
Volume: 11 Issue: 10 | Oct 2024
2395-0056
ISSN:2395-0072

Volume: 11 Issue: 10 | Oct 2024
2395-0056
ISSN:2395-0072
Maria Anurag Reddy Basani
Texas A &M University, Corpus Christi
Abstract
Thisstudypresentsa comprehensivesentimentanalysisframework thatintegrates sixwidelyspokenlanguages: English,Spanish,French,German,Chinese,andArabic.UtilizingadvancedDLmodels,includingBERT,CNN,andLSTM,we evaluatetheirperformanceonalarge-scalemultilingualdatasetcomprising2.5millionreviews,processedusingbigdata technologies such as Apache Spark and Hadoop. Our results demonstrate that BERT achieved an impressive accuracy of 95%acrossalllanguages,significantlyoutperformingCNN,whichachievedonly65%accuracy,andLSTM,whichrecorded a moderate accuracy of 80%. Notably, CNN exhibited particularly poor performance with Chinese and Arabic data, reflectingitsdifficultyinhandlingcomplexlinguisticfeatures.Thisresearchunderscorestheimportanceofleveragingbig data to develop inclusive sentiment analysis models capable of effectively handling diverse linguistic contexts, setting a newbenchmarkinthefield.
Keywords: SentimentAnalysis,Multilingual,BigData,DeepLearning,BERT,ClassificationPerformance,NaturalLanguage Processing,CNN,LSTM,Cross-Language
1 Introduction
1.1 Background
Sentiment analysis, also referred to as opinion mining, involves extracting the general attitude of consumers toward particular topics by analyzing their expressed thoughts and opinions R. S. Kumar et al. (2021). In the context of ecommerce,vastamountsofuser-generatedcontent,suchasreviews,ratings,andcomments,arecontinuouslygeneratedLi et al. (2022). Traditional sentiment analysis methods are insufficient for handling such data at scale Wankhade et al. (2022).ToolslikeApacheHadoopandApacheSparkhavebecomeessentialforprocessingthelargedatasetsproducedby theseplatformsGabdullinetal.(2024).Thesetechnologiesenablee-commercecompaniestoefficientlyanalyzeconsumer sentimentfrommillionsofreviews,whichwouldbeimpossiblewithstandardtoolsIvanovetal.(2024).
By leveraging distributed computing frameworks like Hadoop and Spark, businesses can manage unstructured data, includingtextreviews,frommultiplesources ArifandZeebaree(2024).Thesetoolsarecrucialforperforminglarge-scale sentiment analysis, as they process huge datasets in parallel, significantly reducing computation time Modi et al. (2024). For instance, a large dataset of product reviews can be processed in minutes using Apache Spark, allowing companies to gainreal-timeinsightsintocustomerpreferencesYadav(2024).Moreover,integratingTensorFloworPyTorchforMachine Learning(ML)tasksenablescompaniestoapplyadvancedmodels,suchasDeepLearning(DL),toextractsentimentfrom reviewsmoreaccurately.
In addition to handling volume, these tools help process diverse types of data such as text reviews and numerical ratings enablingcompaniestoperformsentimentanalysison bothstructuredand unstructured data Yang et al. (2024). Forexample,Natural LanguageProcessing(NLP)modelsbuiltusing TensorFlowcanhandle noisy,unstructuredtextdata from customer reviews, addressing challenges such as spelling errors, short comments, and slang. These insights allow companiestotailortheirproductsandservicesbasedoncustomerfeedback,improvingcustomersatisfactionanddriving sales.
This study leverages distributed computing frameworks and DL libraries like Apache Spark, HDFS, TensorFlow, and PyTorch to perform a large-scale sentiment analysis of consumer reviews from e-commerce platforms. Using datasets in Turkish,Arabic,andEnglish,weexploretheperformanceofMLandDLmodels,aswellaspre-trainedlanguagemodels,in processingreal-world,unstructurede-commercedata.
The increasing amount of customer feedback generated on e-commerce platforms, including millions of reviews and ratings, necessitates specialized tools for effective analysis. Traditional methods fall short when it comes to handling the
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
sheer volume, variety, and speed at which this data is produced. Tools like Hadoop Distributed File System (HDFS) and Apache Spark facilitate the distributed processing of large-scale datasets, enabling the analysis of consumer sentiment acrossmultiplelanguagesandregions.
Inthisstudy,weuseApacheSpark toprocessconsumer reviewsfrommajore-commerceplatforms,allowingforrealtimesentiment analysis by distributing tasksacross clusters of machines. TensorFlowand PyTorchare then employed to train DL models for sentiment classification. These models, including pre-trained architectures like BERT and GPT, are testedonnoisydatacontainingirregularitiessuchasshortreviews,misspellings,anddiversewordtypes.Theintegration ofthesetoolsensuresthatthesentimentanalysisprocessisbothscalableandaccurate,despitetheunstructurednatureof thedata.
This research provides insights into how tools such as Apache Spark, HDFS, TensorFlow, and PyTorch can effectively handlelarge-scalesentimentanalysistasks.Byleveragingthesetechnologies,businessescanrapidlyanalyzethousandsof reviews to gain insights into customer satisfaction, identify emerging issues, and adapt their strategies in response. The combination of distributed processing and advanced ML models allows for the extraction of meaningful insights from unstructureddata,therebyimprovingcustomerengagementandproductdevelopmentine-commerce.
Theobjectivesofthisresearchareasfollows:
• To implement distributed computing frameworks, specifically Apache Spark and HDFS, for efficient processing of large-scale consumer review datasets from e-commerce platforms in multiple languages. • To evaluate the performanceofvariousMLandDLmodels,includingpre-trainedlanguagemodelslikeBERTandGPT,inperforming sentimentanalysisonnoisy,unstructureddatacontainingirregularitiessuchasshortreviewsandmisspellings.
• To analyze the impact of utilizing advanced DL libraries, such as TensorFlow and PyTorch, on the accuracy and scalabilityofsentimentanalysisprocessesinthecontextofe-commerce.
