. of Information Technology, SRM University, Kattankulathur Chennai, India
Email: 94.ashwinvee@gmail.com
1. INTRODUCTION
Successful microblogging services such as twitter have come to an integral part of daily life of millions of Internet users. Interest in mining in twitter increased with the widespread use of these services. Because they become the ware house of peoples opinion on current issues. Twitter is the most popular and the second most used social networking site. Since its launch in 2006, the popularity of its use has been drastically increasing, that more than 100 million user post 340 million tweets a day in 2012. As of march 2016, Twitter has more than 310 million monthly active user.
In twitter, users are allowed to create status messages which are called tweets. Tweets are of 140 characters which are written by registered twitter users about their life, opinions on variety of topics and discussions on current issues. As more and more users share their opinion on several fields, their view on current issues, microblogging sites become the assets of user’s opinion and sentiments.
In this research we use a dataset formed by collecting twitter tweets. These tweets are collected and are fed to the classifier which classifies them into several categories like Sports, News, Entertainment, Politics, and Meme. With the help of these categories user may just have to choose the category of his/her interests.
With the increase in popularity of social networks and blogs, analysis and mining has become a field of interest for many researchers. There are a lot of researches done in twitter such as user classification,
Journal homepage: http://iaesjournal.com/online/index.php/IJAI
Trend detection, Sentiment classification, trend detection etc. But this research mainly carries out the task of segregating tweets into several categories for user’s convenience.
In overviewing L.Huag, R.Bhayani and A.Govind, 2009 research, they addressed the classification of tweets based on sentiment. These tweets are classified into either positive or negative with respect to query term. They have also used the emoticons occurring in tweets as “silver” labels i.e., labels with more uncertain status than the ones found in usual “gold” standards for tweet sentiment analysis This research mainly benefits consumers who want to know about the sentiment of products before purchase, or companies that want to monitor the public sentiment of their brand. While J.Read in his research (Read, 2005) he has used emoticons such as “:-)” and “:-(” which serve as noisy labels and formed a training set for sentiment classification. For this purpose, the author collected texts containing emoticons and divided the data set into positive and negative samples
Sankaranarayanan et al. 2009, built a news processing system for identifying the tweets that corresponds to late breaking news. They collected the tweets and they removed noises from them. They clustered the tweets using the clustering algorithm called leader-follower clustering, which allows for clustering in both content and time. The other issue which is addressed in this research is identifying relevant locations associated with the tweets. Pang and Lee, 2002 researched the performance of various machine learning techniques like Naive Bayes, Maximum entropy and SVM in the specific domain of movie reviews. By this they were able to achieve an accuracy of 82%.
Sriram et al. 2010, their work is more relevant to ours. They classified tweets into predefined set of classes such as news, events, opinion, deals and private messages with the use of information about the author and also feature which are extracted from tweets such as “@username”, shortening of words, slang, etc. They classified tweets in order to improve information filtering. Their feature outperformed the bag. Of word model approach in the classification of tweets.
Different from the above works, this research defines a system that would classify all the tweets irrespective of the trend, sentiment, user into categories like News, Meme, Sport, Entertainment which would make twitter far more convenient to use and also saves ample amount of time for the user.
3. SYSTEM DESIGN
Our system here is segregated into different modules.
3.1. Tweet Retrieval Module
The basic requirement for the retrieval of Tweets is the Twitter API. Registration for the API is done using an existing Twitter account. Once registered, the user is provided with a Consumer Key, a Consumer Secret Key, an Access Token and an Access Token Secret using which the tweets are retrieved from the user’s timeline.
3.2. Text Processing Module
To analyse and classify text, there are certain pre-requisite actions that must be performed. The retrieved tweets are written onto a Text File. Each tweet must be written on to a different text file, all of which must be in the same directory. These text files are the Documents that will be used. The documents are first put through the process of cleaning. Cleaning refers to the removal of any and all punctuation marks from within the document. Once the documents are cleaned, the next process is to remove the Stop Words. Stop Words are words like articles, pronouns, prepositions and conjunctions which would not affect the eventual classification. Then, stemming which is the process of extracting the root word from each of the words in the document is carried out. Stemming returns a set of root words that can then be fed into the classifier.
3.3. Conversion Module
The conversion that has to occur is to get an ARFF File to be fed into Weka i.e., Waikato Environment for Knowledge Analysis which is a Machine Learning tool developed at the University of Waikato in New Zealand. The whole directory of Documents is converted into one ARFF File using the Weka’s Core.Converters Library. The conversion is done using the TextDirectoryLoader method that derives from the TextToArff class in Weka. The command weka.core.converters.TextDirectoryLoader dir <Directory Path> > <ARFF File Path> must be entered in Weka’s Command Line Interface which carries out the conversion.
