InternationalResearchJournal of Modernization in EngineeringTechnologyand Science
FACE RECOGNITION ALGORITHMS: A COMPARATIVE STUDY
Himanshu Dorbi*1, Prabhakar Joshi*2
*1,2DepartmentofComputerScience&EngineeringGraphicEraHillUniversity,DehradunUttarakhand,India
DOI:https://www.doi.org/10.56726/IRJMETS41255
ABSTRACT
This research paper analyses Eigenfaces, Fisherfaces, KLT (Kanade-Lucas-Tomasi) and Viola-Jones face recognition algorithms. Examined under various conditions, including lighting changes, design changes, nonsolid deformations, occlusions, anomalies in the dataset, and image variations and resolution, the study examinesitslimitations,strengthsandfunctions.Thetruth,speaking,istogiveinsightintotheircomparisons. Useful tips for choosing an algorithm based on the situation. Eigenfaces and Fisherfaces perform well in a controlled environment with limited variability. Viola-Jones has demonstrated high accuracyin face detection and object detection. KLT is mainly used for feature monitoring and optical measurement. This outcome facilitatesa comprehensive understanding ofthestrengths andlimitationsof eachalgorithm,helpingto make informeddecisionsaboutfacialrecognitioninavarietyofsituations.
I. INTRODUCTION
Face recognition Facial recognition algorithms play an important role in many applications, from security systems to human-computer interaction. This research paper presents an analysis of four face recognition systems: Eigenfaces, Fisherfaces, KLT (Kanade-Lucas-Tomasi) and Viola-Jones. The aim is to evaluate their limitations, strengths and performances in different situations, including lighting changes, lighting changes, non-hard deformations, occlusions, dataset aberrations, image quality and resolution. Based on this analysis, this study aims to offer suggestions for the comparison of algorithms. It examines the accuracy achieved by eachalgorithmandhighlightsitsadvantagesanddisadvantages.Inaddition,recommendationswillbemadeto guidetheselectionalgorithmonthebasisofspecificconditionsandrequirements.Eigenfacesandherringbones based on PCA andFLDAtechniques, respectively,are particularlyuseful incontrol environments with limited variability. Known for its high accuracy in face detection and object recognition, Viola-Jones stands out in situations that require powerful detection capabilities. On the other hand, KLT is mainly used for feature trackingandvisualevaluation,notfacerecognition.Understandingtheuniquepropertiesofeachalgorithmand its performance in different situations is important for making informed decisions in facial recognition. Using these studies, doctors can choose the most appropriate algorithm that will be accurate and effective in their case.
II. METHODOLOGY
Someofthecommonlyusedfacerecognizingalgorithmareasfollows: Eigenfaces- EigenfacesisapopularfacerecognitionalgorithmthatwasintroducedbyMatthewTurkandAlex Pentland in 1991. It revolutionized the field of face recognition by employing the concept of principal componentanalysis(PCA)fordimensionalityreduction.

TheprinciplebehindtheEigenfacesalgorithmistorepresentfacesasalinearcombinationofeigenfaces,which aretheprincipalcomponentsobtainedthroughPCA.
PCA is a statistical technique that aims to capture the most significant variations in a dataset by projecting it ontoalower-dimensionalspace.MaintainingtheIntegrityoftheSpecifications.
TheEigenfacesalgorithmfollowsaseriesofstepstoperformfacerecognition:
● Data Collection: Collect a dataset of face images representing different individuals under various conditions.
● Preprocessing: Enhancefaceimagesthrough grayscale conversion, histogram equalization,andgeometric normalization.
● DimensionalityReduction:ApplyPCAtoreducethedimensionalityofpreprocessedfaceimages,extracting eigenfacesasprincipalcomponents.
e-ISSN:
2582-5208
Peer-Reviewed, Open Access, Fully Refereed International Journal )
Impact Factor- 7.868
www.irjmets.com @InternationalResearchJournalofModernizationinEngineering,TechnologyandScience [9420]
(
Volume:05/Issue:05/May-2023
www.irjmets.com
InternationalResearchJournal of Modernization in EngineeringTechnologyand Science
● Face Representation: Represent each face image as a linear combination of eigenfaces, capturing unique facialcharacteristics.
● Recognition:Projectanewfaceontothefacesubspaceandcompareitwithknownfacesusingasimilarity measuretodetermineidentity.
Fisher faces- Fisherfaces,alsoknownasFisher'sLinearDiscriminantAnalysis(FLDA)forfacerecognition, is an extension of the Eigenfaces algorithm that aims to improve recognition accuracy by considering the discriminativepoweroffacialfeatures.ItwasintroducedbyPeterN.Belhumeur,JoãoP.Hespanha,andDavidJ. Kriegmanin1997.
