
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
Chaitanya Indukuri1 , Mridula Dileepraj Kidiyur2 , Shriya Agarwal3
1IEEE Senior Member, IEEE Computer Society, New York, United States
2IEEE Senior Member, IEEE Computer Society, New York, United States
3Student, University of Cumberlands, Kentucky, United States
Abstract - Thefast-pacedadvancementofdataanalytics has brought about a new era in how industries measure performance. This paper dives into how combining unstructured and structured data can offer deeper insights intoperformancemetrics.Ononehand,structureddata,with its neat, organized format, is easy to analyze, while unstructured data often messy and text-heavy presents opportunities and challenges. We review the methods to extract insights from unstructured data. We also review the processes and techniques to combine unstructured and structured data and extract insights from these two data types.Wedoameta-analysisofallanalyticalmethodsandlist select industry case studies for extracting insights or value from unstructured data. The findings show that a holistic approach to data has the potential to be transformative, offering practical insights for both professionals and researchers.
Keywords: Performance Measurement, Structured Data, Unstructured Data, Data Integration, Analytics, Industry Performance
Thecontemporarybusinesslandscapeisincreasinglydatadriven, with organizations seeking to harness the full potentialofavailableinformationtogainacompetitiveedge. Traditionalperformancemeasurementhasprimarilyrelied on structured data, which is highly organized and easily analyzable.However,theexplosionofunstructureddata such as text, images, and videos presents new opportunities and challenges. This paper investigates the methodstoextractinsightsfromunstructureddataandhow to integrate both data types to enhance the accuracy and depth of performance measurement across various industries.
The advent of big data has resulted in an exponential increase in the volume, variety, and velocity of data generated. Organizations now have access to a wealth of unstructured data, such as weblogs, social media posts, customer reviews, and multimedia content, which, if properlyanalyzed,canrevealvaluableinsights.Integrating thiswithstructureddatacanprovideamoreholisticviewof performancemetrics.
Theprimaryobjectivesofthispaperare:
Unlock insights from unstructured data by converting the unstructured data into actionable andinsightfulmetrics.
Integratestructuredandunstructureddatatogive end-users a holistic visual analysis of user experience.
Apply AI-ML techniques on both structured and unstructureddatatoderiveinsights.
Examine the implications of these methodologies andtechniquesforindustry-specificusecases
Integrating structured and unstructured data to enhance performancemeasurementhasbeenanincreasinglypopular areaofresearch,mirroringthebroadertrendtowarddatadrivendecision-makinginbusiness.Thisliteraturereview explores the historical context, recent advancements, and challengesresearchersandpractitionersfaceinthisdynamic field.
Thejourneyofstructureddatainbusinessanalyticscanbe traced back to the early days of information technology. Companiesprimarilyreliedonstructureddatabasestostore transactionaldataduringthisperiod.Influentialworksby [1]Davenport(1993)and[2]Porter(1985)wereamongthe first to highlight how leveraging structured data could provideacompetitiveedge,enablingbusinessestooptimize operations and refine their strategies. These foundational ideas laid the groundwork for later integrating more complex data types, marking the beginning of a more sophisticatedapproachtodataanalytics.
As the digital landscape evolved, so did the types of data businesses had to manage. The emergence of big data technologiesintheearly2000sbroughtthechallengeand
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
opportunity of unstructured data. [3]Laney's(2001) introduction of the "three Vs" volume, velocity, and variety was pivotal, highlighting how data expanded beyondtraditionalstructuredformats.Researcherslike[4] Mayer-SchönbergerandCukier(2013)laterdelvedintothe transformative potential of big data analytics, particularly theintegrationofunstructureddatasourcessuchassocial media, emails, and multimedia content. These studies underscored how tapping into unstructured data could provide deeper insights into consumer behavior and operationalefficiency,openingnewavenuesforbusinesses toexplore.
The technical challenge of integrating structured and unstructured data has sparked considerable discussion in theliterature.Oneoftheearlycomprehensiveframeworks forextensivedataintegrationwasprovidedby[6]Russom (2011), who outlined methods like data warehousing and the innovative use of data lakes to handle diverse data formatsmoreeffectively.Asdiscussedby[7]White(2012), theadventoftoolssuchasHadoopandNoSQLdatabaseshas been crucial in managing the scalability and real-time processing demands of integrated data systems. These technological advancements have enabled businesses to handlethecomplexinterplayofstructuredandunstructured data,drivingmoreinformeddecision-makingprocesses.
The practical applications of integrated data analytics are evidentacrossvariousindustries.Blendingstructuredand unstructureddatahassignificantlyimprovedthehealthcare, retail,andfinancesectors.Forinstance,integratingpatient recordswithunstructureddatafrommedicalimagingand doctor's noteshasenhancedpatient care and streamlined operations. Similarly, in retail, combining sales data with customerfeedbackfromsocialmediahasenabledcompanies to refine their product offerings and improve customer satisfaction.Detailedcasestudiesby[8]Kudyba(2014)and [9]Georgeetal.(2014)demonstratehowtheseapproaches have translated into measurable gains in efficiency and customerengagement.
The rise of Large Language Models (LLMs) such as GPT-3 and GPT-4 has added a new dimension to the analysis of unstructured data. [10]Vaswani et al. 's 2017 paper "Attention is All You Need" revolutionized NLP by introducingtheTransformermodel,whichisthebackbone ofLLMs.Withtheirabilitytoprocessandgeneratehumanliketext,thesemodelshaveproveninvaluableinextracting insights from large volumes of unstructured data. Studies have demonstrated that LLMs can be fine-tuned to meet specific industry needs, providing more accurate and contextuallyawareanalyses.Thishassignificantlyenhanced
the ability to integrate structured and unstructured data, offering a more comprehensive approach to performance measurement.
While transformative, integrating structured and unstructureddatapresentsseveralchallengesthatremain relevant today. Data volume, variety, and velocity have increasedexponentially,andbusinessesnowfacegrowing complexity in managing, securing, and analyzing this data effectively.Herearesomeofthecriticalchallengescurrently impactingthefield:
Data Privacy and Security: With the growing emphasis on data privacy, regulations such as GDPR and CCPA impose stringentrequirementsonhowdata,especiallyunstructured datafromsourceslikesocialmediaandemails,iscollected, stored, and processed. Ensuring compliance while integrating and analyzing diverse data sources is increasingly difficult. Privacy-preserving technologies and data governance frameworks are essential but still developing.
Data Quality and Consistency: Integrating structured data from traditional databases with the messy, contextdependentnatureofunstructureddata(liketext,images,or audio) poses significant quality challenges. Unstructured data often needs more standardization for seamless integration,leadingtoinconsistencies,missinginformation, orirrelevantdatapointsthatmayskewanalysis.
Scalability and Resource Constraints: Asthevolumeofdata grows, organizations need help with the storage and processing power required to handle both structured and unstructured data simultaneously. Advanced technologies like AI and ML can help process this data, but their computational demands can be prohibitive, especially for smallerbusinesses.
Complexity in Analysis: Extractingmeaningfulinsightsfrom unstructured data requires advanced analytical methods such as Natural Language Processing (NLP) or image recognition,whicharestillevolving.Thesemethodscanbe inaccurateorbiased,especiallywhenworkingwithdatathat needs clear structure or context. Further research is requiredtoenhancethesetools'accuracyandreliability
Data Silos and Integration Challenges: Many organizations stilloperateinsilos,wherestructuredandunstructureddata aremanagedseparately.Breakingdownthesesilostoenable seamlessdataintegrationrequiressignificantinfrastructure investments, and the lack of standardized integration frameworks exacerbates the problem. Future research shouldfocusondevelopingunifiedsystemsthatallowrealtime,seamlessmergingofdiversedatasources.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
Ethical and Bias Concerns in AI-ML Models: WithAI-driven toolsbecomingcentraltodataintegrationandanalysis,there is a growing need to address ethical issues. AI models trainedonunstructureddatamayinheritbiasespresentin thatdata,leadingtoskewedorunfairoutcomes.Mitigating bias and ensuring transparency in AI models remains a pressingconcern.
