
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
Pratham
Kiran Mehta1 , Rahul Jain2 , Manan Batra3
1,2,3B. Tech student, Computer Science and Engineering, Vellore Institute of Technology, Tamil Nadu, India
Abstract - ConvolutionalNeuralNetworks(CNN)havebeen at the forefront of advances in the application of Computer Vision. Their automated and adaptive nature helps in the extraction of the hierarchical structures present in input images, allowing them to capture and interpret complex spatial patterns. This ability has made CNNs a powerful and useful tool in the field of image analysis. The work proposed in this paper reviews the use of CNNs for categorizing images into certain categories and outlines the methods that need to be employed for pre-processing this novel dataset to feed into the CNN model. In this regard, by consideringthetenstandard object classes of CIFAR-10 dataset, several CNN models were trained to classify these images and compared them against the others to show the effectiveness of each. When training and testing the model, its performance is quantitatively evaluated using measures such as accuracy, precision, validation loss and the loss function. These metrics define the degree of success of the selected architecture. This work contributes to the existing knowledge of CNNs applied to image classification tasks with new datasets and can serve as helpful suggestions in changing the basic structure for object recognition aims.
Key Words: Convolutional Neural Network, CIPHAR-10, Image processing, Image classification, ResNet
1.INTRODUCTION
ConvolutionalNeuralNetworks(CNN)areasubtypeofdeep learning algorithms that are mostly used to solve identification and detection problems, such as image recognition,detection,anddivision.TheseCNNsresemble otherneuralnetworksbuttheuseofmultipleconvolutional layers makes them slightly complex. These convolutional layersuseafunctioncalledaconvolution,whichisaformof matrixmultiplication.Thisentailstheuseofsmallpartsof the input data to extract the appearance characteristics, whileatthesametimepreservingthespatialconfigurations ofpixels.
CIFAR-10isanotherpopularsetofimagesthatismaintained bytheCanadianInstituteforAdvancedResearchandisused to train most vision and machine learning models. This is oneofthemostpopulardatasetsusedinstudiesrelatedto machinelearning.CIFAR-10comprisessixtythousandcolor images of 32×32 pixels and are classified into ten classes. Theseclassesincludeairplanes,trucks,cars,frogs,dogs,cats, deer,andbirds,andeachclasshas6000images.
LeNet which was first introduced in 1998 by Yann LeCun andhisco-workersCorinnaCortesandChristopherBurges wastargetedforthehandwrittendigitrecognition.LeNetis oftendescribedasthe ‘HelloWorld ’ofdeeplearningandis one of the first successful convolutional neural network (CNN)architectures.Itsnetworkarchitecturecomprisesof numerous convolutional layers, pooling layers, and fully connected layers. Particularly exceptional, the presented model has five convolutional layers followed by two fully connectedlayers.LeNetwasthefirsttointroduceCNNsin the field of deep learning for computer vision processes. However,themodelabovefailedatfirsttolearnduetowhat isknownasthevanishinggradientsproblem.Torectifythis, max-pooling layers were included to be added within the convolutionallayerstominimizethesizeoftheimages.This isnotonlyusefultoavoidoverfittingbutalsoimprovesthe trainingspeedofCNNs.AlexNetwascreatedbyI.Sutskever, G.HintonandA.Krizhevsky.Therearesimilaritieswiththe LeNet architecture at this level, with a larger number of layers and stacking of convolutional layers. In AlexNet architecture,ithasfiveconvolutionallayersthatareblended with max-pooling and other layers, three fully connected layers, and two dropout layers. In each layer there is an activationfunctionofReLUkind,andtheoutputlayerhasan activationfunctionofSoftmaxkind.Intotal,thearchitecture hasabout60millionparameters.
ZFNet is a CNN architecture composed of convolutional neuralnetworksandfullyconnectedlayersaswell.Itwas created by Rob Fergus and Matthew Zeiler. Like AlexNet, ZFNet also follows the network architecture with several layersofconvolutionallayersandsetsofpoolinglayersbut thesizeofthemiddleconvolutionallayershasbeentuned,as has the stride and the filter size of the first layer. The architectureisbasedonthemodeldevelopedbyZeilerand Fergus which was used to train the models with the ImageNet data set. ZFNet consists of seven layers: a convolutional layer, a downsampling max-pooling layer, a concatenationlayer,anotherconvolutionallayerthatusesa linearactivationfunctionandwhichhasastrideofone.To increasetheregularization,dropoutisimplementedbefore the output layer which is a fully connected layer. After observing the article, ZFNet is more efficient in terms of computational requirements as compared to AlexNet becausedeconvolutionallayersareplacedinbetweenCNNs that provide an approximation inference. GoogLeNet is designedbyJeffDean,ChristianSzegedy,AlexandroSzegegy
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
andtheircolleagues.Thismodelissuperiorintheerrorrate compared with previous ILSVRC competition champions includingAlexNet(the2012winner)andZF-Net(the2013 winner). It also achieves a lower error rate than VGG, the second best algorithm in 2014. There are several unique featuresusedinthearchitecturetoenhanceitsdepth,which includeglobalaveragepoolingand1x1convolutionallayers. Theyincludeshortcutstolinkthefirstconvolutionallayers butaddmorefiltersinotherCNNlayers.Further,itapplies several unpooling layers on the top of CNNs during the trainingstageforremovingthespatialredundancyandthus reducesthenewparameterstobelearned.AsforVGG16,it standsfor ‘VisualGeometryGroup16 ’andwascreatedby AndrewZissermanandKarenSimonyan.TheVGGNethasup to16layersthatareimplementedasCNN layers,andthis modelhasupto95millionparametersthatwereoptimized withthehelpoftrainingthemodelonadatasetcontaining overonebillionimagesbelongingto1000classes.VGGNetis capable of taking large input images of up to 224 by 224 pixels,with4096convolutionalfeatures.Nonethelessifthe inputimagesareusuallysizedbetween100x100to350x 350 pixels which is typical in most image classification problems,architecturessuchasGoogLeNetperformbetter thanVGGNet.ThisissobecauseCNNswithsuchlargefilters as those in VGGNet are costly to train and require large amountsofdata.
