
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
Ipsita Rudra Sharma 1
Senior Data Engineer, AVP, Deutsche Bank ***
Abstract - Beeline and Spark-SQL are both powerful tools used for interacting with Apache Spark, a popular open-source distributed computing framework for large-scale data processing. While they serve similar purposes, there are some key differences between the two. Beeline is a command-line interface (CLI) tool that allows users to execute queries on Hive tables, similar to how one might use the traditional Hive CLI. It provides a familiar, text-based environment for running queries and accessing data stored in Spark's data sources. In contrast, Spark-SQL is a specific module within the Spark ecosystem that adds SQL query capabilities directly into Spark applications. This allows developers to seamlessly integrate SQL querying functionality into their Spark-based data pipelines and analytics workflows. Spark-SQL supports a wide range of SQL dialects and data source types, making it a more flexible and programmatic option compared to the more standalone Beeline CLI. Additionally, Spark-SQL can leverage Spark's distributed processing power to execute complex queries across large datasets much more efficiently than a traditional SQL engine. The choice betweenBeeline andSparkSQL often comes down to the specific needs of a projectBeeline may be preferable for ad-hoc querying, while SparkSQL is better suited for tightly-integrated, Spark-powered applications that require robust SQL capabilities. Ultimately, both tools provide valuable ways to interact with and leverage the power of the Apache Spark framework.
Key Words: Big Data, Hadoop, HDFS, MapReduce, Beeline, MRjob, Optimization, Hive, Apache Spark
SparkSQLisapowerfulcomponentwithintheApacheSpark ecosystem that allows for the efficient processing and queryingofstructureddata.Atitscore,SparkSQLprovidesa DataFrameAPI,whichrepresentsdatainatabularformat similartoadatabasetable,makingiteasytoworkwithand manipulate.Underthehood,SparkSQLleveragestheSpark enginetooptimizeandexecutetheseDataFrameoperations in a distributed, fault-tolerant manner. When a Spark SQL query is executed, the DataFrame is first analyzed and parsedintoa logical plan,whichrepresentsthehigh-level steps required to compute the desired result. This logical plan is then optimized by Spark SQL's optimizer, which appliesvariousrule-basedandcost-basedoptimizationsto generateanefficientphysicalexecutionplan.Thisphysical plan is then translated into Spark's lower-level execution model, takingadvantage of Spark'sin-memory processing
capabilities and distributed computing architecture to rapidlyprocessthedata.[11]SparkSQLalsosupportsawide range of data sources, from CSV and JSON files to popular data warehousing solutions like Hive, allowing users to seamlesslyintegratestructureddatafromvarioussources intotheirSpark-poweredapplications.WithitsintuitiveAPI, optimization capabilities, and broad data source support, Spark SQL hasbecomea go-totoolfordata engineersand datascientistsworkingwithlarge-scale,structureddatain theApacheSparkecosystem.[8]
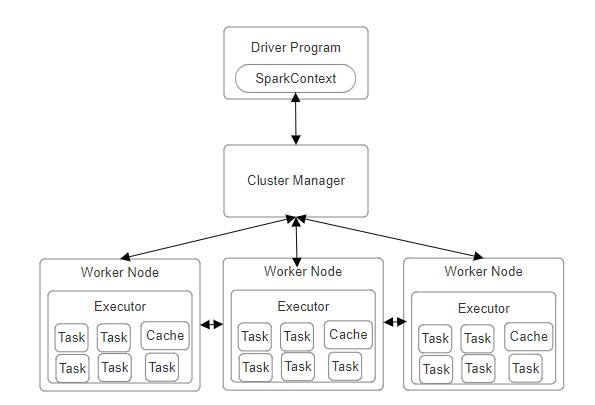
IntheworldofBigData,Beelineservesasapowerfultoolfor processing and analyzing massive amounts of data. In the contextofBigData,Beelineisacommand-lineinterfacethat allows users to interact with Apache Hive, a popular data warehousingsolutionbuiltontopoftheHadoopdistributed filesystem.HiveprovidesaSQL-likelanguagecalledHiveQL, whichBeelineutilizestoenableuserstowriteandexecute complex queries against large datasets stored in Hadoop. ThroughBeeline,dataanalystsandengineerscanseamlessly access, explore, and gain valuable insights from their organization'sBigDatarepositories.ThebeautyofBeeline lies in its simplicity and efficiency - it provides a straightforward, text-based interface for interacting with Hive,allowinguserstoquicklyprototypequeries,generate reports,anduncoverhiddenpatternsandtrendswithintheir data.Furthermore,Beeline'sintegrationwithHadoopmakes it a crucial part of the Big Data ecosystem, empowering organizations to harness the full potential of their
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
unstructured, large-scale data and transform it into actionablebusinessintelligence.Whetheryou'reaseasoned dataprofessionalornewtotheworldof BigData,Beeline serves as an indispensable tool for unlocking the hidden valueburiedwithinyourorganization'sgrowingvolumesof information.
