
28 minute read
3.3 METODOLOGÍA APLICADA

from 40832

3.3.1 Recopilación de datos
Para cumplir con los objetivos de esta investigación se consideró utilizar tres fuentes de datos referentes a los incendios forestales además de información base para la elaboración de mapas.
Advertisement
3.3.1.1 Datos de incendios forestales - SNGRE
En primera instancia se obtuvo los datos generados por el SNGRE, que se encuentran disponibles en su geoportal (https://informacion.gestionderiesgos.gob.ec:8443/centrodedescarga/contenidos/); dentro del cual es posible descargar datos geográficos de diversos eventos peligros a nivel nacional (incendios forestales, inundaciones, movimientos en masa, volcanes, tsunamis y sequías), dicha información está disponible a nivel nacional en formato shapefile. En el caso de esta investigación se obtuvo los datos correspondientes a “Incendios Forestales”.
3.3.1.2 Datos de focos de calor - FIRMS
Por otro lado, se han obtenido los datos de incendios activos "near real-time (NRT)"; es decir en tiempo casi real que se encuentran disponibles en la plataforma de FIRMS ( https://firms.modaps.eosdis.nasa.gov/). Dentro de dicha plataforma es posible obtener los datos disponibles de los incendios activos o focos de calor que se han generado de la observación satelital desde el espectro-radiómetro de imágenes de resolución moderada (MODIS) a bordo de los satélites Aqua y Terra, y el conjunto de radiómetros de imágenes infrarrojas visibles (VIIRS) a bordo del S-NPP y NOAA 20 (formalmente conocido como JPSS1).
La plataforma facilita los datos en formatos shapefiles (.shp), comma-separated text files (.csv) y JSON files (.json), para fines de esta investigación se descargó los archivos en formato shapefile a nivel de país, siendo una de las opciones que tiene la plataforma
3.3.1.3 Capas y referencia espacial
Las capas empleadas para esta investigación fueron generadas bajo la referencia espacial: WGS 1984 UTM Zone 17S. En la Tabla 5 se especifica mayor información de las capas utilizadas:
Tabla 5 Capas de información geográfica
3.3.1.4 Depuración de datos
Ma (2021) menciona que la tasa de error en la detección de incendios por sensores remotos se sitúa en torno al 4% para Sudamérica, según la robustez del rendimiento del algoritmo MCD14ML, en este sentido con la finalidad de evitar los posibles errores de comisión se consideró pertinente eliminar los focos de calor que tienen un nivel de confianza bajo.
Los focos de calor de MODIS se clasifican en tres categorías de nivel de confianza (Earthdata - NASA, 2021b): bajo (0-30%), medio (30-80%) y alto (80-100%), en este contexto se eliminaron aquellos focos de calor con nivel de confianza bajo y para fines de la investigación se utilizó aquellos datos con nivel de confianza medio y alto. Mientras que para los datos de VIIRS los valores de confianza se establecen bajo la clasificación bajo, nominal y alto (Earthdata - NASA, 2021b), asimismo se eliminaron los datos con nivel de confianza bajo y se mantuvo aquellos focos de calor con nivel de confianza nominal y alto.
3.3.2 Identificación de áreas con mayor ocurrencia de incendios forestales
Los incendios forestales se distribuyen de manera irregular sobre el territorio por lo cual es importante evaluar su comportamiento de manera integral Sin embargo, para términos de esta investigación se consideró inicialmente una exploración de los datos basado en el nivel administrativo, para conocer de manera general las áreas más afectadas en la provincia de Imbabura según la ocurrencia de incendios forestales
3.3.2.1 Análisis de densidad espacial
3.3.2.1.1 Unión espacial
Primeramente, se realizó un conteo de los incendios forestales a nivel cantonal, para ello se empleó la herramienta de “Unión Espacial” (SpatialJoin) que permitió la unión espacial de la capa que contiene la localización de los incendios forestales (tres fuentes) con la capa de los límites administrativos y esto generó una nueva cobertura que detalla cuantos incendios forestales ocurrieron por área administrativa.
En la nueva capa generada, en el campo “Join_Count” se tiene el número de incendios forestales, dicho dato se desplegó con simbología de color graduada para mostrar los niveles administrativos con mayor o menor ocurrencia de incendios. Este proceso se realizó para cada una de las tres capas de datos de incendios forestales y para el nivel administrativo mencionado previamente.
3.3.2.1.2 Densidad Kernel
Se ejecutó la herramienta “Densidad Kernel” (Kernel Density) de ArcGIS para cada una de las tres capas con los datos de incendios forestales. Para fines de esta investigación se mantuvieron los parámetros predefinidos por la herramienta a excepción del tamaño de celda de salida, el cual se definió de 100 m además se estableció el límite provincial como entidad de barrera.