Interdisciplinary Collaboration: Finally, integrating structured and unstructured data often requires collaboration between data engineers, analysts, domain experts, and business leaders. This multidisciplinary approachiscrucial formaximizingthevalueofintegrated data, but it requires a coordinated effort and clear communicationacrossteams.
2.7 Future Research Directions
Movingforward, researchmustfocusondevelopingmore advanced, ethical, and scalable methods for handling integrated data. Future innovations in AI, particularly in areas like transfer learning and multimodal data fusion, couldsignificantlyenhanceourabilitytodrawinsightsfrom thecomplexinterplaybetweenstructuredandunstructured data. Additionally, there is a critical need for more robust datagovernanceframeworksandtoolsthatensureprivacy, security,andtransparencythroughoutthedatalifecycle.By addressing these challenges, organizations can unlock the full potential of integrated data analytics, driving deeper insightsandbetterdecision-making.
2.8 Conclusion
The literature indicates a growing trend towards the sophisticated integration of structured and unstructured data, driven by technological advancements and the increasing need for holistic data analysis. As industries evolve, effectively combining different data types will be crucialinmaintainingcompetitiveadvantageandachieving operationalexcellence.
3.1 Definition and Characteristics
Unstructureddataencompassesinformationthatdoesnotfit neatlyintostructuredformats.Itincludestextdocuments, socialmediaposts,images,videos,andmore.Thisdatatype is often rich in context but challenging to process and analyze.
Unstructured data comes in two main types: external and internal.Externaldataincludessocialmediacontent(text, videos,andaudio),customerreviews,andinformationfrom news,blogs,andforums.Internaldatacomprisesweblogs, documents,emails,chatmessages,sensordata,IoTdata,and surveillancefootage.Thisdataisunorganizedandvariesin format,makingitchallengingtoanalyze.
Advantages:
Insightful: Enables insights development when unstructureddataiscomplementedwithstructured data.
Depth: Provides depth of information by offering qualitativecontexttoquantitativedata.
Offers competitive advantage: Offers competitive advantages to enterprises that effectively leverage theseunstructureddataassets.
Limitations:
Complexity: Requires advanced techniques for processingandanalysis.
Scalability: Handlinglargevolumesofunstructured datacanberesource-intensive
ELT (Extract, Load, Transform) is a data processing methodologywheredataisextractedfromvarioussources, loaded into a storage system, and then transformed as neededforanalysis.Whilethismethodologyisalsousedfor structureddatasources,thisapproachisespeciallyfavored for unstructured data sources. When unstructured data is storedas-iswithoutanytransformations,thismethodology enables real-time streaming, handles large volumes of unstructured data, and offers flexibility to ingest any unstructureddatatypes. Transformation isthelaststepthat isdoneaspertheneedtotransformthedataintoactionable metrics.
Extractingunstructureddatainvolvesusingtoolslikeweb scraping,APIs,ordocumentprocessinglibrariesto gather information from sources such as websites, emails, PDFs, andsocialmedia.Thisdataisthenprocessedandstructured foranalysis,enablinginsightsfrompreviouslyunorganized content.
Extracting unstructured data using web scraping involves usingautomatedtoolstocollectinformationfromwebsites. Thisprocesstypicallyincludesscrapingcontentsuchastext, images,andmetadatafromwebpagesthatlackapredefined structure.ToolslikePython'sBeautifulSouporScrapycanbe usedtocrawlwebsitesandextractthisdata,whichisthen cleanedandprocessedintoastructuredformatforanalysis. Web scraping helps gather data from social media, blogs, newssites,ande-commerceplatforms,enablingbusinesses
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
toanalyzetrends,sentiment,orcompetitiveinsightsfrom variousonlinesources.
Text, Image, and Video data via APIs
Extracting unstructured data via APIs involves using applicationprogramminginterfacestoaccessandretrieve datafromvariousplatforms,suchassocialmedia,databases, or cloud services. APIs allow for systematically collecting unstructured data like text, images, videos, or audio by sending requests and receiving responses in a structured formatsuchasJSONorXML.Thisdataisoftenpulledfrom sourceslikeTwitter,Google,orotherwebservicesthatoffer publicorprivateAPIs.Afterextraction,thedataisprocessed, cleaned, and transformed for analysis, providing valuable insightsfromotherwisedisorganizedinformationsources.
Platformslike Facebook,Twitter,andInstagramhostvast amounts of unstructured data in posts, comments, and images.UsesocialmediaAPIsfordataextraction.Manually collect data by saving posts or using third-party tools for aggregation. Platforms like YouTube, Flickr, or Instagram have unstructured data in images and videos APIs or scraping techniques to collect data and employ computer visiontechniquesforanalysis.
Text Documents:
Extract unstructured data from PDFs, Word documents, presentations, and reports using tools like PyPDF2, pdfplumber, and python-docx. These libraries allow for extracting text from various document formats, making it helpful in retrieving information from research papers or corporatereportsforfurtheranalysis.
Email and Communication Data:
Emails, chat logs, and forums are valuable sources of unstructureddata.Emaildatacanbeextractedusingclients or libraries like IMAP, while chat logs from platforms like Slack or Discord can be accessed through APIs or export toolsforanalysis.
Surveys and Forms:
Surveys often produce unstructured data through openended responses, which can be collected using tools like Google Forms or SurveyMonkey and exported in CSV or Excel formats for analysis. News articles and blogs from online portals and magazines also provide unstructured data. These can be aggregated using RSS feeds or scraped directly from news websites for further processing and analysis.
Online Marketplaces and Review Sites:
Websites like Amazon, Yelp, and TripAdvisor contain valuable unstructured data through reviews and product descriptions.Thisdatacanbeextractedusingwebscraping
or APIs and analyzed for insights. Using appropriate tools and techniques is crucial while ensuring compliance with legal and ethical guidelines during data collection.
Thebestpracticeistoloadtheunstructureddataintoadata lakeorNOSQLdatabase,notadatawarehousetypicallyused forstructureddata.
DocumentStores(e.g.,MongoDB,CouchDB):Idealforstoring JSON,BSON,orXMLdocuments.Eachdocumentcanhavea differentstructure,makingitsuitableforunstructureddata.
Key-Value Stores (e.g., Redis, DynamoDB): Store data as a collectionofkey-valuepairs.Itissimpleandcanbeusedto storesmallunstructureddataelements.
Column Family Stores (e.g.,Cassandra,HBase):Suitablefor large volumes of data, such as logs or sensor data, where dataisdistributed.
Graph Databases (e.g.,Neo4j):Theseareusefulforstoring unstructureddatathatinvolvescomplexrelationships,such associalnetworksorrecommendationengines.
Hadoop HDFS: A distributed file system that stores large volumesofunstructureddataacrossmultiplenodes.
Amazon S3: Ascalablecloudstorageservicethatcanstore andretrieveunstructureddata.
Azure Data Lake Storage: Provides a scalable and secure environmentforstoringunstructureddatainthecloud.
AzureBlobStorage: Storesmassiveamountsofunstructured data,suchastext,images,andvideos.
Google Cloud Storage: Object storage service for storing unstructureddata.
Amazon S3 (Simple Storage Service): An object storage servicethatallowsstoringandretrievinglargeamountsof unstructureddata.