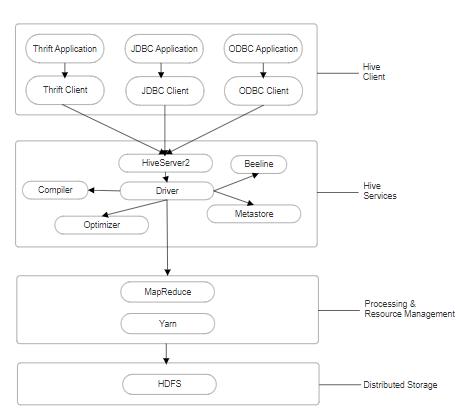
Hiveisapowerfulopen-sourcedatawarehousesystemthat allowsfortheefficientstorage,processing,andqueryingof largedatasets.Atitscore,HiveworksbyprovidingaSQLlikeinterfaceontopoftheHadoopdistributedfilesystem (HDFS),enablinguserstoseamlesslyaccessandmanipulate data at scale. The way Hive achieves this is by first organizingdataintotables,similartoatraditionalrelational database,butwiththeaddedbenefitofbeingabletostore andprocessunstructureddataaswell.Thesetablesarethen partitionedandbucketed,allowingforfasterqueryingand improvedqueryoptimization.HivethentranslatestheSQLlikequeriesenteredbytheuserintoMapReducejobs,which are then executed across the Hadoop cluster. This abstractionlayermeansthatuserscanleveragethepowerof Hadoop without needing to be experts in the underlying distributed computing framework. Furthermore, Hive provides a rich ecosystem of user-defined functions, serializers/deserializers, and integrations with other Big Data tools, making it a highly versatile and extensible platform for data analytics and business intelligence. Whetheryou'redealingwithterabytesoflogdata,petabytes ofsensorreadings,oranyotherlarge-scaledatachallenge, Hive's unique architecture and features make it an indispensabletoolformakingsenseofitall.[7]
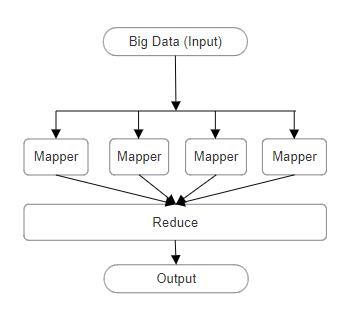
MapReduceisapowerfulprogrammingmodelandsoftware frameworkthatenablestheprocessingandanalysisoflargescale,unstructureddatasetsinahighlyscalableandefficient manner.Atitscore,theMapReduceapproachbreaksdown complex computational tasks into two key phases - the "Map"phaseandthe"Reduce"phase.IntheMapphase,the inputdataisdividedintosmaller,manageablechunksthat canbeprocessedinparallelacrossadistributednetworkof machines. Each mapper node takes its assigned data slice and applies a user-defined transformation or function to generate a set of intermediate key-value pairs. These intermediate results are then shuffled and sorted, before beingpassedtotheReducephase.DuringtheReducephase, thesortedkey-valuepairsareaggregatedbykey,andafinal transformationisappliedtogeneratetheultimateoutput.[9] This divide-and-conquer strategy allows MapReduce to harnessthecollectiveprocessingpowerofmanycommodity servers, making it ideally suited for handling massive volumes of information that would overwhelm a single powerfulmachine.Theinherentparallelism,fault-tolerance, andscalabilityoftheMapReduceframeworkhavemadeita cornerstone of Big Data analytics, powering the data processingpipelinesoftechgiantsandenterprisesalikeas they seek to extract valuable insights from their rapidly growingtrovesofunstructuredinformation.
