2. LITERATUREREVIEW
2.1Inaccuratedataentry
Accurate data collection plays an essential role in facilities management and many other different organisationsand industries. Inaccurate datawillsubstantiallyaffectan organisation inoperational,tactical,andstrategicimpacts(Laranjeiro,2015).Operationalimpactmeansthat itwillbringunhappinesstoboththeemployeeandtheclientasitwillincreasethecosttobring in more resourcestorectifythemistake.
Tacticalimpactreferstotheconsequencesofdecisionmaking,causingstrenuousrestructuring anddistrustwithintheorganisation.Strategicimpactreferstotheriseofimplicationsregarding theimplementationofstrategies.Therefore,inaccuratedatawillnotbenefitanorganisationbut create more wastage of resources leading to an increase in cost. It will also hinder the organisation’sgrowthand developmentinthelongrun.
Therearemanyreasonsandcausesofinaccuratedataretrieval,forexample,manualdataentry. Manualdataentrymayleadtohigherrorratesduringthedatacollectionprocessduetopossible human error1. Data entry personnel might feel fatigued or tired, which leads to losing focus during data entry. Another reason could be due to the high volume of data entry required. Employeeswillhave more data toenter. Therefore theywill be rushedtoenterthe data. They will then start to enter the data mindlessly, hence increasing the rates of error in the collected data.
Researches have been done by many to find ways to reduce human errors. One of them mentioned that double-entry has shown to be more accurate than a single entry (Scott et al., 2008). Double entry means that the data will be entered into the system twice. They experimented with checking for the accuracy among three entry methods (single entry, the single entrywithvisualchecking,anddoubleentry).
Theresultsshowedthatdoubleentryandsingleentrywithvisualcheckinghavebetteraccuracy than a single entry. However, it also stated that visual checking might be unfavourable. Furthermore, thiswouldmean that therewillbean increase in costandtime requiredasmore personnelwillbeneededfordoubleentry.
BEARS#06 5
Thismethodwillbecometediousandineffectivewhendealingwithahugeamountofdata.To obtainaccuratedatawhendealingwithalargenumberofentries,theorganisationwillneedto adopt an automated system. With an automated system, there will be a significant drop in personnel needed. There will also be an increase in accuracy if the automated system is integrated with a proper method to receive the data. This will improve the effectiveness and efficiencyofthe organisation.
2.2Usageofopticalcharacterrecognition
Optical character recognition (OCR) is a process of converting scanned images, handwritten words, and printedtext on images intotext whichare editable for later use. It is a technology thatallowsmachines/systemstoextracttextautomatically(Pateletal.,2012).Therearemany OCRapplications,suchasreadinglicenseplatesand textextractionfromscanneddocuments.
However, whenusingOCR,thereare somecommonproblemsasOCRmighthaveaproblem detectingthedifferencebetweensimilarcharacters(Pateletal.,2012).Forexample,theymight read ”0” as ”o” vice versa. The nature of images might also be a problem as the OCR might have difficulties extracting text from a bad lighted image. Therefore, the average accuracy of differentOCRsoftwarerangesfrom71%to98%.Overtheyears,OCRsoftwarehasbeenmade availableonseveralplatforms.However,onlyafewarefreeandopen-source.
Oneofthefreeandopen-sourceOCRenginesiscalledTesseract.It’sdevelopedatHPbetween 1985 and 1995. It became an open-source library in 2006 and is managed by Google now (Smith, 2013). Tesseract usage is for real-time license plate detection in India (Palekar et al., 2017). As unlicensed plate cars in India have increased, it has led to high congestion in the traffic.Manyhave resultedinbreakingtrafficrulestogetfromplacetoplacefaster.Tesseract wasusedasafastandefficientwaytocapturethelicenseplate.Thiswillspeeduptheprocess ofhandlingfines.
To extract accurate information from the license plate, various image processing operations using the open-source library OpenCV such as thresholding, gaussian blur, dilation, and erosion (Palekaretal.2017). These preprocessingtechniquesarecrucialaseveryimage hasa different text style, font, length, and width, requiring different preprocessing techniques from
BEARS#06 6
the other. Everyimage isobtainedaftereach preprocessing methods. Theimage with the best results sent to the OCR engine. The output is desirable while it contained some errors due to the nature of the image. An ASCII filter was applied to remove some special characters. However, notallspecialcharacterscanberemovedassomeofthembelonginASCII.
AnotherexampleoftheuseofTesseractwastoextracttextfrombillsandinvoices(Sidhwaet al.,2018).Severalpreprocessingtechniquesfromtheopen-sourcelibrarywerealsoadoptedto ensure desirable results. In this case, the methods used are greyscaling, applying the simple threshold, usage of erosion anddilationto get more contours, and the findContour() function. The overall results were good, but there is still some limitation. Tesseract was not able to recognize handwrittentextwell.Tesseractdetectsthefirstcharacter’sposition.Itwillreadthe rest of the text in the same line. Since the handwritten text is not well aligned, the results achievedwerenotverydesirable.
Since Tesseract is free and open-source, it is used in many applications. From both usages of Tesseract example, the preprocessing techniques such as grayscaling, thresholding, and blurringarecrucialinobtaininga good resultfrom the TesseractOCRengine. Severaltesting isneededtodeterminewhichtechniquestoadopt.Toomuchuseorbadusageofpreprocessing techniqueswillnotimprovetheresults. Instead,it mightleadtoadisastrousoutput.
3.0METHODOLOGY
Theconsolidationoftheimageinformationandverificationprocessisstilldonemanually intheindustry.Thecurrentmethodistediousandinefficient.Inthemethodology,an automatedprototypesolutionwillbeintroducedtoconsolidatetheimageinformationand theverificationprocess.
Thefollowingshowsthebasicstepsrequiredinobtaininganaccurateandupdatedasset informationrequirement(AIR):
Step1:ObtaintheequipmentassetlistinPDFformatfromtheclient.
Step2:UsetheAIRtemplategeneratortoextractdatafromPDFfilestoAIR templateExcelsheet.
BEARS#06 7
Step3:Collectonsiteimagesfrombuilding.
Step4:ExtracttextfromonsiteimagesinJPEG/PNGformatintotheAIR tem-plate(Images).
Step5:Checkiftheextractedinformationfromimagesisaccurate.
Step6:UsetheAIRtemplate(Images)toverifyiftheinformationontheAIR templateforPDFfilesiscorrectandupdated.
Step1tostep3hasbeenaddressedinthepreviousproject.Forthismethodology,a prototypewillbeintroducedtocompletethetaskfromstep4to6.Uponcompletingall thesteps,theAIRwillbereadytobeusedasallthedataareaccurateandupdated.
3.1Prototypetools
Forthedevelopmentoftheautomatedprototypesolution,twoprogramminglanguageswillbe used.InthePythonscript,severalopen-sourcelibrarieswereusedtoachievetheobjectivesof thisprototype.
3.1.1 Programming language Python
Pythonwillbethe primary programming language usedforthisprototypeastheextractionof information from images and storing the results onto Excel files are required. Python is compatiblewithseveralsystems,toolsandhasmanyopen-sourceframeworks2.Itisapowerful and open-source programming language. With the usage of several open-source libraries, the desired prototype will be achievable. This ease the process of transferring the data collected fromtheimagestoExcel.
Visual Basic Application (VBA)
VBA is a programming language inside the Microsoft application that can be used to run automated/semi-automated tasks3. VBA will be used in our prototype for the verification processas both data collected fromthe images and the assets equipment list is saved onto the
BEARS#06 8
sameworkbookinExcel.
3.1.2 Open source library
The open-source library is original codes that are made freely available to users and may be modified or changed accordingly to the needs of the user. Several open-source libraries such as OpenCV, Pytesseracts, NumPy, Pandas, Tkinter, Pyzbar, Openpyxl, PIL and OS will be usedfortheprogrammingin Python.
Numpy
Numpy stands for Numerical Python. It encompasses multidimensional array and matrix data structures4.Thelibrariescontainlargenumbersofmathematical,algebraic,andtransformation functions. They are mainly used to perform mathematical operations, such as statistical and algebraicroutines. Itisusedinthe prototype tohandlethenumbersofthearray.
OpenCV
OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning library5. Some of the function that were used from the library includes, cv2.imread(), cv2.imshow(),cv2.write(). This library will be used in the program mainly to read,show,anddosomeprocessingmethodsontheimagesbeforesendingtheimagesintothe OCRenginefortextextraction.
PIL
PILstandsforPythonImagingLibrary6.Itisalsoanimageprocessinglibrarythatissimilarto OpenCV. However, Pillow might be compatible with some of the libraries, while OpenCV mightnot.Intheprogram,PillowwillbeusedtoreadimagesforPytesseract.
Pyzbar
ThePyzbarisusedtodecodebarcodesandQRcodes.Firstly,OpenCVwillbeusedtoreadthe image.Thepyzbar.decodefunctionwillbecalledtodecodetheimage.Thefunctionwillreturn anarrayofobjectsofclassdecoded. Thismeansthatthelibrarycanreadasmanybarcodesor QRcodesinthesameimage.Itwillalsoreturnthreefields,whichinclude,type ofbarcodeon the image, the data which isembedded on the barcode,and the location of the barcode on the image7 .
BEARS#06 9
Pytesseract
Pytesseract stands for python-tesseract. It is an optical character recognition (OCR) tool for python8.Thistoolwillbeabletodetecttextonimagesthenextractthetextfromit.Pytesseract can take images from imaging libraries such as Pillows. Before sending the images to Pytesseract, the images should be preprocessed. The preprocessing methods will improve the outputfromPytesseract.
Pandas
Pandas is a data analysis tool that is used for data manipulation and analysis9. Dataframe can be created by using pandas. The data frame is a 2-dimensional labelled structured data with columns of data. Dataframes are created in the programme to store different parts of the extractedtextfromimages.ThesedataframeswillbestoreinanExcelsheet.
Openpyxl and OS
Openpyxl is mainly used to read and write excel files in the format of xlsx/xlsm/xltx/xltm10. Inthisprogram,afunctioncontainingOpenpyxlwillbeusedtoupdatetheexistingExcelsheet orcreateanewExcelsheet.OSisamodulethatprovidesfunctionstoallowinteractionbetween python and the operating system11. It will be used to obtain folder paths and the opening of theExcelapplicationintheprogramme.
Tkinter
Tkinter is a graphical user interface (GUI) package in python12. Tkinter provides several controls in the window created, such as buttons, download bars, labels, and text boxes. The purposeofthiscontrolistocreateabetterinterface andenvironmentfortheuser.
3.2Userinterfaceprototype
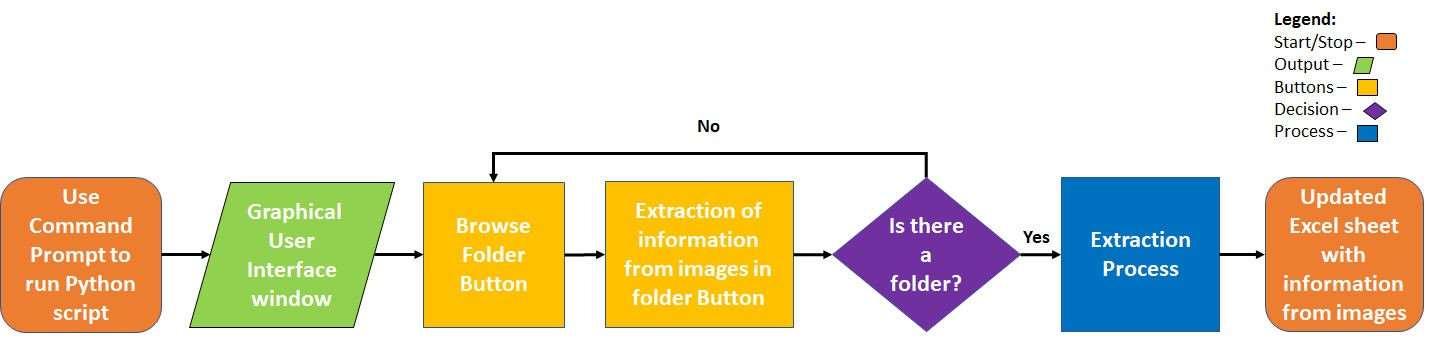
As potential users of the prototype might not have computer programming knowledge, it is crucial to create a prototype that is easy to understand and use. To achieve a user-friendly environment, the Tkinter library was used to create minimal buttons, ensuring that users will not be misguided or be confused about what to do. Figure 2 shows a flowchart of the user interface.Itprovidesaflowchartofhowtheuserinterfaceprocessworks.
BEARS#06 10
Figure2.Flowchartofuserinterfaceprocess
3.2.1 Running Python script using Batch File
Consideringthat users might not have any programming knowledge, a batchfile is created to runthecommandsonthecommandprompt.Abatchfileisascriptfilethatcancontainaseries of commands on the command-line interpreter. The batch file is created by storing all the necessarycommandsonatextfile.ThetextfilewillbesavedasabatchfileasshowninFigure 3.Userswillhavetodouble clickonthebatchfiletorunthePythonscript.
Figure3.Savingtextfileasbatchfile