3.3.3 Determinación de patrones de distribución espacial
Los incendios forestales se distribuyen de manera irregular en el territorio y se presentan de modo disperso en las demarcaciones territoriales (Blas, 2018), por ello antes de aplicar las herramientas de geoestadística es preciso definir cuál será el campo de análisis de los datos, siendo necesario la agregación de los datos de los incendios forestales. En el estudio realizado por Blas (2018) para el análisis estadístico se utilizó como geometría de análisis el nivel administrativo municipal y como unidad de medida se usó el número de incendios por hectárea. En cambio, en la investigación de Ma (2021) propone tres formas para realizar el análisis, la primera es usar el número de incendios por municipio a partir de la unión espacial de las capas correspondiente, la otra opción es crear una red de celdas rectangulares (Fishnet) en la que se pueden analizar los datos con áreas regulares y del mismo tamaño y la tercera forma es transformar la capa de puntos de los incendios forestales a una capa de datos de punto ponderados (Collect Events) de tal modo que el análisis se basa en los puntos donde existe una mayor ocurrencia de incendios. Además, según las recomendaciones de ArcGIS, al momento de aplicar métodos estadísticos, como lo es el análisis de clúster y valores atípicos; es indispensable contar con al menos 30 entidades de entrada para que los resultados sean fiables (ESRI, s/f).
En función de lo mencionado previamente, para fines de esta investigación se descartó la opción de analizar los datos según el nivel administrativo debido a la irregularidad de las superficies, lo que puede conllevar a interpretaciones erradas de los datos. La agregación de los datos se hizo a través de cuadrículas con formas regulares y se eligió aplicar una cuadrícula hexagonal, ya que los hexágono reducen el sesgo del muestreo, permite representar las curvas de los patrones de los datos de una manera más natural y una mayor probabilidad de encontrar un vecino cercano para el análisis (ESRI, s/f). La cuadrícula hexagonal se la generó utilizando la herramienta “Generar teselación” (Generate Tessellations), se escogió la forma tipo hexagonal, se asumió un tamaño de hexágono de 10 km² que es apropiado para este análisis, se definió la referencia espacial WGS_1984_UTM_Zone_17S y finalmente se fijó la extensión de la provincia de Imbabura como entorno de geoprocesamiento.
3.3.3.1 Análisis de patrones
3.3.3.1.1 Autocorrelación espacial – Índice global I de Moran
El análisis de autocorrelación espacial, es el punto de partida para precisar si el conjunto de datos presenta un patrón agrupado estadísticamente (ESRI, s/f) para ello se empleó el índice de I Moran, el cual oscila entre -1 y +1 y mientras más se acerca al cero implica que los patrones espaciales son aleatorios, mientas que los valores positivos apuntan a un agrupamiento de los datos y por el contrario valores negativos corresponden a datos dispersos. Este análisis se lo realizó con la herramienta “Autocorrelación Espacial” usando la cuadrícula hexagonal y como campo de entrada se usó el campo “Join_Count” (número de incendios por hexágono) y se ha aplicado la distancia inversa como parámetro de conceptualizado de las relaciones espaciales de tal manera que las entidades vecinas cercanas tienen una mayor influencia en los cálculos que las que están más lejos (Blas, 2018) y cómo método para el cálculo de las distancias se conservó la distancia euclidiana, es decir la línea recta entre dos puntos.
3.3.3.2 Asignación de clúster
3.3.3.2.1 Análisis de puntos calientes - G local de Getis Ord
Una vez que se ha comprobado que la distribución espacial de los incendios forestales no es aleatoria y por lo contrario presenta un patrón de agrupamiento, el siguiente paso en esta investigación es evidenciar donde se agrupan los puntos calientes y fríos estadísticamente significativos. La herramienta de “Análisis de Puntos Calientes” calcula la estadística Gi* de Getis Ord analizando el valor de una entidad relaciona con las entidades vecinas y si el valor de la función es alta tanto como el de las entidades vecinas entonces se determina como un punto caliente (Blas, 2018). Como lo menciona Ma (2021, pg. 65) “[...] un solo punto con un valor alto no es necesariamente un punto caliente. Se convierte en un punto caliente sólo cuando sus vecinos también tienen valores altos.” El estadístico calcula las puntuaciones z y los valores p para definir donde se agrupan los datos con valores altos y bajos. Si se tiene una puntuación de z alta y el valor de p es pequeño hace referencia a una agrupación de valores altos mientras que, si la puntuación z es negativa y baja, la agrupación es de valores bajos, pero si dicha puntuación se acerca a cero implica que no existe agrupación.
En este caso igualmente se usó la cuadrícula hexagonal como clase de entidad de entrada y el campo de análisis es “Join_Count”, las relaciones espaciales entre las entidades se definieron como banda de distancia fija, la que permite que todas las entidades dentro de la vecindad tengan el mismo peso y se mantuvo el método de cálculo de la distancia en línea recta es decir euclidiana.
3.3.3.2.2 Análisis de clúster y valor atípico - G global de Getis Ord
En los pasos anteriores ya se determinó que existe un agrupamiento de los datos analizados, así como también donde se encuentran concentrados los puntos altos y bajos. Finalmente para complementar la metodología propuesta se consideró analizar la existencia de valores atípicos Para ello se empleó la herramienta de “Análisis de clúster y de valor atípico”, la misma que está basada en la estadística de asociación espacial o Índice Anselin Local del Moran y que permite identificar clústeres espaciales de entidades con valores similares; muy parecido al “Análisis de Puntos Calientes” ; adicional a ello muestra los agrupamientos de los valores atípicos.