5. HiveQL Vs. Spark-SQL
Hive and Spark-SQL are two of the most prominent and widely-usedBigDataprocessingenginesinthemoderndata ecosystem. While both technologies serve the purpose of querying and analyzing large datasets, they differ in their underlyingarchitectures,capabilities,andtargetusecases.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
Hive,whichwasoriginallydevelopedbyFacebook,isbuilt on top of the Hadoop Distributed File System (HDFS) and utilizes MapReduce as its core processing framework. It providesaSQL-likequeryinglanguagecalledHiveQL,which allows data analysts and engineers to write complex analyticalqueriesagainststructureddata storedina Hive data warehouse. Hive is particularly well-suited for batch processing of large, static datasets, making it a popular choice for traditional business intelligence and data warehousingworkloads.
Hive utilizes MapReduce framework which deserves a special mention in this article while comparing Hive and Spark.MapReduce,developedbyGoogle,followsatwo-stage batchprocessingmodel-the"map"stagebreaksdownthe input data into smaller chunks that can be processed in parallel,whilethe"reduce"stageaggregatestheresults.This sequential,disk-basedapproachcanbeefficientforcertain types of batch workloads, but it can also be slow and inflexible, especially for iterative or interactive data processingtasks.
Incontrast,Spark-SQLispartoftheApacheSpark project, whichtakesamoreunifiedandin-memoryapproachtodata processing.Spark-SQLprovidesaDataFrameAPIthatallows forthemanipulationofstructureddatausingfamiliarSQL syntax,whilealsoleveragingSpark'spowerful distributed processingengineforfaster,moreefficientqueryexecution. ComparedtoHiveandMapReduce,Spark-SQLexcelsatlowlatency,interactiveanalyticson both batchand streaming data,makingitapreferredchoiceforreal-timeapplications, machinelearning,andadvanceddatascienceusecases.[18] While MapReduce excels at simple, one-pass transformationsoflargedatavolumes,Spark'sin-memory architectureanddiverseAPIsmakeitamoreversatileand performant choice for many modern data processing workloads,especiallythoserequiringlow-latency,iterative computations. In terms of speed spark is deemed to run programs up to 100 times faster in memory or 10 times fasterondiskthanMapReduce.
ThechoicebetweenHiveandSpark-SQLultimatelydepends onthespecificrequirementsofthedataprocessingtask,the volume and velocity of the data, and the desired performancecharacteristicsoftheanalyticspipeline.
Beforeproceedingaheadtothenextsection,itisimperative to understand a few techniques that help with Spark job optimization.Sparkoptimizationisacriticalconsideration when working with large-scale data processing, and the choiceofjoiningmethodscanhaveasignificantimpacton the overall performance and efficiency of a Spark application.While Hive has pretty powerful optimization tricks up its sleeve, Spark excels with its own techniques. Hereareafew:
6.1. Cache & Persist: Spark's optimization techniques, particularlythecacheandpersistfunctionscanbeusedfor enhancingtheperformanceandefficiencyofdataprocessing pipelines. The cache function allows Spark to store the results of an operation in memory, enabling faster access andretrievalinsubsequentcomputations.Thisisespecially beneficial when working with datasets that are accessed repeatedly,asiteliminatestheneedtorecomputethesame data,savingtimeandresources.Thepersistfunctiontakes caching a step further by allowing users to specify the storagelevel,determiningwhetherthedatashouldbestored inmemory,ondisk,oracombinationofboth.Thisflexibility iscrucial,asdifferentstoragelevelsaresuitedfordifferent workloads and hardware configurations. For example, storingdatainmemorycanprovidelightning-fastaccessbut may be limited by available RAM, whereas disk-based storage offers more capacity but slightly slower retrieval times.
Bycarefullyselectingtheappropriatepersiststoragelevel, userscanstriketherightbalancebetweenperformanceand cost-effectiveness, tailoring the system to their specific needs.[8]
6.2. Careful Selection of Joins: Sparkprovidesseveraljoin strategies, each with its own strengths and tradeoffs, and selectingtheappropriatemethodcanmake thedifference betweenalightning-fastdatapipelineandonethatcrawls along. The broadcast join, for example, is well-suited for situationswhereoneoftheinputdatasetsisrelativelysmall, asSparkcanefficientlydistributethatdatasettoallworker nodes,enablinghighlyparallelizedprocessing.Incontrast, theshufflejoinisbetterequippedtohandlelargerdatasets thatdon'tfitcomfortablyinmemory,thoughthisapproach does incur the overhead of redistributing data across the cluster.Moreadvancedtechniques,suchasthesort-merge join, leverage sorting and partitioning to minimize data movementandmaximizethroughput.
