Master Thesis ǀ Tesis de Maestría
submitted within the UNIGIS MSc programme presentada para el Programa UNIGIS MSc

at/en
Interfaculty Department of Geoinformatics- Z_GIS
Departamento de Geomática – Z_GIS
University of Salzburg ǀ Universidad de Salzburg
Categorización de daños geo-referenciados de los ejes viales de la ciudad Quito, Ecuador usando algoritmos de Inteligencia Artificial y Python.
Classification of georeferenced damages of the road axes of the city Quito, Ecuador using Artificial Intelligence algorithms and Python.
by/por
Ing. Norman Ismael Orellana Ulloa
11938289
A thesis submitted in partial fulfilment of the requirements of the degree of Master of Science (Geographical Information Science y Systems) – MSc (GIS)
Advisor ǀ Supervisor: Leonardo Zurita Arthos PhD
Quito - Ecuador, 20/10/2022
COMPROMISO DE CIENCIA
Por medio del presente documento, incluyendo mi firma personal certifico y aseguro que mi tesis es completamente resultado de mi propio trabajo. He citado todas las fuentes que he usado en mi tesis y en todos los casos he indicado su origen.
 Quito, 20 de octubre 2022 Firma
Quito, 20 de octubre 2022 Firma
AGRADECIMIENTOS
Quiero expresar mi gratitud a Dios, quien con su bendición llena siempre mi vida y a toda mi familia por estar siempre presentes.
Mi profundo agradecimiento a todas las autoridades y personal que forman parte de la UNIGIS, por confiar en mí, abrirme las puertas y permitirme realizar todo el proceso investigativo dentro de su establecimiento educativo.
Finalmente quiero expresar mi más grande y sincero agradecimiento a mis tutores, principales colaboradores y guías durante todo este proceso, quien con su dirección, conocimiento, enseñanza y colaboración permitieron el desarrollo de este trabajo de investigación.
DEDICATORIA
El presente trabajo investigativo lo dedicó principalmente a mi familia, por ser la inspiración que me brinda la fuerza para continuar en este proceso de obtener uno de los anhelos más deseados de mi carrera profesional.
A mis padres, por su amor, trabajo y sacrificio en todos estos años, gracias a ustedes he logrado llegar hasta aquí y convertirme en lo que soy. Ha sido un orgullo y el privilegio ser su hijo, son los mejores padres.
A mi esposa e hijos, por estar siempre presentes, acompañándome y por el apoyo moral, que me brindaron a lo largo de esta etapa de mi vida académica y profesional.
A toda mi familia, a mis amigos y profesores que me han apoyado y han hecho que el trabajo se realice con éxito, en especial a aquellos que me abrieron las puertas y compartieron sus conocimientos.
Norman
RESUMEN
El presente proyecto de investigación tuvo como objetivo principal la categorización de daños georreferenciados en las arterias viales de la ciudad de Quito, usando un algoritmo de inteligencia artificial desarrollado en Python. Se usó la captura de imágenes georeferenciadas mediante la aplicación Android AutoGuard©. Para el procesamiento de esta información se utilizó el programa ArcGIS Pro y su extensión LocateXT, que permitieron gestionar y administrar cartografía vectorial y ráster de los sistemas de información geográfica con los que se capturó la información. Una vez construidos las estructuras de datos con imágenes y videos georreferenciadas mediante etiquetas de identificación para el modelo de reconocimiento de imágenes por computadora se usó la aplicación Roboflow©. Mediante el uso de técnicas de I.A se entrenó el modelo de reconocimiento de daños viales.
Como principales resultados se puede enunciar que, al utilizar herramientas de I.A, los procesos de detección de fallas que el personal de la EMOP Quito realiza se volverán proactivos mediante escaneos rápidos por las calles de la urbe, incrementando los puntos de prevención de accidentes o complicaciones del tráfico frente a una oportuna detección de falla. En lo referente a la tasa de aprendizaje del modelo se coordinó muy detenidamente la cantidad de categorías (clases) definidas para el reconocimiento (balancear clases) y el alto requerimiento de hardware requerido, ya que, si este último no es el mínimo necesario, el modelo será ineficiente. La ineficiencia del modelo podría categorizar generalidades que incremente su tasa de aprendizaje rápidamente, produciendo una sobrestimación de su predictibilidad o haciendo imposible el aprendizaje (resultados como generalidades de reconocimiento). Finalmente, el modelo propuesto en este trabajo de investigación se puede considerar adecuado para la categorización de las fallas en las arterias viales de la ciudad de Quito, Ecuador, debido a que el valor de la fiabilidad de sus clasificadores de imágenes (0.834116667) se encuentra cerca de 1
Palabras claves: algoritmos, daños georreferenciados, inteligencia artificial, reconocimiento, vías
5
ABSTRACT
The main objective of this research project was the categorization of geo-referenced damages in the road arteries of the city of Quito, using an artificial intelligence algorithm developed in Python. The capture of geo-referenced images using the Android AutoGuard© application was used. For the processing of this information, the ArcGIS Pro program and its LocateXT extension were used, which allowed the management and administration of vector and raster cartography of the geographic information systems with which the information was captured. Once the data structures were built with images and videos georeferenced by means of identification labels for the computer image recognition model, the Roboflow© application was used. Using A.I. techniques, the road damage recognition model was trained.
As main results it can be stated that, by using A.I. tools, the fault detection processes that the EMOP Quito staff performs will become proactive through quick scans through the streets of the city, increasing the points of prevention of accidents or traffic complications in the event of a timely fault detection. Regarding the learning rate of the model, the number of categories (classes) defined for recognition (balancing classes) and the high hardware requirement were carefully coordinated, since, if the latter is not the minimum necessary, the model will be inefficient. The inefficiency of the model could categorize generalities that increase their learning rate rapidly, producing an overestimation of their predictability or making learning impossible (results as recognition generalities). Finally, the model proposed in this research work can be considered adequate for the categorization of faults in the road arteries of the city of Quito, Ecuador, because the value of the reliability of its image classifiers (0.834116667) is close to 1.
Key world: Algorithms, georeferenced damage, artificial intelligence, recognition, pathways
6
7 INDICE DE CONTENIDOS COMPROMISO DE CIENCIA....................................................................................................2 AGRADECIMIENTOS...............................................................................................................3 DEDICATORIA 4 RESUMEN 5 ABSTRACT 6 INDICE DE CONTENIDOS 7 ÍNDICE DE FIGURAS..............................................................................................................10 ÍNDICE DE TABLAS................................................................................................................13 TABLA DE ACRÓNIMOS........................................................................................................14 1. INTRODUCCIÓN.....................................................................................................16 1.1. ANTECEDENTES.....................................................................................................17 1.2. OBJETIVO GENERAL 17 1.3. OBJETIVOS ESPECÍFICOS 17 1.4. PREGUNTAS DE INVESTIGACIÓN ..........................................................................18 1.5. HIPÓTESIS..............................................................................................................18 1.6. JUSTIFICACIÓN 18 1.7. ALCANCE ...............................................................................................................20 2. REVISIÓN DE LITERATURA.....................................................................................21 2.1. MARCO TEÓRICO 21 2.1.1. Clasificación y cuantificación de los deterioros del pavimento 21 2.1.2. Procesamiento de imágenes para el análisis de pavimentos...............................26
2.1.3. Arquitectura de la red ResNet-101.......................................................................34
2.1.4. SSD: comprensión de la detección de objetos de disparo único..........................36
2.2. MARCO HISTÓRICO 41
2.2.1. Trabajo final de grado, España: Detector de baches con Deep Learning 41
2.2.2. Artículo científico, Colombia: Técnicas de inteligencia artificial utilizadas en el procesamiento de imágenes y su aplicación en el análisis de pavimentos ........................42
2.2.3. Caso de estudio, United Kingdom: A Fast and Adaptive Road Defect Detection Approach Using Computer Vision with Real Time Implementation ...................................45
2.2.4. Proyecto de Investigación, Louisiana: Object Detection with Deep Learning: A Review. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).................45
2.2.5. Caso de estudio, Cuba: Revisión de algoritmos de detección y seguimiento de objetos con redes profundas para video vigilancia inteligente. .........................................46
2.2.6. Proyecto de investigación, México: Clasificación de obstáculos a través del algoritmo SSD 47 3. METODOLOGÍA .....................................................................................................48 3.1. ÁREA DE ESTUDIO.................................................................................................48 3.2. FLUJOGRAMA DE METODOLOGÍA ........................................................................50
LA METODOLOGÍA.....................................................................53
3.4.1. Capturar la información........................................................................................53
3.4.2. Preparación de datos para entrenamiento ..........................................................57
8
3.3. JUSTIFICACIÓN DE LA METODOLOGÍA 51 3.4. DESARROLLO DE
9 3.4.3. Entrenamiento del modelo de reconocimiento de fallas.....................................62 3.4.4. Preparación de lo Metadata para la validación del reconocimiento de fallas (imágenes) en una secuencia de video ...............................................................................72 3.4.5. Publicar los resultados en un Mapa Web.............................................................75 4. RESULTADOS Y DISCUSIÓN 76 4.1. RESULTADOS.........................................................................................................76 4.1.1. Aplicación de una muestra de imágenes para la validación del modelo .............76 4.1.2. Aplicación de una muestra de video para las pruebas de captura de imágenes del modelo 78 4.2. ANÁLISIS 82 4.2.1. Comparación del Aprendizaje Profundo entre modelos existentes y el modelo propio. Parámetro: Learning Rate 82 5. CONCLUSIONES Y RECOMENDACIONES ...............................................................95 5.1. CONCLUSIONES.....................................................................................................95 5.2. RECOMENDACIONES 97 6. REFERENCIAS.........................................................................................................99 ANEXOS 107 Anexo 1. NORMA NEVI-12 – MTOP: Pavimento rígido – Defectos – Terminología..........107
ÍNDICE DE FIGURAS
10
Figura 1 Terminología usada para la categorización de los pavimentos rígidos................23 Figura 2 Esquema objetivo con array de lentes .................................................................27 Figura 3 Esquema objetivo convencional 27 Figura 4 Algoritmo de clasificación 28 Figura 5 Esquema básico red neuronal...............................................................................29 Figura 6 Arquitectura de un CNN........................................................................................30 Figura 7 Aprendizaje tradicional Vs. Deep Learning 32 Figura 8 Error de entrenamiento (izquierda) y error de test (derecha) 35 Figura 9 Muestra de bloque de una red de aprendizaje por residuos ResNet....................36 Figura 10 Modelo de Detección de Imágenes CNN.............................................................37 Figura 11 Detector de caja múltiple de disparo único 38 Figura 12 Inferencia sobre Imágenes..................................................................................39 Figura 13 Marco SSD...........................................................................................................39 Figura 14 SSD Vs. R-CNN: Precisión y Velocidad.................................................................40 Figura 15 Mapa del área de estudio: Recorridos realizados 49 Figura 16 Flujograma de metodología ...............................................................................50 Figura 17 Estructura de los archivos Meta-data [*.str]......................................................54 Figura 18 Estructura del archivo de atributos personalizados: metadata .........................56
11
19 Entidad geográfica con información georreferenciada con segmentos.............56 Figura 20 Mapa georreferenciado de recorridos................................................................57 Figura 21 App Roboflow© ..................................................................................................58 Figura 22 Etiquetado de falla simple 59 Figura 23 Etiquetado de múltiples fallas (Clases)...............................................................60 Figura 24 Vista previa del DataSet de images con etiquetas de identificación de fallas (clases) .................................................................................................................................60 Figura 25 Estructura del archivo de entrenamiento en formato Pascal VOC.....................61 Figura 26 Proceso de entrenamiento del modelo 62 Figura 27 Visualización de los datos de entrenamiento .....................................................67 Figura 28 Definición de línea base - Predicciones...............................................................68 Figura 29 Salida ejecución comando lr_finfd() ...................................................................69 Figura 30 Salida ejecución comando plot_losses 71 Figura 31 Predictibilidad de imágenes del modelo- Ejemplo 1...........................................76 Figura 32 Predictibilidad de imágenes del modelo- Ejemplo 2...........................................77 Figura 33 Predictibilidad de imágenes del modelo- Ejemplo 3 77 Figura 34 Predictibilidad de imágenes del modelo- Ejemplo 4 78 Figura 35 Creación de una capa de información geográfica usando ArcGIS LocateXT......79 Figura 36 Archivo de video para la validación de la predicción del modelo.......................80 Figura 37 Gráfico de Pérdidas durante el entrenamiento: Train_Loss 86
Figura
Figura 38 Gráfico de Pérdidas con datos nuevos: Valid_Loss.............................................86
Figura 39 Delta Train Loss durante las épocas de aprendizaje del modelo........................91
Figura 40 Delta Valid Loss durante las épocas de aprendizaje del modelo........................91
12
ÍNDICE DE TABLAS
13
Tabla 1 Defectos Superficiales Pavimentos flexibles ..........................................................24 Tabla 2 Tensores y Arrays ...................................................................................................33 Tabla 3 Comparación de las técnicas de inteligencia artificial 43 Tabla 4 Reglas para los atributos personalizados 55 Tabla 5 Librerías para la ejecución del modelo de entrenamiento.....................................65 Tabla 6 Ajuste del modelo en base al Learning Rate ..........................................................70 Tabla 7 Secuencia de comandos para la validación del modelo en capturas de video 80 Tabla 8 Metadata con la predicción de detección en formato VMTI (Video Moving Target Indicator) 81 Tabla 9 Parámetro de Comparación: Learning Rate ..........................................................82 Tabla 10 Precisión promedio sobre pérdidas......................................................................83 Tabla 11 Valores de Pérdida durante el entrenamiento: Train Loss...................................84 Tabla 12 Valores de Pérdida con datos nuevos: Valid Loss 85 Tabla 13 Deep Learning Accuracy por Clase.......................................................................89 Tabla 14 Train Loss y Valid Loss durante las épocas de aprendizaje del modelo ...............90
TABLA DE ACRÓNIMOS
ANI Agencia Nacional de Infraestructura
API Application Programming Interface
APP Aplicación de software diseñada para ejecutarse en los smartphones
CNNs Redes neuronales convolucionales
CNTK Microsoft's Open-Source Deep-Learning Toolkit
CPU Central processing unit
CUDA Compute Unified Device Architecture
CVPR Conference on Computer Vision and Pattern Recognition
DSSTNE Deep Scalable Sparse Tensor Network Engine
EPMMOP Empresa Pública Metropolitana de Movilidad y Obras Públicas
FC Fully Connected
FPS Frames por segundo
GPU Unidades de procesamiento gráfico
HOG Histograma de gradientes orientados
IA Inteligencia Artificial
IL Inhibición lateral
INEC Instituto Nacional de Estadísticas y Censos
ITU International Telecommunication Union
JSON JavaScript Object Notation - Notación de objeto de JavaScript
MBI Modelo BigDataChallenge 2020 India
MBJ Modelo BigDataChallenge 2018 Japón
MOP-OOI-E Especificaciones Técnicas para la Construcción de Caminos y Puentes Ministerio de Obras Públicas.
MOP-OOI-F Especificaciones Generales para la Construcción de Caminos y Puentes Ministerio de Obras Públicas.
MPL Multi Layer Perceptron
MPQ Modelo Propio 2021 Quito
MTOP Ministerio de Transporte y Obra Publicas
PIP Package installer for Python
R-CNN Region-based Convolutional Neural Networks
RESNET Residual neural network
SIFT Scale-invariant feature transform
SIG Sistemas de Información Geográficos
SSD Single Shot Detector
14
VOC Visual Object Classes
XML Extensible Markup Language - Lenguaje de Marcado Extensible
15
1. INTRODUCCIÓN
De acuerdo con Zhao (2017), secretario general de la International Telecommunication Union (ITU, por sus siglas en inglés), la Cumbre Mundial AI for Good del 2017 fue el primer evento que inauguró el diálogo mundial sobre la posible contribución de la inteligencia artificial (IA) al bien común. Mientras que en ella se puso en marcha el primer diálogo mundial inclusivo sobre los beneficios de la IA, la cumbre de 2018 estuvo orientada a la acción y se centró en soluciones de IA eficaces y capaces de generar beneficios a largo plazo para diferentes áreas del conocimiento humano y para aplicaciones que ayudarán a mejorar los niveles de vida en las urbes del mundo(UTI, 2017).
Una de las áreas de aplicación, donde en los últimos años se ha impulsado el uso de herramientas de IA embebidas en aplicaciones GIS son aquellas enfocadas en la infraestructura vial. Los departamentos gubernamentales, nacionales y seccionales responsables del transporte se han visto en la necesidad de implementar herramientas efectivas para gestionar activos, recursos humanos, operaciones viales y administrativas mediante aplicaciones GIS combinadas con IA que les permita planificar, monitorear y gestionar infraestructura de calles, autopistas y rutas, de forma efectiva. Estas aplicaciones les han permitido determinar la capacidad y operaciones de mejoras e identificar las inversiones más estratégicas, como es el caso de éxito de la Agencia Nacional de Infraestructura (ANI) de Colombia, donde como parte de su estrategia de transparencia, la ANI identificó la necesidad de crear una solución que permitiera comunicar, tanto interna como externamente, los avances de los proyectos de infraestructura vial (ANI, 2021)
El éxito de estos desarrollos se ha fundamentado en los sistemas de reconocimiento de objetos. El reconocimiento y clasificación de objetos se realiza mediante técnicas de inteligencia artificial ejecutadas en un computador y, mediante algoritmos, el sistema de reconocimiento de objetos es entrenado mediante ejemplos previos, y se evalúa su comportamiento frente a nuevos objetos de la misma clase para los cuales ya ha sido entrenado (Condori, 2013).
16
1.1. ANTECEDENTES
En la ciudad de Quito, así como en otras ciudades, los daños en las vías son causados por diferentes factores como construcción deficiente, terreno irregular, precipitaciones, carga vehicular entre otros. La ubicación temprana de estos daños en los tramos de las vías permitirá a las organizaciones que realizan el mantenimiento vial, entender que tipos de daños ocurren en diferentes tramos, donde se encuentran ubicadas la mayor cantidad de estos problemas y planificar adecuadamente su mantenimiento preventivo. Tradicionalmente, este proceso se lleva a cabo mediante el registro en formularios de papel de la localización de dichos problemas, para luego sistematizarlos, evaluarlos y categorizar el problema para eventualmente planificar la intervención. Esto implica una gran cantidad de tiempo y recursos que pueden disminuirse utilizando herramientas tecnológicas que simplifiquen el proceso actualmente establecido. Este proceso de investigación tiene como objetivo implementar un modelo de inteligencia artificial, el cual, mediante el uso de imágenes obtenidas a partir de video capturado usando dispositivos móviles-smartphones, permitirá determinar el tipo de daño o grietas que existen en las vías y su ubicación en un mapa
1.2. OBJETIVO GENERAL
Formular una categorización de daños georreferenciados en las arterias viales de la ciudad de Quito (Ecuador) usando un algoritmo de inteligencia artificial desarrollado en Python
1.3. OBJETIVOS ESPECÍFICOS
• Definir una base de datos de imágenes de los daños en las vías de la ciudad de Quito, Ecuador capturadas desde videos georreferenciados.
• Describir el proceso de aprendizaje y categorización de los daños en las vías mediante el uso de un algoritmo de Inteligencia Artificial desarrollado en Python
17
• Evaluar la fiabilidad de la categorización del algoritmo de daños en las vías de la ciudad de Quito, Ecuador utilizando mapas de distribución espacial de las categorías de daños identificados.
1.4. PREGUNTAS DE INVESTIGACIÓN
• ¿Cómo utilizar imágenes desde videos georreferenciados para generar un inventario de daños en las vías de la ciudad de Quito?
• ¿Cómo utilizar herramientas de inteligencia artificial para implementar el proceso de aprendizaje y categorización de los daños en las vías de la ciudad de Quito?
• ¿Cómo evaluar la fiabilidad de la categorización de un algoritmo de detección de daños en las vías de la ciudad de Quito?
1.5. HIPÓTESIS
La aplicación de algoritmos de inteligencia artificial desarrollados en Python mejorará los tiempos de respuesta para la detección y evaluación de daños en las vías de la ciudad de Quito, Ecuador para el año 2021. Para validar esta hipótesis se comparará el tiempo actual que la empresa de movilidad y obras públicas del Municipio de Quito toma para la detección y evaluación de los tipos de daños en las vías y contrastarlo con el tiempo que tomará en procesar el algoritmo de inteligencia artificial para detección del mismo objeto detectado usando una herramienta tecnológica.
1.6. JUSTIFICACIÓN
La inteligencia artificial es una tecnología que desde hace algunas décadas ha estado presente Según Bellman (1978), mencionado por Jatoba et al. (2019, p.97), una de las definiciones de Inteligencia Artificial es “La automatización de actividades que se vinculan con procesos de pensamiento humano, actividades como la toma de decisiones, resolución de problemas, aprendizaje”.
18
En la actualidad, esta tecnología se ha vuelto más accesible, tanto para las necesidades personales como para las organizacionales. Esto se ha vuelto posible debido al avance de las tecnologías informáticas que permiten mayor capacidad de almacenamiento y procesamiento. El trabajo manual y repetitivo que una computadora puede realizar es realmente impresionante, tal como lo demostró Rohit Singh1 en la presentación que se realizó en la conferencia de desarrolladores de ESRI en Palmspring en el año 2019, en la que se mostró cómo se pueden implementar diferentes algoritmos-soluciones con inteligencia artificial. Uno de estos algoritmos que se presentaron fue el diseñado para la detección de fallas en las vías a partir de información recolectada con una cámara de video en un vehículo. Los conceptos usados en esta solución, que se aplicó en otros países como Japón, India y Grecia, podrían ayudar a la ciudad de Quito para resolver una de las preocupaciones constantes de quienes viven en esta ciudad, como es la del mantenimiento de la infraestructura vial. Los daños en las vías ocasionan afectaciones en los vehículos, así como también pueden ser detonantes de accidentes de tránsito. La detección temprana de estos daños o grietas en las vías asfaltadas es responsabilidad de la Empresa Pública Metropolitana de Movilidad y Obras Públicas (EPMMOP), actividad que se la vienen realizando, de acuerdo con los técnicos que manejan el Sistema de Información Geográfica de la EPMMOP, en forma manual y en base de decisiones políticas de acuerdo con las necesidades expresadas desde la ciudadanía. Todo esto debido a que la EPMMOP no cuenta con una herramienta tecnológica que permita realizar de forma automatizada este proceso, tal como se lo ha implementado en otras ciudades. La aplicación de los algoritmos de inteligencia artificial en comunión con los Sistemas de Información Geográfica se ha convertido en una oportunidad favorable para la automatización de tareas manuales con respecto a la ubicación de los problemas viales.
19
1 Director del Centro de Desarrollo e investigación de Inteligencia Artificial en New Delhi de ESRI Inc.
Actuar con un enfoque preventivo permitirá a la EPMMOP considerar realizar el mantenimiento vial a tiempo evitando daños mayores y minimizando los costos de reparación en la capa asfáltica, y con la posibilidad de contrarrestar los tiempos de espera en las inspecciones manuales y determinar el tipo de daño que existe en una ubicación geográfica específica todo esto de manera automatizada, y esto trae un beneficio intrínseco para la ciudadanía.
1.7. ALCANCE
El presente estudio explorará el uso de algoritmos Single Shot Detector (SSD) basados en redes neuronales convolucionales para la detección de imágenes y la eficiencia de la categorización de estas en un inventario de daños de las vías urbanas de la ciudad de Quito, Ecuador en el periodo marzo 2021. El proyecto no se limitará solamente a evaluar un algoritmo de detección de imágenes sino a diseñar e implementar una solución que se aplique en el Departamento de Obras Públicas del Distrito Metropolitano de la ciudad de Quito.
• No se tiene como objetivo el desarrollo de un algoritmo de detección de imágenes, sino la evaluación de un algoritmo en lenguaje Python, basado en una red neuronal ResNet101 y un modelo SSD.
• Los beneficiarios directos de este proyecto de investigación son los responsables del mantenimiento vial del Departamento de Obras Públicas del Distrito Metropolitano de la ciudad de Quito e indirectos las unidades financieras responsables de la elaboración de los presupuestos para mantenimiento vial del GAD del Distrito Metropolitano de la ciudad de Quito. Finalmente, los habitantes del Distrito Metropolitano de la ciudad de Quito se beneficiarán de este proyecto, ya que, al mejorar la calidad de las vías y su mantenimiento, la eficiencia de la movilidad se incrementaría dentro del distrito.
