
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
Deepak Raj Iti1 , Vandana Jada2 , Praveen Kandukuri3 , Divyanjali Peraka4
1Student, Dept. of Electronics Engineering, Indian Institute of Technology (ISM), Dhanbad
2Student, Dept. of Data Science, Texas A&M University, College Station
3Student, Dept. of Metallurgical Engineering, National Institute of Technology, Tiruchirapalli 4Operations Research, UC Berkeley, Berkeley ***
Abstract - Data processing is essential in machine learning pipelines to ensure data quality. Many applications use userdefined functions (UDFs) for this, offering flexibility and scalability. However, the rising demands on these pipelines present three challenges: low-code limitations, dependency issues, and a lack of knowledge awareness. To tackle these,we propose a new design pattern where large language models (LLMs) serve as a generic data operator (LLM-GDO) for effective data cleansing, transformation, andmodeling.Inthis pattern, user-defined prompts (UDPs) replace specific programming languageimplementations,allowingLLMstobe easily managed without runtime dependency concerns. Finetuning LLMs with domain-specific data enhances their effectiveness, makingdataprocessingmoreknowledge-aware. We provide examples to illustrate these benefits and discuss the challenges and opportunities LLMs bring to this design pattern.
Key Words: LargeLanguageModels,DataModeling,Data Cleansing,DataTransformations,DesignPattern
1.INTRODUCTION
Machine learning (ML) drives a variety of data-driven applications across different use cases. A typical machine learningpipelinecomprisesseveralsteps:dataprocessing, feature engineering, model selection, model training, hyperparametertuning,evaluation,testing,anddeployment [1].Manyofthesestepsrequirehigh-qualitydatatoensure thatmachinelearningapplicationsperformasexpected,and they often benefit from large volumes of data to support effectivetraining[2]
However, most reliable datasets are generated through human annotations, a process that is both expensive and time-consuming, making it difficult to scale. As machine learning models become more complex and involve increasing numbers of parameters, the demand for vast amountsofhigh-qualitydatafortrainingcontinuestogrow. Data processing tasks must also adapt to this increasing need for effective data cleansing, transformation, and modeling. Therefore, this work focuses primarily on the transformationprocessasdefinedinatypicalETL(Extract, Transform,Load)frameworkindatawarehousing.
To support the growing demand for data transformation, user-definedfunctions(UDFs)arecommonlyutilized.These functions clean, transform, and model data within a data warehouseordatalake[3].AtypicalUDFtemplateiswritten in a Pythonic style, allowing users to import runtime dependencies,implementprocessinglogic,andhandleinput data. When a UDF is applied to a database, following a narrowtransformationmodelinSpark[4],itprocesseseach rowofdataindividually,storingthetransformedrows.
TheUDFdesignpatternoffersthreesignificantadvantages inlarge-scaledataprocessing:
1.Flexibility:Userscanimplementtheirowndataprocessing logic,evenifitisn'tsupportedbybuilt-infunctions.
2.Modularity:UDFsprovideabstraction,facilitatingbetter understanding,debugging,andreusabilityofcode.
3.Scalability:UDFscaneasilyscaleusingbigdataprocessing engineslikeSpark.
Despitetheseadvantages,UDFsalsofaceseveralchallenges:
1.Notlow-codeorzero-code:Usersmustpossesssubstantial programmingskillsandexperiencetocreateUDFs.
2.Notdependency-free:UDFscanrequirecomplexruntime environments, making dependency management difficult during development and deployment. If UDFs have completelynon-overlappingruntimedependencies,separate pipelinesareneededforeach.
3. Not knowledge-aware: It is challenging to incorporate priorknowledgeintoUDFsfordataprocessingtasks.This knowledgeisoftentask-specific;forinstance,classifyingecommerce item categories requires extensive domain expertise to identify item attributes. Integrating such knowledgedeterministicallyintoUDFsiscomplicateddueto thevastcombinationsofitemattributes.