ResNetCNNarchitecturewasdesignedbyKaimingandhis team,andtheyachievedacclaimbygettingthefiveerrorrate to15percentontheILSVRC2015classificationchallenge. Thisnetworkcanberegardedasverydeepevenaccording tothestandardsofCNNwith152layersandoveramillion parameters. This model was trained on the ILSVRC 2015 dataset for more than forty days on 32 GPUs. As demonstratedbyResNet,thereisstrongevidencethatCNNs canbeusedinNLPtaskssuchasmachinecomprehension andsentencecompletion.
MobileNetsarethetypesofCNNthathavebeendeveloped specificallyforperformanceonmobiledevicesandcan be usedtoservephotoclassificationsandobjectidentification inreal-time.ProvidedbyAndrewG.Trillion,thesecompact CNNarchitecturescanbeusedinreal-timeapplicationssuch assmartphonesanddrones.Thisflexibilityhasbeenshown througharangeofCNNswith100-300layersinmanycases surpassingothernetworkconfigurationssuchasVGGNet.
This paper by Neha Sharma, Vibhor Jain and Anju Mishra presents an experimental analysis to determine the performanceofpopularCNNarchitecturessuchasAlexNet, GoogLeNetandResNet50inreal-timeobjectdetectionand classificationscenarios.Throughtheinputofdatasets like ImageNet,CIFAR-10,andCIFAR-100,thestudyprovesthat GoogLeNet and ResNet50 are more precise compared to AlexNet. It examines the effects of different networks structuresandtrainingstrategiesonCNN’ sperformancein
various image classification tasks and discusses the importanceoffeatureextractionandDeeplearningforthe developmentofComputerVisionapplications.[1]
Krizehvskyetal2012succeededinimprovingperformance throughDeepConvolutionalNeuralNetwork(CNN)byuseof fivelayersofconvolutionandthreelayersoffullconnection where training was enhanced using Rectified Linear Unit (ReLU). This model utilized local response normalization (LRN) adopted from actual neurons that employ lateral inhibition and was trained through stochastic gradient descent with momentums that enable the search for the optimum in the high dimensional loss of deep learning networks.Thewell-organizedstructureofAlexNetplacedit at the top of all the previously developed models in the arenasoftheILSVRC.[2]
IntheresearchstudybySultana,A.SufianandP.Dutta,they investigatetheapplicabilityofdeeplearningmethodssuch asCNNsintheCIFAR-10imageclassificationtask.CNNsare emphasizedontheirusageinhandlinglargeamountofdata andthecapabilityinextractingcomplexfeaturesinmultilayered approach. The research encompasses stages like data preparation, model building, and model assessment, focusingonhowarchitecturaldecisionsandpropertuningof hyperparameterscontributetoachievinghighaccuracyand robustnessinimageclassificationproblems.[3]
Specifically, Ajala’ s studies focus on Convolutional Neural Networks(CNNs)forimageclassificationusingtheCIFAR-10 dataset. The paper includes an analysis of the existing methods based on traditional neural networks and points out their shortcomings, such as the lack of efficiency in featureextractionandlimitedpossibilitiesforgeneralizing the model.However,CNNs, including learnable filters and pooling layers, can learn features on their own, which furtherimprovestheperformanceofthestudy.Toprevent overfittingandincreasethemodelaccuracysometechniques includedropoutandregularizationareused.Italsoanalyzes different structures of CNN and enhances them for higher performancewiththeCIFAR-10dataset,whichisanother focusoftheresearch.[4]
Theauthorsofthepaper ‘ImageclassificationusingSVMand CNN ’seektodemonstratethesuperiorityofCNNmodelin image classification over SVM models. CNN models have convolutional, pooling and fully connected layers, which makesitpossibleforthisnetworktograspspecialhierarchy facilitating feature representation at different levels of abstraction. 75% accuracy of CNN model reveals it can processintricateimagedataandbigdata.[5]
ThestudyfocusesonConvolutionalNeuralNetworks(CNNs) fortheclassificationofimages,targetingcow-teatimagesas asampledataset.Theauthorsbrieflydiscusstheadvantages ofusingCNNsoverconventionalapproachesandnotethat CNNs have the ability to learn and extract hierarchical features from images. An efficient guide to designing and
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
training a CNN from scratch in a paper as it accurately demonstrates its effectiveness in classifying images into certain classes. The study focuses on the options for architecturaldecisionsaswellasoptimizationmeasuresto enhancethemodel’ sperformanceandaccuracylevels.[6]
TheauthorsdiscusstheuseoftheCNNforCBIR,andtheir work specifically uses the CIFAR-10 dataset. This work relatestotheshortcomingsoftraditionaltext-basedimage search techniques and offers an algorithm of enhanced accuracyinimageclassification.Hence,throughtrainingand testingonspecificclasses(airplane,bird,andcar),thestudy showcases the potential of CNNs in achieving 94% classification accuracy based on the features. The study stressestheneedtoenhancetheperformanceofalgorithms forimprovingtheirrecallrates.[7]
CIFAR-10datasetisdiscussedinthispaperastheauthors considerConvolutionalNeuralNetworks(CNNs)forimage classification.Thepaperfocusesonthefundamentalrolesof CNNs in computer vision tasks, for example, object recognition acknowledging the ability to learn multiple layersofrepresentationfromthedata.Thepaperexplores theprocessofbuildingtheCNNmodelarchitecturetogether withthedatapreparation,training,andtestingstages.Italso discusses methods like data augmentation and transfer learning that can be used to enhance model performance. Basedonthefindingsofthestudy,itisarguedthatthrough advancement techniques such as regularization and hyperparameter optimization, CNNs perform enhanced accuracy and generalizable performance on image classificationtasks.[8]
EmmanuelAdetiba,OluwaseunT.Ajayi,JulesR.Kala,JokeA. Badejo, Sunday Ajala, Abdullateef Abayomi,theauthors of thispaper,examinedthepossibilityofdeeplearningmodels for the identification of plant species based on the image dataset called Leafsnap. They underscore how accurate identification of plant species is crucial in disciplines like agriculture, climate change and medicine. The classical approaches of plant identification are usually lengthy and may involve expertise that is not easily accessible. To address these challenges, the authors incorporate deep learning methods, where convolutional neural networks (CNNs) have been proven to succeed in many computer visionapplications.Thestudyexaminesfivepre-trainedCNN models namely VGG-19, AlexNet, MobileNetV2, GoogleNet andResNet50.ThebestmodelsontestingwereMobileNetV2 whereweusedtheADAMoptimizerwiththehighesttesting accuracyofabout92%.Whendiscussingfeatureextraction inplantrecognition,theauthorsstressitsimportanceand mention how CNNs eliminate the need for this type of engineeringtoacertainextent.Thepaperalsoprovidesan experimental comparison of the chosen models on architecture, training, and validation stages. The research thenconcludesthatduetothehighperformanceexhibited byMobileNetV2thenetworkcanbeusedwhendesigningan automaticspeciesrecognitionmobileapplicationthatwould
benefit botanists, farmers, and conservationists when identifyingplantspeciesinthefield.Thisstudyaddstothe knowledgeontheapplicationofdeeplearninginbiological sciences, providing practical solutions for real-world challengesinplantspeciesidentification.[9]
The idea here is to pass as much as different transformed images to our model so that the model learns complex patternsandrestrictsitselffromoverfitting.
