DATOS, TÉCNICAS DE ANÁLISIS DE DATOS Y MODELOS DE CIENCIA DE DATOS


Numéricos
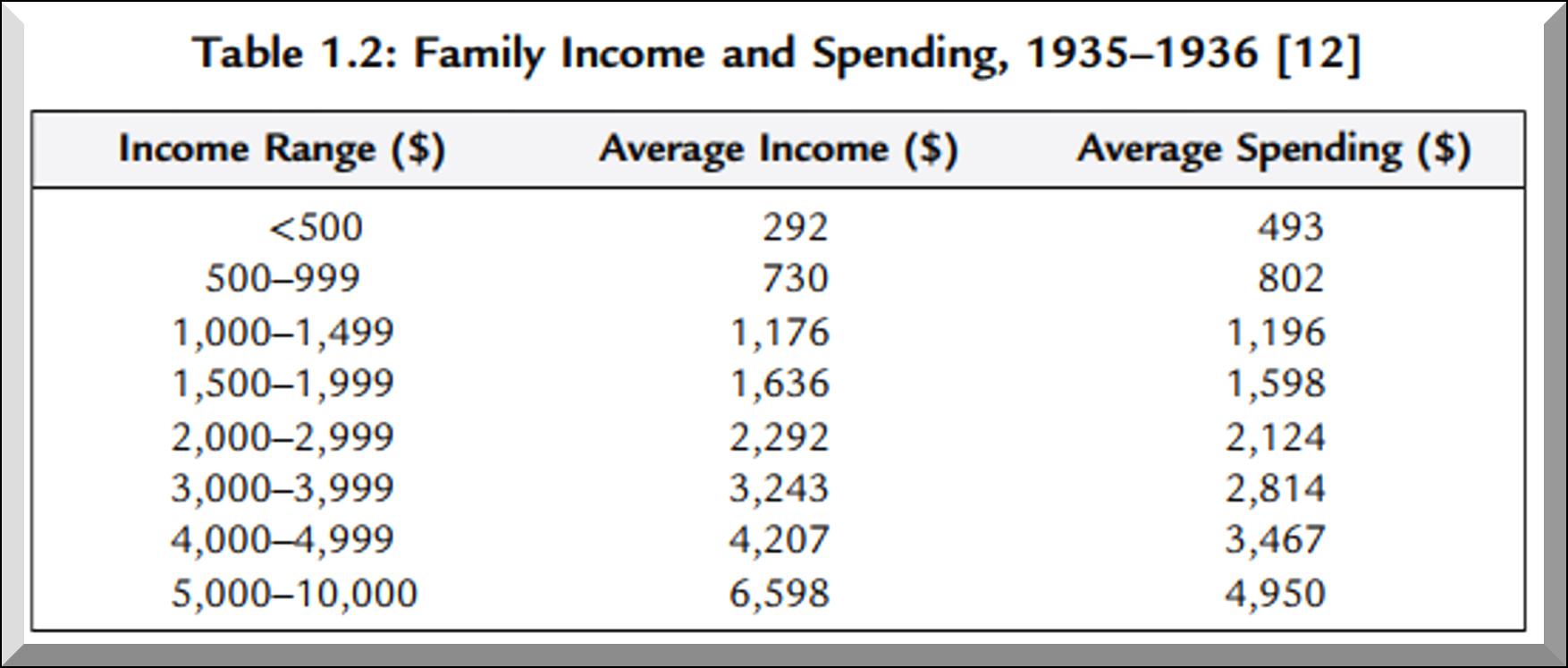
Tasa de desempleo, tasa de inflación, ingreso de los hogares, gasto de los hogares.
Sexo, nivel de instrucción formal, tipo de universidad. Generalmente, se puede
a través de frecuencias (absolutas o relativas).