3.2.2 Running Python script using Batch File
The Python script must contain a class and several functions within the class for the GUI window to work smoothly, as shownin Figure 4. A class is a type of object in Python, which inthiscaseisawindowthatcantakebothfunctionsanddataelements.Thefunctionsinaclass canbe usedtodefinethechangeofstatefromanobject.
BEARS#06 11
Figure4.Classfunction
After the Python script is executed on the command prompt, a window named ”Folder Browser” will appear, as shown in Figure 5. There are four elements in the window, the SelectedFolder bar, the Browse Folder button, the Extract Image Information button, and the Extraction Progress bar. These buttons and folder bars are created using the Tkinter library withintheclass,inthefunctioncalledInit.


Figure5.FolderBrowserwindow
ThecodeintheInitfunctioninFigure6showshowthebuttons,thefolderbar,andtheprogress bar are created. The buttons have a parameter called command. It will be executed when the userclicksonthebutton.WhentheuserclicksontheBrowseFolderButton,the“openfolder” function will be executed. When the user clicks on the Extract Image Information button, the functioncalled“extract”willbeexecuted.
BEARS#06 12
Figure6.InitfunctionCode

The purpose of the ExtractionProgress bar is to allow users to gauge how long the extraction processwilltake.Figure7ashowstheprogressbarwhentheimagesarestillprocessing.Figure 7bshowshowtheprogressbarwilllooklikewhenallthe image filesareprocessed.