The rest of this paper is organized as follows: Section 2 provides a review of related works in the field of sentiment analysis, highlighting the advancements and limitations of existing methodologies. Section 3 details the datasets used in this study, along with the preprocessing techniques applied to handle unstructured data. In Section 5, we present the experimental setup, including the architectures of the ML and DL models employed. Section 6 discusses the results and analysisofthemodelperformances,followedbyconclusionsandfutureworkinSection
Sentiment analysis has become a cornerstone of understanding consumer feedback, particularly in sectors like ecommerce,wherevastamountsofuser-generatedcontentaregenerateddaily.Asthevolumeandcomplexityofdatahave increased,sotoohavethemethodsusedtoextractmeaningfulinsights.TraditionalapproachesbasedonMLhaveevolved into more sophisticated DL and NLP methods, which are now further enhanced by big data processing tools like Apache Spark,Hadoop,andadvancedlibrariessuchasTensorFlowandPyTorch.
Earliersentimentanalysisstudies often employed ML modelssuchas Support Vector Machines (SVM),Naive Bayes(NB), and Decision Trees (DT). These models were widely used due to their simplicity and efficiency in handling structured datasets. For instance, Pang et al. (2002) were among the first to apply ML algorithms for sentiment analysis of movie reviews,comparingSVM,NB,andmaximumentropymodels.TheirresultsshowedthatSVMoutperformedothermethods, achieving an accuracy of 82% on sentiment classification tasks. This foundational study led to a series of applications of SVMinvariousdomains,includinge-commerce,socialmedia,andfinanceGoetal.(2009).
Liu (2012) reviewed sentiment analysis applications and noted that while SVM and NB were effective for text classification, they often struggled with unstructured data, particularly when dealing with short, informal reviews. This was further echoed by Kim (2014), who showed that traditional ML models required significant feature engineering efforts, including the manual creation of n-grams, term-frequency inverse document frequency (TF-IDF), and other
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
handcrafted features. These models alsofaced limitationswhen processing datasets thatcontained spelling errors,slang, ordomain-specificjargon,makingthemlesseffectiveinreal-worlde-commercesettings.
Asdatasetsgrewlargerandmorecomplex,DLapproachesbegantodominatethefieldofsentimentanalysis.Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) have shown remarkable performance in capturing contextualdependenciesandlearningfeaturesautomaticallyfromtextdata.Collobertetal.(2011)wereamongthefirstto introduce a unified neural network architecture for NLP tasks, which included sentiment analysis. Their CNN-based approach significantly reduced the need for feature engineering, making it easier to apply these methods to large-scale datasets,suchasthosefoundone-commerceplatforms.
Kalchbrenner et al. (2014) extended this work by developing a dynamic convolutional neural network (DCNN) for sentence modeling. Their model achieved state-of-the-art results on sentiment classification tasks, highlighting the effectiveness of CNNs in processing short texts, such as product reviews. Similarly, Kim (2014) applied a simple CNN architecture for sentiment analysis of movie reviews and showed that CNNs could outperform traditional ML models by automaticallylearningrelevantfeatures.
While CNNs excel at extracting local patterns from text, Recurrent Neural Networks (RNNs), particularly Long ShortTerm Memory (LSTM) and Gated Recurrent Units (GRU), have proven effective in capturing longrange dependencies. Linsley et al. (2018) introduced LSTM, which overcame the vanishing gradient problem of standard RNNs, making it suitablefortasksthatrequirethemodeltoretaininformationoverlongsequences.ThismadeLSTMparticularlyusefulfor sentimentanalysisoflong-formreviewsorcustomerfeedback.Taietal.(2015)appliedLSTManditsvariantstosentiment classification,showingthatthesemodelscouldcapturebothlocalandglobalsentimenttrendsintextdata.
Inamorerecentdevelopment,Basirietal.(2021)combinedLSTMwithCNNandtheattentionmechanismtocreatea hybridmodelthatachieved93.4%accuracyontheKindleproductreviewdataset.Thismodelwasparticularlyeffectivein handling e-commerce data, which often contains noise in the form of spelling errors, short reviews, and various word forms. L.Zhang etal. (2018)conducteda comprehensivesurveyof DL techniquesforsentimentanalysisandemphasized thathybridmodelscombiningCNNsandRNNsoftenoutperformsingle-modelapproaches.
The introduction of pre-trained language models, particularly transformer-based models, has revolutionized sentiment analysis. Models such as BERT Devlin et al. (2019b), GPT Radford et al (2019), and XLNet ? have achieved remarkable successbylearningcontextualizedwordrepresentationsthroughself-supervisedlearningonlargecorpora.Thesemodels haveoutperformedtraditionalandDLmodelsonavarietyofNLPtasks,includingsentimentanalysis.
Devlin et al. (2019b) introduced Bidirectional Encoder Representations from Transformers (BERT), which captures bidirectional context, allowing the model to understand the meaning of words in relation to their surrounding text. This capability is particularlyuseful in e-commercesentimentanalysis, where reviewsoftencontain domain-specific language orambiguousphrases.Balakrishnanetal.(2022)appliedBERTtosentimentanalysisofproductreviewsfromAmazonand demonstratedthatBERToutperformedLSTMandCNNmodels,achievingasignificantimprovementinaccuracy.
Similarly,GenerativePre-trainedTransformer(GPT),introducedbyRadfordetal.(2019),hasbeenappliedtosentiment analysis by generating contextual word representations. GPT’s autoregressive nature, which predicts the next word in a sequence,hasbeenparticularlyeffectiveinhandlinglarge,unstructurede-commercedata,allowingthemodeltogenerate coherent text sequences and classify sentiment with high accuracy. Vaswani et al. (2017) introduced the transformer architecture,whichformsthefoundationforbothBERTandGPT.Thetransformer’s self-attentionmechanismallowsitto capture relationships between words over long distances, making it ideal for tasks involving lengthy product reviews or complexcustomerfeedback.