TheFisherfacesalgorithmworksbymaximizingtheratioofbetween-classscattertowithin-classscatterinthe feature space, ensuring that different classes of faces are well-separated while faces from the same class are tightly clustered. This discriminative approach allows for more robust face recognition, particularly in scenarioswithsignificantvariationsinlighting,pose,andexpression.
TheFisherfacesalgorithmfollowsaseriesofstepstoperformfacerecognition:
a. Data Collection and Preprocessing: Collect and preprocess a dataset of face images representing different individuals.
b. Compute Class Mean: Calculate the mean face for each individual by averaging their aligned and preprocessedimages.
c. Compute Within-Class Scatter Matrix: Sum the covariance matrices of individual classes to obtain the within-classscattermatrix.
d. Compute Between-Class Scatter Matrix: Compute the covariance matrix of the class mean vectors after subtractingtheoverallmeanface.
e. Perform Dimensionality Reduction: Perform eigenvalue decomposition on the scatter matrices to obtain Fisherfaces,whichmaximizebetween-classscatterandminimizewithin-classscatter.
f. FaceRepresentation:RepresenteachfaceimageinthetrainingsetusingFisherfacesandprojectthemonto theFisherfacesubspace.
g. Recognition: Project a new face onto the Fisherface subspace and compare it with known faces using asimilaritymeasuretodetermineidentity.
Viola Jones-
Viola-Jones is a popular face detection algorithm developed by Paul Viola and Michael Jones in 2001. It revolutionized the field of computer vision and played a crucial role in enabling robust and efficient face detectioninvariousapplications.ThealgorithmcombinesmachinelearningtechniqueswithHaar-likefeatures toachievehighdetectionrateswhilemaintainingcomputationalefficiency.
The Viola-Jones algorithm consists of three main stages: integral image calculation, AdaBoost training, and cascadingclassifiers.
● IntegralImageCalculation:
ThefirststepintheViola-Jonesalgorithmistoconverttheinputimageintoanintegralimage.Anintegral image allows for fast computation of the sum of pixel values within any rectangular region of the image. This calculation is performed in a single pass over the image, which significantly speeds up subsequent featureevaluations.
● AdaBoostTraining:
The next stage involves training a strong classifier using the AdaBoost (Adaptive Boosting) algorithm. AdaBoost is a machine learning technique that combines multiple weak classifiers to create a strong classifier.InthecontextofViola-Jones,weakclassifiersareHaar-likefeatures.
● CascadingClassifiers:
ThefinalstageoftheViola-Jonesalgorithminvolvescombiningthetrainedweakclassifiersintoacascade. The cascade consists of multiple stages, each containing a varying number of weak classifiers. The stages areorganizedinawaythatallowsforearlyrejectionofnon-faceregions,thusreducingthecomputational load.
e-ISSN:2582-5208
( Peer-Reviewed, Open Access, Fully Refereed International Journal ) Volume:05/Issue:05/May-2023 Impact Factor- 7.868 www.irjmets.com www.irjmets.com @InternationalResearchJournalofModernizationinEngineering,TechnologyandScience [9421]
InternationalResearchJournal of Modernization in EngineeringTechnologyand Science
KLT (Kanade-Lucas-Tomasi)-
The Kanade-Lucas-Tomasi (KLT) algorithm, also known as the Lucas-Kanade algorithm, is a popular method usedforfeaturetrackingandopticalflowestimationincomputervision.ItwasproposedbyTakeoKanadeand CarloTomasiinthelate1980sandhassincebecomeafundamentaltechniqueinvariousapplications,including object tracking, motion estimation, and video analysis. The KLT algorithm operates on a sequence of images andtracksasetoffeaturepointsovertimebyestimatingtheirmotion.Itassumesthattheintensityofafeature pointremainsconstantwithinasmallneighbourhoodoverashortperiod.Thealgorithm'smainobjectiveisto findthedisplacement(oropticalflow)ofeachfeaturepointbetweenconsecutiveframes.
Here'showtheKLTalgorithmworks:
● FeatureSelection:Thefirst step istoselecta setoffeature pointsintheinitial framethataredistinctive andcanbereliablytracked.CommonapproachesforfeatureselectionincludetheHarriscornerdetector ortheShi-Tomasialgorithm,whichidentifycornersorcornerswiththehighesteigenvaluesinanimage.
● Feature Tracking: Once the feature points are selected in the initial frame, their positions need to be trackedinsubsequentframes.Foreachfeaturepoint,asmallpatch(typicallyawindow)isdefinedaround it. The algorithm searches for the best matching position of the feature point in the next frame by comparingthepixelintensitieswithinthepatch.