Los parámetros que se usó para esta herramienta fueron los mismos que para el análisis de puntos calientes, es decir el cálculo de la distancia es por método euclidiano y la relación espacio se mantuvo banda de distancia fija, el resto de parámetros se los dejo como viene predeterminado. La herramienta se aplicó para las tres capas con la cuadricula hexagonal y el número de incendios forestales.
El análisis genera una entidad de salida que define las posibles agrupaciones de los datos bajo cuatro combinaciones: Clúster de valores altos (HH), Clúster de valores bajos (LL), Valor atípico en el que un valor alto esta principalmente por valores bajos (HL) y por último Valor atípico en el que un valor bajo está rodeado principalmente por valores altos (LH) (Blas, 2018).
3.3.4 Comparación de resultados
Después de haber realizado los análisis espaciales para determinar los patrones espaciales de los incendios forestales en la provincia de Imbabura, para terminar esta investigación se realizó una comparación de los resultados que se obtuvo para cada uno de los conjuntos de datos analizados y con ello identificar si existe coherencia con los datos analizados.
Para valorar la coherencia de las tres fuentes de datos se lo hizo en dos momentos de la investigación. En un inicio, durante la fase de recopilación de datos, se evaluó el número de registros de incendios forestales/focos de calor que se registraba para cada conjunto de datos y por otro lado se estimó la temporalidad de los datos, con la ayuda de relojes de datos, para los cuales se analizó la información en base a los años y meses según el registro de incendios forestales.
En una segunda instancia, una vez efectuados los análisis geoestadísticos de los datos, se compararon los resultados obtenidos entre los tres conjuntos de datos y se definió similitudes y diferencias en el comportamiento de los datos.
4. RESULTADOS Y DISCUSIÓN
En esta sección se presenta los resultados obtenidos para cada uno de los análisis efectuados con el objetivo de dar respuestas a las preguntas de la investigación.
4.1 Resultados
4.1.1 Recopilación de datos
En la Figura 14 se muestra los mapas con la información de incendios forestales registrados por cada una de las fuentes de datos analizadas durante el período 2015 -2018 en la provincia de Imbabura.
A partir de los mapas generados, se analizó los datos en la tabla de atributos de cada una de las capas generadas, para cuantificar el número de eventos que registran anualmente, los cuales se muestran en la Tabla 6: Tabla 6 Ocurrencia de incendios forestales por año
De esto se puede percibir que los focos de calor del sensor VIIRS registró un mayor número de incidencias, a este le siguieron los datos de incendios forestales generados por la SNGRE con menos de la mitad y por último están los registros de focos de calor del sensor MODIS con muy pocos datos disponibles.

También se disgregó la información mensualmente; para ello se utilizó el gráfico de tipo reloj de datos que permite visualizar los datos temporales en dos dimensiones, para comprender los patrones temporales de los datos. Los resultados que se obtuvo para la estacionalidad de los incendios forestales de los datos de la SNGRE se muestran en la Figura 15a, donde se evidencia una baja ocurrencia de incendios durante los meses de febrero a mayo mientras que para los meses de junio a enero hay un incremento significativo de los incendios forestales sobre todo en los meses de agosto, septiembre y octubre con mayor intensidad para el año 2018. En el año 2017 los datos llaman la atención, pues presentan un patrón distinto al del resto de años analizados y son muy pocos los incendios forestales ocurridos en dicho año.

El reloj de datos resultante para los focos de calor del sensor MODIS, permite distinguir claramente la temporalidad de los incendios, que se caracteriza por ser muy baja durante el primer semestre del año Sin embargo, para el segundo semestre es evidente como cambia el comportamiento de los incendios forestales y hay un incremento importante más que todo en los meses de agosto a octubre en los años 2015 y 2018.
En la Figura 15a, se tiene los resultados para los focos de calor del sensor VIIRS que revelan la baja ocurrencia de incendios forestales durante los meses de enero a julio al igual que los datos de MODIS mientras que los siguientes meses hay un incremento sustancial del número de incendios; es así que en el mes de septiembre de 2015 se tiene el registro más alto de toda la serie. Para los años 2016 y 2018, hubo tres meses que se registró una alta ocurrencia de incendios.
4.1.2 Identificación de áreas con mayor ocurrencia de incendios forestales
4.1.2.1 Análisis de Densidad Espacial - Unión espacial
Para los datos de incendios forestales de la SNGRE, el conteo de incendios por cantón, se muestra en la Figura 16a, en la que se observa que el cantón Ibarra es el más afectado y donde existe mayor ocurrencia de incendios forestales a este le sigue el cantón Otavalo, mientras que en los cantones de Cotacachi, San Miguel de Urcuquí y Pimampiro se registra una menor cantidad de incendios en tanto que el cantón Antonio Ante es en que menos se registran incendios forestales en el periodo analizado.