Thefollowingstepshavebeenimplementedforthesame:
• Image resizing: As the image size from source is 32X32weapply resizefunctionjusttomakesure every image passed to our process is similar in termsofsize.
• Image transformation: We apply different transformation to the image. Details mentioned below. Here one point to note is that we can randomlyapplyeverytypeoftransformationasthis mightleadtounderfitting.Therationaleisthatthe images already have low resolution, andapplying significanttransformationssuchascentercropping, vertical flipping, and others could potentially degrade the model's performance. Apply normalization to image: The mean and standard deviation is taken from different studies researchers have implemented and have them convergefaster.Onecanexperimentwithdifferent imagesizeandstandarddeviationsaswell.
• Apply Random Erasing: It helps in randomly addingsomenoisetotheimage,sothatthemodel canlearntogeneralizebetter.
Stepsfollowedforthemodelingprocess:
1. Definearoughmodelarchitecturetofollow
2. Starting with 2 Convolution layer and 1 fully connectedlayer(fc)
3. Keepaddinghiddenlayerstotheabovemodeland checkofvalidationaccuracyimproves.
4. Noteifweincreasemodellayersandneuronsthis mightleadtoslowertrainingandincreasechances ofoverfitting.Alsoincreasedcomplexitymightlead to getting stuck at saddle point or local minima. Hence to cater all these potential problems, experimented with momentum, dropout & the weightinitialization
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
Thisishowwegetthe8x8imagesizeaftercnn1,maxpool1, cnn2andmaxpool2:
1. 'out_2' is a given parameter when the cnn2 was defined,itistheoutputofcnn2equalto32.
2. 8x8 is the result of the 'image size' after. cnn1, maxpool1,cnn2andmaxpool2:
Inputsizeis32x322.b.aftercnn1,sizeperchannel (totalof16channels)is(32+2*2-5)/1+1=32x32
Aftermaxpool1,sizeperchannel(stilltotalof32 channels)is(32+2*0-2)/2+1(stridesizeisequal tokernelsizeof2)=16x16
Aftercnn2,sizeperchannel is (16+2*2-5)/1+1 =16x16
Aftermaxpool2,sizeperchannelis(16+2*0-2)/2 +1=8x8
3.3 CNN MODELS :
CNNModelV1:
1. 2convolution+maxpoollayers
2. 1 fully connected layers Default runtime using 0 momentumand0dropoutvalue
CNNModelV2:
1. 2convolution&maxpoollayers
2. 2fullyconnectedlayers
3. Defaultruntimeusing0.2momentumanddropout valuep=0.5
CNNModelV3:
1. 2convolution&maxpoollayers
2. 3fullyconnectedlayers
3. Defaultruntimeusing0.2momentumanddropout valuep=0.5
CNNModelV3-V2:
1. 3convolution&maxpoollayers
2. 3fullyconnectedlayers
3. Defaultruntimeusing0.2momentumanddropout valuep=0.5
4. WeightsinitializedusingHeweightinitialization
CNNModelV3-V3:
1. 3convolution&maxpoollayers
2. 4fullyconnectedlayers
3. Defaultruntimeusing0.2momentumanddropout valuep=0.5
CNNModelV3-V4:
Addingonemorehiddenlayer,dropoutvalueandonemore convolutionlayer
1. 3convolutionlayer+BatchNormalization
2. 3Hiddenlayers
3. Defaultruntimeusing0.2momentumanddropout valuep=0.5
4. Results
CNN Model V1:
1. 2convolutions+maxpoollayers
2. 1fullyconnectedlayer
3. Default runtime using 0 momentum and 0 dropout value
International Research Journal of Engineering and Technology (IRJET)
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072

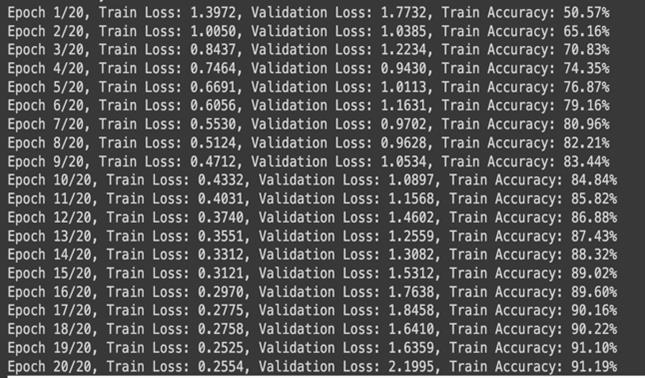
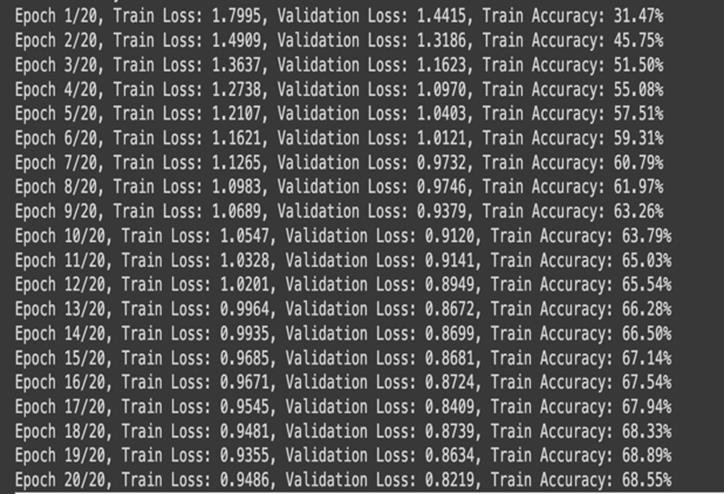
The model was trained over 20 epochs, achieving a final accuracyofover91%andreducingtraininglossfrom1.3972 to 0.2554. The classification report highlights strong performance for the Automobile class (F1-score: 0.7826), whiletheAirplaneclassshowedlowerprecision(0.4422)but highrecall(0.8880).TheoverallweightedaverageF1-score was 0.6512, indicating solid performance with room for improvementincertainclasses.