20
2. REVISIÓN DE LITERATURA
2.1. MARCO TEÓRICO
2.1.1. Clasificación y cuantificación de los deterioros del pavimento
De acuerdo con la historia de la evolución de la Norma Ecuatoriana Vial Norma Ecuatoriana Vial NEVI-12 - MTOP, la infraestructura vial en el Ecuador ha mantenido una historia de afectaciones constantes, como paralizaciones y colapso de puentes y caminos, generadas tanto por el riesgo sísmico cuanto por los factores climáticos a los que por décadas los Gobiernos han tenido que afrontar con soluciones inmediatistas y onerosas para el erario nacional, sin ningún soporte tecnológico que garantice una seguridad adecuada para el desarrollo. Las afectaciones de la red vial antes señaladas a su vez, de forma directa, han incidido negativamente al proceso de desarrollo económico y productivo del Ecuador, fomentando la pobreza y limitando el acceso a bienes, productos y servicios vitales garantizados por la Constitución. Las regulaciones técnicas del Ministerio de Transporte y Obras Públicas (MTOP: MOP-OOI-F y MOPOI-E), generadas en 1974, contribuyeron inicialmente para solucionar los aspectos antes mencionados. En 1993 fueron actualizadas, con mínimos cambios, a través de Acuerdos Ministeriales (Subsecretaria de Infraestructura del Transporte, 2013)
Formas de clasificación de los deterioros del pavimento
Dentro de la Norma NEVI-12 – MTOP para la generación de un inventario de daños visibles es necesario evaluar la condición global de un pavimento. Esta información es la que determina la localización y la extensión de las investigaciones posteriores, con el fin de establecer un juicio apropiado sobre la condición del pavimento que es objeto de la evaluación. Para evaluar los daños de un pavimento la norma considera tres factores (Subsecretaria de Infraestructura del Transporte, 2013):
21
a. Los deterioros se agrupan esencialmente en categorías, de acuerdo con los mecanismos que los originan. Como un primer paso, pueden clasificar de acuerdo con su causa primaria posible, sea ésta la acción del tránsito, sea la acción climática, sean los materiales o el proceso de construcción
b. Otra manera de clasificar los deterioros, es de acuerdo con la relación que ellos tengan con el comportamiento estructural del pavimento. Bajo esta perspectiva, se distinguen dos casos límites: deterioros estructurales y deterioros funcionales.
c. Otras características indeseables, como el excesivo nivel de ruido que afecta a los residentes vecinos a la vía 0 las propiedades ópticas inadecuadas que afectan a los usuarios, pueden ser el resultado de una inapropiada selección de materiales de construcción, pero también se pueden originar en el desgaste o en la polución de la superficie de rodamiento y de la señalización horizontal
Nomenclaturas de la Norma Ecuatoriana NEVI-12 – MTOP para la categorización de los deterioros de los pavimentos
Dentro de la Norma Ecuatoriana NEVI-12 – MTOP se especifica la nomenclatura y la definición de las categorías de daños que pueden presentarse en el sistema vial ecuatoriano. En el estudio “Development of a pavement condition rating procedure for roads, street, and parking lots”, desarrollado por Hein, Eng, y Burak (2007), se hace referencia al concepto de deterioro que fue utilizado como base para esta clasificación en la norma y que fue mencionado por Gabela (2013):
Los deterioros son aquellas modificaciones del pavimento respecto de su estado que se han desarrollado por el desgaste normal, deficiencias de los que lo conforman o lo soportan, factores como: aire, agua, luz ultravioleta, casos fortuitos como: fallas de sistemas de alcantarillado y abastecimiento de agua potable, erupciones volcánicas, entre otros, que disminuyen los niveles de seguridad, comodidad y confianza de los pavimentos, obligando de cierta manera a disminuir la velocidad de los vehículos que transitan, ya sea por seguridad, comodidad o ambos. En casos extremos de deterioro la circulación vehicular puede verse interrumpida (p. 7).
22
En función de esta definición se estableció la terminología usada en la norma ecuatoriana
NEVI-12 – MTOP para pavimentos rígidos, en la cual el MTOP (2012) conceptualiza los defectos como una “anomalía observada en el pavimento debida a problemas en la fundación, por mala ejecución o por mal uso del pavimento. Un defecto puede ser de varios tipos” (p. 122). En el Anexo 1 de este trabajo se encuentra el listado de la terminología usada para la categorización de los pavimentos rígidos. La Figura 1 muestra un resumen de esta terminología:
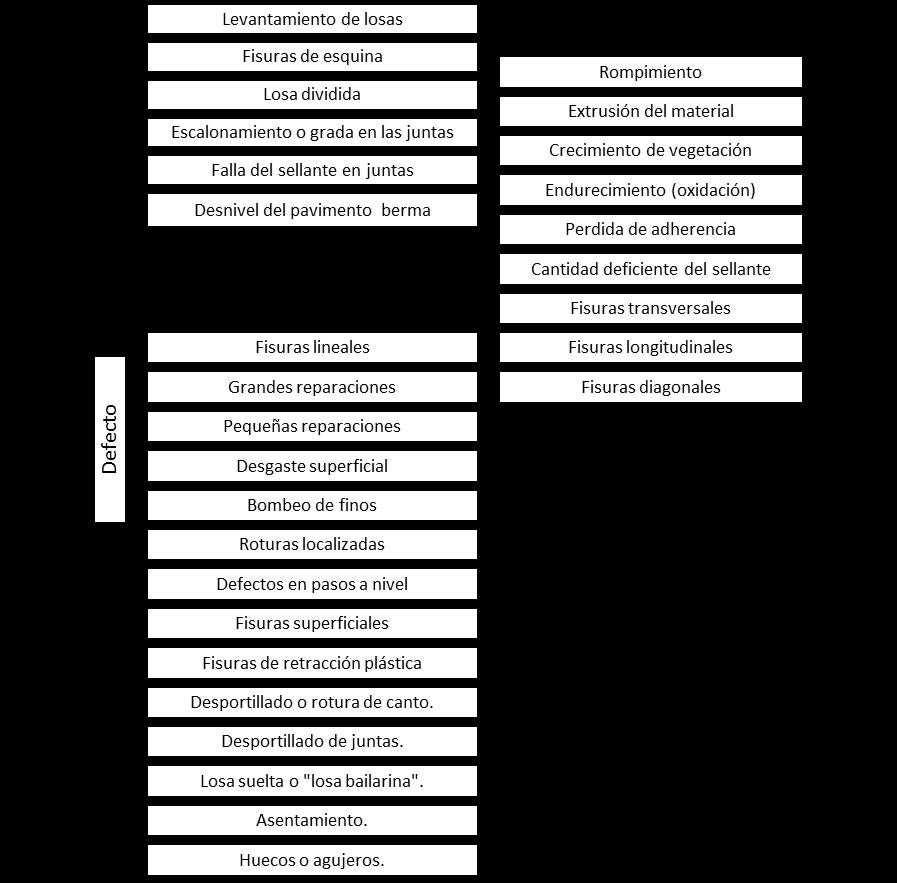
Figura 1
Terminología usada para la categorización de los pavimentos rígidos
Fuente: Adaptado MTOP-CAF-IBCH (2012)
23
Para definir en forma clara y precisa los tipos de deterioro, sus causas y acciones de corrección, en el manual de construcción de pavimentos del MTOP constan una serie de lineamientos que especifican cada uno de los deterioros por tipos de pavimentos (MTOPCAF-IBCH, 2012), los mismos que son resumidos en la Tabla 1
Tabla 1
Defectos Superficiales Pavimentos flexibles Tipo (Descripción)
• Perdida de agregado: Remoción de partículas (d > 6 mm) de la superficie
• Desgranamiento. Pérdida progresiva del material desde la superficie hacia abajo
• Afloramiento del asfalto (exudación). Exceso ligante en la superficie permitiendo una textura suave y resbaladiza, preferentemente en la zona de circulación
Deformaciones superficiales pavimentos flexibles
• Ondulación transversal. Ondulaciones transversales relativamente regulares
• Ondulación por desplazamiento Deformación plástica del pavimento principalmente en sentido longitudinal)
• Ahuellamiento. (Depresión transversal en la zona de circulación)
• Distorsión. Pérdida importante de la geometría transversal original
Agrietamientos Pavimentos Flexibles
• Agrietamiento longitudinal en la zona de circulación (Agrietamiento en el sentido longitudinal situado en la zona de circulación).
• Agrietamiento longitudinal en el centro de la vía. (Grietas longitudinales próximas al eje de la vía. Normalmente formado por sola grieta. Ocasionalmente con grietas secundarias)
• Agrietamiento longitudinal en el centro de la calzada. (Grietas longitudinales próximas al eje central de la calzada).
• Agrietamiento longitudinal en el borde (Grietas longitudinales entre el borde y 0,30 m hacia el centro)
• Agrietamiento sinuoso (Grietas sin dirección fija que se inicia y termina en los bordes)
• Agrietamiento transversal (Grietas perpendiculares al eje de la calzada. Normalmente si se desarrollan a todo lo ancho).
24
Agrietamientos Pavimentos Flexibles
• Agrietamiento tipo piel de cocodrilo. (Grietas que forman una red, en forma de bloques de tamaños irregulares cuyas dimensiones son indicativas del nivel en el cual ocurre la falla. Bloques cuyos lados son menores a 15 cm, indican fallas en las bases. Bloques de dimensiones mayores a 30 cm, indican fallas en la subrasante. Este agrietamiento normalmente va acompañado de deformaciones verticales y ocurre en capas asfáltica de poco espesor)
• Agrietamiento irregular (Grietas in orientación definida, usualmente llamados "grietas mapa", formando grandes bloques)
Defectos superficiales en pavimentos rígidos
• Descascaramiento (Perdida de material superficial en forma de "escamas". En general no tiene efectos estructurales dañinos).
• Desgaste superficial (Pulimiento de la superficie con aparición de agregado grueso, En general no tiene efectos estructurales dañinos)
• Fisuramiento. (Agrietamiento poco severo con aparición de líneas finas interconectadas o familia de fisuras aproximadamente paralelas. En general no tiene efectos estructurales dañinos)
• Excesiva rugosidad
Agrietamiento de pavimentos rígidos
• Agrietamiento transversal (Grieta en dirección perpendicular al eje de la calzada)
• Agrietamiento longitudinal (Grietas en dirección paralela al eje de la calvada ubicada en el interior de la losa).
• Agrietamiento de esquina (Grieta en las esquinas de los paños formando fisuras triangulares. Normalmente en la esquina exterior en pavimentos con juntas rectas y en la esquina del ángulo agudo interior en caso de juntas desviadas)
• Desintegración (Grieta en direcciones, desintegración del pavimento. Perdida de adhesión entre mortero y agregado grueso)
25
Fuente: MTOP-CAF-IBCH (2012)
2.1.2. Procesamiento de imágenes para el análisis de pavimentos
El estudio de imágenes en las mezclas asfálticas en la actualidad se usa para detectar grietas en la estructura utilizando la segmentación de bordes y la manipulación del contraste de la imagen, obteniendo información sobre el tipo falla y elementos útiles para los estudios sobre pavimentos (Li, Zhou, Liu, Li, y Cao, 2016). Para los autores, la recuperación de imágenes es un tema fundamental en el reconocimiento de patrones y adoptan el modelo de inhibición lateral (LI) como paso de preprocesamiento, que ensancha los gradientes de nivel de gris para facilitar el esquema de recuperación de imágenes. Al buscar una coincidencia perfecta entre una plantilla predefinida y una imagen de referencia, se adoptan algoritmos metaheurísticos para una buena capacidad de búsqueda. En la actualidad dos de los métodos más usados para la obtención de imágenes que van a ser procesadas para la detección de baches son:
a) Profundidad de campo. Las imágenes con profundidad de campo se basan en la incidencia de la luz en un objeto y su rebota en diferentes direcciones, que pueden ser captadas por dispositivos capaces de tomar diferentes convergencias de los rayos de luz (distintas direcciones) en una misma toma, y de ese modo se puede obtener imágenes con una cierta profundidad y considerarlas una imagen con profundidad 3D (Garamendi, 2017)
b) Imágenes convencionales 2D. Para este tipo de captura de imágenes se pueden utilizar cámaras de varios tipos:
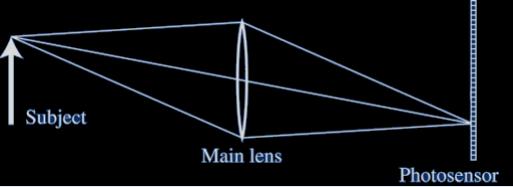
• Cámaras plenópticas. De acuerdo con Roca (2016), las cámaras plenópticas son los dispositivos disponibles en el mercado que utilizan tecnología de matriz de lentes. Con este tipo de cámaras, se puede llegar a extraer de un solo disparo distintos planos focales, permitiendo enfocar varios planos simultáneamente.
En este método, se utiliza un array de lentes, pero en este caso, se colocan detrás de la lente principal del objetivo. De ese modo, y con un sensor más amplio, se consigue desfragmentar los rayos de luz según su ángulo o dirección como se muestra en la Figura 2.
26
Fuente: Adaptado de Roca (2016)
• Cámaras fotográficas normales. La captura es en 2D, únicamente recoge los rayos de luz que inciden en la lente y que posteriormente converjan en el sensor. La Figura 3 muestra que estas imágenes no proporcionan factores de profundidad de campo, pueden ser realizadas con distinta distancia focal (zoom) o variando la apertura del diagrama, conseguir distintos enfoques o profundidad de campo, pero en ningún caso proporcionarán la visión para aplicar una segmentación por la profundidad en el terreno (Illescas, 2021).
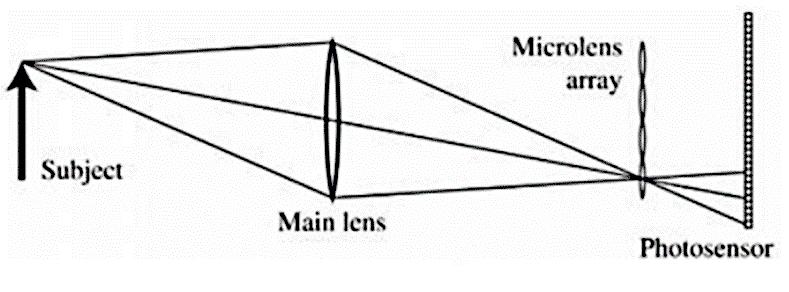
Fuente: Adaptado de Illescas (2021)
De acuerdo con Yu, Yuan, Dong y Riha (2016), estos métodos tradicionales presentan problemas de sensibilidad, por la interferencia de la luz en la captura. Esto interfiere en la nitidez y contraste en la foto. Los autores afirman que en los años recientes se ha trabajado para tratar de mejorar estos sistemas con la implementación de técnicas de inteligencia artificial (IA). Ali, Wook, Pant, y Siarry (2015) definen que las técnicas de IA más utilizadas en las últimas décadas para el procesamiento de imágenes según son las redes neuronales,
27
Figura 2
Esquema objetivo con array de lentes
Figura 3
Esquema objetivo convencional
los sistemas difusos y los algoritmos evolutivos en donde se destacan los sistemas inmunes artificiales y la inteligencia de enjambre
a) La lógica difusa permite valores intermedios para poder definir estados convencionales como sí/no, verdadero/falso, negro/blanco, etc. Este tipo de nociones como más caliente o poco frío pueden expresarse matemáticamente y ser procesados por computadoras. Miranda y Felipe (2015) argumentan que los conjuntos difusos se han usado en el trabajo con imágenes ya que no limitan numéricamente el desarrollo; esto es útil cuando se trabaja con imágenes debido a que sus características no se pueden delimitar de una forma exacta. De acuerdo con Mollajan, Ghiasi-Freez y Memarian (2016), la Figura 4 muestra el algoritmo para reconocimiento de imágenes en sistemas difusos e identifica que su desarrollo se da en 5 etapas:
Fuente. Adaptado de Mollajan et al. (2016)
b) Según Albuquerque, Alexandria, Cortez y Tavares (2009), el cerebro está constituido por neuronas que guardan y procesan una gran cantidad de información, por este motivo las redes neuronales artificiales buscan simular ese comportamiento del
28
Figura 4 Algoritmo de clasificación
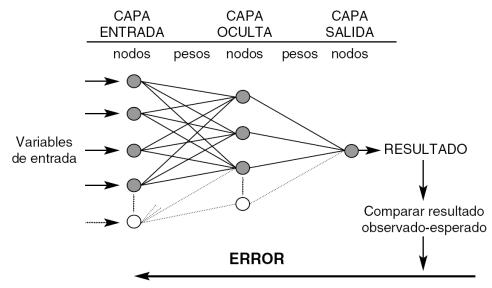
cerebro. En la Figura 5, se muestra la estructura básica por capas neuronales propuesta por los autores, donde una primera capa está compuesta por las neuronas de entrada o input, la siguiente capa es la capa oculta, donde se puede tener varias capas de neuronas y finalmente la última capa es la capa de salida u output
Figura 5
Fuente. Adaptado de Basogain (2019)
En sus estudios, Mashaly y Alazba (2016) presentan dos tipos de redes para el procesamiento de imágenes: la multicapa que es la más utilizada y también las redes neuronales convolucionales, las cuales son especializadas para el trabajo con imágenes.
• La red neuronal multicapa o MPL (Multi Layer Perceptron) se basa en la unión de neuronas organizadas y distribuidas a lo largo de diferentes capas (Islam, Hannan, Basri, y Arebey, 2013). Este tipo de redes sirven para copiar el comportamiento de cualquier sistema usando entradas y salidas conocidas, de esta forma es capaz de clasificar elementos o imitar el funcionamiento de una estructura (Hekayati y Rahimpour, 2017)
• Las redes neuronales convolucionales (CNNs)
Las redes neuronales convolucionales (CNNs)
Las redes neuronales convolucionales (CNNs) se han usado últimamente en tareas de análisis de imágenes, sobre todo destacando su uso en los procedimientos de clasificación
29
Esquema básico red neuronal
y reconocimiento (Zhang, Zeng, Zhang, Zhang, y Wu, 2017). Este modelo de red se ha desarrollado inspirado en el sistema de aprendizaje biológico. Según Zhang, Qu, Ma, Guan y Huang (2016), extraer las características propias de un elemento que lo diferencian de otros es un proceso que realizan los seres humanos con la vista y que las CNNs tratan de emular De acuerdo con Montoya (2018), la CNN es un tipo de Red Neuronal Artificial con aprendizaje supervisado que procesa sus capas imitando al córtex visual del ojo humano para identificar distintas características en las entradas que en definitiva hacen que pueda identificar objetos y “ver”. El mismo Montoya (2018) propone que las principales tareas que realiza una CNN son:
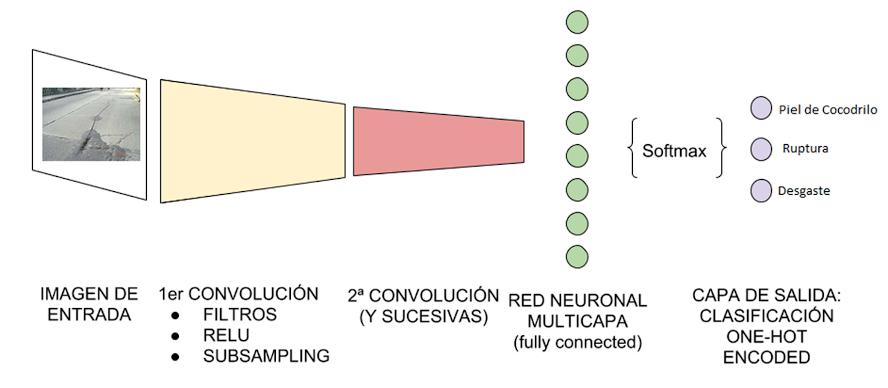
• Detección/categorización de objetos.
• Clasificación de escenas.
• Clasificación de imágenes en general.
Para la realización de estas tareas la CNN contiene varias capas ocultas especializadas (Figura 6) y con una jerarquía: esto quiere decir que las primeras capas pueden detectar líneas, curvas y se van especializando hasta llegar a capas más profundas que reconocen formas complejas (Pérez, Serrano, Acha, y Linares, 2011).
30
Figura 6 Arquitectura de un CNN
Fuente Adaptado de Pérez e al. (2011)
Donde:
• Las covoluciones consisten en tomar “grupos de pixeles cercanos” de la imagen de entrada e ir operando matemáticamente (producto escalar) contra una pequeña matriz que se llama kernel (Montoya, 2018) . Para Paris, Nakano-Miyatake y Robles-Camarillo (2016), las capas convolucionales se entienden como un conjunto de filtros comúnmente llamados: campos receptivos, éstos se ajustan para la extracción de características de una señal. A diferencia de una red neuronal tradicional, en la que cada neurona de una capa se conecta a todas las neuronas de la otra, conocido como Fully Connected (FC), en las CNN se comparten las neuronas a través de filtros que permiten extraer información de las imágenes de entrada.
• La función Softmax, también conocida como softargmax o función exponencial normalizada, es una generalización de la función logística a múltiples dimensiones. Se utiliza en la regresión logística multinomial y, a menudo, se utiliza como la última función de activación de una red neuronal para normalizar la salida de una red a una distribución de probabilidad sobre las clases de salida predichas (Bishop, 2016)
Deep Learning
De acuerdo con Matich (2001), las redes neuronales no son más que otra forma de simular ciertas características de aprendizaje propias del cerebro humano, la capacidad de memorizar y la asociación de hechos. En base a esta definición los autores concluyeron que aquellos problemas que no pueden expresarse a través de un algoritmo tienen una característica en común para su resolución: el aprendizaje a través de la experiencia. Deep Learning (Aprendizaje Profundo) es un algoritmo automático estructurado o jerárquico que emula el aprendizaje humano con el fin de obtener ciertos conocimientos. La Figura 7 hace un resumen comparativo de un algoritmo que aprende representaciones de datos con múltiples niveles de abstracción frente al aprendizaje tradicional (Cifuentes, Mendoza, Lizcano, Santrich, y Moreno, 2019).
31
Figura 7
Aprendizaje tradicional Vs. Deep Learning
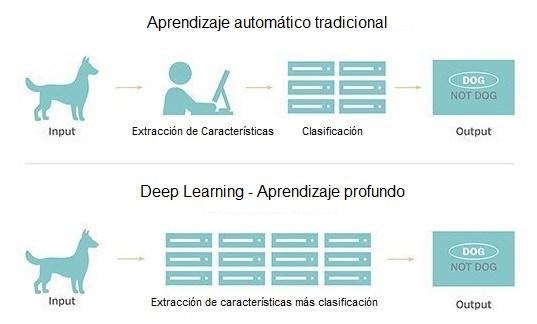
Fuente. Adaptado de Silva (2020)
Autores como Valderrama (2017) proponen una reflexión comparativa para establecer las diferencias entre el aprendizaje tradicional y el Deep Learning:
El aprendizaje tradicional es un proceso completamente supervisado y el desarrollador debe ser muy específico al generar un algoritmo para indicarle al computador qué tipo de características debe buscar en una imagen para decidir si esta contiene una categoría especial de objeto, la tasa de éxito de la detección del objeto depende únicamente de la capacidad del programador para definir con precisión el conjunto de características para categorizar el objeto, mientras que en Deep Learning el algoritmo construye el conjunto de características por sí mismo sin supervisión, lo que vuelve al proceso de detección de imágenes más rápido y más preciso (p.40)
Vázquez (2018) define las características que ofrece la aplicación de Deep Learning y sus avances como ejemplos de su potencial:
• Clasificación de imágenes a nivel casi humano.
• Reconocimiento de voz a nivel casi humano.
• Transcripción de escritura a mano a nivel humano.
32
• Mejora de la traducción automática.
• Mejora de la conversión de texto a voz.
• Asistentes digitales como Google Now o Amazon Alexa.
• Conducción autónoma a nivel humano.
• Mejora de la orientación de anuncios, tal como la utilizan Google, Baidu y Bing.
• Mejora de los resultados de búsqueda en la web.