En la Figura 16b, se muestra el resultado para el conteo de datos de los focos de calor del sensor MODIS y en este caso los cantones con mayor recurrencia de incendios fuero: Ibarra y Cotacachi y les sigue el cantón Otavalo. Los cantones San Miguel de Urcuquí y Pimampiro tuvieron una baja ocurrencia de incendios forestales y nuevamente se repite el cantón Antonio Ante que tuvo el menor número de incendios forestales.
Los focos de calor del sensor VIIRS detectados en el período analizado, arrojaron datos algo similares a los de MODIS, pues el cantón Cotacachi fue el más afectado y con menor intensidad los cantones Ibarra y Otavalo. En el cantón Antonio Ante, hubo menos incendios lo que es recurrente para las tres fuentes de datos (Ver Figura 16c).
4.1.2.2 Análisis de Densidad Espacial - Densidad Kernel
Como se mencionó anteriormente los mapas de densidad permiten visualizar de manera sencilla como se concentran los datos analizados de ocurrencia de incendios forestales Es así que se obtuvo el mapa de “Densidad Kernel” para los datos de incendios forestales de la SNGRE el cual se muestra en la Figura 17a, que la mayor parte de los incendios forestales se registraron en el sur centro de la provincia de Imbabura, principalmente en el cantón Otavalo y se van extendiendo con menor intensidad, en sentido noreste hacia el cantón Antonio Ante y al sur de Ibarra. Además, existen dos agregaciones de datos aisladas, una pequeña al norte de Ibarra y otro con una densidad alta a media al norte del cantón Pimampiro.
En el caso de los focos de calor de MODIS, el comportamiento de los datos es completamente diferente que los datos de la SNGRE, ya que la principal concentración de los incendios forestales se registró al norte de Imbabura como se visualiza en la Figura 17a, donde la mayor densidad de incendios esta al norte del cantón Ibarra ocupando una buena parte del territorio cantonal y que se extiende hacia el sur al cantón San Miguel de Urcuquí. Por otro lado, se obtuvo dos agregaciones, de muy alta y alta intensidad, en dos lugares puntuales: en el cantón Cotacachi al límite con el cantón San Miguel de Urcuquí y el otro es la sureste de Otavalo en el límite con el cantón Ibarra. En el cantón Cotacachi se observa concentración de densidades bajas desde el centro del cantón hacia el oeste.
Con relación a los datos de focos de calor del sensor VIIRS, los resultados de la densidad de los incendios forestales en la Figura 17c muestra que la mayor concentración de datos se encuentra al centro de Otavalo con una densidad muy alta siendo la más significativa para el cantón, pues al norte del cantón hay tres agregaciones de baja densidad.

4.1.3 Determinación de patrones de distribución espacial
4.1.3.1 Análisis de Patrones - Autocorrelación espacial (Índice global I de Moran)
Para determinar la distribución espacial de los incendios forestales en la provincia de Imbabura se usó la autocorrelación espacial en la cuadrícula hexagonal en base al número de incendios por hexágono.
Para los datos de los incendios forestales de la SNGRE se aplicó el análisis a partir de un umbral de distancia de 3379 47 m, la misma que permite que todas las entidades tengan al menos un vecino; y así se obtuvo un valor positivo del índice I de Moran de 0 498088, la puntuación de z 12.961028 y el valor de p fue de 0.000000. Dado que la puntuación de z fue mayor que 2.58 había menos de un 1% de probabilidades de que el patrón de agrupación fuera resultado del azar y por otro lado el valor p era estadísticamente significativo junto con la puntuación de z positiva, se puede dar por rechazada la hipótesis nula. Finalmente se pudo determinar que los incendios forestales de la SNGRE presentaron una distribución espacial agrupada como se observa en el reporte se muestra en la Figura
El reporte que se obtuvo para el análisis de los datos de los focos de calor del sensor MODIS se presenta en la Figura 19, donde se observa un valor positivo del índice I de Moran de 0.201825, la puntuación de z 3.961028 y el valor de p fue de 0.000000. Siguiendo las pautas mencionadas previamente con los datos de la SNGRE se pudo dar por rechazada la hipótesis nula lo que confirma que los datos presentaron estructuras espaciales estadísticamente significativas con tendencia a la concentración de áreas con incendios registrados.

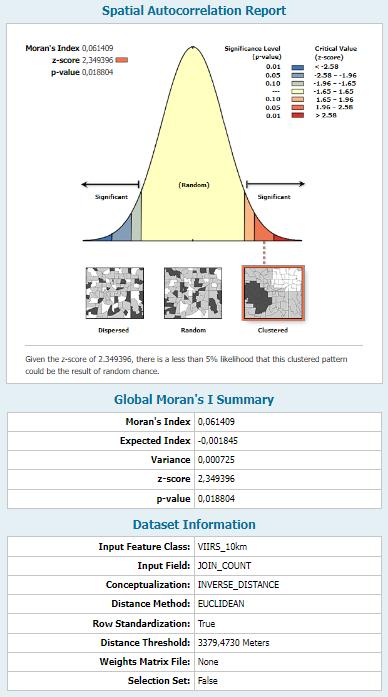
En cuanto al análisis aplicado para los focos de calor del sensor VIIRS (Ver Figura 20), se tuvo un valor positivo del índice I de Moran de 0 061409; el valor de p fue de 0 018804 y la puntuación de z 2.349396 y en el caso de este último valor determinó un nivel de confianza mayor al 95% que el patrón de agrupación fuera resultado del azar. Para esta fuente de datos también se ratificó que los datos presentaron una distribución espacial agrupada.

