
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
1Chetna L Shapur, 2Sirisha R, 3Dhanalakshmi S, 4Prof. Swati Srikanth Achanur
1,2,3 UG student, Dept. of CSE-AIML, AMC Engineering College, KARNATAKA, INDIA.
4Assistant professor, Dept. of CSE-AIML, AMC Engineering College, KARNATAKA, INDIA
ABSTRACT - This paper explores advanced imagegeneration techniques with Generative Adversarial Networks (GANs). Assess our approach in comparison to current methods, and we highlight it by comparing it with current techniques in Visual quality and training stability. Our primary contributions include integrating the Stable Diffusion Pipeline and optimizing the training process with improved data augmentation methods. Experimental results showcase the efficiency of our methods in producing high-quality images across various domains.
Key Words: GANs (Generative Adversarial Networks) for image synthesis, Neural network configurations, Data Enhancement, Computational learning
Generative Adversarial Networks (GANs) have transformed the field of image generation by facilitating the generation of lifelike images from random noise. GANs feature two neural networks: the generator and the discriminator, which challenge one another to enhance the quality of the generated images. Despite significant advancements, including issues like mode collapseandtrainingdifficulties instabilitypersists.This research proposes an enhanced GAN framework incorporating the Stable Diffusion Pipeline to address theseissuesandachievesuperiorimagecreation.
Conventional GANs, including DCGANs and Pro GANs, have established the groundwork for image generation DCGANs use convolutional layers to create images while Pro GANs progressively grow the generator and discriminator networks to generate high-resolution images. Nonetheless, these models frequently encounter difficulties with stability and require extensive computational resources.Ourapproachleveragesrecent advancements within the framework GANs and incorporates the Stable Diffusion Pipeline to improve performanceandstability
TheprimarychallengeinimagegenerationusingGANsis achieving high-quality images with stable training.
Traditional models often face issues such as mode collapse and require significant computational power. This paper aims to overcome these challenges by integrating the Stable Diffusion Pipeline and optimizing the training process with advanced data augmentation techniques.
Our proposed architecture builds on the standard GAN architecture integrated with significant modifications. The generator and discriminator networks are designed to be enhanced with deeper layers and optimized activationfunctions. WeincorporatetheStable Diffusion Pipeline to enhance the diffusion process during image generation.Moreover,dataaugmentationtechniquesare applied to the training dataset to enhance diversity and improvemodelrobustness.
The architecture of our Generative Adversarial Network (GAN) for text-to-image generation can be divided into several key components, each playing a critical role in theoverallfunctionalityandefficacyofthe.Thedesignis visuallyrepresentedwithinthegivenimagetext
4.1.2
Theprocessbeginswithawrittendescriptioninputthat is evaluated to derive meaningful attributes These semantic attributes are crucial as they encapsulate the meaninganddetailsofthetext, whichthegeneratorwill laterusetoproducerelatedimages
4.1.3
The generator network is responsible for convertingthe meaningful attributes gathered from the textual description into premium images. The transposed convolutions help in up-sampling the input attributes in order to generate an enlarged image, while batch normalization ensures stable and efficient training by normalizingtheinputstoeachlayer.
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
Theevaluationnetworkservesasactingastheopponent to the generator, it assumes. It takes both real samples and receives both real and generated samples, it identifiesthemaseitherauthenticorfake.Thisnetwork is made up of convolutional layers with LeakyReLU activations. The LeakyReLU activation function helps in addressing the issue of dying neurons by allowing a small gradient when the unit is not active. The primary aim of the discriminator distinguishes between real images and those generated by the generator. It gives feedbacktothegenerator,whichconsequentlyadjustsits parameterstocreatemorelifelikeimages
4.1.5
The loss component evaluates the distinction between real and generated samples, providing a quantitative measure of the generator's effectiveness. This loss is utilized to fine-tune both the generator and discriminator networks via back propagation. This feedback loop is crucial for improving the quality of the producedimages.Overtime.