CNN Model V2:
1. 2convolution&maxpoollayers
2. 2fullyconnectedlayers
3. Default runtime using 0.2 momentum and dropout valuep=0.5
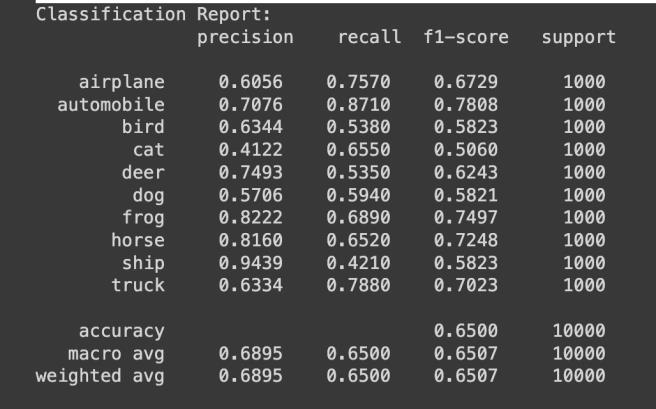
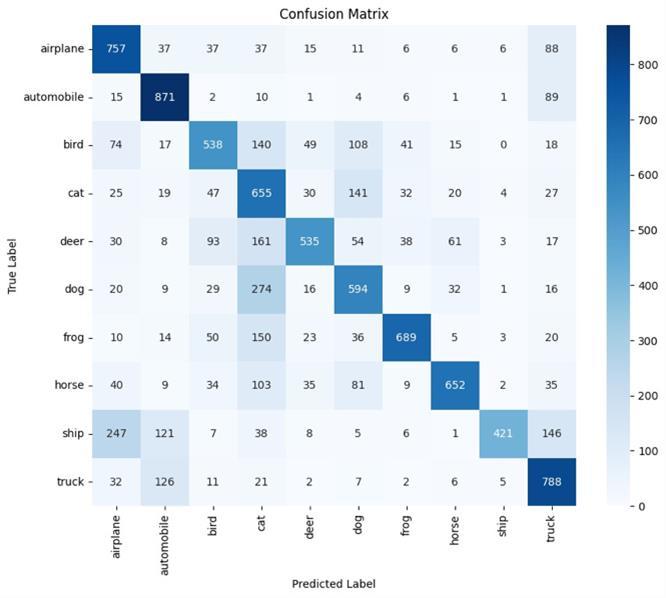

Themodelachieved80%trainingaccuracy afterrunningit for 20 Epochs with validation loss of 0.5569. The model classification report shows average weighted accuracy of 68% with only ship class having accuracy over 90%. The average F1-score came 0.6507 showing room for improvementinthemodel.
CNN Model V3:
1. 2convolution&maxpoollayers
2. 3fullyconnectedlayers
3. Default runtime using 0.2 momentum and dropout valuep=0.5
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
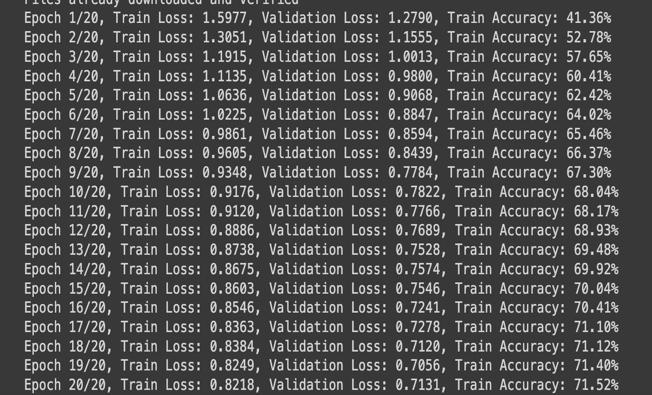
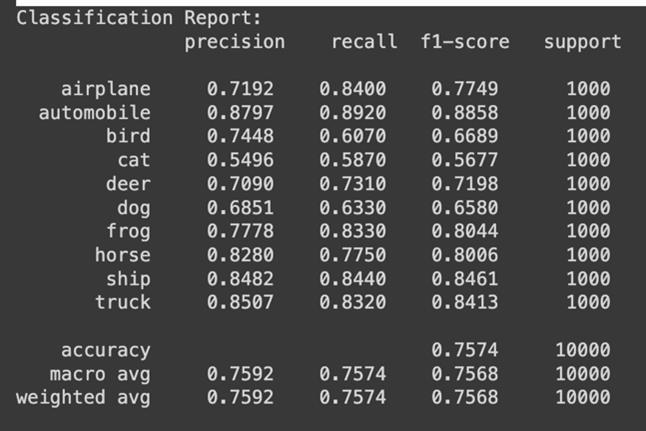

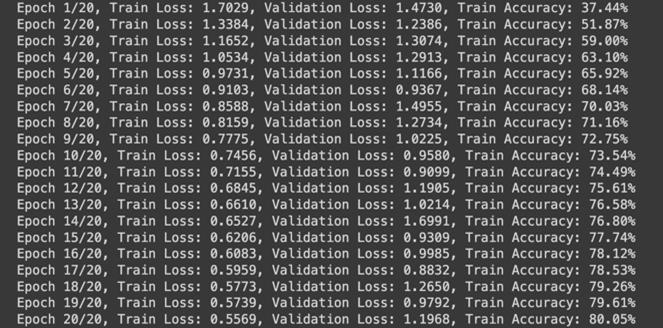
Themodel’strainingaccuracyincreasedfrom40%toover 71% after 20 epochs. Simultaneously, training loss decreased from 1.5977 to 0.8218. Overall, the model achieveda weightedaverageprecisionof0.7592, recall of 0.7574, and F1-score of 0.7568, indicating balanced performance across most classes, yet also shows much neededimprovement.