● Lucas-Kanade Equation: The KLT algorithm uses the Lucas-Kanade equation to estimate the motion of featurepoints.Theequationassumesasimpleaffinemodelofimagemotion,wherethepixelintensityata given position (x, y) in the first frame is approximated by a linear function of the position (x', y') in the secondframe:
I(x,y)=I(x'+Δx,y'+Δy)
Here,I(x,y) andI(x'+Δx,y' +Δy) arethepixel intensitiesatpositions(x,y) and(x'+Δx,y' +Δy) inthe first and second frames, respectively. Δx and Δy represent the displacements (optical flow) to be estimated.
● Optical Flow Estimation: The KLT algorithm solves the Lucas-Kanade equation using the least squares methodtoestimatetheoptimaldisplacement(opticalflow)foreachfeaturepoint.Itminimizesthesumof squaredintensitydifferencesbetweenthepatchcenteredaroundthefeature pointinthefirstframeand the corresponding patch in the second frame.By solving the linear system of equations, the algorithm obtainstheΔxandΔyvaluesthatbestrepresentthemotionofeachfeaturepoint.
● Iterative Refinement: To improve accuracy, the KLT algorithm often employs an iterative refinement process.Afterthe initial optical flowestimation,thedisplacementvaluesareupdated,and the processis repeated using the updated values. This iteration continues until convergence, typically based on a predefined threshold. To improve accuracy, the KLT algorithm often employs an iterative refinement process.Aftertheinitialoptical flowestimation,thedisplacementvaluesareupdated,andtheprocessis repeated using the updated values. This iteration continues until convergence, typically based on a predefinedthreshold.
III. ALGORITHMIC ANALYSIS
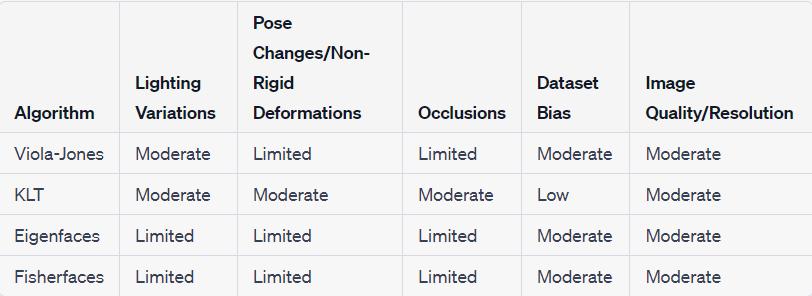
Analyzing algorithm performance is crucial for understanding their limitations and benefits. It helps researchers and practitioners make informed decisions about their applicability. By examining diverse conditions such as lighting variations, pose changes, occlusions, and dataset bias, we can identify weaknesses andareasforimprovement.Thisanalysisdrivesadvancementsincomputervisionbyhighlightingresearchand development needs. Ultimately, it leads to more robust and accurate algorithms in face recognition and other computervisionapplications.
Lightning Variations
Viola-Jones: The Viola-Jones algorithm is relatively robust to lighting variations due to its use of Haar-like features, which capture local intensity patterns. However, extreme lighting conditions can still affect its performance.
KLT:The KLTalgorithm primarilyfocuses on featuretrackingand optical flow estimation, soits performance maybeaffectedbylightingchangeswhentrackingfeaturepointsovertime.
e-ISSN:2582-5208
( Peer-Reviewed, Open Access, Fully Refereed International Journal ) Volume:05/Issue:05/May-2023 Impact Factor- 7.868 www.irjmets.com www.irjmets.com @InternationalResearchJournalofModernizationinEngineering,TechnologyandScience [9422]
InternationalResearchJournal of Modernization in EngineeringTechnologyand Science
Eigenfaces: Eigenfaces are sensitive to lighting variations as they rely on global intensity patterns. Under varyinglightingconditions,theeigenfacesmaynotcapturethenecessarydiscriminativeinformation,leadingto reducedaccuracy.
Fisherfaces:Fisherfacesalsosufferfromsensitivitytolightingvariations,astheyarebasedonglobalintensity patternslikeeigenfaces.
Pose Changes and Non-rigid Deformations
● Viola-Jones: Viola-Jones is primarily designed for frontal face detection and may struggle with significant pose changes and non-rigid deformations. Its performance decreases as faces deviate from the training samples.
● KLT: The KLT algorithm can handle small pose changes and non-rigid deformations to some extent, as it tracksfeaturepoints.However,itmaystrugglewithlargeposevariationsorseveredeformations.