• Responder preguntas de lenguaje natural.
Ahora bien, dentro de Deep Learning, Kossaifi, Panagakis, Anandkumar y Pantic (2018) definen el concepto de tensor como fundamental para la representación de las estructuras de datos en Redes Neuronales y por lo tanto la base fundamental de Deep Learning. Un tensor es la estructura de datos principal utilizada por las redes neuronales. Las entradas, salidas y transformaciones dentro de las redes neuronales se representan utilizando tensores, y como resultado, la programación de redes neuronales utiliza tensores en gran medida. Matemáticamente hablando en el caso general, una matriz de números dispuestos en una cuadrícula normal con un número variable de ejes se conoce como tensor. Los tensores son una representación más generalizada de vectores que interactúan en dimensiones más altas. Tienen dos parámetros llamados dimensiones y rango.
Brownlee (2018) hace una definición más específica del concepto tensor para ciencias computaciones: En ciencias de la computación, se deja de usar palabras como, número, matriz, matriz 2d, y se empieza a usar la palabra matriz multidimensional o nd-array. En la Tabla 2, se indica el número de índices necesarios para tener acceso a un elemento específico dentro de la estructura de información, por lo que el autor concluye que, para fines prácticos en la programación de redes neuronales, tensores y nd-arrays son lo mismo.
Tabla 2
Tensores y Arrays
Índices Requeridos Ciencias computaciones Matemáticas N nd-Arrays nd-Tensor
Fuente: Browlee (2018)
33
Por lo tanto, los tensores son arreglos multidimensionales o nd-arrays. La razón por la que un tensor es una generalización es porque se usa el termino tensor para diferentes formas de arreglos (Browlee, 2018):
• Un escalar es un tensor de 0 dimensiones
• Un vector es un tensor dimensional 1
• Una matriz es un tensor dimensional 2
• Una nd-array es un tensor n dimensional
En Python, al igual que los vectores y matrices, los tensores se pueden representar mediante la matriz N-dimensional (nd array). Un tensor se puede definir en línea para el constructor de array () como una lista de listas. Para Blanco y Ramírez (2018) el uso de tensores es muy extendido en Deep Learning en Python, ya que existen múltiples librerías de código abierto enfocadas a su uso en este lenguaje. Las más importantes son: TensorFlow, Theano, Keras, Caffe, Lasagne, Deep Scalable Sparse Tensor Network Engine (DSSTNE), PrettyTensor, Torch, MXNet, DL4J, y Microsoft Cognitive Toolkit TensorFlow por su parte soporta Python y C++, además de Java y Go entre otros, además, permite distribuir los cálculos en Central processing unit (CPU), Unidades de procesamiento gráfico (GPU) de forma simultánea y escalado horizontal. Keras es una API de redes neuronales de alto nivel, escrita en Python y capaz de ejecutarse sobre TensorFlow, Microsoft's Open-Source DeepLearning Toolkit (CNTK) o Theano que fue desarrollado con un enfoque en permitir la investigación y experimentación rápida.
2.1.3. Arquitectura de la red ResNet-101
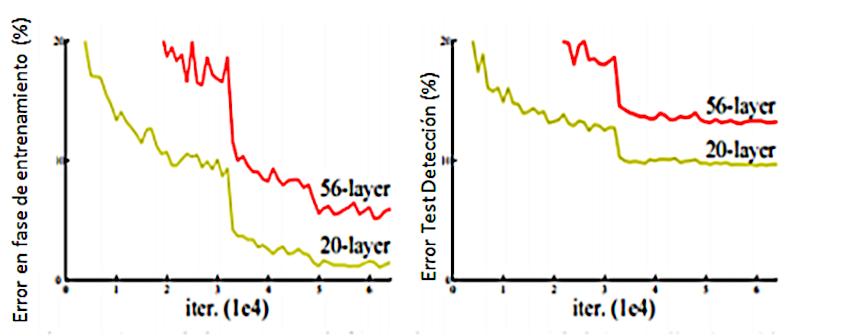
De acuerdo con Domènech (2019), la arquitectura ResNet nace del problema de la profundidad de la red. Se podría pensar que mientras más capas se utilizan para el entrenamiento en la detección de objetos, los resultados serán mejores, pero no es así. Cuando las redes se vuelven muy profundas, con un número de capas alto y las misma empiezan a converger, aparece un problema de degradación: cuanto más profunda es la
34
red, la precisión se satura y luego se degrada rápidamente. Se genera un aumento del error de predicción como se puede ver en la figura 8
Fuente. Adaptado de Ham (2015)
He, Zhang, Ren y Sun (2016) proponen una nueva aproximación de diseño para las redes de neuronas convolucionales: la optimización basada en residuos. Sus autores lanzaron tres arquitecturas inicialmente: ResNet-50, ResNet- 101 y ResNet-152. El número que acompaña al nombre indica el número de capas de la red, que, como se puede ver es mucho más elevado que en las arquitecturas anteriores. Sin embargo, a pesar de ello, esta red tiene una complejidad menor, es decir, el número de operaciones que realiza es menor. Esto es así porque implementa una nueva forma de aprendizaje basada en minimización de residuos, como se evidencia en la Figura 9 cada vez que se añade a la red una serie de capas que incluyan pesos, se añade un “atajo” que va desde la entrada de la primera de las capas a la salida de la última.
35
Figura 8
Error de entrenamiento (izquierda) y error de test (derecha)
Fuente.
Si x es la imagen a la entrada y f(x) la transformación que realizan las distintas capas, el objetivo de esta arquitectura es optimizar la función f(x)+x obtenida al pasar la imagen por dichas capas, de forma que, si una red clásica aprende una función, es decir, una función que, dado x, devuelva el valor y, ResNet lo que intenta aprender es cuánto le “falta” a x para convertirse en y.
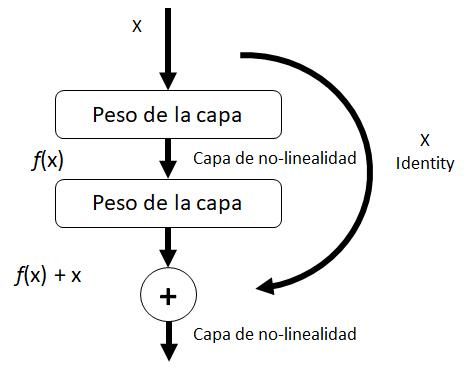
Para poder solucionar el problema de la degradación por la profundidad de capas surgió la arquitectura ResNet. Esta arquitectura se basa en dividir una red profunda en fragmentos de tres capas y pasar la entrada a cada fragmento directamente a la siguiente capa, junto con la salida residual del fragmento anterior que pasa a ser la entrada del siguiente fragmento. Este método ayuda a eliminar el problema de degradación mencionado anteriormente (Domènech, 2019).
2.1.4. SSD: comprensión de la detección de objetos de disparo único
De acuerdo con Gutiérrez (2019), actualmente para la detección computacional de objetos se utilizan modelos basados en redes neuronales convolucionales como Region-based Convolutional Neural Networks (R-CNN), que utiliza una red neuronal de propuesta de región para crear cuadros de límite y utiliza esos cuadros para clasificar objetos (Gutiérrez,
36
Figura 9
Muestra de bloque de una red de aprendizaje por residuos ResNet
Adaptado de Hassan (2019)
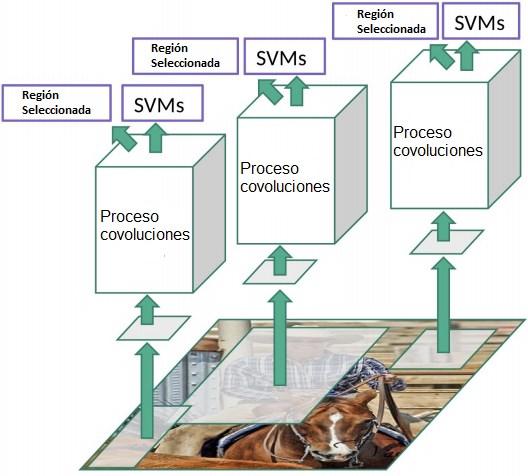
2019). Si bien se considera que la técnica es precisa, todo el proceso se ejecuta a 7 cuadros por segundo, muy por debajo de lo que necesita un procesamiento en tiempo real. Los modelos basados en redes CNN, utiliza un método de búsqueda selectiva que extrae sólo un grupo de regiones de una imagen (Figura 10), y en lugar de intentar clasificar una imagen por un gran número de regiones, se pueden utilizar estas propuestas regionales seleccionadas extraídas para clasificar la imagen (Krizhevsky, Sutskever,
Para García (2018), SSD es un modelo que está diseñado para la detección de objetos en tiempo real. SSD acelera el proceso al eliminar la necesidad de la red de propuesta de la región. Para recuperar la caída en la precisión, SSD aplica algunas mejoras que incluyen funciones de escala múltiple y cajas predeterminadas. En la Figura 11, se puede apreciar cómo estas mejoras permiten que SSD iguale la precisión de Faster R-CNN utilizando imágenes de menor resolución, lo que aumenta aún más la velocidad (Long, Shelhamer, y Darrell, 2019). La detección de objetos SSD se compone de 2 partes:
• Extracción de mapas de características y
• Aplicación de filtros de convolución para detectar objetos.
37
y Hinton, 2019)
Figura 10
Modelo de Detección de Imágenes CNN
Fuente. Adaptado de Xu (2018)
Figura 11
Detector de caja múltiple de disparo único Fuente. Adaptado de Ham (2015)
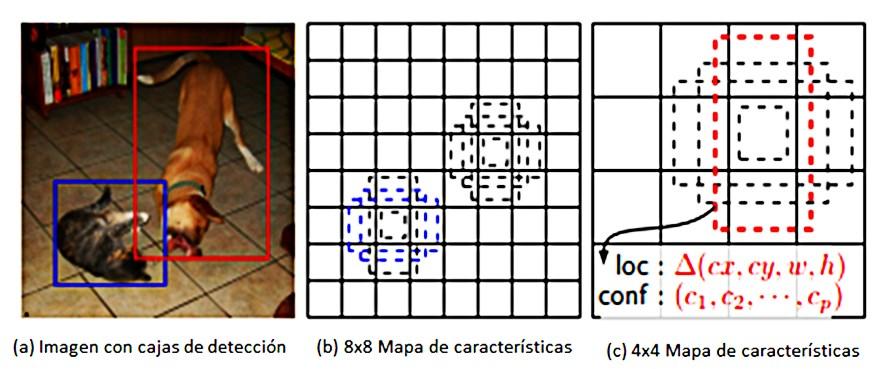
En lugar de regiones, SSD utiliza regiones de predicción, la detección es analizada como un problema de regresión. Cada predicción se compone de un cuadro de límites y n puntuaciones para cada clase (una clase adicional para ningún objeto), y se elige la puntuación más alta como la clase para el objeto delimitado. La Figura 12 muestra los identificadores que genera SSD cuando una predicción contiene algún objeto, sin embargo, SSD reserva una clase "0" para indicar que no tiene objetos una predicción (Ichi.pro, 2021)
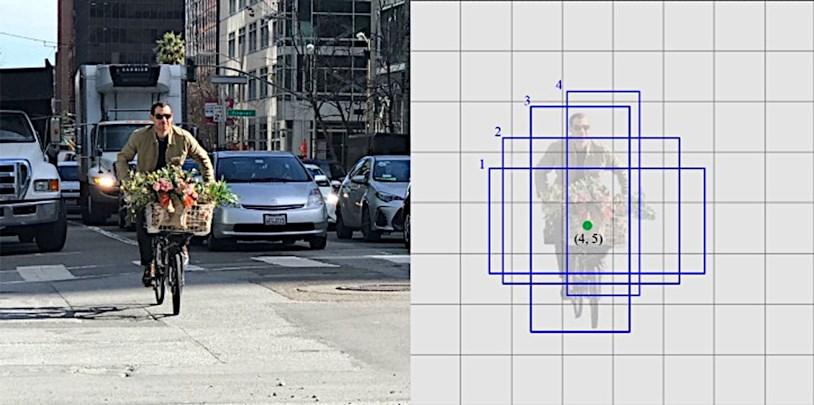
De acuerdo con Hui (2018b), SSD divide la imagen usando una cuadrícula y cada celda de la cuadrícula es responsable de detectar objetos en esa región de la imagen. Cada celda de la cuadrícula en el SSD se puede asignar con múltiples cuadros de anclaje previos. Estos cuadros de anclaje están predefinidos y cada uno es responsable del tamaño y la forma dentro de una celda de la cuadrícula. Como se puede observar en la Figura 13, SSD discretiza el espacio de salida de los cuadros delimitadores en un conjunto de cuadros predeterminados en diferentes proporciones y escalas por ubicación del mapa de características (Sanz, 2019)

38
En el momento de la predicción, la red genera puntuaciones para la presencia de cada categoría de objeto en cada cuadro predeterminado y produce ajustes en el cuadro para que coincida mejor con la forma del objeto. Además, la red combina predicciones de múltiples mapas de características con diferentes resoluciones para manejar de forma natural objetos de varios tamaños.
39
Figura 12
Inferencia sobre Imágenes
Fuente. Adaptado de Arunava (2019)
Figura 13
Marco SSD
Fuente. Adaptado de Ichi.Pro (2021)
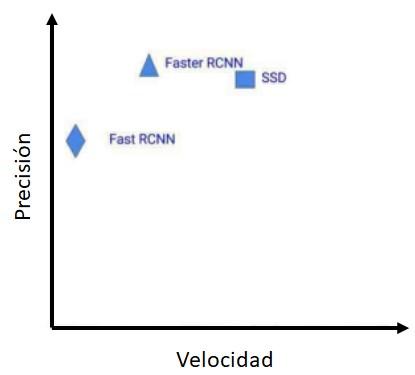
SSD es una arquitectura flexible en cuanto al método de predecir las cajas delimitadoras y la confianza de que esta contenga un objeto) para múltiples categorías de objetos. En caso de que el detector solo utilice un prior por localización del mapa de características de más alto nivel semántico, tendrá un comportamiento similar a la arquitectura de tipo ventana deslizante llamada OverFeat1931 (Redmon, Kumar, Girshick, y Farhadi, 2016) En la Figura 14, Sachan (2019) muestra una comparativa entre los diferentes modelos de detección de imágenes revisados, en cuanto a precisión y velocidad.
Fuente. Adaptado de Silva (2020)
De acuerdo con García (2018), el modelo SSD contiene un entrenamiento simple de extremo a extremo (end-to-end), que incluso para imágenes de baja resolución obtiene buenos resultados de precisión, consiguiendo una mejoría en la velocidad que compensa aún más la precisión obtenida. En fase de entrenamiento, SSD necesita determinar que regiones por defecto concuerdan mejor con el ground truth2. Por tanto, se queda con las regiones por defecto que obtienen mejor porcentaje de IoU3. Los recuadros por defecto respecto del ground truth si superan cierto umbral (típicamente 0.5) son marcados como
2 Etiquetas de detección – predicción de cada imagen
3 También conocido como Jaccard Index, es la métrica utilizada para calcular el solape entre dos recuadros delimitadores o bounding boxes. Es el resultado de dividir la intersección de las regiones entre la unión de estas
40
Figura 14
SSD Vs. R-CNN: Precisión y Velocidad
positivos, mientras que los demás se marcan como negativos. Esto permite a la red aprender y obtener puntaciones altas en varios de los bounding boxes4 por defecto superpuestos en vez de solamente en el mejor. Este sistema implica que hay muchas más muestras negativas que positivas, por lo que se introduce un método para clasificar las regiones por defecto que tienen mayor pérdida de confianza y poder hacer una relación 3:1, como mucho, de negativos y positivos. A este método se le conoce como minería de negativos dura (Hard Negative Mining).
2.2. MARCO HISTÓRICO
2.2.1. Trabajo final de grado, España: Detector de baches con Deep Learning
Para Manzanares (2019), el mantenimiento de las carreteras en muchos países es muy deficiente, ya que en la mayoría de los casos la manera de reportar y detectar daños suele tener un alto costo y estas actividades son realizadas manualmente por grupos de trabajadores que informan de estos daños, a partir de denuncias de usuarios de las carreteras o reportes policiales. Para el autor con el avance de la tecnología hay una tendencia a la desaparición de estos trabajos manuales: llega la automatización de muchas de estas tareas. En su proyecto “Detector de baches con Deep Learning” Manzanares se centró en crear un detector de baches con tecnología Deep Learning, cuyo principal objetivo fue reducir el coste del mantenimiento de las carreteras, automatizando y agilizando el trabajo. Para cumplir con este objetivo el autor utilizó los fundamentos de Deep Learning, una las tecnologías más actuales y con mejores resultados en el campo de la detección de objetos. Luego Manzanares diseño un detector de baches a partir de esta tecnología, pasando por la selección de cuál es la plataforma más adecuada y conveniente
41
4 Conjunto de propuestas de objetos
para este proyecto, explicando cómo se ha entrenado la red neuronal base de su trabajo, comparándola con diferentes modelos de entrenamiento, para finalmente crear una APP (Aplicación de software diseñada para ejecutarse en los smartphones) como un prototipo funcional de detector de baches. Manzanares utilizó Retinanet como detector de objetos, por aportar un coste menor computacional y una alta precisión en la detección, ideal para un detector en tiempo real (Hui, 2018a). Para le generación de la App, el autor usó una máquina virtual con Ubuntu para poder trabajar con las librerías y paquetes que se necesitaba. El entorno virtual pudo construirse a partir de PIP (Package installer for Python) y trabajar desde el terminal de Ubuntu. Como entorno de trabajo para Python, el autor usó PyCharm porque proporcionaba una interfaz clara para programar y hacer ‘debug’ del código. El código de la App está basado en TensorFlow Mobile, una versión menos actual que TFlite, ya que según Manzanares se encontró más información y apoyo para poder trabajar con él. Hernández (2018) estableció que TensorFlow Mobile proporciona una forma más simple de crear este detector de baches, aunque es menos potente y completo que TFlite
2.2.2.
Artículo científico,
Colombia: Técnicas de inteligencia artificial utilizadas en el procesamiento de imágenes y su aplicación en el análisis de pavimentos Reyes, Mejía y Useche-Castelblanco (2019) establecieron que, debido al incremento en los costos de mantenimiento, rehabilitación y construcción de vías, estudiar las estructuras de pavimento para identificar la mecánica dinámica de sus fallas se ha vuelto un campo de gran importancia en las ciencias de ingeniería. Los autores hablan de nuevas herramientas de análisis que buscan hacer este estudio más eficiente, reduciendo su costo y tiempo de detección mediante el reconocimiento digital de imágenes. Para los autores la forma tradicional de analizar una imagen está limitado por la subjetividad del análisis, por eso proponen implementar diferentes técnicas de I.A, para optimizar los algoritmos de procesamiento de imágenes. En el estudio "Técnicas de inteligencia artificial utilizadas en el procesamiento de imágenes y su aplicación en el análisis de pavimentos" Reyes et al.
42
(2019) presentan una comparación entre las diferentes técnicas de I.A enfocadas en el procesamiento de imágenes, enfocándose en los trabajos realizados específicamente con imágenes de pavimentos, su análisis utilizando inteligencia artificial. Como la fortaleza de los modelos de reconocimiento de fallas se basan en arquitecturas de inteligencia artificial, los autores hicieron un análisis comparativo de estas arquitecturas en su proyecto "Técnicas de inteligencia artificial utilizadas en el procesamiento de imágenes y su aplicación en el análisis de pavimentos ", mismo que dividieron en 3 secciones: en la primera se muestran los trabajos realizados con cada técnica en el campo del procesamiento digital de imágenes. La segunda sección revisa las técnicas implementadas, específicamente en pavimentos, y proponen implementaciones para mejorar el procesamiento de imágenes en mezclas asfálticas. La Tabla 3 muestra un resumen de las conclusiones que los autores establecen al realizar un resumen comparativo entre las diferentes metodologías de I.A para el procesamiento de imágenes que fueron analizadas en su artículo:
Tabla 3
Comparación de las técnicas de inteligencia artificial Técnica IA Ventajas Desventajas
Sistemas difusos. (Abdullah y Abdolrazzagh-nezhad, 2014; Lim, Vats, y Seng, 2015)
• Su implementación permite que se pueda aplicar de una forma práctica y sencilla porque maneja un esquema de lenguaje natural.
• Dificultad por la definición subjetiva del problema de forma precisa por medio de etiquetas y su porcentaje de pertenencia
Sistemas difusos.
• Clasificación simple de sistemas complejos sin tener limitaciones a clases de etiquetado.
• No se aconseja para sistemas de alta precisión, debido a la subjetividad de su sistema lingüístico y no numérico
Red neuronal MLP. (Cristea, Leblebici, y Almási, 2016; Jani, Mishra, y Sahoo, 2017)
• Aprendizaje rápido con gran porcentaje de efectividad
• Necesidad periódica de reentrenamiento para no perder poder de capacidad de detección.
43
Técnica IA Ventajas Desventajas
• Capacidad de procesamiento en paralelo, muy útil en sistemas que necesitan "fast answer"
• Implementación simple de una red neuronal MLP
• Gran cantidad de datos para el entrenamiento mientras más clases de categorización existan
Red neuronal convolucional (Galdámez, Raveane, y Arrieta, 2017; Cao, Wang, Ming, y Gao, 2015)
• Red especializada en el trabajo con imágenes en 2D mediante el uso de diferentes matrices de filtros.
• Robustez de la identificación ante variaciones en las imágenes.
• Tiempos extensos para entrenamiento
• La calidad de la identificación depende del tamaño de la base de imágenes usada para el entrenamiento
• Alto costo computacional: trabajo con matrices y Convoluciones entre ellas.
Inteligencia de enjambreColonia de abejas. (Cui et al., 2017; Banitalebi, Abb Aziz, Bahar, y Zainal, 2015)
• Convergencia rápida a la solución del problema en con gran flexibilidad en el aprendizaje
• Necesidad de pocos parámetros de configuración
• Necesidad recurrente de un algoritmo externo de búsqueda global dentro de la región del problema para establecer la mejor solución.
• Situaciones convergencia prematura a una por una mala configuración de la estructura de búsqueda del mejor resultado
Sistema inmune artificial (Bayar, Darmoul, HajriGabouj, y Pierreval, 2015) (Costa, Matos, y Martínez, 2017)
Fuente: Reyes et al. (2019)
• Alta capacidad para la exploración de múltiples soluciones
• Autoaprendizaje estructurado, profundo y simple, tiene la capacidad de aprender de forma autónoma.
• Alto nivel de desarrollo en codificación inicial para estructurar sus capas y funcionamiento
• Baja robustez en su implementación.
44
2.2.3. Caso de estudio, United Kingdom: A Fast and Adaptive Road Defect Detection Approach Using Computer Vision with Real Time Implementation
Karakose et al. (2016) consideraron que el uso del reconocimiento de imágenes para detección de fallas en las vías urbanas no es una concepción nueva y convinieron que el defecto de la carretera es uno de los factores más importantes de accidentes de tráfico, por lo general se producen grietas, surcos y baches en la superficie de la carretera. De acuerdo con los autores de este trabajo, el reconocimiento de estos errores se basa en el hecho de que las personas los han visto. Pero estos errores no se corrigen en poco tiempo y se complican. Para ayudar en la detección de estos errores los autores sugieren técnicas en las que se usa la visión artificial por computador. En este estudio realizado se han adaptado diferentes carreteras por las operaciones realizadas en la detección de errores viales a partir de las imágenes recibidas. Se utilizan imágenes tomadas con la cámara de un vehículo para el estudio, además los autores enfocan en todo su proyecto a la personalización, es decir, en el uso de imágenes borrosas y sin procesas que son mejoradas en el computador usando formatos de imagen binarios y operaciones morfológicas matemáticas.