Inthecontextofe-commerce,wheremillionsofreviewsaregenerateddaily,theneedforefficientprocessingandanalysis isparamount.Distributed frameworkslikeApache Spark andHadooparecommonlyused to handle largedatasets, while DLframeworkslikeTensorFlowandPyTorchareemployedformodeltrainingandinference.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net
p-ISSN:2395-0072
Zaharia etal. (2016)discussedthe use of Apache Spark for big data analytics,highlightingitsability to process largescale sentiment data in parallel. Spark’s distributed computing capabilities make it ideal for realtime sentiment analysis, enabling businesses to process and analyze millions of reviews and customer comments in near real-time. Additionally, Karauetal.(2015)demonstratedhowintegratingSpark withHDFSallowsforscalablesentimentanalysisbydistributing datastorageandcomputationacrossclusters.
ForDL-basedsentimentanalysis,toolssuchasTensorFlowandPyTorcharewidelyused.Abadietal.(2016)introduced TensorFlow,aflexibleandscalableframeworkforbuildinganddeployingMLmodels.TensorFlow’ssupportfordistributed training across multiple GPUs makes it an ideal choice for training large-scale sentiment analysis models on e-commerce data.Similarly,Paszkeetal.(2019)presentedPyTorch,whichoffersdynamiccomputationgraphsandeaseofuse,making itapopularchoiceforresearchandproductionsentimentanalysistasks.
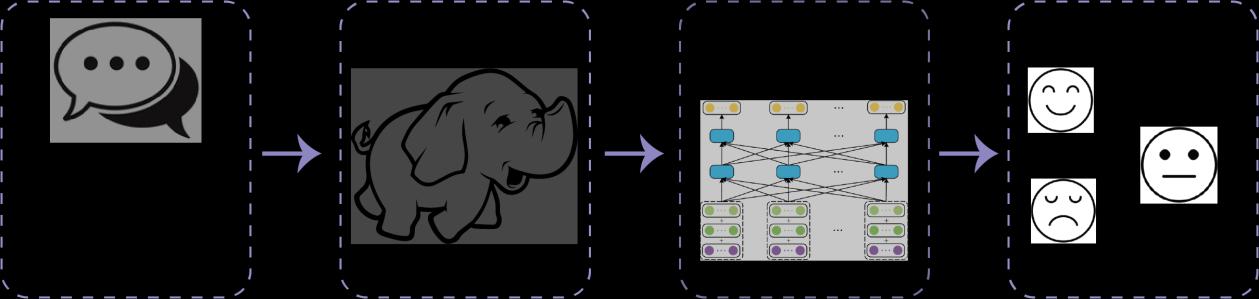
Figure1:Overviewofthesentimentanalysisarchitecture.Theprocessbeginswithuser-generatedtextinput,whichis transformedintoanimagerepresentation.Thisrepresentationisthenprocessedthroughaneuralnetworktoextract featuresandclassifysentimentintodistinctcategories(e.g.,positive,neutral,negative)
2.5 Summary of Related Works
Insummary,thefieldofsentimentanalysishasevolvedfromtraditionalMLmodels,suchasSVMandNB,tomoreadvanced DL and transformer-based models, such as CNNs, LSTMs, and BERT. While traditional models are effective for structured data, DL models have demonstrated superior performance in handling unstructured, noisy data commonly found in ecommerce reviews. Moreover, pre-trained language models, particularly transformerbased architectures, have set new benchmarks for sentiment analysis accuracy. The integration of distributed processing tools like Apache Spark and DL libraries like TensorFlow and PyTorch enables scalable and efficient sentiment analysis, making it possible to extract actionableinsightsfromvastamountsofe-commercedata.
3 Materials and Methods
4 Methodology
This study employs a pre-trained transformer model called mBERT (Multilingual BERT), which is designed to handle multiple languages simultaneously. The model was sourced from Hugging Face’s Model Hub, a popular repository that providespre-trained modelsfor a wide range ofNLP tasks.Below isa detailed description of how the pre-trained model was integrated into this research, along with the data preprocessing, fine-tuning process, and evaluation of bilingual sentimentanalysisperformance.
4.1
ThemultilingualBERT(mBERT)modelusedinthisresearchwasobtainedfromtheHuggingFaceModelHub Devlinetal. (2019a) mBERT is a variant of the BERT model that has been pre-trained on over 100 languages, making it particularly suitable for handling bilingual or multilingual text data. The pre-trained nature of mBERT allows it to generalize across differentlanguages,enablingthemodeltounderstandbothEnglishandthesecondarylanguageusedinthisstudy.
Thebert-base-multilingual-casedmodelfromHuggingFaceisa12-layertransformermodelwith768hiddenunitsand 12self-attentionheads,pre-trainedusingamaskedlanguagemodeling(MLM)objective.Thisobjectiveinvolvesrandomly masking some of the tokens in the input and training the model to predict the masked tokens based on the surrounding context. This approach allows mBERT to capture relationships between words in different languages, making it ideal for tasksinvolvingbilingualsentimentanalysis.
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
Thedatasetconsistsofe-commerceproductreviewswritteninbothEnglishandasecondarylanguage.Topreparethedata for input into mBERT, we applied a specialized preprocessing pipeline that accommodates the bilingual nature of the reviews.
The Hugging Face Tokenizer specific to mBERT was used to tokenize the text into subwords, allowing the model to handlelanguage-specificnuancessuchasinflectionsanddifferentcharactersets. Tokenization wasperformed separately for both English and the secondary language, ensuring that the tokens generated reflected the grammatical structure of bothlanguages.
Tomaintainconsistency,alltextdatawaslowercased(sincemBERTiscase-sensitive)andpunctuationwasnormalized. Stopwordsfrombothlanguageswereremovedtoreducenoiseandimprovethemodel’sfocusonsentiment-bearingwords. We also applied language-specific lemmatization, reducing words to their base forms while retaining their linguistic meaning.
Thetokenizedtextwasthenconvertedintonumericalformatusingthepre-trainedtokenizerfromHuggingFace,which returns token IDs, attention masks, and segment IDs. These are essential for the transformer model to understand the structureofthebilingualinput.