4.1.3.2
Los resultados obtenidos tras realizar el análisis de “Puntos Calientes” se muestra en la Figura 21a, se elaboró un mapa por cada una de las fuentes de datos estudiadas.
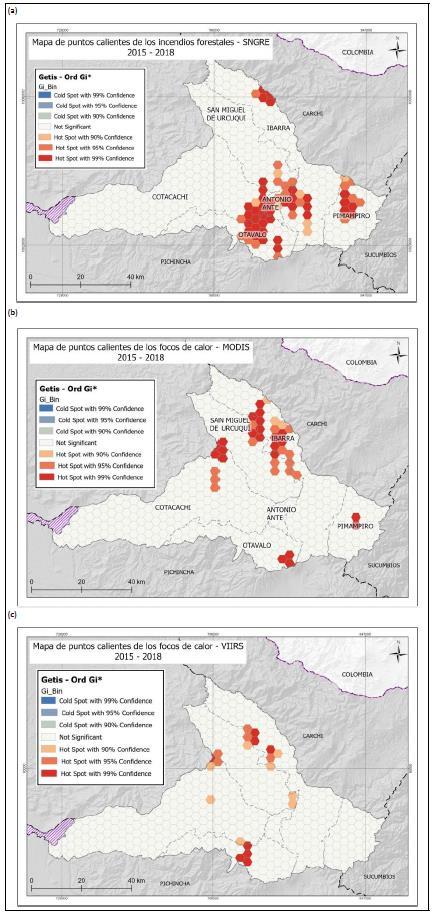
En el mapa de los puntos calientes de los incendios forestales de la SNGRE (Ver Figura 21), se muestra el resultado obtenido, en el que hubo cuatro puntos calientes con diferentes niveles de significación, el más grande de ellos se ubican al este del cantón Cotacachi y en el límite cantonal con Otavalo, ocupando la parte central de dicho cantón; avanzando hacia el oeste por el cantón Antonio Ante hasta llegar al sur de Ibarra. El otro punto se encuentra al norte del cantón Pimampiro, y el punto que le sigue está alejado del resto de puntos en la parte norte del cantón Ibarra, por último, se tiene un pequeño punto caliente al sur este de Otavalo. Para este análisis no se tuvo puntos fríos y en la mayor parte del territorio se ha definido como “No significativo”, es decir no se presentan patrones de significativos de agrupación.
Por otro lado, en la Figura 21b, se observa el resultado obtenido para los focos de calor del sensor MODIS, se puede indicar que para este conjunto de datos solo hubo concentración de puntos calientes que varía según el nivel de significancia, no hubo registro de puntos fríos y el resto de territorio no tuvo agrupación de datos estadísticamente significativos. En el mapa se observan seis puntos calientes localizados principalmente en los cantones Ibarra y San Miguel de Urcuquí y otros puntos calientes más aislados en Cotacachi, Pimampiro y Otavalo.
En el tercer mapa de la Figura 21, se tiene el resultado del análisis para los focos de calor del sensor VIIRS donde se repetí el mismo comportamiento de los datos de las otras dos fuentes de datos, pues solo se crearon grupos de puntos calientes; pero en este caso son mucho más pequeños, cuatro de ellos se encuentran en el límite cantonal del cantón San Miguel de Urcuquí tanto por el este, el oeste y el sur. En el cantón Otavalo hay un grupo de puntos calientes con un nivel de significancia del 99%.
4.1.3.3 Asignación de Clúster - Análisis de clúster y valor atípico (G global de Getis Ord)
Cuando se aplicó el “Análisis de clúster y valor atípico”, se obtuvo un mapa en el cual se despliega la información según el campo tipo clúster y valor atípico (COType), en el que se diferenciaron cuatro categorías con un nivel de confianza del 95%: en color rosado claro los clúster de valores altos (HH), en color celeste los clúster de valores bajos (LL), en color rojo un valor atípico en el que un valor alto está rodeado principalmente por valores bajos (HL) y por último en color celeste un valor atípico en el que un valor bajo está rodeado principalmente por valores altos (LH) (ESRI, s/f). Esto se muestra en los mapas resultantes presentados en la Figura 22.
En el primer mapa de los incendios forestales de la SNGRE se confirmó las zonas con alta concentración de incendios cómo se mostraba en el mapa de “Puntos Calientes”, principalmente en la parte centro del cantón y dirigiéndose hacia el oeste y una pequeña agrupación al norte del cantón Ibarra. No se registraron datos de puntos fríos. Bajo la clase de HL se tuvo un total de veintinueve hexágonos que se distribuyen al largo de todos los cantones y corresponden a valores atípicos con un alto número de incendios forestales pero que sus vecinos tienen valores bajos. En el centro de Otavalo se registró el único valor atípico LH, es decir un valor bajo con vecinos de valores altos.