CNN Model V3-V2:
1. 3convolution&maxpoollayers
2. 3fullyconnectedlayers
3. Default runtime using 0.2 momentum and dropout valuep=0.5
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
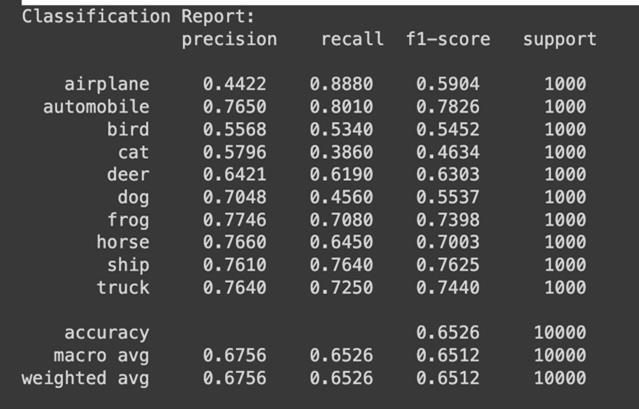
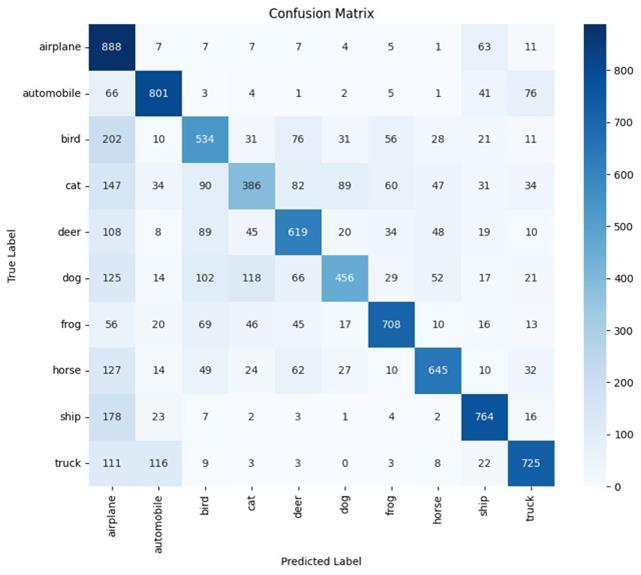
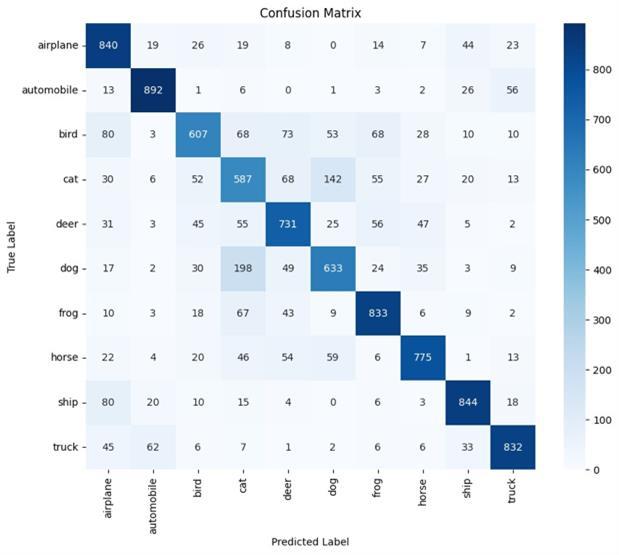
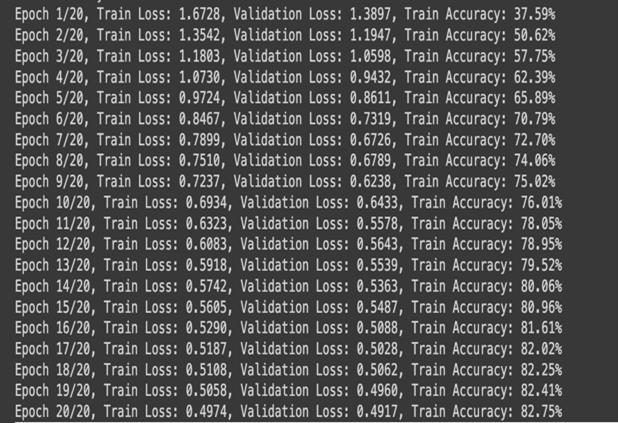
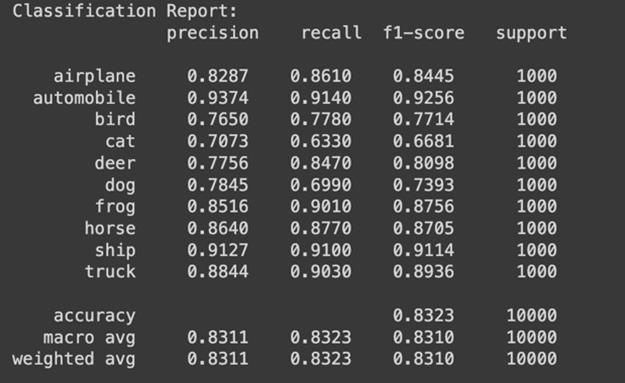
After 20 Epochs training, the model achieved over 83% accuracy.Fromthereport,weseethatthemodeloptimally classifiescertainclasseslikeAutomobiles,ships,andtrucks. However, it struggled to classify bird, cat, and dog images showing further need for improvement and adjustments. TheaverageF1-scoreofthemodelwas0.8310.