IJ-AI Vol. 5, No. 1, March 2016 : 41 – 44
3.4 Classifier Module
We build a classifier using the Naïve Bayes classifier. Naıve Bayes classifier is based on Bayes’ theorem. (1)
Where d is the Document, and c is the Category.
The best class in NB classification is the most likely or maximum a posteriori (MAP) CMAP class:
Document d is represented as feature d1, d2…, dn.
The classifier works after the Attributes (Classification Feature) are mentioned on the ARFF File. Of the documents in the whole set, 70% are used as the training set, i.e., these 70% of the tweets are manually labelled as Sports, News, Entertainment, Technology, Music, TV, Meme, etc. and the remaining 30% is used as the Test set.
3.5. User Module
This can be called the front-end of the application. This includes the Graphic User Interface (GUI). This provides the link between the application and the user. This the module where the user will be displayed with tweets that are categorised as Sports, Entertainment, News, Meme, Private Message.
4. RESULT
This graph shows the accuracies per classes using Naïve Bayes classification. This graph summarizes the result of our classifier. The accuracies in classification into catgories are pretty high which is very good. The classification of tweets into categories are only based on the words contained in the tweets that we used in the training set. These words may contradict in more than one categories which will affect the accuracy. But in our case that impact has been very low except for the category Others because the ambiguity in tweets that fall under the others category is very high and so they fall into some other category resulting in this low accuracy. There are several approaches like 8F, BOW, 9F that can be used to increase the accuracy.

Figure 1. Accuracies per category using Naïve Bayes
5. FUTURE ENHANCEMENT
Mission learning techniques perform well for classification of tweets. We believe that accuracy could still be improved. More advanced comparison approaches can be taken into consideration such as
clustering. And also using machine learning algorithms like SVM, Maximum entropy can be used in addition to the Naïve Bayes classifier to improve the efficiency in classification.
As mentioned earlier, twitter has 500 million tweets every day, hence in near future this mindboggling number is bound to increase and subsequent categories need to be accordingly implemented.
As discussed earlier microblogging nowadays has become one of the major modes of communication among internet users. A recent research has identified it as online word-of-mouth branding (Jansen et al., 2009). The large amount of information contained in microblogging web-sites is what makes them an attractive source of data for mining and analysis. Although twitter messages have unique characteristic compared to other corpora, machine learning algorithm have shown to classify tweets with similar performance.
In this paper we use twitter feeds as our data set and categories them based on their nature and significance of tweet. Further researched is needed to continue to improve the accuracy in difficult domain. Machine learning algorithm can achieve high accuracy for classifying when using this method.
[1] J Sankaranarayanan, H Samet, BE Teitler, MD Lieberman, J Sperling Twitterstand: news in tweets 2009.
[2] B Sriram, D Fuhry, E Demir, H Ferhatosmanoglu, M Demirbas Short text classification in twitter to improve information filtering 2010.
[3] A Go, R Bhayani, L Huang. Twitter sentiment classification using distant supervision. 2009.
[4] M Bush, I Lee, T Wu NLP-based approach to Twitter User Classification 2010.
[5] J Read. Using emoticons to reduce dependency in machine learning techniques for sentiment classification. 2005.
[6] Kathy Lee, Diana Palsetia, Ramanathan Narayanan, Md. Mostofa Ali Patwary, Ankit Agrawal, and Alok Choudhary Twitter Trending Topic Classification 2009.
[7] J Benhardus Streaming Trend Detection in Twitter 2010.
[8] B Pang, L Lee, S Vaithyanathan Sentiment classification using machine learning techniques 2002.
[9] S kabir and M Tahmim Localized twitter opinion mining using sentiment analysis 2009.
[10] Ted Pedersen. A simple approach to building ensembles of naive bayesian classifiers for word sense disambiguation. 2000.
[11] YS Yegin Genc, JV Nickerson. Discovering context: Classifying tweets through a semantic transform based on Wikipedia Proceedings of HCI International 2011.
[12] TM Mitchell. Machine Learning. McGraw-Hill, New York 1997.
[13] Weka 3: Data Mining Software in Java, http://www.cs. waikato.ac.nz/ml/weka/.
[14] Naïve Bayes classifier. Retrieved from https://web.stanford.edu/class/cs124/lec/naivebayes.pdf
[15] Naive Bayes text classification. Retrieved from http://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-textclassification-1.html.
IJ-AI Vol. 5, No. 1, March 2016 : 41 – 44
BIBLIOGRAPHY OF AUTHOR

Ashwin V is from Chennai born on 05/10/1994 Has completed Undergraduate B.Tech degree in Information Technology at SRM University Chennai, India in the year of 2016. And currently working at Emerio Technologies, Guindy, Chennai, India. This is the Author’s first research work.