2.2.4. Proyecto de Investigación, Louisiana: Object
Detection with Deep Learning: A Review. IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao et al. (2019) desarrollaron un trabajo de investigación donde, debido a la estrecha relación de la detección de objetos con el análisis de video y la comprensión de imágenes, expusieron métodos complejos para realizar estas labores, métodos que se basan en características (etiquetado) hechas en computadores y que se pueden entrenar poco a poco hasta convertirse en arquitecturas. Para los autores, el problema principal de la detección de objetos es determinar dónde se encuentran los objetos en una imagen determinada (localización de objetos) y a qué categoría pertenece cada objeto
45
(clasificación de objetos). Con estos fundamentos Zhao et al. canalizan los modelos tradicionales de detección de objetos en tres etapas: determinación de la región para selección, extracción de características y clasificación. El proyecto hace referencia al Deep Learning, basado en redes neuronales convolucionales, para la generación de modelos de reconocimiento de imágenes. Los autores manifiestan que esta arquitectura para reconocer diferentes objetos busca dentro de las imágenes características visuales que puedan proporcionar una representación semántica robusta del objeto. Zhao, Zheng, Xu y Wu mencionan que entre las características más representativas para la identificación de objetos están: SIFT5 , HOG 6 y Haar-like7. Para Lowe (2004) esto se debe al hecho de que estas características pueden producir representaciones asociadas con células complejas en el cerebro humano. Sin embargo, debido a la diversidad de apariencias, condiciones de iluminación y fondos, es difícil diseñar manualmente un descriptor de características robusto para describir perfectamente todo tipo de objetos.
2.2.5. Caso de estudio, Cuba: Revisión
de algoritmos de detección y seguimiento de objetos con redes profundas para video vigilancia inteligente.
En relación con el algoritmo SSD, Sánchez, González y Hernández (2020) exponen, en su trabajo de investigación, que hoy en día cada vez más se utilizan las redes neuronales
5 Scale-invariant feature transform o SIFT es un algoritmo usado en visión artificial para extraer características relevantes de las imágenes que posteriormente pueden usarse en reconocimiento de objetos, detección de movimiento, estereopsis, registro de la imagen y otras tareas (Estados Unidos Patente nº US6711293B1, 2004).
6 El histograma de gradientes orientados, HOG, es un descriptor de características utilizado en la visión por computadora y el procesamiento de imágenes con el fin de detectar objetos. La técnica cuenta las ocurrencias de orientación de gradiente en partes localizadas de una imagen (Mallick, 2016)
7 Las características similares a las de Haar son características de imágenes digitales que se utilizan en el reconocimiento de objetos. Una característica similar a Haar se representa tomando una parte rectangular de una imagen y dividiendo ese rectángulo en varias partes. A menudo se visualizan como rectángulos adyacentes en blanco y negro (Cepalia, 2021)
46
profundas para resolver problemas de visión por computadora, como el reconocimiento y seguimiento de personas a través de una red de cámaras. Los autores realizaron una revisión de los principales algoritmos de rastreo y detección de objetos, basados en redes profundas que permitirían conformar la arquitectura de un sistema de video - vigilancia inteligente y determinaron que los algoritmos one-stage son considerablemente más rápidos que los basados en propuestas de regiones, donde destaca SSD, y los algoritmos de rastreo offline tienen una mayor precisión comparado con los online, destacando a DeepSort como el más eficiente. En el artículo se menciona como uno de los principales usos del Deep Learning el entrenamiento de algoritmos para la detección de objetos en imágenes, entre los que se destaca SSD. Sánchez et al. (2020) fundamentaron esta afirmación debido a que los algoritmos one-stage son considerablemente más rápidos que los basados en propuestas de regiones, aunque tienen dificultades para detectar objetos pequeños, sobre todo si están agrupados. SSD supera a muchos de sus más complejos adversarios en velocidad y precisión en todos los escenarios, incluyendo objetos pequeños. Además, SSD se pudo utilizar en Mobilenet como extractor de características, en estos casos, sacrificando precisión, pudiéndose ejecutar en dispositivos libres de GPU, como celulares de gama media baja y Rasperry.
2.2.6. Proyecto de investigación, México: Clasificación de obstáculos a través del algoritmo SSD
De igual manera Moreno, Ramírez, Ávila y Carrillo (2017) mostraron los resultados de la implementación del algoritmo SSD en la clasificación de obstáculos, no sólo obteniendo resultados satisfactorios en la detección de objetos sino en sistemas autónomos de navegación. Los autores llevaron a cabo varios experimentos y lograron una clasificación del 89.99% de los objetos en tiempo real, con lo que se demostró que el algoritmo puede ser implementado en aplicaciones de navegación con una precisión confiable que permita una navegación segura en sistemas de navegación autónoma frente a la presencia de obstáculos.
47
3. METODOLOGÍA
3.1. ÁREA DE ESTUDIO
El Distrito Metropolitano de Quito es la capital de Ecuador y de la provincia de Pichincha, la gestión territorial abarca el área metropolitana conocida también como Distrito Metropolitano de Quito, ubicado en el centro norte de la provincia de Pichincha a una altitud de 2850 metros sobre el nivel del mar (Gestión de Comunicación M.A, 2017), cuenta con una población de 2,239,191 habitantes según el censo de población y vivienda del Instituto Nacional de Estadísticas y Censos (INEC) realizado en el 2010 (INEC, 2010) y tiene una proyección para el año 2025 de alrededor de 2,736,638 habitantes de los cuales 1,809,362 en la ciudad y 927,276 en el resto del territorio que se encuentra distribuido en 32 parroquias urbanas y 33 parroquias rurales. Según el plan maestro de movilidad para el Distrito Metropolitano de Quito 2009 - 2025 ( Municipio del Distrito Metropolitano de Quito, 2009), el grado de concentración de actividades económicas es significativamente más elevado en la ciudad que en el resto de zonas del Distrito, lo que se le conoce como la macro centralidad en donde se aloja al 72% de la población agrupando también una gran cantidad de equipamiento urbano, servicios públicos, comerciales y financieros lo que demanda de una gran atención a las soluciones para mejorar la movilidad en estos sectores.
En el plan maestro de movilidad para el Distrito Metropolitano de Quito 2009 – 2025 también se describe sobre la red vial, a través de un anillo periférico urbano en donde se incluyen las avenidas Simón Bolívar y Mariscal Sucre; un segundo anillo metropolitano constituido por la Perimetral Regional (E35) tramo Machachi – Sta. Rosa de Cusubamba; y las conexiones distritales conformadas por el acceso Panamericana Sur, Antigua vía QuitoConocoto, Autopista General Rumiñahui, Vía Interoceánica, Panamericana Norte y Vía Manuel Córdova Galarza, estas vías permiten el acceso a las principales zonas comerciales de la ciudad lo que ocasiona situaciones de congestión vehicular.
48
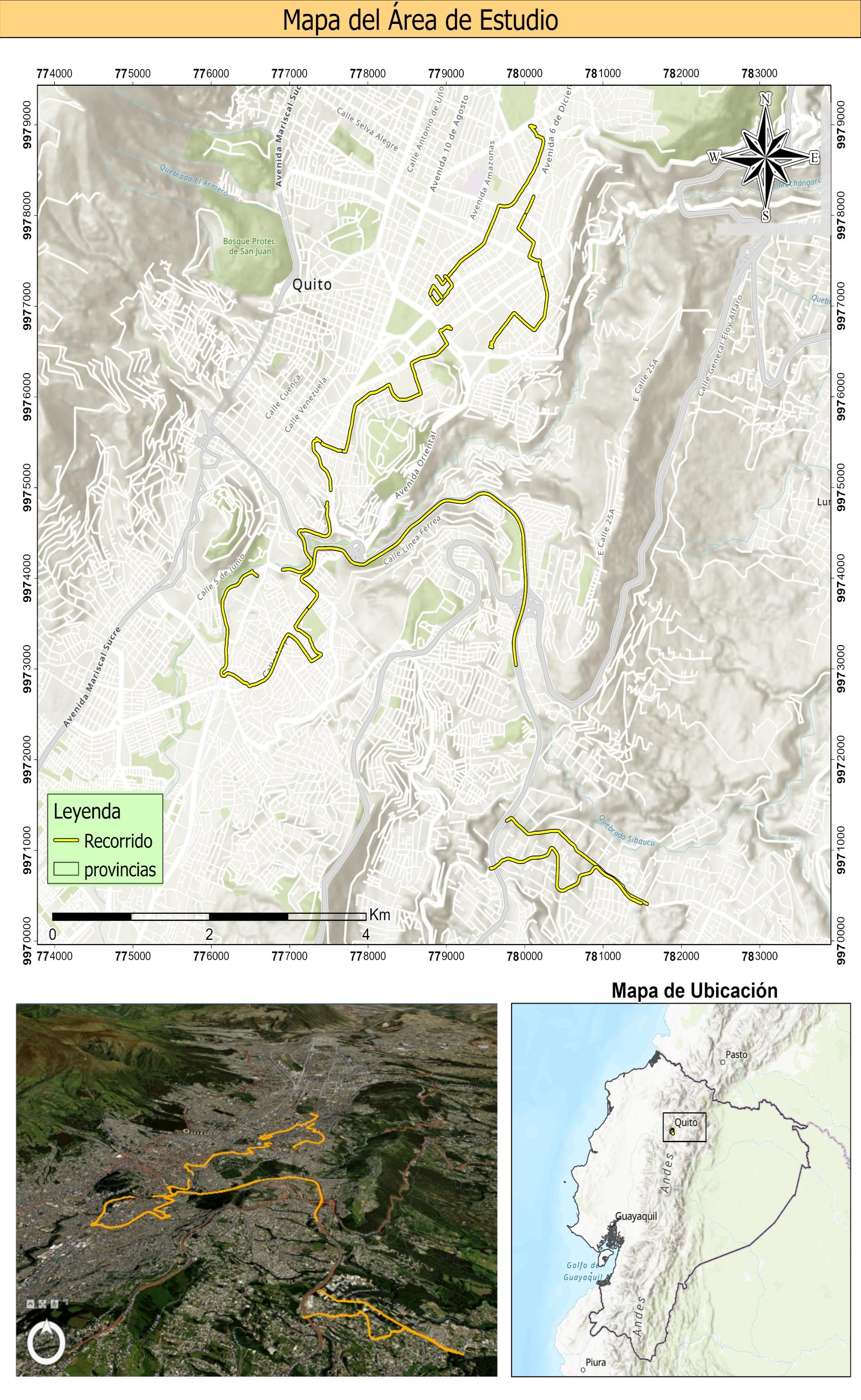
49
Figura 15
Mapa del área de estudio: Recorridos realizados
3.2. FLUJOGRAMA DE METODOLOGÍA
En el presente trabajo de investigación, se desarrolló un modelo de metodología para la implementación de una categorización de daños georreferenciados en las arterias viales de la ciudad de Quito (Ecuador), usando un algoritmo de inteligencia artificial desarrollado en Python. Este modelo metodológico se estructuró en cinco fases: Capturar la información, Preparar datos para entrenamiento del modelo, Entrenar al modelo, Probar la eficiencia del modelo y Publicar los resultados en un mapa Web. La Figura 16 muestra el detalle de las fases de esta propuesta:
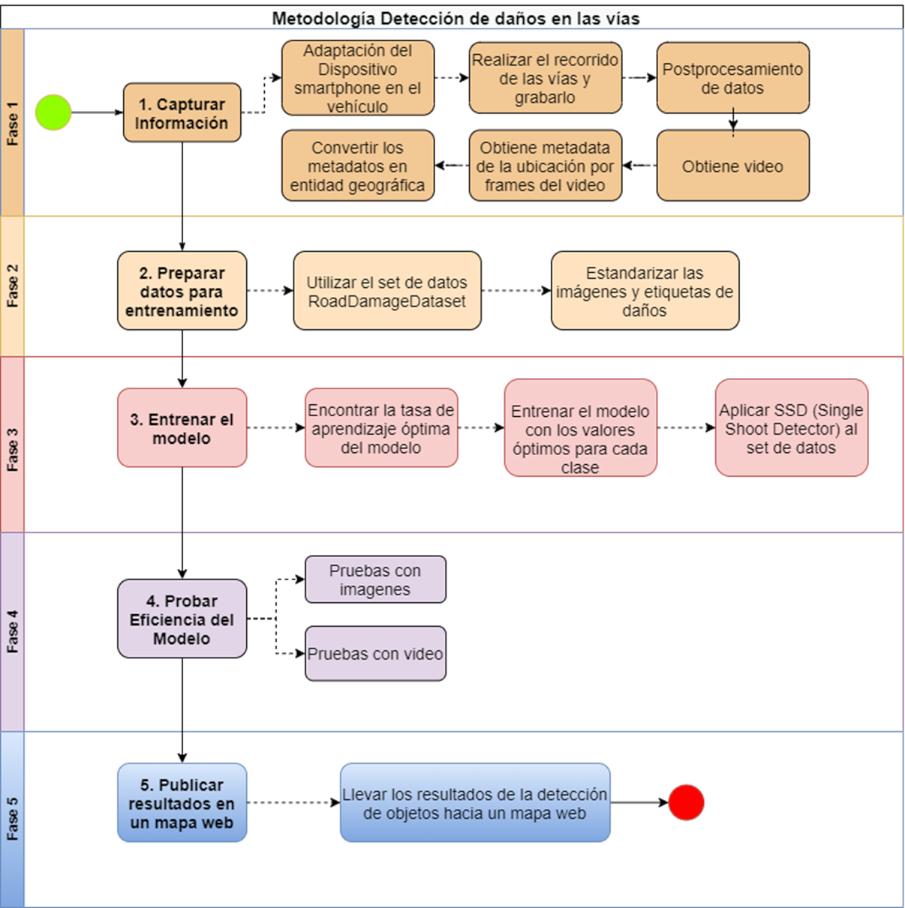
50
Figura 16
Flujograma de metodología
Cada una de las fases contiene actividades con un sustento científico - técnico para que el aprendizaje del modelo pueda arrojar predicciones aceptables y la publicación de los resultados sea una herramienta útil para el departamento de obras públicas del distrito metropolitano de la ciudad de Quito
3.3. JUSTIFICACIÓN DE LA METODOLOGÍA
Para el proceso de la generación del modelo de metodología, se utilizaron varias herramientas tecnológicas aplicadas en diferentes procesos desde la captura de la información hasta los resultados obtenidos. Este modelo es la columna neurálgica de soporte para el cumplimiento de los objetivos de este trabajo de investigación
• Para la captura de las imágenes, desde una secuencia de video, con los que se generará una base de datos de daños georreferenciados en las vías de la ciudad de Quito, Ecuador se utilizó la App AutoGuard©. AutoGuard© es una aplicación móvil disponible para dispositivos Android que permite capturar los datos en campo a partir de un video y geolocalización. Se aprovechó las capacidades de un Smartphone (cámara, GPS, sistema operativo) por ser un dispositivo independiente y accesible. Si bien existen aplicaciones similares, AutoGuard© permite configurar la forma en la que se capturan los datos, su codificación y la calidad del video necesaria para la obtención de las imágenes de alta resolución que se utilizarán en el entrenamiento del modelo.
• El procesamiento de la información geográfica, que está en la metadata de los videos capturados, fue realizado mediante el uso de una de las extensiones de ArcGIS Pro©: LocateXT, la misma que incorpora opciones para la detección de coordenadas en archivos de texto y la extracción de atributos personalizados, adicionalmente, ArcGIS Pro © permite a los usuarios de sistemas de información geográfica gestionar y
51
administrar cartografía vectorial y ráster8 (E.S.R.I, 2021b), así como también ejecutar herramientas de analítica para resolver problemas espaciales. Esto ahorró tiempo en el traslado de la metadata hacia una estructura de datos organizada como es un “feature class”, para posterior convertirla en la metadata del video en formato CSV. Esta es la metadata que conformará la base de datos de imágenes georreferenciadas de los daños en las vías de la ciudad de Quito, Ecuador
El proceso de aprendizaje y categorización de los daños en las vías, mediante el uso de un algoritmo de IA desarrollado en Python, fue realizado en tres herramientas:
• Para el entrenamiento de las imágenes y la creación de la metadata de clases identificadas se utilizó la plataforma Roboflow, que cuenta con la opción de hacer carga de datos, y aplicando el formato de Pascal VOC (Visual Object Classes) permite la creación de las etiquetas de identificación de clases. Adicionalmente cuenta con las opciones de redimensionar el tamaño de las imágenes para una mejora en el entrenamiento y una optimización de los recursos de memoria de la tarjeta gráfica del sistema donde se implementa el modelo de reconocimiento de imágenes
• El entorno de programación Python© de ArcGIS Pro© Mediante el uso de esta API, se permite la integración de las librerías de inteligencia artificial y el entorno. De esta manera, se pudo implementar los scripts en el ambiente Jupyter Notebook.
• Para el proceso de entrenamiento del modelo se utilizó el framework SSD, que permite el uso de una red neuronal resnet101, la cual cuenta con 101 capas de profundidad y un mejor desempeño y precisión al momento de la detección de objetos en video o imágenes. Este tipo de red neuronal fue usada debido a las conclusiones del trabajo de
8 En su forma más simple, un ráster consta de una matriz de celdas (o píxeles) organizadas en filas y columnas (o una cuadrícula) en la que cada celda contiene un valor que representa información, como la temperatura. Los rásteres son fotografías aéreas digitales, imágenes de satélite, imágenes digitales o incluso mapas escaneados (E.S.R.I, 2021b)
52
Manzanares (2019), quien al utilizar Retinanet como detector de objetos, obtuvo un coste menor computacional y una alta precisión en la detección, lo que volvió este tipo de red neuronal en el ideal para un detector en tiempo real.
• Para la publicación rápida de los resultados obtenidos se utilizó ArcGIS Online que permite la creación de mapas en la web de manera fácil y dinámica.
El entorno de programación Python© de ArcGIS Pro© y el framework SSD contienen coeficientes como: Learning Rate, Train Loss, Valid Loss, Machine Learning Accuracy, que permitirán evaluar la fiabilidad de la categorización del algoritmo de daños en las vías de la ciudad de Quito, Ecuador cuando las predicciones se haya cargado en el mapa de distribución espacial de las categorías de daños identificados, como resultado final del modelo de metodología para la implementación de una categorización de daños georreferenciados.
3.4. DESARROLLO DE LA METODOLOGÍA
3.4.1. Capturar la información
Preparación y post-procesamiento de datos
Mediante el uso de la aplicación AutoGuard©, se capturaron los archivos de video [Movies\AutoGuard][*.mp4] con su respectiva meta-data individual [Documents\AutoGuard] [*.str]. La aplicación AutoGuard© grabó los archivos de video y para cada video generó su respectivo archivo de meta-data, los archivos coinciden en su nombre, solo su extensión cambia. La Figura 17 muestra que este archivo de meta-data contiene información de navegación como: velocidad, latitud, longitud, hora, tiempo inicio, tiempo fin, ubicación y hora de la captura realizada
53
La información de los videos y la metada fue procesada utilizando la extensión LocateXT9 de ArcGIS Pro10 (E.S.R.I, 2021a). Generalmente la información que se debe utilizar dentro de la plataforma ArcGIS Pro© debe tener un contexto geográfico y debe estar estandarizada, sin embargo, la metada generada por AutoGuard© corresponden a información no estructurada. Aprovechado las capacidades de LocateXT, se crearon reglas para localizar los atributos (palabras clave dentro del texto de las etiquetas) en los archivos de meta-data (etiquetas) no estructurada, y obtener la información de latitud y longitud para conocer o retornar la ubicación de cada uno de los registros realizados con el programa AutoGuard. En la Tabla 4 se detallan los atributos necesarios que fueron creados para la gestión de cada archivo de meta-data (etiqueta) generadas por la app AutoGuard©:
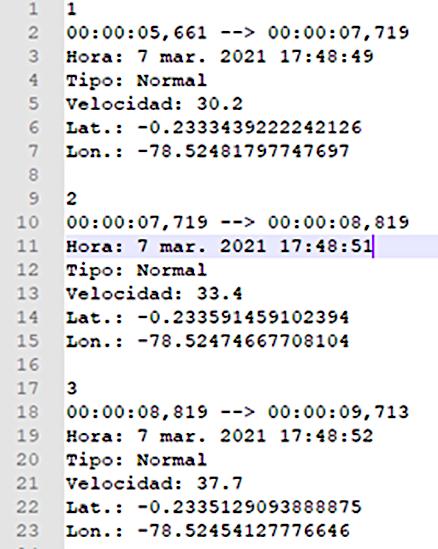
9 La extensión ArcGIS LocateXT permite usar el panel Extraer ubicaciones para buscar datos no estructurados para ubicaciones espaciales y generar entidades de puntos que representan dichas ubicaciones. Los datos no estructurados son cualquier texto o documento
10 ArcGIS es un completo sistema que permite recopilar, organizar, administrar, analizar, compartir y distribuir información geográfica (E.S.R.I, 2021a)
54
Figura 17
Estructura de los archivos Meta-data [*.str]
fecha_hora, tipo, velocidad, latitud, longitud, tiempo_inicio, tiempo_fin. Todos los atributos fueron generados en la sección [Capture Type]
Tabla 4
Reglas para los atributos personalizados
Atributo Definición
fecha_hora Fecha y hora identificada a partir de la palabra clave [fecha_hora] contenida en la etiqueta del video donde se realizará la captura de una línea de texto.
Tipo Tipo de archivo identificado a partir de la palabra clave [Tipo] contenida en la etiqueta del video donde se realizará la captura de una línea de texto.
Velocidad Velocidad del fotograma identificada a partir de la palabra clave [Velocidad] contenida en la etiqueta del video donde se realizará la captura de una línea de texto
Latitud La definición de los atributos latitud y longitud es únicamente informativa en el resultado de la ejecución de la herramienta, porque a nivel interno se reconoce automáticamente estos formatos de datos y los convierte en una entidad geográfica georreferenciada. Para el campo Latitud, se busca la palabra clave “Lat:” y se captura los datos hasta la siguiente cadena o palabra clave “Lon.:”.
Longitud La definición del atributo longitud es mediante la ubicación de la palabra clave [Lon.:] en la meta-data y a partir de esta posición se capturan 18 caracteres que conforman el valor de la longitud de la etiqueta georreferenciada
tiempo_inicio Tiempo de inicio de la grabación de la secuencia de video. Para obtener la definición de este campo se consideró la palabra clave “00:”, ya que al inicio del texto correspondiente a cada frame se hace referencia a este valor. Como parte de la regla se consideró que para cada ubicación cercana se tomen los 120 caracteres antes de los valores de latitud y longitud.
tiempo_fin Este campo representa el tiempo final de la porción de video donde hace referencia a la ubicación geográfica. Para obtenerlo se estableció la palabra clave formada por los siguientes caracteres “ >” y a partir de este elemento se definieron de longitud de 12 caracteres.
Una vez configurado los atributos personalizados se crea un archivo con extensión [*. lxta] que contendrá todas las reglas creadas como lo muestra la Figura 18.
55
Figura 18
Estructura del archivo de atributos personalizados: metadata

Mediante el uso de la herramienta ArcGIS Pro© se combina el archivo de los atributos personalizados [*. lxta] con los video y etiquetas georreferenciadas. Esta combinación se la hace usando el panel [Extract Location]. En este panel se genera una entidad geográfica (Capa de salida) con un nombre, que contiene la ubicación georreferenciada, sus atributos personalizados, de la información de las capturas realizadas por la App AutoGuard©. La Figura 19 muestra la entidad geográfica generada.
