Master Thesis submitted within the UNIGIS MSc programme presentada para el Programa UNIGIS MSc
Department of Geoinformatics - Z_GIS University of Salzburg
Clasificación satelital de cultivos por reconocimiento de patrones en el Valle de Limarí, Chile Crop Classification with Remote Sensingbased pattern recognition in Limarí Valley, Chile by Aldo Andrés Tapia Araya 11851366
A thesis submitted in partial fulfilment of the requirements of the degree of Master of Science – MSc
Advisor I Supervisor: Leonardo Zurita Arthos PhD Ovalle - Chile, Julio de 2024
COMPROMISODECIENCIA Pormediodelpresentedocumento,incluyendomifirmapersonalcertificoyaseguro quemitesisescompletamenteelresultadodemipropiotrabajo.Hecitadotodaslas fuentesqueheusadoenmitesisyentodosloscasosheindicadosuorigen.
(Lugar,Fecha) (Firma)
AGRADECIMIENTOS QuieroexpresarmisinceroagradecimientoaMauricioCortés,coordinadordelLaboratorioPROMMRAygerentedelConsorcioCentroTecnológicodelAguaQuitaiAnkode laUniversidaddeLaSerenaporsupaciencia,apoyoymotivaciónparalarealización deestetrabajo.Nosólomehabrindadoapoyoenestetrabajo,sinoquetambiénenla realizacióndecursos,lacompradelibrosylafacilitacióndeltiemponecesarioparami desarrolloprofesional.
Lodesarrolladoenestetrabajonosóloconsideraelprocesamientodearchivosraster ydiseñodecartografías,competenciadelosSistemasdeInformaciónGeográfica,sino quetambiénseabordaunflujodetrabajobasadoenprogramación,análisisexploratorio dedatosymodelosdeaprendizajeautomático.Estascompetenciashansidodesarrolladasalolargodemividaprofesional,asíqueagradezcoallaboratorioPROMMRA porbrindarmeelespacioytiempoparadesarrollarestashabilidadesdeformaautónoma.
Agradezcoamifamilia,amimadreyhermanos,porsuapoyoincondicionaldurantetodamividay,enespecial,duranteestosúltimosaños.Graciasporperdonarmiserrores, entendermicarácterysiempreestaramilado.
RESUMEN Elconocimientodelasuperficieycomposicióndecultivosenunáreaenparticular permitelatomadedecisionesenlaplanificaciónterritorialgubernamentalylaoperación desistemasdeembalsesdeacumulacióninteranual.Paraello,lateledetecciónesuna herramientaquepermiterealizarclasificacionestemáticasdeimágenesdesatélitecon énfasisencultivosagrícolas,yasípoderdeterminarlasuperficiedecultivospresentes enunáreaenespecífico.Laclasificacióndecultivosagrícolashaestadolimitadaporla fenologíadeloscultivospresentesenunáreaenparticular,debidoaqueloscultivosno seexpresanfenológicamentedeigualmaneraentodaspartes,productodevariables medioambientalesydemanejo.Estetrabajotieneporobjetivoevaluareldesempeño delaclasificacióndecultivosagrícolasporreconocimientodepatronesdecrecimiento y Machinelearning,utilizandoimágenesdelaconstelaciónSentinel2enelValledel Limarí,Chile.
Seestablecióunflujodetrabajoparalaadquisiciónypreprocesodeimágenessatelitales,conuntotalde364escenasutilizadas.Sedividióeláreadeestudioen56 zonasdiferentes,endondeacadaunadeellassefiltraronlasescenasconnubesen suinteriorparaobtenerunaseriemultitemporallibredenubes.
Untotalde2,683muestrasfueronrecolectadaspara16clasesdiferentes,12delas cualescorrespondenacultivosagrícolas.Elanálisisconsistióenevaluar3combinacionesdiferentesdedatosdeentrada(respuestaespectral,índicedevegetaciónde diferencianormalizada,ylasumadeambos)para3clasificadoresdiferentes: DynamicTimeWarping (DTW)ydosmétodosde MachineLearning, RandomForest (RF)y RedesNeuronalesArtificiales(ANN).
Paralosmodelosde MachineLearning,sepreprocesaronlasimágenessatelitalesreduciendolalongituddeladimensióntemporalyestandarizandolarespuestaespectral entrelasdiferenteszonas.Paraelcasode DTW,seutilizólarespuestaespectralde lastodaslasfechasdisponibles,lascualesserellenaronparaaquellasfechasconpresenciadenubes.Seevaluóeldesempeñodelosmodelosapartirdelasmétricasde KappadeCohen,exactitudglobal,exactituddeproductoryexactituddeusuario.
LosresultadosindicanqueelmodelodeRedesNeuronalesArtificiales(KappadeCohende0.96)conestructurasdeaprendizajeprofundoobtuvoelmejordesempeño, seguidopor DTW (KappadeCohende0.931).Elclasificador RandomForest fueel quepeordesempeñoobtuvo(KappadeCohende0.876).Sibien,losdosmejoresmétodosobtuvieronundesempeñosimilar,lasRedesNeuronalesArtificialesclasificaron todaeláreadeestudioenuntiempodeprocesamientoreducido,adiferenciadeloque podríaocurrirconelclasificador DTW
Lainclusióndeclasificadoresqueconsideranlaextraccióndepatronessobreelcon
juntodedatosdeentrenamientosonlosmásadecuadosparapoderclasificarcultivos agrícolasenunáreacondiferenciasenlaexpresióndelcrecimientodecultivos.Esta informaciónesposibledeobtenerapartirdelarespuestaespectraldeloscanalesde laimagensatelital,sinnecesidaddeutilizaríndicesdevegetación.
Palabrasclave:Clasificacióndecultivos, DynamicTimeWarping,RedesNeuronales Artificiales, RandomForest,Sentinel2.
ABSTRACT Knowledgeoftheareaandcompositionofcropsinaparticularareaallowsthedecisionmakingingovernmentalterritorialplanningandtheoperationofinterannualaccumulationreservoirsystems.Forthispurpose,remotesensingisatoolthatallowsforthematic classificationsofsatelliteimageswithemphasisonagriculturalcrops,andthustodeterminetheareaofcropspresentinaspecificarea.Theclassificationofagriculturalcrops hasbeenlimitedbythephenologyofthecropspresentinaparticulararea,because cropsdonotexpressthemselvesphenologicallyinthesamewayeverywhere,asa resultofenvironmentalandmanagementvariables.Thisworkaimstoevaluatetheperformanceofagriculturalcropclassificationbygrowthpatternrecognitionandmachine learning,usingSentinel2constellationimagesintheLimaríValley,Chile.
Aworkflowwasestablishedfortheacquisitionandpreprocessingofsatelliteimages, encompassingatotalof364scenes.Thestudyareawasdividedinto56differentzones, whereeachoneofthemwasfilteredtoobtainacloudfreemultitemporalseries.
Atotalof2,683sampleswerecollectedfor16differentclasses,12ofwhichcorrespondedtocrops.Theanalysisconsistedofevaluating3differentinputdatacombination (spectralresponse,normalizeddifferencevegetationindex,andthesumofboth)for3 differentclassifiers:DynamicTimeWarping(DTW)andtwoMachineLearningmethods, RandomForest(RF)andArtificialNeuralNetworks(ANN).
FortheMachineLearningmodels,satelliteimageswerepreprocessedbyreducingthe lengthofthetemporaldimensionandstandardizingthespectralresponsebetweenthe differentzones.ForDTW,thespectralresponseofallavailabledateswasused,filled inforthosedateswithclouds.Theperformanceofthemodelswasevaluatedbasedon Cohen’sKappa,globalaccuracy,produceraccuracy,anduseraccuracymetrics.
TheresultsindicatethattheArtificialNeuralNetworksmodel(Cohen’sKappaof0.96) withDeepLearningstructuresperformedbest,followedbyDTW(Cohen’sKappaof 0.931).TheRandomForestclassifierwastheworstperformer(Cohen’sKappaof0.876). Althoughthetwobestmethodsperformedsimilarly,theArtificialNeuralNetworksclassifiedthestudyareawithareducedprocessingtime,unlikewhatcouldhappenwiththe DTWclassifier.
Theadditionofclassifiersthatconsidertheextractionofpatternsonthetrainingdataset isthemostappropriatetoclassifycropsinanareawithdifferencesintheexpressionof cropgrowth.Thisinformationcanbeobtainedfromthespectralresponseofthesatellite imagechannels,withouttheneedtousevegetationindices.
Keywords:Cropclassification,DynamicTimeWarping,ArtificialNeuralNetworks,RandomForest,Sentinel2.
GLOSARIO • ANN: ArtificialNeuralNetwork,algoritmodeclasificaciónsupervisada.
• API: ApplicationProgrammingInterface,interfazdeprogramacióndeaplicaciones.
• Bagging:técnicadeagregacióndemodelos.
• Batch:conjuntodedatosqueseprocesaenunaiteración.
• Benchmark:conjuntodedatosdereferenciaparacomparareldesempeñodeun algoritmo.
• Bootstrapping:técnicademuestreoconreemplazo.
• BRDF: BidirectionalReflectanceDistributionFunction,funcióndedistribuciónbidireccionaldereflectancia.
• Callback:funciónqueseejecutaalfinaldeunproceso.
• CIREN:CentrodeInformacióndeRecursosNaturales,instituciónchilenafinanciada conrecursospúblicosencargadodelageneracióndeinformacióngeoespacial.
• CPU: CentralProcessingUnit,unidadcentraldeprocesamiento.
• CONAF: CorporaciónNacionalForestal,organismopúblicochilenoencargadodela administracióndelosrecursosforestales.
• Convolucional:tipoderedneuronalqueutilizacapasconvolucionales,lascuales soncapacesdeextraercaracterísticasdelaimagenapartirdelaconvolucióndeun kernelalolargodela(s)dimensión(es).
• DL: DeepLearning,aprendizajeprofundo.
• Dropout:técnicaderegularizaciónenredesneuronales.
• DNN: DeepNeuralNetwork,redneuronalprofunda.
• DTW: DynamicTimeWarping,algoritmodereconocimientodepatrones.
• Earlystopping:técnicaderegularizaciónquedetieneelentrenamientodeunared neuronalcuandoeldesempeñodelareddejademejorar.
• EC: EuropeanCommission,comisióneuropea.
• Épocao epoch:iteracióncompletadeunconjuntodedatos.
• EO: EarthObservation,observacióndelaTierra.
• ESA: EuropeanSpaceAgency,agenciaespacialeuropea.
• FOCB: FirstObservationCarriedBackward,técnicadeimputacióndedatos.
• FVC:Fraccióndecoberturavegetal.
• geoJSON:formatodearchivopararepresentardatosgeoespacialesenNotaciónde ObjetoJavaScriptoJSON.
• IR: Infrared,infrarrojo.
• GPU: GraphicsProcessingUnit,unidaddeprocesamientográfico.
• LOCF: LastObservationCarriedForward,técnicadeimputacióndedatos.
• LULC: LandUseLandCover,usodesueloycoberturadesuelo.
• Métrica:medidadedesempeñodeunalgoritmo.
• ML: MachineLearning,aprendizajeautomático.
• Multitemporal:observacionesdeunamismazonaendiferentesfechas.
• NIR: NearInfrared,infrarrojocercano.
• NDVI: NormalizedDifferenceVegetationIndex,índicedevegetacióndediferencia normalizada.
• NN: NeuralNetwork,redneuronal.
• OA: OverallAccuracy,exactitudglobal.
• OUA: OrganizacióndeUsuariosdeAguas,organizaciónsinfinesdelucroqueadministraelrecursohídrico.
• Overfitting:sobreajuste,fenómenoenelqueunmodeloseajustademasiadoalos datosdeentrenamiento.
• PA: ProducerAccuracy,exactituddeproductor.
• Pixel:unidadmínimadeunaimagendigital.
• PCA:AnálisisdeComponentesPrincipales.
• ReLu: RectifiedLinearUnit,funcióndeactivación.
• RF: RandomForest,algoritmodeclasificaciónsupervisada.
• RSS: ResidualSumofSquares,sumadelosresiduosalcuadrado.
• SCL: SceneClassificationLayer,capadeclasificacióndeescenas.
• Softmax:funcióndeactivaciónquetransformalosvaloresdeunacapadesalidaen probabilidades.
• Spline:curvamatemáticaqueseutilizaparainterpolarvaloresentredospuntos.
• SVM: SupportVectorMachine,oMáquinasdeVectoresdeSoporte.Algoritmode MachineLearning.
• Transferlearning:técnicadeaprendizajeautomáticoqueconsisteentransferirconocimientosdeunmodeloaotro.
• tSNE: t distributedStochasticNeighborEmbedding oembebidoestocásticodevecinosdistribuidosent.
• UA: UserAccuracy,exactituddeusuario.
• YOLO: YouOnlyLookOnce,algoritmodedeteccióndeobjetos.
LISTADEFIGURAS algoritmosdesiembraautomáticos.ExtraídodeChuvieco(2016).
sisdePCAytSNEparaelgrupodebandasespectrales+
κ yOAparaelclasificador
d
(x,y) paracadamuestra
Anexo18Gráficodecajadeladistanciaentrecadamuestraylamuestramás
Anexo19Gráficodecajadeladistanciaentrecadamuestraylamuestramás
Anexo21Gráficodelafuncióndepérdida(categoricalcrossentropy)paralos datosdeentrenamientoyvalidacióndelexperimento25,grupo2, paraelclasificador
LISTADETABLAS 1 INTRODUCCIÓN 1.1 ANTECEDENTES Lacreacióndemapastemáticosderecursosnaturalessehaaplicadoampliamente sinproblemaengrandesextensionesdesuperficie(Carrãoetal., 2008).Sinembargo, laclasificacióndecultivosagrícolashaestadolimitadaporlafenologíadeloscultivos presentesenelpaisaje,yaqueéstosnoseexpresanfenológicamentedeigualforma alolargodelterritorio,debidoaqueestosdependendevariablesmedioambientalesy demanejo.
Piedeloboetal. (2019)aplicaronunaclasificacióntemáticadeloscultivosagrícolasde lacuencadelDuero(España),lacualseextiendepor78,859km2 conmásde4millones dehectáreascultivadas,siendolaprimeraexperienciadocumentadadeunasuperficie deesascaracterísticas.Enestecaso,seutilizaronregionesespacialesdenominadas tuplekeys,lascualesestánorganizadasencriteriosedáficosyagronómicos.
Existenexperienciasbasadasenpatronesfenológicosdecultivos(Ghazaryanetal., 2018; Liuetal., 2020). Khaliqetal. (2018)evaluaronelusodeunaseriemultitemporal yseriesmonotemporalesparadiferenciarcultivosusandoelalgoritmode RandomForest,siendomayoreldesempeñoconlasseriesmultitemporales. Mazziaetal. (2020) utilizaronredesneuronalesrecurrentesyconvolucionalesparalaidentificacióndecultivosenbaseasucomportamientomultitemporalmediantelastécnicasde DeepLearning.
Algunasexperienciasestánenfocadasaclasificarcadapixeldelaimagenbasándose ensurespuestaespectraloelcomportamientodeuníndicedevegetación(Beeresh etal., 2014; Immitzeretal., 2016; Kobayashietal., 2020; Palchowdhurietal., 2018; Reddy, 2017);mientasotrasseenfocanenunarespuestacompuestadevariospixeles encerradosenunobjetovectorial(Lebourgeoisetal., 2017; Niazmardietal., 2018; Sitokonstantinouetal., 2018).Deestosmétodos,elmétodoorientadoenobjetosproduce
clasificacionesconmayorprecisión(Lietal., 2014; Masseyetal., 2018).Lamayoría delosmétodossebasanenseriesmultitemporalesdeimágenesdesatéliteenbase alacomparaciónporfecha.
Porlotanto,lasexperienciasantesmencionadasconsideranladiscriminaciónentreclasesenbaseaunconjuntodefechas,dondecadadiscriminaciónserealizadentrodela mismafecha.Loqueclasificanestosalgoritmossonpatronescondistincióndefechas.
Csilliketal. (2019)aplicaronunalgoritmodereconocimientodepatronesdenominado DinamycTimeWarping (DTW),estealgoritmocomparadosseriesmultitemporales buscandolaalineaciónmásadecuadaentreambasseriesbuscandolamenordistancia entredosrespuestas.Estaexperienciaresumeloqueotrosautoreshaninvestigadoen cuantoalaaplicaciónde DTW sobreimágenesdesatélite(BelgiuyCsillik, 2018; Guan etal., 2018; Mausetal., 2019; Petitjeanetal., 2012; Simoesetal., 2017; Vianaetal., 2019).
1.2 OBJETIVOS 1.2.1 Objetivogeneral
• Definirunesquemadeclasificacióndecultivosagrícolasporreconocimientode patronesdecrecimientoutilizandoimágenesdesatéliteenelValledelLimarí, Chile.
1.2.2 Objetivosespecíficos
• Establecerdiferenciasenelcrecimientodeloscultivosmásrepresentativosdel vallemediantelacomparacióndeuníndiceespectralderivadodeproductosde teledetección.
• Implementaryevaluareldesempeñodediferentestiposdeclasificadoressobre unaseriemultitemporaldeimágenesdesatélitedesensorpasivo.
• Determinarunesquemadeclasificaciónúnicoqueconsidereelcomportamiento multitemporaldeloscultivosmásrepresentativosalolargodelvalle.
1.3 PREGUNTADEINVESTIGACIÓN • Entrelarespuestadereflectanciaeíndicesespectrales¿Cuálesmásadecuado paraclasificaruncultivo?
• ¿Esposibleaplicarunaúnicaclasificaciónenmúltipleszonascondiferenciasen laexpresióndelcrecimientodecultivos?
• ¿Unaclasificaciónconénfasisenlospatronesdecrecimientodecultivosmedianteelmétodode DTW esmásprecisaquelosmétodosdeclasificaciónde Machine Learning,comoclasificaciónsupervisadautilizandolosalgoritmosdeRedesNeuronalesArtificiales(ANN porsussiglasenInglés)o RandomForest (RF)?
1.4 HIPÓTESIS Lautilizacióndepatronesdecrecimientodecultivosdesimilarescaracterísticasmedianteelclasificadorde DTW aumentalaexactituddelaclasificacióndecultivosagrícolasapartirdeseriessatelitalesmultitemporalesencomparaciónadosmétodosde MachineLearning (ANN y RF).
Siendo δ(X) ladiferenciaentrelaexactituddelaclasificaciónmedianteelmétodode DTW ylaexactituddelaclasificaciónmediantelosmétodosde MachineLearning con unamétrica M:
(X)= M(DTW,X) −M(ML,X) (2)
Paralaevaluacióndelahipótesisseutilizaráeltestdehipótesisdedoscolasconun niveldesignificanciade0,05(α =0, 05)utilizandolapruebadeQdeCochran(Cochran, 1950; Droretal., 2018).
1.5 JUSTIFICACIÓN Elconocimientodelacomposicióndecultivosagrícolasenunazonapermitetomar decisiones.Estasdecisionespuedenserdesdelaseleccióndeuncultivodeterminado enbasealatendenciadeunazonaadecisionesmásglobales,comolaplanificación territorialgubernamental.Unaperiodicidaddetipoanualdeclasificacionestemáticas decultivosagrícolaspermitemedirlasconsecuenciasdeeventosmeteorológicosextremos,comosequías.
Anivellocal,estainformaciónesrelevanteparalasOrganizacionesdeUsuariosde Aguas(OUA).Éstassonorganizacionessinfinesdelucroqueestánacargodela distribucióndelrecursohídrico.EnChile,ladistribucióndeaguasehaceconforme aderecho,denominado DerechodeAprovechamientodeAguas.Estederechose constituyedetallandolafuente(superficialosubterránea),eluso(consuntivoonoconsuntivo)yeltipoejercicio(permanenteoeventual)(MinisteriodeJusticia, 1981).Porlo tanto,lasOUAsdebendistribuirelrecursodeacuerdoalosderechos,loscualesson defuentesuperficial,deusoconsuntivosydeejerciciopermanenteoeventual.Elseguimientodelaextensióndeloscultivosagrícolas,ysucomposición,permiteplanificar laoperacióndelsistemadeembalsesdeacumulacióninteranualqueestánconstruidos enlazona.
1.6 ALCANCE EláreadeestudiocorrespondealazonaagrícoladelValledeLimarí,Chile.Vallecuya
extensiónesde11,800km2,delascualesaproximadamente50,000hacorresponden aterrenosquehansidolabradosconunpromediode35,000hacultivadasanualmente.
Apesardeloslímitesgeográficosdelestudio,lasconclusionesyrecomendacionesse puedenutilizarencualquierzonageográficadesimilarescaracterísticas.
Secontribuyeconunmétododeclasificacióndeimágenesdesatéliteenfocadoen cultivosagrícolasenbasealaevaluacióndetresmétodosdeclasificación: Dynamic
TimeWarping,RedesNeuronalesArtificialesy RandomForest.Esteesquemadeclasificaciónsepuedeaplicaracualquierzonageográficaqueposeacultivosagrícolas, siguiendoelflujodetrabajopropuestoenestetrabajo.
2 REVISIÓNDELITERATURA 2.1 FENOLOGÍADECULTIVOSAGRÍCOLAS Lafenologíaestudiaeltiempoenelqueocurreneventosbiológicosysurelacióncon losfactoresclimáticos.Lafenologíaenplantasestáasociadaalasmanifestaciones temporalesoestacionalescomolafloración,maduraciónycaídadehojas,porejemplo.Latemporalidaddeestasmanifestacionesestáasociadaalascaracterísticasdel vegetalylascondicionesclimáticas.
Lafenologíadeuncultivoestádivididaenfases.Cadafasesecaracterizaporlaaparición,transformaciónodesaparicióndelosórganosdeunaplanta(YzarraTitoyLópezRíos, 2017).Estosórganossontallo,hojas,flores,frutos,entreotros.
Laaparición,transformaciónydesaparicióndehojasenuncontextoespaciotemporal puedesermonitoreadodesdesatélites.Apartirdeellossepuedemonitorearelcomienzodelverdor,delasenescencia,elmomentodemáximocrecimientodelaestacióny lalongituddelaestacióndecrecimientobasadoenelanálisisdelacurvadeíndice devegetación(deBeursyHenebry, 2010).Estatemáticaestáasociadaalcampode lateledetección,lacualeslatécnicadeadquisicióndeinformaciónutilizadaporlos satélites.
2.2 TELEDETECCIÓN Lateledetecciónsedefinecomolaadquisicióndeinformacióndeunobjetosinestar físicamenteencontactoconél.Estainformación,enelcasodelateledetecciónambientallacualestáasociadaalaobservacióndelosfenómenosdelaTierra,corresponde alainteraccióndelaenergíaemitidaporelsolyreflejadaenlasuperficiedelaTierra (Chuvieco, 2016).
Lateledetecciónpuedeserrealizadadesdeaeronavesradiocontroladasnotripuladas,
avionetasosatélites,siendoestosúltimoslosutilizadosparalaobservacióndelaTierra (EO,porsussiglaseninglés).EstosvehículospermitenobservarlaTierradesdeun ángulodiferentealquesepuedelogrardesdelasuperficiedelaTierra.
Elcomponentedeestesistemadestinadoparalacapturadelainformacióneselsensor. Enlateledetecciónambientalseutilizandosclasesdesensores(Chuvieco,2016):
Sensorpasivo:colectalarespuestaderadiaciónderivadadefuentesexternas,ya sealaradiaciónsolarreflejadaolaenergíaemitidaporlaTierra.
Sensoractivo:elsistemaquecontieneelsensoremiteenergíahaciaelobjetivo,la queluegoescolectadaporelsensor.
LosprimerossensorespasivosutilizadosparalaobservacióndelaTierradesdeel airefueronlascámarasfotográficasconlautilizacióndepelículasfotosensibles.Los sistemasmodernospermitenmedirdeformacuantitativalaenergíareflejadaoemitida, apartirdesensoreselectrónicoscuyarespuestasealmacenaenunaimagendigital.
Lairradanciamedida(J/m2)ensuperficiedelaTierrasedenominareflectancia(ρ)y suvaloresadimensional,representandolafraccióndeenergíaemitidaporelsolque esreflejadaporlaTierra.
Lateledeteccióntienediversasaplicaciones,yaseaenlainterpretacióndelasimágenescapturadasoelanálisisdeéstasmediantetécnicasdeextraccióndeinformación. Suusoprincipalesparalaelaboracióndecartografíasdeusodesuelo/cobertura desuelo(LULC)(RoganyChen, 2004).Enagricultura,lateledetecciónseaplicaala identificacióndezonasconpotencialagrícola,estimaciónderequerimientosderiego pordeterminacióndelcoeficientedecultivo(Kc),estimacióndebiomasa,estimaciónde tasasdefertilización,entreotros(Camposetal., 2018; GarridoRubioetal., 2020; Villodreetal., 2017).Dentrodelasaplicacionesdelateledeteccióntambiénseencuentrala clasificacióntemáticadeimágenesdesatélite,lacualpermitediferenciarlascoberturas delasuperficiedelaTierraenbasealarespuestaquepresentanalinteractuarconla energíasolar.Sinperjuiciodeloanterior,lasaplicacionesdelateledetecciónnoestán
limitadasalaagriculturaoalaclasificacióndetemática(usodesuelo)solamente,hay otrasaplicacionesligadasalaforestación,recursoshídricos,geología,medioambiente, recursosmarinos,nieve,entreotros(Navalgundetal., 2007).
2.3 TELEDETECCIÓNYVEGETACIÓN LossistemasdeteledetecciónpodríanmedirlaenergíaemanadadesdelaTierraen cualquierrangoespectral,peroenlaprácticanotodoslosrangosdelespectroelectromagnéticopermitencaracterizarestaenergíadesdeelespacio,yaquehayinterferencia dealgunosgasesopartículasenlaatmósferaqueimpidenquelaradiaciónsolarlleguealasuperficiedelaTierra(Figura 1).Esporelloqueeldesarrollotecnológicode lossatélitessehaenfocadoenaquellasventanasdelespectroelectromagnéticoque interactúanconlasuperficiedelaTierra.
UV Visible Infrarojo
Espectro de la radiación solar Irradancia espectral (W/m 2 /nm)
Radiación solar al tope de la atmósfera
Emisión de un cuerpo negro a 5250 ºC
Radiación a nivel del mar
Bandas de absorción
Longitud de onda (nm)
Figura1:Espectrodelairradianciasolarsobrelaatmósferayaniveldesuperficie. Adaptadode: Ranabhatetal. (2016).
Entérminosderespuestaespectral,lavegetacióninteractúadediversasformasalo
largodelespectroelectromagnético(Figura 2).Departida,lospigmentospresentan unaaltaabsorcióndelaradiaciónsolar.Estosabsorbenselectivamentelaradiación enciertaslongitudesdeonda,cuyacombinaciónproduceelcolorquecomúnmente seobserva.Lashojasensumayoríasonverdes,debidoaqueelpigmentoquese encuentraenmayorproporcióndentrodelashojaseslaclorofila,lacualpresentauna altaabsorciónentrelos380510nmylos620700nm,absorbiendoradiaciónenel espectrodelazulyrojo.Porelcontrario,enelespectrodelverde(510620nm),la reflectanciaesmayor,locualexplicaelcolorverdecaracterísticodelasplantas(Asner, 1998).Estoseaplicaenlasporcionesvegetalesdealtaconcentracióndeclorofila. Enelcasoquelaclorofilasedegradeoqueotrospigmentosseanlospredominantes enelmaterialvegetal,laabsorcióndelaradiacióncambiaráenfuncióndelpigmento predominante,comoxantofilas,carotenosoantocianinas.Estocomúnenfloresyfrutos maduros.
Enelespectroinfrarrojo,comúnmenteconocidoporIRporsussiglaseninglés,sepuedendiferenciardoscomportamientoscaracterísticosdelavegetación.Loscloroplastos yestructuradelparénquimasonlosresponsablesdelaaltareflectanciaenelespectro delinfrarrojocercano(NIR)entrelos740780nm,porelefectodeladispersiónde fotonesenelespacioaéreoalinteriordelmesófilodelahoja(Asner, 1998).Elsegundo comportamiento,enelespectrodelinfrarrojodeondacorta(1,3002,500nm),hay unadisminucióndelareflectanciaporlaabsorcióndelaradiaciónsolarincidentepor elaguapresenteenlahoja(Chuvieco, 2016).