El mapa del clúster y valores atípicos de los focos de calor de MODIS, se muestra en la Figura 22b, en este se obtuvo información similar que el análisis de “Puntos Calientes” pues en el norte de la provincia hay tres agrupamientos de puntos calientes y asimismo no se registraron puntos fríos. En el caso de los valores atípicos HL están dispersos a lo largo de toda la provincia y en mayor numero que los datos analizados previamente pues se tiene un total de cuarenta siete. Los valores atípicos LH alcanzan un total de diecisiete hexágonos y se distribuyen principalmente en los cantones de Ibarra y Cotacachi.
Para completar los análisis geoestadísticos de esta investigación, se obtuvo el mapa de clúster y valores atípico de los datos de focos de calor de VIIRS (Ver Figura 22c). En este caso es importante mencionar que los resultados que se generaron para las agrupaciones de puntos calientes, difieren un poco comparando con los resultados del análisis de “Puntos Calientes, dado que se registran tres hexágonos adicionales que antes no se los identificó como puntos calientes. Por otro este es el único resultado de los tres que ha generado puntos fríos, los mismos que se encuentran en los límites provinciales de los cantones de Pimampiro, San Miguel de Urcuquí así con al oeste del cantón Cotacachi. Solamente se obtuvo un total de cinco valores atípico del tipo HL en los cantones Cotacachi e Ibarra. Los valores atípicos del tipo LH son un total de diecinueve concentrados en la parte norte y sur de la provincia.

4.2 Análisis de resultados
En esta investigación se realizó un análisis de la distribución espacial de los incendios forestales en la provincia de Imbabura durante el período de 2015 a 2018; para ello se empleó técnicas geoestadísticas tales como la autocorrelación espacial, el análisis de puntos calientes y el análisis de clúster y valores atípicos. El proceso realizado se aplicó para tres fuentes de datos diferentes: los incendios forestales compilados por la SNGRE, los focos de calor del sensor MODIS y por último los focos de calor del sensor VIIRS.
A continuación, se da respuesta a las tres preguntas de investigación que orientaron este trabajo:
¿En dónde se concentran la mayor cantidad de incendios forestales en la provincia de Imbabura en el periodo de 2015 al 2018?
Como un primer acercamiento al análisis de los incendios forestales en la provincia de Imbabura se analizó el número de incidencias registradas a nivel cantonal y para cada una de las fuentes de datos utilizadas se obtuvo un resultado distinto.
Para los datos de la SNGRE se tiene que Ibarra es el cantón con un mayor número de incendios y a este le sigue el cantón Otavalo. Por otro lado, al analizar los datos de MODIS se tiene que los dos cantones con mayor número de incendios forestales son Ibarra y Cotacachi y con menor afectación está el cantón Otavalo y finalmente para los datos de VIIRS el comportamiento de los datos muestra que el cantón Cotacachi y con menor intensidad le sigue los cantones Ibarra y Otavalo.
En términos generales los incendios forestales se registran con mayor intensidad en los cantones Ibarra, Otavalo y Cotacachi, y en contraste el cantón con menor número de incendios forestales es Antonio Ante lo que se evidencia para las tres fuentes de datos. Es posible que la escala geográfica utilizada para este análisis no sea la más adecuada, ya que arroja la información para toda la unidad territorial y se pierde el contexto de la localización de los incendios forestales en la unidad territorial como tal, para obtener resultados un poco más detallados se podría utilizar la información a nivel parroquial lo que permitiría saber con mayor precisión en que áreas del cantón se registran los incendios.
Asimismo, paran complementar la respuesta a esta pregunta; se aplicó la densidad de kernel a las tres fuentes de datos, y esto generó resultados mucho más precisos ya que basados en la geolocalización de los incendios la herramienta suaviza la información y determina los lugares donde existen un mayor número de ocurrencia de incendios cercanos entre sí a nivel provincial. Los datos de la SNGRE presentaron una alta densidad de incendios forestales al este del cantón Otavalo que se extiende en dirección noroeste hacia los otros cantones, pero principalmente se concentran en la zona centro oriente de la provincia en tanto que el flanco oriental existe muy poco o es nula ocurrencia de incendios forestales. Por otro lado, se tiene que los datos de MODIS tienen una densidad muy alta al norte del cantón Ibarra que se extienden mayoritariamente por el mismo cantón y la parte oriental del cantón San Miguel de Urcuquí, además en la mayor parte del territorio se presentaron varias zonas densidades medias y altas. En cuanto a los datos de VIIRS a lo largo de la provincia hay una densidad muy baja de incendios forestales y solo existe una densidad alta en el cantón Otavalo.
Al momento de aplicar la herramienta de Densidad Kernel en los datos, hay que tener en cuenta que los resultados pueden variar significativamente según los parámetros que se utilice, y esto dependerá de las necesidades del usuario. Es necesario realizar varias pruebas hasta encontrar el tamaño de celda que se usa para este análisis, ya que por un lado esto puede resultar en que se suavice la curva en la superficie de salida de los datos analizados lo que beneficia para la visualización, pero por otro lado esto podría hacer que se excluyan algunos datos relevantes.