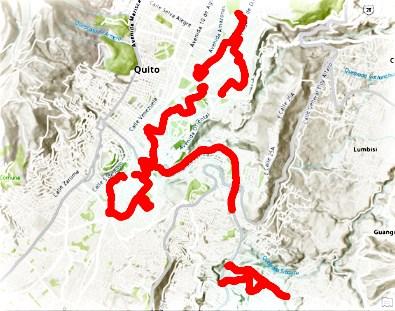
Figura 19
Entidad geográfica con información georreferenciada con segmentos
56
Para una correcta representación de los recorridos georreferenciados los segmentos de la Entidad Geográfica fueron convertidos en una entidad de línea usando la opción [Points to line]. Este proceso es obligatorio, ya que en la entidad geográfica generada se encuentran únicamente georreferenciados las capturas a través de la latitud y longitud Combinando las entidades de línea con la información georreferenciada de las etiquetas se obtendrá el mapa de la Figura 20 que muestra la Entidad Geográfica y los recorridos realizados durante la captura de video
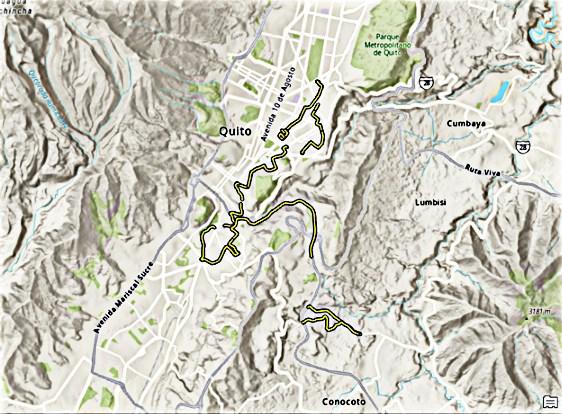
3.4.2. Preparación de datos para entrenamiento
La preparación de los datos para el entrenamiento del modelo de detección de fallas en carreteras comenzó con la generación de una estructura de datos (DataSet). En esta estructura se combinaron imágenes y videos con las etiquetas de identificación para el proceso de construcción de modelos de visión por computadora. Para esta actividad se usó
57
Figura 20 Mapa georreferenciado de recorridos
la aplicación Roboflow©11 , para acceder al uso de las herramientas de Roboflow© fue preciso utilizar una cuenta de GitHub©12
El proceso de creación de se divide en cuatro fases: 1) Creación de la Estructura de datos para entrenamiento; 2) Carga de datos de entrenamiento; 3) Etiquetado de imágenes y finalmente 4) Generación del archivo de datos para el entrenamiento del modelo de detección de imágenes.
1) Creación de la Estructura de datos para entrenamiento. En la herramienta Roboflow© se definió el Dataset para la generación del archivo de entrenamiento, para lo que fue necesario ingresar la siguiente información:
a. Dataset Name: Nombre del Conjunto de datos. Ejemplo: Orellana
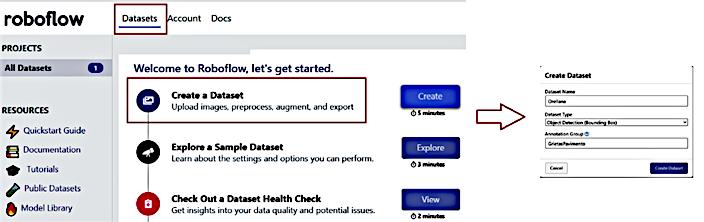
11 Roboflow es un startupque tiene como objetivo simplificar el proceso de construcción demodelos de visión por computadora. Roboflow aloja conjuntos de datos públicos y gratuitos de visión por computadora en muchos formatos populares (incluidos CreateML JSON, COCO JSON, Pascal VOC XML, YOLO v3 y Tensorflow TFRecords) y permite descargar estructuras generadas dentro del startup para uso particular. https://app.roboflow
12 GitHub es una forja para alojar proyectos utilizando el sistema de control de versiones Git. Se utiliza principalmente para la creación de código fuente de programas de ordenador
58
Figura 21 App Roboflow©
Fuente Roboflow (2021)
b. Dataset Type: Tipo de Dataset o uso que se le pretende dar al conjunto de datos, en este caso se debe seleccionar la opción: [Object Detection (Bounding Box)]
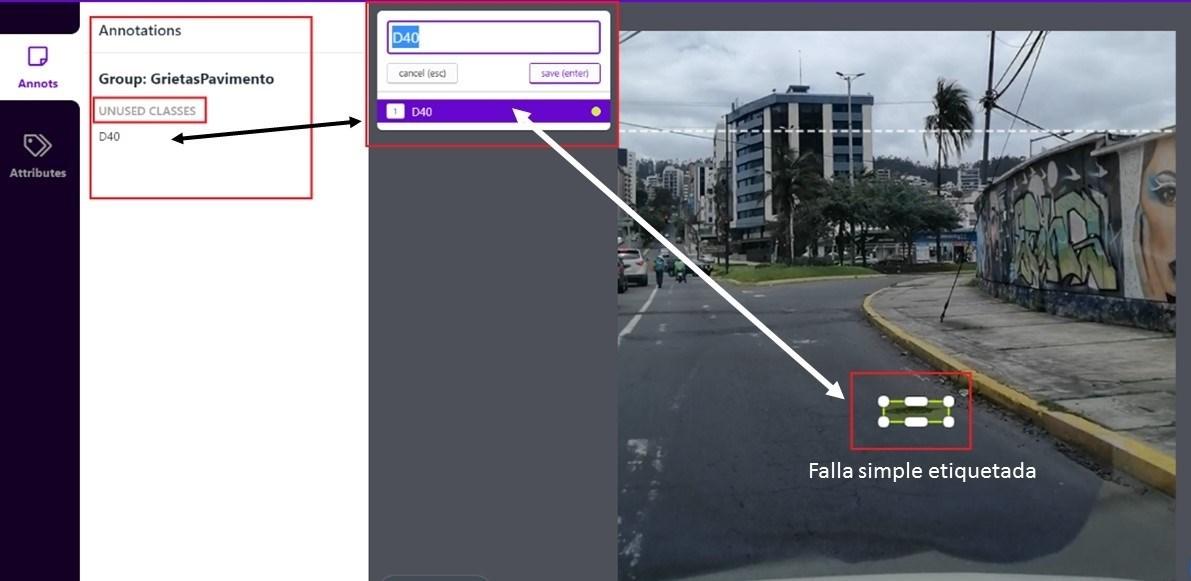
c. Annotation Group: Etiqueta para identificar el uso específico del conjunto de datos. Ejemplo: GrietasPavimento
2) Carga de datos de entrenamiento. Se cargaron las fotos de las fallas que serán usadas como base para el entrenamiento del modelo de reconocimiento de imágenes.
3) Etiquetado de imágenes. Luego de agregar las fotografías, se procedió con el etiquetado o labeling. Este etiquetado consiste en marcar cada falla del pavimento en cada imagen con un nombre (clase). Esta actividad debe realizarse sobre cada fotografía mediante el editor integrado de imágenes en la App Roboflow©.
a) Se debe marcar cada falla identificada en la imagen y etiquetarla como un nombre de clase (categoría de falla) (Figura 22). Estas clases deben ser definidas con anterioridad En ocasiones en una misma imagen se puede etiquetar más de un tipo de falla, en cuyo caso la imagen podría contener más de una clase (Figura 23)
59
Figura 22
Etiquetado de falla simple
b) Una vez agregada las etiquetas de clase en cada imagen cargada, se procedió a exportar las etiquetas de cada imagen y se obtuvo un resumen del conjunto de imágenes (Vista previa del DataSet). Luego se creó una versión del proyecto, asignándole un nombre compuesto por fecha en la que se terminó el proceso de [labeling]
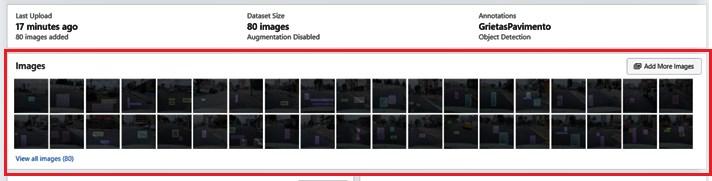
4) Generación del archivo de datos para el entrenamiento del modelo de detección de imágenes. Una vez identificada la versión del proyecto, el proceso se encuentra listo para generar el archivo que se usará en la fase de entrenamiento. Se descargó el Dataset creado en un formato de set de datos - etiquetado que usaba el estándar Pascal
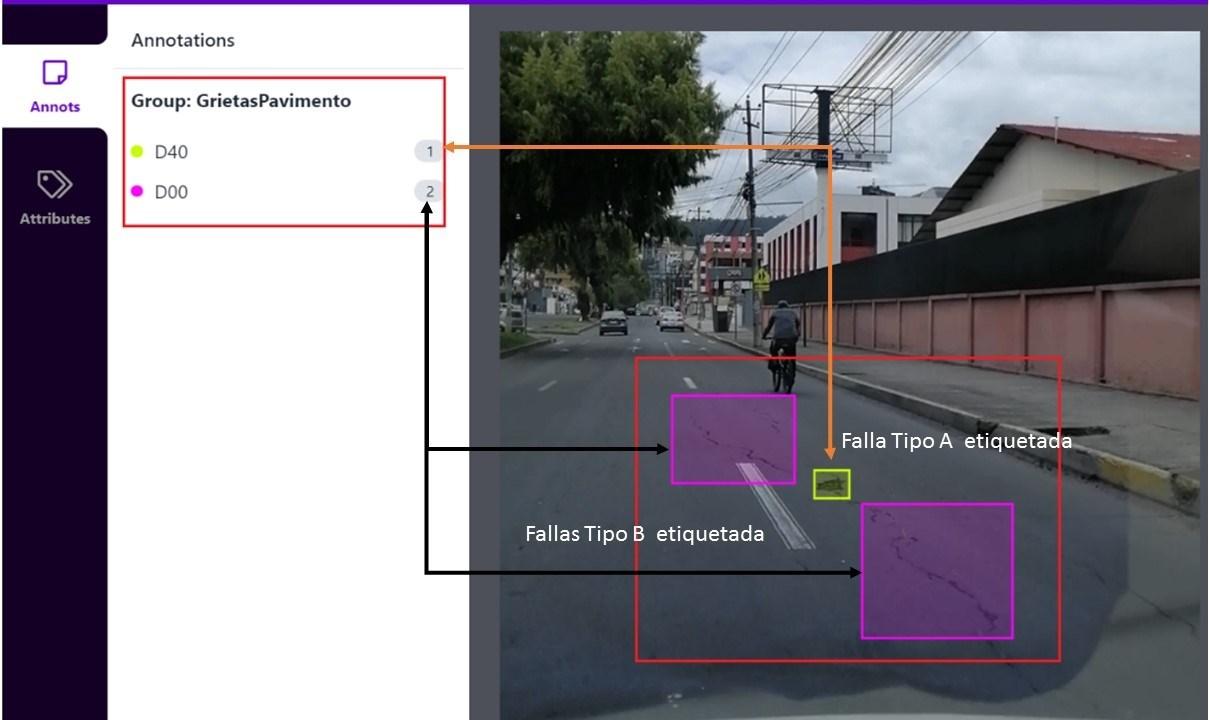
60
Figura 23
Etiquetado de múltiples fallas (Clases)
Figura 24
Vista previa del DataSet de images con etiquetas de identificación de fallas (clases)
VOC13 . El archivo descargado estaba en formato [*.zip], descomprimiendo el archivo se pudo observar que para cada archivo de imagen se había generado un archivo [*.xml], cuya estructura usaba el formato de etiquetado Pascal VOC, el mismo que se utilizará para el entrenamiento del algoritmo de reconocimiento de fallas. La Figura 25 muestra la estructura del archivo generado para cada imagen etiquetada en el Dataset de Imágenes y que será usado en el proceso de entrenamiento del modelo de reconocimiento de imágenes.
13 El formato PASCAL VOC (PASCAL Visual Object Classes):
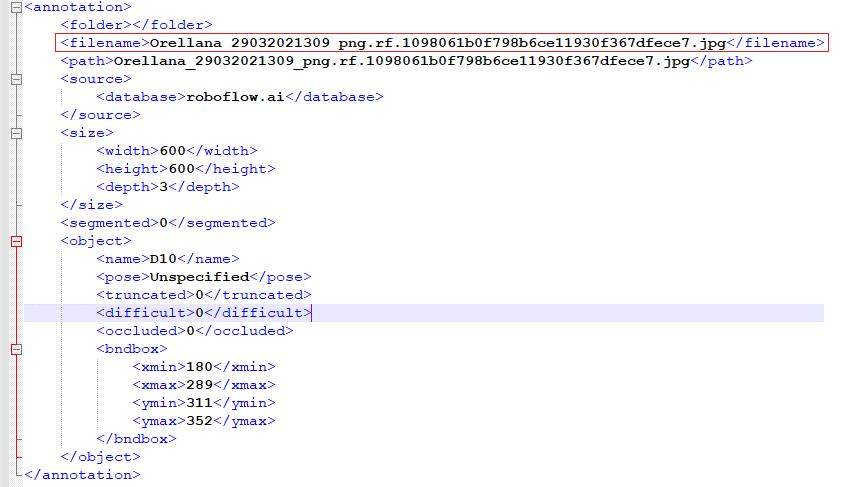
• Proporciona conjuntos de datos de imágenes estandarizados para el reconocimiento de clases de objetos.
• Proporciona un conjunto común de herramientas para acceder a los conjuntos de datos y anotaciones.
• Permite la evaluación y comparación de diferentes métodos.
61
Figura 25
Estructura del archivo de entrenamiento en formato Pascal VOC
3.4.3. Entrenamiento del modelo de reconocimiento de fallas
El proceso de entrenamiento del modelo de reconocimiento de fallas fue dividido en 4 etapas: a) Creación del entorno de desarrollo de Python; b) Uso de Python notebook para cargar las bibliotecas, idles e interfaces de entrenamiento del modelo; c) Preparar el entorno de Python para el entrenamiento del modelo y 4) Entrenamiento del modelo. La Figura 26 muestra las fases de entrenamiento y sus principales características
Creación del entorno de desarrollo de Python (Deep Learning)
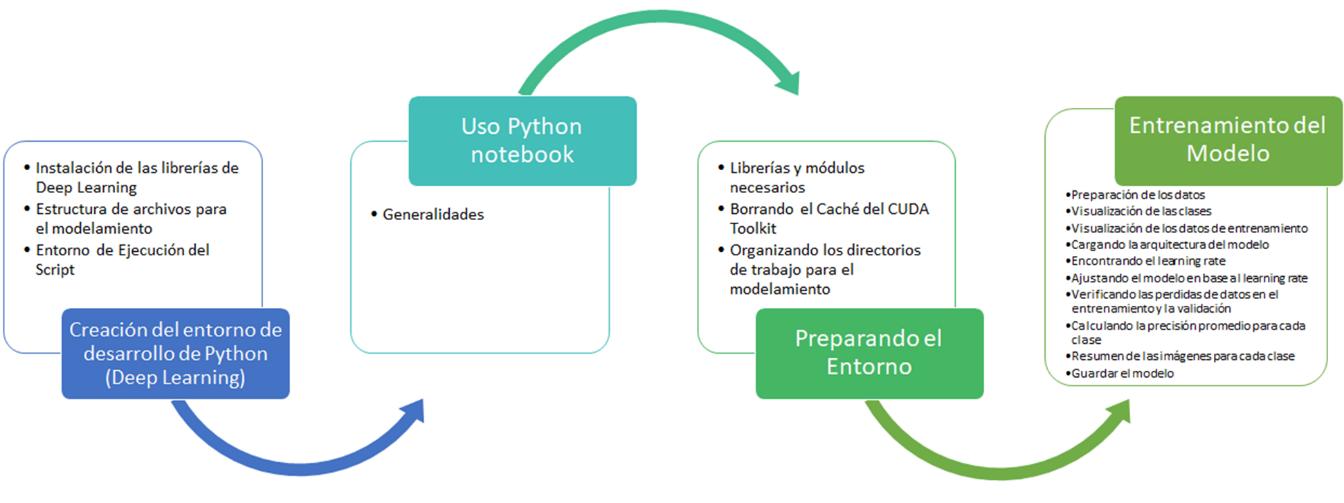
ArcGIS Pro© tiene incorporado el lenguaje de programación Python, para aprovechar las capacidades de las librerías de Deep Learning es necesario crear un clon del entorno de Python utilizando el gestor de paquetes Conda14 . Este procedimiento es recomendable
14 Conda© es un sistema de gestión de paquetes de código abierto y un sistema de gestión del entorno que se ejecuta en Windows, macOS y Linux. Conda instala, ejecuta y actualiza rápidamente paquetes y sus dependencias. Conda crea, guarda, carga y cambia fácilmente entre entornos en su computadora local. Fue creado para programas Python, pero puede empaquetar y distribuir software para cualquier idioma (Anaconda, Inc., 2021)
62
Figura 26 Proceso de entrenamiento del modelo
implementarlo desde la línea de comandos. El procedimiento para crear un clon del entorno de Python es el siguiente:
a) Acceder al directorio de [Scripts] de Python del entorno de ArcGIS Pro©
b) Una vez dentro del directorio se procedió a ejecutar el siguiente comando: Scripts>conda create –name deeplearning2 –clone arcgispro-py3
La ejecución de este comando creará un nuevo ambiente de Python para ArcGIS Pro en el directorio del usuario actual: [deeplearning2]
c) Para activar el nuevo entorno de Python creado se utilizó el comando:
Scripts> activate deeplearning2
d) Instalación de las librerías de Deep Learning. Para la instalación de las librerías de Deep Learning en este nuevo ambiente, clon de Python, se utilizó el comando:
Scripts> conda install -c esri -c fastai -c pytorch arcgis=1.8.5 absl-py=0.11.0 aiohttp=3.6.3 ase=3.19.1 astor=0.8.1 async-timeout=3.0.1 beautifulsoup4=4.9.3 cachetools=4.1.1 catalogue=1.0.0 cloudpickle=1.6.0 cudatoolkit=10.1.243 cudnn=7.6.5 cymem=2.0.4 cython=0.29.21 cython-blis=0.4.1 cytoolz=0.11.0 dask-core=2.30.0 deep-learning-essentials=2.7 fastai=1.0.60 fastprogress=0.2.3 fasttext=0.9.2 filelock=3.0.12 gast=0.2.2 google-auth=1.23.0 google-auth-oauthlib=0.4.2 googlepasta=0.2.0 googledrivedownloader=0.4 graphviz=2.38 grpcio=1.31.0 imageio=2.8.0 isodate=0.6.0 joblib=0.17.0 keepalive=0.5 keras-applications=1.0.8 keras-base=2.3.1 keras-gpu=2.3.1 keraspreprocessing=1.1.0 laspy=1.7.0 libopencv=4.5.0 libprotobuf=3.13.0.1 libwebp=1.1.0 llvmlite=0.34.0 markdown=3.3.3 multidict=4.7.6 murmurhash=1.0.2 ninja=1.10.1 numba=0.51.2 nvidia-ml-py3=7.352.0 onnx=1.7.0 onnx-tf=1.5.0 opencv=4.5.0 opt_einsum=3.1.0 plac=1.1.0 plotly=4.5.4 pooch=1.0.0 preshed=3.0.2 protobuf=3.13.0.1 py-opencv=4.5.0 pyasn1=0.4.8 pyasn1-modules=0.2.8 pytorch=1.4.0 pywavelets=1.1.1 rdflib=5.0.0 retrying=1.3.3 rsa=4.6 sacremoses=0.0.43 scikit-image=0.17.2 scikitlearn=0.23.2 sentencepiece=0.1.91 soupsieve=2.0.1 spacy=2.2.4 sparqlwrapper=1.8.5 srsly=1.0.2 tensorboard=2.3.0 tensorboard-plugin-wit=1.6.0 tensorboardx=2.1 tensorflow=2.1.0 tensorflowaddons=0.9.1 tensorflow-base=2.1.0 tensorflow-estimator=2.1.0 tensorflow-gpu=2.1.0 termcolor=1.1.0 thinc=7.4.0 threadpoolctl=2.1.0 tifffile=2020.10.1 tokenizers=0.8.1 toolz=0.11.1 torch-cluster=1.5.4 torchgeometric=1.5.0 torch-scatter=2.0.4 torch-sparse=0.6.1 torch-spline-conv=1.2.0 torchvision=0.5.0 tqdm=4.51.0 transformers=3.3.0 typeguard=2.7.0 wasabi=0.6.0 werkzeug=0.16.1 yarl=1.6.2
e) Establecer el nuevo entorno de Python [deeplearning2] como predeterminado en ArcGIS
Pro mediante el comando:
Scripts> proswap deeplearning2
Para los siguientes pasos es necesario conocer la ubicación de los archivos de Estructura de datos para el modelamiento, que contienen los datos etiquetados generados a partir del programa Roboflow en formato estándar Pascal VOC.
63
f) Una vez establecido el nuevo entorno de Python como predeterminado en ArcGIS Pro, se procedió a utilizar Jupyter Notebook15 como entorno de ejecución del script. En este entorno se entrenó el modelo y se hicieron las pruebas de fiabilidad correspondientes. Jupyter Notebook se ejecuta bajo un entorno web y la dirección web en la que se genera y donde se encuentra disponible es http://localhost:8888. Para acceder al entorno de Jupyter Notebook se debe ejecutar el comando: [Usuario Windows] [deeplearning2]\Scripts>jupyter-notebook.exe
g) La ejecución de este comando abrió el navegador de internet direccionado a una página local (http://localhost:8888) y permite la creación de un notebook o libro de trabajo en donde se procederá a escribir el código en Python para el entrenamiento del modelo de reconocimiento aprovechando las librerías instaladas.
Uso de Python notebook
El código de Python que se usará para el entrenamiento del modelo se denomina
“Automate Road Surface Investigation Using Deep Learning” y se encuentra disponible en una contribución realizada en GitHub por Tuteja et al. (2021). La dirección en donde se encuentra publicado y de donde recuperó el archivo con el código de Python para el entrenamiento del modelo “Automate Road Surface Investigation Using Deep Learning” es: https://github.com/Esri/arcgis-pythonapi/blob/master/samples/04_gis_analysts_data_scientists/automate_road_surface_inves tigation_using_deep_learning.ipynb .
15 JupyterLab es un entorno de desarrollo interactivo basado en web para cuadernos, código y datos de Jupyter. JupyterLab es flexible: puede configurar y organizar la interfaz de usuario para admitir una amplia gama de flujos de trabajo en ciencia de datos, informática científica y aprendizaje automático (Proyecto y la Comunidad Jupyter, 2021)
64
El archivo descargado fue incorporado al directorio del ambiente de Python creado [deeplearning2] Se recomienda que para una mejor comprensión del archivo descargado este puede ser abierto desde el aplicativo Jupyter Notebook para su revisión y análisis. Este archivo contiene todo el procedimiento a utilizar para el entrenamiento del modelo, las pruebas y la carga de información en un entorno Web-GIS. El notebook de Python empieza con la descripción del procedimiento y los tipos de fallas que se pueden a identificar a través del modelo.
Preparando el Entorno
Para la ejecución del modelo de detección de objetos fue necesario previamente incorporar al script de entrenamiento algunas librerías de Python. Estas librerías se encuentran descritas en la Tabla 5.
Tabla 5
Librerías para la ejecución del modelo de entrenamiento
Librería Descripción
Pandas Librería para manejar tablas de datos y realizar análisis de manera fácil. Os Librería para el manejo de archivos y directorios del sistema operativo. shutil Librería que permite realizar operaciones de alto nivel en archivos y grupos de archivos, las operaciones soportadas son copiar y eliminar.
Pathlib Librería que representan las rutas del sistema de archivos para diferentes sistemas operativos.
SingleShotDetector Módulo de la librería arcgis. learn para crear los modelos de detección de objetos.
Prepare_data Módulo que permite preparar los objetos a partir de una muestra de entrenamiento, entre los formatos compatibles está el Pascal_VOC_rectangles. Este formato es el que se utilizó para las clases identificadas en la fase de preparación de datos. 2 (Fase: 2. Preparar Datos para entrenamiento)
Para importar las librerías necesarias al entorno de Python se debe ejecutar las siguientes instrucciones:
65
In [2] 1 import pandas as pd 2 import os 3 import shutil 4 from pathlib import path
5 from arcgis. gis import GIS
6 from arcgis. features import GeoACCessor
7 from arcgis. learn import Singleshotoetector, prepare_data
Este algoritmo utiliza las unidades de procesamiento gráficas presentes en las tarjetas de video en el computador. El entorno actual donde se desarrolla el modelo de entrenamiento posee una tarjeta gráfica Nvidia Geoforce GTX 1050 Ti. Es recomendable borrar el caché que se encuentra en la tarjeta gráfica a fin de dedicarla al proceso de entrenamiento del modelo (Borrando el Caché del CUDA Toolkit). Para vaciar el cache se utilizó la instrucción:
In [2] 1 torch.cuda.empty_cache()
Para una mejor organización del trabajo, los archivos de etiquetas de clase en formato Pascal VOC [*.xml] (generadas desde el programa Roboflow) y las imágenes [*.jpeg] que iban a ser usadas para el entrenamiento del modelo fueron distribuidas en carpetas: [Imágenes], [labels]. Se debe actualizar en el Notebook de Python los directorios en donde se encuentra ubicados los archivos de datos de las imágenes y de las etiquetas para la detección de fallas en las vías que se van a utilizar para el entrenamiento. Para realizar esta actualización se utilizó la instrucción:
In [3]: 1 data_path= Path (‘[Directorio de ubicación de las carpetas de imagines y etiquetas]’)
Entrenamiento del Modelo
El entrenamiento del modelo fue divido en varias fases: a) Preparación de los datos, b) Visualización de las clases; c) Visualización de los datos de entrenamiento; d) Cargando la arquitectura del modelo; e) Encontrando el Learning Rate; f) Ajustando el modelo en base al Learning Rate; g) Verificando las pérdidas de datos en el entrenamiento y la validación; h) Calculando la precisión promedio para cada clase; i) Resumen de las imágenes para cada clase, y finalmente j) Guardado del modelo.