(a) ExtractionProgressbarwhenextractinginformation
(b) ExtractionProgressbaraftercompletingextraction Figure 7.ExtractionProgressbar
BEARS#06 13
Afewlinesofcodewerewrittenintheforloopintheextractionprocesstocreatetheprogress bar. Firstly, a count was done to identify the number of files in the folder. The number determines how muchincrement the Extraction Progress bar would make after each iteration. The step was subtracted by 0.001 as the Extraction Progress bar will not be able to show full 100% completion on the window. The bar will update itself with a step after each iteration.
Figure8showsthecodefortheExtractionProgressbar.

Figure8.ExtractionProgressbarcode
3.2.3 Open folder function
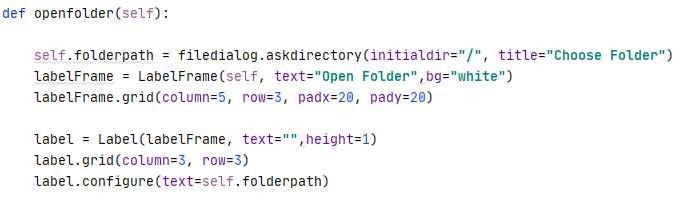
Figure 9 shows the code of the open folder function. It will allow users to select the desired folder. The function will execute when the users click on the Browse Folder Button. Afolder selectionwindowwillpopout,allowingtheusertoselectthefolderthatcontainsalltheimages, asshowninFigure10.OncetheuserhasclickedtheselectFolderbuttononthefolderselection window, the code will identify the folder's folder path and store it inside the Selected Folder bar.ThefolderpathwillalsobedisplayedontheFolderBrowserwindow,asshowninFigure 7b.
BEARS#06 14
Figure9.OpenfolderfunctionCode
Figure10.Openfolderfunctionwindow
3.2.4 Extraction No Folder Function

The extraction process is the most crucial process of the prototype. However, there are instances where the user did not select a folder before pressing the Extract Image Information button.Thereforetheextractionfunctionwillcheckiftheuserchoseafolderpath.IftheExtract ImageInformationbuttonispressedwithoutselectingafolder,itwillexecutetheextractnofile function.
ThecodeofthisfunctionisshowninFigure11a.Inthisfunction,amessage boxwillpopout, asshownin Figure 11bnotifying the user thatafolderneedstobechosen.The user willneed toclose themessageboxandclickontheBrowseFolderbuttontoselectafolder.
(a)Extractnofolderfunctioncode
BEARS#06 15
(b) MessageBox

Figure11.“Extractnofolder”function
3.2.4 AIR Template
The AIRtemplate forextraction of JPEG/PNG formattedimages was made to look similar to theAIRtemplatefortheconsolidationofinformationfromPDFformattedfilesintheprevious project, as shown in Figure 12a and Figure 12b. It was done as the AIR template for the extracted images information will be used to check if the information from PDF files on the AIRtemplateisaccurateandupdated. (a) AIRtemplateforPDFfiles (b)
Figure12.AIRtemplate
Considering that the images might contain additional information, there are four additional columns in the AIR template for JPEG/PNG formatted images, which are the image link, barcodetype,barcodedata,andadditionalinformationcolumn,asshowninFigure 13.


BEARS#06 16
AIRtemplateforJPEG/PNGfiles
Figure 13.AdditionalcolumnsonAIRforJPEG/PNGfiles
3.3ExtractionProcess

Intheextractionprocess,theimagesarepreprocessedbeforesendingthemfortextextraction. The results from the extraction will be sorted out into different columns of the AIR template. Figure 14 shows a flowchart of the extraction process. The process will run for N times dependingon the number of images inthe folder. After allthe images inthe folder have been processed, the excel file which contains the extracted information in the AIR template will openupautomatically.
Figure14.Flowchartoftheextractionprocess
Before proceeding, we have to identify the image path for all the images in the folder. The os.listdir() functionin the OS library will be able to list the file namesin the folder. A loopis created to run the processes for every image in the folder. The folder path and the file name will be concatenated together to form the file path, as shown in Figure 15. The cv2.imread() function from OpenCV will read the file path. The image will be used for the subsequence processes.

BEARS#06 17
Figure15.Extractionprocesscode1(file paths)

3.3.1 Barcode check

Astheimagesmight containbarcodes/QRcodes,thereisaneedforabarcode/QRcodecheck using Pyzbar. As mentioned before, the Pyzbar library can identify barcode/QR code in the image (if thereareany).Itwillreturnthree piecesofinformation,whichincludedthebarcode code type, data, and location. Figure 16a shows the decode function that was called in the extraction process and Figure 16b shows the code of the decode function. After the image is decoded,thereturnedinformationofdataandtypeisstoredintherespective strings. (a)Pyzbarfunctioncode

Figure 16.Extractionprocesscode2(barcodecheck)
3.3.2 Image preprocessing method
Image processingmethodsaredonebyusingOpenCV libraryfunctions.Thecode isas
BEARS#06 18
(b)UsageofPyzbarinextractionprocess
showninFigure17.Theimageprocessingmethodsusedinthisscriptaregrayscaling, resizingoftheimage,gaussianblur,andtheadaptivethreshold.Thereasonfordoingthe followingprocessesistoensurethatthefinalimagewhichissentforthetextextractionwill produceadesirableoutput.Thismeansthattheoutputshouldbeabletoreadmostofthetext ontheimage.

Figure17.Extractionprocesscode3(Imageprocessing)
Grayscale
Grayscalingisaprocessofconvertingacolouredimagetoablackandwhiteimage.Figure 18ashowsanexampleofanimagebeforegrayscaling,andFigure18bshowstheimageafter grayscaling.Agrayscaleimagecontainsdifferentshadesofgreyfromtherangeof0to255.0 willbeblackwhile255willbewhite.Imagesareconvertedtograyscaleascolouredimages mighttakealongtimetoprocess.Italsoproducesabetterresultwhenweapplyother preprocessingmethodsonthegrayscaleimage.
Figure18.Grayscaleexample

BEARS#06 19
(a)Beforegrayscale (b)Aftergrayscale
Figure19ashowstheassetimagebeforethegrayscaling,andFigure19bshowstheimageafter grayscaling.Eventhoughequipmentassetimagescontainlittlecolours,grayscalingisstill recommended.
(a)Beforegrayscale(Assetimage)(b)Aftergrayscale(Assetimage)