Observaciones realizadas en el mismo período de tiempo a un grupo específico (Tabla
Series
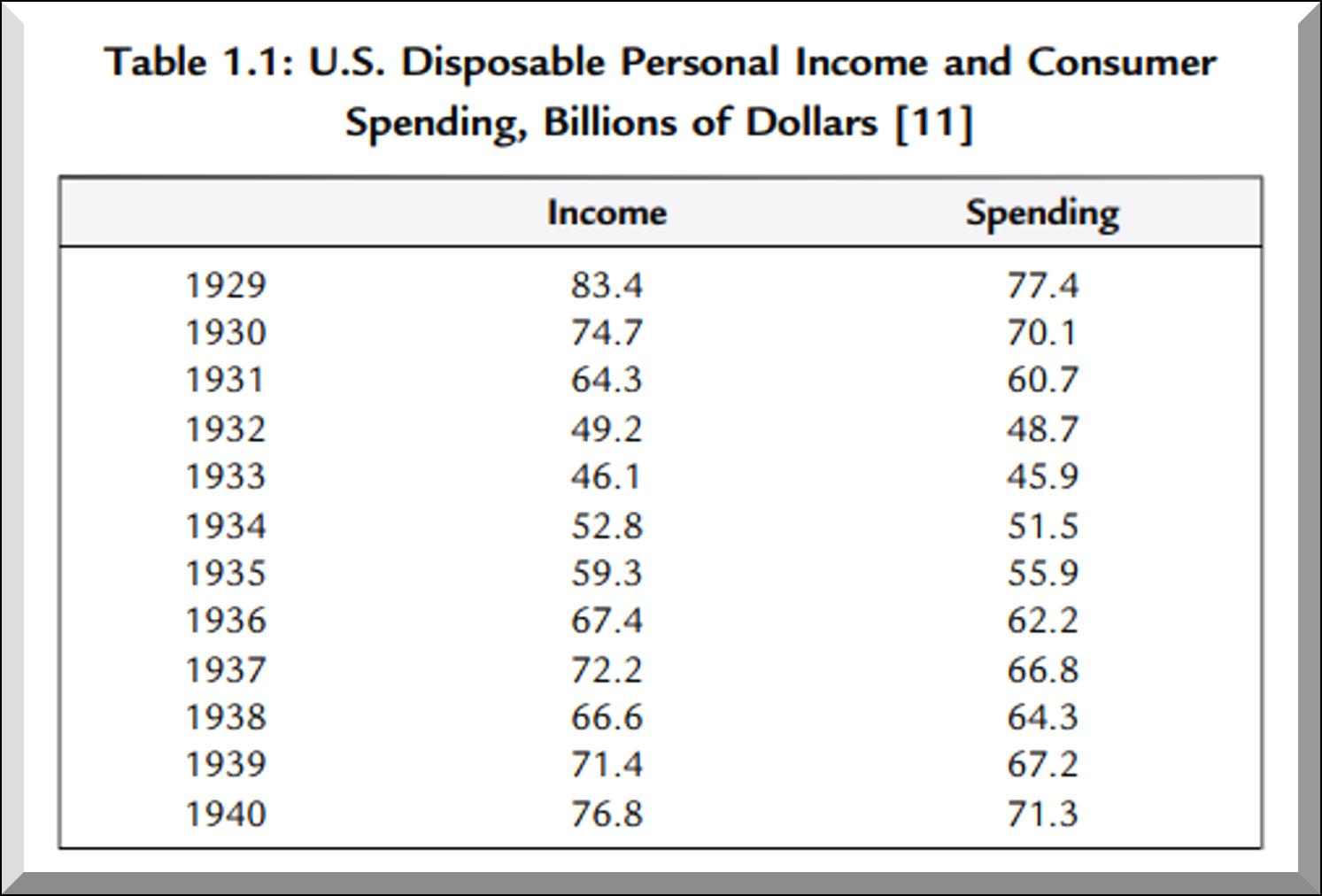
Secuencia de observaciones en diferentes períodos de tiempo de un mismo individuo (Tabla
Datos
Observaciones
(Tabla
Si se observan
Si
observa
precio
en diferentes períodos de
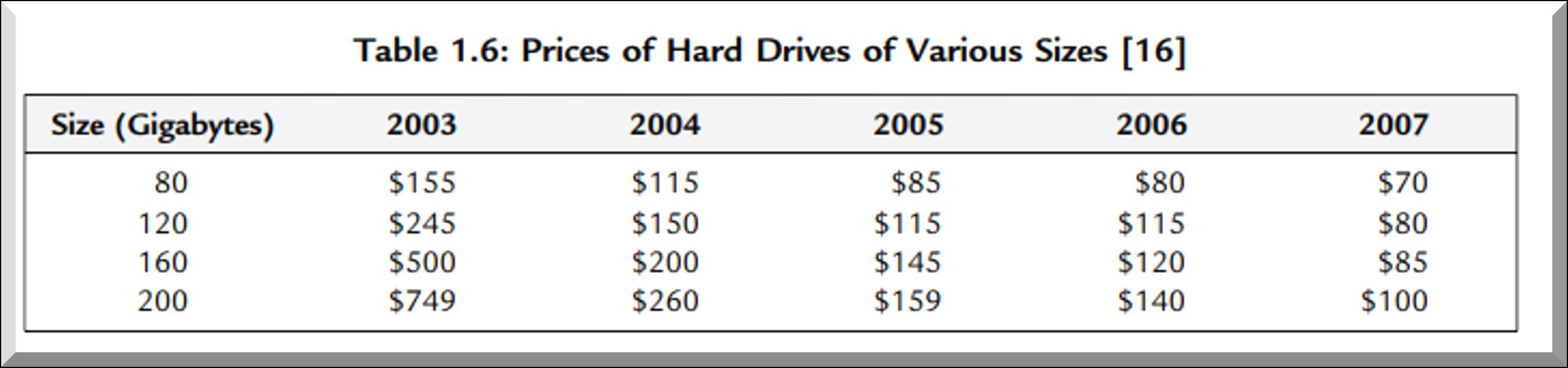
series de tiempo.
un determinado período de
200GB durante
período

Fuente: Smith, G. (2015). Essential Statistics, Regression, and Econometrics. Pgs. 4 10.








Número de hijos de una familia
favorito
Número de libros leídos Estado civil
Número de hijos de una familia
Número de libros leídos
Monto de recauda ción tributaria Precipitación anual en Quito






Análisis cuantitativo de datos secundarios