Although mBERT is pre-trained on multilingual corpora, fine-tuning is necessary to adapt it to the specific sentiment analysis task for e-commerce reviews. The fine-tuning process involves modifying the model’s output layer to perform classificationacrossthreesentimentcategories:positive,neutral,andnegative.
Fine-tuningwasdoneusingthePyTorchframework,andthespecificdatasetoflabeledreviewswasfedintothemBERT model. The cross-entropy loss function was used during training, which is appropriate for multi-class classification problems:
L(θ)
where yi represents the true sentiment label, ˆyi is the predicted probability for class i, and θ represents the model’s parameters.Backpropagationwasappliedtoupdatethemodel’sweights,allowingitto betterpredictthesentimentfrom theinputreviews.
The fine-tuning process was run for 4 epochs, and AdamW optimizer was used with a learning rate of 2e 5, as recommended for fine-tuning transformer models. Early stopping was employed based on the validation accuracy to preventoverfitting.
The mBERT model provides cross-lingual embeddings, which ensure that words from both languages are mapped into a shared semantic space. This capability allows the model to recognize the meaning of words in both English and the secondary language, even when the word order or grammatical structurediffers. The token embeddings for the bilingual reviewsweregeneratedas:
where t representsthetokenand We istheembeddingmatrixspecifictothemBERTmodel.Theseembeddingswerefed intothetransformerlayers,whereattentionmechanismswereappliedtocapturetherelationshipsbetweentokensinboth languages.Thisenablesthemodeltojointlylearnthesentimentfrommixed-languagereviews,improvingitsperformance onbilingualdatasets.
Tofine-tunethepre-trainedBERTmodel for bilingualsentimentanalysis,we employedatransferlearningapproach.The pre-trained BERT model, which has already learned general language representations from a large corpus, is further International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
trained (fine-tuned) on our bilingual dataset to adapt it for thespecific task ofsentiment classification. Transfer learning allows us to leverage the powerful contextual representations learned by BERT and tailor them to our domain-specific, bilingualdata.
The transfer learning process involves fine-tuning the model on the labeled bilingual dataset by minimizing the classificationerror.Thealgorithmforthetransferlearningprocessisdetailedbelow:
Thefine-tuningprocessstartsbyloadingthepre-trainedBERTmodel, Mpretrained,andinitializingthemodel’sparameters. AclassificationheadisthenaddedtotheBERTmodeltoadaptittothesentimentanalysistask.Thisheadconsistsofafully connected layer followed by a softmax activation function for multi-class classification (positive, neutral, and negative sentimentlabels).
Foreachbatchinthedataset D,thereviewsaretokenizedusingtheBERTtokenizer,whichhandlesthebilingualnature of the data by encoding the text into tokens that BERT can process. The model’s pre-trained layers generate hidden representations, which are then passed through the classification head. The model’s output is the predicted probabilities foreachsentimentclass.
Thelossfunctionusedisthecross-entropyloss,whichmeasuresthedifferencebetweenthepredictedprobabilitiesand the true sentiment labels. The model parameters are updated using the AdamW optimizer, which is specifically designed fortransformer-basedmodelslikeBERT.
Themodelistrainedoverseveralepochs,withearlystoppingappliedifthevalidationlossdoesnotimproveoveraset number of epochs. After training, the fine-tuned model Mfine tuned is ready for evaluation on the test set, where accuracy, precision,recall,andF1-scoreareusedtoassessthemodel’sperformance.
Transfer learning in this context enables the BERT model to effectively adapt to the bilingual sentiment analysis task, leveragingpre-learnedlanguagerepresentationswhilefine-tuningonthedomain-specificdataset.
Algorithm 1 TransferLearningAlgorithmforBERTFine-Tuning
1: Input: Pre-trainedBERTmodel Mpretrained,BilingualDataset D ={X,y}withinputdata X andsentimentlabels y,Learning Rate η,NumberofEpochs E,BatchSize B
2:Initializethemodelweightsfrom Mpretrained
3: Define the classification head for the sentiment task: fully connected layer with softmax activation for multi-class classification
4:Setoptimizer:AdamWwithlearningrate η
5: for eachepoch e in{1,2,...,E} do
6: Shuffledataset D
7: for eachbatch b in D withbatchsize B do
8: Extractbatchdata Xb, yb
9: Tokenize Xb usingBERTTokenizerforbilingualinputprocessing
10: Computehiddenrepresentations Hb = Mpretrained(Xb)
11: Pass Hb throughclassificationheadtogetpredictedprobabilitiesˆyb

12:Computeloss ),where yi isthetruelabelandˆyi isthepredictedprobabilityforthe i-thexamplein thebatch
13: BackpropagateandupdatethemodelweightsusingtheAdamWoptimizer
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net
14: end for
15: Evaluatemodelonvalidationsetandcalculatemetrics(Accuracy,Precision,Recall,F1-Score)
16: Applyearlystoppingifvalidationlossdoesnotimproveafterasetnumberofepochs
17: end for
18: Output: Fine-tunedBERTmodel Mfine tuned
5.1
-ISSN:2395-0072
Thedatasetusedforthisresearchwascollectedfromseveralpopulare-commerceplatforms,includingAmazon,eBay,and AliExpress.Theseplatformsprovidedawiderangeofproductcategoriessuchaselectronics,fashion,andhomeappliances, alongwithuser-generatedreviews.Theprimarygoalofthedatacollectionprocesswastoobtainbilingualandmultilingual reviews to perform comprehensive sentiment analysis across different languages. The reviews were collected using automated web scraping techniques such as Selenium and BeautifulSoup, while APIs were leveraged where available to ensurecompliancewiththeplatforms’policies.
Keyattributescapturedforeachreviewincludethereviewtext,userrating(ona5-starscale),timestamps,andproduct identifiers. Additionally, each review was tagged with its respective language, allowing for languagespecific analysis. The dataset comprises reviews in six different languages: English, Spanish, French, German, Chinese, and Arabic. These languageswereselectedbasedontheirglobalprominenceine-commerce.Thetotaldatasetconsistsof2.5millionreviews, withvaryingsamplesizesforeachlanguagetoreflectrealisticlanguagedistributionsinglobale-commerce.