Figure19.Grayscaleimagesonassetimage Resize
Afterconvertingtheimagestograyscale,theimagesareresized.Resizingofimagesmeans addingorsubjectpixelsfromtheimage.Addingpixelsmeansthattheimagesareenlarged, whilesubtractingpixelsmeansthattheimagewillbesmaller.Therearefiveparametersforthe functionofresizingtheimage;twoofthemhavebeenadjustedinthescript.Theyarethescale factoralongthex-axis&y-axis(horizontalandverticalaxis).
Thesetwoparametersaretoadjustthelengthandbreadthoftheimage.Resizingisessential fortheextractionprocessassomeimages'wordswillbetoosmallforPytesseracttoprocess. Henceitmightbemisinterpreted.However,theimagesshouldnotbeoverenlarged,asthe resolutionoftheimagedecreases.Thiswillalsocausethewordsontheimagetobe misinterpreted.Aseriesoftestinghavebeendonebeforedecidingonhowmuchtheimage shouldbeenlarged.
GaussianBlur
ThereareseveraldifferentimageblurringfunctionintheOpencvlibrarysuchascv2.filter2D(),
BEARS#06 20
cv2.blur(),cv2.medianblur(),cv2.gaussianblur()andetc.Thegaussianblurwillbethefunction used in the script as it helps to smooth the image and remove noises from the background, as showninFigure20.Thegaussianblurisdonebyidentifyingthekernelsizeintheparameters. Thefunctionwillaverageoutallthepixelswithinthekernelandapplyitbacktotheimage.
(a)Beforeblurring(b)Afterblurring
Figure20.Blurredimage
Adaptive Threshold
The usage of the threshold is to create a binary image based on the threshold value provided. Unlikeotherthresholds,theadaptivethresholdwillcalculatethethresholdforsmallregionsof the image instead of setting a global threshold for the whole image. This will provide better results as compared to the other threshold. However, to apply a suitable adaptive threshold to an image,the block sizeand the constantC numberhave to be adjusted.The blocksizestands forthesizeoftheneighbouringarea,andtheconstantCisaconstantwhichwillbe subtracted fromthemeanvaluelater.

ToachievethebestblocksizenumberandconstantC,theextractionprocesshasbeenrunmore than40timestoidentifywhichvaluesprovidethebestresults.Inthefollowing,threeexamples ofdifferentvaluesareusedtoshowhowtheimagewilllookaftertheadaptivethreshold.Figure 21b and Figure 21c show the image after applying the threshold of block size = 3, C = 5 and

BEARS#06 21
block size = 70, C = 60. Both results are not acceptable as the words on the image are almost fadedandunclear. Figure21dshowsthethresholdof blocksize=17,C=11,the image results is acceptable as it has removed most of the background noises and the text on the images is clear. Figure 21d is only an example of a possible threshold used. There will still be many acceptable thresholds due to the wide range of numbers. Users may adjust the threshold accordingtothenatureoftheimages.




(a)OriginalImage (b)Blocksize=3C=5 (c)Blocksize=70C=60(d)Blocksize=17C=11
Figure21.AdaptiveThreshold
BEARS#06 22
3.3.3 Optical character recognition
After the images are preprocessed, they are ready for the extraction of text done by the Pytesseract library. Figure 22 shows the code of applying Pytesseract. A temporary file was written and the Pillow library was used to read the file. The temporary image will be deleted after extracting the text from the image by applying OCR. Figure 23 shows the results after applying OCR. All the information is well-read by Pytesseract. The function text.splitline() splitsthetextlinebyline.Thetextfilterwillremoveemptylinesinbetweentheremainingtext willbe storedinalist.


Figure22.Extractionprocesscode4(OCR)
Figure23.Pytesseractresult
BEARS#06 23
3.3.4 Sorting of text information
The retrieved text data have to be sorted out properly by identifying which line belongs to whichcolumnintheAIRtemplateforJPEG/PNGimages.Firstly,asetofstringsiscreatedto storealltherequiredinformationafterthekeywordssearch.Figure24showshowthekeyword searchesaredoneonallthestringsofthelist.
Figure24.Extractionprocesscode5(Keywordsearch)
Forexample,toidentifywhichlinecontainsthemodelnumber,asearchforkeywordssuchas ’MODEL NO.’, ’MODEL’, and ’MOOEL’ is done to the list of strings. Commonly misread words by Pytessract can also be added into the keywords search to identify possible lines. In the model number finding example, after the line was identified, a for loop was created to remove any unnecessary special characters in the string. This was done as Pytesseract might misreadsomenoisesasrandomspecialcharacters.
Awhileloopwasalsocreatedtocheckifthefirstorthelastcharacterofthestringisaspecial character.Ifitis,thespecialcharacterwillberemoved.However,notallspecialcharacterscan be removed as some of them are required. The keyword used to search for the string will be removed from the string itself before it is stored in a new string for the AIR template for JPEG/PNGimages,asshowedinFigure25.

BEARS#06 24
Figure25.Modelkeywordsearchexample

In another example of identifying the capacity number as shown in Figure 26, the new string willonlystoretheinformationafterthefirstintegerofthatparticularlinethatwasidentified.A forloop wasalsocreatedto remove anyunnecessaryspecial charactersinthe string. The code willalsocheckifthestringcontainsthe unit’KW’and willadd itatthe backof the stringif it doesnotexist.Thestringwillalsoberemovedfromtheoriginallist.
Figure26.Capacitykeywordsearchexample

BEARS#06 25
3.3.5 Exporting data to AIR template


Afterallthestringshavebeensortedout,theywillbeplacedinalist.Thislistwillbecreated intoadataframeusingthepandalibrary,asshowninFigure27.Onceallthedataareupdated inthe excelsheet,theextractionprocesswillautomaticallyopentheexcelfileforthe userby usingtheOSlibrary.
Figure27.Extractionprocesscode6(Exportingdata)
A function will be called to update the excel sheet with the data frame. Figure 28 shows the codeofthe function.Thefunctionwillcheckiftheselectedexcelfileexists. Ifthefileexists, it will update the data accordingly on the sheet. If the file does not exist, it will create a new ExcelfileandExcelsheettoupdatethedata.
Figure28.UpdateexcelsheetfunctionCode
BEARS#06 26
Figure 29 shows the output of data after all the images from the folder have completed the extractionprocess.Figure30showsthecolumnwherealltheinformationwhicharenotneeded inAIRisstored.Usersmayusetheinformationwhenrequired.

Figure29.OutputresultsonExcelfile
Figure30.Additionalinformationcolumn

3.4VerificationProcess
Both the AIR template for extracted information from PDF files and the AIR template for extracted information from JPEG/PNG images are stored in the same excel file but on a different sheet. Since both sheets are inExcel, VBA willbe usedto dotheverificationcheck ontheAIRtemplateforthePDFfiles.
BEARS#06 27
3.4.1 Hyperlink function

As the extractedinformation from images will not be 100% accurate, userswill have todoa physicalcheckoneveryimage.Toeasetheprocessofimageschecking,acolumnisaddedto theAIRtemplateforJPEG/PNGimagestostorethefilepathforeveryindividualimage.There willbeabuttonontheAIRtemplateforJPEG/PNGimages,asshowninFigure31.
Figure31Hyperlinkbuttononexcel

A macro is attached to the button. The function is shown in Figure 32. When the button is clicked,thefunctionwillrun,anditwillconvertallpathsintheimagelinkcolumntohyperlink, asshowninFigure33.Userswillbeabletoclickonthehyperlinkfortheindividualimageto checkiftheextractedinformationiscorrectandupdatetheinformationifrequired,insteadof lookingforthecorrectimageinthefolderonebyone.
Figure32.HyperlinkFunctionCode
BEARS#06 28
Whentheusersarecheckingiftheextractedinformationfromimagesiscorrect,theyarealso required to clean up the extracted information. It is needed as Pytesseract may misread backgroundnoisesascharacters. Figure 34 showsthesheetafterthecleanup. Bycleaningup the information, it will smoothen the verification process and ensure that the verified


BEARS#06 29
(a)Filepathincolumns (a)Creatinghyperlinkfromfilepathincolumn Figure33.CreationofHyperlinks
information is correct.
Figure34.AftercleaningtheAIRtemplateforimages
3.4.2 Verification function

InNgandFadeyi(2020),theinformationoftheequipmentassetlistinPDFformathavebeen extractedintotheAIRtemplate,asshowninFigure35.AfterproducinganotherAIRtemplate for the images in JPEG/PNG format, as shown in Figure 34, the purpose is to use the AIR TemplateforimagestoverifyandcheckiftheinformationontheAIRtemplatefromthePDF filesisaccurateandupdated.
For verification of the information, a verification process is required. A ”verify” button is added onto the AIR template for extraction of PDF files, as shown in Figure 36. A macro is attachedtothebutton.ThecodeforthefunctionisshowninFigure37.