Recently,thedevelopmentofartificialintelligence(AI)has made significant progress with the emergence of Large Language Models (LLMs). Models like Llama2 and GPT-4 havedemonstratedtheireffectivenessinaddressingawide rangeofdownstreamtasks,suchasquestionansweringand multi-stepreasoning,thankstotheiremergentabilities.This
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
progress has narrowed the gap between natural language processingandprogramming.
With well-crafted prompts, users who lack extensive experienceindataprocessingcaneffectivelyuseanLLMto extract product features tasks that typically require expertisefrome-commerceprofessionals[6].Thiscapability, which relies solely on natural language instructions and input-output examples without the need to optimize any parameters,isknownasin-contextlearning.Thisin-context learningallowsLLMstounderstandfew-shotandevenzeroshot learning tasks, such as tabular data classification [7] andanomalydetectioninsystemlogs[8].
Likeotherpre-trainedmodels,theperformanceofLLMscan be further enhanced through fine-tuning techniques. Approaches like LoRA and QLora optimize the rank decompositionmatricesofthedenselayerswithinaneural network, leading to LLMs that can achieve humancomparable results in many tasks [9]. This advancement reduces the human effort required for labeling and annotation.
In our paper, we address the limitations of current userdefinedfunction(UDF)-baseddataprocessingpracticesand summarizeanewdesignpatternthatincorporatesLLMsand user-defined prompts (UDPs) to balance flexibility and human-levelaccuracy.WeproposethatLLMswithUDPscan serve as Generic Data Operators (LLM-GDOs) for data cleansing,transformation,andmodeling.Anexampleofthe LLM-GDOdesignpatternisillustratedinFigure1-(b).
IntheLLM-GDOdesign,wesimplifytheUDFconceptwith twomainchanges.First,insteadofdefiningaprogramminglanguage-based UDF, users can create prompts or prompt templatestodescribedataprocessinglogic,resultinginlowcode and zero-code solutions. When the data distribution changes, users can easily update the processing logic by modifying the instructions and examples in the prompts, ratherthanalteringtheprocessingcode.Unlikeatraditional UDF,whichrequiresruntimedependenciesforexecution,an LLM (whether pre-trained or fine-tuned) can act as a compiler for the prompt and execute requests independently,withoutdependencies.
By maintaining the same LLM under appropriate version control, we can align offline development with online serving.Indataprocessing,thedatabasecommunicateswith the remote LLM resource through LLM gateways (suchas APIs or agents), where the LLMs are managed to handle requests.Werefertothisfunctionasan"LLMcall,"withthe implementation details handled by platforms, effectively abstractingcomplexityfromusers.Byfine-tuningLLMs,we can seamlessly integrate domain-specific knowledge into them using a small dataset, thereby enhancing their performanceonspecifictasks.
AlthoughLLMsareversatiletools,theydohavelimitations that we must continue to address. To provide a comprehensive overview of this design pattern, we also explorethechallengesitpresents.
Ourcontributionsaresummarizedasfollows:
- We introduce the LLM-GDO design pattern for machine learning(ML)pipelinesinbigdatacontexts.
-WesummarizethepotentialapplicationsofLLM-GDOs
- We discuss the challenges and opportunities associated withLLM-GDO.
1.NarrowTransformationsandWideTransformations:
Datatransformationsrefertotheinstructionsusedtomodify therowsofadatabase.InSpark,datatransformationscanbe categorizedintonarrowtransformations(Figure2-(a))and wide transformations (Figure 2-(b)), depending on the dependenciesbetweendatapoints.Typically,theoutputofa narrowtransformationdependsononlyoneinputdataset, meaningthereisnodatashufflinginvolved.Incontrast,the outputofawidetransformationreliesonmultipleinputrows andinvolvesdatashuffling.Inourpaper,wefocusonnarrow transformations, as they are predominantly used in earlystagedataprocessingstepstoenhancedataquality.