CNN Model V3-V3:
1. 3convolution&maxpoollayers
2. 4fullyconnectedlayers
3. Default runtime using 0.2 momentum and dropout valuep=0.5
4. WeightsinitializedusingHeweightinitialization
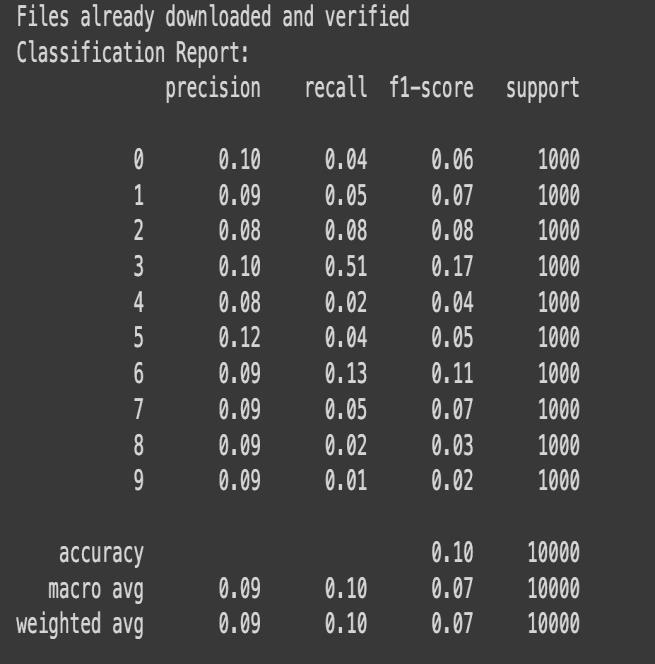
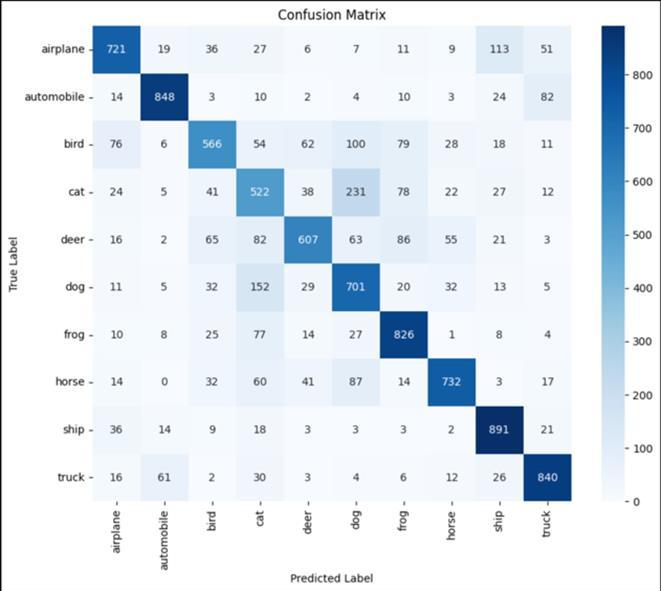

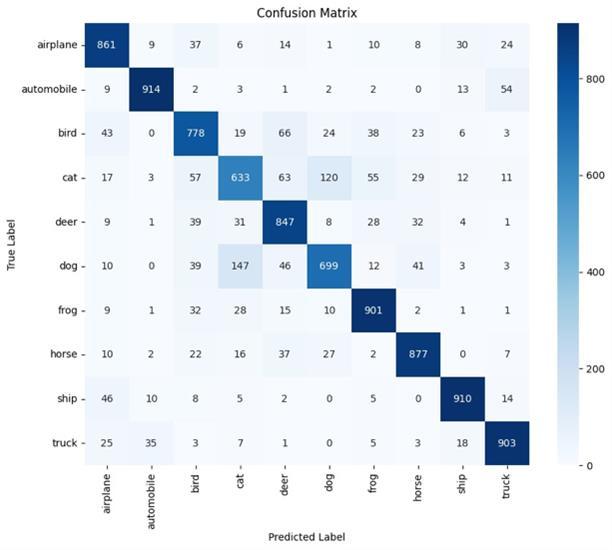
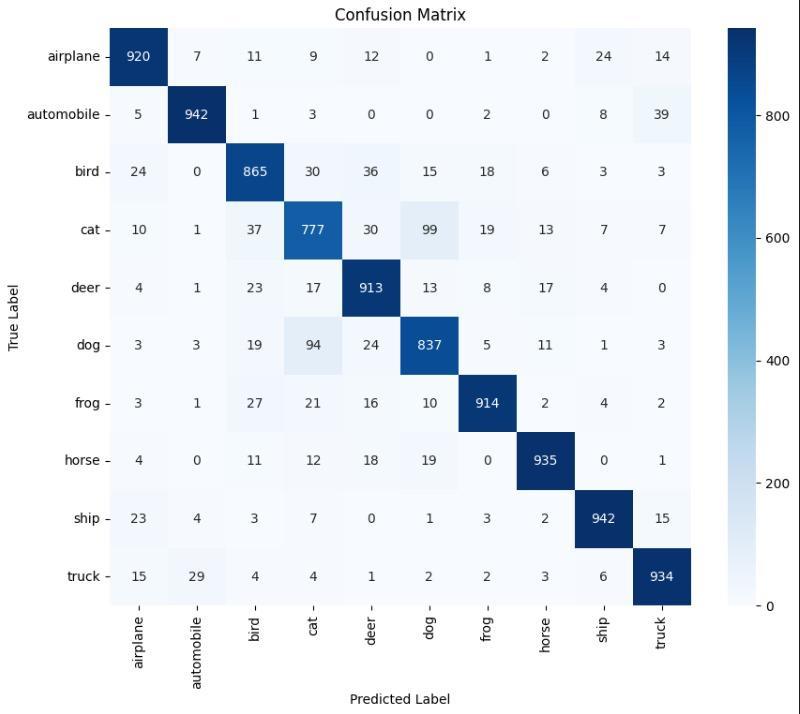
The CNN model V3-V3 demonstrates a decline in both trainingandvalidationlosses,withtrainingaccuracyofless than70%.However,itstrugglestogeneralize,achievinglow validationaccuracy.Theclassificationreporthighlightspoor performanceacrossmostclasses,withclasscathavingthe highest recall and F1-score.The confusion matrix showsa strongtendencytomisclassify,frequentlypredictingcatfor varioustruelabels.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
1. Addingonemorehiddenlayer&dropoutvalue& onemoreconvolutionlayer
2. Total3hiddenlayers,3convolutionlayer&Batch Normalization

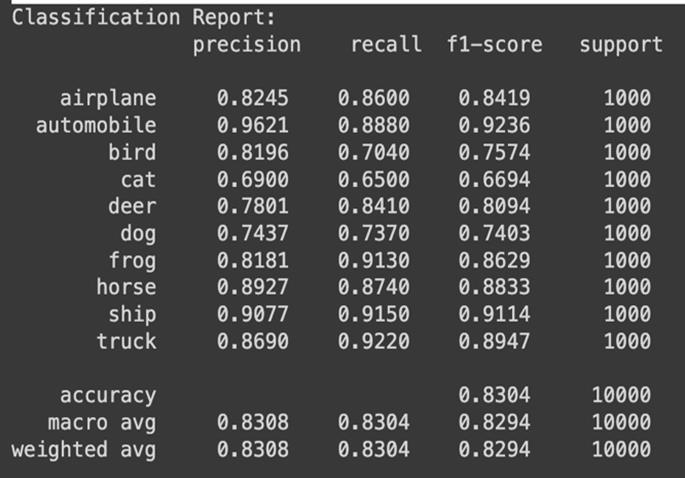
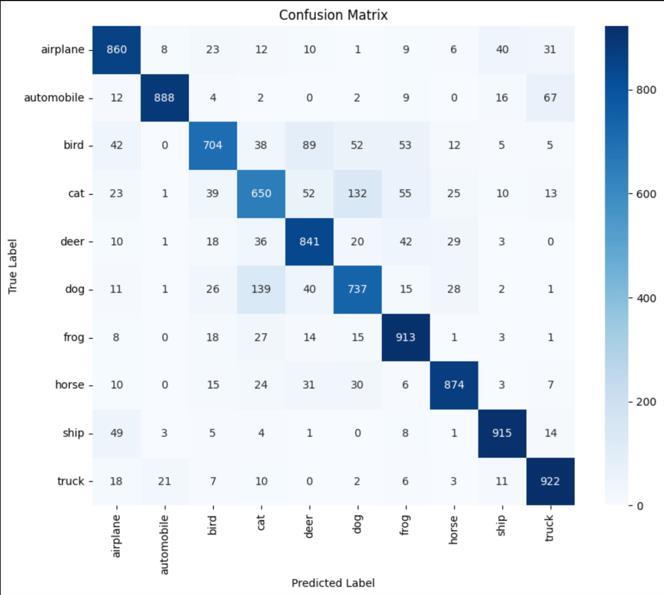