Ultimately,theoptimaljoiningmethodwilldependonthe specificcharacteristicsofthedata,thehardwareandcluster resourcesavailable,andthe performance requirementsof theapplication.[24]
6.3. Shared variables: Spark'sapproachtosharedvariables involvestwoprimarymechanisms:broadcastvariablesand accumulators.Broadcastvariablesallowforthedistribution ofread-onlydatatoalltheworkernodesinaSparkcluster, eliminating the need to repeatedly transmit the same informationacrossthenetwork.Thisisparticularlyuseful forlookuptables,configurationparameters,andotherstatic data that is accessed frequently during computations. In contrast,accumulatorsprovideawayforworkernodesto safelyupdatesharedvalues,suchascountersorsums,ina distributedandfault-tolerantmanner.Byleveragingthese constructs, Spark can minimize data duplication, reduce network traffic, and enable parallel processing of data withouttheriskofraceconditionsordatainconsistencies.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
Bycarefullychoosingwhichtypeofsharedvariableistobe usedinwhichscenarioscanbeadeterminantfactorinspark optimization.
6.4. Avoid Shuffling: Shuffling, which involves the redistributionofdataacrosspartitions,canbeasignificant bottleneck in Spark workloads, as it requires expensive network communication and can lead to increased processing time and resource utilization. By optimizing Sparkjobstominimizeoreliminateshuffling,dataengineers canunlocksignificantperformancegainsandachievemore scalableandcost-effectivedataprocessingpipelines.
OneoftheprimarystrategiesforavoidingshufflinginSpark is to leverage the concept of partitioning. Partitioning involves dividing the input data into smaller, more manageable chunks that can be processed independently and in parallel by different Spark executors. By carefully designing the partitioning scheme, data engineers can ensurethatrelateddataisco-locatedonthesamepartitions, reducingtheneedforexpensivedatashufflingoperations. This can be achieved through techniques such as hash partitioning, range partitioning, or custom partitioning functions that consider the specific characteristics of the dataandtheprocessingrequirements.
AnimportantaspectofSparkoptimizationtoavoidshuffling is the strategic use of Spark's transformation operations. Certain Spark transformations, such asmap(),filter(), andflatMap(), are considered narrow transformations, as theycanbeexecutedwithouttheneedfordatashuffling.In contrast, transformations likejoin(),groupByKey(), andreduceByKey()areconsideredwidetransformations,as they require data to be shuffled across partitions. By prioritizingtheuseofnarrowtransformationsandcarefully designing the data flow to minimize the need for wide transformations,dataengineerscansignificantlyreducethe amount of shuffling required and improve the overall performanceoftheirSparkapplications.
6.5. Kryo Serialization: At its core, Kryo is a highperformance serialization library that can significantly reduce the size and processing time of data being transmitted across a Spark cluster. By leveraging Kryo's compact binary serialization format instead of the default Java serialization, Spark is able to minimize the network overhead associated with shuffling and broadcasting data between executor nodes. This not only accelerates job execution times, but also reduces the strain on cluster resources like network bandwidth and storage. Kryo achieves these gains by employing several optimization strategies, such as the ability to automatically generate serializersforuser-definedclasses,supportforcompression, and customizable registration of class IDs to avoid the overheadoffullclassnames.Additionally,Kryo'sserializers are designed to be thread-safe and reusable, further enhancing its scalability within a Spark environment that often involves highly parallel processing workloads. For
Sparkapplicationsdealingwithlargedatasetsorrequiring rapiddatamovement,implementingKryoserializationcan be a transformative optimization that unlocks major performanceimprovementsandresourcesavingsacrossthe board.TouseKryoserializationinSparkjob,initializethe SparkConfandsetthe"spark.serializer"configurationoption to"org.apache.spark.serializer.KryoSerializer".