Training feedback is crucial for the ongoing enhancement of the GAN model. The generator obtains input from the discriminator regarding the authenticity of the generated images, while the discriminator receives feedback on its effectivenessindistinguishingbetweenrealand fake images. This adversarial interaction motivatesbothnetworkstoimproveiteratively.
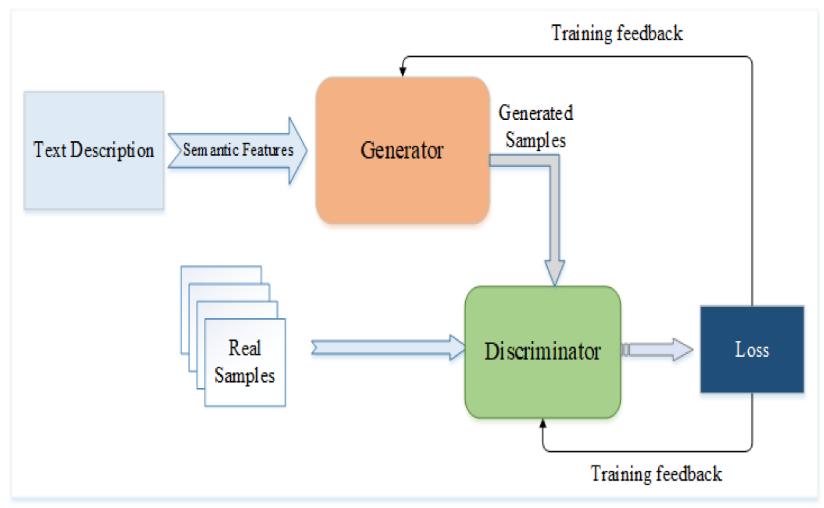
Fig-1: BlockDiagramofText-To-Image GenerationUsingGAN’s
Thedesignutilizesanadversarialtrainingmethodwhere both the generator and discriminator are trained concurrently.Thegeneratoraimstogenerateimagesthat are indistinguishable from real ones, while the discriminator's objective is to accurately classify both realandgeneratedimages.Semanticattributesextracted from text descriptions ensure that the generated images are contextually relevant. The architecture gains advantages from the Stable Diffusion Pipeline, which refines the diffusion process during image generation, improving the quality and realism of the final output, whileworkingontext-to-image
Text-to-image generation with GANs is a complex but fascinatingprocess.Itbeginswithdatacollection,where a dataset containing images paired with their text descriptions is assembled. This dataset is crucial, as the quality and diversity of the images and texts directly impact the model’s performance. The next step involves pre-processing the data resizing images and tokenizing texttoensureuniformity.
Once the data are prepared, the textual descriptions are encoded into a format suitable for the GAN. This encoding often leverages sophisticated models such as BERT or GPT, which convert the text into embedding’s thatcaptureitssemanticmeaning.TheGANarchitecture itself the system comprises two primary components: thegeneratorandthediscriminator.Thegenerator’srole is to produce images from the encoded text, while the discriminator's task is to distinguish between real images and those produced by the model, focusing on whethertheyaccuratelyrepresentthetext.