● Eigenfaces: Eigenfaces are sensitive to pose changes and non-rigid deformations since they rely on global shapeandappearanceinformation.Theyaremoresuitableforfrontalornear-frontalfaces.
● Fisherfaces:Fisherfacesarealsosensitivetoposechangesandnon-rigiddeformations.Theyperformbest whentheposevariationsaresmall.
Occlusions
● Viola-Jones: Viola-Jones may struggle with occlusions, as it primarily relies on global intensity patterns. Partiallyoccludedfacescanleadtoreduceddetectionaccuracy.
● KLT: The KLT algorithm may handle occlusions to some extent, depending on the availability of tracked featurepoints.However,severeocclusionscandisruptthetrackingprocess.
● Eigenfaces: Eigenfaces can be adversely affected by occlusions, as they rely on the entire face for recognition.Occludedregionsmayresultinmisclassificationsorreducedaccuracy.
● Fisherfaces:Fisherfacescanhandleocclusionsrelativelybetterthaneigenfaces,buttheirperformancecan stillbeaffected,particularlyiftheoccludedregionscontaindiscriminativeinformation.
Dataset Bias
● Viola-Jones:TheViola-Jonesalgorithmcanbesensitivetodatasetbias,asitsperformanceheavilydepends onthetrainingdatausedtolearntheweakclassifiers.Biasedtrainingdatamayleadtoreducedaccuracyin detectingfacesfromdifferentpopulationsordemographics.
● KLT:TheKLTalgorithmisnotdirectlyaffectedbydatasetbiasasitprimarilyreliesonfeaturetrackingand optical flow estimation. However, biases in the training data used for other stages of the pipeline can indirectlyimpactitsperformance.
● Eigenfaces:Eigenfacescan besensitivetodatasetbias,particularlyifthetrainingdata doesnotrepresent the target population well. Biases in the training data may result in reduced recognition accuracy for certaingroups.
● Fisherfaces:Fisherfacescanalsobeaffectedbydatasetbias.Ifthetrainingdataisbiasedtowardscertain populationsordemographics,thediscriminationpoweroftheFisherfacesmaybecompromised.
Image Quality and Resolution
● Viola-Jones: The Viola-Jones algorithm is generally robust to variations in image quality and resolution. However,extremelylow-qualityimagesorverylow-resolutionimagesmayaffectitsperformance.
● KLT: The KLT algorithm's performance can be influenced by image quality and resolution, as it relies on accurate pixel intensity comparisons for feature tracking. Noisy or low-resolution images may lead to inaccuratemotionestimation.
● Eigenfaces: Eigenfaces can be sensitive to image quality and resolution. Noisy or low-resolution images maydegradetheperformanceofeigenface-basedrecognition.
● Fisherfaces:Fisherfacescanalsobeaffectedbyimagequalityandresolution.Poor-qualityimagesorlowresolutionimagesmayimpactthediscriminativepowerofFisherfaces
e-ISSN:2582-5208
Peer-Reviewed, Open Access, Fully Refereed International Journal )
Impact Factor- 7.868 www.irjmets.com www.irjmets.com @InternationalResearchJournalofModernizationinEngineering,TechnologyandScience [9423]
(
Volume:05/Issue:05/May-2023
IV. TABLES
V. CONCLUSION
After examining the Viola-Jones, KLT, Eigenfaces and Fisherfaces algorithms, we can draw some conclusions abouttheirstrengthsandlimitationsinvarioussituations.Tomaketherightchoice,weneedtoconsidermany aspectsandspecificrequirementsoftheresearchpaper.
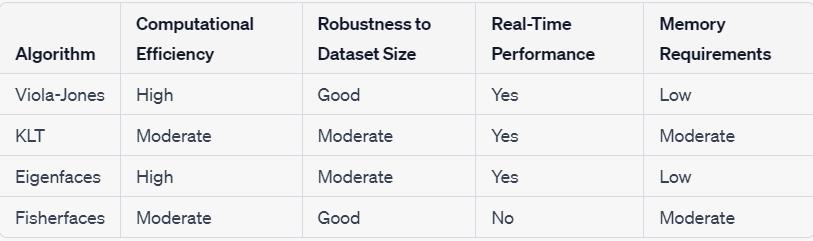
Ifcomputationalefficiencyanduptimeisyourpriority,theViola-Jonesalgorithmisagoodchoice.Itrunsvery fast and requires less effort and memory, making it ideal for real-time use. However, it will be difficult when dealingwithcomplexsituationsinvolvingvariationsandnon-rigiddeformations.