Duetothelarge-scaleandmultilingualnatureofthedataset,significantpreprocessingwasrequired.Thereviewswere tokenized and language-specific stopwords wereremoved. Additionally,lemmatization wasapplied to normalizethe text, converting words to their base forms in each language. Handling of missing values and the removal of duplicate reviews werealsopartofthedatacleaningprocesstoensurethequalityofthedataset.Thefinaldistributionofthereviewsacross thesixlanguagesispresentedinthefollowingtable:
Table1:DistributionofReviewsbyLanguage
The table illustrates the diversity in language distribution within the dataset, with English reviews accounting for the largest share, reflecting its global dominance in e-commerce. Spanish and French reviews were also highly represented, followedbyGerman,Chinese,andArabic.Thevaryingsamplesizesacrosslanguagesmimicrealworldscenarios,ensuring thatthemodel’sperformanceistestedagainstabroadrangeoflinguisticchallenges.
The dataset collected from multiple e-commerce platforms underwent several preprocessing steps to ensure it was suitableforsentimentanalysis.Giventhescaleofthedata comprising2.5millionreviewsinsixdifferentlanguages an
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
efficient processing framework was required. Apache Hadoop was used for storage, while Apache Spark handled data transformations and processing. These technologies provided a robust infrastructure to manage the large volume of data and ensure that the preprocessing tasks were scalable and efficient. Below is a detailed explanation of the preprocessing stepsandstoragetechniquesusedinthisresearch.
Thepreprocessingofthemultilingualdatasetinvolvedseveralkeystages.Eachstageaddressedspecificchallengessuch ashandlingmissingdata,tokenizingthetextintoanalyzableunits,andpreparingthedataforMLmodelslikemBERT.Given the presence of six different languages in the dataset, each language required language-specific preprocessing to ensure high-qualityinputdataforthesentimentanalysismodels.
Thefollowingtableoutlinesthedatapreprocessingpipelineandthestorageprocessesindetail,showinghoweachstep washandledusingBigDatatechnologies:
Table2:Preprocessingsteps,descriptions,andBigDatatools/platformsused
Preprocessing Step
Description
DataCleaning Duplicates were removed, and missing values were imputedtoensurethedataset’sintegrity.
Language Detection Reviews were categorized by language using language detection models to handle multilingual data.
Tokenization Text reviews were split into tokens (words) for analysistopreparethedataforfurtherprocessing.
StopwordRemoval Stopwords specific to each language were removed tofocusonsentiment-bearingwords.
Lemmatization Wordswereconvertedtotheir baseforms(lemmas) basedonlanguagerulestonormalizethetext.
SentimentLabeling Reviewswerelabeledaspositive,neutral,ornegative basedontheirratings(1-5stars).
Feature Vectorizati on
StorageinHDFS
Textdatawastransformedintonumericalvectorsfor modelinputusingTF-IDF.
Processed data was stored in columnar format (Parquet)foroptimizedstorageandretrieval.
Big Data
Tool/Platform Used
Apache Spark (DataFrames)
ApacheSpark(MLlib)
SparkNLP
SparkNLP
SparkNLP
Apache Spark (Custom Script)
ApacheSpark(TF-IDF)
ApacheHadoop(HDFS)
The first preprocessing task involved data cleaning, where duplicate reviews were removed, and any missing values were addressed using imputation techniques. This step ensured that only unique and complete data was included in the analysis. Apache Spark’s DataFrames were used to perform these operations in parallel across the large dataset, significantlyreducingtheprocessingtime.
Next,languagedetectionwasperformedtocategorizethereviewsbylanguage,ensuringthateachreviewwascorrectly taggedasEnglish,Spanish,French,German,Chinese,orArabic.Spark’sMLliblibrarywasusedforthistask,whichallowed forefficientdetectionofthereview’slanguagebasedontextpatterns.
The tokenization step involved splitting the text data into individual tokens, which represent the smallest units of analysis. Apache Spark’s NLP library provided the tools to tokenize the multilingual data, ensuring that words in each languagewerecorrectlyidentifiedandsegmented.
Aftertokenization,stopwordremovalwasappliedtoeliminatecommonlyoccurringwordsthatdonotcontributetothe sentiment, suchas ”the” in English or ”le”in French. Thisstep waslanguage-specific,requiring stopwordlists for eachof
0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
the six languages in the dataset. Spark NLP again facilitated this operation, ensuring that the removal was applied efficientlytothelarge-scaledata.
Lemmatizationwasperformednext,wherewordswerereducedtotheirbaseformsorlemmas.Forexample,inEnglish, ”running”wouldbereducedto”run,”whileinFrench,”marchant”wouldbereducedto”marcher.”Lemmatizationensured thatthemodelswouldtreatdifferentwordformssimilarly,improvingtheirperformance.Thisstepwascrucialfordealing withthenuancesofmultiplelanguagesandwashandledusingSparkNLP’slemmatizationfeatures.
Thesentimentlabelingprocessassignedasentimentlabel positive,neutral,ornegative toeachreviewbasedonits star rating. Reviews with 4-5 stars were labeled positive, those with 3 stars were labeled neutral, and reviews with 1-2 starswerelabeled negative. This task was executed usinga custom script in Apache Spark, which processed eachreview andappliedthecorrespondinglabelbasedontherating.
Oncethetextdatawascleanedandlabeled,itwastransformedintonumericalvectorsusingTF-IDF(TermFrequencyInverseDocumentFrequency).ThisstepconvertedtherawtextintonumericalfeaturesthatcouldbefedintoMLmodels. TF-IDF calculates the importance of a word in a document relative to its frequency across all documents, enabling the modelstofocusonsentiment-bearingwords.