3.3.3
The transform step in ELT (Extract, Load, Transform) for unstructured data involves converting raw, unorganized data into a structured format suitable for analysis. This processincludescleaning,normalizing,andprocessingdata using techniques like natural language processing (NLP), imagerecognition,ordataparsing.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
Thefollowingsectiondivesdeepintothetechniquesusedin theTransformsteptounlockinsightsfromtextdata.Textis themostcritical unstructureddata fororganizations,as it stores information and insights for business operations, decision-making,andstrategy.Organizationsgenerateand store large amounts of unstructured text data, including emails, reports, customer feedback, social media interactions,supporttickets,productreviews,etc.Theseare key communication channels between businesses, customers,andemployees.
Text data is critical in training AI and machine learning modelsforbusinessapplicationssuchasrecommendation engines, fraud detection, and predictive analytics. The availabilityofvastamountsoftextdatahelpsimprovethe accuracyandrelevanceofthesemodels,directlybenefiting organizations.
Natural Language Processing (NLP) techniques are fundamentaltounlockinginsightsfromtexts
4.1 Classical NLP:
Classical Natural Language Processing (NLP) refers to the classical approaches used to analyze and process human languagebeforetheriseofdeeplearningandlargelanguage models.
In the early days, NLP systems relied on manually crafted linguistic rules and symbolic methods. These systems focused on syntactic parsing, using grammar like contextfree grammar (CFG) to understand sentence structures. Early attempts at machine translation and chatbots like ELIZA were developed during this phase, with language understandinglimitedtopredefinedrulesandknowledgebasedsystems.
Withtheriseofcomputationalpowerandlargeannotated datasets, NLP moved toward probabilistic models and statistical methods. Techniques such as n-grams, Hidden Markov Models (HMMs), and Conditional Random Fields (CRFs)becamefamousfortaskslikepart-of-speechtagging, named entity recognition, and machine translation. Word embeddings like Word2Vec and algorithms like Latent Dirichlet Allocation (LDA) revolutionized word representation and topic modeling during this period. Though effective in narrow domains, classical approaches struggled with ambiguity, scalability, and generalization. Thisledtotheeventualshifttowardmachinelearningand deeplearning,revolutionizingNLPbyenablingmorerobust, context-awarelanguageunderstanding.
Whilepartiallyobsolete,ClassicalNLPmethodshavemainly beensupersededbyLLMsbasedondeeplearninginmany applications. However, they are still relevant in specific
domains,especiallywhereinterpretability,datascarcity,and computationalefficiencyarecriticalfactors.
Theintroductionofdeeplearning,particularlywithneural networks and transformers, marked the modern phase of NLP. Recurrent Neural Networks (RNNs) and Long ShortTermMemory(LSTM)networksinitiallyimprovedsequence taskslikemachinetranslation.Thetransformerarchitecture, introducedin2017,pavedthewayformassivepre-trained models like BERT and GPT, enabling state-of-the-art performance in text generation, sentiment analysis, and language understanding across multiple domains. Large languagemodels(LLMs)nowdominatethefield,providing sophisticated,context-aware,andscalablesolutions.
Largelanguagemodels(LLMs)aredeeplearningalgorithms trained on massive datasets of text, enabling them to performvariousnaturallanguageprocessing(NLP)tasks. Thesemodelscan:
Generatehuman-liketext
Translatelanguages
Answerquestions
Summarizedocuments
Writecode
Performtextclassification
LLM models are typically based on deep learning architectures,suchastransformers,andaretrainedonvast datasets that include various text sources (e.g., books, articles, websites). The development of modern LLMs is closely tied to the introduction of the Transformer architecture in 2017 by [10]Vaswani et al. From 2018 onward,researchersfocusedonbuildingincreasinglylarger models.In2019,researchersfromGoogleintroducedBERT [30],thetwo-directional,340-millionparametermodel(the thirdmostsignificantmodelofitskind)thatcoulddetermine context,allowingittoadapttovarioustasks.BERTexcelsat tasks requiring understanding context, like sentiment analysis and question answering. Then, in 2020, they released GPT-3 at 175 billion parameters, which set the standard for LLMs and formed the Large BERT excels at tasks requiring understanding context, like sentiment analysis and question answering. GPT is better at textgenerationtaskslikechatbotsandcreativewriting.
While some LLMs are freely available and can be used, modified,anddistributedunderopen-sourcelicenses,others are proprietary and require licenses or subscriptions to access.
GPT-NeoandGPT-JbyEleutherAI
GPT-2byOpenAI
BERTandT5byGoogle
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
Proprietary LLMs:
GPT-3andGPT-4byOpenAI
ClaudebyAnthropic
GeminibyGoogleDeepMind
Large language models (LLMs) have a wide range of capabilitiesdrivenbytheirdesignandtraining.Someoftheir corecapabilitiesinclude:
Text Generation: LLMs can generate coherent and contextuallyrelevanttextbasedoninputprompts. Thisincludes writingessays,creatingstories,and developingdialogue.
Language Translation: They can translate text between different languages, though the quality may vary depending on the languages and model training.
Text Summarization: LLMs can produce concise summariesoflongertexts,makingiteasiertodigest largeamountsofinformation.
Question Answering: Theycanprovideanswersto questionsbasedontheinformationtheyhavebeen trainedon,oftenusingnaturallanguageprocessing tounderstandandrespond.
SentimentAnalysis: LLMscananalyzethesentiment behind a text, determining whether it is positive, negative,orneutral.
Text Classification: They can categorize text into predefined categories, such as spam detection or topicclassification.
Conversational Agents: LLMs can engage in interactive dialogue, making them useful for chatbotsandvirtualassistants.
Code Generation and Understanding: Somemodels can understand and generate code snippets in variousprogramminglanguages.
Content Moderation: They can help identify and filterinappropriateorharmfulcontent.
Creative Tasks: LLMscanassistwithcreativetasks likepoetry,songwriting,andbrainstormingideas.
Fine-tuning LLMs:
Fine-tuning is adapting a pre-trained LLM to specific tasks or domains by updating its parametersusingtask-specificdata.
Itallowsmodelstoexcelinparticularareaswhile maintaining general language understanding capabilities.
Fine-tuning is an iterative process that requires experimentationtoachieveoptimalresults.Itisapowerful techniqueforunlockingthefullpotentialofLLMsinspecific domainsorapplications,butitneedscarefulconsiderationof data quality, computational resources, and potential limitations.Forsomefinancialsentimentanalysistasks,finetunedBERTmodelsoutperformedGPTmodels.
[32] Retrieval-augmented generation (RAG) for Large Language Models (LLMs) enhances text generation by combining pre-trained language models with external knowledgeretrievalsystems.ItallowsLLMstoaccessup-todate and relevant information beyond their training data, improving accuracy and reducing hallucinations in their responses. In RAG, appropriate information is retrieved fromaknowledgebaseordocumentsandfedintotheLLM to generate more accurate and contextually informed responses. This approach helps overcome limitations in modelmemoryandimprovesthefactualityandrelevanceof thegeneratedcontent.
NLP techniques enable extracting meaningful information from text data, facilitating the integration of unstructured text with structured datasets. A few widely used NLP techniquesareTopicModelingandSentimentAnalysis.
Topic modeling isastatisticalmethodthatuncovershidden themes or "topics" in document collections, making it valuable for text mining. It helps organize, interpret, and summarize large volumes of unstructured text data by revealingunderlyingpatterns.
LatentDirichletAllocation(LDA):
Description: LDA, a popular and straightforward topic modelingtechnique,assumesdocumentsaregeneratedfrom amixoftopics,witheachtopicproducingwordsbasedonits probabilitydistribution.
Use Case: LDAcanidentifytopicsacrossvariousdocuments within a dataset, such as finding common themes from customerreviewsorresearcharticles.
Non-negativeMatrixFactorization(NMF):
Description: NMF is a linear algebraic model that decomposes high-dimensional vectors into a low-
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
dimensional, non-negative representation, suitable for additive combinations, by approximating the tf-idf(term frequency-Inverse Document Frequency) transformed document-termmatrixwithtwoproductmatrices.