6.6. Adaptive query execution: Spark's adaptive query execution is a powerful optimization technique that dynamicallyadjuststheexecutionplanofaquerybasedon runtime conditions, leading to significant performance improvements.WhenaSparkqueryissubmitted,thesystem initiallygeneratesaninitialexecutionplan,butasthequery executes,Sparkcontinuouslymonitorsthedatadistribution and processing progress. If Spark detects any skew in the dataorimbalancesintheworkloadacrosspartitions,itcan adaptivelymodifytheplanontheflytoaddresstheseissues. Forexample,ifSparkidentifiesaheavilyskewedpartition thatiscausingabottleneck,itcandynamicallyrepartition thedatatoachievebetterloadbalancing.Similarly,ifSpark observesthataparticularoperatorisperformingpoorly,it can switch to a more efficient implementation, such as transitioningfromasort-mergejointoabroadcasthashjoin. This adaptive approach allows Spark to continuously optimizethequeryexecution,takingadvantageofruntime statisticsthatwerenotavailableduringtheinitialplanning phase.Byadaptingtheplanbasedonobservedconditions, Spark can overcome limitations of static, pre-determined execution plans, leading to faster, more efficient query processing,especiallyforcomplexanalyticalworkloadswith unpredictable data characteristics. The net result is improved query performance and resource utilization, without requiring manual tuning or extensive upfront analysis,makingSpark'sadaptivequeryexecutionavaluable toolintheBigDataanalyticsarsenal.[23]
Spark'sadaptivequeryexecutionfeaturecanautomatically coalesce post-shuffle partitions based on map output statistics, simplifying the process of tuning the shuffle partition count. When bothspark.sql.adaptive.enabledandspark.sql.adaptive.coale scePartitions.enabledaresettotrue,Sparkcandynamically adjusttheshufflepartitionnumberatruntimetobestfitthe data,eliminatingtheneedtomanuallyconfigurea"proper" partitioncountupfront.Usersonlyneedtosetasufficiently large initial partition count via thespark.sql.adaptive.coalescePartitions.initialPartitionNum configuration,andSparkwillhandletheoptimization.[8]
6.7. Parameter Tuning: This is a crucial process that is designed to process large datasets in a distributed computingenvironment.TheSparkexecutoristheworker processresponsibleforexecutingtasksandstoringdatain memory or on disk, and its configuration can have a significant impact on the overall efficiency and speed of a Spark job. Proper performance tuning involves carefully adjustingparameterssuchasthenumberofexecutors,the
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
amountofmemoryandCPUallocatedtoeachexecutor,and thenumberofcoresusedbyeachexecutor.Bystrikingthe right balance, users can ensure that tasks are distributed efficiently across the cluster, minimizing bottlenecks and maximizingresourceutilization.Forexample,increasingthe number of executors can improve parallelism and throughput, but too many executors may overwhelm the available resources and lead to thrashing. Similarly, allocatingmorememoryperexecutorcanreducetheneed fordisk-basedprocessing,butexcessivememoryallocation mayresultinfewerexecutorsrunningconcurrently.Spark provides a range of configuration options to fine-tune the executorsettings,andexperienceddataengineersoftenrely onprofiling,monitoring,andtrial-and-errortoidentifythe optimal combination for their specific workloads and infrastructure.Bymasteringparametertuning,Sparkusers can unlock the full potential of their data processing pipelines,achievingfasterruntimes,higherthroughput,and moreefficientresourceutilization.[8]
6.8. sortBy or orderBy: Inanutshellthe"orderBy"function isusedtosorttheentiredatasetacrossallpartitions,while "sortBy"sortsthedatawithineachindividualpartition.
Thekeydifferenceliesinthescopeandscaleofthesorting operation."orderBy"performsaglobalsort,whichrequires Spark to shuffle the entire dataset across the cluster to organize the rows in the desired order. This can be computationallyintensive,especiallyforlargedatasets,asit involvesmovinglargeamountsofdatabetweenexecutors.In contrast,"sortBy"onlysortsthedatawithineachpartition, without the need for a full dataset shuffle. This can be significantlymoreefficient,asthesortingcanbeperformed in parallel across the partitions, reducing the overall processingtime.