BEARS#06 30
Figure35AIRtemplateformpreviousprojectwithsampledata


BEARS#06 31
Figure36.Verificationbutton (a)Verifcationfunctioncode1
(b) Verifcationfunctioncode2
Figure37.VerificationCode

When the button is clicked, the function will count the number of cells that are in use on the AIR template for images. It will crosscheck every used cell and compare it with the same particular cell in the AIR template for PDF files. After the process is completed, a message box will pop out to inform the user of the number of differences found after checking both sheets.ThisisshowninFigure38. Thefunctionalsoupdatedthe AIR template forPDFfiles automatically.Theupdatedcellswillbeinred,asshowninFigure39.
Figure38.Messageboxforverification

BEARS#06 32
Figure39.Outputfromtheverificationprocess
3.5Usertesting
Experiments are designed to test the effectiveness of the developed automated AIR template forimagesandtheverificationsolution.Thepurposeofthetestistoindicateifthe developed automated solution has met its objective. It will also determine if any improvement of the prototypeisrequired.
The solution aims to aid users in the extraction process of text from images automatically as well as verifying the data collected from the client’s PDF file with a click of a button. The solutionaimstoenableuserswhohavenoexperienceinconsolidatingAIRinformationtouse this solution. This solution also aims to shorten the whole process without compromising the accuracyofthedatacollected.
3.5.1 Test group
Six participants took the test to fulfill the objectives of the study. All the participants do not have any experience in the consolidation of asset information into an AIR template or have any background on building services engineering. However, the participants have basic knowledgeofhowtouseexcel.Onlyasmallnumberofparticipantswererecruitedasthemain goalistoindicatetheeffectivenessofthedevelopedautomatedsolutionand determineifany improvementisrequired.
3.5.2 Test environment
Since all participants do not have any experience in consolidating asset information, a brief
BEARS#06 33
trainingandintroductionofthedevelopedautomatedsolutionweregiventotheparticipants.
Withthebasicunderstandingofwhytherewasaneedtocreatethesolution,participantswere able to go through with the test to provide relevant and constructive feedback on areas of improvementforthedevelopedprototype.Atotalof10imageswereusedforthestudy.Four factorswereconsideredtoensurethattheconductedtestwasfairandtheresultsdonotcontain anybias.Thefactorswhichwereconsideredarelistedandsummarise,asshowninTable1.
3.5.3 Test tasks
The test includes two sets of experiments. The first set of experiments involves the manual entryofdatafromimagesontotheAIRtemplateinExcel.Theconsolidatedinformationfrom images is used to verify the AIR template for PDF files manually. The second set of experiments involves the use of the developed automated AIR template for images and verificationoftheAIRtemplateforPDFfileswiththe verifybutton.
A copy of raw data collected by manual entry and automated entry was saved to check for accuracyintheconsolidatedinformation.Table2andTable3showthetaskstheparticipants have to complete for both the experiments and the required information recorded during the test.
Table1.Testconditions
S/NFactors
Description
Equipment used for the test:
1 Equipment
Thesamecomputerandmousewereprovidedtoallparticipantsto completetwosetsofthetest.Thiswastoensurethatthereareno implicationsduringthetest.Theperformanceandspecificationofthe computerwillnotaffectthetimingrecordedduringthetest.
Equipment used for measurements:
Thesamemobilephonewasusedduringbothteststorecord thetimingtocompletethegiventasktotheparticipants.
BEARS#06 34
2 Operator
Thesamefacilitatorconductedthetestforallparticipants.Thescope ofthefacilitatorwastoprovideinitialinstructions,recordthetime takenandensurethefairnessofthetest.Theparticipantsareallowed toseekconfirmationfromthefacilitatorduringthetest.
Thetestwasconductedatvariouslocationsandtimingtosuitthe convenienceoftheparticipants.Thespaceconditionswerestrictly adheredtotoensurethatthetestspacewasconsistentand convenient.
Thetestwasconductedinaspacethatmeetsthefollowing conditions:
3 Environment
Air-conditionedroom: Theparticipantsdecidedwhichtemperatureiscomfortablefor them.
Noise: Thetestwasconductedinanenclosedareawithlownoiseto ensurethattheparticipantscanfocusthroughoutthetest.
Stress: Thetestwasconductedinaspacewithlowhuman traffictoreducetheparticipants'pressureandstress.
BEARS#06 35
4 Method Themethodsusedbyallparticipantswasconsistent. Table2.TestflowforManualmethodofextractionandverification Manualmethodforextractionand verification Recordedinformationfor analyse Manuallyconsolidatetheimageinformationonto AIRtemplateforimagesontheexcelsheet. Timetakentoconsolidatethe information AcopyoftheAIRtemplatefor imagesissavedforaccuracycheck.
Checkforerrorsbycross-checkingallthe imagesinthefolder.Updateandremoveany unnecessaryinformationfromtheAIR template.
UsingtheAIRtemplateforimagesto verifytheinformationontheAIRtemplate forPDFfilesmanually.
TimetakentoverifytheAIRtemplatefor PDFfiles.
Table3.Testflowforautomatedmethodofextractionandverification
Automatedmethodforextractionand verification
Automaticallyconsolidatetheimage informationontoAIRtemplateforimageson theexcelsheet.
Checkforerrorsbycross-checkingallthe imagesinthehelpofhyperlinkbutton. Updateandremoveanyunnecessary informationfromtheAIRtemplate.
UsingtheAIRtemplateforimagesto verifytheinformationontheAIR templateforPDFfileswithaclickofa button.
Recordedinformationfor analyse
Timetakentoconsolidatethe information
AcopyoftheAIRtemplatefor imagesissavedforaccuracycheck.
TimetakentoverifytheAIR templateforPDFfiles.
Atotalof11mistakes/errorswerepurposelyincludedintheAIRtemplateforPDFfiles.These mistakes are common in the extraction of data from PDF files. These mistakes are made to make sure thatparticipants were able to pick out the mistakes duringthe verification process andamendthemaccordingly.
Theinstructionforrunningthepythonscriptandtheverificationprocessareasfollows:
BEARS#06 36
Python script
CreateabatchfileorrunthePythonscriptfromthecommandprompt
AwindowwillpopafterrunningthePythonscript,selectfoldercontainingallthetest images.
Clickonthe‘ExtractImageInformation’buttontostarttheextractionprocess
Aftercompletion,theExcelfilecontainingalltheinformationwillopenautomatically.
Checking of Image Information
Checkiftheextractioninformationfromtheimagesarecorrect.
Makenecessarychangesifrequired(e.g.correctmisinterpretedletters)
Verification process
GoontotheAIRtemplateforPDFfilesandclickontheverifybutton
ThedifferencewillbeupdatedwiththeinformationfromtheAIRtemplatesforimage.
3.6Dataanalysis
3.6.1 Test evaluation
After the extractionprocessiscompleted forboth tests,a copy oftheexcelfilewas required tobesaved.Thedatawasrequiredtobecheckedagainsttheoriginalimageforaccuracyand toidentifypossibleerrorsduringtheprocess.Timetakentoconsolidatetheimageinformation and verification process was also recorded for comparison. After the verification process, a copy was also required to be saved to check if the participants corrected all the missing or wronginformationonthe AIRtemplateforPDFfiles.
3.6.2 Survey