Use Case: NMFisoftenusedintextminingtoidentifytopics intextdata.Itcanbeparticularlyeffectivewhendealingwith shortertexts.
LatentSemanticAnalysis(LSA):
Description: LSA,orLatentSemanticIndexing(LSI),employs singularvaluedecomposition(SVD)onthedocument-term matrix to identify patterns in term-concept relationships withinunstructuredtextcollections.
Use Case: It is typically used to improve the accuracy of information retrieval processes and can help identify synonymyandpolysemywithinatextdataset.
AdvantagesofTopicModeling:
Unsupervised Learning: Most topic modeling techniquesareunsupervised,meaningtheydonot require a labeled dataset for training. This makes themversatileandwidelyapplicable.
InsightDiscovery:Helpsdiscoverhiddenthematic patternsinextensivetextcollections,whichcanbe crucial for summarizing, understanding, and extractinginsights.
Dimensionality Reduction: It reduces the dimensionalityoflargetextdatasets,makingthem easiertomanageandanalyze.
Challenges:
Interpretation: The topics generated by these models are sometimes hard to interpret, and the coherencemightonlysometimesalignwithhuman understanding.
ChoosingParameters:Determiningthenumberof topics is a critical and sometimes challenging decisionandrequiresdomainexpertiseoriterative experimentation.
Context Retention: Simple topic modeling approacheslikeLDAmightnoteffectivelycapture the context around the words in the documents, whichcanleadtolessmeaningfultopicdefinitions.
Applications:
Content Recommendation: In digital media, topic models can help recommend similar articles or mediatousersbymatchingtheirinterestswiththe topicsextractedfromthecontent.
MarketResearch:Businessescanusetopicmodels toanalyzecustomerfeedback,socialmediaposts,or product reviews to understand common themes andconcerns.
Document Clustering and Classification: Topic modeling can enhance document clustering algorithms by providing more semantically rich featuresformachinelearningmodels.
Topicmodelingoffersarobustsuiteoftoolsforextracting and exploring the underlying themes in unstructured text data, aiding in better decision-making and insights extractionacrossvariousfields.
Sentimentanalysis,oropinionmining,isabranchofNatural LanguageProcessing(NLP)thataimstoidentifyandextract opinions from text data to determine if the sentiment is positive, negative, or neutral. It is precious for analyzing customer feedback, social media comments, reviews, and other platforms where people share their thoughts and feelings.
EssentialTopicSentimentAnalysisTechniques:
Lexicon-BasedApproach:
Description: Thismethoddeterminesthesentimentofatext byusingapredefinedlistofwordswithassignedsentiment scores, calculating the overall sentiment based on the aggregatescoresofthewordsinthetext.
Techniques:
Polarity Calculation: Computes the overall sentiment by summingupthepredefinedsentimentscoresofeachword.
Rule-Based Systems: Enhances polarity calculation by incorporating grammatical and syntactical rules (e.g., negationhandling,intensifiers,anddiminishers).
Use Case: Effective for quick, rule-based analysis where contextualnuancesareminimal,suchasanalyzingfeedback onspecificfeaturesofaproduct.
MachineLearningApproach:
Description: Uses various machine learning algorithms to classifythesentimentofthetext.Thisapproachrequiresa pre-labeleddatasetfortraining.
Techniques:
Supervised Learning: Common algorithms include Logistic Regression, Support Vector Machines (SVM), and Neural Networks. Models are trained on a labeled dataset (texts labeledaspositive,negative,orneutral).
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
Deep Learning: Utilizes complex structures like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), exceptionally Long Short-Term Memory Networks (LSTMs), for more nuanced understandingandcontextmanagementintexts.
Use Case: Suitableforlarge-scalesentimentanalysiswhere nuancesandcontextualunderstandingsarecritical,suchas socialmediamonitoringandbrandsentimentanalysis.
HybridApproaches:
Description: Combineslexicon-basedandmachine-learning approaches to leverage the strengths of both methods, improvingaccuracyandcontextsensitivity.
Techniques:
Feature Enrichment: Uses lexical features as inputs to machine learning models, enhancing the contextual sensitivityofthealgorithm.
EnsembleMethods: Combinespredictionsfrombothlexiconbasedandmachine-learningmodelstofinalizethesentiment classification.
UseCase: Usefulinscenarioswhereaccuracyandscalability areneeded,suchasreal-timecustomerservicemonitoring.
ChallengesofSentimentAnalysis:
Sarcasm and Irony: Detecting sarcasm and irony remains a significant challenge, as they can completelyinvertthesentimentexpressed.
Context and Polarity: Words might carry different sentiments depending on the context, making it hardtodeterminetheoverallsentimentaccurately.
Language and Dialects: Variations in language, slang, and dialects can affect sentiment detection, requiringadaptableorlocalizedsolutions.
Applications:
Market Research and CRM: Businesses analyze customer sentiment on products, services, and brand reputation to understand better customer needsandimprovecustomerrelationships.
Social Media Monitoring: Allows companies to monitor and respond to public sentiment in realtime, effectively managing PR and marketing strategies.
FinancialMarkets:Tradersusesentimentanalysis to gauge market sentiment from news articles,
socialmedia,andfinancialreportstopredictstock movements.
Overall,sentimentanalysisoffersapowerfulwaytoextract actionableinsightsfromunstructuredtextualdata,helping organizations across various sectors to enhance their strategiesandunderstandtheiraudiencebetter.
Named Entity Recognition (NER) is an essential NLP task that identifies and classifies entities like names, organizations,locations,anddateswithintext,transforming unstructured data into structured data for valuable analyticalinsights.
Rule-Based Approaches: These techniques use predefinedlinguisticrulesandpatternstoidentify entities, which are straightforward and interpretablebutdemandextensivemanualeffort to develop and maintain and often struggle to generalizeacrossdiversetextsources.
Machine Learning Approaches: These involve trainingstatisticalmodelsusinglabeleddata.
Deep Learning Approaches: Leveraging neural networks,thesetechniqueshaveshownsignificant improvementsinNERaccuracy:
Recurrent Neural Networks (RNNs): Long Short-Term Memory (LSTM) networks capture dependencies in the sequenceofwords.
Transformer Models: Models like BERT (Bidirectional EncoderRepresentationsfromTransformers)havesetnew benchmarks in NER by using attention mechanisms to understandthecontextofwordsinasentencedeeply
HybridApproaches: Combiningrule-basedmethods withmachinelearningordeeplearningtoleverage thestrengthsofboth.
AmbiguityandContext:Thesamewordcanreferto different entities depending on the context. For example,"Apple"canrefertoafruitoratechnology company.
Variability in Text: Different formats, typos, abbreviations, and informal language in text data canmakeNERchallenging.
Data Scarcity: High-quality annotated data for trainingNERmodelsisoftenscarceandexpensive.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
Multilingualism:Handlingmultiplelanguagesand the nuance of each language increases the complexityofNER.
Domain Adaptation: NER models trained on one typeoftext(e.g.,newsarticles)mayonlyperform wellonanothertype(e.g.,socialmediaposts)with fine-tuning.
Applications
Information Extraction: Automatically extracting relevant entities from large text corpora, such as company names from financial reports or patient informationfrommedicalrecords.
KnowledgeGraphConstruction:Buildingstructured knowledgegraphsbyidentifyingentitiesandtheir relationshipsfromunstructuredtextdata.
Question Answering Systems: Improving the accuracyofQAsystemsbyidentifyingandfocusing onrelevantentitiesinaquery.
Compliance and Risk Management: Automatically identifying and monitoring mentions of specific entitiesinlegalandregulatorydocuments.
CustomerServiceAutomation:Enhancingchatbots andvirtualassistantsbyenablingthemtorecognize andrespondaccuratelytoqueriesinvolvingspecific entities.