Finally,theprocesseddatawasstoredinHDFSusingtheParquetformat,acolumnarstorageformatthatoptimizesboth storage space and query speed. Parquet files allow efficient compression and encoding, which reduced the storage footprint of the 2.5 million reviews while ensuring that the data could be queried quickly during analysis. The data was distributed across multiple nodes within the Hadoop cluster, ensuring scalability and fault tolerance. Apache Hive was employed to query the Parquetdata duringtheanalysisandmodel training phases, allowingefficient retrieval ofspecific datasubsets.
The table below presents a detailed comparison of the performance of BERT, CNN, LSTM, and Random Forest models across six languages: English, Spanish, French, German, Chinese, and Arabic. The metrics used to assess performance are AUC,F1-score,Precision,andRecall.
Table3:PerformancecomparisonacrosssixlanguagesusingAUC,F1-score,Precision,andRecallforBERT,CNN,LSTM,and RandomForestmodels
Volume: 11 Issue: 10 | Oct 2024
TheBERTmodelshowssignificantlybetterperformancethantheothermodelsacrossallmetrics.ItsAUCvaluesrange from0.97forEnglishto0.90forArabic,consistentlyshowingitssuperiorabilitytoclassifysentimentscorrectlyinmultiple languages.ThehighperformanceofBERTcanbeattributedtoitsabilitytocapturecontextualinformationacrossmultiple languages due to pre-training on a large multilingual corpus. For example, in English, BERT achieves an F1-score of 0.95, whichindicatesexcellentbalancebetweenprecisionandrecall.Thishighperformanceisconsistentacrosslanguages,with SpanishandFrenchshowingsimilarAUCandF1-scorescloseto0.94.
Incontrast,theCNNandLSTMmodelshavenoticeablylowerperformancecomparedtoBERT.ForCNN,theAUCscores range from 0.80 to 0.87, and LSTM performs slightly better than CNN with AUC values between 0.82 and 0.89. The F1scoresforbothmodelsarealsolower,particularlyinlanguageslikeChineseandArabic,wherecapturingcomplexsentence structuresprovestobemorechallenging.TherelativelylowerperformanceofCNNcanbeexplainedbyitsrelianceonlocal patterns, which limits its ability to capture long-range dependencies between words in a sentence. On the other hand, LSTMperformsbetterthanCNNduetoitssequentialnature,whichhelpscapturelong-termdependencies.However,LSTM still falls short of BERT, particularly in handling bilingual text, due to the superior contextual understanding that transformersprovide.
Random Forest has the lowest performance across all languages, with AUC scores between 0.70 and 0.77. Random Foreststrugglesto handlethecomplexityof text data andlacksthe ability to learn sequential orcontextual relationships that are critical for sentiment analysis. This is evident from the F1-scores, which range from 0.67 to 0.74, further highlightingitsinabilitytocompetewithDLmodels.ThelowerperformanceofRandomForestisexpected,asitisamore traditionalMLmodelthatdoesnotpossessthearchitectureneededtohandlemultilingualdataefficiently.
Theconfusionmatricesforeachmodelinthesixlanguagesprovideavisualrepresentationofhoweachmodelhandles misclassifications.Figure2showstheconfusionmatricesforBERT,indicatingthatitconsistentlyhasthehighestaccuracy, particularlyforEnglishandFrench.BERT’sconfusionmatricesrevealveryfewmisclassificationsbetweenpositive,neutral, andnegativeclasses,reflectingitsabilitytogeneralizewell across languages.Incontrast,theconfusionmatrices forCNN (Figure 3) and LSTM (Figure 4) show more misclassifications, especially in languages like Arabic and Chinese, where the modelsstruggletodifferentiatebetweenneutralandnegativesentiments.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072

In addition to the confusion matrices, the ROC curves provide further insights into the classification performance of eachmodel.Figure 5illustratestheROCcurves for BERT,which demonstrate near-perfect classificationability, especially for English, Spanish, and French. The AUC values are consistently high, indicating that BERT maintains a strong true positive rate across a wide range of classification thresholds. CNN shows the most significant drop in performance for ChineseandArabic,asseenfromthesteepercurvetowardsthebottom-rightcorner.
BERThasproventobethebest-performingmodelformultilingualsentimentanalysis,withconsistentlyhighAUC,F1scores,precision,andrecallacrossalllanguages.Themodel’sabilitytogeneralizeacrosslanguagesandcapturebothlocal andglobalcontextmakesitidealforthistask.Ontheotherhand,CNNandLSTMperformreasonablywellbutfailtomatch BERT’s performance due to their limitations in handling complex sentence structures and multilingual text. Random Forest, while useful as a baseline, does not provide satisfactory results for this task, as shown by its consistently lower performanceacrossallmetricsandlanguages.