The survey is crucial to get feedback and improvements ideas on the prototype. Aside from the test results, the participants were required to submit a feedback form. The questions on thefeedbackformcontainbothqualitativeandquantitivequestions.Thequantitivequestions requiretheparticipantstoprovideanswerswithinarange.Thisgivesaclearindicationifthe objective of the prototype is achieved. The qualitative questions required users to answer open-ended questions. These questions are expected to give insights into the improvement
BEARS#06 37
Amessageboxwillpopupnotifyingthenumberofdifferencesfound
neededfortheproposeddevelopedprototypesolution.
4.0RESULTSANDDISCUSSION
The developed automated solutionaims toreduce the time required toobtain the updatedand accurate AIR. The accuracy should not be compromised during the process. The test results showed that the time reduced when the developed automated solution was adopted for the extractionprocess. However, accuracywasnotperfect. However,forthe verification process, the developed automated prototype solution reduced the time taken significantly without compromisingitsaccuracy.
4.1TotaltimetakentoconsolidateimageinformationintoAIRtemplate
Inthefirstpartofbothtests,participantswererequiredtoconsolidateeveryinformationfrom images bythe manualandautomated method. Forthe manualprocess, participantskeyedthe relevant data into their respective column in the AIR template on the excel sheet. The automatedsolutionisbasedonthepythonscripttoextracttheinformationintotheexcelsheet fortheautomatedprocess.
The automated process extracted the relevant information into its respective column and the additionalinformationtotheadditionalcolumn.Table4showsthecomparisonresultsbetween participants'timetoconsolidatethedatafromtheimagesintotheAIRtemplatemanuallyand automatically.Itshowsthatthetimetakentoextracttheinformationfromimagesbyusingthe automatedmethodwassignificantlylesserthanthemanualmethod,asexpected.
Participants took between 9 minutes 20 seconds to 13 minutes 51 seconds for the manual method.However,whentheparticipantsusedtheautomatedretrievalmethod,theparticipants' time was between 1 minute 10 seconds to 1 minute 23 seconds. This finding shows that, on average, the manual process took 683 seconds while the automated method took 75 seconds to extract the information. The time taken to consolidate the image information was reduced by89%.
Furthermore, the automated consolidation also extracted every other information from the images into the excel sheet, while for the manual method, the participants only consolidated therequiredinformation.Eventhoughtheautomatedsolutionextractsmoreinformationthan
BEARS#06 38
the manual method, the automated solution's time was still significantly shorter than the manualconsolidationmethod.
Table4.TimetakentoconsolidatetheimagesinformationintoAIRtemplate
Consolidationofimageinformation (Manualmethod) Timetaken(h:m:s)
Consolidationofimageinformation (Automatedmethod) Timetaken(h:m:s)
Participant1 00:09:20 00:01:15
Participant2 00:10:40 00:01:10
Participant3 00:11:17 00:01:23
Participant4 00:13:46 00:01:14
Participant5 00:13:51 00:01:13
Participant6 00:09:27 00:01:16
4.2TimetakentoverifytheAIRtemplate(PDF)againsttheAIRtemplate(JPEG/PNG)
Forthelastpartofthetest, the participants verified informationin the AIRtemplate for PDF filesagainstthe AIRtemplate forimages. Table 5showsthe comparison ofthe time takento verify the data by the manual method and automated method. The results showed a considerable difference between the manual verification and the verification done by a click of a button. Participants took between 4 minutes 28 seconds to 8 minutes and 57seconds for themanualmethod.
However, when the developed automated verification solution was adopted, the participants tookfrom1secondto3secondsforthe verification.Onaverage,manualverificationmethod took 433 seconds while the automated verification process took 2 seconds. The results from the developed automated solution were almost instantaneous. The time was reduced by 99% ascomparedtothemanualmethod.
Thus, the manual method took an average of 1116 seconds for both processes, while the developed automated solution took only 77 seconds. By considering that the data set of the experiment was 10 images, the actual time taken by the staff in the industry to do both processes will be even longer as the number of asset images will easily be more than 1000 images.Therefore,thedevelopedsolutionhasmetitsobjectiveofsignificantlyreducethetime takentocompletetheverification.
BEARS#06 39
Table5.TimetakentoverifytheAIRtemplate(PDF)againstAIRtemplate(JPEG/PNG)
VerificationofAIRtemplate (PDF)(Manualmethod) Timetaken(h:m:s)
VerificationofAIRtemplate (PDF)(Automatedmethod)Time taken(h:m:s)
Participant1 00:06:56 00:00:02
Participant2 00:08:13 00:00:03
Participant3 00:08:57 00:00:02
Participant4 00:04:28 00:00:01
Participant5 00:08:32 00:00:03
Participant6 00:06:13 00:00:03
4.3Accuracyoftheconsolidatedinformation
All image information consolidated from the manual and automated extraction process was savedandverifiedagainsttheoriginalimages.Thesedataareusedtocheckforaccuracy.Table 6 shows the comparison of the number of errors made during the test by the manual test and the automated test, respectively. 4 out of 6 participants made errors during the extraction process.Thenumberoferrorsmaderangesfrom1-5cellsoferrorsforeachparticipant.
The errors made by the automated extracted process was constant for all participants. There areatotalof7errorsintheautomatedextractionprocess.Fortheverificationprocess,twoout of six participants made errors during the manual verification process as the participants did not manage to verify and update the errors on the AIR template for PDF files. During the automatedverificationprocess,0errorswerefoundasallerrorsontheAIRtemplateforPDF fileswerecheckedandupdated.
Table6.Numberoferrorsinconsolidationprocessandverificationprocess
ManualTest
Errorsin consolidation process (No.ofcells)
Errorsin verification process (No.ofcells)
Errorsin consolidation process (No.ofcells)
AutomatedTest
Errorsin verification process (No.ofcells)
Participant 1 0 0 7 0 Participant 2 4 1 Participant 3 0 0 Participant 4 2 0 Participant 5 2 2 Participant 6 5 0
BEARS#06 40
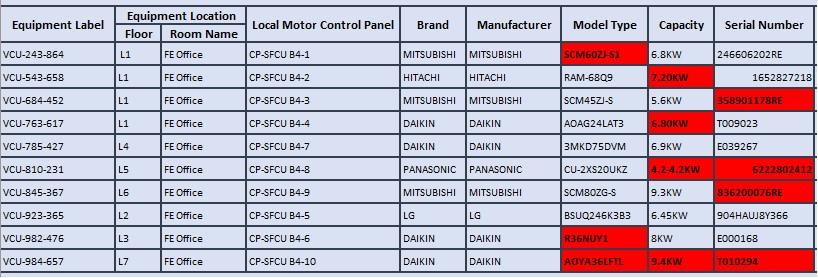
Thefindingshowsthateven withthehelpofPytesseracts,theoutputfromthe imageswillnot be 100% accurate all the time. There were a total of 7 errors from the automated extraction process.Figure 40showsthe errorsthatwereextractedfromtheautomatedsolution.
Figure40.Errorsfromautomatedextractionprocess
Four errors contain misread characters in the cell. For example, the character ’0’ is often misinterpreted byPytesseracts to be ’O’. Figure 41a shows the original images, while Figure 41b shows the extracted information from that image. In this example, Pytesseracts have misinterpreted’3’tobe’S’,’VM’tobe’VIM’,and’0’tobe’O’.Itisinevitabletohavesuch amistakemadebytheOCRenginemachinesashumansalsotendtomakethesamemistake.
Themisinterpretationof’0’to’O’canbeavoidediftherewasastandardformattofollow.For example, a serial number might only have the first and last characters to be alphabetical. Anything in the middle of both characters will be numerical. By following the serial number format,itispossibletoconvert’O’to’0’ifthecharactersliebetweenthefirstandlastalphabet. However, there are various brands for different air-conditioning, which have different serial number formatting. Therefore, it is not possible to implement formatting for this developed automatedprototype.