The model achieved over 83% accuracy in classifying the imageswithanaverageF1-scoreof0.8294and0.8304recall score.Itshowedastrongperformanceinclassifyingclasses like Automobile, Ship and Truck with Automobile class having96.21%precisionand88.80%recall.ClassesBird,Cat and Dog show low precision and recall hinting need for improvementandadjustmentstothemodel.
The CNN model ResNet enhances deep learning accuracy through residual connections, enabling deeper networks Thisarchitectureaddressesthevanishinggradientproblem byallowingalternatepathwaysforgradientstoflow,aiding theeffectivetrainingofdeepnetworks.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072

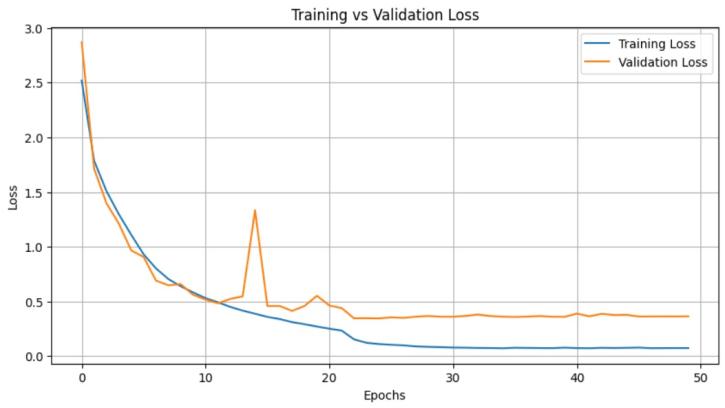
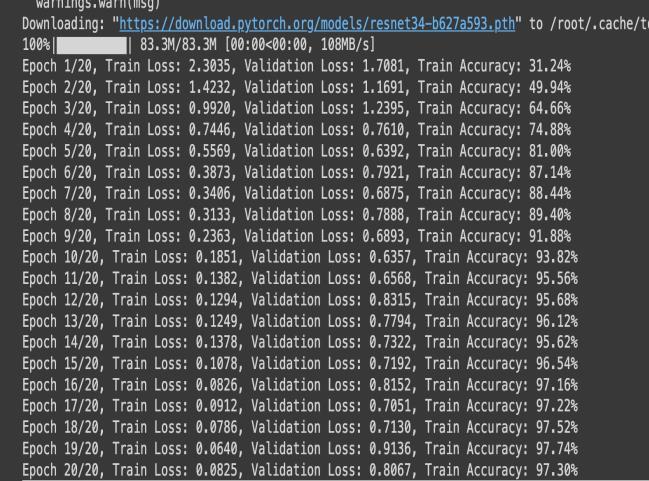
The graph shows the training and validation loss of a ResNet-34 model over 50 epochs. Initially, both losses decrease rapidly, indicating that the model is learning effectively.Aroundepoch10,thetraininglosscontinuesto steadilydecrease,suggestingthemodelisfittingwelltothe training data. However, the validation loss plateaus and showsfluctuations,withanoticeablespikearoundepoch15, indicating potential overfitting. Beyond epoch 20, the validationlossremainsconsistentlyhigherthanthetraining loss, which signifies that the model is learning to fit the trainingdatabutstrugglestogeneralizetothevalidationset.