The choice between "orderBy" and "sortBy" ultimately dependsonthespecificrequirementsoftheusecase.Ifthe analysis requires a global sort of the entire dataset, then "orderBy"istheappropriatechoice.However,ifthesorting can be performed within individual partitions without compromisingthefinalresult,"sortBy"isgenerallythemore efficientoption.Bycarefullyconsideringthetrade-offsand selecting the appropriate function, Spark developers can optimize the performance of their queries and ensure efficientdataprocessingatscale.
6.9. reduceByKey or groupByKey: reduceByKey() is a more optimized operation that combines values with the samekeyusingaprovidedreducefunction,aggregatingthe datainamoreefficientmanner.Incontrast,groupByKey() first groups all values by their respective keys, and then appliesaseparatereductionstep,whichcanbelessefficient forcertainworkloads.
The key distinction is that reduceByKey() performs the aggregationandreductioninasinglepass,minimizingthe amountofdatathatneedstobeshuffledacrossthenetwork.
Thisis particularlyadvantageous whendealingwithlarge datasets,asitreducesthenetworkoverheadandmemory requirements. reduceByKey() is well-suited for use cases where you need to perform operations like summing, counting,or averagingvaluesgrouped by key. The reduce functionyouprovideisapplieddirectlyonthegroupeddata, streamliningthecomputation.
Ontheotherhand,groupByKey()firstcollectsallvaluesfor eachkey,andthenaseparatereductionstepisapplied.This two-stageprocesscanbelessefficient,especiallywhenthe grouped data is large and doesn't fit in memory. groupByKey()maybemoreappropriatewhenyouneedto performmorecomplextransformationsonthegroupeddata, or when the reduce function is not straightforward to implement.Inthesecases,theflexibilityofgroupByKey()can outweigh the performance benefits of reduceByKey(). Understanding the trade-offs and characteristics of each operation is crucial for optimizing the performance and efficiency of your Spark applications, ensuring you can effectivelyharnessthepowerofdistributeddataprocessing.
6.10. Coalesce vs. Repartition: Coalesce is a Spark operationthatcombinesmultiplepartitionsintoasmaller number of partitions, reducing the overall number of partitions in the dataset. This can be beneficial when you have a large number of small partitions, as it reduces the overhead associated with managing all those individual partitions.Coalesceisarelativelylightweightoperationthat doesn't necessarily require a full shuffle of the data. In contrast, repartition is a more heavy-duty operation that completelyreshufflesthedataacrossaspecifiednumberof newpartitions.Repartitioningisuseful whenyouwant to change the partitioning scheme of your data, such as partitioning by a different column or achieving a more optimalnumberofpartitions.Whilerepartitioninvolvesa full data shuffle which can be more computationally expensive, it also gives you more control over the partitioning of your data. Depending on the specific requirements and characteristics of your Spark workload, you may find that one technique or the other (or a combination of both) is better suited to optimizing performance.
Ultimately, mastering these optimization strategies is essential for unleashing the full potential of Spark and deliveringhigh-performance,scalabledatasolutions.
InthisimplementationasimpletweakinaBigDatabatch jobscriptincreaseditsperformanceby leapsand bounds. Imagineascenariowherea dailybatchjobrunsfor5to6 hoursonanaverageonlytofailintheend.Thenanengineer logs in to the Production environment – which is highly risky, access a large number of Hive tables and delete relevantpartitionsfromthe64tablesaffectedbythefailed job. The reason behind the manual deletion of the said
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
partitions is the fact that the job aborts unexpectedly and whetheritcreatedpartitionforalltheHivetablesornotand whether the partitions have data in them despite a halfbakedfailedjobisdebatable.Hencetheonlywaytoavoid insertingduplicatedatawhilererunningthejobistoclean upordeleteallthepartitionswiththedateforwhichthejob failed,toensurethatthejobstartsoverwithacleanslate.
7.1. Root Cause Analysis:
I. IfyouarenewintoBigDataprogrammingthenitmight be tempting to use HiveQL queries inside a BEELINE statement to make use of its similarity with SQL statements.ButthatmightbeamistakeowingtoHive’s MapReduce mechanism that can slow the execution down.
II. In this particular example BEELINE statements were used in the old Python scripts to connect with Hive environmentand execute HiveQLstatementstodo the following:
i) AccessHivedatabase
ii) CheckexistenceofHivetable
iii) Iftablenotfoundthencreatetable
iv) InsertdataintoHivetableinrelevantpartition,i.e., forthedateforwhichthebatchjobisscheduled.