2 LLMs:FunctionCallingandFine-Tuning:
Therearevariousmethodstoaccesslargelanguagemodels (LLMs),withtheOpenAIAPIbeingonepopularoption.Inour paper, we assume that the LLM gateways are mainly maintained by the platforms, whether they are remote or local. In Figure 1-(b), we represent LLM function calling throughthe‘llmcall’function.Thisfunctiontakesaformatted user-defined prompt (UDP) and returns the processed output.LLMscanbefine-tunedusingasmallsampleofhighqualitydata.Asnewdataentersthedatabase,theplatform can seamlessly fine-tune the LLMs by extracting a small sampleofhigh-qualitydata.

-1:(a)UDFdesignpatternand(b)LLM-GDOdesign pattern.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
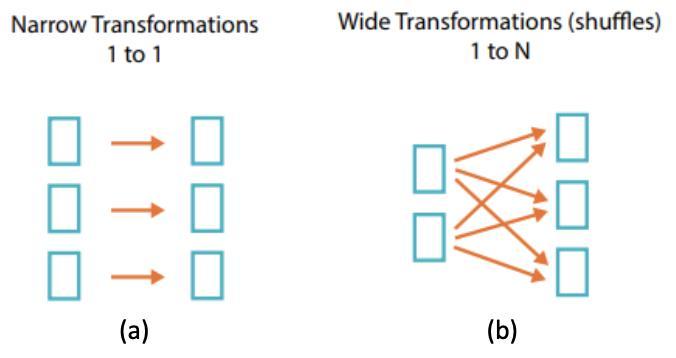
-2:(a)NarrowTransformationsand(b)Wide Transformations
Inthissection,wepresentalistoftaskswhereLLM-GDOs (Large Language Model-Generated Data Operations) could enhance User DefinedFunctions (UDFs).It is importantto note thatLLMsare still evolving,soweprimarily focuson design patterns in this section to illustrate the connection betweenUDFsandLLM-GDOs.Acomprehensivediscussion about the challenges of current LLM-GDO design will be provided in Section IV. For brevity, we will reuse the definitionof"userdefinedfunction"fromFigure1-(b)inthe followingcasestudies.AllexampleLLMoutputsinthispaper weregeneratedusingChatGPT3.5.
A.DataCleansingandTransformation
Datacleansingandtransformationarecrucialstepstoensure theperformanceofamachinelearningpipeline.Tocompare UDFsandLLM-GDOsindatacleansingandtransformation, weconsiderasampletabletitled"itemrating,"asdefinedin Figure 3. The following three tasks illustrate the low-code featureanddependency-freeattributeofLLM-GDOs:

Fig -3:Asampletable‘itemrating’withcolumns‘itemid’, ‘userid’,‘userrating’and‘date’.
1 Data Structural Consistency: Ensuring data structural consistencyisusuallyoneoftheinitialsteps.Ithelpsorganize the data to improve downstream transformations. In the "item rating" table (Figure 3), the "date" column contains datestringsindifferentformats.Figure4showsanexample ofhowtostandardizethedatedata.WithLLM-GDOsinUDFs, wecanspecifythedesiredoutputformat(YYYYMMDD)inthe promptandallowtheLLMstomanagethedataprocessing (see Figure 4-(b)). Traditional UDFs can complete this structuralizationaswell,buttheytypicallyrequireeitherthe enumerationofdateformatsortheuseofvariouspackages.
2. Data Type Conversion: After achieving better structural consistency,wecanconvertdatafromonetypetoanother. Figure 5 presents an example of converting date data into UNIX epoch time. Again, the LLM-GDO performs this data transformation based on the instructions provided in the prompt, while traditional UDF users must understand the definitionofUNIXepochtimetoimplementitorknowwhich packagestoutilize.
3 Data Standardization: Another important task is normalizingnumericdata.Inmanymachinelearning pipelines, the normalization of numeric values enhances the stability of model training. Figure 5 illustratesanexampleinwhichLLM-GDOisemployed tonormalizethe"userrating"columnbyprovidingthe appropriateratingrange.