4.3.4 Text Generation & Summarization Techniques
Advanced machine learning algorithms and artificial intelligence can process and analyze unstructured data, making it possible to derive actionable insights alongside structureddata.
KeyTextGeneration&SummarizationTechniques
Text generation and summarization have evolved significantly with advancements in machine learning and artificialintelligence.Afewprominenttechniquesinclude:
Ø Sequence-to-Sequence Models (Seq2Seq):
These models are designed to handle input and output sequencesofvaryinglengths,makingthemidealformachine translation and summarization tasks. Seq2Seq models are oftenenhancedwithattentionmechanisms,whichallowthe modeltofocusonspecificpartsoftheinputsequencewhen generating the output. This results in more accurate and contextuallyrelevanttext.
Use Case:
ApracticalapplicationofSeq2Seqmodelsisinautomated translation services, such as translating customer support queriesfromonelanguagetoanotherwhilemaintainingthe contextandintentoftheoriginalmessage.
Transformer Models:
Transformers represent a significant leap in NLP, particularlywithmodelslikeGPT(GenerativePre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). Unlike Seq2Seq models, transformers use self-attention mechanisms to processdatainparallel,allowingthemtohandlemuchlarger datasets and generate more sophisticated text. This has made transformers the backbone of many modern text generationandsummarizationsystems.
Use Case:
Transformers are widely used in chatbots that generate natural-soundingresponsesinrealtime,providingamore human-likeinteractionincustomerservicescenarios.
Extractive and Abstractive Summarization:
Summarization techniques are categorized into extractive and abstractive approaches. Extractive summarization identifiesandselectsvitalsentencesorphrasesdirectlyfrom the text, whereas abstractive summarization involves generatingnewsentencesthatencapsulatethemainideasof the original text. While extractive methods are more straightforwardandfaster,abstractivesummarizationoffers amorenaturalandfluentsummary.
Use Case:
In legal, extractive summarization can pull out critical clauses from lengthy contracts. In contrast, abstractive summarization might be employed to generate a concise overview of a court ruling for quick review by legal professionals.
Reinforcement Learning:
Thistechniqueinvolvestrainingmodelstomakesequences of decisions, optimizing for a reward function that encourages desired behaviors. In text generation and summarization,reinforcementlearningcanfine-tunemodels toproducetextthatmeetsspecificqualitycriteria,suchas relevance,conciseness,andreadability.
Use Case:
In news media, reinforcement learning could be used to refine summarization models that generate news digests, ensuringthatthesummariesareinformativeandengaging forreaders.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
Applications
Despitethesechallenges,textgenerationandsummarization techniques have a wide range of applications across industries:
Content Creation: Automated tools can generate blog posts, news articles, and marketing copy, significantlyreducingthetimeandeffortrequired forcontentproduction.Thisisespeciallyusefulfor businesses needing to quickly produce large volumesofcontent.
Customer Support: AI-powered chatbots can generate responses to customer inquiries in realtime, providing personalized and relevant informationwithouthumanintervention.
Summarizing Reports: In sectors like finance, healthcare, and law, summarization tools can condense lengthy reports and documents into concise summaries, helping professionals make quickerdecisionsbasedoncriticalinformation.
Language Translation: Text generation models, particularlythosebasedonSeq2Seq,haveimproved thequalityofmachinetranslation,makingiteasier to communicate across different languages and cultures.
AcademicandResearchSummarization: Researchers andstudentsbenefitfromtoolsthatcansummarize academic papers and articles, allowing them to grasptheessenceofalargebodyofworkquickly
Whilethesetechniquesarepowerful,theycomewiththeir ownsetofchallenges:
Data Quality and Quantity: High-quality training data is crucial for these models' performance. However, acquiring and curating large representativeandunbiaseddatasetsisasignificant challenge.
Handling Ambiguity and Context: Machines often strugglewiththenuancesofhumanlanguage,such assarcasm,idioms,andcontextualmeanings.This can lead to accurate or relevant text generation, particularlyincomplexorsensitivetopics.
Computational Resources: Advanced models, particularly transformers, require substantial computational power for training and inference. This can be a barrier for smaller organizations or projectswithlimitedresources.
Ethical Concerns: Theuseofnext-generationtools raises ethical issues, including the potential for generatingfakenews,biasedcontent,ormalicious text. Ensuring that these models are used responsibly and with proper safeguards is a growingconcern.
Structured data refers to information organized in a predefined manner, often in rows and columns, making it easily searchable and analyzable using traditional data processingtechniques.Examplesincludetransactionaldata, financial records, and customer information stored in relationaldatabases.
While structured and unstructured data structures are different,thegluethatconnectsthevariouskindsofdatais the standard dimensions. For example, the product identifiers are the glue between product review data and profitabilitymetrics.Similarly,patientIDisthegluebetween patient health notes and metrics. Customer ID is the glue betweenthecustomerengagementlogdataandprofitability metrics.
Withallthetechniqueslistedabove,metricsgleanedfrom theunstructureddata,suchassentimentscoresorcustomer bouncerates,willlookmorelikestructuredmetricdata. The criticalsuccessfactorforintegratingunstructureddatawith structured data is extracting insightful metrics from unstructureddata.Then,metricscreatedfromunstructured datacanbejoinedwithmetricsfromstructureddataatthe standardlevelofgranularity.Regardlessofthedatastrategy, whether stored in a data lake or warehouse, the metrics relevant for analysis and insights can be extracted and integratedintosmallerdatasetsforhumananalysis.
Aholisticviewofperformancemetricsfrombothstructured andunstructureddataisexcellentfordevelopinginsights. Oncedataengineerscanintegratetheperformancemetrics from both kinds of data, then visual dashboards and scorecardsthatconsistofmetricsfrombothstructuredand unstructured data can be created. Below (Fig -1) is an exampleofaproductscorecardwithmetricsfromstructured andunstructureddatasources.
Visualizing trends with both structured and unstructured datacanrevealpatternsorcorrelations.Standardmethods includelinechartstocomparestructureddatalikesaleswith unstructured trends like sentiment changes, heatmaps to display correlations between variables such as sales and sentimentovertimeorregions,andwordcloudstovisualize
2024, IRJET | Impact Factor value: 8.315 | ISO 9001:2008 Certified Journal | Page254
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
frequenttopicsinunstructuredtext(e.g.,reviews)alongside structureddatalikeproductratingstotracktherelationship betweenthemesandcustomersatisfaction.
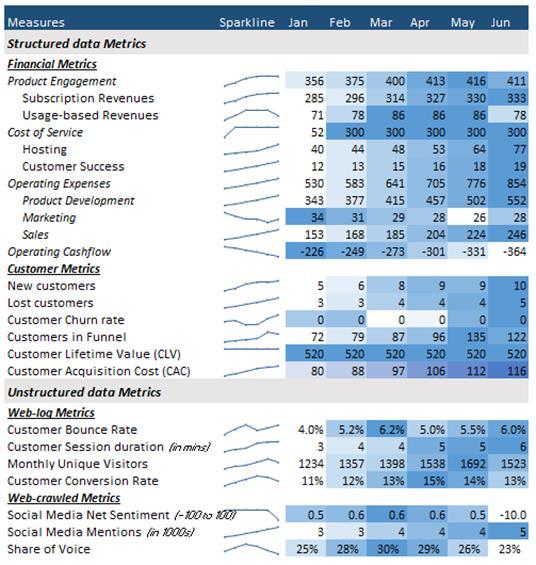
Fig- 1: ProductScorecard
5.3 Machine Learning utilizing both structured and unstructured data
Predictive and prescriptive analytics can be more prosperous with metrics from both structured and unstructureddata.Forexample,anomalyalertsaroundthe negativetrendsinsocialmediasentimentcanbeproactively senttothebusinessstakeholders.Inaddition,theshareof the product's voice in social media could be a leading indicatorofthecustomerrevenuegrowthrate.