Utiliza la base de datos de entrenamiento para realizar predicciones
Aprendizaje
Modelos
Aprendizaje no
Clases: clasificación o categorización y regresión
Aprendizaje
Utiliza inferencias de la base de datos, la misma que no tiene respuestas categorizadas
Clases: clustering y reducción dimensional o asociación
Aprendizaje por
Etiquetado manual, pocos datos etiquetados y mucho no etiquetados
Clases: self learning
Psicología del comportamiento para la toma de decisiones (recompensas y penalidades)
Clases: Componentes y nexos
Predice si un dato pertenece a una clase predeterminada
Árbol de decisión, redes neuronales, modelos Bayesianos
Predice el valor utilizando datos determinados
Predice si un dato es un dato atípico (outlier) comparando con el resto de datos
Utiliza datos históricos para realizar la predicción en un horizonte de tiempo
Identifica clusters naturales en el conjunto de datos utilizando sus propiedades
Identifica las relaciones utilizando datos de transacción
Regresión lineal, regresión logística
Identificación de un consumidor en un grupo de consumidores conocidos
Distancy based, density based, local outlier factor (LOF)
Autorregresive integrated moving average (ARIMA), regresión
Predicción de la tasa de desempleo para el siguiente año
K means, clustering
Detección de transacciones fraudulentas por medio de tarjeta de crédito
Predicción de ventas
Frontera de producción, algoritmo de crecimiento
Segmentos de consumidor en base a transacciones, web
Oportunidades de venta cruzada en función del historial de compra (transacciones)