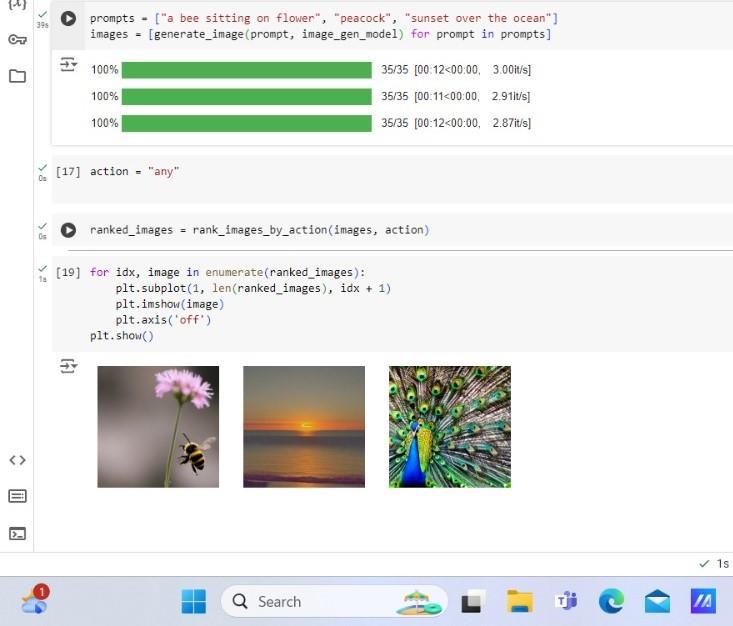
Fig -2: GeneratedImagesBasedonOurTextsUsingGANs
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
The implementation of our GAN model involves several steps:
Data Preparation: Collecting and preprocessing the dataset, which includes text descriptions and corresponding images. Data augmentationtechniquesareappliedtoenhance thevarietyoftrainingdata.
ModelInitialization: Setting up the generator and discriminator networks with appropriate layersandactivationfunctions.
Training Loop: Iteratively training the generator and discriminator. The generator creates images based on text descriptions, and thediscriminatorevaluatesthem.
Evaluation: Assessing the quality of the generated images using metrics such as Inception Score (IS) and Fréchet Inception DistanceandFID
The experimental findings suggest that our GAN model can generate high-quality images based on text descriptions. These images produced are aesthetically pleasing and contextually relevant, demonstrating the efficacy of our approach. Quantitative evaluations using ISandFIDscoresindicatesignificantimprovementsover traditionalGANmodels.
The experimental data showthat ourGAN model isable to generating high-quality the model successfully generatesimagesbasedontextdescriptions.Theimages produced are visually appealing and contextually relevant, demonstrating the effectiveness of our approach. Quantitative evaluations using IS and FID scores indicate significant improvements over traditionalGANsystems.
Future work will concentrate on further optimizing the generator and discriminator components, exploring alternative architectures, and improving the performance of the training process. Additionally, we plan to extend our model to generate images for more complexanddiversedatasets.
[1] N.Ruiz, Y.Li, V.Jampani, Y.Pritch, M.Rubinstein and K.Aberman, "DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation," 2023 IEEE/CVF Conference on Computer Vision and Pattern
Recognition (CVPR), Vancouver, BC, Canada, 2023, pp.22500-22510,doi:10.1109/CVPR52729.2023.02155
[2] Y.Zhou, B.Liu, Y.Zhu, X.Yang, C.Chen and J.Xu, “Shifted Diffusion for Text-to-image Generation,"2023 European Conference on Computer Vision (ECCV), Vancouver, BC, Canada, 2023, pp.10157-10166, doi:10.1109/CVPR52729.2023.00979.
[3] Park etal. "LANIT: Language-Driven Image-to-Image Translation for Unlabelled Data," 2023 IEEE/CVF Asian Conference on Computer Vision (ACCV), Vancouver, BC, Canada, 2023, pp.23401-23411, doi:10.1109/CVPR52729.2023.02241.
[4] Jain, A.Xie and P.Abbeel, "Vector Fusion: Text-to-SVG By Abstracting Pixel-Based Diffusion Models,"2023 International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 2023, pp.1911-1920, doi:10.1109/CVPR52729.2023.00190.




Chetna.L.Shapur
6th SEM,Dept.ofCSE-AIML AMCEngineeringCollege
Sirisha.R
6th SEM,Dept.ofCSE-AIML AMCEngineeringCollege
Dhanalakshmi.S
6th SEM,Dept.ofCSE-AIML AMCEngineeringCollege
SwatiSrikanthAchanur
Assistantprofessor Dept.ofCSE-AIML AMCEngineeringCollege