Identify correlations between bounce rates and various factorsextractedfromunstructureddata,suchasnegative sentiments in user comments or frequent mentions of specific issues like load times. Converging structured and unstructured data in machine learning involves using techniques that can effectively handle the different data formatsandtypes.Herearesomeessentialmachine-learning methodsandapproachesthatcanfacilitatethisintegration:
5.3.1 Data Mining
Anomaly Detection
Anomalydetectioninsentimentanalysisallowsbusinesses toidentifyunusualcustomeropinionsorbehaviorchanges. Sentiment score anomaly detection involves identifying
unusual or unexpected changes in sentiment over time, which can help understand shifts in customer behavior, markettrends,orpublicopinion.Suddenspikesinnegative sentiment can indicate product issues, PR crises, or dissatisfactionthatrequireimmediateaction.
Monitoring anomalies in customer feedback helps track unexpected changes in user satisfaction, while detecting sentiment anomalies on social media can reveal emerging trends,potentialcrises,orreactionstonewproductreleases orevents.Topicmodelingcanautomaticallydiscoverhidden topics in an extensive collection of text documents. AlgorithmssuchasLatentDirichletAllocation(LDA)canbe usedtodetecttopicdistributionwithintextdata.Anomalous documents may show unusual or unexpected topic combinationscomparedtotherestofthecorpus.
These techniques have practical applications in various areas,suchastrackingpublicsentimenttowardsabrandor product,monitoringsocialmediaforemergingtrends,and analyzingcustomerfeedbackorreviewchanges.Thishelps businesses stay informed on public perception and adjust strategiesaccordingly.
TimeseriesanalysisinvolvesusingmodelslikeARIMAand exponentialsmoothingonstructureddata(e.g.,salesfigures) and integrating it with unstructured data (e.g., sentiment scores).For example,combiningsalesdata withcustomer sentiment from reviews can help analyze how shifts in sentimentaffectsalestrends.Byperformingtrendanalysis, businessescanidentifyifnegativereviewscorrespondwith declinesinsalesorifpositivereviewsdrivesalesgrowth.
Regressionanalysishelpsexploretherelationshipbetween structuredandunstructured data.Forinstance,sentiment scoresfromcustomerfeedbackcanbeusedtopredictsales performance. Businesses can determine if positive or negativefeedbackcorrelateswithsalestrendsbyanalyzing howchangesinproductratings(unstructureddata)affect sales(structureddata).
Deep learning is highly effective in processing structured andunstructureddata,oftenachievingsuperiorresultsby learning complex patterns in data. Deep learning can integratebothtypestobuildrobustmodelswhencombining structured (numerical, categorical) and unstructured data (text,images,audio,video).
Combining structured and unstructured data in a single deep-learning model allows you to build more comprehensive models, particularly for tasks like recommendation systems, fraud detection, or predictive maintenance. Deep learning techniques that combine structuredandunstructureddatatypicallyinvolvecreating
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
separate models for each type of data and merging their outputstoleveragetheuniquestrengthsofeach.Hereare some common deep-learning approaches that integrate structuredandunstructureddata:
Thelatefusionapproachinvolvesbuildingseparatemodels for structured and unstructured data, processing each independently,andcombiningtheiroutputslater.Structured dataishandledbytraditionalmodelslikerandomforestsor MLPs,whileunstructureddataisprocessedbydeeplearning models such as CNNs for images or RNNs for text. The outputs are concatenated and passed through a fully connected layer for the final prediction. For example, in a recommendationsystem,aCNNprocessesproductimages, anRNNhandlesproductdescriptions,andanMLPprocesses userdemographicstomakepredictions.
Theearlyfusionapproachinvolvesextractingfeaturesfrom unstructured data, such as text, images, or audio, and merging them with structured data before training a machine learning model. Text data is transformed into numerical vectors using NLP techniques like word embeddings(e.g.,Word2Vec,BERT),whileimagedatauses featureextractorslikepre-trainedCNNs(e.g.,ResNet,VGG). Audiodataisprocessedusingspectrogramsorembeddings fromRNNorCNNmodels.Theseextractedfeaturesarethen combined with structured data and fed into models like XGBoost,logisticregression,orMLPforpredictions.
Multimodal learning that combines structured and unstructured data leverages the strengths of various data types to improve predictive power and provide more comprehensiveinsights.Inthisapproach,structureddata such as numerical values and categorical features are processed using traditional models like decision trees or neural networks, while unstructured data such as text, images, and audio are analyzed using deep learning techniques like Convolutional Neural Networks (CNNs), RecurrentNeuralNetworks(RNNs),ortransformers.These modelsarethenintegrated,oftenthroughfeaturefusionor parallelnetworks,tocreateaunifieddatarepresentation.By combining the rich, contextual information from unstructureddatawithstructureddata'sprecise,organized nature, multimodal learning enables more accurate predictions and profound insights in areas like recommendation systems, fraud detection, and medical diagnostics.
Autoencoders are used for dimensionality reduction by compressingunstructureddata,suchastextorimages,into
lower-dimensional embeddings,whicharethencombined with structured data. For example, compressed image embeddings in healthcare can be merged with structured datalikeageormedicalhistorytopredicthealthoutcomes. Similarly,textdatacanbecompressedandcombinedwith structured features. In a quality control system, autoencoderscompressproductimagesandcombinethem withmanufacturingdatatodetectdefects.
Transferlearningwithfine-tuninginvolves
usingpre-trainedmodelstoprocessunstructured data,
combining the resulting embeddings with structureddataand
We are fine-tuning the model for specific tasks.
For text, models like BERT or GPT are employed for sentimentanalysisorcustomerfeedbackclassificationtasks. Atthesametime,pre-trainedCNNslikeResNetareusedfor image feature extraction. An example is customer churn prediction, where a language model analyzes emails and structureddatalikecustomertenureandpurchasehistory, whichisintegratedwiththetextmodel'soutputtopredict churn.
Fusion of both structured data unlocks superior performance in applications such as fraud detection, recommendationsystems,andhealthcarediagnostics,where a single data type often misses critical context. Excluding unstructured data usually results in losing important context,leadingtosuboptimalmodels.Combiningbothhelps ensurethatnovitalinformationismissed.
Usingbothdatatypesenablesmodelstoexplainoutcomes basedonhardmetrics(fromstructureddata)andqualitative factors (from unstructured data), improving decisionmakingandtrustinthemodel.Unstructureddataprovides thecontextforbetterunderstandingandinterpretationof structured data, allowing deep learning models to make decisionsthatreflectthereal-worldenvironment.
Integratingpatientrecords(structureddata)withdoctor's notesandmedicalimaging(unstructureddata)toimprove patientoutcomesandoperationalefficiency.Hereisa study titled "Implementation of eHealth and AI integrated diagnostics with multidisciplinary digitized data: Are we ready from an international perspective?" published in European Radiology
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
CaseStudySummary
Objective: The study integrates versatile diagnostic information from various sources, such as anamnesis, imaging, histopathology, and clinical chemistry, using AI tools to enhance diagnostic accuracy and therapeutic conduct.
Challenges:
Data Privacy and Integration: Integrating diverse healthdataposessignificantchallenges,particularly withdataprivacy,integrationcomplexity,andthe needforinteroperableITinfrastructure.
Technical and Ethical Barriers: The technical complexityofintegratingandanalyzingdatafrom disparate sources is compounded by ethical considerationsconcerningpatientconsentanddata security.
Methodology:
DataIntegrationandAnalysis: Thecasestudydiscussesusing centralizeddatawarehousesordatalakesthatintegratedata from multiple sources. These platforms facilitate the comprehensiveanalysisofintegrateddata,utilizingAIand machinelearningtoimprovediagnosticprecision.