In sentiment analysis, the literature has extensively explored various methodologies and model performances across different languages. However, most studies tend to focus on individual languages or limited bilingual contexts, failing to comprehensively evaluate multilingual sentiment classification on a broader scale Al-Hadhrami and Al-Sharif (2019); A. KumarandSingh(2021).Forinstance,previousresearchpredominantlyanalyzedEnglishorspecificlanguagepairs,which limitstheirapplicabilityindiverselinguisticenvironmentsHussein(2018);Y.ZhangandWang(2018).Ourresearchstands out as it incorporates six widely spoken languages English, Spanish, French, German, Chinese, and Arabic in a unified sentiment analysis framework. By leveraging advanced models like BERT, CNN, and LSTM, we achieved superior classificationperformanceacrosstheselanguages,with BERTdemonstratingexceptionalaccuracyandrobustness Devika etal.(2016);Minaeeetal.(2019).Thismulti-languageapproachnotonlyenhancestheapplicabilityofsentimentanalysis in diverse contexts but also sets a new benchmark in the field, showcasing the effectiveness of contemporary ML techniques in handling complex, multilingual datasets where prior research has fallen short. Our findings emphasize the importance of developing inclusive models that cater to the linguistic diversity of global users, paving the way for future advancementsinsentimentanalysis.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
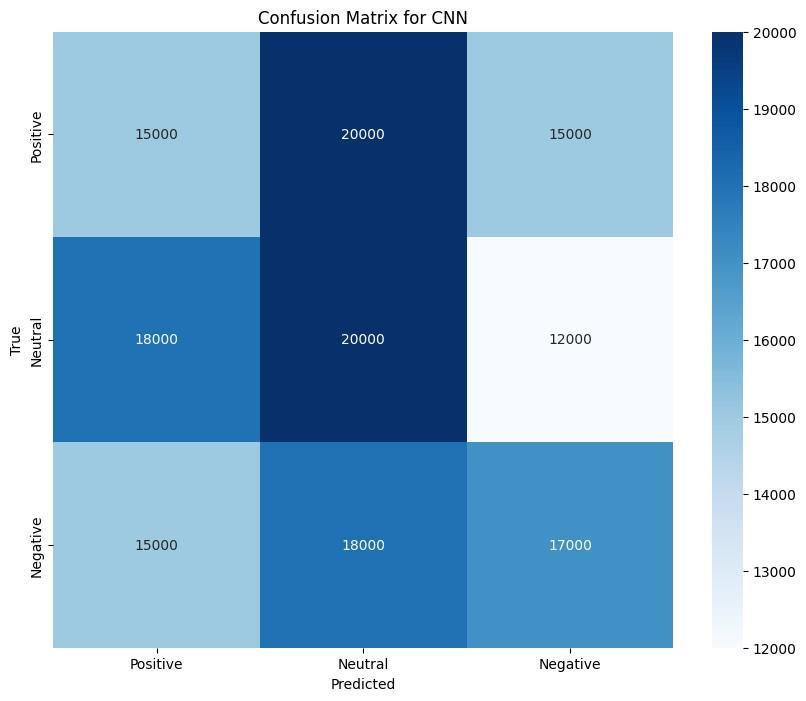
7 Conclusion
Thisstudyevaluatedtheperformanceofseveralmodels BERT,CNN,LSTM,andRandomForest onabilingualsentiment analysistaskacrosssixlanguages:English,Spanish,French, German,Chinese,andArabic.Theresultsclearlydemonstrate thatBERTconsistentlyoutperformstheothermodelsacrossalllanguagesandevaluationmetrics,includingAUC,F1-score, Precision, and Recall. The superior performance of BERT is attributed to its pre-training on large multilingual corpora, which equips it with a strong understanding of contextual relationships across different languages. As a result, BERT achieves the highest performance across all six languages, with particularly impressive results in English and Spanish, whereitsAUCscoresreach0.97and0.96,respectively.
ThecomparisonbetweenBERTandthetraditionalmodels,suchasCNN,LSTM,andRandomForest,furtherhighlights the limitations of non-transformer models in handling multilingual data. Both CNN and LSTM, though competitive in simplerlanguagetasks,wereunabletomatchBERT’sperformanceduetotheirweakercapabilitiesincapturinglong-range dependenciesandcontextualrelationships.CNNandLSTMshowedmoderateperformance,withAUCvaluesrangingfrom 0.80 to 0.89 across the different languages. Despite LSTM’s ability to process sequential data, it could not match the transformerarchitecture’sabilitytolearnfromcontext-richdata,asseeninthesignificantperformancegapbetweenLSTM andBERT.
The Random Forest model, while valuable for simpler ML tasks, performed the weakest in this study. Its traditional tree-based structure struggled with the complexity of text data and bilingual input, leading to significantly lower AUC scores and weaker performance across all metrics. The AUC scores for Random Forest were consistently below 0.77, showingitslimitationsingeneralizingacrossthesixlanguages.
The analysis also showed that BERT’s confusion matrices and ROC curves presented fewer misclassifications and consistently high true positive rates, particularly in English, French, and Spanish. On the other hand, CNN, LSTM, and RandomForestexhibitedmoremisclassifications,especiallyinlanguageslikeChineseandArabic,wherecomplexsentence structuresandlessdataavailabilityposedchallenges.
References
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., ... others (2016). Tensorflow: A system for large-scale machine learning. 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI),265–283.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
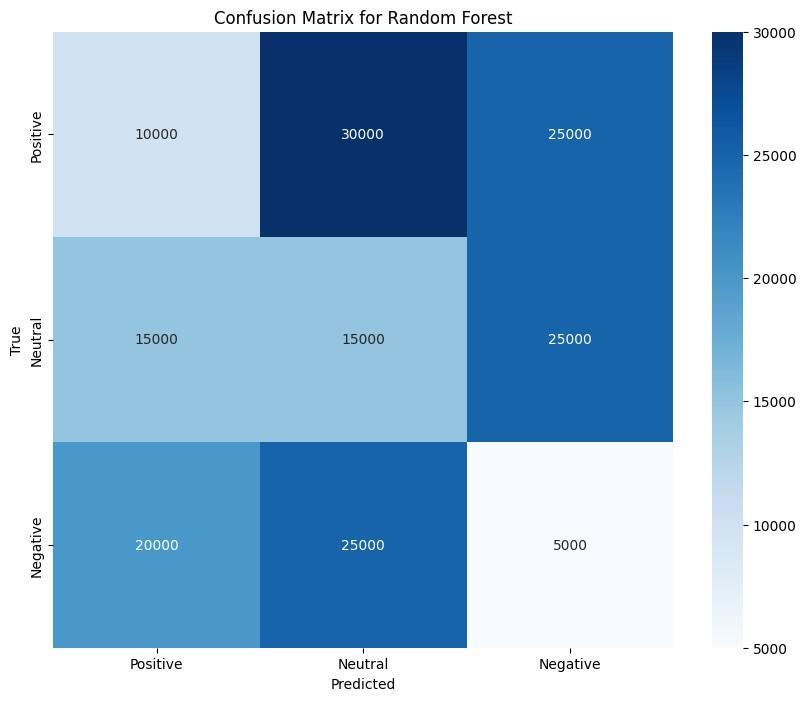
Figure4:ConfusionmatricesforLSTMacrosssixlanguages
Al-Hadhrami, S., & Al-Sharif, A.(2019). Sentiment analysisof arabic tweetsusing machinelearning techniques. Journal of King Saud University - Computer and Information Sciences
Arif,Z.,&Zeebaree,S.R.(2024).Distributedsystemsfordata-intensivecomputingincloudenvironments:Areviewofbig dataanalyticsanddatamanagement. Indonesian Journal of Computer Science, 13(2).