Pigmentos de la hoja
Estructura de la hoja
Contenido de agua
Figura2: Respuestaespectraltípicadeunvegetal.Adaptadode Chenetal. (2019).
Estoposibilitaladiscriminacióndelavegetacióndeotrostiposdesuperficiebasados enestarespuestacaracterísticaasociadaaella.Lacaracterizacióndelosotrostipos decoberturapresentescomúnmenteenelpaisaje,comocuerposdeagua,suelo,edificaciones,entreotros.Estascaracterísticas,enconjuntoconunaseriedefactoresrelacionadosalascaracterísticasdelaimagensatelital,danlaspautasparapoderrealizar unaclasificacióntemática.
2.4 CLASIFICACIÓNTEMÁTICA Laclasificacióntemáticaesuntipodeinterpretaciónlacualinvolucralaasignaciónde untipodecategoríaacadaelementodelaimagen,yaseaporinterpretaciónvisualo interpretacióndigital.Elobjetivodeesteanálisisesetiquetarcadapixeloteseladela imagenconlaetiquetamásapropiada.
Lainterpretacióndigitalsehacemedianteunatécnicadeclasificación.Estatécnicase
Clorofilas, xantofila, carotenos, antocianinas
Cloroplastos, parénquima
aplicasobreunaomásimágenesbrutasocorregidas.Lascorreccionesquesepueden aplicaralaimagensondetipogeométricasyradiométricas,entreellas,lacorrección atmosférica.
Losmétodosdeclasificaciónsecategorizancomo(Richards, 2013):
• Clasificaciónnosupervisada:estemétodointentadefinirlasdiferentesclases espectralesenlaimagenbuscandoagrupacionesdepixelesconnivelesdigitales similares.Cadaniveldigitalrepresentalarespuestaderadiancia,reflectanciau algúnotroniveldelaimagendigital.
• Clasificaciónsupervisada:estemétodoasumeconocimientopreviodelazona deestudioyaseaporfuentesexternasoportrabajodecampo.Bajoestapremisa,elusuariopuedeidentificarlaszonasrepresentativasdecadaunadelas clasesobjetivosenelanálisis.Estaszonasrepresentativassedenominan áreas deentrenamiento.Comosunombreloindica,estasáreaspuedenentrenaraun algoritmoparapodercategorizarcadaunodelospixelesdelaimagenenbaseal niveldigitaldeestos.Juntoconlarecopilacióndeantecedentesparaladefinición deáreasdeentrenamiento,tambiénseutilizaunaporcióndeestosdatospara lafasedevalidación.Nosedebevalidarlaclasificaciónconlosmismosdatos utilizadosparaentrenamiento,yaquealentrenarelalgoritmoconestosdatos, lomásprobableesqueesospixelesseanetiquetadosalosdatosdeentradade formaidéntica.
2.4.1 Preclasificación Enlaetapadepreclasificaciónestádestinadaalapreparacióndelosinsumosnecesariosparalaclasificación.Éstospuedenserobtencióndelosvaloresreflectanciaapartir delacorrecciónradiométrica,latransformacióndelasimágenes(comolosíndicesde diferencianormalizada),olapreparacióndelosdatoscolectadosenterreno(Richards, 2013).Elobjetivodeestaetapaesextraerotransformarlainformacióndeentradapara
adecuarlaalosrequerimientosdelalgoritmodeclasificación.
Unodelosmétodosdetransformacióndelainformación,enparticular,paralareduccióndeladimensionalidaddeunconjuntodedatos,eselAnálisisdeComponentes Principaleso PCA porsussiglaseninglés.Estemétodopermitereducirlacantidadde bandasdeunaimagen,manteniendolamayorcantidaddeinformaciónposible(Hastie etal., 2001).Esteanálisispermitedeterminarelorigendelavariabilidaddeunconjunto dedatos,comolasmuestrasdeterrenoautilizarenelprocesodeclasificación.
Lacoleccióndeinformacióndeterrenoeslabasedereferenciadelasclasesaidentificarenunaclasificaciónsupervisada.Elnousodedichainformaciónlimitaeltipode clasificaciónaunadetiponosupervisada,porende,esdevitalimportanciarealizar estacolectademaneracorrectayeficiente,siguiendolosprotocolosestablecidospara lacolectadeinformacióndeterreno(Congalton, 1991).Estosprotocolospermitenque lainformacióncolectadasearepresentativadelazonadeestudio,loquesetraduceen unaclasificaciónmásprecisa.
Conlainformacióndeterrenoseconstruyenlasmuestrasdeentrenamiento.Lasmuestrasdeentrenamientosedefinencomoelconjuntodepixelesquerepresentanelcomportamientoespectraldelasclasesdeinterés.Estemuestreoestáparcialmentecondicionadoporladistribucióndelasclasesenlaescena.Losesquemasdemuestreos convencionalesasumenquelasmuestrassonindependientesyqueladistribuciónde lasclaseseshomogéneaenlaescena.Sinembargo,enlaclasificacióndeimágenes desatéliteestesupuestonosecumpleporlaaltaautocorrelaciónespacialentreelpixel ysusvecinos(CongaltonyGreen, 2008).Siunpixelesetiquetadoconlaclase n,es muyprobablequeestérodeadodepixelesconlamismaetiqueta.Estoesaúnmás evidenteencultivosagrícolas,dondelasiembraoplantaciónabarcaunaextensiónde terrenoconsiderable.
Laobtencióndemuestrasdeentrenamientosepuederealizardedosformas:a)enterreno,mediantelacolectadeinformacióndecampo,ob)medianteladigitalizaciónde
Pixel con información de subclase
Pixel con información de subclase
Pixel con información de clase
Figura3: Tiposdemuestreoeinformacióndeclaseysubclase.Adaptadode CongaltonyGreen (2008).
polígonosengabinete.Laeleccióndeunouotrométododependedeladisponibilidad derecursosydelaprecisiónrequeridaenlaclasificación.Lacolectadeinformaciónen terrenoeslaformamásprecisadeobtenermuestrasdeentrenamiento,yaquesepuedeverificarlapresenciadelaclasedeinterésenelterreno.Sinembargo,estemétodo escostosoyrequieredeunequipodetrabajoespecializado(Chuvieco, 2016).
Lasmuestrasdeentrenamientopuedenserrepresentadasporpixelesopolígonos, pudiendoserestosúltimosheterogéneosuhomogéneos(Figura 3).Laeleccióndel métodoautilizardependerádelalgortimodeclasificaciónautilizar,siendoelusode polígonosmásadecuadoparaalgoritmosdeclasificaciónorientadosaobjetosyalos algoritmosdeclasificaciónsupervisadatradicionales(Chuvieco, 2016).Almomentode definirlamuestradeentrenamiento,sedebetenerespecialcuidadoenseleccionar pixelesquerepresentenelcomportamientoespectraldelaclasedeinterés,evitando selccionarpixelesquepresentenrespuestamixtaosubclase,yaqueestopuedegenerarconfusiónenlaclasificación(Joyce, 1978)(Figura 3).
Pixel sencillo Polígono heterogéneo Polígono homogéneo
Pixel con información de clase
Clase A
Clase B
Laformacióndelospolígonosserealizaengabineteconapoyodeimágenessatelitales ofotografíasaéreas.Estasáreassepuedendefinirapartirdeunacapadepolígonos quecontengalasáreasdecadaunadeestasclasesoapartirdeunalgoritmode siembraautomáticoquevaairseleccionandopixelesquepresentennivelesdigitales similaresalosiniciales(Figura 4).
Figura4: Áreasdeentrenamientodefinidaspor:a)polígonosdigitalizados;b) algoritmosdesiembraautomáticos.Extraídode Chuvieco (2016).
Sinembargo,enesquemasdeclasificaciónapartirdealgoritmosde MachineLearning, serecomiendalautilizacióndemuestrasdeentrenamientoquetenganlamínimaautocorrelaciónespacial(MillardyRichardson, 2015),porloqueelusodepolígonospuede sercontraproducenteenestetipodeclasificación.
Entérminosgenerales,lasmuestrasdeentrenamientodebenestardispersasenla imagen,evitandolaconcentracióndemuestrasenunsectordelaimagenylaobtención demuestrasenelbordededosomásclases.
Encuántoalnúmerodemuestrasdeentrenamientoporclase,haydiversosenfoques bibliográficos. FitzpatickLins (1981)indicaqueelnúmerodemuestrasdeentrenamientoestádeterminadoporunadistribuciónmultinomial.Paraello,elcálculodelacantidad demuestrasdeentrenamientoporclaseserealizamediantelasiguientefórmula:
Donde:
N =númerodemuestrasdeentrenamientoporclase.
Z =valorde1.96desviacionesestándarparaunniveldeconfianzadel95%dedos colas.Generalizadoen2.
p =precisiónesperada(%).
q = 100 p.
E =erroresperado(%).
Porejemplo,sisedeseaunaprecisióndel95%yunerrordel5%,elnúmerodemuestrasdeentrenamientoporclasesería:
Estacantidaddemuestrasdeentrenamientoessimilaralasrecomendacionesrealizadaspor Joyce (1978)y CongaltonyGreen (2008),dondeserecomiendaentre75100 muestrasdeentrenamientoporclase.
Paraelcasode MachineLearning, Ramezanetal. (2021)evaluaronelefectoquetiene elnúmerodemuestrasdeentrenamientoenlaclasificacióndeimágenesdesatéliteapartirdediversosalgoritmosdeclasificaciónyunesquemadeclasificacióncon muestrasdesequilibradas.Losresultadosindicanqueelusode10.000muestrasen comparacióna315,parauntotalde4clases,sóloaumentalaexactitudenun1%.
Sinembargo,nohayconsensoenelnúmerodemuestrasmínimoautilizarbajoeste enfoquesugiriendoqueelnúmerodemuestrasdeentrenamientodebeserlosuficientementegrandeparaqueelalgoritmopuedaaprenderlascaracterísticasdelasclases deinterés(Maxwelletal., 2018).
Ademásdelacantidaddemuestrasporclase,esmuyimportanteevitarenloposible elefectodesubclaseenlospixelesmuestreados.Sinembargo,lasclasesagrícolas engeneralpresentanunarespuestamixtamuymarcadaenlamayoríadeloscasos, debidoaqueenelcasodelaseriedesatélitesLandsatySentinel,laresoluciónespacialdelpixelnopermitesepararlaplantacultivadadelaentrehilera,porloquela respuestaespectraldelpixelesunamezclaentresuelodescubierto,malezasylaplanta propiamentetal.
LoanteriorllevaaqueserelacioneelÍndicedeVegetacióndeDiferenciaNormalizada (NDVI)conlacoberturavegetalporpixel. GutmaneIgnatov (1998)propusieronun modeloderelaciónentreelNDVIylafraccióndelacoberturavegetal(FVC)basándose enelcomportamientoespectraldeunpixelconvegetacióndensayunpixelconsuelo descubierto.Estamismarelaciónhasidoimplementadaenimágenesdesatélitesdela serieLandsatconbastanteéxito(Zhangetal., 2006),permitiendorelacionarelsuelo descubiertoconeldoseldeplantadecualquiercultivo,generandodiferenciasdeNDVI enfunciónalmarcodeplantación,vigordelcultivoeíndicedeáreafoliar(GonzálezSanpedroetal., 2008).El NDVI sedefinecomo:
Donde:
ρNIR =reflectanciaenelinfrarrojocercano
ρRED =reflectanciaenelrojo
2.4.2 Algoritmos
Sinperjuiciodelalgoritmoutilizado,pararealizarunaclasificaciónsupervisadasedebenconsiderarciertoscriteriosparaaseguraréxitoenlaclasificación(Richards,2012):
1. Elegirlasfuturasclasestemáticasenlacualsequieresegmentarlaimagen.
2. Recopilardatosdeentrenamiento.
3. Estimarlosparámetrosdelalgoritmoseleccionadoenbasealosdatosdeentrenamiento.
4. Usarelalgoritmoparaetiquetarcadapixeldelaimagenconlasclasesdelpunto 1.
5. Realizarmapasytablastemáticasenbasealoclasificadoresumiendolaasignacióndecadaunadelasclasesenlospixelesdelaimagen.
6. Determinarlaexactituddelaclasificaciónenbasealconjuntodedatosdevalidación.
Losalgoritmosmásutilizadosparaestefinsonlosdemáximaverosimilitud,estealgoritmoasignalaclasealaquepertenececadapixelenbasealamediaycovarianza delosdatosdeentrenamientoencomparaciónalpixelanalizado(Sisodiaetal., 2014). Estealgoritmoesutilizadoprincipalmenteparalaclasificacióndeunaescenadeuna fechaenparticular.Paralaclasificacióndecultivoselusodeestetipodealgoritmono esrecomendableyaqueenunafechamásdeunadelasclasesobjetivopuedenposeer respuestasespectralessimilaresporefectodelafenologíadeloscultivos.Estosupone undesafíoparalaclasificacióndeusodesuelodecultivosagrícolasporlasimilitudde respuestasqueposee(Huetal., 2017).
Parapodersuperarestalimitanteseutilizanseriesmultitemporalesdeimágenesde satélite,buscandofechasenlascualessepuedandistinguirloscultivosquedurante otrasfechassonsimilares.Lautilizacióndeunatransformacióndelaimagen,denominadaíndiceespectral,escomúnparaestoscasos(Arvoretal., 2011; Heupeletal., 2018; Simonneauxetal., 2008).
2.4.2.1RedesNeuronalesArtificiales Laredneuronalesunalgoritmode machinelearning oaprendizajeautomáticoque simulaelcomportamientodeunaneuronabiológica.Estasreaccionanmedianteestímulos,paraelcasodeuna ANN (porsussiglaseninglés),estassenutrendela informacióndeotrasunidadesparaserestimuladas.
Cadaneuronaactúacomounnodo,lasconexionesentreunasyotrassonmodeladas medianteenlacesosinapsisparaelcasodelasneuronasbiológicas(Berzal, 2018).La estructurabásicadeunaneuronaseexponeenlaFigura 5.
Figura5: Esquemadeunaneuronaartificial.
Enlafiguraseevidencialosenlacesdeentrada(estímulos)yelenlacedesalida(respuesta).Losenlacesdeentrada(xi)tienensuorigen n capasdeentradaparalas m neuronasdelacapaactual.Lasalidadecadaneuronaestádefinidapor yj ,habitualmenterepresentadoporunvalorbinario(0o1),análogoalestadodeactivaciónreal deunaneuronabiológica(Figura 6).
Figura6: Redneuronalmulticapa,conunaúnicacapaoculta.
Cadapesosináptico wij esusadoparamodelarlasconexionesdeentradaalasneuronas,siendo wij elpesoasociadoalasinapsisqueconectalaentrada iésimacon laneurona jésima.Comoreglageneral,lospesospuedenestardefinidosconvalores positivosparamodelarconexionesexcitatoriasynegativosparamodelarconexiones inhibitorias(Berzal, 2018).
Porlotanto,enlaintegracióndeentradas,laneuronacombinalasdiferentesentradas xi consuspesos wij determinandolaentradaneta zj o netj : zj = netj = i wij xi (5)
Laetapadeactivacióndeunaneuronaartificialutilizaelvalorasociadoasuentrada neta(procesodeintegración)paragenerarunasalida yj o oj : yj = f (zj )= f (netj )= f i wij xi (6)
Elvalorfinalescontrastadoconunumbral uj quedefinirásilaneuronafinalmentealcanzaunvalorsuficienteparalaactivación.Esteumbralpuedeserlineal,comoescalón, sigmoideal,etc.Elmodelomáscomúneseldesigmoidealysedefinecomo:
Otrafuncióndeactivaciónmuycomúnhoyendía,lacualeselestándarenmuchos modelosdeRedesNeuronalesArtificialeseslafuncióndeactivación ReLU (Rectified LinearUnit),lacualsedefinecomo(Berzal, 2018):
Lafuncióndeactivaciónutilizadaenmodelosdeclasificaciónmulticlasesedenomina softmax,lacualsedefinecomo:
Para i =1, 2,...,n y n eselnúmerodeclases.Estafuncióncomprimelasalidadelared neuronalenunrangode0a1,permitiendoquelasumadelassalidasseaiguala1, loquepermitequelasalidadelaredneuronalseainterpretadacomounaprobabilidad depertenenciaaunaclase.
Lacapadesalidasecomportademanerasimilaralacapaoculta,sosteniendosus propiospesos(w ’ jk)yumbraldeactivación(u ’ k).Elentrenamientodelaredneuronal constaensintonizarlosdiferentespesosyumbralesparaobtenerlas k salidas(z)como clasesdeentrenamientoexisten(o).Enotraspalabras,quelosvaloresde zk seanlo mássimilaresalassalidasobservadas ok (Berzal, 2018).
Cada ok representaráunaclasedeinterésenlaclasificación.Elvalormásfrecuente de zk esaquelqueseleasignaalaclase ok
2.4.2.2 RandomForest
Estealgoritmoutilizaárbolesdedecisióncomoclasificadoresbase.Cadaclasificador baseaportaunvotoenladecisiónfinaldelaclasificación,porlotanto,mientrasmás extensoseaelbosque,másvotosestaráninvolucradosenladecisióndelaclasificación final.Laclasemáspopularentrelosvotosserálaclaseasignadaalaunidaddeanálisis (Breiman, 2001),queenestecasoeselpixel.
Sufuncionamientosebasaenirrealizandoparticionessucesivasdelosdatosbuscandomaximizarlahomogeneidaddelasvariables.Cadaparticióndaorigenaunárbol. Unavezquelasparticionessehanvueltohomogéneas,comienzaelprocesodepoda mediantevalidacionescruzadas(CánovasGarcíaetal., 2016).
Paraladefinicióndelosnodosencadaramadelárbolestealgoritmocomputaelíndice deGini,elcualsedefinecomo: Gini =1 c i=1 (pi)2 (10)
Donde pi eslafrecuenciarelativadelaclaseobservaday c representaelnúmerode clases.
ElíndicedeGiniesunamedidadelaimpurezadelosdatos.SielíndicedeGiniesigual a0,significaquelosdatossonpuros,esdecir,todoslosdatospertenecenaunamisma clase.SielíndicedeGiniesiguala1,significaquelosdatossonimpuros,esdecir,los datosestándistribuidosdemanerauniformeentrelasclases(Breiman, 2001).
ApartirdelíndicedeGinisecalculaelíndicedeimpurezadecadanodo,elcualse definecomo:
Donde Ni eselnúmerodeobservacionesenelnodo i, N eselnúmerototaldeobservacionesy Ginii eselíndicedeGinidelnodo i
Elíndicedeimpurezaseutilizaparaseleccionarlavariableyelpuntodecorteque minimizalaimpurezadelosnodos.Elalgoritmoseleccionalavariableyelpuntode cortequeminimizaelíndicedeimpurezadelosnodos.
Estosárbolessonconstruidosdemaneraindependiente,porloquenoexisterelación entreellos.Laclasificaciónfinalserealizamediantelavotacióndelosárboles,donde laclasemásvotadaeslaclaseasignadaalaunidaddeanálisis(BelgiuyDrăguţ, 2016).
Paraevitarelsobreajusteu overfitting,elalgoritmoutilizalatécnicade bagging,lacual consisteenentrenarcadaárbolconunamuestraaleatoriadelosdatos.Estatécnica permitequecadaárbolseaentrenadoconunamuestradiferente,loqueevitaquelos árbolesseanidénticosy,porlotanto,evitaelsobreajuste.
Ademásdel bagging,elalgoritmoutilizalatécnicade subspacesampling,lacualconsisteenseleccionarunsubconjuntoaleatoriodelasvariablesparaentrenarcadaárbol. Estatécnicapermitequecadaárbolseaentrenadoconunsubconjuntodiferentedelas variables,aportandoaaleatorizarelproceso.
Finalizadoelprocesodeentrenamiento,elalgoritmorecopilalainformacióndecada árbolycalculalaimportanciadelasvariables.Laimportanciadelasvariablessecalculacomoladisminucióndelaimpurezadelosnodosqueresultadelainclusiónde lavariableenelárbol.Laimportanciadelasvariablesseutilizaparaseleccionarlas variablesmásimportantesparalaclasificación.
Dadoloanterior,estetipodemodeloesmuyutilizadoenlaclasificacióndeimágenes
satelitales,yaqueescapazdemanejargrandesvolúmenesdedatosyesrobustoala presenciaderuidoenlosdatos,evitandoel overfitting (BelgiuyDrăguţ, 2016).
2.4.2.3 DynamicTimeWarping Elalgoritmo DynamicTimeWarping (Deformacióndinámicadeltiempo DTW)funciona comparandounafirmatemporalsobreunfenómenoconocido.Elalgoritmocompara ambasseriesdetiempoproduciendounamedidadedisimilitudcomoresultado(Kate, 2016).Unodelosusosprincipalesdeestealgoritmoeselreconocimientodevoz,yaque comparaelpatróndepalabrasconocidasconlaseñaldeunaudio(RabineryJuang, 1993).Yaquelavelocidaddelhabladifieredepersonaenpersona,elalgoritmoencaja lospatronesconocidosconlaseñalaevaluar.Estealgoritmoresuelveelproblemadel ajusteeuclidianoenlaalineacióndedatos(Figura 7).
Sequencia X
Sequencia Y
Tiempo
Ajuste euclidiano
Sequencia X
Sequencia Y
Tiempo
Dynamic Time Warping
Figura7: Diferenciaentreajusteeuclidianoyelalgoritmo DTW.
Losparámetrosdeentradadeestealgoritmoson:Secuenciadedatos Q ycadenade búsqueda C paralos n elementos.
= {q1,q2,...qn}
Laalineaciónentreelpatrónylamuestraserealizamediantelaconstruccióndeuna matriz D de n por m elementos,dondecadaelemento dij contieneladistanciaentre loselementos qi y cj .Deestamatrizsedefineelcaminodedeformación ω
Elcaminodedeformaciónestádefinidocomo wk =(i,j)k paracadaelemento n.Se construyen K caminosdonde W = w1,w2,...wk.Lamejorsoluciónserádefinidacomo:
Estasoluciónserálaquepresentemenordeformación,y,enconsecuencia,siladeformaciónesmínima,seconsideraqueelpatrónhalogradounajustepositivoconla muestra.
Estealgoritmohasidoutilizadoenlaclasificacióntemáticadecultivoagrícolasparaciclosdeunatemporada,dejandodeladocultivoscuyafenologíaesdesarrolladaenmás deunatemporada. Mausetal. (2016)hapropuestounamodificaciónalalgoritmocon laincorporacióndelaponderaciónportiempo.Estepermiteclasificarcultivosconciclos multitemporalesoconsuelosconrotacióndecultivosdurantelatemporada.
2.4.3 Métricasdeevaluación Paraevaluareldesempeñodeunalgoritmodeclasificaciónseutilizanmétricasde evaluación.Estasmétricaspermitencuantificarloscasosdeaciertosyerroresdela clasificación.Lasmétricasmásutilizadassonlaexactitudglobal,elcoeficienteKappa
deCohenylamatrizdeconfusión.Existenmétricasespecíficasparaevaluareldesempeñodeclasificadoresbinarios,comolasmétricas precision, recall y F1score (Nicolau etal., 2024).Sinembargo,paraelcasodeclasificadoresmulticlase,estasmétricas nosoncomunesparaevaluareldesempeñodeunclasificador,siendoelcoeficiente KappadeCohen,laexactituddelproductorylaexactituddelusuariolasmásutilizadas (Congalton, 1991; MaxwellyWarner, 2020; Stehman, 1997).
Lamatrizdeconfusiónesunatablaquepermitevisualizarlosaciertosyerroresdela clasificación(CongaltonyGreen, 2008).Estamatrizesde k por k elementos,donde k eselnúmerodeclasesaclasificar.Ladiagonalprincipaldelamatrizrepresentalos aciertosdelaclasificación,mientrasqueloselementosfueradeladiagonalprincipal representanloserroresdelaclasificación.Lasumadeloselementosdeladiagonal principal(delaclase 1 alaclase k)representalacantidaddeaciertosdelaclasificación, mientrasquelasumadetodosloselementosdelamatrizrepresentalacantidadde pixelesclasificados.
ElesquemadelamatrizdeconfusiónsepuedeobservarenlaTabla 1,dondelasfilas (i)representanlasmuestrasdereferenciaylascolumnas(j)representanlasmuestras clasificadas.Esteeselordenestándarenevaluacióndedesempeñoparaclasificadores de machinelearning
Tabla1: Ejemplomatemáticodelamatrizdeconfusión.
j =Clasificación
i =Referencia
Laexactitudglobaleslamétricamásutilizadaparaevaluareldesempeñodeunclasificador.Estamétricasedefinecomolaproporcióndepixelescorrectamenteclasificados conrespectoaltotaldepixelesdelaimagen(CongaltonyGreen, 2008).Históricamente,seconsideraqueunnivelde85%deaciertoesadecuadoparaunclasificadoranalizado(Foody, 2008).Apesardeserlamétricamásutilizada,existenciertaslimitantes ensuuso,yaquenoconsideraladistribucióndeloserroresenlamatrizdeconfusión, porloquenoesposibleidentificarsilaclasificaciónpresentaerroresdecomisióno deomisión,porlotantonoserecomiendautilizarsóloestamétricacomoreferencia (Foody, 2008; Shaoetal., 2019).Laexactitudglobalsedefinecomo:
Exactitudglobal(OA) = k i=1 nii n (14)
Paracomplementarlamétricadeexactitudglobal,serecomiendaaplicarlasmétricas exactituddelproductoryexactituddelusuario.Laexactituddelproductorsedefinecomolaproporcióndepixelescorrectamenteclasificadosconrespectoaltotaldepixeles delaclase i.Porotrolado,laexactituddelusuariosedefinecomolaproporciónde pixelescorrectamenteclasificadosconrespectoaltotaldepixelesclasificadoscomo clase j (CongaltonyGreen, 2008).Estasmétricaspermitenidentificarsilaclasificaciónpresentaerroresdecomisiónodeomisión.Laexactituddelproductorsedefine como:
Exactituddelproductor(PA) = nii ni+ (15)
Exactituddelusuario(UA) = njj n+j (16)
ElcoeficienteKappadeCohenesunamétricaquepermiteevaluareldesempeñode unclasificadorenfunciónalaprobabilidaddecoincidenciaalazaroprobabilidadde
error(CongaltonyGreen, 2008).Estamétricasedefinecomo:
CoeficientedeKappa (κ)= OA pc 1 pc (17)
Siendo pc laprobabilidaddecoincidenciaalazaroprobabilidaddeerror,definidaco
mo:
(18)
Enconsecuencia,elcoeficienteKappadeCohenpuedeserdefinidocomo:
(19)
ElcoeficienteKappadeCohenesunamétricaquevaríaentre1y1,donde1representa unaclasificaciónperfecta,0representaunaclasificaciónalazary1representauna clasificacióntotalmenteerrónea(CongaltonyGreen, 2008).
Parapodercomparareldesempeñodeunclasificadorconotro,seutilizalapruebaestadísticadeQdeCochran(Cochran, 1950; Droretal., 2018).Estapruebapermiteevaluar siexisteunadiferenciasignificativaentredosclasificadoresmulticlase,provienedela generalizacióndelapruebadeMcNemar,pruebaquetieneporobjetivoevaluarladiferenciaentredosclasificadoresbinariosapartirdelatabladecontingencias.Laprueba deQdeCochransedefinecomo:
Donde:
Q =valordelapruebadeCochran
k =númerodeclasificadores
Gj =númerodeaciertosdelclasificador j
Li =númerodeaciertosdelaclase i
N =númerodemuestras
Elvalorde Q secomparaconelvalorcríticodeladistribución χ2 con k 1 gradosde libertad.Sielvalorde Q esmayoralvalorcríticodeladistribución χ2,serechazala hipótesisnula,porloqueseconcluyequeexisteunadiferenciasignificativaentrelos clasificadoresanalizados.
2.4.4 Experienciasprevias Existenvariasexperienciasdeclasificacióndecultivosagrícolasutilizando Machine Learning y DTW apartirdeimágenessatelitales. Mausetal. (2016)propusieronun modelodeclasificacióndecultivosagrícolasutilizando DTW yseriestemporalesde índicesdevegetación.EstemodelofueaplicadoenunaregióndeBrazil.
Belgiuetal. (2020)aplicaron3variacionesde DTW enlaclasificacióndecultivosagrícolassobreáreasdecultivoenCalifornia,EstadosUnidos.Losresultadosindicanque elmodelode DTW escapazdeclasificardiferentestiposdehortalizasapartirdelanálisisde NDVI.Elusodeíndicesdevegetaciónhasidounaestrategiacomúnenla clasificacióndecultivosagrícolas(Pengetal., 2023).