Conviene subrayar que, dadas las condiciones de este estudio, es decir que se han usado tres fuentes de datos no es posible dar una sola respuesta a la pregunta de investigación, como se ha podido evidenciar cada conjunto de datos arroja valores diferentes o hasta opuestos.
¿Cuáles son los patrones de distribución espacial de los incendios forestales en la provincia de Imbabura en el periodo de 2015 al 2018?
En primer lugar, los resultados obtenidos para la autocorrelación espacial muestran la tendencia a la concentración de los incendios forestales para las tres fuentes de datos, aunque no se en las mismas zonas como se evidenció con los resultados de la densidad de los incendios previamente. Para los datos de la SNGRE y de MODIS se puede confirmar que la concentración de los incendios forestales no es aleatoria con un nivel de significancia del 99% a diferencia de los datos de VIIRS que mostraron un nivel de confianza de 95%.
Una vez que se comprobó que hay un patrón de agrupamiento para los incendios forestales, fue posible continuar con los puntos calientes y los valores atípicos, pero antes de eso fue necesario definir la formar de agregar los datos para el respectivo análisis. Aquí se tuvo ciertas consideraciones para el caso de estudio, primeramente, se usaría la ubicación de los incendios forestales pero la herramienta de análisis de “Puntos Calientes” requiere hacer el análisis de una variable ponderada, por lo que se tuvo en cuenta la recomendación de ESRI y se aplicó la herramienta “Recopilar eventos” para las tres fuentes de datos. Sin embargo, el resultado no fue el esperado, pues por la naturaleza de los datos hubo muy pocos eventos que se localizarán en la misma ubicación por tal razón la mayoría de los eventos tenían una ponderación de 1 y no había variabilidad en los datos. No fue posible usar este campo, pues la herramienta lo rechazó.
En este sentido se optó por agregar los datos en una cuadrícula hexagonal, pues esta forma reduce el sesgo del muestreo y tiene una mayor probabilidad de encontrar un vecino cercano como se mencionó previamente, de este modo se usó como dato ponderado el conteo de incendios forestales registrados dentro de cada hexágono. Otra de las consideraciones es que para esta investigación se atribuyó usar un hexágono de 10km², es importante precisar que el hecho de optar por otro tamaño o ya sea otra forma de cuadrícula evidentemente los resultados serán diferentes, en este contexto para otros estudios se puede tener la consideración de hacer varias pruebas previas para definir la agregación de los datos o ya bien sea usar varios escenarios de análisis Y otra consideración fue que para el uso de las herramientas de geoestadística es necesario tener al menos 30 entidades para que el análisis sea fiable y en el caso de la cuadrícula hexagonal se cuenta con 543 entidades.
En cuanto al análisis de puntos calientes los resultados muestran que para las tres fuentes de datos únicamente se obtuvo concentración de puntos calientes con diferentes niveles de confianza y no se registraron puntos fríos para ninguno de los casos. En este caso en particular, si no se conoce a profundidad los datos se podría considerar la opción de realizar el análisis con la herramienta de “Puntos Caliente Optimizado”, dicha herramienta define los parámetros de manera eficaz y no es necesario agregar los datos pues la herramienta lo hace automáticamente.
Para terminar, se aplicó el análisis de clúster y valor atípico el cual resulta fundamental para complementar los resultados obtenidos con el análisis previo. El resultado de los datos de la SNGRE presenta los mismos puntos calientes del análisis previo y la ausencia de puntos fríos, sin embargo, hay varios valores atípicos altos rodeados por valores bajos que están dispersos por la provincia de Imbabura y en su mayoría distantes a los puntos calientes. Existe un solo registro de valor atípico bajo rodeado de valores altos al sur del punto caliente en el cantón Otavalo.
Ahora bien, para los datos de MODIS, los resultados son muy interesantes, se mantiene los mismos puntos calientes definidos previamente, pero en este caso hay un mayor número de valores atípicos altos rodeados de valores bajos que están un tanto más agrupado en comparación con los datos de la SNGRE, también es notorio la presencia de valores típicos bajos rodeados de valores altos los que se encuentran cerca de puntos calientes en su gran mayoría.
Por último, los resultados de los datos de VIIRS, se mantiene los mismos puntos calientes, pero para este único caso, el análisis arroja puntos fríos que anteriormente no se consideraron y están en los limites cantonales en el cantón Pimampiro, San Miguel de Urcuquí y al oeste de Cotacachi. Los valores atípicos altos rodeados de valores bajos son muy pocos en comparación con los otros dos tipos de datos y para los valores atípicos bajos rodeados de altos se localizan junto a los puntos calientes.
Esta investigación se enfocó en explorar la distribución espacial de los incendios forestales basados puntualmente en la localización de estos y validar diferentes fuentes de datos, no obstante, se ha dejado por fuera el análisis de otras variables que intervienen en la ocurrencia de incendios como por ejemplo: la cercanía a vías o centros poblados, la cobertura de suelo, la disponibilidad de combustibles, las condiciones climatológicas entre tantas otras y que son necesarias para entender los patrones espaciales con mayor detalle.