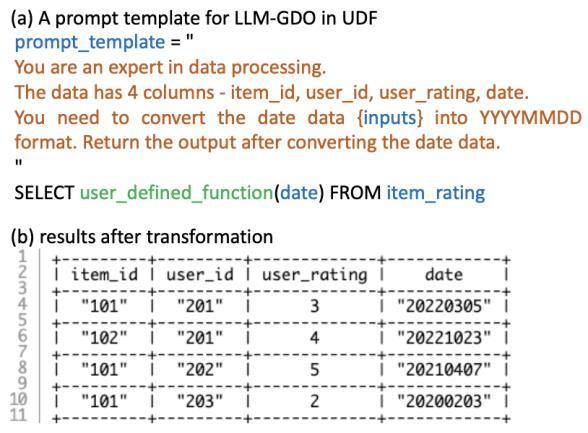
Fig -4:LLM-GDO-baseddatatransformationfordata structuralconsistency.
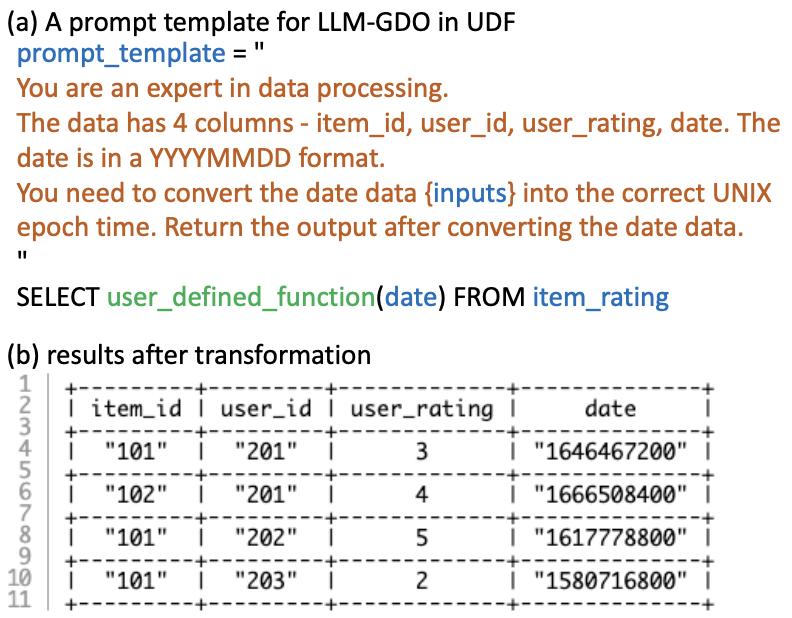
Fig -5:LLM-GDO-baseddatatransformationfordatatype conversion.
In addition to data cleansing and transformation, many featureengineeringstepsrequiremachinelearningmodels forbasicreasoningandgeneratinghigh-qualityfeatures.For
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
example,inmanynaturallanguageprocessing(NLP)tasks, word annotations and tagging are critical features for modeling [10] [11]. These features often necessitate a dedicatedmachinelearningpipelinetoextractthem,which canbeinconvenienttomaintainwithoutpropersupportfrom machine learning operations. Users must thoroughly understandthemachinelearningpipelinetoexecuteauserdefinedfunction(UDF)thatutilizesthesecomplexmodels, managing dependencies and an additional layer of data processing.
However, LLM-GDOs (Large Language Model-based GeneralizedDataOperations)maintainthesameconvenience withauniformapproach.Weconsideranewsampletable, ‘iteminformation,’asdefinedinFigure6.Wehighlightthis advantagethroughthefollowingtwotasks:
1 Reasoning:Inthistask,weneedtoparseeachrowofdata and perform reasoning (e.g., classification) to generate output.Acommonusecaseisdetectinganomalousvaluesin the database. For instance, in many system log databases, systemerrormessagesarecategorizedbyseveritylevelsor typesofevents.Anotherexampleiscategorizingitemsinto product types in e-commerce for item display. While classification may yield invalid outcomes, identifying anomaliescan be challenging due to the vast data volume. Anomaly detection could be achieved through separate machine learning pipelines, but integrating them into the database poses difficulties. First, these machine learning pipelines come with different dependencies and require domainknowledge.Second,astheunderlyingdatachanges, modelsmaynotbeupdatedwithoutaproperorchestration systemformodelretraining.