Sibienelalgoritmo DTW haobtenidounbuendesempeño,lostiemposdecómputo hansidounfactorlimitanteenlaaplicacióndeestealgoritmoenlaclasificaciónde
cultivosagrícolas.Paraello,diversosautoreshanaplicadoestrategiasparareducirlos tiemposdecómputo,comolareduccióndeladimensióndelosdatos,laparalelización delalgoritmoylautilizaciónpocasmuestrasdurantelafasedeentrenamiento(Petitjean etal., 2012; Singhetal., 2021; Zhangetal., 2022).
Elprocesodeclasificacióndecultivosagrícolasutilizandoalgoritmosde MachineLearning conalgoritmoscomo RandomForest y RedesNeuronalesArtificiales hasidoampliamenteestudiadoenlaliteratura. BelgiuyDrăguţ (2016)resumelasprincipalesaplicacionesde RandomForest enlaclasificacióndeimágenessatelitalesydestacala capacidaddeestealgoritmodeevitarel overfitting.Larevisiónde Teixeiraetal. (2023) compilaunagrancantidaddeestudiosqueaplican RedesNeuronalesArtificiales enla clasificacióndecultivosagrícolas.Dentrodelametodologíadeclasificacióndecultivos agrícolas,lautilizacióndeíndicesdevegetaciónhasidounaestrategiacomúnpara estosclasificadores(Pengetal., 2023; Saini, 2023).
3 METODOLOGÍA Enestasecciónsepresentaeláreaenlacualseextiendeelestudio,asítambién losmétodosutilizadosparapoderrespondercadaunadelaspreguntasdeinvestigación.
Losmétodosseránpresentadosenbaseasuapariciónenelflujograma(Figura 11),el cualrepresentalasecuenciadepasosquesedebenseguirparapoderresponderlas preguntasdeinvestigación.
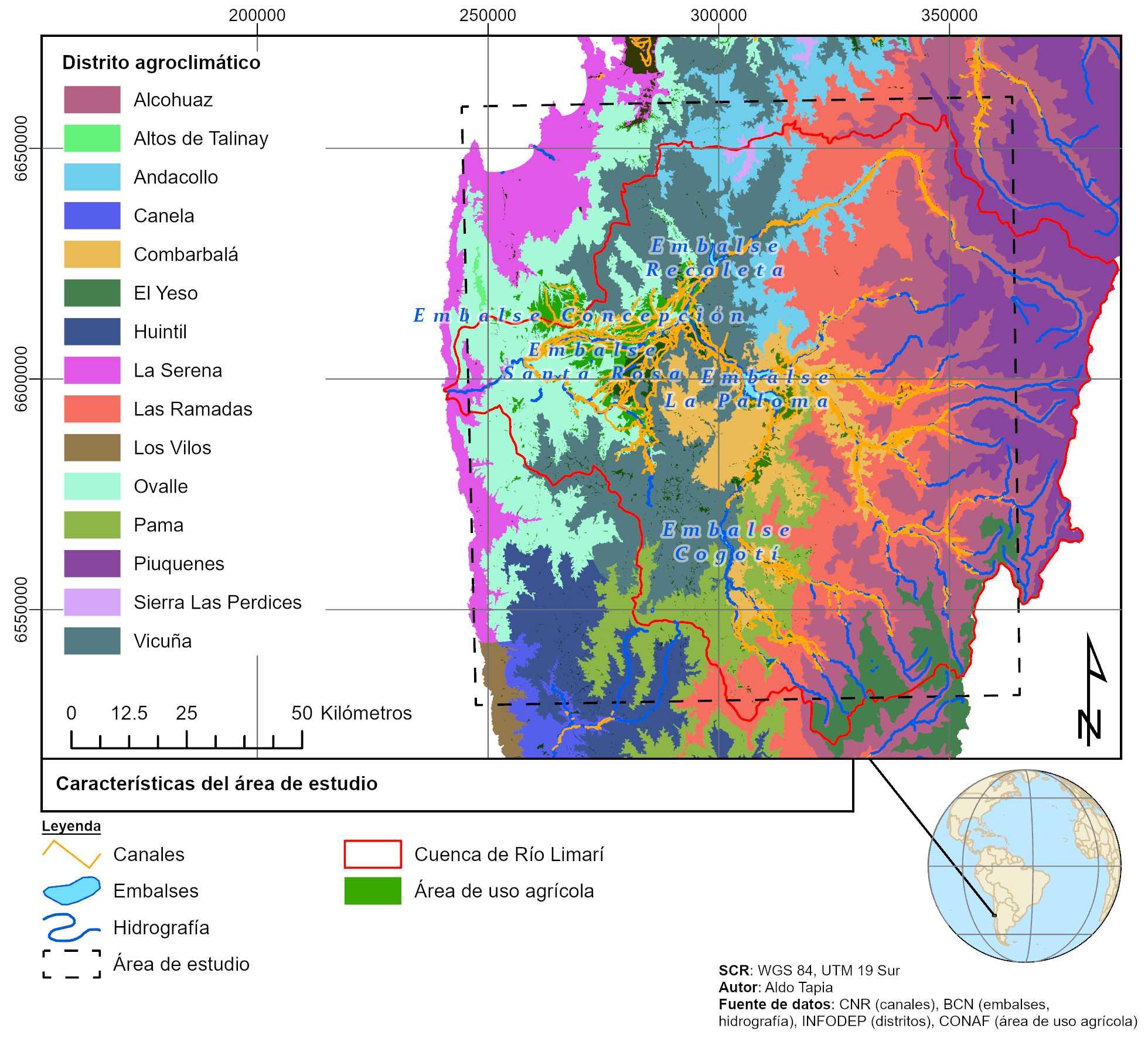
3.1 ÁREADEESTUDIO EláreadeestudioeslazonaagrícoladelacuencadelRíoLimarí,Chile.Estacuenca seubicaadministrativamenteenlaProvinciadeLimarí,RegióndeCoquimbo,Chile.
Abarcaunasuperficiedeaproximadamente11,800m2.Elclimadeestacuencaes semiárido,caracterizadoporprecipitacionesconcentradasenlaestacióndeinvierno.
Elrégimenhídricodeestacuencaesnivopluvial(DGA, 2008).Alserderégimenmixto, seproducendoscrecidasdecaudalenelaño.Laprimera,duranteelinviernoproducto delasprecipitaciones.Lasegunda,durantelaprimaverayveranoproductodelderretimientodelanieveacumuladaenlacordillera.
Lasuperficieconpotencialagrícolaenestacuencaesdeaproximadamente50,000ha (Figura8),delascuales30.000hasecultivanenunperiodonormal.Laidentificacióndel áreaagrícolaprovienedeCONAF(2004),lacualsetomócomobaseparadeterminar eláreadeestudio.
Figura8: Cartografíadeubicacióndeláreadeestudio.
Chilesecaracterizaporserunpaísconunaaltavariabilidadclimática(AlvarezGarreton etal., 2018),lacuencadelRíoLimarínoeslaexcepción.Existeungradientetérmicode maracordillera,gradientequesevereflejadoenlaacumulacióndehorasfríoygrados día(Tabla Anexo1).Estacondiciónclimáticadeterminaladistribucióndeloscultivos enlacuenca,cercanoalacostaseencuentranloscultivosdeolivoyvidindustrial;en lazonamedia,seencuentranloscultivosdeviddemesaycítricos;enlazonaalta,se encuentratambiénunagrancantidaddeviddemesa,cítricoynogal(Figura 9).
Figura9: CartografíadesuperficiefrutalsegúnCIREN(2021).
EnlaFigura 8 tambiénseaprecialasestructurasdeconducciónyalmacenamiento delrecursohídrico,lascualesseextiendenentodaeláreadeestudio.Productode ladiferenciaentreprecipitaciónyevapotranspiración,loscultivospresentesenlazona sonregadosmedianteriegotecnificado,principalmenteporgoteoymicroaspersión.El recursohídricoesalmacenadoenembalses,loscualesseencuentranenlazonaalta delacuenca,yesconducidoatravésdecanalesderiego,loscualesseextiendena lolargodetodalacuenca.Lapresenciadecultivosdesecanosóloseapreciaenla costa,duranteañoshúmedos.
3.2 FLUJODETRABAJO LasprincipalesactividadesquesedebenrealizarpararesponderlaspreguntasdeinvestigaciónsonlaspresentadasenlaFigura 10.
Obtencion escenas
Obtención escenas de S2 L2A y probabilidad de nubes
Selección escenas
Obtencion de muestras
Selección por nubosidad
Evaluación clasificadores
Transformación de escenas, análisis exploratorio y selección de muestras
Evaluación de modelos de DTW, ANN y RF, comparación métricas y evaluación de hipótesis
Figura10: Actividadesprincipalesdelestudio.
Enresumen,lasactividadesprincipalesson:
1. Obtencióndeescenas:seobtienenlasescenasdelaconstelaciónSentinel2 paraeláreadeestudioylamáscaradenubes.
Elusodeplataformasde cloudcomputing paraestefinhasidoampliamenteutilizadoenexperienciaspreviasporlafacilidaddeaccesoalasimágenesylacapacidaddeprocesamiento(Ghazaryanetal., 2018; Liuetal., 2020; Masseyetal., 2018).
2. Seleccióndeescenas:seseleccionanlasescenasqueseránutilizadasparael estudioenbaseasuposicióndentrodeláreayalanubosidadsobreella.
Eldescartedeescenaspornubosidadesunprocesocomúnenlaobtenciónde
imágenessatelitales(Heupeletal., 2018; Lebourgeoisetal., 2017; Palchowdhuri etal., 2018; Pengetal., 2023).
3. Obtencióndemuestras:seobtienenlasmuestrasdeentrenamiento,validación ypruebaparalosclasificadoresaevaluar.
4. Evaluaciónclasificadores:seevalúanlosclasificadoresseleccionadosenbase alasmuestrasobtenidas,seeligeelmejorpormétodoyseevalúalahipótesis.
Elusodeíndicesdevegetaciónenlaclasificacióndecultivosagrícolashasido ampliamenteutilizadoenlaliteratura(Arvoretal., 2011; Heupeletal., 2018; Lu etal., 2023; Palchowdhurietal., 2018).
Porotrolado,losclasificadoresevaluadoshansidoevaluadosenlaclasificación deimágenesdesatélite(Afrasiabietal., 2020; Mausetal., 2019; Simoesetal., 2017; Xiaoetal., 2023).Lasmétricasdeevaluaciónutilizadasenesteestudioson comunesenlaevaluacióndeclasificadoresdeimágenessatelitales(Congaltony Green, 2008; MaxwellyWarner, 2020; Stehman, 1997).
Elpasoapasodecadaactividad,oflujograma,delestudiosepresentaenlaFigura 11.Enélseindicanlosinsumosdeentrada,lacadenadeprocesosyelproductoobtenidoporcadaetapa,siguiendoelestándarde AmericanNationalStandardInstitute (1973).
Obtención escenas
S2 L2A
S2 Cloud Probab.
Ajuste NBAR
Mosaico Mosaico
BBDD imágenes
Datos refinados
Reducción de datos por celda
Mosaico
Extracción por vector
Separación muestras
Bootstraping y normalización
Datos entrenamiento
Datos validación
Selección escenas
BBDD imágenes
Evaluación nubosidad
Grilla de análisis
Corte por celda
Re-evaluación nubosidad Cálculo NDVI
Remoción imágenes con nubes
Datos refinados
Datos validación
Datos entrenamiento
Exploración modelos ANN
Evaluación combinaciones
Selección mejor modelo
Cálculo de métricas
Obtención de muestras
Análisis exploratorio
Datos secundarios
Vectorización y etiquetado
Datos prueba
Datos prueba
Exploración modelos RF
Evaluación combinaciones
Selección mejor modelo
Cálculo de métricas
Evaluacion hipótesis
Adición de celda a tabla de atributos
Exploración modelos DTW
Evaluación combinaciones
Selección mejor modelo
Cálculo de métricas
Obtención de muestras
Evaluación clasificadores
3.2.1 Obtencióndeescenas LaobtencióndelasescenasdelaconstelaciónSentinel2(S2)serealizamediantelos geoportalesdelaAgenciaEspacialEuropea(ESA)ydelaComisiónEuropea(EC).
Tambiénsepuedenobtenerdesdelasplataformasde cloudcomputing comoGoogle EarthEngineyAmazonWebServices.
Paraesteestudio,seutilizaronescenasdenivelL2AdelaconstelaciónSentinel2.Una escenanivelL2Aestácorregidaatmosféricamente,locualpermiteobtenervaloresde reflectanciaensuperficie.Lacorrecciónatmosféricaserealizamedianteelprocesador Sen2Cor,elcualeselprocesadoroficialdelaESAparaestetipodeproducto(Louiset al.,2016).Lacorrecciónatmosféricaimplicalautilizacióndelareflectanciaenlabasede laatmósfera(oreflectanciaensuperficie)(ρBOA),adiferenciadelareflectanciaaltope delaatmósfera(ρTOA)lacualeslaqueposeeunproductosatelitalquesólopresenta correccionesgeométricasyortorectificación.ParaelcasodelprocesadorSen2Cor,las escenastambiénsoncorregidastopográficamente,corrigiendoelniveldebrillocaptado porcadacanalespectralenfunciónalapendienteyorientacióndelasuperficie.
Elperiododeestudioeslatemporadaagrícola20202021,lacualseextiendedesdeel 1demayodel2020al30deabrildel2021.Porloqueseobtuvoimágenesdeunmes antesyunmesdespuésdelperiodomencionado,pararellenarlosvacíosdenubosidad quesepuedanpresentarenelperiododeestudio.
ParalaobtencióndeestasescenasseutilizóelAPI(ApplicationProgrammingInterface)dePythondelaCopernicusutilizandolalibrería sentinelsat.EsteAPIpermitela obtencióndeimágenesmedianteellenguajedeprogramaciónmencionado,evitando laintervencióndeunusuarioenlaselecciónydescargadecadaescena.
Ladescargadeunaescenanoserealizadescargandosolounconjuntodedatos.Las escenasdelaconstelaciónSentinel2seencuentrandivididasenunagrillade100x100 km,cadaunadeestasdivisionessedenomina tile.Cada tile poseeunidentificador
único,elcualseutilizaparaladescargadelasescenas.Deigualforma,paraevitar descargarescenasincompletas,seutilizóelnúmerodeórbitarelativa,queparaeste casoesel96.Estenúmerodeórbitarelativaseutilizaparaladescargadeescenasque seencuentranenlamismaórbita,evitandoladescargadeescenasqueseencuentran enlamismaposición,peroenórbitasdiferentes,yenconsecuencia,fechasdiferentes yescenasincompletas.
Sibien,elprocesodecorrecciónatmosféricageneraunabandadenominadaSCL(SceneClassificationLayer),lacualpermiteidentificarlasnubesysombrasdenubes,esta bandanoessuficienteparaidentificarlanubosidadenunaescena(Tarrioetal., 2020). Paramejorarladeteccióndenubesenlaescena,seutilizóelproductoobtenidopor elalgoritmodedeteccióndenubesdelequipodeSentinelHub,elcualconapoyode técnicasde MachineLearning permiteidentificarnubesysombrasdenubesconmayorprecisiónquelabandaSCLmezclandolosproductosdeFMask,Sen2CoryMaja (Skakunetal., 2022).
Losproductosdelalgoritmoantesseñaladofueronobtenidosdesdelaplataformade cloudcomputing GoogleEarthEngine,descargandolasimágenesdelacolección S2 CLOUDPROBABILITY deCopernicusparaelmismoperiododelasescenasdeS2obtenidasdesdeelAPIdelamismafuentededatos.
DebidoaqueelángulodecampodevisióndelaconstelaciónSentinel2esde20.6°, seaplicóunalgoritmodecorrecciónelefectodelareflectanciasobresuperficienolambertianautilizandolafuncióndedistribuciónbidireccionaldelterreno(BRDF)de Roy etal. (2017).Estealgoritmopermitecorregirelefectodelareflectanciasobresuperficie nolambertiana,elcualesgeneradoporlainteraccióndelaluzsolarconlasuperficie terrestre.Esteefectoesmásnotorioensuperficiesconpendientespronunciadas,como eselcasodelacuencadelRíoLimarí.ElalgorithmodecorrecciónBRDFseaplicósobre lasbandasde10metrosdecadaescena,utilizandolalibreríadePython sen2nbar Luego,tantolasescenasdeS2comolasimágenesdenubosidadfueronmosaicadas
parajuntarcada tile enunaúnicaimagen.Paraelmosaicodeambosproductosse utilizólibrería rioxarray dePython.
3.2.2 Seleccióndeescenas Paraseleccionarlasescenaspornubosidad,loprimeroqueserealizófuegeneraruna grillaparapodercortarlosmosaicosgenerados.Elobjetivodeutilizarunagrillaes podermantenerpartedelaescenacuyospixelesestánlibresdenubesydesecharla partedelaescenaqueseencuentranublada.Lagrillageneradatieneuntamañode 12,800x12,800metros,loqueequivalea1,280x1,280.EstagrillasegeneróenQGIS, seleccionandoaquellasceldasqueseencuentrandentrodeláreadeestudio.Entotal, seseleccionaron56celdas,lascualesseutilizaronparacortarlosmosaicosdeS2a partirdelosvaloresdenubosidad.
Estagrillaescompatiblelaoptimizaciónderecursosdela GraphicalProcessingUnit (GPU)paralaejecucióndeprocesos MachineLearning,mejorandolaeficienciaenla asignacióndememoriaenlastarjetasgráficasparaacelerarlosprocesosdecómputo (MülleryGuido, 2016).
Paraseleccionarlasescenasporlapresenciadenubes,seutilizólalibrería terra de
R.Elprocesoincorporólaaplicacióndelalgoritmo 1:
Algoritmo1: Selecciónescenaspornubosidad
Data: rraster,vvector
Result: rraster
rcargarbandasdeS2L2A;
rcargarproductodeteccióndenubes; for i encadaceldaenv do rcortarnubesporcelda; ragregarpixelesdenubes(ventana:15x15,función:máximo); raplicarfunciónfocal(ventana:7x7,función:máximo); raplicarclasificaciónbinaria(umbral80%nubosidad); robtenerpromedionubosidadsobreeláreadela celda; if promediocelda<0.1 then
rcortarbandas; rexportarbandas; else
omitircelda;
Posterioralaseleccióndelasescenaspornubosidad,seprocedióagenerarseriesde tiempode NDVI parahacerunasegundaselecciónmanual.
Luegodehaberidentificadolasescenas,seeliminaronaquellasqueposeennubespara generarunabasededatosdeescenaslibresdenubes.Sibien,sepuedeenmascarar lasnubesparagenerarseriesdetiempo,lapresenciadenubesenunaescenapuede generarerroresenlaclasificación,especialmenteporlassombrasqueestasgeneran. Porello,seoptóporeliminarlasescenasconnubesparaevitarestoserrores.
ElresultadoesunabasededatosrefinadadeescenasdeS2libresdenubes,lascualesseutilizaronparalaobtencióndemuestrasdeentrenamiento,validaciónyprueba.
EstasescenasestánalmacenadasenarchivosTIFFmonobanda(unabandaporarchi
vo),seleccionandosóloaquellasbandasde10metrosderesoluciónespacial(bandas 2,3,4y8).
3.2.3 Obtencióndemuestras Paraobtenerlasmuestrasdeentrenamiento,validaciónyprueba,loprimeroquese realizófuelageoreferenciacióndeobservacionesdelasdiferentesclasesdeinterés sobreeláreadeestudio.Paraidentificarestasclases,seutilizólacapaCatastroFrutícoladelaRegióndeCoquimbo(macrorregiónqueenglobalaCuencadeLimarí)versión2021(CIREN, 2021)yvisitasaterreno.LacapaCatastroFrutícoladelaRegión deCoquimboesunacapavectorialquecontienelaubicacióndelosprediosagrícolas conproduccióndefrutafrescadelaregión,ademásdelasuperficieyelcultivoquese encuentraencadapredio.Estacapaseelaboraapartirdelainterpretaciónvisualde imágenesdelsatéliteSPOTparaladelimitaciónyencuestasenterrenoparaellevantamientodelosatributosdecadapredio.
Lasmuestrasseetiquetaronenlassiguientescategorías:
almond (Almendro) :Prediosconcultivodealmendro.
avocado (Palto) :Prediosconcultivodepalto.
barren (Suelodesnudo) :Prediosconsuelodesnudoosuelossincultivo.
barrenshadowed (Suelodesnudoconsombra) :Prediosconsuelodesnudoosuelossincultivoconsombraduranteinvierno(resultaenun NDVI cercanoa0o negativo),principalmenteenladerasdecerro.
forage (Pradera) :Prediosconcultivodepradera(comoalfalfa).
industrialgrape (Uvaindustrial) :Prediosconcultivodeuvaindustrialparafabricacióndevinoopisco.
lemon (Limón) :Prediosconcultivodelimón.
mandarin (Mandarina) :Prediosconcultivodemandarina.
olive (Olivo) :Prediosconcultivodeolivo.
orange (Naranjo) :Prediosconcultivodenaranjo.
riversidevegetation (Vegetaciónderibera) :Vegetaciónderibera,comobosques deriberaomatorrales,cercanosaesterosyríos.
shortcyclecrop (Cultivodeciclocorto) :Prediosconcultivodeciclocorto,como hortalizasocultivosanuales.
tablegrape (Uvademesa) :Prediosconcultivodeuvademesa.
urban (Urbano) :Áreasurbanas.
walnut (Nogal) :Prediosconcultivodenogal.
water (Agua) :Cuerposdeagua,comotranques,embalses,etc.
Estetotalde16etiquetasdiferenteslogracaracterizardemaneraadecuadalazonade estudio.Existencultivosqueseencuentranenunamuypequeñaproporciónalinterior delazonadeestudioquenofueronconsiderados,comopecana,arándano,granado ehiguera,que,porinsuficienciademuestrasparaentrenarunclasificador,nofueron considerados.Porotrolado,loscultivosdeciclocortoseagruparonenunaúnicacategoría,yaqueporsunaturaleza,estoscultivosseencuentranenlazonadeestudio porunperiododetiempomuycorto,porloquenoesposibleidentificarlaespecieal realizarelrecorridoenterrenonialevaluarlasimágenessatelitales.Porlomencionado enlosantecedentes,ladiversidaddecaracterísticasmeteorológicaseneltranscurso delatemporadaagrícola,ladiversidaddeespeciesysuelos,seoptóporagruparlos cultivosdeciclocortoenunaúnicacategoría.
Lasmuestrasfueronvectorizadasenunacapadepuntos.Enlasecciónresultadosse desglosaelnúmerodemuestrasporcategoría.Paraanalizarelclasificador DTW utilizandolasseriesdetiempodelasescenasdeS2,seintersectólacoberturademuestras conlagrilladeladeseleccióndenubosidadparaañadirelatributodeidentificadorde celdaacadamuestra.
Debidoaquenotodaslasceldasanalizadasposeenlamismacantidaddeescenas, serealizóunprocesodereduccióndedimensionesparahomogenizarlosdiferentes fragmentosdelasescenasdelsatéliteS2aunaúnicalongitud,ydeestaformapoder evaluarlosmodelosde MachineLearning.Seutilizóajustede Splines,métodoquese hausadoextensamenteparasuavizarlarespuesta,reducirdimensionesyrellenarvacíosdeinformaciónenimágenesdesatéliteeíndicesespectrales(deCarvalhoetal., 2007; Graesseretal., 2022; Lopesetal., 2020; Stolzetal., 2023; Thapaetal., 2021; Tziokasetal., 2023; Vianaetal., 2019; VorobiovayChernov, 2017).Sibien,existen otrosmétodospopulares,comoelfiltrodeSavitzkyGolay,elmétododeinterpolación por Splines permitegeneralizarlarespuestaencultivosdealtadinámica(comolaspraderas)yademásobtenerunpuntajedebondaddeajuste(sumatoriaderesidualesal cuadrado,o RSS),permitiendodiferenciarcultivosdebajadinámica(comoloscultivos frutalesdehojapersistente)deaquellosdealtadinámica,comolasmencionadaspraderasoloscultivosdeciclocorto.Paraelloseproponeelalgoritmo 2 dereducciónde
dimensiones:
Algoritmo2: Reduccióndedimensiones
Data: rserietiemporasterdelongitud n,dfechasdeescenas,nvectornumérico
Result: rraster(14bandas)
for i encadacelda do rcargarseriedetiempodeS2L2Adecelda i; dextraerfechasdeescenas; dconvertirfechaaformatonumérico; if longitudd<=4 then retornar0x14; else najustarsplinecúbica(x:d, y:r),suavizadode0.4(Silverman, 1993); npredecirvaloresdeseriedetiempo(x:d,y:r)cada5días; nagregarvalorespredichospormesdetemporadaagrícola; retornarrasterde14bandas:12valoresmensualesagregados, RSS, n; rexportarresultado;
Posterioralareduccióndedimensiones,ycomocadaceldaposee14bandas,seprocedióarealizarunmosaicosobretodaeláreadeestudio.Deestaforma,esposible evaluarlasmúltiplesmuestrasconunacantidaddeinsumosreducidaeigualentrelas diferentesceldasdeanálisis.
Paralaevaluación,seextrajoelvalordecadaunadelas14bandaspormuestradigitalizada,obteniendolosinsumosparaelanálisisexploratorio.Parahomogenizarelvalor delasumaderesidualesalcuadradoentrelasáreas,sedividióel RSS porlacantidad deescenasutilizadasenlareduccióndedimensiones,debidoaqueentremásescenas seutilicen,mayorseráelvaloresperadode RSS.Enfuncióndeentregarantecedentes pararesponderalaprimerapreguntadeinvestigación,secompararonlasmuestras condiferentesgruposdedimensionesreducidaspor Spline.Estosgruposson:
• Grupo1: Bandas2,3,4y8deS2.
• Grupo2: ValoresdeNDVIdeS2.
• Grupo3: Bandas2,3,4y8deS2yvaloresdeNDVIdeS2.
PararealizarelanálisisexploratoriosecomputóelPCAdelosinsumoscon n 1 componentes,siendo n lacantidaddebandasdecadagrupo.Esteanálisispermiteidentificar lavarianzaexplicadaporcadacomponenteprincipalparadeterminarlavariabilidadde losdatosdeentrada(Estornelletal., 2013).
TambiénserealizóelanálisisdetSNE(tdistributedStochasticNeighborEmbedding o embebidoestocásticodevecinosdistribuidosent)consalidade2componentespara identificarlaagrupacióndelasmuestrasenelespaciodelosresultantededichoscomponentes(vanderMaatenyHinton, 2008).EltSNEsecomputóutilizandoladistancia deManhattan,lacualtiendeamejorareldesempeñoenelprocesodeagrupaciónde datosencomparaciónaladistanciaeuclidiana(Suwandaetal., 2020).Ladistanciade Manhattansedefinecomo:
Donde:
dij =distanciadeManhattanentrelasmuestras i y j
xik =coordenadasdelpunto i enladimensión k
xjk =coordenadasdelpunto j enladimensión k
ElPCAyeltSNEserealizaronconlalibrería scikit-learn dePython.Delresultado deltSNE,sevolvióacalcularladistanciaconlamétricadeManhattanentrecada muestraelconjunto,conservandoladistanciamínimaparacadaetiquetadeclase. Esteanálisispermiteidentificarlacercaníaentrelosdiferentesgrupos(grupos1al3)
demuestras.
Luego,parapoderentrenarlosdiferentesclasificadores,sedividieronlasmuestrasen tresconjuntosdedatos:entrenamiento,validaciónyprueba.
Deltotaldemuestras,seestablecióunmínimode100muestrasporclaseparaelconjuntodeentrenamiento,30muestrasporclaseparaelconjuntodevalidacióny30 muestrasporclaseparaelconjuntodeprueba.Losdatosdevalidaciónsonutilizadosparaajustarloshiperparámetrosdelosclasificadores,mientrasquelosdatosde pruebasonutilizadosparaevaluareldesempeñodelosclasificadores.Elconjuntode entrenamientoesutilizadoparaconfigurarlosclasificadores.