¿Existe relación en los datos generados sobre los incendios forestales en la provincia de Imbabura en el periodo de 2015 al 2018 tanto por la SNGRE (a nivel nacional) y los datos de los focos de calor de la plataforma FIRMS?
Desde un inicio de esta investigación, el interés de comprender el comportamiento de los incendios forestales se originó desde dos perspectivas, por un lado, el hecho de saber que Imbabura es una de las provincias más afectadas por los incendios forestales y por otro lado por la escaza información que existe sobre la temática a nivel nacional. Posiblemente la falta de información afecta en las tareas de prevención y control de incendios forestales de los entes responsables. En este contexto el estudio se encamino para evaluar la información generada a nivel nacional por la SNGRE y contrastarla con los datos generados por sensores remotos.
Partiendo desde el acceso a los datos vale mencionar que, a la fecha de esta investigación, la SNGRE es el ente encargado de compilar los datos y estadísticas de los incendios forestales, sin embargo, no existe un repositorio actualizado donde se pueda encontrar la información abiertamente. Para fines de esta investigación se accedió al archivo disponible en la página web de la SNGRE, en el cual hay datos hasta el año 2018 y justamente esta ha sido la razón para delimitar el análisis para el periodo de cuatro años. En reiteradas ocasiones se solicitó el acceso a información actualizada de incendios forestales, pero lastimosamente no se tuvo éxito. Por otro lado, la información de los sensores remotos se encuentra disponible en la plataforma FIRMS y es de fácil acceso, no obstante, la información está condicionada a la funcionalidad de los satélites y sensores, así como su vigencia y temporalidad de adquisición de los datos.
Con relación a los datos obtenidos para cada una de las fuentes de datos, se evidenció que estos conjuntos de datos difieren el uno del otro como se puede visualizar en los mapas de la sección 4.1.1., que a simple vista la distribución de los incendios o focos de calor presentan diferentes patrones. Los datos de la SNGRE se concentran principalmente al centro del cantón Ibarra y se orientan hacia el noroeste con un total de 507 eventos, por otro lado los 297 datos del sensor MODIS se muestran dispersos por la mayor parte del territorio provincial a excepción de la parte oriental del cantón Cotacachi y el norte de San Miguel de Urcuquí, igualmente los datos de VIIRS presentan una distribución de los datos muy similar a la de MODIS pero la diferencia es que este otro sensor tiene un mayor de número de ocurrencias de incendios forestales en el período analizado sumando un total de 1297 registros. Esta distribución de los datos, indudablemente condicionaron a los resultados obtenidos para los análisis geoestadísticos realizados para este estudio.
De manera muy breve se analizó la temporalidad de los datos a través de relojes de datos, de los resultados obtenidos se puede generalizar que para las tres fuentes de datos hay dos épocas para los incendios forestales, la primera que va de enero a junio donde no hay mayor ocurrencia de incendios forestales en la provincia de Imbabura y la otra época que va de julio a diciembre, en la que hay mayor ocurrencia de incendios sin embargo los meses con mayor incidencia son agosto, septiembre y octubre. Esta temporalidad de los incendios forestales está estrechamente vinculada a las estaciones húmedas y secas, que para la sierra ecuatoriana la estación húmeda va de octubre a mayo y mientras que la estación seca va de junio a septiembre. Con esto quiero decir que la época más intensa de incendios (julio a diciembre) empieza con la estación seca y avanza hasta la mitad de la estación húmeda.
Este patrón señalado previamente, se repite en los años 2015, 2016 y 2018 pero en el 2017 el comportamiento de los incendios forestales es muy diferente, pues durante el año solo hay dos meses que se registra incendios forestales y en comparación con el resto de los años el número de ocurrencias es muy baja. A lo mejor esto responde a los patrones que se hace referencia con períodos de cada 3 años, y posterior a un año húmedo, el siguiente año es probable que tenga una alta afectación
Otro aspecto a considerar al evaluar los datos de este estudio es que la información de la SNGRE se basa en el registro que se tiene a partir del aviso de un posible incendio a las autoridades competentes, así como del control del mismo. Probablemente hay una gran cantidad de eventos que nos son registrados ya sea porque no se dio aviso, o no hubo intervención de control por las entidades responsables o incluso en algunos casos se originan en zonas poco concurridas o son inasequibles. Mientras que para los focos de calor el algoritmo permita que detecte un punto de la superficie que presenta una temperatura elevada en comparación a los pixeles vecinos, esto a su vez puede significar un potencial incendio, pero a su vez puede tratarse de otro tipo de evento o incluso falsas alarmas. En definitiva, para comprender la relación de los datos sería necesario hacer un análisis más profundo que permita evaluar si los mismos eventos se registrar para diferentes fuentes de datos. Considero que los datos de los sensores remotos deben ser usados primordialmente para complementar la información de incendios forestales que se genera a nivel nacional, así como también para diseñar programas de alerta temprana que faciliten las acciones de prevención y mitigación de incendios forestales.