Interoperability Standards: Efforts focus on creating interoperablesystemsthatintegrateandanalyzedatafrom varioushealthdatasystems.
Results:
Improved Diagnostic Accuracy: By integrating structureddata(suchasEHRs)withunstructured data(likemedicalimaginganddoctor'snotes),the study highlights potential improvements in diagnostic accuracy and the ability to deliver personalizedpatientcare.
Operational Efficiency: Enhanced data integration supports better resource allocation, reduces redundancy,andimprovestheoverallefficiencyof healthcareoperations.
Future Directions:
Addressing Technical Challenges: The study identifies the need for continued development in data integration technologiesandAItohandlehealthcaredata'sincreasing volumeandcomplexity.
Strengthening Data Privacy Measures: As data integration advances,itiscriticaltostrengthendataprivacymeasuresto protect patient information and comply with regulatory requirements.
Itcombinessalesdata(structured)withcustomerfeedback from social media and reviews (unstructured) to enhance product development and customer satisfaction. One exampleistheZaracasestudyonintegratingSalesDatawith CustomerFeedbackforEnhancedProductDevelopmentand CustomerSatisfaction.
Zara,aleaderinthefast-fashionindustry,hasleveragedits ability to quickly respond to the ever-changing fashion trends by integrating customer feedback with sales data. This integration has allowed Zara to consistently meet customerexpectationsandmaintainacompetitiveedgein themarket.
Objective: Theprimarygoalwastointegratestructuredsales datawithunstructuredcustomerfeedbackfromsocialmedia andonline reviews.Thisdata integrationaimedto inform Zara'sproductdevelopmentprocessandenhancecustomer satisfaction.
Approach:
Data Collection: Zarautilizedadvancedanalyticstoprocess sales data and monitor inventory levels in real-time Simultaneously,theyemployednaturallanguageprocessing (NLP) techniques to analyze customer sentiments from socialmediaplatformsandonlinereviews.
RapidResponseSystem: Theinsightsobtainedfromthisdata integrationwerefedintoZara'ssupplychainmanagement system, enabling fast responses to emerging trends and customer preferences. This system allowed Zara to adjust productionvolumesanddelivernewdesignstostoreswithin weeks.
Results:
Dynamic Product Development: By understanding customer preferences and dissatisfaction areas, Zara could instantly adapt its designs, enhancing product offerings and increasing customer satisfaction.
IncreasedSalesandCustomer Loyalty: Theabilityto quickly meet market demands led to higher sales and reinforced customer loyalty, as consumers increasinglyreliedonZaraforthelatesttrends.
Operational Efficiency: Theintegrationallowedfor betterinventorymanagement,reducingoverstocks and stockouts, thereby optimizing operational efficiency.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
To demonstrate how a bank can utilize NLP-driven news sentiment analysis to enhance its risk management framework,focusingonpredictingfinancialrisks,managing reputationalthreats,andensuringregulatorycompliance.
A leading international bank wants to improve its risk management capabilities by integrating NLP-based news sentimentanalysis.Thebankaimstomonitorandanalyze news articles, press releases, and social media posts to detectearlysignsoffinancialrisks,reputationalissues,and regulatorychanges.
Approach:
DataCollection: FinancialnewswebsiteslikeBloombergand Reuters and social media platforms like Twitter and LinkedIn provide essential sources of real-time financial information and insights. Regulatory announcements and pressreleasesofferauthoritativeupdatesonpolicychanges orlegaldevelopments.Toefficientlygatherdatafromthese sources,webscrapingtoolslikeBeautifulSoup andScrapy andAPIsfromnewsaggregatorsandsocialmediaplatforms canbeemployed,allowinguserstoautomateextractingand aggregatingrelevantcontentforanalysis.
Data Preprocessing: Techniques used in text processing include tokenization, which involves splitting text into individual words or phrases, and word removal, which eliminates common but unimportant words like "and" or "the."Stemmingand lemmatization reduce wordstotheir rootorbaseformsforconsistencyinanalysis.NamedEntity Recognition (NER) identifies essential entities such as company names, people, and locations. At the same time, Part-of-Speech (POS) tagging assigns grammatical categories,likenounsorverbs,toeachword,aidinginbetter textcomprehensionandanalysis.
Tools for text processing include libraries like NLTK and SpaCy,whichofferawiderangeoffunctionsfortaskssuch as tokenization, word removal, stemming, lemmatization, andNamedEntityRecognition(NER).Additionally,custom scriptscanbedevelopedtocleanandpreprocesstextdata, tailoring the process to specific requirements or datasets. These tools are essential for preparing raw text for more advancednaturallanguageprocessing(NLP)analysis.
Sentiment Analysis: Pre-trained models like BERT, GPT-3, andothertransformer-basedmodelsareusedfornuanced sentiment detection, providing a solid foundation for understanding the text. Custom models, fine-tuned with proprietarydata,canfurtherimproveaccuracyforspecific tasks.Theprocesstypicallyinvolvessentimentclassification, categorizingsentimentsaspositive,negative,orneutral,and scoring,quantifyingthesentiment'sintensity.Toolssuchas
HuggingFaceTransformersarecommonlyusedforworking with advanced models, while Scikit-learn is used for traditionalmachine-learningapproaches.
Aggregation and sentiment analysis involve collecting sentimentscoresovervarioustimeframestoidentifytrends andpatternsinsentimentchanges.Thishelpstotrackshifts in public perception or market sentiment over time. Integrationwithriskmanagementsystemsallowssentiment analysis results to be linked with existing dashboards, providingreal-timeinsightsintopotentialrisks.Additionally, alertsystemscanbesetuptonotifydecision-makerswhen significantsentimentshiftsoccur,enablingmoreproactive riskmanagementanddecision-making.
Results:
FinancialRiskPrediction
Stock Price Movement: The bank observed a correlation betweennegativesentimentinnewsarticlesandsubsequent dropsinstockprices.
Market Volatility: Early detection of market turbulence throughincreasednegativesentimentacrossfinancialnews.
ReputationalManagement
Brand Monitoring: Real-time tracking of brand sentiment helpedthebankmitigatepotentialreputationaldamageby addressingissuespromptly.
Crisis Management: The bank successfully navigated a potentialPRcrisisbyswiftlyrespondingtonegativesocial mediasentiment.
RegulatoryCompliance
Regulatory Announcements: The bank stayed ahead of regulatory changes by monitoring sentiment around key regulatoryannouncements.
ComplianceRisks: Earlydetectionofcompliance-relatedrisks throughsentimenttrendsinrelevantnews.
Challenges:
Iamdetectingsarcasmandcontext-dependentmeanings. Solution:Fine-tuningmodelswithdomain-specificdataand incorporatingcontext-awareanalysistechniques.Ensuring data relevance and accuracy. Solution: Implement robust datavalidationprocessesandfilteroutnoiseandirrelevant information. Scaling infrastructure for real-time analysis. Solution: Utilizing cloud-based solutions and scalable architecturestohandlelargedatavolumesefficiently.
Conclusion: The bank significantly enhanced its risk management capabilities by integrating NLP-driven news sentiment analysis. The ability to predict financial risks,
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
manage reputational threats, and ensure regulatory complianceprovidedthebankwithacompetitiveedge.This case study demonstrates the practical applications and benefitsofusingadvancedNLPtechniquesinthefinancial sectorforrobustriskmanagement.
Shopifysuccessfullyuseslargelanguagemodels(LLMs)to enhance customer support by automating responses to commoninquiriesandprovidingpersonalizedassistance.
CaseStudySummary
ShopifyintegratedLargeLanguageModels(LLMs)likeGPT3 into its customer support system to handle complex inquiries, reduce response times, and improve customer satisfaction. This integration allows for faster resolutions andimprovedcustomerexperiencewhilefreeinguphuman agentsformorecomplicatedissues. Shopifypreviouslyused a rule-based chatbot and human agents, which struggled withcomplexqueriesasthecompany'suserbasegrew.The goal was to develop a more dynamic and responsive LLM supportsystem.