Fig -6:Asampletable‘iteminformation’withcolumns ’itemid’,‘itemtypes’and‘itemname’.

Fig -7:AnLLM-GDOapplicationfordatareasoningand anomalydetectiononitemtypeclassification.
LLM-GDOcanperformreasoningtodetectanomaliesinsuch cases. Figure 7 illustrates an example of LLM-GDO for anomaly detection in the ‘item information’ table. We can observe that LLM-GDO successfully identifies and corrects theincorrectitemtypeforitem‘103’showninFigure6.In this prompt, we can leverage the in-context learning capabilities of LLMs by designing a suitable prompt. In contrast to traditional UDFs, where users must define complex heuristics or different versions of deep learning models to complete the task, LLM-GDO simplifies logic developmentandmaintenance.LLMsonthebackendcanbe managed centrally, allowing tasks to be powered without exposingtheunderlyingdetailstousers.
2. EmbeddingDatabase:Anothersignificantusecasefordata processingisembeddinggeneration.WithLLM-GDO,wecan producehigh-qualityembeddingsbasedonthe‘itemname’ column.Duetospaceconstraints,wewillomittheprompt examples and output embeddings here. However, this approach enables timely updates to the embeddings for downstreammodeling.
Despite the remarkable human-compatible and programmableperformanceoflargelanguagemodels(LLMs) in data transformation, it is essential to highlight the opportunitiesandchallengesinherentintheLLM-Generative DataOptimization(GDO)designpattern.Thisunderstanding can illuminate potential future research directions and enhanceourcomprehensionofthisevolvingfield.
1.LLMInferenceand Scalability:WhileLLMs demonstrate greater scalability compared to traditional user-defined functions (UDFs), they require significantly more computationalresources.Thisisduetothemassivenumber of parameters in LLMs, which demand extensive computationalresourcesformodelinference.Forinstance,a GPT-3-sizedLLMnecessitatestheuseofeight80GA100GPUs forinference.Additionally,currentcommercialLLMs,suchas GPT-3.5 and PaLM2, have limited response speeds. Nonetheless, research on LLM knowledge distillation [12] and compression [13] presents promising avenues for reducingLLMsizeandcomputationaldemands,ultimately makingthemmorecost-effective,efficient,andscalable.
2. LLMHallucination:Hallucinationreferstoinstanceswhere an LLM generates content that does not exist in the real worldordoesnotmeetthecriteriaspecifiedintheprompt. While hallucination can be advantageous in creative use cases,ittypicallyposeschallengesindata processing[14]. For example, when the desired output format is tabseparatedvalues(TSV),itiscriticaltoavoidinconsistencies, such as using alternative separators, especially when integrating an LLM into a production data engineering pipeline.Variousmethodshavebeenproposedtomitigate andquantifyhallucinationsinLLMs,includingreducingthe model’stemperature,providingmorecontextintheprompt,
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
employing a chain-of-thought approach, ensuring selfconsistency,andspecifyingpreciseformattingrequirements withintheprompt.Despitetheseefforts,effectivelydetecting andpreventinghallucinationsinLLMsduringdataprocessing remainsasignificantchallenge.
3. LLM Unit Testing and Evaluation: Traditional UDFs are typicallydeterministic,whichfacilitatesthedevelopmentof unitteststoassesstheircorrectness.Incontrast,LLMsusea generativeapproachtoproduceresultsbasedonprobability [15], making universal testing more challenging. Recently, someteamshaveleveragedlargerLLMstogenerateunittest cases (e.g., expected outputs) for prospective LLMs. We believethatLLMunittestingwillgarnermoreattentionin LLMdevelopmentandapplication.
4.LLMPrivacy:Fine-tuninganindustry-levelLLMfordata processing may require data from various departments, which involves data transition and sharing. For instance, when processing data from a social application, customer profiles and preferences are highly sensitive. Such data sharingincreasesthelikelihoodofdataleaksandmayviolate data privacy policies [16]. Recent studies in federated learning address privacy concerns related to LLMs. We anticipategrowingresearchinterestinLLMprivacyissues.