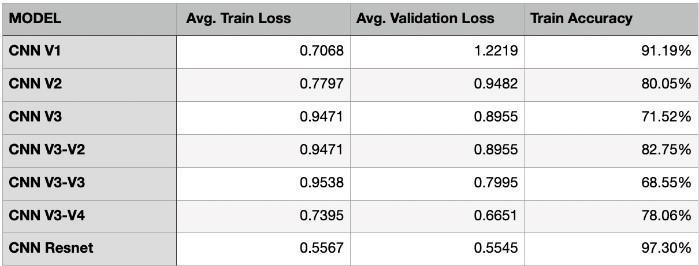
31.ComparisondataofallCNNmodels
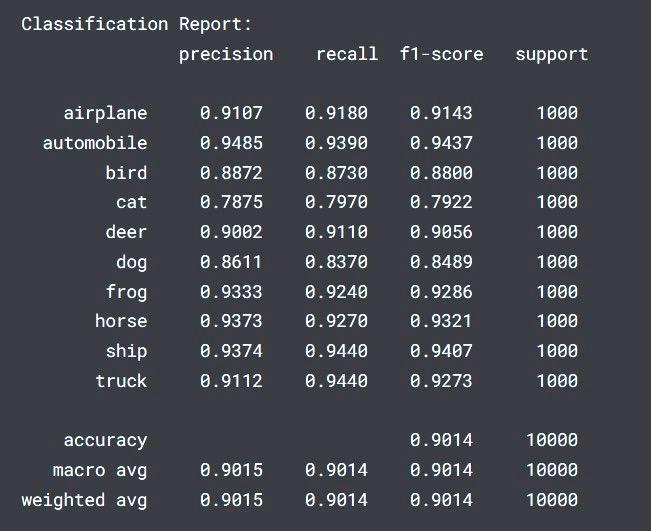
The tablesummarizes the performanceofvarious CNN modelsthatweretrainedandusedforthispaper.Amongst thesemodels,ResNetemergedontopachievingthelowest average training and validation losses and the highest trainingaccuracy,recallandF1-score.Thissuggeststhatthe ResNetarchitecturewasparticularlyeffectiveinlearningthe underlying patterns in the Cifar10 data. While CNN V1 exhibitedhightrainingaccuracy,itsufferedfromoverfitting, as evidenced by the significant gap between training and validationloss.Othermodels,suchasCNNV2andCNNV3, demonstrated moderate performance, with variations in trainingaccuracy.DifferentvariantsofCNNV3showedmixed results, indicating that architectural modifications did not consistently improve performance. Overall, ResNet architecture's superior performance highlights its effectivenessinclassifyingCifar10images.
CNNmodels,includingsimpleCNNsandadvancedResNet34architectures,effectivelyclassifyimages.SimpleCNNsare quick and efficient for smaller datasets but limited in performance. ResNet-34, with deeper layers and residual connections, offers significantly better accuracy. For high accuracyandlargedatasets,ResNet-34withSWAandmixed precisionisideal.Forquicker,lessresource-intensivetasks, a simple CNN suffices. The choice depends on the application'scomplexityandavailableresources.
[1] D. Kornack and P. Rakic, “Cell Proliferation without NeurogenesisinAdultPrimateNeocortex,”Science,vol.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 11 | Nov 2024 www.irjet.net p-ISSN: 2395-0072
294, Dec. 2001, pp. 2127-2130, doi:10.1126/science.1065467.
[2] NehaSharma,VibhorJain,AnjuMishra,AnAnalysisOf ConvolutionalNeuralNetworksForImageClassification, Procedia Computer Science, Volume 132, 2018, Pages 377-384, ISSN 1877-0509, https://doi.org/10.1016/j.procs.2018.05.198.
[3] AlexKrizhevsky,IlyaSutskever,andGeoffreyE.Hinton. 2012.ImageNetClassificationwithDeepConvolutional NeuralNetworks.InNIPS.1106–1114.
[4] F. Sultana, A. Sufian and P. Dutta, "Advancements in Image Classification using Convolutional Neural Network," 2018 Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 2018, pp. 122-129, doi: 10.1109/ICRCICN.2018.8718718.
[5] Ajala, Sunday. (2021). Convolutional Neural Network ImplementationforImageClassificationusingCIFAR-10 Dataset.10.13140/RG.2.2.27690.54724.
[6] S. Y. Chaganti, I. Nanda, K. R. Pandi, T. G. N. R. S. N. Prudhvith and N. Kumar, "Image Classification using SVM and CNN," 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 2020, pp. 1-5, doi: 10.1109/ICCSEA49413.2020.9132851. keywords: {Support vector machines;Deep learning;Computer science;Neural networks;Education;Support vector machine;Hardware;Python;Support Vector Machines (SVM)andConvolutionalNeuralNetworks(CNN)}.
[7] AlexeyDosovitskiy,LucasBeyer,AlexanderKolesnikov, DirkWeissenborn,XiaohuaZhai,ThomasUnterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, SylvainGelly,JakobUszkoreit,&NeilHoulsby.(2021). An Image is Worth 16x16 Words: Transformers for ImageRecognitionatScale.
[8] Sharma,Atul.(2021).INTERNATIONALCONFERENCE ONINNOVATIVECOMPUTINGANDCOMMUNICATION (ICICC2021)ImageClassificationUsingCNN.
[9] ImageClassificationusingCNNwithCIFAR-10Dataset", International Journal of Emerging Technologies and InnovativeResearch(www.jetir.org),ISSN:2349-5162, Vol.10,Issue7,pageno.702-707,July,2023.
[10] Adetiba,E.,Ajayi,O.T.,Kala,J.R.,Badejo,J.A.,Ajala,S.& Abayomi, A. (2021). LeafsnapNet: An Experimentally EvolvedDeepLearningModelforRecognitionofPlant Species based on Leafsnap Image Dataset. Journal of Computer Science, 17(3), 349-363. https://doi.org/10.3844/jcssp.2021.349.36.
[11] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D.,...&Rabinovich, A.(2015) "Going deeper with convolutions." in Proceedings of the IEEE conferenceoncomputervisionandpatternrecognition (pp.1-9).
[12] Chen,L.;Li,S.;Bai,Q.;Yang,J.;Jiang,S.;Miao,Y.Review of Image Classification Algorithms Based on ConvolutionalNeuralNetworks.RemoteSens.2021,13, 4712.https://doi.org/10.3390/rs13224712.
[13] P.GavaliandJ.SairaBanu, “DeepConvolutionalNeural NetworkforImageClassificationonCUDAPlatform”in DeepLearningandParallelComputingEnvironmentfor BioengineeringSystems,A.K.Sangaiah,Ed.,Academic Press,2019,pp.99-122.
[14] R. Doon, T. Kumar Rawat and S. Gautam, "Cifar-10 Classification using Deep Convolutional Neural Network,"2018IEEEPunecon,Pune,India,2018,pp.15, doi: 10.1109/PUNECON.2018.8745428. keywords: {Convolution;Max-pooling;CIFAR-10}.
[15] Pang,Y.,Shah,G.,Ojha,R.,Thapa,R.,&Bhatta,B.(2023). ComparisonofCNNArchitectureonImageClassification Using CIFAR10 Datasets. International Journal on Engineering Technology, 1(1), 37–52. https://doi.org/10.3126/injet.v1i1.60898.
© 2024, IRJET | Impact Factor value: 8.315 | ISO