• Preparación de los datos. Para realizar el entrenamiento del modelo, fue necesario invocar la función prepare_data. Esta función es parte del módulo de [arcgis.learn] para
66
aprendizaje profundo, y consiste en preparar un objeto a partir de muestras de entrenamiento o clasificaciones realizadas con anterioridad a través de las etiquetas creadas en formato Pascal VOC. Para la aplicación de esta función se requiere como parámetros: el directorio donde se encuentran las carpetas (label e images), el tamaño de la muestra, seed, y el tipo de dataset (ArcGIS, 2021)
In [4]: 1 data = prepare_data (data_path, batch_size=8, chip_size=600, seed=42, dataset_type=’PASCAL_VOC_rectangles’)
• Visualización de las clases. Para visualizar el objeto data, que contiene las clases utilizadas para el entrenamiento a partir de las etiquetas creadas en formato Pascal VOC, se usó la siguiente línea de comando (ArcGIS, 2021) :

In [5]: 1 data.classes
Out[5]: [‘backgroud’, ‘D00’, ‘D01’,’D02’,’D10’,’D11’,’D20’,’D40’]
• Visualización de los datos de entrenamiento. Para la visualización de los datos de entrenamiento se utilizó el comando data.show_batch(), el cual permite mostrar, en n filas, imágenes aleatorias usadas para el entrenamiento del modelo (ArcGIS, 2021) como lo muestra la Figura 27.
In [6]: 1 data.show_batch (rows=2)
67
Figura 27
Visualización de los datos de entrenamiento
• Cargando la arquitectura del modelo
Para las tareas de detección de objetos las librerías de arcgis. learn contienen el modelo SingleShotDetector, el cual está basado en la red neuronal convolucional "resnet01", misma que es utilizado en este proyecto. Para cargar esta arquitectura de detección al proyecto se utilizó el siguiente comando:

In [7]: 1 ssd=SingleShotDetector(data, backbone=' resnet101' , focal_loss=true
Con esta arquitectura cargada al proyecto para ver los resultados preliminares se usó el comando:
In [8]: 1 ssd.show_results (thresh=0.1)
En la Figura 28 se muestra la salida de la ejecución del comando en el que se verifica la calidad del reconocimiento de clases (imágenes) de manera rápida, sin entrenar antes el modelo, a fin de determinar posibles resultados. Estas salidas pueden variar una vez que el modelo haya sido entrenado.
68
Figura 28
Definición de línea base - Predicciones
• Encontrando el Learning Rate
Los resultados del modelo, sin entrenamiento, no permiten una correcta clasificación de los daños identificados en las vías, por tal motivo, es necesario encontrar el valor de aprendizaje a través del método lr_find (). La sintaxis que se usó para la ejecución de este comando fue la siguiente:
In [10]: 1 lr = ssd.lr_find ()
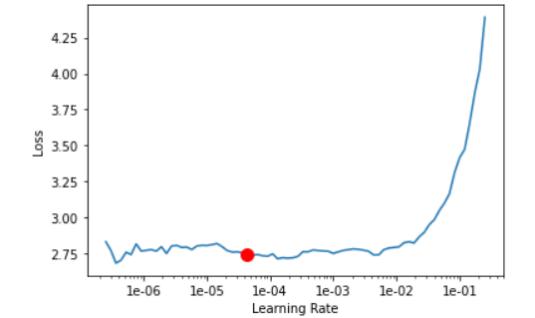
2 lr
En la Figura 29 se puede observar la salida gráfica de la ejecución del método lr_find () que genera una tasa de aprendizaje ajustada mínima para identificar un valor de línea base de aprendizaje para el entrenamiento del modelo (0.00004365158322401661).
Out[5]: Figura 29 Salida ejecución comando lr_finfd()
lr: 0.00004365158322401661
• Ajustando el modelo en base al Learning Rate
A través del método fit () se ajustó el modelo en función de un total de "n" ciclos para el entrenamiento de los datos. En este proyecto se consideró el valor de 30 ciclos para el entrenamiento. Para usar este método se usó la siguiente línea de comando:
In [10]: 1 ssd.fit (30, lr=lr)
En la Tabla 6 se muestran los valores obtenidos luego del ajuste del modelo, en función de los 30 ciclos definidos para el entrenamiento:
69
Tabla 6
70
Epoch (Ciclo) train_loss (Pérdida de vía) valid_loss (Pérdida válida) Time (Tiempo) 0 2.798923 2.496634 01:36 1 2.771694 2.501391 01:36 2 2.761559 2.461212 01:36 3 2.747524 2.472212 01:36 4 2.758761 2.388711 01:36 5 2.709701 2.401406 01:37 6 2.687511 2.449729 01:37 7 2.710849 2.418972 01:37 8 2.685020 2.421107 01:37 9 2.703858 2.383961 01:37 10 2.666029 2.360645 01:37 11 2.689095 2.388524 01:37 12 2.728049 2.410475 01:37 13 2.687363 2.440787 01:37 14 2.642908 2.371115 01:37 15 2.651582 2.359567 01:37 16 2.672254 2.279596 01:37 17 2.710192 2.281152 01:37 18 2.663953 2.304837 01:37 19 2.682378 2.450552 01:37 20 2.677585 2.377788 01:37 21 2.640088 2.303919 01:37 22 2.698398 2.309424 01:37 23 2.644331 2.294707 01:37 24 2.668097 2.485241 01:37 25 2.658653 2.449100 01:37 26 2.658929 2.287819 01:37 26 2.658929 2.287819 01:37 27 2.674130 2.273660 01:37 28 2.674368 2.353177 01:37 29 2.678896 2.292129 01:37
Ajuste del modelo en base al Learning Rate
• Verificando las pérdidas de datos en el entrenamiento y la validación. Para verificar la pérdida de datos en el entrenamiento se usó la función plot_losses (), la que permite visualizar las perdidas en el modelo. Para usar este método se usó la siguiente línea de comando:
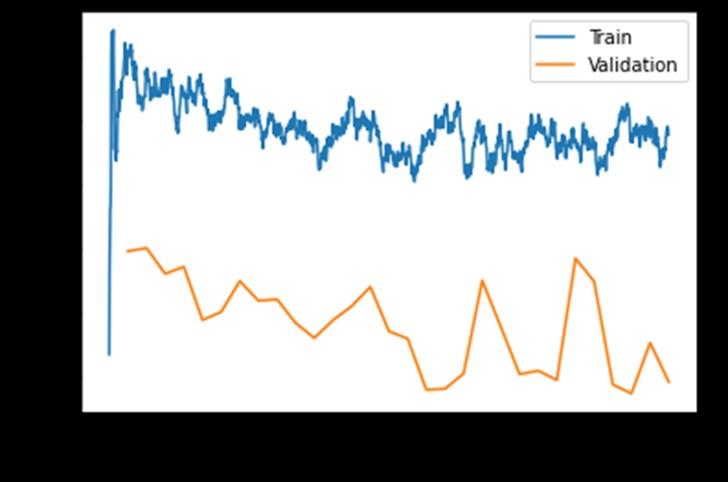
In [12]: 1 ssd.learn.recorder.plot_losses ()
En la Figura 30, se puede observar la salida gráfica de la ejecución del método plot_losses, el cual genera dos líneas, que serán tomadas como base para el entrenamiento del modelo, una línea con la perdida de datos (Train) (Errores en la categorización-reconocimiento) y una línea con los datos procesados (Validation) (Aciertos en la categorización-reconocimiento).
Out [12]: Figura 30
Salida ejecución comando plot_losses
• Calculando la precisión promedio para cada clase. A través del método average_precision_score () se obtuvo un resumen de la precisión promedio de cada clase identificada en el modelo. Para usar este método se usó la siguiente línea de comando:
In [13]: 1 ssd. average_precision_score ()
Out [13]: {'D00': 0.5066196870714972, ‘D01': 0.047500001043081275, 'D10': 0.194961257351833, ‘D11': 0.034090910106897354, 'D20': 0.4954447993796771, 'D40': 0.28371212258934975}
71
• Resumen de las imágenes para cada clase. A través de la siguiente rutina se pudo obtener el total de las imágenes donde se encuentren presentes cada clase entrenada:
In [13]: all_classes = []
for i, bb in enumerate (data. train_ds.y. y): all_classes += bb.data [1]. tolist ()
df= pd.value_counts (all_clasess, sort=False)
df. Index= [data. Classes[i] for i in df. Index] df
Out [13]: D00: 180 D01: 121
D10: 169 D11: 93
D20: 101 D40: 100
dtype: int64
• Guardar el modelo Una vez ejecutado el modelo se lo guardó para su referencia y uso posterior en la validación y detección sobre otras imágenes. El archivo generado se guardó con extensión [*.emd] que se encuentra dentro de la carpeta del mismo nombre.
3.4.4. Preparación de lo Metadata para la validación del reconocimiento de fallas (imágenes) en una secuencia de video
a) Preparación de los metadatos
Para realizar este procedimiento es necesario grabar algunos videos a partir de un mapa de recorridos y generar su respectiva metadata en formato *.csv. A esta información, convertida en una metadata, debe agregarse etiquetas de identificación, en especial de la fecha de las capturas de ubicación, que tiene que ir incorporadas en el archivo de metadata [*.srt]. Para crear la capa de información de recorridos, se usará la
72
herramienta LocateXT 16 de ArcGIS Pro y, a partir de esta capa, se exportará el etiquetado a un formato de archivo de Excel. Este archivo se usará para un tratamiento previo a la ejecución del modelo y validar la detección de los daños en las vías en un archivo de video. Si se desea realizar una corrección de algún campo de información de la Metadata, se recomienda el uso de Microsoft Excel, debido a la facilidad de manejo de la metadata en esta aplicación ofimática y que la herramienta LocateXT puede exportar/importar la metadata a un archivo de Microsoft Excel. Las principales correcciones que deben realizarse son:
• Los valores del campo fecha_hora, extraídos desde la herramienta LocateXT, debe tener el formato dd/mm/yyyy. Esta corrección es necesaria debido al formato de fecha que necesita como parámetro el modelo de Python.
• Los campos Latitud y Longitud deben contener valores numéricos (“.” Decimal, sin símbolo de miles).
• Adicionar una nueva columna a la metadata que contenga el valor de la fecha en formato UNIX Time Stamp17 en milisegundos. Para el cálculo de este valor se aplicará la fórmula: =([fecha_hora]-25569) *86400, donde el valor de 25,569 es el total de días desde el 1 de enero de 1900 hasta el 1 de enero de 1970 y el valor de 86,400 es el número de segundos que tiene un día (24*60*60)
b) Creación de las variables para el análisis en el video Usando el comando [os.path.join] se establecerá la ruta hacia los archivos de video y también hacia la respectiva metadata generada en el paso anterior.
16 ArcGIS LocateXT es un software de extracción de entidades para el análisis de datos no estructurados, lo que le permite extraer rápidamente información de ubicación a partir de cantidades masivas de datos. Su capacidad de búsqueda de sentido identifica automáticamente la información de ubicación dentro de grandes volúmenes de sus datos no estructurados para traer información geoespacial a la superficie (ArcGIS, 2021).
17 Tiempo Unix es un sistema para la descripción de instantes de tiempo: es la cantidad de segundos transcurridos desde la medianoche UTC del 1-01-1970, sin segundos intercalares (DansTools.com, 2021)
73
1 video file = os.path.join(Path('[Directorio de Videos de Entrenamiento] ), '[Nombre del Video de entrenamiento]')
2 video file
1 file_metadata = os.path.join(Path([Directorio de metadata de Entrenamiento] ' ), '[Nombre de la metadata de entrenamiento])
2 file_metadata
c) Ejecución del modelo entrenado sobre el video
Usando la función predict_video () se verificará, sobre la secuencia del video, la idoneidad de la detección de los daños en las vías de acuerdo con el modelo entrenado.
1 ssd.predict_video (input_video_path=[video_file], metadata_file=[file_metadata], threshold=0.1, visualize= True, resize= True)
donde:
• Input_video_path: Ruta hacia el archivo de video sobre el que se ejecutará la predicción de los daños.
• Metadata_file: Ruta para el archivo csv que contiene los metadatos del video y de cada una de las posiciones geográficas donde fue grabado el video
• Threshold: Indica la probabilidad por sobre la que la detección puede ser considerada.
• Visualize: Activa/Desactiva la opción (true o false) de crear un archivo nuevo de video con las predicciones incorporadas.
• Resize: Activa/Desactiva la opción (true o false) para redimensionar el tamaño del video en el tamaño del chip_size que se utilizó al momento del entrenamiento
d) Visualización de los Resultados
La función predict_video () generará un archivo de video con el nombre [Video]_predictions.avi que contendrá las predicciones incorporadas. Este nombre es el mismo del archivo de video que se usó para el entrenamiento del modelo [Video].avi
al que se le agrego el sufijo _predictions. Adicionalmente se generará un archivo metadata.csv en el que se aloja una nueva columna con la predicción en formato VMTI
(Video Moving Target Indicator)
74
3.4.5. Publicar los resultados en un Mapa Web
Para la visualización de los daños identificados en las vías se creó una aplicación web de mapas utilizando la información geográfica georeferenciada en la plataforma ArcGIS
Online:
• Enlace Mapa Web Resultados: https://testec.maps.arcgis.com/apps/dashboards/11a6c5f092814cd6aa43824654ce8 79d
• Enlace – Notebook Python: Estructura del Modelo de IA aplicado para el Deep Learning de la propuesta.
75
4. RESULTADOS Y DISCUSIÓN
4.1. RESULTADOS
4.1.1. Aplicación de una muestra de imágenes para la validación del modelo
Una vez terminada la fase de entrenamiento del modelo MPQ (Modelo Propio Quito), para el análisis de su efectividad en el reconocimiento de imágenes, se usaron nuevas capturas de fallas (fotos) de los ejes viales para validar el modelo (Valid Loss) y determinar si era capaz de reconocer las nuevas imágenes incorporadas (predecir la categoría de la imagen cargada) Las nuevas imágenes fueron exportadas desde Roboflow y se distribuyeron en las carpetas que contenían el DataSet que fue usado en el entrenamiento inicial del modelo de detección de fallas. Para probar la predictibilidad del modelo se usó la función ssd.predict(). A continuación se presenta 4 ejemplos de uso del modelo MPQ para el reconocimiento de fallas y la salida visual de su predicción:

In [1]: bbox_data= ssd.predict (r'[Ruta de Entrenamiento del Modelo][Nuevo archivo de Imagen(1)]', threshold=0.1, visualize=True)
Out[18]: Figura 31
Predictibilidad de imágenes del modelo- Ejemplo 1
76
In [1]: bbox_data= ssd.predict (r'[Ruta de Entrenamiento del Modelo][Nuevo archivo de Imagen(2)]', threshold=0.1, visualize=True)
Out[19]: Figura 32
Predictibilidad de imágenes del modelo- Ejemplo 2


In [1]: bbox_data= ssd.predict (r'[Ruta de Entrenamiento del Modelo][Nuevo archivo de Imagen(3)]', threshold=0.1, visualize=True)
Out[20]: Figura 33
Predictibilidad de imágenes del modelo- Ejemplo 3
77
In [21]: bbox_data= ssd.predict (r'[Ruta de Entrenamiento del Modelo][Nuevo archivo de Imagen(4)]', threshold=0.1, visualize=True)
Out[21]: Figura 34

Predictibilidad de imágenes del modelo- Ejemplo 4
Resultados:
• En la Figura 31 el modelo reconoció 7 fallas en la captura de la imagen procesada.
• En la Figura 32 el modelo reconoció 3 fallas en la captura de la imagen procesada.
• En la Figura 33 el modelo reconoció 7 fallas en la captura de la imagen procesada.
• En la Figura 34 el modelo reconoció 4 fallas en la captura de la imagen procesada
4.1.2. Aplicación de una muestra de video para las pruebas de captura de imágenes del modelo
Una vez terminado las épocas de entrenamiento del modelo MPQ (Modelo Propio Quito) y con el propósito de analizar efectividad en la categorización de imágenes dentro de una secuencia de video para validar el modelo (Valid Loss) y determinar si era capaz de
78
reconocer las nuevas imágenes incorporadas (predecir la categoría de las imágenes en la secuencia de video cargada)
a) Preparación de los metadatos
Con la herramienta LocateXT de ArcGIS Pro se creó una capa de información geográfica y a partir de esta capa se exportó el etiquetado a un formato de archivo de Excel. La Figura 35 muestra la capa de información geográfica que fue exportada a Microsoft Excel.
En el archivo exportado se realizaron las siguientes correcciones:
• A los valores del campo fecha_hora, extraídos desde la herramienta LocateXT, se les aplicó una corrección en el nombre del mes, reemplazando la cadena “mar.” (mes de captura de la información) por la cadena “/03/” y se eliminó la “,” al final de la fecha.
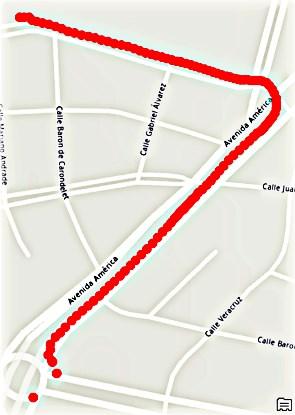
• De los campos Latitud y Longitud se removió el símbolo “,” para que se considere el contenido de estos campos como valores numéricos.
• Se adicionó una nueva columna a la metadata que contenía el valor de la fecha en formato UNIX Time Stamp en milisegundos.
79
Figura 35
Creación de una capa de información geográfica usando ArcGIS LocateXT
b) En la Tabla 7 se puede observar la secuencia de comandos para la creación de las variables para el análisis en el video y la ejecución del modelo entrenado sobre el video
Tabla 7
Secuencia de comandos para la validación del modelo en capturas de video
1 video file = os.path.join(Path('[Directorio de Videos de Validación] ), '[Nombre del Video de Validación]')
2 video file
3 file_metadata = os.path.join(Path([Directorio de metadata de Validación] ' ), '[Nombre del metadata de Validación])
4 file_metadata
5 ssd.predict_video (input_video_path=[video_file], metadata_file=[file_metadata], threshold=0.1, visualize= True, resize= True)

c) Visualización de los resultados
La ejecución de los comandos definidos en el literales b) genera el archivo de video con Validacion predictions.avi que contiene las predicciones incorporadas. La Figura 36 muestra los resultados de la incorporación de las predicciones al video de verificación.
Figura 36
Archivo de video para la validación de la predicción del modelo
En la Figura 36 su puede observar como el modelo reconoció 5 fallas en la captura de la imagen procesada de la secuencia de video. Adicional se generó un archivo metadata.csv que contiene una nueva columna con la predicción en formato VMTI (Video Moving Target Indicator), tal y como se lo puede ver en la Tabla 8.
80
Tabla 8
Metadata con la predicción de detección en formato VMTI (Video Moving Target Indicator
81
4.2. ANÁLISIS
4.2.1. Comparación del Aprendizaje Profundo entre modelos existentes y el modelo propio. Parámetro: Learning Rate
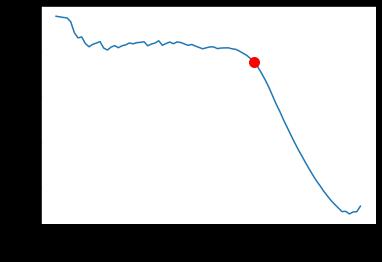
Como se puede observar en la Tabla 9, la taza de aprendizaje es muy baja (≈ 0.00004) para el modelo de aprendizaje desarrollado en este proyecto, al igual a los valores bajos (≈ 0.005 y ≈ 0.0002) de los modelos BigDataChallenge 2018 Japon y BigDataChallenge 2020 India respectivamente, por lo modelos requerirán más ciclos de entrenamiento.
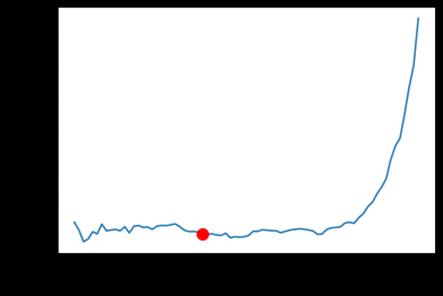
82
Parámetro de Comparación: Learning Rate Modelo Learning Rate Gráfico de Learning Rate Modelo Propio 2021 Quito (MPQ) 0.000043651 Modelo BigDataChallenge 2018 Japon (MBJ) 0.00524807
Tabla 9
0.00027542
2020 India (MBI)
En la Tabla 10 se puede observar el valor promedio de la precisión de cada clase y de cada modelo de entrenamiento. Si bien los valores de la precisión promedio sobre pérdidas son bastante significativos en el modelo de este proyecto (entre ≈ 0.5 y ≈ 0.047), esto puede deberse a la poca cantidad de imágenes ingresadas en el modelo (764) frente al gran número de imágenes ingresadas en los otros desarrollos (13,949 y 7,382).