Approach:
Model Training: Fine-tuned the LLM using Shopify's extensive data on customer interactions and product documentation.
Testing and Validation: Focused on handling complex queriesandgeneratingappropriateresponses.
Phased Deployment: Rolled out gradually to monitor performancebeforefulldeployment.
Results:
ImprovedCustomerSatisfaction:TheLLMprovided moreaccurate,context-awareresponses,resulting inhighersatisfaction.
Faster Response Times: Automation reduced responsetimes,allowinghumanagentstofocuson morecomplexissues.
Operational Cost Savings: Handling routine inquiries with the LLM reduced the need for additionalsupportstaff,yieldingcostsavings.
Challenges:
Data Privacy: Implemented strict governance policiestoprotectsensitivecustomerinformation.
Model Bias: Addressed with real-time monitoring andhumaninterventionmechanisms.
Conclusion: Shopify's LLM-powered chatbot improved customerserviceandoperationalefficiency,settinga new standardforAI-drivensupportinthee-commerceindustry.
Integratingstructuredandunstructureddatarepresentsa significant advancement in performance measurement acrossindustries.Byleveragingthestrengthsofbothdata types, organizations can gain more profound, more actionable insights that drive better decision-making and competitive advantage. Continued innovation and collaborationwillbecrucialinovercomingchallengesand fullyrealizingthepotentialofthisintegratedapproach.
[1]Davenport,T.H.,&Harris,J.G.(2007).Competingon Analytics: The New Science of Winning. Harvard BusinessReviewPress.
[2]Porter, M. E. (1985). Competitive Advantage: CreatingandSustainingSuperiorPerformance.New York:FreePress.
[3]Chen, H., Chiang, R. H. L., & Storey, V. C. (2012). BusinessIntelligenceandAnalytics:FromBigData to Big Impact. MIS Quarterly, 36(4), 1165–1188. doi:10.2307/41703503.
[4]Laney,D.(2001).3DDataManagement:Controlling DataVolume,Velocity,andVariety.MetaGroup.
[5]Mayer-Schönberger,V.,&Cukier,K.(2013).BigData: A Revolution That Will Transform How We Live, Work, and Think. Eamon Dolan/Houghton Mifflin Harcourt.
[6]Russom, P. (2011). Big Data Analytics. TDWI Best PracticesReport,4thQuarter,pp.1–35.Available: Link.
[7]White, T. (2012). Hadoop: The Definitive Guide. O'ReillyMedia,Inc.
[8]Kudyba,S.(2014).BigData,Mining,andAnalytics: Components of Strategic Decision Making. CRC Press.
[9]George, G., Haas, M. R., & Pentland, A. (2014). Big Data and Management. Academy of Management Journal, 57(2), 321–326. doi:10.5465/amj.2014.4002.
[10] Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. Advances in NeuralInformationProcessingSystems,30,59986008.
[11]Agrawal,D.,Das,S.,&Abbadi,A.E.(2011).BigData and Cloud Computing: Current State and Future Opportunities. EDBT '11: Proceedings of the 14th International Conference on Extending Database Technology, 530-533. doi:10.1145/1951365.1951432.
2024, IRJET | Impact Factor value: 8.315 | ISO 9001:2008
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 10 | Oct 2024 www.irjet.net p-ISSN: 2395-0072
[12] Snijders, C., Matzat, U., & Reips, U. D. (2012). Big Data:BigGapsofKnowledgeintheFieldofInternet Science. International Journal of Internet Science, 7(1),1-5.
[13] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D.(2020). LanguageModelsareFew-ShotLearners.Advances in Neural Information Processing Systems, 33, 1877-1901.
[14] Gandomi,A.,&Haider,M.(2015).BeyondtheHype: Big Data Concepts, Methods, and Analytics. InternationalJournalofInformationManagement, 35(2), 137-144. doi:10.1016/j.ijinfomgt.2014.10.007.
[15] Fan,W.,&Gordon,M.D.(2014).ThePowerofSocial Media Analytics. Communications of the ACM, 57(6),74-81.doi:10.1145/2602574.
[16] Provost,F.,&Fawcett,T.(2013).DataScienceand its Relationship to Big Data and Data-Driven Decision Making. Big Data, 1(1), 51–59. doi:10.1089/big.2013.1508.
[17] Jagadish, H. V., Gehrke, J., Labrinidis, A., Papakonstantinou,Y.,Patel,J.M.,Ramakrishnan,R., & Shahabi, C. (2014). Big Data and Its Technical Challenges.CommunicationsoftheACM,57(7),86–94.doi:10.1145/2611567.
[18] Kaisler,S.,Armour,F.,Espinosa,J.A.,&Money,W. (2013). Big Data: Issues and Challenges Moving Forward.46thHawaiiInternationalConferenceon System Sciences, 995–1004. doi:10.1109/HICSS.2013.645.
[19] Hashem,I.A.T.,Yaqoob,I.,Anuar,N.B.,Mokhtar,S., Gani,A.,&Khan,S.U.(2015).TheRiseof"BigData" on Cloud Computing: Review and Open Research Issues. Information Systems, 47, 98-115. doi:10.1016/j.is.2014.07.006.
[20] McAfee,A.,&Brynjolfsson,E.(2012).BigData:The ManagementRevolution.HarvardBusinessReview, 90(10),60–68.Available:Link.
[21] Bizer,C.,Boncz,P.,Brodie,M.L.,&Erling,O.(2012). TheMeaningfulUseofBigData:FourPerspectives–Four Challenges. SIGMOD Record, 40(4), 56-60. doi:10.1145/2094114.2094129.
[22] Mikolov,T.,Chen,K.,Corrado,G.,&Dean,J.(2013). Efficient Estimation of Word Representations in VectorSpace.arXivpreprintarXiv:1301.3781.
[23] Riedel,S.,Yao,L.,McCallum,A.,&Marlin,B.(2013). RelationExtraction withMatrixFactorizationand Universal Schemas. Proceedings of the 2013 Conference of the North American Chapter of the AssociationforComputationalLinguistics:Human LanguageTechnologies,pp.74–84.
[24] Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification.Proceedingsofthe2015Conference
on Empirical Methods in Natural Language Processing,pp.253–263.
[25]Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. Advances in Neural Information ProcessingSystems,27,3104-3112.
[26]Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language UnderstandingbyGenerativePre-Training.OpenAI Blog.
[27]Kudyba,S.,&Hoptroff,R.(2001).DataMiningand BusinessIntelligence:AGuidetoProductivity.Idea GroupPublishing.
[28]Ghani, R. (2016). Big Data Analytics in Retail: A Guide to Measuring and Predicting Consumer Behavior.AnalyticsMagazine.Available:Link.
[29]Radford,A.,Wu,J.,Child,R.,Luan,D.,Amodei,D.,& Sutskever, I. (2019). Language Models are UnsupervisedMultitaskLearners.OpenAIGPT-2
[30]Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In ProceedingsofNAACL-HLT.
[31]Raffel,C.,Shazeer,N.,Roberts,A.,Lee,K.,Narang,S., Matena, M., ... & Liu, P. J. (2020). Exploring the LimitsofTransferLearningwithaUnifiedText-toText Transformer. Journal of Machine Learning Research,21(140),1-67.
[32]Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Riedel, S. (2020). Retrieval-Augmented Generation for KnowledgeIntensive NLP Tasks. Advances in Neural InformationProcessingSystems,33,9459-9474.
[33]Zhang,Y.,Sun,S.,Galley,M.,Chen,Y.-C.,Brockett,C., Gao,X.,...&Dolan,B.(2020).DialogPT:Large-Scale Generative Pre-training for Conversational ResponseGeneration.ProceedingsofACL.