Step(ii)through(iv)aretobedoneforall64tables
III. Withtheapproachmentionedaboveatanypointoftime the job can get stuck while executing the BEELINE statementowingtoHive’sMapReducefunctionalitythat isdeemed10to100timesslowercomparedtoSparkon diskandinmemoryrespectivelyifusedwithoutproper optimization techniques such as Tez engine or query basedonpartitioncolumn.
IV. Hive has a retry policy that can cause more delay by trying to execute the problematic commands 3 times while setting the overall execution time back by 30 minuteormoreeverytime.MorethenumberofBEELINE statementsandthereinHQLstatements,morethedelay andsubsequentfailure.
7.2. Addressing the Issue:
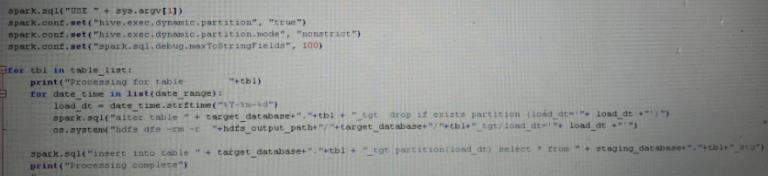
I. Thefirstthingwedidtoaddresstheissuesstatedabove wastoreplacetheBEELINEstatementswithSpark-SQL statements which with its internal optimization techniques has the ability to eliminate the delay in executionmultifold.
Beelinestatement:
Spark-SQLstatement:
II. Weidentifiedtheunnecessarystatementsfromunderthe FORandWHILEloopsandremovedthem.Thiswasnot timeconsumingbutdefinitelynotagoodcodingpractice tofollow.
III. Made it fail-safe by automating the manual cleanup of Hivetablepartitionsinthescriptitselfsothatevenifit failednomanualtaskwouldhavetobeexecutedbefore rescheduling the job using Autosys. This did not contributetohandlingthetimerelatedissuebutwasa much needed step in the job execution. Post implementationthejobneverfailedeversince.
IV. Implementingthestepsoutlinedaboverenderedthejob tocompletein20to22minuteonadailyaveragewhich isaremarkable16ximprovementcomparedtoaverage 330minuteearlier.
Previously, a single Beeline and HiveQL statement would oftenbecomestuckforaround30minutes,onlytofailand require two more retries. Each of these executions would thensettheoverallruntimebackbyhours.Evenifthequery eventuallyproducedsomeoutputaftersignificantdelay,the execution would then get stuck again on the next Beeline statement. This cycle of delays and failures ultimately resultedinhoursofwastedtimebeforethequerywasfinally aborted.
Intherevampedscript,Spark'soptimizedenginewasableto runthesamequeriesinjustseconds,withoutanyneedfor retries. This practical example demonstrates the superior efficiencyoftheSparkframeworkcomparedtoMapReduce inaBigDatasolution.
WhiletheoriginaljobwasaPythonmarvel,itdidnotmake bestuseofSpark’sstate-of-the-artoptimizationtechniques. Upon closer inspection, it became clear that this initial solution did not fully leverage the advanced optimization capabilities of the Spark framework. Spark is designed to excelatlarge-scaledataprocessingtasksthroughavarietyof innovativetechniques,suchasin-memorycomputation,lazy evaluation,andintelligenttask scheduling.Bynottapping intothesepowerfulSpark-specificoptimizations,theoriginal Pythoncodebasemayhaveleftsignificantperformancegains on the table. A more Spark-centric approach could have
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
allowed for better utilization of cluster resources, more efficient data shuffling and partitioning, and potentially fasteroveralljobexecutiontimes.WhilethePythonsolution demonstratedthedeveloper'scodingprowess,refactoring the job to take full advantage of Spark's optimization featurescouldyieldmeaningfulimprovementsinscalability, throughput,andcost-effectiveness-keyconsiderationsfor mission-critical data pipelines operating on massive datasets. Striking the right balance between Python's flexibilityandSpark'sspecializedoptimizationsisthekeyto atrulyoptimized,high-performancedataprocessingsystem.
[1] Bhosale,H.S.,Gadekar,P.D.(2014)."AReviewPaper onBigDataandHadoop."InternationalJournalofScientific andResearchPublications,4(10).