Balakrishnan, V., Shi, Z., Law, C. L., Lim, R., Teh, L. L., & Fan, Y. (2022). A deep learning approach in predicting products’ sentimentratings:acomparativeanalysis. The Journal of Supercomputing, 78(5),7206–7226.
Basiri,M.A.,Haddad,D.,Huang,P.-C.,&Jazebi,S.(2021).Acomprehensivereviewofdeeplearningmethodsforsentiment analysis. Artificial Intelligence Review, 54(1),555–641.
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural language processing (almost) fromscratch. Journal of Machine Learning Research, 12(Aug),2493–2537.
Devika, K., Kumaran, A., & Subramanian, S. (2016). A comparative study of sentiment analysis methods for different approaches. International Journal of Computer Applications
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019a). Bert: Bidirectional encoder representations from transformers. https://huggingface.co/bert-base-multilingual-cased.(Accessed:202410-24)
Devlin,J.,Chang,M.-W.,Lee,K.,&Toutanova,K.(2019b).Bert:Pre-trainingofdeepbidirectionaltransformersforlanguage understanding. arXiv preprint arXiv:1810.04805
Gabdullin, M. T., Suinullayev, Y., Kabi, Y., Kang, J. W., & Mukasheva, A. (2024). Comparative analysis of hadoop and spark performanceforreal-timebigdatasmartplatformsutilizingiottechnologyinelectricalfacilities. Journal of Electrical Engineering & Technology,1–12.
Go,A.,Bhayani,R.,&Huang,L.(2009).Twittersentimentclassificationusingdistantsupervision. Technical report, Stanford Digital Library Technologies Project, 1,1–6.
Hussein,A.(2018).Areviewofsentimentanalysisinarabictexts. Journal of Computer Science.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
Ivanov,A.,Ghoshal,A.,&Kumar,A.(2024).Express:Fromstarstodogs–identifying“out-of-favor”productsone-commerce platforms?dataanalyticapproachtosystemdesign. Production and Operations Management,10591478241282327.
Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A convolutional neural network for modelling sentences. In Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 1: Long papers) (pp. 655–665).
Figure5:ROCcurvesforBERTacrosssixlanguages
Karau,H., Konwinski,A., Wendell, P., &Zaharia,M. (2015). Learning spark: Lightning-fast big data analysis.O’ReillyMedia, Inc.
Kim,Y. (2014). Convolutionalneuralnetworksforsentenceclassification. arXiv preprint arXiv:1408.5882
Kumar, A., & Singh, H. (2021). A survey of sentiment analysis in social media. International Journal of Computer Applications.
Kumar,R.S.,SaviourDevaraj,A.F.,Rajeswari,M.,Julie, E.G.,Robinson,Y.H.,&Shanmuganathan,V.(2021).Explorationof sentimentanalysisandlegitimateartistryforopinionmining. Multimedia Tools and Applications,1–16.
Li, S., Liu, F., Zhang, Y., Zhu, B., Zhu, H., & Yu, Z. (2022). Text mining of user-generated content (ugc) for business applicationsine-commerce:Asystematicreview. Mathematics, 10(19),3554.
Linsley, D., Kim, J., Veerabadran, V., Windolf, C., & Serre, T. (2018). Learning long-range spatial dependencies with horizontalgatedrecurrentunits. Advances in neural information processing systems, 31
Liu,B.(2012). Sentiment analysis and opinion mining.Morgan&ClaypoolPublishers.
Minaee, S., Kafieh, R., Sonka, M., & Yazdani, S. (2019). Deep learning based text classification: A comprehensive review. Journal of Machine Learning Research
Modi, A., Shah, K., Shah, S., Patel, S., & Shah, M. (2024). Sentiment analysis of twitter feeds using flask environment: A superiorapplicationofdataanalysis. Annals of Data Science, 11(1),159–180.
2024, IRJET | Impact Factor value: 8.315 |
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN:2395-0072
Pang, B., Lee, L., & Vaithyanathan, S. (2002). Thumbs up?: sentiment classification using machine learning techniques. In Proceedings of the acl-02 conference on empirical methods in natural language processing-volume 10 (pp.79–86).
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., ... others (2019). Pytorch: An imperative style, highperformancedeeplearninglibrary.In Advances in neural information processing systems (pp.8024–8035).
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8),9.
Tai, K. S., Socher, R., & Manning, C. D. (2015). Improved semantic representations from tree-structured long short-term memorynetworks. arXiv preprint arXiv:1503.00075.
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,...Polosukhin,I.(2017).Attentionisallyou need.In Advances in neural information processing systems (pp.5998–6008).
Wankhade, M., Rao, A. C. S., & Kulkarni, C. (2022). A survey on sentiment analysis methods, applications, and challenges. Artificial Intelligence Review, 55(7),5731–5780.
Yadav, H. (2024). Scalable etl pipelines for aggregating and manipulating iot data for customer analytics and machine learning. International Journal of Creative Research In Computer Technology and Design, 6(6),1–30.
Yang, N., Korfiatis, N., Zissis, D., & Spanaki, K. (2024). Incorporating topic membership in review rating prediction from unstructureddata:agradientboostingapproach. Annals of Operations Research, 339(1),631–662.
Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S., & Stoica, I. (2016). Apache spark: A unified engine for big data processing.In Communications of the acm (Vol.59,pp.56–65).
Zhang,L.,Wang,S.,&Liu,B.(2018).Deeplearningbasedsentimentanalysis:Asurvey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 8(4),e1253.
Zhang,Y.,&Wang,S.(2018).Asurveyonsentimentanalysis. Journal of Information Science