5. CONCLUSIONS
In this paper, we introduce a novel design pattern called LLM-GDO, which aims to enhance the efficiency and reliabilityofdatatransformation.LLM-GDOleverageslowcodeanddependency-freeimplementationsforknowledgeaware data processing. However, it also faces challenges associatedwithlargelanguagemodels(LLMs).Weexplore these challenges and opportunities, providing a comprehensiveperspectiveontheLLM-GDOdesignpattern.
[1] M.Zaharia,A.Chen,A.Davidson,A.Ghodsi,S.A.Hong,A. Konwin-ski, S. Murching, T. Nykodym, P. Ogilvie, M. Parkhe et al., “Accelerating the machine learning lifecyclewithmlflow.”IEEEDataEng.Bull.,vol.41,no.4, pp.39–45,2018.
[2] J.Deng,W.Dong,R.Socher,L.-J.Li,K.Li,andL.Fei-Fei, “Imagenet:Alarge-scalehierarchicalimagedatabase,”in 2009IEEEconferenceoncomputervisionandpattern recognition.Ieee,2009,pp.248–255.
[3] A. Nambiar and D. Mundra, “An overview of data warehouse and data lake in modern enterprise data management,”BigDataandCognitiveComputing,vol.6, no.4,p.132,2022.
[4] M.Zaharia,R.S.Xin,P.Wendell,T.Das,M.Armbrust,A. Dave,X.Meng,J.Rosen,S.Venkataraman,M.J.Franklin et al., “Apache spark: a unified engine for big data
processing,”CommunicationsoftheACM,vol.59,no.11, pp.56–65,2016.
[5] https://www.anyscale.com/blog/fine-tuning-llama-2-acomprehensive-case-study-for-tailoring-models-tounique-applications
[6] H.Touvron,L.Martin,K.Stone,P.Albert,A.Almahairi,Y. Babaei,N.Bashlykov,S.Batra,P.Bhargava,S.Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXivpreprintarXiv:2307.09288,2023.
[7] OpenAI,“Gpt-4technicalreport,”2023.
[8] G. Pang, C. Shen, L. Cao, and A. V. D. Hengel, “Deep learning for anomaly detection: A review,” ACM computingsurveys(CSUR),vol.54,no.2,pp.1–38,2021.
[9] C.-Y. Hsieh, C.-L. Li, C.-K. Yeh, H. Nakhost, Y. Fujii, A. Ratner, R. Krishna, C.-Y. Lee, and T. Pfister, “Distilling step-by-step! Outperforming larger language models withlesstrainingdataandsmallermodelsizes,” arXiv preprintarXiv:2305.02301,2023.
[10] X. Zhu, J. Li, Y. Liu, C. Ma, and W. Wang, “A survey on model compression for large language models,” arXiv preprintarXiv:2308.07633,
[11] 2023.
[12] M. Zhang, O. Press, W. Merrill, A. Liu, and N. A. Smith, “How language model hallucinations can snowball,” arXivpreprintarXiv:2305.13534,2023.
[13] Z.Zhang,A.Zhang,M.Li,andA.Smola,“Automaticchain ofthoughtpromptinginlargelanguagemodels,”arXiv preprintarXiv:2210.03493,2022.
[14] [23]J.Huang,S.S.Gu,L.Hou,Y.Wu,X.Wang,H.Yu,and J.Han,“Largelanguagemodelscanself-improve,”arXiv preprintarXiv:2210.11610,2022.
[15] Y. Chang, X. Wang, J. Wang, Y. Wu, K. Zhu, H. Chen, L. Yang, X. Yi, C. Wang, Y. Wang et al., “A survey on evaluation of large language models,” arXiv preprint arXiv:2307.03109,2023.
[16] S.Ghayyur,J.Averitt,E.Lin,E.Wallace,A.Deshpande, and H. Luthi, “Panel: Privacy challenges and opportunitiesinLLM-Basedchatbotapplications.”Santa Clara,CA:USENIXAssociation,Sep.2023.