Debidoaquehaygruposqueposeenmenosmuestrasdeloslímitesestablecidos,se determinórealizar bootstrapping paraaumentarlacantidaddemuestrasdecadaclase. El bootstrapping esunmétododeremuestreoqueconsisteengenerarmuestrasdeuna poblaciónapartirdelamismapoblación,conelobjetivodeaumentarlacantidadde muestrasdeunaclaseenparticular(Tibshirani, 1994).Elprocesode bootstrapping se realizóconelalgoritmo 3 demuestreoyremuestreo:
Algoritmo3: bootstrapping demuestrasdelasclases 1 a n
Data: vvectordemuestras i de n clases,nnúmerodemuestras
Result: vvectorconlosIDsdelasmuestrasseleccionadas if n>longitudv then nmuestreoaleatorioIDssinreemplazo; else
n1asignaciónIDsdemuestrasdelongitudv; n2muestraaleatoriadeIDssinreemplazodelongitudnlongitudv; nconcatenaciónden1yn2; retornarn
Cabemencionarqueelconjuntodedatosdeentrenamiento,validaciónypruebano compartenIDsdemuestras,porloquenohaymuestrasrepetidasentrelosconjuntosde
datos.Estoesunrequisitoprimordialparaevitarel overfitting enlosclasificadores.
3.2.4
Evaluaciónclasificadores Paralaevaluacióndelosclasificadores,seestablecierondiferentesenfoquesehiperparámetrosparaelentrenamientodecadaclasificador,enbasealosdatosdeentrenamientoyvalidación.Elsetdedatosdepruebafuereservadosóloparalaevaluacióndel desempeñodelclasificador,siguiendoelprocesodeselecciónyevaluacióndemodelosdeaprendizajeestadístico,comolosonlosmodelosde MachineLearning (Hastie etal., 2001).
Elprocesodeselecciónyevaluacióndelosclasificadoresseejecutódelasiguiente forma:
1. Determinacióndeestructuraehiperparámetrosdelosexperimentos
2. Entrenamientodelosclasificadoresconlos3gruposdedatos
3. GráficodepasoapasodeKappadeCohen(κ)yexactitudglobal(OA)paralos experimentosdecadagrupoanalizado
4. EvaluaciónenbaseaKappadeCohen(κ)paraseleccióndelmejormodelopor clasificador
5. Comparaciónde κ delosmejoresmodelosporclasificadorenbasealaprueba QdeCochran
Acontinuación,selistanlosexperimentosrealizadosparacadaclasificador.
DTW
Comopasoprevioalaevaluacióndeesteclasificador,seregularizaronlasmuestras deentrenamiento,validaciónypruebaparaquetodaslasmuestrasposeanlamisma
cantidaddefechasaevaluar.Elalgoritmo DTW requierequelosdatosdeentradasean seriesdetiemporegulares,tantoparalasmuestrasdeentrenamientocomoparalas muestrasaclasificar.Puedeocurrirqueunamuestraposeamásfechasqueotra,la
cualesposibledepoderincorporaralalgoritmo DTW,peronoesposiblecompararel resultadode dDTW (x,y) entremuestrasdediferenteextensióntemporal.
Esporelloquesehomogenizólacantidaddefechasaevaluarpormuestra,utilizando unaserietemporalencomúnyrellenandolosvacíosdeinformaciónconmétodosde imputaciónsimples(Salgadoetal., 2016):interpolaciónlineal, lastobservationcarried forward (LOCF)y firstobservationcarriedbackward (FOCB).Luegodeimputarlos datos,secortóparaelperiododeestudio,elcualseextiendedesdeel1demayodel 2020al30deabrildel2021.
Paraelclasificador DTW,serealizaron5x3experimentos,estosfueronorganizados segúnelTabla 2.
Tabla2: Característicasdelosexperimentosde DTW
N°Características
1 Conservarlaetiquetadelaclaseconmenor dDTW (x,y)
2 Conservarlaetiquetadeclasemodalentrelas3conmenor dDTW (x,y)
3
4
5
Conservarlaetiquetadeclasemodalentrelas5conmenor dDTW (x,y)
Conservarlaetiquetaconmenor d’ DTW (x,y) promedioentrelas3 primerascomparacionesconmenor dDTW (x,y)
Conservarlaetiquetaconmenor d’ DTW (x,y) promedioentrelas5 primerascomparacionesconmenor dDTW (x,y)
Donde d’ DTW (x,y) esladistancianormalizadade DTW,definidacomo:
d’ DTW (x,y)=
dDTW (x,y) n i=1
dDTW (x,yi) (22)
Donde:
d’ DTW (x,y) =distancianormalizadade DTW entrelamuestra x ylamuestra y
dDTW (x,y) =distanciade DTW entrelamuestra x ylamuestra y
dDTW (x,yi) =distanciade DTW entrelamuestra x ylamuestra y delaclase i
Eltipoderesultadotradicionaldelclasificador DTW eslaetiquetadelaclaseconmenor distanciaentrelamuestraylasmuestrasdeentrenamiento.Sinembargo,debidoa queelalgoritmode DTW puedeasemejardosmuestrasdeclasesdiferentes,perode comportamientosimilar,seoptóporrealizarexperimentosquepermitanobteneruna etiquetadeclasemásrobusta,como d’ DTW (x,y)
Paraelcálculode dDTW (x,y) seutilizólalibrería dtwParallel dePython,lacuales capazdecalculardistanciaentreseriedetiempomultivariables(EscuderoArnanzet al., 2023).Debidoaquedosdelostresgruposaanalizarconsideranmásdeuncanal deinformación,seutilizóestalibreríaparacalcularladistanciaentrelasmuestras.
Otraventajaqueposeeestalibreríaesqueparalelizaelcálculodeladistancia,loque permitereducireltiempodecómputo.Paraestecaso,debidoaquemúltiplesautores hanseleccionadolamétricadedistanciaeuclidianaparaelcálculodeladistanciaentre seriesdetiempo(Belgiuetal., 2020; Csilliketal., 2019; Fuetal., 2008; Petitjeanetal., 2012),seoptóporutilizarestamétricaparaelcálculodeladistanciaentrelasmuestras alutilizarelalgoritmo DTW.
Sibienlalibrería dtwParallel mejoralostiemposdecómputoalparalelizarelcálculode ladistancia,elcálculodeladistanciaentrelasmuestrasesunprocesoquerequierede untiempoconsiderable,porloqueseoptóporrealizarunanálisisde benchmarking para evaluareltiempodecómputodelosexperimentos.Elanálisisconsistióenevaluaruna
combinacióndenúmerodefechasynúmerodemuestrasascendentehastaalcanzar unvalorcercanoalosresultadosobtenidos.Paraello,elconjuntodenúmerodefechas sedenominó n,mientrasqueelnúmerodemuestrasaevaluarsedenominó samples.
Esteanálisisconsiderarepetircadacombinación30vecesyevaluareltiempomedio enejecutarelproceso.
Elfindeincorporaresteanálisisesdeterminarsiesteclasificadorpuedeserutilizadoen contextooperacional,esdecir,sieltiempodecómputoesrazonableparaserutilizado enunprocesodeclasificacióndeimágenessatelitalesfrecuentesobreunagranárea.
Elanálisisde benchmarking serealizóconlalibrería time dePython.
ANN LosmodelosdeRedesNeuronalesArtificiales(ANN)puedenclasificarsesegúnlaestructuraqueposeen.Losmodelosdeunaúnicacapadensasedenominan NN (NeuralNetwork oredneuronal),mientrasquelosmodelosconmásdeunacapadensa sedenominan DNN (DeepNeuralNetwork oredneuronalprofunda).Porotrolado, losmodelosqueposeencapasconvolucionalessedenominan DL (DeepLearning o aprendizajeprofundo).
Paraelpresenteestudioseestableciólasiguienteestructuraporbloquedecapadensa:
• Capaoculta: n neuronas,funcióndeactivación ReLU
• Normalización: normalizacióndecapaanterior(promediocercanoa0ydesviaciónestándarcercanaa1).
• Dropout: cierrealeatoriode p neuronas,pordefectoseutilizó p =0.15.Necesario paraevitar overfitting
Enelcasodelacapaconvolucional,laestructuradeunbloqueeslasiguiente:
• Capaconvolucional: n filtros,funcióndeactivación ReLU,tamañodekernelde 3, padding de1.
• Normalización: normalizacióndecapaanterior(promediocercanoa0ydesviaciónestándarcercanaa1).
• Extraccióndevalormáximoporfiltro: extraccióndelmáximovalorreduciendo eltamañodefiltroalamitad.
Cabedestacarqueparaaquellosexperimentosqueincorporanunbloqueconvolucional seincorporóunaestructuraparaaplanarlasalidadelacapaconvolucional,demanera quesepudieraincorporarlasalidaalacapadensa.
Lacapafinaldecadamodeloesunacapadensacon16neuronas,funcióndeactivación softmax.Estafunciónpermiteobtenerlaprobabilidaddecadaclase,lacualesla adecuadaparaclasificaciónmulticlase(Fuetal., 2017; Labanetal., 2020; Rakhlinet al., 2018; Songetal., 2019).Lafuncióndepérdidautilizadaes categoricalcrossentropy, lacualeslarecomendadaparaestetipodeproblemadeclasificación(Murphy, 2022). Comooptimizador,seutilizóAdamconunatasadeaprendizajede0.01,incorporando un callback parareducirlatasadeaprendizajeenun50%cada10épocassinmejora enlafuncióndepérdidasobrelosdatosdevalidación.
Seutilizóun batchsize de8,yaquelacantidaddedatoseslosuficientementebaja comoparaqueelentrenamientodelosmodelosnoseveaafectadoporlimitaciones dememoriadelatarjetagráfica.Paraelentrenamientodelosmodelos,seutilizóun máximode600épocas,conun earlystopping de40épocassinohaymejoraenla funcióndepérdidasobrelosdatosdevalidación.Elentrenamientodelosmodelosse realizóconlalibrería tensorflow dePython.
Paraelmodelo ANN,serealizaron26x3experimentos,estosfueronorganizadossegún lopresentadoenelTabla 3
Tabla3: Característicasdelosexperimentosde ANN.Donde, CD: Capadensa; CC: Capaconvolucional; NN: redneuronal; DNN: redneuronalprofunda; DL: aprendizajeprofundo.
Tabla3: (continuacióndepáginaprevia)
N°Neuronas(CD)Filtros(CC)Tipodemodelo
Paraelcasodelmodelode RandomForest,serealizaron3x3x4x3experimentos.Los 3factoresqueseevaluaronsonelnúmerodeestimadores,laprofundidadmáximade losárbolesylacantidadmínimademuestrasporhoja.
Elnúmerodeestimadorescorrespondealacantidaddeárbolesqueseentrenanen elmodelo.Laprofundidadmáximadelosárbolescorrespondealacantidaddenivelesqueposeecadaárbol.Lacantidadmínimademuestrasporhojacorrespondeala cantidadmínimademuestrasquedebetenercadahojaporárbol.Estossonconsideradoshiperparámetrosdelmodelo,loscualesdebenserajustadosparaobtenerel mejordesempeñodelmodelo(Breiman, 2001; Hastieetal., 2001; MillardyRichardson, 2015).
Elmodelofueentrenadoutilizandolafunción RandomForestClassifier delalibrería scikit-learn dePython.LascombinacionesevaluadassepresentanenelTabla 4.
Tabla4: Combinacionesdelosexperimentosde RF.Donde, ne: númerodeestimadores; md: máximaprofundidad; msl: cantidadmínimademuestrasporhoja.
NºnemdmslNºnemdmslNºnemdmsl
Tabla4: (continuacióndepáginaprevia) N°nemdmslN°nemdmsl
5 100201 17 200201 29 300201
6 100202 18 200202 30 300202
7 100203 19 200203 31 300203
8 100204 20 200204 32 300204
9 100251 21 200251 33 300251
10 100252 22 200252 34 300252
11 100253 23 200253 35 300253
12 100254 24 200254 36 300254
Realizacióndeexperimentos LosexperimentosfueronrealizadosenuncomputadorLenovoLegion515ACH6Hcon procesadorAMDRyzen75800H,16GBdeRAMytarjetagráficaNVIDIAGeForce RTX3060de8GB.Estascaracterísticasbrindanunentornodetrabajoadecuadopara elentrenamientodelosmodelosutilizandolacapacidadcomputacionaldelatarjeta gráficaoGPU.
Losexperimentosdesarrolladospara ANN utilizanlaGPUparaacelerarelentrenamientoypredicción,utilizandolalibrería tensorflow (Abadietal., 2016).Porotrolado,losexperimentosdesarrolladospara RF utilizanlaCPUparaelentrenamientoy predicción,utilizandolalibrería scikit-learn (Pedregosaetal., 2011).Elclasificador DTW utilizalosnúcleosdisponiblesenlaCPUparaparalelizarloscálculosalcomputar dDTW (x,y),presentándosecomoopcióneficienteenelcálculodeladistanciaentre seriesdetiempo.
Evaluacióndiferenciassignificativasentreclasificadores
Finalmente,paraevaluarlasdiferenciassignificativasentrelosclasificadores,seutilizó lapruebaQdeCochran(Cochran, 1950).Paraello,seseleccionóelmejormodelo obtenidoentrecombinacióndeexperimentosygruposyseevaluóladiferenciaentre lamétrica(M)KappadeCohen(κ)entrelosmejoresmodelosporclasificadorpara determinar δX
LapruebadeQdeCochranesunapruebadehipótesisnoparamétrica,porloqueno seasumeunadistribuciónnormaldelosdatos,loqueesadecuadoparaelanálisis declasificadores.Estapruebaseaplicasobrelatabladecontingenciaentrelosdatos observadosylosdatospredichos,considerandounacontingenciamuestraamuestra,lacualdifieredeotrosanálisisdehipótesisqueconsideranunacontingenciade frecuenciasdeclases,comolapruebadeMcNemar(Ross, 2017).
Además,secomputólamatrizdeconfusión,KappadeCohen(κ),OA(OverallAccuracy oexactitudglobal),PA(Producer’sAccuracy oexactituddelproductor),UA(User’s Accuracy oexactituddelusuario)paraelmejormodeloporclasificador(Congaltony Green, 2008).Lamatrizdeconfusiónpermiteidentificarlacantidaddemuestrasclasificadascorrectamenteeincorrectamenteporclase,enconsecuencia,identificarla clasequepresentadificultadesensuclasificaciónporasemejarseaotra.ElKappa deCohenpermiteidentificarlaexactituddelclasificador,considerandolaprobabilidad declasificarcorrectamenteunamuestradeformaaleatoria.LaOApermiteidentificar laexactitudglobaldelclasificador,considerandolacantidaddemuestrasclasificadas correctamentesobreeltotal.LaPApermiteidentificarlaexactituddelproductor,considerandolacantidaddemuestrasclasificadascorrectamentesobreeltotalporclase. LaUApermiteidentificarlaexactituddelusuario,considerandolacantidaddemuestrasclasificadascorrectamentesobreeltotaldemuestrasclasificadasparaunaclase (Congalton, 1991; MaxwellyWarner, 2020; Stehman, 1997).
Aplicacióndelmejormodelo Comopasofinal,seaplicóelmejormodeloobtenidosobreeláreadeanálisis.Acontinuación,seextrajolaclasemásfrecuenteparacadapolígonodeunacoberturavectorialquerepresentaloscamposlabradasdentrodeláreadeanálisis,cedidaporel LaboratorioPROMMRAdelaUniversidaddeLaSerena,conelfindecompararlaclasificaciónobtenidaconlosdatosdereferencia.
4 RESULTADOS Enestasecciónsepresentalosresultadosdelflujodetrabajopropuestoenlasección demetodología(Sección 3).LatotalidaddelflujodetrabajoserealizóenPythonyR. Elaccesoalcódigoasociadoalflujodetrabajo,parareproducirlopresentadoenesta secciónsepresentaenelAnexo A.
Serealizóseleccióndeescenasporáreasde1,280x1,280pixelesde10metros,las cualesfueronfiltradasenbasealapresenciadenubes.Seobtuvountotalde13,340 archivosrasterdelas364escenasdescargadas,loscualesfueronutilizadosparael análisisexploratoriodedatosenbasealasmuestrasdigitalizadas.
Sepresentaelresultadodeaplicaciónde15experimentosde DTW,78de ANN y144 de RF.Sepresentaelresultadodelaevaluacióndelosmejoresmodelosobtenidos porclasificador,enbasealamétricaKappadeCohen(κ)ylapruebaQdeCochran. Finalmente,sepresentalaclasificaciónobtenidaporelmejormodeloobtenidoporclasificadorylacomparaciónconlosdatosdereferencia.
4.1 OBTENCIÓNDEESCENAS PararealizarlaconsultadelAPIdeCopernicusmediantelalibrería sentinelsat de Python.Seutilizócomoconfiguraciónenlaconsultalaórbitadescendentenúmero96 ylacajadelimitadoradeláreadeestudiomedianteladefinicióngeoJSONlistadaenel Anexo B
Seestableciócomofechainicialel1demarzodel2021ycomofechafinalel1de juniodel2022.Entotalsedescargaron364escenascorrespondientesalaszonasde distribucióndeSentinel2 T19JBF, T19JCG, T19JCF y T19BG delamisiónSentinel2. LaFigura 12 muestralaórbitadevueloylos tiles consultados.
Figura12: Órbitadevueloy tiles consultadasdelamisiónSentinel2.
Delasescenasdescargadas,lamayoríadeellasinformanunniveldenubosidadsuperioral10%(Tabla 5)segúnloqueindicaelmetadatodelaescena.Los tiles más cercanosalacosta(T19JBFyT19JBG)secaracterizanportenerunamayorcantidad dentrodelperiodoanalizado.EstosedebeaquelacostadelaregióndeCoquimbo secaracterizaportenerunamayorcantidaddenubosidadqueelinteriordelaregión, debidoalainfluenciadelacorrientedeHumboldtyalapresenciade camanchaca o nieblamatutina(Cerecedaetal., 2008; Larrainetal., 2002; Strubetal., 2019).
Tabla5: Caracteristicasdenubosidadpor tile delasescenasdescargadas.
Lanubosidadpresenteenlasimágenesaumentadurantelaestacióndeinviernoy disminuyeenelverano(Figura 13).Sinembargo,noexisteperiododelañoenque lanubosidadseanula,porloquesedebeconsiderarlanubosidadenelprocesode clasificación.
Figura13: Distribucióndelanubosidadpor tile yfecha.Encelestesemarcala estacióndeinvierno.
Esporello,quesedescargóelproducto S2CLOUDPROBABILITY (Skakunetal., 2022)
parapoderfiltrarlasescenasenbasealapresenciadenubes.Paraello,secreóuna grilladeanálisisparapoderfiltrarcadaceldadedichagrillaenfunciónalapresencia denubes.
4.2 SELECCIÓNDEESCENAS Lagrillade56celdasde1,280x1,280pixeles.Seaplicóelalgoritmo 1 dejandofuera aquellasescenasqueposeennubosidad.Luego,serealizóunasegundaselecciónde escenasenbaseainspecciónvisualapartirdeescenasde NDVI.Seutilizóeste índiceparafacilitarsuevaluación,yaquelainterpretacióndeunaimagensatelitala partirdeunaúnicabandaescompleja(Figura 14).
Figura14: Númerodefechasválidasporceldadelagrilladeanálisisdeláreade estudio. Entotalsegeneraron13,340archivosrástercorrespondientesalasbandasdelas escenasdescargadasyalasceldasdelagrillautilizadaparaladiscriminaciónpor nubosidad.
4.3 OBTENCIÓNDEMUESTRAS ApartirdelacoberturatemáticadelCatastroFrutícola(CIREN, 2021),yconayuda desalidasaterrenoyconocimientopreviodelterritorio,seobtuvountotalde2683 muestras,considerandounmáximode2muestrasporcuartelozonademanejoagrícolahomogénea,paraevitarlasobrerepresentacióndeunaclaseporrepeticiónde respuesta.LaFigura 15 muestraladistribucióndelasmuestrasporclase.
Figura15: Númerodemuestrascolectadasporclase.
Lasmuestrasestánesparcidasalolargodeláreadeestudio,condicionesquepermiten obtenerunarepresentaciónadecuadadelavariabilidaddelasclasespresentesen eláreadeestudio.LaFigura 16 presentaladistribucióndelasmuestrasenelárea deestudioylaubicacióndecadaunadelasceldasseleccionadasenelanálisisde seleccióndeescenas.
Figura16: Distribuciónespacialdemuestrasporclaseyceldasdeanálisis.
4.3.1 Característicasdelasclasespresenteseneláreadeestudio
Paradefinirlascaracterísticasdelasclaseseneláreadeestudio,secalculóel NDVI paracadaunadelasmuestrasdeformaenquesepuedarepresentarlafenologíapara cadaclase.Acontinuación,sedescribeelcomportamientodecadaclaseenfunción dedichoíndiceespectral.
almond (Almendro,Figura Anexo2):elalmendroesuncultivofrutaldehojacaducaque
poseeunperiododefloraciónanticipadoenrelaciónaotroscultivosfrutales,comolavid oelnogal(Gil, 2019b).Estosevereflejadoenel NDVI delaclase,dondeseobserva unaumentodelíndiceespectralenelmesdeagosto,correspondientealperiodode floracióndelcultivo(Figura Anexo2).
Adiferenciadeotrosfrutalesdehojacaduca,lamagnituddel NDVI noestanelevada, loquepuededeberseprincipalmentealaestructuradeplantación,dejandounespacio entreysobrehileradealmenos3metrosparalaextraccióndelproductoconmecanizaciónagrícola(Gil, 2019a),porloquegranpartedelarespuestade NDVI seve influenciadaporelsuelodesnudoentrehilerasysobrehileras.
avocado (Palto,Figura Anexo3):elpaltoesuncultivodehojapersistente,porloque poseehojasdurantetodalatemporada.Estecultivosecaracterizaportenerungran tamañoydosel,almenosenlaformadeconducciónymantencióntradicional(Gil, 2019b).Debidoaesto,el NDVI delaclasepresentaunamagnitudaltadurantetoda latemporada.
barren (Suelodesnudo,Figura Anexo4):elsuelodesnudosecaracterizaportenerun NDVI cercanoa0,2,debidoaquenoposeevegetación.Enelcasodelaclase barren, seobservaunaumentodel NDVI enelmesdejunioyjulio,loquepuededeberseala presenciadevegetaciónespontánea,comomalezasovegetaciónnativaqueemergió luegodelaslluviasdeinvierno.
barrenshadowed (Suelodesnudoconsombra,Figura Anexo5):elsuelodesnudocon sombrasecaracterizaportenerun NDVI cercanoa0.2aligualquelaclase barren.
Ladiferenciaconlaclase barren esqueestaclaseseencuentraenzonasdesombra, comoladerasdecerrosozonasconpendientepronunciada,loquepuedegeneraruna respuestadiferenteenel NDVI,aligualqueenlasbandasespectrales,durantelos mesesdeinvierno.
La ρNIR y ρRED esbajaproductodelasombra,y,alposeervalorescercanosa0,
cualquiervariaciónderespuestaenel NIR o RED generaunagranvariaciónenel NDVI.Esporelloquelarespuestade NDVI paraestaclaseestandinámicadurante losmesesdeinvierno.
forage (Pradera,FiguraAnexo6):lapradera,comolaalfalfa,secaracterizaportenerun NDVI elevadoduranteelaño.Estaclasepuedellegaravalorescercanosa avocado.
Lagrandiferenciaencomparaciónacultivosfrutalesdehojaperenneeseldinamismo desurespuestadurantelatemporada.
Laspraderastienencomofinlaproduccióndeforrajeparaalimentaciónanimal,porlo queserealizancortesdelavegetaciónparasuconsumo.Estogeneraunarespuesta enel NDVI quesevereflejadaenlaFigura Anexo6,dondeseobservanaumentosy disminucionesalolargodelaño,reflejandoencadaunadeellaselcorterealizado.
industrialgrape (Uvaindustrial,Figura Anexo7):lauvaesuncultivodehojacaduca queposeediferentesformasdeconducciónenfunciónalavariedadydestinodela producción(Gil, 2019a).Paraelcasodelauvaindustrial,cuyodestinoeslafabricación devinoypisco,laformadeconducciónparaestecasoesporespalderaoparrón español.
Lasvariedadesdeuvaindustrialsecaracterizanportenerunhábitodefructificación diferentealasvariedadesdeuvademesa,porloquelapodaparaelcasodelas primerasserealizade2a5yemas,mientrasqueparalassegundasserealizade8a 12yemas(Gil, 2019a).Estogeneraquelarespuestade NDVI paralauvaindustrial seamásbajaporelmenordesarrollovegetativodelaplanta.
lemon (Limón,Figura Anexo8):ellimónesuncultivodehojapersistentequesecaracterizaportenerunhábitodecrecimientoarbustivo,porloquesurespuestade NDVI essimilaraladelasclases mandarin y orange.
mandarin (Mandarina,Figura Anexo9):lamandarinaesuncultivodehojapersistente quesecaracterizaportenerunhábitodecrecimientoarbustivo,porloquesurespuesta
de NDVI essimilaraladelasclases lemon y orange
olive (Olivo,Figura Anexo10):elolivoesuncultivodehojapersistenteque,parael casodelaRegióndeCoquimbo,secultivaenaltadensidad,debidoaqueelobjetivode produccióneslaobtencióndeaceitedeoliva(Gil, 2019a).Estogeneraquelarespuesta de NDVI seabajaenrelaciónaotrasespeciesfrutalesdehojapersistente,yaquegran partedelasuperficiesensadaessuelodescubierto.
orange (Naranjo,Figura Anexo11):elnaranjoesuncultivodehojapersistentequese caracterizaportenerunhábitodecrecimientoarbustivo,porloquesurespuestade NDVI essimilaraladelasclases lemon y mandarin
riversidevegetation (Vegetaciónderibera,FiguraAnexo12):lavegetaciónderibera secaracterizaportenerunarespuestasimilaraladelasespeciesfrutalesdehoja persistente,salvoaqueesmuyheterogéneaensucomposición.
shortcyclecrop (Cultivodeciclocorto,Figura Anexo13):loscultivosdeciclocorto, comohortalizasocultivosanuales,secaracterizanportenermúltiplesrespuestasentre lasdiferentesmuestras.Estosedebeaquelarespuestade NDVI dependedela fenologíadelcultivo,porloque,altenermúltiplescultivosdeciclocorto,larespuestade NDVI esmuyheterogénea.Laduracióndeestoscultivosesmenoraladeloscultivos frutalesdehojacaduca,porloqueesadiferenciapodríaserútilparaladiferenciación deestasclases.
tablegrape (Uvademesa,Figura Anexo14):adiferenciadelaclase industrial grape,lauvademesasecaracterizaportenerunhábitodecrecimientodiferente.Por lacantidaddeyemasquesedejanenlapoda,larespuestade NDVI paralauvade mesaesmásaltaporelmayordesarrollodedoselqueposeelaplanta,pudiendollegar acubrirel100%delsueloencuartelesdeparrónespañolgilFruticulturaPotencialProductivo2019.
urban (Urbano,Figura Anexo15):laclaseurbanasecaracterizaportenerun NDVI
entre0a0.2.Elvalorde NDVI durantetodoelperiodoesestable,yaquenohay vegetaciónpresenteenlaclase(apesarqueenzonasurbanasescomúnqueexista vegetaciónentreelasfaltoyhormigón).
walnut (Nogal,Figura Anexo16):elnogalesuncultivodehojacaducaquesecaracterizaportenerunhábitodecrecimientosimilaraldelauvademesa,salvoqueel desarrollodedoselesmayorenverticalconunadistanciasobreyentrehilerassuperior alauvademesa,debidoaque,aligualqueelalmendro,esuncultivocuyaproducción seextraeconmecanizaciónagrícola(Gil, 2019a).
water (Agua,Figura Anexo17):laclaseaguasecaracterizaportenerun NDVI negativoomuycercanoacero(cuandoelcuerpodeaguaessuperficial).Enconsecuencia, esmuydiferentealrestodelasclases.
Porotrolado,lareduccióndelasescenasmultitemporalesaproductosde14bandas deinformaciónserealizóutilizandoelalgoritmo 2,reduciendoefectivamentelacantidad deinformaciónaprocesarenelsiguientepaso.Laceldaconmenorcantidaddefechas libredenubesposee24fechas,mientrasquelaceldaconmayorcantidaddefechas libresdenubesposee73fechas(Figura 14).Enconsecuencia,sepudohomogenizar lacantidaddecanalesdeinformaciónparapoderserincorporadasalosmodelosde
ANN y RF.