BEARS#06 41
Another three errors made during the automated extraction process were that the prototype could not remove unnecessary words that were on the same line as the required information. Theprototypewasabletoremovethekeywordfromthestring,suchas’MODEL’. Itwasnot abletodeterminewhatotherwordsarenotrequired.
Figure42ashowstheassetimagesthatcontainadditionalwordsonthesame line,andFigure 42b shows what was extracted from the image. For the extraction of the model number, it contained the extra characters of ‘R36NUY1OUTDOORUSE’. However, only ‘R36NUY1’ wasrequiredtobeinthecell. (a) Originalimage2


BEARS#06 42
(a)Originalimage1 (b)Extractedinformationfromimage Figure41.Error1bytheautomatedsolution
(b) Extractedinformationfromimage
Figure42. Error2bytheautomatedsolution
Eventhoughthemanualextractionprocesscontainslessererrorsascomparedtotheautomated solution,theerrorsmadearemorediversesuchas:(i)Userskeyinginwrongcharactersinthe cell, (ii) Users missing out information from the image, and (iii) Users entering the wrong informationinto the wrongcolumn. Itwill be easierforthe usersto pick uperrors during the check against the original images as the automated solution's errors are common and follow thesamepattern.
The time taken to extract the image information with the automated method is significantly shorter than that of the manual method. Therefore they will not feel additional fatigue when checkingagainsttheoriginalimage.However,forthemanualsolution,theextractionprocess willdraintheirenergy,andtheusersmightnotbeabletoconcentratewhentheyaredoingthe check.Thismightleadtoafailureinthecheckastheymightnotbeabletoidentifytheerrors correctly.
The automated verification process was able to identify all differences and update the information respectively on the AIR template for PDF files with just a click of a button. For themanualprocess,someparticipantsdidnotmanagetoidentifyandupdatesomeoftheerrors in the AIR template for PDFfiles. With increasing numbers of cells to verify in the industry, humanerrorsmadeduringthe processwillalsoincrease. The automatedverification solution eliminatesthepossibilityofusersmissingoutonthedataduringtheverificationprocess.This willenablethefinalAIRtobecorrectandupdated.
4.4Surveyresults
Thepurposeofsurveyingthetestistoobtaininsightsandfeedbackonthedevelopedprototype solution.Thequantitativeanswersindicateifthedevelopedsolutionhasmetitsobjective.The qualitative questions allow the participants to provide feedback and the improvement needed forthedevelopedprototypesolution.Thefirsttwoquestionsweretoobtainfeedbackonwhich consolidation method the participants prefer and their reason for choosing their preferred method.
BEARS#06 43
As expected, all participants preferred the automated consolidation of image information, as shown in Figure 43a. One of the reasons is that the automated solution is less tedious, especiallywhentheimageincreases.Anotherreasonstatedwasthatitreducesthetimeneeded toconsolidatetheimageinformation.TheanswersareshowninFigure43b.

(a) Question1
(b) Question2
Figure43.Question1and2ofsurvey
The next question was to obtain feedback and insights on the preferred method for the

BEARS#06 44
verification process. All participants preferred the automated verification process instead of the manual verification method, as shown in Figure 44a. Figure 44b shows the reasons why the participants preferred the automated verification process. Some reasons are because it is time-saving. It prevents users from overlooking some of the cells, and the updated cells are highlightedinred,whichallowsuserstoidentifythemeasily.

(a) Question3
(b) Question4 Figure44.Question3and4ofsurvey

BEARS#06 45
Four questions were asked to indicate if the developed prototype solution has met the objectives. Figure 45shows the questionsandtheir respectiveanswers. “1”means“not”,"2" means"slightly","3"means"moderately", "4"means"just",and“5”means“very”Generally, theresultsshowedthatthedevelopedprototypesolutionhadmetitsobjectives.
All participants agree to the user interface's friendliness of the developed automated solution for the extraction process, as shown in Figure 45a. All participants felt that the developed prototype solution was smooth and useful, as shown in Figure 45b and Figure 45d. Five participantsfeltthattheverificationprocessisnottedious,asshowninFigure45c.


(a) Question5
(b) Question6
BEARS#06 46
(c) Question7
(d) Question8
Figure45.Question5to8ofsurvey

The last three qualitative questions were asked to gather insights and feedback on how the developedautomatedprototypesolutioncanbeimproved.Figure46showstheanswerswhen asked if there were any problems faced during the developed automated process. Some participantsfeltthatthe waytorun the developedprototype mightbe confusingforfirst-time usersandthatusersmightneedtotakesometimetogetusedtothewholeprocess.

BEARS#06 47
Figure46.Question9ofsurvey
Participants provided their thoughts about the extracted information using the automated extraction process, as shown in Figure 47. The participants stated that the accuracy of the extracted information is considered accurate, but some misinterpreted and additional characters were extracted well. They mentioned that it would be ideal if the program can removeallthesemistakes.