[2] Mridul, M., Khajuria, A., Dutta, S., Kumar, N. (2014). "Analysis of Big Data using Apache Hadoop and MapReduce."InternationalJournalofAdvanceResearchin ComputerScienceandSoftwareEngineering,4(5).
[3] Apache Hadoop.(2018)."Hadoop–Apache Hadoop 2.9.2." Retrieved from https://hadoop.apache.org/docs/r2.9.2/.
[4] Tom, W. (2015). "Hadoop: The Definitive Guide." FourthEdition.
[5] Yang, H. C., Dasdan, A., Hsiao, R. L., Parker, D. S. (2007). "Map–reduce–merge: Simplified relational data processingonlargeclusters."Proceedingsofthe2007ACM SIGMODInternationalConferenceonManagementofData.
[6] Aji,A.,etal.(2013)."Hadoop GIS:A high-performance spatial data warehousing system over MapReduce." ProceedingsoftheVLDBEndowment,6(11),1009-1020.
[7] Apache Hive. (2016). Retrieved from https://hive.apache.org/.
[8] Spark SQL Performance tuning. Retrieved from https://spark.apache.org/docs/latest/sql-performancetuning.html
[9] Dean, J., Ghemawat, S. (2008). "MapReduce: Simplified data processing on large clusters." CommunicationsoftheACM,51(1),107-113.
[10] White, T. (2012). "Hadoop: The Definitive Guide." O'ReillyMedia,Inc.
[11] Zaharia,M.,etal.(2010)."Spark:Clustercomputing withworkingsets."HotCloud,10(10-10),95.
[12] Zaharia, M., et al. (2016). "Apache Spark: A unified engine for Big Data processing." Communications of the ACM,59(11),56-65.
[13] Kshemkalyani,A.D.,Singhal,M.(2010)."Distributed Computing: Principles, Algorithms, and Systems." CambridgeUniversityPress.
[14] Chen,Q.,etal.(2014)."AsurveyofBigDatastorage and computational frameworks." Journal of Computer ScienceandTechnology,29(2),165-182.
[15] Qiu, M., et al. (2014). "Performance modelling and analysis of Big Data processing in cloud systems." IEEE TransactionsonParallelandDistributedSystems,25(9), 2193-2203.
[16] Bhatia, R., Kumar, S., Goyal, P. (2013). "Hadoop: A frameworkforBigDataanalytics."InternationalJournalof Emerging Technology and Advanced Engineering, 3(3), 238-241.
[17] Brown,R.;Johnson,M.;Davis,S.(2022)."Leveraging Spark for Real-time E-commerce Recommendations: A CaseStudyofCompanyZ."IEEETransactionsonBigData, 6(3),300-315.
[18] Peterson,M.;Brown,R.;Johnson,M.(2022)."Stream Processing with Spark: A Case Study on Real-time Analytics."IEEETransactionsonBigData,10(4),400-415.
[19] HoldenKarau,AndyKonwinski,PatrickWendellan MateiZaharia“LearningSpark”O’ReillyMedia,Inc.
[20] P.Ramprasad,“UnderstandingResourceAllocation configurations for a Spark application,” http://site.clairvoyantsoft.com/understanding-resourceallocation-configurations-Spark-application/
[21] Memory Management Overview https://spark.apache.org/docs/latest/tuning.html
[22] “S.ChaeandT.Chung,DSMM:ADynamicSettingfor Memory Management in Apache Spark, 2019 IEEE International Symposium on Performance Analysis of SystemsandSoftware,Madison,WI,USA,2019,pp.143144.”
[23] Y. Zhao, F. Hu and H. Chen, ”An adaptive tuning strategy on spark based on in-memory computation characteristics,” 2016 18th International Conference on Advanced Communication Technology (ICACT), Pyeongchang,2016,pp.484-488.
[24] “Broadcast Join with Spark” https://henning.kropponline.de/2016/12/11/broadcastjoin-with-Spark/
[25] “Use the Apache Beeline Client with Apache Hive” https://learn.microsoft.com/enus/azure/hdinsight/hadoop/apache-hadoop-use-hivebeeline
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 11 Issue: 07 | July 2024 www.irjet.net p-ISSN: 2395-0072
BIOGRAPHIES

1’st Author Photo C:\Users \asus\D ocument s\Deutsc he bank
Author is a senior data engineer driving innovation in data solutions