EnlaFigura 17 sepresentanejemplosde NDVI crudoyreducidoporclase.Enelcaso delaclase forage (Figura 17a),lareducciónporestemétodoextraelarespuestamedia paralamuestra.Sedisminuyetantoelmínimocomoelmáximodelaserietemporal,lo quepuedeserútilparalaclasificacióndeestaclase,yaquelarespuestade NDVI es muydinámicadurantelatemporada.Parapoderincluirlavariabilidaddeestaclase,el valorde RSS,queparaestecasoes0.28sobre50escenas,permitecaracterizardicha variabilidad.
Porotrolado,losejemplosdelasclases industrialgrape (Figura 17b)y orange (Figura 17c)muestranquelareducciónporestemétodoextraeunarespuestamuysimilar
aladeentrada,tansolosuavizandolarespuestade NDVI.Paraestosejemplos,el valorde RSS esde0.004y0.0098sobre48y42escenas,respectivamente.
(a) Muestrade forage
(b) Muestrade industrialgrape
(c) Muestrade orange
Figura17: Ejemplosde NDVI crudoyreducidoporclase.
Posterioralareduccióndedimensionesapartirdelmétodopor Spline (Algoritmo 2), seprocedióacontinuarconelanálisisexploratoriodelosdatos.Talcomoseindicaen laseccióndemetodología,serealizóunanálisisdePCAytSNEparaevaluarlaseparabilidaddelasclasesenelespaciodeloscomponentesprincipales.Paraestecaso, debidoaquelosdatosdeentradaposeendiferenteslongitudesporlavariabilidadde lasfechaslibresdenubes,serealizóunanálisisconsiderandoelproductodereducción dedimensionespor Spline
Debidoaqueelresultadodelsplineson14bandas,siendolaúltimatansóloelnúmerodeescenasválidas,sedecidiótransformarelvalorde RSS normalizandoporel númerodeescenasyluegoescalandoparapoderserrepresentadoenelespaciode loscomponentesprincipales.Elprocedimientofueelsiguiente:
RSSnorm = RSS nescenas
RSSscaled = RSSnorm min(RSSnorm) max(RSSnorm) min(RSSnorm) (23)
Losvaloresdelasbandas(01)y NDVI nofueronescaladosninormalizados,debido aqueyaposeenvaloresadecuadosparapoderserincorporadosalanálisisdePCAy tSNE.
Ambosanálisisfueronaplicadossobre3gruposdedatos:
• Grupo1: Bandas2,3,4y8deS2.
• Grupo2: ValoresdeNDVIdeS2.
• Grupo3: Bandas2,3,4y8deS2yvaloresdeNDVIdeS2.
ParaelcasodePCA,elnúmerodecomponentesaextraerfuede n 1 componentes,siendo n lacantidaddebandasdecadagrupo.EnlaFigura 18 sepresentanlos resultadoslavarianzaacumuladaexplicadaporcadacomponenteparacadagrupo.
Evidentemente,dadoaquelosgruposposeenunacantidaddiferentedebandas,la cantidaddecomponentespresentadosenlafiguraesdisímilentrelosgrupos.
Figura18: Varianzaexplicadaporcadacomponenteprincipal,todoslosgrupos.
Loquesepuedeinterpretardelafigura,enprimerlugar,esqueelgrupode NDVI logra representarlamayorcantidaddevariabilidadentrelostresprimeroscomponentes,a diferenciadelosotrosdosgrupos.Yacon3componentes,dichogruporepresentamás del90%delavariabilidaddelosdatos.Porotrolado,elgrupodebandasespectrales lograrepresentarmásdel90%delavariabilidadcon6componentes,mientrasqueel grupodebandasespectrales+ NDVI lograrepresentarmásdel90%delavariabilidad con4componentes.
Estoindicaquelagranvariabilidadpresenteenelgrupode NDVI nosedebesóloa labajacantidaddedatosdeentrada,sinoaloquerepresentaesteíndiceespectral. Alincorporarlojuntoconelgrupodebandasespectrales,selograreducirlacantidad decomponentesnecesariospararepresentarmásdel90%delavariabilidaddelos datos.
Estoindicaquelatransformaciónde ρ en NDVI permitereducirlacantidaddeinformaciónnecesariapararepresentarlavariabilidaddelosdatos,loquepuedeserútil
paralaclasificacióndelasclasespresenteseneláreadeestudio.
Cabemencionarquelavariabilidadrepresentadaenesteconjuntodedatosabarcasólo lasmuestrascolectadaseneláreadeestudio,porloquenosepuedeasegurarquela variabilidadrepresentadaenesteconjuntodedatosseasuficientepararepresentarla variabilidaddelosdatosdeentrada.
ParaelanálisisdetSNE,paralostresgruposseutilizólamismaconfiguración:2 componentes,distanciamedidaporlamétricadeManhattan,1000iteracionesynivel deperplejidadde50.
ElresultadodelosanálisisdePCAytSNEparaelgrupo NDVI sepresentaenla
Figura 19.EnelcasodePCA,sepresentanlosdosprimeroscomponentes,mientras queparatSNEsepresentanlosdoscomponentesobtenidosporelanálisis.
Figura19: Representaciónvisualdelosdosprimeroscomponentesdelanálisis dePCAytSNEparaelgrupo NDVI
ElresultadodelPCAparaelgrupode NDVI muestraquelaclasequepresentamenor variabilidadeslaclase urban,locualsepuedecorroborarconelcomportamientoejemplomostradoenlaFigura Anexo15,siendounarespuestamuyestabledurantetodo elaño.Porotrolado,elcomponente1diferencialoscultivos(valoresnegativos)delas muestrasde water (valorespositivos),locualesesperableporlanaturalezadelares
puestade NDVI paraestasclases,dondeelvalorde NDVI paraloscultivossealeja delvalorde NDVI decuerposdeagua,comotranquesoembalses.Latransiciónentre ambosgrandesgruposestádadaporlasclases water, barren y barrenshadowed,las cualessecaracterizaportenerun NDVI entre0a0.2,comosedescribióenpárrafos anteriores.
EncuantoalsegundocomponenteprincipaldelanálisisdePCA,seseparanloscultivosfrutalescaducos(valorespositivos)delosfrutalesdehojapersistente(valores alrededorde0ynegativos),locualmuestraotraimportantefuentedevariaciónentre lasmuestras.Sinembargo,lamayorvariaciónfueobservadaenlaclase shortcycle crop,lacualsecaracterizaportenerunarespuestade NDVI muydinámicadurante latemporada,ynosóloresponderaunúnicocultivo,sinoqueamúltiplescultivosde diferentescaracterísticas.
Elhechodequeseagrupenpormacrogrupos(comofrutalesdehojacaducayfrutalesdehojapersistente)indicaquelavariabilidadpresenteenelgrupode NDVI es suficientepararepresentarlavariabilidaddeestosmacrogrupos,peroesinsuficiente parapoderdiscriminarporespecie.
EnelcasodelanálisisdetSNE,elanálisisagrupódeformamuchomáseficientelas diferentesclases,separandodemejormaneralosmacrogruposdecultivos,loscultivosdeciclocortoyaquellasclasesquenoposeencultivos(barren, barrenshadowed, water y urban).Sinembargo,noselogradiscriminarporespecie,locualesesperable porlavariabilidadpresenteenelgrupode NDVI.Paraamboscasos,laspraderas semezclanconloscultivosfrutalesdehojapersistente,indicandoqueentreelloshay semejanzaenlarespuestade NDVI
ElresultadodelosanálisisdePCAytSNEparaelgrupodebandasespectralesse presentaenlaFigura 20.EnelcasodePCA,sepresentanlosdosprimeroscomponentes,mientrasqueparatSNEsepresentanlosdoscomponentesobtenidosporel análisis.
Figura20: Representaciónvisualdelosdosprimeroscomponentesdelanálisis dePCAytSNEparaelgrupodebandasespectrales.
ElresultadodelPCAparaelgrupodebandasespectralesmuestraunarespuestacompletamentediferentealoexpuestoalgrupode NDVI,teniendolaclase water menos pesosobrelavariabilidaddelosdatos,respuestaqueesesperabledebidoaqueelagua líquidapresentaunmenornivelde ρ enelrangodelongitudesdeondadeteledetección.
Luego,seformaunatransversalentrelasclases barren y barrenshadowed.
Enestecaso,loscultivosseencuentranmezcladosentresí,sinpoderdiferenciarentre frutalesdehojacaducayfrutalesdehojapersistentealniveldelgrupo NDVI.Estose debeaquelarespuestade ρ paraestoscultivosesmuysimilar,porloquelavariabilidad presenteenelgrupodebandasespectralesnoessuficienteparapoderdiscriminarpor macrogrupos.
Porotrolado,dichavariabilidadessuficienteparapodersepararlasclasesevaluadas conelanálisisdetSNEdemejormaneraqueelgrupode NDVI.Dehecho,logra aislarciertosgruposdeotros.Peseaello,aúnexistebastanteconfusiónentrelaclase olive y rivervegetation,locualesesperableporlasimilitudenlarespuestade ρ entreambasclasesyunacoloraciónsimilarenelespectrodelvisible.
Laclase forage seseparademejormaneraqueenelgrupode NDVI,peroaúnexiste
confusiónentreestaclaseyalgunasmuestrasdefrutalesdehojaspersistente.
ElresultadodelosanálisisdePCAytSNEparaelgrupodebandasespectrales+ NDVI sepresentaenlaFigura 21.EnelcasodePCA,sepresentanlosdosprimeros componentes,mientrasqueparatSNEsepresentanlosdoscomponentesobtenidos porelanálisis.
Figura21: Representaciónvisualdelosdosprimeroscomponentesdelanálisis dePCAytSNEparaelgrupodebandasespectrales+ NDVI.
Sibien,lacantidaddeinformaciónquebrindael NDVI algrupodebandasespectrales+ NDVI esequivalenteal20%deltotaldelainformación,elanálisisdePCA resultanteesmuysimilaralgrupo1,elde NDVI.Estodemuestralaimportanciaque tieneel NDVI enlavariabilidaddelosdatos,yaque,alincorporaresteíndicealgrupo debandasespectrales,selograreducirlacantidaddecomponentesnecesariospara representarmásdel90%delavariabilidaddelosdatos.
ParaelcasodelanálisisdetSNE,selograsepararlevementemejorlaclase forage delasclasesdefrutalesdehojapersistente.Sinembargo,laseparaciónentretodas lasclasesnoesposibleparaningúngrupotantoenPCAcomoentSNE.
Parapoderanalizardeformacuantitativalaseparaciónentreclases,secalculóladistanciadeManhattanmínimaentrecadaunadelasmuestrasylamuestramáscercana
paracadaunadelasclases.Productodeltamañodelasfiguras,estassonpresentadas enlaseccióndeAnexos,Figuras Anexo18, Anexo19 y Anexo20
ParaelGrupo1(NDVI),lasclases forage, lemon, mandarin, olive y orange secaracterizanporposeerunabajadistanciaentreellas,loqueindicaquepuedenserconfundidasfácilmente.Porotrolado,lasclases industrialgrape, tablegrape y walnut se caracterizanporposeerunadistanciabajaentreellastambién,perounmayorgrado dedistanciaencomparaciónalasantesmencionadas.
Lasclases shortcyclecrop, water, almond y urban poseenungradodedistancia mayorencomparaciónamuestrasdelamismaclaseversusdeclasedistinta,porlo queseesperaríaqueunclasificadorpuedadiscriminarlasdemejormanera,enrelación alasantesmencionadas.
ParaelGrupo2(bandasespectrales),ladistanciaentrelasclasesproblemáticasdel Grupo1mejoran,esdecir,aumentalevementeladistanciaentreotrasclasesdisminuyendolaconfusiónentreellas.Sinembargo,ladistanciaentrelasclases forage, lemon, mandarin, olive y orange siguesiendobaja,loqueindicaqueaúnexisteconfusiónentreellas.
SibienenelGrupo3(bandasespectrales+ NDVI)hayclasesqueigualposeenuna distanciarelativamentebaja,eselproductoquelograseparardemayormaneralas diversasclasesanalizadas.Estograciasatodalavariabilidadentregadaporlasbandas yel NDVI
Finalmente,luegoderealizarelanálisis,serealizóelprocesode boostraping parasepararlasmuestrasdeentrenamiento(100muestrasporclase),validación(30muestras porclase)yprueba(30muestrasporclase).
4.4 EVALUACIÓNCLASIFICADORES Sibien,elclasificador DTW fueevaluadocon69fechaspormuestray1600muestrasde entrenamiento,elanálisisde benchmarking serealizóconunnúmeromenordefechas ymuestrasvariable.Paraello,seutilizólacombinacióndelossiguientesconjuntos: n = {20, 30, 40, 50, 60} y samples = {200, 400, 800, 1200},donde n eselnúmerodefechasa evaluary samples,elnúmerodemuestrasdeentrenamiento.
Serealizaron30corridasparacadacombinaciónde n y samples (Figura 22a),obteniendoeltiempodecómputopromedioparacadacombinación.Eltiempodecómputode dDTW (x,y) paracadacombinaciónde n y samples sepresentaenlaFigura 22b
Losresultadosindicanqueelfactorquemásafectaeldesempeñodelclasificadoresel númerodemuestrasdeentrenamientoparacompararcadamuestradeprueba.Enel casodelacantidaddefechaspormuestra,eltiempodecómputonovaríademanera significativa,loqueindicaquelareduccióndelacantidaddefechasnodeberíagenerar unadiferenciasignificativaeneltiempodecómputo.Porotrolado,lareduccióndela cantidaddemuestrasdeentrenamientodisminuyeeltiempodecómputodemanera significativa,siendounfactoraconsiderarparapoderproducirunmodelooperacional (Figura 22b).
Amododerecordatorio,losgruposdeanálisisdescritosenestasecciónson:
• Grupo1: Bandas2,3,4y8deS2.
• Grupo2: ValoresdeNDVIdeS2.
• Grupo3: Bandas2,3,4y8deS2yvaloresdeNDVIdeS2.
Seutilizarálaetiqueta(1,2y3)paradescribirlosresultadosdecadagrupo.
(a) Gráficodecajadelostiemposdecómputode dDTW (x,y) paralas30muestrasporgrupo de n y sample
(b)Tiempodecómputoparaelclasificador DTW enfuncióndelacantidaddefechaspormuestra ylacantidaddemuestrasdeentrenamiento.
Figura22: Análisisde benchmarking paraelclasificador DTW.
Serealizaron5experimentosporgrupo,15experimentosentotal.Losresultadosde κ yOAparacadagruposepresentanenlaFigura 23.Losgrupos2y3sonaquellos quepresentanelmejordesempeño,siendoelgrupo2ligeramentesuperior.Paralos experimentosrealizadosparaelgrupo1,entodosloscasoseldesempeñofueinferior alosotrosdosgrupos.LamatrizdeconfusiónparaelexperimentodemejordesempeñosepresentaenlaFigura 24.Paradichoexperimento,enlaFigura 25 sepresenta ladistribucióndelasdistanciasde dDTW (x,y) paracadamuestraylareferenciamás cercana.
(a) Valoresde κ (b) ValoresdeOA
Figura23: Gráficosdeescalónderesultadosde κ yOAparaelclasificador DTW paralosgruposanalizados.
Figura24: Matrizdeconfusiónparaelexperimentodemejordesempeñoparael clasificador DTW.
Figura25: Gráficodecajadelasdistanciasde dDTW (x,y) paracadamuestrayla referenciamáscercana.
ANN
Serealizaron26experimentosparacadagrupo,78experimentosentotal.Losresultadosde κ yOAparacadagruposepresentanenlaFigura 26.Esteclasificadorobtuvo unresultadosimilaral DTW,siendolosgrupos2y3aquellosquepresentanelmejor desempeño,siendoelgrupo2significativamentemejor.Peroadiferenciadel DTW,el grupo1obtuvoundesempeñoqueenlamayoríadeloscasosseasemejóaaquellos demenordesempeñoparaelgrupo2y3.
Entérminosdeconsistencia,elgrupo3eselmásestableentrelasdiferentesconfiguraciones.Sinembargo,esinsuficienteparasuperareldesempeñodelgrupo2.Elgrupo 1,porotrolado,eselquepresentaeldesempeñomásvariable,obteniendovaloresde κ desde0.8a0.9.
Elexperimentoquemejordesempeñoobtuvoestáconformadopordosbloquesde redesconvolucionalesde64y32filtros,respectivamente,seguidopordosbloques
(a) Valoresde κ (b) ValoresdeOA
Figura26: Gráficosdeescalónderesultadosde κ yOAparaelclasificador ANN paralosgruposanalizados.
densosde32y16neuronas,respectivamente.Lafuncióndeactivaciónutilizadafue relu paratodaslascapas,exceptuandolaúltima,queutilizó softmax.Lafunciónde pérdidautilizadafue categoricalcrossentropy yeloptimizadorutilizadofue adam.Al analiarlafuncióndepérdida,seapreciaqueelmodelonopresenta overfitting,yaque lacurvadelapérdidasobrelosdatosdevalidaciónconvergeconlacurvadelapérdida sobrelosdatosdeentrenamiento(Figura Anexo21).
Estemodeloposeeestructurasdecontrolde overfitting,como dropout y batchnormalization Tambiénseincluyeroncapasde maxpooling y flatten paralareduccióndeladimensionalidaddelosdatosentrebloquesconvolucionalesyelpasoabloquesdensos (Figura 27).
LaentradadelmodelocorrespondealarepresentacióndelvalormensualdelasbandasespectralesdeS2(B02,B03,B04yB08)yelvalordel RSSscaled.Entotalson52 entradasen1dimensión.Estainformaciónesingresadaalprimerbloqueconvolucional quecumpleunrolmuyimportanteparaeléxitologradoporelclasificador ANN pormediodeestaestructurade DeepLearning.Lamatrizdeconfusiónparaelexperimento
demejordesempeñosepresentaenlaFigura 28
Probabilidad por clase
Figura27: Estructuradelmodelode(tipo DeepLearning)demejordesempeño paraelclasificador ANN
Figura28: Matrizdeconfusiónparaelexperimentodemejordesempeñoparael clasificador ANN.
Bloque convolucional
Bloque convolucional
Bloques densos
Salida plana
Serealizaron36experimentosparacadagrupo,108experimentosentotal.Losresultadosde κ yOAparacadagruposepresentanenlaFigura 29.Adiferenciadelos clasificadores DTW y ANN,elgrupo3fueelqueobtuvoelmejordesempeñoparaesteclasificador.Talcomoparaelclasificador DTW,elgrupo1fueelquepresentóel desempeñomásbajo,sinpoderllegaraalcanzaralosotrosgrupos.
(a) Valoresde κ (b) ValoresdeOA
Figura29: Gráficosdeescalónderesultadosde κ yOAparaelclasificador RF paralosgruposanalizados.
Delosclasificadoresanalizados,esteesaquelquelogróelpeordesempeño.Dehecho, paraelgrupo1elmejordesempeñofuede κ de0.775.Yelgrupodemejordesempeño, elgrupo3,alcanzó κ de0.876.
Elexperimentoquelogróeldesempeñoantesmencionadoesaquelqueutilizó300 árbolesdedecisiónconunaprofundidadde20nivelesyunamuestramínimade4 observacionesparadividirunnodo.
Lamatrizdeconfusiónparaelexperimentodemejordesempeñosepresentaenla Figura 30.Laclasequepresentómayorconfusiónfue lemon,lacualfueconfundida con almond
Matrizdeconfusiónparaelexperimentodemejordesempeñoparael clasificador RF
Figura30:
Comparaciónentremodelos Losresultadosde κ yOAparalosclasificadores DTW, ANN y RF sepresentanen
laTabla 6.Elclasificador ANN fueelqueobtuvoelmejordesempeño,seguidoporel clasificador DTW.Elclasificador RF fueelqueobtuvoelpeordesempeño.
Tabla6: Resultadosde κ yOAparalosclasificadores DTW, ANN y RF
LosresultadosdePAyUAparalosclasificadores DTW, ANN y RF sepresentanenla
Tabla 7.
Tabla7: Exactituddeproductor(PA)yexactituddeusuario(UA)paralosclasificadores DTW, ANN y RF.
Tabla7: (continuacióndepáginaprevia)
Pruebadehipótesis Lapruebadehipótesisserealizóparaevaluarsieldesempeñodelosclasificadores
DTW, ANN y RF esestadísticamentediferente.LosresultadosdelapruebadeQde Cochran,elvalorde p y δ(X) sepresentanenlaTabla 8.Losresultadosindicanque eldesempeñodelosclasificadores DTW, ANN y RF esestadísticamentediferente,lo cualrefuerzaloexpresadoenelanálisisdelosresultadosdelosclasificadores,conun κ de0,931,0,960y0,876,respectivamente.
Tabla8: ResultadosdelapruebadeQdeCochran,valorde p y δ(X)
ModelosevaluadosQValorde pδ(X) Niveldesignificancia*
* Interpretaciónporreglageneral,según Ross (2017)
Encuantoalaevaluacióndehipótesisdepares,seapreciaqueeldesempeñodelos
clasificadores DTW y ANN esestadísticamentediferente,conun δ(X) de0.029,lo queindicaqueeldesempeñodelclasificador ANN essuperioraldelclasificador DTW Elvalorde p esde0.037,loqueindicaqueeldesempeñodelosclasificadores DTW y ANN esestadísticamentediferente,peroconunniveldesignificanciadeentreelrango0.010.05,loqueindicaqueeldesempeñodelclasificador ANN essuperioraldel clasificador DTW conunniveldeevidenciamoderada.Porloquequeambosclasificadorespresentanundesempeñosimilar,peroconunaleveventajaparaelclasificador
ANN.
Porotrolado,eldesempeñodelosclasificadores DTW y RF esestadísticamentediferente,conun δ(X) de0.055,loqueindicaqueeldesempeñodelclasificador DTW es superioraldelclasificador RF.Elvalorde p esde0.0014,loqueindicaqueeldesempeñodelosclasificadores DTW y RF esestadísticamentediferente,conunnivelde significanciadeentreelrango0.0010.01,siendoclasificador DTW essuperioraldel clasificador RF conunniveldeevidenciafuerte.
Estoimplicaqueelclasificador DTW,clasificadorporreconocimientodepatrones,puedediscriminardemejormaneralasclasespresenteseneláreadeestudioencomparaciónalclasificadorde MachineLearning denominado RandomForests,clasificadores poraprendizajesupervisado.Sinembargo,elclasificador ANN,tambiénde Machine Learning,essuperioralclasificador DTW,loqueindicaqueelusode DeepLearning esunaopciónviableparalaclasificacióndecultivoseneláreadeestudio.
4.5 APLICACIÓNDELMEJORCLASIFICADOR Debidoaqueelmodelodemejordesempeñofueelclasificador ANN,seaplicóeste modelosobreeláreadeestudio.Losresultadosdelaclasificaciónsepresentanenla Figura 31,aplicadosobrelas56celdasde1,280x1,280pixelesquecomponenelárea deestudio.
Parapoderaplicarelmodelosobreeláreadeestudio,serealizóunpreprocesamiento
Aplicacióndeclasificador ANN sobreeláreadeestudio.
Figura31:
delosdatosdeentrada,queconsistióenlanormalizaciónde RSS paraobtener RSSscaled Seutilizaronlosmismosvaloresdenormalizaciónqueseutilizaronparaelentrenamientodelmodelo,cuyoslímitessuperioreseinferioressepresentanenlaTabla 9.
Tabla9: Valoresde RSSmax yde RSSmin utilizadosparaobtener RSSscaled.
Bandaespectral
6
6
6 B08 0.0053743.0703x106
Laaplicaciónserealizóconun batchsize de4096,loqueimplicaqueencadaiteración seclasificaron4096pixeles,elcualesdiferenteal batchsize utilizadoparaelentrenamientodelmodelo,quefuede8,paraunmejorajustedelared.Enelcasodela predicción,el batchsize esunfactorqueinfluyeeneltiempodecómputo,yaquea mayor batchsize,menortiempodecómputo,peroacostadeunamayordemandade memoriaRAM.
Eltiempodecómputoporceldafuede2segundos,realizando400iteraciones(1,280 x1,280pixeles,4096pixelesporiteración),cadaiteracióntardó5ms.Eltiempototal enobtenerlosresultadosdesdelaredneuronal,prepararlosarchivosrásterdesalida (probabilidadovotoporclase,probabilidadmásaltaporpixelyclasefinal)yguardarlos eneldiscofuede5minutos37segundos.
Losarchivosrasterdesalida,poseenlassiguientespropiedades:
• Probabilidadporclase: Archivorasterqueposee16bandas,cadabandacorrespondealaprobabilidaddepertenenciaaunaclase.Haciendolaequivalencia conlopresentadoenlarevisióndeliteratura(Sección 2.4.2.1),correspondea zk, donde k eslaclasey z eslaprobabilidaddepertenenciaalaclase.
• Probabilidadmásaltaporpixel: Archivorasterqueposee1banda,dondeel valordecadapixelcorrespondealvotomásaltoentrelasclasesevaluadas,de rango01.Seríaequivalentea zmax,donde zmax = max(z1,...,zk).
• Clasefinal: Archivorasterqueposee1banda,dondeelvalordecadapixelcorrespondealaclasefinalenformatodenúmeroentero,donde1eslaprimera clasey16eslaúltimaclase.Correspondea o,donde o = argmax(z1,...,zk).
Apartirdelresultadoobtenido,sedeterminólaclasemásfrecuenteparacadapolígono delacapacedidamencionadaenlaseccióndemetodología(Figura 32).Además, sedeterminólaprobabilidadpromedioparaseñalarcadaunadelasclases(Figura 33).
LosresultadosdelaextraccióndelaclasemodalporpolígonosepresentanenlaTabla 10
Tabla10: Estadísticasdeclasedelacoberturavectorialconlaextraccióndela clasemodalporpolígono.
Tabla10: (continuacióndepáginaprevia) Cartografíaconlaclasemásfrecuenteporpolígono.
Figura32:
Figura33: Cartografíaconlaprobabilidadpromediodelaclaseasignadaporpolígono.
5 DISCUSIÓN 5.1 CLASIFICADORES 5.1.1 DTW
Alparecer,utilizarsóloelvalorde NDVI noessuficienteparapoderdiscriminarde maneraadecuadalasclasespresenteseneláreadeestudio.Porotrolado,laincorporacióndelasbandasespectralesdeS2algrupode NDVI mejoraeldesempeño delclasificador,loqueindicaquelavariabilidadpresenteenlasbandasespectralesde S2essuficienteparapoderdiscriminardemaneraadecuadalasclasespresentesenel áreadeestudio.Sinembargo,elhechodeincluirel NDVI algrupodebandasespectralesdeS2leaportaalgodeconfusiónalclasificador,loquesereflejaeneldesempeño delgrupo3.Estoindicaquecultivosconfenologíasimilar,loquesevereflejadoenla respuestade NDVI,puedenserconfundidosporelclasificador DTW.
Elexperimentoquemejordesempeñoobtuvofueaquelqueconservólaetiquetacon menor d’ DTW (x,y) promedioentrelas5primerascomparacionesconmenor dDTW (x,y)
Siendoestaconfiguraciónsuperioralresto,implicaqueelsólousodelaetiquetacon menor dDTW (x,y) noessuficienteparaobtenerelmejordesempeñodelclasificador
DTW.Lacomparaciónconungrupode5etiquetasdemenor dDTW (x,y) esunaconfiguraciónquepermitereducirlaconfusiónentreclases.
Alanalizarlamatrizdeconfusión,seapreciaquelasclasesqueobtuvieronmayor confusióncon urban, rivervegetation y walnut (Figura 24).Laclase urban fueconfundidacon barren,teniendounimpactobajoconelfindeclasificarcultivosagrícolas, yaquesonclasesquenorepresentanespeciescultivadas.Laclase rivervegetation fueconfundidacon olive,loqueindicaqueambospresentancaracterísticassimilares de ρ enlasbandasevaluadas.Finalmente,laclase walnut fueconfundidacon almond, industrialgrape y olive,dondelasdosprimerasclasesesesperablequeocurraun fenómenodeconfusión,yaquesontresclasesquerepresentancultivosfrutalesde
hojacaduca,aunquelaconfusióncon olive esinesperada.