Figure47.Question10ofsurvey

BEARS#06 48
Thelastquestionwastoallowparticipantstoprovidepossibleimprovementstothedeveloped automated prototype solution shown in Figure 48. Some suggestions include removing all extra random characters and allowing the user to cross-check the extracted information with theoriginalimagesfirstbeforeinputtingitintotheexcelsheet.
Figure48.Question11ofsurvey
4.5Limitationandneedforcontinuousimprovement
Based on all the survey results, the developed automated solution has met its objectives of creatingauser-friendlyprototypeandreducingthetimetakentoobtaintheupdatedandcorrect AIR. Most participants agreed that the user interface and the developed automated solution's usefulness were up to standard. However, there is some limitation, such as running the prototype on the command prompt and not removing unwanted text and characters from the extractedinformationbeforeinputtingitintotheAIRtemplate.
Thenature ofimagessuchasdifferentanglesorlightingwillprovidedifferentoutputasonly onesetofthethresholdwasusedinthisprototype.Someimprovementshavetobeintegrated into the current prototype to improve further the developed automated prototype solution's efficiencyandeffectiveness.
4.5.1 Flexible threshold input for the images
Since theimageswillnotbe ofthesame threshold allthetimedue to severalreasonssuch as lighting,size,andimages'angle.Theuseofonesetofthethresholdwillnotbeenoughforthe

BEARS#06 49
number of asset images in building assets. One way to produce more desirable results for different images is to develop an automated prototype solution that should enable users to apply a different threshold to different images. A preview screen can be added into the user interface to allow users to determine which set of threshold produce better results than the other.Withasuitablethreshold,theunwantedtextfromtheoutputcouldalsobereduced.
4.5.2 Multiple asset type input
The current developed automated prototype solution was based on only one asset (airconditioningsystem)toextractinformationfromimages.However,therearemanyothertypes of buildingassets, such as plumbingsystem, fire protection system, and sanitary system. For the prototype to be more efficient and effective, the prototype must be able to determine the categoriesof imagesandextractthemunderthosecategories.Whentheprototypecanextract information of images from all categories anduse it for verificationfor the AIR template for PDFfiles,theprototypewillserveitsfullpurposeintheindustry.
5.0CONCLUSION
In the facilities management industry's current practice, the onsite images are still manually consolidated into the AIR template, and the verification is done manually. Manual consolidation of the image information is a very tedious process as the onsite images may easily be more than 1000 images. Furthermore, with such a large amount, the rate of human errorswillalsoincrease.However,thereisnoothersolutiontoresolvethecurrentissuefaced intheindustry.
Theaimofthisprojectistodevelopaprototypesolutionthattacklesthehighlightedproblems facedintheindustry.Theconclusionmadeisthatthedevelopedsolutioncanreduce thetime neededtoconsolidatetheimageinformationandverificationprocess.Byreducingtheamount oftimerequired,thecompanieswillbeabletoreducetheheadcountneededforconsolidation.
Eventhoughtheextractionofimagesisnot100%accurate,theuserswillfindtheerroreasier whentheyare notwornoutfromconsolidatingalltheimageinformationmanually.Thus,the time takento generate an AIR template with accurate information will be significantlylower
BEARS#06 50
thanthatofthemanualmethodcurrentlyusedintheindustry.
Withthedevelopedsolution,theAIRhasthepotentialtobe100%accurateandupdatedwith considerable comfort and convenience. The AIR will then be ready to be used for the maintenance and operation process and integration into the BIM model. However, based on thetest'sfeedbackandresults,thereisstillroomforimprovementforthedevelopedprototype. Some improvements include creating a flexible threshold input that will be suitable for differentimagesandtakingmultipleassettypeinput.
ACKNOWLEDGEMENT
The Singapore Institute of Technology funds this project through a SEED grant (R-MOEA403-G008). Ms. Nu Qin Kwok did the project work and writing of this paper as part of her SIT-Technical University of Munich Bachelor of Science joint degree in the Electrical EngineeringandInformationTechnology.Dr.MoshoodOlawaleFadeyiandDr.MalcolmLow guided the development of the developed automated solution and experimental design and execution.Dr.FadeyiandDr.MalcolmLowalsocontributedtothedevelopmentofthisarticle. ThesupportofMs.NgHuiMinduringthedevelopmentoftheautomatedsolutionisgratefully acknowledged.
REFERENCES
Australia BIM Advisory Board (2018). Asset information requirements guide: Information required for the operation and maintenance of an asset. http://www.abab.net.au/wpcontent/uploads/2018/12/ABAB_AIR_Guide_FINAL_07-12-2018.pdf (Accessed January 2021)
Laranjeiro,N.,Soydemir,S.N.,&Bernardino,J.(2015).Asurveyondataquality:classifying poor data. In 2015 IEEE 21st Pacific rim international symposium on dependable computing (PRDC) (pp.179-188).IEEE.
Mydin, M. A. O. (2017). Significance of building maintenance management on life-span of buildings. Robotica &Management, 22(1),40-44.
BEARS#06 51
Ng HM and Fadeyi MO (2020). Development of a solution to optimise the process for consolidating asset information into asset information requirements (AIR) template. Built Environment Applied Research Sharing #02,ISSUUDigitalPublishingPlatform.
Palekar, R. R., Parab, S. U., Parikh, D. P., & Kamble, V. N. (2017). Real time license plate detectionusingopenCVandtesseract.In 2017internationalconferenceoncommunicationand signal processing (ICCSP) (pp. 2111-2115).IEEE.
Patel,C.,Patel,A.,&Patel,D.(2012).OpticalcharacterrecognitionbyopensourceOCRtool tesseract:Acasestudy. International Journal of Computer Applications, 55(10), 50-56.
Scott, J. R., Thompson, A. R., Wright-Thomas, D., Xu, X., & Barchard, K. A. (2008). Data EntryMethods:IsDoubleEntrytheWaytoGo?. JournalofHuman-ComputerInteraction, 17, 25-36.
Sidhwa,H.,Kulshrestha,S.,Malhotra,S.,&Virmani,S.(2018,October).Textextractionfrom bills and invoices. In 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN) (pp.564-568).IEEE.
Smith, R. W. (2013, February). History of the Tesseract OCR engine: what worked and what didn't. In Document Recognition and Retrieval XX (Vol. 8658, p. 865802). International SocietyforOpticsandPhotonics.
Referenced reading materials for the programming languages
1AshConversionsInternational.https://www.ashconversions.com/blog/generalcategory/the-top-five-most-common-manual-data-entry-mistakes
2MindfireSolutions. https://medium.com/@mindfiresolutions.usa/python-7-importantreasons-why-you-should-use-python-5801a98a0d0b
3WillKenton.Visualbasicforapplications(vba). https://www.investopedia.com/terms/v/visual-basic-for-applications-vba.asp
BEARS#06 52
4FarhadMalik.Whyshould weusenumpy? https://medium.com/_ntechexplained/whyshould-we-use-numpy-c14a4fb03ee9
5OpenCV.About. https://opencv.org/about/
6Howtousepillow(pil:Pythonimaginglibrary). https://note.nkmk.me/en/python-pillowbasic/
7SatyaMallick.(2018)BarcodeandQRcodescannerusingZBarandOpencv. https://www.learnopencv.com/barcode-and-qr-code-scanner-using-zbar-and-opencv/
8RobleyGori.Pytesseract:Simplepythonopticalcharacterrecognition). https://stackabuse.com/pytesseract-simple-python-optical-character-recognition/
9SaitejaKura.Introductiontothepandaslibrary.https://medium.com/towards-artificialintelligence/introduction-to-the-pandas-library-4e00f07fc18
10Python|readinganexcel_le usingopenpyxlmodule. https://www.geeksforgeeks.org/python-reading-excel-file-using-openpyxl-module/
11Osmoduleinpython:Allyou needtoknow. https://www.edureka.co/blog/os-module-inpython#what
12Aditya Sharma.IntroductiontoGUIwithtkinterin python. https://www.datacamp.com/community/tutorials/gui-tkinter-python
BEARS#06 53




