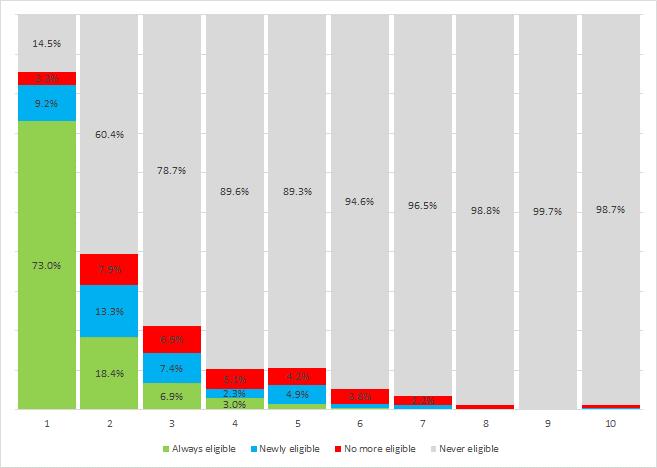
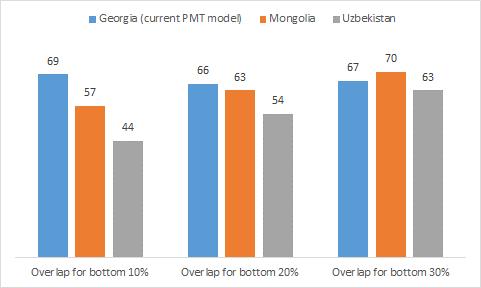
This paper investigates reasons of Georgian Targeted Social Assistance (TSA)’s declining performance and proposes a new PMT model estimated on the most recent household income and expenditure survey data (2018).The paper finds that the proposed updated formula performs better in terms of its ranking property, coverage of the poor and benefit incidence among the poor. The updated PMT formula would improve the coverage of the poorest decile by raising it from 69% to 77% and the benefit incidence in the poorest decile from 60 to 65 percent. The analysis also finds that most of the “winners” are in the poorest quintile while the losers in the top quintiles. In the medium term, the paper highlights the potential benefits of moving to a hybrid targeting approach, whereby reported income is used as a first-stage exclusion criterion before a PMT assessment.