Enbasealadistancia dDTW (x,y) paracadamuestraylareferenciamáscercana,se apreciaquelaclase lemon eslaquepresentalamenordistanciayvariabilidad,mientras quelasclases forage y water sonlasquepresentanmayorvariabilidad.Estoindica quelarespuestadeestasdosúltimasclasesesmuydinámicadurantelatemporada,lo quepuedeserunfactorquegeneremayor dDTW (x,y) encomparaciónalrestodelas clases.Comosemencionóenseccionesanteriores,loscortesenpraderasprovocan quelarespuestaseamuydinámicayestosevereflejadoenunaumentodeladistanciaentrelasmuestrasdelamismaclase,apesarqueseanmuyparecidas.Misma situaciónocurreconloscuerposdeagua,quedurantelatemporadavanacumulandoydistribuyendoagua,loquesevereflejadoenlarespuestade ρ enlasbandas evaluadas.
5.1.2 ANN Estemodeloobtuvounmejordesempeñoencomparaciónalclasificador DTW,locual seapreciaenlamatrizdeconfusión(Figura 28).Laclasequemayorconfusiónpresentó esla mandarin,lacualseconfundiócon olive, orange y riversidevegetation.Esto esesperabledebidoaquelas2primerasclasessonfrutalesdehojaperenne,mientras quelaúltimaesunaclasequepresentacaracterísticassimilaresalasclasesantes mencionadasalservegetaciónsiempreverdecercanaacursosdeagua.
Laclase avocado tambiénseconfundiócon mandarin,siendotambiéndoscultivosde hojaperenne.Seobservaquelaconfusiónestáconcentradaenelgrupodefrutalesde hojaperenne,queporsuscaracterísticasderespuestade ρ enlasbandasespectrales deS2,sondifícilesdediscriminar,yaquesurespuestatiendeaserestabledurantela temporada.
Apesardeello,eldesempeñodeestemodeloessuperioraldelclasificador DTW,lo queindicaqueelusode DeepLearning esunaopciónviableparalaclasificaciónde
cultivoseneláreadeestudio,siendounmodelodeclasificaciónapartirdepatrones identificadospor MachineLearning,adiferenciadelreconocimientodepatronespor mediodeladistanciaentreseriesdetiempoquerealizaelclasificador DTW.
Adiferenciadelclasificador DTW,elclasificador ANN generaunmodelocompletamenteoperacionalcontiemposdecómputosbajos,permitiendoextenderlosresultadosde esteestudiosobreunagranáreadeanálisisenuntiemporazonable.
5.1.3 RF Sibienlaclase almond obtuvounagranprecisióndeproductor,laprecisióndeusuariofuede0.38,loqueindicaqueestaclasefueconfundidaconotrasclases,perono necesariamentefuemaletiquetadaenelprocesodemuestreo.Estaasimetríaentrela exactituddeproductoryusuarioesunindicadordequehayunproblemaenlaestructuradelclasificadorentérminosde overfitting,yaqueelmodeloseajustademanera muyprecisaalasclasesdeentrenamientoprivilegiandolaprecisióndeproductoren desmedrodelaprecisióndeusuario,y,específicamente,sesgadahaciaunaclaseen particular.
5.2 DTW ENCONTEXTOOPERACIONAL Laevaluacióndegenerarunmodelooperacionalutilizandoelclasificador DTW apartir delanálisisde benchmarking demuestraquelostiemposdecómputossonmuyelevadosalcompararcadaseñal(ofirmaespectral)deunaceldacontodaslasseñalesde entrenamiento.Estosedebeaqueelcálculodeladistanciaentreseriesdetiempoa partirde DTW implicaelcálculodeunamatrizde n x m celdascomparandoladistancia entrelamuestraobjetivode n fechasconlamuestraobservadacon m fechas.Elanálisisbrindainformaciónrelevantesobrelaeleccióndelaconfiguraciónadecuadapara ejecutarestealgoritmosobreseriesdetiempodegranescala,loqueesfundamental parapoderobtenerunmodelooperacional.
Elanálisisconsideró30corridasporcadacombinación.Sibien,haycuestionamientos sobrelareglageneraldeque30muestraseselmínimonecesariopararepresentar elpromediodeunapoblaciónsegúnelteoremadellímitecentral(Changetal., 2006; Islaqm, 2018),ladistribucióndelostiemposdecómputorespondenaunadistribución normal,porloquelacantidaddemuestrasessuficienteparaobtenerunpromediorepresentativo(Figura 22a).Seapreciaqueladispersióndelostiemposdecómputoes muybaja,porloque30muestrasessuficienteparaobtenerunpromediorepresentativo,talcomoseplanteóanteriormente.
Considerandoqueseestáevaluandocadamuestradelsetdedatosdeprueba(480 muestras)versus1600muestrasdeentrenamiento(1215observacionesúnicas),el procesodecómputodedistanciaparaunamuestraversustodaslasdeentrenamiento tardacercade2.8segundosparaelGrupo1(NDVI),sinconsiderarelanálisisde seleccióndelaetiquetafinal.
Pensandoenlaconfiguracióndelactualanálisis,conunaceldade1,280x1,280pixeles, untotalde91,750,400pixelesporcelda,eltiempodecómputoseríadecercade52 días,tiempoquehaceinviablecualquieraplicaciónoperacionaldeesteclasificador. Variosañosparaobtenerlosresultadosdeunatemporadaconsiderandotodalagrilla esuntiempoinaceptableparacualquieraplicaciónoperacional.
Debidoaqueseestáexplorandolaaplicacióndeesteclasificadorenelcontextode laclasificacióndecultivos,lacantidaddemuestrasutilizadasparalaevaluacióndel clasificadorpodríaserreducida,yaquenoesnecesarioevaluartodaslasmuestrasde entrenamientoenuncontextooperacional.
Paraello,sepodríacalcularla dDTW (x,y) paraelconjuntodemuestrasdeentrenamientoyeliminaraquellasmuestrasqueseanmuysimilaresdentrodeunaclase.Deesta manera,sereduciríalacantidaddemuestrasdeentrenamientoy,enconsecuencia,el tiempodecómputodelaclasificacióndeunamuestra.
Unareduccióna200muestrasdeentrenamientoparaelclasificador DTW reduciríade
52díasa9díaseltiemponecesarioparaclasificarunaceldade1,280x1,280pixeles. Porotrolado,lareduccióndelacantidaddefechaspormuestranogeneraríauna diferenciasignificativaeneltiempodecómputo,porloquenoseríanecesarioreducirla cantidaddefechaspormuestraparapoderreducireltiempodecómputo.Sinembargo, 9díasporceldasiguesiendountiempoinaceptableparaunaaplicaciónoperacional, porloquesedescartaelusodelclasificador DTW paraunaaplicaciónoperacionalo paralaclasificacióndeunazonadegranescala.
Encontraste,laaplicacióndelosmodelosde ANN y RF norequierendeunanálisisde seleccióndelaetiquetafinal,yaqueelmodeloyafueentrenadocondatosetiquetados. Porlotanto,eltiempodecómputoparalaclasificacióndeunamuestraesmuchomenor queparaelclasificador DTW,loquehacequeestosmodelosseanmáseficientes entérminosdetiempodecómputoparapoderlograrobtenerunmodelooperacional. Ademásdeposeerunmodeloentrenado,lalongituddeladimensióntemporalesmucho menoralposeerdatosyareducidos.
Entérminodelenfoquequecadaclasificadorutilizaparalaclasificación, ANN y RF utilizanunenfoquedeaprendizajesupervisado,endondeseentrenaunmodeloque luegopuedeserutilizadoparalaprediccióndeclases.Porotrolado,elclasificador DTW utilizaunenfoquedemétrica,endondesecalculaladistanciaentreseriesde tiempoparaluegoclasificarlasenfunciónaladistanciacalculada.
Ladiferenciaentreestosdosenfoquesesfundamentalparacrearunmodeloquepueda serejecutadooperacionalmente,yaque,paraelcasode ANN y RF,elmodelodebeser entrenadocondatosetiquetados,procesoquepuedetardaruntiempoconsiderable(y esendondeelusodelaGPUesfundamental).Porotrolado,elclasificador DTW no requieredeunentrenamientoprevio,porloquepuedeserejecutadooperacionalmente sinnecesidaddeentrenarunmodelo.
Apesardelasdificultadescomputacionales,existenexperienciasregistradaseneluso deestealgoritmoenlaclasificacióndeimágenesdesatélite. Belgiuetal. (2020)apli
carontresvariacionesdeesteutilizando50muestrasdeentrenamientoparacadauna delas7clasesevaluadassobreseriesdetiempode NDVI.Encomparación,escerca del20%delacantidaddemuestrasutilizadasenelpresenteanálisis.Paraacelerarlos tiemposdecómputo,sóloseconsideraronaquellasfechasrelevantesparadiferenciar lasclasesevaluadasenbaseasufenología. ChengyWang (2019)utilizaronalrededorde50muestrasparaentrenamientoy50muestrasparavalidaciónpara8clases diferentesparaevaluareldesempeñode DTW
Paramejorarlaeficienciadeaplicaciónde DTW sobreseriesdetiemposdeimágenes desatélite, Petitjeanetal. (2012)aplicaronunalgoritmodeclusterización(Kmeans) previoalaaplicacióndelclasificadorparareducirlasmuestrasaevaluaragregando áreasdegrantamañoytansoloevaluandolarespuestadelcentroidedichasáreas. Conesteenfoquesereducesignificativamenteelnúmerodemuestrasaevaluar,y,en consecuencia,eltiempodecómputo.
Zhangetal.(2022)utilizaronestealgoritmoincorporandolímitesinferioresdebúsqueda parareducireltiempodecómputo,como LB_Kim (Kimetal., 2001)y LB_Keogh (Keogh yRatanamahatana, 2005),yunsetdemuestrasreducidoparapodercalcularladistanciaentreseriesdetiempo,lascualesfueronasignadasalaclasefinalmediante clusterizaciónpor Kmeans (de3a7grupos).Seevaluóelalgoritmosobreimágenes multitemporalesdelaserieLandsat,utilizandoceldasmultitemporalesde600x600 pixeles.Elusodeestoslímitesinferioresdebúsquedaredujoeltiempodecómputo considerablementepudiendodesarrollarunmodelooperacional.
Paraacelerarelprocesodeclasificación, Singhetal. (2021)utilizaronlaextracción depatronesdelasrespuestas(Mausetal., 2019)yaplicaronelclasificadorenGPU utilizandolalibrería dtwDsat (Mausetal., 2016)enR,lacualestáadaptadaparala clasificacióndeimágenesdesatéliteconestealgoritmo. Pengetal. (2023)obtuvieron unbuendesempeñoenlaidentificacióndelcultivodemaízalanalizarmúltiplesíndices espectralescomoinsumosparalaclasificación.
5.3 MODELODE DEEPLEARNING Losmodelosde DeepLearning soncapacesdeaprenderpatronesenlosdatosde entrada,loqueloshacemuyeficientesenlaclasificacióndeimágenesdesatélite.La estructurade DeepLearning utilizadaenelpresenteanálisisescapazdeextraercaracterísticasdelosdatosdeentradamedianteelusodefiltros.Estosfiltrosseinicializan demaneraaleatoriaysevanajustandoduranteelentrenamientodelmodelo(Chollet, 2021).Estopermiteiridentificandopatronesenlosdatosdeentrada,patronesquevan pasandodeunbloqueaotro,parafinalizarenbloquesdensosquepermitenlaclasificacióndelasclasespresenteseneláreadeestudio.Esporestascaracterísticas queestosfiltrossonmuyrelevantesenlaclasificacióndeimágenes(Sharmaetal., 2018).
Laaparicióndemodelosde DeepLearning revolucionóelanálisisdeimágenesyvideos (Baietal.,2021).DesarrolloscomoYOLO(YouOnlyLookOnce)handemostradoeluso decapasconvolucionaleseselestándarmínimoalahoradedesarrollarunalgoritmo devisióncomputacional(Chaietal., 2021; Jiangetal., 2022).Estosmodelosutilizan capasconvolucionalesde2dimensiones,dondelaentradaesunaimagenylasalida esunamatrizdecaracterísticasquerepresentalaimagendeentrada.Estascapasson capacesdeidentificarpatronesenlasimágenes,comobordes,texturasyformas,lo quepermitelaidentificacióndeobjetosenlasimágenes,porloqueenmuchoscasos, partedelprocesoesconvertirespaciosdecolortridimensionalesaespaciosdecolor bidimensionalesparapoderaplicarestascapas,comolatransformacióndeunaimagen digitalRGBaescaladegrises(Chollet, 2021).
Elusodecapasconvolucionalesnohasidorestringidoalespaciobidimensional,sino queexistenestructurasparalidearcondatosde1y3dimensiones(Huangetal., 2018; Kiranyazetal., 2021; Noshirietal., 2023).Paraelpresentecaso,comoseestáclasificandounaimagensatelitalconunefoquepixelpixel,elusodeestructurasmonodimensionalespermitenincluirlainformacióndelasbandasespectralesoíndicesde
vegetaciónenelmodelo,tratandodeidentificarpatronesalconcatenarestasdiferentes fuentesdevariaciónaunarreglode nx1 características.
Lietal. (2023)evaluaroneldesempeñodeclasificacióndeimágenesdesatéliteutilizandocapasconvolucionalesde1,2y3dimensiones,asítambiénlainclusiónderedes neuronalesrecurrentes,comparandoeldesempeñoconelclasificador RF.Tantolaestructurade1dimensióncomolasredesrecurrentesobtuvieronunmejordesempeño queelclasificador RF,perolainclusióndemodelosmixtosentreestasdosestructuras permitieronmejorarconsiderablementelaexactituddelclasificador.Tambiénseseñalaquelainclusióndeinformaciónespacial(2D)ytemporal(3D)permitenmejorarel desempeñodelaredneuronal.
Luetal. (2023)tambiénincluyeronelusodecapasde3dimensionesenlaclasificación decultivosagrícolasutilizandoescenasdeSentinel2.Seevaluólaclasificaciónde3 cultivosdeciclocorto(maíz,arrozysoya)endondeseevaluólaseparabilidaddemuestrasmedianteelmismoanálisispresentadoenesteanálisis(tSNEyPCA).Seincluyó laextraccióndecaracterísticasdecadaclasemedianteunprocesode Transferlearning utilizandomodelospreentrenadosdevisióncomputacional(ResNet18,VGG19y ResNet50)paraluegoaplicarunmodelode DeepLearning concapasconvolucionales de3dimensiones.Seobservóquelatransformacióndelasmuestraspermitemejorar laseparabilidaddeclases.
Esteestudiocompartemuchassimilitudesalpresentealprepararsetdeexperimentos devariosmodelos(modelopropuesto, RF, SVM, KernelSVM,y XGBoost)apartirde laobtencióndelmejorclasificadorparacadamodeloenbaseaajustedehiperparámetros.Losresultadosindicanqueelmodelode DeepLearning superaconcrecesalos otrosmodelos,conun κ de0.86sobre0.73,0.69,0.73y0.74,respectivamente.Por loqueelusodemodelodeaprendizajeprofundoevidenciaunmejordesempeñoen laclasificacióndecultivosenimágenesdesatélitequemodelosde MachineLearning tradicionales.
Existenotrosestudiosdelusode Transferlearning paralaextraccióndecaracterísticas delasmuestrascomopreprocesodentrodelamismaredneuronalparalaclasificación decultivosapartirdeseriesmultitemporales(Antonijevićetal., 2023; Chamundeeswarietal., 2022; Teixeiraetal., 2023; Wangetal., 2023).Estatécnicaseenfocaenutilizar bloquesconvolucionalespreentrenadosapartirdesetsdedatosdegranescalaenfocadosenvisióncomputacional,paraluegoextraerlahabilidaddedetectarpatronesy sertransferidosenlaclasificacióndeimágenesdesatélite.Sibienestatécnicaseha utilizadoenclasificacióndemonotemporal(Nowakowskietal., 2021),elusodeésta enseriesdetiempoesalgorelativamentereciente.
Explorarestatécnicaenelpresenteanálisispodríapermitirmejorarlaseparabilidadde lasclases,peroellorequeriríamodificarlosdatosdeentrenamientopasandodemuestrasenformatovectorialdetipopuntoatipopolígono,locualnopodríasercomparado alosresultadosobtenidosporlosotrosclasificadores2D(dimensionesbandaespectral ytiempo),porlocualnoesadecuadoparaelpresenteanálisis.
5.4 DESEMPEÑODECLASIFICADORES Enaplicacionesdeteledetección,elusodecapasconvolucionalesde1dimensiónpara clasificaciónesalgorelativamentereciente(Chengetal., 2023; Ivandaetal., 2023; Ma etal., 2021; Sidikeetal., 2018; Zhangetal., 2023),enalgunoscasosacompañadosde estructurasdeanálisistemporalcomosonlasredesneuronalesrecurrentes(Rawatet al., 2021).Demomentonosehaencontradoliteraturaquecompareelclasificadorpor DTW conclasificacionespor DeepLearning apartirdeestructurasdecapasconvolucionales1Denelcontextodelaclasificacióndeimágenesdesatélite.Sinembargo, debidoalacapacidaddequeposeeelalgoritmode DTW paraelanálisisdeseries detiempo,sehaincorporadoésteaflujosdetrabajosde DeepLearning ocomoenla estructuraderedesneuronalesrecurrentes(Afrasiabietal., 2020; Boulilaetal., 2021; Iwanaetal., 2020; TrelinskiyKwolek, 2021).
Síexisteexperienciascomparandoelclasificadorencuestiónconelmodelo Random
Forests ChengyWang (2019)evaluaroneldesempeñode DTW, RF y SVM (Support VectorMachine,otroalgoritmode MachineLearning)enlaclasificacióndeimágenes desatéliteutilizandountotalde12imágenesdesatéliteparaelanálisis.Eldesempeño de DTW fuesuperioralde RF y SVM,obteniendounvalorde κ de0.93,0.9y0.88, respectivamente. Xiaoetal. (2023)evaluaroneldesempeñode DTW y RF enlaclasificacióndecultivosenimágenesdesatéliteincorporandolosenfoquesdeclasificación pixelpixelybasadaenobjetoenunanálisisbifactorial.Paralosdosenfoques, DTW obtuvounmejordesempeñoque RF. Sahaetal. (2020)evaluaronlaclasificaciónde especiesdeárbolescomparando DTW, RF yárbolesdedecisión,obteniendounmejor desempeñopara DTW encomparaciónalosotrosclasificadores.Enconstraste, Mohamedi (2019)utilizólamismalibreríaparacompraresteclasificadorcon RandomForest, peroenestecasoenparticularelsegundomodeloobtuvounmejordesempeño.
Enelpresenteestudio,elclasificador RF obtuvountotalde78votospositivosdentro deluniversode300muestrasparalaclase almond.Estevalorsevereflejadoenlaexactituddelusuario,porloqueelmodeloprobablementetieneunsesgohacialaprimera clasequeseencuentraenelsetdeentrenamientoenelcasoquenopuedadefiniruna claseconcerteza.Estonorepresentaunresultadoesperado,debidolaestructurade RF queescapazdemanejarelproblemadeoverfittingdemaneramáseficienteque otrosclasificadoresmedianteelusodetécnicascomo bagging y bootstrapping (BelgiuyDrăguţ, 2016; Breiman, 2001; NadiyMoradi, 2019).Apesardeello,seregistran experienciasde RF conundesempeñosimilaraotrosmodelosde MachineLearning (Azizetal., 2024; Pelletieretal., 2016; Saini, 2023; Sheykhmousaetal., 2020)
5.5 MÉTRICASDEEVALUACIÓN Sibien,lamétricade κ noesunindicadordeexactitudperse,paraelpresentecaso lamagnitud κ conOAessimilar.Lamétrica κ esunamedidadelaconcordanciaentre dosclasificadores,enestecaso,elclasificadorylamuestra,porloquelamagnitudde estamétricaesunindicadordelacapacidaddelclasificadordereproducirelmuestreo.
Esinsensiblealadistribucióndelasclases,porloqueesunamétricaadecuadapara elanálisisdeclasificacióndeimágenesdesatélite.Porotrolado,lamétricaOAes unamedidadelaexactituddelclasificadorentrenado,porloqueesunindicadorde lacapacidaddelclasificadordeclasificardemaneracorrectalasclasespresentesen eláreadeestudio,peroesmuysensiblealadistribucióndelasclases(Foody, 2020). Apesardequeambaspresentenmagnitudesalazar,elconsensodelacomunidad científicaesque κ eslamétricaadecuadaparaelanálisisdeclasificadoresporlas razonesantesmencionadas(BenDavid, 2008; FitzgeraldyLees, 1994; Foody, 2020), siendoéstalamétricaaevaluadaenlapruebadehipótesis.
Porejemplo,siladistribucióndelasmuestrasestádesbalanceada,presentándoseuna mayorcantidadderegistrosdeunaclaseenparticularendesmedrodelresto,lamétricaOApuedesersesgadahacialaclaseconmayorcantidadderegistros.Alcontrario, lamétricade κ esinsensiblealadistribucióndelasclases,yaqueincorporalaprobabilidaddecoincidenciaalazardepertenenciadeunaclasesobreeltotaldemuestras (CongaltonyGreen,2008).Dadoqueelpresenteanálisisconsideróunadistribuciónhomogéneademuestrasdeentrenamiento,validaciónyprueba,esesperablequeambas métricasposeanvaloressimilares,yaquetodaslasclasesposeenlamismaprobabilidaddeserseleccionadasenelmuestreo.
Asimismo,lasmétricasdeexactituddeproductor(PA)yusuario(UA)proporcionan informaciónadicionalsobreeldesempeñodelosclasificadores,siendométricasrecomendadasparasostenereldesempeñodelosclasificadoresapartirdelasmétricasde κ yOA(Liuetal., 2007; Olofssonetal., 2014,1).
Alevaluarlaexactituddelproductor,seobservaquehayclasesalascualesseles puedeasociarunbajoerrordecomisión,como almond, barren, barrenshadowed, industrialgrape, tablegrape y water.Estoindicaqueaquellasclasesnipresentanerroresdeetiquetadonideconfusiónconotrasclasesduranteelprocesoderecopilacióndeantecedentes.Porotrolado,hayclasesquepresentanunaltoerrorde comisión,como lemon, mandarin, olive y walnut.Noobstante,labajaPApresentada
enestasclasesseconcentraenelclasificador RF,loqueindicaqueelmodeloesel queestáasignandolaetiquetademaneraincorrecta,ypuedequeelproblemanoesté enlosdatosdeentrada,sinoenlaestructuradelmodelo.
Estosevereflejadoenlaexactituddeusuario,dondeelclasificador RF presentauna muybajaUAenlaclasificacióndelaclase almond,loqueindicaqueelmodeloestá asignandolaetiquetademaneraincorrectaendesmedrodelasotrasclases.Talcomosemencionóenelanálisisdelamatrizdeconfusión(Figura 30),esteclasificador estásobreajustandolaclase almond,loqueindicaqueelmodeloestáprivilegiandola precisióndeusuarioendesmedrodelaprecisióndeproductor.Esmás,estemodelo presenta11categoríasconunaUAde1,másquelosotrosdosmodelos,peroconuna clasificacióndesbalanceada,loquesereflejaenelvalorde κ.Esporelloqueserefuerzaloexpresadoanteriormente,dondeelanálisisdeldesempeñodelosclasificadores sedeberealizardemaneraholísticaynosologuiándoseporunamétricaenparticular, yaquesepuedenencontrarparadojascomolasantesmencionadas.
5.6 APLICACIÓNSOBREELÁREADEESTUDIO Laaplicacióndelmodelode ANN sobreeláreadeestudiopermitióobtenerunmapa declasificacióndecultivosenbaseaimágenesdesatélite.Además,sepudoobtener informaciónsobrelaprobabilidaddepertenenciaaunaclaseylaprobabilidadmásalta porpixel,siendoinsumosquepuedenserutilizadosparacomprendereldesempeño delmodeloypoderrealizarajustesenelcasoqueseanecesario.
Porejemplo,laprobabilidaddepertenenciaaunaclasepuedeserutilizadaparaevaluarlaconfianzadelmodeloenlaclasificacióndeunacelda.Silaprobabilidaddepertenenciaaunaclaseesmuybaja,sepuedeinferirqueelmodelonoestásegurode laclasificacióndelacelda,porloquesepuedeconsiderarlaclasificacióndelacelda conprecaución.EnlaFigura 34 sepresentaunejemploderesultadosdeclasificación, probabilidadmásalta,unaimagendereferenciaylaposicióndelejemplodentrodela grilladeanálisis.
Figura34: Comparativaentre:etiquetafinal;porcentajedevotosobtenidospara laetiquetafinaljuntoalasmuestrasdeentrenamiento;imagendereferencia;y grilladeanálisis. Ejemplo1.
Seobservaqueloscultivosestánbiendefinidosenelespacio,conbajoefectodesaly pimienta,efectoqueseproduceporlapresenciaderuidoenlasimágenes.(Chuvieco, 2016).Losbordesdelasimágenesestánconclasificaciónerrónea,dondeelmodelo noestásegurodelaclasificacióndelpixel,loqueseevidenciaenlabajaprobabilidad asignadaparalaclasefinal.Estoseprovocaprincipalmentealarespuestamixtaentre lareflectanciadelcultivoyelsueloquelarodea(Jainetal., 2013)yaunproblema nativodeortorectificacióndelaconstelaciónSentinel2(Barazzettietal., 2016),lacual provocaquelasimágenesnoesténperfectamentealineadas,loquesereflejaenla clasificacióndelosbordesdelasimágenes.
Tambiénenlaimagenseapreciaconfusiónentreuncultivoclasificadocomo almond con industrialgrape,loquesereflejaenlabajaprobabilidadasignadaparalaclasefinal, dondeparaelsegundocultivo,laprobabilidadesbaja.Porello,sepodríaestablecer unmínimodeprobabilidadparalaclasificacióndeunpixel,dondesilaprobabilidad depertenenciaaunaclaseesmenoraunumbral,sepuedeconsiderarcomopixelno clasificado.
EnlasFiguras 35 y 36 sepresentanotrosejemplosdezonasconbajaprobabilidad
depertenenciaaunaclase,loquesereflejaenzonasconefectodesalypimienta. Estaszonasestánmásasociadasazonasdescubiertas,quebradasyzonascercanas acursosdeagua.
Figura35: Comparativaentre:etiquetafinal;porcentajedevotosobtenidospara laetiquetafinaljuntoalasmuestrasdeentrenamiento;imagendereferencia;y grilladeanálisis. Ejemplo2.
Enzonasurbanas(Figura36)seobservaqueelmodeloasignalaclasecorrectaengran partedeloscasos,aunquesepresentaunaconfusiónconlaclase barren yseaprecia deigualformaefectosalypimientadeclasedecultivosenmediodelaciudad.Es esperablequeseproduzcaesteefecto,yaquedentrodeciudadtambiénsepresentan zonasconvegetación,propiedadesconhuertos,plazaspúblicasyparques.
Porotrolado,vallesangostoscomoelpresentadoenlaFigura 37 presentanunaclasificacióncorrecta,apesardeltamañodeloshuertosenaquellaszonas.Loscuerpos deaguatambiénpresentanunaclasificacióncorrecta,esperableporlarespuestaespectraldelaclase water.
Enzonasalejadasazonasdeproducción,sepresentaconfusióndesuelosdescubiertosconcuerposdeagua,zonaurbanaycultivodeforraje(Figura 38).Estosedebeala respuestaespectraldelaclase barren,lacualseasemejaalarespuestaespectralde cuerposdeaguaysuelosdescubiertos.Loscerrosdeestaszonasposeenunacom
Figura36: Comparativaentre:etiquetafinal;porcentajedevotosobtenidospara laetiquetafinaljuntoalasmuestrasdeentrenamiento;imagendereferencia;y grilladeanálisis. Ejemplo3
Figura37: Comparativaentre:etiquetafinal;porcentajedevotosobtenidospara laetiquetafinaljuntoalasmuestrasdeentrenamiento;imagendereferencia;y grilladeanálisis. Ejemplo4
binacióngeológicadiferenteazonasbajas,especialmenteporqueenestaszonasse presentanafloramientosderocas,loqueseasemejanalarespuestaespectraldela clase urban.Duranteloseventosdeprecipitación,estaszonasacumulannieve,lacual sederriteduranteprimaverayalimentalosríosdelacuenca.Estetipoderespuesta, porsudinámicatemporal,elmodelolacategorizacomopradera(productodelosmúltiplescortes)ocomocuerposdeagua(porladinámicadeestosmismos,reflejadoen elvalorde RSS).Loscursosdeaguaalimentadosporestanieveposeenvegetación ribereña,lacualsevebienidentificadaporelmodelo.