On the other hand, if your research focuses on tracking features and visual evaluation, the KLT algorithm is reliable.Itperformswellinmanysituationsandhasgoodperformance.However,youshouldcarefullyconsider histimeandawarenesstomakesureit'sworthyourresources.Whenitcomestofacialrecognition,Eigenfaces andFisherfacesarewidelyused.Eigenfacesareusuallycarefullycalculatedanddesigned.
However, they are sensitive to changes in light, facial expressions and movements. Therefore, they will not performwellinbrightlightorwhentherearelargechangesintheface.Ontheotherhand,Fisherfacesprovides betteraccuracycomparedtoEigenfaces,butmayrequiremoreinvestmentandeffort.
In summary, certain studies and limitations must be considered when choosing an algorithm. Factors such as computational efficiency, data availability, power consumption, processing time and memory usage must be considered. If the limitations of traditional methods pose a significant challenge to your research goals, it is recommended that you consider tradeoffs carefully and explore other methods such as deep learning. Deep learning techniques have gained popularity due to their ability to process complex and diverse data. They providea learningcurvethatcanbeadjustedaccordingtochangesininputdata.However,itshouldbenoted thatdeeplearningusuallyrequiresmoremoney,moreknowledgeandlongerstudytime.
In conclusion, it is important to understand your research and limitations when choosing an algorithm. Evaluatefactorssuchascomputationalefficiency,dataavailability,processingtime,memoryusage,andability tosolvespecificproblems.Iftraditionalmethodsareshort,exploringothermethodssuchasdeeplearningmay beagoodoption,butbeawareofadditionalresourcesandbusinessimplications.
e-ISSN:2582-5208 InternationalResearchJournal of Modernization in EngineeringTechnologyand Science ( Peer-Reviewed, Open Access, Fully Refereed International Journal ) Volume:05/Issue:05/May-2023 Impact Factor- 7.868 www.irjmets.com www.irjmets.com @InternationalResearchJournalofModernizationinEngineering,TechnologyandScience [9424]
Table 1:Comparisononprimaryfactors
Table 2: Comparisononsecondaryfactors
InternationalResearchJournal of Modernization in EngineeringTechnologyand Science
VI. REFERENCES
[1] Viola, P., & Jones, M. (2001). Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR),Vol.1,pp.I-511.
[2] Lucas, B.D., & Kanade, T. (1981). An iterative image registration technique with an application to stereo vision.InternationalJointConferenceonArtificialIntelligence(IJCAI),Vol.81,pp.674-679.
[3] Turk,M.,&Pentland,A.(1991).Eigenfacesforrecognition.JournalofCognitiveNeuroscience,Vol.3,No.1, pp.71-86.
[4] Belhumeur, P. N., Hespanha, J. P., & Kriegman, D. J. (1997). Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), Vol.19,No.7,pp.711-720.
[5] Yang,M.H.,Kriegman,D.J.,&Ahuja,N.(2002).Detectingfacesinimages:Asurvey.IEEETransactionson PatternAnalysisandMachineIntelligence(PAMI),Vol.24,No.1,pp.34-58.
[6] Tomasi, C., & Kanade, T. (1991). Detection and tracking of point features. Carnegie Mellon University TechnicalReportCMU-CS-91-132.
[7] Belhumeur, P. N., Hespanha, J. P., & Kriegman, D. J. (1999). Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. In Proceedings of the European Conference on Computer Vision (ECCV), Vol.2,pp.45-58.
[8] Yang,J.,Zhang,D.,Frangi,A.F.,&Yang,J.Y.(2004).Two-dimensionalPCA:Anewapproachtoappearancebased face representation and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence(PAMI),Vol.26,No.1,pp.131-137.
[9] Cootes,T.F.,Edwards,G.J.,&Taylor,C.J.(2001).Activeappearancemodels.IEEETransactionsonPattern AnalysisandMachineIntelligence(PAMI),Vol.23,No.6,pp.681-685.
[10] Chen, X., & Yuille, A. L. (2003). Detecting and reading text in natural scenes. In Proceedings of the IEEE InternationalConferenceonComputerVision(ICCV),Vol.2,pp.366-373.
[11] Moghaddam, B., & Pentland, A. (1997). Probabilistic visual learning for object representation. IEEE TransactionsonPatternAnalysisandMachineIntelligence(PAMI),Vol.19,No.7,pp.696-710.
e-ISSN:2582-5208
Peer-Reviewed, Open Access, Fully Refereed International Journal )
Impact Factor- 7.868 www.irjmets.com www.irjmets.com @InternationalResearchJournalofModernizationinEngineering,TechnologyandScience [9425]
(
Volume:05/Issue:05/May-2023