Tabla 10
Precisión promedio sobre pérdidas
Modelo Precisión promedio sobre pérdidas Total, de imágenes por cada clase
Modelo Propio 2021
Quito (MPQ)
D00: 0.5066196,
D01: 0.0475000,
D10: 0.1949612,
D11: 0.0340909,
D20: 0.4954447, D40: 0.2837121
D00: 180
D01: 121
D10: 169
D11: 93
D20: 101
D40: 100
Modelo
BigDataChallenge
2018 Japon (MBJ)
'D00': 0.29482, 'D01': 0.65394, 'D10': 0.0, 'D11': 0.0, 'D20': 0.63001, 'D40': 0.0, 'D43': 0.640496, 'D44': 0.512773
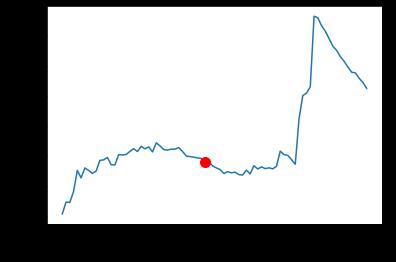
D43 753
D00 2477
D44 3369
D01 3418
D10 677
D11 574
D20 2290
D30 22
D40 369
83 Modelo Learning Rate Gráfico de Learning Rate Modelo
BigDataChallenge
Modelo Precisión promedio sobre pérdidas Total, de imágenes por cada clase
Modelo
BigDataChallenge
2020 India (MBI)
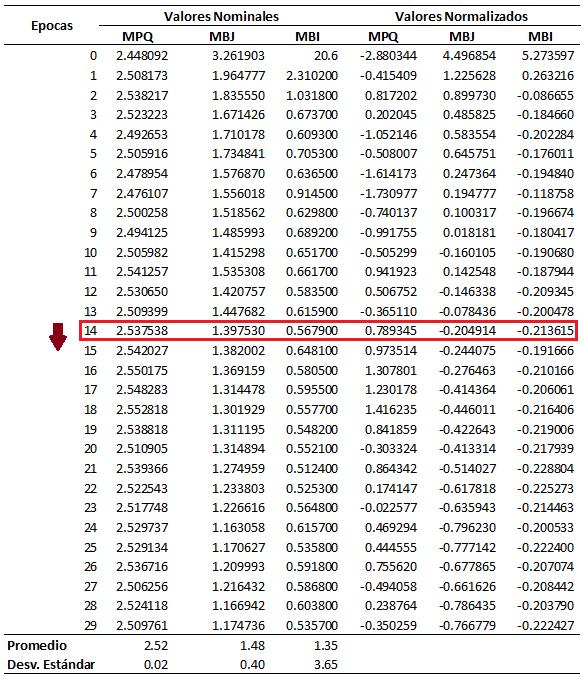
'D00': 0.0, 'D01': 0.0, 'D10': 0.0, 'D11': 0.0, 'D20': 0.21095, 'D40': 0.03752, 'D43': 0.0, 'D44': 0.0, 'D50': 0.0
D10 55
D43 52
D00 1416
D11 35
D44 937
D01 163
D20 1812
D50 27
D40 2885
Tabla 11
Valores de Pérdida durante el entrenamiento: Train Loss
84
Tabla 12
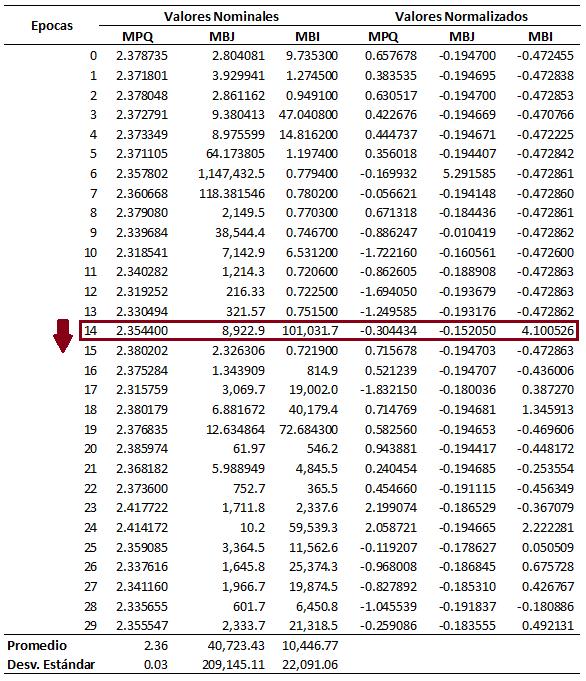
85
Valores de Pérdida con datos nuevos: Valid Loss
Train_Loss (Normalizados)
Valid_Loss (Normalizados)
El desafío que se encontró al entrenar el modelo propio aprendizaje profundo implicó seleccionar cuidadosamente la tasa de aprendizaje, ya que está es el hiper- parámetro más importante del modelo. Para el modelo propio inicialmente se comenzó con una tasa de aprendizaje de 0.01 como punto de partida y se finalizó con una tasa de 0.00251189, superior a las tasas de aprendizaje de los otros modelos debido a que una tasa de aprendizaje demasiado grande puede hacer que el modelo converja demasiado rápido a una solución sub-óptima, mientras que una tasa de aprendizaje demasiado pequeña puede
86
Figura 37
Gráfico de Pérdidas durante el entrenamiento: Train_Loss
Figura 38
Gráfico de Pérdidas con datos nuevos: Valid_Loss
-4.0000 -3.0000 -2.0000 -1.00001.0000 2.0000 3.0000 4.0000 5.0000 6.0000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Train_Loss Epocas
MPQ MBJ MBI -3 -2 -1 0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Épocas
MPQ MBJ MBI
hacer que el proceso se detenga. Desafortunadamente no se puede calcular analíticamente la tasa de aprendizaje óptima para un modelo dado en un conjunto de datos dado. Para resolver este inconveniente se determinó una tasa de aprendizaje buena (o suficientemente buena) mediante prueba y error18 Como ayuda se utilizaron gráficas de diagnóstico sobre cada modelo y se determinó que el mejor parámetro de la Tasa de Deep Learning es el definido para el modelo propio debido a que:
• La tasa de aprendizaje durante las épocas de entrenamiento en los modelos MBI y MBJ es volátil, tanto rápido como lento, mientras que en el modelo MPQ el aprendizaje se mantiene constante con el parámetro Learning Rate seleccionado (Figura 37)
• Los modelos MBI y MBJ presentan un aprendizaje demasiado rápido, aumento pronunciado en el gráfico de pérdidas, y aprendizajes demasiados lentos, cambio mínimo o nulo durante las épocas de entrenamiento Mientras que el modelo MPQ registra un aprendizaje constante y al final de las épocas de entrenamiento se puede observar, meseta en el gráfico de pérdidas, un aprendizaje acelerado. Este comportamiento genera un sobreajuste durante las épocas de validación de los modelos MBI y MBJ, mientras que el modelo MPQ, si bien sus valores reflejan una discriminación volátil durante las mismas épocas, permiten tomar la decisión de generar una mejor categorización de clases de daños viales y un aumento de las épocas de entrenamiento (Figura 38)
• En los modelos MBI y MBJ se presentan la tasa de aprendizaje demasiado grande debido a las oscilaciones en el gráfico de pérdidas.
En el Gráfico Learning Rate de la Tabla 9 del modelo MPQ, se encuentra que la pérdida está bajando abruptamente en 0.00251189 y se eligió eso como la tasa de aprendizaje más alta.
18 Los pesos de una red neuronal no se pueden calcular mediante un método analítico. En cambio, los pesos deben descubrirse mediante un procedimiento de optimización empírico llamado descenso de gradiente estocástico.
87
La tasa de aprendizaje más baja es aproximadamente una décima parte de eso. Se comenzó con 0.001 para tener más cuidado de no alterar demasiado los pesos de la columna vertebral pre entrenada y validar contra las pérdidas de los otros modelos. Es por eso por lo que se eligió una tasa de aprendizaje de Slice (0.00027542, 0.00251189) para entrenar el modelo. Con esos valores de Slice el modelo no tuvo una tasa de aprendizaje demasiado lenta o acelerada que podría producir sobreestimaciones en la detección de objetos.
Al estar utilizando un conjunto de datos base, además del utilizado para entrenar la red, la pérdida de entrenamiento es el error en el conjunto de datos de entrenamiento mientras que la pérdida de validación es el error después de ejecutar el conjunto de datos de validación a través de la red entrenada.
Como se puede observar en la Tabla 11 y en la Tabla 12, a medida que aumentan las épocas en el modelo MPQ disminuyen tanto el error de entrenamiento, como el error en la validación, respectivamente. Sin embargo, en cierto punto en los otros modelos, MBI y MBJ (Época 14), mientras el error de entrenamiento continúa disminuyendo, la red aprende los datos cada vez mejor, el error de validación comienza a aumentar, esto determina que en estos modelos existe un sobreajuste19 .
Para determinar el valor de la fiabilidad del modelo (Machine Learning Accuracy) MPQ se usaron matrices de confusión (Tabla 13) para aplicar la siguiente formula en cada una de las clases definidas en el modelo:
19 Overfitting por su definición en inglés: El sobreajuste se refiere a un modelo que modela demasiado bien los datos de entrenamiento. Esto ocurre cuando un modelo aprende los detalles y el ruido en los datos de entrenamiento en la medida en que impacta negativamente el rendimiento del mismo en nuevos datos.
88
Accuracy= ����+���� ����+����+����+����; [���� ���� ���� ����]
89
Clase Matriz de Confusión Accuracy (Precisión) D00 Actual Positives (1) Negatives (0) Predicted Positives (1) 98 2 Negatives (0) 1 6 0.9720 D01 Actual Positives (1) Negatives (0) Predicted Positives (1) 48 1 Negatives (0) 1 6 0.9643 D10 Actual Positives (1) Negatives (0) Predicted Positives (1) 5 63 Negatives (0) 2 3 0.1096 D11 Actual Positives (1) Negatives (0) Predicted Positives (1) 22 0 Negatives (0) 0 1 1 D20 Actual Positives (1) Negatives (0) Predicte dPositives (1) 21 0 Negatives (0) 0 2 1 D40 Actual Positives (1) Negatives (0) Predicted Positives (1) 74 10 Negatives (0) 2 11 0.8763
Tabla 13 Deep Learning Accuracy por Clase
Durante el entrenamiento, el algoritmo envió la pérdida de entrenamiento actual a la consola. La pérdida es calculada como un promedio móvil de todos los lotes procesados, lo que significa que, en la etapa inicial de entrenamiento, Fase I, cuando la pérdida cae rápidamente, el primer lote de una época tendrá una pérdida mucho mayor que el anterior, como se puede observar en la Figura 39 (Delta Train Loss). Cuando se finalizó la época, la pérdida de entrenamiento mostrada no es la pérdida de entrenamiento al final de la época, sino la pérdida de entrenamiento promedio desde el principio hasta el final de la época en las dos corridas. Para el caso del modelo MPQ se realizaron dos corridas con el mismo número de épocas, en la Tabla 14 se muestran los valores obtenidos de estas corridas:
Tabla 14
Train Loss y Valid Loss durante las épocas de aprendizaje del modelo
90
Épocas MPQ (Corrida I) MPQ (Corrida II) DELTA Train_Loss DELTA Valid_Loss Train_Loss Valid_Loss Train_Loss Valid_Loss 0 2.44809 2.37874 2.798923 2.496634 14.33% 4.96% 1 2.50817 2.37180 2.771694 2.501391 10.51% 5.46% 2 2.53822 2.37805 2.761559 2.461212 8.80% 3.50% 3 2.52322 2.37279 2.747524 2.472212 8.89% 4.19% 4 2.49265 2.37335 2.758761 2.388711 10.68% 0.65% 5 2.50592 2.37111 2.709701 2.401406 8.13% 1.28% 6 2.47895 2.35780 2.687511 2.449729 8.41% 3.90% 7 2.47611 2.36067 2.710849 2.418972 9.48% 2.47% 8 2.50026 2.37908 2.68502 2.421107 7.39% 1.77% 9 2.49413 2.33968 2.703858 2.383961 8.41% 1.89% 10 2.50598 2.31854 2.666029 2.360645 6.39% 1.82% 11 2.54126 2.34028 2.689095 2.388524 5.82% 2.06% 12 2.53065 2.31925 2.728049 2.410475 7.80% 3.93% 13 2.50940 2.33049 2.687363 2.440787 7.09% 4.73% 14 2.53754 2.35440 2.642908 2.371115 4.15% 0.71% 15 2.54203 2.38020 2.651582 2.359567 4.31% -0.87% 16 2.55018 2.37528 2.672254 2.279596 4.79% -4.03% 17 2.54828 2.31576 2.710192 2.281152 6.35% -1.49% 18 2.55282 2.38018 2.663953 2.304837 4.35% -3.17% 19 2.53882 2.37684 2.682378 2.450552 5.65% 3.10% 20 2.51091 2.38597 2.677585 2.377788 6.64% -0.34% 21 2.53937 2.36818 2.640088 2.303919 3.97% -2.71% 22 2.52254 2.37360 2.698398 2.309424 6.97% -2.70% 23 2.51775 2.41772 2.644331 2.294707 5.03% -5.09% 24 2.52974 2.41417 2.668097 2.485241 5.47% 2.94%
El objetivo de la doble corrida es hacer que la pérdida de validación sea lo más baja posible. Un poco de sobreajuste es casi siempre algo bueno. Todo lo que importa al final es: es la pérdida de validación lo más baja posible. Como ambos valores, en las dos corridas, terminan siendo aproximadamente iguales y también se puede observar que los valores están convergiendo (gráfica la pérdida a lo largo del tiempo), entonces es muy probable que el modelo lo esté haciendo muy bien en su discriminación de las fallas.
DELTA Train_Loss
DELTA Valid_Loss
91 Épocas MPQ (Corrida I) MPQ (Corrida II) DELTA Train_Loss DELTA Valid_Loss Train_Loss Valid_Loss Train_Loss Valid_Loss 25 2.52913 2.35909 2.658653 2.4491 5.12% 3.82% 26 2.53672 2.33762 2.658929 2.287819 4.82% -2.13% 27 2.50626 2.34116 2.67413 2.27366 6.70% -2.88% 28 2.52412 2.33566 2.674368 2.353177 5.95% 0.75% 29 2.50976 2.35555 2.678896 2.292129 6.74% -2.69%
Figura 39
Delta Train Loss durante las épocas de aprendizaje del modelo
Figura 40
0.00% 5.00% 10.00% 15.00% 20.00% 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
Delta Valid Loss durante las épocas de aprendizaje del modelo
-6.00% -4.00% -2.00% 0.00% 2.00% 4.00% 6.00% 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
Como se puede observar en la Tabla 14, el modelo propuesto funciona mejor con los datos de entrenamiento que con los datos de validación desconocidos (Los valores Delta del coeficiente Train Loss son mayores que los Delta del coeficiente Validation Loss). Este sobreajuste es normal, pero se hace necesario regular cantidades más altas con técnicas como la deserción para garantizar la generalización. Además, al observar la Figura 40 (Delta Valid Loss) se puede concluir que el modelo funciona mejor con los datos de validación, luego del aumento de las épocas de entrenamiento. Esto sucedió debido a que se realizó un aumento en los datos de entrenamiento, lo que dificultó la predicción en comparación con las muestras de validación no modificadas.
Como resultado final del análisis realizado se pudo generar una base de datos [Dataset] de clases con la información de categorización de los daños en las vías que alimentó la metadata de aprendizaje del modelo. El proceso de aprendizaje de la identificación y clasificación de fallas se realizó usando las herramientas ©Roboflow y su integración con la extensión LocateXT de ArcGIS Pro permitió crear una capa de información geográfica y a partir de esta capa se exportó el etiquetado a un formato de archivo de Excel, para un tratamiento previo a la ejecución del modelo y validar la detección de los daños en las vías en un archivo de video. Finalmente, se evaluó la fiabilidad de la categorización del algoritmo de daños en las vías de la ciudad mediante el uso de mapas de distribución espacial de las categorías de daños identificados y su comparación con la base de categorías generadas durante el proceso de aprendizaje del modelo obteniendo valores de 0.9643, 0.1096, 1, 1 y 0.8763 en la fiabilidad de reconocimiento de cada clase (categoría) definidas en el aprendizaje.
Luego del análisis realizado se puede responder a las preguntas de investigación planteadas que dieron origen a los objetivos de este proyecto
• ¿Cómo utilizar imágenes desde videos georreferenciados para generar un inventario de daños en las vías de la ciudad de Quito?
Para generar un inventario de daños en las vías en la ciudad de Quito usando imágenes georreferenciadas es necesario el uso de herramientas SIG, como ArcGIS Pro y su
92
extensión LocateXT que permite buscar datos no estructurados en ubicaciones espaciales y generar entidades de puntos que representan dichas ubicaciones, e implementado la metodología expuesta en el proyecto puede georreferenciarse las ubicaciones de las fallas capturadas mediante dispositivos móviles usando una App como AutoGuard©
• ¿Cómo utilizar herramientas de inteligencia artificial para implementar el proceso de aprendizaje y categorización de los daños en las vías de la ciudad de Quito?
Para para implementar el proceso de aprendizaje y categorización de los daños en las vías de la ciudad de Quito usando herramientas de I.A se vuelve necesario un entorno de desarrollo que integre un lenguaje de programación, como Python, que permita el uso de algoritmos de aprendizaje de procesos de I.A. ArcGIS Pro© tiene incorporado el lenguaje de programación Python utilizando el gestor de paquetes Conda. Adicionalmente, existen sitios públicos de colaboración donde se pueden acceder a una base de algoritmos que pueden utilizarse para el reconocimiento de imágenes (fallas) usando métodos de I.A, con lo que el tiempo de implementación se reduciría considerablemente para el Municipio de Quito
• ¿Cómo evaluar la fiabilidad de la categorización de un algoritmo de detección de daños en las vías de la ciudad de Quito?
Para la medición de la fiabilidad del modelo se puede utilizare el coeficiente Accuracy (Precisión), sin embargo, para la mejora de la implementación el proceso de aprendizaje y categorización de los daños en las vías con el algoritmo de Inteligencia
Artificial se recomienda utilizar métricas adicionales al coeficiente Accuracy (Precisión) como:
✓ Recall, Sensibilidad o TPR: Es el número de elementos identificados correctamente como positivos del total de positivos verdaderos.
✓ Especificidad o TNR (Tasa Negativa Verdadera): Es el número de ítems correctamente identificados como negativos fuera del total de negativos.
✓ Tasa de falso positivo o Error tipo I: Número de elementos identificados erróneamente como positivos de total negativos verdaderos
✓ Tasa falso negativo o error de tipo II: Número de elementos identificados erróneamente como s negativo del total de verdaderos positivos.
93
Todas estas métricas pueden ser obtenidas usando las matrices de confusión.
Para aumentar la fiabilidad del modelo se recomienda balancear las clases de las variables de destino. Es decir, seleccionar el mismo objeto en cada clase, ya que, si se introduce una falla X para cada clase, entonces la precisión sería sea 0.9, pero, de hecho, el modelo simplemente predice la falla X en la clase sin importar cuál sea la entrada. Entonces, el problema sería que la precisión de la línea de base puede ser muy alta para un conjunto de datos, incluso del 99%, y eso lo hace difícil para interpretar los resultados. Hay que tener en cuenta que, en su nivel más básico, una función de pérdida, función que validad la fiabilidad del modelo, cuantifica qué tan "bueno" o "malo" es un predictor dado clasificando los puntos de datos de entrada en un conjunto de datos. Hay que tratar que la pérdida sea la menor posible, con lo que se podría modelar mejor el clasificador de la relación entre los datos de entrada y los objetivos de salida
Finalmente, la generación de una base de datos con imágenes georreferenciadas puede ser un proceso lento que implica recopilar y adecuar los cuadros de imágenes de entrenamiento y las etiquetas en el formato específico que necesita cada modelo de aprendizaje profundo. Para una mejor categorización, los grupos de imagen que se usan para formar la base de datos deben exportarse con un tamaño mayor que el que se usó para entrenar el modelo. De forma predeterminada, un tamaño de imagen de 448 x 448 píxeles funciona bien, pero esto se puede ajustar según la cantidad de contexto que desee proporcionar al modelo, así como la cantidad de memoria GPU disponible.
94
5. CONCLUSIONES Y RECOMENDACIONES
5.1. CONCLUSIONES
Los proyectos de investigación donde se vea involucrado la I.A se han vuelto el factor común en el desarrollo de los sistemas GIS, debido a que se potencializa y se da un valor agregado al uso de los mapas electrónicos como ubicaciones espaciales, con todas las utilidades que los mismos brindan, dotándoles además de esquemas que ayudan en la toma de decisiones y mejoran los procesos cuando se identifica y cataloga imágenes que ayudan en el trabajo, especialmente del sector gubernamental. Es por estos antecedentes que se combinó el algoritmo de detección de imágenes en Python y las imágenes espaciales de los sistemas GIS. El presente trabajo determinó las siguientes conclusiones:
La clasificación de imágenes en la visión por computadora toma una imagen y predice el objeto en una imagen, mientras que la detección de objetos no solo predice el objeto, sino que también encuentra su ubicación en términos de cuadros delimitadores. Usando esta definición se generó una base de datos de imágenes de los daños en las vías de la ciudad de Quito, Ecuador con etiquetas georreferenciadas, para lo que se utilizó un equipo con una resolución de imagen de y una calidad de video de 120 fps (Frames por segundo) y la App AutoGuard ©
Se implementó un proceso de aprendizaje y categorización de los daños en las vías con el algoritmo de Inteligencia Artificial con una Tasa de Learning Rate del 0.00251189 y un conjunto de 30 épocas con lo que el modelo diseñado no tuvo una tasa de aprendizaje demasiado lenta o acelerada que podría producir sobreestimaciones en la detección de objetos La tasa de aprendizaje controla la rapidez con la que el modelo se adapta al problema. Las tasas de aprendizaje más pequeñas requieren más épocas de entrenamiento dados los cambios más pequeños realizados en los pesos en cada actualización, mientras que las tasas de aprendizaje más grandes dan como resultado cambios rápidos y requieren menos épocas de entrenamiento
95
Con la utilización de imágenes georreferenciadas se creó una base de datos para el entrenamiento del modelo, sin embargo, durante la etapa de aprendizaje se requiere de equipos de altas prestaciones para que la mismo no se vuelva lento. La confiabilidad del reconocimiento fue alta, pero se disminuyó la categorización de las fallas debido a los requisitos de hardware para el procesamiento de imágenes durante la etapa de aprendizaje.
Al utilizar herramientas de I.A se logrará generar procesos proactivos en los que el personal de la EMOP Quito realizará escaneos rápidos en los recorridos por las calles de la urbe, incrementando los puntos de prevención de accidentes o complicaciones del tráfico frente a una oportuna detección de falla.
La fiabilidad promedio de la categorización del algoritmo de daños en las vías de la ciudad de Quito, Ecuador utilizando mapas de distribución espacial de las categorías de daños identificados fue de 0.834116667, siendo esta medida la más directa de la calidad de los clasificadores, como está entre un valor entre 0 y 1 y cuanto más alto, mejor, se la puede considerar adecuada. Sin embargo, esto puede ocasionar problemas si las clases de variables de destino en los datos no están balanceadas
En términos generales se pudo determinar que la implementación de algoritmos de inteligencia artificial para la detección y evaluación de daños en las vías de la ciudad de Quito por parte de la EMOP-Q convertirá esta actividad en un proceso proactivo, lo que disminuirá los tiempos de respuesta de la EMOP-Q ya que el personal de la organización dejará de depender de las llamadas de los usuarios de las vías y podrá planificar de mejorar manera, tanto su tiempo de acción, como la determinación más eficiente de los presupuestos asignados al mantenimiento de las vías del distrito metropolitano.
Finalmente, el procesamiento de imágenes georreferenciadas, mediante herramientas de Startups de dominio público, facilitará la generación de un inventario de daños en las vías de la ciudad de Quito ya que las clases (categorías) podrán personalizarse, con el uso de
96
herramientas de inteligencia artificial, de acuerdo a la realidad del medio pero tomando como base fuentes de conocimiento generadas y compartidas a nivel mundial como los modelos de los proyectos BigDataChallenge 2018 Japón (MBJ) y BigDataChallenge 2020 India (MBI). Para concluir si bien la fiabilidad de la categorización de un algoritmo de detección de daños en las vías de la ciudad de Quito fue medida a través del coeficiente Accuracy (Precisión) y este valor fue alto (0.834116667), para mejorar su predictibilidad pueden utilizarse otras métricas.
5.2. RECOMENDACIONES
Las técnicas de aprendizaje profundo y las redes neuronales facilitan que la visión por computadora entienda lo que está viendo y se acerque más al sistema cognitivo visual humana. Además, la visión por computadora es superior a la visión humana en muchas tareas, como: el reconocimiento de patrones, la falta de fatiga física, etc., por lo que los resultados de la visión por computadora son más consistentes. Es por esta razón que, para actividades recurrentes, en los que intervenga el reconocimiento de imágenes, se puede generar procesos donde intervenga la I.A para disminuir los tiempos de respuesta. Para el caso de la Empresa Pública Metropolitana de Movilidad y Obras Públicas (EPMMOP) sistemas georreferenciados no solo podría limitarse al reconocimiento de fallas, sino a la planificación de planes de intervención proactiva, en donde la calidad del pavimento sufra un desgaste fuerte por la alta circulación vehicular.
Adicionalmente, el presente proyecto de investigación hace uso del Deep Learning, un subconjunto del aprendizaje automático en el que las redes neuronales (algoritmos inspirados en el cerebro humano) aprenden de grandes cantidades de datos, un proceso al que muchas empresas municipales asignan personal con el único propósito de acudir al lugar reportado de la falla vial, pero que con las herramientas adecuadas puede ahorrar ingentes cantidades de horas-hombre en la detección, categorización e intervención de fallas en los ejes viales. Los resultados de este proyecto pueden ser utilizados para generar
97
nuevos estudios y de esta manera volver más eficientes los procesos de los responsables municipales del mantenimiento de las calles de una población.
Finalmente, como una recomendación técnica y debido al alto nivel de trabajo de la GPU (Unidad de Procesamiento Gráfico) por el número de datos de origen que se tiene que procesar, debe realizarse un permanente chequeo y limpieza del cache del servidor de mapas de forma habitual. En Python se puede utilizar una secuencia de comandos (manageCacheTiles.py) para ejecutar automáticamente la herramienta de geoprocesamiento y administrar el caché de mapas.
98
6. REFERENCIAS
Abdullah, S., y Abdolrazzagh-nezhad, M. (2014). Fuzzy job-shop scheduling problems. Information Sciences, 380–407.
Albuquerque, V., Alexandria, A., Cortez, P., y Tavares, J. (2009). Valuation of multilayer perceptron and self-organizing map neural network topologies applied on microstructure segmentation from metallographic images. NDT y E. International, 644-651.