Parapodermejorarladiscriminacióndeestassuperficiesporelmodelo,sedebiera incorporarnuevasclasespararepresentarestadiversidad.Dadoaqueelpresente estudioseenfocaencultivosagrícolas,estasclasesnofueronincluidasporestarlejos dezonasdeproducción.
ElresultadoensuperficieporclasesepresentóenlaTabla 10.Encomparaciónala coberturatemáticadeCIREN(2021),lasuperficiedeviddemesaestásobrestimada (3,095versus3,895,CIRENyesteestudio,respectivamente),probablementeelmodeloseconfundióconlaclasecorrespondienteavidindustrial,debidoaqueeslamisma especieperodevariedaddiferente,locualnosepuededeterminardebidoaqueeste últimogruponoestáconsideradoenelreportedeCIREN(2021).Porelcontrario,el nogalfuesobredimensionado(1,000versus3,052ha,CIRENyesteestudio,respectivamente).
Enelgrupodeloscítricos,segúnCIREN(2021)eltotaldesuperficieparaestegrupo esde4,892ha.Elresultadodeesteestudioseñalaqueeltotalesde3.406ha,loque indicaqueelmodelosubestimólasuperficiedecítricos.Probablementelaconfusión deprodujoconelgrupodeolivo,queparaCIREN(2021)lasuperficiefuede3.095ha versus3,891haobtenidosenesteestudio.Elpaltotambiénfuesubdimensionado,con 2,119versus1,578ha.Entotal,elgrupodefrutalesdehojapersistentesparaCIREN (2021)esde10,861ha,mientrasqueelresultadodeesteestudioesde8,875ha, loqueindicaqueelmodelosubestimólasuperficiedeestegrupo.Probablemente,la
Figura38: Comparativaentre:etiquetafinal;porcentajedevotosobtenidospara laetiquetafinaljuntoalasmuestrasdeentrenamiento;imagendereferencia;y grilladeanálisis. Celda54/56.
confusiónseprodujoconlaclasecorrespondientealavegetaciónribereña.
Cabemencionarquelasmuestrascolectadasparaelanálisisseobtuvierondepixeles representativosparacadaclase,porloqueunmanejoineficienteenunprediopuede quegenereunarespuestaespectralquenoseasimilaralarepresentativaparacada cultivo.
Además,elcatastrodeCIREN(2021)considerapredioscontodoslosnivelesdedesarrollo,desdesuperficiereciénplantadaasuperficieenplenaproducción,porloque larespuestaespectraldecadaclasepuedevariarenfunciónalaetapadedesarrollo enqueseencuentreelcultivo.
Paramejorareldesempeñodelmodelo,sepodríaevaluarlainclusióndemuestrasde entrenamientodepixelessinunarespuestarepresentativa,aunqueesopodríacontribuiralaconfusiónentreclases.CabemencionarquelosdatosreportadosporCIREN (2021)selevantaronduranteelaño2020,adiferenciadelasimágenesutilizadasenesteestudio,quecorrespondenalatemporada20212022.Sinembargo,loscambiosde superficieentreunatemporadayotrasonmínimos,porloquenoseesperaqueestos cambiosafectensignificativamenteladiscusióndelosresultadosobtenidos.
5.7 PREGUNTASDEINVESTIGACIÓN Encuantoalaspreguntasdeinvestigaciónplanteadasenesteestudio,lasrespuestas acadaunadeellassepresentanacontinuación:
a. Entrelarespuestadereflectanciaeíndicesespectrales¿Cuálesmásadecuadoparaclasificaruncultivo?
Delosgruposevaluados: NDVI,bandasespectrales,ylacombinaciónentre ambos,elgrupode NDVI presentómayorvariabilidadentrelasmuestras,estose apreciaenlavarianzaexplicadaenlosprimeroscomponentesdelPCA.Apesar deello,ladiscriminaciónentrelosdiferentescultivosfuemásefectivautilizandoel
grupodebandasespectralesolacombinaciónentreellos.Enparticular,elmejor modelotantode DTW y ANN selogróutilizandosólolasbandasespectrales.Por lotanto,seconcluyequeelusodelasbandasespectralesesmásadecuadopara caracterizarelcrecimientodeuncultivo.
b. ¿Esposibleaplicarunaúnicaclasificaciónenmúltipleszonascondiferenciasenlaexpresióndelcrecimientodecultivos?
Sí,elniveldedesempeñologradoporlosmodelosevaluados,reflejadosenel valorde κ,demuestranqueesposibleutilizarunúnicomodeloparaclasificar múltipleszonascondiferenciasenlaexpresióndelcrecimientodecultivos.
c. ¿Unaclasificaciónconénfasisenlospatronesdecrecimientodecultivos medianteelmétodode DTW esmásprecisaquelosmétodosdeclasificaciónde MachineLearning,comoclasificaciónsupervisadautilizandolos algoritmosdeRedesNeuronalesArtificialeso RandomForest?
Noentodosloscasos,elalgoritmode DTW presentóundesempeñosimilarauno delosalgoritmosde MachineLearning evaluados,siendosuperiorqueelmodelo obtenidoporelclasificador RandomForest.Sinembargo,nofuesuperioralmodelodeRedesNeuronalesArtificiales.Cabemencionar,queesteúltimomodelo incorporaestructurasdereconocimientodepatrones,losbloquesconvolucionales,porloquesepodríaconsiderarqueambosmodelospresentanunenfoque similarenlaclasificacióndeimágenesdesatélite.Dichoesto,unmodeloqueincorporaladiscriminaciónporpatronesesmásadecuadoparaelanálisisdeseries multitemporales,comoeselcasodelaclasificacióndeimágenesdesatélite.
5.8 EVALUACIÓNFINALDELAHIPÓTESISDEINVESTIGACIÓN Lahipótesisplanteaquelautilizacióndelclasificador DTW esmásadecuadopara laclasificacióndecultivosenbaseaimágenesdesatélitequelosclasificadoresde MachineLearning tradicionales,debidoasucapacidaddereconocerpatronesenseries
detiempo.Losresultadosobtenidosenesteestudiopermitenrechazarlahipótesis planteada,yaqueelclasificador ANN presentóunmejordesempeñoqueelclasificador DTW,obteniendounvalorde κ de0.960,seguidoporelclasificador DTW,conun valorde0.931,yfinalmenteelclasificador RF,conunvalorde0.876.Porlotanto,se concluyequeelusodeunclasificadorde MachineLearning tradicional,enestecaso,el clasificador ANN,esmásadecuadoparalaclasificacióndecultivosenbaseaimágenes desatélitequeelclasificador DTW
Sinembargo,esimportantemencionarqueelclasificador ANN poseeunaestructura capasconvolucionales,lascualescomúnmenteseutilizanparaelreconocimientode patrones,loquelohacemásadecuadoparaelanálisisdeseriesmultitemporales, comoeselcasodelaclasificacióndeimágenesdesatélite.Porlotanto,lahipótesis planteadanoesdeltodoincorrecta,yaqueelclasificador ANN presentaunenfoque similaraldelclasificador DTW,peroconunmejordesempeñoenlaclasificaciónde cultivosenbaseaimágenesdesatélite.
Enconsecuencia,paraestetipodetareas,elusodeestructurasdereconocimientode patronesesmásadecuadoqueelusodealgoritmosde MachineLearning tradicionales, yaquepermitenunamejordiscriminaciónentrelasdiferentesclasespresentesenel áreadeestudio.
6 CONCLUSIONES Sedescargaronyprocesaron364escenascorrespondientesaunatemporadaagrícola pararealizarunanálisisdeclasificadoresdecultivosenbaseaimágenesdesatélite. Parapoderdescartaraquellasescenasqueposeennubes,sedividióelterritorioen 56celdasdeanálisis,cadaunade1,280x1,280pixeles.Secortaronlasescenasdescargadasenfunciónalasceldasmencionadas,seutilizaronlasbandas2,3,4y8de laserieSentinel2,cuyaresoluciónespacialesde10metros,porlotanto,cadacelda poseeuntamañode12,800x12,800metros.
Seseleccionóuntotalde13,340archivosrásterparaelanálisis,loqueequivalea3,335 celdasindividualesconfechaúnica.Laseleccióndelasfechasserealizóenfunción aunalgoritmopropuestoparalaevaluacióndenubosidad,procesoquefuerevisado manualmentedondeseprodujounasegundaselección.
Selevantóuntotalde2,683muestrasde16clasesdiferentes,clasesqueprincipalmentecorrespondenacultivosagrícolas,salvolasdesuelodescubierto,zonasurbanasy cuerposdeagua.Estasmuestrasfueronlevantadasconayudadeunacoberturatemáticadefrutalesdelaregión,juntoalaayudadevisitasaterrenoyconocimiento experto.
Serealizóunanálisisexploratorio(PCAytSNE)paraevaluarlavariabilidaddelas muestras.Desdeestemomentosedividióenanálisisentresgrupos:respuestade NDVI,respuestadebandasespectrales,yrespuestabandasespectralesmás NDVI. Lasmuestrasdecultivosfrutalesdemismohábitodecrecimientosimilar(frutalesde hojacaducayfrutalesdehojapersistente)mostraronmayorcercaníaentrelosresultadosdelosdosanálisis.Porotrolado,seobservóqueelíndicedevegetaciónaporta mayorvariabilidadalconjuntodedatos.
Lasmuestrassedividieronentresgrupos,unodeentrenamiento,unodevalidacióny unodeprueba,con100,30y30muestrascadauno,respectivamente.Paraaquellas
clasesquepresentaronunacantidaddemuestrasmenoraloestablecido,serealizó bootstrapping parapoderequilibrarlacantidaddemuestrasentrelasclases.
Seevaluóeldesempeñodetresclasificadores, DTW, ANN y RF,enlaclasificaciónde cultivosenbaseaimágenesdesatélite,utilizandounenfoquedeclasificaciónpixelpixel.Serealizaron15experimentosparaelclasificador DTW,78experimentosparael clasificador ANN y87experimentosparaelclasificador RF,utilizandodiferentesconfiguracionesdeparámetrosparacadaclasificadoryanalizandolosdiferentesgrupos descritos.Seevaluóeldesempeñodelosclasificadoresutilizandolasmétricasde κ, OA,PAyUA,yserealizóunapruebadehipótesisparaevaluarsieldesempeñodelos clasificadoresesestadísticamentediferente.
Losresultadosobtenidospermitenconcluirque:
• Utilizarsólouníndiceespectral, NDVI enestecaso,esinsuficienteparaclasificar loscultivospresenteseneláreadeestudio.Apesardequeesteíndicepresentó mayorvariabilidadenelconjuntodedatos,ladiscriminaciónentrelosdiferentes cultivosfuemásefectivautilizandolasbandasespectralesolacombinaciónentre lasbandasyel NDVI.
• Delosmodelosevaluados,elquepresentómejordesempeñoeselclasificador ANN,conunvalorde κ de0.960,seguidoporelclasificador DTW,conunvalor de0.931,yfinalmenteelclasificador RF,conunvalorde0.876.
• Eldesempeñodelosclasificadores DTW, ANN y RF esestadísticamentediferente,porloquelaseleccióndeunclasificadorescrucialparaelanálisisdeclasificacióndecultivosenbaseaimágenesdesatélite.
• Elclasificador DTW presentaundesempeñosimilaraldelclasificador ANN,pero conunaleveventajaparaelclasificador ANN.Porotrolado,elclasificador DTW presentaundesempeñosuperioraldelclasificador RF.Estoindicaquealgoritmosconunenfoquedereconocimientodepatronessonmásadecuadosparael
análisisdeclasificacióndecultivosenbaseaimágenesdesatélite.
• Elusodereduccióndedimensiones,comoelenfoquepropuestoenesteestudioapartirdeajustepor Spline,permiteobtenerunconjuntodedatoslivianoy homogéneoparaevaluareláreaensutotalidad.
Recomendaciones Elpresenteestudioseenfocóenlaclasificacióndecultivosenbaseaimágenesde satéliteconelenfoquepixelpixel,porloqueserecomiendarealizarunanálisisdeclasificaciónbasadoenobjetos,endondesepuedaevaluarlaclasificacióndecultivosen basealaestructuradelasunidadeshomogéneas(cuarteles,pañosdecultivos,entreotros),ynosoloenbasealarespuestaespectraldelosmismos.Estopermitiría incorporarinformaciónadicionalalanálisis,comolaformayeltamañodelasunidadeshomogéneas,textura,dispersiónestadística,entreotros,loquepermitiríaexplorar nuevasvíasdeanálisisparalaclasificacióndecultivosenbaseaimágenesdesatélite.
Paramejorarlostiemposdecómputodelclasificador DTW,serecomiendaexplorar laaplicacióndealgoritmosdeclusterizaciónprevioalaclasificación,como Kmeans, parareducirlacantidaddemuestrasaevaluar.Tambiénelusodelímitesinferiores debúsqueda,como LB_Kim y LB_Keogh,parabuscarelmismofin.Deestaforma,los resultadosobtenidosenelpresenteestudiopodríanserutilizadosenuncontextooperacional.
Porotrolado,serecomiendaexplorarlaaplicacióndemodelosde DeepLearning enla clasificacióndecultivosenbaseaimágenesdesatélite,enparticular,elusoderedes neuronalesrecurrentes,quepermitiríanincorporarlainformacióntemporaldelasseries detiempoenelanálisis.También,seguirexplorandoelusodebloquesconvolucionalesparaextraerpatronesapartirdedatosmultidimensionales,asignandoáreasde entrenamientoenvezdemuestrasvectorialesdetipopuntual.Esteenfoquepodríaser
complementadocon TransferLearning enbaseamodelosyaentrenados,paramejorar laseparabilidaddelasclases.
Sielclasificadorseleccionadoes ANN,serecomiendaincorporarvariablesadicionales alanálisisparadarcontextoacadaclase.Porejemplo,lavegetaciónrivereñaseespera queseencuentrecercadecursosdeagua,porloquesepodríaincorporarinformación dedistanciaacursosdeaguaalanálisis.Tambiénsepodríaincorporarinformaciónde pendiente,orientación,alturadevalle,entreotros.Estomejoraríaladiscriminaciónen aquellasclasesquepresentanunabajaexactituddeusuarioenunmodelode Machine Learning
REFERENCIAS Abadi,M.,Barham,P.,Chen,J.,Chen,Z.,Davis,A.,Dean,J.,Devin,M.,Ghemawat,S., Irving,G.,Isard,M.,Kudlur,M.,Levenberg,J.,Monga,R.,Moore,S.,Murray,D.G., Steiner,B.,Tucker,P.,Vasudevan,V.,Warden,P.,Wicke,M.,Yu,Y.,yZheng,X. (2016).TensorFlow:Asystemforlargescalemachinelearning.En Proceedingsof the12thUSENIXConferenceonOperatingSystemsDesignandImplementation, OSDI’16,pp.265–283,USA.USENIXAssociation.
Afrasiabi,M.,khotanlou,H.,yMansoorizadeh,M.(2020).DTWCNN:TimeseriesbasedhumaninteractionpredictioninvideosusingCNNextractedfeatures. The VisualComputer:InternationalJournalofComputerGraphics,36(6):1127–1139.
AlvarezGarreton,C.,PabloA.Mendoza,Boisier,J.P.,Addor,N.,Galleguillos,M., ZambranoBigiarini,M.,Lara,A.,Puelma,C.,Cortes,G.,Garreaud,R.,McPhee, J.,yAyala,A.(2018).TheCAMELSCLdataset:Catchmentattributesandmeteorologyforlargesamplestudies–Chiledataset. HydrologyandEarthSystem Sciences,22(11):5817–5846.
AmericanNationalStandardInstitute(1973).Flowchartsymbolsandtheirusagein informationprocessing.
Antonijević,O.,Jelić,S.,Bajat,B.,yKilibarda,M.(2023).Transferlearningapproach basedonsatelliteimagetimeseriesforthecropclassificationproblem. Journalof BigData,10(1):54.
Arvor,D.,Jonathan,M.,Meirelles,M.S.P.,Dubreuil,V.,yDurieux,L.(2011).ClassificationofMODISEVItimeseriesforcropmappinginthestateofMatoGrosso, Brazil. InternationalJournalofRemoteSensing,32(22):7847–7871.
Asner,G.P.(1998).Biophysicalandbiochemicalsourcesofvariabilityincanopyreflectance. RemoteSensingofEnvironment,64(3):234–253.
Aziz,G.,Minallah,N.,Saeed,A.,Frnda,J.,yKhan,W.(2024).Remotesensingbased forestcoverclassificationusingmachinelearning. ScientificReports,14(1):69.
Bai,X.,Wang,X.,Liu,X.,Liu,Q.,Song,J.,Sebe,N.,yKim,B.(2021).Explainable deeplearningforefficientandrobustpatternrecognition:Asurveyofrecentdevelopments. PatternRecognition,120:108102.
Barazzetti,L.,Cuca,B.,yPrevitali,M.(2016).EvaluationofregistrationaccuracybetweenSentinel2andLandsat8.En Proc.SPIE9688,FourthInternationalConferenceonRemoteSensingandGeoinformationoftheEnvironment(RSCy2016),, volumen9688,p.968809,Paphos.
Beeresh,V.,MrsLathaB.,B.M.,ThimmarajaYadava,G.,yNaveen,D.(2014).An ApproachforIdentificationandClassificationofCropsusingMultispectralImages.
InternationalJournalofEngineeringResearch&Technology,3(5).
Belgiu,M.yCsillik,O.(2018).Sentinel2croplandmappingusingpixelbasedand objectbasedtimeweighteddynamictimewarpinganalysis. RemoteSensingof Environment,204:509–523.
Belgiu,M.yDrăguţ,L.(2016).Randomforestinremotesensing:Areviewofapplicationsandfuturedirections. ISPRSJournalofPhotogrammetryandRemoteSensing,114:24–31.
Belgiu,M.,Zhou,Y.,Marshall,M.,yStein,A.(2020).DynamicTimeWarpingforCrops Mapping. TheInternationalArchivesofthePhotogrammetry,RemoteSensingand SpatialInformationSciences,XLIIIB32020:947–951.
BenDavid,A.(2008).ComparisonofclassificationaccuracyusingCohen’sWeighted Kappa. ExpertSystemswithApplications,34(2):825–832.
Berzal,F.(2018). RedesNeuronales&DeepLearning.Independentlypublished,Granada.
Boulila,W.,Ghandorh,H.,Khan,M.A.,Ahmed,F.,yAhmad,J.(2021).Anovel CNNLSTMbasedapproachtopredicturbanexpansion. EcologicalInformatics, 64:101325.
Breiman,L.(2001).RandomForests. MachineLearning,45(1):5–32.
Campos,I.,GonzálezGómez,L.,Villodre,J.,GonzálezPiqueras,J.,Suyker,A.E.,y Calera,A.(2018).Remotesensingbasedcropbiomasswithwaterorlightdriven cropgrowthmodelsinwheatcommercialfields. FieldCropsResearch,216:175–188.
CánovasGarcía,F.,Alonso,F.,yCastillo,F.(29,30dejunioy1dejulio2016).ModificacióndelalgoritmoRandomForestparasuempleoenclasificacióndeimágenes deteledetección.En AplicacionesdeLasTecnologíasdeLaInformaciónGeográfica(TIG)ParaElDesarrolloEconómicoSostenibleXVIICongresoNacionalde TecnologíasdeInformaciónGeográfica,pp.359–368,Málaga.
Carrão,H.,Gonçalves,P.,yCaetano,M.(2008).ContributionofmultispectralandmultitemporalinformationfromMODISimagestolandcoverclassification. Remote SensingofEnvironment,112(3):986–997.
Cereceda,P.,Larrain,H.,Osses,P.,Farías,M.,yEgaña,I.(2008).Theclimateofthe coastandfogzoneintheTarapacáRegion,AtacamaDesert,Chile. Atmospheric Research,87(3):301–311.
Chai,J.,Zeng,H.,Li,A.,yNgai,E.W.T.(2021).Deeplearningincomputervision:A criticalreviewofemergingtechniquesandapplicationscenarios. MachineLearning
withApplications,6:100134.
Chamundeeswari,G.,Srinivasan,S.,Bharathi,S.P.,Priya,P.,Kannammal,G.R.,y Rajendran,S.(2022).Optimaldeepconvolutionalneuralnetworkbasedcropclassificationmodelonmultispectralremotesensingimages. Microprocessorsand Microsystems,94:104626.
Chang,H.J.,Huang,K.,yWu,C.H.(2006).Determinationofsamplesizeinusing centrallimittheoremforweibulldistribution. Internationaljournalofinformationand managementsciences,17(3):31–46.
Chen,Y.,Guerschman,J.P.,Cheng,Z.,yGuo,L.(2019).Remotesensingforvegetation monitoringincarboncapturestorageregions:Areview. AppliedEnergy,240:312–326.
Cheng,K.yWang,J.(2019).ForestTypeClassificationUsingTimeWeightedDynamicTimeWarpingAnalysisinMountainAreas:ACaseStudyinSouthernChina. Forests,10(11):1040.
Cheng,X.,Sun,Y.,Zhang,W.,Wang,Y.,Cao,X.,yWang,Y.(2023).ApplicationofDeep LearninginMultitemporalRemoteSensingImageClassification. RemoteSensing, 15(15):3859.
Chollet,F.(2021). DeepLearningwithPython.Manning,ShelterIsland,NewYork,2da edición.
Chuvieco,E.(2016). FundamentalsofSatelliteRemoteSensing:AnEnvironmental Approach,SecondEdition.CRCPress,BocaRaton,2daedición.
CIREN,CentrodeInformacióndeRecursosNaturales(2021).CatastroFruticola.RegióndeCoquimbo.Actualización2021.Informetécnico,CentrodeInformaciónde RecursosNaturales,SantiagodeChile.
Cochran,W.G.(1950).Thecomparisonofpercentagesinmatchedsamples. Biometrika,37(34):256–266.
CONAF,CorporaciónNacionalForestal(2004).CatastrodeUsodeSueloyVegetación. CuartaRegióndeCoquimbo.
Congalton,R.(1991).Areviewofassessingtheaccuracyofclassificationsofremotely senseddata. RemoteSensingofEnvironment,37:35–46.
Congalton,R.yGreen,K.(2008). AssessingtheAccuracyofRemotelySensedData: PrinciplesandPractices.CRCPress,BocaRaton,FL,USA,2edición.
Csillik,O.,Belgiu,M.,Asner,G.P.,yKelly,M.(2019).ObjectBasedTimeConstrained DynamicTimeWarpingClassificationofCropsUsingSentinel2. RemoteSensing, 11(10):1257.
deBeurs,K.M.yHenebry,G.M.(2010).SpatioTemporalStatisticalMethodsforModellingLandSurfacePhenology.EnHudson,I.L.yKeatley,M.R.,editores, PhenologicalResearch:MethodsforEnvironmentalandClimateChangeAnalysis,pp. 177–208.SpringerNetherlands,Dordrecht.
deCarvalho,O.A.,Guimaraes,R.F.,TrancosoGomes,R.A.,ydaSilva,N.C.(2007). Timeseriesinterpolation.En 2007IEEEInternationalGeoscienceandRemote SensingSymposium,pp.1959–1961.
DGA,DireccionGeneraldeAguas(2008).EvaluacióndelosrecursoshídricossubterráneosdelacuencadelRíoLimarí.Informetécnico268,MinisteriodeObras Públicas,GobiernodeChile,Santiago.
Dror,R.,Baumer,G.,Shlomov,S.,yReichart,R.(2018).TheHitchhiker’sGuideto TestingStatisticalSignificanceinNaturalLanguageProcessing.EnGurevych,I.y Miyao,Y.,editores, Proceedingsofthe56thAnnualMeetingoftheAssociationfor ComputationalLinguistics(Volume1:LongPapers),pp.1383–1392,Melbourne, Australia.AssociationforComputationalLinguistics.
EscuderoArnanz,Ó.,Marques,A.G.,SogueroRuiz,C.,MoraJiménez,I.,yRobles,G. (2023).dtwParallel:APythonpackagetoefficientlycomputedynamictimewarping betweentimeseries. SoftwareX,22:101364.
Estornell,J.,MartíGavilá,J.M.,Sebastiá,M.T.,yMengual,J.(2013).Principalcomponentanalysisappliedtoremotesensing. ModellinginScienceEducationand Learning,6:83–89.
Fitzgerald,R.W.yLees,B.G.(1994).Assessingtheclassificationaccuracyofmultisourceremotesensingdata. RemoteSensingofEnvironment,47(3):362–368.
FitzpatickLins,K.(1981).Comparisonofsamplingproceduresanddataanalysisfora landuseandlandcovermap. PhotogrammetricEngineeringandRemoteSensing, 47(3):343–351.
Foody,G.M.(2008).Harshnessinimageclassificationaccuracyassessment. InternationalJournalofRemoteSensing,29(11):3137–3158.
Foody,G.M.(2020).Explainingtheunsuitabilityofthekappacoefficientintheassessmentandcomparisonoftheaccuracyofthematicmapsobtainedbyimage classification. RemoteSensingofEnvironment,239:111630.
Fu,A.W.C.,Keogh,E.,Lau,L.Y.H.,Ratanamahatana,C.A.,yWong,R.C.W.(2008). Scalingandtimewarpingintimeseriesquerying. TheVLDBJournal,17(4):899–921.
Fu,G.,Liu,C.,Zhou,R.,Sun,T.,yZhang,Q.(2017).ClassificationforHighResolution RemoteSensingImageryUsingaFullyConvolutionalNetwork. RemoteSensing,
9(5):498.
GarridoRubio,J.,GonzálezPiqueras,J.,Campos,I.,Osann,A.,GonzálezGómez,L., yCalera,A.(2020).Remotesensing–basedsoilwaterbalanceforirrigationwateraccountingatplotandwateruserassociationmanagementscale. Agricultural WaterManagement,238:106236.
Ghazaryan,G.,Dubovyk,O.,Löw,F.,Lavreniuk,M.,Kolotii,A.,Schellberg,J.,yKussul,N.(2018).Arulebasedapproachforcropidentificationusingmultitemporal andmultisensorphenologicalmetrics. EuropeanJournalofRemoteSensing, 51(1):511–524.
Gil,G.(2019a). FruticulturaElpotencialproductivo.TiendaEdicionesUC.Ediciones UC,Santiago,4taedición.
Gil,G.(2019b). FruticulturaLaproduccióndefruta.TiendaEdicionesUC.Ediciones UC,Santiago,3eraedición.
GonzálezSanpedro,M.C.,LeToan,T.,Moreno,J.,Kergoat,L.,yRubio,E.(2008). SeasonalvariationsofleafareaindexofagriculturalfieldsretrievedfromLandsat data. RemoteSensingofEnvironment,112(3):810–824.
Graesser,J.,Stanimirova,R.,yFriedl,M.A.(2022).ReconstructionofSatelliteTime SeriesWithaDynamicSmoother. IEEEJournalofSelectedTopicsinAppliedEarth ObservationsandRemoteSensing,15:1803–1813.
Guan,X.,Liu,G.,Huang,C.,Meng,X.,Liu,Q.,Wu,C.,Ablat,X.,Chen,Z.,yWang,Q. (2018).AnOpenBoundaryLocallyWeightedDynamicTimeWarpingMethodfor CroplandMapping. ISPRSInternationalJournalofGeoInformation,7(2):75.
Gutman,G.eIgnatov,A.(1998).Thederivationofthegreenvegetationfractionfrom NOAA/AVHRRdataforuseinnumericalweatherpredictionmodels. International JournalofRemoteSensing,19(8):1533–1543.
Hastie,T.,Tibshirani,R.,yFriedman,J.H.(2001). TheElementsofStatisticalLearning: DataMining,Inference,andPrediction.SpringerScience&BusinessMedia.
Heupel,K.,Spengler,D.,eItzerott,S.(2018).AProgressiveCropTypeClassificationUsingMultitemporalRemoteSensingDataandPhenologicalInformation. PFG–JournalofPhotogrammetry,RemoteSensingandGeoinformationScience, 86(2):53–69.
Hu,Q.,Wu,W.b.,Song,Q.,Lu,M.,Chen,D.,Yu,Q.y.,yTang,H.j.(2017).Howdo temporalandspectralfeaturesmatterincropclassificationinHeilongjiangProvince,China? JournalofIntegrativeAgriculture,16(2):324–336.