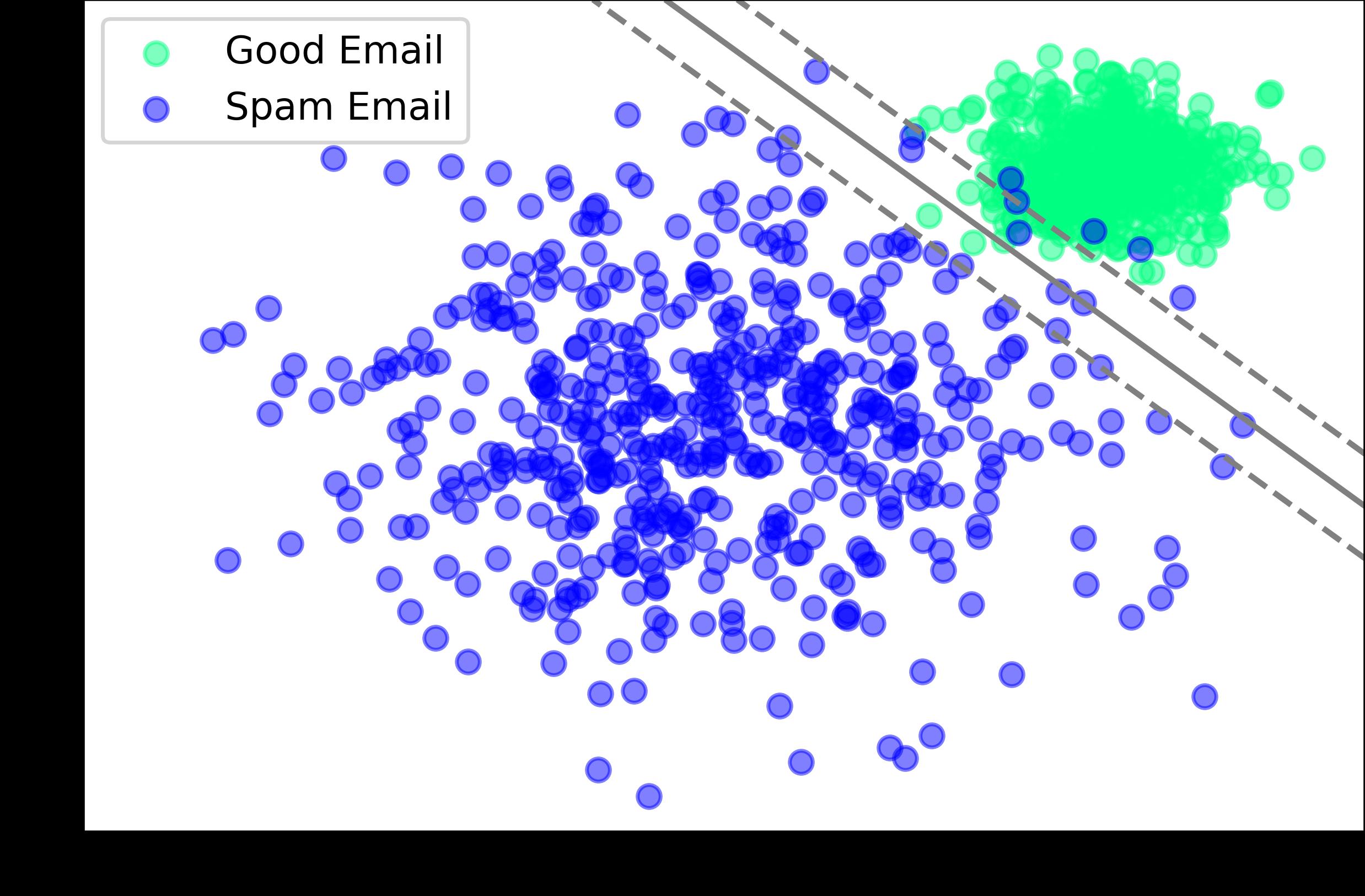
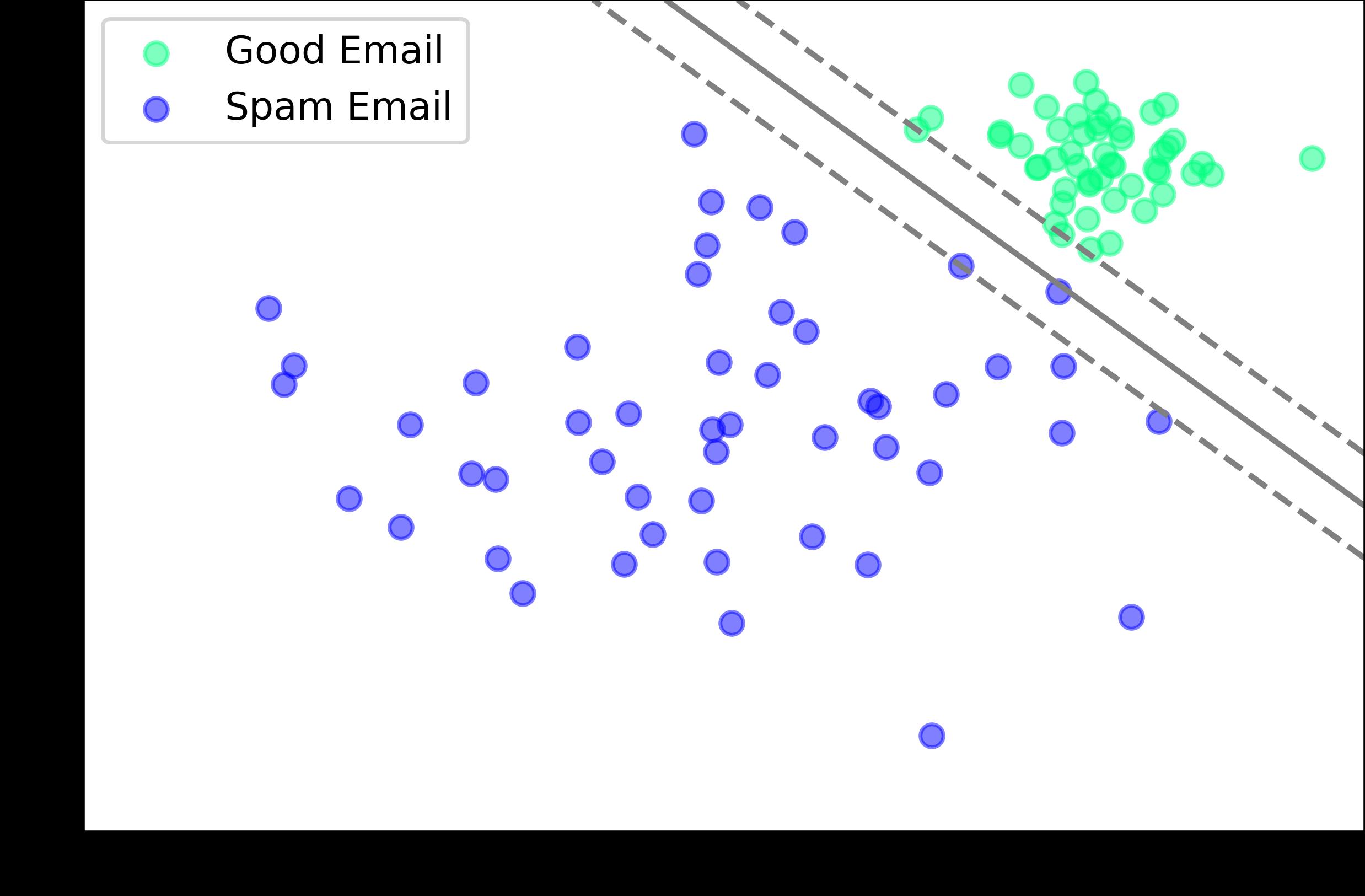
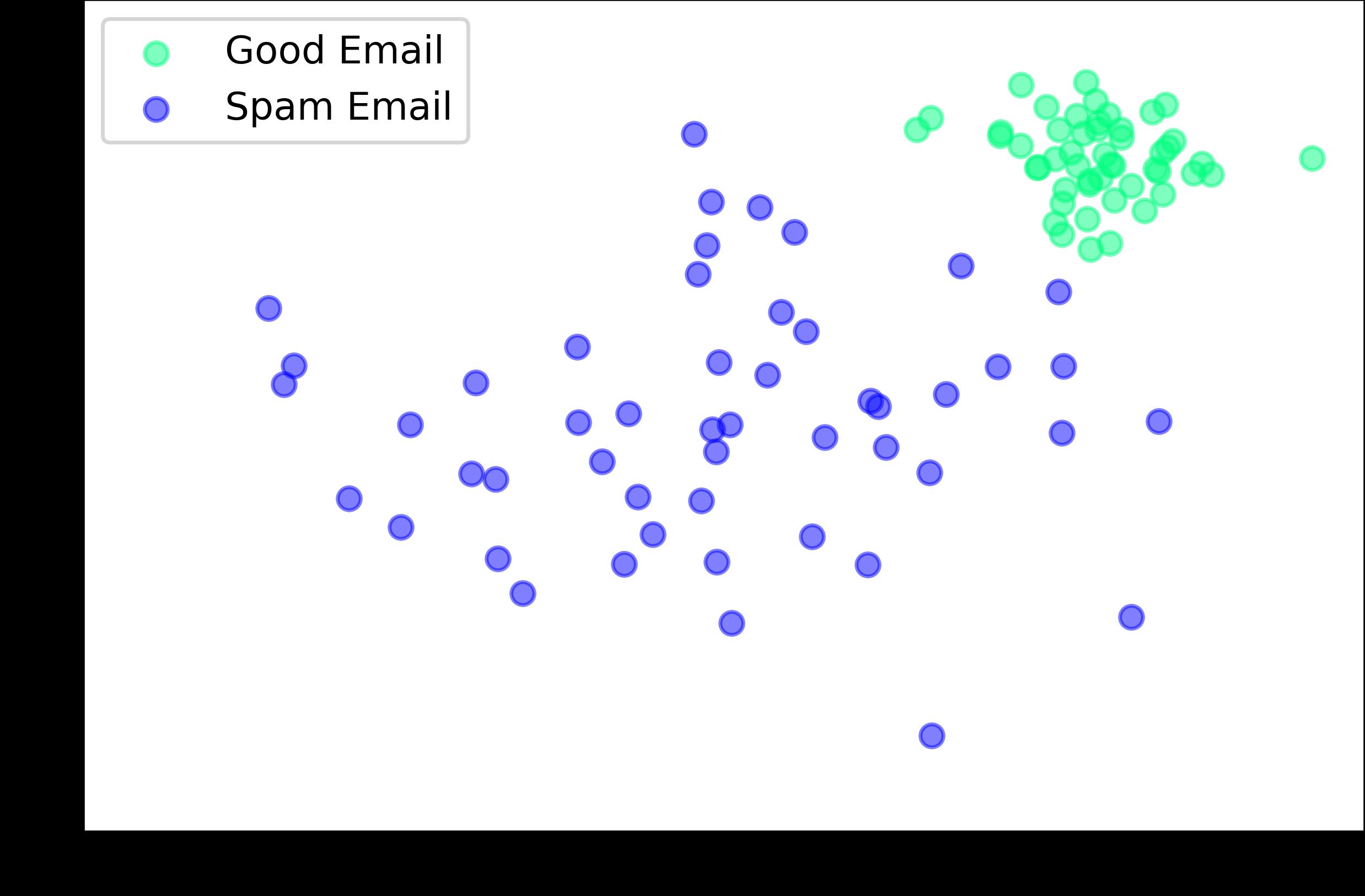
Entrenar el modelo a través de múltiples interacciones de datos de entrenamiento para mejorar la precisión y velocidad de predicción




Realizar predicciones y evaluar el modelo
Elegir un modelo utilizando un algoritmo de aprendizaje supervisado: naturaleza clasificación o regresión.
Recopilar y limpiar los datos de entrenamiento
Seleccionar el tipo de datos de entrenamiento, determinar la naturaleza de los datos
Objetivo:
de nuevos
con base a las observaciones pasadas.
de la etiqueta, la clasificación puede ser binaria (etiqueta discreta, 0 o 1) o multiclase (múltiples categorías).
se utiliza con etiquetas discretas
Árbol de decisión (clasificación)
Línea recta como gráfico de la ecuación, método de Mínimo Cuadrados Ordinarios (MCO), utiliza datos continuos
Clasificación binaria, resultado: probabilidad de que pertenezca a una clase, utiliza datos discretos
Similar al diagrama de flujo, se evalúan valores en cada nodo para llegar a la clasificación final
Combinación de árboles de decisión independientes entre sí para reducir la varianza



de
Segmentación de
éxito
fallo de la
Incremento del comercio
través
de





estudio de
Identificación de
Personalización de las pólizas de seguros

de los hábitos de los
Detección de
Géron, A. (2017).
Build
Mayer, S. (s/f).
Saura, R., Palos Sanchez, P., & Grilo, A. (2019).

Scikit-Learn & Tensor Flow.
Systems. O’Reilly.
en: https://sven-
Smith, G. (2015).
Statistics,
Econometrics. Elsevier.