Ali, M., Wook, C., Pant, M., y Siarry, P. (2015). An image watermarking scheme in wavelet domain with optimized compensation of singular value decomposition via artificial bee colony,. Information Sciences, 44-60.
Anaconda, Inc. (18 de Mayo de 2021). Documentación de Conda. Obtenido el 14 de Junio de 2021 de: https://docs.conda.io/en/latest/
ANI, Agencia Nacional de Infraestructura. (18 de Junio de 2021). Sistema de control de Proyectos ANI. ArcGis Pro. Obtenido el 27 de Agosto de 2021 de: https://www.arcgis.com/apps/webappviewer/index.html?id=4af6b3903803471d8 49c35615dae0877
ArcGIS. (18 de Junio de 2021). Functions for calling the Deep Learning Tools. ArcGIS Developers. Obtenido el 14 de Agosto de 2021 de: https://developers.arcgis.com/python/api-reference/arcgis.learn.toc.html
Arunava, I. (19 de Abril de 2019). iArunava/YOLOv3-Object-Detection-with-OpenCV GitHub Obtenido el 25 de Junio de 2021 de: https://github.com/iArunava/YOLOv3-ObjectDetection-with-OpenCV/blob/master/README.md
Banitalebi, A., Abb Aziz, M., Bahar, A., y Zainal, A. (2015). Enhanced compact artificial bee colony. Information Sciences, 491–511.
Basogain, X. (2019). Redes Neuronales y sus aplicaciones. Bilbao: Escuela Superior de Ingeniería de Bilbao, EHU.
Bayar, N., Darmoul, S., Hajri-Gabouj, S., y Pierreval, H. (2015). Fault detection , diagnosis and recovery using Artificial Immune Systems. Engineering Applications of Artificial Intelligence, 43–57.
Bellman, R. (1978). An introduction to artificial intelligence: Can computers think? San Francisco: Boyd y Fraser Publishing Company.
99
Bishop, C. (2016). Pattern Recognition and Machine Learning. Estados Unidos: Ediciones Springer.
Blanco, E., y Ramírez, F. (24 de Mayo de 2018). Deep Learning con Python: Introducción a TensorFlow (Parte II) Ideas Locas, CDO de Telefónica. Acerca de nosotros: Telefónica Tech. Obtenido el 4 de Junio de 2021 de: https://empresas.blogthinkbig.com/deeplearning-python-introducciontf2/
Browlee, J. (5 de Septiembre de 2018). A Gentle Introduction to Tensors for Machine Learning with NumPy. Machine Learning Mastery . Obtenido el 7 de Junio de 2021 de: https://machinelearningmastery.com/introduction-to-tensors-for-machinelearning/
Cao, W., Wang, X., Ming, Z., y Gao, J. (2015). A review on neural networks with random weights. Neurocomputing, 1–10.
Cepalia, A. (15 de Junio de 2021). Haar Like Feature. Real Python. Obtenido el 5 de Julio de 2021 de: https://realpython.com/lessons/haar-like-features/
Cifuentes, A., Mendoza, E., Lizcano, M., Santrich, A., y Moreno, S. (2019). Desarrollo de una red neuronal convolucional para reconocer patrones en imágenes. Investigación y Desarrollo en TIC,, 10(2), 7-17.
Condori, E. (2013). Reconocimiento y clasificación de objetos usando inteligencia artificial basada en SVM y visión estereoscópica. Lima: Universidad Nacional de Ingeniería del Perú - Facultad de Mecanotrónica.
Costa, G., Matos, W., y Martinez, R. (2017). Artificial immune systems applied to fault detection and isolation : A brief review of immune response based aproaches and a case study. Applied Soft Computing Journal, 118–131.
Cristea, V., Leblebici, Y., y Almási, A. (2016). Neurocomputing, 31–41.
Cui, L., Li, G., Zhu, Z., Lin, Q., Wen, Z. L., Wong, K., y Chen, J. (2017). A novel artificial bee colony algorithm with an adaptive population size for numerical function optimization. Information Sciences, 53–67.
DansTools.com. (19 de Mayo de 2021). The Current Epoch Unix Timestamp. DansTools.com. Obtenido el Obtenido el 22 de Junio de 2021 de: https://www.unixtimestamp.com/
Domènech, T. (2019). Clasificación de imágenes dermatoscópicas utilizando Redes Neuronales Convolucionales e información de metadatos. Barcelona: Universidad Politécnica de Catalunya.
E.S.R.I. Environmental Systems Research Institute (18 de Noviembre de 2021a). Introducción a ArcGIS. ArcGIS Resources. Obtenido el el 24 de Noviembre de 2021
100
de: https://resources.arcgis.com/es/help/gettingstarted/articles/026n00000014000000.htm
E.S.R.I. Environmental Systems Research Institute (29 de Noviembre de 2021b). ¿Qué son los datos ráster?. ArcMap 10.3. Obtenido el 02 de Diciembre de 2022 de: https://desktop.arcgis.com/es/arcmap/10.3/manage-data/raster-andimages/what-is-raster-data.htm
Gabela, H. (2013). Plan de mantenimiento de la carpeta asfáltica de la sección del paso lateral de Ambato comprendida entre Huachi Grande y el redondel del Terremoto. Quito: Pontificia Universidad Católica del Ecuador.
Galdámez, P., Raveane, W., y Arrieta, A. (2017). A brief review of the ear recognition process using deep neural networks. Journal of Applied Logic, 62–70.
Garamendi, J. (2017). Image processing in Light Field Photography. Barcelona: Universitat Pompeu Fabra.
García, K. (2018). Sistema de Detección de Objetos para Reconocimiento Gestual mediante Redes Neuronales Convolucionales. Valencia: Universidad Politécnica de Valencia.
Gestión de Comunicación M.A. (19 de Abril de 2017). Distrito Metropolitano de Quito. Prefectura de Pichincha. Obtenido el 22 de Mayo de 2021 de: https://www.pichincha.gob.ec/cantones/distrito-metropolitano-de-quito
Gutiérrez, C. (2019). Detección de armas en vídeos mediante técnicas de Deep Learning. Navarra: Universidad Politécnica de Navarra.
Ham, D. (05 de Mayo de 2015). Deep Residual Learning for Image Recognition. Icarus Web Site. Obtenido el 14 de Abril de 2021 de: https://davidham3.github.io/blog/2018/03/04/deep-residual-learning-for-imagerecognition/
Hassan, M. (23 de Enero de 2019). Acerca de Nosotros: ResNet (34, 50, 101): Residual CNNs for Image Classification Tasks. Obtenido el 17 de Agosto de 2021 de Popular networks: https://neurohive.io/en/popular-networks/resnet/
He, K., Zhang, X., Ren, S., y Sun, J. (2016). Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition (pág. 19). Nueva York: Computer Science.
Hein, D., Eng, P., y Burak, R. (2007). Development of a pavement condition rating procedure for roads, street, and parking lots. Burlington, Ontario: Interlocking Concrete Pavement Institute.
101
Hekayati, J., y Rahimpour, M. (2017). Estimation of the saturation pressure of pure ionic liquids using MLP artificial neural networks and the revised isofugacity criterion. Journal of Molecular Liquids journal, 85-95.
Hernández, M. (19 de Noviembre de 2018). Introducción a Machine Learning con TensorFlow. Adictos al trabajo. Obtenido el 13 de Junio de 2021 de: https://www.adictosaltrabajo.com/2018/04/18/introduccion-a-machine-learningcon-tensorflow/
Hui, J. (19 de Noviembre de 2018a). Object detection: speed and accuracy comparison (Faster R-CNN, R-FCN, SSD, FPN, RetinaNet and YOLOv3). Every idea needs a Medium. Obtenido el 5 de Mayo de 2021 de: https://jonathanhui.medium.com/object-detection-speed-and-accuracy-comparison-faster-r-cnnr-fcn-ssd-and-yolo-5425656ae359
Hui, J. (20 de Noviembre de 2018b). SSD object detection: Single Shot MultiBox Detector for real-time processing. Medium - Explore new perspectives, Deep Learning. Obtenido el 8 de Mayo de 2021 de: https://jonathan-hui.medium.com/ssd-object-detectionsingle-shot-multibox-detector-for-real-time-processing-9bd8deac0e06
Ichi.pro. (16 de Abril de 2021). Una parada para detectores de objetos. Obtenido el 5 de Junio de 2021 de Ichi.Pro: https://ichi.pro/es/una-parada-para-detectores-deobjetos-49039309573200
Illescas, S. (18 de Junio de 2021). La Profundidad de Campo Explicada con Ejemplos DZoom Obtenido el 5 de Julio de 2021 de: https://www.dzoom.org.es/profundidad-decampo/
INEC, Instituto Nacional de Estadísticas y Censos. (18 de Marzo de 2010). Ecuador en cifras Censo de Población y Vivienda. Obtenido el 5 de Marzo de 2021 de: https://www.ecuadorencifras.gob.ec/censo-de-poblacion-y-vivienda/
Islam, S., Hannan, M., Basri, H., y Arebey, M. (2013). Solid waste bin detection and classification using Dynamic Time Warping and MLP classifier. Waste Management, 281-290.
Jani, D., Mishra, M., y Sahoo, P. (2017). Application of artificial neural network for predicting performance of solid desiccant cooling systems–A review. Renewable and Sustainable Energy Reviews, 80, 352–366.
Jatoba, M., Gutierriz, I., Fernandes, P., Teixeira, J., y Moscon, D. (2019). Artificial Intelligence in the Recruitment y Selection: Innovation and Impacts for the Human Resources Management. 43° International Scientific Conference on Economic and Social Development - Rethinking Management in the Digital Era: Challenges from Industry 4.0 to Retail Management (págs. 96-104). Aveiro: National Funds through the Foundation for Science and Technology.
102
Karakose, M., Akarsu, B., Parlak, K., Sarimeden, A., y Akin, E. (2016). A Fast and Adaptive Road Defect Detection Approach Using Computer Vision with Real Time Implementation. International Journal of Applied Mathematics, Electronics and Computers, 290–295.
Kossaifi, J., Panagakis, K., Anandkumar, A., y Pantic, M. (2016). TensorLy: Tensor Learning en Python. Londres: Imperial College London.
Krizhevsky, A., Sutskever, I., y Hinton, G. (2019). ImageNet Classification with Deep Convolutional Neural Networks. Neural Information Processing Systems, 25.
Li, B., Zhou, C., Liu, H., Li, Y., y Cao, H. (2016). Image retrieval via balance-evolution artificial bee colony algorithm and lateral inhibition. Optik, 11775-11785.
Lim, C., Vats, E., y Seng, C. (2015). Fuzzy human motion analysis. Pattern Recognition journal, 1773–1796.
Long, J., Shelhamer, E., y Darrell, T. (2019). Fully convolutional networks for semantic segmentation. Congreso sobre el reconocimiento de patrones y la visión por ordenador (Conference on Computer Vision and Pattern Recognition) (pág. 22). Long Beach, California: IEEE Computer Society - University of Colorado Colorado Springs.
Lowe, D. (2004). International Journal of Computing Vision, 91–110.
Lowe, D. (2004). Algoritmo SIFT (Estados Unidos Patente nº US6711293B1). U.S. Patent and Trademark Office. https://portal.unifiedpatents.com/patents/patent/US6711293-B1.
Mallick, S. (18 de Junio de 2016). Histogram of Oriented Gradients explained using OpenCV. Aprenda OpenCV. Obtenido el 9 de Julio de 2021 de: https://learnopencv.com/histogram-of-oriented-gradients/
Manzanares, A. (2019). Detector de baches con Deep Learning. Barcelona: Universidad Pompeu Fabra - Escuela Superior Politécnica.
Mashaly, A., y Alazba, A. (2016). MLP and MLR models for instantaneous thermal efficiency prediction of solar still under hyper-arid environment. Computers and Electronics in Agriculture, 146–155.
Matich, D. (2001). Redes Neuronales: Conceptos Básicos y Aplicaciones. Rosario: Universidad Tecnológica Nacional – Facultad Regional Rosario .
Miranda, G. y Felipe, J. (2015). Computer-aided diagnosis system based on fuzzy logic for cancer categorization. Computers in Biology and Medicine, 334-346.
103
Mollajan, A., Ghiasi-Freez, J., y y Memarian, H. (2016). Improving pore type identification from thin section images using an integrated fuzzy fusion of multiple classifiers. Journal of Natural Gas Science and Engineering, 31(1), 396–404. doi:https://doi.org/10.1016/j.jngse.2016.03.030
Montoya, O. (2018). Redes Neuronales Convolucionales Profundas para el Reconocimiento de Emociones en Imágenes. Madrid: Universidad Politécnica de Madrid.
Moreno, L., Ramírez, A., Avila, J., y Carrillo, J. (2017). Clasificación de obstáculos a través del algoritmo SSD. Tecnocultura - Revista del Tecnológico de Estudios Superiores de Ecatepec, 32-41.
MTOP, Ministerio de Transporte y Obras Públicas. (2012). Tomo 2: Normas de Pavimento Rígido. En I. B. IBCH, Manual Pavimentos Rígidos (págs. 122-125). Quito: Instituto Boliviano del Cemento y el Hormigón - CAF.
MTOP-CAF-IBCH, Ministerio de Transporte y Obras Públicas, Coorporación Andina de Fomento e Instituto Boliviano del Cemento y El Hormigón (2012). Manual de Pavimentos. Quito: Ministerio de Transporte y Obras Públicas-CAF.
Municipio del Distrito Metropolitano de Quito. (2009). Plan maestro de movilidad para el Distrito Metropolitano de Quito 2009-2025. En M. d. Quito. Quito: Municipio del Distrito Metropolitano de Quito.
Paris, J. L. G. S., Nakano-Miyatake, M., y Robles-Camarillo, D. (2016). Comparación de Arquitecturas de Redes Neuronales Convolucionales para la Clasificación de Imágenes de Ojos. Simposio Iberoamericano Multidisciplinario de Ciencias e Ingenierías (págs. 26-68). Pachuca, México: Universidad Politécnica de Pachuca.
Pérez, J., M., Serrano, M., Acha, B., y Linares, B. (2011). Red neuronal convolucional rápida sin fotograma para el reconocimeinto de dígitos. XXVI Simposio de la URSI (págs. 14). Madrid: Universidad Carlos III.
Proyecto y la Comunidad Jupyter. (21 de Junio de 2021). Proyecto y la Comunidad Jupyter. Obtenido el 22 de Agosto de 2021 de: https://jupyter.org/
Redmon, J., Kumar, S., Girshick, R., y Farhadi, A. (2016). You only look once: Unified, realtime object detection. Nueva York: Cornell University.
Reyes, O., Mejia, M., y Useche-Castelblanco, J. (2019). Técnicas de inteligencia artificial utilizadas en el procesamiento de imágenes y su aplicación en el análisis de pavimentos. Revista EIA, 189-207.
Roboflow. (18 de Abril de 2021). Roboflow. Obtenido el 14 de Mayo de 2021 de Dataset: https://app.roboflow
104
Roca, J. (19 de Marzo de 2016). El concepto de Cámara fotográfica 3.0: de Campo Lumínico o Cámaras Plenópticas en El Blog de Joan Roca. Obtenido el 2 de Mayo de 2021 de: https://joanrocablog.com/index.php/2015/06/15/el-concepto-de-camarafotografica-3-0-de-campo-luminico-o-camaras-plenopticas/
Sachan, A. (14 de Noviembre de 2019). Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD. CV-Tricks Learn Machine Learning, AI y Computer vision. Obtenido el 5 de Septiembre de 2021 de: https://cvtricks.com/object-detection/faster-r-cnn-yolo-ssd/
Sánchez, D., Gonzales, H., y Hernández, Y. (2020). Revisión de algoritmos de detección y seguimiento de objetos con redes profundas para videovigilancia inteligente. Revista Cubana de Ciencias Informáticas, 165-195.
Sanz, D. (2019). Desarrollo e implementación IOT de un sistema de reconocimiento de imágenes a nivel industrial Valladolid: Universidad Internacional de la Rioja.
Silva, A. (2020). Estudio comparativo de modelos de clasificación automática de señales de tráfico. Pamplona: Universidad Pública de Navarra.
Subsecretaria de Infraestructura del Transporte. (2013). Norma Ecuatoriana Vial NEVI-12MTOP. Quito: Ministerio de Transporte y Obras Públicas del Ecuador .
Tuteja, P., Vitales, D., Aggarwal, M., y Pathak, S. (29 de Abril de 2021). Automate Road Surface Investigation Using Deep Learning GitHub. Obtenido el 22 de Mayo de 2021 de: https://github.com/Esri/arcgis-pythonapi/blob/master/samples/04_gis_analysts_data_scientists/automate_road_surfac e_investigation_using_deep_learning.ipynb
UTI, Unión Internacional de Telecominicaciones. (2018). Inteligencia Artificial para el bien del mundo. ITU New Magazine, 1.
UTI, Unión Internacional de Telecominicaciones. (2017). Cumbre Mundial AI for Good de 2017. Welcome Address, Popov Room (pág. 1). Ginebra: Principal de Medios y Comunicaciones, UIT.
Valderrama, J. (2017). Clasificación de objetos usando aprendizaje profundo implementado en un sistema embebido. Santiago de Cali: Universidad Autónoma de Occidente.
Vázquez, F. (20 de Octubre de 2018). Deep Learning fácil con DeepCognition. Planeta ChatBot. Obtenido el 11 de Mayo de 2021 de: https://planetachatbot.com/deeplearning-f%C3%A1cil-con-deepcognition-9af43b2319ba
Xu, J. (9 de Junio de 2018). Deep Learning for Object Detection: A Comprehensive Review DeepLarningItalia. Obtenido el 11 de Junio de 2021 de:
105
https://www.deeplearningitalia.com/deep-learning-for-object-detection-acomprehensive-review/
Yu, X., Yuan, X., Dong, E., y Ríha, K. (2016). Target extraction of banded blurred infrared images by immune dynamical algorithm with two-dimensional minimum distance immune field. Infrared Physics y Technology, 94-99.
Zhang, G., Zeng, Z., Zhang, S., Zhang, Y., y Wu, W. (2017). SIFT Matching with CNN Evidences for Particular Object Retrieval. Neurocomputing, 399-409.
Zhang, W., Qu, C., Ma, L., Guan, J., y Huang, R. (2016). Learning structure of stereoscopic image for no-reference quality assessment with convolutional neural network. Pattern Recognition, 176-187.
Zhao, H. (7-9 de Junio de 2017). La Cumbre Mundial AI for Good da la bienvenida a la "nueva frontera" para el desarrollo sostenible [Discurso de apertura]. Obtenido el 11 de Abril de 2021 de UIT, Unión Internacional de Telecomunicaciones: https://www.itu.int/es/mediacentre/Pages/2017-PR23.aspx
Zhao, Q., Zheng, P., Xu, S., y Wu, X. (2015). Object Detection with Deep Learning: A Review. IEEE Conference On Computer Vision And Pattern Recognition (CVPR) (págs. 21-27). Louisiana: University of Louisiana at Lafayette,.
106
ANEXOS
Anexo 1. NORMA NEVI-12 – MTOP: Pavimento rígido – Defectos – Terminología
Defecto: anomalía observada en el pavimento debida a problemas en la fundación, por mala ejecución o por mal uso del pavimento. Un defecto puede ser de varios tipos:
1.1. Levantamiento de losas. Desnivel producido en las juntas o en las fisuras transversales de las losas y eventualmente, en la proximidad de canales de drenaje o de intervenciones hechas en el pavimento
1.2. Fisuras de esquina. Es una fisura que intercepta las juntas a una distancia menor o igual a la mitad del largo de los bordes o juntas del pavimento (longitudinal y transversal). Se mide a partir de su borde. Esta fisura generalmente compromete a todo el espesor de la losa.
1.3. Losa dividida. Es la losa que presenta fisuras dividiéndola en cuatro o más partes
1.4. Escalonamiento o grada en las juntas. Se caracteriza por la aparición de desplazamientos verticales diferenciados y permanentes entre una losa y su adyacente, en coincidencia con la junta transversal.
1.5. Falla del sellante en juntas. Es cualquier avería en el material sellante que posibilite la acumulación de material incompresible en la junta o que permita la infiltración de agua. Las principales fallas observadas al material sellante son:
• Rompimiento, por tracción o compresión
• Extrusión del material
• Crecimiento de vegetación
• Endurecimiento (oxidación) del material
107
• Perdida de adherencia a las losas de hormigón
• Cantidad deficiente del sellante de juntas
1.6. Desnivel del pavimento berma (espaldón). Es escalonamiento formado entre la berma y el borde del pavimento, generalmente acompañado de una separación de estos bordes
1.7. Fisuras lineales. Son fisuras que comprometen todo el espesor de la losa de hormigón, dividiéndose en dos o tres partes. Cuando las fisuras dividen la losa en cuatro o más partes el defecto se conoce como de losa dividida. Las fisuras lineales son:
• Fisuras transversales que aparecen en dirección del ancho de la losa, perpendiculares al eje longitudinal en el pavimento.
• Fisuras longitudinales que ocurren en la dirección del largo de la losa, paralelo al eje longitudinal del pavimento
• Fisuras diagonales con dirección inclinada que interceptan las juntas del pavimento a una distancia mayor que la mitad del largo de esas juntas o bordes.
1.8. Grandes reparaciones. Se entiende como "Gran reparación" un área de pavimento original mayor a 0,45 m2, que fue removida y posteriormente intervenida con material de relleno.
1.9. Pequeñas reparaciones Se entienden como "Pequeña reparación" a un área de pavimento original menor o igual a 0,45 m2, que fue removido y posteriormente intervenido con material de relleno.
1.10. Desgaste superficial. Se caracteriza por la remoción del mortero superficial, haciendo que los agregados afloren en la superficie del pavimento, y con el transcurso del tiempo queden con superficie pulida
108
1.11. Bombeo de finos. Consiste en la expulsión de finos plásticos existentes en el suelo de fundación del pavimento, a través de las juntas, bordes o fisuras, cuando se produce el paso de las cargas solicitantes. Los finos bombeados se depositan sobre la superficie como barro fluido, siendo identificados por la presencia de manchas terrosas a lo largo de las juntas, bordes.
1.12. Roturas localizadas. Son áreas de las losas que se muestran fisuradas y partidas en pequeños pedazos, teniendo formas variadas, se sitúan generalmente entre una fisura y una junta o entre dos fisuras próximas entre sí (alrededor de 1.5 m)
1.13. Defectos en pasos a nivel. Estos son defectos que se producen en los pasos a nivel que consisten en depresiones o elevaciones cerca de las huellas.
1.14. Fisuras superficiales (cuarteado) y escamado. Las fisuras superficiales (cuarteado) son fisuras capilares que ocurren apenas en la superficie de la losa, tienden a interceptarse, formando ángulos de 120°. El escamado se caracteriza por la remoción de la capa superficial fisurada, pudiendo deberse a otros defectos, tal como el desgaste superficial.
1.15. Fisuras de retracción plástica. Son fisuras poco profundas (superficiales), de pequeña abertura (inferior a 0,5 mm) y de largo limitado. Su incidencia tiende a ser aleatoria y ellas se desarrollan formando ángulos de 45° a 60° con el eje longitudinal de la losa.
1.16. Desportillado o rotura de canto. Son roturas que aparecen en los bordes de las losas, teniendo forma de cuña que ocurre a una distancia no superior a 60 cm del borde. Este defecto difiere de la fisura de canto, porque intercepta la junta en un determinado ángulo (rotura en cuña), en cambio la fisura de canto ocurre verticalmente en todo el espesor de la losa.
109
1.17. Desportillado de juntas. El desportillado de juntas se caracteriza la quiebra de los bordes de la losa de hormigón (rotura de junta) en las juntas, con el largo máximo de 60 cm, no compromete el espesor de la losa
1.18. Losa suelta o "losa bailarina". Es la losa cuyo movimiento vertical es visible bajo la acción del tráfico, principalmente en la región de las juntas
1.19. Asentamiento. Se caracteriza por el hundimiento del pavimento, creando ondulaciones superficiales de gran extensión, pudiendo ocurrir que el pavimento permanezca integro.
1.20. Huecos o agujeros. Son huecos cóncavos, observados en la superficie de la losa causada la pérdida de hormigón en el lugar, presentando área y profundidad bien definida
110