Huang,H.,Hu,X.,Zhao,Y.,Makkie,M.,Dong,Q.,Zhao,S.,Guo,L.,yLiu,T.(2018).
ModelingTaskfMRIDataViaDeepConvolutionalAutoencoder. IEEETransactions onMedicalImaging,37(7):1551–1561.
Immitzer,M.,Vuolo,F.,yAtzberger,C.(2016).FirstExperiencewithSentinel2Data forCropandTreeSpeciesClassificationsinCentralEurope. RemoteSensing, 8(3):166.
Islaqm,M.(2018).SamplesizeanditsroleinCentralLimitTheorem(CLT). Journalof Physics&Mathematics,,1(1):37–47.
Ivanda,A.,Šerić,L.,Žagar,D.,yOštir,K.(2023).Anapplicationof1Dconvolutionand deeplearningtoremotesensingmodellingofSecchidepthinthenorthernAdriatic Sea. BigEarthData,0(0):1–33.
Iwana,B.K.,Frinken,V.,yUchida,S.(2020).DTWNN:Anovelneuralnetwork fortimeseriesrecognitionusingdynamicalignmentbetweeninputsandweights. KnowledgeBasedSystems,188:104971.
Jain,M.,Mondal,P.,DeFries,R.S.,Small,C.,yGalford,G.L.(2013).Mappingcropping intensityofsmallholderfarms:Acomparisonofmethodsusingmultiplesensors. REMOTESENSINGOFENVIRONMENT,134:210–223.
Jiang,P.,Ergu,D.,Liu,F.,Cai,Y.,yMa,B.(2022).AReviewofYoloAlgorithmDevelopments. ProcediaComputerScience,199:1066–1073.
Joyce,A.T.(1978). ProceduresforGatheringGroundTruthInformationforaSupervisedApproachtoaComputerimplementedLandCoverClassificationofLandsatacquiredMultispectralScannerData.NationalAeronauticsandSpaceAdministration,ScientificandTechnicalInformationOffice.
Kate,R.J.(2016).Usingdynamictimewarpingdistancesasfeaturesforimprovedtime seriesclassification. DataMiningandKnowledgeDiscovery,30(2):283–312.
Keogh,E.yRatanamahatana,C.A.(2005).Exactindexingofdynamictimewarping. KnowledgeandInformationSystems,7(3):358–386.
Khaliq,A.,Peroni,L.,yChiaberge,M.(2018).Landcoverandcropclassificationusing multitemporalsentinel2imagesbasedoncropsphenologicalcycle.En 2018IEEE WorkshoponEnvironmental,Energy,andStructuralMonitoringSystems(EESMS), pp.1–5,Salerno.
Kim,S.W.,Park,S.,yChu,W.(2001).Anindexbasedapproachforsimilaritysearch supportingtimewarpinginlargesequencedatabases.En Proceedings17thInternationalConferenceonDataEngineering,pp.607–614.
Kiranyaz,S.,Avci,O.,Abdeljaber,O.,Ince,T.,Gabbouj,M.,eInman,D.J.(2021).1D convolutionalneuralnetworksandapplications:Asurvey. MechanicalSystemsand
SignalProcessing,151:107398.
Kobayashi,N.,Tani,H.,Wang,X.,ySonobe,R.(2020).CropclassificationusingspectralindicesderivedfromSentinel2Aimagery. JournalofInformationandTelecommunication,4(1):67–90.
Laban,N.,Abdellatif,B.,Ebied,H.M.,Shedeed,H.A.,yTolba,M.F.(2020).Multiscale SatelliteImageClassificationUsingDeepLearningApproach.EnHassanien,A.E., Darwish,A.,yElAskary,H.,editores, MachineLearningandDataMininginAerospaceTechnology,StudiesinComputationalIntelligence,pp.165–186.Springer InternationalPublishing,Cham.
Larrain,H.,Velásquez,F.,Cereceda,P.,Espejo,R.,Pinto,R.,Osses,P.,ySchemenauer,R.S.(2002).Fogmeasurementsatthesite“FaldaVerde”northofChañaral comparedwithotherfogstationsofChile. AtmosphericResearch,64(1):273–284.
Lebourgeois,V.,Dupuy,S.,Vintrou,É.,Ameline,M.,Butler,S.,yBégué,A.(2017).A CombinedRandomForestandOBIAClassificationSchemeforMappingSmallholderAgricultureatDifferentNomenclatureLevelsUsingMultisourceData(SimulatedSentinel2TimeSeries,VHRSandDEM). RemoteSensing,9(3):259.
Li,M.,Zang,S.,Zhang,B.,Li,S.,yWu,C.(2014).AReviewofRemoteSensingImage ClassificationTechniques:TheRoleofSpatiocontextualInformation. European JournalofRemoteSensing,47(1):389–411.
Li,Q.,Tian,J.,yTian,Q.(2023).DeepLearningApplicationforCropClassificationvia MultiTemporalRemoteSensingImages. Agriculture,13(4):906.
Liu,C.,Frazier,P.,yKumar,L.(2007).Comparativeassessmentofthemeasuresof thematicclassificationaccuracy. RemoteSensingofEnvironment,107(4):606–616.
Liu,X.,Zhai,H.,Shen,Y.,Lou,B.,Jiang,C.,Li,T.,Hussain,S.B.,yShen,G.(2020). LargeScaleCropMappingFromMultisourceRemoteSensingImagesinGoogle EarthEngine. IEEEJournalofSelectedTopicsinAppliedEarthObservationsand RemoteSensing,13:414–427.
Lopes,M.,Frison,P.L.,Durant,S.M.,SchultetoBühne,H.,Ipavec,A.,Lapeyre,V., yPettorelli,N.(2020).Combiningopticalandradarsatelliteimagetimeseriesto mapnaturalvegetation:Savannasasanexample. RemoteSensinginEcologyand Conservation,6(3):316–326.
Louis,J.,Debaecker,V.,Pflug,B.,MainKnorn,M.,Bieniarz,J.,MuellerWilm,U.,Cadau,E.,yGascon,F.(9al13deMayode2016).Sentinel2SEN2COR:L2A processorforusers.En LivingPlanetSymposium2016,volumenSP740,Praga.
Lu,T.,Gao,M.,yWang,L.(2023).Cropclassificationinhighresolutionremotesensing
imagesbasedonmultiscalefeaturefusionsemanticsegmentationmodel. FrontiersinPlantScience,14.
Ma,N.,Sun,L.,Zhou,C.,yHe,Y.(2021).CloudDetectionAlgorithmforMultiSatellite RemoteSensingImageryBasedonaSpectralLibraryand1DConvolutionalNeural Network. RemoteSensing,13(16):3319.
Massey,R.,Sankey,T.T.,Yadav,K.,Congalton,R.G.,yTilton,J.C.(2018).Integrating cloudbasedworkflowsincontinentalscalecroplandextentclassification. Remote SensingofEnvironment,219:162–179.
Maus,V.,Câmara,G.,Appel,M.,yPebesma,E.(2019).dtwSat:TimeWeightedDynamicTimeWarpingforSatelliteImageTimeSeriesAnalysisinR. JournalofStatisticalSoftware,88:1–31.
Maus,V.,Câmara,G.,Cartaxo,R.,Sanchez,A.,Ramos,F.M.,ydeQueiroz,G.R. (2016).ATimeWeightedDynamicTimeWarpingMethodforLandUseandLandCoverMapping. IEEEJournalofSelectedTopicsinAppliedEarthObservations andRemoteSensing,9(8):3729–3739.
Maxwell,A.E.yWarner,T.A.(2020).ThematicClassificationAccuracyAssessment withInherentlyUncertainBoundaries:AnArgumentforCenterWeightedAccuracy AssessmentMetrics. RemoteSensing,12(12):1905.
Maxwell,A.E.,Warner,T.A.,yFang,F.(2018).Implementationofmachinelearning classificationinremotesensing:Anappliedreview. InternationalJournalofRemote Sensing,39(9):2784–2817.
Mazzia,V.,Khaliq,A.,yChiaberge,M.(2020).ImprovementinLandCoverandCrop ClassificationbasedonTemporalFeaturesLearningfromSentinel2DataUsing RecurrentConvolutionalNeuralNetwork(RCNN). AppliedSciences,10(1):238.
Millard,K.yRichardson,M.(2015).OntheImportanceofTrainingDataSampleSelectioninRandomForestImageClassification:ACaseStudyinPeatlandEcosystem Mapping. RemoteSensing,7(7):8489–8515.
MinisteriodeJusticia(1981).DecretoFuerzadeLey1122.FijaTextodelCódigode Aguas.
Mohamedi,M.(2019). AssessingTheTransferabilityOfRandomForestAndTimeWeightedDynamicTimeWarpingForAgricultureMapping.TesisdeMaestría, UniversityofTwente,Enschede,PaísesBajos.
Müller,A.yGuido,S.(2016). IntroductiontoMachineLearningwithPython:AGuide forDataScientists.Sebastopol,CA.
Murphy,K.P.(2022). ProbabilisticMachineLearning:AnIntroduction.MITPress.
Nadi,A.yMoradi,H.(2019).Increasingtheviewsandreducingthedepthinrandom forest. ExpertSystemswithApplications,138:112801.
Navalgund,R.R.,Jayaraman,V.,yRoy,P.S.(2007).Remotesensingapplications:An overview. CurrentScience,93(12):1747–1766.
Niazmardi,S.,Homayouni,S.,Safari,A.,McNairn,H.,Shang,J.,yBeckett,K.(2018). Histogrambasedspatiotemporalfeatureclassificationofvegetationindicestimeseriesforcropmapping. InternationalJournalofAppliedEarthObservationand Geoinformation,72:34–41.
Nicolau,A.P.,Dyson,K.,Saah,D.,yClinton,N.(2024).AccuracyAssessment:QuantifyingClassificationQuality.EnCardille,J.A.,Crowley,M.A.,Saah,D.,yClinton, N.E.,editores, CloudBasedRemoteSensingwithGoogleEarthEngine:FundamentalsandApplications,pp.135–145.SpringerInternationalPublishing,Cham. Noshiri,N.,Beck,M.A.,Bidinosti,C.P.,yHenry,C.J.(2023).Acomprehensivereviewof 3Dconvolutionalneuralnetworkbasedclassificationtechniquesofdiseasedand defectivecropsusingnonUAVbasedhyperspectralimages. SmartAgricultural Technology,5:100316.
Nowakowski,A.,Mrziglod,J.,Spiller,D.,Bonifacio,R.,Ferrari,I.,Mathieu,P.P.,GarciaHerranz,M.,yKim,D.H.(2021).Croptypemappingbyusingtransferlearning. InternationalJournalofAppliedEarthObservationandGeoinformation,98:102313.
Olofsson,P.,Foody,G.M.,Herold,M.,Stehman,S.V.,Woodcock,C.E.,yWulder, M.A.(2014).Goodpracticesforestimatingareaandassessingaccuracyofland change. RemoteSensingofEnvironment,148:42–57.
Olofsson,P.,Foody,G.M.,Stehman,S.V.,yWoodcock,C.E.(2013).Makingbetter useofaccuracydatainlandchangestudies:Estimatingaccuracyandareaand quantifyinguncertaintyusingstratifiedestimation. RemoteSensingofEnvironment, 129:122–131.
Palchowdhuri,Y.,ValcarceDiñeiro,R.,King,P.,ySanabriaSoto,M.(2018).Classificationofmultitemporalspectralindicesforcroptypemapping:Acasestudyin Coalville,UK. TheJournalofAgriculturalScience,156(1):24–36.
Pedregosa,F.,Varoquaux,G.,Gramfort,A.,Michel,V.,Thirion,B.,Grisel,O.,Blondel, M.,Prettenhofer,P.,Weiss,R.,Dubourg,V.,Vanderplas,J.,Passos,A.,Cournapeau,D.,Brucher,M.,Perrot,M.,yDuchesnay,É.(2011).Scikitlearn:Machine LearninginPython. TheJournalofMachineLearningResearch,12(null):2825–2830.
Pelletier,C.,Valero,S.,Inglada,J.,Champion,N.,yDedieu,G.(2016).Assessing therobustnessofRandomForeststomaplandcoverwithhighresolutionsatellite imagetimeseriesoverlargeareas. RemoteSensingofEnvironment,187:156–168.
Peng,Q.,Shen,R.,Dong,J.,Han,W.,Huang,J.,Ye,T.,Zhao,W.,yYuan,W.(2023). Anewmethodforclassifyingmaizebycombiningthephenologicalinformationof multiplesatellitebasedspectralbands. FrontiersinEnvironmentalScience,10.
Petitjean,F.,Inglada,J.,yGancarski,P.(2012).SatelliteImageTimeSeriesAnalysis UnderTimeWarping. IEEETransactionsonGeoscienceandRemoteSensing, 50(8):3081–3095.
Piedelobo,L.,HernándezLópez,D.,Ballesteros,R.,Chakhar,A.,DelPozo,S., GonzálezAguilera,D.,yMoreno,M.A.(2019).ScalablepixelbasedcropclassificationcombiningSentinel2andLandsat8datatimeseries:Casestudyofthe Dueroriverbasin. AgriculturalSystems,171:36–50.
Rabiner,L.R.yJuang,B.H.(1993). FundamentalsofSpeechRecognition.PTR PrenticeHall,EnglewoodCliffs,N.J.
Rakhlin,A.,Davydow,A.,yNikolenko,S.(2018).LandCoverClassificationfromSatelliteImagerywithUNetandLovászSoftmaxLoss.En 2018IEEE/CVFConference onComputerVisionandPatternRecognitionWorkshops(CVPRW),pp.257–2574.
Ramezan,C.,Warner,T.,Maxwell,A.,yPrice,B.(2021).EffectsofTrainingSetSize onSupervisedMachineLearningLandCoverClassificationofLargeAreaHighResolutionRemotelySensedData. RemoteSensing,13:368.
Ranabhat,K.,Patrikeev,L.,Revina,A.,Andrianov,K.,Lapshinsky,V.,ySofronova,E. (2016).Anintroductiontosolarcelltechnology. JournalofAppliedEngineering Science,14(4):481–491.
Rawat,A.,Kumar,A.,Upadhyay,P.,yKumar,S.(2021).Deeplearningbasedmodels fortemporalsatellitedataprocessing:Classificationofpaddytransplantedfields. EcologicalInformatics,61:101214.
Reddy,D.S.(2017).CropTypeIdentificationandClassificationbyReflectanceUsing SatelliteImages. InternationalJournalofResearchandScientificInnovation,4(5).
Richards,J.A.(2012). RemoteSensingDigitalImageAnalysis:AnIntroduction.Springer,Berlin,edición:5thed.2013edición.
Richards,J.A.(2013).ImageClassificationinPractice.En RemoteSensingDigital ImageAnalysis,pp.381–435.SpringerBerlinHeidelberg.
Rogan,J.yChen,D.(2004).Remotesensingtechnologyformappingandmonitoring landcoverandlandusechange. ProgressinPlanning,61(4):301–325.
Ross,S.M.(2017).Chapter9TestingStatisticalHypotheses.EnRoss,S.M.,editor, IntroductoryStatistics(FourthEdition),pp.381–432.AcademicPress,Oxford.
Roy,D.P.,Li,Z.,yZhang,H.K.(2017).AdjustmentofSentinel2MultiSpectralIns
trument(MSI)RedEdgeBandReflectancetoNadirBRDFAdjustedReflectance (NBAR)andQuantificationofRedEdgeBandBRDFEffects. RemoteSensing, 9(12):1325.
Saha,A.,Sastry,S.,Dave,V.A.,yGhosh,R.(2020).EvaluationofTreeSpecies ClassificationMethodsusingMultiTemporalSatelliteImages.En 2020IEEELatin AmericanGRSS&ISPRSRemoteSensingConference(LAGIRS),pp.40–43.
Saini,R.(2023).IntegratingVegetationIndicesandSpectralFeaturesforVegetation MappingfromMultispectralSatelliteImageryUsingAdaBoostandRandomForestMachineLearningClassifiers. GeomaticsandEnvironmentalEngineering, 17(1):57–74.
Salgado,C.M.,Azevedo,C.,Proença,H.,yVieira,S.M.(2016).MissingData.EnMIT CriticalData,editor, SecondaryAnalysisofElectronicHealthRecords,pp.143–162.SpringerInternationalPublishing,Cham.
Shao,G.,Tang,L.,yLiao,J.(2019).Oversellingoverallmapaccuracymisinformsabout researchreliability. LandscapeEcology,34(11):2487–2492.
Sharma,N.,Jain,V.,yMishra,A.(2018).AnAnalysisOfConvolutionalNeuralNetworks ForImageClassification. ProcediaComputerScience,132:377–384.
Sheykhmousa,M.,Mahdianpari,M.,Ghanbari,H.,Mohammadimanesh,F.,Ghamisi, P.,yHomayouni,S.(2020).SupportVectorMachineVersusRandomForestfor RemoteSensingImageClassification:AMetaAnalysisandSystematicReview. IEEEJournalofSelectedTopicsinAppliedEarthObservationsandRemoteSensing,13:6308–6325.
Sidike,P.,Asari,V.K.,ySagan,V.(2018).ProgressivelyExpandedNeuralNetwork (PENNet)forhyperspectralimageclassification:Anewneuralnetworkparadigm forremotesensingimageanalysis. ISPRSJournalofPhotogrammetryandRemote Sensing,146:161–181.
Silverman,BernardW.,P.J.G.(1993). NonparametricRegressionandGeneralized LinearModels:ARoughnessPenaltyApproach.ChapmanandHall/CRC,New York.
Simoes,R.,Pletsch,M.,Santos,L.,Câmara,G.,yMaus,V.(28a31deMayode2017). Satellitemultisensorspatiotemporalanalysis:ATWDTWpreviewapproach.En AnaisDoXVIIISimpósioBrasileirodeSensoriamentoRemotoSBSR,SaoPaulo. Simonneaux,V.,Duchemin,B.,Helson,D.,ErRaki,S.,Olioso,A.,yChehbouni,A.G. (2008).Theuseofhighresolutionimagetimeseriesforcropclassificationand evapotranspirationestimateoveranirrigatedareaincentralMorocco. International JournalofRemoteSensing,29(1):95–116.
Singh,R.K.,Rizvi,J.,Behera,M.D.,yBiradar,C.(2021).Automatedcroptypemapping usingtimeweighteddynamictimewarpingAbasistoderiveinputsforenhanced foodandNutritionalSecurity. CurrentResearchinEnvironmentalSustainability, 3:100032.
Sisodia,P.S.,Tiwari,V.,yKumar,A.(2014).AnalysisofSupervisedMaximumLikelihoodClassificationforremotesensingimage.En InternationalConferenceon RecentAdvancesandInnovationsinEngineering(ICRAIE2014),pp.1–4,Jaipur.
Sitokonstantinou,V.,Papoutsis,I.,Kontoes,C.,LafargaArnal,A.,ArmestoAndrés, A.P.,yGarrazaZurbano,J.A.(2018).ScalableParcelBasedCropIdentificationSchemeUsingSentinel2DataTimeSeriesfortheMonitoringoftheCommon AgriculturalPolicy. RemoteSensing,10(6):911.
Skakun,S.,Wevers,J.,Brockmann,C.,Doxani,G.,Aleksandrov,M.,Batič,M.,Frantz, D.,Gascon,F.,GómezChova,L.,Hagolle,O.,LópezPuigdollers,D.,Louis,J., Lubej,M.,MateoGarcía,G.,Osman,J.,Peressutti,D.,Pflug,B.,Puc,J.,Richter,R.,Roger,J.C.,Scaramuzza,P.,Vermote,E.,Vesel,N.,Zupanc,A.,yŽust, L.(2022).CloudMaskIntercomparisoneXercise(CMIX):Anevaluationofcloud maskingalgorithmsforLandsat8andSentinel2. RemoteSensingofEnvironment, 274:112990.
Song,J.,Gao,S.,Zhu,Y.,yMa,C.(2019).AsurveyofremotesensingimageclassificationbasedonCNNs. BigEarthData,3(3):232–254.
Stehman,S.V.(1997).Selectingandinterpretingmeasuresofthematicclassification accuracy. RemoteSensingofEnvironment,62(1):77–89.
Stolz,J.,Forkel,M.,vanderMaaten,E.,Martin,J.,yvanderMaatenTheunissen,M. (2023).Througheagleeyes—thepotentialofsatellitederivedLAItimeseriesto estimatemastingeventsandtreeringwidthofEuropeanbeech. RegionalEnvironmentalChange,23(2):74.
Strub,P.T.,James,C.,Montecino,V.,Rutllant,J.A.,yBlanco,J.L.(2019).Ocean circulationalongthesouthernChiletransitionregion(38◦–46◦S):Mean,seasonal andinterannualvariability,withafocuson2014–2016. ProgressinOceanography, 172:159–198.
Suwanda,R.,Syahputra,Z.,yZamzami,E.M.(2020).AnalysisofEuclideanDistance andManhattanDistanceintheKMeansAlgorithmforVariationsNumberofCentroidK. JournalofPhysics:ConferenceSeries,1566(1):012058.
Tarrio,K.,Tang,X.,Masek,J.G.,Claverie,M.,Ju,J.,Qiu,S.,Zhu,Z.,yWoodcock,C.E. (2020).ComparisonofclouddetectionalgorithmsforSentinel2imagery. Science ofRemoteSensing,2:100010.
Teixeira,I.,Morais,R.,Sousa,J.J.,yCunha,A.(2023).DeepLearningModelsforthe
ClassificationofCropsinAerialImagery:AReview. Agriculture,13(5):965.
Thapa,S.,GarciaMillan,V.E.,yEklundh,L.(2021).AssessingForestPhenology: AMultiScaleComparisonofNearSurface(UAV,SpectralReflectanceSensor, PhenoCam)andSatellite(MODIS,Sentinel2)RemoteSensing. RemoteSensing, 13(8):1597.
Tibshirani,R.J.,B.E.(1994). AnIntroductiontotheBootstrap.ChapmanandHall/CRC, NewYork.
Trelinski,J.yKwolek,B.(2021).CNNbasedandDTWfeaturesforhumanactivity recognitionondepthmaps. NeuralComputingandApplications,33(21):14551–14563.
Tziokas,N.,Zhang,C.,Drolias,G.C.,yAtkinson,P.M.(2023).Downscalingsatellitenighttimelightsimagerytosupportwithincityapplicationsusingaspatially nonstationarymodel. InternationalJournalofAppliedEarthObservationandGeoinformation,122:103395.
vanderMaaten,L.yHinton,G.(2008).VisualizingDatausingtSNE. JournalofMachineLearningResearch,9(86):2579–2605.
Viana,C.M.,Girão,I.,yRocha,J.(2019).LongTermSatelliteImageTimeSeriesfor LandUse/LandCoverChangeDetectionUsingRefinedOpenSourceDataina RuralRegion. RemoteSensing,11(9):1104.
Villodre,J.,Campos,I.,LopezCorcoles,H.,GonzalezPiqueras,J.,González,L.,Bodas,V.,SanchezPrieto,S.,Osann,A.,yCalera,A.(2017).MappingOptimum NitrogenCropUptake. AdvancesinAnimalBiosciences,8(2):322–327.
Vorobiova,N.yChernov,A.(2017).CurvefittingofMODISNDVItimeseriesinthetask ofearlycropsidentificationbysatelliteimages. ProcediaEngineering,201:184–195.
Wang,H.,Chang,W.,Yao,Y.,Yao,Z.,Zhao,Y.,yLiu,Z.(2023).Cropformer:Anew generalizeddeeplearningclassificationapproachformultiscenariocropclassification. FrontiersinPlantScience,14:1130659.
Xiao,X.,Jiang,L.,Liu,Y.,yRen,G.(2023).LimitedSamplesBasedCropClassification UsingaTimeWeightedDynamicTimeWarpingMethod,Sentinel1Imagery,and GoogleEarthEngine. RemoteSensing,15(4):1112.
YzarraTito,W.J.yLópezRíos,F.M.(2017).Manualdeobservacionesfenológicas. RepositorioInstitucionalSENAMHI
Zhang,H.K.,Roy,D.P.,yLuo,D.(2023).Demonstrationoflargearealandcover classificationwithaonedimensionalconvolutionalneuralnetworkappliedtosingle
pixeltemporalmetricpercentiles. RemoteSensingofEnvironment,295:113653.
Zhang,X.,Yan,G.,Li,Q.,Li,Z.L.,Wan,H.,yGuo,Z.(2006).Evaluatingthefraction ofvegetationcoverbasedonNDVIspatialscalecorrectionmodel. International JournalofRemoteSensing,27(24):5359–5372.
Zhang,Z.,Tang,P.,Hu,C.,Liu,Z.,Zhang,W.,yTang,L.(2022).SeededClassificationof SatelliteImageTimeSerieswithLowerBoundedDynamicTimeWarping. Remote Sensing,14(12):2778.
ANEXOS A ACCESOADATOS Elpresenteestudiofuedesarrolladoenellenguajedeprogramación R y Python.El códigofuenteutilizadoparaelanálisisdeesteestudioseencuentradisponibleenun repositoriodeGitHubenelsiguienteenlace:
https://github.com/aldotapia/S2-classification.
Dentrodeesterepositorioseencuentraunresumendelanálisisyelcódigoparadescargaryprocesarlasimágenesdesatélite,asícomoelcódigoparaelanálisisdelos clasificadores.
Losdatosutilizadosparaelanálisisdeesteestudionoseencuentrandisponiblespara descargaporeltamañodelosarchivos.Enelmismorepositorioseencuentranlos metadatosdelosdatosoriginalesparapoderreplicarelanálisis.
B CAJADELIMITADORADEREFERENCIAPARAELÁREADEES TUDIO ArchivoenformatogeoJSONquedelimitaeláreadeestudio.Estearchivoseutilizópara descargarlasimágenesdesatéliteyparadelimitareláreadeestudioenelanálisisde clasificación.
{ { ”type”:”FeatureCollection”, ”name”:”footprint”, ”crs”:{”type”:”name”,”properties”: {”name”:”urn:ogc:def:crs:OGC:1.3:CRS84”}}, ”features”:[ {”type”:”Feature”,”properties”:{},”geometry”: { ”type”:”Polygon”, ”coordinates”: [[[−71.655,−31.343], [−71.655,−30.173], [−70.416,−30.173], [−70.416,−31.343], [−71.655,−31.343]]]}} ] } }
Anexo1: Característicasdelosdistritosagroclimáticospresenteseneláreade estudio.
Déficithídrico
Evapotranspiraciónanual(mm)
Precipitaciónanual(mm)
NumeroTotaldeheladas (N°dediasconT<0°C)
Sumadehoras defrioanuales
Sumadías gradosanuales
Temperaturamínimajulio(°C)
Temperaturamáximajulio(°C)
Temperaturamínimadeenero(°C)
Temperaturamáximaenero(°C)
Nombre
Anexo2: NDVI delaclase almond para20muestrasalazar.
Anexo3: NDVI delaclase avocado para20muestrasalazar.
Anexo4: NDVI delaclase barren para20muestrasalazar.
Anexo5: NDVI delaclase barrenshadowed para20muestrasalazar.
Anexo6: NDVI delaclase forage para20muestrasalazar.
Anexo7: NDVI delaclase industrialgrape para20muestrasalazar.
Anexo8: NDVI delaclase lemon para20muestrasalazar.
Anexo9: NDVI delaclase mandarin para20muestrasalazar.
Anexo10: NDVI delaclase olive para20muestrasalazar.
Anexo11: NDVI delaclase orange para20muestrasalazar.
Anexo12: NDVI delaclase riversidevegetation para20muestrasalazar.
Anexo13: NDVI delaclase shortcyclecrop para20muestrasalazar.
Anexo14: NDVI delaclase tablegrape para20muestrasalazar.
Anexo15: NDVI delaclase urban para20muestrasalazar.
Anexo16: NDVI delaclase walnut para20muestrasalazar.
Anexo17: NDVI delaclase water para20muestrasalazar.
Anexo18: Gráficodecajadeladistanciaentrecadamuestraylamuestramás cercanaporclase,grupo NDVI.
Anexo19: Gráficodecajadeladistanciaentrecadamuestraylamuestramás cercanaporclase,grupobandas.
Anexo20: Gráficodecajadeladistanciaentrecadamuestraylamuestramás cercanaporclase,grupobandas+ NDVI.
Anexo21: Gráficodelafuncióndepérdida(categoricalcrossentropy)paralos datosdeentrenamientoyvalidacióndelexperimento25,grupo2,paraelclasificador ANN.